Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected]. This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing 1 Gender-driven Emotion Recognition through Speech Signals for Ambient Intelligence Applications Igor Bisio, Alessandro Delfino, Fabio Lavagetto, Mario Marchese, and Andrea Sciarrone Abstract—The paper proposes a system that allows recognizing people emotional state starting from audio signal registrations. The provided solution is aimed at improving the interaction among humans and computers so allowing effective Human-Computer Intelligent Interaction (HCII). The system is able to recognize six emotions (anger, boredom, disgust, fear, happiness, sadness) and the neutral state. This set of emotional states is widely used for emotion recognition purposes. It also distinguishes a single emotion versus all the other possible ones, as proven in the proposed numerical results. The system is composed of two subsystems: Gender Recognition (GR) and Emotion Recognition (ER). The experimental analysis shows the performance in terms of accuracy of the proposed emotion recognition system. The results highlight that the a priori knowledge of the speaker gender allows a performance increase. The obtained results show also that the features selection adoption assures a satisfying recognition rate and allows reducing the employed features. Future developments of the proposed solution may include the implementation of this system over mobile devices such as smartphones. Index Terms—Human-Computer Intelligent Interaction, Gender Recognition, Emotion Recognition, Pitch Estimation, Support Vector Machine ✦ 1 I NTRODUCTION R ECENTLY there has been a growing interest to improve human-computer interaction. It is well- known that, to achieve effective Human-Computer In- telligent Interaction (HCII), computers should be able to interact naturally with the users, i.e. the mentioned interaction should mimic human-human interactions. HCII is becoming really relevant in applications such as smart home, smart office and virtual reality, and it may acquire importance in all aspects of future peoples life. A peculiar and very important developing area concerns the remote monitoring of elderly or ill people. Indeed, due to the increasing aged population, HCII systems able to help live independently are regarded as useful tools. Despite the significant advances aimed at supporting elderly citizens, many issues have to be addressed in order to help aged ill people to live independently. In this context recognizing people emotional state and giving a suitable feedback may play a crucial role. As a consequence, emotion recognition represents a hot research area in both industry and academic field. There is much research in this area and there have been some successful products [1]. Usually, emotion recognition systems are based on facial or voice features. This paper proposes a solution, designed to be employed in a Smart Environment, able to capture the emotional state of a person starting from a registration of the speech signals The authors are with the Department of Electrical, Electronic, Telecommuni- cations Engineering and Naval Architecture (DITEN), University of Genoa, Via Opera Pia 13 16145, Genoa, Italy. E-mail:{igor.bisio, alessandro.delfino, fabio.lavagetto, mario.marchese, andrea.sciarrone}@unige.it in the surrounding obtained by mobile devices such as smartphones. Main problems to be faced concern: the concept of emotion, which is not precisely defined for the context of this paper; the lack of a widely accepted taxonomy of emotions and emotional states; the strong emotion man- ifestation dependency of the speaker. Emotion recogni- tion is an extremely difficult task. This paper presents the implementation of a voice- based emotion detection system suitable to be used over smartphone platforms and able to recognize six emotions (anger, boredom, disgust, fear, happiness, sadness) and the neutral state, as widely used for emotion recognition. Particular attention is also reserved to the evaluation of the system capability to recognize a single emotion ver- sus all the others. For these purposes, a deep analysis of the literature is provided and state-of-the-art approaches and emotion related features are evaluated. In more detail, to capture emotion information, 182 different features related to speech signals’ prosody and spectrum shape are used; the classification task is performed by adopting the Support Vector Machine (SVM) approach. The main contributions of this paper concern: i) a system able to recognize people emotions composed of two sub- systems, Gender Recognition (GR) and Emotion Recog- nition (ER); ii) a gender recognition algorithm, based on pitch extraction, and aimed at providing a priori informa- tion about the gender of the speaker; iii) a SVM-based emotion classifier, which employs the gender informa- tion as input. Reduced feature sets, obtained by fea- ture selection, performed through Principal Component

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
1
Gender-driven Emotion Recognition throughSpeech Signals for Ambient Intelligence
ApplicationsIgor Bisio, Alessandro Delfino, Fabio Lavagetto, Mario Marchese, and Andrea Sciarrone
Abstract—The paper proposes a system that allows recognizing people emotional state starting from audio signal registrations. Theprovided solution is aimed at improving the interaction among humans and computers so allowing effective Human-Computer IntelligentInteraction (HCII). The system is able to recognize six emotions (anger, boredom, disgust, fear, happiness, sadness) and the neutralstate. This set of emotional states is widely used for emotion recognition purposes. It also distinguishes a single emotion versus all theother possible ones, as proven in the proposed numerical results.The system is composed of two subsystems: Gender Recognition (GR) and Emotion Recognition (ER).The experimental analysis shows the performance in terms of accuracy of the proposed emotion recognition system. The resultshighlight that the a priori knowledge of the speaker gender allows a performance increase.The obtained results show also that the features selection adoption assures a satisfying recognition rate and allows reducing theemployed features. Future developments of the proposed solution may include the implementation of this system over mobile devicessuch as smartphones.
Index Terms—Human-Computer Intelligent Interaction, Gender Recognition, Emotion Recognition, Pitch Estimation, Support VectorMachine
F
1 INTRODUCTION
R ECENTLY there has been a growing interest toimprove human-computer interaction. It is well-
known that, to achieve effective Human-Computer In-telligent Interaction (HCII), computers should be ableto interact naturally with the users, i.e. the mentionedinteraction should mimic human-human interactions.HCII is becoming really relevant in applications such assmart home, smart office and virtual reality, and it mayacquire importance in all aspects of future peoples life.A peculiar and very important developing area concernsthe remote monitoring of elderly or ill people. Indeed,due to the increasing aged population, HCII systems ableto help live independently are regarded as useful tools.Despite the significant advances aimed at supportingelderly citizens, many issues have to be addressed inorder to help aged ill people to live independently.In this context recognizing people emotional state andgiving a suitable feedback may play a crucial role. Asa consequence, emotion recognition represents a hotresearch area in both industry and academic field. Thereis much research in this area and there have been somesuccessful products [1]. Usually, emotion recognitionsystems are based on facial or voice features. This paperproposes a solution, designed to be employed in a SmartEnvironment, able to capture the emotional state of aperson starting from a registration of the speech signals
The authors are with the Department of Electrical, Electronic, Telecommuni-cations Engineering and Naval Architecture (DITEN), University of Genoa,Via Opera Pia 13 16145, Genoa, Italy. E-mail:igor.bisio, alessandro.delfino,fabio.lavagetto, mario.marchese, [email protected]
in the surrounding obtained by mobile devices such assmartphones.Main problems to be faced concern: the concept ofemotion, which is not precisely defined for the contextof this paper; the lack of a widely accepted taxonomy ofemotions and emotional states; the strong emotion man-ifestation dependency of the speaker. Emotion recogni-tion is an extremely difficult task.This paper presents the implementation of a voice-based emotion detection system suitable to be used oversmartphone platforms and able to recognize six emotions(anger, boredom, disgust, fear, happiness, sadness) andthe neutral state, as widely used for emotion recognition.Particular attention is also reserved to the evaluation ofthe system capability to recognize a single emotion ver-sus all the others. For these purposes, a deep analysis ofthe literature is provided and state-of-the-art approachesand emotion related features are evaluated. In moredetail, to capture emotion information, 182 differentfeatures related to speech signals’ prosody and spectrumshape are used; the classification task is performed byadopting the Support Vector Machine (SVM) approach.The main contributions of this paper concern: i) a systemable to recognize people emotions composed of two sub-systems, Gender Recognition (GR) and Emotion Recog-nition (ER); ii) a gender recognition algorithm, based onpitch extraction, and aimed at providing a priori informa-tion about the gender of the speaker; iii) a SVM-basedemotion classifier, which employs the gender informa-tion as input. Reduced feature sets, obtained by fea-ture selection, performed through Principal Component

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
2
Analysis (PCA), have been investigated and applied.In order to train and test the mentioned SVM-basedemotion classifier, a widely used emotional database(called Berlin Emotional Speech Database, BESD) hasbeen employed.Experimental results show that the proposed system isable to recognize the emotional state of a speaker with anaccuracy level often higher than the evaluated methodstaken from the literature, without applying any pre-processing on the analysed speech signals. The obtainedresults show also that adopting a feature selection algo-rithm assures good recognition rate levels also when aconsistent reduction of the used features is applied. Thisallow a strong limitation of the number of operationsrequired to identify the emotional content of a particularaudio signal. These peculiarities make the proposedsolution suitable to operate on mobile platforms suchas smartphones and tablets, in which the availabilityof computational resources and the energy consumptionconstitute issues of primary relevance.The obtained results also show a strong dependency ofthe overall system reliability on the database adoptedfor training and testing phases: the use of a simulateddatabase (i.e., a collection of emotion vocal expressionsplayed by actors) allows obtaining a higher level ofcorrectly identified emotions. In addition, the performedtests show that the SVM-based emotion classifier can bereliably used in applications where the identification ofa single emotion (or emotion category) versus all theother possible ones is required, as in case of panic orannoyance detection.
2 RELATED WORK
If the phone is aware of its owner mood can offer morepersonal interaction and services. Mobile sensing, inrecent years, has gone beyond the mere measure ofphysically observable events. Scientist studying affectivecomputing [2], [3] have published techniques able todetect the emotional state of the user [2], [4]–[6] allowingthe development of emotion-aware mobile applications[7]. Existing work focused on detecting emotions relyon the use of invasive means such as microphones andcameras [5], [6], [8], and body sensors worn by the user[7]. The proposed method based on the employment ofaudio signals represents an efficient alternative to thementioned approaches. In the literature a traditionalspeech-based emotion recognition system consists offour principal parts:
• Feature Extraction: it involves the elaboration of thespeech signal in order to obtain a certain number ofvariables, called features, useful for speech emotionrecognition.
• Feature Selection: it selects the more appropriate fea-tures in order to reduce the computational load andthe time required to recognize an emotion.
• Database: it is the memory of the classifier; it containssentences divided according to the emotions to berecognized.
• Classification: it assigns a label representing the rec-ognized emotion by using the features selected bythe Feature Selection block and the sentences in theDatabase.
Given the significant variety of different techniques ofFeature Extraction, Feature Selection, and Classification,and the breadth of existing databases, it is appropriateto analyse in detail each block.
2.1 Features ExtractionMany different speech feature extraction methods havebeen proposed over the years. Methods are distin-guished by the the ability to use information about hu-man auditory processing and perception, by the robust-ness to distortions, and by the length of the observationwindow. Due to the physiology of the human vocaltract, human speech is highly redundant and has severalspeaker-dependent features, such as pitch, speaking rateand accent. An important issue in the design of a speechemotion recognition system is the extraction of suitablefeatures that efficiently characterize different emotions.Although there are many interesting works about auto-matic speech emotion detection [9], there is not a silverbullet feature for this aim.Since speech signal is not stationary, it is very common todivide the signal in short segments called frames, withinwhich speech signal can be considered as stationary.Human voice can be considered as a stationary processfor intervals of 20− 40 [ms]. If a feature is computed ateach frame is called local, otherwise, if it is calculated onthe entire speech is named global. There is not agreementin the scientific community on which between local andglobal features are more suitable for speech emotionrecognition.
2.1.1 Gender Recognition FeaturesTogether with the Mel Frequency Cepstral Coefficients(MFCC) [10], pitch is the most frequently used feature[11]–[14] since it is a physiologically distinctive trait of aspeaker’s gender. Other employed features are formantfrequencies and bandwidths, open quotient and sourcespectral tilt correlates [12], energy between adjacentformants [15], fractal dimension and fractal dimensioncomplexity [13], jitter and shimmer (pitch and amplitudemicro-variations, respectively), harmonics-to-noise-ratio,distance between signal spectrum and formants [16].
2.1.2 Emotion Recognition FeaturesCoherently with the wide literature in the field, in thispaper a set of 182 features has been analysed for eachthe recorded speech signal, including:• Mean, variance, median, minimum, maximum and
range of the amplitude of the speech;• Mean and variance of the speech Energy;

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
3
• Mean, variance, median, minimum, maximum andrange of the pitch;
• Mean, variance, minimum, maximum and range ofthe first 4 formants;
• Energy of the first 22 Bark sub-bands [17];• Mean, variance, minimum, maximum and range of
the first 12 Mel-Frequency Cepstrum Coefficients[13], [14];
• Spectrum shape features: Center of Gravity, Stan-dard Deviation, Skewness and Kurtosis;
• Mean and standard deviation of the glottal pulseperiod, jitter local absolute, relative average pertur-bation, difference of difference period and five-pointperiod perturbation quotient.
2.2 Features Selection and Reduction
A crucial problem for all emotion recognition systemsis the selection of the best set of features to charac-terize the speech signal. The purpose of this part isto appropriately select a subset of features from theoriginal set in order to optimize the classification timeand the accuracy. In the case of real-time applicationsreducing the number of used feature is crucial in orderto limit the computational complexity and the requiredtime to complete the emotion recognition process. Anincrease in classification performance usually would beexpected when more features are used. Nevertheless, theperformance can decrease for an increasing number offeatures if the number of patterns is too small. This phe-nomenon is known as the curse of dimensionality. Thispart also aims at reducing the speech features set sizeeither by selecting the most relevant feature subset andremoving the irrelevant ones or by generating few newfeatures that contain most valuable speech information.The most performant strategy to get the best features setis an exhaustive search but it is often computationallyimpractical. Therefore, many sub-optimum algorithmshave been proposed.
2.3 Database
The database, also called dataset, is a very important partof a speech emotion recognizer. The role of databases isto assemble instances of episodic emotions. It is usedboth to train and to test the classifier and it is composedof a collection of sentences with different emotionalcontent.The most used are:• Reading-Leeds database [18]: project begun in 1994
to meet the need for a large, well-annotated setof natural or near-natural speeches orderly storedon computers. The essential aim of the project wasto collect speeches that were genuinely emotionalrather than acted or simulated.
• Belfast database: it was developed as part of a projectcalled Principled Hybrid Systems and Their Appli-cation (PHYSTA) [19], whose aim was to develop a
system capable of recognizing emotion from facialand vocal signs.
• CREST-ESP (Expressive Speech Database): databasebuilt within the ESP project [20]. Research goalwas to collect a database of spontaneous, expressivespeeches.
• Berlin Emotional Speech (BES): this is the databaseemployed in this paper. For this reason paragraph3.2.4 has been dedicated to it.
2.4 Classification Methods
The last part is needed to train and build a classificationmodel by using machine learning algorithms to predictthe emotional states on the basis of the speech instances.The key task of this stage is to choose an efficientmethod to provide accurate predicted results for emotionrecognition. Each classifier requires an initial phase inwhich it is trained to perform a correct classification anda subsequent phase in which the classifier is tested. Thereare several techniques to manage the two phases:
• Percentage split: the database is divided into twoparts, used, respectively to train and to test theclassifier.
• K-fold cross-validation [21]: it is a statistic techniqueusable when the training set contains many sen-tences. It allows mitigating the overfitting problem.In practice, the dataset is randomly divided intok parts of equal size. The algorithm acts in steps.At each step, one of these parts is used as test setwhile all the others are employed as training set.The procedure iterates until all the k parts have beenused to test the classifier. Finally, the results of eachstep are averaged together.
• Leave-one-out cross-validation [22]: it is a variant ofthe K-fold cross-validation in which k is equal to thenumber of folds. In Leave-one-out cross-validationthe class distributions in the test set are not relatedto the ones in the training data. Therefore it tends togive less reliable results. However it is still useful todeal with small datasets since it utilizes the greatestamount of training data from the dataset.
• The database is used both for the training phase andfor the test phase.
Each classification method has advantages and draw-backs. Among the many available approaches, the mostused are Maximum Likelihood Bayes (MLB) classi-fier [23], Support Vector Machine (SVM) [24], HiddenMarkov Model (HMM) [9], Artificial Neural Network(ANN) [25], k-Nearest Neighbours (k-NN) [26]. Alsoother interesting classifiers are used in a significantnumber of studies dedicated to the problem of speechemotion recognition and deserve to be referenced: FuzzyClassifier [27], Decision Tree [28], Random Forest [29],Linear Discriminant Classifier (LDC) [30], GenerativeVector Quantization (GVQ) [31].

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
4
2.5 Paper Contributions
The paper presents a gender-driven emotion recognitionsystem whose aim, starting from speech recordings, is toindividuate the gender of speakers and then, on the basisof this information, to classify the emotion characterizingthe speech signals.Concerning the first step, the paper proposes a genderrecognition method based on the pitch. This methodemploys a typical speech signal feature and a novelextraction method. It guarantees excellent performance:100% accuracy. In practice, it always recognises thegender of the speaker.Concerning the emotion recognition approach, the paperproposes a solution based on traditional features setsand classifiers but, differently from the state of the art,it employs two classifiers (i.e., two Support Vector Ma-chines): the one trained on the basis of signals recordedby male speakers and the other one trained by femalespeech signals. The choice between the two classifiers isdriven by the gender information individuated throughthe gender recognition method.To the best of authors’ knowledge, the proposed gender-driven emotion recognition system represents a novelapproach with respect to the literature in the field.
3 GENDER-DRIVEN EMOTION RECOGNITIONSYSTEM ARCHITECTURE
The system is aimed at recognizing 7 different emotions:anger, boredom, disgust, fear, happiness, sadness, andneutral state. The overall system scheme is reported inFig. 1.
EmotionFront-End
Feature Extraction
Gender-DrivenEmotion
Recognizer
Fig. 1. Proposed emotion recognition scheme overallarchitecture.
The quantity s(t) represents the original continuous in-put audio signal. The Front-End block acquires s(t) andsamples it with frequency FS = 16 [KHz] in order to ob-tain the discrete sequence s(n). After this step, a featurevector Ω is computed by the Features Extraction block. Itis worth noticing that Ω includes the features ΩGR andΩER respectively employed by the Gender Recognitionand the Emotion Recognition subsystems. In practice thefeature vector may be written as Ω = ΩGR,ΩER. Ωis employed by the Gender-driven Emotion Recognitionblock that provides the output of the overall process:the recognized emotion. As already said and discussedin the reminder of this Section, this block is divided intotwo subsystems: Gender Recognition (GR) and EmotionRecognition (ER).
3.1 Gender Recognition (GR) subsystemAs reported in papers such as [10], [11], [13], [32], [33]audio-based Gender Recognition (GR) has many appli-cations. For example: gender-dependent model selectionfor the improvement of automatic speech recognitionand speaker identification, content-based multimedia in-dexing systems, interactive voice response systems, voicesynthesis and smart human-computer interaction. In thispaper, the recognition of the gender is used as input forthe emotion recognition block. As shown in the numer-ical result section, this pre-filtering operation improvesthe accuracy of the emotion recognition process.
Different kinds of classifiers are used to identify thespeaker gender starting from features: e.g., ContinuousDensity Hidden Markov Models [13], [16], GaussianMixture Model (GMM) [14], [16], Neural Networks [10],[32], Support Vector Machines [12], [33]. The percentagesof correct recognition of the speaker gender are reportedin Table 1 for most classifiers referenced above.
TABLE 1Classification accuracy (percentage) obtained by the
evaluated GR methods
Reference Accuracy
[10] 100[33] 100[14] 98.35[12] 95[32] 91.7[13] 90.9[34] 90
3.1.1 Proposed Gender Recognition AlgorithmThe proposed GR method is designed to distinguish amale from a female speaker and has been thought to berealized over mobile devices, such as smartphones. It isdesigned to operate in an open-set scenario and is basedon audio pitch estimation. In a nutshell: it is based onthe fact that pitch values of male speakers are on averagelower than pitch values of female speakers because malevocal folds are longer and thicker compared to femaleones. In addition, being male and female pitch frequencyseparated, we realized that satisfying results in termsof accuracy of the GR can be obtained by using asingle-feature threshold γthr classifier rather than morecomplex and time-consuming ones. Furthermore, beingmobile devices the target technology, time constraintsmust be carefully considered in the design, in particularin view of real-time applications.The chosen feature is the mean of the Probability DensityFunction (PDF), whose definition is reported in Section3.1.3, of a number of frames of the voice signal, asexplained below.The signal to be classified as ”Male” or ”Female” is iden-tified as s(n), n = 1, .., N . The GR method introduced inthis paper is composed of the following steps:
Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
5
1) The signal s(n) is divided into frames.2) The pitch frequency for each frame is estimated.3) A number of frames of s(n) is grouped into a odd-
number of blocks.4) The pitch PDF is estimated for each block.5) The mean of each pitch PDF (PDFmean) is com-
puted.6) The decision about ”Male” or ”Female” is taken,
for each block, by comparing their PDFmean with afixed threshold γthr computed by using the trainingset.
7) The final decision on the whole signal genderis taken by the majority rule: the signal s(n) isclassified as ”Male” if the majority of its blocks areclassified as ”Male”. Otherwise, it is classified as”Female”.
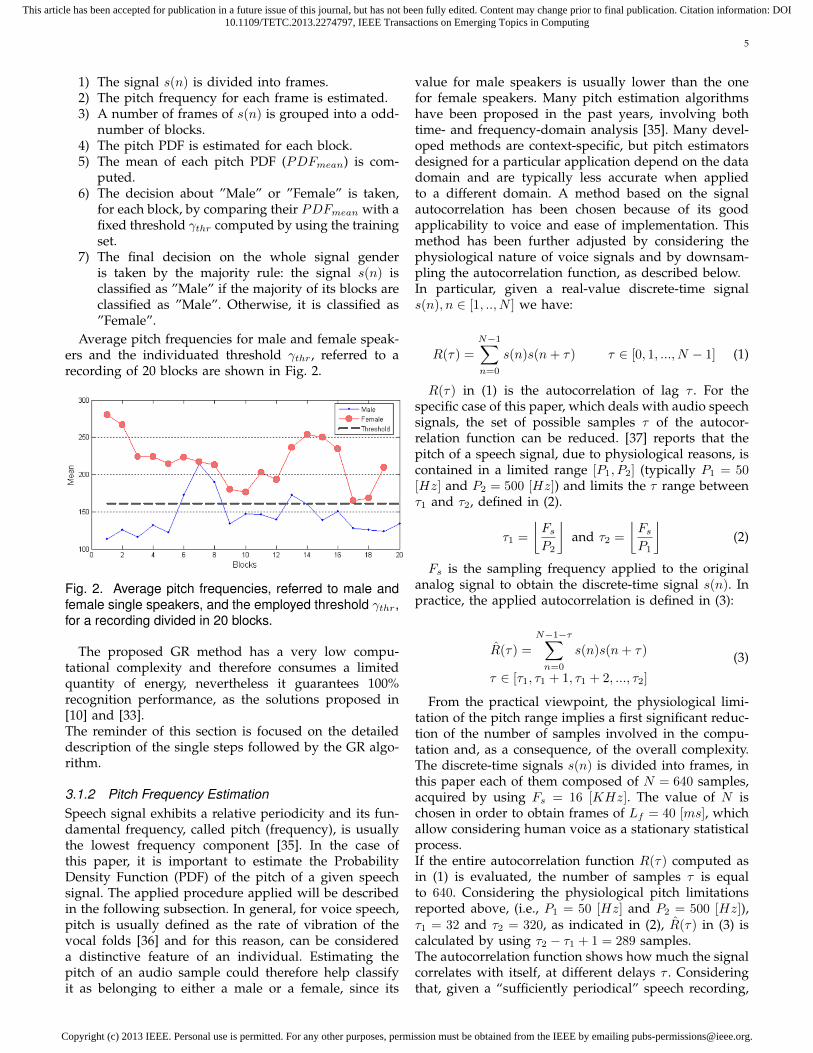
Average pitch frequencies for male and female speak-ers and the individuated threshold γthr, referred to arecording of 20 blocks are shown in Fig. 2.
Fig. 2. Average pitch frequencies, referred to male andfemale single speakers, and the employed threshold γthr,for a recording divided in 20 blocks.
The proposed GR method has a very low compu-tational complexity and therefore consumes a limitedquantity of energy, nevertheless it guarantees 100%recognition performance, as the solutions proposed in[10] and [33].The reminder of this section is focused on the detaileddescription of the single steps followed by the GR algo-rithm.
3.1.2 Pitch Frequency EstimationSpeech signal exhibits a relative periodicity and its fun-damental frequency, called pitch (frequency), is usuallythe lowest frequency component [35]. In the case ofthis paper, it is important to estimate the ProbabilityDensity Function (PDF) of the pitch of a given speechsignal. The applied procedure applied will be describedin the following subsection. In general, for voice speech,pitch is usually defined as the rate of vibration of thevocal folds [36] and for this reason, can be considereda distinctive feature of an individual. Estimating thepitch of an audio sample could therefore help classifyit as belonging to either a male or a female, since its
value for male speakers is usually lower than the onefor female speakers. Many pitch estimation algorithmshave been proposed in the past years, involving bothtime- and frequency-domain analysis [35]. Many devel-oped methods are context-specific, but pitch estimatorsdesigned for a particular application depend on the datadomain and are typically less accurate when appliedto a different domain. A method based on the signalautocorrelation has been chosen because of its goodapplicability to voice and ease of implementation. Thismethod has been further adjusted by considering thephysiological nature of voice signals and by downsam-pling the autocorrelation function, as described below.In particular, given a real-value discrete-time signals(n), n ∈ [1, .., N ] we have:
R(τ) =
N−1∑n=0
s(n)s(n+ τ) τ ∈ [0, 1, ..., N − 1] (1)
R(τ) in (1) is the autocorrelation of lag τ . For thespecific case of this paper, which deals with audio speechsignals, the set of possible samples τ of the autocor-relation function can be reduced. [37] reports that thepitch of a speech signal, due to physiological reasons, iscontained in a limited range [P1, P2] (typically P1 = 50[Hz] and P2 = 500 [Hz]) and limits the τ range betweenτ1 and τ2, defined in (2).
τ1 =
⌊FsP2
⌋and τ2 =
⌊FsP1
⌋(2)
Fs is the sampling frequency applied to the originalanalog signal to obtain the discrete-time signal s(n). Inpractice, the applied autocorrelation is defined in (3):
R(τ) =
N−1−τ∑n=0
s(n)s(n+ τ)
τ ∈ [τ1, τ1 + 1, τ1 + 2, ..., τ2]
(3)
From the practical viewpoint, the physiological limi-tation of the pitch range implies a first significant reduc-tion of the number of samples involved in the compu-tation and, as a consequence, of the overall complexity.The discrete-time signals s(n) is divided into frames, inthis paper each of them composed of N = 640 samples,acquired by using Fs = 16 [KHz]. The value of N ischosen in order to obtain frames of Lf = 40 [ms], whichallow considering human voice as a stationary statisticalprocess.If the entire autocorrelation function R(τ) computed asin (1) is evaluated, the number of samples τ is equalto 640. Considering the physiological pitch limitationsreported above, (i.e., P1 = 50 [Hz] and P2 = 500 [Hz]),τ1 = 32 and τ2 = 320, as indicated in (2), R(τ) in (3) iscalculated by using τ2 − τ1 + 1 = 289 samples.The autocorrelation function shows how much the signalcorrelates with itself, at different delays τ . Consideringthat, given a “sufficiently periodical” speech recording,

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
6
its autocorrelation will present the highest value at de-lays corresponding to multiples of pitch periods [35] [37].Defining the pitch period as
τpitch = arg maxτ
R(τ) (4)
the frequency of pitch is computed as
ρpitch =Fsτpitch
(5)
To further reduce the computational complexity ofthe proposed pitch estimation method, a downsampledversion of the autocorrelation function is introduced inthis paper by using a downsampling factor r < 1 and1r ∈ N . Being N the cardinality of the original setof autocorrelation samples, the downsampled versionuses K = rN samples. In practice, the downsampledautocorrelation is defined as:
R(τ) =
N−1−τ∑n=0
s(n)s(n+ τ)
τ ∈[τ1, τ1 + 1
r , τ1 + 2r , ..., τ2
] (6)
It means that R(τ) considers just one sample of R(τ)out of 1
r in the interval [τ1, ..., τ2].As a consequence (4) and (5) become:
τpitch = arg maxτ
R(τ) (7)
ρpitch =Fsτpitch
(8)
In order to still correctly determine the maximum ofthe autocorrelation in (3), thus preventing errors in pitchestimation, a maximum “Fine Search” method has beendesigned and implemented in this paper to partiallycompensate the inaccuracies introduced by downsam-pling. Starting from the delay corresponding to the pitchτpitch, obtained by the downsampled autocorrelationfunction, the values of R(τ), in (3), are computed for allthe τ values adjacent to τpitch up to a depth of ±
∣∣ 1r − 1
∣∣.Their maximum is taken as new pitch period τ ′pitch.Analytically:
τ ′pitch = arg maxτ R(τ)
τ ∈[τpitch − 1
r + 1, ..., τpitch − 1, τpitch,τpitch + 1, ..., τpitch + 1
r − 1] (9)
ρ′pitch =Fsτ ′pitch
(10)
ρ′pitch is the reference pitch value in the remainderof this paper. Autocorrelation downsampling may causethe “Fine Search” to be applied around a local maximumof the autocorrelation in (3) instead of the global one.This occurs only if the delay corresponding to the globalmaximum of R(τ) is farther than ±
∣∣ 1r − 1
∣∣ samples fromthe delay corresponding to the global maximum of R(τ).This event occurs rarely and, as a consequence, the new
approach guarantees a good estimation and represents areasonable compromise between performance and com-putational complexity energy saving, making feasiblethe implementation of the GR algorithm over mobileplatforms.
3.1.3 PDF EstimationLooking at the list of steps in 3.1.1 but providing moredetail, the signal s(n), n = 1, ..., N is divided into F =⌊NL
⌋frames, where L is the number of the sample in each
frame. The value of L directly derives from L = Fs ·Lf .Generic i-th frame is defined as
fi = s(n) : n = (i− 1)L+ 1, ..., iL , i = 1, ..., F. (11)
A pitch estimate is computed for each frame byapplying the method described in Section 3.1.2. Setsof consecutive frames are grouped together in blocks,in order to allow the computation of a pitch PDF foreach block. Consecutive blocks are overlapped by Vframes (i.e., the last V frames of a block are the firstV frames of the following one) in order to take intoaccount the possibility that a signal portion representinga speech falls across consecutive blocks if blocks were notoverlapped. The signal contribution to the classificationprocess would be divided between two separate blocks.The overlap implies there are B =
⌊F−VD−V
⌋blocks. The
t-th block can be defined as
bt = fi : i = (t− 1)(D − V ) + 1, ...,tD − (t− 1)V , t = 1, ..., B.
(12)
For each bt block there are V pitch values computed asin (10) identified as ρbt,vpitch, v = 1, ..., V . bt block PDFs spanover a frequency interval ranging from the minimumto the maximum computed pitch value. Such frequencyinterval is divided into H smaller frequency bins of ∆p[Hz] size determined through extensive tests. Being p isthe variable identifies the frequency the PDF for eachblock bt is estimated by a weighted sum of the numberof occurrences of single ρbt,vpitch, v = 1, ..., V within eachfrequency bin h = 0, ...,H − 1. In formula:
PDF (p) =
H−1∑h=0
wh · rect
(p−
[(12 + h
)∆p]
∆p
)(13)
wh is the coefficient associated to the h-th bin andimplements the mentioned weighted sum, as explainedin the following. If wh is the number of ρbt,vpitch, v = 1, ..., V ,whose values fall within the h-th bin, then the PDF issimply estimated through the number of occurrencesand is called ”histogram count”. In order to have a moreprecise PDF estimation and, consequently, more accuratefeatures vectors, this paper links the coefficient wh to theenergy distribution of the signal s(n) in the frequencyrange of the PDF.

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
7
Given the Discrete Fourier Transform (DFT) of s(n),
DFT (s(n)) = S(k) =
N−1∑n=0
s(n) · e−j2πn kN , ∀k ∈ [0, ..., N −
1], the signal energy (Es) definition and the ParsevalRelation, written for the defined DFT , we have Es =N−1∑n=0
|s(n)|2 =1
N
N−1∑k=0
|S(k)|2. A single energy compo-
nent is |S(k)|2, where k represents the index of thefrequency fk = k
N , k = 0, ..., N − 1. To evaluate theenergy component of each frequency bin h, we wouldneed to know the energy contribution carried by eachpitch occurring within bin h. In practice, the quantity∣∣∣S(ρbt,vpitch)
∣∣∣2 , v = 1, ..., V would be necessary but the DFT
is a function of an integer number k and ρbt,vpitch ∈ R.So, to allow the computation for real numbers, ρbt,vpitch isapproximated by the closest integer number ρbt,vpitch,int,defined as follows:
ρbt,vpitch,int =
⌊ρbt,vpitch
⌋if ρbt,vpitch −
⌊ρbt,vpitch
⌋< 1
2⌈ρbt,vpitch
⌉if ρbt,vpitch −
⌊ρbt,vpitch
⌋≥ 1
2
(14)
Consequently, the coefficient wh, properly normalized,is defined as
wh =
V∑v=1
∣∣∣S(ρbt,vpitch,int)∣∣∣2
H−1∑h=0
V∑v=1
∣∣∣S(ρbt,vpitch,int)∣∣∣2 (15)
The sums with index v must be computed for eachρbt,vpitch ∈ bin h. Directly from (15), higher-energy pitchestimates become more relevant than lower-energy ones.Actually the underlying hypothesis is that higher-energypitches derive from fully voiced (without silence in-tervals) frames and are therefore more reliable. Thissection leads to more distinct PDFs and more accuratefeatures vector, thus significantly improving the GRmethod performance compared to computing PDFs bysimply executing a “histogram count”, for which wh isthe number of pitches whose value falls within the h-thbin.
3.1.4 Features Vector Definition and Gender Classifica-tion Policy
In order to determine the best feature vector ΩGR thatmaximizes the efficiency of the proposed GR method,different feature vectors were evaluated by combiningdifferent individual features:• PDF maximum: PDFmax;• PDF mean: PDFmean;• PDF standard deviation: PDFstd;• PDF roll-off: PDFroll−off ;
By using a general set of features, the feature vectorwould be composed, for each block, by
ΩGR =ωGR1 , · · · , ωGRz , · · · , ωGRZ
(16)
where z ∈ [1, Z] and Z is the size of the definedfeatures vector. In this paper, each element of ΩGR isone of the features extracted from the Pitch PDF listedabove so that ΩGR =
ωGR1 , ωGR2 , ωGR3 , ωGR4
.
For sake of completeness, different subsets of the featureslisted above have been tested as features vector ΩGR.However, due to the separation between male and fe-male pitch frequency, practical experiments have shownthat the employment of the PDFmean is sufficient toseparate the two classes. For this reason the featurevector is reduced to a simple scalar ΩGR = ωGR1 =PDFmean.From an analytical viewpoint, PDFmean is computedas follows:
ΩGR = ωGR1 = PDFmean =
H−1∑h=0
ph · wh (17)
where ph represents the central frequency of the h-thbin and wh is computed as in (15). The label g of therecognized gender is obtained through (18). g has value1 for the Male and −1 for Female.
g = g(ΩGR) = g(ωGR1 ) = −sgn(ωGR1 − γthr) =
= −sgn(H−1∑h=0
ph · wh − γthr) (18)
In practice, g = 1 ifH−1∑h=0
ph · wh ≤ γthr, g = −1 oth-
erwise. Starting from experimental tests, the employedthreshold γthr has been estimated to be 160 [Hz]. Thisnumerical value has been employed in the proposedgender-driven emotion recognition system.
Numerical results, not reported here for sake ofbrevity, have shown that the proposed method is ableto recognize the gender with 100% accuracy.
3.2 Emotion Recognition (ER) subsystem
+Emotion
Gender Recognizer
MaleSVM
FemaleSVM
Fig. 3. Emotion Recognition (ER) subsystem.
The implemented Emotion Recognition (ER)subsystem is based on two inputs: the features extracted

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
8
by the Features Extraction Block Ω, in particular the sub-set ΩER of features needed for the emotion recognitionand the recognized speaker gender provided by theGR subsystem. Differently from the the GR subsystemin which the employed feature has been individuated(the Pitch), concerning the ER subsystem the selectionof feature(s) to be employed is still an open issue. Forthis reason, this paper does not provide a fixed set offeatures but proposes a study that takes into account themost important features employed in the literature andtheir selection through a features selection algorithm.Indeed, the features employed in the ER subsystem arebased on a set of features (182 in this paper) or on asub-set of them. Sub-sets have been individuated byusing a Principal Component Analysis (PCA) algorithmand have been evaluated in terms of recognition rate.The recognition rate obtained by varying the selectedfeatures has been reported in Section 4.
3.2.1 Principal Emotion FeaturesFor the sake of completeness, in the reminder of thissubsection, the definitions of the considered principalfeatures are listed and defined. Energy and amplitudeare simply the energy and the amplitude of the au-dio signals and no explicit formal definition is neces-sary. Concerning Pitch related features the extractionapproach is based on the pitch estimation described inSection 3.1.2.The other considered features can be defined as follows:
3.2.1.1 Formants: in speech processing, formantsare the resonance frequencies of the vocal tract. The es-timation of their frequency and their -3 [dB] bandwidthis fundamental for the analysis of the human speechas they are meaningful features able to distinguish thevowel sounds.In this paper, we employ a typical method to computethem, which is based on the Linear Predictive Coding(LPC) analysis. In more detail, the speech signal s(n) isre-sampled at twice the value Fmax = 5.5 [Hz], which isthe maximum frequency applied within the algorithm tosearch formants. Then, a pre-emphasis filter is applied.The signal is divided in audio frames (0.05 [s] long inthe case of formant extraction) and a Gaussian windowis applied to each frame. After that LPC Coefficients arecomputed by using the Burg method [38]. Being zi =rie±θi the i-th complex root pair of the prediction (LPC)
polynomial, the frequency, called Υi, and the -3 [dB]bandwidth, indicated with ∆i, of the i-th formant relatedto the i-th complex root pair of the LPC polynomial, canbe estimated by applying the following formulae [39]:
Υi =Fs2πθi (19)
∆i = −Fsπ
ln ri (20)
The algorithm finds all the formants in the range [0 −Fmax] [Hz]. Some artefacts of the LPC algorithm can
produce “false” formants near 0 and Fmax [Hz] thereforethe formants below 50 and over (Fmax − 50[Hz]) areremoved.
3.2.1.2 Mel-Frequency Cepstrum Coefficients:Mel-Frequency Cepstrum (MFC) is a widely used repre-sentation of the short-term power spectrum of a sound(i.e., an audio signal). Mel-Frequency Cepstral Coeffi-cients (MFCCs) allow describing MFC. MFCCs compu-tation is based on the subdivision of the audio signalinto analysis frames, whose duration is 30 [ms], selectedso that the distance between the centres of two adjacentframes is equal to 10 [ms] (i.e., two consecutive framesare overlapped for one third of their duration). For eachframe the spectrum is shaped through the so called “mel-scale”, using 13 triangular overlapping filters. Finally,the MFCCs of each frame are computed by using theDiscrete Cosine Transform (DCT).
MFCCi =13∑j=1
Pj cos
(iπ
13(j − 0.5)
), i ∈ [1,M ] (21)
where Pj represent the power, in [dB], of the output thej-th filter and M is the number of considered MFFCs. Inour case, M = 12.
3.2.1.3 Center of Gravity: the spectral Centre OfGravity (COG) is a measure of how high the frequenciesin a spectrum are. For this reason the COG gives anaverage indication of the spectral distribution of thespeech signal under observation. Given the considereddiscrete signal s(n) and its DFT S(k), the COG has beencomputed by:
fCOG =
N∑k=1
fk |S(k)|2
N∑k=1
|S(k)|2(22)
where, as defined in Section 3.1.3, fk = kN , k =
0, ..., N − 1 represents the k-th frequency composing theDFT.
3.2.1.4 Spectrum Central Moments: the m-th cen-tral spectral moment of the considered sequence s(n) hasbeen computed by:
µm =
N∑k=1
(fk − fCOG)m |S(k)|2
N∑k=1
|S(k)|2(23)
3.2.1.5 Standard Deviation (SD): the standard de-viation of a spectrum is defined as the measure of howmuch the frequencies in a spectrum can deviate from thecentre of gravity. SD corresponds to the square root ofthe second central moment µ2:
σ =√µ2 (24)

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
9
3.2.1.6 Skewness: the skewness of a spectrum isa measure of symmetry and it is defined as the thirdcentral moment of the considered sequence s(n), dividedby the 1.5 power of the second central moment:
γ1 =µ3√µ32
(25)
3.2.1.7 Kurtosis: the excess of Kurtosis is definedas the ratio between the fourth central moment and thesquare of the second central moment of the consideredsequence s(n) minus 3:
γ2 =µ4
µ22
− 3 (26)
3.2.1.8 Glottal Pulses: human speech, in the timedomain, presents a periodic pattern. Each of the iden-tifiable repeating patterns is called ”cycle” and eachpeak in a cycle is called ”glottal pulse”. The durationof each cycle is called ”period of the glottal pulse”. TheDynamic Waveform Matching (DWM) has been used tofind Glottal Pulses. The mean of the glottal pulse period(T ) is defined as follows:
T =1
Q
Q∑q=1
Tq (27)
where Tq is the duration of the q-th glottal pulse periodand Q is the number of periods. Among the GlottalPulses, only the following have been used:
• Jitter Local Absolute (JLA) is often used as a mea-sure of voice quality. JLA is defined as the aver-age absolute difference between consecutive glottalpulses intervals:
JLA =1
Q− 1
Q∑q=2
|Tq − Tq−1| (28)
• Relative average perturbation (JRAP ) is a jitter mea-sure between an interval and its two neighbours:
JRAP =1
(Q− 1)T
Q−1∑q=2
∣∣∣∣Tq − Tq−1 + Tq + Tq+1
3
∣∣∣∣(29)
• Difference of Difference Period (JDDP ) is defined asfollows:
JDDP =1
(Q− 2)T
Q−1∑q=2
(Tq+1 − Tq)(Tq − Tq−1) (30)
• Five-points period perturbation quotient (J5PPQ)is a jitter measure between an interval Tq andthe average of Tq and its four closest neighbours:Tq−2, Tq−1, Tq+1 and Tq+2.
J5PPQ = 1(Q−4)T
Q−3∑q=3
∣∣∣∣Tq−Tq−2 + Tq−1 + Tq + Tq+1 + Tq+2
5
∣∣∣∣ (31)
3.2.2 Emotion Features Selection
As a preliminary step, the Principal Components Anal-ysis (PCA) algorithm has been used in order to reduceand limit the number of features. PCA is a techniquethat, given high-dimensional feature vectors reduces thenumber of features used in the vector without losing toomuch information, by using the dependencies betweenfeatures and by identifying the principal directions inwhich the features vary.From each feature involved in the algorithm the meanvalue is subtracted, in order to obtain zero-mean featureset. After this step, PCA computes new variables calledPrincipal Components (PCs) which are obtained as linearcombinations of the original features. The first PC isrequired to have the largest possible variance (which,considering zero-mean feature sets, is equivalent to theconcept of inertia, originally employed in the PC def-inition, see [40]). The second component is computedunder the constraint of being orthogonal to the first oneand to have, again, the largest possible variance. Theother components are computed in a similar way. Thevalues of PCs for the features are called factor scoresand can be interpreted geometrically as the projectionsof the features onto the principal components [40]. Theimportance of a feature for a PC is directly proportionalto the correspondent squared factor score. This value iscalled the contribution of the feature to the PC.
The value of the contribution is between 0 and 1 and,for a given PC, the sum of the contributions of all featuresis equal to 1. From a practical viewpoint, larger the valueof the contribution, bigger the feature contributes to thePC.Contribution values will be used in the numerical resultssection, in order to evaluate the Emotion Recognitionblock when different number of features are employed,starting from the one which presents the highest contri-bution.
3.2.3 Emotions Classifiers
Usually, in the literature of the field, a Support VectorMachine (SVM) is used to classify sentences. SVM is arelatively new machine learning algorithm introducedby Vapnik [24] and derived from statistical learning the-ory in the 90s. The main idea is to transform the originalinput set into a high-dimensional feature space by usinga kernel function and, then, to achieve optimum classifi-cation in this new feature space, where a clear separationamong features obtained by the optimal placement of aseparation hyperplane under the precondition of linearseparability.Differently from the previously proposed approaches,two different classifiers, both kernel-based Support Vec-tor Machines (SVMs), have been employed in this paperas shown in Figure 3.
The first one (called Male-SVM) is used if a malespeaker is recognized by the Gender Recognition block.The other SVM (Female-SVM) is employed in case of

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
10
female speaker. Male-SVM and Female-SVM classifiershave been trained by using speech signals of the em-ployed reference DataBase (DB) generated, respectively,by male and female speakers.Being g = 1,−1 the label of the gender as definedin Section 3.1.4, the two SVMs have been trained by thetraditional Quadratic Programming (QP) as done in [41].In more detail, the following problem has been solvedfor each gender g:
minλg
Γg(λg) =1
2
`g∑u=1
`g∑v=1
yug yvgφ(xug ,x
vg)λ
ugλ
vg −
`g∑u=1
λug ,
`g∑u=1
λugyug = 0,
0 ≤ λug ≤ C, ∀u.
(32)
where λg = λ1g · · ·λug · · ·λ`gg represents the well-
known Lagrangian Multipliers vector of the QP prob-lem written in dual form. Vectors x1
g, · · · ,xug , · · · ,x`gg
are features vectors while scalars y1g , · · · , yug , · · · , y`gg are
related labels (i.e., the emotions in this paper). They rep-resent the vectors of the training set for the g-th gender.(xug , y
ug ),∀u ∈ [1, `g] is the related association, also called
observation, between the u-th input features vector xugand its label yug . The quantity `g is the total amount ofobservations composing the training set. The quantity C(C > 0) is the Complexity constant which determinesthe trade-off between the flatness (i.e., the sensitivity ofthe prediction to perturbations in the features) and thetolerant level for misclassified samples. Higher value ofC means that is more important minimising the degreeof misclassification. C = 1 is used in this paper.Equation (32) represents a non-linear SVM and the func-tion φ(xug ,x
vg) is the Kernel function that, in this paper,
is φ(xug ,xvg) = (xug )T (xvg) + 1.
Coherently with [41], the QP problems (one for each gen-der) in equation (32) are solved by the Sequential MinimalOptimization (SMO) approach that provides an optimalpoint, not necessarily unique and isolated, of (32) if andonly if Karush-Kuhn-Tucker (KKT) conditions are verifiedand matrices yug y
vgφ(xug ,x
vg) are positive semi-definite.
Details about the KKT conditions and the SMO approachemployed to solve problem (32) can be found in [41] andreferences therein.
3.2.4 Employed Signal Dataset: Berlin EmotionalSpeech (BES)As described in [42], and here reported for the sakeof completeness, BES is a public database of actedspeeches. The sentences are recorded by 10 Germanactors (5 male and 5 female) that produced 10 utteranceseach (5 short and 5 long phrases). Each utterance isclassified with one among 7 different labels: anger,boredom, disgust, fear, happiness, sadness, and neutral.
The sentences were evaluated by 20 listeners to checkthe emotional state and only those that had a recognitionrate of 80% or above were retained, getting about 500speeches. Additionally, two more perception tests werecarried out: one to rate the strength of the displayedemotion for each speech, the other to judge the syllablestress of every speech. Emotional strength was usedas a control variable in statistical analysis. Evaluatingthe syllable stress was necessary because objectivestress measurements are not available. This last testwas performed only by phonetically trained subjects.Speeches were recorded within an anechoic chamberwith high-quality recording equipment. Recordings aresampled at 16 [KHz].
4 PERFORMANCE EVALUATION
In this Section the performance evaluation of the overallEmotion Recognition (ER), in terms of accuracy (i.e.,correct detection rate), of the system is presented. Therecognized emotions are: anger (AN), boredom (BO),disgust (DI), fear (FE), happiness (HA), sadness (SA),together with the neutral (NE) state. The reported resultsare divided into two main parts. The first part shows theperformance of the system if no information about thegender of the speaker is exploited in the emotion recog-nition process. The second part of the results providesthe performance obtained by exploiting the knowledgerelated to the speakers’ gender. The experimental resultshighlight that the gender information allows increment-ing the accuracy of the emotion recognition system onaverage.
4.1 Without Gender RecognitionIn this subsection, the accuracy of a traditional approach,without having any “a priori” information on the genderof the speaker, is shown. In this case, a single SVMhas been trained with both male and female speeches.In more detail, the SVM has been trained and tested,considering the overall BES signals, by the k-fold cross-validation approach. The original BES signals are ran-domly partitioned into k equal size subsets. Among thek subsets, a single subset is retained to test the SVM,and the other k− 1 subsets are employed to train it. Thecross-validation process is then repeated k times, witheach of the k subsets used once as validation set. Theobtained k results are then averaged to produce a singleresult. In this paper, in all considered cases, k = 10 hasbeen employed.The obtained results are reported in Table 2, whichreports the confusion matrix of the recognition rate. Thereported values have been obtained by employing allthe aforementioned 182 features (i.e., no PCA has beenapplied). In more detail, as for all the confusion matricesreported in this Performance Evaluation Section, thefirst row represents the recognized emotion while thefirst column contains the ground truth. For example, in

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
11
Table 2, given anger (AN) as ground truth, the system”decides”: AN in the 92.1% of the tests, never BO,DI in the 1.6% of the tests, and so on. Moreover, themean value of the main diagonal of the matrix givesthe average accuracy. If the mean of the main diagonalis computed from Table 2, it is possible to see that themethod provides a good percentage of correct recogni-tion for each emotion: the average value is about 77.4%.It is also clear that some emotions are better recognized(i.e., Anger and Sadness, recognized in the 92.1% and88.7% of the cases, respectively) than other ones (suchas Happiness, identified only in the 59.2% of the cases).
TABLE 2Confusion Matrix without applying any Gender
Recognition
AN BO DI FE HA NE SAAN 0.921 0 0.016 0.008 0.055 0 0BO 0 0.852 0 0.025 0 0.123 0DI 0.065 0.022 0.673 0.087 0.087 0.043 0.022FE 0.029 0.043 0.043 0.783 0.043 0.043 0.014HA 0.268 0.014 0.028 0.084 0.592 0.014 0NE 0 0.240 0.013 0.025 0 0.709 0.013SA 0 0.016 0 0.032 0 0.065 0.887
4.2 With Gender Recognition
Differently from the previous Section, now we evaluatethe system performance when the “a priori” informationon the gender of the speaker is used. This informationhas been obtained by exploiting, in the testing phase, theGender Recognition subsystem introduced in Section 3.1and providing 100% gender recognition. In this case, asdepicted in Fig. 3 and as extensively explained before,two SVMs, one for each gender, have been trained: thefirst SVM through male speeches signals, the secondthrough female ones.Also in this case, SVM training and testing phases havebeen carried out by two k-fold (k = 10) cross-validationsand, again, the overall BES signals have been employedby dividing male speech from female speech signals.Reported results show that the employment of infor-mation related to speaker gender allows improving theperformance. The overall set of features (182) has beenemployed for these tests. In more detail, Table 3 andTable 4 show the confusion matrices concerning maleand female speech signals, respectively.The average percentage of correct classification if male
speakers are recognized, is almost 79%. In the caseof female speeches, the average value of the correctrecognition is almost 84%. Globally, the performancein terms of correct emotion recognition (accuracy), incase of gender recognition is 81.5%, which representsa performance improvement of about the 5.3% withrespect to the results shown in Table 2, where no genderinformation is employed.
TABLE 3Confusion Matrix of Male Speech Signals by applying
Gender Recognition
AN BO DI FE HA NE SAAN 0.983 0 0 0.017 0 0 0BO 0 0.743 0 0 0 0.200 0.057DI 0.091 0.091 0.454 0.273 0 0 0.091FE 0 0 0.056 0.805 0.056 0.056 0.028HA 0.259 0 0 0.074 0.667 0 0NE 0 0.103 0 0.026 0.026 0.846 0SA 0 0.040 0 0 0 0 0.960
TABLE 4Confusion Matrix of Female Speech Signals by applying
Gender Recognition
AN BO DI FE HA NE SAAN 0.881 0 0.030 0 0.089 0 0BO 0 0.848 0 0 0 0.152 0DI 0.029 0 0.857 0.057 0.029 0.029 0FE 0.030 0 0 0.909 0.030 0.030 0HA 0.341 0 0.091 0.045 0.477 0.045 0NE 0 0.150 0 0 0 0.850 0SA 0 0 0 0 0 0 1.000
4.3 Features Reduction
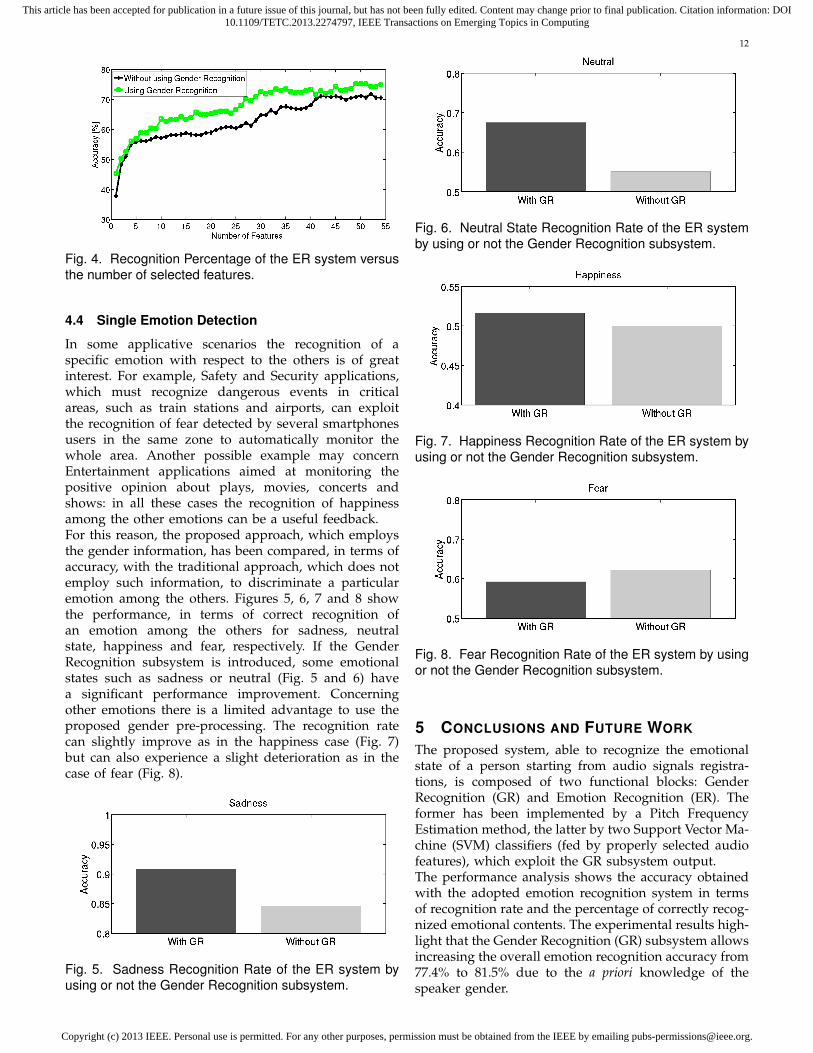
As described previously in the paper, the considered ap-proaches (i.e., a single SVM trained without distinguish-ing the gender and two SVMs driven by the proposedGR subsystem) can be implemented by employing a re-duced number of features. A reduced number of featuresimplies a reduction of the computational load neededto carry out the emotion recognition process and thisopens the doors to the practical implementation of theproposed solution over mobile devices such as modernsmartphones but performance must be satisfactory. Inthis paragraph a performance study of the accuracy byreducing the number of employed features, obtained bythe PCA approach, is shown. In particular, as reportedin Fig. 4, which shows the recognition percentage ofthe ER block by varying the number of used features,the average emotion recognition accuracy increases asthe number of the employed features increases. Thefeatures are added in the emotion recognition processby following their contribution value, as described inSection 3.2.2. From a numerical viewpoint, the accuracyreaches a values slightly above 70% of correctly classi-fied emotions, if the GR subsystems is not employed,and a value of about 75%, if the GR subsystem drivesthe emotion recognition process. This performance isobtained when only 55 features are employed in thewhole recognition process. The obtained accuracy is notso much lower than the accuracy (81.5%) obtained byusing 182 features as reported above. We think that thisperformance decrease represents a reasonable trade-offbetween performance and computational load in viewof future implementation over mobile platforms.
Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
12
Fig. 4. Recognition Percentage of the ER system versusthe number of selected features.
4.4 Single Emotion Detection
In some applicative scenarios the recognition of aspecific emotion with respect to the others is of greatinterest. For example, Safety and Security applications,which must recognize dangerous events in criticalareas, such as train stations and airports, can exploitthe recognition of fear detected by several smartphonesusers in the same zone to automatically monitor thewhole area. Another possible example may concernEntertainment applications aimed at monitoring thepositive opinion about plays, movies, concerts andshows: in all these cases the recognition of happinessamong the other emotions can be a useful feedback.For this reason, the proposed approach, which employsthe gender information, has been compared, in terms ofaccuracy, with the traditional approach, which does notemploy such information, to discriminate a particularemotion among the others. Figures 5, 6, 7 and 8 showthe performance, in terms of correct recognition ofan emotion among the others for sadness, neutralstate, happiness and fear, respectively. If the GenderRecognition subsystem is introduced, some emotionalstates such as sadness or neutral (Fig. 5 and 6) havea significant performance improvement. Concerningother emotions there is a limited advantage to use theproposed gender pre-processing. The recognition ratecan slightly improve as in the happiness case (Fig. 7)but can also experience a slight deterioration as in thecase of fear (Fig. 8).
Fig. 5. Sadness Recognition Rate of the ER system byusing or not the Gender Recognition subsystem.
Fig. 6. Neutral State Recognition Rate of the ER systemby using or not the Gender Recognition subsystem.
Fig. 7. Happiness Recognition Rate of the ER system byusing or not the Gender Recognition subsystem.
Fig. 8. Fear Recognition Rate of the ER system by usingor not the Gender Recognition subsystem.
5 CONCLUSIONS AND FUTURE WORK
The proposed system, able to recognize the emotionalstate of a person starting from audio signals registra-tions, is composed of two functional blocks: GenderRecognition (GR) and Emotion Recognition (ER). Theformer has been implemented by a Pitch FrequencyEstimation method, the latter by two Support Vector Ma-chine (SVM) classifiers (fed by properly selected audiofeatures), which exploit the GR subsystem output.The performance analysis shows the accuracy obtainedwith the adopted emotion recognition system in termsof recognition rate and the percentage of correctly recog-nized emotional contents. The experimental results high-light that the Gender Recognition (GR) subsystem allowsincreasing the overall emotion recognition accuracy from77.4% to 81.5% due to the a priori knowledge of thespeaker gender.

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
13
The results show that with the employment of a fea-tures selection algorithm, a satisfying recognition ratelevel can still be obtained also reducing the employedfeatures and, as a consequence, the number of operationsrequired to identify the emotional contents. This makesfeasible future development of the proposed solutionover mobile devices.The obtained results underline that our system can bereliably used to identify a single emotion, or emotioncategory, versus all the other possible ones.Possible future developments of this work can followdifferent directions: i) evaluation of the system perfor-mance by grouping the considered emotions in biggersets (i.e., negative vs positive emotions); ii) evaluationof different classification algorithms; iii) implementationand related performance investigation of the proposedsystem on mobile devices; iv) computational load andenergy consumption analysis of the implemented sys-tem.
ACKNOWLEDGMENTSThe authors wish to thank Dr. Angelo Cirigliano e Dr.Fabio Patrone for their precious support in the testingphase of this research work and for their importantsuggestions.
REFERENCES[1] F. Burkhardt, M. van Ballegooy, R. Englert, and R. Huber, “An
emotion-aware voice portal,” Proc. Electronic Speech Signal Process-ing ESSP, pp. 123–131, 2005.
[2] J. Luo, Affective computing and intelligent interaction. Springer,2012, vol. 137.
[3] R. W. Picard, Affective computing. MIT press, 2000.[4] G. Chittaranjan, J. Blom, and D. Gatica-Perez, “Who’s who with
big-five: Analyzing and classifying personality traits with smart-phones,” in ISWC’11, 2011, pp. 29–36.
[5] A. Vinciarelli, M. Pantic, and H. Bourlard, “Social signalprocessing: Survey of an emerging domain,” Image VisionComput., vol. 27, no. 12, pp. 1743–1759, Nov. 2009. [Online].Available: http://dx.doi.org/10.1016/j.imavis.2008.11.007
[6] Z. Zeng, M. Pantic, G. Roisman, and T. Huang, “A survey of affectrecognition methods: Audio, visual, and spontaneous expres-sions,” Pattern Analysis and Machine Intelligence, IEEE Transactionson, vol. 31, no. 1, pp. 39–58, 2009.
[7] A. Gluhak, M. Presser, L. Zhu, S. Esfandiyari, andS. Kupschick, “Towards mood based mobile services andapplications,” in Proceedings of the 2nd European conferenceon Smart sensing and context, ser. EuroSSC’07. Berlin,Heidelberg: Springer-Verlag, 2007, pp. 159–174. [Online].Available: http://dl.acm.org/citation.cfm?id=1775377.1775390
[8] K. K. Rachuri, M. Musolesi, C. Mascolo, P. J. Rentfrow, C. Long-worth, and A. Aucinas, “Emotionsense: a mobile phones basedadaptive platform for experimental social psychology research,”in UbiComp’10, 2010, pp. 281–290.
[9] M. El Ayadi, M. S. Kamel, and F. Karray, “Survey on speech emo-tion recognition: Features, classification schemes, and databases,”Pattern Recognition, vol. 44, no. 3, pp. 572–587, 2011.
[10] R. Fagundes, A. Martins, F. Comparsi de Castro, and M. Fe-lippetto de Castro, “Automatic gender identification by speechsignal using eigenfiltering based on hebbian learning,” in NeuralNetworks, 2002. SBRN 2002. Proceedings. VII Brazilian Symposiumon, 2002, pp. 212–216.
[11] Y.-M. Zeng, Z.-Y. Wu, T. Falk, and W.-Y. Chan, “Robust gmmbased gender classification using pitch and rasta-plp parametersof speech,” in Machine Learning and Cybernetics, 2006 InternationalConference on, 2006, pp. 3376–3379.
[12] Y.-L. Shue and M. Iseli, “The role of voice source measures onautomatic gender classification,” in Acoustics, Speech and SignalProcessing, 2008. ICASSP 2008. IEEE International Conference on,2008, pp. 4493–4496.
[13] F. Yingle, Y. Li, and T. Qinye, “Speaker gender identification basedon combining linear and nonlinear features,” in Intelligent Controland Automation, 2008. WCICA 2008. 7th World Congress on, 2008,pp. 6745–6749.
[14] H. Ting, Y. Yingchun, and W. Zhaohui, “Combining mfcc andpitch to enhance the performance of the gender recognition,” inSignal Processing, 2006 8th International Conference on, vol. 1, 2006,pp. –.
[15] D. Deepawale and R. Bachu, “Energy estimation between adjacentformant frequencies to identify speaker’s gender,” in InformationTechnology: New Generations, 2008. ITNG 2008. Fifth InternationalConference on, 2008, pp. 772–776.
[16] F. Metze, J. Ajmera, R. Englert, U. Bub, F. Burkhardt, J. Stegmann,C. Muller, R. Huber, B. Andrassy, J. Bauer, and B. Littel, “Com-parison of four approaches to age and gender recognition fortelephone applications,” in Acoustics, Speech and Signal Processing,2007. ICASSP 2007. IEEE International Conference on, vol. 4, 2007,pp. IV–1089–IV–1092.
[17] E. Zwicker, “Subdivision of the audible frequency range intocritical bands (frequenzgruppen),” The Journal of the AcousticalSociety of America, vol. 33, no. 2, pp. 248–248, 1961. [Online].Available: http://link.aip.org/link/?JAS/33/248/1
[18] R. Stibbard, “Automated extraction of tobi annotation data fromthe reading/leeds emotional speech corpus,” in ISCA Tutorial andResearch Workshop (ITRW) on Speech and Emotion, 2000.
[19] R. Cowie, E. Douglas-Cowie, N. Tsapatsoulis, G. Votsis, S. Kollias,W. Fellenz, and J. G. Taylor, “Emotion recognition in human-computer interaction,” Signal Processing Magazine, IEEE, vol. 18,no. 1, pp. 32–80, 2001.
[20] N. Campbell, “Building a corpus of natural speech-and toolsfor the processing of expressive speech-the jst crest esp project,”in Proc. 7th European Conference on Speech Communication andTechnology. Center for Personkommunikation (CPK), Aalborg, 2001,pp. 1525–1528.
[21] R. Kohavi et al., “A study of cross-validation and bootstrap foraccuracy estimation and model selection,” in International jointConference on artificial intelligence, vol. 14. Lawrence ErlbaumAssociates Ltd, 1995, pp. 1137–1145.
[22] W. H. Rogers and T. J. Wagner, “A fine sample distribution-freeperformance bound for local discrimination rules,” vol. 6, no. 3,pp. 506–514, 1978.
[23] R. Hanson, J. Stutz, and P. Cheeseman, Bayesian classification theory.NASA Ames Research Center, Artificial Intelligence ResearchBranch, 1991.
[24] V. Vapnik, The nature of statistical learning theory. springer, 1999.[25] B. Yegnanarayana, Artificial neural networks. PHI Learning Pvt.
Ltd., 2004.[26] T. Cover and P. Hart, “Nearest neighbor pattern classification,”
Information Theory, IEEE Transactions on, vol. 13, no. 1, pp. 21–27,1967.
[27] A. A. Razak, R. Komiya, M. Izani, and Z. Abidin, “Comparisonbetween fuzzy and nn method for speech emotion recognition,”in Information Technology and Applications, 2005. ICITA 2005. ThirdInternational Conference on, vol. 1. IEEE, 2005, pp. 297–302.
[28] O. Pierre-Yves, “The production and recognition of emotions inspeech: features and algorithms,” International Journal of Human-Computer Studies, vol. 59, no. 1, pp. 157–183, 2003.
[29] L. Breiman, “Random forests,” Machine learning, vol. 45, no. 1, pp.5–32, 2001.
[30] F. Dellaert, T. Polzin, and A. Waibel, “Recognizing emotion inspeech,” in Spoken Language, 1996. ICSLP 96. Proceedings., FourthInternational Conference on, vol. 3. IEEE, 1996, pp. 1970–1973.
[31] M. Westerdijk, D. Barber, and W. Wiegerinck, “Generative vectorquantisation,” 1999.
[32] H. Harb and L. Chen, “Gender identification using a general au-dio classifier,” in Multimedia and Expo, 2003. ICME ’03. Proceedings.2003 International Conference on, vol. 2, 2003, pp. II–733–6 vol.2.
[33] M. Kotti and C. Kotropoulos, “Gender classification in two emo-tional speech databases,” in Pattern Recognition, 2008. ICPR 2008.19th International Conference on, 2008, pp. 1–4.
[34] G. Tzanetakis, “Audio-based gender identification using boot-strapping,” in Communications, Computers and signal Processing,

Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing [email protected].
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TETC.2013.2274797, IEEE Transactions on Emerging Topics in Computing
14
2005. PACRIM. 2005 IEEE Pacific Rim Conference on, 2005, pp. 432–433.
[35] D. Gerhard, “Pitch extraction and fundamental frequency: Historyand current techniques,” Tech. Rep., 2003.
[36] A. de Cheveigne and H. Kawahara, “Yin, a fundamentalfrequency estimator for speech and music,” The Journal of theAcoustical Society of America, vol. 111, no. 4, pp. 1917–1930, 2002.[Online]. Available: http://link.aip.org/link/?JAS/111/1917/1
[37] Speech signal analysis, londons global university depart-ment of phonetics and linguistics. [Online]. Available:http://www.phon.ucl.ac.uk/ courses/spsci/matlab/lect10.html
[38] J. Burg, “Modern spectrum analysis,” Childers, DG (ed.), pp. 34–41,1978.
[39] R. Snell and F. Milinazzo, “Formant location from lpc analysisdata,” Speech and Audio Processing, IEEE Transactions on, vol. 1,no. 2, pp. 129–134, 1993.
[40] H. Abdi and L. J. Williams, “Principal componentanalysis,” Wiley Interdisciplinary Reviews: Computational Statistics,vol. 2, no. 4, pp. 433–459, 2010. [Online]. Available:http://dx.doi.org/10.1002/wics.101
[41] J. C. Platt, “Advances in kernel methods,” B. Scholkopf, C. J. C.Burges, and A. J. Smola, Eds. Cambridge, MA, USA: MITPress, 1999, ch. Fast training of support vector machinesusing sequential minimal optimization, pp. 185–208. [Online].Available: http://dl.acm.org/citation.cfm?id=299094.299105
[42] F. Burkhardt, A. Paeschke, M. Rolfes, W. F. Sendlmeier, andB. Weiss, “A database of german emotional speech,” in INTER-SPEECH, 2005, pp. 1517–1520.
Igor Bisio (S’04-M’08) got his Laurea degree inTelecommunication Engineering at the Univer-sity of Genoa, Italy in 2002 and his Ph.D. degreein 2006. He is currently Assistant Professor andhe is member of the Digital Signal Processing(DSP) and Satellite Communications and Net-working (SCNL) Laboratories at the Universityof Genoa. His main research activities concernResource Allocation and Management for Satel-lite and Space Communication systems, SignalProcessing over Smartphones.
Alessandro Delfino got his B.Sc in Telecommu-nication Engineering in 2007 from University ofGenoa. He got his M.Sc in TelecommunicationEngineering in 2010 from University of Genoawith a thesis on Audio Fingerprinting. In 2010 heworked on MAC protocols for Cognitive Radio atEuropean funded Joint Research Center (JRC)of Ispra, Italy. He is currently Ph.D. student at theUniversity of Genoa and his main research ac-tivity concerns: Audio Fingerprinting and AudioInformation Retrieval, Cognitive Radio.
Fabio Lavagetto is currently full professor inTelecommunications at the DITEN Departmentof the University of Genoa. Since 2008 he isVice-Chancellor with responsibility for Researchand Technology Transfer at the University ofGenoa. Since 2005 he is Vice-Chair of the Insti-tute for Advanced Studies in Information Tech-nology and Communication. Since 1995, he isthe head of research of the Digital Signal Pro-cessing Laboratory of the University of Genoa.He was General Chair of several international
scientific conferences and has authored over 100 scientific publicationsin international journals and conferences.
Mario Marchese (S’94-M’97-SM’04) receivedthe Laurea degree (cum laude) in electronicengineering and the Ph.D. Degree in telecom-munications from the University of Genoa, Italy,in 1992 and 1996, respectively. He is currentlyan Associate Professor with the DITEN Depart-ment, University of Genoa. His main researchactivity concerns satellite and radio networks,transport layer over satellite and wireless net-works, quality of service and data transport overheterogeneous networks, and applications for
smartphones.
Andrea Sciarrone got his Bachelor Degree inTelecommunication Engineering at the Univer-sity of Genoa in 2007; in 2009 he achieveda Master Degree Cum Laude in Telecommuni-cation Engineering at the same university. Hecurrently is a Ph. D. Student at the DITENDepartment, University of Genoa. His main re-search activity concerns: Signal Processing overPortable Devices such as Smartphones, Contextand Location Awareness, Indoor Localization,Security and e-health Applications, Android Op-
erative System.
Related Documents











