International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565, Volume 09, Special Issue 1, May 2019, Page 87-96 http://indusedu.org Page 87 This work is licensed under a Creative Commons Attribution 4.0 International License FAST PHRASE SEARCH FOR ENCRYPTED CLOUD STORAGE Dr. P. Penchalaiah 1 , D. Anusha 2 ,N.Vani 3 , K.Madhuri 4 , Ch.Sai Sahithya 5 . 1 Professor in Deportment of CSE, Narayana Engineering College, Gudur, Nellore Dist, AP. 2,3,4 Computer Science & Engineering, Narayana Engineering College, Gudur, Nellore Dist, AP. Abstract: Cloud computing has generated much interest in the research community in recent years for its many advantages but has also raise security and privacy concerns. The storage and access of confidential documents have been identified as one of the central problems in the area. In particular, many researchers investigated solutions to search over encrypted documents stored on remote cloud servers. Cloud registering is a technology, which gives low cost, scalable computational limit. The capacity and access of report have been significant issue in this area. While, many plans have been proposed to perform conjunctive keyword search, less consideration has been noted. In this paper, we show an expression seek strategy inlight of sprout filters, which is speedier than existing framework. Our systems utilize conjunctive catchphrase inquiry to help functionalities. This approach additionally depicted the false positive rate. Keywords: Phrase Search, Conjunctive Keyword Search, Bloom Filters, False Positive Rate, Hashing _________________________________________________*****________________________________________________ I. INTRODUCTION Distributed computing [1] has produced much enthusiasm for the examination group in late years. To look over encoded archives put away on cloud numerous plans has been proposed yet less consideration have been noted on more hunt techniques. To conquer the capacity and access of classified reports put away in cloud. We proposed an expression seek utilizing sprout channels which is quicker than existing system. Our procedures utilize a conjunctive watchword which is downside of existing framework to get the put away record speedier and get to secure [2]. This approach likewise portrayed the false positive rate for the catchphrase look. Record streams are made and conveyed in different structures on the Internet, for example, news streams, messages, smaller scale blog articles, visiting messages, look into paper documents, web gathering talks, et cetera. The substance of these records by and large focusses on some disconnected get-togethers and clients' qualities, in actuality. To mine these snippets of data, agreat deal of looks into of content mining concentrated on separating themes from report accumulations and archive streams through different probabilistic subject models, for example, established PLSI, LDA and their augmentations. Exploiting these separated themes in report streams, the vast majority of existing works broke down the development of individual subjects to recognize and foresee get-togethers and in addition client practices. In any case, few investigates focused on the relationships among various subjects showing up in progressive records distributed by a particular client, so some covered up yet critical data to uncover customized practices has been ignored. Keeping in mind the end goal to describe client practices in

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 87
This work is licensed under a Creative Commons Attribution 4.0 International License
FAST PHRASE SEARCH FOR ENCRYPTED CLOUD STORAGE
Dr. P. Penchalaiah1, D. Anusha
2,N.Vani
3, K.Madhuri
4, Ch.Sai Sahithya
5.
1Professor in Deportment of CSE, Narayana Engineering College, Gudur, Nellore Dist, AP.
2,3,4 Computer Science & Engineering, Narayana Engineering College, Gudur, Nellore Dist, AP.
Abstract: Cloud computing has generated much interest in the research community in recent years for its many
advantages but has also raise security and privacy concerns. The storage and access of confidential
documents have been identified as one of the central problems in the area. In particular, many researchers
investigated solutions to search over encrypted documents stored on remote cloud servers. Cloud
registering is a technology, which gives low cost, scalable computational limit. The capacity and access of
report have been significant issue in this area. While, many plans have been proposed to perform
conjunctive keyword search, less consideration has been noted. In this paper, we show an expression seek
strategy inlight of sprout filters, which is speedier than existing framework. Our systems utilize
conjunctive catchphrase inquiry to help functionalities. This approach additionally depicted the false
positive rate.
Keywords: Phrase Search, Conjunctive Keyword Search, Bloom Filters, False Positive Rate, Hashing
_________________________________________________*****________________________________________________
I. INTRODUCTION
Distributed computing[1]
has produced much
enthusiasm for the examination group in late
years. To look over encoded archives put
away on cloud numerous plans has been
proposed yet less consideration have been
noted on more hunt techniques. To conquer
the capacity and access of classified reports
put away in cloud. We proposed an
expression seek utilizing sprout channels
which is quicker than existing system. Our
procedures utilize a conjunctive watchword
which is downside of existing framework to
get
the put away record speedier and get to
secure[2].
This approach likewise portrayed
the false
positive rate for the catchphrase look.
Record streams are made and conveyed in
different structures on the Internet, for
example, news streams, messages, smaller
scale blog articles, visiting messages, look
into paper documents, web gathering talks,
et cetera. The substance of these records by
and large focusses on some disconnected
get-togethers and clients' qualities, in
actuality. To mine these snippets of data,
agreat deal of looks into of content mining
concentrated on separating themes from
report accumulations and archive streams
through different probabilistic subject
models, for example, established PLSI, LDA
and their augmentations. Exploiting these
separated themes in report streams, the vast
majority of existing works broke down the
development of individual subjects to
recognize and foresee get-togethers and in
addition client practices. In any case, few
investigates focused on the relationships
among various subjects showing up in
progressive records distributed by a
particular client, so some covered up yet
critical data to uncover customized practices
has been ignored. Keeping in mind the end
goal to describe client practices in

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 88
This work is licensed under a Creative Commons Attribution 4.0 International License
distributed record streams, we ponder on the
connections among points removed from
these reports, particularly the successive
relations, and determine them as Sequential
Topic Examples (STPs)[3]
. Every one of
them records the entire and rehashed
conduct of a client when she is distributing a
series of archives and are appropriate for
inducing clients' inborn attributes and
mental statuses. Right off the bats,
contrasted with singular themes, STPs[3]
catch the two mixes and requests of points,
so can work well for as discriminative units
of semantic relationship among archives in
vague circumstances. Also, contrasted with
record
based examples, point based examples
contain conceptual data ofreport substance
and are accordingly valuable in bunching
comparative archives and discovering a few
regularities about Internet clients. Thirdly,
the probabilistic depiction of subjects keeps
up and amass the vulnerability level of
individual points and can in this way
achieve high certainty level in design
coordinating for dubious information.
For an archive stream, some STP’s [3]
may
happen every now and again and
accordingly reflect normal practices of
included clients. Past that, there may even
now exist some different examples which
are universally uncommon for the all
inclusive community, yet happen generally
regularly for some particular client or some
particular gathering of clients. We call them
User-mindful Rare STPs (URSTPs)[3]
.
Contrasted with visit ones, finding them is
particularly intriguing and critical.
Hypothetically, it characterizes another sort
of examples for uncommon occasion
mining, which can describe customized and
irregular practices for exceptional clients.
For all intents and purposes, it can be
connected in some genuine situations of
client conduct examination, as represented
in the following case. Situation 1 (Real-time
observing on anomalous client practices). As
of late, smaller scale web journals, for
example, Twitter are pulling in an ever-
increasing number of considerations
everywhere throughout the world. Smaller
scale blog messages are constant,
unconstrained reports of what the clients are
feeling, considering and doing, so mirror
clients' qualities and statuses. Be that as it
may, the genuine expectations of clients for
distributing these messages are difficult to
uncover straightforwardly from singular
messages, yet both substance data and
fleeting relations of messages are required
for examination, particularly for anomalous
practices without earlier information. Also,
if unlawful practices are included,
recognizing and observing them is
especially huge for government disability
reconnaissance. For instance, the lottery
extortion practices by means of Internet
ordinarily accord with the accompanying
four stages, which are typified in the points
of distributed messages: (1) make grant
allurements; (2) diddle other clients' data;
(3) get different expenses by bamboozling;
(4) take unlawful terrorizing if their
solicitations are denied. STPs happen to
have the capacity to join a progression of
between correlated messages, and would
thus be able to catch such practices and
related clients. Moreover, regardless of
whether some unlawful practices are
developing, and their successive principles
have not been unequivocal yet, we can at
present uncover them by URSTPs, as long
as they fulfill the properties of both
worldwide rareness and neighborhood
recurrence. That can be viewed as essential
hints for doubt and will trigger focused on
examinations. Consequently, mining
URSTPs is a decent means for ongoing
client conduct checking on the Internet.
PROPOSED SYSTEM

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 89
This work is licensed under a Creative Commons Attribution 4.0 International License
OBJECTIVE:
• To diminished the pursuit time
• To empower the multi catchphrase
look over cloud information Scope:
• The conspire is additionally
versatile, where reports can undoubtedly be
evacuated and added to the corpus.
• We additionally portray changes to
the plan to bring down capacity cost at a
little cost accordingly time and to safeguard
against cloud suppliers with factual
information on put away information.
Fig.1: Proposed framework design
II. RELATED WORK
Subject mining in record accumulations has
been extensivelystudied in the writing.
Subject Detection and Tracking (TDT)[4]
errand, meant to recognize and track themes
(occasions) in news streams with grouping
construct procedures in light of
catchphrases. Considering the co-event of
words and their semantic affiliations, a great
deal of probabilistic generative models for
removing themes from reports were likewise
proposed, for example, PLSI,LDA[5][6]
and
their expansions incorporating diverse
highlights of records , and in addition
models for short messages, similar to
Twitter-LDA. In numerous genuine
applications, record accum[5][6]
ulations by
and large convey fleeting data and would
thus be able to be considered as report
streams. Different dynamic theme
demonstrating techniques have been
proposed to find subjects after some time in
record streams, and afterward to anticipate
disconnected get-togethers. Be that as it
may, these strategies were intended to build
the development model of individual points
from a report stream, as opposed to examine
the relationships among numerous themes
extricated from progressive records for
particular clients. Successive example
mining is an essential issue in information
mining, and has likewise been very much
concentrated up until this point. In
thecontext of deterministic information, a
complete study can be found in. The idea
bolster is the most famous measure for
assessing the recurrence of a successive
example, and is characterized as the number
or extent of information arrangements
containing the example in the objective
database. Numerous mining calculations
have been proposed in view of help, for
example, Prefix Span, Free Spanand
SPADE. They found regular consecutive
examples whose help esteems are at least a
client characterized edge, and were reached
out by SLPMiner to manage
lengthdecreasing bolster requirements. By
and by, the obtainedpatterns are not
continually intriguing for our motivation, in
light of the fact that those uncommon
however huge attempts speaking to
customized and irregular practices are
pruned because of low backings. Moreover,
the calculation on deterministic databases
isn’t pertinent for archive streams, as they
neglected to deal with the vulnerability in
subjects.
For unverifiable information, the majority of
existing works considered continuous
itemset mining in probabilistic databases,
yet nearly less looks into tended to the issue
of consecutive example mining. Muzammal

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 90
This work is licensed under a Creative Commons Attribution 4.0 International License
et al. concentrated on arrangement level
vulnerability in successive databases, and
proposed strategies to assess the recurrence
of a consecutive example in view of
expected help, in the casing of applicant
create and-test or design development. Since
anticipated support would lose the
likelihood conveyance of the help, a better
measure recurrence likelihood was
characterized for general itemsets , and
utilized as a part of digging incessant
successive examples for arrangement level
and component level dubious databases. In
any case, these works did notconsider where
the indeterminate databases originate from
and how the probabilities in the first
information are processed, so can't be
specifically utilized for our concern which
takes record streams as information.
Besides, they additionally centered around
visit examples and along these lines can't be
used to find uncommon, yet fascinating
examples related with extraordinary clients.
In the part of consecutive examples for
points, Hariri et al. displayed an approach
for setting mindful music proposal in light
of successive relations of inert subjects. The
theme set of every melody is at first
controlled by a limit on the point
probabilities acquired from LDA[5][6]
.
At that point, visit theme based consecutive
examples happening among playlists are
found to foresee the following melody in the
present cooperation. By and by, the subject
sets here are deterministic, so the
vulnerability level of points is lost because
of the estimate in the limit based sifting.
Furthermore, the objective isn't a distributed
report stream, and the all around irregularity
was not considered to discover customized
and unprecedented examples. This paper is
an augmentation of our past work, and has
huge changes on the accompanying
perspectives:
• The issue of mining URSTPs[3]
is
characterized all the more formally and
efficiently, and the application field centers
around distributed record streams;
• The recipe to figure the relative
uncommonness of a STP for a client is
altered to wind up completely client
particular and more precise;
• The preprocessing techniques including
theme extraction and session distinguishing
proof are displayed in detail, where a few
heuristic strategies are examined;
• Besides enhancing the guess calculation
given in which finds STP competitors with
evaluated bolster esteems, this paper
introduces a dynamic programming based
calculation to precisely process the help
estimations of determined STPs, which
gives an exchange off amongst exactness
and productivity;
• Experiments are led for new calculations
on more genuine Twitter datasets and more
summed up engineered datasets, and
quantitative outcomes for the genuine case
are given to approve our approach.
III. LITERATURE SURVEY
D. Boneh [7]
has proposed one of the most
punctual chips away at key phrase
searching. Their plan utilizes open key
encryption to enable key words to be
accessible without uncovering data content.
Waters. [8]
explored the issue for looking
over encoded review logs. A large number
of the early works concentrated on single
key phrase findings. As of latest, scientists
have proposed arrangements on conjunctive
key phrase searches, which includes
different keywords [9], [10].
Other fascinating
issues, for example, the positioning of
indexed lists [11]
, [12]
, [13]
and looking with
key phrases that may contain faults [14]
, [15]
named fuzzy keyword search, have
additionally been considered. The capacity
to scan for phrases was likewise as of
examined [16]
, [17]
, [18]
. Some have inspected
the security of the proposed arrangements

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 91
This work is licensed under a Creative Commons Attribution 4.0 International License
and, where defects were discovered,
solutions were proposed with the
explanations [19]
.
Accessible encryption systems [20]
, [21]
can
somewhat satisfy the requirement for secure
given file search. Secure search over the
encoded cloud data which diminishes the
calculation. The privacy preserving search
of records strategies and client authorization
system are utilized to take care of the issue
of secure multi-level keyword scan for
different data owners and multi level data
clients in distributed cloud computing.
Depending on PEKS plot [22]
, a great deal of
works have generally flow around the
criteria of conjunctive keywords search. If at
all that the client is keen on a few key
phrases of report, the client may either
depend on a convergence estimation to
decide the right arrangement of archives or
store extra data on the server to encourage
such pursuits. Thus, open key encryption
with conjunctive keyword search (PECK)
method is efficient to refer.
Normally, PEKS and PECK [22]
, give a sort
of system that enables recipient to acquire
messages that contain one or a few specific
keywords by giving an indirect access
comparing to the keywords from email
server, while the email server and various
other beneficiary can't pick up whatever else
about the email.
A privacy-preserving query framework for
encrypted cloud storage was proposed in
Phrase Search for Encrypted Cloud Storage
[23]. The framework adopts symmetric-key
encryption and a tree-based search structure
to maintain query performance and ensure
query privacy. The secure searchable index
(BFEST) in the framework is jointly
operated by the EU and the CSS to reduce
computation and network communication
costs of the EU.
IV. METHODOLOGY and
DISCUSSION
In this approach we utilized three system
which is utilized to recover information
from cloud quick and secure. The
calculation and convention is utilized to
scramble the records and catchphrase and
took the incentive for all watchwords and
record to unscramble the record speedier put
away in the cloud server.Here we utilizing a
real time cloud Drive HQ to store archive
• AES ALGORITHM
• TDES ALGORITHM
• HASHING
AES ALGORITHM
The encryption process uses a set of
specially derived keys called round keys.
These are applied, along with other
operations, on an array of data that holds
exactly one block of data?the data to be
encrypted. This array we call the state array.
You take the following aes steps of
encryption for a 128-bit block:
1. Derive the set of round keys from the
cipher key.
2. Initialize the state array with the
block data (plaintext).
3. Add the initial round key to the
starting state array.
4. Perform nine rounds of state
manipulation.
5. Perform the tenth and final round of
state manipulation.
6. Copy the final state array out as the
encrypted data (ciphertext).
The reason that the rounds have been listed
as "nine followed by a final tenth round" is
because the tenth round involves a slightly
different manipulation from the others.

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 92
This work is licensed under a Creative Commons Attribution 4.0 International License
The block to be encrypted is just a sequence
of 128 bits. AES works with byte quantities
so we first convert the 128 bits into 16 bytes.
We say "convert," but, in reality, it is almost
certainly stored this way already. Operations
in RSN/AES are performed on a two-
dimensional byte array of four rows and four
columns. At the start of the encryption, the
16 bytes of data, numbered D0 ? D15, are
loaded into the array as shown in Table A.5.
Each round of the encryption process
requires a series of steps to alter the state
array. These steps involve four types of
operations called:
SubBytes
ShiftRows
MixColumns
XorRoundKey
SubBytes
This operation is a simple substitution
that converts every byte into a different
value. AES defines a table of 256 values
for the substitution. You work through
the 16 bytes of the state array, use each
byte as an index into the 256-byte
substitution table, and replace the byte
with the value from the substitution
table. Because all possible 256 byte
values are present in the table, you end
up with a totally new result in the state
array, which can be restored to its
original contents using an inverse
substitution table. The contents of the
substitution table are not arbitrary; the
entries are computed using a
mathematical formula but most
implementations will simply have the
substitution table stored in memory as
part of the design.
ShiftRows
As the name suggests, ShiftRows
operates on each row of the state array.
Each row is rotated to the right by a
certain number of bytes as follows:
1st Row: rotated by 0 bytes (i.e., is not changed)
2nd Row: rotated by 1 byte
3rd Row: rotated by 2 bytes
4th Row: rotated by 3 bytes
As an example, if the ShiftRows
operation is applied to the stating state
array shown in Table A.8, the result is
shown in Table A.9.
MixColumns
This operation is the most difficult, both
to explain and perform. Each column of
the state array is processed separately to
produce a new column. The new column
replaces the old one. The processing
involves a matrix multiplication. If you
are not familiar with matrix arithmetic,
don't get to concerned?it is really just a
convenient notation for showing
operations on tables and arrays.
XorRoundKey
After the MixColumns operation, the
XorRoundKey is very simple indeed and
hardly needs its own name. This
operation simply takes the existing state
array, XORs the value of the appropriate
round key, and replaces the state array
with the result. It is done once before the
rounds start and then once per round,
using each of the round keys in turn.

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 93
This work is licensed under a Creative Commons Attribution 4.0 International License
Figure: Summary of AES Encryption
MODULES:
• System Framework
• Data Owner
• Data User
• Cloud Server
MODULES DISCUSSION:
Framework: In this system, we outlined a
standard catchphrase seek convention. Amid
setup, the information proprietor produces
the required encryption keys for hashing and
encryption tasks. At that point, all reports in
the database are parsed for watchwords.
Blossom channels fixing to hashed
watchwords and n-grams are appended. The
reports are then symmetrically encoded and
transferred to the cloud server. To add
documents to the database, the information
proprietor parses the records as in setup and
transfers them with Bloom channels
appended to the cloud server. To expel a
document from the information, the
information
proprietor essentially sends the demand to
the cloud server, who evacuates the
document alongside the appended Bloom
channels. To play out a pursuit, the
information client enters watchword then it
figures and sends a trapdoor encryption of
the questioned catchphrases to the cloud to
start a convention and returns exact record.
Here we execute a few modules they are
Data Owner, Data User and Cloud Server.
Information Owner: In Data Owner module,
Initially Data Owner must need to enroll
their detail and after login he/she needs to
confirm their login through OTP. At that
point information Owner can transfer
records into cloud server with encoded
watchwords and hashing calculations.
He/she can see the documents that are
transferred in cloud. Information Owner can
affirm or dismiss the document ask for sent
by information clients.
Information User: In Data User module,
Initially Data Users must need to enlist their
detail and afterward login into cloud.
Information Users can look through every
one of the records transfer by information
proprietors. He/she can send demand to the
documents and afterward demand will send
to the information proprietors. On the off
chance that information proprietor favors the
demand then he/she will get the
unscrambling key in enrolled mail Cloud
Server: In this module, we create Cloud
Server module. In Cloud Server module,
Cloud Provider can see every one of the
Data proprietors and information clients'
subtle elements. CP can capable see the
documents in cloud transferred by the
information proprietors.
International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 94
This work is licensed under a Creative Commons Attribution 4.0 International License
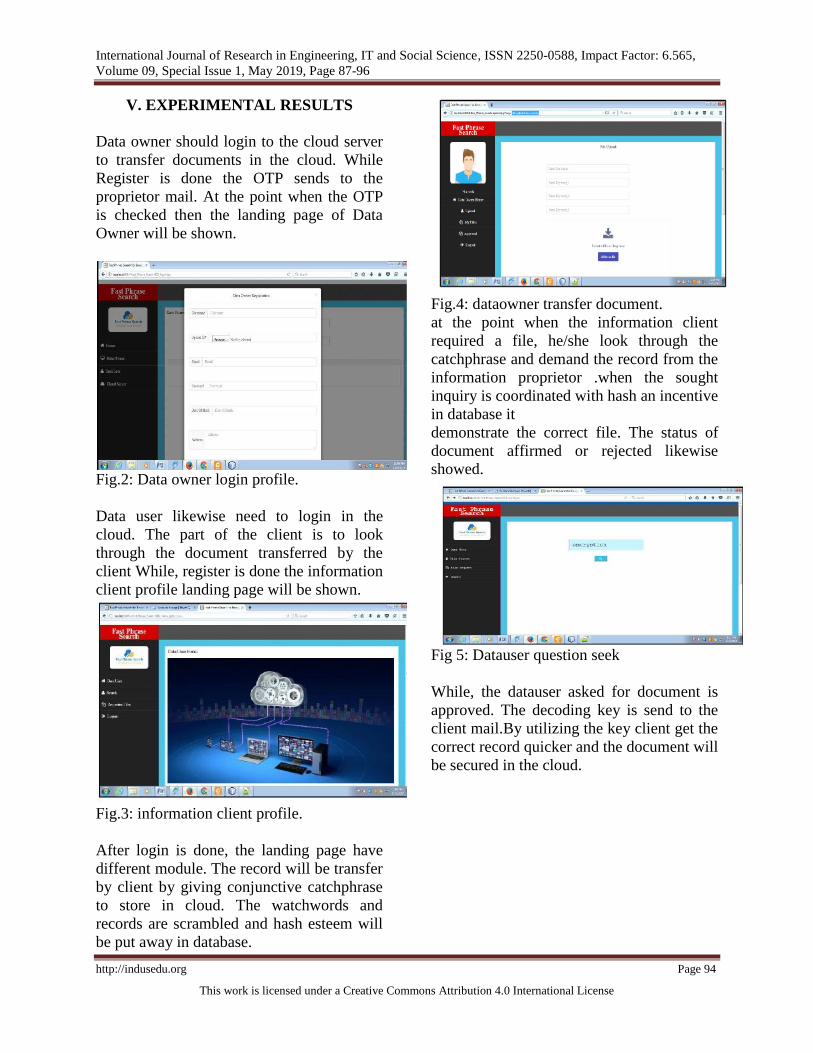
V. EXPERIMENTAL RESULTS
Data owner should login to the cloud server
to transfer documents in the cloud. While
Register is done the OTP sends to the
proprietor mail. At the point when the OTP
is checked then the landing page of Data
Owner will be shown.
Fig.2: Data owner login profile.
Data user likewise need to login in the
cloud. The part of the client is to look
through the document transferred by the
client While, register is done the information
client profile landing page will be shown.
Fig.3: information client profile.
After login is done, the landing page have
different module. The record will be transfer
by client by giving conjunctive catchphrase
to store in cloud. The watchwords and
records are scrambled and hash esteem will
be put away in database.
Fig.4: dataowner transfer document.
at the point when the information client
required a file, he/she look through the
catchphrase and demand the record from the
information proprietor .when the sought
inquiry is coordinated with hash an incentive
in database it
demonstrate the correct file. The status of
document affirmed or rejected likewise
showed.
Fig 5: Datauser question seek
While, the datauser asked for document is
approved. The decoding key is send to the
client mail.By utilizing the key client get the
correct record quicker and the document will
be secured in the cloud.

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 95
This work is licensed under a Creative Commons Attribution 4.0 International License
Fig 6: check unscrambling key
The record sought by client is get speedier
immediately and furthermore dataowner
document will be secured by utilizing this
method.
Fig 7: User get correct document speedier
V. CONCLUSION AND FUTURE
WORK
In this paper, we introduced an expression
seek conspire in light of Bloom channel that
is fundamentally speedier than Existing
methodologies, requiring just a solitary
round of correspondence and Bloom channel
verifications. Our approach is additionally
the first to successfully permit state pursuit
to run freely without first playing out a
conjunctive catchphrase hunt to recognize
applicant records. The method of developing
a Bloom channel file empowers quick check
of Bloom channels in an indistinguishable
way from ordering. As indicated by our
examination, it additionally accomplishes a
lower stockpiling cost than every single
existing arrangement aside from where a
higher computational cost was traded for
bring down capacity.
While displaying comparative
correspondence cost to driving existing
arrangements, the proposed arrangement can
likewise be changed in accordance with
accomplish greatest speed or rapid with a
sensible stockpiling cost contingent upon the
application.
VI. REFERENCES
[1] [19] Miller M (2008) Cloud Computing: Web-
Based Applications That Change the Way You Work
and Collaborate Online. Que Publishing, Indianapolis
[2] K. Cai, C. Hong, M. Zhang, D. Feng, and Z.Lv,
“A secure conjunctive keywords search over
encrypted cloud data against inclusion-relation
attack,” in IEEE International Conference on Cloud
Computing Technology and Science, 2013, pp. 339–
346.
[3]. A. M. A. Ali, K. Nagaraj, "Background
calibration of operational amplifier gain error in
Pipelined A/D converter", IEEE Trans. Circuits Syst.
II Analog Digit. Signal Process., vol. 50, no. 8, pp.
631-634, Sep. 2003.
[4] James Allan, Stephen Harding, David Fisher,
"Taking Topic Detection from Evaluation to Practice
[A]", Proceedings of the 38th Hawaii International
Conference on System Sciences [C], 2005.
[5]. S. Fabrizio, "Machine learning in automated text
categorization", ACM Computing Surveys, vol. 34,
no. 1, pp. 1-47, 2002.
[6]. S. Fabrizio, and Z. Alessandro, Text Mining and
its Applications, Southampton, UK: WIT Press, 2005,
pp. 109-129.
[7] D. Boneh, G. D. Crescenzo, R. Ostrovsky, and G.
Persiano, “Public key encryption with keyword
search,”
in In proceedings of Eurocrypt, 2004, pp. 506–522.

International Journal of Research in Engineering, IT and Social Science, ISSN 2250-0588, Impact Factor: 6.565,
Volume 09, Special Issue 1, May 2019, Page 87-96
http://indusedu.org Page 96
This work is licensed under a Creative Commons Attribution 4.0 International License
[8] B. Waters, D. Balfanz, G. Durfee, and D. K.
Smetters,
“Building an encrypted and searchable audit log,” in
Network and Distributed System Security
Symposium, 2004.
[9] M. Ding, F. Gao, Z. Jin, and H. Zhang, “An
efficient
public key encryption with conjunctive keyword
search
scheme based on pairings,” in IEEE International
Conference onNetwork Infrastructure and Digital
Content, 2012, pp. 526–530.
[10] F. Kerschbaum, “Secure conjunctive keyword
searches for unstructured text,” in International
Conference on Network and System Security, 2011,
pp. 285–289.
[11] C. Hu and P. Liu, “Public key encryption with
ranked
multi keyword search,” in International Conference
on
Intelligent Networking and Collaborative Systems,
2013,
pp. 109–113.
[12] Z. Fu, X. Sun, N. Linge, and L. Zhou,
“Achieving
effective cloud search services: multi keyword ranked
search over encrypted cloud data supporting synonym
query,” IEEE Transactions on Consumer Electronics,
vol.
60, pp. 164–172, 2014.
[13] C. L. A. Clarke, G. V. Cormack, and E. A.
Tudhope,
“Relevance ranking for one to three term queries,”
Information Processing and Management: an
International
Journal, vol. 36, no. 2, pp. 291–311, Jan. 2000.
[14] H. Tuo and M. Wenping, “An effective fuzzy
keyword
search scheme in cloud computing,” in International
Conference on Intelligent Networking and
Collaborative
Systems, 2013, pp. 786–789.
[15] M. Zheng and H. Zhou, “An efficient attack on a
fuzzy keyword search scheme over encrypted data,”
in
International Conference on High Performance
Computing and Communications and Embedded and
Ubiquitous Computing, 2013, pp. 1647–1651.
[16] S. Zittrower and C. C. Zou, “Encrypted phrase
searching in the cloud,” in IEEE Global
Communications
Conference, 2012, pp. 764– 770.
First Author: P. Penchalaiah M.Tech, P.hD,
Associate Professor in Deportment of CSE ,
Narayana Engineering College, Gudur,
Nellore Dist, AP.
Second Author:
D. Anusha, Pursuing B.Tech(CSE) from
Narayana Engineering College, Gudur,
Nellore Dist, AP.
N.Vani, Pursuing B.Tech(CSE) from
Narayana Engineering College, Gudur,
Nellore Dist, AP.
K.Madhuri, Pursuing B.Tech(CSE) from
Narayana Engineering College, Gudur,
Nellore Dist, AP.
Ch.Sai Sahithya, Pursuing B.Tech(CSE)
from Narayana Engineering College, Gudur,
Nellore Dist, AP.
Related Documents