Flexible Load Distribution for Hybrid Distributed Virtual Environments Emanuele Carlini b,a , Laura Ricci c,a , Massimo Coppola a a Institute of Information Science and Technologies CNR-ISTI, Pisa, Italy b Institute for Advanced Studies Lucca IMT, Lucca, Italy c Department of Computer Science, University of Pisa, Pisa, Italy Abstract This paper proposes an architecture for Distributed Virtual Environment (DVE) integrating cloud and peer nodes. We define the overall structure of the archi- tecture and propose a flexible strategy to distribute the load due to the man- agement of the entities of the DVE. The proposed approach takes into account the utilization of the nodes, the economical cost due to their use of bandwidth, and their probability failure. A greedy heuristics is exploited to reduce the com- putational cost of the algorithm in order to maintain a fair interactivity level to the end user of the DVE. A mobility model generating realistic Second Life traces is exploited to evaluate our algorithm. The experimental results show the effectiveness of our approach. Keywords: Cloud Computing, Peer-to-Peer, Virtual Environment, Load Balancing, Distributed Hash Table 1. Introduction Distributed Virtual Environments (DVEs), like massively multiplayer games or distributed simulations, acquired lots of popularity in the last years from both commercial enterprises and research communities. Currently, most DVE rely on a centralized architecture which supports a straightforward management of the main functionalities of the DVE, such as user login, state management, synchro- nization between players and billing. However, as the number of simultaneous users keeps growing, centralized architectures show their scalability limitations. To overcome these limitations, server clusters have to be bought and operated to withstand service peaks, also balancing computational and electrical power constraints. However, a cluster-based centralized architecture concentrates all communication bandwidth at one data centre, requiring the static provisioning of large bandwidth capability. Further, a large static provisioning leaves the Email addresses: [email protected] (Emanuele Carlini), [email protected] (Laura Ricci), [email protected] (Massimo Coppola) Preprint submitted to Elsevier June 21, 2012

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Flexible Load Distribution for Hybrid DistributedVirtual Environments
Emanuele Carlinib,a, Laura Riccic,a, Massimo Coppolaa
aInstitute of Information Science and Technologies CNR-ISTI, Pisa, ItalybInstitute for Advanced Studies Lucca IMT, Lucca, Italy
cDepartment of Computer Science, University of Pisa, Pisa, Italy
Abstract
This paper proposes an architecture for Distributed Virtual Environment (DVE)integrating cloud and peer nodes. We define the overall structure of the archi-tecture and propose a flexible strategy to distribute the load due to the man-agement of the entities of the DVE. The proposed approach takes into accountthe utilization of the nodes, the economical cost due to their use of bandwidth,and their probability failure. A greedy heuristics is exploited to reduce the com-putational cost of the algorithm in order to maintain a fair interactivity levelto the end user of the DVE. A mobility model generating realistic Second Lifetraces is exploited to evaluate our algorithm. The experimental results showthe effectiveness of our approach.
Keywords: Cloud Computing, Peer-to-Peer, Virtual Environment, LoadBalancing, Distributed Hash Table
1. Introduction
Distributed Virtual Environments (DVEs), like massively multiplayer gamesor distributed simulations, acquired lots of popularity in the last years from bothcommercial enterprises and research communities. Currently, most DVE rely ona centralized architecture which supports a straightforward management of themain functionalities of the DVE, such as user login, state management, synchro-nization between players and billing. However, as the number of simultaneoususers keeps growing, centralized architectures show their scalability limitations.To overcome these limitations, server clusters have to be bought and operatedto withstand service peaks, also balancing computational and electrical powerconstraints. However, a cluster-based centralized architecture concentrates allcommunication bandwidth at one data centre, requiring the static provisioningof large bandwidth capability. Further, a large static provisioning leaves the
Email addresses: [email protected] (Emanuele Carlini),[email protected] (Laura Ricci), [email protected] (Massimo Coppola)
Preprint submitted to Elsevier June 21, 2012

DVE operators with unused resources when the load on the platform is not atits peak.
Cloud Computing [1] allows to solve the aforementioned scalability and hard-ware ownership problems because of on-demand resource provisioning [2, 3]. Thepossibility of renting machines lifts the DVE operators from the burden of buy-ing and maintaining hardware, whereas offers the illusion of infinite machines,with good effects on scalability. Also, the pay-per-use model adheres with theseasonal access pattern of the DVE (e.g. more users in weekends than in themiddle of the week). However, Cloud Computing may be still costly for plat-form operators. Besides server time, bandwidth cost represents a major expensewhen operating a DVE [4]. Thus, even if an approach based exclusively on thecloud approach is feasible, its cost might be still too high for DVE operators.
On the other hand, many research efforts have been done to design pure Peer-to-Peer (P2P) infrastructures for DVEs [5, 6, 7]. These are inherently scalable,and may reduce the load on centralized servers by exploiting the capacity ofthe peers. Furthermore, if a peer fails, the network is able to self-repair andreorganize, so providing robustness to the DVE; network traffic is distributedamong the users involved. Furthermore, these properties pair with little costs forthe DVE operators. However, P2P infrastructures require mechanisms to ensurethe persistence of the game state. When users leave the system they removeboth their resources and the data they have managed so far, unduly stressingthe self-repair features of the system. The lack of a central authority makes itcomplicated to enforce security and soundness of updates to the system stateat any time. Moreover, user machines typically have strict and heterogeneousconstraints on computational power and network capability, which makes themcomplex to be exploited.
These drawbacks are incentives to combine these two orthogonal approaches:Cloud (or on-demand ) computing and P2P infrastructures. In [8] we have dis-cussed the requirements and the issues for such kind of architecture. We havealso presented the initial design of a hybrid and flexible architecture combin-ing the advantages of the two approaches. In this paper we continue the workinitiated in [8] by completing and refining the proposed architecture. In par-ticular, we separate the functionality of neighbours discovery (i.e to find theentities of the DVE relevant for a player) from the management of their state.This has lead us to the definition of two distinct distributed components of thearchitecture, the localization component, which manages only the positions ofthe DVE entities, and the shared access component, which manages their state.Both components are distributed, and typical P2P techniques are used to definethe overlay structure, i.e. Distributed Hash Tables [9].
The definition of two distinct components allows the minimization of thedata transfers between nodes due to the dynamic movement of the DVE en-tities. The data transfer involves only the localization component, while thewhole state of each entity is permanently mapped to a node of the shared accesscomponent. This avoids a continuous transfer of the whole object state betweendifferent nodes, which can jeopardize the smoothness of the DVE. Furthermore,the definition of two different components allows to achieve a better optimiza-
2

tion for each of them. The presence of hotspots in the DVE makes the loadof the localization component inherently unbalanced. Advanced spatial dataretrieval techniques taking into account both data locality and load balancingin hotspot may be leveraged. On the other way round, even if uniform hashingtechniques may be exploited to map the entities to the nodes of the shared ac-cess component, load unbalance may still occur due to the heterogeneity of theentities of the DVE. For instance, popular objects that are accessed by a hugeamount of players. In this case the node which manages the popular objects isheavily loaded because of both the rate of state updates and the resolutions ofconflict updates.
In this paper we focus on massively multiplayer games applications, sincethese are currently the most widespread DVE applications. This work describesthe overall P2P/Cloud architecture proposed and in particular it focuses on theshared access component. We propose a flexible load distribution algorithmfor the shared access component taking into account the main characteristics ofthe hybrid architecture. The assignment of tasks to nodes takes into accountthe computational power of the nodes, i.e. heavy tasks are assigned to cloudnodes, while lighter ones to peer nodes. In order to minimize the economicaleffort for the game operator, the algorithm considers also the economical cost ofthe bandwidth consumed for the access to the cloud nodes. Finally the failureprobabilities of the nodes are taken into account as well, in order to avoid tocharge users peer with too much sensible information.
The algorithm has been evaluated through extensive simulations, by takingadvantage of realistic DVE workloads. The results show that the proposedalgorithm greatly outperforms a solution where no load balancing strategy isexploited. In particular, our results show that our load distribution policybecomes useful when the system approaches to its peak load.
The rest of the paper is structured as follows. In Section 2 we provide anoverview of the current hybrid DVE architectures and of the load balancingstrategies for DVE architectures. Section 4 describes our architecture, whereasSection 5 presents the mechanisms and the policies for load distribution. Section6 describes the workload used to evaluate our algorithms and Section 7 discussesthe experimental results. Finally, Section 8 concludes the paper.
2. Related Work
Several hybrid architectures and load distribution mechanisms for DVEshave been proposed during the last decade. In the rest of this section, wecollect and compare the approaches that, to the best of our knowledge, aremore relevant with respect to our proposal.
2.1. Hybrid Architectures for DVE
Hybrid architectures aim to exploit and combine user resources (i.e. referredas peers in the rest of this section) and centralized servers. A wide-used methodis to divide the Virtual Environment (VE) into regions or cells, whose dimension
3

can be either fixed or variable. These regions are in turn assigned to a peeror a server, that becomes the manager of the entities in that region. Hybridarchitectures follow mostly two different approaches: (i) a region can be assignedto either a peer or to a server without any restriction, or (ii) only a subset ofthe cells can be assigned to peers.
The work proposed in [10] belongs to the first category. The authors considersquare cells, that are initially managed by a central server. The first peer withenough computational and bandwidth capabilities to enter a cell becomes thecell manager. Afterwards, a fixed number of peers that enters the same cellact as backup managers in order to increase failure robustness. Similarly, [11]proposes an hybrid system, including a central server and a pool of peers. Thecentral server runs the DVE and, as soon as it reaches the maximum of itscapacity, it delegates part of the load to the peers.
The same authors of [11] propose in [12] an approach belonging to the sec-ond category. A central server executes the main game whereas the peer runauxiliary games which are typical of certain games genres, such as MassivelyMultiplayer Online Role-Playing Games (MMORPGs). They are separated in-stance of the DVE, shared only by a fixed (and usually not high) number ofplayers. In a similar way, [13] proposes a functional partition of the DVE tasks.Central servers operate user authentication, game persistence and manage re-gions characterized by high-density user interactions, whereas peer support onlylow-density interaction regions. Authors of [14] provide an interesting distinc-tion between positional and state-changing actions. They propose an hybridarchitecture where peers manage positional actions, that are more frequent andprone to be maintained locally. Central servers handle state-changing actions,that are not transitory and require a larger amount computational power.
The idea of distinguishing positional and state-changing actions is in factan interesting idea which we have exploited in the design of our architecture.However, rather than assigning different actions to different type of nodes, wedefine two different and independent distributed structures, i.e. two DistributedHash Tables, that manage, respectively, positional and state-changing actions.The management of the nodes of each DHT can be assigned to a peer or to acloud node.
In other words, we exploit an intermediate approach. On one hand, somefunctionalities, like authentication, must be handled by centralized and full con-trollable servers. On the other hand, other functionalities may be mapped tocentral servers or to peers. This requires a complete dynamic strategy allowingfor more flexibility in load distribution, which allows a fine-grained managementof the resources by the DVE operator. Resources control is very important forour approach, since the seamless combination of cloud and P2P requires tokeep under control the cost and to effectively deal with the implicit uncertaintyrelated to peers. Therefore, a basic issue for the exploitation of hybrid archi-tectures is the definition of effective load distribution mechanisms. The nextsection reviews the main approaches in this area.
4

2.2. Load Distribution in DVE Architectures
The management of avatars and passive objects constitutes the typical com-putational and bandwidth load of a DVE. Avatars move across the DVE andinteract with each other. This interaction can be direct or indirect. In the for-mer case, an avatar directly modifies the state of another one, while the lattercase is that of an avatar modifying the state of a passive object so affectingthe behaviour or the state of other avatars. Both direct and indirect interac-tions consume resources on the nodes, in terms of bandwidth and computationalpower. Such load is assumed to grow exponentially with the number of avatars,with a quadratic or cubic trend according to the game genre [2]. For thesereason, the distribution of the load in a DVE architecture offers unquestionableadvantages but remains an important research issue in these architectures.
As for the definition of the hybrid architectures, a common way to dealwith the distribution of load is to consider the VE a collection of cells. Severalapproaches (such as [15, 16]) exploit the concept of microcells, which have arelatively small size with respect to the entire VE dimension. In particular, [15]assigns to each server a macrocell which is a cluster of multiple microcells. Serverexchange microcells according to their load, in fact by modifying the shape ofthe macrocells. By comparison, [16] divides the DVE into hexagonal microcellsand moves them according to the message generation rate of the avatars. Abuffer zone among adjacent microcells of different servers is implemented tosoften the transfer of players from one microcell to another.
Other approaches ([17, 18, 19]) model the relationships among the cells asa graph. Each cell is a vertex of a graph, whose edges connect neighbour cells.Such graph is then used to build load distribution mechanisms that exploit thelocal knowledge at a cell level. The main rationale behind graph modelling isto minimize the communication among servers. In particular [19] models loadmigration as an heat diffusion process. The amount of load to transfer betweennodes is proportional to the difference between the temperature (i.e. load) of twocells. According to this process, highly loaded zones transfer load to unloadedzones in order to balancing load distribution. Although the graph approachesare interesting and appealing, all of them try to organize the VE partitioning inorder to minimize the inter-server communications. Conversely, our objectiveis to diminish solely the costly communications in pay-per use models, i.e. thecommunication from the cloud to the external nodes.
The works discussed so far exploit a static division of the VE. Other ap-proaches distribute the load by dynamically adapting the regions size assignedto servers. The work in [20] exploits a Voronoi partition of the VE surface, andassigns a server to each Voronoi cell. Servers move on the surface according totheir capacity, in order to distribute the load. For example, powerful serversmove towards heavy loaded zones.
Authors of [21] exploit a different division of the VE. They assign to eachserver a cluster of avatars. Each server then manages the squared region thatencloses all the avatars in the cluster. When avatars move in the VE, the size ofthe region is adjusted in order to enclose them. Avatars are transferred between
5

servers in two cases: (i) a server is not able to handle the load generated byavatars and (ii) there is an overlap among regions, meaning that multiple serversconcurrently manage the same region, which, in turn, can lead to inconsistencies.Similarly, [22] assigns to each server a region defined by a cluster of players.Whenever the load of a server exceeds its capacity, load is distributed eitherby moving the entire cluster to another server or by moving some players fromone cluster to another (in case, splitting the cluster). Cluster-based approachespresent some similarities with our work. However, we do not specifically focuson cluster management and tracking, since, when moving a cluster, the numberof involved players (directly and indirectly) might be too high.
In summary, there are two main differences between our work and thoseproposed in the current state of the art. First, all of the approaches definethe load by considering only direct interactions. On the contrary, we focus onthe load generated from indirect interactions generated by interactions with thepassive objects of the VE. Second, most of the approaches presented focus onnode capacity (either in terms of players number or bandwidth) as the mainaspect driving load distribution. Although this aspect is certainly a relevantissue, we argue that it is not sufficient when considering a highly heterogeneousplatform, where others aspects, like the economical cost or the churn of thepeers must be taken into consideration.
3. The DVE Hybrid Architecture
This section introduces the overall structure of the proposed DVE hybridarchitecture. In order to motivate the design choices of our architecture, we firstbriefly review the main characteristics of a classical client/server architecturefor DVE. Players connect to the server by means of a game client whose maintask is to show on the screen the visual representation of the DVE and tomap the actions of the player (i.e. movement and/or interaction with objects)into communications with the server. As shown in the previous section, theactions of the player can be classified as positional-actions and state-actions.Positional actions correspond to the movement of players or objects across theVE. Positional actions result in a perspective changing of players, which receiveon their screen the visual representation of the zone they have moved in and ofthe objects entered in their visibility radius. This experience is realized by thegame client, which informs the server of the new position of the player (or ofa moved object) and gets from the server the description of the entities in theplayer’s Area of Interest (AOI) so performing the AOI resolution. State-actionscorresponds to the changes of the state of the entities, as for instance closing adoor or attacking an opponent player. In this case, the game client sends theupdated state to the server and retrieves the updated state (not the position)of the entities the player’s AOI.
Recent client/server DVE architectures assume the definition of multipleservers and their distribution on multiple nodes. This issue makes the overallarchitecture more complex, for instance it requires the definition of a strategyfor dividing the VE into sectors, including a subset of the entities and the
6

assignment of each sector to a different node acting as a server for such entities.Some architectures exploit a spatial division of the VE into regions and assignall the objects in a region to a sector, whilst other ones perform a randomassignment of objects to sectors. Area partitioning is efficient for AOI resolution:since objects are clustered according to their spatial position, resolving AOI isa relatively easy task. However, entities distribution is far from being uniform,because of the presence of hotspots in the DVE. This can generate an hugeload on a single server paired with a heavy crowded area. Furthermore, due tothe spatial division, positional-actions may trigger a change into entity-sectorassignment, implying the transfer of entities among servers. This may reduce theinteractiveness of the game, since during the transfer an entity is not accessible,in fact denying any possible state-action on it. This is even more critical whenconsidering the rate of transfer that in turn depends on the rate of positional-actions (usually high) and the dimension of the regions.
A random assignment of entities to sectors presents complementary charac-teristics. Since the association of an entity to a sector does not depend on theposition of the entity but is fixed, positional-actions do not trigger any migra-tion of objects among servers. Also, due to the random assignment, entitiesin a hotspot are with high probability managed by different servers so thatload is more balanced with respect to area partitioning. However, this solutionmakes AOI resolution impractical (the objects of an AOI may be spread amongdifferent nodes) and therefore it is rarely used in practice.
stateactions
positionalactions
GAME CLIENTS
SAMPAM
PROVISIONING
Distributor
NODE POOL
CLOUD P2P
Figure 1: Overall architecture
The architecture we propose tries to exploit the advantages of the two dif-ferent approaches we have discussed.
Fig. 1 presents the main components of our architecture. The two core dis-
7

tributed components are the Positional Action Manager (PAM) and the StateAction Manager (SAM). PAM manages only the positions of the entities andorganizes the VE according to principles of area partitioning, so that AOI res-olution is simplified. Instead, SAM is organized according to a random object-to-sector assignment, and this allows to handle the state of the entities withoutany transfer of the entities across servers due to positional-actions. Such trans-fer may anyway occur, but instead of being triggered by positional-actions, it isperformed to optimize the distribution of the entities (and as a consequence, ofthe load) among the nodes.
The core components of the architecture store both the avatars, which arethe virtual representation of the users in the virtual world, and the passiveobjects which are not controlled by players, and are characterized by a statewhich is shared and modifiable by the avatars. Any entity, both avatars andpassive objects, is stored in both the components of the system. The positionof the entity is stored by the PAM so that the load on PAM is mostly dueto the positional-actions of the entities. The rest of the state of the objects,for instance the level of energy of an avatar or the state of a door, is insteadstored by SAM. The load on SAM is generated by direct interactions betweenavatars or by indirect interactions between avatars due to avatars interactionwith passive objects. We mostly focus on the load due to indirect interactions,since, as the best of our knowledge, this issue has been not investigated untilnow.
The architecture includes two further components, the distributor and theprovisioner. The distributor actively orchestrates the assignment sector-to-nodes. To this end, the distributor takes into account different aspects, such asnodes utilization factors, cost of bandwidth and failure probability of the nodes.Note that there is no distributor in PAM. In fact, load on the PAM is verydynamic, because it is generated by positional-actions that are more frequentthan state-actions. Hence, the effectiveness of a distribution mechanism wouldbe invalidated from the high rate of load modification. A detailed analysis ofthe mechanisms used by the SAM’s distributor is presented in the followingsections.
The provisioner coordinates the enrolment of new nodes and the disposal ofunused nodes within the system. To this end, the provisioner maintains a poolof candidate nodes that contains both users node and cloud nodes. User re-sources, (or simply peers) correspond to the Personal Computer or Workstationexecuting DVE client. Only a subset of the peers enter in the provisioner pool,and after a selection process that takes into account their stability and hardwareprofile. On the other hand, cloud nodes are powerful high-end machine, and, ina certain sense, their presence into the pool is merely logical. Indeed, thanks tothe mechanisms offered by cloud providers, it is relatively easy to add on the flynew nodes to the existing system. However, cloud nodes come with a cost forthe DVE operator, whereas peers are completely free. Table 1 summarizes theprincipal differences among cloud and peer nodes. The goal of the provisioneris to add or remove nodes from the network, in accordance with the requestsof PAM and SAM. A detailed description of the provisioning mechanism is not
8

Cloud Resources User Resourcesreliable performance unreliable performancecontrolled environment possible security holesscale with costs scale freereliable presence churn
Table 1: Main differences between Cloud and User resources.
the focus of this work, so in the following we assume SAM to have the nodes itneeds at its disposal.
4. The Architecture of SAM
SAM, the component which manages the state actions, exploits a DHT [23, 9]approach to manage state information (Figure 2). In a typical DHT, the log-ical address space is partitioned among the nodes and the overlay guaranteesO(logN) bounds, where N is the number of nodes of the DHT, both for therouting hops and for the size of the routing tables. A Virtual Servers (VS) [24]layer is defined over the DHT, in order to guarantee a flexible assignment of sec-tors to the physical nodes exploiting the heterogeneity of the hybrid architecturein a seamless way.
The Virtual Server approach introduces a clear separation between the log-ical and the physical nodes. Each VS is in charge of an address range of theDHT. However, VSs are not permanently paired with the same physical node,and each physical node can host several VSs. Even if this approach presentshigher implementation complexity, as nodes need to manage multiple VSs, theVSs approach has some evident advantages: (i) more powerful nodes may re-ceive an higher number of VSs than less powerful ones, (ii) heavy loaded nodesmay trade VSs with unloaded ones, (iii) in case of a physical node failure, itsVSs are possibly transferred/reassigned to different, unloaded, physical nodes,so reducing the risk of overloaded nodes. The migration of a VS to a differentnode does not affect the organization of the address space at the DHT level.The migration only requires the exchange of data managed by the VS as wellas the update of the mapping between the logical identifier of the VS and thephysical address of the node hosting it.
SAM maps each entity of the DVE into a VS. Each entity in the VE isassigned an identifier (ID) in the DHT space, thought the application of a hashfunction (i.e. SHA1). The application of the SHA1 guarantees IDs to be evenlydistributed across the space. However, load may be unbalanced due to thepresence of more popular entities, for instance objects belonging to an hotspotreceive an higher amount of updates.
Each VS is assigned to a physical node, either a cloud or a peer one. Anode can manage multiple VSs and it has to manage at least one VS. Evenif the association entities-to-VS remain fixed during the system lifetime, themapping of VS to physical nodes may change over time. For instance, all VSs
9

VS
VSVS
VSVS
NODE ANODE B
DISTR
IBUTO
R
SAM
CLIENT
CLIENT
DHT RING
CLIENT
object
Figure 2: The SAM architecture
may be mapped to cloud nodes at bootstrap time and then transferred to peernodes afterwards. The policies adopted to decide when and what VSs has to betransferred are discussed in the following section.
From a client perspective, a VS acts as a state server for all the entitiesmapped to it. Each player can move and perform an action at each time tick.PAM is exploited by game clients to perform AOI resolution in order to interactwith the surrounding environments. For our purpose it is sufficient to know thatPAM provides the list of all entities – players and objects – in a given player’sAOI and, for each entity, the logical identifier ID of the VS storing that entityin the SAM. The client then searches for such ID in the SAM address space,using key based routing techniques, directly inherited from DHT, which allowto reach any VS in a logarithmic number of steps [23]. After the AOI resolution,each player may update directly the objects in its visibility radius. This resultin a flow of messages coming from different clients to the same VS. The VSresolves possible conflicting state actions and broadcasts the updated states tothe interested clients. Due to best effort nature of the Internet, client updatesmay be lost or be received after a long delay. VSs cope with this effect (calledlag) by using one of the numerous techniques for lag reduction, as for instancetime warp and local lag [25].
Since each object in the AOI may be managed in principle by a different VS,each client may have multiple simultaneous connection to different DHT nodes.For instance, in Figure 2, a game client is connected with node A and B at thesame time. As a limit situation, each player can connect to a different node pereach object, so that the number of connections for each player is bounded bythe amount of entities in its AOI. Nevertheless, it is worth noticing that not allthe connections are active altogether, since each VS pushes the updates of theentities only when they happen. The connection to a VS is dropped by a clientwhen the entity managed by the VS departs from its AOI.
As discussed in the previous section, SAM relies on a distributor entity thatmanages the transfer of VSs among the nodes of the DHT. An important issue
10

is the choice of the nodes actually playing the role of the distributor. Thesimplest solution is to define a centralized distributor executed by a cloud nodewhich may be either dedicated to this task or shared with the SAM. In thissolution, every SAM node sends notifications to the central distributor, whichperiodically computes new assignments based on the received information. Thenotifications may include, for instance, the current bandwidth load of the node.However, a distributed solution is feasible as well. For instance, it is possible toadopt a mechanism similar to the one presented in [26]. A number d of DHTaddresses are chosen and the nodes managing one of these addresses play therole of sub-distributors. Each SAM node then chooses randomly, but once forall, one of the d sub-distributor and sends to it its notifications. Each sub-distributor operates like the centralized distributor, but on a reduced number ofVSs. Although this mechanism distributes the burden of the distributor amongmultiple nodes, it might also impair the result of the assignments. We leave theanalysis of the distributed solution as a future work.
4.1. Virtual Servers Migration
VSs migration is a prerequisite for a flexible management of the hybridarchitecture, since it allows to move load between nodes. The transfer of aVS should be performed carefully, as it may affect the interactivity of the DVE.During the transient time due to the transfer of an entity from a node to anotherone, an entity can not be accessed. During this time period, players cannotinteract with the object inside the VS that is migrating.
Also, it can be the case when a player modifies the state of the object onlylocally, to see it reverted back only when the migration of the VS is completed.To this end, it is important to keep the transition time as short as possible, inorder to provide an acceptable level of interactivity for the DVE clients.
In SAM, VSs migration exploits the inherent mechanisms of the DHT. Inorder to clearly present the migration procedure, let us consider the followingexample. Let us suppose that a VS V moves from a source node A to a des-tination node B. The actions involved (presented in the sequential diagram inFigure 3) are the following:
Distributor Node A Node B
JOIN
3b. changeServer
DHT stabilization
LEAVE
1. initTransfer(VS, node B) 2. startTransfer
3a. endTransf
state-actionstate-actiontransition
time
Players
Figure 3: Transferring of a VS from a node A to a node B
11

1. The distributor notifies to node A a reference to V and the address ofrecipient node B.
2. A sends V to B, together with the list of players connected to V . In thetransient time that is needed to complete the transfer, players still sendentity update messages to A, which in turn forwards them to B. Note thatin this transient period, objects may go out-of-sync and, as a consequence,players may perceive some visual inconsistencies.
3. Once received the message, node B notifies the players it has became themanager of V . From this point on, players are able to modify V ’s objectsstate. However, the routing tables of the DHT have to be updated inorder to assure correct routing resolutions.
4. To this end, V executes a join operation having B as target in order toupdate its references in the DHT. This operation updates the routing tableof the node that are in the path from V to B, still leaving references toA as the manager of V . To make sure all references are consistent, thestabilization process of the DHT is executed.
5. Finally, a leave operation is executed by V on A in order to complete theprocess.
This procedure assures that during a VS migration, the management ofthe VS is kept on running. Indeed, the service remains active until all theconnections are up to date and all the VS data has been transferred. A greatadvantage of using VS is that, despite the transfer, the overlay topology doesnot change, but only the mapping between the logic identifier of the virtualserver and the node IP is modified. Moreover, this approach is DHT-agnostic,since it can work with any DHT. The only step that needs to be tuned accordingto the used DHT is the stabilization. For example, our implementation exploitsthe Chord DHT [23], and, in order to stabilize the overlay, we employ a solutionbased on reverse finger tables [27]. Each VS stores an additional table whichcontains a reference to each node including in its finger table a reference to VSwith its current IP. This table can be used to inform all the nodes about thenew IP address corresponding to the new host of VS.
4.2. Replication and Fault Tolerance
This section provides a brief overview on the replication mechanism providedby SAM. An extensive description and evaluation of the replication mechanismis not the aim of this paper, nevertheless, a more detailed description can befound in [8].
In a distributed system, the need of replication comes from the intrinsicunreliability of nodes. Since we target an heterogeneous system including bothpeer and cloud nodes, a fair orchestration of replication is a relevant issue. Ourapproach is based on the reasonable assumption that, in general, cloud nodes canbe considered reliable whereas peer nodes are unreliable, due to the high degreeof churn which characterizes P2P systems. This difference is mainly due to thelack of control over peers, which are prone to unexpected failures, and may leavethe system abruptly. On the other hand, cloud nodes generally belong to a stable
12

infrastructure based on virtualization, and this greatly increases their robustnessand flexibility. In order to cope with the unreliability of peers, we propose thatevery VS assigned to a peer is always specially replicated. The replica, calledbackup Virtual Server (bVS), is then assigned to a trusted resource, i.e. a cloudnode. To keep the state of the bVS up-to-date with the original, peers sendperiodic updates to the cloud nodes.
The presence of a bVS provides some concrete advantages and opportuni-ties. First, backup data are managed by trusted resources that can be used incase of peer failures. Let us assume the peer P to manage a single VS and thatthe respective bVS is managed by the cloud node C. Let us also assume thatP departs, either abruptly or gracefully, from the system. In this case, C be-comes the manager of the primary replica, in place of P . As consequence, usersconnected to P must then connect to C. In the case of a gracefully departureof P , P itself may inform all the users about the new role of C. On the otherhand, in case of unexpected departure, the involuntary departure of P can bedetected either by C, since it receives no more updates from P , or from theDHT neighbours of P , due to the repairing mechanism of DHTs. These nodesare able to notify the players to send their notification to C.
The second advantage of bVS is that cloud nodes can perform cheating miti-gation (i.e. preventing malicious players to obtain unfair advantages), acting asreferee on the data managed by the bVS. Naturally, the use of bVSs for cheatingmitigation makes sense if the workload imposed on the physical resource by therole of referee is less than the workload generated from the full-blown server role.This assumption is often true, for instance several referee-based [28] strategiesperform random-sampling checks.
In summary, the bVS mechanism is able to deal with the unreliability ofpeers, so to avoid unexpected failures that may affect the interactivity of theDVE. Furthermore, bVSs can be also used for cheating mitigation, which assuresa fair experience to users.
5. Load Distribution
In this section we describe the load distribution strategy adopted in SAM.We first investigate the requirements derived from the characteristics of a DVEapplication driving our design, and then we describe the proposed approach inmore details. We consider the load of each VS generated by the management ofthe passive objects of the DVE, since we are interested in undirect interactionsbetween avatars. However, the management of active objects (like avatars orbots) presents similar characteristics.
A load distribution mechanism for a DVE application has to cope with a setof issues typical of this kind of applications. First of all, DVEs are interactiveand fast-paced applications. Hence, the bandwidth requirements are volatile,changing rapidly as the distributed simulation progresses. As a consequence, theassignment of the VSs to the nodes should be executed often in order to adhereto the changes in the DVE scenario. The high rate of the distribution exposesthe second requirement, that is the computational cost of the algorithm should
13

be low. In other words, the system cannot afford to run a computationally heavyalgorithm every few seconds. Further, the distributor can be executed in a nodethat is also managing VSs. If the computational demands of the algorithm aretoo high, users’ experience might be affected. Third, the distributor has toassign the VS by taking into account nodes heterogeneity, in terms of capacityand economic cost. The exploitation of peer resources provides a number ofbenefits, but usually such resources are unreliable. Hence, the distributor shouldnot assign large or sensible VSs to a single peer node, in order to avoid bothpossible data loss and the overhead due to the data transfer to backup servers.Finally, the migration of VSs is a critical task. Users may perceive a lack ofinteractivity during this phase, since during migration the objects mapped to thetransferred VS are not liable to interactions. As a consequence, the distributorhas to keep under control the amount of VS migrations at each step.
5.1. System Model
In order to orchestrate the assignment of VSs to nodes, we propose a modelallowing the comparison of different node-VSs configurations. To this end, wehave developed a model of the system and a scoring mechanism which allowsus to compare different system configurations, with the goal to optimize themapping of VSs to nodes.
First of all, the properties of VSs and nodes taken into account by themodel must be defined. Nodes are characterized by the following properties:(i) capacity, which is the maximum amount of available outgoing bandwidth(indicated by C); (ii) failure probability, which is the probability a node leavesthe network (indicated by F ); and (iii) bandwidth cost, which is the economicalcost related to the usage of a bandwidth unit (indicated by B). These valuesstrictly depend on the type of a node: a peer has no cost for bandwidth whereasa high failure probability can be expected. Conversely, cloud nodes have ahigher amount of bandwidth available coming with an associated price. Also,compared with peers, cloud nodes have a lower failure probability.
VSs store and manage entities of the DVE and use bandwidth to notify thestate of entities to the interested players. The number of entities mapped to avirtual server is known. The load of a virtual server V is defined as the amountof bandwidth consumed by V in a time interval. The node load is the sum ofthe bandwidth consumed by all the virtual servers which are assigned to thatnode and, in a similar, way, the number of objects associated to a node is thesum of the objects paired with each virtual server mapped on that node. Allthis information are needed for the execution of the load distribution algorithm.The following values describe the state of a node:
• utilization factor, α, is the ratio between the node load and its capacity.
α =L
C(1)
An utilization factor close to zero implies that the node is unloaded. Con-versely, if α is close to one the node is loaded around its maximum capacity.
14

If α is larger than one, the current capacity of node is not sufficient tomanage the VSs assigned to the node.
• bandwidth cost, β, is expressed in currency (e.g. dollar cents), and isproportional to the bandwidth consumed by the node.
β = L×B (2)
• risk, γ, models the risk of assigning VSs to the node. It takes in accountthe failure probability of the node and the number of objects managedby the node. Informally, the larger is the failure probability the smallershould be the number of objects assigned to it.
γ = F ∗ num objects (3)
where num objects is the amount of objects currently managed by theconsidered node.
To evaluate the state of the entire system, we combine the different aspectof the state of the nodes. First of all, we need to correlate the cost and the riskof the system to their respective maximum values. To this end, we introducethe following measures:
• Maximum Cost of Bandwidth, βmax, which is computed by assigningthe maximum amount of load to the most expensive nodes of the system,without exceeding the capacity limits of the nodes.
• Maximum Risk, γmax, which is computed by assigning the maximumnumber of objects to the nodes with the highest degree of risk, withoutexceeding the capacity limits of the nodes.
The value of βmax can be computed by considering a system where all thevirtual servers are assigned to cloud nodes, and, for γmax, a system where allthe virtual servers are assigned to the peers node with higher failure probability.Considering these values as upper bound on risk and bandwidth cost, we areable to compute the measure of the total cost/risk of the system w.r.t the worstcase.
β∆ =
∑i∈N βi
βmax(4)
γ∆ =
∑i∈N γi
γmax(5)
where 0 ≤ β∆ ≤ 1 and 0 ≤ γ∆ ≤ 1. βi(s) and γi(s) are respectively thebandwidth cost of ith node and its risk of the system state s.
When evaluating a system state, we must also consider the degree of balanceamong the utilization factors of the different nodes. To this end, we exploit the
15

Gini Coefficient [29], which is often exploited to evaluate load balancing indistributed systems. The Gini coefficient measures the inequality among valuesof a distribution with a value ranging from 0 to 1. A Gini coefficient of 0expresses perfect balancing, whereas a Gini coefficient of 1 expresses maximalinequality among values. Let us denote as GS the Gini coefficient of the α ofthe nodes in the system. The representation rS of a system S is then definedas:
rS = [GS , β∆, γ∆]
To compare two different system states, we compute an aggregation of thedifferent components. First of all, the values of β∆, γ∆ are inversely related, i.e.the higher the risk, the smaller the cost. When aggregating these values, we mayconsider a factor z, whose value may be defined by the system administrator,which allows to give more importance to a factor w.r.t the other one. Let usdefine:
ρS = zβ∆ + (1− z)γ∆ (6)
where 0 ≤ ρS ≤ 1 models the tradeoff between risk and cost, and 0 ≤ z ≤ 1represents the preference for one or the other aspects. Finally, the system score,referred to a state s of the system is defined as follows:
scoreS = xρS + (1− x)GS (7)
where x represents the preference given to the risk/cost tradeoff with respectto the Gini coefficient. The distribution algorithms presented in the followingsection are based on a set of heuristics whose goal is to minimize the score ofthe system.
5.2. Distribution Policies
In this section we show how the model introduced in the previous sectioncan be exploited to define an efficient load distribution strategy.
From the analysis of the DVE requirements, we have shown that the loaddistribution strategy must be computationally light. The distributor cannotafford to find the optimal system configuration at each time step, because ofits computational cost. Moreover, this solution would not be scalable in thenumber of nodes and/or VSs. Another point to consider is the amount oftransfers of VS between nodes. Even if an optimal strategy is able to findthe best VS assignment, the number of transfers can be simply too high to befeasible without affecting the application interactivity.
For these reasons, we exploit two heuristic-based algorithms in order toobtain acceptable results, and, at the same time, to maintain the approachscalable. The two heuristics are inspired by the algorithm for load balancingpresented by Godfrey et al. in [24].
No Distribution (ND). This is the baseline policy and implies no VStransfers among nodes. In other words, the system maintains the random initialassociation node-VSs along the entire simulation.
16

Greedy Heuristic (GH). GH tries to improve the system score with in-cremental steps. The algorithm does not perform any effort to learn from thepast or to avoid unfortunate situations. This in fact results in two peculiarbehaviours. First, it causes VSs oscillations. For example, a VS is transferredfrom node a to node b during the ith tick, the same VS is then transferred fromnode b to node a during the next tick, and so on. Second, if the algorithm entersa local optimum there is a very little chance to exit, due to the limited numberof transfers allowed and the blindness of the algorithm.
Algorithm 1: Greedy Heuristic
input: maxtr, maximum allowed transfers of virtual serversData: POOL ← ∅Old score ← getSystemScore();
foreach n ∈ NODES docomputeScore(n) ;
while (size(POOL) < maxtr) dosource ← n : score(n) is max;VT ← V:load(V)=min(load(V’, V’ ∈ VS(source)) ;POOL ← POOL ∪ [VT, source] ;remove V from VS(source);update score(source);
sort POOL in descending order w.r.t VSs loads;
foreach [V,source] ∈ POOL dodest ← n : score(n) is min when V is assigned to n;if ] VS(source)=0 then
VE ← W ∈ dest : score(source) is min if W is mapped to source;Move(VE, source);
Move(V, dest);
if getSystemScore() > Old score thenrollback;
Algorithm 1 presents the pseudo code of GH. The algorithm exploits thescore function to evaluate the state of nodes. In the current implementation thescore of a node is simply computed as the sum of its cost, risk and utilizationfactor. More complex scoring function can be used as well. GH fills a pool withthe VS coming from nodes with the higher scores with the goal to reduce thescore of such nodes.
Subsequently, the pool is sorted in an descending order, i.e. GH tries toassign the VS with higher load beforehand. For each virtual server V , thedestination node is chosen such that it has the minimum score among all thenodes in the system if V is assigned to it. Note that in the case no virtual server
17

are assigned to the source node after the migration, a virtual server must bechosen from the destination node and transferred to the source node. Finally,GH checks whether the movement of the virtual server to the new node hasimproved the system score. If this is not the case, GH executes a rollback torestore the configuration VS-nodes to the initial state.
Greedy Heuristic with State (GHS). The GHS general behaviour issimilar to that of GH, but it introduces a new feature. Indeed, GHS sets aminimum interval of time steps during which a recently transferred VS cannotbe further moved. In other words, GHS adds a state to the basic heuristicsdefined by GH; such state stores the information about the time instant whenVSs have been moved. This state is exploited before filling the pool; if a VShas been moved recently it would not be considered as a suitable candidate fora transfer, and hence it is not added to the pool. The introduction of the stateshould allow GHS to yield better performance and to avoid remaining stuck intolocal optimal configurations.
6. Workload Definition
The following section presents a set of experimental results evaluating thedistribution policies of the SAM. This section presents the simulation scenario,i.e. the objects distribution in the DVE, the mobility model exploited to gener-ate realistic traces of the avatar movements, the model of the avatars and passiveobjects interactions and finally the bandwidth model we exploit to measure thebandwidth consumed by each node of the SAM.
The workload has been designed so that the largest part of the area is coveredby zones with a low concentration of entities whereas the remaining area iscovered by few hotspots, which is a typical DVE scenario [30]. We consider a VEdefined on a squared region of 5000 x 5000 tiles. The 20% of the total area of theDVE includes hotspots, i.e. places attracting avatars, while the remaining 80%is outland. The number of hotspots is fixed to 5 and 65% of the total numberof the passive objects of the DVE lie in hotspot areas where their concentrationfollows a power law distribution, with a peak in the hotspot center (Figure 4bshows an example of objects distribution). The total amount of objects in thesimulation is 1000, and the AOI of player has a radius of 50 tiles. Objectsinside hotspots are characterized by a popularity, modelling the probability ofan interaction between that object and a player. Object’s popularity is assignedaccording to a power law distribution, each value computed regardless of theobject’s position inside the hotspot. The remaining 35% of the objects lay in theoutland area and it is distributed according to a uniform random distribution,and their popularity is fixed to a constant value (1 in the experiments).
Our evaluation considers load related to the management of passive objectsonly, while it does not take into account the bandwidth consumed for othertasks, like backup management, intra-server communications, and other servicesat application level (e.g. voice over IP). For this reason the simulation definesnodes whose bandwidth capacity is reduced with respect to their real capac-ity. The bandwidth capacity of a peer node is modelled according to a normal
18

0
200
400
600
800
1000
Nu
mb
er
of
pla
ye
rs
0
2
4
0 50 100 150 200
Lo
ad
(M
B/s
)
Ticks
(a) How bandwidth load and number of playervary according to time
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
(b) Objects placement over the DVE area
Figure 4: Workload characterization
distribution, with mean 64Kbyte/s and variance 32Kbyte/s and the bandwidthcapacity of a cloud node is computed according to a normal distribution withmean 640Kbyte/s, and variance 128Kbyte/s. Variance is higher in peer nodessince their heterogeneity is undoubtedly higher. Similarly, failure probabilitiesof peer nodes are computed according to a normal distribution, with mean 0.1and variance 0.1. Note that 0 has been taken as failure probability in case of anegative value. As far as concerns the cloud nodes, we use a failure probabilityfixed to 0.001.
6.1. Mobility Patterns
Avatars move on the map according to realistic mobility traces that havebeen computed according the mobility model presented by Legtchenko et al.[30], which simulates avatars movement in a commercial DVE, Second Life [31].We have provided an implementation of this model and a comparison of it withother models in [32] The model defines of a set of hotspots corresponding tocities or interesting locations of the DVE. When an avatar reaches a hotspot,it explores the hotspot for a span of time and eventually moving to anotherhotspot. This behaviour is defined by a state finite automata characterized bythree states: halted, exploring and travelling. When in halted state avatars staystill, whereas in the exploring state avatars explore a portion of the DVE closeto their current position. Finally when in travelling state avatars move fromone hotspot to another. This mobility model exposes a fair balance between thetime spent by avatars in hotspots and outland. Furthermore, the path followedby avatars when moving between hotspots is random, i.e. no predefined pathconnects two hotspots.
As shown in Figure 4a, the number of players in the simulation follows aseasonal behaviour. The amount of players grows from 100 up to the maximumof 1000 players and then decreases down to the initial number. This patternimplies a variation in the bandwidth load during the simulation. The peak
19

load (about 4MB/s) is reached around the 100th simulation tick, about halfwayduring the simulation.
6.2. Modelling Bandwidth Usage
We measure the bandwidth usage for the managements of passive objectsby considering outgoing bandwidth, i.e. the communications from the nodesexecuting the VSs to the players. The decision to consider only outgoing band-width is due to the following reasons. First, besides machine time, a typicalcloud computing platform charges outgoing and not ingoing bandwidth Sec-ond, peers usually exploit asymmetric connections to the public network, andthis implies that the outgoing bandwidth is the resource to optimize, since itsavailability is smaller compared to ingoing bandwidth.
In our model bandwidth is sampled according to a discrete time step model,with each step, or tick, lasting one minute. During each time interval, the band-width required for the management of a generic passive object o is computedaccording to:
• the players that acquire o in their AOI. This event is directly derived bymobility traces.
• the bandwidth needed to broadcast the state updates of an object o tothe players. To compute this value, we distinguish outland objects fromthose located in a hotspot. If at least a player is located close to anoutland object, we suppose that the player modifies that object in anycase, because the player has moved to that location just to access thatobject. Instead, the objects located in a hotspot, for instance a city, arecharacterized by a popularity defining the probability that a player close tothat object modifies it. Hence, objects are always updated and broadcastif located in outland areas, whereas the rate of updates and broadcastdepends on players number and popularity for objects in hotspots.
• the actual length of the upload message, which we assume to be the samefor every object (100KB in the experiments).
7. Simulation Result
This section shows the experiments we have conducted to evaluate our dis-tribution policies. We have evaluated the following aspects: (i) the impact ofthe parameters of the model on the behaviour of the system; (ii) how the loadfluctuation affects the distribution policies; (iii) the behaviour of the policieswhen the number of the VSs increases.
The baseline system configuration exploited for the experiments is the fol-lowing:
• Node Configuration: includes 2 Cloud and 50 peer nodes. This configu-ration has been chosen so that the peak load corresponds to 80% of thetotal capacity of the system which is computed as the sum of availablebandwidth of all the nodes.
20

• Virtual Server configuration: includes 100 VSs, i.e. about twice the totalnumber of nodes. This allows the distribution policies to exploit a fairdegree of freedom when moving VSs.
The VSs are distributed randomly to the nodes at the start of the simulation.All results are shown by aggregating outcomes of 100 runs.
7.1. Impact of Model Weights
When deploying a DVE on a distributed hybrid architecture, the systemadministrator may make different choices regarding the importance of the cost,risk and load balancing on the configuration of the system.
In our model this is possible by assigning different values to the parameters ofthe model, i.e. x and z. Proper combinations of these values allow to control theimpact of the bandwidth cost, of the level of risk, and of the load distribution ofthe policies. We have selected three different system profiles (PR) correspondingto different combinations of these values:
• PR1 (z = 0.9, x = 0.9) corresponds to a situation where the optimizationof the bandwidth cost is the main issue. This may be the case of a sys-tem administrator that prefers to have a higher risk by assigning a largeamount of load to peers, or of a DVE where the interactivity/performancerequirements are not the primary goal;
• PR2 (z = 0.1, x = 0.9) minimizes the risk, at the expense of possible loadimbalances and additional costs;
• PR3 (z = 0.2, x = 0.5) gives priority to balancing load with respect to theother factors. This can be the case of an homogeneous platform, wherecost and risk do not represent the main issues, while load balancing isvaluable. For example, this can be the case of a platform that includesproprietary machines.
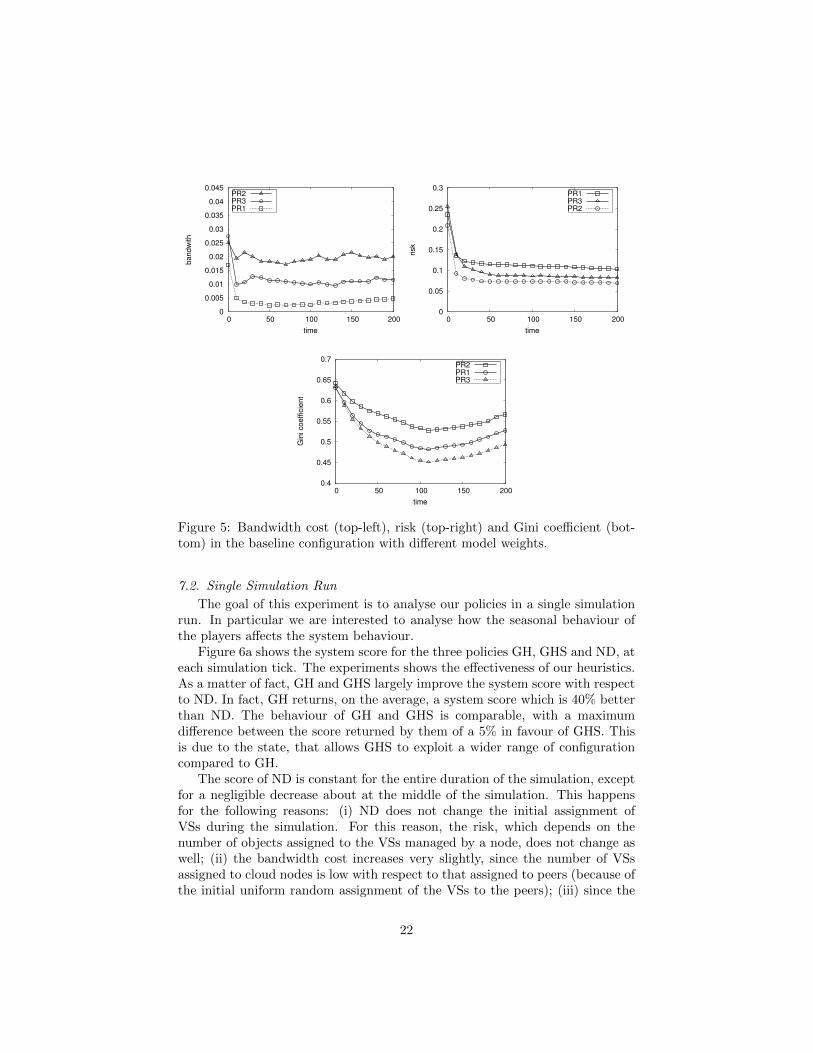
Figure 5 shows the bandwidth cost, the risk level and the Gini index atdifferent simulation ticks and with respect to the different profiles. All theresults are obtained with the baseline configuration. We considered GH2 asdistribution policy, since the outcomes are qualitatively equivalent to GH.
In general the results are clear and compliant with the expectations. Inparticular the tradeoff between risk and cost is well explained by the behaviour ofPR1 and PR2. In fact, PR1 obtains the best result when considering bandwidthcost, since it moves most of the load to peers. Conversely, PR2 has, as expected,the best result when taking into account the risk. However, compared with PR1,PR2 has an higher bandwidth cost, due to the higher usage of cloud nodes. Forthis reason, PR2 also obtains a worse Gini coefficient than PR1. Certainly, thisresult is because of the presence of only two cloud nodes and 50 peers. WhenPR2 moves load on cloud to reduce the risk, the load distribution becomesinevitably unbalanced. Basically, PR3 lies halfway between PR1 and PR2 ifconsidering bandwidth cost and risk. However, as expected, PR3 yields thebest result when considering the Gini coefficient.
21
0
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
0.045
0 50 100 150 200
ba
nd
with
time
PR2
PR3
PR1
0
0.05
0.1
0.15
0.2
0.25
0.3
0 50 100 150 200
risk
time
PR1
PR3
PR2
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0 50 100 150 200
Gin
i co
eff
icie
nt
time
PR2
PR1
PR3
Figure 5: Bandwidth cost (top-left), risk (top-right) and Gini coefficient (bot-tom) in the baseline configuration with different model weights.
7.2. Single Simulation Run
The goal of this experiment is to analyse our policies in a single simulationrun. In particular we are interested to analyse how the seasonal behaviour ofthe players affects the system behaviour.
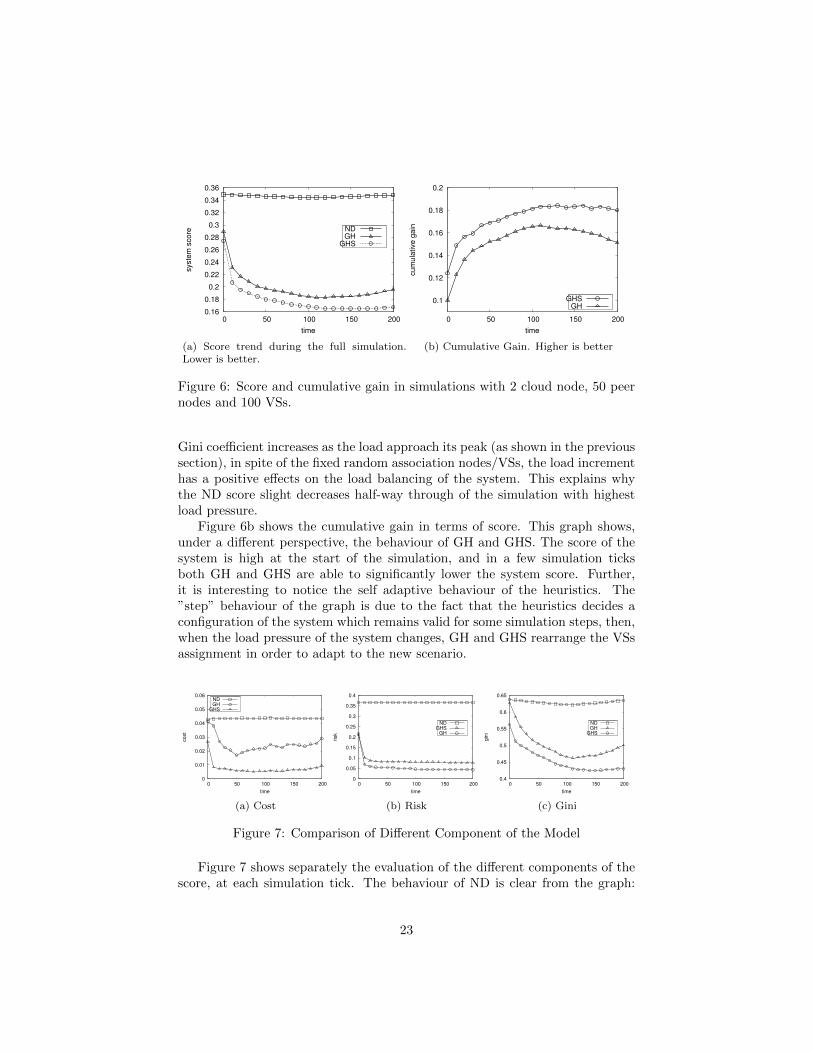
Figure 6a shows the system score for the three policies GH, GHS and ND, ateach simulation tick. The experiments shows the effectiveness of our heuristics.As a matter of fact, GH and GHS largely improve the system score with respectto ND. In fact, GH returns, on the average, a system score which is 40% betterthan ND. The behaviour of GH and GHS is comparable, with a maximumdifference between the score returned by them of a 5% in favour of GHS. Thisis due to the state, that allows GHS to exploit a wider range of configurationcompared to GH.
The score of ND is constant for the entire duration of the simulation, exceptfor a negligible decrease about at the middle of the simulation. This happensfor the following reasons: (i) ND does not change the initial assignment ofVSs during the simulation. For this reason, the risk, which depends on thenumber of objects assigned to the VSs managed by a node, does not change aswell; (ii) the bandwidth cost increases very slightly, since the number of VSsassigned to cloud nodes is low with respect to that assigned to peers (because ofthe initial uniform random assignment of the VSs to the peers); (iii) since the
22
0.16
0.18
0.2
0.22
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0 50 100 150 200
syste
m s
co
re
time
NDGH
GHS
(a) Score trend during the full simulation.Lower is better.
0.1
0.12
0.14
0.16
0.18
0.2
0 50 100 150 200
cu
mu
lative
ga
in
time
GHSGH
(b) Cumulative Gain. Higher is better
Figure 6: Score and cumulative gain in simulations with 2 cloud node, 50 peernodes and 100 VSs.
Gini coefficient increases as the load approach its peak (as shown in the previoussection), in spite of the fixed random association nodes/VSs, the load incrementhas a positive effects on the load balancing of the system. This explains whythe ND score slight decreases half-way through of the simulation with highestload pressure.
Figure 6b shows the cumulative gain in terms of score. This graph shows,under a different perspective, the behaviour of GH and GHS. The score of thesystem is high at the start of the simulation, and in a few simulation ticksboth GH and GHS are able to significantly lower the system score. Further,it is interesting to notice the self adaptive behaviour of the heuristics. The”step” behaviour of the graph is due to the fact that the heuristics decides aconfiguration of the system which remains valid for some simulation steps, then,when the load pressure of the system changes, GH and GHS rearrange the VSsassignment in order to adapt to the new scenario.
0
0.01
0.02
0.03
0.04
0.05
0.06
0 50 100 150 200
co
st
time
ND
GH
GHS
(a) Cost
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0 50 100 150 200
risk
time
ND
GHS
GH
(b) Risk
0.4
0.45
0.5
0.55
0.6
0.65
0 50 100 150 200
gin
i
time
NDGH
GHS
(c) Gini
Figure 7: Comparison of Different Component of the Model
Figure 7 shows separately the evaluation of the different components of thescore, at each simulation tick. The behaviour of ND is clear from the graph:
23

0
0.02
0.04
0.06
0.08
0.1
100 200 300 400 500 600 700 800 900 1000
Ave
rag
e c
ost
Number of VS
GHGHS
(a) Cost
0
0.02
0.04
0.06
0.08
0.1
100 200 300 400 500 600 700 800 900 1000
Ave
rag
e r
isk
Number of VS
GHGHS
(b) risk
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
100 200 300 400 500 600 700 800 900 1000
Ave
rag
e G
ini
Number of VS
GHGHS
(c) gini
Figure 8: Trends of score components when increasing the amount of VSs
values of cost, risk and Gini coefficient are higher compared to the heuristics.This confirms that employing the heuristics yields a dramatic improvement. Thetrend of cost in GHS is definitely lower than GH, whereas the risk is comparablefor the two heuristics. As regarding the Gini coefficient, GH is affected by thefluctuation of the load and achieves the best value at the peak load. After that,the coefficient increases as the load diminishes. Similarly, GHS obtains the bestGini coefficient at the peak load, but, conversely from GH, it keeps this valueuntil the end of the simulation.
7.3. Increasing the Number of Virtual Servers
The goal of this experiment is to evaluate the behaviour of the policies whenthe number of VSs increases. To this end, we increase the number of VS in thebaseline system configuration up to 1000, leaving the number of clouds nodesand peer nodes, as in the baseline configuration.
Regarding the risk and load balancing, both GH and GHS generally performbetter when the number of VS is larger, since they allow a finer control on theload distribution. When approaching the maximum number of VSs (1000),the risk and Gini coefficient of GH and GHS are comparable, whereas witha lower amount of VSs GHS outperforms GH. This happens because, due tothe presence of the state, GHS is able to effectively exploit a larger number ofalternative configurations, even with a smaller number of VSs. Conversely tothe risk and Gini coefficient, the bandwidth cost increases as the number of VSsgrows. However, GHS still obtains better performances with a bandwidth costthat is, in general, evidently lower compared to GH.
8. Conclusion
The combination of cloud and P2P computing is the next milestone in thearea of DVEs. The embedded flexibility of these architectures is a valuablecharacteristic for DVE operators, which are able to decide at real time whichnodes of the platform to exploit. In this direction, this paper proposes a hybridarchitecture which leverage the different characteristics of P2P and cloud nodesto offer a valid support for DVE applications. Efficient and effective provision
24

and load distribution algorithms are mandatory to realize DVEs that may scaleto larger and larger communities of users. We have proposed a load distribu-tion strategy taking into account a number of relevant issues, such as balancingthe infrastructure usage and reducing the economic cost. To this end, we havedesigned and evaluated two greedy heuristic policies characterized by low com-putational requirements. The experimental results show the effectiveness of ourapproach.
We plan to to investigate heuristics with different characteristics and toexploit the model presented in this paper to drive the provisioning process.We also are currently investigating a set of strategies for the definition of thePAM, the component that supports the AOI-resolution process, and we plan tointegrate a P2P gossip strategy as a further tool to decrease the rate of accessingcloud nodes.
Acknowledgments
The authors acknowledge the support of Project FP7-257438, Contrail: OpenComputing Infrastructures for Elastic Services. We would like to thank Alessan-dro Lulli who have helped in the preparation of the workload.
References
[1] R. Buyya, C. Yeo, S. Venugopal, J. Broberg, I. Brandic, Cloud comput-ing and emerging IT platforms: Vision, hype, and reality for deliveringcomputing as the 5th utility, Future Generation computer systems 25 (6)(2009) 599–616.
[2] V. Nae, A. Iosup, S. Podlipnig, R. Prodan, D. Epema, T. Fahringer, Effi-cient management of data center resources for Massively Multiplayer OnlineGames, 2008 SC - International Conference for High Performance Comput-ing, Networking, Storage and Analysis (2008) 1–12.
[3] V. Nae, R. Prodan, A. Iosup, T. Fahringer, A new business modelfor massively multiplayer online games, in: Proceeding of the secondjoint WOSP/SIPEW international conference on Performance engineering,ACM, 2011, pp. 271–282.
[4] K. Chen, P. Huang, C. Lei, Game traffic analysis: An MMORPG perspec-tive, Computer Networks 50 (16) (2006) 3002–3023.
[5] A. Bharambe, J. Douceur, J. Lorch, T. Moscibroda, J. Pang, S. Seshan,X. Zhuang, Donnybrook: Enabling large-scale, high-speed, peer-to-peergames, ACM SIGCOMM Computer Communication Review 38 (4) (2008)389–400.
[6] E. Buyukkaya, M. Abdallah, R. Cavagna, VoroGame: A Hybrid P2P Ar-chitecture for Massively Multiplayer Games, in: 6th Consumer Communi-cations and Networking Conference, (CCNC), IEEE, 2009, pp. 1–5.
25

[7] S. Hu, J. Chen, T. Chen, VON: a scalable peer-to-peer network for virtualenvironments, Network, IEEE 20 (4) (2006) 22–31.
[8] E. Carlini, M. Coppola, L. Ricci, Integration of P2P and clouds to supportmassively multiuser virtual environments, in: Network and Systems Sup-port for Games (NetGames), 9th Annual Workshop on, IEEE, 2010, pp.1–6.
[9] R. Steinmetz, K. Wehrle, Peer-to-Peer Systems and Applications, Vol. 3485,Lecture Notes in Computer Science, 2005.
[10] K. Kim, I. Yeom, J. Lee, HYMS: A hybrid mmog server architecture, IEICETransactions on Information and Systems E87 (2004) 2706–2713.
[11] I. Barri, F. Gine, C. Roig, A Scalable Hybrid P2P System for MMOFPS,2010 18th Euromicro Conference on Parallel, Distributed and Network-based Processing (2010) 341–347.
[12] I. Barri, F. Gine, C. Roig, A Hybrid P2P System to Support MMORPGPlayability, 2011 IEEE International Conference on High PerformanceComputing and Communications (2011) 569–574.
[13] A. Chen, R. Muntz, Peer clustering: a hybrid approach to distributedvirtual environments, in: Proceedings of 5th ACM SIGCOMM workshopon Network and system support for games, ACM, 2006, p. 11.
[14] J. Jardine, D. Zappala, A hybrid architecture for massively multiplayeronline games, in: Proceedings of the 7th ACM SIGCOMM Workshop onNetwork and System Support for Games, ACM, 2008, p. 60.
[15] B. De Vleeschauwer, B. Van Den Bossche, T. Verdickt, F. De Turck,B. Dhoedt, P. Demeester, Dynamic microcell assignment for massively mul-tiplayer online gaming, in: Proceedings of 4th ACM SIGCOMM workshopon Network and system support for games, ACM, 2005, pp. 1–7.
[16] D. Ahmed, S. Shirmohammadi, A microcell oriented load balancing modelfor collaborative virtual environments, in: Virtual Environments, Human-Computer Interfaces and Measurement Systems, 2008. VECIMS 2008.IEEE Conference on, no. July, IEEE, 2008, pp. 86–91.
[17] C. Bezerra, C. Geyer, A load balancing scheme for massively multiplayeronline games, Multimedia Tools and Applications 45 (1) (2009) 263–289.
[18] K. Lee, D. Lee, A scalable dynamic load distribution scheme for multi-server distributed virtual environment systems with highly-skewed userdistribution, in: Proceedings of the ACM symposium on Virtual realitysoftware and technology, ACM, 2003, pp. 160–168.
[19] Y. Deng, R. Lau, Heat diffusion based dynamic load balancing for dis-tributed virtual environments, in: Proceedings of the 17th ACM Sympo-sium on Virtual Reality Software and Technology, ACM, 2010, pp. 203–210.
26

[20] M. Esch, E. Tobias, Decentralized scale-free network construction andload balancing in Massive Multiuser Virtual Environments, in: Collabo-rative Computing: Networking, Applications and Worksharing (Collabo-rateCom), 2010 6th International Conference on, IEEE, 2010, pp. 1–10.
[21] R. Chertov, S. Fahmy, Optimistic load balancing in a distributed virtualenvironment, in: Proceedings of the 2006 international workshop on Net-work and operating systems support for digital audio and video, ACM,2006, pp. 1–6.
[22] S. Rieche, K. Wehrle, M. Fouquet, H. Niedermayer, T. Teifel, G. Carle,Clustering players for load balancing in virtual worlds, International Jour-nal of Advanced Media and Communication 2 (4) (2008) 351–363.
[23] I. Stoica, R. Morris, D. Liben-nowell, D. R. Karger, M. F. Kaashoek,F. Dabek, H. Balakrishnan, Chord: A Scalable Peer-to-Peer Lookup Pro-tocol for Internet Applications, IEEE/ACM Transactions on Networking(TON) 11 (1) (2003) 17–32.
[24] B. Godfrey, K. Lakshminarayanan, S. Surana, R. Karp, I. Stoica, Load bal-ancing in dynamic structured P2P systems, in: INFOCOM 2004. Twenty-third AnnualJoint Conference of the IEEE Computer and CommunicationsSocieties, Vol. 4, IEEE, 2004, pp. 2253–2262.
[25] M. Mauve, J. Vogel, V. Hilt, W. Effelsberg, Local-lag and timewarp: Pro-viding consistency for replicated continuous applications, IEEE Transac-tions on Multimedia 6 (1) (2004) 47–57.
[26] A. Rao, K. Lakshminarayanan, S. Surana, R. Karp, I. Stoica, Load balanc-ing in structured P2P systems, Peer-to-Peer Systems II (2003) 68–79.
[27] C. Chen, C. Yao, S. Liang, Towards Practical Virtual Server-based LoadBalancing for Distributed Hash Tables, in: Parallel and Distributed Pro-cessing with Applications, 2008. ISPA’08. International Symposium on,IEEE, 2008, pp. 35–42.
[28] S. Webb, S. Soh, W. Lau, W. Perth, RACS: a referee anti-cheat scheme forP2P gaming, in: Proc. NOSSDAV, Vol. 07, ACM, 2007, pp. 37–42.
[29] T. Pitoura, N. Ntarmos, P. Triantafillou, Replication, Load Balancing andEfficient Range Query Processing in DHTs, in: Proceedings of the Advancesin Database Technology - EDBT 2006, ACM, 2006, pp. 131–148.
[30] S. Legtchenko, S. Monnet, G. Thomas, Blue Banana: resilience to avatarmobility in distributed MMOGs, in: Dependable Systems and Networks(DSN), 2010 IEEE/IFIP International Conference on, IEEE, 2010, pp. 171–180.
[31] Second life website, http://secondlife.com/.
27

[32] E. Carlini, M. Coppola, L. Ricci, Evaluating compass routing based aoi-castby mogs mobility models, in: Proceedings of the 4th International ICSTConference on Simulation Tools and Techniques, ICST, 2011, pp. 328–335.
28
Related Documents











