GPU Programming with CUDA – Accelerated Architectures Mike Griffiths GPUComputing@Sheffield http://gpucomputing.sites.sheffield.ac.uk/

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

GPU Programming with CUDA – Accelerated
ArchitecturesMike Griffiths
GPUComputing@Sheffieldhttp://gpucomputing.sites.sheffield.ac.uk/

• Why Accelerators?• Architectural Details• Latest Products• Accelerated Systems
Overview

• Why Accelerators?• Architectural Details• Latest Products• Accelerated Systems
Overview

• Power = Frequency x Voltage²• Performance Improvements traditionally realised by increasing
frequency• Voltage decreased to maintain steady power
• Voltage cannot be decreased any further• 1’s and 0’s represented by different voltages• Need to be able to distinguish between the two
CPU Limitations

Moores Law: A doubling of transistors every couple of years BUT Clock speeds are not increasing Longer more complex pipelines?
Increase performance by adding parallelism Perform many operations per clock cycle
More cores More operations per core
Keep power per core low
Moores Law

• Much of the functionality of CPUs is unused for HPC• Branch prediction, out of order execution, etc.
• Ideally for HPC we want: Simple, Low Power and Highly Parallel cores
• Problem: Still need operating systems, I/O, scheduling• Solution: “Hybrid Systems” – CPUs provide management,
“Accelerators” (or co-processors) provide compute power.
Accelerators

• Why Accelerators?• Architectural Details• Latest Products• Accelerated Systems
Overview

• Chip fabrication prohibitively expensive• HPC market relatively small
• Graphics Processing Units (GPUs) have evolved from the desire from improved graphical realism in games
• Significantly different architecture• Lots of number crunching cores• Highly parallel
• Initially GPUs started to be used for general purpose use (GPGPU)• NVIDIA and AMD now tailor their architectures for HPC
Designing an Accelerator

• Intel Xeon Phi – Many Integrated Core (MIC) architecture• Lots of Pentium cores with wide vector units
• Closer to traditional multi-core• Simplifies programming?
• Codenamed “Larrabee, Knights Ferry, Knights Corner, Knights Landing”
• Many simple-low power cores
What are the alternatives

Accelerators in HPC 48,000 Xeon Phi boards
Equal number of Opterons to GPUS

• AMD 12-core• Not much space is dedicated to compute
Architecture of a Multi-Core CPU
= compute unit (core)

• NVIDIA Fermi GPU• Much more space dedicated to compute (at the cost of cache and
advanced features)
Architecture of a NVIDIA GPU
= streaming multiprocessors compute unit (each with 32 cores)

• Similarly has large amounts of dedicated compute space
Architecture of a Xeon Phi
= compute unit (core)

• Accelerators use dedicated Graphics Memory• Separate to CPU “main” memory
• Many HPC applications require high memory bandwidth
Memory
GPUs and Xeon Phi use Graphics DRAMCPUs use DRAM

• Why Accelerators?• Architectural Details• Latest Products (with a focus on NVIDIA GPUs)• Accelerated Systems
Overview

• NVIDIA – Tesla GPUs, specifically for HPC (using same architecture as Ge-Force)
• AMD – FirePro HPC, specifically for HPC (evolved from ATI Radeon)
• Intel – Xeon Phi – recently emerged to compete with GPUs
Latest Products

• Chip partitioned into Streaming Multiprocessors (SMs)
• Multiple cores per SM• Not cache coherent. No
communication possible across SMs.
Tesla Series GPUs

• Less scheduling units than cores • Threads are scheduled in groups
of 32, called a warp• Threads within a warp always
execute the same instruction in lock-step (on different data elements)
NVIDIA Streaming Multiprocessor

Tesla Range Specifications
“Fermi” 2050
“Fermi” 2070
“Fermi” 2090
“Kepler”K20
“Kepler” K20X
“Kepler”K40
CUDA cores 448 448 512 2496 2688 2880
DP Performance
515 GFlops
515 GFlops
665 GFlops
1.17 TFlops
1.31 TFlops
1.43 Tflops
Memory Bandwidth
144 GB/s 144 GB/s 178 GB/s 208 GB/s 250 GB/s 288 GB/s
Memory 3 GB 6 GB 6 GB 5 GB 6 GB 12 GB

NVIDIA Roadmap

• Why Accelerators?• Architectural Details• Latest Products• Accelerated Systems
Overview

CacheCP
P P P P
C C C C
Interconnect
Memory
Shared-memory system.
e.g. Sunfire, SGI Origin, Symetric Multiprocessors
Can use interconnect + memory as a communications network
Machine architectures
P P P P
C C C C
Interconnect
M M M M
Distributed memory system
e.g. Beowulf clusters.
Architecture matches message passing paradigm.
Processor

• CPUs and Accelerators are used together• GPUs cannot be used instead of CPUs• GPUs perform compute heavy parts
• Communication is via PCIe bus
Accelerated Systems
DRAM GDRAM
CPU GPU/Accelerator
I/O I/OPCIe

• Can have multiple CPUs and Accelerators within each “Shared Memory Node”
• CPUs share memory but accelerators do not!
Larger Accelerated Systems
DRAMGDRAM
CPU GPU/Accelerator
I/O I/OPCIe
GDRAM
CPU GPU/Accelerator
I/O I/OPCIe
Interconnect
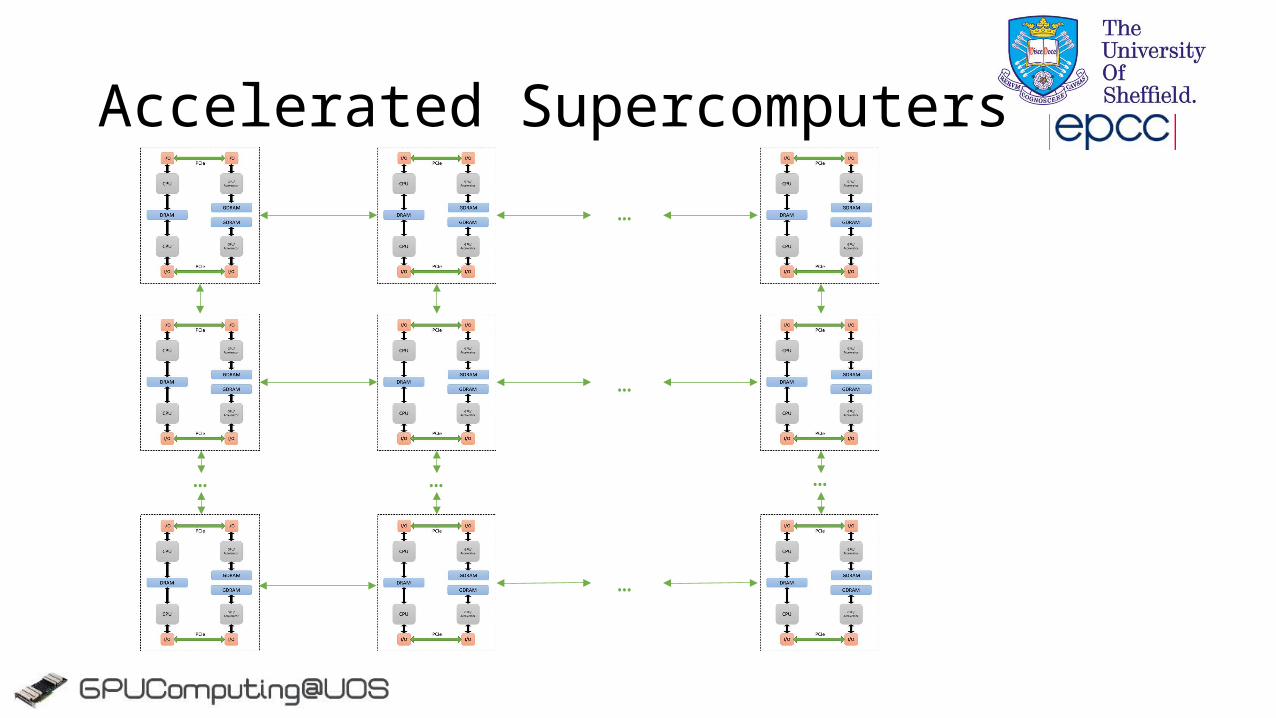
Accelerated Supercomputers
…
…
…
………

• (Normally) use one host CPU core (thread) per accelerator• Program manages communication between host CPUs
• MPI for distributed memory• OpenMP for shared memory on the same node
Multiple Accelerators in Parallel

• Insert your accelerator into PCI-e• Make sure that
• There is enough space• Your power supply unit (PSU)is up
to the job• You install the latest drivers
Simple Accelerated Workstation

• Multiple Servers can be connected via interconnect
• Several vendors offer GPU servers
• For example 2 multi core CPUs + 4 GPUS
GPU Workstation Server

• Dedicated HPC Blades for scalable HPC• E.g. Cray XK7
• 4 CPUs + 4 GPUS + 2 interconnect chips (shared by 2 computer nodes
Compute Blades

The Iceberg GPU Nodes
C410X with 8 Fermi GPU
2xC6100 with dual Intel westmere6core CPU’s

• GPU Accelerated Libraries and Applications (MATLAB, Ansys, etc)• GPU mostly abstracted from end user
• GPU Accelerated Directives (OpenACC)• Helps compiler auto generate code for the GPU
• CUDA for NVIDIA GPUs• Extension to the C language (more to follow)
• OpenCL• Similar to CUDA but cross-platform• No access to cutting edge NVIDIA functionaility
Programming Techniques

• Accelerators have higher compute and memory bandwidth capabilities than CPUs
• Silicon dedicated to many simplistic cores• Use of graphics memory
• Accelerators are typically not used alone, but work in tandem with CPUs
• Most common are NVIDIA GPUs and Intel Xeon Phis.• Including current top 2 systems on top500 list
• Architectures differ• GPU accelerated systems scale from simple workstations to large-scale
supercomputers
Summary
Related Documents











