IJCSI IJCSI International Journal of Computer Science Issues Volume 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 © IJCSI PUBLICATION www.IJCSI.org

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IJCSIIJCSI
International Journal of
Computer Science Issues
Volume 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
© IJCSI PUBLICATION www.IJCSI.org

IJCSI proceedings are currently indexed by:
© IJCSI PUBLICATION 2010 www.IJCSI.org

IJCSI Publicity Board 2010 Dr. Borislav D Dimitrov Department of General Practice, Royal College of Surgeons in Ireland Dublin, Ireland Dr. Vishal Goyal Department of Computer Science, Punjabi University Patiala, India Mr. Nehinbe Joshua University of Essex Colchester, Essex, UK Mr. Vassilis Papataxiarhis Department of Informatics and Telecommunications National and Kapodistrian University of Athens, Athens, Greece

EDITORIAL In this third edition of 2010, we bring forward issues from various dynamic computer science areas ranging from system performance, computer vision, artificial intelligence, software engineering, multimedia , pattern recognition, information retrieval, databases, security and networking among others. As always we thank all our reviewers for providing constructive comments on papers sent to them for review. This helps enormously in improving the quality of papers published in this issue. IJCSI will maintain its policy of sending print copies of the journal to all corresponding authors worldwide free of charge. Apart from availability of the full-texts from the journal website, all published papers are deposited in open-access repositories to make access easier and ensure continuous availability of its proceedings. The transition from the 2nd issue to the 3rd one has been marked with an agreement signed between IJCSI and ProQuest and EBSCOHOST, two leading directories to help in the dissemination of our published papers. We believe further indexing and more dissemination will definitely lead to further citations of our authors’ articles. We are pleased to present IJCSI Volume 7, Issue 3, May 2010, split in eleven numbers (IJCSI Vol. 7, Issue 3, No. 11). The acceptance rate for this issue is 37.88%. We wish you a happy reading! IJCSI Editorial Board May 2010 Issue ISSN (Print): 1694-0814 ISSN (Online): 1694-0784 © IJCSI Publications www.IJCSI.org

IJCSI Editorial Board 2010 Dr Tristan Vanrullen Chief Editor LPL, Laboratoire Parole et Langage - CNRS - Aix en Provence, France LABRI, Laboratoire Bordelais de Recherche en Informatique - INRIA - Bordeaux, France LEEE, Laboratoire d'Esthétique et Expérimentations de l'Espace - Université d'Auvergne, France Dr Constantino Malagôn Associate Professor Nebrija University Spain Dr Lamia Fourati Chaari Associate Professor Multimedia and Informatics Higher Institute in SFAX Tunisia Dr Mokhtar Beldjehem Professor Sainte-Anne University Halifax, NS, Canada Dr Pascal Chatonnay Assistant Professor MaÎtre de Conférences Laboratoire d'Informatique de l'Université de Franche-Comté Université de Franche-Comté France Dr Yee-Ming Chen Professor Department of Industrial Engineering and Management Yuan Ze University Taiwan

Dr Vishal Goyal Assistant Professor Department of Computer Science Punjabi University Patiala, India Dr Natarajan Meghanathan Assistant Professor REU Program Director Department of Computer Science Jackson State University Jackson, USA Dr Deepak Laxmi Narasimha Department of Software Engineering, Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia Dr Navneet Agrawal Assistant Professor Department of ECE, College of Technology & Engineering, MPUAT, Udaipur 313001 Rajasthan, India Prof N. Jaisankar Assistant Professor School of Computing Sciences, VIT University Vellore, Tamilnadu, India

IJCSI Reviewers Committee 2010 Mr. Markus Schatten, University of Zagreb, Faculty of Organization and Informatics, Croatia Mr. Vassilis Papataxiarhis, Department of Informatics and Telecommunications, National and Kapodistrian University of Athens, Athens, Greece Dr Modestos Stavrakis, University of the Aegean, Greece Dr Fadi KHALIL, LAAS -- CNRS Laboratory, France Dr Dimitar Trajanov, Faculty of Electrical Engineering and Information technologies, ss. Cyril and Methodius Univesity - Skopje, Macedonia Dr Jinping Yuan, College of Information System and Management,National Univ. of Defense Tech., China Dr Alexis Lazanas, Ministry of Education, Greece Dr Stavroula Mougiakakou, University of Bern, ARTORG Center for Biomedical Engineering Research, Switzerland Dr Cyril de Runz, CReSTIC-SIC, IUT de Reims, University of Reims, France Mr. Pramodkumar P. Gupta, Dept of Bioinformatics, Dr D Y Patil University, India Dr Alireza Fereidunian, School of ECE, University of Tehran, Iran Mr. Fred Viezens, Otto-Von-Guericke-University Magdeburg, Germany Dr. Richard G. Bush, Lawrence Technological University, United States Dr. Ola Osunkoya, Information Security Architect, USA Mr. Kotsokostas N.Antonios, TEI Piraeus, Hellas Prof Steven Totosy de Zepetnek, U of Halle-Wittenberg & Purdue U & National Sun Yat-sen U, Germany, USA, Taiwan Mr. M Arif Siddiqui, Najran University, Saudi Arabia Ms. Ilknur Icke, The Graduate Center, City University of New York, USA Prof Miroslav Baca, Faculty of Organization and Informatics, University of Zagreb, Croatia Dr. Elvia Ruiz Beltrán, Instituto Tecnológico de Aguascalientes, Mexico Mr. Moustafa Banbouk, Engineer du Telecom, UAE Mr. Kevin P. Monaghan, Wayne State University, Detroit, Michigan, USA Ms. Moira Stephens, University of Sydney, Australia Ms. Maryam Feily, National Advanced IPv6 Centre of Excellence (NAV6) , Universiti Sains Malaysia (USM), Malaysia Dr. Constantine YIALOURIS, Informatics Laboratory Agricultural University of Athens, Greece Mrs. Angeles Abella, U. de Montreal, Canada Dr. Patrizio Arrigo, CNR ISMAC, italy Mr. Anirban Mukhopadhyay, B.P.Poddar Institute of Management & Technology, India Mr. Dinesh Kumar, DAV Institute of Engineering & Technology, India Mr. Jorge L. Hernandez-Ardieta, INDRA SISTEMAS / University Carlos III of Madrid, Spain Mr. AliReza Shahrestani, University of Malaya (UM), National Advanced IPv6 Centre of Excellence (NAv6), Malaysia Mr. Blagoj Ristevski, Faculty of Administration and Information Systems Management - Bitola, Republic of Macedonia Mr. Mauricio Egidio Cantão, Department of Computer Science / University of São Paulo, Brazil Mr. Jules Ruis, Fractal Consultancy, The Netherlands

Mr. Mohammad Iftekhar Husain, University at Buffalo, USA Dr. Deepak Laxmi Narasimha, Department of Software Engineering, Faculty of Computer Science and Information Technology, University of Malaya, Malaysia Dr. Paola Di Maio, DMEM University of Strathclyde, UK Dr. Bhanu Pratap Singh, Institute of Instrumentation Engineering, Kurukshetra University Kurukshetra, India Mr. Sana Ullah, Inha University, South Korea Mr. Cornelis Pieter Pieters, Condast, The Netherlands Dr. Amogh Kavimandan, The MathWorks Inc., USA Dr. Zhinan Zhou, Samsung Telecommunications America, USA Mr. Alberto de Santos Sierra, Universidad Politécnica de Madrid, Spain Dr. Md. Atiqur Rahman Ahad, Department of Applied Physics, Electronics & Communication Engineering (APECE), University of Dhaka, Bangladesh Dr. Charalampos Bratsas, Lab of Medical Informatics, Medical Faculty, Aristotle University, Thessaloniki, Greece Ms. Alexia Dini Kounoudes, Cyprus University of Technology, Cyprus Mr. Anthony Gesase, University of Dar es salaam Computing Centre, Tanzania Dr. Jorge A. Ruiz-Vanoye, Universidad Juárez Autónoma de Tabasco, Mexico Dr. Alejandro Fuentes Penna, Universidad Popular Autónoma del Estado de Puebla, México Dr. Ocotlán Díaz-Parra, Universidad Juárez Autónoma de Tabasco, México Mrs. Nantia Iakovidou, Aristotle University of Thessaloniki, Greece Mr. Vinay Chopra, DAV Institute of Engineering & Technology, Jalandhar Ms. Carmen Lastres, Universidad Politécnica de Madrid - Centre for Smart Environments, Spain Dr. Sanja Lazarova-Molnar, United Arab Emirates University, UAE Mr. Srikrishna Nudurumati, Imaging & Printing Group R&D Hub, Hewlett-Packard, India Dr. Olivier Nocent, CReSTIC/SIC, University of Reims, France Mr. Burak Cizmeci, Isik University, Turkey Dr. Carlos Jaime Barrios Hernandez, LIG (Laboratory Of Informatics of Grenoble), France Mr. Md. Rabiul Islam, Rajshahi university of Engineering & Technology (RUET), Bangladesh Dr. LAKHOUA Mohamed Najeh, ISSAT - Laboratory of Analysis and Control of Systems, Tunisia Dr. Alessandro Lavacchi, Department of Chemistry - University of Firenze, Italy Mr. Mungwe, University of Oldenburg, Germany Mr. Somnath Tagore, Dr D Y Patil University, India Ms. Xueqin Wang, ATCS, USA Dr. Borislav D Dimitrov, Department of General Practice, Royal College of Surgeons in Ireland, Dublin, Ireland Dr. Fondjo Fotou Franklin, Langston University, USA Dr. Vishal Goyal, Department of Computer Science, Punjabi University, Patiala, India Mr. Thomas J. Clancy, ACM, United States Dr. Ahmed Nabih Zaki Rashed, Dr. in Electronic Engineering, Faculty of Electronic Engineering, menouf 32951, Electronics and Electrical Communication Engineering Department, Menoufia university, EGYPT, EGYPT Dr. Rushed Kanawati, LIPN, France Mr. Koteshwar Rao, K G Reddy College Of ENGG.&TECH,CHILKUR, RR DIST.,AP, India

Mr. M. Nagesh Kumar, Department of Electronics and Communication, J.S.S. research foundation, Mysore University, Mysore-6, India Dr. Ibrahim Noha, Grenoble Informatics Laboratory, France Mr. Muhammad Yasir Qadri, University of Essex, UK Mr. Annadurai .P, KMCPGS, Lawspet, Pondicherry, India, (Aff. Pondicherry Univeristy, India Mr. E Munivel , CEDTI (Govt. of India), India Dr. Chitra Ganesh Desai, University of Pune, India Mr. Syed, Analytical Services & Materials, Inc., USA Dr. Mashud Kabir, Department of Computer Science, University of Tuebingen, Germany Mrs. Payal N. Raj, Veer South Gujarat University, India Mrs. Priti Maheshwary, Maulana Azad National Institute of Technology, Bhopal, India Mr. Mahesh Goyani, S.P. University, India, India Mr. Vinay Verma, Defence Avionics Research Establishment, DRDO, India Dr. George A. Papakostas, Democritus University of Thrace, Greece Mr. Abhijit Sanjiv Kulkarni, DARE, DRDO, India Mr. Kavi Kumar Khedo, University of Mauritius, Mauritius Dr. B. Sivaselvan, Indian Institute of Information Technology, Design & Manufacturing, Kancheepuram, IIT Madras Campus, India Dr. Partha Pratim Bhattacharya, Greater Kolkata College of Engineering and Management, West Bengal University of Technology, India Mr. Manish Maheshwari, Makhanlal C University of Journalism & Communication, India Dr. Siddhartha Kumar Khaitan, Iowa State University, USA Dr. Mandhapati Raju, General Motors Inc, USA Dr. M.Iqbal Saripan, Universiti Putra Malaysia, Malaysia Mr. Ahmad Shukri Mohd Noor, University Malaysia Terengganu, Malaysia Mr. Selvakuberan K, TATA Consultancy Services, India Dr. Smita Rajpal, Institute of Technology and Management, Gurgaon, India Mr. Rakesh Kachroo, Tata Consultancy Services, India Mr. Raman Kumar, National Institute of Technology, Jalandhar, Punjab., India Mr. Nitesh Sureja, S.P.University, India Dr. M. Emre Celebi, Louisiana State University, Shreveport, USA Dr. Aung Kyaw Oo, Defence Services Academy, Myanmar Mr. Sanjay P. Patel, Sankalchand Patel College of Engineering, Visnagar, Gujarat, India Dr. Pascal Fallavollita, Queens University, Canada Mr. Jitendra Agrawal, Rajiv Gandhi Technological University, Bhopal, MP, India Mr. Ismael Rafael Ponce Medellín, Cenidet (Centro Nacional de Investigación y Desarrollo Tecnológico), Mexico Mr. Supheakmungkol SARIN, Waseda University, Japan Mr. Shoukat Ullah, Govt. Post Graduate College Bannu, Pakistan Dr. Vivian Augustine, Telecom Zimbabwe, Zimbabwe Mrs. Mutalli Vatila, Offshore Business Philipines, Philipines Dr. Emanuele Goldoni, University of Pavia, Dept. of Electronics, TLC & Networking Lab, Italy Mr. Pankaj Kumar, SAMA, India Dr. Himanshu Aggarwal, Punjabi University,Patiala, India Dr. Vauvert Guillaume, Europages, France

Prof Yee Ming Chen, Department of Industrial Engineering and Management, Yuan Ze University, Taiwan Dr. Constantino Malagón, Nebrija University, Spain Prof Kanwalvir Singh Dhindsa, B.B.S.B.Engg.College, Fatehgarh Sahib (Punjab), India Mr. Angkoon Phinyomark, Prince of Singkla University, Thailand Ms. Nital H. Mistry, Veer Narmad South Gujarat University, Surat, India Dr. M.R.Sumalatha, Anna University, India Mr. Somesh Kumar Dewangan, Disha Institute of Management and Technology, India Mr. Raman Maini, Punjabi University, Patiala(Punjab)-147002, India Dr. Abdelkader Outtagarts, Alcatel-Lucent Bell-Labs, France Prof Dr. Abdul Wahid, AKG Engg. College, Ghaziabad, India Mr. Prabu Mohandas, Anna University/Adhiyamaan College of Engineering, india Dr. Manish Kumar Jindal, Panjab University Regional Centre, Muktsar, India Prof Mydhili K Nair, M S Ramaiah Institute of Technnology, Bangalore, India Dr. C. Suresh Gnana Dhas, VelTech MultiTech Dr.Rangarajan Dr.Sagunthala Engineering College,Chennai,Tamilnadu, India Prof Akash Rajak, Krishna Institute of Engineering and Technology, Ghaziabad, India Mr. Ajay Kumar Shrivastava, Krishna Institute of Engineering & Technology, Ghaziabad, India Mr. Deo Prakash, SMVD University, Kakryal(J&K), India Dr. Vu Thanh Nguyen, University of Information Technology HoChiMinh City, VietNam Prof Deo Prakash, SMVD University (A Technical University open on I.I.T. Pattern) Kakryal (J&K), India Dr. Navneet Agrawal, Dept. of ECE, College of Technology & Engineering, MPUAT, Udaipur 313001 Rajasthan, India Mr. Sufal Das, Sikkim Manipal Institute of Technology, India Mr. Anil Kumar, Sikkim Manipal Institute of Technology, India Dr. B. Prasanalakshmi, King Saud University, Saudi Arabia. Dr. K D Verma, S.V. (P.G.) College, Aligarh, India Mr. Mohd Nazri Ismail, System and Networking Department, University of Kuala Lumpur (UniKL), Malaysia Dr. Nguyen Tuan Dang, University of Information Technology, Vietnam National University Ho Chi Minh city, Vietnam Dr. Abdul Aziz, University of Central Punjab, Pakistan Dr. P. Vasudeva Reddy, Andhra University, India Mrs. Savvas A. Chatzichristofis, Democritus University of Thrace, Greece Mr. Marcio Dorn, Federal University of Rio Grande do Sul - UFRGS Institute of Informatics, Brazil Mr. Luca Mazzola, University of Lugano, Switzerland Mr. Nadeem Mahmood, Department of Computer Science, University of Karachi, Pakistan Mr. Hafeez Ullah Amin, Kohat University of Science & Technology, Pakistan Dr. Professor Vikram Singh, Ch. Devi Lal University, Sirsa (Haryana), India Mr. M. Azath, Calicut/Mets School of Enginerring, India Dr. J. Hanumanthappa, DoS in CS, University of Mysore, India Dr. Shahanawaj Ahamad, Department of Computer Science, King Saud University, Saudi Arabia Dr. K. Duraiswamy, K. S. Rangasamy College of Technology, India Prof. Dr Mazlina Esa, Universiti Teknologi Malaysia, Malaysia

Dr. P. Vasant, Power Control Optimization (Global), Malaysia Dr. Taner Tuncer, Firat University, Turkey Dr. Norrozila Sulaiman, University Malaysia Pahang, Malaysia Prof. S K Gupta, BCET, Guradspur, India Dr. Latha Parameswaran, Amrita Vishwa Vidyapeetham, India Mr. M. Azath, Anna University, India Dr. P. Suresh Varma, Adikavi Nannaya University, India Prof. V. N. Kamalesh, JSS Academy of Technical Education, India Dr. D Gunaseelan, Ibri College of Technology, Oman Mr. Sanjay Kumar Anand, CDAC, India Mr. Akshat Verma, CDAC, India Mrs. Fazeela Tunnisa, Najran University, Kingdom of Saudi Arabia Mr. Hasan Asil, Islamic Azad University Tabriz Branch (Azarshahr), Iran Prof. Dr Sajal Kabiraj, Fr. C Rodrigues Institute of Management Studies (Affiliated to University of Mumbai, India), India Mr. Syed Fawad Mustafa, GAC Center, Shandong University, China Dr. Natarajan Meghanathan, Jackson State University, Jackson, MS, USA Prof. Selvakani Kandeeban, Francis Xavier Engineering College, India Mr. Tohid Sedghi, Urmia University, Iran Dr. S. Sasikumar, PSNA College of Engg and Tech, Dindigul, India Dr. Anupam Shukla, Indian Institute of Information Technology and Management Gwalior, India Mr. Rahul Kala, Indian Institute of Inforamtion Technology and Management Gwalior, India Dr. A V Nikolov, National University of Lesotho, Lesotho Mr. Kamal Sarkar, Department of Computer Science and Engineering, Jadavpur University, India Dr. Mokhled S. AlTarawneh, Computer Engineering Dept., Faculty of Engineering, Mutah University, Jordan, Jordan Prof. Sattar J Aboud, Iraqi Council of Representatives, Iraq-Baghdad Dr. Prasant Kumar Pattnaik, Department of CSE, KIST, India Dr. Mohammed Amoon, King Saud University, Saudi Arabia Dr. Tsvetanka Georgieva, Department of Information Technologies, St. Cyril and St. Methodius University of Veliko Tarnovo, Bulgaria Dr. Eva Volna, University of Ostrava, Czech Republic Mr. Ujjal Marjit, University of Kalyani, West-Bengal, India Dr. Prasant Kumar Pattnaik, KIST,Bhubaneswar,India, India Dr. Guezouri Mustapha, Department of Electronics, Faculty of Electrical Engineering, University of Science and Technology (USTO), Oran, Algeria Mr. Maniyar Shiraz Ahmed, Najran University, Najran, Saudi Arabia Dr. Sreedhar Reddy, JNTU, SSIETW, Hyderabad, India Mr. Bala Dhandayuthapani Veerasamy, Mekelle University, Ethiopa Mr. Arash Habibi Lashkari, University of Malaya (UM), Malaysia Mr. Rajesh Prasad, LDC Institute of Technical Studies, Allahabad, India Ms. Habib Izadkhah, Tabriz University, Iran Dr. Lokesh Kumar Sharma, Chhattisgarh Swami Vivekanand Technical University Bhilai, India Mr. Kuldeep Yadav, IIIT Delhi, India Dr. Naoufel Kraiem, Institut Superieur d'Informatique, Tunisia

Prof. Frank Ortmeier, Otto-von-Guericke-Universitaet Magdeburg, Germany Mr. Ashraf Aljammal, USM, Malaysia Mrs. Amandeep Kaur, Department of Computer Science, Punjabi University, Patiala, Punjab, India Mr. Babak Basharirad, University Technology of Malaysia, Malaysia Mr. Avinash singh, Kiet Ghaziabad, India Dr. Miguel Vargas-Lombardo, Technological University of Panama, Panama Dr. Tuncay Sevindik, Firat University, Turkey Ms. Pavai Kandavelu, Anna University Chennai, India Mr. Ravish Khichar, Global Institute of Technology, India Mr Aos Alaa Zaidan Ansaef, Multimedia University, Cyberjaya, Malaysia Dr. Awadhesh Kumar Sharma, Dept. of CSE, MMM Engg College, Gorakhpur-273010, UP, India Mr. Qasim Siddique, FUIEMS, Pakistan Dr. Le Hoang Thai, University of Science, Vietnam National University - Ho Chi Minh City, Vietnam Dr. Saravanan C, NIT, Durgapur, India Dr. Vijay Kumar Mago, DAV College, Jalandhar, India Dr. Do Van Nhon, University of Information Technology, Vietnam Mr. Georgios Kioumourtzis, University of Patras, Greece Mr. Amol D.Potgantwar, SITRC Nasik, India Mr. Lesedi Melton Masisi, Council for Scientific and Industrial Research, South Africa Dr. Karthik.S, Department of Computer Science & Engineering, SNS College of Technology, India Mr. Nafiz Imtiaz Bin Hamid, Department of Electrical and Electronic Engineering, Islamic University of Technology (IUT), Bangladesh Mr. Muhammad Imran Khan, Universiti Teknologi PETRONAS, Malaysia Dr. Abdul Kareem M. Radhi, Information Engineering - Nahrin University, Iraq Dr. Mohd Nazri Ismail, University of Kuala Lumpur, Malaysia Dr. Manuj Darbari, BBDNITM, Institute of Technology, A-649, Indira Nagar, Lucknow 226016, India Ms. Izerrouken, INP-IRIT, France Mr. Nitin Ashokrao Naik, Dept. of Computer Science, Yeshwant Mahavidyalaya, Nanded, India Mr. Nikhil Raj, National Institute of Technology, Kurukshetra, India Prof. Maher Ben Jemaa, National School of Engineers of Sfax, Tunisia Prof. Rajeshwar Singh, BRCM College of Engineering and Technology, Bahal Bhiwani, Haryana, India Mr. Gaurav Kumar, Department of Computer Applications, Chitkara Institute of Engineering and Technology, Rajpura, Punjab, India Mr. Ajeet Kumar Pandey, Indian Institute of Technology, Kharagpur, India Mr. Rajiv Phougat, IBM Corporation, USA Mrs. Aysha V, College of Applied Science Pattuvam affiliated with Kannur University, India Dr. Debotosh Bhattacharjee, Department of Computer Science and Engineering, Jadavpur University, Kolkata-700032, India Dr. Neelam Srivastava, Institute of engineering & Technology, Lucknow, India Prof. Sweta Verma, Galgotia's College of Engineering & Technology, Greater Noida, India Mr. Harminder Singh BIndra, MIMIT, INDIA Dr. Lokesh Kumar Sharma, Chhattisgarh Swami Vivekanand Technical University, Bhilai, India Mr. Tarun Kumar, U.P. Technical University/Radha Govinend Engg. College, India Mr. Tirthraj Rai, Jawahar Lal Nehru University, New Delhi, India

Mr. Akhilesh Tiwari, Madhav Institute of Technology & Science, India Mr. Dakshina Ranjan Kisku, Dr. B. C. Roy Engineering College, WBUT, India Ms. Anu Suneja, Maharshi Markandeshwar University, Mullana, Haryana, India Mr. Munish Kumar Jindal, Punjabi University Regional Centre, Jaito (Faridkot), India Dr. Ashraf Bany Mohammed, Management Information Systems Department, Faculty of Administrative and Financial Sciences, Petra University, Jordan Mrs. Jyoti Jain, R.G.P.V. Bhopal, India Dr. Lamia Chaari, SFAX University, Tunisia Mr. Akhter Raza Syed, Department of Computer Science, University of Karachi, Pakistan Prof. Khubaib Ahmed Qureshi, Information Technology Department, HIMS, Hamdard University, Pakistan Prof. Boubker Sbihi, Ecole des Sciences de L'Information, Morocco Dr. S. M. Riazul Islam, Inha University, South Korea Prof. Lokhande S.N., S.R.T.M.University, Nanded (MH), India Dr. Vijay H Mankar, Dept. of Electronics, Govt. Polytechnic, Nagpur, India Dr. M. Sreedhar Reddy, JNTU, Hyderabad, SSIETW, India Mr. Ojesanmi Olusegun, Ajayi Crowther University, Oyo, Nigeria Ms. Mamta Juneja, RBIEBT, PTU, India Dr. Ekta Walia Bhullar, Maharishi Markandeshwar University, Mullana Ambala (Haryana), India Prof. Chandra Mohan, John Bosco Engineering College, India Mr. Nitin A. Naik, Yeshwant Mahavidyalaya, Nanded, India Mr. Sunil Kashibarao Nayak, Bahirji Smarak Mahavidyalaya, Basmathnagar Dist-Hingoli., India Prof. Rakesh.L, Vijetha Institute of Technology, Bangalore, India Mr B. M. Patil, Indian Institute of Technology, Roorkee, Uttarakhand, India Mr. Thipendra Pal Singh, Sharda University, K.P. III, Greater Noida, Uttar Pradesh, India Prof. Chandra Mohan, John Bosco Engg College, India Mr. Hadi Saboohi, University of Malaya - Faculty of Computer Science and Information Technology, Malaysia Dr. R. Baskaran, Anna University, India Dr. Wichian Sittiprapaporn, Mahasarakham University College of Music, Thailand Mr. Lai Khin Wee, Universiti Teknologi Malaysia, Malaysia Dr. Kamaljit I. Lakhtaria, Atmiya Institute of Technology, India Mrs. Inderpreet Kaur, PTU, Jalandhar, India Mr. Iqbaldeep Kaur, PTU / RBIEBT, India Mrs. Vasudha Bahl, Maharaja Agrasen Institute of Technology, Delhi, India Prof. Vinay Uttamrao Kale, P.R.M. Institute of Technology & Research, Badnera, Amravati, Maharashtra, India Mr. Suhas J Manangi, Microsoft, India Ms. Anna Kuzio, Adam Mickiewicz University, School of English, Poland Dr. Debojyoti Mitra, Sir Padampat Singhania University, India Prof. Rachit Garg, Department of Computer Science, L K College, India Mrs. Manjula K A, Kannur University, India Mr. Rakesh Kumar, Indian Institute of Technology Roorkee, India

TABLE OF CONTENTS 1. Efficient Algorithm for Redundant Reader Elimination in Wireless RFID Networks Nazish Irfan, Mustapha C.E. Yagoub 2. On One Approach to Scientific CAD/CAE Software Developing Process George Sergia, Alexander Demurov, George Petrosyan, Roman Jobava 3. Modeling Throughput Performance in 802.11 WLAN Moses Ekpenyong, Joseph Isabona 4. Hello Flood Attack and its Countermeasures in Wireless Sensor Networks Virendra Pal Singh, Sweta Jain, Jyoti Singhai 5. Faster and Efficient Web Crawling with Parallel Migrating Web Crawler Akansha Singh, Krishna Kant Singh 6. The morphological analysis of Arabic verbs by using the surface patterns A. Yousfi 7. Real-Time Video Streaming Over Bluetooth Network Between Two Mobile Nodes Sourav Banerjee, Dipansu Mondal, Sumit Das, Ramendu Bikash Guin 8. A New Semantic Similarity Metric for Solving Sparse Data Problem in Ontology based Information Retrieval System K. Saruladha, G. Aghila, Sajina Raj
Pg 1-8 Pg 9-15 Pg 16-22 Pg 23-27 Pg 28-32 Pg 33-36 Pg 37-39 Pg 40-48

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
1
Efficient Algorithm for Redundant Reader Elimination in Wireless RFID Networks
Nazish Irfan and Mustapha C.E. Yagoub
School of Information Technology and Engineering (SITE), University of Ottawa, Ottawa, Ontario, Canada
Abstract
Radio Frequency Identification (RFID) systems, due to recent technological advances, are being deployed in large scale for different applications. However, this requires a dense deployment of readers to cover the working area. Without optimizing reader's distribution and number, many of the readers will be redundant, reducing the efficiency of the whole RFID system. The problem of eliminating redundant readers has motivated researchers to propose different algorithms and optimization techniques. In this paper, the authors presented a new and efficient redundant reader elimination technique based on weights associated with reader's neighbor and coverage. Simulation results demonstrate that the proposed algorithm eliminates more redundant readers than those of other well-known techniques like Redundant Reader Elimination (RRE), Layered Elimination Optimization (LEO) and LEO+RRE algorithms while preserving the coverage ratio quite close to those obtained by RRE, LEO and LEO+RRE. Keywords: Large Scale, LEO, Reader, Redundancy, RFID, RRE.
1. Introduction
Radio Frequency Identification (RFID) is based on radio communication for tagging and identifying an object [1]. It consists of two blocks namely, RFID transceivers (readers) and RFID transponders (tags). The RFID tag consists of a small integrated circuit for storing information and an antenna for communication. A basic RFID system is based on wireless communication between a reader and a tag. RFID readers can read information stored in no-line-of- sight RFID tags and communicate information to central database system through wired or wireless interface [2]. Over the last few years, RFID has drawn a great deal of attention and now is widely believed that RFID can bring revolutionary changes [3]. Indeed, applications of RFID systems include supply chain automation, security and access control, cold chain management (temperature logging) and identification of products at check-out points, to name a few. Some of the major retailors have already invested significantly in RFID
and mandated their manufacturers to place tags on cases and pallets, which resulted in mass production of inexpensive RFID tags [4]. Integration of RFID systems with wireless sensors has broadened the scope of RFID applications. RFID tags can be interfaced with external sensors such as shock, temperature, and light sensors. Similar to wireless sensor networks, RFID systems can be deployed on-line instead of pre-installed statically [2]. To accurately monitor the area of interest, dense deployment of RFID readers and tags is sometimes required. However, this dense deployment of RFID systems in large scale results in unwanted effects. In fact, when multiple readers share the same working environment and communicate over shared wireless channels, a signal from one reader may reach other readers and cause frequency interference. This frequency interference occurs when a reader transmits the communication signal to read a tag and its signal interferes with signals from other readers who are trying to read the same tag. A reader may also interfere with other reader's operation even if the interrogation zones do not overlap because the back-scattered signal from a tag is weak enough to be easily affected by any interference. Thus, signals transmitted from distant readers may be strong enough to hamper accurate decoding of the communication signals back-scattered from adjacent tags. Therefore, frequency interference in the interrogation zones results into inaccurate reads and long reading intervals. Hence, the effect of reader interference on the RFID interrogation range should be analyzed before any large scale deployment of readers in a RFID system [5, 6]. Indeed, unnecessary readers in the network may consume power which can be wasteful. Therefore, finding redundant readers is of great importance for an optimal deployment of a large-scale RFID network. This ensures a user that the minimum number of readers should be used to cover all the tags in a specified zone.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
2
The problem of redundant reader elimination has been studied extensively in [2, 7, 8, 9]. In this paper, we proposed an efficient redundant reader elimination algorithm based on weights assigned to reader's neighbor and coverage. In this algorithm, a reader that has more neighbors and minimum or no coverage is a potential candidate for elimination. To validate the performance of the proposed technique, we have also implemented other well-known methods like RRE [2] and LEO [7]. The proposed technique’s performance proves that more redundant readers are removed than those of RRE, LEO and LEO+RRE. The remainder of this paper is organized as follows: Section 2 examines the existing redundant reader elimination techniques and presents a brief survey of related works. Section 3 details the proposed algorithm. Section 4 presents results and discussions. Finally, Section 5 concludes the proposed work.
2. Related Work
During the last decade, the RFID collision problem has been extensively covered in literature. It can be categorized as reader to reader interference or reader to tag interference. Reader to reader interference occurs when the interrogation zones of two readers intersect and interfere with each other. Two readers may also interfere each other even if their interrogation zones do not overlap. This interference is due to the use of wireless radio frequencies for communication. Reader to tag interference occurs when more than one reader try to read the same tag simultaneously. In this type of interference, each reader may believe that it is the only reader communicating with the tag while the tag, in fact, is communicating with multiple readers at the same time. The reader collision problem not only results in incorrect operation but also results in reduction of overall read rate of the RFID system [6, 10, 11]. To separate the individual participant signal from one another, many procedures have been developed. Basically, there are four main procedures namely, the Carrier Sense Multiple Access (CSMA), the Frequency Domain Multiple Access (FDMA), the Time Domain Multiple Access (TDMA) and the Code Division Multiple Access (CDMA) [12]. CSMA enables individual data transmission by detecting whether the communication medium is busy. In CSMA, the interrogation zones of two readers do not overlap. However, the signals at particular tag from two readers can interfere each other that make carrier sensing ineffective in the RFID network. FDMA relates to techniques in which several transmission channels on
various carrier frequencies are simultaneously available to the communicating participants. Since RFID tags do not have a frequency tuning circuit, tags cannot select particular frequency for communication. It can be achieved by the addition of a frequency tuning circuit, which adds to the cost of the RFID system. TDMA relates to techniques in which the entire available channel capacity is divided among the participants chronologically. In TDMA technique, each reader is allocated different time slot to avoid simultaneous transmissions. In a dynamic RFID system, time slot should be reshuffled adaptively to get better read rate. In case of mobility, reader may come closer and start interfering. CDMA uses spread spectrum modulation techniques based on pseudo random codes to spread the data over the entire system. To implement CDMA, a tag requires extra circuitry which will increase its cost. Moreover, assignment of codes to all tags at the development site may be complicated. Therefore, CDMA may not be a cost effective solution. There are many algorithms, which cover reader collision problem available in literature [11, 13, 14, 15, 16]. Colorwave [13] is a TDMA based distributed algorithm with no guaranteed method of communication between neighboring nodes. In this technique, each reader monitors the percentage of successful transmissions and this procedure also assumes that the readers are able to detect collision in the RFID system. HiQ [14] is an online algorithm based on Q-learning to solve the reader collision problem. Q-learning is a form of reinforcement learning, which allocates resources to maximize the number of readers communicating at a single time period. At the same time, it also minimizes the number of collisions among communicating readers. The Pulse [11] is a distributed algorithm based on a beaconing mechanism in which a specific reader while reading a tag periodically broadcasts a beacon on a separate control channel. Any other readers in the network sense the control channel for a beacon before it starts communicating with the tag. If a reader does not receive any beacon at a given time, it starts transmitting a beacon and begins communicating with the tag. This process is expected to achieve fairness among all readers. The DiCa [15] is a distributed and an energy efficient anti-collision algorithm similar to the Pulse. The DiCa contains both a data channel and a control channel. Each reader contends through the control channel for the use of data channel. The reader who wins reads the tags through the data channel. This algorithm adjusts the control channel’s range at twice the radius from the first reader to address the hidden and exposed terminal problem. The DiCa algorithm consumes less dissipated energy than that of CSMA, ALOHA and Pulse algorithms. The Gentle [16] is

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
3
a CSMA based protocol that uses RFID multi-channel and beacon messages to mitigate reader collision. In this algorithm, readers can also put tag information in their beacon messages in order to forward the information to their close readers. Therefore, readers using Gentle algorithm can avoid reader collision more efficiently and reduce waiting time to get tag’s information. Another approach to avoid collision is to reduce the number of redundant readers in the RFID network. In a RFID network, a reader is redundant if all of its tags are also covered by at least one of the other readers in the network. Figure (1) shows a typical example of the redundant reader in a RFID network. It consists of three
Fig. 1 Redundant reader example in RFID network. readers R1 to R3 and five tags T1 to T5. The tags T2, T3 and T4 that are covered by R2 are also covered by R1 and R3, respectively. Therefore, R2 is a redundant reader, which can be safely removed without violating the full coverage of tags. Eliminating redundant readers from a RFID network has two-fold advantages; First, it increases the lifetime of the overall RFID network by saving the wasteful power used by redundant readers. Second, it improves the RFID network service quality by alleviating the interference among readers. A simple approach to remove redundant reader is that all readers broadcast query messages simultaneously to all tags in their interrogation zones. Each tag may reply by signaling its ID. So, if a reader covers no tags in its interrogation zone or receives no reply from any tags due to reader colllision, it may be called as a redundant reader. There are some major drawbacks to the above approach. First, it requires strict time synchronization among readers, which is not practical in most RFID systems. Second, by turning all redundant readers, the network coverage may be violated.
The redundant reader elimination (RRE) problem was first introduced by [2]. The RRE algorithm is based on greedy method. The main idea of this algorithm is to record “tag count", i.e., the number of tags a reader covers into RFID tag’s memory. The reader, which has the maximum number of tag-count, will be the holder of the corresponding tag. This procedure iterates the above steps until all the tags in a network are assigned to readers. Finally, readers with no tags assigned are eliminated as redundant readers. In [7], the authors illustrated that RRE algorithm failed to eliminate redundant readers from some specific RFID network topologies. Therefore, they introduced the LEO algorithm, which uses a layered approach. The term "layered" represents the relationship between early query readers and later query readers. The later query readers may have higher probability to be a redundant reader. The fundamental approach of this procedure is "first read first own". In a RFID network, all readers send command signals to RFID tags in their coverage zones to get the record of the tags. The reader that first sends its signal is the owner of the tag. If this tag already has other reader ID as its owner, then tags ID cannot be changed. Finally, the readers in the network with no tags in their coverage zones are eliminated as redundant readers. The authors have also shown that LEO and RRE algorithms can be combined for better performance. In LEO+RRE scheme, first LEO is implemented to eliminate redundant readers. Then, for all the remaining readers, RRE is implemented to eliminate some more redundant readers. The authors have shown that the LEO algorithm can reduce the number of readings and writings effectively. On the other hand, the LEO procedure determines the owner of the tags in a random way. Therefore, the quality of owner selection for a tag is unreliable. Moreover, if a wrong reader is eliminated from the RFID network in the beginning, it may cause unsatisfactory results. In [8], the authors have proposed an algorithm, which takes the advantage of the concept of neighboring reader density to assess the priority of reading. In this algorithm, the priority value of a reader depends on the number of its neighboring readers. Two readers are considered neighbors when they have at least one tag covered by both the two readers. At first step, all readers in the RFID network send commands to tags in their interrogation zones to read them. The readers then increase the reader_num stored in the tag’s memory by 1 and write their IDs as well as the new value of reader_num into the covered tags. Secondly, all readers communicate with tags to obtain the number of neighboring readers and holder information by virtue of reader_num and Rid (reader ID) respectively. Then, each reader calculates the priority in

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
4
terms of reader_num and writes its ID as a new owner according to the priority comparison. Finally, any reader owing no tag is eliminated as a redundant reader. The density based algorithm works on "first arrive first serve" methodology, i.e., the time delay required by a reader to read a tag defines the priority of that reader among its neighbors. Consider a simple scenario in a RFID network with readers R1, R2 and tags T1, T2. If the delay time in reading a tag T1 by the reader R1 is smaller than R2, then R1 owns T1. However, if R2 reads both T1 and T2, but the delay time in reading T1 is greater than R1, R2 can not own T1. In this way, both readers are kept in the network. In our proposed work, since both coverage and neighbors are taken into consideration, R2 will own T1 and T2, whereas R1 will be eliminated. In [9], the authors have proposed the algorithm TREE which is very similar to LEO. In TREE, reader Ri , with its identifier, sends query packet to all tags in its interrogation zone. When tags respond to the query message, the stored reader identifier is returned by them. The tag can respond to a query of a reader with two possible replies i.e. it may reply NULL reader identifier or stored reader identifier. If a NULL reader identifier is returned by the tag, it indicates that the tag is not identified by other readers and the tag writes the reader identifier Ri
on it. If the tag returns identifier Rk and Rk ≠ Ri , then the reader Ri will ignore this query. In this algorithm, if a reader identifier Ri never receives the tag’s response as a NULL identifier, this reader is redundant and will be eliminated from the network. Similar to LEO algorithm, TREE also works on the principle of “first read first own”. Since TREE has fewer write operations, it reduces the time and communication complexity than that of RRE. As TREE and LEO works in a similar manner, the shortcomings of LEO mentioned above are also applicable to TREE.
3. Proposed Algorithm
In any arbitrary RFID network, any reader that covers more tags and has fewer number of neighbor readers must be given priority. A reader with more neighbors has higher probability of getting its operation interfered by the neighbor readers. It is known that a reader interferes other reader's operations if it intersects each others interrogation zones. Even though, readers do not overlap other reader's interrogation zones, they can still interfere [6]. Therefore, selecting readers with fewer numbers of neighbors will have higher probability of not interfering one another and results in an efficient working of RFID system.
With above stated fact, the proposed algorithm assigns weights to each reader based on its number of neighbors and the number of covered tags. In this way, the algorithm ensures that the best possible readers are selected for the efficient working of any RFID network.
Some of the assumptions of the proposed technique are:
Reader coordinates are easily available. Coverage information i.e. the number of tags
each reader has covered in initial round can easily be obtained by data processing subsystem.
It can be noted that the second assumption of collecting coverage information i.e. the total number of tags covered by each reader at central host system does not require new setup to RFID systems. Indeed, such processing system is already included in existing RFID setup. Therefore, this assumption adds no extra cost to the RFID systems. The normal read range for a 1W reader to read a passive tag whose IC consumes about 10 - 30µW to operate when being read is about 3 meters [17]. Since proposed work is based on the number of neighbors to a reader, the neighbor is defined as: Reader A is a neighbor to reader B if (d>0 meter & d< 2D meters), where d is the distance between readers A and B whereas D is the read range of a reader. Total weights assigned to a reader are a function of cost functions and multiplication factor. Cost function of a reader is defined in terms of its coverage and the number of neighbors. Cost function of a reader due to its coverage and number of neighbors is given by Eq. (1) and (2) respectively. The equations are as follows:
))(coverage
)(coverage
Rmax ︵
r
cf (1)
))(neighbor(
))(neighbor(1
Rmaxr
fn (2)
where r defines each individual reader in a network and R is the list of all readers in the network with their individual tag counts and neighbor counts, respectively. A user-defined multiplication factor α, usually between 1 and 3, is used so that the cost functions due to coverage and neighbors are in proportion and can influence each other.
nnccreader flflTW (3)
where lc and ln are the load factors assigned to a cost function of a reader for coverage fc and the number of
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
5
neighbors fn, respectively. Load factors lc and ln are user defined that satisfy the criteria lc + ln = 1. Basic operations of the proposed work can be summarized as follows:
1. All readers in the RFID network send commands
to all tags in their interrogation zones. 2. Each reader coverage information is sent to the
central host station, i.e., how many tags (with IDs) each reader has read.
3. For each tag in the RFID network, the proposed algorithm checks how many readers have read it. Further, the algorithm compares the weights of readers that have read the tag. The reader having the maximum weight owns the tag.
4. All the readers of the network with no assigned tags are eliminated as redundant readers.
After eliminating the redundant readers with no assigned tags, the algorithm switches to its second part which is optimization of the network. In the optimization mode, the algorithm picks a reader from the remaining readers based on minimum coverage and maximum neighbors and then eliminate it. Based on the number of readers left and total tags covered by the remaining readers, the algorithm again assigns weigts using Eq. (1), (2) and (3) respectively. Further, the algorithm follows step 2 of its operation to reorder the readers based on total weights assigned to each remaining reader. The procedure iterates until all readers have a number of neighbors equals or less than 3.
4. Simulation Setups and Results
4.1 Simulation Setups
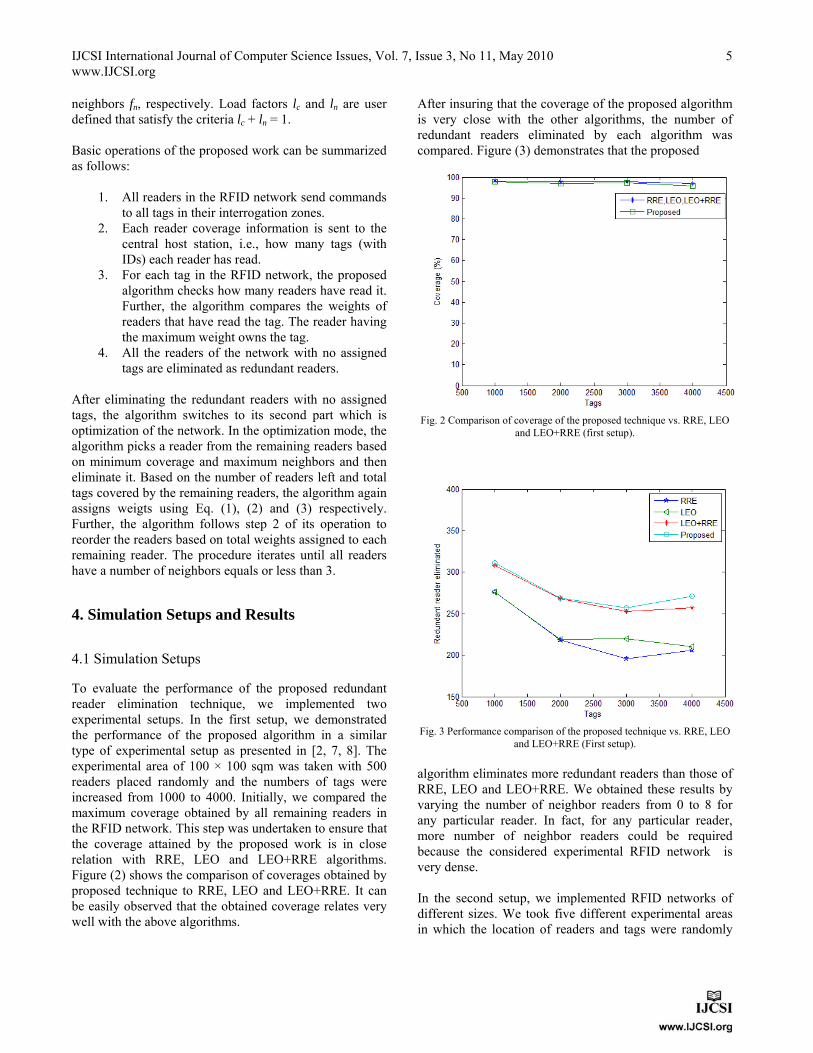
To evaluate the performance of the proposed redundant reader elimination technique, we implemented two experimental setups. In the first setup, we demonstrated the performance of the proposed algorithm in a similar type of experimental setup as presented in [2, 7, 8]. The experimental area of 100 × 100 sqm was taken with 500 readers placed randomly and the numbers of tags were increased from 1000 to 4000. Initially, we compared the maximum coverage obtained by all remaining readers in the RFID network. This step was undertaken to ensure that the coverage attained by the proposed work is in close relation with RRE, LEO and LEO+RRE algorithms. Figure (2) shows the comparison of coverages obtained by proposed technique to RRE, LEO and LEO+RRE. It can be easily observed that the obtained coverage relates very well with the above algorithms.
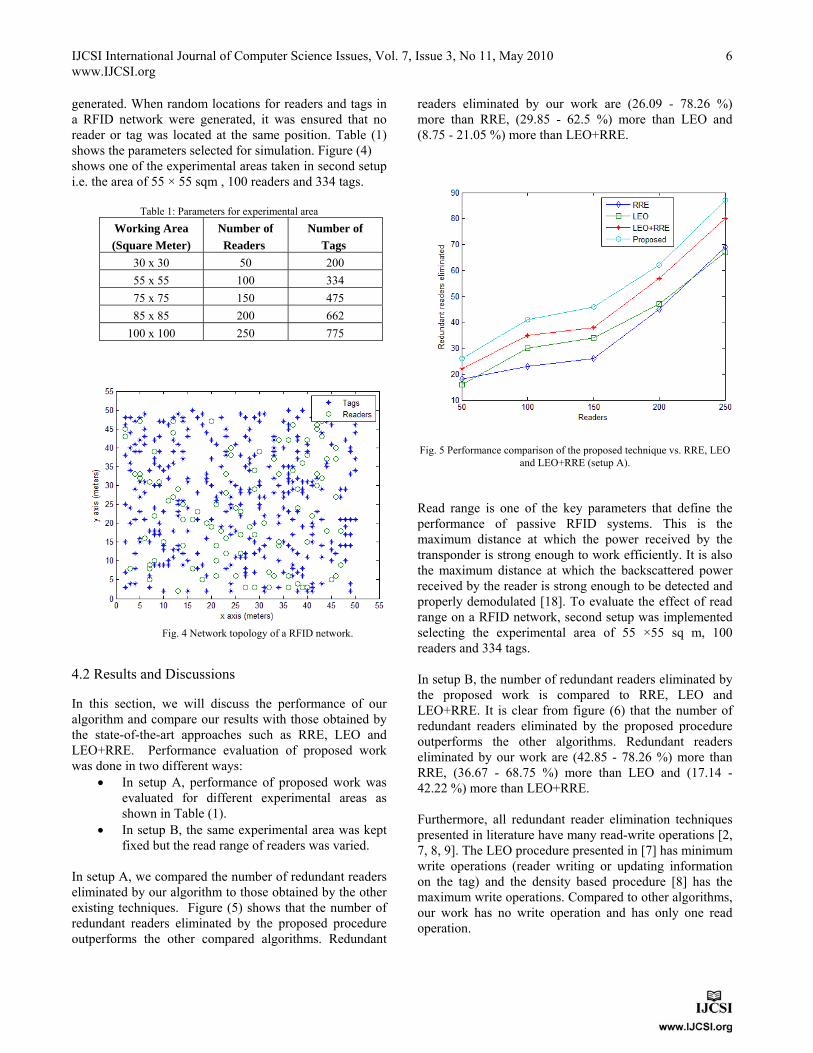
After insuring that the coverage of the proposed algorithm is very close with the other algorithms, the number of redundant readers eliminated by each algorithm was compared. Figure (3) demonstrates that the proposed
Fig. 2 Comparison of coverage of the proposed technique vs. RRE, LEO
and LEO+RRE (first setup).
Fig. 3 Performance comparison of the proposed technique vs. RRE, LEO
and LEO+RRE (First setup). algorithm eliminates more redundant readers than those of RRE, LEO and LEO+RRE. We obtained these results by varying the number of neighbor readers from 0 to 8 for any particular reader. In fact, for any particular reader, more number of neighbor readers could be required because the considered experimental RFID network is very dense. In the second setup, we implemented RFID networks of different sizes. We took five different experimental areas in which the location of readers and tags were randomly
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
6
generated. When random locations for readers and tags in a RFID network were generated, it was ensured that no reader or tag was located at the same position. Table (1) shows the parameters selected for simulation. Figure (4) shows one of the experimental areas taken in second setup i.e. the area of 55 × 55 sqm , 100 readers and 334 tags.
Table 1: Parameters for experimental area
Working Area Number of Number of
(Square Meter) Readers Tags
30 x 30 50 200
55 x 55 100 334
75 x 75 150 475
85 x 85 200 662
100 x 100 250 775
Fig. 4 Network topology of a RFID network.
4.2 Results and Discussions
In this section, we will discuss the performance of our algorithm and compare our results with those obtained by the state-of-the-art approaches such as RRE, LEO and LEO+RRE. Performance evaluation of proposed work was done in two different ways:
In setup A, performance of proposed work was evaluated for different experimental areas as shown in Table (1).
In setup B, the same experimental area was kept fixed but the read range of readers was varied.
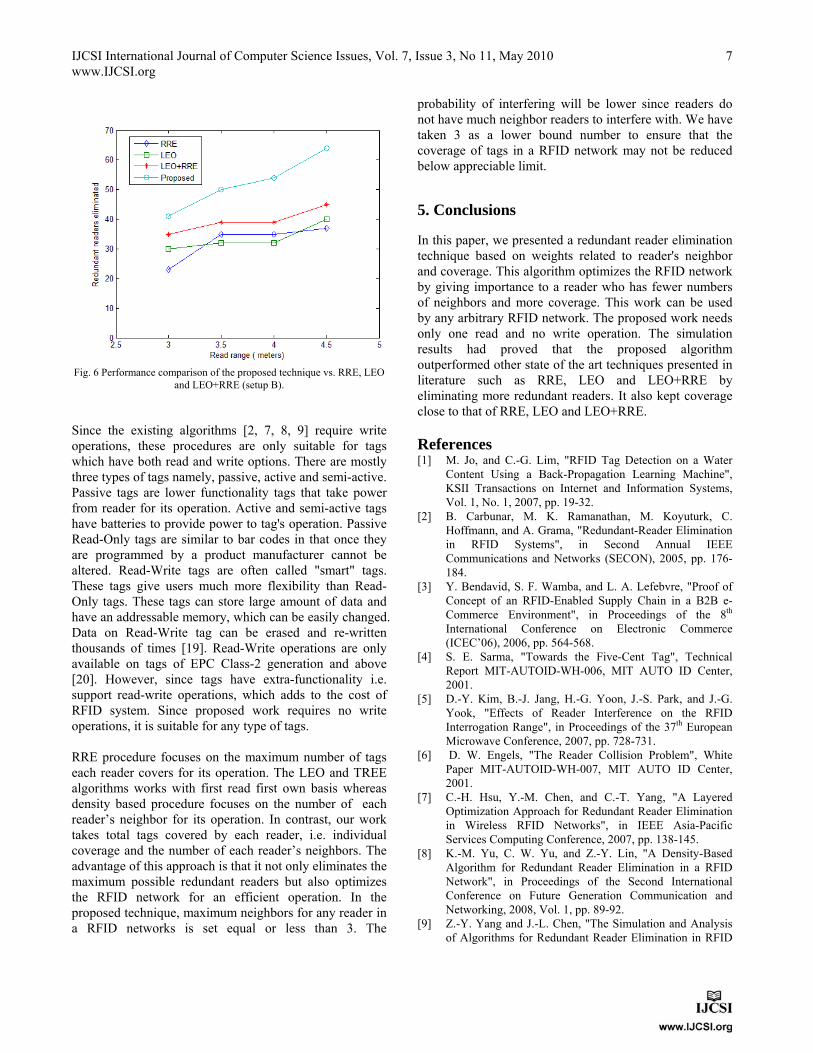
In setup A, we compared the number of redundant readers eliminated by our algorithm to those obtained by the other existing techniques. Figure (5) shows that the number of redundant readers eliminated by the proposed procedure outperforms the other compared algorithms. Redundant
readers eliminated by our work are (26.09 - 78.26 %) more than RRE, (29.85 - 62.5 %) more than LEO and (8.75 - 21.05 %) more than LEO+RRE.
Fig. 5 Performance comparison of the proposed technique vs. RRE, LEO
and LEO+RRE (setup A). Read range is one of the key parameters that define the performance of passive RFID systems. This is the maximum distance at which the power received by the transponder is strong enough to work efficiently. It is also the maximum distance at which the backscattered power received by the reader is strong enough to be detected and properly demodulated [18]. To evaluate the effect of read range on a RFID network, second setup was implemented selecting the experimental area of 55 ×55 sq m, 100 readers and 334 tags. In setup B, the number of redundant readers eliminated by the proposed work is compared to RRE, LEO and LEO+RRE. It is clear from figure (6) that the number of redundant readers eliminated by the proposed procedure outperforms the other algorithms. Redundant readers eliminated by our work are (42.85 - 78.26 %) more than RRE, (36.67 - 68.75 %) more than LEO and (17.14 - 42.22 %) more than LEO+RRE. Furthermore, all redundant reader elimination techniques presented in literature have many read-write operations [2, 7, 8, 9]. The LEO procedure presented in [7] has minimum write operations (reader writing or updating information on the tag) and the density based procedure [8] has the maximum write operations. Compared to other algorithms, our work has no write operation and has only one read operation.
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
7
Fig. 6 Performance comparison of the proposed technique vs. RRE, LEO
and LEO+RRE (setup B). Since the existing algorithms [2, 7, 8, 9] require write operations, these procedures are only suitable for tags which have both read and write options. There are mostly three types of tags namely, passive, active and semi-active. Passive tags are lower functionality tags that take power from reader for its operation. Active and semi-active tags have batteries to provide power to tag's operation. Passive Read-Only tags are similar to bar codes in that once they are programmed by a product manufacturer cannot be altered. Read-Write tags are often called "smart" tags. These tags give users much more flexibility than Read-Only tags. These tags can store large amount of data and have an addressable memory, which can be easily changed. Data on Read-Write tag can be erased and re-written thousands of times [19]. Read-Write operations are only available on tags of EPC Class-2 generation and above [20]. However, since tags have extra-functionality i.e. support read-write operations, which adds to the cost of RFID system. Since proposed work requires no write operations, it is suitable for any type of tags. RRE procedure focuses on the maximum number of tags each reader covers for its operation. The LEO and TREE algorithms works with first read first own basis whereas density based procedure focuses on the number of each reader’s neighbor for its operation. In contrast, our work takes total tags covered by each reader, i.e. individual coverage and the number of each reader’s neighbors. The advantage of this approach is that it not only eliminates the maximum possible redundant readers but also optimizes the RFID network for an efficient operation. In the proposed technique, maximum neighbors for any reader in a RFID networks is set equal or less than 3. The
probability of interfering will be lower since readers do not have much neighbor readers to interfere with. We have taken 3 as a lower bound number to ensure that the coverage of tags in a RFID network may not be reduced below appreciable limit.
5. Conclusions
In this paper, we presented a redundant reader elimination technique based on weights related to reader's neighbor and coverage. This algorithm optimizes the RFID network by giving importance to a reader who has fewer numbers of neighbors and more coverage. This work can be used by any arbitrary RFID network. The proposed work needs only one read and no write operation. The simulation results had proved that the proposed algorithm outperformed other state of the art techniques presented in literature such as RRE, LEO and LEO+RRE by eliminating more redundant readers. It also kept coverage close to that of RRE, LEO and LEO+RRE. References [1] M. Jo, and C.-G. Lim, "RFID Tag Detection on a Water
Content Using a Back-Propagation Learning Machine", KSII Transactions on Internet and Information Systems, Vol. 1, No. 1, 2007, pp. 19-32.
[2] B. Carbunar, M. K. Ramanathan, M. Koyuturk, C. Hoffmann, and A. Grama, "Redundant-Reader Elimination in RFID Systems", in Second Annual IEEE Communications and Networks (SECON), 2005, pp. 176-184.
[3] Y. Bendavid, S. F. Wamba, and L. A. Lefebvre, "Proof of Concept of an RFID-Enabled Supply Chain in a B2B e-Commerce Environment", in Proceedings of the 8th International Conference on Electronic Commerce (ICEC’06), 2006, pp. 564-568.
[4] S. E. Sarma, "Towards the Five-Cent Tag", Technical Report MIT-AUTOID-WH-006, MIT AUTO ID Center, 2001.
[5] D.-Y. Kim, B.-J. Jang, H.-G. Yoon, J.-S. Park, and J.-G. Yook, "Effects of Reader Interference on the RFID Interrogation Range", in Proceedings of the 37th European Microwave Conference, 2007, pp. 728-731.
[6] D. W. Engels, "The Reader Collision Problem", White Paper MIT-AUTOID-WH-007, MIT AUTO ID Center, 2001.
[7] C.-H. Hsu, Y.-M. Chen, and C.-T. Yang, "A Layered Optimization Approach for Redundant Reader Elimination in Wireless RFID Networks", in IEEE Asia-Pacific Services Computing Conference, 2007, pp. 138-145.
[8] K.-M. Yu, C. W. Yu, and Z.-Y. Lin, "A Density-Based Algorithm for Redundant Reader Elimination in a RFID Network", in Proceedings of the Second International Conference on Future Generation Communication and Networking, 2008, Vol. 1, pp. 89-92.
[9] Z.-Y. Yang and J.-L. Chen, "The Simulation and Analysis of Algorithms for Redundant Reader Elimination in RFID

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
8
System", in Third UKSim European Symposium on Computer Modeling and Simulation, 2009, pp. 494-498.
[10] D.-H. Shih, P.-L. Sun, D. C. Yen, and S.-M. Huang, "Taxonomy and Survey of RFID Anti-Collision Protocols", Computer Communications, Vol. 29, No. 11, 2006, pp. 2150-2166.
[11] S. M. Birari, and S. Iyer, "Mitigating the Reader Collision Problem in RFID Networks with Mobile Readers", in 13th IEEE International Conference on Networks, 2005, Vol. 1, pp. 463-468.
[12] K. Finkenzeller, RFID Handbook Fundamentals and Applications in Contactless Smart Cards and Identification, Chichester, UK: John Wiley and Sons Ltd., 2003.
[13] J. Waldrop, D. W. Engles, and S. E. Sarma, "Colorwave: A Mac for RFID Reader Networks", in IEEE Wireless Communications and Networking Conference, 2003, pp. 1701-1704.
[14] J. Ho, D. W. Eagles, and S. E. Sarma, "HiQ: A Hierarchical Q-Learning Algorithm to Solve the Reader Collision Problem", in International Symposium on Applications and the Internet Workshops (SAINT), 2006, pp. 88-91.
[15] K.-I. Hwang, K.-T. Kim and D.S. Ecom, "DiCa: Distributed Tag Access with Collision-Avoidance Among Mobile RFID Readers", in EUC Workshops, 2006, pp. 413-422.
[16] J. Yu and W. Lee, "GENTLE: Reducing Reader Collision in Mobile RFID Networks", in The 4th International Conference on Mobile Ad-hoc and Sensor Networks, 2008, pp. 280-287.
[17] D. M. Dobkin, The RF in RFID Passive UHF RFID in Practice, Oxford, UK: Elsevier Inc., 2008.
[18] I. Mayordomo, R. Berenguer, and A. G. Alonso, "Design and Implementation of a Long-Range RFID Reader for Passive Transponder", IEEE Transactions on Microwave Theory and Techniques, Vol. 57, No. 5, 2009, pp. 1283-1290
[19] V. D. Hunt, A. Puglia, and M. Puglia, RFID-A Guide to Radio Frequency Identification, Hoboken (N.J.), USA: John Wiley and Sons Inc., 2007
[20] M. A. Khan, M. Sharma, and R. B. Prabhu, "A Survey of RFID Tags", International Journal of Recent Trends in Engineering, Vol. 1, No. 4, 2009, pp. 68-71.
Nazish Irfan received his B.E. degree in Electrical from GEC Raipur, India in 1992, MASc in Electrical Engineering from University of Ottawa, Canada, 2007. Presently he is a Ph.D candidate in University of Ottawa, Canada. His research interests include RFID, reader/tag anti-collision protocols, neural networks, and genetic algorithm. Mustapha C.E. Yagoub received the Dipl.-Ing. degree in Electronics and the Magister degree in Telecommunications, both from the Ecole Nationale Polytechnique, Algiers, Algeria, in 1979 and 1987 respectively, and the Ph.D. degree from the Institut National Polytechnique, Toulouse, France, in 1994. After few years working in industry as a design engineer, he joined the Institute of Electronics, Université des Sciences et de la Technologie Houari Boumédiene, Algiers, Algeria, first as an Lecturer during 1983-1991 and then as an Assistant Professor during 1994-1999. From 1996 to 1999, he has been head of the
communication department. From 1999 to 2001, he was a visiting scholar with the Department of Electronics, Carleton University, Ottawa, ON, Canada, working on neural networks applications in microwave areas. In 2001, he joined the School of Information Technology and Engineering (SITE), University of Ottawa, Ottawa, ON, Canada, where he is currently a Professor. His research interests include RF/microwave device/system CAD, neural networks, RFID systems, , and applied electromagnetics. He has authored or coauthored over 250 publications in these topics in international journals and referred conferences. He is the first author of Conception de circuits linéaires et non linéaires micro-ondes (Cépadues, Toulouse, France, 2000), and the co-author of Computer Manipulation and Stock Price Trend Analysis (Heilongjiang Education Press, Harbin, China, 2005). Dr. Yagoub is a senior member of the IEEE Microwave Theory and Techniques Society and a member of the Professional Engineers of Ontario, Canada.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
9
On One Approach to Scientific CAD/CAE Software Developing Process
George Sergia1, Alexander Demurov2, George Petrosyan3, Roman Jobava4
1 Exact and Natural Sciences department, Tbilisi State University
Tbilisi, 0160, Georgia
2 Exact and Natural Sciences department, Tbilisi State University Tbilisi, 0160, Georgia
3 EM Consulting and Software Ltd., (EMCoS) Tbilisi, 0160, Georgia
4 EM Consulting and Software Ltd., (EMCoS) Exact and Natural Sciences department, Tbilisi State University
Tbilisi, 0160, Georgia
Abstract — Development of science-intensive software products is a complex and time-consuming process that requires good management and coordinated teamwork of all members, involved in the development. Each complex software product has a number of special features; as well as each development team has some unique capabilities. In such conditions it is not always possible to apply standard methods of software engineering without adapting to the specific case. In this paper, we present a development process of large-scale CAD/CAE systems for investigation of electromagnetic compatibility issues.
Keywords: Software Development, Software Engineering, CAD Systems, CAE Systems, Development Process
1. Introduction For many years, software engineering has been
continuously evolving and providing solutions to improve practices of software development. Many different methods and approaches have been invented to overcome difficulties, arising during software development process. Some of them have been standardized as typical software engineering techniques.
All of these standards and approaches, like waterfall model[1], agile methods[2] and extreme programming[3], have shown their benefits and disadvantages when applied to specific situations. Despite the fact, that each approach offers a fairly clear advice and guidance, the practice shows
that quite often these rules cannot be applied without some modifications and adaptations to specific processes.
This happens due to many factors. Among main reasons that can be identified, one of the most important is, for example, the nature of the product being developed. Development process of science-intensive programs, that perform complex calculations and simulations, differs from developing a client/server application, creating website or online store. Also, structure and members of development team have a major impact on the process, because team consists of people with different characters, skills and experience. Success of the development largely depends on how harmoniously and professionally team members cooperate.
These and other factors must be considered when choosing and applying a particular approach to a specific software development process. If necessary, selected approach must be optimized and adapted according to the known recommendations, or by introducing new recommendations, based on existing experience.
2. CAD/CAE system description As new technologies appear, penetrating all spheres of
human activity, need for high quality scientific software grows. Today's scientific software products are sophisticated CAD/CAE systems for simulation, visualization and analysis of real world objects and

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
10
processes. A lot of work is required to create such systems, together with knowledge and experience of people from different fields and with different skills.
The process, described in this paper, has been established during development of several CAD/CAE systems, used for modeling and studying the problems of electromagnetic compatibility in electrical systems of modern vehicles.
The software products introduced below represent the result of years of collaborative efforts of developers, academic experts in the field of electrodynamics, testers, technical writers and designers of graphical user interface. These systems are being constantly improved, updated and expanded to meet the needs of customers and target market, taking the increasing competition into account.
The first complex system we will shortly describe is EMC Studio [4] - a powerful program package for the sophisticated computer analysis of electromagnetic compatibility (EMC) problems. This system allows user to simulate, conduct physical calculations and analyze the results. To handle the complexity of the numerous required tools and methods all functions and modules were integrated into one, easy to use program interface. This interface combines all tools for model generation and various methods for calculation.
Fig.1 shows a screenshot of the program with an automobile model.
Fig. 1. Screenshot showing model and a result of a hybrid EMC Studio
calculation
For the calculation of large systems the following analysis types are necessary and are provided by EMC Studio:
EM-Analysis of linear electromagnetic field and current coupling problems in frequency and time domain with MoM. Electrical field integral
equation for harmonic excitation is applied to the calculation model.
Circuit Analysis of linear and non-linear circuits in frequency and time domain with a SPICE 3f5 compatible calculation core.
Static Analysis of linear and non-linear low frequency problems in frequency and time domain with a quasi-static approach.
Cross Talk: Analysis of linear and non-linear terminated complex cable structures in frequency and time domain. A circuit model of an arbitrary transmission line structure is generated. The included 2D field solver calculates the transmission line parameters with respect to the reference conductor. An arbitrary shaped metallic surface structure can be the reference conductor.
Radiation Hybrid: Emission analysis of linear and non-linear complex cable-antenna coupling problems in frequency and time domain. A circuit model of an arbitrary transmission line structure is automatically generated. Common mode currents on transmission lines are calculated and converted into impressed current sources on MoM segments. MoM calculates radiation and coupling to antenna.
Susceptibility Hybrid: Immunity analysis of linear and non-linear complex field-cable coupling problems in frequency and time domain. Field distribution along the cable structure is calculated. The transmission line circuit is supplemented with sources reflecting the incident field. Analysis model is calculated with a SPICE 3f5 compatible solver.
Calculation results can be viewed and analyzed in EMC Studio Post-Processing module. It is possible to view results as 3D and 2D charts:

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
11
Fig. 2. Screenshot showing calculation results
Another CAD/CAE system for analysis of EMC problems is Harness Studio [5]. This program allows user to create, analyze and maintain a database of cable harness of vehicles.
Harness Studio supports four different visualizations of cable harness database – Table View, 3D View, Schematic View and Cross Section View. Extended modules for harness development and analysis, like an Expert System Option or Electrical and Thermal Analysis Option, enable fast design, rule checking or the calculation of physical properties of the harness.
Fig. 3. Screenshot showing Harness Engine structure
Table view contains detailed information about
different objects in a current database. Data in table can be sorted, searched and arranged in multiple ways.
3D Browser is a powerful viewer. It supports
visualization of any objects of a harness database as well as the topology. Comfortable functions for zooming, rotating, and moving make
evaluation of any harness database object or complete harnesses very easy. 3D Browser has auto-rotate functionality, which allows rotation of a model in arbitrary direction with user-defined speed. Also 3D Browser has Auto Locate function. This function brings selected object to the center of the 3D Browser area and zooms the view to provide the best fit for the model.
Schematic Viewer can schematically visualize
connectors or splices and their connections with other connectors or splices in database. It provides user with convenient tools for scheme rearrangement and manipulation.
Fig. 4. Harness Engine schematic viewer
Cross Section Viewer shows the cross-section of
any segment interactively. User can click on any cable and the appropriate selection in the cable table will be shown. Colors are shown according to a customizable color list, which gives the user more realistic view of cable bundles. Cable objects are linked to the database. It provides convenient way for distance measurement between arbitrary points in cross section area.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
12
Fig. 5. Harness Engine schematic viewer
Expert System module extends Harness Studio to powerful rule checker with full functionality, developed on the basis of Expert System language CLIPS. Complex cable harnesses can be checked for compliance with arbitrary electrical, mechanical and economical rules. The use of Expert System functionality is very comfortable due to the sophisticated pre- and post-processing functions. Similar to the natural language, IF-THEN rules can be formulated and applied to cable harness systems.
As it can be seen from the description of complex software systems, many different specialists are involved in the development process. Correct and optimal organization of the process is crucial for achieving success.
3. Software Engineering Process Any software development process begins with
specification of basic requirements for the final product. When it comes to upgrading of an existing version, then new requirements must be formulated, which define a changed project scope. For software products described in the previous section, we deal with this particular case. These products are being developed for several years and constantly require innovations and new functionality. The introduction of new features and technologies does not always go smoothly. This often leads to the need for significant changes in software architecture to meet the new requirements and conditions.
Requirements are formulated based on market analysis and requests from customers, using earlier versions of the product. Since the described systems are positioned as commercial products, targeting certain categories of customers, the goals and development objectives are mainly generated by marketing group, which monitors and analyzes the current market trends, determines which requirements must be implemented, and what can be postponed to the future releases.
Based on the specified requirements, the list of tasks is compiled, which basically involves changes and additions to the existing functionality, improved user interface and other required features. The list of tasks is then extended to the basic implementation plan. When creating a general plan, sometimes it is difficult to determine what amount of work has to be performed during each task, so entire development period is divided to several main stages, each ending with a specific milestone [6]. Within these stages, a preliminary assessment of work is performed and more realistic schedule is determined. Milestones provide an opportunity to get a limited, but working version of the product at some stage during development. At the same time Milestones help to evaluate the performed activities and identify general problems of the development process.
The number of milestones should not exceed 4, including the phase of beta testing of the product. The duration of each phase should be limited to 1.5 - 2 months. This is a flexible approach for easily switching from development version to beta testing stage, when for some reasons, the product must be released earlier, or it is necessary to correct task lists in case of a risk of falling behind the schedule.
During development, resources for tasks are allocated according to their priority and complexity. Higher priority and time-consuming tasks must be performed at the early stages and should be included in the first and second milestone versions. Priority should be given to the tasks, which introduce new important functionality, because such approach provides additional competitive advantages to the product. It should be noted that the priority might also be affected by the complexity of the task. Since the complex systems consist of a set of subsystems, or modules, often changes may affect multiple subsystems. Sometimes improvements and optimizations may be considered for modules that already have passed an extensive testing. As a result, the task becomes complicated and requires a careful approach for further development. In order to maintain the overall quality of the product, number of scheduled time-consuming tasks should be kept to a minimum as development process reaches milestone of beta-version
preparation.
Practice has shown that when working on a specific task, if the estimated time required for the task exceeds 3-4 weeks, better results can be achieved by breaking it into several subtasks.
As it was already mentioned, a subtask may require development, or changes in the different software modules of the system. Different modules within a single task developed and managed by independent groups, often lead to the loss of overall control, failure to meet the scheduled deadlines, reduction of product quality, etc. The main reason for this is the problem of communication between

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
13
groups that may occur due to objective reasons. Past experience, gained during development of the mentioned software products shows us that when working plans of each independent group are poorly coordinated, the development process slows down. Since these products are being developed during several years and many different specialists were being involved in the process at different stages, situations occurred when there has been a conflict between software modules due to the inconsistent approaches or development technologies.
Problems may also arise in case, when the requirements contain specific scientific information. Usually, when such requirements are considered, scientific experts can initiate theoretical researches in order to investigate tasks in depth. After researches, a prototype of calculation module is created and verified for reliability. Information about research results and overall task must be clearly formulated to all groups involved in the implementation of the subtask. Therefore, if the work is carried out in parallel, there is a need for scientific experts to participate in all working groups at the same time, which may be physically impossible.
Human factor is also very important in software development process. Conflict of interests between the group leaders due to technical or organizational issues may seriously harm the development process.
Naturally, increasing the time for discussions and agreements on various aspects of development can minimize such problems, but frequent discussions will inevitably arise the idea of bringing together the necessary human resources under the single management mechanism and uniting the all these works as a one whole.
Our practice has shown that separate project team should be created for each subtask (project). As mentioned above, building a complex scientific system needs resources, knowledge and experience of people of different professions. Typical human resources that are needed for such projects are: project manager, graphical interface developers, computational methods developers, technical writer, graphics designer, tester, customer (or product manager), and science field experts.
Fig. 5. Available human resources
The project team is created from the available human resources (Fig. 5). Specialists in different areas are involved in the process, depending on the main goals. During team creation a situation may arise, when the necessary human resources are members of other projects teams. In this case, based on the priority of the task the decision should be made to postpone the new task until all the necessary resources are available, or launch a new project, pausing the current project(s). Such decision should be made as a result of agreement between all responsible persons involved in the current and upcoming projects. This means that the working team is not a constant group of developers, but is created "on-the-fly" for each specific project.
For example, lets consider following requirements: it was decided to create new calculation solver to introduce new optimized methodic for calculation and analysis of specific electromagnetic problems. New solver must be included in system, therefore GUI support for this solver must be provided. This means that several changes must be made in system interface: user must be able to set up the task and run calculation with different parameters, using this solver and system must give possibility to analyze results of calculation in 2D/3D post-processing of software. Based on this description, we can decide who must be included in project group in order to fulfill task. These must be: developer of solver and field expert (sometimes is the same person), developers of graphical user interface (2-3 persons, because changes are separated on several modules – calculation module, post processing module etc.), technical writers (describe new solvers and changes in GUI), testers (no more than 1-2 persons – testing and benchmarking of solver and testing of GUI can be done separately at the beginning of project, but overall testing must be conducted at the end). Accept mentioned persons, project manager and product manager are included in the group as well. So, we have got a project group consisting of maximum 8-10 persons. Here we considered complicated task, but usually tasks are not so complicated and in one project group there can be up to 5-7 persons at average.
Given the above recommendations, described problems can be eliminated within a project team. Estimated total amount of work, the execution flow and the role of each participant of the project team can be clearly stated and agreed. A single person - project manager - is responsible for the project during development process.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
14
Fig. 6. Project group creation
Each project manager can choose any approaches of development from the wide range of existing methods, including extreme programming model, because one of the main conditions of this approach is met - a customer (product manager) is a member of the project team. For the described products project managers have been using iterative development techniques. Based on our experience, the average period of iterations should not exceed one week, or 10 days at the most. Iteration includes planning, development and testing. The main planning works are done during the first iteration, and are subject to revision at the beginning of each subsequent iteration. Testing can begin by the end of the first iteration and must be performed continuously until the completion of the project.
For improving control and eliminating misunderstanding, the development process must be well documented. The documents usually include proposal, software requirements specification, GUI design presentation, architectural design, technical documentation, overall description of the project and test report. Each project team member is responsible to prepare documentation concerning its part of process, but project manager is the person who accumulates all documents, archives them and passes to all interested departments (for example, to quality assurance department, or support
department).
When stage of beta release arrives, the intensity of product's quality control must be increased, at the same time reducing the intensity of the development. After beta version release, all processes related to implementation of new features must be finished.
4. Conclusions Present paper describes some recommendations for development of complex CAD/CAE systems. These
recommendations have formulated based on experience that has been gained in a specific environment. Using mentioned rules and recommendations in practice, helped us to improve overall development process thus making it more flexible and well controlled.
Despite the fact that described approach does not apply for universality, formulated ideas can become the basis of more general recommendations for development processes of similar complex software products
There are some questions, not mentioned in this paper, which should be optimized and improved, so researches in that direction will be continued.
References [1] Winston W. Royce, "Managing the Development of Large Software
Systems", Proceedings of IEEE WESCON, 1970 [2] Alistair Cockburn, “Agile Software Development”, Addison-Wesley,
2001 [3] Kent Beck, “Extreme Programming Explained: Embrace Change”,
Addison-Wesley, 1999.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
15
[4] EMC Studio Manual, Version 5.0, EMCoS Ltd., http://www.emcos.com
[5] Harness Studio Manual, Version 4.0, EMCoS Ltd., http://www.emcos.com
[6] Ed Sullivan, “Under Pressure and on Time”. Microsoft Pr., 2001 George Sergia: PhD research scholar at the Exact and Natural Sciences department, Tbilisi State University. Area of research is software engineering and development of complex scientific CAD/CAE systems. Has a Master degree in Computer Science from Tbilisi State University. Awarded with “Best Scientific paper” by Georgian National Scientific Fund for Paper, presented on WSEAS European Computing Conference (ECC’09). Currently works as a project manager in one of the leading EM software development companies, EMCoS (www.emcos.com), Georgia Alexander Demurov: PhD research scholar at the Exact and Natural Sciences department, Tbilisi State University. Area of research is development of complex CAD systems for simulation of PCB problems. Has a Master degree in Computer Science from Tbilisi State University. Currently works as a product manager in one of the leading EM software development companies, EMCoS (www.emcos.com), Georgia George Petrosyan: Has received his Master degree at the Exact and Natural Sciences department, Tbilisi State University in 2010. Area of research is development of expert system for analysis of automotive cable harnesses. Currently works as a project manager in one of the leading EM software development companies, EMCoS (www.emcos.com), Georgia Roman Jobava: (M’97) was born in Georgia, in 1965. He received the M.S. and Ph.D. degrees in Radiophysics from I. Javakhishvili Tbilisi State University, Tbilisi, Georgia, in 1987 and 1990, respectively. Since 1996 he has been working at I.Javakhishvili Tbilisi State University as Associate Professor. From 1987 to 2000 he was a Senior Researcher in Laboratory of Applied Electrodynamics of the same University, responsible for computer simulation of transient electromagnetic phenomena and development of numerical and software tools. In 2001 he began leading EM Consulting and Software, EMCoS Ltd. His research interests include numerical methods in applied electrodynamics, computer simulation of EMC problems, ESD, and transient field calculations, software development for solving EM/EMC problems.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
16
Modeling Throughput Performance in 802.11 WLAN
Moses Ekpenyong1 and Joseph Isabona2
1 Department of Computer Science, University of Uyo Uyo, Akwa Ibom State 520001, Nigeria
2 Department of Basic Sciences, Benson Idahosa University Benin City, Benin, Nigeria
Abstract
This paper presents a mathematical framework for maximizing throughput in Wireless Local Area Network (WLAN) channels using key system design parameters such as packet length and transmission rate. We study the tradeoff between the throughput and choice of some design variables through extensive computer simulation. We observe from the simulation results that the design parameters are highly signal dependent and can dynamically be adapted to improve the overall system performance, principally in the area of data transmission and reception in WLAN channels. Keywords: Throughput optimization, WLAN system, payload traffic, AWGN channels.
1. Introduction
Wireless Local Area Networks have become common place network technology. Recent advances in wireless technologies provide portable devices with wireless capabilities that allow network communication for both mobile and non-mobile users. Wireless technologies have several key benefits that can be applied to new and existing networks. Some of these benefits include flexibility, integrity and reliability, reduced cost, scalability and adaptability. Just like wired LANs, which use twisted or fibre-optic cables as transmission medium, WLANs also transmit through a medium. WLAN employ either infrared (IR) light or radio frequency (RF). Of these two media, RF is far more popular for its longer range, higher bandwidth and wider coverage. Most WLANs today use the 2.4GHz frequency band, the only portion of the RF spectrum reserved around the world for unlicensed devices. The freedom and flexibility of wireless networking can be applied both within and between buildings and can be used to replace or augment an existing wired network. As with wired LAN systems; the actual throughput in WLAN is product and set-up dependent. The factors
affecting throughput include the number of users, propagation factors such as distance and multipath, the type of WLAN system employed, as well as the latency and bottlenecks on wireless portions of the LAN. Throughput is defined as the ratio of the expected delivered data payload to the expected transmission time. It is the percentage of undistorted data packets received without errors. Moreover, most voice and video applications prefer very small payload sizes to ensure reliable and minimum delay service delivery. Throughput is what the user sees after overheads. Overheads consume part of the nominal bit rate including:
(i) lost air time from collisions between access points (APs) and stations (STAs) trying to transmit simultaneously.
(ii) Idle guard times, built into the protocol. (iii) Airtime absorbed by beacon frames. (iv) Protocol overheads (e.g. synchronization,
address, acknowledgement and control). (v) Switching to ensure compatibility.
In this paper, we study the WLAN data transmission configurations, propose and simulate a reliable data transmission model for efficient network deployment.
2. Statement of the Problem
Throughput is affected by several factors. It is the percentage of undistorted packets the user sees after overheads. The resulting impact on throughput efficiency depends on the traffic mix. We highlight below the problems affecting WLAN throughput:
(i) Nominal bit rate downshifts with distance As the distance increases, the radio signal gets weaker and more distorted. As the signal degrades further, a “downshift” to a lower bit rate occurs. Downshifting allows the radio link to use simpler modulation scheme that makes it easier

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
17
for the equipment to distinguish between digital zeroes and ones.
(ii) Contention between multiple-active users The throughput decreases if there are multiple simultaneously-active users transmitting data on the WLAN radio channel. The reason for this decrease is that these users experience collision and the colliding parties must wait for a defined “backoff” period before retransmitting. This results in lost airtime which affects the system’s throughput.
(iii) Interference and coexistence The unlicensed nature of radio-based WLANs means that other products that transmit energy in the same frequency spectrum can potentially provide some measure of interference to a WLAN system. Microwave ovens are of potential concern, but most WLAN manufacturers design their products to account for this interference. Interference is a growing headache as WLAN popularity grows. It mostly arises from other APs and STAs on the same and/or adjacent radio channels, and can be mutual and harmful. To minimize interference, different radio channels can be used. Frequency optimization products are emerging to help manage interference. Another concern is the co-location of multiple WLAN. While WLANs from some manufacturers interfere, other coexists without interference. This issue is best addressed with the appropriate vendors.
(iv) Interoperability of wireless devices Wireless LAN systems from different vendors may not be interoperable for the following reasons: First, different technologies will not interoperate. For instance, a system based on spread spectrum frequency hopping technology will not communicate with another system based on spread spectrum direct sequence technology. Secondly, systems using direct frequency bands will not interoperate even if they employ same technology. Thirdly, systems from different vendors may not interoperate even if they both employ same technology.
Due to increasing users’ capacity and variety of wireless applications, telecommunication service providers need to provide better quality of service (QoS) to the end users. In this paper, we investigate how to provide improved system’s throughput and guarantee quality services in WLAN communication, taking into account the impact of the channel conditions.
3. Review of Related Works
Several researches [3-4, 7] have studied the efficiency of the IEEE 802.11 protocol by investigating the maximum achievable throughput under various network configurations. They analyze the backoff mechanism and propose alternatives to improve the performance of existing standard mechanisms. In [3], a simple analytical model that computes saturation throughput performance assuming finite number of stations and ideal channel conditions is presented. This model extended in [4], with a consideration of the frame retry limits, which precisely predicts 802.11 DCF throughput. However, no known work yet exist that considers finite load throughput of 802.11 DCF and that which considers protocol parameters such as timeouts. A number of studies have emerged on the performance of WLANs using the 802.11 MAC protocol. Some preliminary investigations on the voice capacity of the IEEE 802.11b network have been conducted in [1], where they observed that in good channel conditions, a higher number of voice users can be supported by using larger payload sizes. The use of theoretical framework for rate adaptation to evaluate IEEE 802.11 is investigated in [2]. The authors propose a computationally expensive dynamic programming approach to find the optional data rates that can be used for fairly simple wireless channel variation models with known probability of transitions from good to bad states and vice versa. They accomplished this by using a discrete Markov Chain. A link adaptation strategy for IEEE 802.11b is provided in [5], where the frame lengths are classified into three broad categories: 0 - 100 bytes, 100 - 1000 bytes and 1000 - 2400 bytes. An early investigation on the effect of payload size on throughput is conducted in [6]. This paper considers the payload length as an optimization parameter and proposes a cross-layer scheme that jointly optimizes users’ throughput in IEEE 802.11a WLAN based on channel conditions. The theoretical formulation in this paper allows payload to be varied continuously over a wider range. A mathematical framework is then formulated to dynamically adapt the payload length to maximize the throughput for Additive White Gaussian Noise (AWGN) under different fading channels.
4. Throughput System Modeling
We have defined throughput as the number of payload bits per second received correctly. For initial analysis, we consider the effect of payload variation in AWGN

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
18
channels and assume that the acknowledgements from the receiver are free of errors. The throughput corresponding to the physical layer (PHY) mode j is given by:
LbPbRCL
LjT s
jsj
j
,,)(
(1)
where L is the payload length in bits
jC is the header and DCF overhead corresponding to
rate ‘j’ in bits. jR is the data rate corresponding to PHY mode j.
b is the number of bits per MQAM symbol j
sP is the packet success rate (PSR) defined as the probability of receiving a packet correctly corresponding to PHY mode j.
s is the SNR per symbol and is given by
soo
ss RN
PN (2)
where PandNos ,, represents the energy per symbol, the one-sided noise power spectral density and the received power respectively.
jC takes into account the
CSMA/CA channel access time and the header overhead as specified by the IEEE 802.11 protocol. The time delay is converted to bytes for the purpose of optimization by the expression
ovhsj TRC (3)
where sR is the transmission rate corresponding to PHY
mode ‘s’ and ovhT is the total protocol overhead. Since any symbol error in the packet results in a loss of the packet, the packet success rate (PSR) is given in terms of the symbol error rate eP by
sj
ess bLPLbP ,,1,, (4)
where the eP of MQAM in AWGN channels for the various PHY models in IEEE 802.11a is derived in [2]. In order to find the optimal payload length, L , we assume that the payload length L continuously varies. Differentiating equation (1) with respect to L and applying equation (4) produces the derivative in equation (5).
Lse
jj
je
L
sj
ej
j PL
CRPP
CL
LR
L
jT
11ln1)(2
(5)
Setting this derivative to zero, we obtain a quadratic equation in L with the root.
bP
bCC
CL
se
jj
j
,1ln4
21
22
(6)
Thus, the optimal packet length L depends on the SNR per symbol s and the probability of the symbol error eP . To find the data rate
jR that maximizes the throughput,
we differentiate equation (1) with respect to jR and obtain
the following condition
js
sj
js
jj R
LPR
CL
LLP
CL
L
R
jT
,
,)( (7)
jo
j
s
sjs
jj RN
PLPRLP
CL
L
R
jT
,
,)( (8)
Next, we set this derivative in equation (8) to zero
0,,
sjo
js
LP
RN
PLP
(9)
Hence
s
ss
LfLP
,, (10)
We adopt the notation for signal-to-interference and noise ratio (SNR) that satisfies equation (10). Combining equation (10) and (4), we arrive at an equation for obtaining the preferred SNR per symbol
s thus,
b
LbPbP se
sss
ses
,1, (11)
where eP of MQAM in AWGN channels [7] is approximately given by:
sbb
se QbP 12
3214, 2/* (12)
where Q is the error function and is given by 2/)( 2
21)( xtexQ
Once s is determined, the optimal symbol rate is
obtained from equation (2) as
oss N
PR *
(13)
Note that the solution s in equation (11) and (12)
depends on only design parameters b and L, but is independent of the received power level. Using equations (2) – (12), equation (1) can be rewritten as
sbb
sj QbRL
CLT
1232141 2/ (14)
Equation (14) is computed under non-fading or slowly fading channels where the fade duration is longer than a packet period. Considering a flat Rayleigh fading

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
19
channel, the average probability of the symbol error
eP approximates to [8]:
sb
sbse bP
3122
31212, 2/ (15)
Also, rewriting equation (1) from equation (15) gives
sb
sbsj bR
L
CLT
3122
31212 2/
(16)
5. Simulation Input and Form Design Table 1 shows the parameter list and values for the simulation input. The table represents empirical parameters obtained from ideal conditions. Our reason for simulating with ideal environmental conditions is to make the simulation real and suitable for precise prediction.
Table 1. Model input parameters
Parameter Value Packet Length (L) 64, 128, 256 Data rate (Rs) 500, 250, 150 Date transmission overhead ovhT
20
Number of bits (b) 1, 2, 4, 6, 8 Bit error rate seP 0.01 – 0.1
SNR s (1 – 10)dB
Input forms were designed to accept the various parameters for the simulation. Figures 1- 3 show the sample input forms for the simulation:
Figure 1. Input form for Optimum packet length
simulation
The input parameters were used to simulate the derived model in section 4. The following section analyses and interprets the results obtained from the simulation.
Figure 2. Input form for Symbol error rate simulation
Figure 3. Input form for simulation interface
6. Discussion and Interpretation of Simulation Results
In this section, we represent the simulation results graphically to enable us interpret them with precision. In Figure 4, the optimum packet length (L*) is a decreasing function of the bit error rate (BER). As the bit error rate decreases, the packet error rate approaches zero, and the optimum packet length increases without bounds. In Figure 5, since BER decreases with increased SNR, the optimum packet length increases monolithically with the SNR. This shows that better channels support longer packets. Of course, in practice, the packet length (L) is an
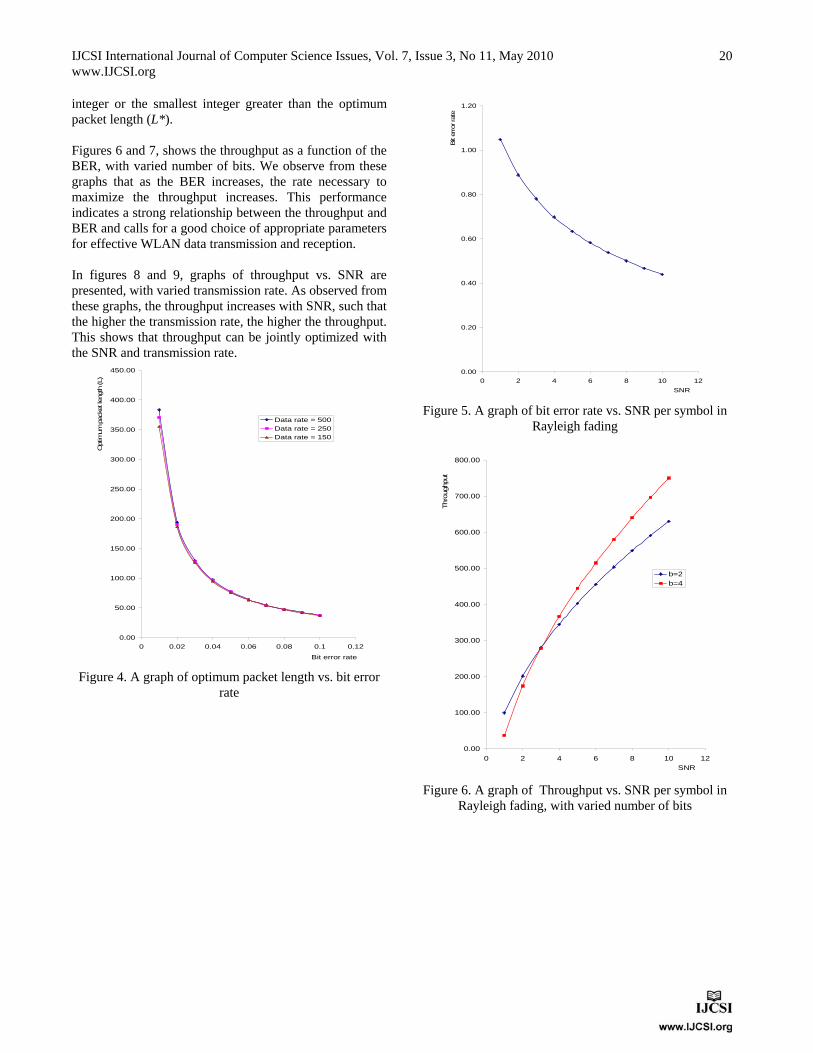
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
20
integer or the smallest integer greater than the optimum packet length (L*). Figures 6 and 7, shows the throughput as a function of the BER, with varied number of bits. We observe from these graphs that as the BER increases, the rate necessary to maximize the throughput increases. This performance indicates a strong relationship between the throughput and BER and calls for a good choice of appropriate parameters for effective WLAN data transmission and reception. In figures 8 and 9, graphs of throughput vs. SNR are presented, with varied transmission rate. As observed from these graphs, the throughput increases with SNR, such that the higher the transmission rate, the higher the throughput. This shows that throughput can be jointly optimized with the SNR and transmission rate.
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
400.00
450.00
0 0.02 0.04 0.06 0.08 0.1 0.12
Bit error rate
Opt
imum
pac
ket le
ngth
(L)
Data rate = 500
Data rate = 250Data rate = 150
Figure 4. A graph of optimum packet length vs. bit error
rate
0.00
0.20
0.40
0.60
0.80
1.00
1.20
0 2 4 6 8 10 12
SNR
Bit
erro
r ra
te
Figure 5. A graph of bit error rate vs. SNR per symbol in
Rayleigh fading
0.00
100.00
200.00
300.00
400.00
500.00
600.00
700.00
800.00
0 2 4 6 8 10 12SNR
Thro
ughpu
t
b=2b=4
Figure 6. A graph of Throughput vs. SNR per symbol in
Rayleigh fading, with varied number of bits
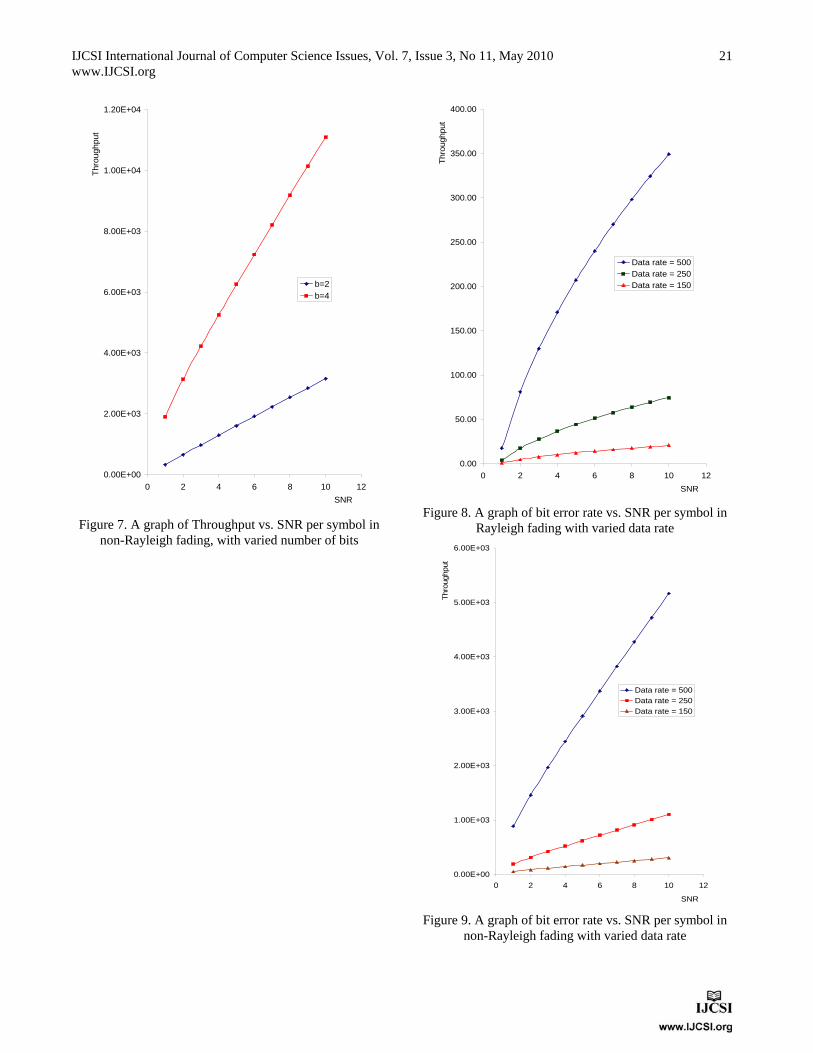
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
21
0.00E+00
2.00E+03
4.00E+03
6.00E+03
8.00E+03
1.00E+04
1.20E+04
0 2 4 6 8 10 12
SNR
Thr
ough
put
b=2b=4
Figure 7. A graph of Throughput vs. SNR per symbol in
non-Rayleigh fading, with varied number of bits
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
400.00
0 2 4 6 8 10 12
SNR
Thro
ughpu
t
Data rate = 500
Data rate = 250Data rate = 150
Figure 8. A graph of bit error rate vs. SNR per symbol in
Rayleigh fading with varied data rate
0.00E+00
1.00E+03
2.00E+03
3.00E+03
4.00E+03
5.00E+03
6.00E+03
0 2 4 6 8 10 12
SNR
Thr
ough
put
Data rate = 500Data rate = 250
Data rate = 150
Figure 9. A graph of bit error rate vs. SNR per symbol in
non-Rayleigh fading with varied data rate

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
22
5. Conclusions
This paper has presented a framework for achieving higher throughput by careful adaptation of packet (payload) length and data rate with varying channel conditions. We studied the WLAN data configurations, and have proposed a reliable data transmission model for efficient network deployment. A mathematical model under fading and non fading channels that improves the system’s throughput for optimal performance in generic WLAN systems is also presented. The proposed model has been evaluated through extensive computer simulation subject to both Rayleigh and Non-Rayleigh fading channels. The simulation results were analyzed and relationships between the model parameters established.
References [1] D. P. Hole and F. A. Tobagi. “Capacity of an IEEE
802.11b Wireless LANS Supporting VOIP”, in Proceedings of IEEE ICC, 2004, pp. 196 – 201.
[2] D. Qiao, S. Choi and K. G. Shin. “Goodput Analysis and Link Adaptation for IEEE 802.11a Wireless LANs”. IEEE Transactions on Mobile Computing. Vol. 1. No. 4, pp. 278-292.
[3] G. Bianchi. “Performance Analysis of the IEEE 802.11 Distributed Coordination Function”. IEEE Journal on Selected Areas in Communications. Vol. No. 3, 2000, pp. 535-547.
[4] H. Wu, Y. Peng, K. Long, J. Cheng and J. Ma. “Performance of Reliable Transport Protocol over IEEE 802.11 Wireless LAN: Analysis and Enhancement”, in Proceedings of IEEE INFOCOMM, Vol. 2, pp. 599-607.
[5] J. P. Pavon and S. Choi. “Link Adaptation Strategy for IEEE 802.11 WLAN via Received Signal Strength Measurement”, in Proceedings of IEEE ICC, 2003, pp. 1108-1113.
[6] P. Lettieri and M. B. Srivastava. “Adaptive Frame Length Control for Improving Wireless Link Throughput, Range and Engery Efficiency”, in INFOCOM, Vol. 2, 1998, pp. 564-571.
[7] J. G. Proakis. Digital Communications. New York, NY, McGraw-Hill Inc., third ed., 1995.
[8] A. Goldsmith and S. G. Chua, “Variable-rate variable-power M-QAM for fading channels,” IEEE Transaction on Communication., vol. 45, pp. 1218–1230.
Ekpenyong, Moses. Moses Ekpenyong is a lecturer the Department of Mathematics, Statistics and Computer Science, University of Uyo, Nigeria. He obtained his B.Sc. and M.Sc. degrees in Computer Science, but his PhD (in view) is in the area of Speech Technology. He is a member of the following professional bodies: Nigerian Association of Mathematical Physics
(NAMP), Nigeria Computer Society (NCS), International Speech and Communications Association (ISCA), Nigeria Mathematical Society (NMS), Nigerian Statistical Association (NSA) and West-African Linguistics Society (WALS). He is an International researcher and enjoys fruitful collaboration with academicians both within Nigeria and abroad (from other fields) and has published widely in the area of wireless communications. His area of specialization is speech modeling and communications technology. Isabona, Joseph is a Lecturer at the Benson Idahosa University, Benin City, Nigeria. He has B.Sc. and M.Sc. degrees in Theoretical Physics and Physics Electronics/ Communications respectively. His PhD (in view) is in the area of Physics Electronics. He is a member of the Nigerian Association of Mathematical Physics (NAMP). He has published both nationally and internationally in the area of wireless communications. His area of specialization is signal processing and radio resource management in wireless networks.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
23
Hello Flood Attack and its Countermeasures in Wireless Sensor Networks
Virendra Pal Singh1, Sweta Jain2 and Jyoti Singhai3
1 Department of Computer Science and Engineering, MANIT Bhopal, M.P., India
2 Department of Computer Science and Engineering, MANIT Bhopal, M.P., India
3 Department of Electronic and Telecommunication, MANIT Bhopal, M.P., India
Abstract Wireless sensor network have emerged as an important application of the ad-hoc networks paradigm, such as for monitoring physical environment. These sensor networks have limitations of system resources like battery power, communication range and processing capability. Low processing power and wireless connectivity make such networks vulnerable to various types of network attacks. One of them is hello flood attack, in which an adversary, which is not a legal node in the network, can flood hello request to any legitimate node and break the security of WSN. The current solutions for these types of attacks are mainly cryptographic, which suffer from heavy computational complexity. Hence they are less suitable for wireless sensor networks. In this paper a method based on signal strength has been proposed to detect and prevent hello flood attack. Nodes have been classified as friend and stranger based on the signal strength. Short client puzzles that require less computational power and battery power have been used to check the validity of suspicious nodes. Keywords: WSN, client puzzles, signal strength.
1. Introduction
Wireless sensor networks are a particular type of ad hoc network, in which the nodes are ‘smart sensors’. Sensors are small devices equipped with advanced sensing functionalities (for monitoring temperature, pressure, acoustics etc.), a small processor, and a short-range wireless transceiver [1]. In this type of network, the sensors exchange information about the environment in order to build a global view of the monitored region. This information is made accessible to the external user through one or more gateway nodes. Sensor networks are expected to bring a breakthrough in the way natural phenomena are
observed: the accuracy of the observation will be considerably improved, leading to a better understanding and forecasting of such phenomena. WSN technology enables monitoring of vast and remote geographical region, in such a way that abnormal events can be quickly detected. The cost of sensor nodes varies from hundreds of dollars to a few cents, depending upon their size and complexity. Size and cost constraints on sensor nodes result in corresponding constraints on resources such as energy, memory, computational speed and transmission range. [1]
2. Attacks on Sensor Networks
Most sensor network routing protocols are quite simple, and for this reason are sometimes even more susceptible to network attacks as compared to general ad-hoc routing protocols. Most network layer attacks against sensor networks fall into one of the following categories: [2]
2.1 Spoofed, altered, or replayed routing information
One direct attack against a routing protocol is to target the routing information exchanged between nodes by spoofing, altering, or replaying routing information. Adversaries may be able to create routing loops, attract or repel network traffic, extend or shorten source routes, generate false error messages, partition the network, increase end-to-end latency by using this type of attack. [2] 2.2 Selective forwarding

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
24
In selective forwarding attack, malicious nodes may refuse to forward certain messages and simply drop them, ensuring that they are not propagated any more. A simple form of this attack is: when a malicious node behaves like a black hole and refuses to forward every packet it receives. However, such an attacker runs the risk that neighboring nodes will conclude that this node has failed and decides to seek another route. A more subtle form of this attack is when an adversary selectively forwards packets. An adversary interested in suppressing or modifying packets originating from few selected nodes can reliably forward the remaining traffic and limit suspicion of its wrongdoing. [2]
2.3 Sinkhole attacks
In a sinkhole attack, the attacker’s goal is to lure nearly all the traffic from a particular area through a compromised node, creating a sinkhole with the adversary at the centre like black hole attack in ad hoc networks. Sinkhole attacks typically work by making a compromised node look attractive to surrounding nodes with respect to the routing algorithm. [2]
2.4 The Sybil attack
In Sybil attack, a single node presents multiple identities to other nodes in the network. The Sybil attack can significantly reduce the effectiveness of fault-tolerant schemes such as distributed storage, multipath routing, and topology maintenance. Replicas, storage partitions and routes believed to be used by disjoint nodes could in actuality be used by one single adversary presenting multiple identities. [2] 2.5 Wormholes In the wormhole attack, an attacker tunnels messages received in one part of the network over a low latency link and replays them in a different part of the network. The wormhole puts the attacker nodes in a very powerful position compared to other nodes in the network. For instance in reactive routing protocols such as AODV or DSR, the attackers can tunnel each route request RREQ packet to another attacker which near to destination node of the RREQ. When the neighbors of the destination hear this RREQ, they will rebroadcast this RREQ and then discard all other received RREQs in the same route discovery process. [2]
2.6 Hello flood attack
Some routing protocols in WSN require nodes to broadcast hello messages to announce themselves to their neighbors. A node which receives such a message may assume that it is within a radio range of the sender. However in some cases this assumption may be false; sometimes a laptop-class attacker broadcasting routing or other information with large enough transmission power could convince every other node in the network that the attacker is its neighbor. For example, an adversary advertising a very high quality route to the base station could cause a large number of nodes in the network to attempt to use this route. But those nodes which are sufficiently far away from the adversary would be sending the packets into oblivion. Hence the network is left in a state of confusion. Protocols which depend on localized information exchange between neighboring nodes for topology maintenance or flow control are mainly affected by this type of attack. [3]
An attacker does not necessarily need to construct legitimate traffic in order to use the hello flood attack. It can simply re-broadcast overhead packets with enough power to be received by every other node in the network. [3]
Figure 1(a) shows an attacker broadcasting hello packets with more transmission power than a base station. Figure 1(b) shows that a legitimate node considers attacker as its neighbor and also as an initiator. [3]

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
25
3. Countermeasures against Hello Flood Attack
Multi-path multi-base station data forwarding technique is proposed in [3], in which a sensor node maintains number of different secrets (keys) in a multiple tree. Sensor node can forward its sensed data to multiple routes by using these secrets. There are multiple base stations in the network that have control over specific number of nodes and also, there are common means of communication among base stations. Each base station has all the secrets that are shared by all the sensor nodes, covered by it, according to the key assignment protocol. Given the shared secret and the generated new key between two sensor nodes, the process of route setup requires much processing hence is inefficient. In [4] author suggests that hello flood attack can be counteracted by using “identity verification protocol”. This protocol verifies the bi-directionality of a link with encrypted echo-back mechanism, before taking meaningful action based on a message received over that link. This defense mechanism becomes in effective when an attacker has a highly sensitive receiver and a powerful transmitter. If an attacker compromises a node before the feedback message, it can block all its downstream nodes by simply dropping feedback messages. Thus, such an attacker can easily create a wormhole to every node within range. Since the links between these nodes and attacker are bidirectional, the above approach will unlikely be able to locally detect or prevent a “hello flood”. Considering the scarcity of energy resources of sensor nodes, the authors have proposed in [5] a probabilistic based approach, which forces few randomly selected nodes to report to base station about hello requests. The base station then further analyzes the request authenticity. In [2] a cryptographic technique is used to prevent the hello flood attack. Any two sensors share the same secret key. Every new encryption key is generated on fly during the communication. This phenomenon ensures that only reachable nodes can decrypt and verify the message and hence prevent the adversary from attacking the network. But the main drawback of this approach is that any attacker can spoof its identity and then generate attacks. In [6] the authors have proposed a security solution framework tailored to the base station for defending against DoS attack. After initial DoS detection, base station challenges clients with cryptographic puzzles to protect itself from different types of attacks. Compared with traditional puzzle schemes, they introduce a novel reputation based client puzzles, which applies a dynamic
policy to adjust the puzzle difficulty for each node in terms of node’s reputation value. Hence the punishment for malicious nodes becomes more and more pressing without introducing extra unnecessary burden to most normal nodes. A security mechanism based on signal strength and geographical information is proposed in [7] for detecting malicious nodes that launching hello flood and wormhole attack. The idea is to compare the signal strength of a reception with its expected value, calculated using geographical information and the pre-defined transceiver specification. The detection rate of the solution depends on different parameters such as network density, transmission power multiplier of the malicious node, message checking probability etc. In [8] a compromised network scenario, when the adversary with sensitive receiver, broadcasts a request like Hello with noticeable power, many nodes hear it at the same time, the nodes try to reply using two way or more way handshake protocol, to this message in order to announce their presence. However the healthy nodes have small transmission and carrier sense ranges. So those located farther than the carrier sense range of each other will try to send the messages back simultaneously. The core idea is to tune the channel access and transmission parameters so that the responses of these nodes collide with each other due to the high density in arrival time and prevent the adversary from decoding the messages correctly. This way the adversary will not be able to hear the victims’ replies and is obliged to reduce his power and act just like a normal node in the ideal form. This is like a well-known hidden node effect in wireless ad hoc networks. In fig. 2, node “A” represents the attacker with high transmission range equipped with sensitive receiver while “B”, “C” and “D” stand for healthy nodes whose carrier sense ranges are shown by dark circles around them. “b”, is a healthy node whose transmission is blocked and backed off due to the transmission of other nodes[8].

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
26
Figure (2)
A threshold based solution is proposed in [9] to defend against flooding attacks in MANET. The mobile nodes use a threshold value to check whether its neighbors are intruders or not. When the number of route request packets broadcasted by a node exceeds the predefined threshold value, it is treated as an intruder and the node stops providing its services to the intruder.
4. Proposed Scheme
In this paper we have proposed a solution for detection of hello flood attack which is based on signal strength and client puzzles method. Signal strength of all sensor nodes is assumed to be same in a radio range. Each node checks the signal strength of the received hello messages with respect to known radio range strength; if they are same then sender node is classified as a “friend” else sender is classified as a “stranger”. When any node is classified as a stranger, we try to check its validity using some client puzzles. Dynamic policy technique is used to adjust the difficulty of puzzle level for each node in terms of number of hello messages sent. The more the number of hello message sent by a node, more will be the difficulty of the puzzles it has to solve. Some primary assumption are- (1) Communication is within fixed radio range. (2) All sensor nodes in a fixed radio range have same transmitting and receiving signal strength. (3) All sensor nodes are homogeneous (same hardware and software, battery power etc.). (4) Every sensor node knows the fixed signal strength used in its communication range. (5) A time threshold is used, which denotes the expected time of reply message. (6) A hello message counter has been used by all sensors to keep the record of number of hello requests received in an allotted time. Initially signal strength is calculated as two ray propagation model [10] Pr= (Pt*Gt*Gr*Ht
2*Hr2)/(d4*L) (1)
In eq. 1 Pr is received signal power (in watts), Pt is transmission power (in watts), Gt is the transmission antenna gain , Gr is the receiver antenna gain, Ht is the transmitter antenna height(in meter) and Hr is the receiving antenna height(in mete), d is the distance between transmitter and receiver (in meter), and L is the system loss(a constant). A signal is only detected by a
receiving node if the received signal power Pr is equal or greater than the received signal power threshold Pthres. When any laptop class attacker sends hello message to a legitimate node in a fixed radio range then the receiving node checks its hello message signal strength, if it is same then requesting node is a legal node of the network; if it differs, it categorizes the sender node as stranger. Signal strength = Fixed signal strength in radio range=friend Signal strength > Fixed signal strength in radio range=stranger If signal strength of received hello message is approximately same but not equal to fixed signal strength then it may be a stranger or a friend. To distinguish between a friend and a stranger we apply a technique based on client puzzles. The puzzles used take less memory and computation power. The node sends some puzzles to the requesting node; if the correct reply comes in allotted time threshold then the node is considered as a friend, if not then it is treated as stranger. 4.1 Algorithm for hello flood prevention Begin INPUT: Signal Strength 1: If a node receives hello message from a node S then 2: if Signal strength of received hello message = fixed signal strength in radio range 3: then node s is classified as a friend 4: Node accepts hello message and perform necessary function 5: Else 6: if Signal strength of received hello message ≈ fixed signal strength in radio range 7: then nodes sends puzzle to node S 8: If reply message of correct answers comes in fixed time threshold 9: then Node is classified as friend and accepts the request and performs function 10: Else Signal strength of received message > fixed signal strength in radio range 11: then Node S is classified as stranger and rejects the further requests from S. 12: End 4.2 Client Puzzle Method Puzzle is basically a number that is used to check the validity of node. The difficulty level of Unicode is based on the left bit. Changes in left bits increase or decrease the

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
27
difficulty of puzzles. The core idea of hello message based client puzzles scheme (MBCP) is that the larger the number of hello messages sent, the sender will have to solve more difficult puzzles. Hence the difficulty of puzzles for stranger will increase according to number of hello messages sent. Each node has a counter to count the hello message in allotted time and a puzzle generating capability. If any node sends x hello message then it has to solve pth level difficult puzzles. For example A, B, C are three nodes that send x1, x2, x3(x1<x2<x3) hello message respectively to node N. N counts the number of hello messages sent and sends puzzles p1, p2, p3 according to increasing order of difficulty level (p1<p2<p3). This means C has to solve more difficult puzzles than B and B has to solve more difficult puzzle than A. So, when any node sends X hello requests then it has to solve pth level difficult puzzles. X α p (2) Equation (2) shows that if the number of hello message increases, then difficulty of puzzles also increases. 4.3 Other solutions for preventing hello flood attacks Each node checks the number of hello message received in a fixed time interval with the help of a counter. The node then tries to solve these requests in inverse proportionality of the number of incoming hello requests. This means a node which sends less number of hello messages, its request will be solved first and a node which sends more number of hello messages, its request will be solved later. Another solution for preventing hello flood attacks is based on time threshold. When a node does not receive reply message in a predefined time threshold then it treats the sender to be an attacker and this information is broadcasted to other nodes in the network which contains the attacker node id and the related path.
5. Conclusions
Security plays a crucial role in the proper functioning of wireless sensor networks. Our proposed security framework for hello flood detection via a signal strength and client puzzle method requires less computational power and energy, and hence it is quite suitable for sensor networks. In future we will be implementing the proposed scheme in ns-2 to check its effectiveness in securing sensor networks. References [1] Luis E. Palafox, J. Antonio Garcia-Macias,(2008) Security in
Wireless Sensor Networks, IGI Global, Chapter 34.
[2] Chris Karlof, David Wagner,(2003) Secure Routing in Wireless Sensor Networks: Attacks and Countermeasures, IEEE.
[3] A Hamid, S Hong, (2006) Defense against Lap-top Class Attacker in Wireless Sensor Network, ICACT
[4] Venkata C. Giruka, Mukesh Singhal, James Royalty, Srilekha Varanasi, (2006), Security in wireless networks, Wiley Inter Science
[5] Dr. Moh. Osama K., (2007),Hello flood counter measure for wireless sensor network, International Journal of Computer Science and Security, volume (2) issue (3)
[6] Zhen Cao, Xia Zhou, Maoxing Xu, Zhong Chen, Jianbin Hu, Liyong Tang , (2006), Enhancing Base Station Security against DoS Attacks in Wireless Sensor Networks, IEEE
[7] Waldir Ribeiro Pires J´unior Thiago H. de Paula Figueiredo Hao Chi Wong Antonio A.F. Loureiro, (2004), Malicious Node Detection in Wireless Sensor Networks, IEEE
[8] Mohammad Sayad Haghighi , Kamal Mohamedpour, (2008), Securing Wireless Sensor Networks against Broadcast Attacks, IEEE
[9] Bo-Cang Peng, Chiu-Kuo Liang, (2006), Prevention Techniques for Flooding Attacks in Ad Hoc Networks, IEEE
[10]T.S.Rappaport,(200), Wireless communication: Principles and practice, Prentice hall 2nd edition.
Virendra Pal Singh. I have completed my B. Tech. degree from Uttar Pradesh Technical University, Lucknow, Uttar Pradesh (India) in Information Technology in the year 2005. Presently I am pursuing M. Tech. (Information Security) from Computer Science Department, Maulana Azad National Institute of Technology, Bhopal, Madhya Pradesh, India. My current research interests include Wireless Sensor Network, Network Security and computer networks. Sweta Jain. I have done B.Tech.(CSE) and M.Tech. (CSE) from Computer Science and Engg. Department of Maulana Azad National Institute of Technology, Bhopal, Madhya Pradesh, India in the year 2004 and 2009 respectively. Presently I am pursuing PhD from the same institute. I am working as an Assisstant Professor in Computer Science & Engineering Department of MANIT, Bhopal, India. My current research interests include Mobile Ad hoc Networks, specifically clustering and security issues in MANETs. Jyoti Singhai. I have completed B.Tech. (ET&C) from Maulana Azad National Institute of Technolgy, Bhopal in the year 1991. Also completed my M.Tech.(Digital communications) and PhD from the same institute in the year 1997 and 2005 respectively. I am working as an Associate Professor in Electronics and Telecommunications deptt. Of MANIT, Bhopal. My research interests include Mobile Ad hoc Networks and Image processing.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
28
Faster and Efficient Web Crawling with Parallel Migrating Web Crawler
Akansha Singh1 , Krishna Kant Singh2
1Deptt. Of Information Technology , AKGEC
Ghaziabad, India
2Deptt. Of Electronics & Communication
AKGEC
Ghaziabad, India
Abstract
A Web crawler is a module of a search engine that fetches data from various servers. Web crawlers are an essential component to search engines; running a web crawler is a challenging task. It is a time-taking process to gather data from various sources around the world. Such a single process faces limitations on the processing power of a single machine and one network connection. This module demands much processing power and network consumption. This paper aims at designing and implementing such a parallel migrating crawler in which the work of a crawler is divided amongst a number of independent and parallel crawlers which migrate to different machines to improve network efficiency and speed up the downloading. The migration and parallel working of the proposed design was experimented and the results were recorded.
Keywords: web crawler, url ,Migrating
1. Introduction
The World Wide Web is a system of interlinked hypertext documents accessed via the Internet. English physicist Tim Berners-Lee, now the Director of the World Wide Web Consortium, wrote a proposal in March 1989 for what would eventually become the World Wide Web [1]. With the ever expanding Internet, it is difficult to keep track of information added by new sites and new pages being uploaded or changed everyday. While the Internet is nearing chaos, it is difficult for a user to find correct information in a timely manner. Today’s search engines are greatly used to get whereabouts of relevant information very quickly. They are like maps and signs which point the user in right direction. A search engine consists of following modules:
A crawling module which fetches pages from Web servers known as web crawler.
Indexing and analysis modules which extract information from the fetched pages and organize the information
A front-end user interface and a supporting querying engine which queries the database and presents the results of searches.
2. Web Crawler
Web crawlers are a part of the search engines that fetch pages from the Web and extract information [3]. A simple crawler algorithm is as follows:
Crawler ( )
1. Do Forever
2. Begin
3. Read a URL from the set of seed URL’s
4. Determine the IP-address for the Host name
5. Download the Robot.txt file, which carries download information and also includes the files to be excluded by the crawler
6. Determine the protocol of underlying Host like HTTP, FTP, GOPHER
7. Based on this protocol, download the document
8. Check whether the document has already been downloaded or not
9. If the document is a fresh one,
10. Then
11. store it and extract the links and references to other sides from that document
12. Else
13. Abandon the document
14. End
The Web crawler is given a start-URL and the Crawler follows all links found in that HTML page. This usually leads to more links, which will be followed again, and so on. [2]
3. Related Work
The literature survey shows that a number of modifications in the basic crawler have been done to improve the crawling

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
29
speed.PARALLEL CRAWLERS [6], A crawler can either be centrally managed or totally distributed. The authors mention that distributed crawlers are advantageous than multithreaded crawlers or standalone crawlers on the counts of scalability, efficiency and throughput. If network dispersion and network load reduction are done, parallel crawlers can yield good results. Their system utilizes memory of the machines and there is no disk access.
PARCAHYD [2] In this, work it has been proposed that if the links contained within a document become available to the crawler before an instance of crawler starts downloading the documents itself, then downloading of its linked documents can be carried out in parallel by other instances of the crawler. Therefore, it is proposed that meta-information in the form Table Of Links (TOL) consisting of the links contained in a document be provided and stored external to the document in the form of a file with the same name as document but with different extension . This one time extraction of TOL can be done at the time of creation of the document
MIGRATING CRAWLER [4], an alternative approach to Web crawling is based on mobile crawlers. The authors propose that the crawlers are transferred to the source(s) where the data resides in order to filter out any unwanted data locally before transferring it back to the search engine. This reduces network load and speeds up the indexing phase inside the search engine.
MERCATOR [7] is a scalable and extensible crawler, now rolled into the Altavista search engine. The authors of [7] discuss implementation issues to be acknowledged for developing a parallel crawler like traps and bottlenecks, which can deteriorate performance. They discuss pros and cons of different coordination modes and evaluation criteria. In brief, they concur that the communication overhead does not increase linearly as more crawlers are added, throughput of the system increases linearly as more nodes are added and the quality of the system, i.e. the ability to get “important” pages first, does not decrease with increase in the number of crawler processes.
4. The Problem
With the help of a study done on the various crawling methods several problems were identified, these are as follows
Due to the rapid growth of the Web the downloading creates a bottleneck at the downloader side.
Further the pages may be downloaded in duplicates that generates unnecessary network load.
In addition, Kahle [9] reports that the average online time of a page is only 75 days, which leads to an update rate of 600GB per month that should be downloaded to keep collection up to date. So, the crawler should revisit the already downloaded pages to check the updation.
Thus, in order to keep the database of a search engine up to date, crawlers must constantly retrieve/update Web pages as fast as possible.
5. Proposed Solution
The proposed solution to the above problems is to decentralize and perform site-based distribution of work among the machines and simultaneously crawl as many domains as possible. This paper aims at designing a centrally managed migrating parallel crawler to crawl websites. The crawling function is logically migrated to different machines which send back the filtered and compressed data to the central machine which saves time and bandwidth. The architecture proposed in this paper is shown in figure 1. The major focus is on the design proposed for the crawler system, which implements the idea of parallel migrating crawler. The crawler system itself consists of several specialized components, in particular a central crawler, one or more crawl frontiers, and a local database of each crawl frontier. This data is transferred to the central crawler after compression and filtering which reduces the network bandwidth overhead. These crawl frontiers, are logically migrated on different machines to increase the system performance. The central crawler is responsible for receiving the URL input stream from the applications and forwarding it to the available crawl frontiers. The crawler system is composed of a central crawler and a number of crawl frontiers which perform the task of crawling.
1. Central Crawler: The central crawler is the central component of the system, and the first component that is started up. Afterwards, other components are started and register with the central crawler to offer or request services. It is like the server in Client server. It is the only component visible to the other components, as the crawl frontiers work independently. In general, the goal of the central crawler is to download pages in approximately the order specified by the application, while reordering requests as needed to maintain high performance without putting too much load on any particular web server. The central crawler has a list of URLs to crawl. The URLs are sent in batches to the crawl frontiers, making sure that a certain interval between requests to the same server is observed. The central crawler has a seed URL list which is to be crawled unlike conventional crawling the central crawler has a set of available crawl frontiers which have registered themselves with the central crawler which are logically migrated to different locations. The central crawler assigns different URLs to all the crawl frontiers and in turn the crawl frontiers begin to crawl the received URL. As the crawl frontier completes its crawling, the central crawler receives the compressed downloaded content from the crawl frontiers. The central crawler is implemented using java RMI .The Algorithm is as follows:
Central Crawler ()
1. Do Forever

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
30
2. Begin
3. Register crawl frontiers
4. Read a URL from the set of seed URL’s
5. Determine the IP-address for the Host n€ame
6. Download the Robot.txt file, which carries download information and also includes the files to be excluded by the crawler.
7. while seed URL list is not empty or crawl frontiers are available
8. Dispatch URL to available crawl frontier.
9. Wait for result from crawl frontiers.
Figure 1: Proposed Architecture
10. receive downloaded content from crawl frontiers.
11. store the local data of each crawl frontier in the central database.
12. End
2. Crawl Frontiers (CF): The crawl frontier component, implemented in JAVA, performs the basic function of a breadth first crawler, i.e., it fetches files from the web by opening up connections to different servers. It is like the client in client /server architecture The files are written in the local document database available with each crawl frontier. The application then parses each downloaded page
for hyperlinks, checks whether these URLs have already been encountered before, and if not, adds them to the queue containing the links to be visited. The crawl frontier also shows the time taken by it a crawl a particular url , i.e., the url and the hyperlinks found on visiting that url. In the implementation there are two queues one which contains the internal links of the website and the other contains the external links encountered. This is done to set a priority that first all the internal links are visited and then the external links are visited. The downloaded files are then compressed using java classes and transferred to the central database. The crawl frontiers is also implemented in java. The algorithm is as follows:
Crawl frontier ()
1. Do Forever
2. Begin
3. Register with central server by sending the IP address of the machine.
4. Wait for URL to crawl
5. Receive URL from central crawler.
6. Add this URL to the list of URLs to visit.
7. while URL list is not empty
8. remove the first URL from the list
9. visit the URL.
10. save the page in the local database.
11. parse the page and find the URL hyper links in the page
12. if the links are not present in the to visit list
13. add the URL to the to_visit list
14. Compress the downloaded content.
15. Send the compressed content to the central crawler crawler.
16. End
3. Local Document Database (LDDB): When the crawl frontier runs it requires some memory space to save the downloaded content for this purpose each crawl frontier has its own local database which is known as the local document database. The crawl frontiers save the downloaded content in a directory in this database .It is the storage area of the machine on which the crawl frontier is running.
4. Central Database: As in conventional crawlers this database is the one that communicates with the database of the search engine. The central database stores the list of URLs received from the application and it also stores the final downloaded documents which is composed of the various documents downloaded by the different crawl frontiers.
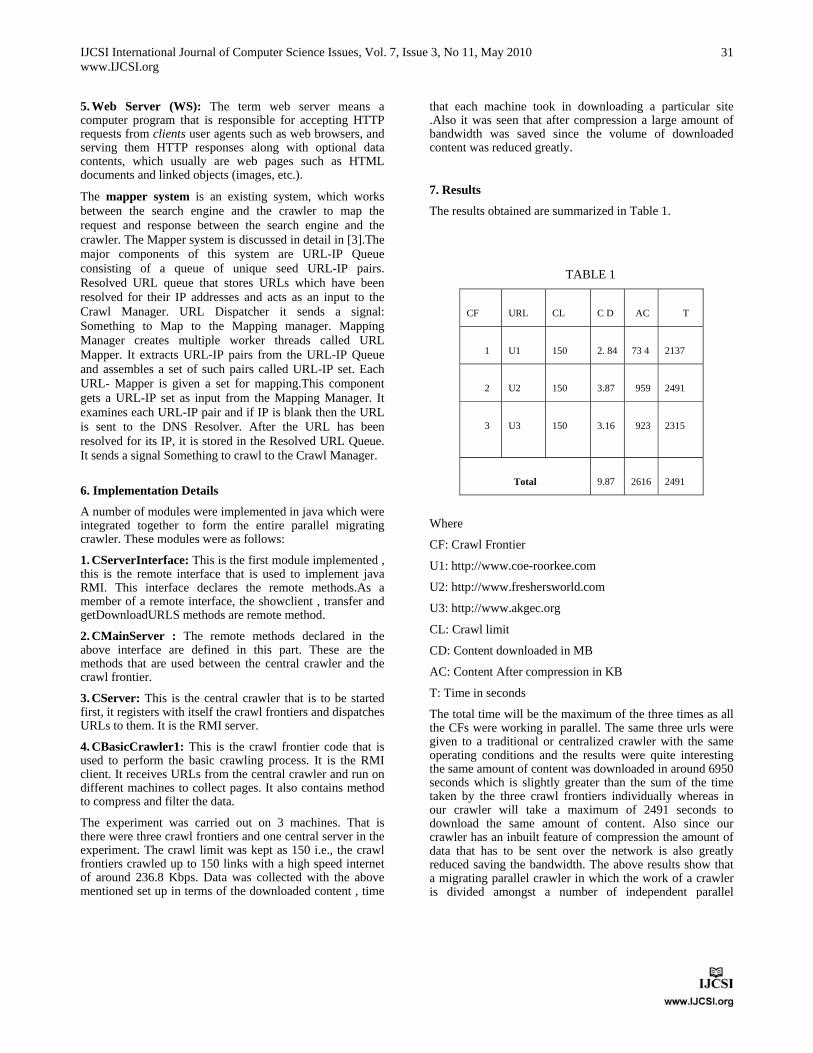
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
31
5. Web Server (WS): The term web server means a computer program that is responsible for accepting HTTP requests from clients user agents such as web browsers, and serving them HTTP responses along with optional data contents, which usually are web pages such as HTML documents and linked objects (images, etc.).
The mapper system is an existing system, which works between the search engine and the crawler to map the request and response between the search engine and the crawler. The Mapper system is discussed in detail in [3].The major components of this system are URL-IP Queue consisting of a queue of unique seed URL-IP pairs. Resolved URL queue that stores URLs which have been resolved for their IP addresses and acts as an input to the Crawl Manager. URL Dispatcher it sends a signal: Something to Map to the Mapping manager. Mapping Manager creates multiple worker threads called URL Mapper. It extracts URL-IP pairs from the URL-IP Queue and assembles a set of such pairs called URL-IP set. Each URL- Mapper is given a set for mapping.This component gets a URL-IP set as input from the Mapping Manager. It examines each URL-IP pair and if IP is blank then the URL is sent to the DNS Resolver. After the URL has been resolved for its IP, it is stored in the Resolved URL Queue. It sends a signal Something to crawl to the Crawl Manager.
6. Implementation Details
A number of modules were implemented in java which were integrated together to form the entire parallel migrating crawler. These modules were as follows:
1. CServerInterface: This is the first module implemented , this is the remote interface that is used to implement java RMI. This interface declares the remote methods.As a member of a remote interface, the showclient , transfer and getDownloadURLS methods are remote method.
2. CMainServer : The remote methods declared in the above interface are defined in this part. These are the methods that are used between the central crawler and the crawl frontier.
3. CServer: This is the central crawler that is to be started first, it registers with itself the crawl frontiers and dispatches URLs to them. It is the RMI server.
4. CBasicCrawler1: This is the crawl frontier code that is used to perform the basic crawling process. It is the RMI client. It receives URLs from the central crawler and run on different machines to collect pages. It also contains method to compress and filter the data.
The experiment was carried out on 3 machines. That is there were three crawl frontiers and one central server in the experiment. The crawl limit was kept as 150 i.e., the crawl frontiers crawled up to 150 links with a high speed internet of around 236.8 Kbps. Data was collected with the above mentioned set up in terms of the downloaded content , time
that each machine took in downloading a particular site .Also it was seen that after compression a large amount of bandwidth was saved since the volume of downloaded content was reduced greatly.
7. Results
The results obtained are summarized in Table 1.
TABLE 1
CF URL CL
C D
AC T
1 U1 150
2. 84
73 4 2137
2 U2 150
3.87
959 2491
3
U3 150
3.16
923 2315
Total
9.87
2616 2491
Where
CF: Crawl Frontier
U1: http://www.coe-roorkee.com
U2: http://www.freshersworld.com
U3: http://www.akgec.org
CL: Crawl limit
CD: Content downloaded in MB
AC: Content After compression in KB
T: Time in seconds
The total time will be the maximum of the three times as all the CFs were working in parallel. The same three urls were given to a traditional or centralized crawler with the same operating conditions and the results were quite interesting the same amount of content was downloaded in around 6950 seconds which is slightly greater than the sum of the time taken by the three crawl frontiers individually whereas in our crawler will take a maximum of 2491 seconds to download the same amount of content. Also since our crawler has an inbuilt feature of compression the amount of data that has to be sent over the network is also greatly reduced saving the bandwidth. The above results show that a migrating parallel crawler in which the work of a crawler is divided amongst a number of independent parallel

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
32
crawlers called crawl frontiers improve network efficiency and speed up the downloading.
8.Conclusion
Crawlers are being used more and more often to collect Web data for search engine, caches, and data mining. As the size of the Web grows, it becomes increasingly important to use parallel crawlers. Unfortunately, very little is known (at least in the open literature) about options for parallelizing and migrating crawlers and their performance. This paper addresses this shortcoming by presenting a parallel migrating architecture, and by studying its performance. The authors believe that this paper offers some useful guidelines for crawler designers, helping them select the right number of crawling processes, or select the proper inter-process coordination scheme. In summary, the main conclusions of my design, implementation and the results obtained were the following:
Decentralizing the crawling process is a good solution for catering the needs of the ever increasing size of web.
When a number of crawling processes migrate to different locations and run parallel they make the crawling process fast and they save enormous amount of time in crawling.
The documents collected at each site are filtered. So only the relevant pages are sent back to the central crawler and this saves network bandwidth.
The documents before being sent to the central crawler are compressed locally and then sent to the central crawler which saves a large amount network bandwidth.
References
[1] Douglas E. Comer, “The Internet Book”, Prentice Hall of India, New Delhi, 2001.
[2] Monica Peshave, “How Search Engines Work And A Web Crawler Application”
[3] A.K. Sharma, J.P. Gupta, D. P. Aggarwal, “PARCAHYDE: An Architecture of a Parallel Crawler based on Augmented Hypertext Documents.”
[4] Joachim Hammer,Jan Fiedler “Using Mobile Crawlers to Search the Web Efficiently”
[5] V. Shkapenyuk , T. Suel, “Design and implementation of a high performance distributed Web crawler”. In Proceedings of the 18th International Conference on Data Engineering (ICDE'02), San Jose, CA Feb. 26--March 1, pages 357 -368, 2002,
[6] J. Cho and H.Garcia-Molina, “Parallel crawlers”. In Proceedings of the Eleventh International World Wide Web Conference, 2002, pp. 124 - 135,
[7] A. Heydon and M. Najork, “Mercator: A scalable, extensible web crawle”r.World Wide Web, vol. 2, no. 4, pp. 219 -229, 1999.
[8] P. Boldi, B. Codenotti, M. Santini, and S. Vigna, “Ubicrawler: A scalablefully distributed web crawler”. In Proceedings of
AusWeb02 - The Eighth Australian World Wide Web Conference, Queensland, Australia, 2002,
[9] B. Kahle. Achieving the Internet. Scientific American, 1996.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 33 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
The morphological analysis of Arabic verbs by using the surface patterns
A. Yousfi
The institute of studies and research for the arabization University Mohamed V Souissi, Rabat, Morocco
Abstract
In this article, we present a new system of morphological analysis using the surface patterns of the word to be analyzed. This approach required in the initial phase a classification of all Arabic verb roots by using the morphological rules of these last, and the second phase is the construction of data base of conjugated surface patterns.
This system is capable to analyze all Arabic verbs by decomposing the word to the prefixes, suffixes and roots. This approach has been tested on a corpus of 4000 verbs, the results were encouraging, and the error rate is 4%. Keywords: Arabic verbs, Morphological Analysis, Surface pattern, degree of similarity. 1. Introduction The morphological analysis has been widely used in several fields of Natural Language Processing (NLP) such as Information Retrieval (IR) systems, data mining, electronic dictionary, tagging systems and language model.
The several works have been done in the area of the Arabic morphological analysis. The three approaches are used in these works [1]:
The Symbolic approach: this approach is based on removing all attached prefixes and suffixes in an attempt to extract the root of a given Arabic surface word. Several morphological analyzers have been developed, e.g. [2], [3], [4], [5], [6], [7], and [8].
The statistical approach: this approach computes the probability that a prefix, a suffix, or a template would appear from a corpus of surface word [9].
The hybrid approach: this approach uses combination rules of morphemes with statistics. This method is based to build morphological rules and to estimate the probability that a prefix, a suffix, or a template would appear [1].
These approaches have the disadvantages, one mentions for example:
The dictionary of stems is very large and it is very difficult to build a dictionary containing all Arabic
stems. These dictionaries (of stems) contain a sort of repetition of the verbs having the same morphological rules ( "يفتح - فتح "، "يجمع -جمع " ).
These approaches use several rules at the time of the morphological analysis.
To remedy these problems, we have developed a morphological analyzer independent of stems dictionary and don't use the rules at time of the morphological analysis. Our system uses only the surface patterns of the word to be analyzed.
2. Classification of verbs by using the
surface patterns The word pattern permits to detect the letters of the root of the word. The pattern of "يكتبون" is "يفعلون" , the letters
" ف،ع،ل " replace the letters of root of "يكتبون" , and the pattern of "نال" is "فعل" [10]. This type of pattern cannot present the morphological variations of the word, it is why we proposed an adapted pattern called surface pattern. The construction method of this new pattern is: If one supposes that the word to find his pattern is:
nlllw ...21 ( il is letter), and R is her root.
The surface pattern of w is nfffp ...21 , with:
if is one of the three letters " ف،ع،ل" if il is in R
ii lf if il is not in R
And the surface pattern of the root kgggR ...21 ( ig
is letter) is kfffp '...'' 21 , with:
'if is one of the three letters " ف،ع،ل" if ig is a steady
letter at the time of the conjugation of the R.
ii gf ' else
Example: The conjugation of verb "أخذ" to the imperfect and 1st person, is "آخذ" , then the surface pattern of root "أخذ" is
"أعل" and "آعل" of "آخذ" .
The surface pattern of "نلت" is "فلت" and "فال" of "نال"

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 34 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
For the construction of data base of surface patterns of Arabic verbs, we classified more than 9800 root according to the conception of the surface pattern. We got more 100 surface patterns (Table1) of these roots [11].
Classe Surface pattern
أعل 7
أعل 8
أعل 9
آعى 20
استفعأ 70
انفعل 66
فال 10
فعل 1
فعل 2
لفع 3
فعلل 50
Table1: a part of the surface patterns of roots 3. Construction of data base of surface
patterns of verbs For the construction of data base (DB) of all surface patterns of Arabic verbs, we developed a program writes in JAVA to conjugate the 100 surface patterns of roots to all tenses (8 tenses) and all persons (13 persons and 5 persons of imperative tense (األمر)). The number of the conjugated surface patterns in the data base is: 100*8*13+100*5=10900. In order to eliminate the decomposition phase of the word to the prefixes, suffixes and roots (during the morphological analysis), we attached all prefixes and suffixes to the conjugated surface patterns of DB (the total number of surface patterns in DB is the order of 350000). The DB contains other information of types: tense, person, surface pattern of root … (Table2).
Surface pattern
Tense Person Surface
pattern of root
سيفعلهالمضارع المعلوم
المرفوع فعل هو
سيفعلهالمضارع المعلوم
المرفوع فعل هو
فال أنا الماضي المعلوم وفلت
آعلكالمضارع المعلوم
المرفوع أعل أنا
... ... ... ...
Table2: an example of a part of the DB. 4. The approach used in our analyzer
morphological Let w the word to be analysed and NpppE ,...,, 21
is the DB of the surface patterns. Our approach consists to finding all surface patterns of w, by using the degree of similarity s between w and surface pattern, s permits to count the number of letters that repeated in w and in surface pattern. The set of possible surface patterns of w is:
0),( wpsEpSol
We indexed the DB by using s; the research of surface pattern gets only in a query of size inferior to 20. This indexation decreases the duration of research in the DB. After the obtaining the set Sol, we get the information associated to these surface patterns (tense, person, surface pattern of root …). Example:
The morphological analysis of the word "نفأعلمه" is achieved by the following stages:
The system search the surface patterns of "فأعلمهن" , it finds "فأفعلهن" . This surface pattern is repeated three times in our DB :
معلوم هو أفعل-فأفعلهن ماضي *
منصوب أنا فعل -معلوم-مضارعفأفعلهن *
منصوب أنا فعل-معلوم-فأفعلهن مضارع *
The system uses these solutions to extract the roots associated to these solutions. Its finds the following roots: "أعلم"، "علم"، "علم" .
The system verifies if these roots exist in the base of the Arabic roots.
To the final phase the system presents the just morphological analysis (Fig. 1).

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 35 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
Fig. 1: The interface of our morphological analysis
program. Among the advantages of our system, we mention: - The phase of decomposition of word (at the time of the
morphological analysis) in prefix, a suffix and root is eliminated. This operation will decrease the duration of the morphological analysis.
- Our system doesn't use the morphological rules at time of the morphological analysis.
- Our system doesn't use the dictionaries of stems. 5. Implementation The evaluation of our approach is made by the realization of a program in java. This program is constituted of four packages: Package of conjugation the surface patterns of roots to
all tenses and all persons. Package that permits to attach the different suffixes and
prefixes to the conjugate surface patterns. Package of indexation of data base of all surface
patterns. Package of morphological analysis. This package is
constituted of two modules (Fig. 2), Module1 permits to find the different surface patterns of word (Input), Module2 extracts all possible solutions and verify the validity of these last.
This approach has been evaluated on 4000 verbs, the error rate is 4% and the duration of these verbs is 10 seconds (2,5ms for each verb). The majority of these errors (4%) are mainly that the entered words for the analysis are not the associated surface patterns. 6. Conclusions In this article, we presented a new approach of morphological analysis. This approach has been applied on the verbs. This approach remains always true for the derivative names [12], [13] it is sufficient to construct date base of surface patterns of derivative names.
This data base of surface patterns of derivative names is under construction by the help of the linguists.
Fig. 2
7. References
[1] Darwish, K. : “Building a shallow Arabic morphologi-cal analyser in one day” in Proceedings of the ACLWorkshop on Computational Approaches to Semitic Lan-guages, Philadelphia, PA, 2002.
[2] Buckwalter, T. : 2002, Buckwalter Arabic Morphological Analyzer. Version 1.0. Linguistic Data Consrtium, catalog. Number LDC2002L49 and ISBN 1-58563-257-0.
[3] Hegazi, N., and ElSharkawi, A. A. 1986. Natural Arabic Language Processing, Proceedings of the 9th National Computer Conference and Exhibition, Riyadh, Saudi Arabia, 1-17.
[4] Koskenniemi, Kimmo. Two Level Morpology: A General Computational Model for Word-form Recognition and Production. Publication No. 11, Dep. of General Linguistics, University of Helsinki, Helsinki, 1983.
[5] Beesly KR: Arabic Morphology Using Only Finate-State Operations, Proceedings of the Workshop on Computational Approaches to Semetic languages. Montreal, Quebec, pp 50-57.
[6] El-Sadany, T. A., and Hashish, M. A. 1989. An Arabic Morphological System. IBM Systems Journal. Vol.28, No.4, 600-612.
[7] Soudi, A.: 2002, A Computational Lexeme-Based, Treatment of Arabic Morphology. Doctorat d’état, Mohamed V University.
[8] Khoja S., Garside R.. Stemming Arabic text. Computer Science Departement, Lancaster University, Lancaster, UK.
Module1 Pattern
Module2
Output
Input
Patterns
Data Base

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 36 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
[9] Goldsmith, J.A. (2001). Unsupervised Learning of the Morphology of a Natural Language. Computational Linguistics, 27:2 pp. 153-198. [10] Mustapha G., الشيخ مصطفى الغالييني، جامع الدروس العربية . 1999 , المكتبة العصرية،[11] Sam A, Youssef D., سام عمار، يوسف ديشي، مجموعة
.العربية بيشرال األفعال 1999أآتوبر 5هاتييه باريس،
[12] Yousfi, A., Sabri, S., Bouyakhf, E., Système d’analyse morphologique des noms Arabes. JETALA (Journées d’Etudes sur le Traitement Automatique de la Langue Arabe), 2006, Rabat 5-7 juin, 2006. [13] Yousfi, A., Sabri, S., Bouyakhf, E., Système
d’analyse morphologique des noms Arabes. MCSEAI’06 December 07-09, 2006, Agadir.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
37
Real-Time Video Streaming Over Bluetooth Network Between Two Mobile Nodes
Sourav Banerjee, Dipansu Mondal, Sumit Das and Ramendu Bikash Guin
Kalyani Government Engineering College,
Kalyani, Nadia-741235, W.B.(INDIA)
University of Kalyani, Kalyani, Nadia-741235, W.B.(INDIA)
JIS College of Engineering, Kalyani, Nadia-741235, W.B.(INDIA)
Kalyani Government Engineering College, Kalyani, Nadia-741235, W.B.(INDIA)
Abstract The Bluetooth arrangement provides a very robust and powerful technology within a short range wireless communication. The communication over Bluetooth is complicated with a heavy security threat. Here, in this paper we proposed for a system, Bluetooth Enabled surveillance System (BESS) that will help transmitting live video streaming in between two mobile phone via built-in cell phone camera. This system can be useful for surveillance of a secret area or monitoring of any important work. This system can help to prevent certain attack within a small range.
1. Introduction
The Bluetooth [2] network is used to connect mobile nodes and other pervasive devices over the ISM band at 2.420-2.485GHz, using a spread spectrum, frequency hopping, full-duplex signal at a nominal rate of 1600 hops/sec. The large scale use of Bluetooth technology and mobile devices has generated to provide the services which are currently available in wired network [1]. Another important thing is power optimization [4] which will discuss later in this paper. Mobile phones are very important and useful gadget and most of them have camera using this feature our proposed plan will succeed. The video data transfer from one mobile node to other is very difficult to implement. The video data input, accepted through one mobile camera will be converted into byte stream and is directed in the output stream using Bluetooth link. In the other side, mobile node which is now ready to accept the byte stream will accept the input
stream. The accepted byte stream will be now redirected to video format. Video over wireless communication (VoW) provides access to streaming video and supports various types of critical application. The VoW technology serves two main purposes, surveillance and monitoring. In the Bluetooth Version 1.1, there is no facility provided regarding video transmission. However, in enabling VoW to the end-user level, especially home appliances, mobile phones there is still no standard defined. Although there are some Audio/Video protocols specified after exploration of version 1.1, they are not finalized and the latest Bluetooth version Bluetooth 2.0+EDR [3] only offers a significant speed bump over its predecessor. This opens an opportunity for research into this field. The video data streaming is tedious, but not so difficult.
2. The Architecture for Bluetooth
Bluetooth is based on IEEE802.11 standard. Bluetooth is a low cost, low power radio technology operating in the ISM band. It consists of multiple mobile nodes which maintain network connectivity through wireless communication link. The Bluetooth architecture is so flexible to use with low overhead. The Bluetooth network is dynamic and completely deployable. Bluetooth technology employs frequency hopping, to allow for concurrent Bluetooth communications within radio range of each other without perceptible interference. The Bluetooth technology supports mainly three types of connection pattern for forming ad-hoc networks: point-to-point, piconet, scatternet. The point-to-point

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
38
communication enables two nodes to communicate with each other in some standard fashion. The piconet is actually point-to-multipoint communication. In the piconet, there is a master and seven slaves are there to serve. The Scatternet is more difficult to implement. In a scatternet one of the nodes from a piconet can participate to other piconet as a slave or a master. This is possible using TDM technique. Most Bluetooth devices are available in USB and UART dongles, or PC card for PCMCIA interface.
Fig.1 Protocol Stack for Bluetooth
The specification for BT Radio layer is primarily concerned with the design of Bluetooth transceivers. The baseband layer defines how Bluetooth devices search for and connect to other devices. The baseband layer supports two types of links: Synchronous Connection Oriented (SCO) and Asynchronous Connection-less (ACL). The Link manager layer implements the Link Manager Protocol (LMP), which manages the properties of air-interface link between devices. The LMP manages bandwidth allocation for all general data. The Logical Link Control and Adaptation protocol layer provides the interface between the higher-layer protocol and lower-layer transport protocols. The L2CAP supports multiplexing of several higher-layer protocols. This allows multiple protocols and applications to share the air-interface. It is also responsible for packet segmentation and reassembly. The Host Control Interface (HCI) layer defines a standard interface for upper-level application to access lower layers of the stack. Its purpose is to enable interoperability among devices and the use of existing higher-level protocols and applications.
3. Acquiring video data
Traditional video streaming over wired/wireless networks typically has band-width, delay and loss-requirements due
to its real time nature.
Fig. 2 Architecture for video streaming over Bluetooth
Moreover, there are many potential reasons including time-varying features, out-of-range devices and interference with other external devices that make bluetooth links more challenging for video streaming.
Image frames Acquisition Camera I/P
Image Processing technique
Bluetooth Network
Image Processing Technique
Image Frames Reforming
Display

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 www.IJCSI.org
39
Fig. 3 video streaming using Bluetooth
Our proposed system (BESS) will acquire video image through mobile camera and will process the video data through several steps. Our system will be available in a single chip. It will operate in two modes: the master mode and the other is slave mode. This will act as a sender as well as receiver. The mobile phones which are going to be used for secret surveillance have to deploy this pre-programmed BESS chip in both senders end as well as receiver end. At the sender’s end the BESS master mode should be enabled. It is now capable of transmitting continuous video data. The data must be compressed before the transmission starts. The aim of video compression is to remove redundant information from a digitized video sequence. The compressed video streams are partitioned into packets of the chosen intermediate layer (for example, L2CAP, HCI, IP, see fig. 2, where packets are packetized and segmented). Now it is ready for sending segmented packets to Bluetooth module for transmission. On the receiving end the media packets are received from air and are reassembled. After these steps they are decompressed. The image frames will be reformed and at the receiving end one can see the reorganized video stream. The power consumption is optimized here using low power dissipation. The duration of data transfer may vary depending upon situation. But there is a constraint in our proposed system that it can continue up to 2 -3 hours. 4. Conclusions In this paper we proposed for a system which is capable of compressing and streaming of live videos over Bluetooth network. Three major aspects are to be taken into consideration namely video compression, Quality of Service (QoS) control and intermediate protocols. Video compression is to remove redundancy to achieve efficiency in a limited bandwidth network. QoS includes congestion control and error control. It is to check packet loss, reduce delay and improving video quality. It will give an enormous benefit in the area of surveillance work. These are not a new problem but this approach is very much identical in pragmatic scenario. References [1] F. Forno; G. Malnati, and G. Portelli,. “Design and implementation of a Bluetooth ad hoc network for indoor positioning”, IEE proceedings- Software, pp. 223-228, Oct. 2005. [2] Specification of Bluetooth System –Core vol.1, ver1.1 ww.bluetooth.com [3] http://www.brighthand.com/
[4] Mark C. Toburen, Thomas M. Conte, Matt Reilly,. “Instruction Scheduling for Low Power Dissipation in High Performance Microprocessors” Mr. Sourav Banerjee. Presently working as a lecturer in the Department of Computer Sc. & Engg, Kalyani Government Engineering College, West Bengal, India since March,2008. He completed his M.Tech degree in Computer Sc and Engineering from University of Kalyani in the year 2006. He worked as a lecturer in JIS College of Engineering from 2006 to February,2008. Mr. Dipansu Mondal Presently Working as a Programmer in the University of Kalyani, He is an M.Tech in Information Technology and was a lecturer of JIS College of Engineering, Kalyani, West Bengal, India. Mr. Sumit Das He is an M.Tech in Computer Sc. & Engg and achieved this degree from the University of Kalyani, West Bengal, presently working as a lecturer in the Department of Information Technology, JIS College of Engineering, Kalyani, West Bengal, India. Mr. Ramendu Bikash Guin is a student of 3rd year in Computer Science & Engineering Department in Kalyani Government Engineering College.

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
A New Semantic Similarity Metric for Solving Sparse Data
Problem in Ontology based Information Retrieval System
K.Saruladha1, Dr.G.Aghila2, Sajina Raj3
1Research Scholar, Department of Computer Science & Engg.
Pondicherry Engineering College, Pondicherry 605 014, India.
2Department of Computer Science, Pondicherry University,
Pondicherry 605 014, India.
3Post Graduate Student,
Pondicherry Engineering College, Pondicherry 605 014, India.
Abstract Semantic similarity assessing methods play a
central role in many research areas such as Psychology, cognitive science, information retrieval biomedicine and Artificial intelligence. This paper discuss the existing semantic similarity assessing methods and identify how these could be exploited to calculate accurately the semantic similarity of WordNet concepts. The semantic similarity approaches could broadly be classified into three different categories: Ontology based approaches (structural approach), information theoretic approaches (corpus based approach) and hybrid approaches. All of these similarity measures are expected to preferably adhere to certain basic properties of information. The survey revealed the following drawbacks The information theoretic measures are dependent on the corpus and the presence or absence of a concept in the corpus affects the information content metric. For the concepts not present in the corpus the value of information content tends to become zero or infinity and hence the semantic similarity measure calculated based on this metric do not reflect the actual information content of the concept. Hence in this paper we propose a new information content metric which provides a solution to the sparse data problem prevalent in corpus based approaches. The proposed measure is corpus independent and takes into consideration hyponomy and meronomy relations. Empirical studies of finding similarity of R&G data set using existing Resnik, lin and J& C semantic similarity methods with the proposed information content metric is to be studied. We also propose a new semantic similarity measure
based on the proposed information content metric and hypernym relations.
The correctness of the information content metric proposed is to be proved by comparing the results against the human judgments available for R& G set. Further the information content metric used earlier by Resnik, lin and Jiang and Cornath methods may produce better results with alternate corpora other than brown corpus. Hence the effect of corpus based information content metric on alternate corpora is also investigated. Keywords-Ontology, similarity method, information retrieval, conceptual similarity, taxonomy, corpus based
1 . INTRODUCTION The goal of Information retrieval process is to retrieve Information relevant to a given request. The aim is to retrieve all the relevant information eliminating the non-relevant information. An information retrieval system comprises of representation, semantic similarity matching function and Query. Representation comprises the abstract description of documents in the system. The semantic similarity matching function defines how to compare query requests to the stored descriptions in the representation.
The percentage of relevant information we get mainly depends on the semantic similarity matching function we used. So far, there are several semantic similarity methods used which have certain limitations despite the advantages. No one method replaces all the semantic similarity methods. When a new information retrieval system is going to be build,
40

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
several questions arises related to the semantic similarity matching function to be used. In the last few decades, the number of semantic similarity methods developed is high.
This paper discusses the overall view of different similarity measuring methods used to compare and find very similar concepts of ontology. We also discuss about the pros and cons of existing similarity metrics. We have presented a new approach which is independent of the corpora for finding the semantic similarity between two concepts. Section II, a set of basic intuitive properties are defined to which the compatibility of similarity measures in information is preferable. Section III discusses various approaches used for similarity computation and the limitations of those methods. In Section IV, comparison among different semantic similarity measures are discussed. In Section V we introduce a new semantic similarity approach and an algorithm for finding the similarity between all the relations in the WordNet taxonomy. The results based on new similarity measure is promising.
2. ONTOLOGY SIMILARITY In this section, a set of intuitive and qualitative properties that a similarity method should adhere to is discussed.[20]
Basic Properties Any similarity measure must be compatible with the basic properties as they express the exact notion of property.
o CommonalityProperty o Difference Property o Identity Property
Retrieval Specific Properties The similarity measure cannot be symmetrical in case of ontology based information retrieval context. The similarity is directly proportional to specialization and inversely proportional to generalization.
o Generalization Property Structure Specific Properties The distance represented by an edge should be reduced with an increasing depth.
o Depth Property o Multiple Paths Property
3. APPROACHES USED FOR SIMILARITY
COMPUTATION
In this section, we discuss about various similarity methods[20]. The similarity methods are
Path Length Approaches Depth-Relative Approaches Corpus-based Approaches Multiple-Paths Approaches
3.1 Path Length Approach The shortest path length and the weighted shortest path are the two taxonomy based approaches for measuring similarity through inclusion relation. Shortest Path Length A simple way to measure semantic similarity in a taxonomy is to evaluate the distance between the nodes corresponding to the items being compared. The shorter distance results in high similarity. In Rada et al. [1989][1][14], shortest path length approach is followed assuming that the number of edges between terms in a taxonomy is a measure of conceptual distance between concepts.
distRada(ci; cj) = minimal number of edges in a path from ci to cj
This method yields good results. since the paths are restricted to ISA relation, the path lengths corresponds to conceptual distance. Moreover, the experiment has been conducted for specific domain ensuring the hierarchical homogeneity. The drawback with this approach is that, it is compatible only with commonality and difference properties and not with identity property. 3.1.2. Weighted Shortest Path Length This is another simple edge-counting approach. In this method, weights are assigned to edges. In brief, weighted shortest path measure is a generalization of the shortest path length. Obviously it supports commonality and difference properties.
- Similarity of immediate specialisation -Similarity of immediate generalisation
P=(p1,…..,pn) where,
Pi ISA pi+1 or Pi+1 ISA pi For each I with x=p1 and y=pn
Given a path P=(p1,…..pn), set s(P) to the number of specializations and g(P) to the number of generalizations along the path P as follows:
s(P)= |{i\pi ISA pi+1}| (1) g(P)=|{i|Pi+1 ISA pi}| (2)
If p1,……pm are all paths connecting x and y, then the degree to which y is similar to x can be defined as follows:
simWSP(x,y)=max{ s(pj) s(pj)}(3) j=1,….m
The similarity between two concepts x and y, sim(x,y) WSP(weighted Shortest Path) is calculated as the maximal product of weights along the paths between x and y. Similarity can be derived as the products of weights on the paths.
s(pj) g(Pj s(Pj) and g(Pj) = 0
41

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
Hence the weighted shortest path length overcomes the limitations of shortest path length wherein the measure is based on generalization property and achieves identity property. 3.2 Depth-Relative Approaches Even though the edge counting method is simple, it limits the representation of uniform distances on the edges in the taxonomy. This approach supports structure specific property as the distance represented by an edge should be reduced with an increasing depth. 3.2.1 Depth Relative Scaling In his depth-relative scaling approach Sussna[1993][2] defines two edges representing inverse relations for each edge in a taxonomy. The weight attached to each relation r is a value in the range [minr; maxr]. The point in the range for a relation r from concept c1 to c2 depends on the number nr of edges of the same type, leaving c1, which is denoted as the type specifc fanout factor:
W(c1→r c2)=maxr-{maxr--minr/nr(c1)} The two inverse weights are averaged and scaled by depth d of the edge in the overall taxonomy. The distance between adjacent nodes c1 and c2 are computed as:
dist sussna(c1,c2)=w(c1→ r c2)+ (c1→ r’ c2)/2d (4) where r is the relation that holds between c1 and c2, and r’ is its inverse. The semantic distance between two arbitrary concepts c1 and c2 is computed as the sum of distances between the pairs of adjacent concepts along the shortest path connecting c1 and c2. 3.2.2 Conceptual Similarity Wu and Palmer [1994][3], propose a measure of semantic similarity on the semantic representation of verbs in computer systems and its impact on lexical selection problems in machine translation. Wu and Palmer define conceptual similarity between a pair of concepts c1 and c2 as: Sim wu&palmer(c1,c2)= (5) Where N1 is the number of nodes on the path from c1 to a concept c3. , denoting the least upper bound of both c1 and c2. N2 is the number of nodes on a path from c2 to c3. N3 is the number of nodes from c3 to the most general concept.
3.2.3 Normalised Path Length Leacock and Chodorow [1998][4], proposed an approach for measuring semantic similarity as the shortest path using is a hierarchies for nouns in WordNet. This measure determines the semantic similarity between two synsets (concepts) by finding the shortest path and by scaling using the depth of the taxonomy: Sim Leacock&Chaodorow(c1,c2)= -log(Np(c1,c2)/2D) (6) Np (c1,c2) denotes the shortest path between the synsets (measured in nodes), and D is the maximum depth of the taxonomy.
3.3 Corpus-based Approach
The knowledge disclosed by the corpus analysis is used to intensify the information already present in the ontologies or taxonomies. In this method, presents three approaches that incorporate corpus analysis as an additional, and qualitatively different knowledge source. 3.3.1 Information Content In this method rather than counting edges in the shortest path, they select the maximum information content of the least upper bound between two concepts. Resnik [1999] [5], argued that a widely acknowledged problem with edge-counting approaches was that they typically rely on the notion that edges represent uniform distances. According to Resnik's measure, information content, uses knowledge from a corpus about the use of senses to express non-uniform distances. Let C denote the set of concepts in a taxonomy that permits multiple inheritance and associates with each concept c 2 C, the probability p(c) of encountering an instance of concept c. For a pair of concepts c1 and c2, their similarity can be defined as:
SimResnik (7)
where, S(c1,c2): Set of least upper bounds in the taxonomy of c1 and c2 p(c) :Monotonically non-decreasing as one moves up in
the taxonomy, p(c1) ≤ p(c2), if c1 is a c2.
The similarity between the two words w1 and w2 can be computed as: wsimResnik (8)
Where, s(wi): Set of possible senses for the word wi.
Resnik describes an implementation based on information content using WordNet's [Miller, 1990][6], taxonomy of noun concepts [1999]. The information content of each concept is calculated using noun frequencies
Freq(c) = where, words(c): Set of words whose senses are subsumed by concept c.
(c)=freq(c)/N where , N: is the total number of nouns. The major drawback of the information content approach is that they fail to comply with the generalization property, due to symmetry. 3.3.2 Jiang and Conrath's Approach(Hybrid Method) Jiang and Conrath [1997][7]proposed a method to synthesize edge-counting methods and information content
42

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
into a combined model by adding the information content as a corrective factor. The edge weight between a child concept cc and a parent concept cp can be calculated by considering factors such as local density in the taxonomy, node depth, and link type as, Wt(cc,cp)=
(9)
Where, d(cp) : Depth of the concept cp in the taxonomy, E(cp) :Number of children of cp (the local density) (¹E) : Average density in the entire taxonomy, LS(cc, cp) : Strength of the edge between cc and cp, T(cc,cp) : Edge relation/type factor The parameters 0 and ,0 1 control the in°uence of concept depth and density, respectively. strength of a link LS(cc; cp) between parent and child concepts is proportional to the conditional probability p(cc|cp) of encountering an instance of the child concept, cc, given an instance of the parent concept, cp:
LS(cc, cp) = -log p(cc|cp) Resnik assigned probability to the concepts as p(cc \cp) = p(cc), because any instance of a child concept cc is also an instance of the parent concept cp. Then:
p(Cc|Cp) =
p(Cc|Cp) =
If IC(c) denotes the information content of concept c. then: LS(Cc,Cp) = IC(Cc)-IC(Cp)
Jiang and Conrath then defined the semantic distance between two nodes as the summation of edge weights along the shortest path between them [J. Jiang, 1997]: distjiang&conrath(C1,C2)=
(10) Where, path(c1, c2) : the set of all nodes along the shortest path between c1 and c2 parent(c) : is the parent node of c LSuper(c1, c2) : is the lowest superordinate (least upper bound) on the path between c1 and c2.. Jiang and Conrath's approach made information content compatible with the basic properties and the depth property, but not to the generalization property. 3.3.3 Lin's Universal Similarity Measure Lin [1997; 1998][8][13] defines a measure of similarity claimed to be both universally applicable to arbitrary objects and theoretically justified. He achieved generality from a set of assumptions. Lin's information-theoretic definition of similarity builds on three basic properties, commonality, difference and identity. In addition to these properties he assumed that the commonality between A and B is measured by the amount of
information contained in the proposition that states the commonalities between them, formally:
I(common(A,B)) = -log p(common(A,B) where,
I(s): Negative logarithm of the probability of the proposition, as described by Shannon[1949].
The difference between A and B is measured by:
I(description(A,B)) – I(common(A,B)) Where, description(A;B) : Proposition about what A and B are. Lin proved that the similarity between A and B is measured by,
simLin(A,B)= (11)
The ratio between the amount of information needed to state the commonality of A and B and the information needed to describe them fully. Lin’s similarity between two concepts in a taxonomy ensures that:
SimLin(c1,c2)= (12)
where, LUB(c1, c2): Least upper bound of c1 and c2 p(x) : Estimated based on statistics from a sense tagged corpus. This approach comply with the set of basic properties and the depth property, but would fail to comply with the generalization property as it is symmetric. 3.4 Multiple-Paths Approaches This approach solves the problem with single path approach. Single path as a measure for the similarity, fails to truly express similarity whenever the ontologies allow multiple inheritance. In multiple-path approach measurement is made by taking into account all the semantic relations in ontologies, considering more than one path between concepts. Attributes should influence the measure of similarity, thus allowing two concepts sharing the same attribute to be considered as more similar, compared to concepts not having this particular attribute. 3.4.1 Medium-Strong Relations Hirst and St-Onge [Hirst and St-Onge, 1998; St-Onge, 1995] [9][15], distinguishes the nouns in the Wordnet as extra-strong, strong and medium-strong relations. The extra-strong relation is only between a word and its literal repetition. 3.4.2 Generalised Weighted Shortest Path The principle of weighted path similarity can be generalized by introducing similarity factors for the semantic relations. However, there does not seem to be an obvious way to differentiate based on direction. Thus, we can generalize simply by introducing a single similarity factor
43
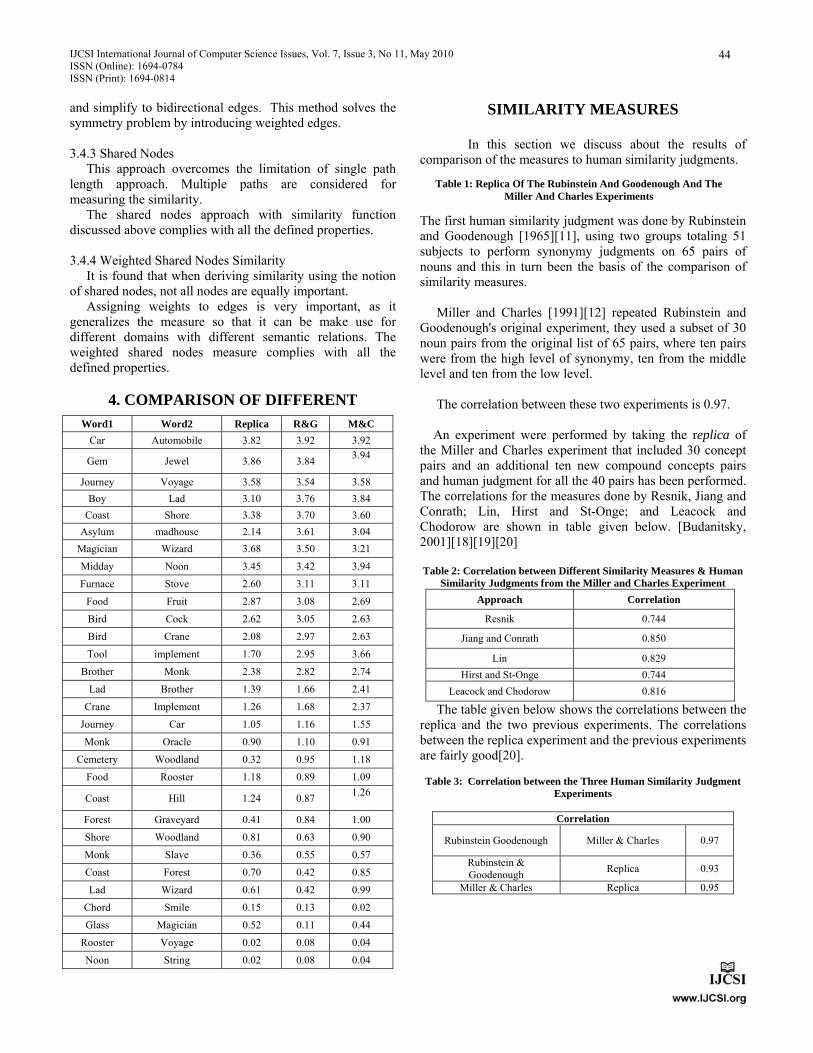
IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
and simplify to bidirectional edges. This method solves the symmetry problem by introducing weighted edges. 3.4.3 Shared Nodes This approach overcomes the limitation of single path length approach. Multiple paths are considered for measuring the similarity. The shared nodes approach with similarity function discussed above complies with all the defined properties. 3.4.4 Weighted Shared Nodes Similarity It is found that when deriving similarity using the notion of shared nodes, not all nodes are equally important. Assigning weights to edges is very important, as it generalizes the measure so that it can be make use for different domains with different semantic relations. The weighted shared nodes measure complies with all the defined properties.
4. COMPARISON OF DIFFERENT
SIMILARITY MEASURES
In this section we discuss about the results of comparison of the measures to human similarity judgments. The first human similarity judgment was done by Rubinstein and Goodenough [1965][11], using two groups totaling 51 subjects to perform synonymy judgments on 65 pairs of nouns and this in turn been the basis of the comparison of similarity measures. Miller and Charles [1991][12] repeated Rubinstein and Goodenough's original experiment, they used a subset of 30 noun pairs from the original list of 65 pairs, where ten pairs were from the high level of synonymy, ten from the middle level and ten from the low level. The correlation between these two experiments is 0.97. An experiment were performed by taking the replica of the Miller and Charles experiment that included 30 concept pairs and an additional ten new compound concepts pairs and human judgment for all the 40 pairs has been performed. The correlations for the measures done by Resnik, Jiang and Conrath; Lin, Hirst and St-Onge; and Leacock and Chodorow are shown in table given below. [Budanitsky, 2001][18][19][20] Table 2: Correlation between Different Similarity Measures & Human
Similarity Judgments from the Miller and Charles Experiment
Approach Correlation
Resnik 0.744
Jiang and Conrath 0.850
Lin 0.829
Hirst and St-Onge 0.744
Leacock and Chodorow 0.816
The table given below shows the correlations between the replica and the two previous experiments. The correlations between the replica experiment and the previous experiments are fairly good[20].
Table 3: Correlation between the Three Human Similarity Judgment
Experiments
Correlation
Rubinstein Goodenough Miller & Charles 0.97
Rubinstein & Goodenough
Replica 0.93
Miller & Charles Replica 0.95
Word1 Word2 Replica R&G M&C
Car Automobile 3.82 3.92 3.92
Gem Jewel 3.86 3.84 3.94
Journey Voyage 3.58 3.54 3.58
Boy Lad 3.10 3.76 3.84
Coast Shore 3.38 3.70 3.60
Asylum madhouse 2.14 3.61 3.04
Magician Wizard 3.68 3.50 3.21
Midday Noon 3.45 3.42 3.94
Furnace Stove 2.60 3.11 3.11
Food Fruit 2.87 3.08 2.69
Bird Cock 2.62 3.05 2.63
Bird Crane 2.08 2.97 2.63
Tool implement 1.70 2.95 3.66
Brother Monk 2.38 2.82 2.74
Lad Brother 1.39 1.66 2.41
Crane Implement 1.26 1.68 2.37
Journey Car 1.05 1.16 1.55
Monk Oracle 0.90 1.10 0.91
Cemetery Woodland 0.32 0.95 1.18
Food Rooster 1.18 0.89 1.09
Coast Hill 1.24 0.87 1.26
Forest Graveyard 0.41 0.84 1.00
Shore Woodland 0.81 0.63 0.90
Monk Slave 0.36 0.55 0.57
Coast Forest 0.70 0.42 0.85
Lad Wizard 0.61 0.42 0.99
Chord Smile 0.15 0.13 0.02
Glass Magician 0.52 0.11 0.44
Rooster Voyage 0.02 0.08 0.04
Noon String 0.02 0.08 0.04
Table 1: Replica Of The Rubinstein And Goodenough And The Miller And Charles Experiments
44

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
4.1 Sparse Data Problem in Corpus based
Approaches
Following the standard definition from Shannon and Weaver’s information theory [1949], the information content of concept c is −log p(c).
Information content in the context of WordNet is drawn from the Brown university standard corpus This corpus refers to a collection of documents of widely varying genres collected in 1961 which was updated in 1971and 1979 to reflect new literatures shown in table 4 The collection of more than 1 million words was manually tagged with about 80 parts of speech. The presently available list of WordNet concepts tagged in the brown corpus includes approximately 420000 words. There are more number of concepts in WordNet which are not tagged in Brown Corpus.
Table 4: Brown corpus categories
We ran a small experiment on the Brown corpus
and found that the words soccer, fruitcake, world, trade centre were not not found in the corpus.
Table 5: Incompleteness of Brown Corpus
Nouns which are not present in Brown Corpus
Soccer
Fruitcake
CPU
Autograph
Serf
Slave
The IC value tends to become zero for concepts not existing in the corpora as –log(p(c)) formula is used for IC calculation..
4.2 Significanse of the work
We have proposed an algorithm based on new information content which takes into consideration the meronomy relations. The Information content metric proposed by Pierro [2009] takes into concern the holonym relations that a concept has with other concepts.. All of the concepts of the WordNet will not have all of the relation types. Some of the concepts will have holomy relation and few with meronomy relations etc. The information content metric if it ignores the other type of relations and if it produces a zero value it means that the concept has no information which is not correct. Hence we decided to consider both the meronym and holonym relations. If a concept do not have holonymy relation then the information imparted by meronomy is taken into consideration and the information content will become zero when the concept has no relations with other concepts which is a very rare case.
5. PROPOSED WORK
The semantic similarity measures are mostly based on the information content.
Most of the corpus based similarity methods like Lin[13], Jiang Cornath[2] and resnik[11] are IC based and the IC calculation is done using Brown corpus. Brown corpus suffers from the following drawbacks. The Parts of speech tags from the Brown corpus does not correspond to the hierarchical structure of concepts in WordNet. All concepts of WordNet are not present in the Brown Corpus. The noun such as autograph, serf and slave are not present in the Brown Corpus.
Similarity measures that rely on information content can produce a zero value for even the most intuitive pairs because the majority of WordNet concepts occur with a frequency of zero. This makes the Lin method and Jiang cornath method to return zero or infinity in the continuous domain and hence the similarity measure is not true or reliable.
Hence the computation of Information content should be computed in a different way so that the similarity measure becomes reliable.
Press : reportage (Political Sports,Society,Spot News,Financial,Cultural
Press: Editorial (Institutional Daily, Personal, Letters to the
Editor)
Press: Reviews (Theatre, Books, Music, Dance)
Religion (Books, Periodicals, Tracts)
Skill and Hobbies (Books, Periodicals)
Popular Lore (Books, Periodicals)
Belles-Lettres (Books, Periodicals)
Miscellaneous: US Government & House Organs (Government
Documents, Foundation Reports, College Catalog, Industry
House organ)
Learned (Natural Sciences, Medicine, Mathematics, Social and
Behavioral Sciences, Political Science, Law, Education,
Humanities, Technology and Engineering)
45

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
5.1 Proposed Corpora Independent Similarity Measure to Solve Sparse Data Problem
The objective of this work is twofold. 1. To design a new information metric which solves
sparse data problem which is independent of the corpora and which is based on semantic relations available in WordNet. 2. To investigate the existing IC metric on corpora other than brown corpus.
Table 5: Relations defined in wordnet taxonomy
The Existing Similarity methods do not consider the Holonymy/Meronymy relationships defined in Wordnet. Hence we propose to devise a new similarity measure which considers these relationships and experimentally evaluate and compare it with the existing similarity measures using R&G data set and extended data set.
The fig.1 shows the semantic similarity system architecture.
Fig. 1 Semantic Similarity System Architecture
5.2 Proposed IC Calculation Involving Meronym
The intrinsic IC for a concept c is defined as:
IC(c) = 1- log(hypo(c)+mero(c)+1 ---(16)
Log(maxcon)
where, Hypo(c)-Function returns the number of hyponyms Mero(c)-Function returns the number of meronyms Maxcon- is a constant that indicates the total number of concepts in the considered taxonomy Note: Assume hypo(c), mero(c)>=0 & maxcon>0
The function hypo and mero returns the number of hyponyms and meronyms of a given concept c. Note that concepts representing leaves in the taxonomy will have an IC of one, since they do not have hyponyms. The value of one states that a concept is maximally expressed and cannot be further differentiated. Moreover maxcon is a constant that indicates the total number of concepts in the considered taxonomy.
5.3 PROPOSED SIMILARITY FUNCTION BASED ON PROPOSED IC
According to our new formula, the similarity between the two concepts c1 and c2 can be defined as,
Simext(c1,c2) =
IC (LCS (c1,c2))-
-hyper
(c1 c2) ----(17)
where, the function LCS finds the lowest common subsumer of the two concepts c1 and c2 and the function hyper finds all the hypernyms of c1 and c2 upto the LCS node.
The Proposed IC formula will be used in existing semantic similarity methods such as Resnik, Lin and Jiang and cornath for computation of similarity measure suing R&G and M&C data sets. The influence of meronomy and hyponomy relations in calculation of similarity measure will be studied. The proposed similarity function will be tested with R&G and M&C data sets.
The proposed similarity function with noun pairs of R&G data set was tested for Resnik method and the correlation coefficient with human judgment were calculated. The results were promising. We have to test the proposed similarity measure against other data set.
Most of the IC based approaches are tested against the well known corpus. The concepts not present in Brown
Relation Example Meronym(Part-of) Engine is a Meronym of Car
Holonym(Has-part)
Car is a Holonym of Engine
Meronym(Has-Member) Team has member player Holonym
(Member-of)
Player is the member of Team
Brown Corpus
Compute Frequency of
Wordnet Concepts
Reuters Corpus
Human Judgments for
Extended R&G Data set
Compute Correlation Coefficient
Performance Analysis
WordNet Taxonomy
Rubenstein & Goodenough
Extended DataSet
Semantic Similarity computation
Resnik Jiang & Conrath
Lin Pirro&Seco
Google based corpus
46

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
corpus may be present in alternate corpora like Reuters 20
news groups and google.
In WordNet taxonomy they do not take into consideration all the relation like meronymy. Since we are considering all the relationship present in the WordNet taxonomy, the new metric gives accurate results.
6. Conclusion
This paper has discussed the various approaches that could be used for finding similar concepts in an ontology and between ontologies. We have done a survey to exploit the similarity methods for ontology based query expansion to aid better retrieval effectiveness of Information retrieval models. The experiments conducted by early researches provide better correlation values which gives promising direction of using them in Ontology based retrieval models. A new semantic similarity metric has been introduced which overcomes the shortcomings of existing semantic similarity methods mainly sparse data problem. We are working with the new similarity function which will combine the advantages of the similarity methods discussed in this paper and we will test it with ontologies of particular domain.
7. REFERENCES
[1] Roy Rada, H. Mili, Ellen Bicknell, and M. Blettner.
“Development and application of a metric on semantic nets”
IEEE Transactions on Systems, Man, and Cybernetics, 19(1),
17{30}, January 1989.
[2] Michael Sussna: “Word sense disambiguation for tree-text
indexing using a massive semantic network” In Bharat Bhargava
[3] Zhibiao Wu and Martha Palmer. “Verbs semantics and lexical
selection”, In Proceedings of the 32nd annual meeting on
Association for Computational Linguistics”, Association for
Computational Linguistics, 1994. pages 133{138, Morristown,
NJ, USA
[4] Claudia Leacock and Martin Chodorow: “Combining local
context and wordnet similarity for word sense identification”. In
Christiane Fellbaum, editor, WordNet: An Electronic Lexical
Database. MIT Press, 1998.
[5] Philip Resnik.: “Semantic similarity in a taxonomy: An
information-based measure and its application to problems of
ambiguity in natural language”, 1999.
[6] George A. Miller, Richard Beckwith, Christiane Fellbaum,
Derek Gross, and K.J. Miller.[Resnik, 1995] Philip Resnik.
“Using information content to evaluate semantic similarity in a
taxonomy”. In IJCAI, pages 448{453, 1995.
[7] D. Conrath J. Jiang.: “Semantic similarity based on
corpusstatistics and lexical taxonomy”. In Proceedings on
Input (noun1, noun2), Output (similarity score)
Step 1: For each sense c1 and c2 in noun1 and noun2 If c1 and c2 are hyponyms
Calculate IC (c1) for hyponyms i.e
IC(c) = 1- log(hypo(c)+1)
log(maxcon)
go to step 3
Else if c1 and c2 are meronyms
Calculate IC(c1) for meronyms i.e
IC(c) = 1- log(mero(c)+1)
log(maxcon)
go to step 3
Step 2: For IC value for both hyponyms and meronyms using the proposed IC formula,
IC(c) = 1- log(hypo(c)+mero(c)+1)
log(maxcon)
go to step 3
Step 3: Call the existing semantic similarity function Simres(c1,c2), SimLin(c1,c2), SimJ&C(c1,c2)
And then go to step 4.
Step 4: Call the proposed semantic similarity function for the given concepts c1 & c2
Simext(c1,c2) = IC(LCS(c1,c2))-
-
hyper(c1 c2)
Step 5: Collect human judgments and save it as a separate table for the R&G and M&C data sets
Step 6: Calculate the correlation coefficients between results of the similarity measures and human judgments Step 7: Compare the similarity measures for R&G data set using the proposed IC and proposed similarity existing similarity measures.
5.4 Proposed Algorithm
47

IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 11, May 2010 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814
International Conference on Research in Computational
Linguistics, Taiwan, pages 19{33, 1997.
[8] Dekang Lin.: “An information-theoretic definition of A
similarity”. In Jude W. Shavlik, editor, ICML, pages 296{304.
Morgan Kaufmann, 1998. ISBN 1-55860-556-8.
[9] Graeme Hirst and David St-Onge: “Lexical chains as
representation of context for the detection and correction
malapropisms” In Christiane Fellbaum, editor, WordNet: An
Electronic Lexical Database. MIT Press, 1998.
[10] Troels Andreasen, Rasmus Knappe, and Henrik Bulskov: ”
Domain-specifiic similarity and retrieval”. In Yingming Liu,
Guoqing Chen, and Mingsheng Ying, editors, 11th International
Fuzzy Systems Association World Congress, volume 1, pages
496{502, Beijing, China, 2005. IFSA 2005, Tsinghua
University Press.
[11] Rubinstein and Goodenough, H. Rubinstein and J. B. a
Goodenough: “Contextual correlates of synonymy”.
Communications of the ACM, 8(10), 1965.
[12] George A. Miller and W. G. Charles: “Contextual correlates of
semantic similarity”. Language and Cognitive Processes,
6(1):1{28, 1991.
[13] Dekang Lin: “Using syntactic dependency as local context to
resolve word sense ambiguity”. In ACL, pages 64{71, 1997.
[14] Roy Rada and Ellen Bicknell: “Ranking documents with a
thesaurus”.JASIS, 40(5):304{310,1989.Timothy Finin, and
Yelena Yesha, editors, Proceedings of the 2nd International
Conference on Information and Knowledge
a. Management, pages 67{74, New York, NY, USA,
November 1993. ACM Press.
[15] Alexander Budanitsky: “University of Toronto Graeme Hirst,
University of Toronto Evaluating WordNet-based Measus Of
Lexical Semantic Relatedness”, Association for Computational
Linguistics,2006
[16] Philip Resnik: “Using Information Content to Evaluate Semantic
Similarity in a Taxonomy”, Sun Microsystems Laboratories,
1995
[17] Henrik Bulskov Styltsvig: “Ontology-based Information
Retrieval Computer Science Section Roskilde University”, 1996
[18] A. Budanitsky. “Lexical semantic relatedness and its application
in natural language processing”, 1999.
[19] A. Budanitsky. Semantic distance in wordnet: An experi mental,
application-oriented evaluation of ¯ve measures, 2001.
[20] H. Bulskov: “Ontology-based Information Retrieval”, PhD
Thesis. Andreasen, T., Bulskov, H., & Knappe, R. (2006).
[21] N. Seco, T. Veale, J. Hayes: “ An intrinsic information content metric for semantic similarity in WordNet, in : Proceedings of ECAI, 2004, pp. 1089–1090. [22] Giuseppe Pirró: “A semantic similarity metric combining eatures and intrinsic information content”, Data & Knowledge Engineering 68(2009) 1289–1308 2009.
48

IJCSI CALL FOR PAPERS NOVEMBER 2010 ISSUE
V o l u m e 7 , I s s u e 6
The topics suggested by this issue can be discussed in term of concepts, surveys, state of the art, research, standards, implementations, running experiments, applications, and industrial case studies. Authors are invited to submit complete unpublished papers, which are not under review in any other conference or journal in the following, but not limited to, topic areas. See authors guide for manuscript preparation and submission guidelines. Accepted papers will be published online and authors will be provided with printed copies and indexed by Google Scholar, Cornell’s University Library, ScientificCommons, CiteSeerX, Bielefeld Academic Search Engine (BASE), SCIRUS and more. Deadline: 30th September 2010 Notification: 31st October 2010 Revision: 10th November 2010 Online Publication: 30th November 2010 Evolutionary computation Industrial systems Evolutionary computation Autonomic and autonomous systems Bio-technologies Knowledge data systems Mobile and distance education Intelligent techniques, logics, and
systems Knowledge processing Information technologies Internet and web technologies Digital information processing Cognitive science and knowledge
agent-based systems Mobility and multimedia systems Systems performance Networking and telecommunications
Software development and deployment
Knowledge virtualization Systems and networks on the chip Context-aware systems Networking technologies Security in network, systems, and
applications Knowledge for global defense Information Systems [IS] IPv6 Today - Technology and
deployment Modeling Optimization Complexity Natural Language Processing Speech Synthesis Data Mining
For more topics, please see http://www.ijcsi.org/call-for-papers.php All submitted papers will be judged based on their quality by the technical committee and reviewers. Papers that describe research and experimentation are encouraged. All paper submissions will be handled electronically and detailed instructions on submission procedure are available on IJCSI website (www.IJCSI.org). For more information, please visit the journal website (www.IJCSI.org)

© IJCSI PUBLICATION 2010
www.IJCSI.org

IJCSIIJCSI
© IJCSI PUBLICATIONwww.IJCSI.org
The International Journal of Computer Science Issues (IJCSI) is a refereed journal for scientific papers dealing with any area of computer science research. The purpose of establishing the scientific journal is the assistance in development of science, fast operative publication and storage of materials and results of scientific researches and representation of the scientific conception of the society.
It also provides a venue for researchers, students and professionals to submit on-going research and developments in these areas. Authors are encouraged to contribute to the journal by submitting articles that illustrate new research results, projects, surveying works and industrial experiences that describe significant advances in field of computer science.
Indexing of IJCSI:
1. Google Scholar2. Bielefeld Academic Search Engine (BASE)3. CiteSeerX4. SCIRUS5. Docstoc6. Scribd7. Cornell’s University Library8. SciRate9. ScientificCommons
IJCSIIJCSI
© IJCSI PUBLICATIONwww.IJCSI.org
The International Journal of Computer Science Issues (IJCSI) is a refereed journal for scientific papers dealing with any area of computer science research. The purpose of establishing the scientific journal is the assistance in development of science, fast operative publication and storage of materials and results of scientific researches and representation of the scientific conception of the society.
It also provides a venue for researchers, students and professionals to submit on-going research and developments in these areas. Authors are encouraged to contribute to the journal by submitting articles that illustrate new research results, projects, surveying works and industrial experiences that describe significant advances in field of computer science.
Indexing of IJCSI:
1. Google Scholar2. Bielefeld Academic Search Engine (BASE)3. CiteSeerX4. SCIRUS5. Docstoc6. Scribd7. Cornell’s University Library8. SciRate9. ScientificCommons
Related Documents











