Motivation Gilbert Evaluation Conclusion Gilbert: Declarative Sparse Linear Algebra on Massively Parallel Dataflow Systems Till Rohrmann 1 Sebastian Schelter 2 Tilmann Rabl 2 Volker Markl 2 1 Apache Software Foundation 2 Technische Universität Berlin March 8, 2017 1 / 25

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Motivation Gilbert Evaluation Conclusion
Gilbert: Declarative Sparse Linear Algebra onMassively Parallel Dataflow Systems
Till Rohrmann 1 Sebastian Schelter 2 Tilmann Rabl 2
Volker Markl 2
1Apache Software Foundation
2Technische Universität Berlin
March 8, 2017
1 / 25

Motivation Gilbert Evaluation Conclusion
Motivation
2 / 25

Motivation Gilbert Evaluation Conclusion
Information Age
Collected data grows exponentiallyValuable information stored in dataNeed for scalable analytical methods
3 / 25

Motivation Gilbert Evaluation Conclusion
Distributed Computing and Data Analytics
Writing parallel algorithms is tediousand error-proneHuge existing code base in form oflibrariesNeed for parallelization tool
4 / 25

Motivation Gilbert Evaluation Conclusion
Requirements
Linear algebra is lingua franca of analyticsParallelize programs automatically to simplify developmentSparse operations to support sparse problems efficiently
Goal
Development of distributed sparse linear algebra system
5 / 25

Motivation Gilbert Evaluation Conclusion
Gilbert
6 / 25

Motivation Gilbert Evaluation Conclusion
Gilbert in a Nutshell
7 / 25
Motivation Gilbert Evaluation Conclusion
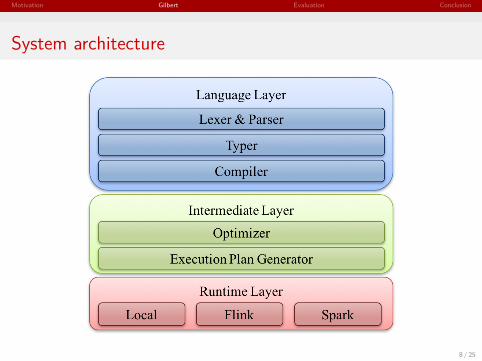
System architecture
8 / 25

Motivation Gilbert Evaluation Conclusion
Gilbert Language
Subset of MATLAB R© languageSupport of basic linear algebraoperationsFixpoint operator serves as side-effectfree loop abstractionExpressive enough to implement a widevariety of machine learning algorithms
1 A = rand (10 , 2 ) ;2 B = eye ( 1 0 ) ;3 A’∗B;4 f = @( x ) x . ^ 2 . 0 ;5 eps = 0 . 1 ;6 c = @( p , c ) norm ( p−c , 2 ) < eps ;7 f i x p o i n t (1/2 , f , 10 , c ) ;
9 / 25

Motivation Gilbert Evaluation Conclusion
Gilbert Typer
Matlab is dynamically typedDataflow systems require type knowledge at compile typeAutomatic type inference using the Hindley-Milner type inferencealgorithmInfer also matrix dimensions for optimizations
1 A = rand (10 , 2 ) : Mat r i x ( Double , 10 , 2)2 B = eye ( 1 0 ) : Mat r i x ( Double , 10 , 10)3 A’∗B: Matr i x ( Double , 2 , 10)4 f = @( x ) x . ^ 2 . 0 : N −> N5 eps = 0 . 1 : Double6 c = @( p , c ) norm ( p−c , 2 ) < eps : (N,N) −> Boolean7 f i x p o i n t (1/2 , f , 10 , c ) : Double
10 / 25

Motivation Gilbert Evaluation Conclusion
Intermediate Representation & Gilbert Optimizer
Language independent representation of linear algebra programsAbstraction layer facilitates easy extension with new programminglanguages (such as R)Enables language independent optimizations
Transpose push downMatrix multiplication re-ordering
11 / 25

Motivation Gilbert Evaluation Conclusion
Distributed Matrices
(a) Row partitioning (b) Quadratic block partitioning
Which partitioning is better suited for matrix multiplications?
io_costrow = O(n3) io_costblock = O
(n2√n
)
12 / 25
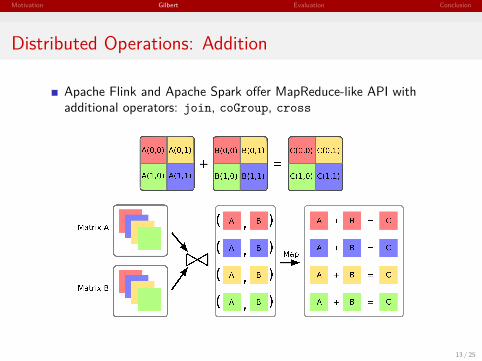
Motivation Gilbert Evaluation Conclusion
Distributed Operations: Addition
Apache Flink and Apache Spark offer MapReduce-like API withadditional operators: join, coGroup, cross
13 / 25

Motivation Gilbert Evaluation Conclusion
Evaluation
14 / 25

Motivation Gilbert Evaluation Conclusion
Gaussian Non-Negative Matrix Factorization
Given V ∈ Rd×w find W ∈ Rd×t and H ∈ Rt×w such that V ≈WHUsed in many fields: Computer vision, document clustering andtopic modelingEfficient distributed implementation for MapReduce systems
Algorithm
H ← randomMatrix(t, w)W ← randomMatrix(d , t)while ‖V −WH‖2 > eps do
H ← H · (W T V /W T WH)W ←W · (VHT /WHHT )
end while
15 / 25

Motivation Gilbert Evaluation Conclusion
Testing Setup
Set t = 10 and w = 100000V ∈ Rd×100000 with sparsity 0.001Block size 500× 500Numbers of cores 64Flink 1.1.2 & Spark 2.0.0Gilbert implementation: 5 linesDistributed GNMF on Flink: 70 lines
1 V = rand ( $rows , 100000 , 0 , 1 , 0 . 0 0 1 ) ;2 H = rand (10 , 100000 , 0 , 1 ) ;3 W = rand ( $rows , 10 , 0 , 1 ) ;4 nH = H. ∗ ( (W’∗V ) . / (W’∗W∗H) )5 nW = W. ∗ (V∗nH ’ ) . / (W∗nH∗nH ’ )
16 / 25
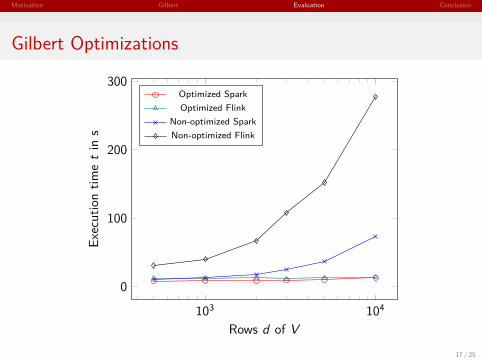
Motivation Gilbert Evaluation Conclusion
Gilbert Optimizations
103 104
0
100
200
300
Rows d of V
Executiontim
etin
sOptimized SparkOptimized Flink
Non-optimized SparkNon-optimized Flink
17 / 25

Motivation Gilbert Evaluation Conclusion
Optimizations Explained
Matrix updatesH ← H · (W T V /W T WH)W ←W · (VHT /WHHT )
Non-optimized matrix multiplications
∈R10×100000︷ ︸︸ ︷(W T W
)︸ ︷︷ ︸∈R10×10
H
∈Rd×10︷ ︸︸ ︷(WH)︸ ︷︷ ︸∈Rd×100000
HT
Optimized matrix multiplications
∈R10×100000︷ ︸︸ ︷(W T W
)︸ ︷︷ ︸∈R10×10
H
∈Rd×10︷ ︸︸ ︷W(HHT )︸ ︷︷ ︸∈R10×10
18 / 25
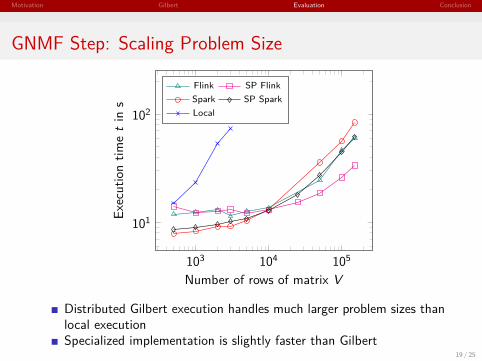
Motivation Gilbert Evaluation Conclusion
GNMF Step: Scaling Problem Size
103 104 105
101
102
Number of rows of matrix V
Executiontim
etin
s
Flink SP FlinkSpark SP SparkLocal
Distributed Gilbert execution handles much larger problem sizes thanlocal executionSpecialized implementation is slightly faster than Gilbert
19 / 25

Motivation Gilbert Evaluation Conclusion
GNMF Step: Weak Scaling
100 101 1020
20
40
60
Number of cores
Executiontim
etin
sFlinkSpark
Both distributed backends show good weak scaling behaviour20 / 25

Motivation Gilbert Evaluation Conclusion
PageRank
Ranking between entities with reciprocal quotations and references
PR(pi) = d∑
pj∈L(pi )
PR(pj)D(pj)
+ 1− dN
N - number of pagesd - damping factorL(pi) - set of pages being linked by pi
D(pi) - number of linked pages by pi
M - transition matrix derived from adjacency matrix
R = d ·MR + 1− dN · 1
21 / 25

Motivation Gilbert Evaluation Conclusion
PageRank Implementation
MATLAB R©
1 i t = 10 ;2 d = sum (A, 2) ;3 M = ( d iag (1 . / d ) ∗ A) ’ ;4 r_0 = ones ( n , 1) / n ;5 e = ones ( n , 1) / n ;6 f o r i = 1 : i t7 r = .85 ∗ M ∗ r + .15 ∗ e8 end
Gilbert1 i t = 10 ;2 d = sum (A, 2) ;3 M = ( d iag (1 . / d ) ∗ A) ’ ;4 r_0 = ones ( n , 1) / n ;5 e = ones ( n , 1) / n ;6 f i x p o i n t ( r_0 ,7 @( r ) . 85 ∗ M ∗ r + .15 ∗ e ,8 i t )
22 / 25
Motivation Gilbert Evaluation Conclusion
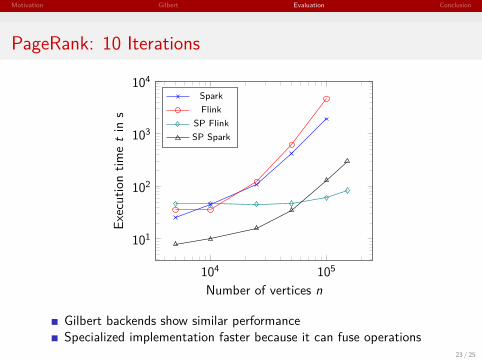
PageRank: 10 Iterations
104 105
101
102
103
104
Number of vertices n
Executiontim
etin
s
SparkFlink
SP FlinkSP Spark
Gilbert backends show similar performanceSpecialized implementation faster because it can fuse operations
23 / 25
Motivation Gilbert Evaluation Conclusion
Conclusion
24 / 25

Motivation Gilbert Evaluation Conclusion
Conclusion
Easy to use sparse linear algebraenvironment for people familiar withMATLAB R©
Scales to data sizes exceeding a singlecomputerHigh-level linear algebra optimizationsimprove runtimeSlower than specializedimplementations due to abstractionoverhead
25 / 25
Related Documents











