Folien zur Vorlesung Statistik II (Wahrscheinlichkeitsrechnung und schließende Statistik) Sommersemester 2011 Donnerstag, 10.15 - 11.45 Uhr (regelm¨ aßig) Montag, 30.05.2011, 10.15 - 11.45 Uhr (1. Zusatztermin) Montag, 20.06.2011, 10.15 - 11.45 Uhr (2. Zusatztermin) H¨orsaal: Aula am Aasee Prof. Dr. Bernd Wilfling Westf¨ alische Wilhelms-Universit¨ atM¨unster

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Folien zur Vorlesung
Statistik II
(Wahrscheinlichkeitsrechnungund schließende Statistik)
Sommersemester 2011Donnerstag, 10.15 - 11.45 Uhr (regelmaßig)
Montag, 30.05.2011, 10.15 - 11.45 Uhr (1. Zusatztermin)Montag, 20.06.2011, 10.15 - 11.45 Uhr (2. Zusatztermin)
Horsaal: Aula am Aasee
Prof. Dr. Bernd Wilfling
Westfalische Wilhelms-Universitat Munster

Inhalt
1 Einleitung1.1 Organisatorisches1.2 Was ist ’Schließende Statistik’?
2 Zufallsvorgange und Wahrscheinlichkeiten2.1 Zufallsvorgange und Ereignisse2.2 Wahrscheinlichkeiten2.3 Bedingte Wahrscheinlichkeit und Unabhangigkeit
2.4 Totale Wahrscheinlichkeit und das Bayes-Theorem
3 Zufallsvariable und Verteilungen3.1 Grundbegriffe und Definitionen3.2 Erwartungswert und Varianz einer Zufallsvariablen3.3 Spezielle diskrete Verteilungen3.4 Spezielle stetige Verteilungen
4 Gemeinsame Verteilung und Grenzwertsatze
4.1 Gemeinsame Verteilung von Zufallsvariablen4.2 Grenzwertsatze
5 Stichproben und Statistiken5.1 Zufallsstichprobe
5.2 Statistiken5.3 Exkurs: χ2- und t-Verteilung5.4 Statistiken bei normalverteilter Stichprobe
6 Schatzverfahren fur Parameter
6.1 Punktschatzung6.2 Eigenschaften von Punktschatzern
6.3 Intervallschatzung
7 Hypothesentests
7.1 Grundbegriffe des Testens7.2 Tests fur Erwartungswerte
7.3 Tests fur Varianzen
i

Literatur
Deutschsprachig:
Hartung, J. (2005). Statistik (14. Auflage). Oldenbourg Verlag, Munchen.
Mosler, K. und F. Schmid (2008). Wahrscheinlichkeitsrechnung und schließende Statistik(3. Auflage). Springer Verlag, Heidelberg.
Schira, J. (2009). Statistische Methoden der VWL und BWL – Theorie und Praxis (3. Auf-lage). Pearson Studium, Munchen.
Englischsprachig:
Barrow, M. (2009). Statistics for Economics, Accounting and Business Studies (5th Editi-on). Prentice Hall, Singapore.
Mood, A.M., Graybill, F.A. and D.C. Boes (1974). Introduction to the Theory of Statistics(3rd Edition). McGraw-Hill, Tokyo.
ii

1. Einleitung
1.1 Organisatorisches
Ziel der Vorlesung:
• Einfuhrung in die
Wahrscheinlichkeitsrechnung
’schließende Statistik’(auch: induktive Statistik)
1

Internet-Seite der Vorlesung:
• http://www1.wiwi.uni-muenster.de/oeew/
−→ Studium −→ Veranstaltungen im Sommersemester 2011
−→ Bachelor −→ Statistik II
Vorlesungsstil:
• Freier Vortrag anhand von Projektor-Folien
• Folien stehen als PDF-Dateien auf Internetseite zur Verfugung(Beschaffung der Folien wird unbedingt empfohlen)
2

Literatur:
• Mosler, K. , Schmid, F. (2008). Wahrscheinlichkeitsrech-nung und schließende Statistik (3. Auflage), Springer-Verlag
• Formelsammlung ”Definitionen, Formeln und Tabellen zurStatistik” (6. Auflage) von Bomsdorf/Grohn/Mosler/Schmid(notwendiges Hilfsmittel, in der Klausur zugelassen)
3

Klausurvorbereitung:
• Stoff der Vorlesung
• Aufgaben der Tutoriums
Ansprechpartner: Frau Dipl.-Vw. Heike Bornewasser-Hermes
• Klausurtraining durch Ferienarbeitsgruppen
4

Zugelassene Hilfsmittel in der Klausur:
• Taschenrechner (nicht programmierbar)
• Formelsammlung ”Definitionen, Formeln und Tabellen zurStatistik” von Bomsdorf/Grohn/Mosler/Schmid, 6. (aktuelleund fruhere) Auflage(n)Akzeptierte außere Form fur die Klausur:
– Zulassig sind nur Unter- bzw. Uberstreichungen, Verweiseauf Seiten bzw. Nummern
– Nicht zulassig sind somit z.B. verbale Erlauterungen, ma-thematische Umformungen, grafische Darstellungenu.a., die als Losungshilfen fur Klausuraufgaben angese-hen werden konnen
5

Ansprechpartner:
• Frau Heike Bornewasser-Hermes(Koordinatorin der Tutorien)
• Tutorinnen und Tutoren(Adressen und Nummern: siehe Tutorien)
6

1.2 Was ist ’Schließende Statistik’?
Stoff der VL ’Statistik I’:
• Deskriptive Statistik
Ziel:
Beschreibung erhobener Daten x1, . . . , xn
Problem:
• Erhobene Daten x1, . . . , xn sind i.d.R. nur ’Stichprobe’(keine Vollerhebung)
7

Deshalb Frage:
• Wie konnen (deskriptive) Ergebnisse fur die Stichprobe zurBeurteilung der (unbekannten) Grundgesamtheit genutzt wer-den?
Antwort:
• Mit Methoden der ’Schließenden Statistik’
Synonyme Bezeichnungen:
• Induktive Statistik
• Statistische Inferenz
8

Wesenszuge der schließenden Statistik:
• Schlussfolgerung von Stichprobe auf Grundgesamtheit
• Statistische Schlusse sind nicht sicher, sondern gelten nurmit ’bestimmter Wahrscheinlichkeit’
−→ Unbedingtes Erfordernis:
Beschaftigung mit Wahrscheinlichkeitsrechnung
9

Zwischenfazit:
• Schließende Statistik
ubertragt Stichprobenergebnisse auf GGbasiert auf Wahrscheinlichkeitsrechnung
Man beachte: Wahrscheinlichkeitsrechnung
• ist mehr als Grundlage der schließeden Statistik
• hat enorme eigenstandige okonomische Bedeutung z.B. in
MikrookonomikInvestition und FinanzierungPortfoliotheorie
10

Praktische Anwendungen der schließenden Statistik
Beispiel 1: (Qualitatskontrolle):
• Unternehmen produziert 5000 Gluhbirnen pro Tag
• Frage:
Wie hoch ist der Anteil p defekter Gluhbirnen in der Tages-produktion?
• Statistisches Problem:
Schatzen des Anteils p aufgrund einer Stichprobe
11

Beispiel 2: (Ausgabenplanung des Staates):
• Wichtigste Einnahmequelle des Staates: Steuern
• Problem:
Fur Ausgabenplanung sind Steuereinnahmen zu schatzen(Steuereinnahmen sind aufgrund von Erhebungsproblemenlange Zeit unbekannt)
• Statistisches Problem:
Angabe eines (moglichst engen) Intervalls, das den tat-sachlichen unbekannten Wert der Steuereinnahmen mit’hoher’ Wahrscheinlichkeit uberdeckt
12

Beispiel 3: (Effizienz von Werbung) [I]
• Einfluss von Werbemaßnahmen auf den Absatz von 84 US-Unternehmen(vgl. Statistik I)
• Statistisches Modell (Y = Absatz, X = Werbeausgaben)
yi = α + β · xi + ui
(α, β unbekannte Parameter, ui Fehler)
13

Stichprobenergebnisse fur 84 Unternehmen
14
480
500
520
540
560
0 20 40 60 80 100
Werbeausgaben in Mill. US-$
Abs
atz
in M
ill. U
S-$
Schätzung: Absatz = 502.92 + 0.218 * Werbeausgaben

Beispiel 3: (Effizienz von Werbung) [II]
• Eine mogliche Schatzung von α, β uber KQ-Methode:
a = 502.9174, b = 0.2183
• Statistische Fragen:
Sind die KQ-Werte a, b ’zuverlassige’ Schatzwerte fur die(unbekannten) tatsachlichen Parameter α, β?
Ist der wahre unbekannte Steigungsparameter β wirklichvon Null verschieden, d.h. gilt
β = 0 oder β 6= 0?
(Im Falle von β = 0 hatten Werbeausgaben keinen Ein-fluss auf den Absatz)
15

Fazit:
• Grundlegende Aufgaben der schließenden Statistik:
Punktschatzungen von unbekannten Parametern
Intervallschatzungen von unbekannten Parametern
Testen von Hypothesen uber unbekannte Parameter
16

2. Zufallsvorgange und Wahrscheinlichkeiten
Ziel des Kapitels:
• Einfuhrung elementarer Begriffe der Wahrscheinlichkeitsrech-nung (definitorisch)
Ziel der Wahrscheinlichkeitsrechnung:
• Modellierung von zufalligen Vorgangen, wie z.B.
(zukunftiger) Umsatz eines Unternehmens(zukunftige) Rendite einer Kapitalanlage(zukunftige) Wachstumsraten einer VW(zukunftige) Arbeitslosenquote
17

Zu prazisierende Begriffe:
• Zufallsvorgang, Zufallsexperiment
• (Zufalls)Ereignis, Wahrscheinlichkeit
Mathematische Hilfsmittel:
• Mengenlehre, Kombinatorik
• Analysis (Differential-, Integralrechnung)
18

2.1 Zufallsvorgange und Ereignisse
Definition 2.1: (Zufallsvorgang, Zufallsexperiment)
Unter einem Zufallsvorgang verstehen wir einen Vorgang, beidem
(a) im Voraus feststeht, welche moglichen Ausgange dieser theo-retisch haben kann,
(b) der sich einstellende, tatsachliche Ausgang im Voraus jedochunbekannt ist.
Zufallsvorgange, die geplant sind und kontrolliert ablaufen, heißenZufallsexperimente.
19

Beispiele fur Zufallsexperimente:
• Ziehung der Lottozahlen
• Roulette, Munzwurf, Wurfelwurf
• ’Technische Versuche’(Hartetest von Stahlproben etc.)
In der VWL:
• Oft keine Zufallsexperimente(historische Daten, Bedingungen nicht kontrollierbar)
• Moderne VWL-Disziplin: ’Experimentelle Okonomik’
20

Definition 2.2: (Ergebnis, Ergebnismenge)
Die Menge aller moglichen Ausgange eines Zufallsvorgangs heißtErgebnismenge und wird mit Ω bezeichnet. Ein einzelnes Ele-ment ω ∈ Ω heißt Ergebnis. Wir notieren die Anzahl aller Ele-mente von Ω (d.h. die Anzahl aller Ergebnisse) mit |Ω|.
Beispiele: [I]
• Zufallsvorgang ’Werfen eines Wurfels’:
Ω = 1,2,3,4,5,6
• Zufallsvorgang ’Werfen einer Munze solange, bis Kopf er-scheint’:
Ω = K,ZK,ZZK,ZZZK,ZZZZK, . . .
21

Beispiele: [II]
• Zufallsvorgang ’Bestimmung des morgigen Wechselkurseszwischen Euro und US-$’:
Ω = [0,∞)
Offensichtlich:
• Die Anzahl der Elemente von Ω kann endlich, abzahlbar un-endlich oder nicht abzahlbar unendlich sein
Jetzt:
• Mengentheoretische Definition des Begriffes ’Ereignis’
22

Definition 2.3: (Ereignis)
Unter einem Ereignis verstehen wir eine Zusammenfassung vonErgebnissen eines Zufallsvorgangs, d.h. ein Ereignis ist eine Teil-menge der Ergebnismenge Ω. Man sagt ’Das Ereignis A trittein’, wenn der Zufallsvorgang ein ω ∈ A als Ergebnis hat.
Bemerkungen: [I]
• Notation von Ereignissen: A, B, C, . . . oder A1, A2, . . .
• A = Ω heißt das sichere Ereignis(denn fur jedes Ergebnis ω gilt: ω ∈ A)
23

Bemerkungen: [II]
• A = ∅ (leere Menge) heißt das unmogliche Ereignis(denn fur jedes ω gilt: ω /∈ A)
• Falls das Ereignis A eine Teilmenge des Ereignisses B ist(A ⊂ B), so sagt man: ’Das Eintreten von A impliziert dasEintreten von B’(denn fur jedes ω ∈ A folgt ω ∈ B)
Offensichtlich:
• Ereignisse sind Mengen
−→ Anwendung von Mengenoperationen auf Ereignisse ist sin-nvoll
24

Ereignisverknupfungen (Mengenoperationen): [I]
• Durchschnittsereignis (-menge):
C = A ∩B tritt ein, wenn A und B eintreten
• Vereinigungsereignis (-menge):
C = A ∪B tritt ein, wenn A oder B eintritt
• Differenzereignis (-menge):
C = A\B tritt ein, wenn A eintritt, aber B nicht
25

Ereignisverknupfungen (Mengenoperationen): [II]
• Komplementarereignis:
C = Ω\A ≡ A tritt ein, wenn A nicht eintritt
• Die Ereignisse A und B heißen unvereinbar oder disjunkt,wenn A ∩B = ∅(beide Ereignisse konnen nicht gleichzeitig eintreten)
Jetzt:
• Ubertragung der Konzepte von 2 auf n Mengen A1, . . . , An
26

Ereignisverknupfungen: [I]
• Durchschnittsereignis:
n⋂
i=1Ai tritt ein, wenn alle Ai eintreten
• Vereinigungsereignis:
n⋃
i=1Ai tritt ein, wenn mindestens ein Ai eintritt
27

Ereignisverknupfungen: [II]
• Die Mengen A1, . . . , An heißen Partition (oder vollstandigeZerlegung) von Ω, falls gilt:
n⋃
i=1Ai = Ω
Ai ∩Aj = ∅ fur alle i 6= j
Ai 6= ∅ fur alle i
28

Wichtige Rechenregeln fur Mengen (Ereignisse):
• Kommutativ-, Assoziativ-, Distributivgesetze
• De Morgansche Regeln:
A ∪B = A ∩B
A ∩B = A ∪B
29

2.2 Wahrscheinlichkeiten
Ziel:
• Jedem Ereignis A soll eine Zahl P (A) zugeordnet werden,welche die Wahrscheinlichkeit fur das Eintreten von A repra-sentiert
• Formal:
P : A −→ P (A)
Frage:
• Welche Eigenschaften sollte die Zuordnung (Mengenfunk-tion) P besitzen?
30

Definition 2.4: (Kolmogorov’sche Axiome)
Die folgenden 3 Mindestanforderungen an P werden als Kol-mogorov’sche Axiome bezeichnet:
• Nichtnegativitat: Fur alle A soll gelten: P (A) ≥ 0
• Normierung: P (Ω) = 1
• Additivitat: Fur zwei disjunkte Ereignisse A und B (d.h. furA ∩B = ∅) soll gelten:
P (A ∪B) = P (A) + P (B)
31

Es ist leicht zu zeigen:
• Die 3 Kolmogorov’schen Axiome implizieren bestimmte Ei-genschaften und Rechenregeln fur Wahrscheinlichkeiten vonEreignissen
32

Satz 2.5: (Eigenschaften von Wahrscheinlichkeiten)
Aus den Kolmogorov’schen Axiomen ergeben sich folgende Eigen-schaften fur die Wahrscheinlichkeit beliebiger Ereignisse:
• Wahrscheinlichkeit des Komplimentarereignisses:
P (A) = 1− P (A)
• Wahrscheinlichkeit des unmoglichen Ereignissses:
P (∅) = 0
• Wertebereich der Wahrscheinlichkeit:
0 ≤ P (A) ≤ 1
33

Satz 2.6: (Rechenregeln fur Wahrscheinlichkeiten) [I]
Aus den Kolmogorov’schen Axiomen ergeben sich die folgendenRechenregeln fur die Wahrscheinlichkeit von beliebigen Ereignis-sen A, B, C:
• Additionssatz fur Wahrscheinlichkeiten:
P (A ∪B) = P (A) + P (B)− P (A ∩B)
(Wahrscheinlichkeit, dass A oder B eintritt)
• Additionssatz fur 3 Ereignisse:
P (A ∪B ∪ C) = P (A) + P (B) + P (C)
−P (A ∩B)− P (B ∩ C)
−P (A ∩ C) + P (A ∩B ∩ C)
(Wahrscheinlichkeit, dass A oder B oder C eintritt)
34

Satz 2.6: (Rechenregeln fur Wahrscheinlichkeiten) [II]
• Wahrscheinlichkeit des Differenzereignisses:
P (A\B) = P (A ∩B)
= P (A)− P (A ∩B)
Man beachte:
• Wenn das Ereignis B das Ereignis A impliziert (d.h.wenn B ⊂ A gilt), dann folgt
P (A\B) = P (A)− P (B)
35

Beispiel: [I]
• In einer Stadt erscheinen 2 Lokalzeitungen, die Morgenpostund der Stadtspiegel. Die Wahrscheinlichkeit, dass ein Be-wohner der Stadt
die Morgenpost liest (Ereignis A) sei 0.6,
den Stadtspiegel liest (Ereignis B) sei 0.5,
die Morgenpost oder den Stadtspiegel liest sei 0.9
36

Beispiel: [II]
• Die Wskt., dass jemand beide Blatter liest, betragt
P (A ∩B) = P (A) + P (B)− P (A ∪B)
= 0.6 + 0.5− 0.9 = 0.2
• Die Wskt., dass jemand kein Blatt liest, betragt
P (A ∪B) = 1− P (A ∪B)
= 1− 0.9 = 0.1
• Die Wskt., dass jemand genau eines der beiden Blatter liest,betragt
P ((A ∪B)\(A ∩B)) = P (A ∪B)− P (A ∩B)
= 0.9− 0.2 = 0.737

Bisher:
• Formale Anforderungen an Wahrscheinlichkeiten
−→ Eigenschaften und grundlegende Rechenregeln
Noch ungeklart:
• Wie wird eine explizite Wskt. fur ein bestimmtes Ereignis Auberhaupt festgelegt?
Verschiedene Wahrscheinlichkeitsbegriffe:
• Klassische Wahrscheinlichkeit (Laplace-Experiment)
• Statistische Wahrscheinlichkeit (Haufigkeitstheorie)
• Subjektive Wahrscheinlichkeit (durch Experimente)
38

Zentraler Begriff der VL:
• Der Laplace-sche Wahrscheinlichkeitsbegriff:
Pierre-Simon Marquis de Laplace, 1812:
Wenn ein Experiment eine Anzahl verschiedener undgleich moglicher Ausgange hervorbringen kann und einigedavon als gunstig anzusehen sind, dann ist die Wahr-scheinlichkeit eines gunstigen Ausgangs gleich dem Ver-haltnis der Anzahl der gunstigen zur Anzahl der moglichenAusgange.
39

Offensichtlich:
• Dem Laplace-schen Wahrscheinlichkeitsbegriff liegt die Vor-stellung eines Zufallsexperimentes zugrunde, bei dem die Er-gebnismenge Ω aus n Ergebnissen ω1, . . . , ωn besteht, die alledie gleiche Eintrittswahrscheinlichkeit 1/n aufweisen
Jetzt:
• Formale Definition
40

Definition 2.7: (Laplace-Experiment, -Wahrscheinlichkeit)
Ein Zufallsexperiment heißt Laplace-Experiment, wenn die Ergeb-nismenge Ω aus n Ergebnissen besteht (d.h. Ω = ω1, . . . , ωn)und jedes Ergebnis ωi die gleiche Wahrscheinlichkeit 1/n besitzt,d.h.
P (ωi) =1n
fur alle i = 1, . . . , n.
Die Laplace-Wahrscheinlichkeit eines Ereignisses A ⊂ Ω ist danndefiniert als
P (A) =Anzahl der Elemente von AAnzahl der Elemente von Ω
=|A||Ω|
=|A|n
.
41

Offensichtlich:
• Laplace-Wahrscheinlichkeit erfullt die Kolmogorov’schen Ax-iome (Definition 2.4), denn
P (A) ≥ 0
P (Ω) = nn = 1
Fur die Ereignisse A, B mit A ∩B = ∅ gilt:
P (A ∪B) =|A|+ |B|
n=|A|n
+|B|n
= P (A) + P (B)
42

’Fairer’ Wurfelwurf als Beispiel fur Laplace-Experiment:
• Es ist:
Ω = ω1, ω2, ω3, ω4, ω5, ω6 = 1,2,3,4,5,6Es gilt:
P (ωi) =16
fur alle i = 1, . . . ,6
• Laplace-Wahrscheinlichkeit fur das Ereignis A = ’Wurfelneiner geraden Zahl’
Es ist:
A = 2,4,6
−→ Laplace-Wahrscheinlichkeit:
P (A) = |A|/|Ω| = 3/6 = 0.5
43

Offensichtlich:
• Laplace-Wahrscheinlichkeit erfordert Berechnung von Anzahlen
Mathematische Technik hierfur:
• Kombinatorik
Einige grundsatzliche Fragen der Kombinatorik:
• Wie Moglichkeiten gibt es, bestimmte Objekte anzuordnen?
• Wie viele Moglichkeiten gibt es, bestimmte Objekte aus einerMenge auszuwahlen?
44

Mathematische Werkzeuge der Kombinatorik:
• Fakultat
• Binomialkoeffizient
Zunachst:
• Definitionen von Fakultat und Binomialkoeffizient
45

Definition 2.8: (Fakultat)
Es sei n ∈ N eine naturliche Zahl. Unter der Fakultat von n,in Zeichen n!, versteht man das Produkt der naturlichen Zahlenvon 1 bis n, d.h.
n! = 1 · 2 · . . . · n.
Fur n = 0 wird die Fakultat definitorisch festgelegt als
0! = 1.
Beispiele:
• 2! = 1 · 2 = 2
• 5! = 1 · 2 · . . . · 5 = 120
• 10! = 1 · 2 · . . . · 10 = 3628800
46

Offensichtlich:
• Fakultaten wachsen sehr schnell an
Definition 2.9: (Binomialkoeffizient)
Es seien n, k ∈ N zwei naturliche Zahlen mit n > 0, k ≥ 0 undn ≥ k. Unter dem Binomialkoeffizienten, gesprochen als ’n uberk’, versteht man den Ausdruck
(nk
)
=n!
k! · (n− k)!
47

Beispiele:
• ’Einfaches Rechenbeispiel’:(32
)
=3!
2! · (3− 2)!=
62 · 1
= 3
• ’Komplizierteres Rechenbeispiel’:(94
)
=9!
4! · 5!=
1 · 2 · 3 · 4 · 5 · 6 · 7 · 8 · 91 · 2 · 3 · 4 · 1 · 2 · 3 · 4 · 5
=6 · 7 · 8 · 91 · 2 · 3 · 4
= 126
• ’Formales Beispiel’:(nk
)
=n!
k! · (n− k)!=
n!(n− k)! · (n− (n− k))!
=( nn− k
)
48

Jetzt:
• Inhaltliche (kombinatorische) Bedeutung von Fakultat undBinomialkoeffizient fur die Bestimmung der Anzahl von An-ordnungs- bzw. Auswahlmoglichkeiten
−→ Bestimmung von Laplace-Wahrscheinlichkeiten
Zunachst Fundamentalprinzip der Kombinatorik:
• Wenn ein erster Sachverhalt auf n1 Arten erfullt werden kannund ein zweiter Sachverhalt unabhangig davon auf n2 Arten,so ist die Gesamtzahl der Moglichkeiten, gleichzeitig beideSachverhalte zu erfullen, gerade gleich dem Produkt n1 · n2
49

Beispiel:
• Ein Fußballtrainer hat fur den Posten des Torwarts 3 Kan-didaten und fur die Besetzung des Mittelsturmers 4 (an-dere) Kandidaten zur Auswahl. Insgesamt kann er also dasMannschaftsgespann (Torwart, Mittelsturmer) auf 3 · 4 = 12Arten besetzen
Verallgemeinerung:
• Gegeben seien k Sachverhalte, die unabhangig voneinanderauf jeweils n1, n2, . . . , nk Arten erfullt werden konnen
−→ Anzahl der Moglichkeiten, die k Sachverhalte gleichzeitigzu erfullen, betragt
n1 · n2 . . . · nk
50

Spezialfall:
• n1 = n2 = . . . = nk ≡ n
−→ Anzahl der Moglichkeiten, die k Sachverhalte gleichzeitigzu erfullen, betragt
n1 · n2 . . . · nk = n · n · . . . · n︸ ︷︷ ︸
k mal= nk
Beispiel:
• Wie viele Autokennzeichen kann die Stadt Munster vergeben,wenn nach dem Stadtkurzel ’MS’ 1 oder 2 Buchstaben undeine 1 bis 3 stellige Zahl vergeben wird?Losung:
27 · 26 · 10 · 10 · 10 = 702000
51

Zwischenfazit:
• Die Bestimmung von Laplace-Wahrscheinlichkeiten erfordertdie Bestimmung von Anzahlen. Die Kombinatorik liefertMethoden zur Berechnung
der Anzahlen moglicher Anordnungen von Objekten (Per-mutationen)
der Moglichkeiten, Objekte aus einer vorgegebenen Mengeauszuwahlen (Variationen, Kombinationen)
52

Definition 2.10: (Permutation)
Gegeben sei eine Menge mit n Elementen. Jede Anordnung alldieser Elemente in irgendeiner Reihenfolge heißt eine Permuta-tion dieser n Elemente.
Beispiel:
• Aus der Menge a, b, c lassen sich die folgenden 6 Permuta-tionen bilden:
abc bac cab acb bca cba
Allgemein gilt:
• Die Anzahl aller Permutationen von n verschiedenen Objek-ten betragt
n · (n− 1) · (n− 2) · . . . · 1 = n!
53

Jetzt:
• Von den n Objekten sollen nicht alle verschieden sein. Viel-mehr sollen sich die n Objekte in J Kategorien aufteilen mitden Kategorienanzahlen n1 (z.B. Anzahl weiße Kugeln), n2(Anzahl rote Kugeln) bis nJ (Anzahl schwarze Kugeln)
Es gilt:
• n = n1 + n2 + . . . + nJ
• Die Anzahl aller Permutationen der n Objekte ist gegebendurch
n!n1! · n2! · . . . · nJ!
54

Bemerkungen:
• Die Anordnungen, bei denen Objekte der gleichen Art per-mutiert werden, sind nicht unterscheidbar
• Sind alle n Objekte verschieden, so ist die Anzahl aller mog-lichen Permutationen gleich n! (vgl. Folie 54)
Beispiel:
• Die Anzahl der Permutationen der n = 9 Buchstaben desWortes STATISTIK betragt
9!2! · 3! · 1! · 2! · 1!
= 15120
55

Jetzt:
• Auswahl von Objekten aus einer vorgegebenen Menge
Definition 2.11: (Kombination)
Gegeben sei eine Menge mit n unterscheidbaren Elementen (z.B.Kugeln mit den Nummern 1,2, . . . , n). Jede Zusammenstellung(bzw. Auswahl) von k Elementen aus dieser Menge heißt Kom-bination der Ordnung k.
56

Unterscheidungsmerkmale von Kombinationen:
• Berucksichtigung der Auswahl-ReihenfolgeJa −→ Kombination wird Variation genannt
Nein −→ Keine besond. Bezeichnung (Kombination)
• Auswahl mit oder ohne Zurucklegen
Insgesamt also 4 alternative Falle:
• Variationen mit Zurucklegen
• Variationen ohne Zurucklegen
• Kombinationen ohne Zurucklegen
• Kombinationen mit Zurucklegen
57

1. Fall: Variationen mit Zurucklegen
Beim Ziehen mit Zurucklegen unter Berucksichtigung der Rei-henfolge gibt es nach dem Fundamentalprinzip der Kombinatorik
n · n · . . . · n︸ ︷︷ ︸
k Faktoren= nk
verschiedene Moglichkeiten
Beispiel:
• Ein ’fairer’ Wurfel werde 4 mal hintereinander geworfen unddas Ergebnis in einer 4-Sequenz notiert (z.B. 1,5,1,2). DieAnzahl aller moglichen Ergebnissequenzen betragt
6 · 6 · 6 · 6︸ ︷︷ ︸
4 Wurfe= 64 = 1296
58

2. Fall: Variationen ohne Zurucklegen
Beim Ziehen ohne Zurucklegen unter Berucksichtigung der Rei-henfolge gibt es nach dem Fundamentalprinzip der Kombinatorik
n · (n− 1) · (n− 2) · . . . · (n− k + 1)︸ ︷︷ ︸
k Faktoren=
n!(n− k)!
verschiedene Moglichkeiten (k ≤ n)
Beispiel:
• Im olympischen Finale eines 100-Meter-Laufes starten 8 Teil-nehmer. Die Anzahl der verschiedenen Kombinationen furGold, Silber und Bronze betragt
8!(8− 3)!
= 8 · 7 · 6 = 336
59

3. Fall: Kombinationen ohne Zurucklegen
Beim Ziehen ohne Zurucklegen ohne Berucksichtigung der Rei-henfolge ist die Anzahl der verschiedenen Kombinationen gleichder Anzahl der Moglichkeiten, aus einer Menge vom Umfang neine Teilmenge vom Umfang k (k ≤ n) zu entnehmen. Die An-zahl dieser Moglichkeiten betragt
n!k! · (n− k)!
=(nk
)
(Binomialkoeffizient, vgl. Definition 2.9, Folie 47)
60

Begrundung:
• Betrachte die Formel fur Variationen ohne Zurucklegen ausFall 2. Die dort bestimmte Anzahl n!/(n − k)! muss nunnoch durch k! dividiert werden, da es in jeder Menge mit kElementen auf die Reihenfolge der Elemente nicht ankommt
Beispiel:
• Ziehung der Lotto-Zahlen ’6 aus 49’. Anzahl der moglichenKombinationen betragt:
(496
)
= 13983816
61

4. Fall: Kombinationen mit Zurucklegen
Beim Ziehen mit Zurucklegen ohne Berucksichtigung der Rei-henfolge betragt die Anzahl der verschiedenen Kombinationen
(n + k − 1)!(n− 1)! · k!
=(n + k − 1
k
)
=(n + k − 1
n− 1
)
(Binomialkoeffizient, vgl. Definition 2.9, Folie 47)
Begrundung:
• Etwas technisch, vgl. eines der angegebenen Standardlehrbu-cher, z.B. Mosler / Schmid (2008)
62

Beispiel: (Haufungswahl)
• Bei einer Wahl stehen 10 Kandidaten zur Auswahl. EinWahler hat 3 Stimmen und das Recht, bei einem Kandidatenmehr als 1 Kreuz zu machen. Die Anzahl der MoglichkeitenKreuze zu setzen betragt somit
(10 + 3− 13
)
=(123
)
= 220
63

Uberblick Kombinationen
Anzahl der Moglichkeiten,aus n verschiedenen Objekten k auszuwahlen
ohne mitBerucksichtigung Berucksichtigungder Reihenfolge der Reihenfolge(Kombinationen) (Variationen)
ohne Zurucklegen(nk
) n!(n− k)!
mit Zurucklegen(n + k − 1
k
)
nk
64

Beispiel fur die Berechnung einer Laplace-Wskt: [I]
• Wskt. fur ’4 Richtige im Lotto’
• Zunachst: Anzahl aller moglichen Kombinationen betragt(496
)
= 13983816
• Jetzt gesucht: Anzahl von Kombinationen, die einen Viererdarstellen
• Fur einen Vierer mussen 4 von den 6 Richtigen und gleich-zeitig 2 von den 43 Falschen zusammenkommen
65

Beispiel fur die Berechnung einer Laplace-Wskt: [II]
• Nach dem Fundamentalprinzip der Kombinatorik ergeben sich(64
)
·(432
)
= 15 · 903 = 13545
verschiedene Viererkombinationen
−→ Hieraus folgt fur die Laplace-Wahrscheinlichkeit:
P (’4 Richtige im Lotto’) =13545
13983816= 0.0009686
66

2.3 Bedingte Wahrscheinlichkeiten und Unab-hangigkeit
Jetzt:
• Berechnung von Wahrscheinlichkeiten unter Zusatzinforma-tionen
Genauer:
• Berechnung der Wahrscheinlichkeit des Ereignisses A, wennbekannt ist, dass ein anderes Ereignis B bereits eingetretenist
67

Beispiel:
• Betrachte ’fairen Wurfelwurf’
• Ereignis A: Wurfeln der ’6’. Es gilt zunachst
P (A) = 1/6
• Ereignis B: ’Wurfeln einer geraden Zahl’ soll bereits einge-treten sein (Vorinformation)−→ Wskt. von A unter der Bedingung B ist
P (A|B) = 1/3
• Grund:Mussen zur Berechnung der Wskt. von A nur noch die Ergeb-nisse 2, 4, 6 aus B betrachten
68

Andererseits:
• Betrachte Ereignis C: Wurfeln der ’3’
• Offensichtlich gilt:
P (C|B) = 0
• Grund: Ereignisse B und C konnen nicht gemeinsam ein-treten, d.h. P (B ∩ C) = 0
Frage:
• Wie kommt man mathematisch zur bedingten Wskt.
P (A|B) = 1/3
69

Antwort:
• Indem man die Wskt. des gemeinsamen Eintretens von Aund B (d.h. von A ∩ B) zur Wskt. des Eintretens von B inBeziehung setzt
Definition 2.12: (Bedingte Wahrscheinlichkeit)
Es seien A und B zwei Ereignisse, wobei P (B) > 0 gelten soll. DieWahrscheinlichkeit fur das Eintreten von A unter der Bedingung,dass B bereits eingetreten ist, kurz: die bedingte Wahrschein-lichkeit von A unter der Bedingung B, ist definiert als
P (A|B) =P (A ∩B)
P (B).
70

Beispiel 1 (Fairer Wurfelwurf):
• A: Wurfeln der ’6’, d.h. A = 6
• B: Wurfeln einer geraden Zahl, d.h. B = 2,4,6
−→ A ∩B = 6
−→ P (A|B) =P (A ∩B)
P (B)=
P (6)P (2,4,6)
=1/63/6
=13
71

Beispiel 2 (2-facher fairer Wurfelwurf): [I]
• Ein Wurfel werde zweimal geworfen und das Ergebnis in einer2-Sequenz notiert. Wie groß ist die Laplace-Wahrscheinlich-keit, dass in einer der beiden Wurfe eine 6 fallt unter derBedingung, dass die Augensumme der beiden Wurfe großerals 9 ist?
• Mogliche Ergebnisse des Experimentes:
(1,1) (1,2) (1,3) (1,4) (1,5) (1,6)(2,1) (2,2) (2,3) (2,4) (2,5) (2,6)(3,1) (3,2) (3,3) (3,4) (3,5) (3,6)(4,1) (4,2) (4,3) (4,4) (4,5) (4,6)(5,1) (5,2) (5,3) (5,4) (5,5) (5,6)(6,1) (6,2) (6,3) (6,4) (6,5) (6,6)
72

Beispiel 2 (2-facher fairer Wurfelwurf): [II]
• A = ’mindestens eine 6’, d.h.
A = (6,1), (6,2), (6,3), (6,4), (6,5), (6,6),
(1,6), (2,6), (3,6), (4,6), (5,6)
• B = ’Augensumme > 9’, d.h.
B = (6,4), (6,5), (6,6), (5,5), (5,6), (4,6)
• Somit gilt
P (B) =636
=16
73

Beispiel 2 (2-facher fairer Wurfelwurf): [III]
• Der Schnitt ergibt sich zu
A ∩B = (6,4), (6,5), (6,6), (5,6), (4,6)
• Somit gilt
P (A ∩B) =536
• Fur die bedingte Wahrscheinlichkeit ergibt sich:
P (A|B) =P (A ∩B)
P (B)=
5/366/36
=56
74

Jetzt verallgemeinerte Sichtweise:
• Betrachte die bedingte Wskt. P (A|B) fur beliebige EreignisseA ⊂ Ω (in Zeichen: P (·|B))
Es gilt:
• Die bedingte Wskt. P (·|B) erfullt die Kolmogorov’schen Ax-iome (vgl. Definition 2.4, Folie 31)
Beweis: [I]
• Fur jedes A gilt:
P (A|B) =P (A ∩B)
P (B)≥ 0
75

Beweis: [II]
• Fur das sichere Ereignis Ω gilt:
P (Ω|B) =P (Ω ∩B)
P (B)=
P (B)P (B)
= 1
• Fur A1 ∩A2 = ∅ gilt:
P (A1 ∪A2|B) =P ((A1 ∪A2) ∩B)
P (B)
=P ((A1 ∩B) ∪ (A2 ∩B))
P (B)
=P (A1 ∩B)
P (B)+
P (A2 ∩B)P (B)
= P (A1|B) + P (A2|B)
76

Konsequenz:
• Die aus den Kolmogorov’schen Axiomen folgenden Rechen-reglen fur Wahrscheinlichkeiten gelten weiter, z.B.
P (A|B) = 1− P (A|B)
P (∅|B) = 0
0 ≤ P (A|B) ≤ 1
P (A1 ∪A2|B) = P (A1|B) + P (A2|B)− P (A1 ∩A2|B)
. . .
77

Aus Definition 2.12 folgt unmittelbar:
P (A ∩B) = P (A|B) · P (B)
Ebenso gilt:
P (A ∩B) = P (B ∩A) = P (B|A) · P (A)
Fazit:
• Die Wskt. fur das gleichzeitige Eintreten zweier EreignisseA und B (d.h. fur A ∩ B) ist jeweils das Produkt einer be-dingten Wskt. mit der unbedingten Wskt. des bedingendenEreignisses
• Die beiden obigen Formeln heißen Multiplikationssatz fur zweiEreignisse
78

Naturliche Erweiterung:
• Multiplikationssatz fur n Ereignisse A1, . . . , An
(d.h. Formel fur Wskt. des gleichzeitigen Eintretens)
• nicht hier, siehe z.B. Mosler / Schmid (2008)
Hier:
• Multiplikationssatz fur 3 Ereignisse A, B, C:
P (A ∩B ∩ C) = P (A|B ∩ C) · P (B ∩ C)
= P (A|B ∩ C) · P (B|C) · P (C)
79

Beispiel (Bestehen der Statistik-II-Klausur): [I]
• Fur den Erwerb des Statistik-II-Scheines hat man 3 Ver-suche. Fur die 3 Ereignisse Ai: ’StudentIN besteht beimi-ten Versuch’, (i = 1, . . . ,3), seien folgende Wahrschein-lichkeiten bekannt:
P (A1) = 0.6
P (A2|A1) = 0.5
P (A3|A1 ∩A2) = 0.4
• Frage:Wie hoch ist die Wskt., den Schein zu erwerben?
80

Beispiel (Bestehen der Statistik-II-Klausur): [II]
• Die gesuchte Wskt. ergibt sich zu:
P (A1 ∪A2 ∪A3) = 1− P (A1 ∪A2 ∪A3)
= 1− P (A1 ∩A2 ∩A3)
= 1− P (A3 ∩A2 ∩A1)
= 1− P (A3|A1 ∩A2) · P (A2|A1) · P (A1)
= 1− (1− 0.4) · (1− 0.5) · (1− 0.6)
= 0.88
81

Betrachte nun den folgenden Fall:
• Das Eintreten des Ereignisses A hat keinerlei Einfluss auf dasEintreten des Ereignisses B (und umgekehrt)
−→ Begriff der stochastischen Unabhangigkeit
Definition 2.13: (Stochastische Unabhangigkeit)
Zwei Ereignisse A und B heißen stochastisch unabhangig (oderkurz: unabhangig), falls
P (A ∩B) = P (A) · P (B)
gilt. A und B heißen abhangig, falls die Ereignisse nicht un-abhangig sind.
82

Bemerkungen: [I]
• In Definition 2.13 sind die Rollen von A und B vertauschbar
• Unter der Annahme P (B) > 0 gilt:
A und B sind unabhangig ⇐⇒ P (A|B) = P (A)
Unter der Annahme P (A) > 0 gilt:
A und B sind unabhangig ⇐⇒ P (B|A) = P (B)
(Bei Unabhangigkeit hangen die bedingten Wskt.’en nichtvon den jeweils bedingenden Ereignissen ab)
83

Bemerkungen: [II]
• Mit A und B sind auch die folgenden Ereignisse jeweils un-abhangig:
A und B, A und B, A und B
• Ist A ein Ereignis mit P (A) = 0 oder P (A) = 1, so ist A vonjedem beliebigen Ereignis B unabhangig
• Wenn A und B disjunkt (d.h. A ∩ B = ∅) und die Wskt.’enP (A), P (B) > 0 sind, konnen A und B nicht unabhangig sein
84

Beispiel: [I]
• Betrachte zweimaligen Munzwurf (Z=Zahl, K=Kopf). Er-gebnisse des Laplace-Experimentes werden als 2-Sequenzennotiert. Es ist
Ω = (Z, Z), (Z, K), (K, Z), (K, K)
• Betrachte die Ereignisse
A : Zahl beim ersten Wurf
B : Kopf beim zweiten Wurf
C : Kopf bei beiden Wurfen
85

Beispiel: [II]
• Fur die Ereignisse A und B gilt:
P (A ∩B) = P ((Z, K)) = 1/4
sowie
P (A) · P (B) = P ((Z, Z), (Z, K)) · P ((Z, K), (K, K))= 1/2 · 1/2 = 1/4
= P (A ∩B)
=⇒ A und B sind stochastisch unabhangig
86

Beispiel: [III]
• Fur die Ereignisse B und C gilt:
P (B ∩ C) = P ((K, K)) = 1/4
sowie
P (B) = P ((Z, K), (K, K)) = 1/2
P (C) = P ((K, K)) = 1/4
=⇒ P (B) · P (C) = 1/2 · 1/4 = 1/8 6= 1/4 = P (B ∩ C)
=⇒ B und C sind stochastisch abhangig
87

Jetzt:
• Verallgemeinerung des Unabhangigkeitsbegriffes von 2 auf nEreignisse
Definition 2.14: (Unabhangigkeit von n Ereignissen)
Die n Ereignisse A1, A2, . . . , An heißen paarweise unabhangig, fallsfur alle i, j = 1, . . . , n mit i 6= j gilt
P (Ai ∩Aj) = P (Ai) · P (Aj).
Die n Ereignisse A1, A2, . . . , An heißen vollstandig unabhangig,falls fur jede Auswahl von m Indizes,
i1, i2, . . . , im ∈ 1,2, . . . , n, 2 ≤ m ≤ n,
gilt
P (Ai1 ∩Ai2 ∩ . . . ∩Aim) = P (Ai1) · P (Ai2) · . . . · P (Aim).
88

Bemerkungen:
• Fur den Fall n = 3 ist die paarweise Unabhangigkeit gegeben,falls gilt
P (A1 ∩A2) = P (A1) · P (A2)
P (A1 ∩A3) = P (A1) · P (A3)
P (A2 ∩A3) = P (A2) · P (A3)
Die 3 Ereignisse sind vollstandig unabhangig, falls gilt
P (A1 ∩A2 ∩A3) = P (A1) · P (A2) · P (A3)
• Vorsicht: vollstandige und paarweise Unabhangigkeit sindnicht das gleiche. Das Konzept der vollstandigen Unabhan-gigkeit ist strenger
89

Beispiel: [I]
• Betrachte das Laplace-Experiment des zweifachen Wurfel-wurfes mit den Ereignissen
A1: Augenzahl beim 1. Wurf ist ungeradeA2: Augenzahl beim 2. Wurf ist ungeradeA3: Augensumme ungerade
• Es gilt zunachst:
P (A1 ∩A2) = 1/4 = 1/2 · 1/2 = P (A1) · P (A2)P (A1 ∩A3) = 1/4 = 1/2 · 1/2 = P (A1) · P (A3)P (A2 ∩A3) = 1/4 = 1/2 · 1/2 = P (A2) · P (A3)
=⇒ A1, A2, A3 sind paarweise unabhangig
90

Beispiel: [II]
• Es gilt weiterhin:
P (A1 ∩A2 ∩A3) = 0 6= 1/8
= 1/2 · 1/2 · 1/2
= P (A1) · P (A2) · P (A3)
=⇒ A1, A2, A3 sind nicht vollstandig unabhangig
91

2.4 Totale Wahrscheinlichkeit und das Bayes-Theorem
Idee des Konzeptes der totalen Wahrscheinlichkeit:
• Man kann die (unbedingte) Wskt. des Ereignisses A ausrech-nen, wenn man bestimmte bedingte Wskt.’en von A und diezugehorigen Wskt.’en der Bedingungen kennt
Satz 2.15: (Satz von der totalen Wahrscheinlichkeit)
Es seien A1, . . . , An eine Partition der Ergebnismenge Ω und B einbeliebiges Ereignis. Dann gilt fur die (unbedingte) Wahrschein-lichkeit von B:
P (B) =n
∑
i=1P (B|Ai) · P (Ai).
92

Herleitung: [I]
• Da A1, . . . , An eine vollstandige Zerlegung von Ω darstellt,folgt
B = (B ∩A1) ∪ (B ∩A2) ∪ . . . ∪ (B ∩An)
• Man beachte, dass die Mengen
(B ∩A1), (B ∩A2), . . . , (B ∩An)
paarweise disjunkt sind
93

Herleitung: [II]
• Aus der paarweisen Disjunktheit, dem 3. Kolmogorov’schenAxiom (vgl. Folie 31) sowie der Definition der bedingtenWahrscheinlichkeit folgt:
P (B) = P
n⋃
i=1(B ∩Ai)
=n
∑
i=1P (B ∩Ai)
=n
∑
i=1P (B|Ai) · P (Ai)
Fazit:
• Die (unbedingte) Wskt. von B ergibt sich aus gewichtetenbedingten Wskt.’en von B
94

Beispiel: [I]
• Ein und derselbe Massenartikel werde auf zwei Maschinengefertigt. Die schnellere Maschine M1 hinterlaßt 10% Auss-chuss, produziert aber doppelt soviel wie die langsamere Mas-chine M2, die aber nur einen Ausschuss von 7% aufweist.Wie groß ist die Wskt., dass ein zufallig aus der Gesamtpro-duktion gezogenes Einzelstuck defekt ist?
• Definition der Ereignisse:
B: Stuck ist defekt
A1: Stuck auf M1 produziert
A2: Stuck auf M2 produziert
95

Beispiel: [I]
• Folgende Wskt.’en sind gegeben:
P (B|A1) = 0.1P (B|A2) = 0.07
P (A1) = 2/3P (A2) = 1/3
• Daraus folgt:
P (B) =2
∑
i=1P (B|Ai) · P (Ai)
= 0.1 · 2/3 + 0.07 · 1/3= 0.09
96

Jetzt:
• Verbindung zwischen bedingten Wahrscheinlichkeiten, bei de-nen die Rollen zwischen bedingtem und bedingendem Ereig-nis vertauscht sind(etwa Zusammenhang zwischen P (A|B) und P (B|A))
−→ Bayes-Theorem
97

Herleitung des Bayes-Theorems: [I]
• Betrachte den Multiplikationssatz fur zwei Ereignisse(vgl. Folie 78)
P (A ∩B) = P (A|B) · P (B) = P (B|A) · P (A)
• Daraus folgt:
P (A|B) =P (A) · P (B|A)
P (B)
• Diese Beziehung gilt fur zwei beliebige Ereignisse und deshalbauch fur jedes Ai, i = 1, . . . , n, einer beliebigen Partition derGrundmenge Ω:
P (Ai|B) =P (Ai) · P (B|Ai)
P (B)
98

Herleitung des Bayes-Theorems: [II]
• Ersetzt man P (B) durch den Ausdruck aus dem Satz 2.15der totalen Wahrscheinlichkeit (vgl. Folie 92), so erhalt mandas Bayes-Theorem
Satz 2.16: (Bayes-Theorem)
Es seien A1, . . . , An eine Partition der Ergebnismenge Ω und Bein beliebiges Ereignis mit P (B) > 0. Dann gilt fur jedes Ai:
P (Ai|B) =P (B|Ai) · P (Ai)
n∑
i=1P (B|Ai) · P (Ai)
.
99

Beispiel: [I]
• An Patienten einer bestimmten Population wird durch einenLabortest untersucht, ob eine bestimmte Krankheit vorliegtoder nicht. Der Anteil der Kranken in der Population istbekannt und wird mit π bezeichnet. Falls ein konkret unter-suchter Patient krank ist, zeigt der Test die Krankheit miteiner Wskt. von 99% an (Ergebnis ’positiv’). Falls er nichtkrank ist, zeigt der Test die Krankheit (falschlicherweise) miteiner Wskt. von 2% an.
• Wie groß ist die Wskt., dass die Krankheit vorliegt unter derBedingung, dass der Test positiv ausfallt?
100

Beispiel: [II]
• Definition der Ereignisse:
A1: Krankheit liegt vorA2 = A1: Krankheit liegt nicht vor
B: Test zeigt Krankheit an
• Folgende Wskt.’en sind gegeben:
P (B|A1) = 0.99P (B|A2) = 0.02
P (A1) = π
• Gesucht: P (A1|B)
101

Beispiel: [III]
• Mit dem Bayes-Theorem gilt:
P (A1|B) =P (B|A1) · P (A1)
P (B|A1) · P (A1) + P (B|A2) · P (A2)
=0.99 · π
0.99 · π + 0.02 · (1− π)
• Offensichtlich:Krankenanteil π hat starken Einfluss auf die gesuchte Wahr-scheinlichkeit
102

Beispiel: [III]
• Beispielswerte:
P (A1|B) = 0.846 (π = 0.1)
P (A1|B) = 0.333 (π = 0.01)
P (A1|B) = 0.047 (π = 0.001)
P (A1|B) = 0.005 (π = 0.0001)
103

3. Zufallsvariable und Verteilungen
Haufige Situation in der Praxis:
• Es interessiert nicht so sehr das konkrete Ergebnis ω ∈ Ωeines Zufallsexperimentes, sondern eine Zahl, die von ω ab-hangt
Beispiele:
• Gewinn in Euro im Roulette
• Gewinn einer Aktie an der Borse
• Monatsgehalt einer zufallig ausgewahlten Person
104

Intuitive Bedeutung einer Zufallsvariablen:
• Vorschrift, die das ’abstrakte’ ω in eine Zahl ubersetzt
Begrifflichkeiten:
Deskriptive Statistik Wskt.-Rechnung
Grundgesamtheit ←→ Ergebnismenge
Merkmal ←→ Zufallsvariable
Messwert ←→ Realisation
105

3.1 Grundbegriffe und Definitionen
Definition 3.1: (Zufallsvariable [kurz: ZV])
Unter einer Zufallsvariablen versteht man formal eine (mathema-tische) Funktion
X : Ω −→ Rω −→ X(ω).
Bemerkungen:
• Eine Zufallsvariable ordnet jedem Ergebnis ω ∈ Ω eine reelleZahl zu
106

Zufallsvariable als Abbildung der Ergebnismenge auf die reelle Zahlenachse(vgl. Schira, 2009, S. 258)
107

Bemerkungen: [I]
• Intuition:Eine Zufallsvariable X charakterisiert eine Zahl, deren Wertman noch nicht kennt
• Nach der Durchfuhrung des Zufallsexperimentes realisiert sichdie Zufallsvariable X im Wert x
• x heißt die Realisation oder Realisierung der ZV X nachDurchfuhrung des zugehorigen Zufallsexperimentes
• In dieser VL:Zufallsvariablen werden immer mit Großbuchstaben, Reali-sationen immer mit Kleinbuchstaben bezeichnet
108

Bemerkungen: [II]
• Die Zufallsvariable X beschreibt die Situation ex ante, d.h.vor der tatsachlichen Durchfuhrung des Zufallsexperimentes
• Die Realisation x beschreibt die Situation ex post, d.h. nachder Durchfuhrung des Zufallsexperimentes
• Wahrscheinlichkeitsaussagen kann man nur uber die Zufalls-variable X treffen
• Fur den Rest der VL sind Zufallsvariablen von zentraler Be-deutung
109

Beispiel 1:
• Betrachte den 1-maligen Munzwurf (Z=Zahl, K=Kopf). DieZV X bezeichne die ’Anzahl der Kopfe’ bei diesem Zufallsex-periment
• Es gilt:
Ω = K, Z
• Die ZV X kann 2 Werte annehmen:
X(Z) = 0, X(K) = 1
110

Beispiel 2:
• Betrachte den 3-maligen Munzwurf. Die ZV X bezeichneerneut die ’Anzahl der Kopfe’
• Es gilt:
Ω = (K, K, K)︸ ︷︷ ︸
=ω1
, (K, K, Z)︸ ︷︷ ︸
=ω2
, . . . , (Z, Z, Z)︸ ︷︷ ︸
=ω8
• Die Zufallsvariable X ist definiert durch
X(ω) = Anzahl der K in ω
• Offensichtlich:X ordnet verschiedenen ω dieselbe Zahl zu, z.B.
X((K, K, Z)) = X((K, Z, K)) = X((Z, K, K)) = 2
111

Beispiel 3:
• Aus einer Personengruppe werde zufallig 1 Person ausgewahlt.Die ZV X soll den Erwerbsstatus der ausgewahlten Personbezeichnen
• Es gilt:
Ω = ’erwerbstatig’︸ ︷︷ ︸
=ω1
, ’nicht erwerbstatig’︸ ︷︷ ︸
=ω2
• Die ZV X kann definiert werden durch
X(ω1) = 1, X(ω2) = 0
(Codierung)
112

Beispiel 4:
• Das Zufallsexperiment bestehe in der Messung des morgigenKurses einer bestimmten Aktie. Die ZV X bezeichne diesenAktienkurs
• Es gilt:
Ω = [0,∞)
• X ist definiert durch
X(ω) = ω
113

Zwischenfazit:
• Die ZV X kann verschiedene Werte annehmen und zwar mitbestimmten Wskt’en
Vereinfachende Schreibweise: (a, b, x ∈ R)
• P (X = a) ≡ P (ω|X(ω) = a)
• P (a < X < b) ≡ P (ω|a < X(ω) < b)
• P (X ≤ x) ≡ P (ω|X(ω) ≤ x)
114

Frage:
• Wie kann man diese Wskt’en bestimmen und mit diesen rech-nen?
Losung:
• Die Berechnung solcher Wskt’en kann uber die sogenannteVerteilungsfunktion der ZV’en X erfolgen
Intuition:
• Die Verteilungsfunktion der ZV’en X charakterisiert dieWahrscheinlichkeiten, mit denen sich die potenziellen Reali-sationen x auf der reellen Zahlenachse verteilen(die sogenannte Verteilung der ZV’en X)
115

Definition 3.2: (Verteilungsfunktion [kurz: VF])
Gegeben sei die Zufallsvariable X. Unter der Verteilungsfunk-tion der ZV’en X (in Zeichen: FX) versteht man die folgendeAbbildung:
FX : R −→ [0,1]
x −→ FX(x) = P (ω|X(ω) ≤ x) = P (X ≤ x).
116

Beispiel: [I]
• Betrachte das Laplace-Experiment des 3-fachen Munzwurfes.Die ZV X messe die ’Anzahl Kopf’.
• Zunachst gilt:
Ω = (K, K, K)︸ ︷︷ ︸
= ω1
, (K, K, Z)︸ ︷︷ ︸
= ω2
, . . . , (Z, Z, Z)︸ ︷︷ ︸
= ω8
• Fur die Wskt’en der ZV X errechnet sich:
P (X = 0) = P ((Z, Z, Z)) = 1/8P (X = 1) = P ((Z, Z, K), (Z, K, Z), (K, Z, Z)) = 3/8P (X = 2) = P ((Z, K, K), (K, Z, K), (K, K, Z)) = 3/8P (X = 3) = P ((K, K, K)) = 1/8
117

Beispiel: [II]
• Daraus ergibt sich die VF:
FX(x) =
0.000 furx < 00.125 fur 0 ≤ x < 10.5 fur 1 ≤ x < 2
0.875 fur 2 ≤ x < 31 furx ≥ 3
Graph der Verteilungsfunktion
118

Bemerkungen:
• Es genugt (fast immer), lediglich die VF FX der ZV X zukennen
• Oft ist es in praxi gar nicht moglich, den Grundraum Ω oderdie explizite Abbildung X : Ω −→ R anzugeben(jedoch kann man meistens die VF FX aus sachlogischenUberlegungen heraus angeben)
119

Allgemeingultige Eigenschaften von FX:
• FX(x) ist monoton wachsend
• Es gilt stets:
limx→−∞
FX(x) = 0 und limx→+∞
FX(x) = 1
• FX ist rechtsseitig stetig, d.h.
limz→xz>x
FX(z) = FX(x)
(vgl. Eigenschaften der empirischen Verteilungsfunktion ausder VL Statistik I)
120

Fazit:
• VF FX(x) der ZV’en X gibt Antwort auf die Frage
’Wie hoch ist die Wahrscheinlichkeit, dass X hochstens denWert x annimmt?’
Jetzt:
• Antwort auf die Frage
’Welchen Wert wird die ZV’e X mit einer vorgegebenenWahrscheinlichkeit p ∈ (0,1) nicht uberschreiten?’
−→ Quantilfunktion der ZV’en X
121

Definition 3.3: (Quantilfunktion)
Gegeben sei die ZV X mit VF FX. Fur jeden reellen Wert p ∈(0,1) versteht man unter der Quantilfunktion von X (in Zeichen:QX(p)) die folgende Abbildung:
QX : (0,1) −→ Rp −→ QX(p) = minx|FX(x) ≥ p.
Der Wert der Quantilfunktion xp = QX(p) heißt p −Quantil derZV’en X.
122

Bemerkungen:• Das p-Quantil xp ist die kleinste Zahl x ∈ R mit der Eigen-
schaft, dass FX(x) den Wert p erreicht oder uberschreitet.
• Interpretiert man p ∈ (0,1) als eine Wahrscheinlichkeit, so istdas p-Quantil xp die kleinste Realisation der ZV’en X, die Xmit Wskt. p nicht uberschreitet.
Spezielle Quantile:• Median: p = 0.5
• Quartile: p = 0.25,0.5,0.75
• Quintile: p = 0.2,0.4,0.6,0.8
• Dezile: p = 0.1,0.2, . . . ,0.9
123

Frage:
• Warum diese ’scheinbar komplizierte’ Definition?
Betrachte 3 Falle:
• Stetige, streng monoton wachsende VF FX
• Stetige, teilweise konstante VF FX
• Rechtsseitig stetige Treppen-VF FX
124

Stetige, streng monoton wachsende Verteilungsfunktion
125

Stetige, teilweise konstante Verteilungsfunktion
126

Rechtsseitig stetige Treppen-Verteilungsfunktion
127

Jetzt:
• Typisierung von ZV’en(diskrete vs. stetige ZV’en)
Grund:
• Unterschiedliche mathematische Methoden zur Behandlungvon ZV’en
• Bei diskreten ZV’en:
Endliche und unendliche Summen
• Bei stetigen ZV’en:
Differential- und Integralrechnung
128

Definition 3.4: (Diskrete Zufallsvariable)
Die ZV X heißt diskret, wenn sie entweder
1. nur endlich viele Realisationen x1, x2, . . . , xJ oder
2. abzahlbar unendlich viele Realisationen x1, x2, . . .
mit streng positiver Wahrscheinlichkeit annehmen kann, d.h. fallsfur alle j = 1, . . . , J, . . . gilt
P (X = xj) > 0 undJ,...∑
j=1P (X = xj) = 1.
129

Typische diskrete Merkmale sind:
• Zahlmerkmale (’X = Anzahl von . . .’)
• Codierte qualitative Merkmale
Definition 3.5: (Trager einer diskreten Zufallsvariablen)
Die Menge aller Realisationen, die eine diskrete ZV X mit strengpositiver Wskt. annehmen kann, heißt Trager von X (in Zeichen:TX):
TX = x1, . . . , xJ bzw. TX = x1, x2, . . ..
130

Definition 3.6: (Wahrscheinlichkeitsfunktion)
Fur eine diskrete ZV X heißt die Funktion
fX(x) = P (X = x)
die Wahrscheinlichkeitsfunktion von X.
Bemerkungen: [I]
• Die Wahrscheinlichkeitsfunktion fX der ZV X nimmt nur furdie Elemente des Trager TX positive Werte an. Fur Werteaußerhalb des Tragers, d.h. fur x /∈ TX, gilt fX(x) = 0:
fX(x) =
P (X = xj) > 0 furx = xj ∈ TX0 furx /∈ TX
131

Bemerkungen: [II]
• Die Wahrscheinlichkeitsfkt. fX hat die Eigenschaften
fX(x) ≥ 0 fur alle x
∑
xj∈TX
fX(xj) = 1
• Fur eine beliebige Menge B ⊂ R berechnet sich die Wskt. desEreignisses ω|X(ω) ∈ B = X ∈ B durch
P (X ∈ B) =∑
xj∈BfX(xj)
132

Beispiel: [I]
• Betrachte 3-fachen Munzwurf und X = ’Anzahl Kopf’
• Offensichtlich: X ist diskret mit dem Trager
TX = 0,1,2,3
• Die Wahrscheinlichkeitsfunktion ist gegeben durch
fX(x) =
P (X = 0) = 0.125 furx = 0P (X = 1) = 0.375 furx = 1P (X = 2) = 0.375 furx = 2P (X = 3) = 0.125 furx = 3
0 furx /∈ TX
133

Beispiel: [II]
• Die Verteilungsfunktion ist gegeben durch (vgl. Folie 118)
FX(x) =
0.000 furx < 00.125 fur 0 ≤ x < 10.5 fur 1 ≤ x < 2
0.875 fur 2 ≤ x < 31 furx ≥ 3
134

Wahrscheinlichkeits- und Verteilungsfunktion
135

Offensichtlich:• Fur die Verteilungsfunktion gilt
FX(x) = P (X ≤ x) =∑
xj∈TX |xj≤x
=P (X=xj)︷ ︸︸ ︷
fX(xj)
Fazit:• Die VF einer diskreten ZV’en X ist eine Treppenfunktion
mit Sprungen an den Stellen xj ∈ TX. Die Sprunghohe ander Stelle xj betragt
FX(xj)− limx→xjx<xj
F (x) = P (X = xj) = fX(xj),
d.h. die Sprunghohe ist der Wert der Wskt.-Funktion(Beziehung: Verteilungs- und Wahrscheinlichkeitsfunktion)
136

Jetzt:
• Definition von stetigen Zufallsvariablen
Intuition:
• Im Gegensatz zu diskreten ZV’en (vgl. Definition 3.4, Folie129) sind stetige ZV’e solche, die uberabzahlbar viele Reali-sationen (z.B. jede reelle Zahl in einem Intervall) annehmenkonnen
Tatsachlich:
• Definition stetiger ZV’en komplizierter (technischer)
137

Definition 3.7: (Stetige ZV, Dichtefunktion)
Eine ZV X heißt stetig, wenn sich ihre Verteilungsfunktion FXals Integral einer Funktion fX : R −→ [0,∞) schreiben lasst:
FX(x) =∫ x
−∞fX(t)dt fur alle x ∈ R.
Die Funktion fX(x) heißt Dichtefunktion [kurz: Dichte] von X.
Bemerkungen:
• Die VF FX einer stetigen ZV’en X ist (eine) Stammfunktionder Dichtefunktion fX
• FX(x) = P (X ≤ x) ist gleich dem Flacheninhalt unter derDichtefunktion fX von −∞ bis zur Stelle x
138

Verteilungsfunktion FX und Dichte fX
139
x
fX(t)
P(X ≤ x) = FX(x)
t

Eigenschaften der Dichtefunktion fX:
1. Die Dichte fX ist niemals negativ, d.h.
fX(x) ≥ 0 fur alle x ∈ R
2. Die Flache unter der Dichte ist gleich 1, d.h.∫ +∞
−∞fX(x)dx = 1
3. Wenn FX(x) differenzierbar ist, gilt
fX(x) = F ′X(x)
140

Beispiel: (Gleichverteilung uber [0,10]) [I]
• Gegeben sei die ZV X mit Dichtefunktion
fX(x) =
0 , fur x /∈ [0,10]0.1 , fur x ∈ [0,10]
• Berechnung der VF FX: [I]
Fur x < 0 gilt:
FX(x) =∫ x
−∞fX(t) dt =
∫ x
−∞0 dt = 0
141

Beispiel: (Gleichverteilung uber [0,10]) [II]
• Berechnung der VF FX: [II]
Fur x ∈ [0,10] gilt:
FX(x) =∫ x
−∞fX(t) dt
=∫ 0
−∞0 dt
︸ ︷︷ ︸
=0
+∫ x
00.1 dt
= [0.1 · t]x0
= 0.1 · x− 0.1 · 0
= 0.1 · x142

Beispiel: (Gleichverteilung uber [0,10]) [III]
• Berechnung der VF FX: [III]
Fur x > 10 gilt:
FX(x) =∫ x
−∞fX(t) dt
=∫ 0
−∞0 dt
︸ ︷︷ ︸
=0
+∫ 10
00.1 dt
︸ ︷︷ ︸
=1
+∫ ∞
100 dt
︸ ︷︷ ︸
=0
= 1
143

Verteilungsfunktion und Dichte der Gleichverteilung uber [0,10]
144

Jetzt:
• Wskt.’en fur Intervalle, d.h. (fur a, b ∈ R, a < b)
P (X ∈ (a, b]) = P (a < X ≤ b)
• Es gilt:
P (a < X ≤ b) = P (ω|a < X(ω) ≤ b)
= P (ω|X(ω) > a ∩ ω|X(ω) ≤ b)
= 1− P (ω|X(ω) > a ∩ ω|X(ω) ≤ b)
= 1− P (ω|X(ω) > a ∪ ω|X(ω) ≤ b)
= 1− P (ω|X(ω) ≤ a ∪ ω|X(ω) > b)
145

= 1− [P (X ≤ a) + P (X > b)]
= 1− [FX(a) + (1− P (X ≤ b))]
= 1− [FX(a) + 1− FX(b)]
= FX(b)− FX(a)
=∫ b
−∞fX(t) dt−
∫ a
−∞fX(t) dt
=∫ b
afX(t) dt
146

Intervall-Wahrscheinlichkeit mit den Grenzen a und b
147
a x b
fX(x)
P(a < X ≤ b)

Wichtiges Ergebnis fur stetige ZV X:
P (X = a) = 0 fur alle a ∈ R
Begrundung:
P (X = a) = limb→a
P (a < X ≤ b) = limb→a
∫ b
afX(x) dx
=∫ a
afX(x)dx = 0
Fazit:
• Die Wskt., dass eine stetige ZV X einen einzelnen Wert an-nimmt, ist immer Null!!
148

Punkt-Wahrscheinlichkeit bei stetiger ZV
149
a b1b2b3
fX(x)
x

Vorsicht:
• Das bedeutet nicht, dass dieses Ereignis unmoglich ist
Konsequenz:
• Da bei stetigen ZV’en fur alle a ∈ R stets P (X = a) = 0 gilt,folgt fur stetige ZV stets
P (a < X < b) = P (a ≤ X < b) = P (a ≤ X ≤ b)
= P (a < X ≤ b) = FX(b)− FX(a)
(Ob Intervalle offen oder geschlossen sind, spielt fur dieWskt.-Bestimmung bei stetigen ZV keine Rolle)
150

3.2 Erwartungswert und Varianz einer Zufallsvari-ablen
Jetzt:
• Beschreibung der Wskt.-Verteilung der ZV’en X durch bes-timmte Kenngroßen
• In dieser VL lediglich Betrachtung von
Erwartungswert
Varianz
151

Zunachst:
• Der Erwartungswert einer ZV’en X ist eine Maßzahl fur dieLage der Verteilung
• Der Erwartungswert einer ZV’en X ahnelt in seiner Bedeu-tung dem arithmetischen Mittel einer Datenreihe(vgl. deskriptive Statistik, VL Statistik I)
152

Wiederholung:
• Fur eine gegebene Datenreihe x1, . . . , xn ist das arithmetischeMittel definiert als
x =1n
n∑
i=1xi =
n∑
i=1
(
xi ·1n
)
• Jeder Summand xi · 1/n entspricht einem Datenpunkt × rel-ativer Haufigkeit
Jetzt:
• Ubertragung dieses Prinzips auf die ZV X
153

Definition 3.8: (Erwartungswert)
Der Erwartungswert der ZV’en X (in Zeichen: E(X)) ist definiertals
E(X) =
∑
xj∈TXxj · P (X = xj) , falls X diskret ist
∫ +∞
−∞x · fX(x) dx , falls X stetig ist
.
Bemerkungen: [I]
• Der Erwartungswert der ZV’en X entspricht also (in etwa)der Summe aller moglichen Realisationen jeweils gewichtetmit der Wskt. ihres Eintretens
154

Bemerkungen: [II]
• Anstelle von E(X) schreibt man haufig µX
• Anstelle der Formulierung ’Erwartungswert der ZV’en X’sagt man haufig ’Erwartungswert der Verteilung von X’
• Es gibt ZV’en, die keinen Erwartungswert besitzen(kein Gegenstand dieser VL)
155

Beispiel 1: (Diskrete ZV) [I]• Man betrachte den 2-maligen Wurfelwurf. Die ZV X stehe
fur die (betragliche) Differenz der Augenzahlen. Man berechneden Erwartungswert von X
• Zunachst ergibt sich als Trager der Zufallsvariablen
TX = 0,1,2,3,4,5
• Die Wahrscheinlichkeitsfunktion ist gegeben durch
fX(x) =
P (X = 0) = 6/36 furx = 0P (X = 1) = 10/36 furx = 1P (X = 2) = 8/36 furx = 2P (X = 3) = 6/36 furx = 3P (X = 4) = 4/36 furx = 4P (X = 5) = 2/36 furx = 5
0 furx /∈ TX
156

Beispiel 1: (Diskrete ZV) [II]
• Als Erwartungswert ergibt sich
E(X) = 0 ·636
+ 1 ·1036
+ 2 ·836
+ 3 ·636
+ 4 ·436
+ 5 ·236
=7036
= 1.9444
• Achtung:In diesem Beispiel ist E(X) eine Zahl, die die ZV X selbstgar nicht annehmen kann
157

Beispiel 2: (Stetige ZV)
• Es sei X eine stetige ZV mit der Dichte
fX(x) =
x4
, fur 1 ≤ x ≤ 3
0 , sonst
• Zur Berechnung des Erwartungswertes spaltet man das Inte-gral auf:
E(X) =∫ +∞
−∞x · fX(x) dx =
∫ 1
−∞0 dx +
∫ 3
1x ·
x4
dx +∫ +∞
30 dx
=∫ 3
1
x2
4dx =
14·[13· x3
]3
1
=14·(27
3−
13
)
=2612
= 2.1667
158

Haufige Situation:
• Kenne ZV X mit Wskt.- oder Dichtefunktion fX
• Suche den Erwartungswert der transformierten ZV
Y = g(X)
159

Satz 3.9: (Erwartungswert einer Transformierten)
Gegeben sei die ZV X mit Wskt.- oder Dichtefunktion fX. Fureine beliebige (Baire)Funktion g : R −→ R berechnet sich derErwartungswert der transformierten ZV Y = g(X) als
E(Y ) = E(g(X))
=
∑
xj∈TXg(xj) · P (X = xj) , falls X diskret ist
∫ +∞
−∞g(x) · fX(x) dx , falls X stetig ist
.
160

Bemerkungen:
• Alle Funktionen, die im VWL- und/oder BWL-Studium auf-tauchen, sind Baire-Funktionen
• Fur den Spezialfall g(x) = x (die Identitatsfunktion) fallt derSatz 3.9 mit der Definition 3.8 zusammen
161

Rechnen mit Erwartungswerten (Teil 1):
• Betrachte die (lineare) Transformation
Y = g(X) = a + b ·X mit a, b ∈ R
• Ist X stetig mit Dichtefunktion fX, so gilt:
E(Y ) = E(a + b ·X) =∫ +∞
−∞(a + b · x) · fX(x) dx
=∫ +∞
−∞[a · fX(x) + b · x · fX(x)] dx
= a ·∫ +∞
−∞fX(x) dx
︸ ︷︷ ︸
=1
+b ·∫ +∞
−∞x · fX(x) dx
︸ ︷︷ ︸
=E(X)
= a + b · E(X)
162

Bemerkung:
• Der Erwartungswert ist ein linearer Operator, d.h.
E(a + b ·X) = a + b · E(X)
fur reelle Zahlen a, b ∈ R(Spezialfalle: a = 0, b 6= 0 bzw. a 6= 0, b = 0)
163

Rechnen mit Erwartungswerten (Teil 2):
• Betrachte die aufgespaltene Funktion
Y = g(X) = g1(X) + g2(X)
• Ist X stetig mit Dichtefunktion fX, so gilt:
E(Y ) = E[g1(X) + g2(X)]
=∫ +∞
−∞[g1(x) + g2(x)] · fX(x) dx
=∫ +∞
−∞g1(x) · fX(x) dx
︸ ︷︷ ︸
=E[g1(X)]
+∫ +∞
−∞g2(x) · fX(x) dx
︸ ︷︷ ︸
=E[g2(X)]
= E[g1(X)] + E[g2(X)]
164

Bemerkung:
• Fur diskrete ZV’en sind die Herleitungen analog
Satz 3.10: (Zusammenfassung)
Es seien X eine beliebige ZV (stetig oder diskret), a, b ∈ R reelleZahlen und g1, g2 : R −→ R (Baire)Funktionen. Dann gelten diefolgenden Rechenregeln:
1. E(a + b ·X) = a + b · E(X).
2. E[g1(X) + g2(X)] = E[g1(X)] + E[g2(X)].
165

Jetzt:
• Beschreibung des Streuungsverhaltens einer ZV X
Wiederholung aus deskriptiver Statistik:
• Fur eine gegebene Datenreihe x1, . . . , xn ist die empirischeVarianz definiert durch
s2 =1n
n∑
i=1(xi − x)2 =
n∑
i=1
[
(xi − x)2 ·1n
]
• Jeder Summand entspricht der quadratischen Abweichungdes Datenpunktes xi vom arithmetischen Mittel x gewichtetmit seiner relativen Haufigkeit
166

Definition 3.11: (Varianz, Standardabweichung)
Fur eine beliebige stetige oder diskrete ZV X ist die Varianzvon X [in Zeichen: V (X)] definiert als die erwartete quadrierteAbweichung der ZV von ihrem Erwartungswert E(X), d.h.
V (X) = E[(X − E(X))2].
Unter der Standardabweichung von X [in Zeichen: σ(X)] ver-steht man die (positive) Wurzel aus der Varianz, d.h.
σ(X) = +√
V (X).
167

Bemerkungen:
• Offensichtlich ist die Varianz von X ein Erwartungswert. Mitg(X) = [X − E(X)]2 und Satz 3.9 (Folie 160) gilt fur dieVarianz von X:
V (X) = E[g(X)]
=
∑
xj∈TX[xj − E(X)]2 · P (X = xj) , fur diskretes X
∫ +∞
−∞[x− E(X)]2 · fX(x) dx , fur stetiges X
• Es gibt ZV’en, die keine endliche Varianz besitzen(nicht Gegenstand dieser VL)
168

Beispiel: (Diskrete ZV)
• Betrachte erneut den 2-maligen Munzwurf mit der ZV Xals (betraglicher) Differenz der Augenzahlen (vgl. Beispiel 1,Folie 156). Fur die Varianz gilt:
V (X) = (0− 70/36)2 · 6/36 + (1− 70/36)2 · 10/36
= (2− 70/36)2 · 8/36 + (3− 70/36)2 · 6/36
= (4− 70/36)2 · 4/36 + (5− 70/36)2 · 2/36
= 2.05247
169

Jetzt:
• Rechenregeln fur Varianzen
Man beachte:
• Varianz ist per definitionem ein Erwartungswert
−→ Rechenregeln fur Erwartungswerte anwendbar
Rechenregel 1: [I]
• Betrachte die (lineare) Transformation
Y = g(X) = a + b ·X mit a, b ∈ R
170

Rechenregel 1: [II]
• Es gilt
V (Y ) = V [g(X)]
= E[[g(X)− E(g(X))]2]
= E[[a + b ·X − a− b · E(X)]2]
= E[b2 · [X − E(X)]2]
= b2 · E[[X − E(X)]2]
= b2 · V (X)
−→ Spezialfall: b = 0, a ∈ R (Varianz einer Konstanten)
V (a) = 0
171

Rechenregel 2:
• Vereinfachte Varianzberechnung:
V (X) = E[(X − E(X))2]
= E[X2 − 2 · E(X) ·X + [E(X)]2]
= E(X2)− 2 · E(X) · E(X) + [E(X)]2
= E(X2)− [E(X)]2
172

Ubungsaufgabe:
• Berechnen Sie anhand dieser Formel die Varianz der stetigenZV’en X mit Dichte
fX(x) =
x4
, fur 1 ≤ x ≤ 3
0 , sonst
Satz 3.12: (Zusammenfassung)
Es seien X eine beliebige ZV (stetig oder diskret) sowie a, b ∈ Rreelle Zahlen. Es gelten die folgenden Rechenregeln:
1. V (X) = E(X2)− [E(X)]2.
2. V (a + b ·X) = b2 · V (X).
173

3.3 Spezielle diskrete Verteilungen
Jetzt:
• Einige wichtige diskrete Verteilungen:
Bernoulli-Verteilung
Binomial-Verteilung
Geometrische Verteilung
Poisson-Verteilung
174

1. Die Bernoulli-Verteilung
Ausgangssituation:
• Ein Zufallsexp. habe nur 2 interessierende Ausgange:
Ω = A ∪A
• Oft bezeichnet man das Ereignis A als Erfolg und A als Mis-serfolg oder Niete
Definition 3.13: (Bernoulli-Experiment)
Ein Zufallsexperiment, bei dem man sich nur dafur interessiert,ob ein Ereignis A eintritt oder nicht, nennt man ein Bernoulli-Experiment.
175

Jetzt:
• Definiere die codierte ZV X als
X =
1 , falls A eintritt (Erfolg)0 , falls A eintritt (Misserfolg)
Beispiele: [I]
• Das Geschlecht einer zufallig ausgewahlten Person aus einerPopulation:
X =
1 , falls die Person weiblich ist0 , falls die Person mannlich ist
176

Beispiele: [II]
• Eine Urne enthalt insgesamt N Kugeln, von denen M rot undN −M weiß sind. Betrachte das Experiment des 1-maligenZiehens einer Kugel:
X =
1 , falls die Kugel rot ist0 , falls die Kugel weiß ist
Offensichtlich:
P (X = 1) =MN≡ p
P (X = 0) =N −M
N= 1−
MN
= 1− p ≡ q
177

Definition 3.14: (Bernoulli-Verteilung)
Die ZV X reprasentiere ein Bernoulli-Experiment und fur einfestes p ∈ [0,1] gelte
P (X = 1) = P (A) = p,
P (X = 0) = P (A) = 1− p ≡ q.
Dann heißt die ZV X Bernoulli-verteilt mit Parameter (Erfol-gswskt.) p und man schreibt X ∼ Be(p).
Berechnung des E-Wertes bzw. der Varianz:
• E(X) = 0 · (1− p) + 1 · p = p
• V (X) = (0− p)2 · (1− p) + (1− p)2 · p = p · (1− p) = p · q
178

Wahrscheinlichkeits- und Verteilungsfunktion der Bernoulli-Verteilung
179

2. Die Binomial-Verteilung
Jetzt:
• Betrachte n gleichartige und unabhangig voneinanderdurchgefuhrte Bernoulli-Experimente(alle mit derselben Erfolgswahrscheinlichkeit p)
• Die ZV X bezeichne die Anzahl der Erfolge, d.h. der Tragervon X ist
TX = 0,1, . . . , n
Gesucht:
• Wskt. genau x Erfolge zu erzielen, d.h. P (X = x)
180

Herleitung:
• Bei n unabhangigen Bernoulli-Experimenten gibt es genau(
nx
)
Versuchsreihen, die exakt x Erfolge und gleichzeitig n−xMisserfolge aufweisen
• Wegen der Unabhangigkeit der Bernoulli-Experimente ist dieWskt. jeder einzelnen dieser
(
nx
)
Versuchsreihen px ·(1−p)n−x
• Wegen der Disjunktheit der(
nx
)
Versuchsreihen folgt fur diegesuchte Wskt.
P (X = x) =(nx
)
· px · (1− p)n−x
181

Definition 3.15: (Binomial-Verteilung)
Eine diskrete ZV X mit Trager TX = 0,1, . . . , n und Wahrschein-lichkeitsfunktion
P (X = x) =(nx
)
· px · (1− p)n−x fur x = 0,1, . . . , n,
heißt binomialverteilt mit den Parametern n und p [in Zeichen:X ∼ B(n, p)].
Bemerkung:
• Die Bernoulli-Verteilung aus Definition 3.14 (Folie 178) istein Spezialfall der Binomialverteilung, denn es gilt
X ∼ Be(p) ist das gleiche wie X ∼ B(1, p)
182

Beispiel: [I]
• Eine Urne enthalt 10 Kugeln, davon 3 rote und 7 weiße. Eswerden 2 Kugeln mit Zurucklegen gezogen. Gesucht sind dieWskt’en dafur, genau 0,1 bzw. 2 rote Kugeln zu ziehen
• Es bezeichne X die Anzahl der gezogenen roten Kugeln.Die Wskt. bei genau einem Zug eine rote Kugel zu ziehen,betragt p = 3/10 = 0.3
−→ X ∼ B(n = 2, p = 0.3)
183

Beispiel: [II]
• Berechung der Wskt. Funktion:
P (X = 0) =(20
)
· 0.30 · (1− 0.3)2−0 = 0.49
P (X = 1) =(21
)
· 0.31 · (1− 0.3)2−1 = 0.42
P (X = 2) =(22
)
· 0.32 · (1− 0.3)2−2 = 0.09
E-Wert und Varianz einer Bernoulli-Verteilung:
• E(X) = n · p
• V (X) = n · p · (1− p)(Beweise: spater mit Ergebnissen aus Kapitel 4)
184

Wahrscheinlichkeits- und Verteilungsfunktion der Binomial-Verteilung
185

3. Die Geometrische Verteilung
Ausgangssituation:
• Bernoulli-Experiment (Ausgange A bzw. A, P (A) = p) kannprinzipiell beliebig oft wiederholt werden(gleichartige unabhangige Experimente)
Von Interesse:
• Zeitpunkt des 1. Erfolges, d.h. ZV
X = Anzahl der Experimente bis zum 1. Ausgang A
186

Offensichtlich:
• Trager von X ist TX = 1,2, . . . = N
Berechnung der Wskt.-Funktion:
P (X = 1) = pP (X = 2) = (1− p) · p = p · (1− p)P (X = 3) = (1− p) · (1− p) · p = p · (1− p)2
...
Allgemein gilt:
P (X = x) = (1− p) · . . . · (1− p)︸ ︷︷ ︸
x−1 mal·p = p · (1− p)x−1
187

Definition 3.16: (Geometrische Verteilung)
Eine diskrete ZV X mit Trager TX = N und der Wahrschein-lichkeitsfunktion
P (X = x) = p · (1− p)x−1 fur x ∈ N
heißt geometrisch verteilt mit Parameter p ∈ (0,1) [in Zeichen:X ∼ G(p)].
Bemerkung:
• Bei der Berechnung diverser Verteilungseigenschaften spieltdie unendliche geometrische Reihe eine Rolle, z.B.
∞∑
x=1P (X = x) =
∞∑
x=1p · (1− p)x−1 = p ·
11− (1− p)
= 1
188

Satz 3.17: (Kenngroßen der geometrischen Verteilung)
Die diskrete ZV X sei geometrisch verteilt mit Parameter p,d.h. X ∼ G(p). Dann sind der Erwartungswert bzw. die Varianzvon X gegeben durch
E(X) =∞∑
x=1x · p · (1− p)x−1 =
1p
V (X) =∞∑
x=1(x− 1/p)2 · p · (1− p)x−1 =
1− pp2 .
189

Beispiel: [I]
• Aus einer Urne mit 10 Kugeln (4 rote, 6 weiße) wird mitZurucklegen gezogen. Gesucht werden
1. die Wskt., dass bei der 3. Ziehung erstmalig eine roteKugel gezogen wird,
2. die Wskt., dass fruhestens bei der 3. Ziehung erstmaligeine rote Kugel gezogen wird,
3. der Erwartungswert fur das erstmalige Ziehen einer rotenKugel,
4. die Varianz fur das erstmalige Ziehen einer roten Kugel.
190

Beispiel: [II]
• Betrachte ZV
X = Nummer der Ziehung, bei der erstmalig eine roteKugel gezogen wird
• Offensichtlich: X ∼ G(0.4). Damit gilt:
1. P (X = 3) = 0.4 · 0.62 = 0.144
2.∞∑
x=3P (X = x) = 1− P (X = 1)− P (X = 2) = 0.36
3. E(X) = 1/0.4 = 2.5
4. V (X) = (1− 0.4)/(0.42) = 3.75
191

3. Die Poisson-Verteilung
Haufiges Anwendungsgebiet:
• Warteschlangenmodelle, z.B. zur Modellierung von
Schlangen vor einem BankschalterAuftragsschlangen bei einem Internet-Server
In dieser VL:
• Keine sachlogische Herleitung, sondern nur
formale DefinitionAngabe von Erwartungswert und Varianz
192

Definition 3.18: (Poisson-Verteilung)
Die diskrete ZV X mit dem Trager TX = 0,1, . . . = N∪0 undder Wahrscheinlichkeitsfunktion
P (X = x) = e−µ ·µx
x!fur x = 0,1,2, . . .
heißt Poisson-verteilt mit Parameter µ > 0 [in Zeichen: X ∼Po(µ)].
Bemerkung:
• e bezeichnet die Eulersche Zahl und die Funktion ex dienaturliche Exponentialfunktion(vgl. Abschnitt 2.2, VL Statistik I)
193

Satz 3.19: (Kenngroßen der Poisson-Verteilung)
Die diskrete ZV X sei Poisson-verteilt mit Parameter µ, d.h. X ∼Po(µ). Dann sind der Erwartungswert bzw. die Varianz von Xgegeben durch
E(X) = µ sowie V (X) = µ.
194

Herleitungen: [I]
• Fur den Erwartungswert gilt:
E(X) =∞∑
x=0x · e−µ ·
µx
x!= e−µ
∞∑
x=1x ·
µx
x!
= e−µ∞∑
x=1µ ·
µx−1
(x− 1)!
= µ · e−µ∞∑
x=0
µx
x!
= µ · e−µ · eµ
= µ
195

Herleitungen: [II]
• Zur Bestimmung der Varianz berechnet man zunachst
E(X2) =∞∑
x=0x2 · e−µ ·
µx
x!
= . . .
= µ2 + µ
• Nach Satz 3.12(a) (vgl. Folie 173) folgt damit fur die Vari-anz:
V (X) = E(X2)− [E(X)]2 = µ2 + µ− µ2 = µ
196

3.4 Spezielle stetige Verteilungen
Jetzt:
• Drei bekannte stetige Verteilungen
Gleichverteilung
Exponentialverteilung
Normalverteilung
197

1. Die Gleichverteilung
Definition 3.20: (Gleichverteilung)
Die stetige ZV X heißt gleichverteilt uber dem Intervall [a, b], a <b, [in Zeichen: X ∼ U(a, b)], falls X die folgende Dichtefunktionbesitzt:
fX(x) =
1b− a
, falls a ≤ x ≤ b
0 , sonst.
198

Bemerkungen:
• Die ZV X auf Folie 141 ist gleichverteilt uber dem Intervall[0,10], d.h. X ∼ U(0,10)
• Die Gleichverteilung U(a, b) sinnvoll, falls X keinerlei Wertezwischen a und b ’bevorzugt’ annimmt
• Die Verteilungsfunktion berechnet sich zu
FX(x) =∫ x
−∞fX(t) dt =
0 , falls x < ax− ab− a
, falls a ≤ x ≤ b
1 , falls x > b
199

Dichte- und Verteilungsfunktion der Gleichverteilung uber [a, b]
200

Satz 3.21: (E-Wert, Varianz)
Fur die stetige, gleichverteilte ZV X ∼ U(a, b) sind Erwartungswertund Varianz gegeben durch
E(X) =∫ +∞
−∞x · fX(x) dx =
a + b2
,
V (X) =∫ +∞
−∞[x− E(X)]2 · fX(x) dx =
(b− a)2
12.
201

2. Die Exponentialverteilung
Definition 3.22: (Exponentialverteilung)
Die stetige ZV X heißt exponentialverteilt mit Parameter λ > 0[in Zeichen: X ∼ Exp(λ)], falls X die folgende Dichtefunktionbesitzt:
fX(x) =
0 , falls x < 0λ · e−λ·x , falls x ≥ 0
.
Bemerkung:
• Die Verteilungsfunktion berechnet sich zu
FX(x) =∫ x
−∞fX(t) dt =
0 , falls x < 01− e−λ·x , falls x ≥ 0
202

Dichtefunktionen der Exponentialverteilung
203
0
1
2
3
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5
fX(x)
x
λ = 3
λ = 2
λ = 1

Verteilungsfunktionen der Exponentialverteilung
204
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5
FX(x)
x
λ = 1
λ = 2
λ = 3

Satz 3.23: (E-Wert, Varianz)
Fur die stetige, exponentialverteilte ZV X ∼ Exp(λ) sind Er-wartungswert und Varianz gegeben durch
E(X) =∫ +∞
−∞x · fX(x) dx =
1λ
,
V (X) =∫ +∞
−∞[x− E(X)]2 · fX(x) dx =
1λ2.
205

3. Die Normalverteilung
Einfuhrende Bemerkungen: [I]
• Normalverteilung (auch Gaußverteilung) ist die wichtigsteVerteilung uberhaupt
Praxis:
−→ Relevanz resultiert aus zentralem Grenzwertsatz(vgl. Kapitel 4)
Theorie:
−→ Relevant fur Entwicklung von Schatz- und Testverfahren(vgl. Kapitel 5-7)
206

Einfuhrende Bemerkungen: [II]
• Viele Phanomene lassen sich gut durch eine Normalverteilungapproximieren, z.B.
Biometrische Großen(Korpergroßen, Gewicht etc.)
Okonomische Großen(Veranderungsraten)
Zufallige Fehler(Messfehler, Produktionsfehler)
207

Definition 3.24: (Normalverteilung)
Die stetige ZV X heißt normalverteilt mit Parametern µ ∈ Rund σ2 > 0 [in Zeichen: X ∼ N(µ, σ2)], falls X die folgendeDichtefunktion besitzt:
fX(x) =1√
2π · σ· e−
12
(
x−µσ
)2
, x ∈ R.
Bemerkungen:
• Die Parameter µ und σ2 geben der Dichtefunktion ihre spezielleGestalt
• Die Normalverteilung N(0,1) heißt Standardnormalverteilung.Ihre Dichte wird oft mit ϕ(x) bezeichnet
208

Dichtefunktionen der Normalverteilung
209
0 5 x
fX(x)
N(0,1) N(5,1)
N(5,3)
N(5,5)

Satz 3.25: (Eigenschaften der Normalverteilung) [I]
Es sei X ∼ N(µ, σ2). Dann gilt:
1. Die Dichte fX(x) hat ihr einzige lokales Maximum an derStelle x = µ.
2. Die Dichte fX(x) ist symmetrisch um µ.
3. Die Dichte fX(x) besitzt Wendepunkte an den Stellen x =µ + σ und x = µ− σ.
210

Satz 3.25: (Eigenschaften der Normalverteilung) [II]
4. Fur Erwartungswert und Varianz von X gilt:
E(X) = µ und V (X) = σ2.
5. Auch die linear transformierte ZV Y = a + b ·X mit a, b ∈ Rist normalverteilt mit Erwartungswert E(Y ) = a + b · µ undVarianz V (Y ) = b2 · σ2, d.h.
Y ∼ N(a + b · µ, b2 · σ2).
211

Jetzt:
• Bestimmung der Verteilungsfunktion FX:
FX(x) = P (X ≤ x) =∫ x
−∞fX(t) dt
=∫ x
−∞
1√2π · σ
· e−12
(
t−µσ
)2
dt
Problem:
• Keine mathematisch geschlossene Losung des Integrals
• VF’en konnen nur approximativ berechnet werden(durch numerische Verfahren)
212

(Approximative) Verteilungsfunktionen der Normalverteilung
213
0 5
0.5
1
FX(x)
x
N(0,1)
N(5,1)
N(5,3)
N(5,5)

Bezeichnung:
• Die Verteilungsfunktion der Standardnormalverteilungwird oft mit Φ(x) bezeichnet, also
Φ(x) ≡ FX(x) = P (X ≤ x)
fur X ∼ N(0,1)
Zentrales Ergebnis:
• Fur jede beliebige normalverteilte ZV X ∼ N(µ, σ2) kanndie VF FX(x) = P (X ≤ x) auf die VF der Standardnor-malverteilung zuruckgefuhrt werden
214

Herleitung: [I]
• Fur die VF von X ∼ N(µ, σ2) gilt
FX(x) = P (X ≤ x) = P
(X − µ)/σ︸ ︷︷ ︸
≡ Y≤ (x− µ)/σ
• Nach Satz 3.25(e) folgt
Y =X − µ
σ=
1σ
︸︷︷︸
≡ b
·X −µσ
︸︷︷︸
≡ aist normalverteilt, und zwar
Y ∼ N(a + b · µ, b2 · σ2) = N
−µσ
+1σ· µ
︸ ︷︷ ︸
= 0
,1σ2 · σ
2
︸ ︷︷ ︸
= 1
= N(0,1)
215

Herleitung: [II]
• Insgesamt gilt also fur die ZV X ∼ N(µ, σ2):
FX(x) = P (X ≤ x) = P
Y︸︷︷︸
∼N(0,1)≤
x− µσ
= Φ(x− µ
σ
)
Beispiel: [I]
• Uberdeckungswahrscheinlichkeiten bei der Normalverteilung
• Es seien X ∼ N(µ, σ2) und k ∈ R eine reelle Zahl
• Gesucht: Wahrscheinlichkeit dafur, dass sich X im Intervall[µ− k · σ, µ + k · σ] realisiert
216

Beispiel: [II]
• Es gilt:
P (µ− k · σ ≤ X ≤ µ + k · σ) = FX(µ + k · σ)− FX(µ− k · σ)
= Φ(µ + k · σ − µ
σ
)
−Φ(µ− k · σ − µ
σ
)
= Φ(k)−Φ(−k)
• Die VF Φ(x) der Standardnormalverteilung ist in allen Statistik-Lehrbuchern ausreichend tabelliert(z.B. in Mosler/Schmid, 2008)
217

Beispiel: [III]
• Außerdem:Φ(x) kann in allen statistischen Programmpaketen berechnetwerden(z.B. in Excel, EViews, SPSS)
• Fur k = 1,2,3 gilt:
k = 1 : Φ(1)−Φ(−1) = 0.6827
k = 2 : Φ(2)−Φ(−2) = 0.9545
k = 3 : Φ(3)−Φ(−3) = 0.9973
218

Uberdeckungswahrscheinlichkeiten der Normalverteilung
219
µµ − σ µ + σµ − 2 σ µ + 2 σµ − 3 σ µ + 3 σ
5 34 21
F l ä c h e n i n h a l t e :1 : 0 . 6 8 2 71 + 2 + 4 : 0 . 9 5 4 51 + 2 + 3 + 4 + 5 : 0 . 9 9 7 3

4. Gemeinsame Verteilung und Grenzwertsatze
Haufig in der Praxis:
• Man muss mehrere (n) ZV’en gleichzeitig betrachten(vgl. Statistik I, Kapitel 6)
Zunachst Vereinfachung:
• Betrachte n = 2 Zufallsvariablen (X und Y )
220

Beispiele:
• Zufallig ausgewahlter Haushalt:
X = HaushaltsgroßeY = Anzahl Autos
• Tagesrenditen zweier Aktien:
X = Rendite der VW-AktieY = Rendite der BASF-Aktie
• 2-facher Wurfelwurf:
X = Minimum der AugenzahlenY = Maximum der Augenzahlen
221

4.1 Gemeinsame Verteilung von Zufallsvariablen
Situation:
• Betrachte zwei ZV’en X und Y zu ein und demselben Zufall-sexperiment, d.h.
X : Ω −→ RY : Ω −→ R
222

Definition 4.1: (Gemeinsame Verteilungsfunktion)
Fur die beiden ZV’en X und Y heißt die Funktion
FX,Y : R2 −→ [0,1]
mit
FX,Y (x, y) = P (ω|X(ω) ≤ x und Y (ω) ≤ y)
= P (X ≤ x, Y ≤ y)
die gemeinsame Verteilungsfunktion von X und Y .
223

Bemerkung:
• Die gemeinsame VF von X und Y ist die Wskt. dafur, dasssich gleichzeitig
1. X kleiner oder gleich dem Wert x und
2. Y kleiner oder gleich dem Wert y realisieren
Einige Eigenschaften der gemeinsamen Verteilungsfunktion:
• FX,Y (x, y) ist monoton steigend in x und y
• limx→+∞,y→+∞ FX,Y (x, y) = 1
224

Jetzt:
• Unterscheidung zwischen
1. diskreten gemeinsamen Verteilungen
2. stetigen gemeinsamen Verteilungen
225

Definition 4.2: (Gemeinsam diskrete Zufallsvariablen)
Die beiden ZV’en X und Y heißen gemeinsam diskret verteilt,falls es endlich viele oder abzahlbar unendlich viele Realisationenx1, x2, . . . und y1, y2, . . . gibt, so dass
pjk ≡ P (X = xj, Y = yk) > 0
mit...∑
j=1
...∑
k=1pjk =
...∑
j=1
...∑
k=1P (X = xj, Y = yk) = 1
gilt. Fur die gemeinsam diskret verteilten ZV’en X und Y heißtdie Funktion
fX,Y (x, y) =
pjk = P (X = xj, Y = yk) , fur x = xj und y = yk0 , sonst
die gemeinsame Wahrscheinlichkeitsfunktion der diskreten ZV’enX und Y .
226

Bemerkung:
• Die gemeinsame Wahrscheinlichkeitsfunktion kann in einerWahrscheinlichkeitstabelle dargestellt werden:
X/Y y1 y2 y3 . . .x1 p11 p12 p13 . . .x2 p21 p22 p23 . . .... ... ... ... ...
227

Beispiel: [I]
• X = Haushaltsgroße, Y = Anzahl Autos
• Wahrscheinlichkeitstabelle
X/Y 0 1 21 0.10 0.14 0.012 0.05 0.15 0.103 0.02 0.10 0.084 0.02 0.06 0.075 0.01 0.05 0.04
228

Beispiel: [II]
• Berechnung der gemeinsamen Verteilungsfunktion:
FX,Y (x, y) =∑
j|xj≤x
∑
k|yk≤ypjk
• Z.B. gilt
FX,Y (3,1) = P (X ≤ 3, Y ≤ 1)= 0.10 + 0.14 + 0.05 + 0.15 + 0.02 + 0.10= 0.56
oder
FX,Y (1.5,3.2) = P (X ≤ 1.5, Y ≤ 3.2)= 0.10 + 0.14 + 0.01= 0.25
229

Jetzt:
• X = und Y seien beides stetige Zufallsvariablen
Definition 4.3: (Gemeinsam stetige Zufallsvariablen)
Die beiden ZV’en X und Y heißen gemeinsam stetig verteilt, fallssich ihre gemeinsame Verteilungsfunktion FX,Y als Doppelinte-gral einer Funktion fX,Y : R2 −→ [0,∞) schreiben lasst, d.h. wenngilt
FX,Y (x, y) = P (X ≤ x, Y ≤ y)
=∫ y
−∞
∫ x
−∞fX,Y (u, v) du dv fur alle (x, y) ∈ R2.
Die Funktion fX,Y (x, y) heißt gemeinsame Dichtefunktion von Xund Y .
230

Gemeinsame Dichtefunktion der Zufallsvariablen X und Y
231

Bemerkungen: [I]
• Rechnen mit gemeinsamen stetigen Verteilungen erfordertDifferential- und Integralrechnung mit Funktionen mehrererVeranderlicher(partielles Differenzieren, Doppelintegrale)
• Bei partieller Differenzierbarkeit gilt
fX,Y (x, y) =∂2
∂x∂yFX,Y (x, y)
(Zusammenhang: gemeinsame Dichte- und gemeinsame VF)
232

Bemerkungen: [II]
• Fur alle (x, y) ∈ R2 gilt fX,Y (x, y) ≥ 0(gemeinsame Dichte ist uberall positiv)
• Das Volumen unter der Dichte ist 1, d.h.∫ +∞
−∞
∫ +∞
−∞fX,Y (x, y) dx dy = 1
• Durch Doppelintegration der Dichte erhalt man Intervall-wahrscheinlichkeiten, z.B.
P (x1 ≤ X ≤ x2, y1 ≤ Y ≤ y2) =∫ y2
y1
∫ x2
x1fX,Y (x, y) dx dy
(vgl. eindimensionalen stetigen Fall auf Folien 145, 146)
233

Gemeinsame Dichte- und Verteilungsfunktion der ZV’en X = ’Rendite
VW-Aktie’ und Y = ’Rendite BASF-Aktie’
234

Jetzt folgende Ausgangssituation:
• X und Y seien (diskret oder stetig) gemeinsam verteilt mitder gemeinsamen Verteilungsfunktion FX,Y (x, y)
Gesucht:
• Verteilung von X bzw. von Y , wenn man die jeweils andereVerteilung ignoriert(die sogenannten Randverteilungen)
235

Es gilt: [I]
1. Randverteilungsfunktionen FX bzw. FY
FX(x) = limy→+∞
FX,Y (x, y) = P (X ≤ x, Y ∈ R)
FY (y) = limx→+∞
FX,Y (x, y) = P (X ∈ R, Y ≤ y)
2. Randwahrscheinlichkeiten gemeinsam diskreter ZV’en
pj,· ≡ P (X = xj) =...∑
k=1P (X = xj, Y = yk) =
...∑
k=1pjk
p·,k ≡ P (Y = yk) =...∑
j=1P (X = xj, Y = yk) =
...∑
j=1pjk
236

Es gilt: [II]
3. Randdichten gemeinsam stetiger ZV’en
fX(x) =∫ +∞
−∞fX,Y (x, y) dy
fY (y) =∫ +∞
−∞fX,Y (x, y) dx
Wichtig:
• Die Randverteilungen ergeben sich eindeutig aus der gemein-samen Verteilung von X und Y
• ABER:Die gemeinsame Verteilung ist nicht eindeutig durch die Rand-verteilungen bestimmt
237

Relevanz der Randverteilungen:
• Mit den Randverteilungen einer gemeinsamen Verteilung defi-niert man den Begriff der ’Stochastischen Unabhangigkeit’von Zufallsvariablen(vgl. Definition 2.13, Folie 82)
Definition 4.4: (Unabhangigkeit von Zufallsvariablen)
Die ZV’en X und Y heißen (stochastisch) unabhangig, falls ihregemeinsame Wahrscheinlichkeitsfunktion (diskreter Fall) bzw. ihregemeinsame Dichtefunktion (stetiger Fall) dem Produkt der Rand-verteilungen entspricht, d.h. falls
fX,Y (x, y) = fX(x) · fY (y) fur alle x, y ∈ R.
238

Bemerkungen:
• Fur gemeinsam diskret verteilte ZV’en X und Y bedeutet dieDefinition 4.4: X und Y sind stochastisch unabhangig, wennfur alle j = 1,2, . . . und k = 1,2, . . . gilt:
P (X = xj, Y = yk) = P (X = xj) · P (Y = yk)
• Alternativ druckt man die stochastische Unabhangigkeit uberdie gemeinsame Verteilungsfunktion aus:
Satz 4.5: (Stochastische Unabhangigkeit)
Die ZV’en X und Y sind genau dann stochastisch unabhangig,falls sich ihre gemeinsame Verteilungsfunktion als Produkt derRandverteilungsfunktionen darstellen lasst, d.h. falls
FX,Y (x, y) = FX(x) · FY (y) fur alle x, y ∈ R.
239

Beispiel 1: (Diskreter Fall) [I]
• Es bezeichnen
X die Haushaltsgroße
Y die Anzahl Autos pro Haushalt
240

Beispiel 1: (Diskreter Fall) [II]
• Wahrscheinlichkeitstabelle:
X/Y y1 = 0 y2 = 1 y3 = 2 pj· = P (X = xj)x1 = 1 0.10 0.14 0.01 0.25x2 = 2 0.05 0.15 0.10 0.30x3 = 3 0.02 0.10 0.08 0.20x4 = 4 0.02 0.06 0.07 0.15x5 = 5 0.01 0.05 0.04 0.10
p·k = P (Y = yk) 0.20 0.50 0.30 1.00
241

Beispiel 1: (Diskreter Fall) [III]
• X und Y sind stochastisch abhangig, denn
P (X = 1, Y = 0) = 0.10
aber
P (X = 1) · P (Y = 0) = 0.25 · 0.20 = 0.05
d.h.
P (X = 1, Y = 0) = 0.10 6= 0.05 = P (X = 1) · P (Y = 0)
242

Beispiel 2: (Stetiger Fall) [I]
• Es seien X und Y stetig verteilt mit gemeinsamer Dichte-funktion
fX,Y (x, y) =
x + y , fur 0 ≤ x ≤ 1,0 ≤ y ≤ 10 , sonst
243

Beispiel 2: (Stetiger Fall) [II]
• Die Randdichte von X ergibt sich als
fX(x) =∫ +∞
−∞fX,Y (x, y) dy =
∫ 10 (x + y) dy , fur 0 ≤ x ≤ 1
0 , sonst
=
[
x · y + 12 · y
2]1
0, fur 0 ≤ x ≤ 1
0 , sonst
=
x · 1 + 12 · 1
2 − (x · 0 + 12 · 0
2) , fur 0 ≤ x ≤ 10 , sonst
=
x + 12 , fur 0 ≤ x ≤ 1
0 , sonst
244

Beispiel 2: (Stetiger Fall) [III]
• Auf analoge Art errechnet sich die Randdichte von Y :
fY (y) =∫ +∞
−∞fX,Y (x, y) dx =
y + 12 , fur 0 ≤ y ≤ 1
0 , sonst
• X und Y sind stochastisch abhangig, denn
fX(0.2) · fY (0.2) = (0.2 + 0.5) · (0.2 + 0.5) = 0.49
aber
fX,Y (0.2,0.2) = 0.2 + 0.2 = 0.4
d.h.
fX,Y (0.2,0.2) = 0.4 6= 0.49 = fX(x) · fY (y)
245

Weiteres wichtiges Konzept:
• Bedingte Verteilung(vgl. Abschnitt 2.3, Folie 67 ff.)
Grundlegende Frage:
• Wie ist die ZV X verteilt, wenn der Wert der ZV’en Ybekannt ist
Hier:
• Beschrankung auf diskrete ZV’en
246

Definition 4.6: (Bedingte Wahrscheinlichkeit)
Es seien X und Y zwei gemeinsam diskret verteilte ZV’en mitder gemeinsamen Wahrscheinlichkeitsfunktion
fX,Y (x, y) =
pjk = P (X = xj, Y = yk) , fur x = xj und y = yk0 , sonst
.
Dann ist die bedingte Wahrscheinlichkeit fur X = xj unter derBedingung Y = yk definiert durch
P (X = xj|Y = yk) =P (X = xj, Y = yk)
P (Y = yk)
fur alle Realisationen x1, x2, . . . der ZV’en X.
247

Bemerkungen: [I]
• Die Definition 4.6 entspricht exakt der Definition 2.12 aufFolie 70 fur die Ereignisse (Mengen) A und B
• Wenn die ZV’en X und Y stochastisch unabhangig im Sinneder Definition 4.4 von Folie 238 sind, so gilt:
P (X = xj|Y = yk) =P (X = xj, Y = yk)
P (Y = yk)
=P (X = xj) · P (Y = yk)
P (Y = yk)= P (X = xj)
−→ Bei stochastischer Unabhangigkeit sind die bedingtenWahrscheinlichkeiten von X unter Y = yk gleich denunbedingten Wahrscheinlichkeiten von X
248

Bemerkungen: [III]
• Mit der bedingten Wahrscheinlichkeitsfunktion aus Definition4.6 definiert man
die bedingte Verteilungsfunktion
FX|Y =yk=
∑
j|xj≤xP (X = xj|Y = yk)
den bedingten Erwartungswert
E(X|Y = yk) =∑
xj∈TXxj · P (X = xj|Y = yk)
249

Beispiel: [I]
• X = Haushaltsgroße, Y = Anzahl Autos pro Haushalt
• Wahrscheinlichkeitstabelle:
X/Y y1 = 0 y2 = 1 y3 = 2 pj· = P (X = xj)x1 = 1 0.10 0.14 0.01 0.25x2 = 2 0.05 0.15 0.10 0.30x3 = 3 0.02 0.10 0.08 0.20x4 = 4 0.02 0.06 0.07 0.15x5 = 5 0.01 0.05 0.04 0.10
p·k = P (Y = yk) 0.20 0.50 0.30 1.00
250

Beispiel: [II]
• Bedingte Verteilung von Y unter der Bedingung X = 2:
yk P (Y = yk|X = 2)0 0.05/0.30 = 0.16671 0.15/0.30 = 0.50002 0.10/0.30 = 0.3333
• Bedingter Erwartungswert von Y unter der Bedingung X = 2:
E(Y |X = 2) = 0 · 0.1667 + 1 · 0.5 + 2 · 0.3333
= 1.1667
251

Jetzt:
• Definition des Erwartungswertes einer Funktion
g : R2 −→ R(x, y) 7−→ g(x, y)
zweier gemeinsam verteilter Zufallsvariablen X und Y(d.h. E[g(X, Y )])
Bedeutung:
• Gewinnung diverser praktischer Ergebnisse und hilfreicherRechenregeln
252

Definition 4.7: (E-Wert einer Funktion)
Es seien X und Y zwei gemeinsam (diskret oder stetig) verteilteZV’en mit Wahrscheinlichkeits- bzw. Dichtefunktion fX,Y (x, y)und g(x, y) eine Funktion. Dann ist der Erwartungswert derFunktion definiert als
E[g(X, Y )] =∑
xj∈TX
∑
yk∈TY g(xj, yk) · P (X = xj, Y = yk),
falls X und Y gemeinsam diskret bzw.
E[g(X, Y )] =∫ +∞
−∞
∫ +∞
−∞g(x, y) · fX,Y (x, y) dx dy,
falls X und Y gemeinsam stetig verteilt sind.
253

Beispiel 1: [I]
• Es seien X und Y gemeinsam stetig verteilte ZV’en mitDichtefunktion fX,Y (x, y)
• Fur g(x, y) = y gilt:
E[g(X, Y )] =∫ +∞
−∞
∫ +∞
−∞g(x, y) · fX,Y (x, y) dx dy
=∫ +∞
−∞
∫ +∞
−∞y · fX,Y (x, y) dx dy
=∫ +∞
−∞y ·
(
∫ +∞
−∞fX,Y (x, y) dx
)
︸ ︷︷ ︸
= fY (y) (Randdichte)
dy
254

Beispiel 1: [II]
und somit
E[g(X, Y )] =∫ +∞
−∞y · fY (y) dy
= E(Y )
• Ebenso erhalt man fur g(x, y) = x:
E[g(X, Y )] = E(X)
• Analoges Ergebnis fur diskrete ZV’en X und Y
255

Beispiel 2: [I]• Fur g(x, y) = x + y gilt:
E[g(X, Y )] = E(X + Y ) =∫ +∞
−∞
∫ +∞
−∞(x + y) · fX,Y (x, y) dx dy
=∫ +∞
−∞
∫ +∞
−∞
[
x · fX,Y (x, y) + y · fX,Y (x, y)]
dx dy
=∫ +∞
−∞
∫ +∞
−∞x · fX,Y (x, y) dx dy
+∫ +∞
−∞
∫ +∞
−∞y · fX,Y (x, y) dx dy
=∫ +∞
−∞x · fX(x) dx +
∫ +∞
−∞y · fY (y) dy
= E(X) + E(Y )256

Bemerkung:
• Unter bestimmten (hier erfullten) Voraussetzungen kann dieIntegrationsreihenfolge vertauscht werden
Jetzt:
• Maßzahl zur Messung des Zusammenhangs zwischen zweiZV’en X und Y
Konzept: [I]
• Betrachte Abweichung einer jeden ZV’en vom jeweiligen Er-wartungswert, d.h.
X − E(X) sowie Y − E(Y )
257

Konzept: [II]
• Das Produkt der Abweichungen,
[X − E(X)] · [Y − E(Y )]
ist eine ZV und gibt Auskunft daruber, ob die beiden ZV’enX und Y tendenziell in die gleiche oder in unterschiedlicheRichtungen von ihren jeweiligen Erwartungswerten abweichen
• Der Erwartungswert dieser ZV’en, d.h.
E[(X − E(X)) · (Y − E(Y ))]
ist ein plausibles Maß fur den Zusammenhang zwischen Xund Y
258

Definition 4.8: (Kovarianz)
Es seien X und Y zwei ZV’en mit den jeweiligen ErwartungswertenE(X) und E(Y ). Dann heißt die Große
Cov(X, Y ) ≡ E[(X − E(X)) · (Y − E(Y ))]
die Kovarianz zwischen X und Y .
Bemerkungen: [I]
• Die Kovarianz ist der Erwartungswert der Funktion
g(X, Y ) = (X − E(X)) · (Y − E(Y )).
259

Bemerkungen: [II]
• Gemaß Definition 4.7 (Folie 253) berechnet sich dieser Er-wartungswert als
Cov(X, Y ) =∑
xj∈TX
∑
yk∈TY
(
xj − E(X))
· (yk − E(Y )) · pjk
mit pjk = P (X = xj, Y = yk) falls X und Y gemeinsam diskretbzw.
Cov(X, Y ) =∫ +∞
−∞
∫ +∞
−∞(x− E(X))·(y − E(Y ))·fX,Y (x, y) dx dy,
falls X und Y gemeinsam stetig verteilt sind
• Nutzliche Umformung:
Cov(X, Y ) = E(X · Y )− E(X) · E(Y )
260

Zentrales Resultat:
• Zusammenhang zwischen stochastischer Unabhangigkeit derZV’en X und Y und deren Kovarianz
Satz 4.9: (Unabhangigkeit und Kovarianz)
Es seien X und Y zwei ZV’en mit den jeweiligen ErwartungswertenE(X) und E(Y ). Sind X und Y stochastisch unabhangig, so folgt
Cov(X, Y ) = 0.
261

Beweis: (fur stetige ZV’en) [I]
• Zunachst gilt:
E(X · Y ) =∫ +∞
−∞
∫ +∞
−∞x · y · fX,Y (x, y) dx dy
=∫ +∞
−∞
∫ +∞
−∞x · y · fX(x) · fY (y) dx dy
=∫ +∞
−∞y · fY (y) dy
︸ ︷︷ ︸
=E(Y )
·∫ +∞
−∞x · fX(x) dx
︸ ︷︷ ︸
=E(X)
= E(X) · E(Y )
262

Beweis: (fur stetige ZV’en) [II]
• Damit gilt:
Cov(X, Y ) = E(X · Y )− E(X) · E(Y )
= E(X) · E(Y )− E(X) · E(Y )
= 0
Vorsicht:
• Die Umkehrung gilt nicht, d.h. aus
Cov(X, Y ) = 0
folgt nicht die Unabhangigkeit von X und Y
263

Aber:
• Aus
Cov(X, Y ) 6= 0
folgt, dass X und Y stochastisch abhangig sind
Nachteil der Kovarianz:
• Cov(X, Y ) ist nicht normiert
−→ Normierung der Kovarianz fuhrt zum Korrelationskoef-fizienten
264

Definition 4.10: (Korrelationkoeffizient)
Es seien X und Y zwei ZV’en mit den Erwartungswerten E(X), E(Y )und den Varianzen V (X), V (Y ). Dann ist der Korrelationskoef-fizient zwischen X und Y definiert durch
Corr(X, Y ) =Cov(X, Y )
√
V (X) ·√
V (Y ).
Eigenschaften des Korrelationskoeffizienten: [I]
• Corr(X, Y ) ist dimensionslos
• Corr(X, Y ) ist symmetrisch, d.h.
Corr(X, Y ) = Corr(Y, X)
265

Eigenschaften des Korrelationskoeffizienten: [II]
• Sind X und X stochastisch unabhangig, so gilt
Corr(X, Y ) = 0
(Vorsicht: Die Umkehrung gilt nicht)
• Der Korrelationskoeffizient ist normiert, d.h. es gilt stets
−1 ≤ Corr(X, Y ) ≤ 1
• Der Korrelationskoeffizient misst die Starke des linearen Zusam-menhangs zwischen den ZV’en X und Y
266

Bisher gezeigt:
• Sind X und Y zwei (diskrete oder stetige) ZV, so gilt:
E(X + Y ) = E(X) + E(Y ) (vgl. Folie 256)
E(X · Y ) = E(X) · E(Y ) + Cov(X, Y ) (vgl. Folie 260)
Jetzt:
• Varianz einer Summe von ZV’en
267

Varianz einer Summe von ZV’en:
V (X + Y ) = E
[X + Y − E (X + Y )]2
= E
[(X − E(X)) + (Y − E(Y ))]2
= E [X − E(X)]2︸ ︷︷ ︸
=V (X)
+E [Y − E(Y )]2︸ ︷︷ ︸
=V (Y )
+2 · E [X − E(X)] · [Y − E(Y )]︸ ︷︷ ︸
=Cov(X,Y )
= V (X) + V (Y ) + 2 ·Cov(X, Y )
268

Satz 4.11: (Rechenregeln)
Sind X und Y (diskrete oder stetige) ZV’en mit ErwartungswertenE(X), E(Y ) und Varianzen V (X), V (Y ), so gilt:
1. E(X + Y ) = E(X) + E(Y ),
2. E(X · Y ) = E(X) · E(Y ) + Cov(X, Y ),
3. V (X + Y ) = V (X) + V (Y ) + 2 ·Cov(X, Y ).
Sind X und Y zusatzlich stochastisch unabhangig, so folgt wegenCov(X, Y ) = 0:
E(X · Y ) = E(X) · E(Y )
V (X + Y ) = V (X) + V (Y ).
269

Bemerkung:
• Es seien X und Y (diskrete oder stetige) ZV’en und a, b ∈ Rreelle Zahlen
−→ a ·X + b · Y ist ebenfalls eine ZV und es gilt:
E (a ·X + b · Y ) = a · E(X) + b · E(Y )
V (a ·X + b · Y ) = a2 · V (X) + b2 · V (Y )
+2 · a · b ·Cov(X, Y )
270

Beispiel: [I]
• In einem Portfolio befinden sich 2 Aktien
X : Jahresrendite der Aktie A (in %)Y : Jahresrendite der Aktie B (in %)
• Bekannt seien
E(X) = 7 σ(X) =√
V (X) = 25
E(Y ) = 15 σ(Y ) =√
V (Y ) = 45Corr(X, Y ) = −0.4
• a = 70% des Vermogens wurden in Aktie A investiert
• b = 30% des Vermogens wurden in Aktie B investiert
271

Beispiel: [II]
• Die Jahresrendite des Portfolios ist
Z = a ·X + b · Y
• Fur die erwartete Rendite des Portfolios folgt:
E(Z) = E(a ·X + b · Y )
= a · E(X) + b · E(Y )
= 0.7 · 7 + 0.3 · 15
= 9.4
272

Beispiel: [III]
• Fur die Varianz des Portfolios gilt:
V (Z) = V (a ·X + b · Y )
= a2 · V (X) + b2 · V (Y ) + 2 · a · b ·Cov(X, Y )
= a2 · V (X) + b2 · V (Y )
+2 · a · b · σ(X) · σ(Y ) ·Corr(X, Y )
= 0.72 · 252 + 0.32 · 452 + 2 · 0.7 · 0.3 · 25 · 45 · (−0.4)
= 299.5
• Fur die Standardabweichung folgt:
σ(Z) =√
V (Z) =√
299.5 = 17.31
273

Offensichtlich:
• Durch Diversifikation erreicht man
σ(Z) = 17.31 < 25 = σ(X) < 45 = σ(Y ),
(Standardabweichung des Portfolios ist geringer als die Stan-dardabweichungen der Einzelaktien)
−→ Nobelpreise fur
H. Markowitz (1990)
J. Tobin (1981)
274

Jetzt:
• Erweiterung der Rechenregeln auf n ZV’en
Beachte zunachst:
• Es seien X1, X2, . . . , Xn ZV’en und a1, . . . , an ∈ REs folgt:
Z =n
∑
i=1ai ·Xi = a1 ·X1 + . . . + a ·Xn
ist ebenfalls eine Zufallsvariable
275

Satz 4.12: (Rechenregeln fur gewichtete Summen)
Es seien X1, . . . , Xn (diskrete oder stetige) Zufallsvariablen unda1, . . . , an ∈ R reelle Zahlen. Dann gelten fur den Erwartungswertbzw. die Varianz der gewichteten Summe:
E
n∑
i=1ai ·Xi
=n
∑
i=1ai · E(Xi)
V
n∑
i=1ai ·Xi
=n
∑
i=1a2
i · V (Xi)
+n
∑
i=1
n∑
j=1j 6=i
ai · aj ·Cov(Xi, Xj).
276

Bemerkungen: [I]
• Fur n = 2 gilt:
V (X1 + X2) =2
∑
i=1a2
i · V (Xi) +2
∑
i=1
2∑
j=1j 6=i
ai · aj ·Cov(Xi, Xj)
= a21 · V (X1) + a2
2 · V (X2)
+a1 · a2 ·Cov(X1, X2) + a2 · a1 ·Cov(X2, X1)
= a21 · V (X1) + a2
2 · V (X2)
+2 · a1 · a2 ·Cov(X1, X2)
277

Bemerkungen: [I]
• Sind X1, . . . , Xn paarweise stochastisch unabhangig, so folgt
Cov(Xi, Xj) = 0 fur alle i 6= j,
und damit
V
n∑
i=1ai ·Xi
=n
∑
i=1a2
i · V (Xi)
278

4.2 Grenzwertsatze
Situation:
• Gegeben sei eine unendliche Folge von ZV’en
X1, X2, X3, . . . ,
die alle die gleiche Verteilung besitzen und alle paarweisestochastisch unabhangig sind(d.h. Cov(Xi, Xj) = 0 fur alle i 6= j)
• Betrachte fur gegebenes n das arithmetische Mittel sowie dieVariablensumme
Xn =1n·
n∑
i=1Xi Sn =
n∑
i=1Xi
279

Man beachte:
• Xn und Sn sind selbst ZV’en
Inhalt von Grenzwertsatzen:
• Was passiert mit der Verteilung von Xn und Sn fur n →∞?
Wichtige Grenzwertsatze:
• Schwaches bzw. starkes Gesetz der großen Zahlen
• Glivenko-Cantelli-Grenzwertsatze
Hier nur:
• Zentraler Grenzwertsatz
280

Satz 4.13: (E-Werte und Varianzen von Xn und Sn)
Angenommen, jede ZV der unendlichen Folge X1, X2, . . . (allepaarweise unabhangig) hat die gleiche Verteilung wie die ZV X,wobei E(X) = µ und V (X) = σ2. Dann gilt:
E(Sn) = E
n∑
i=1Xi
=n
∑
i=1E(Xi) = n · µ,
V (Sn) = V
n∑
i=1Xi
=n
∑
i=1V (Xi) = n · σ2,
E(Xn) = E
1n·
n∑
i=1Xi
=1n·
n∑
i=1E(Xi) = µ,
V (Xn) = V
1n·
n∑
i=1Xi
=1n2 ·
n∑
i=1V (Xi) =
σ2
n.
281

Jetzt:
• Essenz des zentralen Grenzwertsatzes
• Begrundung fur die Wichtigkeit der Normalverteilung
Dazu:
• Betrachte Folge von ZV’en X1, X2, . . . , Xn mit folgenden Eigen-schaften:
X1, X2, . . . , Xn sind paarweise stochastisch unabhangig(d.h. Cov(Xi, Xj) = 0 fur alle i 6= j)
Jede der ZV’en Xi hat eine beliebige Verteilung mit Er-wartungswert E(Xi) und Varianz V (Xi)
282

Bemerkung:
• Dieses Szenario ist allgemeiner als die dargestellte Situationauf Folie 279
• Dort hatten alle Xi die gleiche Verteilung und damit alle dengleichen Erwartungswert und alle die gleiche Varianz
283

Beispiel: (Vier unabhangige Gleichverteilungen)
• Betrachte die 4 ZV’en
X1 ∼ U(0,1)
X2 ∼ U(0,2)
X3 ∼ U(0,3)
X4 ∼ U(0,4)
• Erzeuge je 1000 Realisationen der ZV’en durch einen Zufall-szahlengenerator (z.B. in Excel)
• Darstellung der Realisationen in Histogrammen
284
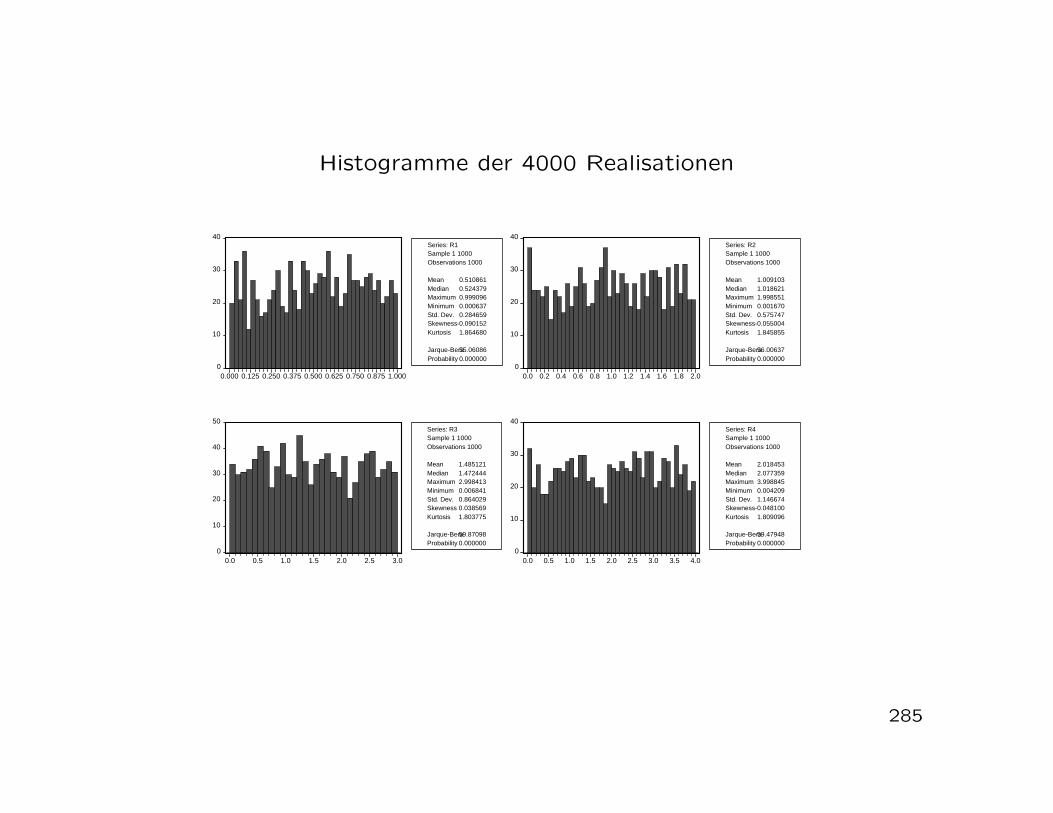
Histogramme der 4000 Realisationen
285
0
10
20
30
40
0.000 0.125 0.250 0.375 0.500 0.625 0.750 0.875 1.000
Series: R1Sample 1 1000Observations 1000
Mean 0.510861Median 0.524379Maximum 0.999096Minimum 0.000637Std. Dev. 0.284659Skewness -0.090152Kurtosis 1.864680
Jarque-Bera 55.06086Probability 0.000000
0
10
20
30
40
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0
Series: R2Sample 1 1000Observations 1000
Mean 1.009103Median 1.018621Maximum 1.998551Minimum 0.001670Std. Dev. 0.575747Skewness -0.055004Kurtosis 1.845855
Jarque-Bera 56.00637Probability 0.000000
0
10
20
30
40
50
0.0 0.5 1.0 1.5 2.0 2.5 3.0
Series: R3Sample 1 1000Observations 1000
Mean 1.485121Median 1.472444Maximum 2.998413Minimum 0.006841Std. Dev. 0.864029Skewness 0.038569Kurtosis 1.803775
Jarque-Bera 59.87098Probability 0.000000
0
10
20
30
40
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
Series: R4Sample 1 1000Observations 1000
Mean 2.018453Median 2.077359Maximum 3.998845Minimum 0.004209Std. Dev. 1.146674Skewness -0.048100Kurtosis 1.809096
Jarque-Bera 59.47948Probability 0.000000

Offensichtlich:
• Histogramme ”ahneln” den Dichtefunktionen
Frage:
• Was passiert, wenn die ZV’en sukzessive aufsummiert wer-den?
Betrachte dazu
S1 = X1, S2 =2
∑
i=1Xi S3 =
3∑
i=1Xi S4 =
4∑
i=1Xi
286

Histogramme der Summenrealisationen der ZV’en S1, S2, S3, S4
287
0
10
20
30
40
0.000 0.125 0.250 0.375 0.500 0.625 0.750 0.875 1.000
Series: R1Sample 1 1000Observations 1000
Mean 0.510861Median 0.524379Maximum 0.999096Minimum 0.000637Std. Dev. 0.284659Skewness -0.090152Kurtosis 1.864680
Jarque-Bera 55.06086Probability 0.000000
0
10
20
30
40
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0
Series: R2Sample 1 1000Observations 1000
Mean 1.009103Median 1.018621Maximum 1.998551Minimum 0.001670Std. Dev. 0.575747Skewness -0.055004Kurtosis 1.845855
Jarque-Bera 56.00637Probability 0.000000
0
10
20
30
40
50
0.0 0.5 1.0 1.5 2.0 2.5 3.0
Series: R3Sample 1 1000Observations 1000
Mean 1.485121Median 1.472444Maximum 2.998413Minimum 0.006841Std. Dev. 0.864029Skewness 0.038569Kurtosis 1.803775
Jarque-Bera 59.87098Probability 0.000000
0
10
20
30
40
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
Series: R4Sample 1 1000Observations 1000
Mean 2.018453Median 2.077359Maximum 3.998845Minimum 0.004209Std. Dev. 1.146674Skewness -0.048100Kurtosis 1.809096
Jarque-Bera 59.47948Probability 0.000000

Offensichtlich:
• Histogramme der Summenrealisationen ”ahneln” dem His-togramm einer Normalverteilung
Erwartungswert der Summenverteilung S4:
E(S4) = E(X1 + . . . + X4) =4
∑
i=1E(Xi)
= 0.5 + 1.0 + 1.5 + 2.0
= 5.0
288

Varianz der Summenverteilung S4:
V (S4) = V (X1 + . . . + X4)
Unabh.=
4∑
i=1V (Xi)
=112
+412
+912
+1612
=52
= 2.5
Daraus ergibt sich die Standardabweichung
σ(S4) =√
2.5 = 1.5811
289

Ergebnis:
• Wird die Summe Sn ”sehr groß” (d.h. n → ∞), so ist dieseannahernd normalverteilt
−→ Dies ist die Essenz des zentralen Grenzwertsatzes
Fazit:
• Setzt sich ein Zufallsvorgang additiv aus vielen kleinen un-abhangigen Einflussen zusammen, so ist der Zufallsvorgangannahernd normalverteilt
• Aus diesem Grund spielt die Normalverteilung in der Praxiseine entscheidende Rolle
290

5. Stichproben und Statistiken
Problem:
• Es sei X eine ZV, die einen interessierenden Zufallsvorgangreprasentiere
• Man mochte die tatsachliche Verteilung von X kennenlernen(z.B. mittels der VF FX(x) = P (X ≤ x))
291

Man beachte:
• In praxi ist die Verteilung X zunachst unbekannt
Deshalb:
• Sammle Informationen uber die unbekannte Verteilung desZufallsvorgangs, indem man diesen (und damit die ZV’e X)mehrfach beobachtet
−→ Zufallsstichprobe
292

5.1 Zufallsstichprobe
Situation:
• Es sei X die ZV, die den interessierenden Zufallsvorgangreprasentiere
• Man beabsichtigt, den Zufallsvorgang (d.h. X) insgesamt n-mal beoachten
• Vor den Realisierungen kann man die n potenziellen Beobach-tungen als ZV’en X1, . . . , Xn auffassen
293

Definition 5.1: (Zufallsstichprobe)
Die ZV’en X1, . . . , Xn heißen einfache Zufallsstichprobe aus X,wenn
1. jedes Xi wie X verteilt ist,
2. X1, X2, . . . , Xn stochastisch unabhangig sind.
Die Anzahl n heißt Stichprobenumfang.
Bemerkung:
• Man geht davon aus, dass der interessierende Zufallsvorgangprinzipiell beliebig oft wiederholt werden kann
294
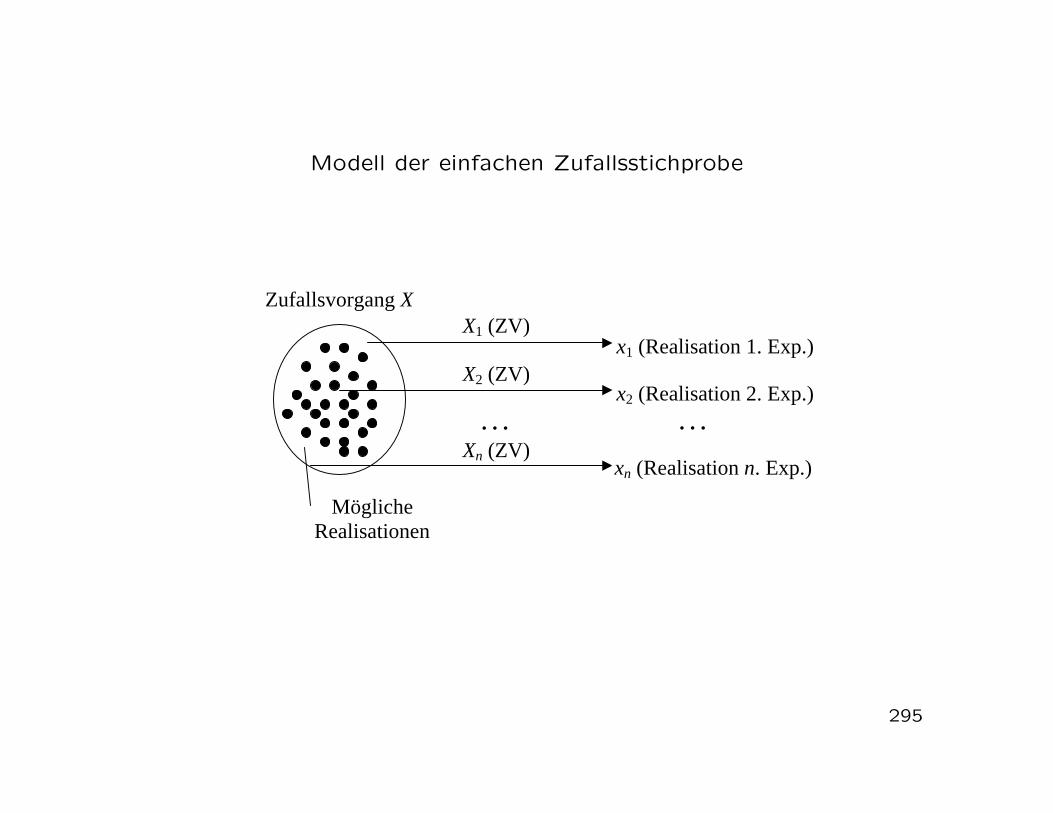
Modell der einfachen Zufallsstichprobe
295
Zufallsvorgang X
Mögliche Realisationen
X1 (ZV) x1 (Realisation 1. Exp.)
X2 (ZV)
Xn (ZV)
x2 (Realisation 2. Exp.)
xn (Realisation n. Exp.)
. . . . . .

Achtung:
• Die Definition 5.1 stimmt nicht mit der umgangssprachlichenVerwendung des Wortes Stichprobe uberein
• Eine Stichprobe in unserem Sinne besteht nicht aus dentatsachlich beobachteten Daten
• Die tatsachlich beobachteten Daten seien x1, . . . , xn
• Man bezeichnet x1, . . . , xn als den Wert oder die Realisierungder Stichprobe X1, . . . , Xn(oder auch als die konkrete Stichprobe)
296

Beispiel 1:
• X sei der Lohn eines Arbeiters der Metallindustrie
• Wir interessieren uns fur E(X) (den erwarteten Lohn)
• Es sollen n = 100 Arbeiter befragt werden
• Jeder Arbeiter habe die gleiche Auswahlwahrscheinlichkeit
• Xi sei das Einkommen des i-ten befragten Arbeiters
• Die X1, . . . , Xn sollen unabhangig sein
• Die tatsachlich beobachteten Daten sind x1, . . . , xn
297

Beispiel 2:
• X sei die Lebensdauer eines Fernsehers (in Jahren)
• Der Produzent gibt eine 2-Jahres-Garantie
• Wir interessieren uns fur P (X < 2)
• Wir untersuchen die Lebensdauern von n = 25 zufallig ausder Produktion ausgewahlten Fernsehern
• Xi sei die Lebensdauer des i-ten Fernsehers
• Die X1, . . . , Xn sollen unabhangig sein
• Die tatsachlich erhobenen Daten sind x1, . . . , xn
298

Beispiel 3:
• Wir interessieren uns fur den Anteil der FDP-Wahler in NRW
• Die ZV
X =
0 , befragte Person wahlt nicht FDP1 , befragte Person wahlt FDP
ist Bernoulli verteilt (vgl. Definition 3.14, Folie 178)
• Wir suchen den Wert des Parameters p
• Es sollen n = 1000 Personen befragt werden
• Xi sei die Wahlabsicht der befragten Person
299

5.2 Statistiken
Definition 5.2: (Statistik, Stichprobenfunktion)
Es seien X1, . . . , Xn eine einfache Stichprobe aus X sowie g :Rn −→ R eine reellwertige Funktion mit n Argumenten. Dannnennt man die ZV
T = g(X1, . . . , Xn)
eine Statistik oder Stichprobenfunktion.
Beispiele: [I]
• Stichprobenmittel:
X = g(X1, . . . , Xn) =1n·
n∑
i=1Xi
300

Beispiele: [II]• Stichprobenvarianz:
S2 = g(X1, . . . , Xn) =1n·
n∑
i=1
(
Xi −X)2
• Stichprobenstandardabweichung:
S = g(X1, . . . , Xn) =
√
√
√
√
1n·
n∑
i=1
(
Xi −X)2
Bemerkung:• Die Statistik T = g(X1, . . . , Xn) ist eine Funktion von ZV’en
und damit selbst eine ZV−→ Eine Statistik hat eine Verteilung
(d.h. auch einen Erwartungswert und eine Varianz)
301
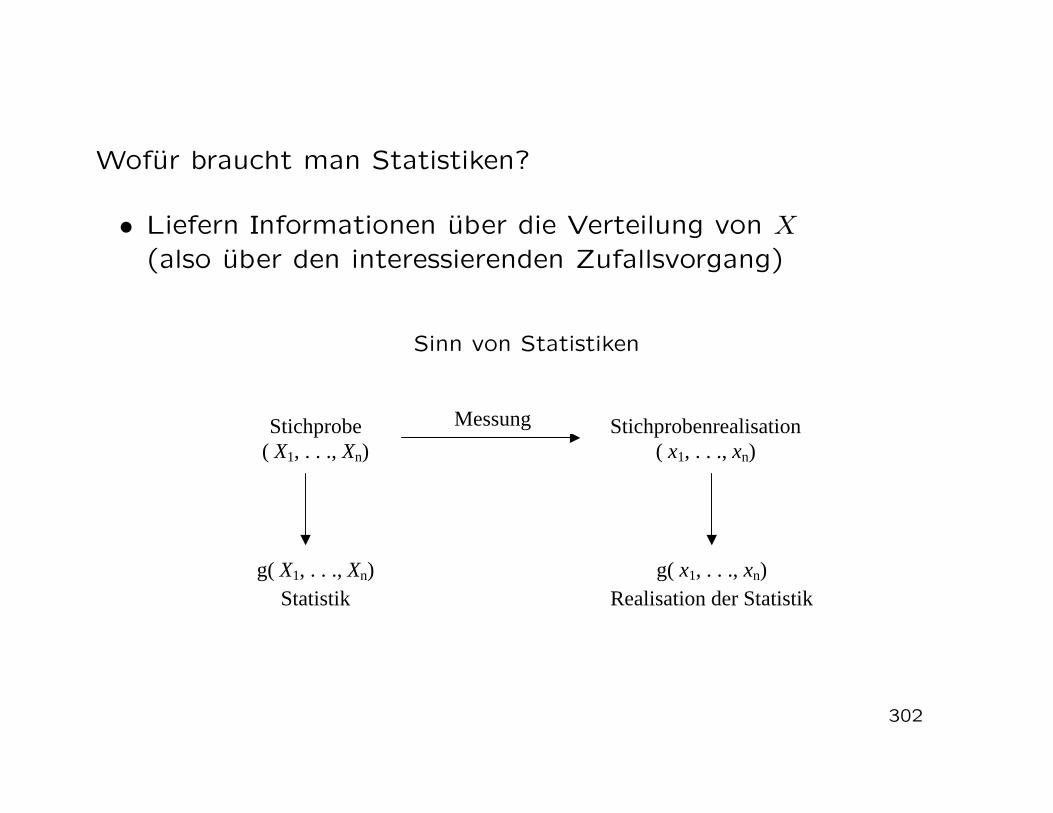
Wofur braucht man Statistiken?
• Liefern Informationen uber die Verteilung von X(also uber den interessierenden Zufallsvorgang)
Sinn von Statistiken
302
Stichprobe
( X1, . . ., Xn)
Messung Stichprobenrealisation ( x1, . . ., xn)
g( X1, . . ., Xn) Statistik
g( x1, . . ., xn) Realisation der Statistik

Statistiken sind Grundbausteine beim
• Schatzen von Parametern
• Testen von Hypothesen uber Parameter(Statistische Inferenz, Statistisches Schließen)
303

5.3 Exkurs: χ2- und t-Verteilung
Bisherige Erkenntnis:
• Eine Statistik T = g(X1, . . . , Xn) ist eine ZV
−→ Statistik T hat
eine Verteilung
einen Erwartungswert
eine Varianz
304

Jetzt:
• Betrachte eine einfache Zufallsstichprobe X1, . . . , Xn aus einerNormalverteilung, d.h.
X1, . . . , Xn ∼ N(µ, σ2)
und X1, . . . , Xn sind stochastisch unabhangig
• Bestimmte Statistiken g(X1, . . . , Xn) aus einer Normalvertei-lung haben spezielle, wohlbekannte Verteilungen
• Zwei solcher Verteilungen sind die
χ2-Verteilung
t-Verteilung
305

Bemerkungen:
• χ2- und t-Verteilung sind spezielle stetige Verteilungen
• Sie werden definiert uber ihre Dichtefunktionen(vgl. Abschnitt 3.4)
Definition 5.3: (χ2-Verteilung)
Die stetige ZV Q heißt χ2-verteilt mit Parameter n > 0, [inZeichen: Q ∼ χ2(n)], falls Q die folgende Dichtefunktion besitzt:
fQ(x) =1
2n/2 · Γ(n/2)· xn/2−1 · e−x/2.
306

Bemerkungen:
• Die Funktion Γ(·) heißt vollstandige Gammafunktion und istin der Literatur hinreichend tabelliert
• Der Parameter n der χ2-Verteilung wird als Freiheitsgradbezeichnet
• E-Wert und Varianz der χ2-Verteilung lauten:
E(Q) = n
V (Q) = 2n
307

Definition 5.4: (t-Verteilung)
Die stetige ZV W heißt t-verteilt mit Parameter n > 0, [in Zei-chen: W ∼ t(n)], falls W die folgende Dichtefunktion besitzt:
fW (x) =Γ[(n + 1)/2]
(n · π)1/2 · Γ(n/2)·[
1 + (x2/n)]−(n+1)/2
.
Bemerkungen:
• Der Parameter n der t-Verteilung wird als Freiheitsgrad bezei-chnet
• E-Wert und Varianz der t-Verteilung lauten:
E(Q) = 0, falls n ≥ 2
V (Q) =n
n− 2, falls n ≥ 3
308

5.4 Statistiken bei normalverteilter Stichprobe
Ausgangssituation:
• X1, . . . , Xn sei eine Stichprobe aus X ∼ N(µ, σ2), d.h.
X1, . . . , Xn ∼ N(µ, σ2)
mit X1, . . . , Xn sind paarweise stochastisch unabhangig
• Bezeichnungen fur das arithmetische Stichprobenmittel sowiedie Stichprobenvarianz:
X =1n
n∑
i=1Xi sowie S2 =
1n
n∑
i=1
(
Xi −X)2
309

Gesucht:
• Verteilung bestimmter Statistiken g(X1, . . . , Xn)
Satz 5.5: (Statistiken aus einer Normalverteilung) [I]
Es sei X ∼ N(µ, σ2) und X1, . . . , Xn eine einfache Stichprobe ausX. Dann gilt fur die Verteilung
(a) des Stichprobenmittels
X ∼ N
(
µ,σ2
n
)
,
(b) des (parameter-)standardisierten Stichprobenmittels
√n ·
X − µσ
∼ N(0,1),
310

Satz 5.5: (Statistiken aus einer Normalverteilung) [II]
(c) des standardisierten Stichprobenmittels
√n− 1 ·
X − µS
∼ t(n− 1),
(d) der Statistikn
∑
i=1
(Xi − µσ
)2∼ χ2(n),
(e) der Statistik
n · S2
σ2 =n
∑
i=1
(
Xi −Xσ
)2
∼ χ2(n− 1).
311

Offensichtlich:
• Verteilung vieler Statistiken mit X und S2 sind bekannt, wenndie Parameter µ und σ2 bekannt sind
−→ Diese Erkenntnisse werden spater ausgenutzt
Zunachst aber:
• Wie kann man Informationen uber die unbekannten Param-eter µ und σ2 bekommen
−→ Schatzverfahren fur unbekannte Parameter
312

6. Schatzverfahren fur Parameter
Ausgangssituation:
• Ein interessierender Zufallsvorgang werde durch die ZV Xreprasentiert
• X habe eine unbekannte Verteilungsfunktion FX(x)
• Wir interessieren uns fur einen (oder mehrere) Parameter derVerteilung von X
313

Wichtige Parameter sind:
• Der Erwartungswert von X
• Die Varianz von X
• Werte der VF FX(x)
• Quantile der VF FX(x) (vgl. Definition 3.3, Folie 122)
314

Ansatz zur Informationsbeschaffung:
• Betrachte eine einfache Zufallsstichprobe X1, . . . , Xn aus X
• Schatze den unbekannten Parameter von X anhand einergeeigneten Statistik
T = g(X1, . . . , Xn)
der Zufallsstichprobe(vgl. Definition 5.2, Folie 300)
315

6.1 Punktschatzung
Bezeichnungen:
• Der unbekannte Parameter von X sei θ(z.B. θ = E(X))
• Die Statistik der einfachen Zufallsstichprobe X1, . . . , Xn ausX zur Schatzung des unbekannten Parameters θ wird haufigmit θ(X1, . . . , Xn) bezeichnet(memotechnisch sinnvoll)
316

Definition 6.1: (Schatzer, Schatzwert)
Die Statistik θ(X1, . . . , Xn) heißt Schatzer (auch Schatzfunktion)fur den Parameter θ. Hat sich die Zufallsstichprobe X1, . . . , Xn inden Werten x1, . . . , xn realisiert, so bezeichnet man die damit ver-bundene Realisierung des Schatzers θ(x1, . . . , xn) als Schatzwert.
Bemerkungen:
• Der Schatzer θ(X1, . . . , Xn) ist eine Zufallsvariable
−→ Schatzer hat Vtlg., E-Wert und Varianz
• Der Schatzwert θ(x1, . . . , xn) ist dagegen eine Zahl(vgl. Abbildungen auf den Folien 295 + 302)
317

Frage:
• Wozu braucht man das scheinbar komplizierte theoretischeKonzept des Schatzers als Zufallsvariable?
Antwort:
• Um alternative Schatzer fur ein und denselben Parameter θim Hinblick auf ihre jeweilige ’Genauigkeit’ miteinander ver-gleichen zu konnen
318

Beispiel:
• Es sei θ = V (X) die Varianz von X
• Zwei alternative Schatzer fur θ sind
θ1(X1, . . . , Xn) = S2 =1n
n∑
i=1
(
Xi −X)2
θ2(X1, . . . , Xn) = S∗2 =1
n− 1
n∑
i=1
(
Xi −X)2
Frage:
• Welcher Schatzer ist ’besser’ und warum?
−→ Eigenschaften von Punktschatzern
319

6.2 Eigenschaften von Punktschatzern
Ziel:
• Formulierung von Qualitatskriterien zur Beurteilung der Eigen-schaften eines Schatzers θ(X1, . . . , Xn) fur θ
Hier 3 Kriterien:
• Erwartungstreue
• Mittlerer quadratischer Fehler
• (schwache) Konsistenz
320

Definition 6.2: (Erwartungstreue)
Der Schatzer θ(X1, . . . , Xn) fur den unbekannten Parameter θheißt erwartungstreu, falls sein Erwartungswert mit dem zu schat-zenden Parameter θ ubereinstimmt, d.h. falls
E[
θ(X1, . . . , Xn)]
= θ.
Bemerkung:
• Anschaulich bedeutet Erwartungstreue, dass der Schatzerθ(X1, . . . , Xn) nicht ’systematisch daneben’ schatzt, wennman den Schatzer nicht nur fur eine, sondern fur ’viele’ Stich-proben auswertet(Gedankenexperiment: Wiederholte Stichprobe)
321

Beispiel 1: [I]
• Es sei θ = E(X)
• Betrachte den Schatzer
θ(X1, . . . , Xn) = X =1n
n∑
i=1Xi
(arithmetisches Stichprobenmittel)
322

Beispiel 1: [II]
• Es gilt:
E[
θ(X1, . . . , Xn)]
= E
1n
n∑
i=1Xi
=1n
n∑
i=1E(Xi) =
1n
n∑
i=1E(X)
=1n
n∑
i=1θ =
1n· n · θ = θ
−→ θ(X1, . . . , Xn) = X ist erwartungstreu fur θ = E(X)
(vgl. Satz 4.13, Folie 281)
323

Beispiel 2: [I]
• Es sei θ = V (X) die Varianz von X
• Betrachte den Schatzer
θ1(X1, . . . , Xn) = S2 =1n
n∑
i=1
(
Xi −X)2
(Stichprobenvarianz)
• Hier gilt
E[
θ1(X1, . . . , Xn)]
= E(S2) =n− 1
n· θ
−→ S2 ist nicht erwartungstreu fur θ = V (X)
324

Beispiel 2: [II]
• Betrachte korrigierte Stichprobenvarianz
θ2(X1, . . . , Xn) = S∗2 =1
n− 1
n∑
i=1
(
Xi −X)2
=n
n− 1· S2
• Hier gilt:
E[
θ2(X1, . . . , Xn)]
= E(S∗2) = E( n
n− 1· S2
)
=n
n− 1E(S2) =
nn− 1
·n− 1
n· θ
= θ = V (X)
−→ S∗2 ist erwartungstreu fur θ = V (X)
325

Satz 6.3: (E-treue Schatzer fur E(X) und V (X))
Es sei X1, . . . , Xn eine Stichprobe aus X und X sei beliebig verteiltmit unbekanntem Erwartungswert µ = E(X) sowie unbekannterVarianz σ2 = V (X). Dann sind die beiden Schatzer
µ(X1, . . . , Xn) = X =1n·
n∑
i=1Xi
bzw.
σ2(X1, . . . , Xn) = S∗2 =1
n− 1·
n∑
i=1
(
Xi −X)2
stets erwartungstreu fur die Parameter µ = E(X) und σ2 =V (X).
326

Vorsicht:
• Erwartungstreue pflanzt sich bei Parametertransformationennicht beliebig fort
Beispiel:
• Zwar ist S∗2 erwartungstreu fur σ2 = V (X)
• Jedoch ist S∗ nicht erwartungstreu fur σ =√
V (X)
Bemerkung:
• Im ubrigen ist auch S nicht E-treu fur σ =√
V (X)
327

Ubersicht:
• Weitere Parameter von X und zugehorige potenzielle Schatzer,wie sie aus der deskriptiven Statistik (Statistik I) bekannt sind
Parameter Potenzieller SchatzerWahrscheinlichkeit relative HaufigkeitVerteilungsfunktion emp. VerteilungsfunktionQuantil QuantilStandardabweichung emp. StandardabweichungGemeinsame Wskt. gem. relative HaufigkeitKovarianz emp. KovarianzKorrelationskoeffizient emp. Korrelationskoeffizient
Vorsicht:
• Die potenziellen Schatzer sind oft, aber nicht immer er-wartungstreu fur die zu schatzenden Parameter
328

Jetzt:
• Strengeres Qualitatskriterium fur Schatzer
Dichtefunktionen zweier erwartungstreuer Schatzer fur den Parameter θ
329
θ
),,( von Dichte 11 nXX K∧θ
),,( von Dichte 12 nXX K∧θ

Intuition:• Ist ein Schatzer erwartungstreu, so ist es gunstig, wenn er
eine kleine Varianz aufweist
−→ Optimal: Erwartungstreuer Schatzer mit minimaler Vari-anz
Problem:• Solche Schatzer sind oft schwer oder gar nicht auffindbar
Ausweg:• Kennzahlen zum Vergleich zweier alternativer Schatzer
Bekannteste Kennzahl:• Mittlerer quadratischer Fehler
330

Definition 6.4: (Mittlerer quadratischer Fehler)
Es sei θ(X1, . . . , Xn) einer Schatzer fur den unbekannten Param-eter θ. Dann heißt die Kennzahl
MSE(θ) = E[(θ − θ)2]
der mittlere quadratische Fehler (englisch: mean squared error)des Schatzers θ.
Bemerkung:
• Der mittlere quadratische Fehler lasst sich auch schreiben als
MSE(θ) = V (θ) +[
E(θ)− θ]2
︸ ︷︷ ︸
Verzerrung−→ Bei erwartungstreuen Schatzern ist der MSE gleich der
Varianz des Schatzers
331

Weiteres Gutekriterium fur einen Schatzer:
• Konsistenz eines Schatzers
Intuition:
• Ein Schatzer θ(X1, . . . , Xn) fur den unbekannten Parameter θheißt konsistent, falls die Schatzung bei zunehmenden Stich-probenumfang immer genauer wird(Konzept wird hier nicht genauer behandelt)
332

Weitere zentrale Fragestellung:
• Wie findet man geeignete Schatzer
Es gibt allgemeine Konstruktionsprinzipien, z.B. die:
• Methode der Kleinsten-Quadrate
• Momenten-Methode
• Maximum-Likelihood-Methode
(Gegenstand der Okonometrie-VL im Hauptstudium)
333

6.3 Intervallschatzung
Bisher:
• Schatzung des Parameters θ auf der Basis einer Stichprobedurch Punktschatzung θ(X1, . . . , Xn)
Problem:
• Punktschatzung trifft in der Regel den exakten Wert desunbekannten Parameters θ nicht
• Bei Stichproben aus stetigen Verteilungen gilt sogar
P(
θ(X1, . . . , Xn) = θ)
= 0 bzw. P(
θ(X1, . . . , Xn) 6= θ)
= 1
334

Alternativer Ansatz:
• Konstruktion eines zufalligen Intervalls anhand einerStichprobe X1, . . . , Xn, das den Parameter θ mit einer vorgebe-nen Wskt. uberdeckt
Vorteil:
• Genauigkeit der Schatzung wird ’quantifiziert’
Ansatz:
• Wahle 2 Statistiken θu(X1, . . . , Xn) und θo(X1, . . . , Xn), der-art dass das zufallige Intervall
I =[
θu(X1, . . . , Xn), θo(X1, . . . , Xn)]
θ mit einer vorgegebenen Wahrscheinlichkeit uberdeckt
335

Definition 6.5: (Konfidenzintervall)
Es sei X1, . . . , Xn eine Zufallsstichprobe aus X, θ ein unbekannterParameter und α ∈ [0,1] eine reelle Zahl. Dann bezeichnet mandas zufallige Intervall
[
θu(X1, . . . , Xn), θo(X1, . . . , Xn)]
mit der Eigenschaft
P(
θu(X1, . . . , Xn) ≤ θ ≤ θo(X1, . . . , Xn))
= 1− α
als Konfidenzintervall fur θ zum Konfidenzniveau 1−α. Die Zahlα ∈ [0,1] heißt Irrtumswahrscheinlichkeit.
336

Bemerkungen:
• Die Grenzen des Intervalls sind ZV’en
• Nach Realisation der Stichprobe heißt das Intervall[
θu(x1, . . . , xn), θo(x1, . . . , xn)]
konkretes Konfidenzintervall
337

Konfidenzintervall 1: [I]
• Der interessierende Zufallsvorgang reprasentiert durch die ZVX sei normalverteilt, d.h.
X ∼ N(µ, σ2),
wobei µ unbekannt und σ2 bekannt sein sollen
• Gesucht wird (1− α)-Konfidenzintervall fur µ
• Betrachte Stichprobe X1, . . . , Xn aus X
• Wissen aufgrund von Satz 5.5(b), Folie 310:
√n ·
X − µσ
∼ N(0,1)
338

N(0,1)-Dichtefunktion der Statistik√
n · X−µσ
Konfidenzintervall 1: [II]
• c ist das (1− α/2)-Quantil der N(0,1)-Verteilung
339
− c 0 c
Dichte von )1,0(~ NXnσµ−
⋅
α / 2 α / 2

Konfidenzintervall 1: [III]
• Das p-Quantil der Standardnormalverteilung wird im LehrbuchMosler/Schmid mit up bezeichnet, d.h. c = u1−α/2
• Es gilt also:
P(
−c ≤√
n · X − µσ ≤ c
)
= 1− α
⇐⇒ P(
−u1−α/2 ≤√
n · X − µσ ≤ u1−α/2
)
= 1− α
⇐⇒ P(
X − u1−α/2 ·σ√n≤ µ ≤ X + u1−α/2 ·
σ√n
)
= 1− α
340

Konfidenzintervall 1: [IV]
• Ein Konfidenzintervall fur µ zum Niveau 1− α ist also[
X − u1−α/2 ·σ√n
, X + u1−α/2 ·σ√n
]
• Z.B. gilt fur 1− α = 0.95:
1−α = 0.95 =⇒ α = 0.05 =⇒ u1−α/2 = u0.975 = 1.96
(vgl.Formelsammlung Bomsdorf/Grohn/Mosler/Schmid)
341

Konkretes Beispiel: [I]
• Es sei X das tatsachliche Gewicht (in Gramm) einer 200g-Tafel Schokolade
• Angenommen, X ∼ N(µ,4) mit unbek. Erwartungswert µ
• Eine einfache Stichprobe vom Umfang n = 8 liefert
x1 x2 x3 x4 x5 x6 x7 x8201.15 197.57 201.38 203.15 199.92 198.99 203.44 200.50
342

Konkretes Beispiel: [II]
• Ein Punktschatzwert fur µ ist x = 200.7625
• Ein konkretes 0.95-Konfidenzintervall fur µ ist[
x− 1.96 ·2√8
, x + 1.96 ·2√8
]
= [199.3766 , 202.1484]
343

Konfidenzintervall 2: [I]
• Der interessierende Zufallsvorgang reprasentiert durch die ZVX sei normalverteilt, d.h.
X ∼ N(µ, σ2),
wobei sowohl µ als auch σ2 unbekannt sein sollen
• Gesucht wird (1− α)-Konfidenzintervall fur µ
• Betrachte Stichprobe X1, . . . , Xn aus X
• Wissen aufgrund von Satz 5.5(c), Folie 311:
√n− 1 ·
X − µS
∼ t(n− 1)
344

Dichtefunktion der t(n)-Verteilung
Konfidenzintervall 2: [II]
• c ist das (1− α/2)-Quantil der t(n)-Verteilung
345
0.4
0.0
0.1
0.2
0.3
-2 -1 0 1 2
n = 10
Dic
htef
unkt
ion
n = 1
x

Konfidenzintervall 2: [III]
• Das p-Quantil der t(ν)-Verteilung wird in Mosler/Schmid mittν,p bezeichnet, d.h. c = tn−1,1−α/2
• Es gilt also:
P(
−c ≤√
n− 1 · X − µS ≤ c
)
= 1− α
⇐⇒ P(
X − c · S√n− 1
≤ µ ≤ X + c · S√n− 1
)
= 1− α
346

Konfidenzintervall 2: [IV]
• Ein Konfidenzintervall fur µ zum Niveau 1− α ist somit[
X − tn−1,1−α/2 ·S√
n− 1, X + tn−1,1−α/2 ·
S√n− 1
]
• Z.B. gilt fur 1− α = 0.95:
1−α = 0.95 =⇒ α = 0.05 =⇒ tn−1,1−α/2 = t7,0.975 = 2.3646
(vgl. Formelsammlung Bomsdorf/Grohn/Mosler/Schmid)
347

Konkretes Beispiel: [I]
• Es sei X das tatsachliche Gewicht (in Gramm) einer 200g-Tafel Schokolade
• Angenommen, X ∼ N(µ, σ2) mit unbekanntem Erwartungswertµ und unbekannter Varianz σ2
• Eine einfache Stichprobe vom Umfang n = 8 war
x1 x2 x3 x4 x5 x6 x7 x8201.15 197.57 201.38 203.15 199.92 198.99 203.44 200.50
348

Konkretes Beispiel: [II]
• Ein Punktschatzwert fur µ ist x = 200.7625
• Ein Punktschatzwert fur σ ist s = 1.8545
• Ein konkretes 0.95-Konfidenzintervall fur µ ist[
x− 2.3646 ·1.8545√
7, x + 2.3646 ·
1.8545√7
]
= [199.1051 , 202.4199]
• KI ist breiter als das KI auf Folie 343, weil Schatzung derunbekannten Varianz σ2 durch S2 zusatzliche Unsicherheitbirgt
349

7. Hypothesentests
Ausgangssituation erneut:
• ZV X reprasentiere einen Zufallsvorgang
• X habe die unbekannte VF FX(x)
• Interessieren uns fur einen unbekannten Parameter θ der Ver-teilung von X
350

Bisher:
• Versuch, unbekannten Parameter θ mit einer StichprobeX1, . . . , Xn zu schatzen(Punktschatzung, Intervallschatzung)
Jetzt:
• Testen von Hypothesen uber unbekanntes θ anhand einerStichprobe X1, . . . , Xn
Man beachte:
• Testprobleme spielen in der empirischen Wirtschaftsforschungeine zentrale Rolle
351

Beispiel 1:
• In einer Studentenkneipe sollen geeichte Bierglaser im Auss-chank 0.4 Liter Bier enthalten. Wir haben die Vermutung,dass der Wirt haufig ’zu wenig’ ausschenkt.
• X reprasentiere den Zufallsvorgang ’Fullen eines 0.4-LiterBierglases durch den Wirt’
• Es bezeichne θ = E(X) die erwartete Fullmenge eines Glases
• Durch eine Stichprobe X1, . . . , Xn soll getestet werden
θ = 0.4 gegen θ < 0.4
352

Beispiel 2:
• Wir wissen aus der Vergangenheit, dass das Risiko einer Aktie(die Standardabweichung der Aktienrenditen) bei 25 % lag.Im Unternehmen wird nun das Management ausgetauscht.Verandert sich dadurch das Risiko der Aktie?
• X sei die Aktienrendite
• θ = σ(X) sei die Standardabweichung der Renditen
• Durch eine Stichprobe X1, . . . , Xn soll getestet werden
θ = 0.25 gegen θ 6= 0.25
353

7.1 Grundbegriffe des Testens
Definition 7.1: (Parametertest)
Es sei X eine Zufallsvariable und θ ein unbekannter Parameterder Verteilung von X. Ein Parametertest ist ein statistischesVerfahren, mit dem eine Hypothese uber den unbekannten Pa-rameter θ anhand einer einfachen Zufallsstichprobe X1, . . . , Xnaus X uberpruft wird.
Formulierung eines statistischen Testproblems: [I]
• Es sei Θ die Menge aller moglichen Parameterwerte(d.h. θ ∈ Θ)
• Es sei Θ0 ⊂ Θ eine Teilmenge der Parametermenge
354

Formulierung eines statistischen Testproblems: [II]
• Betrachte folgende Aussagen:
H0 : θ ∈ Θ0 gegen H1 : θ ∈ Θ/Θ0 = Θ1
• H0 heißt Nullhypothese, H1 Gegenhypothese oder Alternative
Wichtig:
• Bei der Formulierung eines Testproblems mussen sich Null-hypothese und Alternative gegenseitig ausschließen
355

Arten von Hypothesen:
• Sind |Θ0| = 1 (d.h. Θ0 = θ0) und H0 : θ = θ0, so nenntman H0 einfach
• Andernfalls bezeichnet man H0 als zusammengesetzt
• Analoge Bezeichnungen gelten fur H1
356

Arten von Testproblemen:
• Es sei θ0 ∈ Θ eine feste reelle Zahl. Dann heißt
H0 : θ = θ0 gegen H1 : θ 6= θ0
zweiseitiges Testproblem
• Die Testprobleme
H0 : θ ≤ θ0 gegen H1 : θ > θ0
bzw.
H0 : θ ≥ θ0 gegen H1 : θ < θ0
heißen einseitig (rechts- bzw. linksseitig)
357

Jetzt:
• Betrachte das allgemeine Testproblem
H0 : θ ∈ Θ0 gegen H1 : θ ∈ Θ1 = Θ/Θ0
Allgemeine Vorgehensweise:
• Entscheide anhand einer Stichprobe X1, . . . , Xn aus X, ob H0zugunsten von H1 abgelehnt wird oder nicht
358

Explizites Vorgehen:
• Wahle ’geeignete’ Teststatistik T (X1, . . . , Xn) und bestimmeeinen ’geeigneten’ kritischen Bereich K ⊂ R
• Testentscheidung:
T (X1, . . . , Xn) ∈ K =⇒ H0 wird abgelehntT (X1, . . . , Xn) /∈ K =⇒ H0 wird nicht abgelehnt
Man beachte:
• T (X1, . . . , Xn) ist eine ZV (Stichprobenfunktion)
−→ Die Testentscheidung ist zufallig−→ Fehlentscheidungen sind moglich
359

Mogliche Fehlentscheidungen:
TestergebnisRealitat H0 ablehnen H0 nicht ablehnenH0 richtig Fehler 1. Art kein FehlerH0 falsch kein Fehler Fehler 2. Art
Fazit:
• Fehler 1. Art: Test lehnt H0 ab, obwohl H0 richtig
• Fehler 2. Art: Test lehnt H0 nicht ab, obwohl H0 falsch
360

Wann treten die Fehlentscheidungen auf?
• Der Fehler 1. Art tritt auf, falls
T (X1, . . . , Xn) ∈ K,
obwohl fur den wahren Parameter gilt θ ∈ Θ0
• Der Fehler 2. Art tritt auf, falls
T (X1, . . . , Xn) /∈ K,
obwohl fur den wahren Parameter gilt θ ∈ Θ1
361

Frage:
• Wann besitzt ein statistischer Test fur das Problem
H0 : θ ∈ Θ0 gegen H1 : θ ∈ Θ1 = Θ/Θ0
’gute’ Eigenschaften?
Intuitive Vorstellung:
• Test ist ’gut’, wenn er moglichst geringe Wahrscheinlichkeitenfur die Fehler 1. und 2. Art aufweist
Jetzt:
• Formales Instrument zur Messung der Fehlerwahrscheinlich-keiten 1. und 2. Art
362

Definition 7.2: (Gutefunktion eines Tests)
Man betrachte einen statistischen Test fur das obige Testprob-lem mit der Teststatistik T (X1, . . . , Xn) und einem ’geeignet ge-wahlten’ kritischen Bereich K. Unter der Gutefunktion des Testsversteht man die Funktion G, die, in Abhangigkeit des wahrenParameters θ ∈ Θ, die Wahrscheinlichkeit dafur angibt, dass derTest H0 ablehnt:
G : Θ −→ [0,1]
mit
G(θ) = P (T (X1, . . . , Xn) ∈ K).
363

Bemerkung:
• Mit der Gutefunktion sind die Wahrscheinlichkeiten fur denFehler 1. Art gegeben durch
G(θ) fur alle θ ∈ Θ0
sowie fur den Fehler 2. Art durch
1−G(θ) fur alle θ ∈ Θ1
Intuitive Vorstellung eines idealen Tests:
• Ein Test ist ideal, wenn die Fehlerwahrscheinlichkeiten 1. und2. Art stets (konstant) gleich Null sind
−→ Test trifft mit Wskt. 1 die richtige Entscheidung
364

Beispiel:
• Es sei θ0 ∈ Θ. Betrachte das Testproblem
H0 : θ ≤ θ0 gegen H1 : θ > θ0
Gutefunktion eines idealen Tests
365

Leider:
• Es kann mathematisch gezeigt werden, dass ein solcher ide-aler Test im allgemeinen nicht existiert
Praktische Vorgehnsweise: [I]
• Betrachte fur eine geeignete Teststatistik T (X1, . . . , Xn) diemaximale Fehlerwahrscheinlichkeit 1. Art
α = maxθ∈Θ0
P (T (X1, . . . , Xn) ∈ K) = maxθ∈Θ0
G(θ)
• Lege den kritischen Bereich K dann so fest, dass α einenvorgegebenen kleinen Wert animmt
366

Praktische Vorgehnsweise: [II]
−→ Alle Fehlerwahrscheinlichkeiten 1. Art sind dann durch α be-grenzt (d.h. kleiner oder gleich α)
• Haufig benutzte α-Werte sind α = 0.01, α = 0.05, α = 0.1
Definition 7.3: (Signifikanzniveau eines Tests)
Man betrachte einen statistischen Test fur das Testproblem aufFolie 358 mit der Teststatistik T (X1, . . . , Xn) und einem geeignetgewahlten kritischen Bereich K. Dann bezeichnet man die max-imale Fehlerwahrscheinlichkeit 1. Art
α = maxθ∈Θ0
P (T (X1, . . . , Xn) ∈ K) = maxθ∈Θ0
G(θ)
als das Signifikanzniveau des Tests.367

Konsequenzen dieser Testkonstruktion: [I]
• Die Wskt., H0 aufgrund des Tests abzulehmen, obwohl H0richtig ist (d.h. die Wskt. fur den Fehler 1. Art) ist hochstensα (mit α = 0.01,0.05,0.1)
−→ Wird H0 aufgrund einer Testrealisation abgelehnt, so kannman ziemlich sicher davon ausgehen, dass H0 tatsachlichfalsch ist(Man sagt auch: H1 ist statistisch gesichert)
368

Konsequenzen dieser Testkonstruktion: [II]• Die Wskt. fur den Fehler 2. Art (d.h. H0 nicht abzulehnen,
obwohl H0 falsch ist), kann man dagegen nicht kontrollieren
−→ Wird H0 aufgrund einer Testrealisation nicht abgelehnt,so hat man keinerlei Wahrscheinlichkeitsaussage uber einemogliche Fehlentscheidung(Nichtablehung von H0 heißt nur: Die Daten sind nichtunvereinbar mit H0)
Wichtig deshalb:• Es ist entscheidend, wie man H0 und H1 formuliert
• Das, was man zu zeigen hofft, formuliert man in H1(in der Hoffnung, H0 anhand des konkreten Tests ablehnenzu konnen)
369

Beispiel:
• Betrachte Beispiel 1 auf Folie 352
• Kann man anhand eines konkreten Tests H0 verwerfen, sokann man ziemlich sicher sein, dass der Wirt in der Regel zuwenig ausschenkt
• Kann man H0 nicht verwerfen, so kann man nichts explizitesuber die Ausschankgewohnheiten des Wirtes sagen.(Die Daten stehen lediglich nicht im Widerspruch zu H0)
370

7.2 Tests fur Erwartungswerte
Situation:
• Der interessierende Zufallsvorgang X sei normalverteilt, d.h.
X ∼ N(µ, σ2),
wobei µ unbekannt und σ2 bekannt sein sollen(vgl. Konfindenzintervall 1, Folie 338)
• Betrachte fur gegebenes µ0 ∈ R das Testproblem:
H0 : µ = µ0 gegen H1 : µ 6= µ0
371

Testkonstruktion:• Suche eine geeignete Teststatistik T (X1, . . . , Xn)
• Lege den kritischen Bereich K fest
Geeignete Teststatistik lautet:
T (X1, . . . , Xn) =√
n ·X − µ0
σ
Begrundungen:• T (X1, . . . , Xn) misst im wesentlichen den Abstand zwischen
dem unbekannten Parameter µ und dem Vergleichswert µ0
• Wenn H0 gultig ist (d.h. falls µ = µ0), dann gilt
T (X1, . . . , Xn) ∼ N(0,1)
(vgl. Satz 5.5(b), Folie 310)
372

N(0,1)-Dichte der Teststatistik T (X1, . . . , Xn) im Falle der Gultigkeit von H0
373
uα / 2
(= − u1−α / 2) 0 u1−α / 2
N(0,1)-Dichte von T unter H0
α / 2 α / 2

Explizite Testregel:
• Lege das Signifikanzniveau α fest
• Wahle den kritischen Bereich als
K = (−∞,−u1−α/2) ∪ (u1−α/2,+∞) = t ∈ R : |t| > u1−α/2
d.h.
Lehne H0 ab, falls T (X1, . . . , Xn) ∈ K
Lehne H0 nicht ab, falls T (X1, . . . , Xn) /∈ K
374

Beispiel: [I]
• Es sei X ∼ N(µ,4) das tatsachliche Gewicht (in Gramm)einer 200g-Tafel Schokolade(vgl. Beispiel auf Folie 342)
• Statistisches Testproblem
H0 : µ = 200 gegen H1 : µ 6= 200
• Wert der Teststatistik:
T (x1, . . . , xn) =√
n ·x− µ0
σ=√
8 ·200.7625− 200
2= 1.078
375

Beispiel: [II]
• Fur das Signifikanzniveau α = 0.05 gilt:
u1−α/2 = u0.975 = 1.96
• Offensichtlich ist
T (x1, . . . , xn) = 1.078 /∈ (−∞,−1.96) ∪ (1.96,+∞) = K
−→ Fur α = 0.05 wird H0 nicht abgelehnt(Daten sind nicht unvereinbar mit H0)
376

Gutefunktion des Tests zum Signifikanzniveau α = 0.05
Bemerkungen:• Test wird mit zunehmendem n immer trennscharfer
• Der vorgestellte Test heißt zweiseitiger Gaußtest
377
0.0
0.2
0.4
0.6
0.8
1.0
198 199 200 201 202
n = 8
n = 20 n = 1000
G(µ)
µ

Jetzt:
• 2 zweiseitige Tests fur den Erwartungswert in der SituationX ∼ N(µ, σ2), bei bekannter Varianz σ2
(ohne Herleitung)
1. Rechtsseitiger Gaußtest: [I] (µ0 ∈ R fest gegeben)
H0 : µ ≤ µ0 gegen H1 : µ > µ0
• Teststatistik ist erneut
T (X1, . . . , Xn) =√
n ·X − µ0
σ
378

1. Rechtsseitiger Gaußtest: [II]
• Kritischer Bereich zum Signifikanzniveau α ist
K = (u1−α,+∞)
(u1−α ist (1− α)-Quantil der N(0,1)-Verteilung)
−→ Lehne H0 zum Signifikanzniveau α ab, falls
T (X1, . . . , Xn) > u1−α
379

2. Linksseitiger Gaußtest: (µ0 ∈ R fest gegeben)
H0 : µ ≥ µ0 gegen H1 : µ < µ0
• Teststatistik ist wiederum
T (X1, . . . , Xn) =√
n ·X − µ0
σ
• Kritischer Bereich zum Signifikanzniveau α ist
K = (−∞,−u1−α)
(−u1−α = uα ist α-Quantil der N(0,1)-Verteilung)
−→ Lehne H0 zum Signifikanzniveau α ab, falls
T (X1, . . . , Xn) < −u1−α = uα
380

Beispiel: [I]
• Es sei X ∼ N(µ,4) das tatsachliche Gewicht (in Gramm)einer 200g-Tafel Schokolade mit der konkreten Stichprobevon Folie 342
• Statistisches Testproblem:
H0 : µ ≤ 198 gegen H1 : µ > 198
• Fur die konkrete Stichprobe gilt
T (x1, . . . , xn) =√
n ·x− µ0
σ=√
8 ·200.7625− 198
2= 3.9068
381

Beispiel: [II]
• Zum Signifikanzniveau α = 0.05 ergibt sich der kritischeBereich als
K = (u0.95,+∞) = (1.6449,+∞)
• Also folgt
T (x1, . . . , xn) = 3.9068 > 1.6449 = u0.95
−→ Lehne H0 zum Signifikanzniveau α = 0.05 ab
382

Jetzt:
• Tests fur den Erwartungswert einer Normalverteilung bei un-bekannter Varianz, d.h.
X ∼ N(µ, σ2)
mit unbekannten µ und σ2
• Betrachte fur µ0 ∈ R zunachst den 2-seitgen Test
H0 : µ = µ0 gegen H1 : µ 6= µ0
383

Geeignete Teststatistik:
T (X1, . . . , Xn) =√
n− 1 ·X − µ0
S
Begrundungen:
• T (X1, . . . , Xn) schatzt im wesentlichen den Abstand zwischenunbekanntem µ und dem Vergleichswert µ0
• Wenn H0 richtig ist (d.h. falls µ = µ0), dann gilt
T (X1, . . . , Xn) ∼ t(n− 1)
(vgl. Satz 5.5(c), Folie 311)
384

Herleitung des kritischen Bereiches:
• Analoges Vorgehen wie beim zweiseitigen Gaußtest, nur mitt(n− 1)- anstatt mit der N(0,1)-Verteilung
• Kritischer Bereich ist
K = (−∞,−tn−1,1−α/2) ∪ (tn−1,1−α/2,+∞)
= t ∈ R : |t| > tn−1,1−α/2
d.h.
Lehne H0 ab, falls T (X1, . . . , Xn) ∈ K
Lehne H0 nicht ab, falls T (X1, . . . , Xn) /∈ K
385

Bemerkungen: [I]
• Dieser Test heißt zweiseitiger t-Test
• Fur den rechtsseitigen t-Test
H0 : µ ≤ µ0 gegen H1 : µ > µ0
ergibt sich bei Benutzung der Teststatistik
T (X1, . . . , Xn) =√
n− 1 ·X − µ0
Szum Signifikanzniveau α der kritische Bereich
K = (tn−1,1−α,+∞)
386

Bemerkungen: [II]
• Fur den linksseitigen t-Test
H0 : µ ≥ µ0 gegen H1 : µ < µ0
ergibt sich bei Benutzung der Teststatistik
T (X1, . . . , Xn) =√
n− 1 ·X − µ0
Szum Signifikanzniveau α der kritische Bereich
K = (−∞,−tn−1,1−α)
387

Beispiel:
• Es sei X ∼ N(µ, σ2) mit unbekannten µ und σ2
• Betrachte zweiseitigen t-Test zum Niveau α = 0.05
• Einfache Stichprobe mit n = 8 Werten ergibt:
1.6611 4.5674 1.2770 5.34063.6215 7.6635 2.6660 3.8029
• Wert der Teststatistik:
t =√
n− 1 ·x− µ0
s=√
7 ·3.8250− 6
1.9411= −2.9633
• Es gilt: |t| = 2.9633 > 2.3646 = t7,0.975−→ Ablehnung von H0
388

7.3 Tests fur Varianzen
Situation:
• Der interessierende Zufallsvorgang sei normalverteilt, d.h.
X ∼ N(µ, σ2),
wobei sowohl µ als auch σ2 unbekannt sein sollen
• Betrachte fur geg. σ20 ∈ R das zweiseitige Testproblem
H0 : σ2 = σ20 gegen H1 : σ2 6= σ2
0
389

Geeignete Teststatistik lautet:
T (X1, . . . , Xn) =n · S2
σ20
=n
∑
i=1
(
Xi −Xσ0
)2
Begrundungen:
• T (X1, . . . , Xn) schatzt im wesentlichen das Verhaltnis zwis-chen unbekannter Varianz σ2 und dem Vergleichswert σ2
0
• Wenn H0 gultig ist (d.h. falls σ2 = σ20), dann gilt:
T (X1, . . . , Xn) ∼ χ2(n− 1)
(vgl. Satz 5.5(e), Folie 311)
390

χ2(3)-Dichte von T (X1, . . . , Xn) bei Gultigkeit von H0
391
0.00
0.05
0.10
0.15
0.20
0.25
0 2 4 6 8 10 12 14
χ2-Dichte von T unter H0

Bezeichnung:
• Das p-Quantil der χ2(ν)-Verteilung wird in Mosler / Schmidmit χ2
ν,p bezeichnet
• Kritischer Bereich ist
K = (−∞, χ2n−1,α/2) ∪ (χ2
n−1,1−α/2,+∞)
d.h.
Lehne H0 ab, falls T < χ2n−1,α/2 oder T > χ2
n−1,1−α/2
Lehne H0 nicht ab, falls T ∈ [χ2n−1,α/2, χ2
n−1,1−α/2]
392

Bemerkungen: [I]
• Die Dichte der χ2(ν)-Verteilung ist nicht symmetrisch, d.h.
χ2ν,p 6= −χ2
ν,1−p
• Fur den rechtsseitigen Varianztest
H0 : σ2 ≤ σ20 gegen H1 : σ2 > σ2
0
ergibt sich bei Benutzung der Teststatistik
T (X1, . . . , Xn) =n · S2
σ20
=n
∑
i=1
(
Xi −Xσ0
)2
zum Signifikanzniveau α der kritische Bereich
K = (χ2n−1,1−α,+∞)
(d.h. verwerfe H0, falls T > χ2n−1,1−α)
393

Bemerkungen: [II]
• Fur den linksseitigen Varianztest
H0 : σ2 ≥ σ20 gegen H1 : σ2 < σ2
0
ergibt sich bei Benutzung der Teststatistik
T (X1, . . . , Xn) =n · S2
σ20
=n
∑
i=1
(
Xi −Xσ0
)2
zum Signifikanzniveau α der kritische Bereich
K = (−∞, χ2n−1,α)
(d.h. verwerfe H0, falls T < χ2n−1,α)
394

Bemerkungen: [III]
• Falls der E-Wert µ der Normalverteilung bekannt ist, ver-wende die Teststatistik
T (X1, . . . , Xn) =n
∑
i=1
(
Xi − µσ0
)2
und die Quantile der χ2(n)-Verteilung(vgl. Satz 5.5(d), Folie 311)
395

Beispiel: [I]
• Gegeben seien folgende Messungen aus einer Normalverteilung(µ, σ2 unbekannt):
1001, 1003, 1035, 998, 1010, 1007, 1012
• Man betrachte den folgenden Test z.N. α = 0.05:
H0 : σ2 ≤ 100 gegen H1 : σ2 > 100
• Es gilt:
T (x1, . . . , xn) =n · S2
σ20
=7 · 129.96
100= 9.0972
396

Beispiel: [II]
• Fur α = 0.05 findet man das Quantil χ26,0.95 = 12.592
• Es folgt:
T (x1, . . . , xn) = 9.0972 < 12.592 = χ26,0.95
−→ H0 kann nicht verworfen werden
397
Related Documents











