Feature Selection, Acoustic Modeling and Adaptation SDSG REVIEW of recent WORK Technical University of Crete Speech Processing and Dialog Systems Group Presenter: Alex Potamianos

Feature Selection, Acoustic Modeling and Adaptation SDSG REVIEW of recent WORK Technical University of Crete Speech Processing and Dialog Systems Group.
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Feature Selection, Acoustic Modeling and Adaptation
SDSG REVIEW of recent WORK
Technical University of Crete
Speech Processing and
Dialog Systems Group
Presenter: Alex Potamianos

TUC - SDSG
Outline
• Prior Work – Adaptation– Acoustic Modeling– Robust Feature Selection
• Bridge over to HIWIRE work-plan– Robust Features, Acoustic Modeling, Adaptation– New areas: audio-visual, microphone arrays

TUC - SDSG
Adaptation
• Transformation-based adaptation• MAP Adaptation (Bayesian learning
approximation)• Speaker Clustering / Speaker space
models.• Robust Feature Selection• Combinations

TUC - SDSG
Acoustic Model Adaptation: SDSG Selected Work
• Constrained Estimation Adaptation• Maximum Likelihood Stochastic
Transformations• Combined Transformation-MAP adaptation• MLST Basis Vectors• Incremental Adaptation• Dependency modeling of biases• Vocal Tract Norm. with Linear Transformation

TUC - SDSG
Constrained Estimation Adaptation (Digalakis 1995)
• Hypothesize a sequence of feature-space linear transformations:
• Adapted models (A) are then:
• diagonal.
• Adaptation is equivalent to estimating the state dependent
stst byAx
ss bA ,
))(,;()|()|(1
Tsisssisst
N
iitA ASAbmAxNspsxP
sA

TUC - SDSG
Compared to MLLR (Leggeter 1996)
• Both published at the same time.
• MLLR is only model adaptation.
• MLLR transforms only the model means
• in MLLR is block diagonal.
• Constrained estimation is more generic.
),;()|()|(1
ississt
N
iitA SbmAxNspsxP
sA

TUC - SDSG
Limitations of the Linear Assumption
• Linear assumption may be too restrictive in modeling the training testing dependency.
• Goal: Try a more complex transformation.
• All Gaussians in a class are restricted to be transformed identically using the same transformation.
• Goal: Let each Gaussian in a class to decide for its own transformation.
• Which transformation transforms each Gaussian is predefined.
• Goal: Let the system to automatically choose the transformation-Gaussian couples.

TUC - SDSG
ML Stochastic Transformations (MLST) (Diakoloukas Digalakis 1997)
• Hypothesize a sequence of feature-space stochastic transformations of the form:
NiNsNtsN
ists
ists
t
lspbyA
lspbyA
lspbyA
x
),|(y probabilit with,
),|(y probabilit with,
),|(y probabilit with,
2222
1111

TUC - SDSG
MLST: model-space
• Use a set of MLSTs instead of linear transformations. • Adapted observation densities:
– MLST-Method I
• is diagonal
– MLST-Method II
• is block diagonal
)ASA,bmA;N(xs)|p()s,|p(s)|(xP Tjsisjsjsisjst
N
1i
N
1=jiijtA
sjA
)S,bmA;N(xs)|p()s,|p(s)|(xP isjsissjt
N
1i
N
1=jiijtA
sjA

TUC - SDSG
MLST: Reduce the number of mixture components
• The adapted mixture densities consist of Gaussians.
• Reduce the Gaussians back to their SI number:– HPT: Apply the component transformation with the highest
probability to each Gaussian.
– LCT: Linear combination of all component transforms.
– MTG: Merge the transformed Gaussians.
NN
N
jsjijs
N
jsjijs bspbAspA
11
),|( and ),|(
2)(
1
2)(2)(2)(
1
)()(
~),|(~
),|(~
di
N
j
dji
djiij
di
N
j
djiij
di
sp
sp
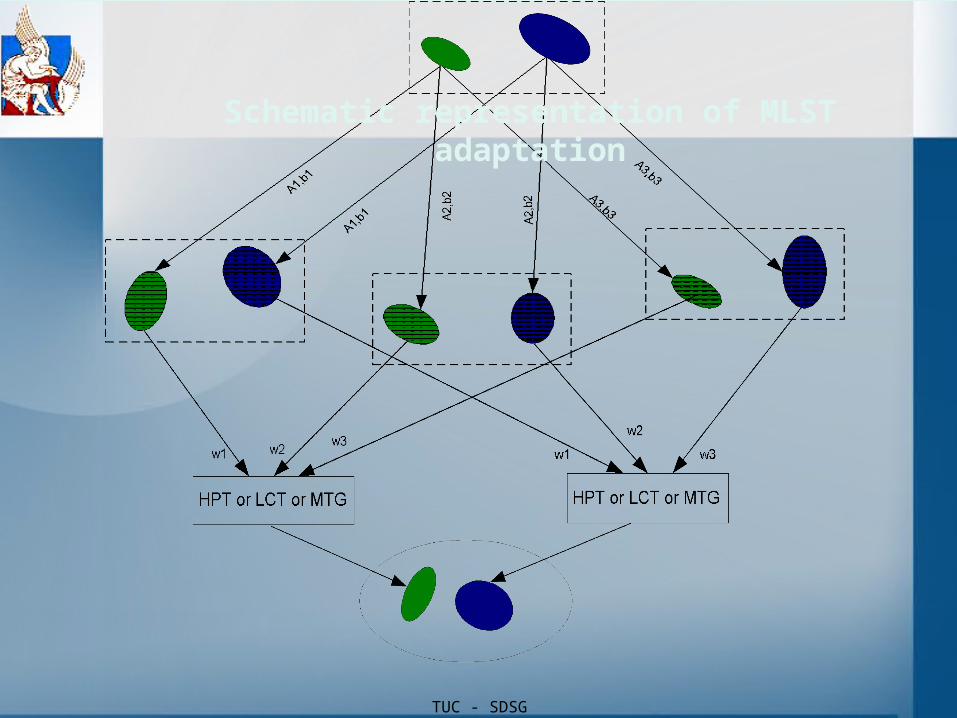
TUC - SDSG
Schematic representation of MLST adaptation

TUC - SDSG
MLST properties
• Asj, bsj are shared at a state or state-cluster level
• Transformation weights lj are estimated at a Gaussian level
• MLST combines transformed Gaussians • MLST is flexible on how to select a transformation for
each Gaussian.• MLST chooses arbitrary number of transformations
per class.

TUC - SDSG
MLST compared to ML Linear Transforms
• Hard versus Soft decision: – Choose the linear component based on the
training samples.
• Adaptation Resolution: – Linear components are common to a
transformation class– Choose the transformation at a Gaussian level– Increased adaptation resolution - robust
estimation

TUC - SDSG
MLST basis transforms (Boulis Diakoloukas Digalakis 2000)
• Algorithm steps:– Cluster the training speaker space into classes– Train MLST component transforms using data from
each training speaker class – Adaptation data is used to estimate the
transformation weight
• It is like having a-priori knowledge to the estimation process
• Results in rapid speaker adaptation• Significant gains for medium and small data
sets
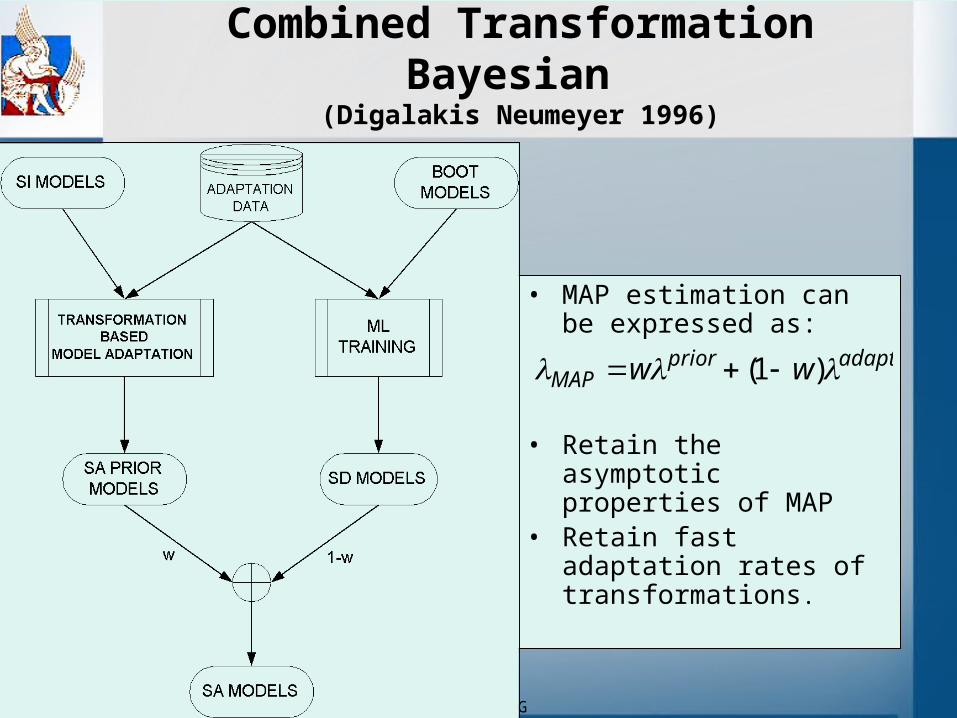
TUC - SDSG
Combined Transformation Bayesian (Digalakis Neumeyer 1996)
• MAP estimation can be expressed as:
• Retain the asymptotic properties of MAP
• Retain fast adaptation rates of transformations.
adaptpriorMAP ww )1(

TUC - SDSG
Rapid Speech Recognizer Adaptation (Digalakis et.al 2000)
• Dependence models of the bias components of cascaded transforms. Techniques:– Gaussian multiscale process– Hierarchical tree-structured prior– Explicit correlation models– Markov Random Fields

TUC - SDSG
VTN with Linear Transformation(Potamianos and Rose 1997, Potamianos and Narayanan 1998)
• Vocal Tract Normalization:
Select optimal warping factor according to
= arg max P(Xª|a, , H)
where H is the transcription, and Xª frequency
warped observation vector by factor a.• VTN with linear transformation
{, } = arg max P(Xª|a, , , H)
where h() is a parametric linear transformation
with parameter

TUC - SDSG
Acoustic Modeling:SDSG Selected Work
• Genones: Generalized Gaussian mixture
tying scheme
• Stochastic Segment Models (SSMs)

TUC - SDSG
Genones: Generalized Mixture Tying (Digalakis Monaco Murveit 1996)
• Algorithm Steps:– Clustering of HMM states based on the similarity of
their distributions– Splitting: Construct seed codebooks for each state
cluster• Either identify the most likely mixture component subset • Or cluster down the original codebook
– Reestimation of the parameters using Baum-Welch
• Better trade-off between modelling resolution and robustness
• Genones are used in Decipher and Nuance

TUC - SDSG
Segment Models
• HMM limitations:– Weak duration modelling– Conditional independence of observations assumption– Restrictions on feature extraction imposed by frame-based
observations
• Segment models motivation:– Larger number of degrees of freedom in the model– Use segmental features– Model correlation of frame-based features – Powerful modelling of transitions and longer-range speech
dynamics– Less distortion for segmental coding segmental recognition
more efficient
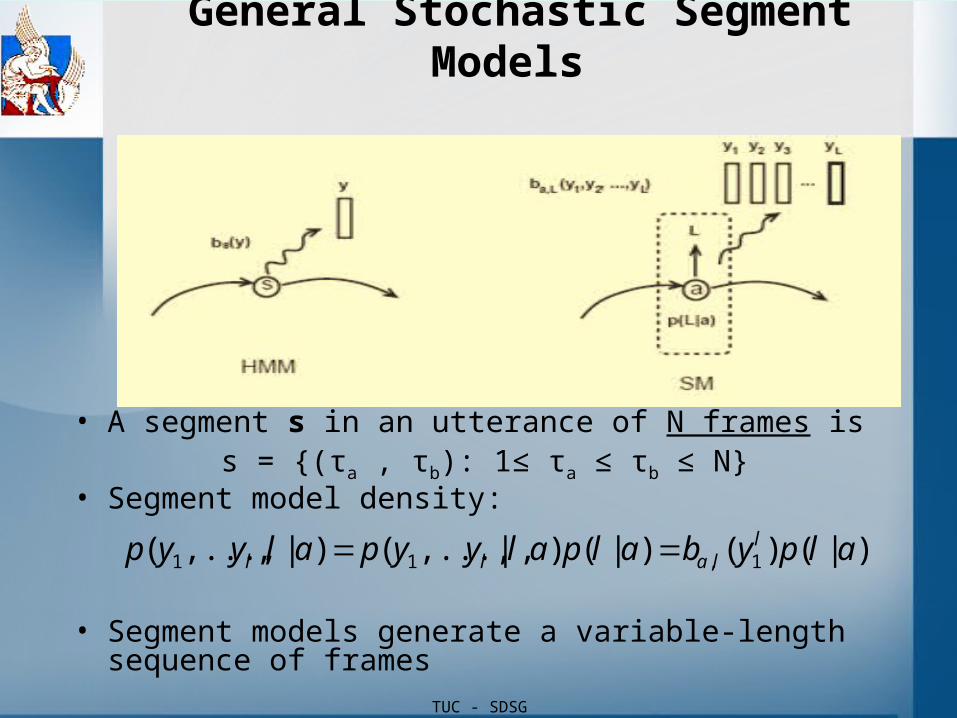
TUC - SDSG
General Stochastic Segment Models
• A segment s in an utterance of N frames iss = {(τa , τb): 1≤ τa ≤ τb ≤ N}
• Segment model density:
• Segment models generate a variable-length sequence of frames
)|()()|(),|,...,()|,,...,( 1,11 alpybalpalyypalyyp llall

TUC - SDSG
Stochastic Segment Model (Ostendorf Digalakis 1992)
• Problem: Model time correlation within a segment
• Solution: Gaussian model variations based on assumptions about the form of statistical dependency– Gauss-Markov model– Dynamical System model– Target State model.

TUC - SDSG
SSM Viterbi Decoding (Ostendorf Digalakis Kimball 1996)
• HMM Viterbi recognition:• State to Word sequence mapping:
• SSM analogous solution:
• Map the segment label sequence to the appropriate word sequence:
1 1 11arg max ( | ) ( )ˆ
TT T Tp pys s s
1 1( )ˆ ˆ
T Thw s
11
ˆ
1 1 1 1 1 11( , ) { ( | , ) ( | ) ( )}
,
ˆ arg max maxˆN N
TN N N N N Np p
N a lp ya l a l a aN
1 1( )ˆ ˆ
K Nfw a

TUC - SDSG
From HMMs to Segment Models(Ostendorf Digalakis 1996)
• Unified view of stochastic modeling
• General stochastic model that encompasses most SM type models
• Similarities in terms of correlation and parameter tying assumptions
• Analogies between segment models and HMMs

TUC - SDSG
Robust Feature Selection
• Time-Frequency Representation for ASR(Potamianos and Maragos 1999)
• Confidence Measure Estimation for ASR Features
sent over wireless channels (“missing features”)(Potamianos and Weerackody 2001)
• AM-FM Model Based Features(Dimitriadis et al 2002)

TUC - SDSG
Other Work
• Multiple source separation using microphone
arrays (Sidiropoulos et al. 2001)
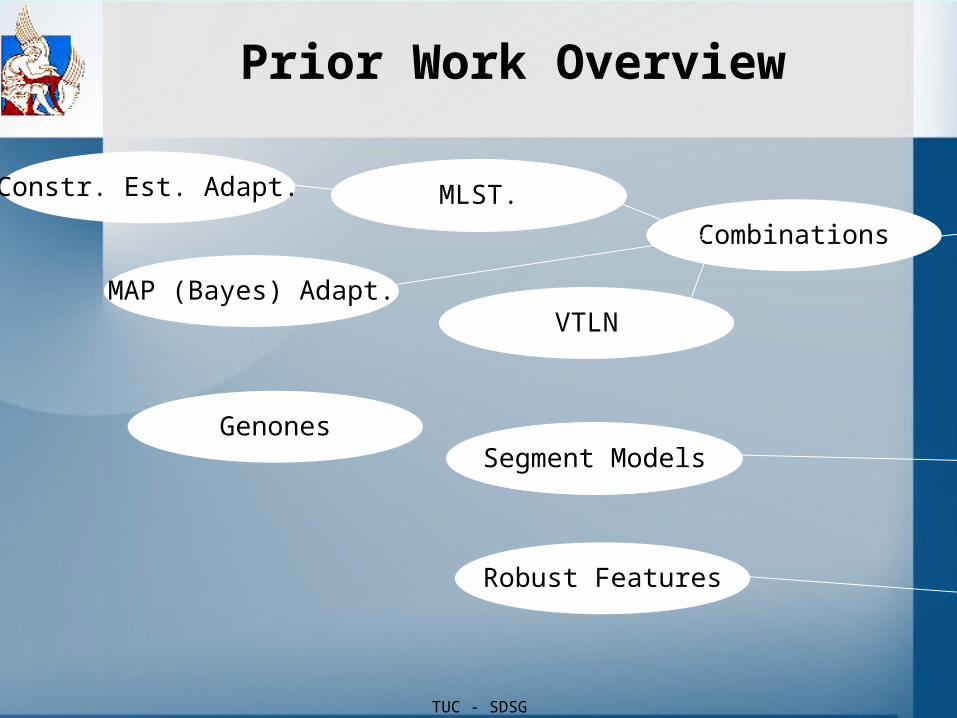
TUC - SDSG
Prior Work Overview
MLST.Constr. Est. Adapt.
MAP (Bayes) Adapt.
GenonesSegment Models
VTLN
Combinations
Robust Features
TUC - SDSG
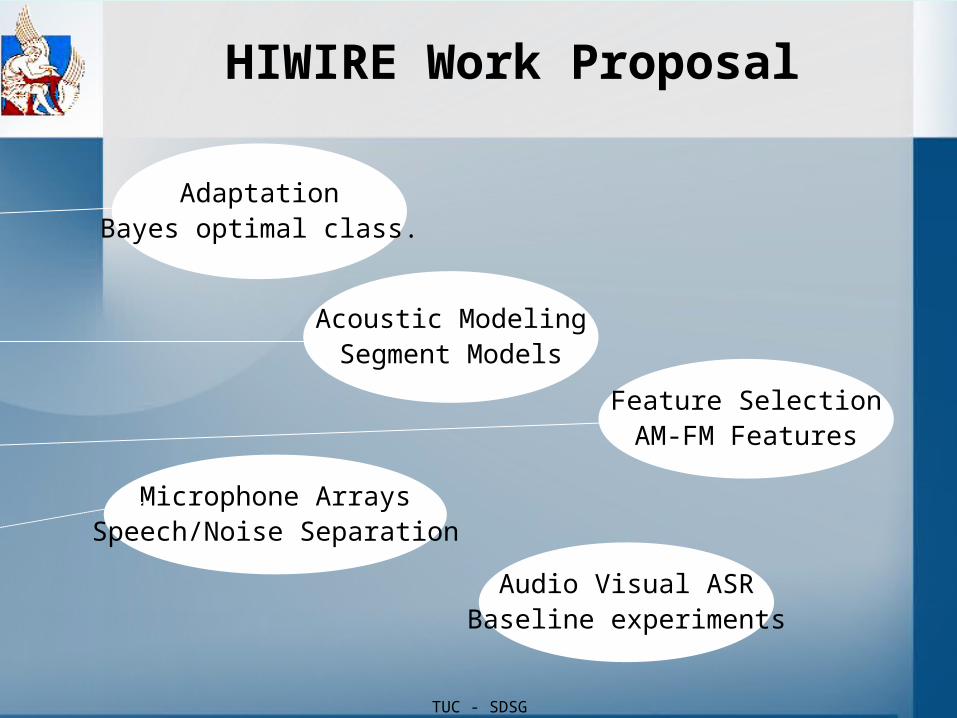
HIWIRE Work Proposal
AdaptationBayes optimal class.
Audio Visual ASRBaseline experiments
Microphone ArraysSpeech/Noise Separation
Feature SelectionAM-FM Features
Acoustic ModelingSegment Models

TUC - SDSG
Bayes optimal classification (HIWIRE proposal)
• Classifier decision for a test data vector xtest:
• Choose the class that results in the highest value:
),...,,|(maxarg)( 21jN
jjtest
jtest xxxxpcxc
dxxxpxpxxxxp jN
jjtest
jN
jjtest ),...,,|()|(),...,,|( 2121
TUC - SDSG
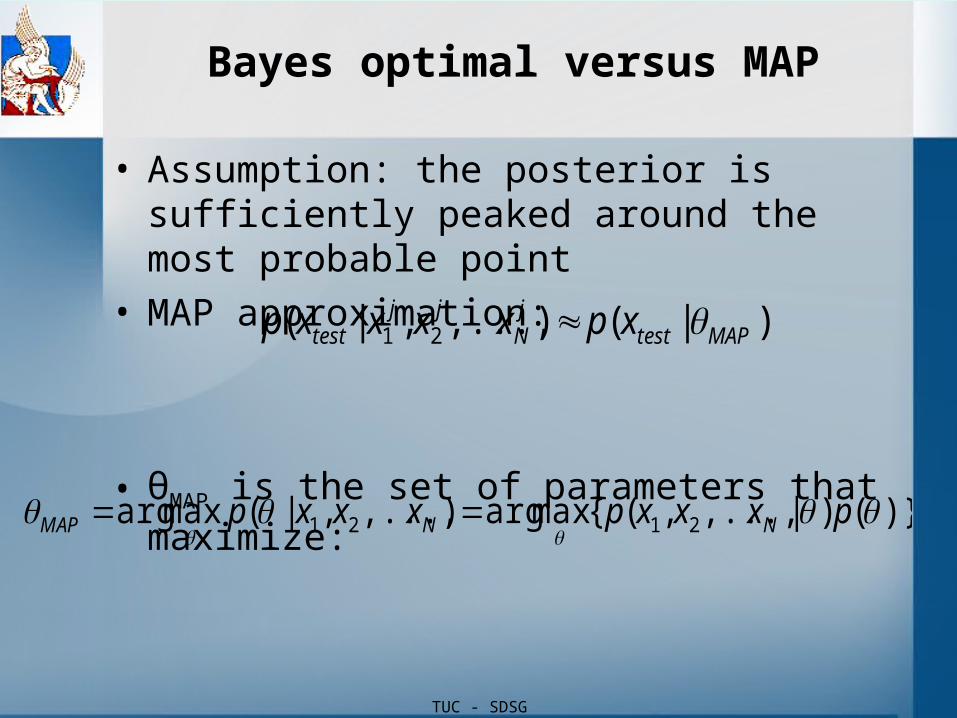
Bayes optimal versus MAP
• Assumption: the posterior is sufficiently peaked around the most probable point
• MAP approximation:
• θMAP is the set of parameters that maximize:
)|(),...,,|( 21 MAPtestjN
jjtest xpxxxxp
)}()|,...,,({maxarg),...,,|(maxarg 2121
pxxxpxxxp NNMAP

TUC - SDSG
Why Bayes optimal classification
• Optimal classification criterion• The prediction of all the parameter hypotheses is
combined• Better discrimination• Less training data • Faster asymptotic convergence to the ML estimate
• However: – Computationally more expensive– Difficult to find analytical solutions– ....hence some approximations should still be
considered

TUC - SDSG
Segment Models
• Phone Transition modeling
– New features
• Combine with HMMs
• Parametric modeling of feature trajectories

TUC - SDSG
AM-FM Features
• See NTUA presentation
TUC - SDSG
Audio-Visual ASR
• Baseline

TUC - SDSG
Microphone Array
• Speech – Noise source separation algorithms
Related Documents











