Derry Wijaya Tom Mitchell Partha Talukdar Machine And Language Learning (MALL) Lab SERC & CSA, Indian Institute of Science Matt Gardner Bryan Kisiel From Big Text to Big Knowledge Carnegie Mellon University

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Derry WijayaTom Mitchell
Partha TalukdarMachine And Language Learning (MALL) Lab
SERC & CSA, Indian Institute of Science
Matt Gardner Bryan Kisiel
From Big Text to Big Knowledge
Carnegie Mellon University

IISc Overview

Indian Institute of Science (IISc), Bangalore
• Top research institute in India • Exceptional research freedom • Various programs: PhD, MSc,
Integrated PhD, MTech • Beautiful campus, great city

6
CSA : RESEARCH AREAS
MACHINE LEARNING, AI, PATTERN RECOGNITION,
DATA MINING, ANALYTICS, NLP M. N. Murty, Chiranjib Bhattacharyya Shirish Shevade, Shalabh Bhatnagar,
Susheela Devi, Shivani Agarwal, Ambedkar, Partha Talukdar
GAME THEORY AND MECHANISM DESIGN
Y. Narahari, Shalabh Bhatnagar,
Shirish Shevade Shivani Agarwal
STOCHASTIC CONTROL AND OPTIMIZATION,
REINFORCEMENT LEARNING
Shalabh Bhatnagar, Ambedkar, Chairanjib Bhattacharya,
Shivani Agarwal
ALGORITHMS, COMPLEXITY, GRAPH THEORY,
COMBINATORICS, GEOMETRY Sunil Chandran, Satish Govindarajan,
Vijay , Chandan, Arnab, R. Hariharan, R.Kannan, Neeldhara
INFO. THEORY, CODING,
ALGORITHMIC ALGEBRA
D. Ambedkar, Arnab, PVK, D. Patil, Bhavana
AUTOMATA THEORY, FORMAL METHODS,
LOGICS Deepak D’Souza, Aditya Kanade, K.V. Raghavan,
K. Gopinath
PROG. LANGUAGES, COMPILERS,
SOFTWARE ENGINEERING Y. N. Srikant, K.V. Raghavan,
Aditya Kanade, Murali Krishna, Uday Kumar, D. D’Souza,
R. Govindarajan,K. Gopinath,
ARCHITECTURE, OS, STORAGE, NETWORKS, DISTRIBUTED COMPUTING Matthew Jacob, R. Govindarajan,
K. Gopinath, R.C. Hansdah, Shalabh, Uday Kumar, Murali Krishna, Arpita,
Bhavana
DATABASE SYSTEMS
Jayant Haritsa, R.C. Hansdah,Partha Talukdar
CRYPTOLOGY, SECURITY
Sanjit Chatterjee, Arpita, Bhavana,
K. Gopinath, R.C. Hansdah
VISUALIZATION, GRAPHICS,
COMP. TOPOLOGY Vijay Natarajan
Satish Govindarajan

6
CSA : RESEARCH AREAS
MACHINE LEARNING, AI, PATTERN RECOGNITION,
DATA MINING, ANALYTICS, NLP M. N. Murty, Chiranjib Bhattacharyya Shirish Shevade, Shalabh Bhatnagar,
Susheela Devi, Shivani Agarwal, Ambedkar, Partha Talukdar
GAME THEORY AND MECHANISM DESIGN
Y. Narahari, Shalabh Bhatnagar,
Shirish Shevade Shivani Agarwal
STOCHASTIC CONTROL AND OPTIMIZATION,
REINFORCEMENT LEARNING
Shalabh Bhatnagar, Ambedkar, Chairanjib Bhattacharya,
Shivani Agarwal
ALGORITHMS, COMPLEXITY, GRAPH THEORY,
COMBINATORICS, GEOMETRY Sunil Chandran, Satish Govindarajan,
Vijay , Chandan, Arnab, R. Hariharan, R.Kannan, Neeldhara
INFO. THEORY, CODING,
ALGORITHMIC ALGEBRA
D. Ambedkar, Arnab, PVK, D. Patil, Bhavana
AUTOMATA THEORY, FORMAL METHODS,
LOGICS Deepak D’Souza, Aditya Kanade, K.V. Raghavan,
K. Gopinath
PROG. LANGUAGES, COMPILERS,
SOFTWARE ENGINEERING Y. N. Srikant, K.V. Raghavan,
Aditya Kanade, Murali Krishna, Uday Kumar, D. D’Souza,
R. Govindarajan,K. Gopinath,
ARCHITECTURE, OS, STORAGE, NETWORKS, DISTRIBUTED COMPUTING Matthew Jacob, R. Govindarajan,
K. Gopinath, R.C. Hansdah, Shalabh, Uday Kumar, Murali Krishna, Arpita,
Bhavana
DATABASE SYSTEMS
Jayant Haritsa, R.C. Hansdah,Partha Talukdar
CRYPTOLOGY, SECURITY
Sanjit Chatterjee, Arpita, Bhavana,
K. Gopinath, R.C. Hansdah
THEORY
VISUALIZATION, GRAPHICS,
COMP. TOPOLOGY Vijay Natarajan
Satish Govindarajan

6
CSA : RESEARCH AREAS
MACHINE LEARNING, AI, PATTERN RECOGNITION,
DATA MINING, ANALYTICS, NLP M. N. Murty, Chiranjib Bhattacharyya Shirish Shevade, Shalabh Bhatnagar,
Susheela Devi, Shivani Agarwal, Ambedkar, Partha Talukdar
GAME THEORY AND MECHANISM DESIGN
Y. Narahari, Shalabh Bhatnagar,
Shirish Shevade Shivani Agarwal
STOCHASTIC CONTROL AND OPTIMIZATION,
REINFORCEMENT LEARNING
Shalabh Bhatnagar, Ambedkar, Chairanjib Bhattacharya,
Shivani Agarwal
ALGORITHMS, COMPLEXITY, GRAPH THEORY,
COMBINATORICS, GEOMETRY Sunil Chandran, Satish Govindarajan,
Vijay , Chandan, Arnab, R. Hariharan, R.Kannan, Neeldhara
INFO. THEORY, CODING,
ALGORITHMIC ALGEBRA
D. Ambedkar, Arnab, PVK, D. Patil, Bhavana
AUTOMATA THEORY, FORMAL METHODS,
LOGICS Deepak D’Souza, Aditya Kanade, K.V. Raghavan,
K. Gopinath
PROG. LANGUAGES, COMPILERS,
SOFTWARE ENGINEERING Y. N. Srikant, K.V. Raghavan,
Aditya Kanade, Murali Krishna, Uday Kumar, D. D’Souza,
R. Govindarajan,K. Gopinath,
ARCHITECTURE, OS, STORAGE, NETWORKS, DISTRIBUTED COMPUTING Matthew Jacob, R. Govindarajan,
K. Gopinath, R.C. Hansdah, Shalabh, Uday Kumar, Murali Krishna, Arpita,
Bhavana
DATABASE SYSTEMS
Jayant Haritsa, R.C. Hansdah,Partha Talukdar
CRYPTOLOGY, SECURITY
Sanjit Chatterjee, Arpita, Bhavana,
K. Gopinath, R.C. Hansdah
THEORY
COMPUTER SYSTEMS
VISUALIZATION, GRAPHICS,
COMP. TOPOLOGY Vijay Natarajan
Satish Govindarajan

6
CSA : RESEARCH AREAS
MACHINE LEARNING, AI, PATTERN RECOGNITION,
DATA MINING, ANALYTICS, NLP M. N. Murty, Chiranjib Bhattacharyya Shirish Shevade, Shalabh Bhatnagar,
Susheela Devi, Shivani Agarwal, Ambedkar, Partha Talukdar
GAME THEORY AND MECHANISM DESIGN
Y. Narahari, Shalabh Bhatnagar,
Shirish Shevade Shivani Agarwal
STOCHASTIC CONTROL AND OPTIMIZATION,
REINFORCEMENT LEARNING
Shalabh Bhatnagar, Ambedkar, Chairanjib Bhattacharya,
Shivani Agarwal
ALGORITHMS, COMPLEXITY, GRAPH THEORY,
COMBINATORICS, GEOMETRY Sunil Chandran, Satish Govindarajan,
Vijay , Chandan, Arnab, R. Hariharan, R.Kannan, Neeldhara
INFO. THEORY, CODING,
ALGORITHMIC ALGEBRA
D. Ambedkar, Arnab, PVK, D. Patil, Bhavana
AUTOMATA THEORY, FORMAL METHODS,
LOGICS Deepak D’Souza, Aditya Kanade, K.V. Raghavan,
K. Gopinath
PROG. LANGUAGES, COMPILERS,
SOFTWARE ENGINEERING Y. N. Srikant, K.V. Raghavan,
Aditya Kanade, Murali Krishna, Uday Kumar, D. D’Souza,
R. Govindarajan,K. Gopinath,
ARCHITECTURE, OS, STORAGE, NETWORKS, DISTRIBUTED COMPUTING Matthew Jacob, R. Govindarajan,
K. Gopinath, R.C. Hansdah, Shalabh, Uday Kumar, Murali Krishna, Arpita,
Bhavana
DATABASE SYSTEMS
Jayant Haritsa, R.C. Hansdah,Partha Talukdar
CRYPTOLOGY, SECURITY
Sanjit Chatterjee, Arpita, Bhavana,
K. Gopinath, R.C. Hansdah
THEORY
COMPUTER SYSTEMS
INTELLIGENT SYSTEMS
VISUALIZATION, GRAPHICS,
COMP. TOPOLOGY Vijay Natarajan
Satish Govindarajan

Publications (2008-2013)
■ Number of Publications Books and Monographs 11 Book Chapters 25 Journal Publications 151 Conference Publications 260
■ Journals include SIAM, IEEE, ACM, JMLR, NC, ML, JA, TCS, JGT, JCSS, I&C, DCG, JCT, SN, etc.
■ Conferences include STOC, FOCS, SODA, SOCG, ICALP, STACS, LFCS, ISAAC, CC, ICDE, VLDB, AAMAS, NIPS, ICML, UAI, ICDM, COLT, ICPR, IJCAI, AAAI, IJCNN, SIGIR, SIGKDD, SIGMOD, WINE, SDM, ICDAR, IEEE VIS, PLDI, POPL, ICSE, OOPSLA, CGO, EMSOFT, CASES, FORMATS, SAS, SC, FAST, HotOS, HotStorage, SIGMETRICS, PPoPP, PACT

Sponsors and Collaborators ■ Govt. of India: UGC (CAS), UGC (Infrastructure), DST-FIST, DST
SERC (12 Projects), DBT, DRDO, DIT ■ Universities: MIT, Technion, Harvard, UCB, UCD, UCSC, IITB, IITM,
CMI, ISI, JNU, TIFR, MPI, SUNY, MSU, Alberta, EURANDOM, CMI, Waterloo, Grenoble, Zurich, Leipzig, INRIA, CMU, York, Chalmers
■ Industry Collaborative Projects: IBM, Infosys, TRDDC, Motorola, GM R & D, SUN, NetApp, AOL, Xerox, TI, Microsoft Research India, Philips, Intel, AMD, Yahoo!, SAP, Nokia, Adobe
■ Industry Faculty Awards: IBM, TRDDC, GM R & D, Microsoft Research India, AMD, Yahoo!, Google, Bell Labs
■ Overseas Agencies: ONR, Lawrence Livermore, AOARD, Swiss Bilateral, Indo-German, UKERI, Max-Planck

Supercomputer Education & Research Centre (SERC)
• A multi-disciplinary department in IISc • A state-of-the-art supercomputing research
facility with a cutting-edge research program


Research at SERC

Research at SERC
Computer Systems� CAD for VLSI � Cloud Computing � Computer Architecture � Database Systems � Distributed Systems � High Performance Computing � Information Systems � Middleware Research � Machine Learning and NLP � Parallel Computing � Visualization & Graphics � Video Analytics

Research at SERC
Computer Systems� CAD for VLSI � Cloud Computing � Computer Architecture � Database Systems � Distributed Systems � High Performance Computing � Information Systems � Middleware Research � Machine Learning and NLP � Parallel Computing � Visualization & Graphics � Video Analytics
Computational Science� Computational
Electromagnetics � Computational Photonics � Medical Imaging � Scientific Computing and
Mathematical Libraries � Computational Fluid
Dynamics � Computational Biology and
Bioinformatics � Quantum Computing

Machine Learning @ IISc
• 13+ faculty from multiple departments (CSA, SERC, ECE, EE)
• Highly active research group, strong international presence
• http://drona.csa.iisc.ernet.in/~mlcenter/index.html

Research Programs at IISc� Ph.D. and M.Sc [Engg] � Min. Qualification:
➢ ME / M Tech or BE / B Tech or equivalent degree in any Engineering discipline or
➢ M Sc or equivalent degree in Mathematics, Physics, Statistics, Electronics, Instrumentation or Computer Sciences or
➢ Master’s in Computer Application. � Selection process
➢ Shortlisting (GATE scores) and Interview

Research Programs at IISc� Ph.D. and M.Sc [Engg] � Min. Qualification:
➢ ME / M Tech or BE / B Tech or equivalent degree in any Engineering discipline or
➢ M Sc or equivalent degree in Mathematics, Physics, Statistics, Electronics, Instrumentation or Computer Sciences or
➢ Master’s in Computer Application. � Selection process
➢ Shortlisting (GATE scores) and Interview
Come Join Us!

Back to Text & Knowledge

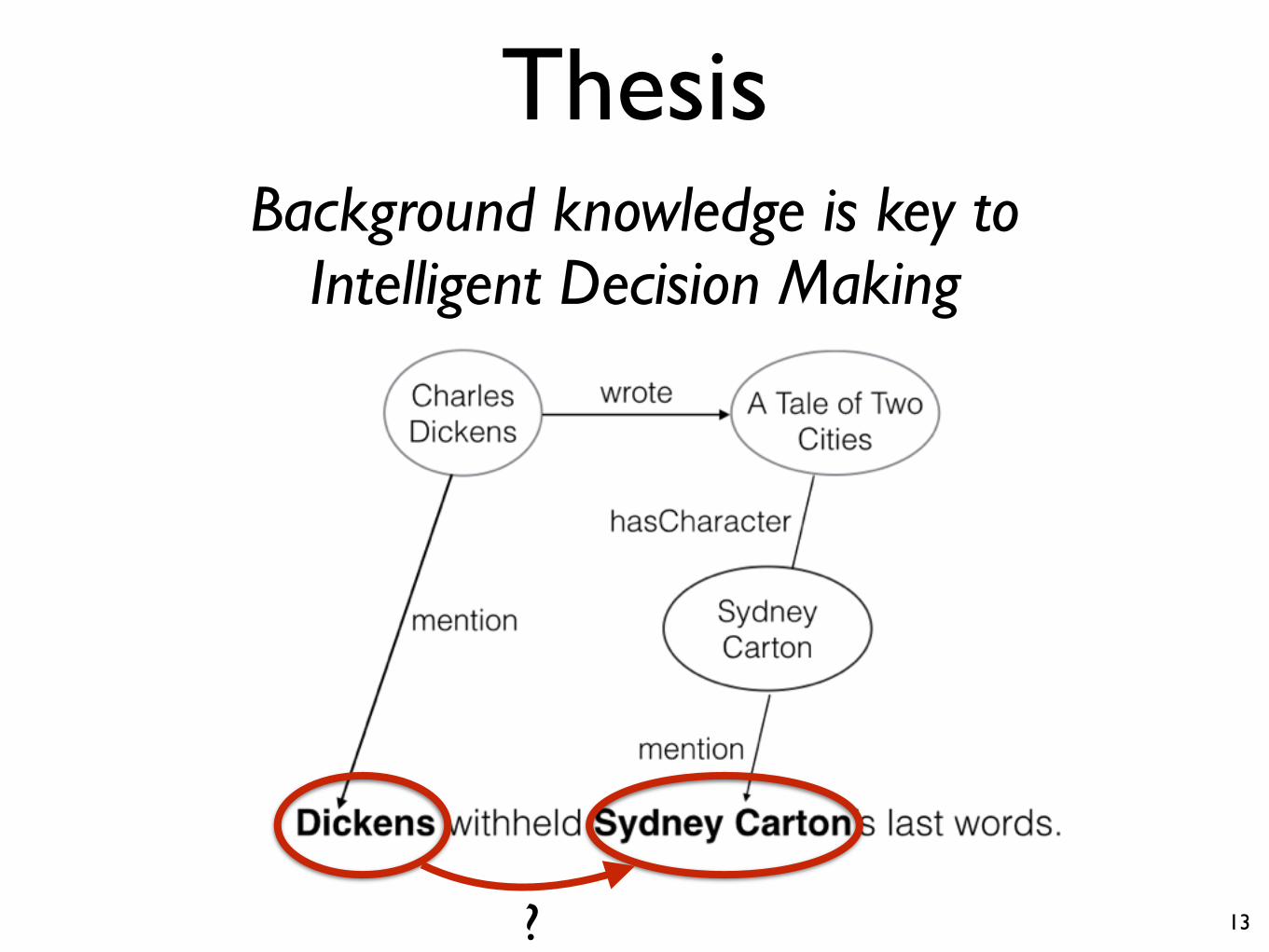
Thesis
13
Background knowledge is key to Intelligent Decision Making

Thesis
13
Background knowledge is key to Intelligent Decision Making

Thesis
13
Background knowledge is key to Intelligent Decision Making
?
Thesis
13
Background knowledge is key to Intelligent Decision Making
?

Thesis
13
Background knowledge is key to Intelligent Decision Making
inventedCharacter

Explosion of Unstructured Text Data
14

Explosion of Unstructured Text Data
14
Sources: http://royal.pingdom.com/2012/01/17/internet-2011-in-numbers/, http://blog.twitter.com/2011/06/200-million-tweets-per-day.html
300 million new websites added in 2011 alone (a 117% growth)

Explosion of Unstructured Text Data
500 million Tweets per day (circa Oct 2012)
14
Sources: http://royal.pingdom.com/2012/01/17/internet-2011-in-numbers/, http://blog.twitter.com/2011/06/200-million-tweets-per-day.html
300 million new websites added in 2011 alone (a 117% growth)

Explosion of Unstructured Text Data
500 million Tweets per day (circa Oct 2012)Time to read for one person: 31years
14
Sources: http://royal.pingdom.com/2012/01/17/internet-2011-in-numbers/, http://blog.twitter.com/2011/06/200-million-tweets-per-day.html
300 million new websites added in 2011 alone (a 117% growth)

Explosion of Unstructured Text Data
500 million Tweets per day (circa Oct 2012)Time to read for one person: 31years
14
Sources: http://royal.pingdom.com/2012/01/17/internet-2011-in-numbers/, http://blog.twitter.com/2011/06/200-million-tweets-per-day.html
300 million new websites added in 2011 alone (a 117% growth)
Need to harvest knowledge from unstructured text data

What is Knowledge HarvesBng from Unstructured Text?
15

What is Knowledge HarvesBng from Unstructured Text?
15
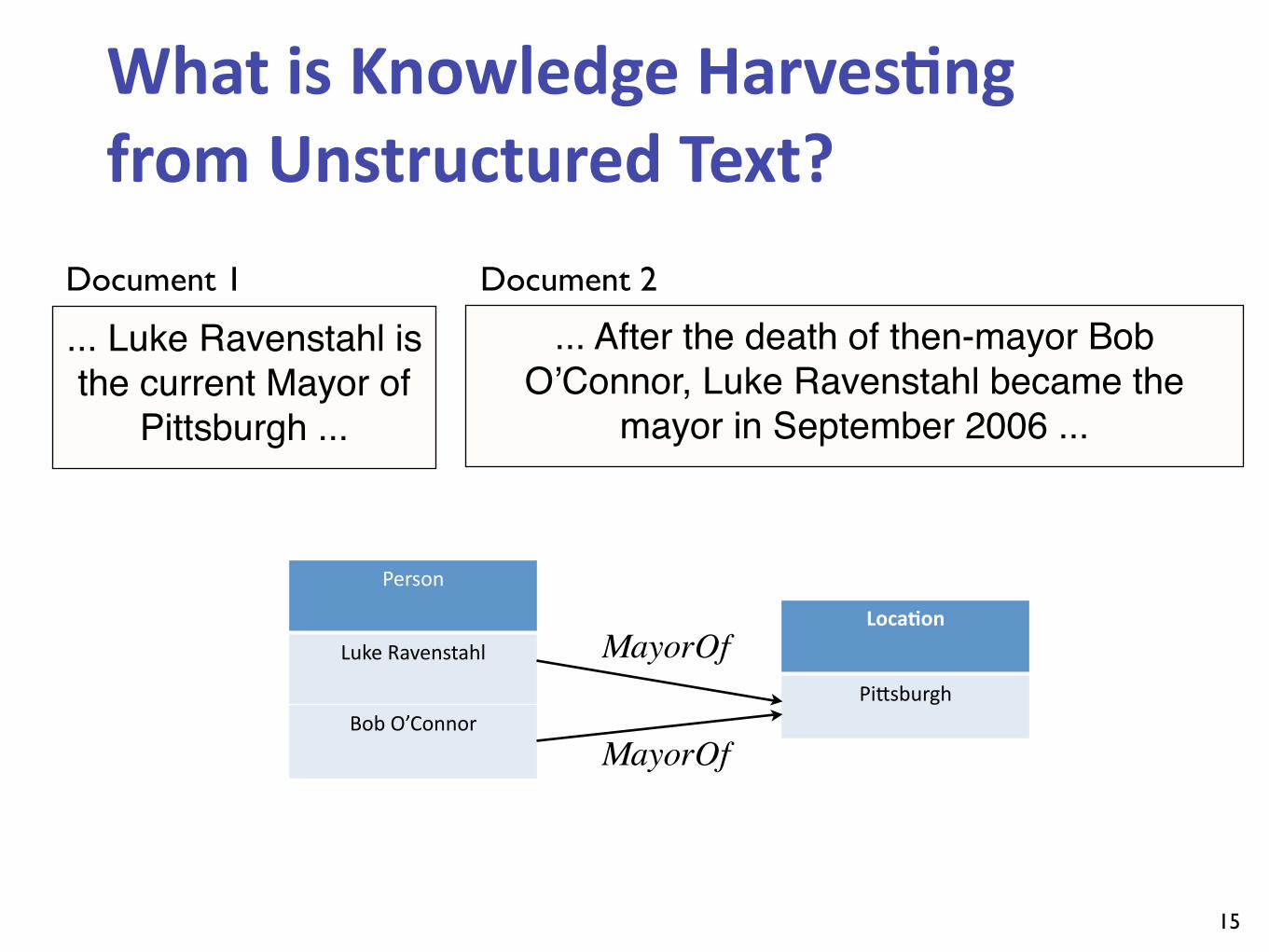
... Luke Ravenstahl is the current Mayor of
Pittsburgh ...
... After the death of then-mayor Bob O’Connor, Luke Ravenstahl became the
mayor in September 2006 ...
Document 1 Document 2

What is Knowledge HarvesBng from Unstructured Text?
15
Person
Luke Ravenstahl
Bob O’Connor
... Luke Ravenstahl is the current Mayor of
Pittsburgh ...
... After the death of then-mayor Bob O’Connor, Luke Ravenstahl became the
mayor in September 2006 ...
Document 1 Document 2

What is Knowledge HarvesBng from Unstructured Text?
15
Person
Luke Ravenstahl
Bob O’Connor
LocaBon
PiIsburgh
... Luke Ravenstahl is the current Mayor of
Pittsburgh ...
... After the death of then-mayor Bob O’Connor, Luke Ravenstahl became the
mayor in September 2006 ...
Document 1 Document 2
What is Knowledge HarvesBng from Unstructured Text?
15
Person
Luke Ravenstahl
Bob O’Connor
LocaBon
PiIsburgh
MayorOf
MayorOf
... Luke Ravenstahl is the current Mayor of
Pittsburgh ...
... After the death of then-mayor Bob O’Connor, Luke Ravenstahl became the
mayor in September 2006 ...
Document 1 Document 2

What is Knowledge HarvesBng from Unstructured Text?
15
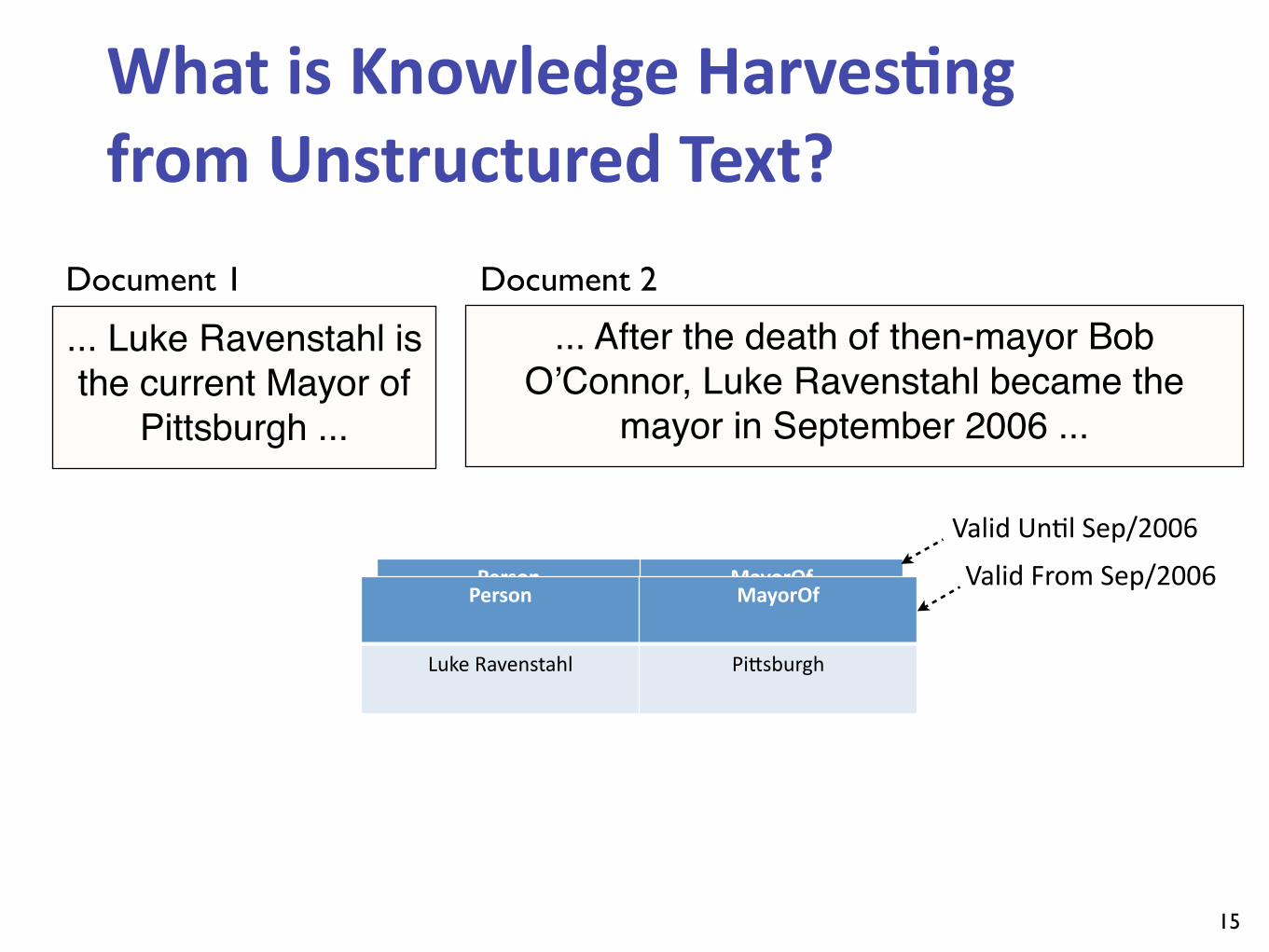
Person MayorOf
Bob O’Connor PiIsburgh
Valid UnLl Sep/2006
... Luke Ravenstahl is the current Mayor of
Pittsburgh ...
... After the death of then-mayor Bob O’Connor, Luke Ravenstahl became the
mayor in September 2006 ...
Document 1 Document 2
What is Knowledge HarvesBng from Unstructured Text?
15
Person MayorOf
Bob O’Connor PiIsburgh
Valid UnLl Sep/2006
Person MayorOf
Luke Ravenstahl PiIsburgh
Valid From Sep/2006
... Luke Ravenstahl is the current Mayor of
Pittsburgh ...
... After the death of then-mayor Bob O’Connor, Luke Ravenstahl became the
mayor in September 2006 ...
Document 1 Document 2

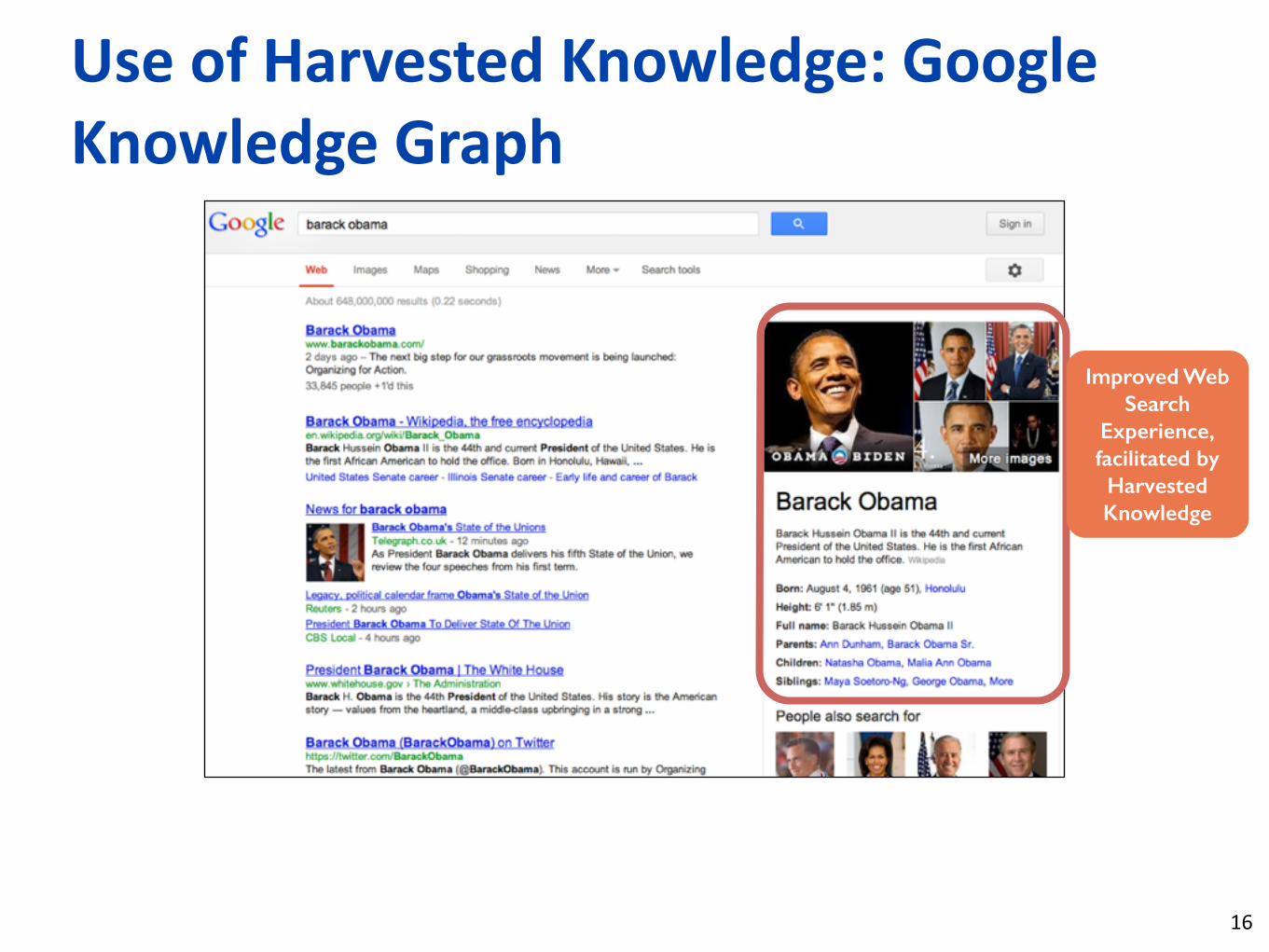
Use of Harvested Knowledge: Google Knowledge Graph
16
Use of Harvested Knowledge: Google Knowledge Graph
16
Improved Web Search
Experience, facilitated by Harvested Knowledge

Use of Harvested Knowledge: Google Knowledge Graph
16
Improved Web Search
Experience, facilitated by Harvested Knowledge
No Structured Information

Use of Harvested Knowledge: Google Knowledge Graph
16
Improved Web Search
Experience, facilitated by Harvested Knowledge
No Structured Information
http://venturebeat.com/2013/01/22/larry-page-on-googles-knowledge-graph-were-still-at-1-of-where-we-want-to-be/
“We’re sBll at 1 percent of where we should be.” -- Larry Page (Google CEO) on Knowledge Graph [Jan 22, 2013]

New paradigm for Machine Learning:
Never Ending Learning agent
17

New paradigm for Machine Learning:
Never Ending Learning agentPersistent soSware individual
17

New paradigm for Machine Learning:
Never Ending Learning agentPersistent soSware individualLearns many funcLons / knowledge types
17

New paradigm for Machine Learning:
Never Ending Learning agentPersistent soSware individualLearns many funcLons / knowledge typesLearns easier things first, then more difficult
17

New paradigm for Machine Learning:
Never Ending Learning agentPersistent soSware individualLearns many funcLons / knowledge typesLearns easier things first, then more difficultThe more it learns, the more it can learn next
17

New paradigm for Machine Learning:
Never Ending Learning agentPersistent soSware individualLearns many funcLons / knowledge typesLearns easier things first, then more difficultThe more it learns, the more it can learn nextLearns from experience, and from advice
17

NELL: Never Ending Language Learner
18

NELL: Never Ending Language LearnerInputs:
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
The task:
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
The task:• run 24x7, forever
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
The task:• run 24x7, forever• each day:
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
The task:• run 24x7, forever• each day:
• extract more facts from the web
18

NELL: Never Ending Language LearnerInputs:•iniLal ontology •few seed examples of each ontology predicate•the web•occasional interacLon with human trainers
The task:• run 24x7, forever• each day:
• extract more facts from the web • learn to read (perform #1) beIer than yesterday
18

NELL Today
19

NELL TodayRunning 24x7, since January, 12, 2010
Result: KB with > 70 million candidate beliefs, growing daily learning to reason, as well as read automaLcally extending its ontology
19

NELL TodayRunning 24x7, since January, 12, 2010
Result: KB with > 70 million candidate beliefs, growing daily learning to reason, as well as read automaLcally extending its ontology
19

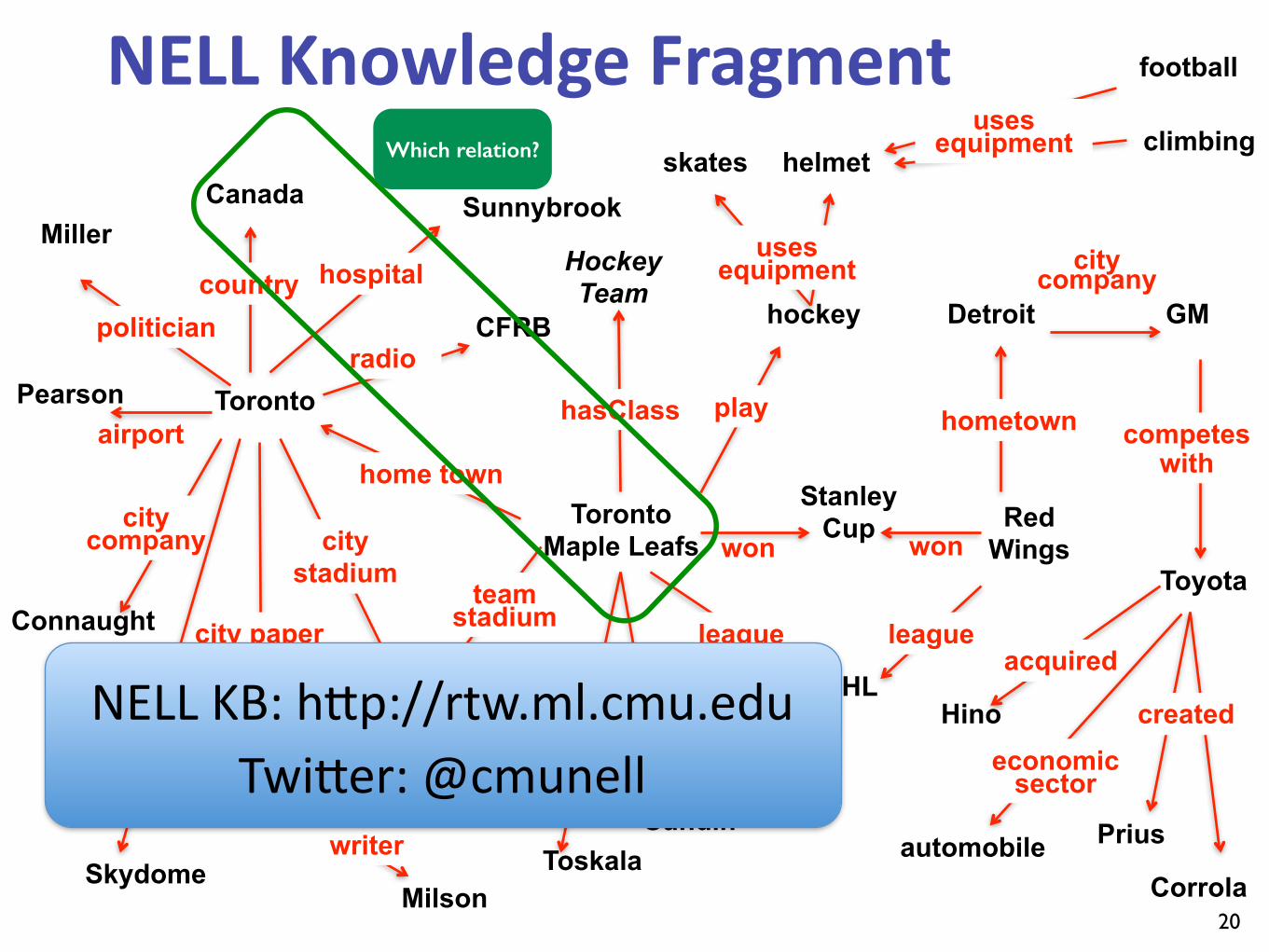
NELL Knowledge Fragment
20
Globe and Mail
Stanley Cup
hockey
NHL
Toronto
CFRB
HockeyTeam
playhasClass
wonToronto
Maple Leafs
home town
city paper league
Sundin
Milson
writer
radio
Air Canada Centre
team stadium
Canada
city stadium
politiciancountry
Miller
airport
member
Toskala
Pearson
Skydome
Connaught
Sunnybrook
hospital
city company
skates helmet
uses equipment
wonRed
Wings
Detroit
hometown
GM
city company
competes with
Toyota
plays in
league
Prius
Corrola
createdHino
acquired
automobile
economic sector
city stadium
climbing
football
uses equipment

NELL Knowledge Fragment
20
Globe and Mail
Stanley Cup
hockey
NHL
Toronto
CFRB
HockeyTeam
playhasClass
wonToronto
Maple Leafs
home town
city paper league
Sundin
Milson
writer
radio
Air Canada Centre
team stadium
Canada
city stadium
politiciancountry
Miller
airport
member
Toskala
Pearson
Skydome
Connaught
Sunnybrook
hospital
city company
skates helmet
uses equipment
wonRed
Wings
Detroit
hometown
GM
city company
competes with
Toyota
plays in
league
Prius
Corrola
createdHino
acquired
automobile
economic sector
city stadium
climbing
football
uses equipment
NELL KB: hIp://rtw.ml.cmu.edu TwiIer: @cmunell
NELL Knowledge Fragment
20
Globe and Mail
Stanley Cup
hockey
NHL
Toronto
CFRB
HockeyTeam
playhasClass
wonToronto
Maple Leafs
home town
city paper league
Sundin
Milson
writer
radio
Air Canada Centre
team stadium
Canada
city stadium
politiciancountry
Miller
airport
member
Toskala
Pearson
Skydome
Connaught
Sunnybrook
hospital
city company
skates helmet
uses equipment
wonRed
Wings
Detroit
hometown
GM
city company
competes with
Toyota
plays in
league
Prius
Corrola
createdHino
acquired
automobile
economic sector
city stadium
climbing
football
uses equipment
NELL KB: hIp://rtw.ml.cmu.edu TwiIer: @cmunell
Which relation?
NELL Knowledge Fragment
20
Globe and Mail
Stanley Cup
hockey
NHL
Toronto
CFRB
HockeyTeam
playhasClass
wonToronto
Maple Leafs
home town
city paper league
Sundin
Milson
writer
radio
Air Canada Centre
team stadium
Canada
city stadium
politiciancountry
Miller
airport
member
Toskala
Pearson
Skydome
Connaught
Sunnybrook
hospital
city company
skates helmet
uses equipment
wonRed
Wings
Detroit
hometown
GM
city company
competes with
Toyota
plays in
league
Prius
Corrola
createdHino
acquired
automobile
economic sector
city stadium
climbing
football
uses equipment
NELL KB: hIp://rtw.ml.cmu.edu TwiIer: @cmunell
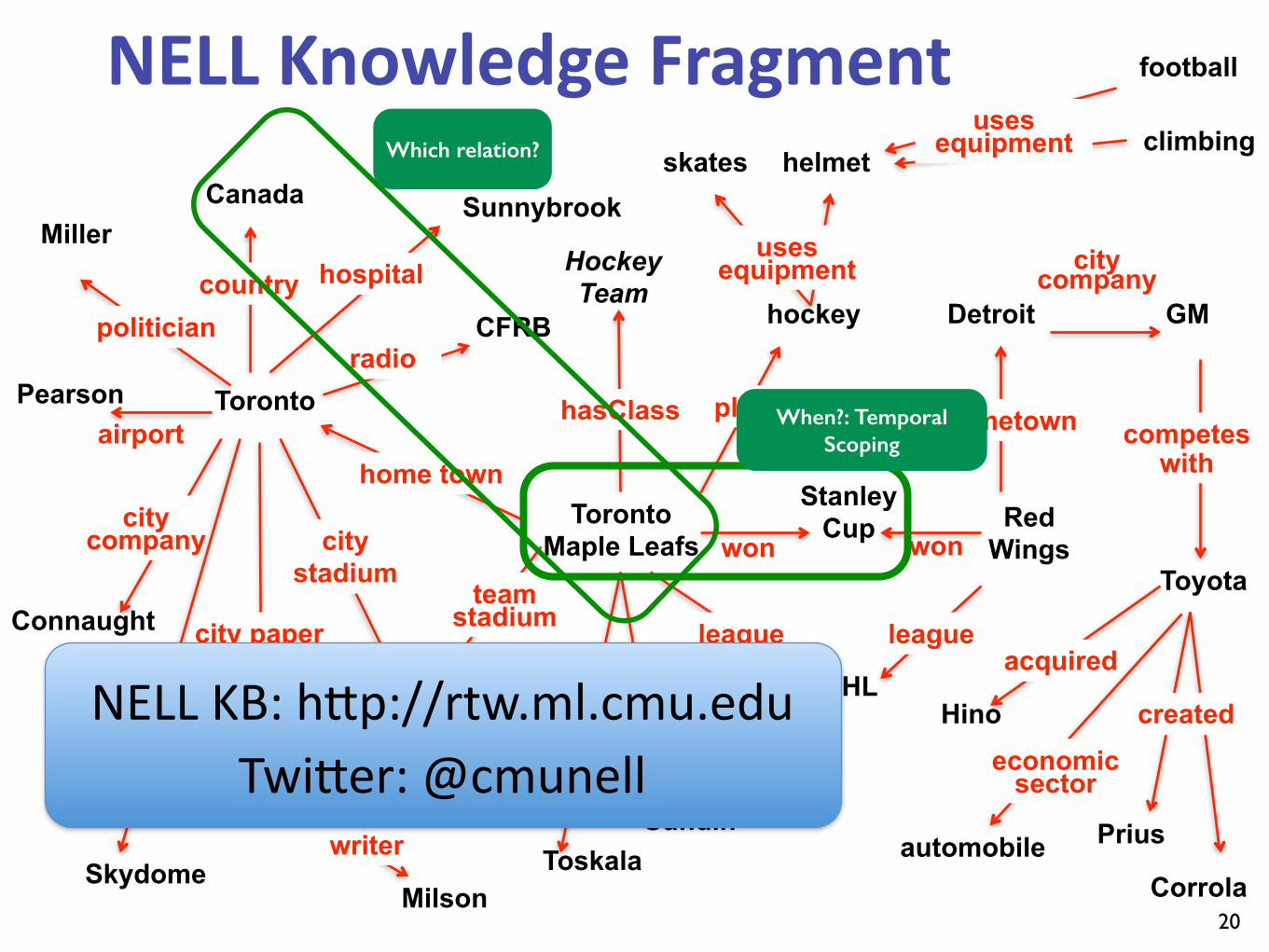
When?: Temporal Scoping
Which relation?

Other Related Efforts
21

AAAI 2015
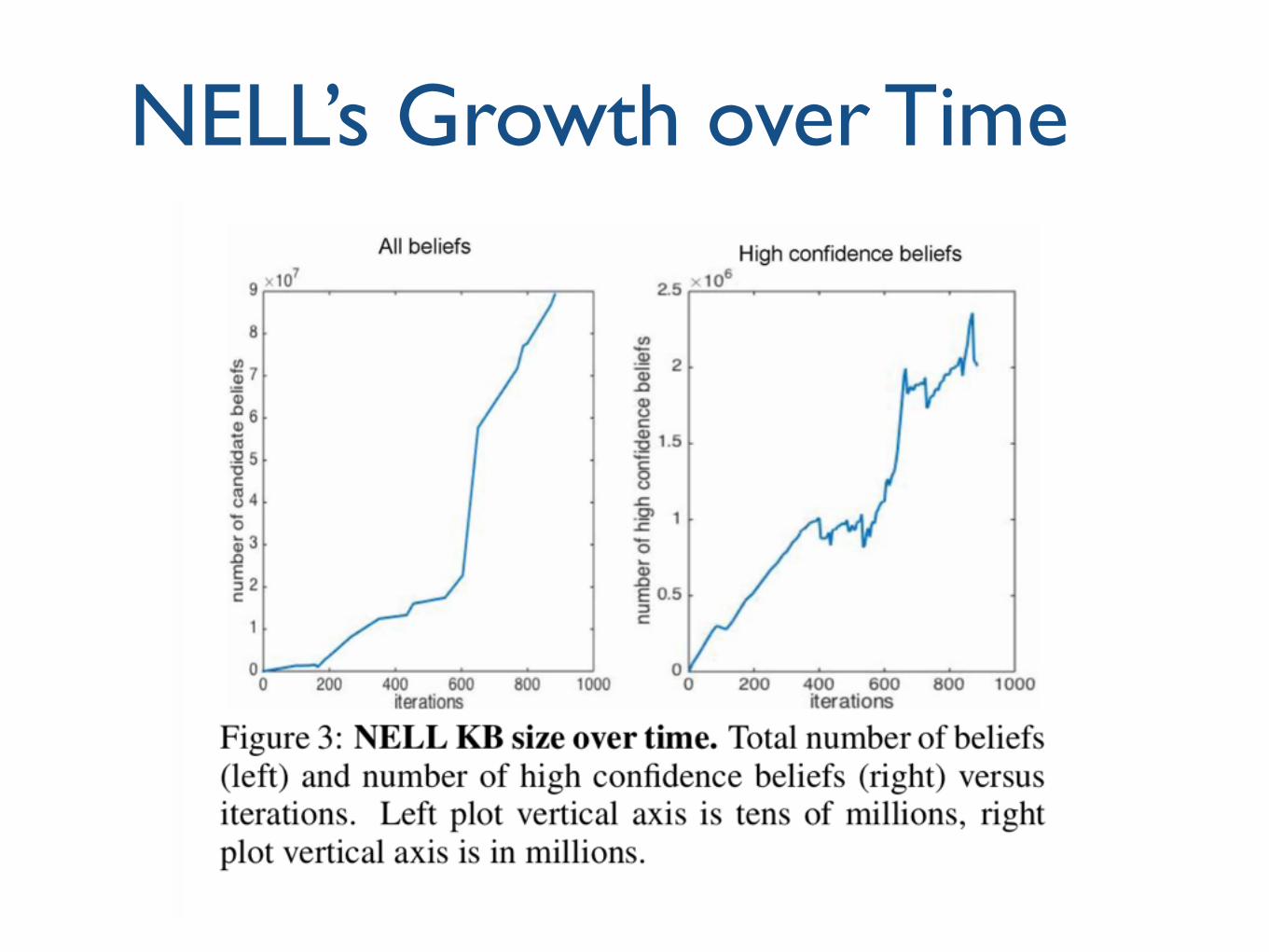
NELL’s Growth over Time

24
NELL’s Accuracy over Time

Need knowledge to be …
25

Need knowledge to be …
•Available or inferable
25

Need knowledge to be …
•Available or inferable
•Fresh (temporally scoped)
25

Need knowledge to be …
•Available or inferable
•Fresh (temporally scoped)
25
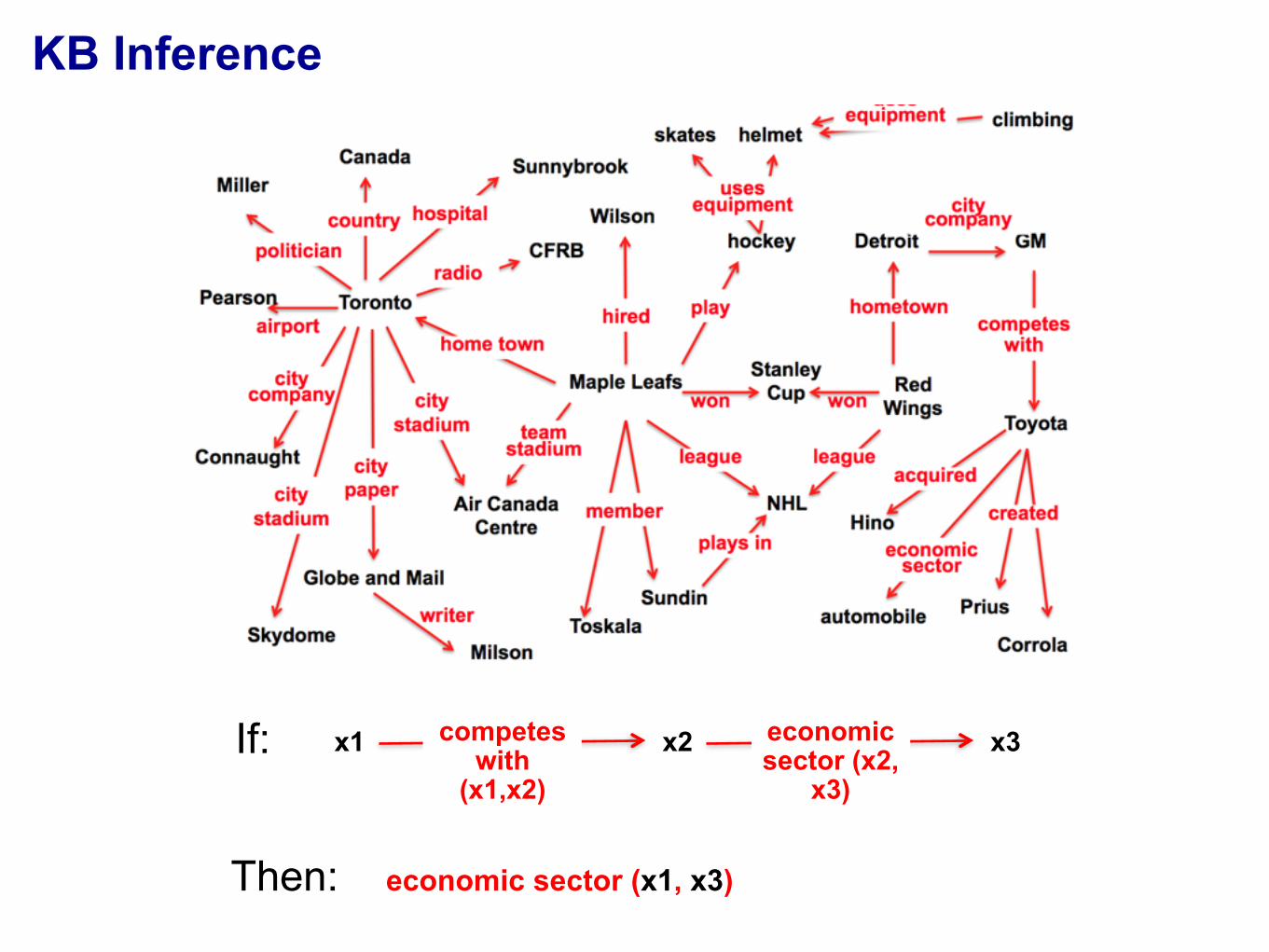
KB Inference
If: x1 competes with
(x1,x2)
x2 economic sector (x2,
x3)
x3
Then: economic sector (x1, x3)

PRA: Inference by KB Random Walks [Lao et al, EMNLP 2011]
KB:
Random walk path type:
logistic function for R(x,y) ith feature: probability of arriving at node y starting at node x, and taking a random walk along path type i
model Pr(R(x,y)):
x competes with ? economic
sector y
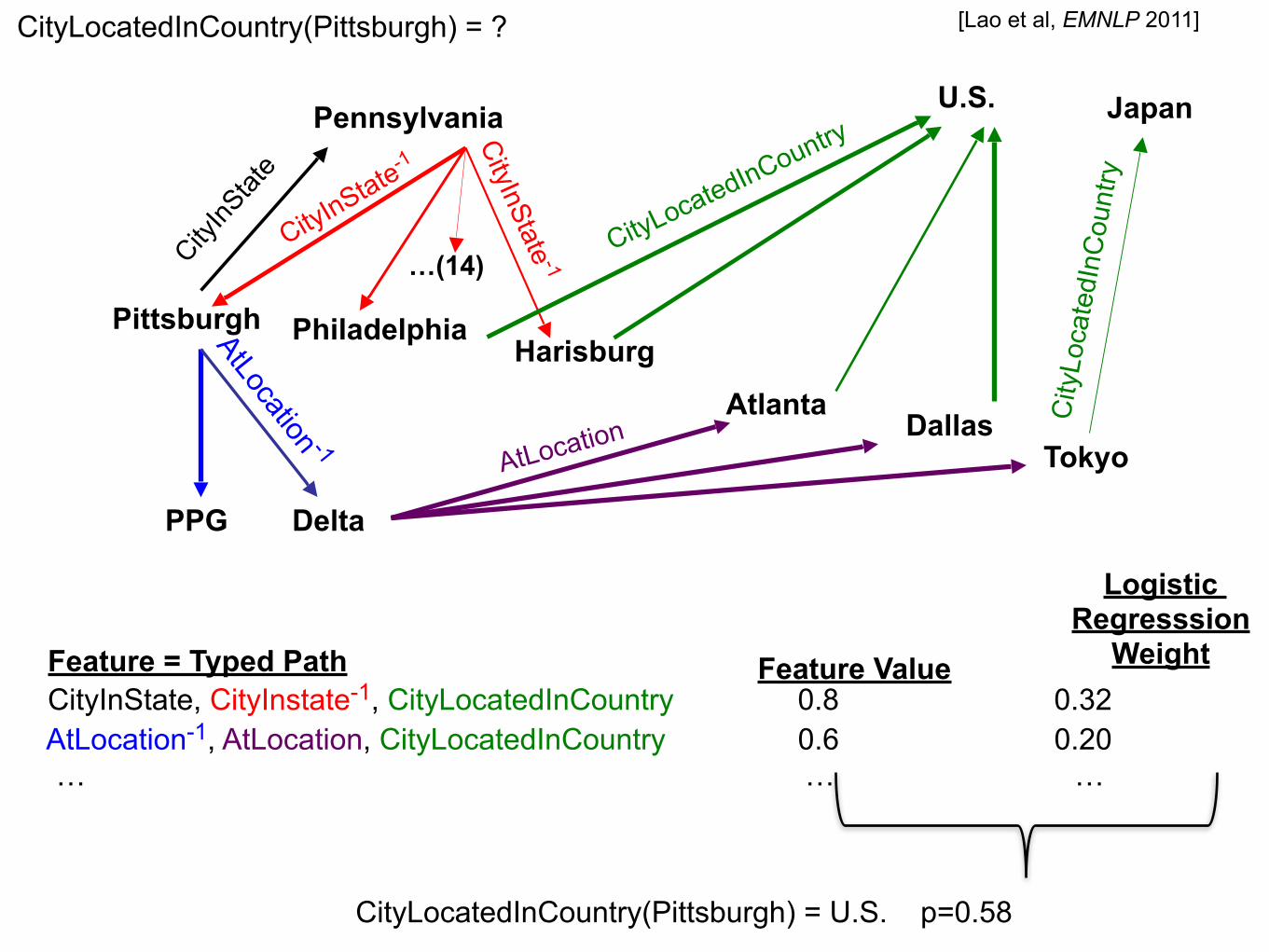
Feature = Typed Path CityInState, CityInstate-1, CityLocatedInCountry 0.8 0.32 AtLocation-1, AtLocation, CityLocatedInCountry 0.6 0.20 … … …
Pittsburgh
Pennsylvania
CityInS
tate
CityInState-1
CityInState -1
PhiladelphiaHarisburg
…(14)
U.S.
Feature Value
Logistic Regresssion
Weight
CityLocatedInCountry(Pittsburgh) = U.S. p=0.58
CityLocatedInCountry
DeltaPPG
AtLocation -1 AtLocationAtlanta
DallasTokyo
Japan
CityLocatedInCountry(Pittsburgh) = ?
City
Loca
tedI
nCou
ntry
[Lao et al, EMNLP 2011]

PRA: learned path types
CityLocatedInCountry(city, country):
8.04 cityliesonriver, cityliesonriver-1, citylocatedincountry
5.42 hasofficeincity-1, hasofficeincity, citylocatedincountry 4.98 cityalsoknownas, cityalsoknownas, citylocatedincountry 2.85 citycapitalofcountry,citylocatedincountry-1,citylocatedincountry
2.29 agentactsinlocation-1, agentactsinlocation, citylocatedincountry
1.22 statehascapital-1, statelocatedincountry 0.66 citycapitalofcountry . . . 7 of the 2985 learned paths for CityLocatedInCountry

PRA: Challenges
30

PRA: Challenges
• Works great when the KB graph is well connected
30

PRA: Challenges
• Works great when the KB graph is well connected
‣But, sparsity in the KB graph is the main challenge we wanted to solve!
30
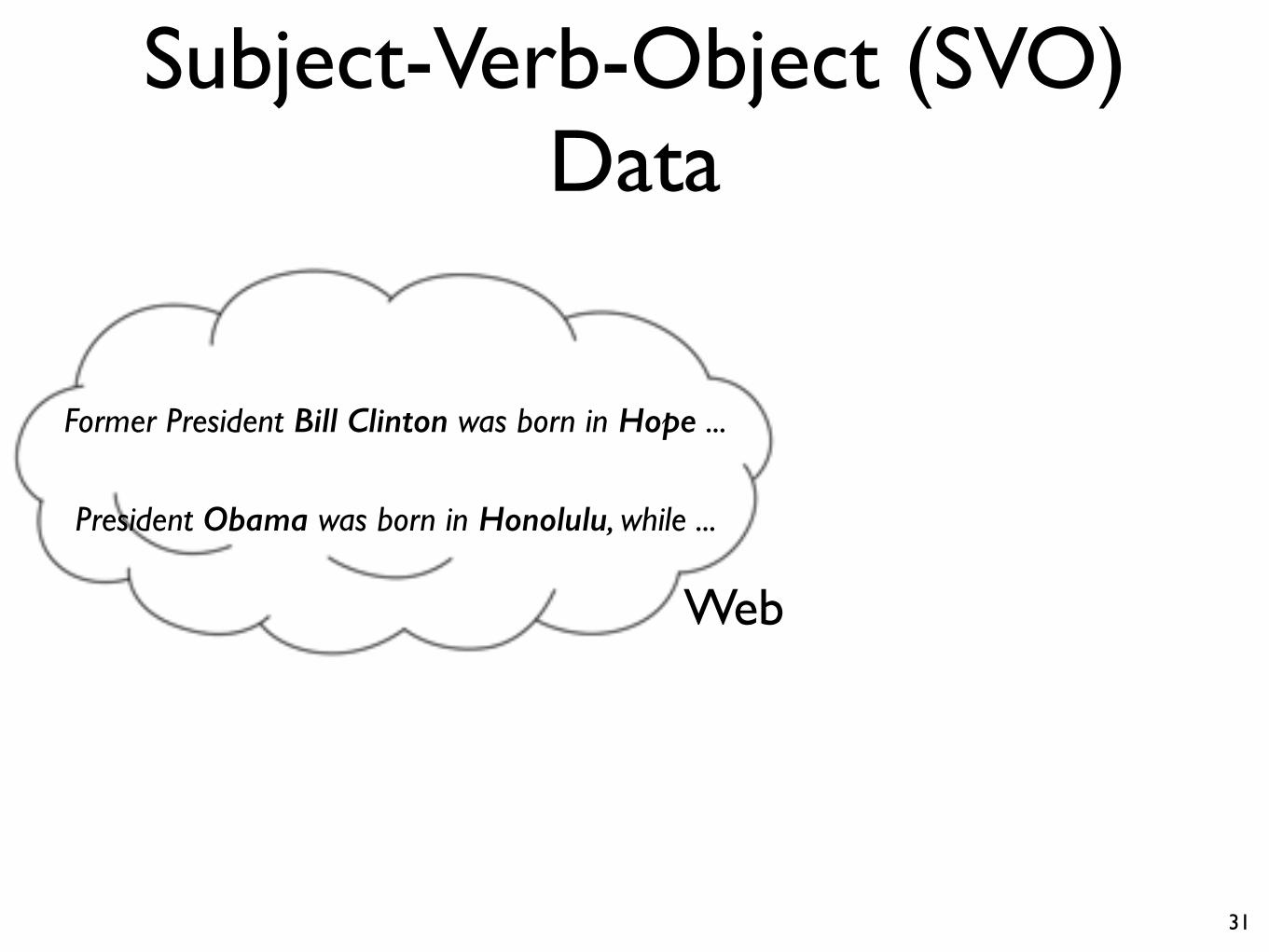
Subject-Verb-Object (SVO) Data
Web
Former President Bill Clinton was born in Hope ...
President Obama was born in Honolulu, while ...
31
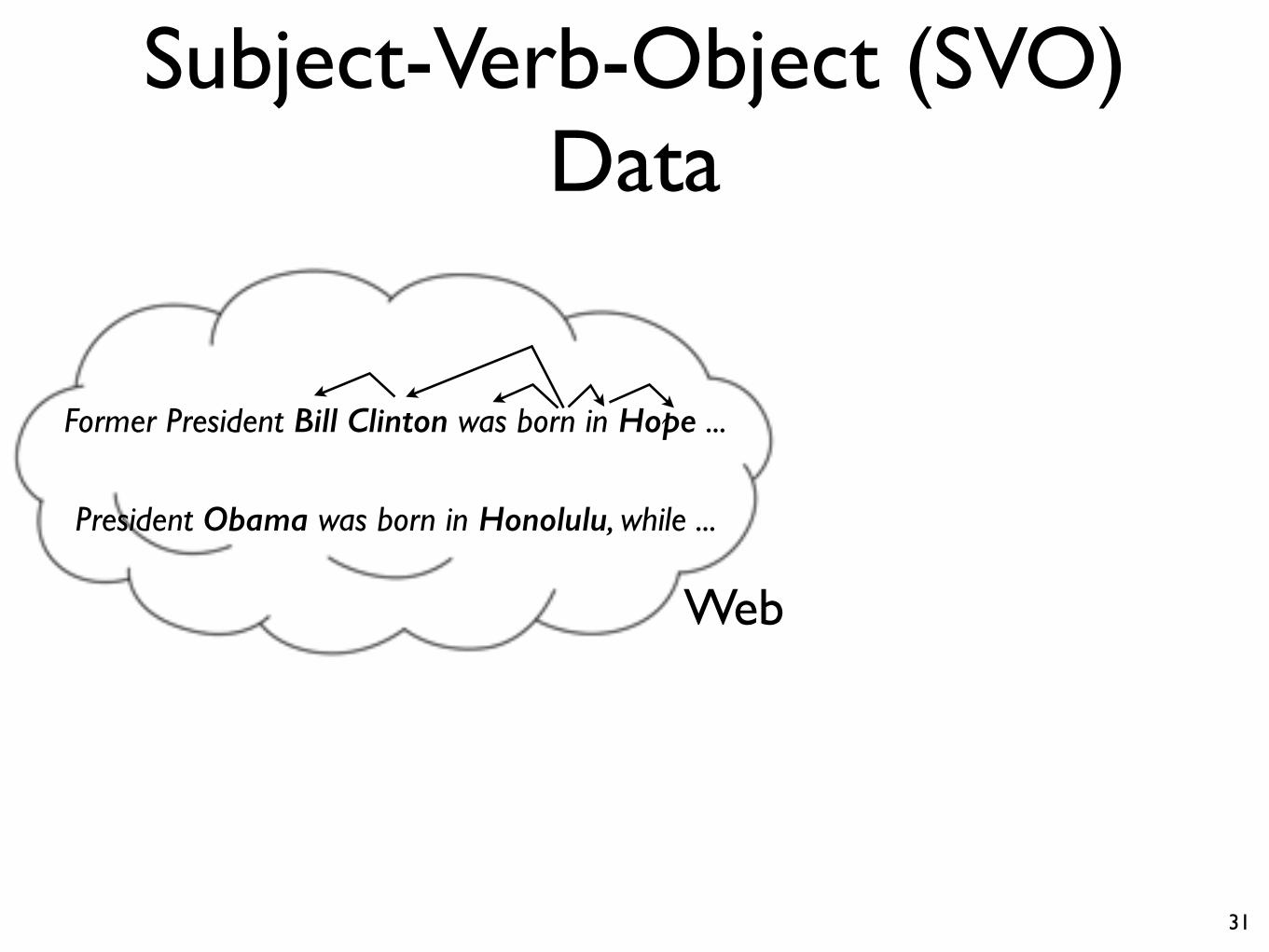
Subject-Verb-Object (SVO) Data
Web
Former President Bill Clinton was born in Hope ...
President Obama was born in Honolulu, while ...
31

Subject-Verb-Object (SVO) Data
Web
Former President Bill Clinton was born in Hope ...
President Obama was born in Honolulu, while ...
31

Subject-Verb-Object (SVO) Data
Web
Former President Bill Clinton was born in Hope ...
President Obama was born in Honolulu, while ...
SVO“Bill Clinton”, “was born in”, “Hope”“Obama”, “was born in” , “Honolulu”
Extract 600m Subject-Verb-Object (SVO) triples from a parsed web corpus of 230 billion tokens
31

Our Approach: PRA over KB + SVO Graph (Gardner et al., EMNLP 2013)
32

Our Approach: PRA over KB + SVO Graph (Gardner et al., EMNLP 2013)
32
AlexRodriguez(concept)
NY Yankees(concept)
WorldSeries
(concept)
teamPlaysIn
KB Relation Label

Our Approach: PRA over KB + SVO Graph (Gardner et al., EMNLP 2013)
32
AlexRodriguez(concept)
NY Yankees(concept)
WorldSeries
(concept)
teamPlaysIn
KB Relation Label
“plays for”
“bats for”
AlexRodriguez NY Yankees
mention mention

Our Approach: PRA over KB + SVO Graph (Gardner et al., EMNLP 2013)
32
AlexRodriguez(concept)
NY Yankees(concept)
WorldSeries
(concept)
teamPlaysIn
KB Relation Label
“plays for”
“bats for”
AlexRodriguez NY Yankees
mention mention
Lexicalized edges can explode number of paths, feature sparsity => Latent PRA

Latent PRA (Discretized)
33

Latent PRA (Discretized)
33
Step 1: Embed lexicalized edge labels

Latent PRA (Discretized)
33
Step 1: Embed lexicalized edge labels
“plays for”
(A R
od., N
Y Yan
kees
)
“bats for”
(B. Jo
nes,
NY
Mes
)

Latent PRA (Discretized)
33
Step 1: Embed lexicalized edge labels
DimensionalityReduction
“plays for”
(A R
od., N
Y Yan
kees
)
“bats for”
(B. Jo
nes,
NY
Mes
)

Latent PRA (Discretized)
33
Step 1: Embed lexicalized edge labels
DimensionalityReduction
“plays for”
(A R
od., N
Y Yan
kees
)
“bats for”
(B. Jo
nes,
NY
Mes
)
L1 L2 L3
“plays for”
“bats for”
0.9 0.01 -0.3
0.6 0.01 -0.4
LatentDimensions

Latent PRA (Discretized)
33
Step 1: Embed lexicalized edge labels
DimensionalityReduction
“plays for”
(A R
od., N
Y Yan
kees
)
“bats for”
(B. Jo
nes,
NY
Mes
)
L1 L2 L3
“plays for”
“bats for”
0.9 0.01 -0.3
0.6 0.01 -0.4
LatentDimensions
Discretize

Latent PRA (Discretized)
33
Step 1: Embed lexicalized edge labels
“plays for”
“bats for”
+L1 -L3
+L1 -L3
DimensionalityReduction
“plays for”
(A R
od., N
Y Yan
kees
)
“bats for”
(B. Jo
nes,
NY
Mes
)
L1 L2 L3
“plays for”
“bats for”
0.9 0.01 -0.3
0.6 0.01 -0.4
LatentDimensions
Discretize

Latent PRA (Discretized)
34

Latent PRA (Discretized)
34
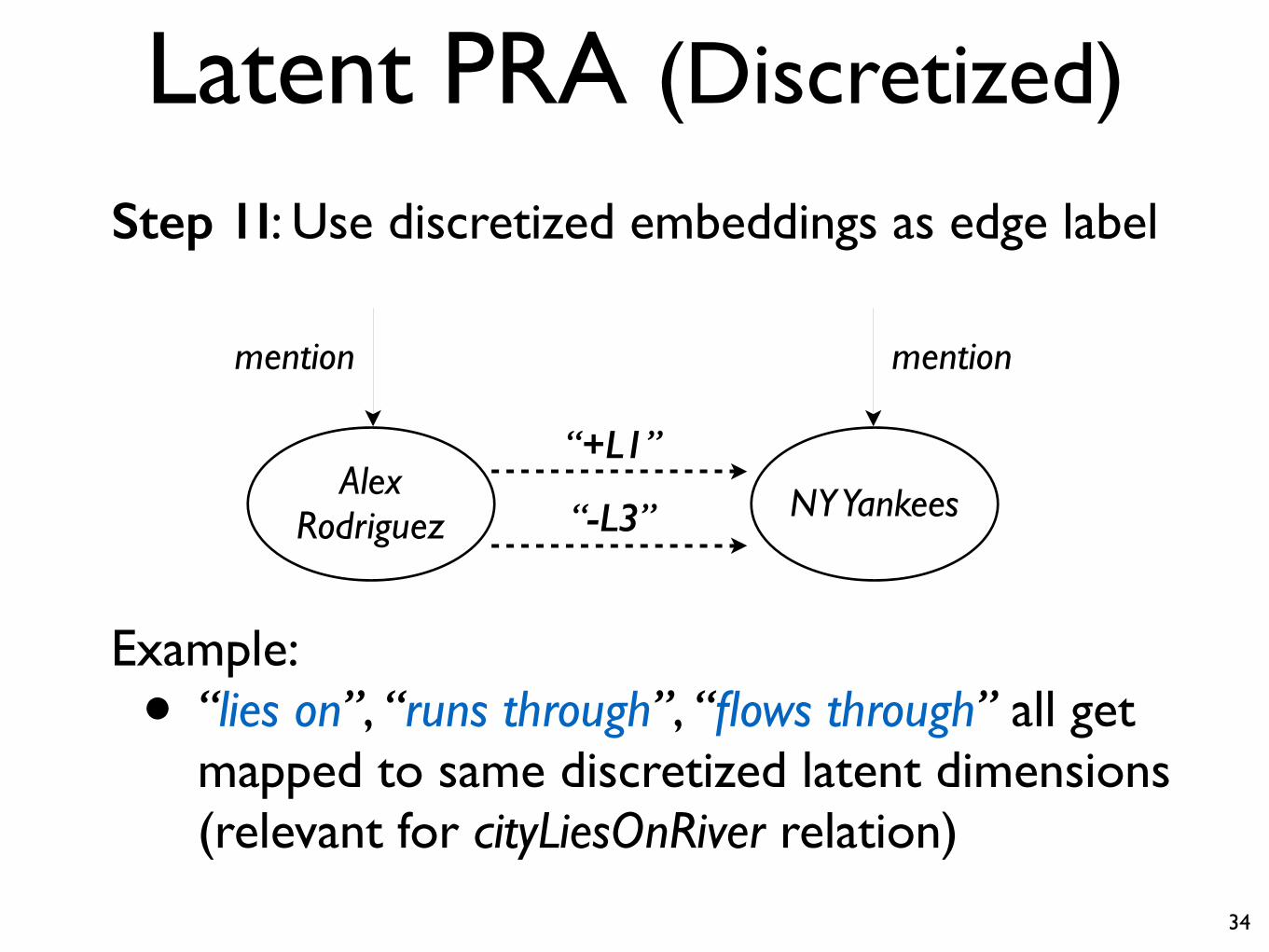
Step 1I: Use discretized embeddings as edge label

Latent PRA (Discretized)
34
Step 1I: Use discretized embeddings as edge label
“+L1”Alex
Rodriguez NY Yankees
mention mention
“-L3”
Latent PRA (Discretized)
34
Step 1I: Use discretized embeddings as edge label
“+L1”Alex
Rodriguez NY Yankees
mention mention
“-L3”
Example:• “lies on”, “runs through”, “flows through” all get
mapped to same discretized latent dimensions (relevant for cityLiesOnRiver relation)

Latent PRA Experiments
35

Latent PRA Experiments
35
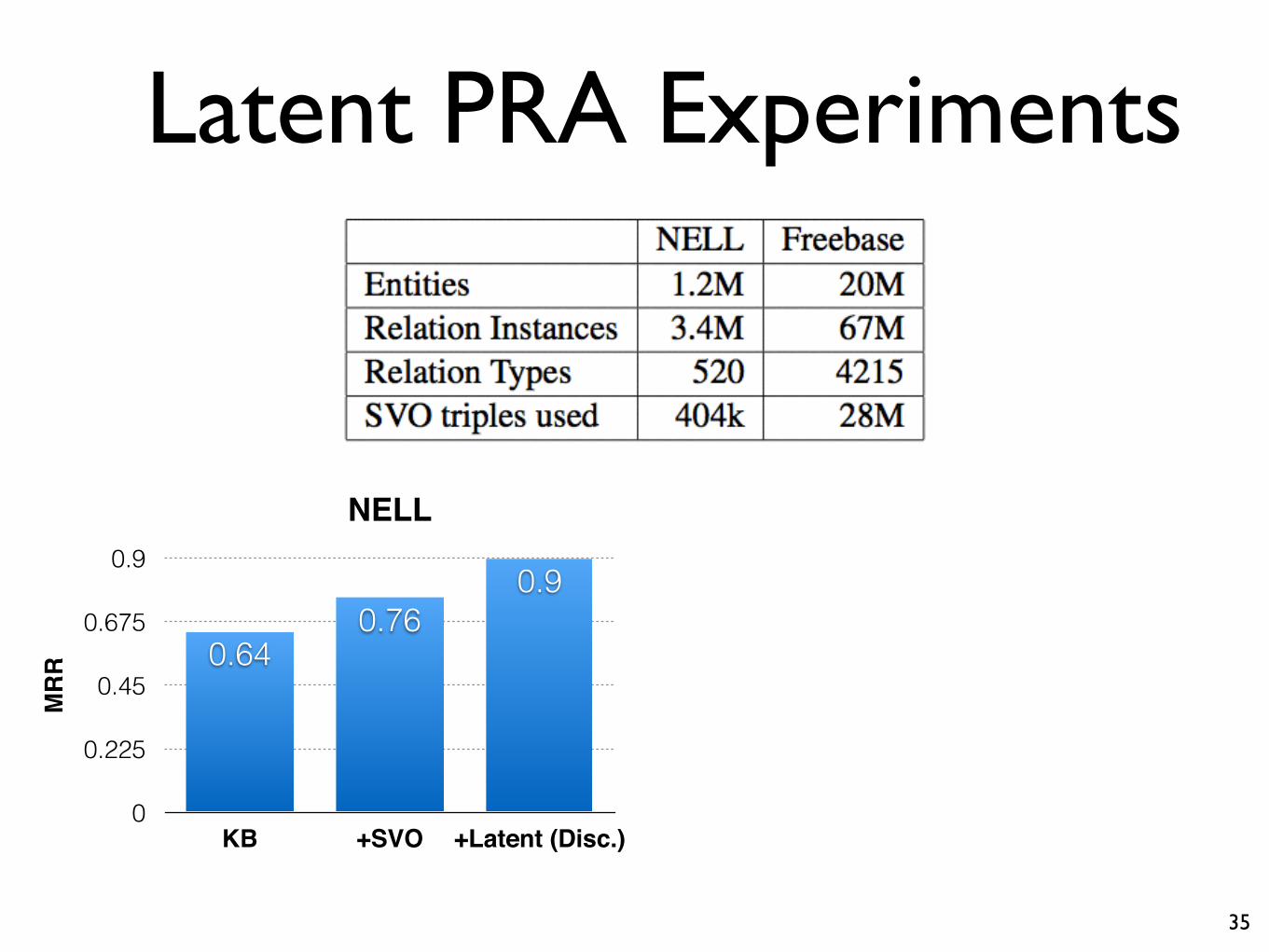
Latent PRA Experiments
35
NELL
MR
R
0
0.225
0.45
0.675
0.9
KB +SVO +Latent (Disc.)
0.90.76
0.64
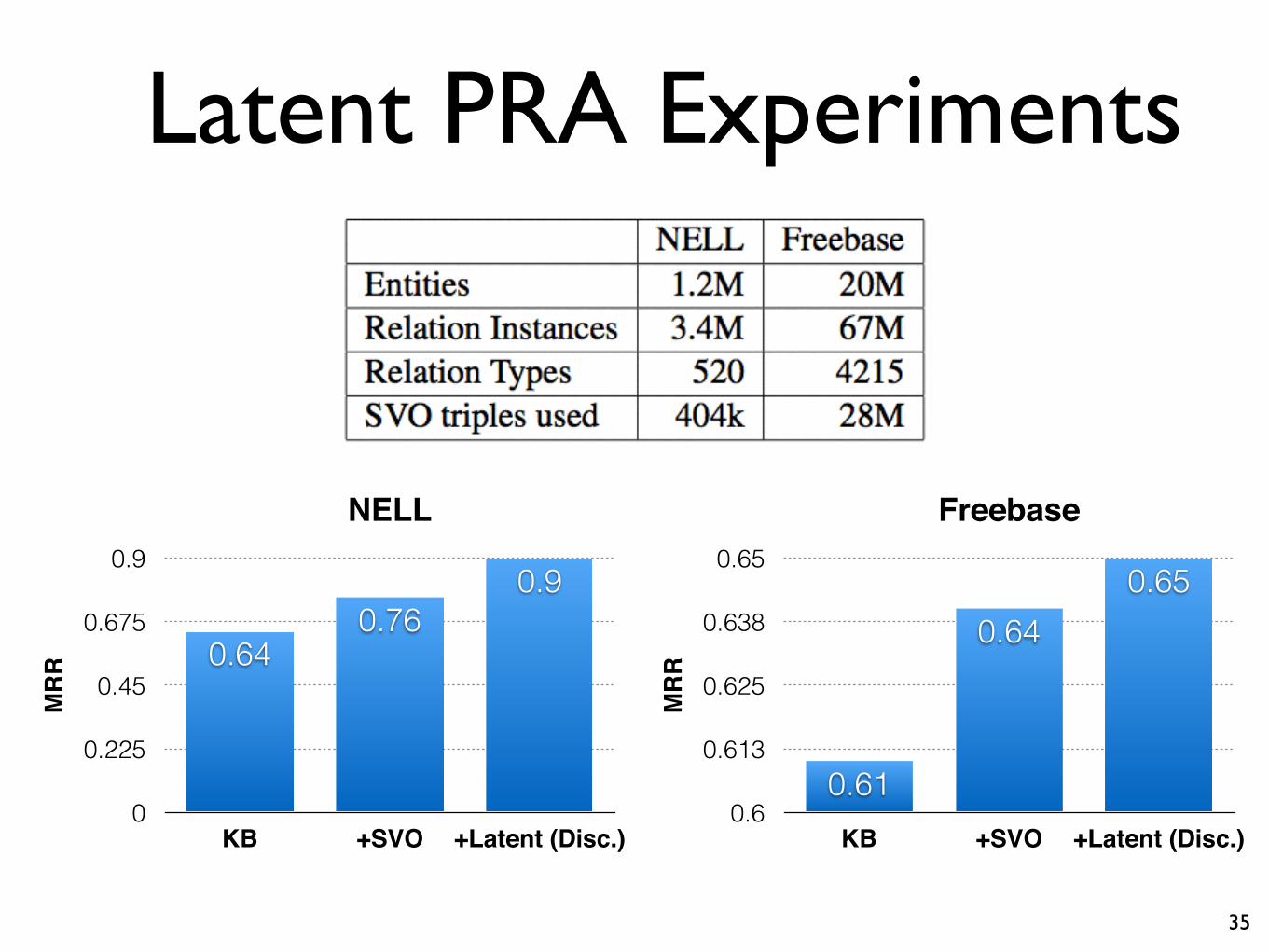
Latent PRA Experiments
35
NELL
MR
R
0
0.225
0.45
0.675
0.9
KB +SVO +Latent (Disc.)
0.90.76
0.64
Freebase
MR
R
0.6
0.613
0.625
0.638
0.65
KB +SVO +Latent (Disc.)
0.650.64
0.61
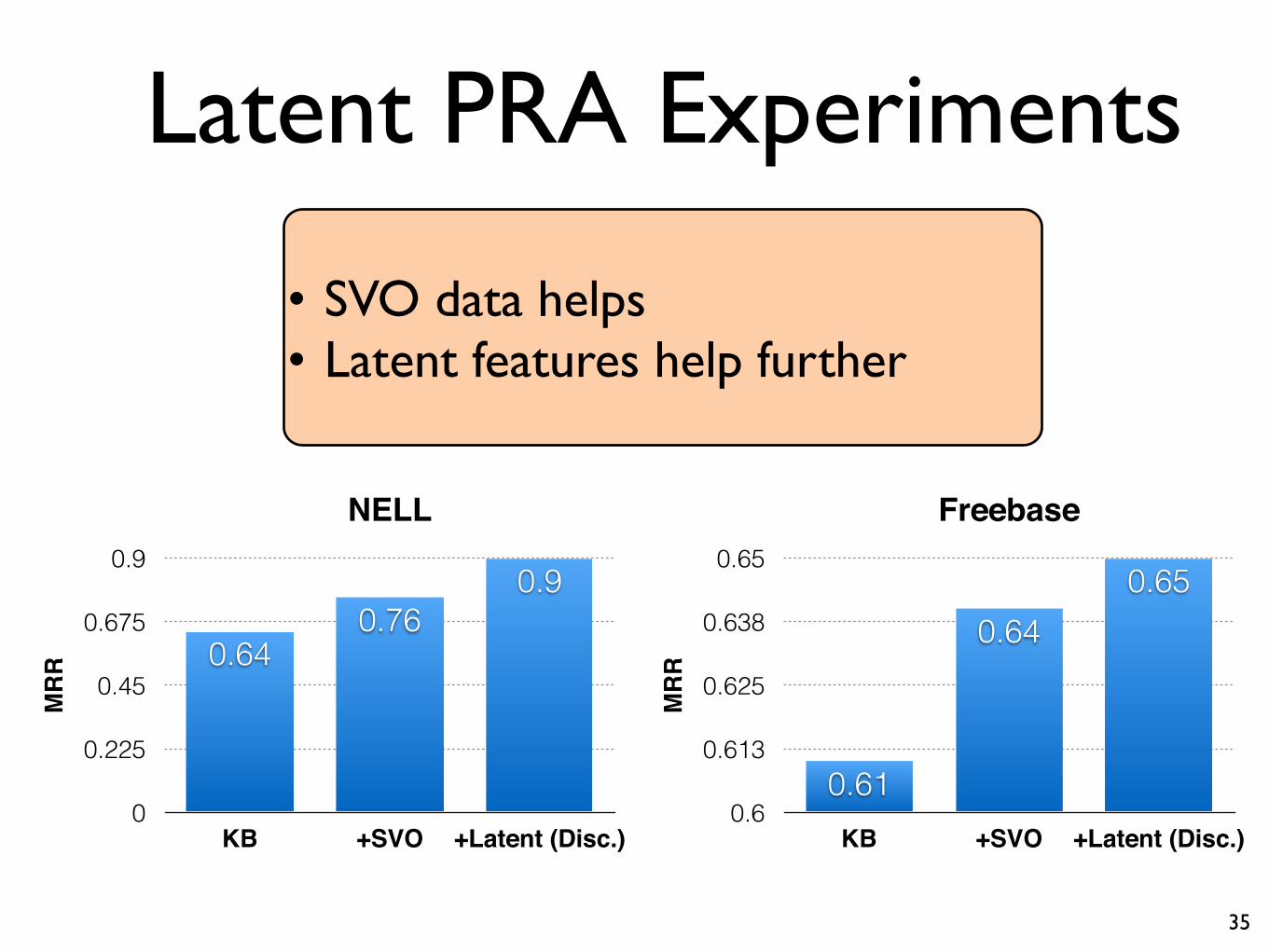
Latent PRA Experiments
35
NELL
MR
R
0
0.225
0.45
0.675
0.9
KB +SVO +Latent (Disc.)
0.90.76
0.64
Freebase
MR
R
0.6
0.613
0.625
0.638
0.65
KB +SVO +Latent (Disc.)
0.650.64
0.61
• SVO data helps• Latent features help further

Latent PRA: Summary
36

Latent PRA: Summary
• Makes PRA robust to KB sparsity
36

Latent PRA: Summary
• Makes PRA robust to KB sparsity
• Increases KB coverage, makes lexicalized edge labels possible
36

Latent PRA: Summary
• Makes PRA robust to KB sparsity
• Increases KB coverage, makes lexicalized edge labels possible
• Combines global and local statistics
36

Latent PRA: Summary
• Makes PRA robust to KB sparsity
• Increases KB coverage, makes lexicalized edge labels possible
• Combines global and local statistics
• Brings Ontological and OpenIE together
36

Upcoming EMNLP 2015 papers to overcome sparsity in NELL

Need knowledge to be …
•Available or inferable
•Fresh (temporally scoped) (WSDM ’12, CIKM ‘12)
38

Need knowledge to be …
•Available or inferable
•Fresh (temporally scoped) (WSDM ’12, CIKM ‘12)
38

Source of Weak Supervision: Doc PublicaBon Time ~ Fact Time
39

Source of Weak Supervision: Doc PublicaBon Time ~ Fact Time
39
President Clinton
December 23, 1995

Source of Weak Supervision: Doc PublicaBon Time ~ Fact Time
39
President Clinton
December 23, 1995
AssumpLon: Fact is true at the Lme of document publicaLon

Temporal Profile of Facts
40

Temporal Profile of Facts
Key Idea: Temporally scoping mulLple facts jointly can reduce uncertainty
40

Temporal Constraint Examples
41

Temporal Constraint Examples
Across RelaBons
41

Is CollecBve Inference EffecBve?

Is CollecBve Inference EffecBve?

Is CollecBve Inference EffecBve?
CollecBve Temporal Scoping
Independent Temporal Scoping

Is CollecBve Inference EffecBve?
CollecBve Temporal Scoping
Independent Temporal Scoping
CollecLve temporal scoping improves performance compared to temporally scoping each fact
separately

Learning Temporal Constraints [Talukdar, Wijaya, Mitchell, CIKM 2012]
43
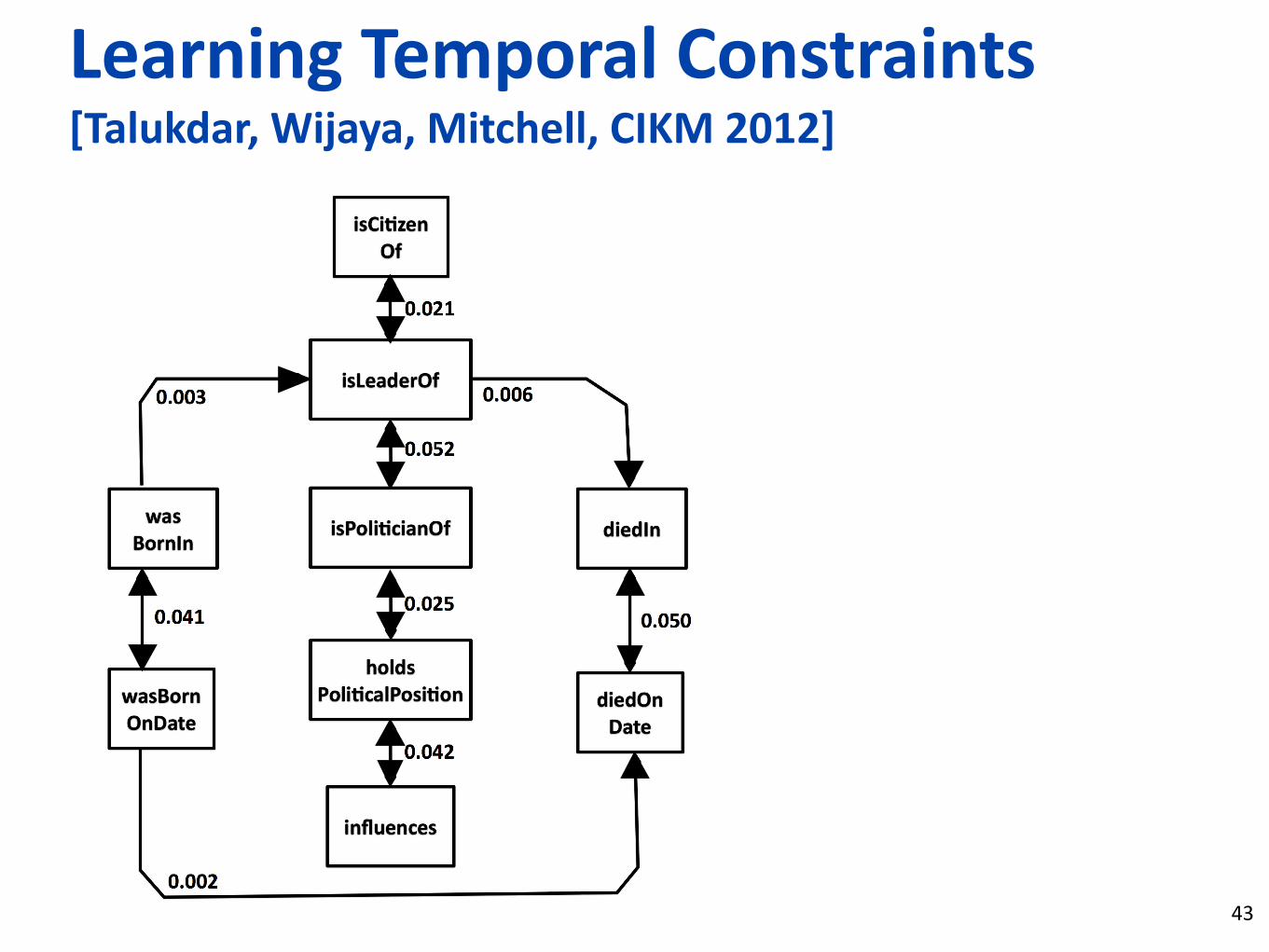
Learning Temporal Constraints [Talukdar, Wijaya, Mitchell, CIKM 2012]
43

Learning Temporal Constraints [Talukdar, Wijaya, Mitchell, CIKM 2012]
43
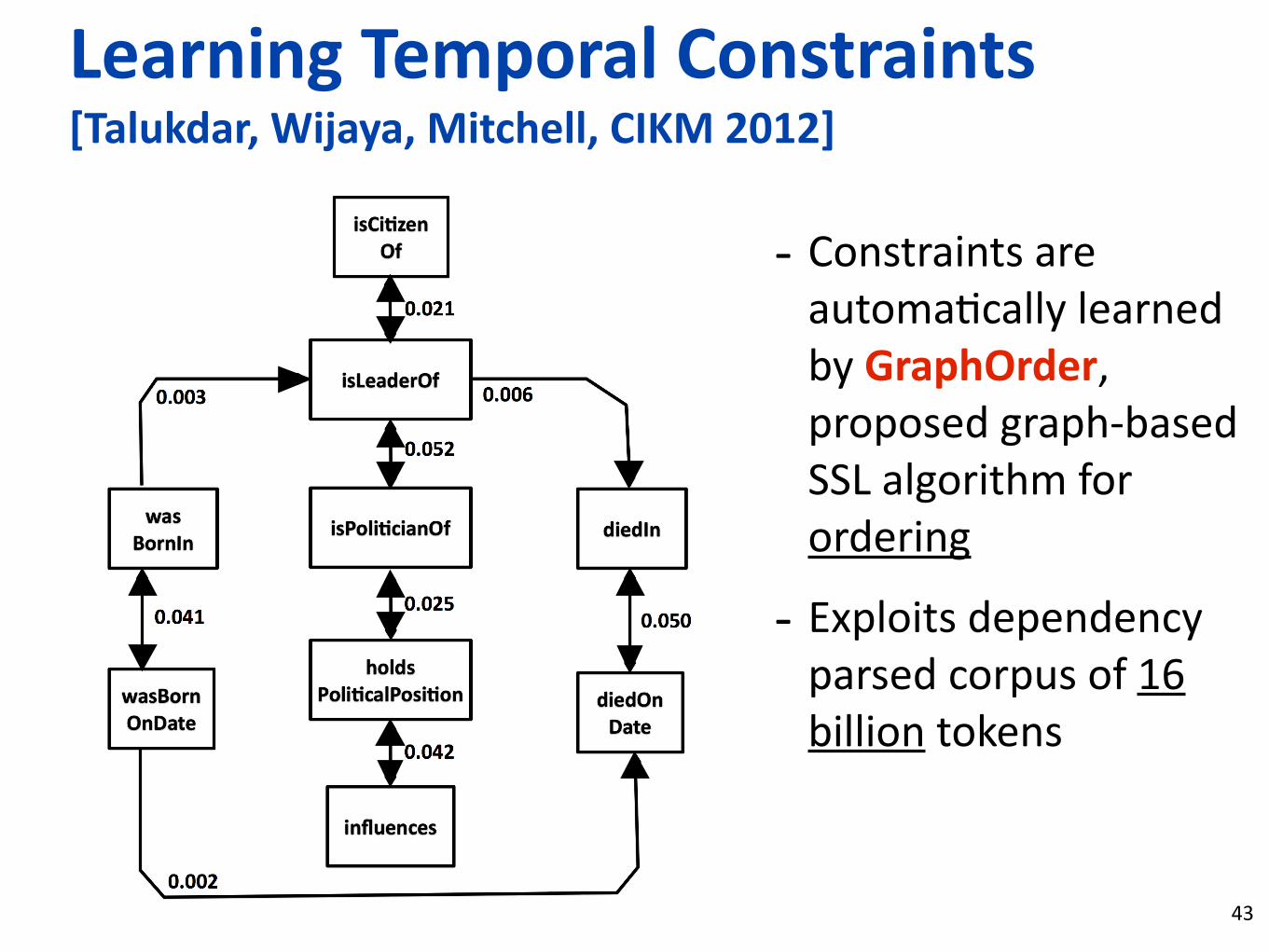
-‐ Constraints are automaLcally learned by GraphOrder, proposed graph-‐based SSL algorithm for ordering
Learning Temporal Constraints [Talukdar, Wijaya, Mitchell, CIKM 2012]
43
-‐ Constraints are automaLcally learned by GraphOrder, proposed graph-‐based SSL algorithm for ordering
-‐ Exploits dependency parsed corpus of 16 billion tokens

Broader Interest: Latent Conceptual OrganizaBon in Brains and Text
44
Text Data

Broader Interest: Latent Conceptual OrganizaBon in Brains and Text
44
Text Data
Focus of Past Research

Broader Interest: Latent Conceptual OrganizaBon in Brains and Text
44
Text Data
Focus of Past Research
fMRI Brain State

Broader Interest: Latent Conceptual OrganizaBon in Brains and Text
44
Text Data
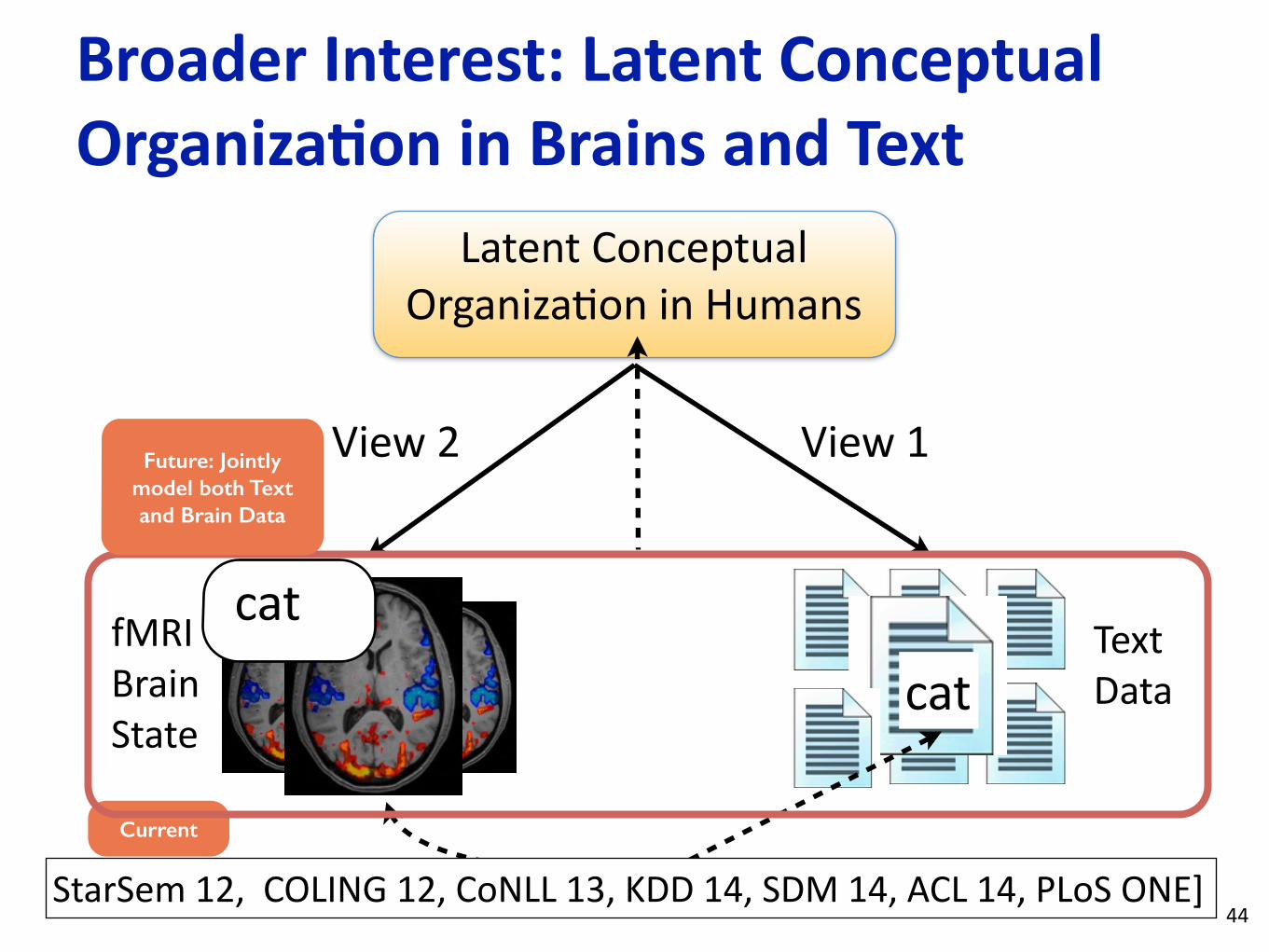
View 1View 2
Latent Conceptual OrganizaLon in Humans
Focus of Past Research
fMRI Brain State

Broader Interest: Latent Conceptual OrganizaBon in Brains and Text
44
Text Data
View 1View 2
Latent Conceptual OrganizaLon in Humans
Focus of Past Research
fMRI Brain State
cat
StarSem 12, COLING 12, CoNLL 13, KDD 14, SDM 14, ACL 14, PLoS ONE]
Current
cat
Broader Interest: Latent Conceptual OrganizaBon in Brains and Text
44
Text Data
View 1View 2
Latent Conceptual OrganizaLon in Humans
fMRI Brain State
cat
StarSem 12, COLING 12, CoNLL 13, KDD 14, SDM 14, ACL 14, PLoS ONE]
Current
cat
Future: Jointly model both Text and Brain Data

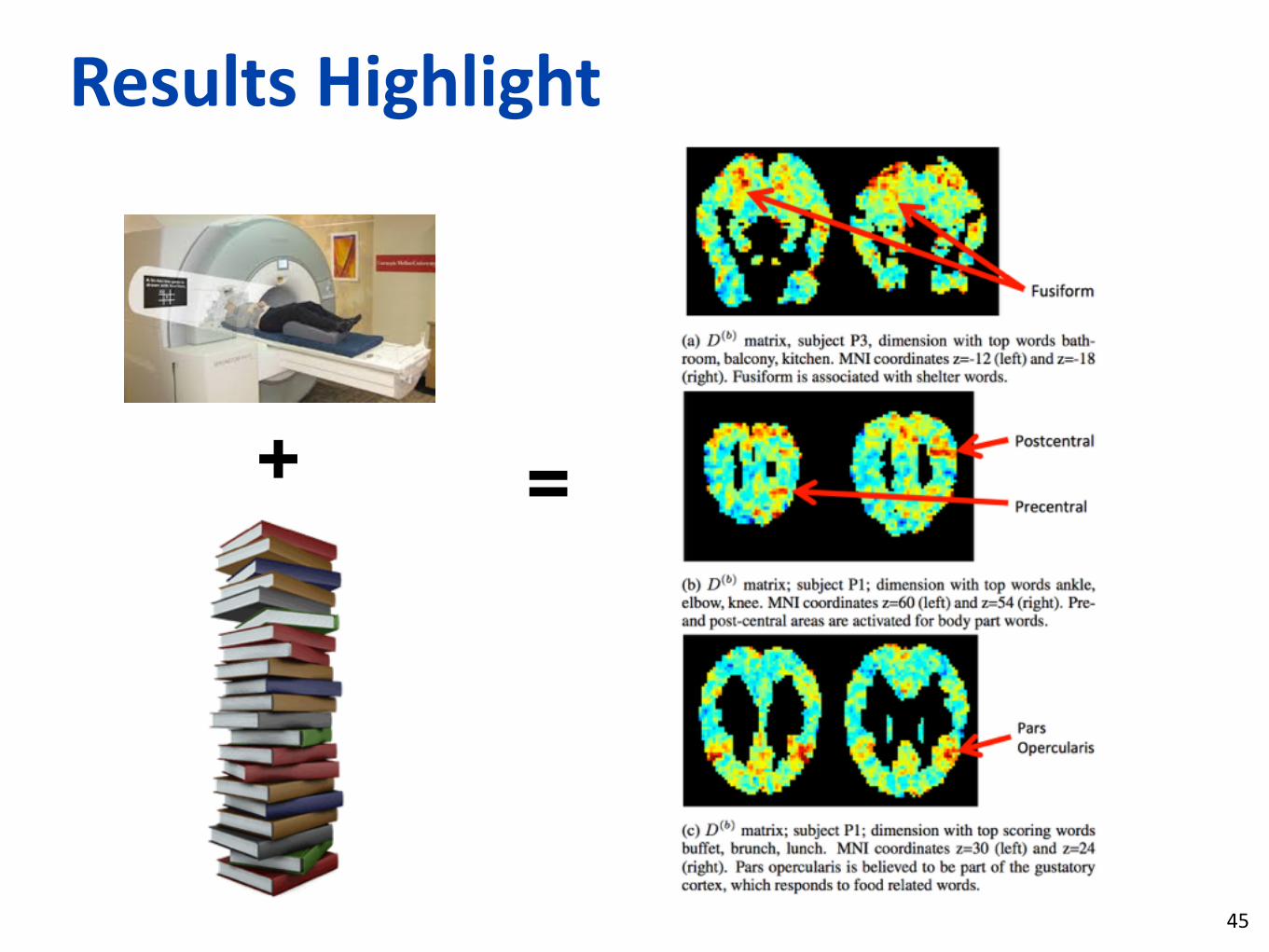
Results Highlight
45

Results Highlight
45
+
Results Highlight
45
+ =
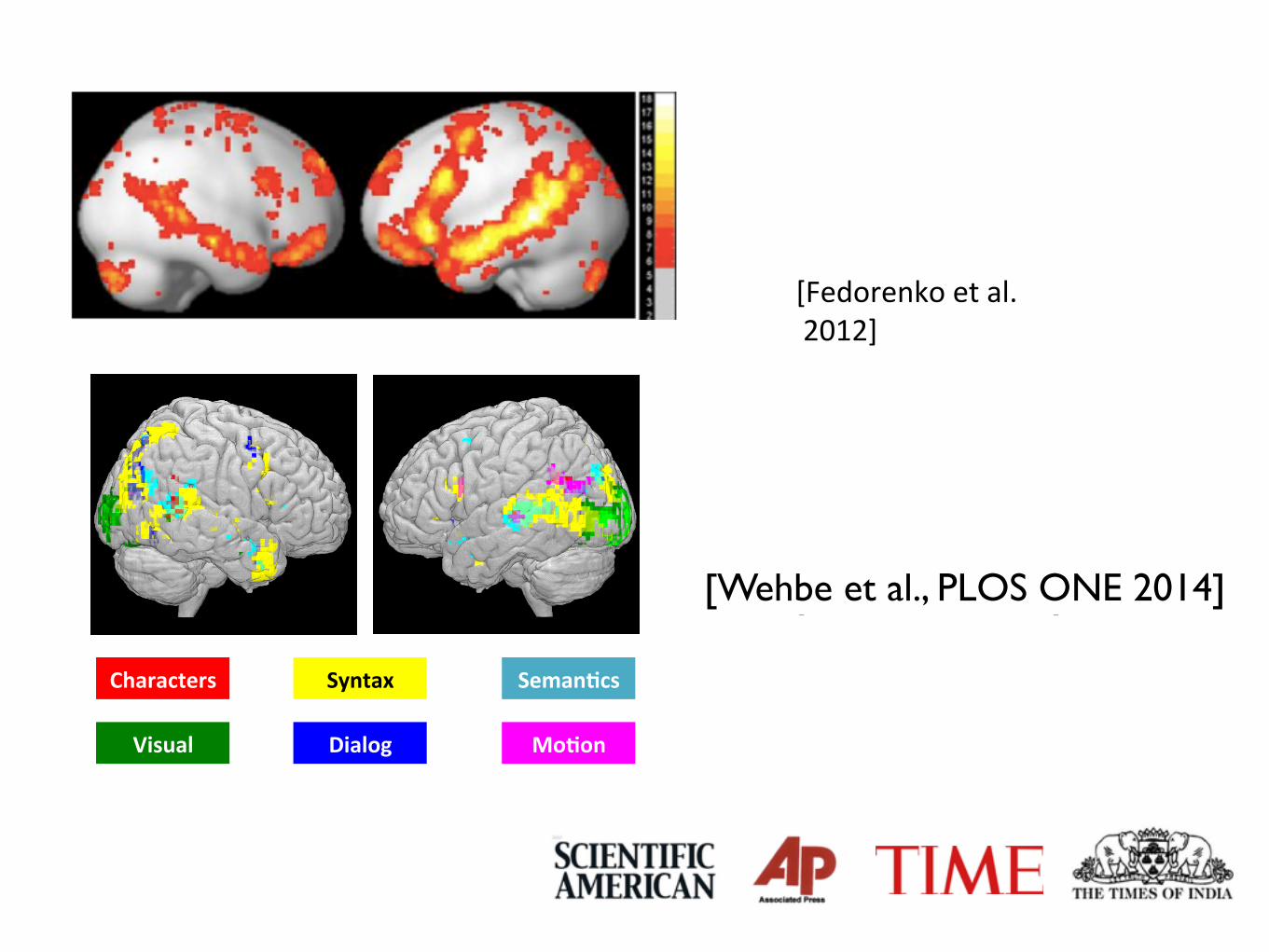
Leila&Wehbe&
[Fedorenko&et&al.&&2012]&
[Wehbe&et&al.,&2014]&
Author's personal copy
E. Fedorenko et al. / Neuropsychologia 50 (2012) 499– 513 505
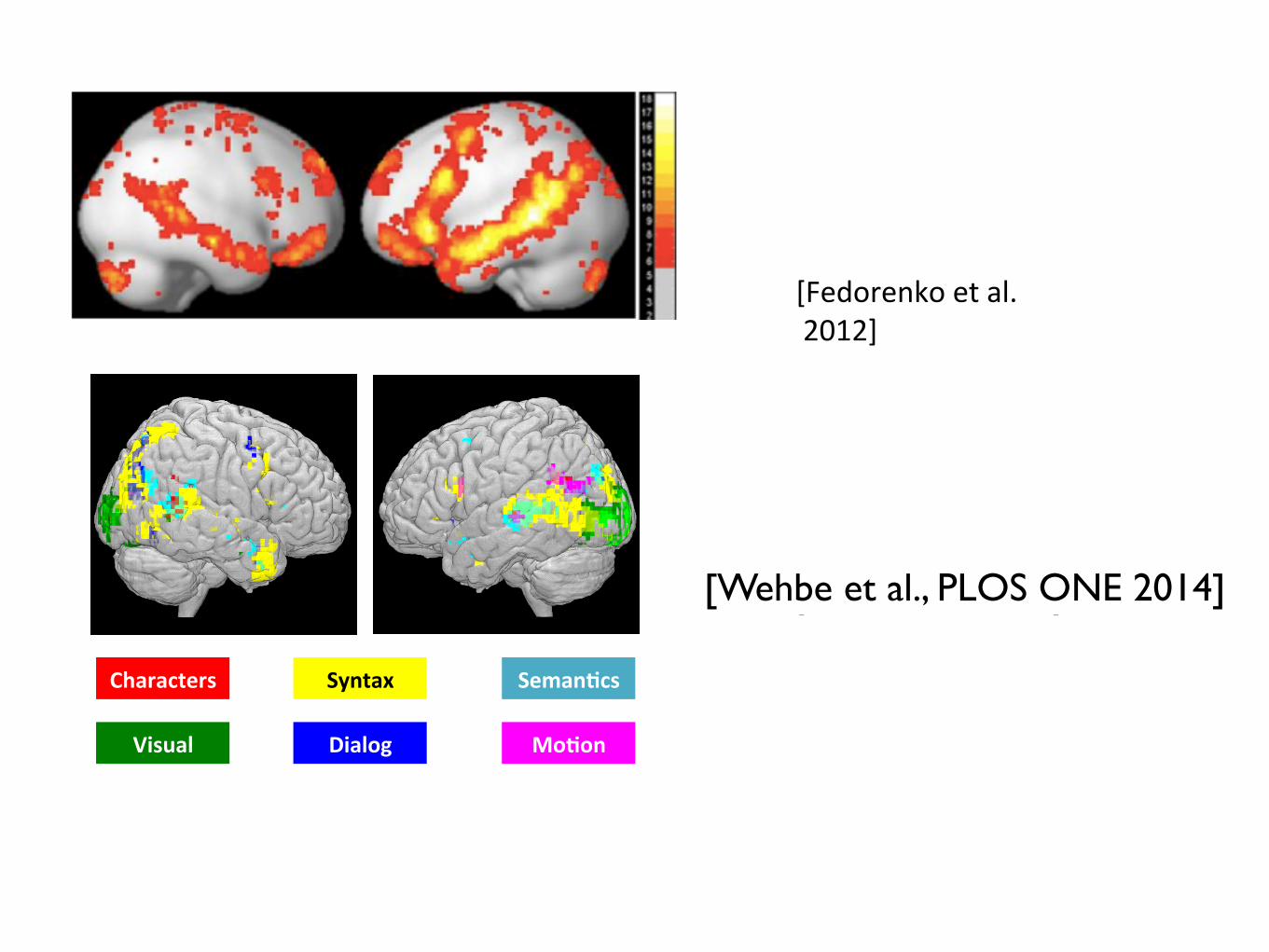
Fig. 5. Top: A probabilistic overlap map showing in each voxel how many of the 25 individual subjects show a significant (at p < .05, FDR-corrected) effect for the Sen-tences > Nonwords contrast. Bottom: The main functional parcels derived from the probabilistic overlap map using an image parcellation (watershed) algorithm, as describedin more detail in Fedorenko et al. (2010).
nonword-list a memory probe was presented (a word in the sentences and word-listconditions, and a nonword in the jabberwocky and nonword-list conditions), andparticipants had to decide whether the probe was present in the preceding stimulus.As discussed in Fedorenko et al. (2010), the two versions of the task (passive readingvs. reading with a memory probe at the end) produced similar activation patterns;we therefore collapsed across the two subsets of the subjects in our analyses in thatpaper and we do the same here. Each participant completed between 6 and 8 runs(i.e., between 24 and 32 blocks per condition; see Fedorenko et al., 2010, for detailsof the timing).
In Section 3, we report the results of: (a) region-of-interest-based (ROI-based)MVPA analyses on a set of key language-sensitive regions and (b) whole-brainsearchlight-style analyses (Kriegeskorte et al., 2006).
2.1. ROI-based analyses
We chose to use as ROIs for our MVPA analyses the thirteen group-level func-tional parcels6 (Fig. 5, bottom) that were derived from the probabilistic overlapmap for the Sentences > Nonword-lists activations7 (Fig. 5, top), as described inFedorenko et al. (2010). These group-based ROIs represent the locations whereindividual activations tend to be found most consistently across subjects. So, forany given subject, a parcel will include some voxels that respond reliably morestrongly to Sentences than Nonwords, and some voxels that do not show this prop-erty. We chose to use these group-level parcels instead of subject-specific functionalROIs in these analyses for two reasons. First, it has been previously demonstrated
6 These parcels were created in order to systematize and automate the proce-dure for defining subject-specific functional ROIs (fROIs): in particular, for any givenregion, an individual subject’s fROI is defined by intersecting the relevant parcel withthe subject’s thresholded activation map. In other words, these functional parcelsserve as spatial constraints on the selection of subject-specific voxels, akin to usingborders of anatomical regions (see Julian, Fedorenko, & Kanwisher, submitted, foran extension of this method to ventral visual regions).
7 Although these group-level functional parcels were created from the 25 subjectswhose data we examine here, non-independence issues (Vul & Kanwisher, 2009) donot arise in examining the discriminability between word lists and jabberwockysentences because the data from those conditions were not used in creating theparcels. Some non-independence is present when we examine the discriminabilityamong all four conditions (Section 3.1). This non-independence should be taken intoconsideration when interpreting the results from the ROI-based analyses. However,the fact that the results of the whole-brain searchlight analyses, which do not suf-fer from such non-independence problems, look similar to those of the ROI-basedanalyses largely alleviates the concerns.
(Haxby et al., 2001; Kriegeskorte et al., 2006) that even voxels that do not show aparticular functional signature relevant to the to-be-discriminated conditions cancontribute to classification accuracy. For example, Haxby et al. (2001) showed thatremoving voxels from the ventral visual regions that respond most strongly to somevisual category does not strongly affect the ability to discriminate that categoryfrom other categories. Consequently, voxels in the vicinity of language-sensitiveregions in each individual subject may contain information about various aspectsof linguistic knowledge even though they do not show the functional signature oflanguage-sensitive voxels. And second, because we wanted to examine neural activ-ity patterns across all four conditions, we could not use any of the conditions fordefining subject-specific fROIs. (However, in addition to these whole-parcel-basedanalyses, we did conduct one analysis where we looked at the ability of subject-specific functional ROIs (fROIs), defined by the Sentences > Nonword-lists contrast,to discriminate between word lists and jabberwocky sentences. The results of thisanalysis are reported in Appendix A.)
For each condition we divided the data into odd-numbered and even-numberedruns (each subject performed between 6 and 8 runs total). Then, for each subjectand for each ROI, and across the two independent halves of the data, we computedthe within- vs. between-condition spatial correlations for each pair of conditions (asschematically shown in Fig. 4 above), considering all the voxels within the parcel.For example, to see how well the pattern of activity for the Sentences condition isdiscriminated from the pattern of activity for the Word-lists condition, we computed(i) a within-condition correlation value for the Sentences condition by comparing thepattern of activity for the Sentences condition in the odd vs. even runs (all the r valuesare Fisher-transformed); (ii) a within-condition correlation value for the Word-listscondition by comparing the pattern of activity for the Word-lists condition in theodd vs. even runs; and (iii) a between-condition correlation value by comparing thepattern of activation for the Sentences condition in the odd/even runs and for theWord-lists condition in the even/odd runs (these two values are averaged to createone between-condition value). Finally, for each ROI we performed an F-test on thewithin vs. between-condition correlation values across subjects to see whether thewithin-condition values are reliably higher than the between-condition values. Ifso, this would suggest that the distinction between the two conditions in questionis represented in the relevant ROI.
We deviated from Haxby’s analysis strategies in one way. In particular, Haxbyapplied centering to his data by subtracting the mean level of activation of a voxelfrom the activation level for each of the conditions. This is equivalent to consideringthe activation from each condition with respect to a baseline activation level com-puted as the average activation across all conditions, instead of using an independentfixation baseline as we used in our analyses. The centering procedure potentiallyincreases sensitivity of the MVPAs by removing one source of variance from acrossthe voxels and leaving only between-condition differences in play. However, cen-tering also introduces between-condition dependencies in the estimation of thewithin-condition similarity measures, which complicates their interpretation.
a"
b"
Seman(cs"Characters" Syntax"
Dialog" Mo(on"Visual"
[Wehbe et al., PLOS ONE 2014]
Leila&Wehbe&
[Fedorenko&et&al.&&2012]&
[Wehbe&et&al.,&2014]&
Author's personal copy
E. Fedorenko et al. / Neuropsychologia 50 (2012) 499– 513 505
Fig. 5. Top: A probabilistic overlap map showing in each voxel how many of the 25 individual subjects show a significant (at p < .05, FDR-corrected) effect for the Sen-tences > Nonwords contrast. Bottom: The main functional parcels derived from the probabilistic overlap map using an image parcellation (watershed) algorithm, as describedin more detail in Fedorenko et al. (2010).
nonword-list a memory probe was presented (a word in the sentences and word-listconditions, and a nonword in the jabberwocky and nonword-list conditions), andparticipants had to decide whether the probe was present in the preceding stimulus.As discussed in Fedorenko et al. (2010), the two versions of the task (passive readingvs. reading with a memory probe at the end) produced similar activation patterns;we therefore collapsed across the two subsets of the subjects in our analyses in thatpaper and we do the same here. Each participant completed between 6 and 8 runs(i.e., between 24 and 32 blocks per condition; see Fedorenko et al., 2010, for detailsof the timing).
In Section 3, we report the results of: (a) region-of-interest-based (ROI-based)MVPA analyses on a set of key language-sensitive regions and (b) whole-brainsearchlight-style analyses (Kriegeskorte et al., 2006).
2.1. ROI-based analyses
We chose to use as ROIs for our MVPA analyses the thirteen group-level func-tional parcels6 (Fig. 5, bottom) that were derived from the probabilistic overlapmap for the Sentences > Nonword-lists activations7 (Fig. 5, top), as described inFedorenko et al. (2010). These group-based ROIs represent the locations whereindividual activations tend to be found most consistently across subjects. So, forany given subject, a parcel will include some voxels that respond reliably morestrongly to Sentences than Nonwords, and some voxels that do not show this prop-erty. We chose to use these group-level parcels instead of subject-specific functionalROIs in these analyses for two reasons. First, it has been previously demonstrated
6 These parcels were created in order to systematize and automate the proce-dure for defining subject-specific functional ROIs (fROIs): in particular, for any givenregion, an individual subject’s fROI is defined by intersecting the relevant parcel withthe subject’s thresholded activation map. In other words, these functional parcelsserve as spatial constraints on the selection of subject-specific voxels, akin to usingborders of anatomical regions (see Julian, Fedorenko, & Kanwisher, submitted, foran extension of this method to ventral visual regions).
7 Although these group-level functional parcels were created from the 25 subjectswhose data we examine here, non-independence issues (Vul & Kanwisher, 2009) donot arise in examining the discriminability between word lists and jabberwockysentences because the data from those conditions were not used in creating theparcels. Some non-independence is present when we examine the discriminabilityamong all four conditions (Section 3.1). This non-independence should be taken intoconsideration when interpreting the results from the ROI-based analyses. However,the fact that the results of the whole-brain searchlight analyses, which do not suf-fer from such non-independence problems, look similar to those of the ROI-basedanalyses largely alleviates the concerns.
(Haxby et al., 2001; Kriegeskorte et al., 2006) that even voxels that do not show aparticular functional signature relevant to the to-be-discriminated conditions cancontribute to classification accuracy. For example, Haxby et al. (2001) showed thatremoving voxels from the ventral visual regions that respond most strongly to somevisual category does not strongly affect the ability to discriminate that categoryfrom other categories. Consequently, voxels in the vicinity of language-sensitiveregions in each individual subject may contain information about various aspectsof linguistic knowledge even though they do not show the functional signature oflanguage-sensitive voxels. And second, because we wanted to examine neural activ-ity patterns across all four conditions, we could not use any of the conditions fordefining subject-specific fROIs. (However, in addition to these whole-parcel-basedanalyses, we did conduct one analysis where we looked at the ability of subject-specific functional ROIs (fROIs), defined by the Sentences > Nonword-lists contrast,to discriminate between word lists and jabberwocky sentences. The results of thisanalysis are reported in Appendix A.)
For each condition we divided the data into odd-numbered and even-numberedruns (each subject performed between 6 and 8 runs total). Then, for each subjectand for each ROI, and across the two independent halves of the data, we computedthe within- vs. between-condition spatial correlations for each pair of conditions (asschematically shown in Fig. 4 above), considering all the voxels within the parcel.For example, to see how well the pattern of activity for the Sentences condition isdiscriminated from the pattern of activity for the Word-lists condition, we computed(i) a within-condition correlation value for the Sentences condition by comparing thepattern of activity for the Sentences condition in the odd vs. even runs (all the r valuesare Fisher-transformed); (ii) a within-condition correlation value for the Word-listscondition by comparing the pattern of activity for the Word-lists condition in theodd vs. even runs; and (iii) a between-condition correlation value by comparing thepattern of activation for the Sentences condition in the odd/even runs and for theWord-lists condition in the even/odd runs (these two values are averaged to createone between-condition value). Finally, for each ROI we performed an F-test on thewithin vs. between-condition correlation values across subjects to see whether thewithin-condition values are reliably higher than the between-condition values. Ifso, this would suggest that the distinction between the two conditions in questionis represented in the relevant ROI.
We deviated from Haxby’s analysis strategies in one way. In particular, Haxbyapplied centering to his data by subtracting the mean level of activation of a voxelfrom the activation level for each of the conditions. This is equivalent to consideringthe activation from each condition with respect to a baseline activation level com-puted as the average activation across all conditions, instead of using an independentfixation baseline as we used in our analyses. The centering procedure potentiallyincreases sensitivity of the MVPAs by removing one source of variance from acrossthe voxels and leaving only between-condition differences in play. However, cen-tering also introduces between-condition dependencies in the estimation of thewithin-condition similarity measures, which complicates their interpretation.
a"
b"
Seman(cs"Characters" Syntax"
Dialog" Mo(on"Visual"
[Wehbe et al., PLOS ONE 2014]

From Strings to Things and Beyond

From Strings to Things and Beyond
Construct

From Strings to Things and Beyond
Construct
New Data
Maintain

From Strings to Things and Beyond
Construct
New Data
Maintain Apply

From Strings to Things and Beyond
Construct
New Data
Maintain Apply

Ongoing Research at MALL Lab• Continuous KB evaluation
• Temporal Micro Reading
• Representation Learning
• Large-scale Learning
• Goal-directed KB expansion
48
Prakhar Pjha (IISc)
Arabinda Moni (IISc)
Yogesh D. (BTech, IIT BHU)
Chandrahas (IISc)
Uday Saini (BTech, IIT Ropar)
Madhav N. (IISc)
3 PhD, 3 Masters, 4 Project Assistants, 1 Intern

External CollaboraBon & Support
49

Final Thoughts
50

Final Thoughts
50

Final Thoughts
50

Final Thoughts
50
Unprecedented opportunity to bring world knowledge into AI systems -‐-‐ focus of my research
Big Text Big Knowledge

Thank You! [email protected] www.talukdar.net
Machine Learning
Big Data Processing
Natural Language Processing
Decisions
Related Documents











