Fine-Grain Performance Scaling of Soft Vector Processors Peter Yiannacouras Jonathan Rose Gregory J. Steffan ESWEEK – CASES 2009, Grenoble, France Oct 13, 2009

Fine-Grain Performance Scaling of Soft Vector Processors Peter Yiannacouras Jonathan Rose Gregory J. Steffan ESWEEK – CASES 2009, Grenoble, France Oct.
Jan 01, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Fine-Grain Performance Scaling of Soft Vector Processors
Peter YiannacourasJonathan RoseGregory J. Steffan
ESWEEK – CASES 2009, Grenoble, FranceOct 13, 2009
2
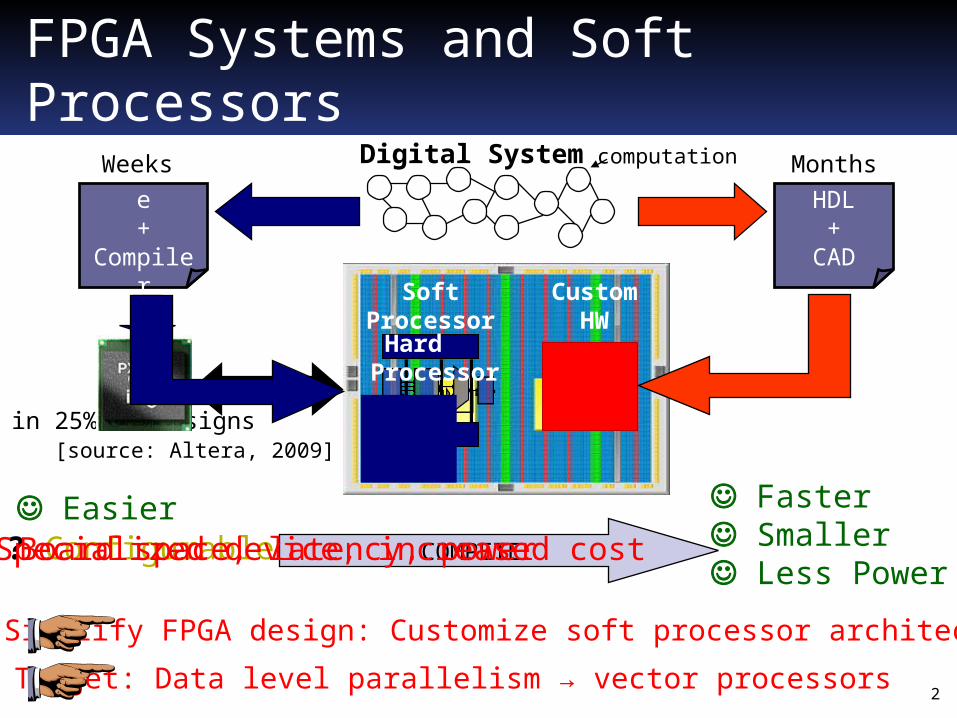
FPGA Systems and Soft Processors
SoftProcessor
CustomHW
HDL+
CAD
Software+
Compiler
Easier Faster Smaller Less Power
Simplify FPGA design: Customize soft processor architecture
? Configurable COMPETE
Weeks Months
Target: Data level parallelism → vector processors
Used in 25% of designs [source: Altera, 2009]
Digital System
Hard Processor
Board space, latency, power Specialized device, increased cost
computation
3
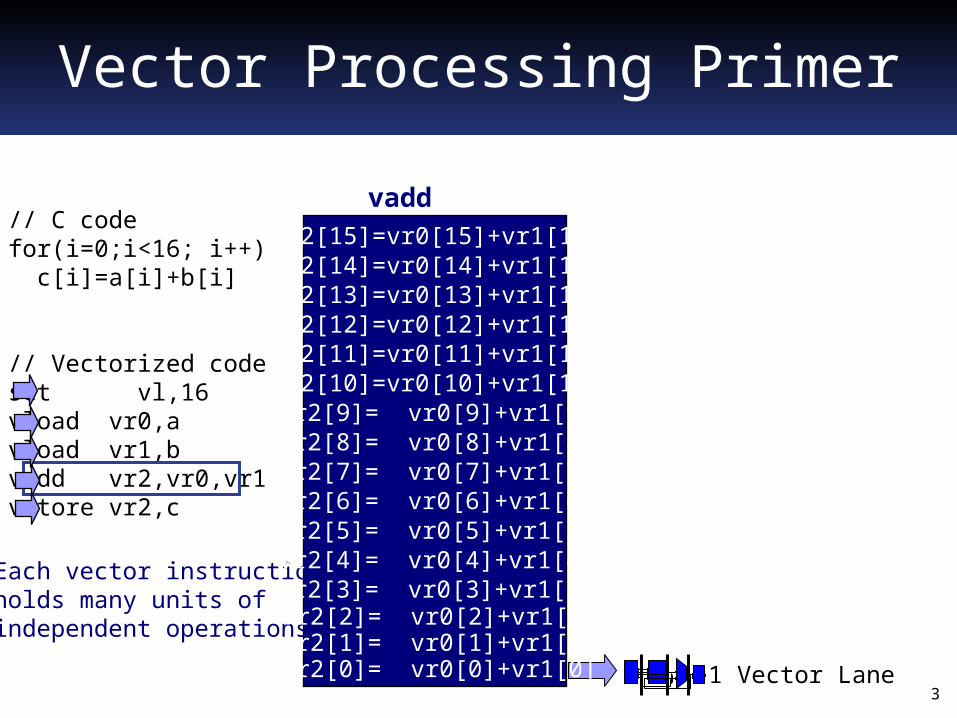
Vector Processing Primer
// C codefor(i=0;i<16; i++) c[i]=a[i]+b[i]
// Vectorized codeset vl,16vload vr0,avload vr1,bvadd vr2,vr0,vr1vstore vr2,c
Each vector instructionholds many units of independent operations
vr2[0]= vr0[0]+vr1[0]vr2[1]= vr0[1]+vr1[1]vr2[2]= vr0[2]+vr1[2]
vr2[4]= vr0[4]+vr1[4]vr2[3]= vr0[3]+vr1[3]
vr2[5]= vr0[5]+vr1[5]vr2[6]= vr0[6]+vr1[6]vr2[7]= vr0[7]+vr1[7]vr2[8]= vr0[8]+vr1[8]vr2[9]= vr0[9]+vr1[9]
vr2[10]=vr0[10]+vr1[10]vr2[11]=vr0[11]+vr1[11]vr2[12]=vr0[12]+vr1[12]vr2[13]=vr0[13]+vr1[13]vr2[14]=vr0[14]+vr1[14]vr2[15]=vr0[15]+vr1[15]
vadd
1 Vector Lane

4
Vector Processing Primer
// C codefor(i=0;i<16; i++) c[i]=a[i]+b[i]
// Vectorized codeset vl,16vload vr0,avload vr1,bvadd vr2,vr0,vr1vstore vr2,c
Each vector instructionholds many units of independent operations
vadd16 Vector Lanes
vr2[0]= vr0[0]+vr1[0]vr2[1]= vr0[1]+vr1[1]vr2[2]= vr0[2]+vr1[2]
vr2[4]= vr0[4]+vr1[4]vr2[3]= vr0[3]+vr1[3]
vr2[5]= vr0[5]+vr1[5]vr2[6]= vr0[6]+vr1[6]vr2[7]= vr0[7]+vr1[7]vr2[8]= vr0[8]+vr1[8]vr2[9]= vr0[9]+vr1[9]
vr2[10]=vr0[10]+vr1[10]vr2[11]=vr0[11]+vr1[11]vr2[12]=vr0[12]+vr1[12]vr2[13]=vr0[13]+vr1[13]vr2[14]=vr0[14]+vr1[14]vr2[15]=vr0[15]+vr1[15]
16x speedup
Previous Work (on Soft Vector Processors):1. Scalability2. Flexibility3. Portability
CASES’08

5
VESPA Architecture Design(Vector Extended Soft Processor Architecture)
ScalarPipeline3-stage
VectorControlPipeline3-stage
VectorPipeline6-stage
Icache Dcache
Decode RFALU
MUX WB
VCRF
VSRF
VCWB
VSWB
Logic
DecodeRepli-cate
Hazardcheck
VRRF
VRWB
VRRF
VRWB
Decode
Supports integerand fixed-point operations [VIRAM]
32-bit Lanes
Shared Dcache
Legend Pipe stage Logic Storage
Lane 1 ALU,Mem UnitLane 2 ALU, Mem, Mul

6
In This Work
1. Evaluate for real using modern hardware Scale to 32 lanes (previous work did 16 lanes)
2. Add more fine-grain architectural parameters1. Scale more finely
Augment with parameterized vector chaining support
2. Customize to functional unit demand Augment with heterogeneous lanes
3. Explore a large design space

7
Evaluation Infrastructure
Binary
InstructionSet
Simulation
EEMBCBenchmarks
RTLSimulation
SOFTWARE HARDWARE
Verilog
FPGACAD
Software
cyclesarea, power,clock frequency
GCCCompiler
verification verification
Full hardware design of VESPA soft vector processor
Evaluate soft vector processors with high accuracy
Stratix III 340
DDR2
Vectorizedassembly
subroutines
GNU as
ld
8
0
5
10
15
20
25
Wal
l Clo
ck S
peed
up 1 Lane
2 Lanes
4 Lanes
8 Lanes
16 Lanes
32 Lanes
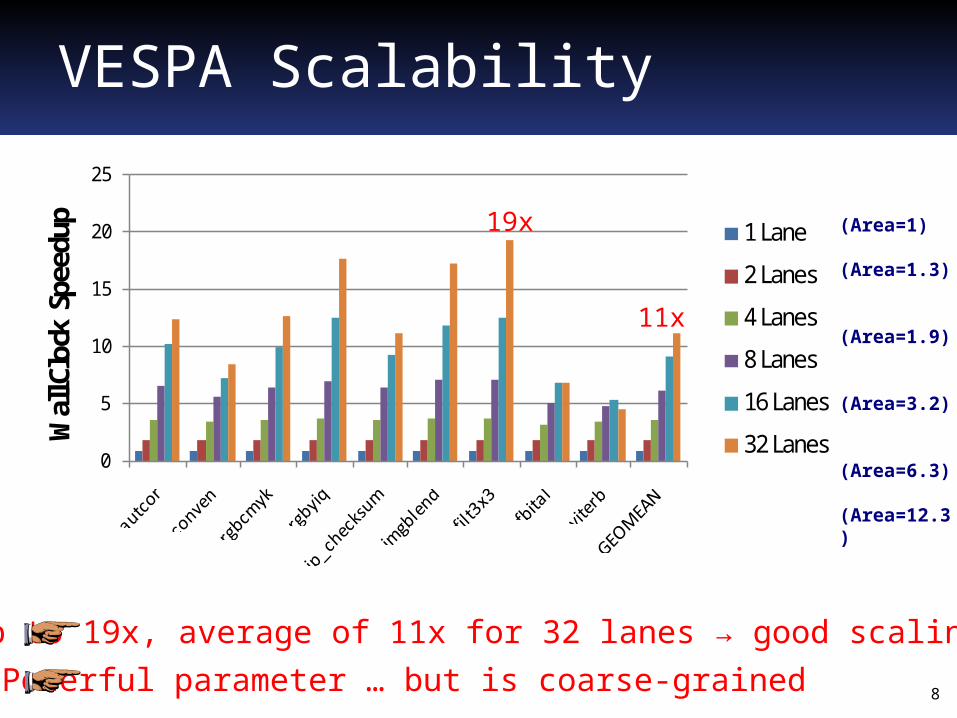
VESPA Scalability
Up to 19x, average of 11x for 32 lanes → good scaling
19x
11x
(Area=1)
(Area=1.3)
(Area=1.9)
(Area=3.2)
(Area=6.3)
(Area=12.3)
Powerful parameter … but is coarse-grained

9
Vector Lane Design Space
1 Lane
2 Lanes
4 Lanes
8 Lanes
16 Lanes32 Lanes
0.0625
0.125
0.25
0.5
1
2048 4096 8192 16384 32768 65536
Wal
l Clo
ck T
ime
Area
Too coarse grain! Reprogrammability allows more exact-fit
8% of largest FPGA
(Equivalent ALMs)

10
In This Work
1. Evaluate for real using modern hardware Scale to 32 lanes (previous work did 16 lanes)
2. Add more fine-grain architectural parameters1. Scale more finely
Augment with parameterized vector chaining support
2. Customize to functional unit demand Augment with heterogeneous lanes
3. Explore a large design space

11
Vector Chaining
Simultaneous execution of independent element operations within dependent instructions
vadd vr10, vr1,vr2
vmul vr20, vr10,vr11
dependency
0 1 2 3 4 5 6 7
0
vadd
vmul
Dependent Instructions
1 2 3 4 5 6 7
Independent ElementOperations

12
Vector Chaining in VESPA
Unified
ALU
VectorRegister File
B=1
B=2
Bank 0
VectorRegister File
Bank 1
MUX
MUX
vmulvadd
vmulvadd
Single Instruction Execution
Multiple Instruction Execution
time
time
No VectorChaining
With VectorChaining
ALU
ALU
ALU
Mem
ALU
ALU
ALU
MemMem
ALU
Mul
MemMemMemMul
Lanes=4
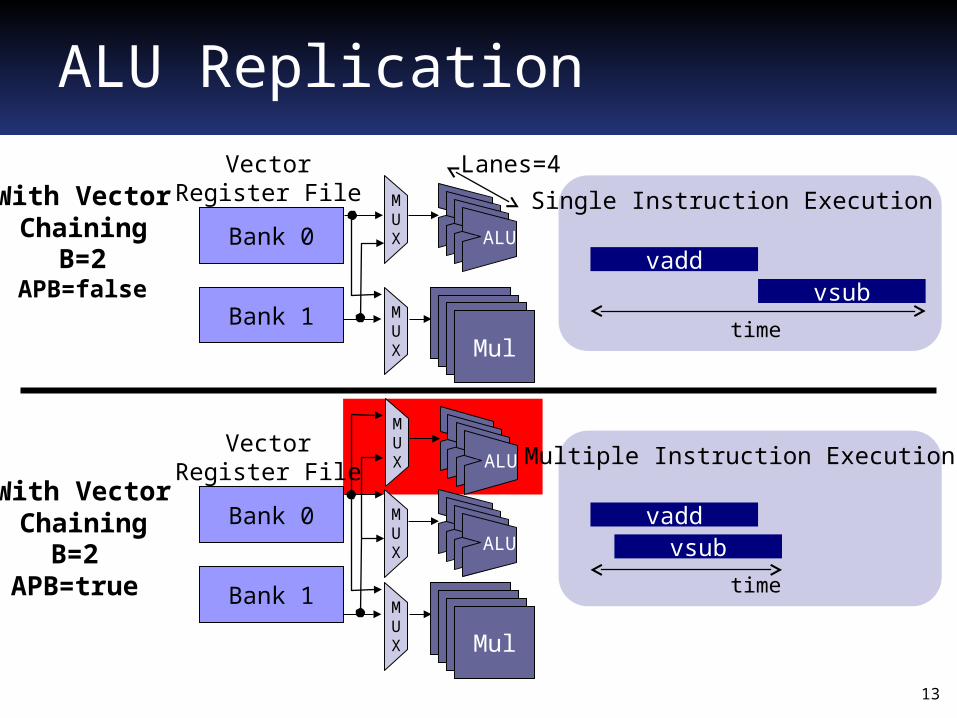
Performance increase if instructions correctly scheduled
13
ALU Replication
B=2APB=false
Bank 0
VectorRegister File
Bank 1
MUX
vsubvadd
Single Instruction Execution
time
With VectorChaining
MemMemMem
ALU
Mul
MUX
ALUALUALU
B=2APB=true
Bank 0
VectorRegister File
Bank 1
MUX
With VectorChaining
MemMemMem
ALU
Mul
MUX
ALUALUALU
MUX
ALUALUALUALU
vsubvadd
Multiple Instruction Execution
time
Lanes=4
14
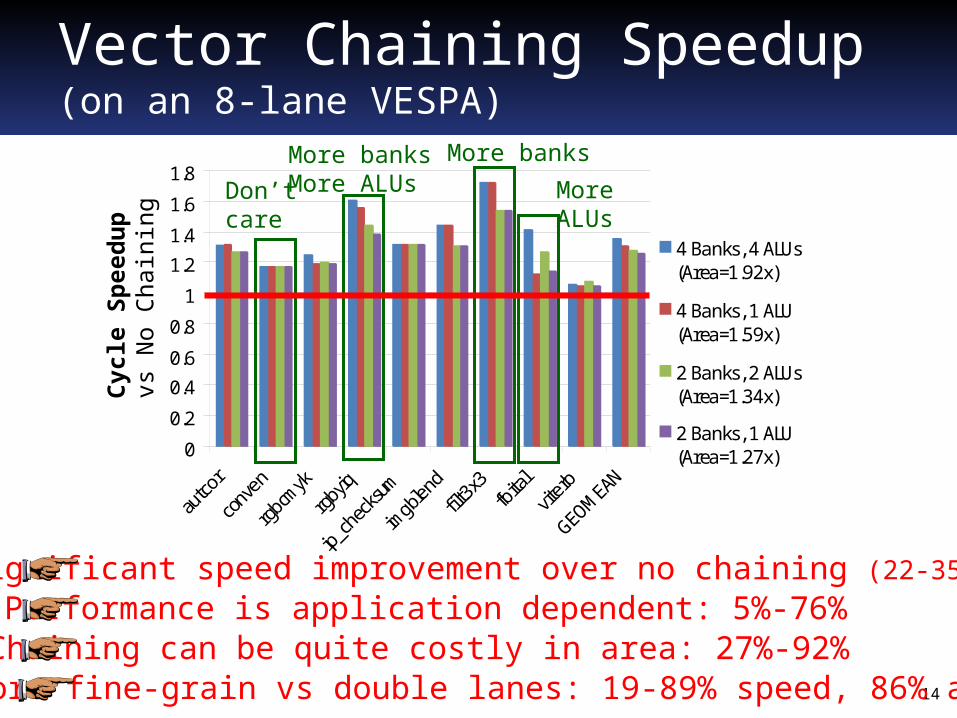
Vector Chaining Speedup(on an 8-lane VESPA)
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
autco
r
conve
n
rgbcm
ykrgb
yiq
ip_chec
ksum
imgble
ndfilt3
x3fbita
lvit
erb
GEOMEAN
Cycl
e Sp
eedu
p 4 Banks, 4 ALUs(Area=1.92x)
4 Banks, 1 ALU(Area=1.59x)
2 Banks, 2 ALUs(Area=1.34x)
2 Banks, 1 ALU(Area=1.27x)
Don’tcare
More banksMore ALUs
More banks
More ALUs
Chaining can be quite costly in area: 27%-92%Performance is application dependent: 5%-76%Significant speed improvement over no chaining (22-35% avg)
More fine-grain vs double lanes: 19-89% speed, 86% area
Cyc
le S
pee
du
p
vs N
o C
hain
ing

15
In This Work
1. Evaluate for real using modern hardware Scale to 32 lanes (previous work did 16 lanes)
2. Add more fine-grain architectural parameters1. Scale more finely
Augment with parameterized vector chaining support
2. Customize to functional unit demand Augment with heterogeneous lanes
3. Explore a large design space

16
Heterogeneous Lanes
Mul
ALU
Mul
ALU
Mul
ALU
Mul
ALU
Lane 1
Lane 2
Lane 3
Lane 4
vmul
4 Lanes (L=4)
2 Multiplier Lanes (X=2)

17
Heterogeneous Lanes
Mul
ALU
Mul
ALU
ALU
ALU
Lane 1
Lane 2
Lane 3
Lane 4
vmul
STALL!
Save area, but reduce speeddepending ondemand on themultiplier
4 Lanes (L=4)
2 Multiplier Lanes (X=2)

18
Impact of Heterogeneous Lanes(on a 32-lane VESPA)
0
0.2
0.4
0.6
0.8
1
1.2
autco
r
conve
n
rgbcm
ykrgb
yiq
ip_chec
ksum
imgble
ndfilt3
x3fbita
lvit
erb
GEOMEAN
Cycl
e Sp
eedu
p
X=1 (Area=0.87)
X=2 (Area=0.87)
X=4 (Area=0.88)
X=8 (Area=0.9)
X=16 (Area=0.94)
X=32 (Area=1)
Free Expensive Moderate
Performance penalty is application dependent: 0%-85%
Modest area savings (6%-13%) – dedicated multipliers

19
In This Work
1. Evaluate for real using modern hardware Scale to 32 lanes (previous work did 16 lanes)
2. Add more fine-grain architectural parameters1. Scale more finely
Augment with parameterized vector chaining support
2. Customize to functional unit demand Augment with heterogeneous lanes
3. Explore a large design space
20
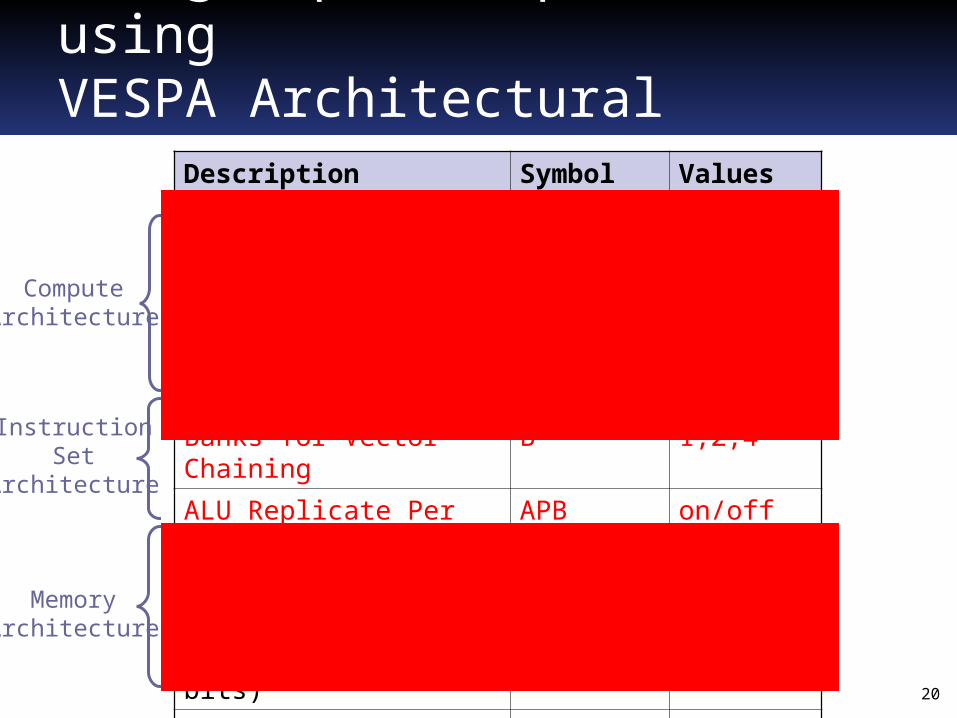
Design Space Exploration usingVESPA Architectural Parameters
Description Symbol Values
Number of Lanes L 1,2,4,8, …
Memory Crossbar Lanes M 1,2, …, L
Multiplier Lanes X 1,2, …, L
Banks for Vector Chaining B 1,2,4
ALU Replicate Per Bank APB on/off
Maximum Vector Length MVL 2,4,8, …
Width of Lanes (in bits) W 1-32
Instruction Enable (each) - on/off
Data Cache Capacity DD any
Data Cache Line Size DW any
Data Prefetch Size DPK < DD
Vector Data Prefetch Size DPV < DD/MVL
ComputeArchitecture
MemoryArchitecture
InstructionSet
Architecture
21
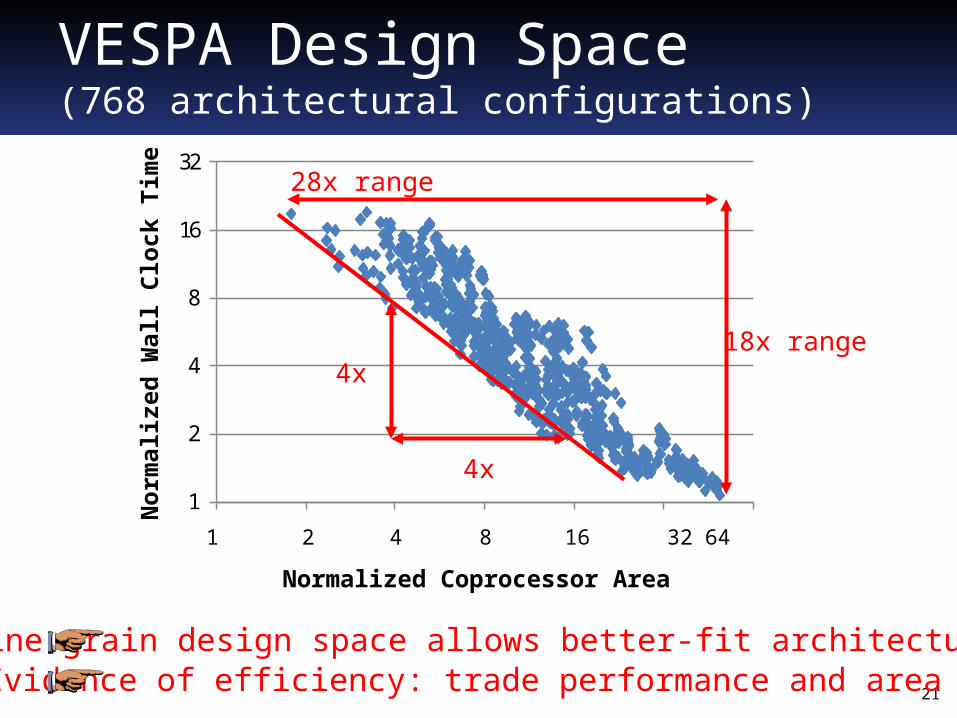
VESPA Design Space (768 architectural configurations)
1
2
4
8
16
32
1024 2048 4096 8192 16384 32768 65536
Wal
l Clo
ck T
ime
Area
Fine-grain design space allows better-fit architecture
28x range
18x range4x
4x
Evidence of efficiency: trade performance and area 1:1
1 2 4 8 16 32
Normalized Coprocessor Area
64
No
rmal
ized
Wal
l C
lock
Tim
e

22
Summary
1. Evaluated VESPA on modern FPGA hardware Scale up to 32 lanes with 11x average speedup
2. Augmented VESPA with fine-tunable parameters1. Vector Chaining (by banking the register file)
22-35% better average performance than without Chaining configuration impact very application-dependent
2. Heterogeneous Lanes – lanes w/o multipliers Multipliers saved, costs performance (sometimes free)
3. Explored a vast architectural design space 18x range in performance, 28x range in area
Use software for non-critical data-parallel computation

23
Thank You!
VESPA release: http://www.eecg.utoronto.ca/VESPA
24
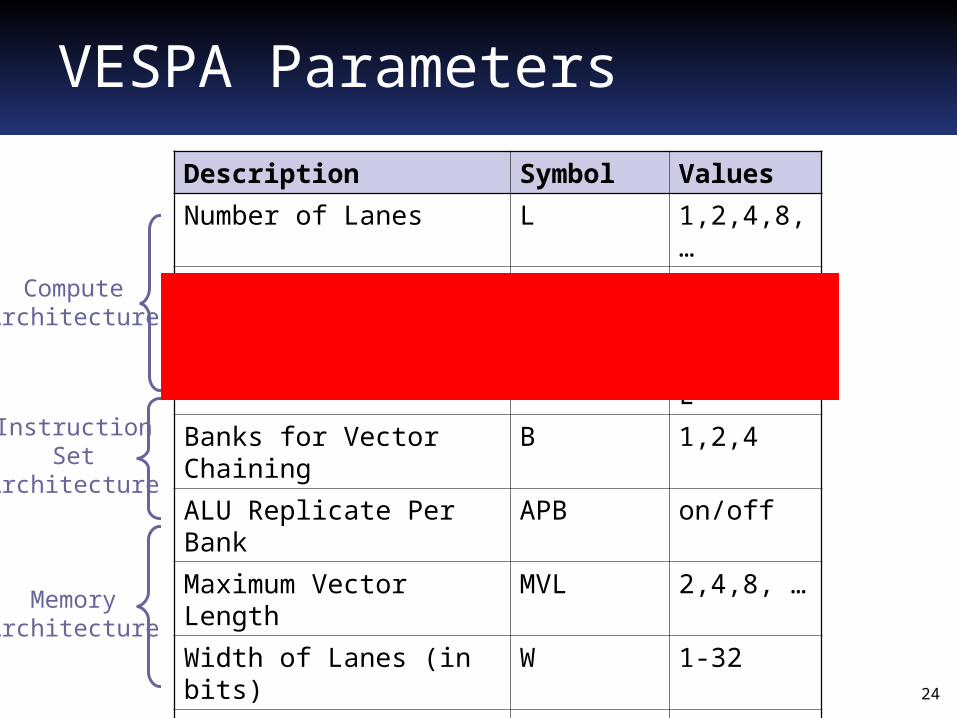
VESPA Parameters
Description Symbol Values
Number of Lanes L 1,2,4,8, …
Memory Crossbar Lanes M 1,2, …, L
Multiplier Lanes X 1,2, …, L
Banks for Vector Chaining B 1,2,4
ALU Replicate Per Bank APB on/off
Maximum Vector Length MVL 2,4,8, …
Width of Lanes (in bits) W 1-32
Instruction Enable (each) - on/off
Data Cache Capacity DD any
Data Cache Line Size DW any
Data Prefetch Size DPK < DD
Vector Data Prefetch Size DPV < DD/MVL
ComputeArchitecture
MemoryArchitecture
InstructionSet
Architecture
25
0
5
10
15
20
25
30
Cycl
e Sp
eedu
p vs
1 La
ne
1 Lane
2 Lanes
4 Lanes
8 Lanes
16 Lanes
32 Lanes
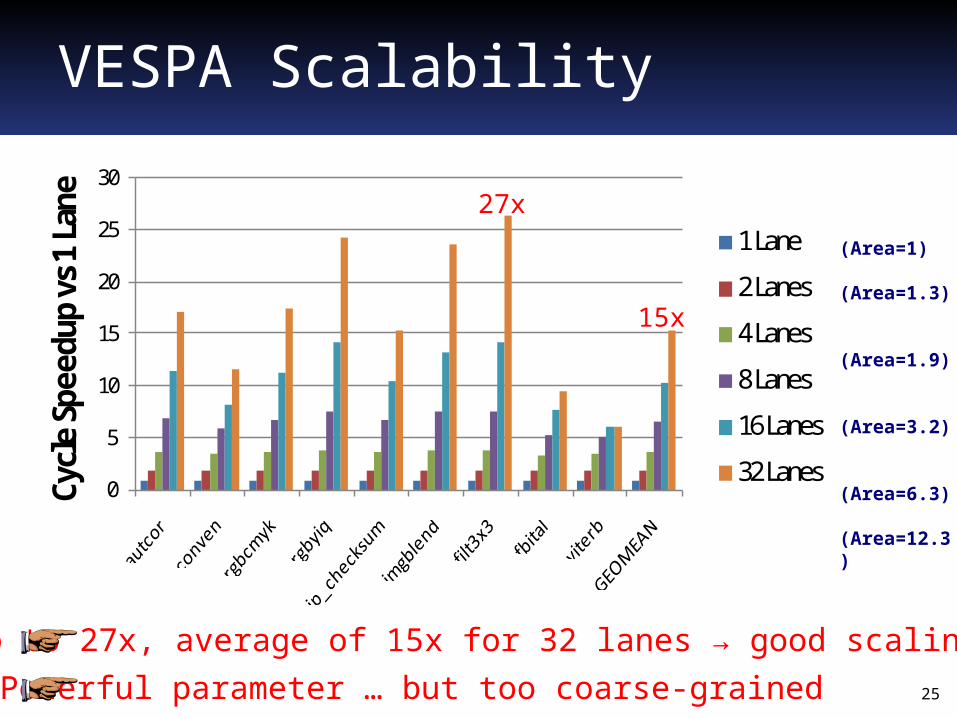
VESPA Scalability
Up to 27x, average of 15x for 32 lanes → good scaling
27x
15x
(Area=1)
(Area=1.3)
(Area=1.9)
(Area=3.2)
(Area=6.3)
(Area=12.3)
Powerful parameter … but too coarse-grained
26
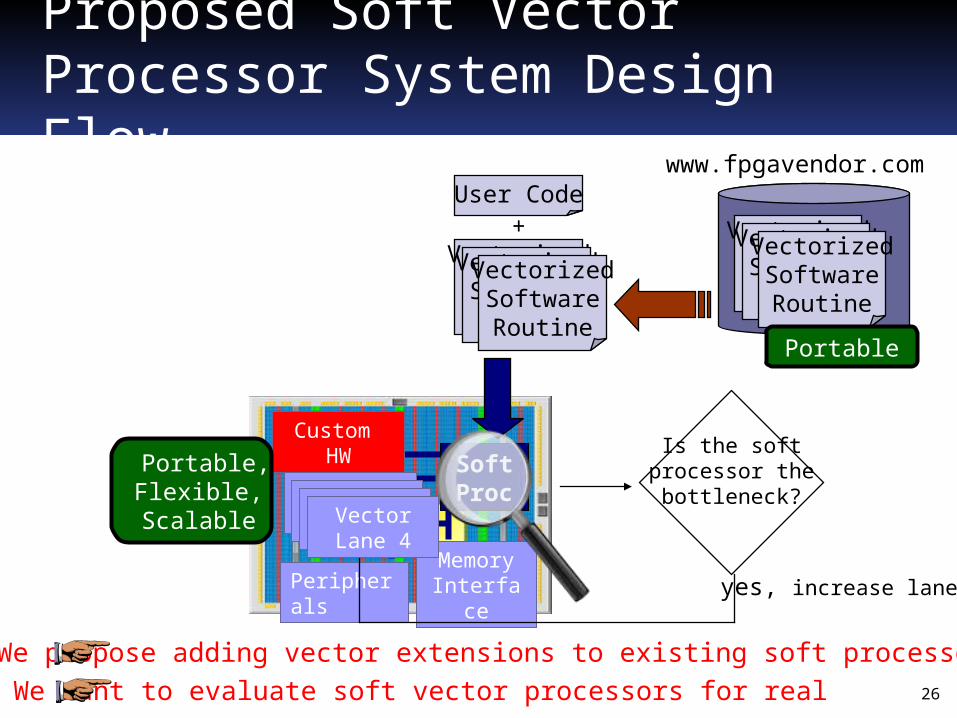
Proposed Soft Vector Processor System Design Flow
MemoryInterface
Custom HW
Peripherals
Soft ProcVector
Lane 1
Is the softprocessor thebottleneck?
yes, increase lanes
www.fpgavendor.com
We propose adding vector extensions to existing soft processors
User Code+
Portable, Flexible, Scalable
VectorizedSoftwareRoutine
VectorizedSoftwareRoutine
VectorizedSoftwareRoutine
Portable
VectorizedSoftwareRoutine
VectorizedSoftwareRoutine
VectorizedSoftwareRoutine
Vector Lane 2Vector Lane 3Vector Lane 4
We want to evaluate soft vector processors for real

27
Vector Memory Unit
Dcache
base
stride*0
index0
+MUX
...
stride*1
index1
+MUXstride*L
indexL
+MUX
MemoryRequestQueue
ReadCrossbar
…Memory Lanes=4
rddata0rddata1
rddataL
wrdata0wrdata1
wrdataL ...
WriteCrossbar
MemoryWrite
Queue
L = # Lanes - 1……

28
Overall Memory System Performance
00.10.20.30.40.50.60.70.8
16-byte line 64-byte line 64-byte line +prefetch
Fra
ction o
f Tota
l Cycle
s
Memory Unit Stall Cycles
Miss Cycles
(4KB) (16KB)
67%
48%
31%
4%
15
Wider line + prefetching reduces memory unit stall cycles significantly
Wider line + prefetching eliminates all but 4% of miss cycles
16 lanes
Related Documents











