Fast Statistical Spam Filter by Approximate Classifications Authors: Kang Li Zhenyu Zhong University of Georgia Reader: Deke Guo

Fast Statistical Spam Filter by Approximate Classifications Authors: Kang Li Zhenyu Zhong University of Georgia Reader: Deke Guo.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Fast Statistical Spam Filter by Approximate Classifications
Authors:Kang LiZhenyu ZhongUniversity of Georgia
Reader: Deke Guo

Outline
Motivations of this paper The concrete problems Basic idea and solutions Questions needed to clarify

Motivations1. Speedup the classification process in
order to defense against spam quickly, furthermore, improve the throughout of system.
2. Improve the scalability of the statistical-based classification methods.
3. Keep high classification accuracy.

The background and concrete problem
Background Statistical-based Bayesian filters and its variants are
used to block spam. The statistical value of each individual token is
stored by a dictionary. A decision-making is based on the summarization of
values of much tokens. Problems needed to research
How to improve the performance of value retrieval operation for each individual token. (the motivation 1 and 2)
The solutions should not have much negative effect on the classification accuracy. (the motivation 3)

Basic idea and solutions (1) A straightforward idea
Use the Bloom filters to store the values of tokens, and retrieve the value of any token on demand.
The first obstacle How to extend the standard Bloom filter?
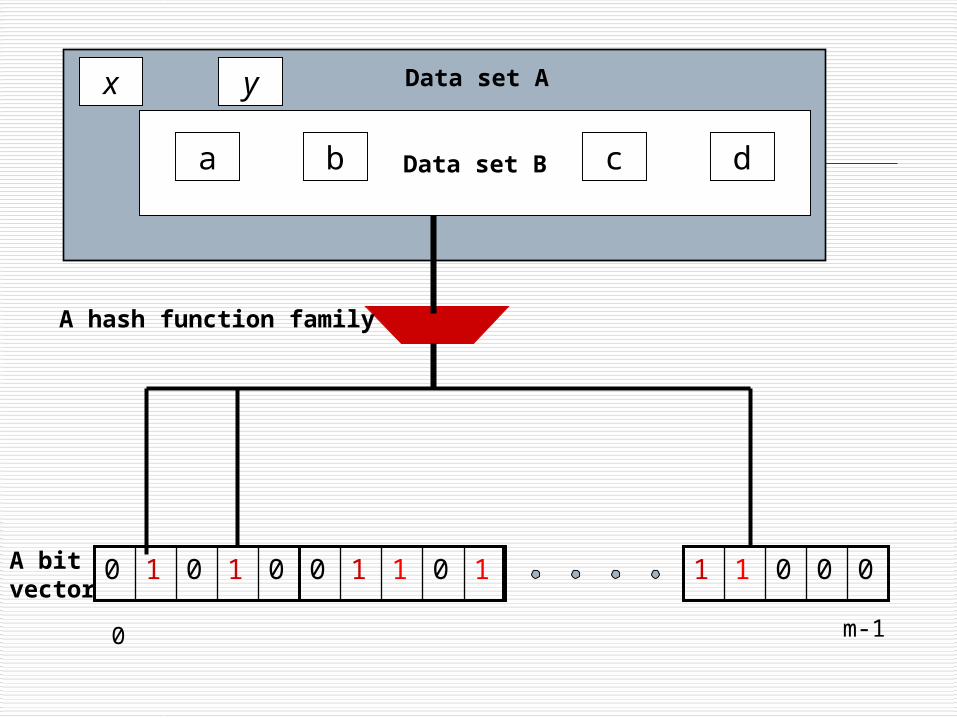
01010 10110
Data set B
00011
a b c d
x y Data set A
A hash function family
A bit vector
m-10

00010 00000
test set B
00010
token1
x y token universe
A hash function family
01000 00000 00000
01010 00000 00010
Multi-bit vector
Bit-wise AND
0
1
0output value
token2 token4token3
q-1
0
First dimension
Second dimension

Basic idea and solutions (2) Instead the bit vector with a two dimensions
vector, with (multiply m by q) size. The first dimension denotes the hash locations for
each token in a m bits vector, the same as the standard Bloom filter.
The second dimension of each hash locations denotes the value of token. One bit for one identical value.
The second obstacle The size of value universe is usually large even
huge. It is impossible to allocate bits in the second dimension for all elements of the value universe.

Basic idea and solutions (3) Encode
In this field, the value universe ranges from 0 to 1.
This paper does not propose new encoding method, just use a algorithm referred from the paper [20].
Choose and tune the parameter q , which denotes the number of possible elements resulting from encoding algorithm.

Why the idea can meet the motivation one and two? Space (for the set of pairs (token, value))
If use the extended Bloom filter to store them, it need less space than others . K bits for each token.
Given the allocated memory, the solution can store more pairs (token, value) than others.
Time Extended Bloom filter are small enough to load in
memory. No other I/O operations. The response delay is a constant for the query with
any input no matter how many pairs have been stored.
In the same time slot, the solution can retrieve the values of more tokens than previous solutions.

The negative effects on the classification accuracy (1) The query based on the extended Bloom
filter may output two kinds of mistake. For any query with a token outside of the test
data set as input, may get a useful output entry (just one bit is set to 1).
For any query with a token inside the test data set as input, may get a conflict output entry (more than one bits are set to 1).
For any token, the decoding result usually does not equal the real statistical value.

01010 00000
token set B
00010
token1
x y token set A
A hash function family
01000 00000 00000
01010 00000 00010
Multi-bit vector
Bit-wise AND
1
1
0output value
token2 token4token3
q-1
0
First dimension
Second dimension

The negative effects on the classification accuracy (2) The misclassification
The former error will affect the summarization of values of a message, and maybe influence the decision.
For a multi-bits error, choose the smallest value. If it is wrongly chosen, the error only makes the classification result less likely as spam, and maybe result in a false negative. This can be tolerated.
The decoding deviation It can not been avoided. Design better
algorithms and/or select the parameters carefully.

Questions needed to clarify(1) For a query output entry, the possibility for a single bit of the
output entry being zero asPm,n,h(0)=1-Pm,n,h(fpos)
=1-(1-(1-1/m)n*h)h
For a query output entry , the probability of the former case:
Pm,n,h,q(fpos)=1-(Pm,n,h(0))q (6)
The probability of the latter case: Pm,n,h,q(multi)=1-(Pm,n,h(0))q
-q* (1-Pm,n,h(0))(q-1) (7)

Questions needed to clarify(1) The formulas 6 and 7 are wrong or not
consistent with the error definitions. The probability of the event (just one bit of
the output entry is set to 1) is:
The probability of the event (more than one
bits of the output entry are set to 1) is: One minus the probability of all bits being set to
0 and the probability of only one bit getting 1.
1
, , , , , , ,P (fpos) P fpos P 01
q
m n h q m n h m n h
q
, , , , , , , ,P (multi) 1 P (0) P (fpos)qm n h q m n h m n h q

Questions needed to clarify(2) In order to store and retrieve values, can
this idea be a general way to improve the standard Bloom filter? The size of value universe. The multi-bit output error. Deletion operation of pairs (key,value).

Questions and Answers

Beyond Bloom Filters: From Approximate MembershipChecks to Approximate State Machines
Authors:Flavio BonomiMichael MitzenmacherRina Panigrahy
SIGCOMM 2006
Reader: Deke Guo

Questions
How to track the simultaneous state of a large number of connections at each network device.
The size of tracking result should be small in order to load in on-chip memory.

Solution(1)
Uses standard bloom filters to summarize the simultaneous state of a large number of connections.
lookups the state of each connection according to its summarization.
Introduces a new error named “don’t know” besides false positive and false negative.

Solution(1) Introduces the timing-based deletion
mechanism to deal with ill-behaving or non-terminating.
Operations: Put (id, state) Lookup (id) or Lookup (id, state) Delete (id, state) Update (id, old state, new state)
Ill-behaving or attacking may result in false negative error.

01010 10110
Data set B
00011
h1(x) h2(x) hk(x)h3(x)
a b c d
x doesn’t belong to set B, yet its bits have been set 1h1(y) h2(y) hk(y)h3(y)
y doesn’t belong to set B, and its bits aren’t all 1.a belongs to set B, and its bits are all 1.
x y Data set A

00010 10010
Data set B
00001
a b c d
x y Data set A
a belongs to set B, and its bits are not all 1 after the false deletion of x.
A false positive error may result in at most k false negative.

Solution(2)
Introduce the Stateful Bloom Filter Approach. Instead the bit vector used by standard bloo
m filters with cell vector. Its rate of false positive is less than that of st
andard bloom filters. Note that the storage space used by two filters are not same. Thus, it is need to compare more carefully.

01010 12001
20
Data set B
00031
h1(x) h2(x) hk(x)h3(x)
a b c d
X don’t belong to set B.The lookup based on the filter also make right judge .
x y Data set A

Solution(3)
An Approach Using d-left Hashing The authors did not explain why it is the best
solution among the three solutions through formal compare and analysis.
The simulation tries to prove it, but it is not strong enough, especially don’t compare under the same space used.

Data set B
00031
a b c d
x y Data set A
00231 00031

Questions needed to analyze Analyze the relationship between false positive and false
negative, and try to give formula. If the old value of a cell was “don’t know”, then the cell
keeps the value before its register becomes 0. Analyze the fraction of cell which value is “don’t know”,
and compute the rate of this error. If the register becomes 1 from a larger value, value
“don’t know” should become a identify value, but SBF can’t support this transformation.
If we use the idea of SBF to redesign the standard Bloom Filters, whether we can achieve some benefits, such as lower false positive rate.
Related Documents





![Perception Deception: Physical Adversarial Attack Challenges and … · 2019. 12. 21. · Dr. Tao Wei Dr. Yunhan Jia Dr. Zhenyu(Edward) Zhong edwardzhong [at] baidu DOT com Weilin](https://static.cupdf.com/doc/110x72/60b65e55da6df575da620eae/perception-deception-physical-adversarial-attack-challenges-and-2019-12-21.jpg)





