MapReduce and Hadoop Frankie Pike

Frankie Pike. 2010: 1.2 zettabytes 1.2 trillion gigabytes DVDs past the moon 2-way = 6 newspapers everyday ~58% growth per year Why care?
Dec 27, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

MapReduce and HadoopFrankie Pike

2010: 1.2 zettabytes1.2 trillion gigabytesDVDs past the moon2-way = 6 newspapers everyday~58% growth per year
Why care?

Why care?

Why care?
Google’s capacity = 1 exabyte 24 hours of Youtube > Internet in 2000 4 years of video / day on Youtube 100 trillion words online

Common Architecture
http://www.adopenstatic.com/images/resources/blog/Kerberos6.jpg

Common Architecture
Single point of failureSpace-constraintsMulti-tenancy difficultiesRe-writing of programs or
changes to network config

MapReduce

The PromiseHigh reliability
any node can go downHigh scalability
easy to add nodesMulti-tenancyCost Reduction“Cloud-friendly”Java, C++, C#, Python, RTransparent Parallelization

The Kryptonite
Data set needs to be
“big enough”
Consistency mid-processing

Two Steps in MapReduce
MapReduce

Mapping
Input K/V pairs -> Intermediate K/V PairsInput and Intermediate can be different(Server Key, Blog Data) -> (Blog Key, Post Count)
Sorted and Partitioned for reduction
Number of maps depends on task and cluster10TB data with blocksize 128MB = 82,000 maps10-100 maps per node ideal

ReducingIntermediate K/V -> Intermediate K/V (smaller)
Matching keys consolidated(A, 15); (B, 6); (A, 3) -> (A, 18); (B, 6)
Number of Reductions >= 0Hopefully smaller dataset at each iterationReduce as much as needed

An Example{
"type": "post", "name": "Raven's Map/Reduce functionality", "blog_id": 1342, "post_id": 29293921, "tags": ["raven", "nosql"], "post_content": "<p>...</p>", "comments": [
{ "source_ip": '124.2.21.2', "author": "martin", "text": "..." }
] } Want count of comments for blog
http://ayende.com/blog/4435/map-reduce-a-visual-explanation

Step 1: Map to final format
http://ayende.com/blog/4435/map-reduce-a-visual-explanation

Step 2: Reduce (Partition)
http://ayende.com/blog/4435/map-reduce-a-visual-explanation

Step 3: Reduce (more)
http://ayende.com/blog/4435/map-reduce-a-visual-explanation

Step 4: Reduce (most)
http://ayende.com/blog/4435/map-reduce-a-visual-explanation
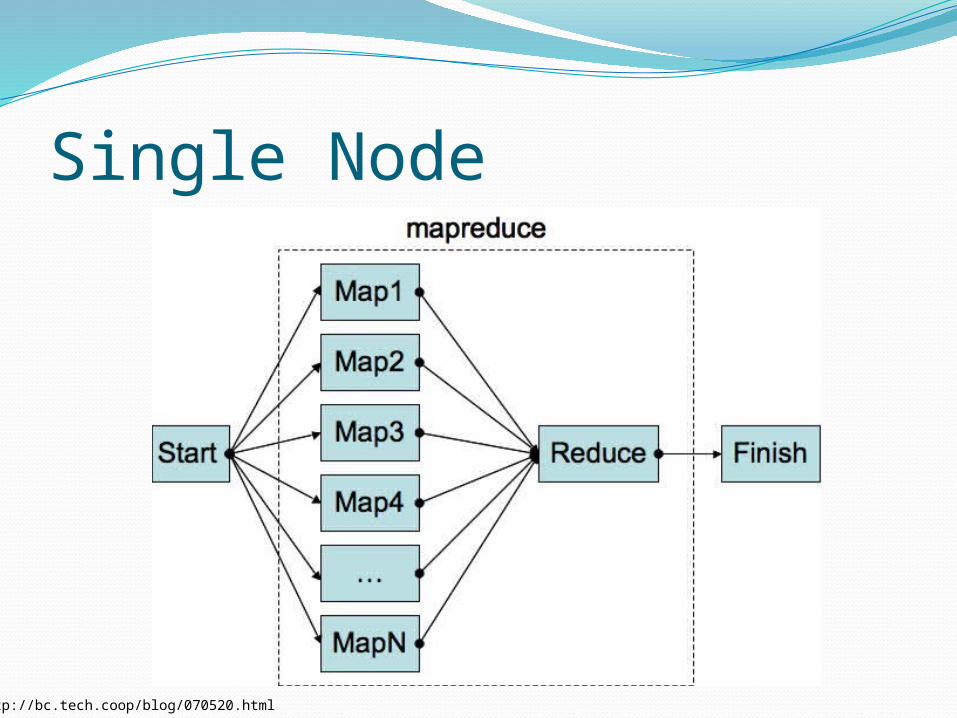
Single Node
http://bc.tech.coop/blog/070520.html

Dual Node
http://map-reduce.wikispaces.asu.edu/

N-Nodes
http://www.inventoland.net/img/blog/mapReduce.png

Dealing with Failure
WorkersOccasional check-in pings by masters
MastersData structures get periodic auto-saves and consistency
checks. Can restart from periodic savesBandwidth
Tasks attempt to pair with local storage

Has it worked?
PatentedRegenerated index

Apache Hadoop“open source software for reliable, scalable, distributed
computing”
Hadoop Distributed File System (HDFS)Hadoop MapReduceCassandra (multi-master database)HBase (scalable, distributed, structured database)Mahout (data mining and machine learning libs)ZooKeeper (coordination service)

Sources
Avankipu & Sdsalvi, Cloud Computing - An Overview. http://map-reduce.wikispaces.asu.edu
Ayende Rahien, Map/Reduce – A Visual Explanation. http://ayende.com/blog/4435/map-reduce-a-visual-explanation
http://hadoop.apache.org/http://en.wikipedia.org/wiki/MapReduce/
Related Documents











