Fast indexing and searching strategies for feature-based image database systems Li-Wei Kang Jin-Jang Leou National Chung Cheng University Department of Computer Science and Information Engineering Chiayi, Taiwan 621 E-mail: [email protected] Abstract. Because visual data require a large amount of memory and computing power for storage and processing, it is greatly de- sired to efficiently index and retrieve the visual information from im- age database systems. We propose efficient indexing and searching strategies for feature-based image database systems, in which un- compressed and compressed domain image features are employed. Each query or stored image is represented by a set of features extracted from the image. The weighted square sum error distance is employed to evaluate the ranks of retrieved images. Many fast clustering and searching techniques exist for the square sum error distance used in vector quantization (VQ), in which different features have identical weighting coefficients. In practice, different features may have different dynamic ranges and different importances, i.e., different features may have different weighting coefficients. We de- rive a set of inequalities based on the weighted square sum error distance and employ it to speed up the indexing (clustering) and searching procedures for feature-based image database systems. Good simulation results show the feasibility of the proposed ap- proaches. © 2005 SPIE and IS&T. [DOI: 10.1117/1.1866148] 1 Introduction Multimedia database systems become more and more popular with the advent of high-powered PCs, low-cost computer storage devices, broadband networks, and visual/ audio compression standards. Because visual data require a large amount of memory and computing power for storage and processing, it is greatly desired to efficiently index and retrieve ~search! the visual information from multimedia database systems. Some existing systems include the fa- mous QBIC system from IBM, the Safe system from Co- lumbia University, the VIR Image Engine from Virage, and the Photobook from Massachusetts Institute of Technology. 1–3 Traditionally, database systems are usually accessed by text-based queries, 4,5 such as keywords, cap- tions, and filenames, which are not suitable for a modern image database system. Image retrieval based on image content is greatly desir- able in a number of applications. 6 As shown in Fig. 1, fea- ture vectors representing images are usually extracted, or- ganized, and stored properly in a multimedia database system when it is created. In the query process, a feature vector ~or a set of features! representing a query image is extracted from the query image, and then the similarity ~or distance! measures between the query image and stored im- ages in the image database system are evaluated. Finally, the most similar image~s! will be presented to the user. For a feature-based image database system, each image can be represented by a k-dimensional feature vector, i.e., an image is converted into a k-attribute numeric data in a k-dimensional Euclidean space. To make the image data- base scalable to a very large size, efficient multidimen- sional indexing and searching techniques must be explored. Traditional multidimensional data structures, such as R-tree, kDB-tree, and grid files, are not suitable for image feature indexing due to inability to scale to high dimensionality. 7 A kind of famous multidimensional index- ing structure is the tree-based indexing technique that can be classified into data partitioning ~DP!-based and space partitioning ~SP!-based index structures. A DP-based index structure consists of bounding regions arranged in a spatial containment hierarchy, such as R-tree, X-tree, 8 and SR-tree. 9 An SP-based index structure consists of space re- cursively partitioned into mutually disjoint subspaces. The hierarchy of partitions forms the tree structures, such as kd-tree, 10 kDB-tree, 11 and hB-tree. 12 Berchtold et al. 13 proposed an indexing method, called the pyramid-technique, for high-dimensional data spaces. It is claimed that the pyramid technique outperforms the X-tree and the Hilbert R-tree. Kim et al. 14 proposed an en- hanced version of the R*-tree. Chakrabarti and Mehrotra 7 proposed a multidimensional data structure called the hy- brid tree for indexing high-dimensional feature spaces. It is claimed that the hybrid tree outperforms both purely DP- based and SP-based indexing structure. Wu 15 presented a context-based indexing technique, called ContIndex, which is formally defined by adapting a classification tree con- cept. A special neural network model was developed to create node categories by fusing multimodal feature mea- sures. Gong et al. 16 presented an indexing scheme using color histogram, in which a B 1 -tree is used to store the numerical keys of color histograms in the database system. Vazirgiannis et al. 17 proposed two indexing schemes using the R-tree indexing structure for large multimedia applica- tions. Paper 020030 received Apr. 10, 2000; revised manuscript received Feb. 22, 2001; accepted for publication May 14, 2004; published online Feb. 24, 2005. 1017-9909/2005/$22.00 © 2005 SPIE and IS&T. Journal of Electronic Imaging 14(1), 013019 (Jan– Mar 2005) 013019-1 Journal of Electronic Imaging Jan – Mar 2005/Vol. 14(1)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Journal of Electronic Imaging 14(1), 013019 (Jan–Mar 2005)
Fast indexing and searching strategies forfeature-based image database systems
Li-Wei KangJin-Jang Leou
National Chung Cheng UniversityDepartment of Computer Science and Information Engineering
Chiayi, Taiwan 621E-mail: [email protected]
orstuairegend
e fo-,o
lly-ern
sir
, oastur
is
im-ally,
age.,
ata-n-
red.asgeh-caneexatial
re-heas
ds. Itthe
hy-t isP-
ichn-to
ea-ngeem.ga-200
Abstract. Because visual data require a large amount of memoryand computing power for storage and processing, it is greatly de-sired to efficiently index and retrieve the visual information from im-age database systems. We propose efficient indexing and searchingstrategies for feature-based image database systems, in which un-compressed and compressed domain image features are employed.Each query or stored image is represented by a set of featuresextracted from the image. The weighted square sum error distanceis employed to evaluate the ranks of retrieved images. Many fastclustering and searching techniques exist for the square sum errordistance used in vector quantization (VQ), in which different featureshave identical weighting coefficients. In practice, different featuresmay have different dynamic ranges and different importances, i.e.,different features may have different weighting coefficients. We de-rive a set of inequalities based on the weighted square sum errordistance and employ it to speed up the indexing (clustering) andsearching procedures for feature-based image database systems.Good simulation results show the feasibility of the proposed ap-proaches. © 2005 SPIE and IS&T. [DOI: 10.1117/1.1866148]
1 Introduction
Multimedia database systems become more and mpopular with the advent of high-powered PCs, low-cocomputer storage devices, broadband networks, and visaudio compression standards. Because visual data reqularge amount of memory and computing power for storaand processing, it is greatly desired to efficiently index aretrieve ~search! the visual information from multimediadatabase systems. Some existing systems include thmous QBIC system from IBM, the Safe system from Clumbia University, the VIR Image Engine from Virageand the Photobook from Massachusetts InstituteTechnology.1–3 Traditionally, database systems are usuaaccessed by text-based queries,4,5 such as keywords, captions, and filenames, which are not suitable for a modimage database system.
Image retrieval based on image content is greatly deable in a number of applications.6 As shown in Fig. 1, fea-ture vectors representing images are usually extractedganized, and stored properly in a multimedia databsystem when it is created. In the query process, a fea
Paper 020030 received Apr. 10, 2000; revised manuscript received Feb. 22,accepted for publication May 14, 2004; published online Feb. 24, 2005.1017-9909/2005/$22.00 © 2005 SPIE and IS&T.
01301Journal of Electronic Imaging
e
l/a
a-
f
-
r-ee
vector ~or a set of features! representing a query imageextracted from the query image, and then the similarity~ordistance! measures between the query image and storedages in the image database system are evaluated. Finthe most similar image~s! will be presented to the user.
For a feature-based image database system, each imcan be represented by ak-dimensional feature vector, i.ean image is converted into ak-attribute numeric data in ak-dimensional Euclidean space. To make the image dbase scalable to a very large size, efficient multidimesional indexing and searching techniques must be exploTraditional multidimensional data structures, suchR-tree, kDB-tree, and grid files, are not suitable for imafeature indexing due to inability to scale to higdimensionality.7 A kind of famous multidimensional indexing structure is the tree-based indexing technique thatbe classified into data partitioning~DP!-based and spacpartitioning~SP!-based index structures. A DP-based indstructure consists of bounding regions arranged in a spcontainment hierarchy, such as R-tree, X-tree,8 andSR-tree.9 An SP-based index structure consists of spacecursively partitioned into mutually disjoint subspaces. Thierarchy of partitions forms the tree structures, suchkd-tree,10 kDB-tree,11 and hB-tree.12
Berchtoldet al.13 proposed an indexing method, callethe pyramid-technique, for high-dimensional data spaceis claimed that the pyramid technique outperformsX-tree and the Hilbert R-tree. Kimet al.14 proposed an en-hanced version of the R*-tree. Chakrabarti and Mehrotra7
proposed a multidimensional data structure called thebrid tree for indexing high-dimensional feature spaces. Iclaimed that the hybrid tree outperforms both purely Dbased and SP-based indexing structure. Wu15 presented acontext-based indexing technique, called ContIndex, whis formally defined by adapting a classification tree cocept. A special neural network model was developedcreate node categories by fusing multimodal feature msures. Gonget al.16 presented an indexing scheme usicolor histogram, in which a B1-tree is used to store thnumerical keys of color histograms in the database systVazirgianniset al.17 proposed two indexing schemes usinthe R-tree indexing structure for large multimedia applictions.
1;
9-1 Jan–Mar 2005/Vol. 14(1)

te-nchan
us.tee
usege
forred
ecs,hif a
nce-allonth
disngr-enre,suypex
-gex-age
tsn-ingimd-
he
s-ing
nyceQ
n
hbor
e
Kang and Leou
For other existing image indexing and searching stragies, Jain and Vailaya6 developed an efficient image retrieval method using a clustering technique and a braand bound-based matching scheme, whereas JainVailaya18 proposed a trademark image retrieval methoding object shape information and a two-stage hierarchy
In this study, each query or stored image is represenby a set of uncompressed and compressed featurestracted from the image and a new distance measure isto evaluate the ranks of the retrieved images. In the imaindexing phase, the feature vectors and the auxiliary inmation for all stored images are first calculated and stoin the database system. Then all the images~or feature vec-tors! in the database system are classified into a prespfied numberK of clusters by fast clustering techniquebased on the new distance measure. In the image searcphase, the feature vector and the auxiliary information oquery image is first calculated. Then a small numberM ofclosest clusters are determined by computing the distabetween the query image and all theK cluster centers. Second, the mostN similar images are found among the smnumberM of closest clusters. A set of inequalities basedthe new distance measure is derived to speed up bothimage indexing~clustering! and searching phases.
A popular distance measure is the square sum errortance, in which different features have identical weighticoefficients.1 In practice, different features may have diffeent dynamic ranges and different importances, i.e., differfeatures may have different weighting coefficients. Hethe new distance measure called the weighted squareerror distance is employed. On the other hand, the first tof features, such as color, texture, shape, or sketch, istracted from uncompressed images,11,19–22whereas the second type of features is extracted from compressed imadirectly.23,24 In this study, two types of image features etracted from both uncompressed and compressed imare employed to represent images.
The paper is organized as follows. Section 2 presenbrief overview of existing fast algorithms for vector quatization ~VQ!. Section 3 addresses the proposed indexand searching strategies for image database systems. Slation results are included in Sec. 4, followed by concluing remarks.
2 Existing Fast Algorithms for VQ
VQ is25–30 a generalization of scalar quantization to tquantization of a vector. Within VQ, a vectorx5(x1 ,x2 ,...,xk) is compared with all the vectors~codewords! in the codebook to find the closest vector~codeword! yi5(yi1 ,yi2 ,...,yik) using the square sum error ditance function. The basic idea employed in most exist
Fig. 1 Generalized content-based image database (retrieval)system.
01301Journal of Electronic Imaging
-
d-
dx-d-
-
i-
ng
s
e
-
t
me-
s
s
a
u-
fast algorithms is to use some inequalities to reject maunlike vectors, without detailed calculating of the distanfunctions between vectors. Several fast algorithms for Vare introduced briefly as follows.
2.1 Mean Difference Method
Within the mean difference method~MDM ! proposedby Lee and Chen,25 let x5(x1 ,x2 ,...,xk) be an inputk-dimensional vector and y5(y1 ,y2 ,...,yk) be ak-dimensional vector~code word! in the codebook. Definethe mean values ofx andy as
mx51
k (j 51
k
xj , ~1!
my51
k (j 51
k
yj . ~2!
For the square sum error distance function betweenx andy,i.e., d2(x,y)5( j 51
k (xj2yj )2, we have
d2~x,y!>k~mx2my!2. ~3!
That is, for a vector~code word! y in the codebook, ifk(mx2my)
2 is larger than the current minimum distortiodmin
2 , y will not be the closest vector~code word! to theinput vectorx and thus can be rejected.
2.2 Equal-Average Equal-Variance Nearest-Neighbor Search Algorithm
For the equal-average equal-variance nearest-neigsearch~EENNS! algorithm proposed by Lee and Chen,26
the varianceVx2 of x is defined as
Vx25(
j 51
k
~xj2mx!2. ~4!
It can be proved that
d~x,y!>uVx2Vyu. ~5!
Within the EENNS algorithm, the vectors~code words!whose means are similar tomx , but whose variances arvery different fromVx
2 will be rejected accordingly.
2.3 Baek et al.’s Method
Within the algorithm proposed by Baeket al.,27 we haved2(x,y)5( j 51
k (xj2yj )2, then
d2~x,y!>k~mx2my!21~Vx2Vy!2. ~6!
2.4 Integral Projection Mean-Sorted Partial SearchAlgorithm
For the integral projection mean-sorted partial search~IP-MPS! algorithm proposed by Lin and Tai,28 for an inputk-dimensional vectorx( i , j ) arranged by two indices (i , j )with k5n3n, wherei, j 51,2,...,n, the three kinds of in-tegral projections are defined as follows:
9-2 Jan–Mar 2005/Vol. 14(1)

es
-
n-
ingar
-
entanhe
ldol-
vec-
om
ices.of-e ofical
ereo
orfeal-
Fast indexing and searching strategies . . .
1. vertical projection:vpx~ j !5(i 51
n
x~ i , j !, 1< j <n, ~7!
2. horizontal projection:hpx~ i !5(j 51
n
x~ i , j !, 1< i<n,
~8!
and
3. massive projection:mpx5(i 51
n
(j 51
n
x~ i , j !. ~9!
For the three simple distortion measures given by
dm2 ~x,y!5~mpx2mpy!2, ~10!
dv2~x,y!5(
l 51
n
@vpx~ l !2vpy~ l !#2, ~11!
dh2~x,y!5(
l 51
n
@hpx~ l !2hpy~ l !#2, ~12!
we have
dm2 ~x,y!<n2d2~x,y!, ~13!
dv2~x,y!<nd2~x,y!, ~14!
and
dh2~x,y!<nd2~x,y!. ~15!
2.5 Chang and Hu’s Method
In the generalized integral projection~GIP! model devel-oped by Chang and Hu,29 a k-dimensional vector can bpartitioned into anyp segments and each segment haqcomponents~pixels!, wherep andq are two positive inte-gers withk5p3q. For each of thep segments of a codevectorx, the q components~pixel values! can be summedto obtain a projectionPx( l ), for l 51,2,...,p. If the distor-tion measure between two codevectors is given by
d~p,q!2 ~x,y!5(
l 51
p
@Px~ l !2Py~ l !#2, ~16!
wherePx( l ) and Py( l ), l 51,2,...,p, are projections of thecodevectorsx andy, respectively, we have
d~p,q!2 ~x,y!<q3d2~x,y!. ~17!
3 Proposed Fast Indexing and SearchingStrategies for Image Database Systems
3.1 Features Extracted from Uncompressed andCompressed Images
In this study, the first type of features extracted from ucompressed images is the color coherence vector31 ~CCV!,
01301Journal of Electronic Imaging
which is a type of histogram-based features incorporatthe spatial information. Within the CCV, each pixel ingiven color bucket is classified into either ‘‘coherent’’ o‘‘incoherent.’’ A pixel is coherent if the size of its connected component exceeds a predefined thresholdt; other-wise, it is incoherent. A CCV stores the number of coherand incoherent pixels for each color bucket. The CCV ctake spatial information into account and outperform ttraditional color histogram method.31 In the CCV method,31
the numbern of color buckets is set to 64 and the threshot is set to be 1% of the size of an image, which are flowed in this study. That is,n564 and the thresholdt is setto be 655~the size of an image is 65,536!. Hence the CCVfor an image can be represented as a 128-dimensionaltor @(a1 ,b1),(a2 ,b2),...,(a64,b64)#.
In this study, the second type of features extracted fruncompressed images is the five~among 14! statistical tex-ture measures derived by Haralicket al.,32 which can becomputed based on the gray-scale cooccurrence matrHaralick et al. derived the 14 measures, but only fivethem are found to be truly useful.33 The gray-scale cooccurrence matrices, which describe spatial dependencpixels in a gray-scale image, are often used in statistanalysis of textures. Figure 2~a! shows a 434 image blockwith gray values 0 to 3, and Fig. 2~b! shows the corre-sponding general form of a cooccurrence matrix, wheach element (i , j ) denotes the occurrence frequency of twneighboring pixels with gray-valuesi and j. If Su(d) de-notes a cooccurrence matrix with distanced and directionu, Fig. 2~c! shows the neighboring gray-value pairs fcomputingS0 deg(1) and Fig. 2~d! shows the contents oS0 deg(1), where ‘‘⇔’’ denotes a neighboring gray-valupair. The other cooccurrence matrices can be similarly cculated.
If N denotes the number of gray values andSu( i , j ud)denotes the (i , j )’th element inSu(d), the five texture mea-sures are given by32
1. energy: f 15 (i 50
N21
(j 50
N21
@Su~ i , j ud!#2, ~18!
Fig. 2 Computation of cooccurrence matrices for a 434 block: (a) a434 image block with gray-values 0 to 3, (b) the general form of acooccurrence matrix, (c) neighboring gray-value pairs for computingS0 deg(1), and (d) the contents of S0 deg(1).
9-3 Jan–Mar 2005/Vol. 14(1)

rdl
veuani-
-ond.eage
t t
m
omforT- di-
m.ns
Kang and Leou
2. entropy: f 252 (i 50
N21
(j 50
N21
Su~ i , j ud!logSu~ i , j ud!,
~19!
3. correlation: f 351
sxsy(i 50
N21
(j 50
N21
~ i 2ux!~ j 2uy!
3Su~ i , j ud!, ~20!
4. inverse different moment~IDM):
f 45 (i 50
N21
(j 50
N21 Su~ i , j ud!
11~ i 2 j !2, ~21!
5. inertia: f 55 (i 50
N21
(j 50
N21
~ i 2 j !2Su~ i , j ud!. ~22!
In Eq. ~20!, ux , uy , sx , andsy are the means and standadeviations ofSu( i , j ud) along the horizontal and verticadirections, respectively, which are given by
ux5 (i 50
N21
i (j 50
N21
Sx~ i , j ud!, ~23!
uy5 (i 50
N21
j (j 50
N21
Sy~ i , j ud!, ~24!
sx25 (
i 50
N21
~ i 2ux!2 (
j 50
N21
Sx~ i , j ud!, ~25!
sy25 (
j 50
N21
~ j 2uy!2 (i 50
N21
Sy~ i , j ud!. ~26!
To reduce the time complexity for computing these fitexture measures, the gray levels of an image are reqtized to contain only 16 gray levels by using a simple uform quantization scheme32 and only d51, u50, 45, 90,and 135 deg are used.33 For each of the five texture measures, the means and the variances of the four corresping values foru50, 45, 90, and 135 deg are computeThen the means and the variances of the five texture msures form a 10-D feature vector for representing an ima
The seven invariant moments developed by Hu34 areused as shape features in this study, which are invariantranslation, rotation, and scaling.34,35 The 128 color fea-tures, 7 shape features, and 10 texture features for145-D feature vector for an uncompressed image.
On the other hand, the image features extracted frcompressed images are the discrete cosine trans~DCT!-based coefficients extracted from block-based DCcompressed images.24 The two-dimensional~2-D! DCT andinverse DCT~IDCT! are given by
01301Journal of Electronic Imaging
n-
d-
-.
o
a
m
C~u,v !5a~u!a~v ! (x50
N21
(y50
N21
f ~x,y!
3cosF ~2x11!up
2N GcosF ~2y11!vp
2N Gfor u,v50,1,2,...,N21, ~27!
f ~x,y!5 (u50
N21
(v50
N21
a~u!a~v !C~u,v !
3cosF ~2x11!up
2N GcosF ~2y11!vp
2N Gfor x,y50,1,2,...,N21, ~28!
where
a~u!5H S 1
ND 1/2
for u50,
S 2
ND 1/2
for u51,2,...,N21.
~29!
In this study, a set of nine features (f 1 , f 2 ,...,f 9) is de-termined as follows:
f 15C~0,0! ~ the dc coefficient!, ~30!
f 25C~0,1!1C~0,2!1C~1,0!1C~1,1!1C~2,0!, ~31!
f 35C~0,3!1C~0,4!1C~1,2!1C~1,3!1C~2,1!1C~2,2!
1C~3,0!1C~3,1!1C~4,0!, ~32!
f 45C~0,5!1C~0,6!1C~1,4!1C~1,5!1C~2,3!1C~2,4!
1C~3,2!1C~3,3!1C~4,1!1C~4,2!1C~5,0!
1C~5,1!1C~6,0!, ~33!
f 55C~0,0!1C~1,0!1C~2,0!1C~3,0!1C~4,0!1C~5,0!
1C~6,0!1C~7,0!, ~34!
f 65C~1,1!1C~2,1!1C~3,1!1C~4,1!1C~5,1!1C~6,1!
1C~7,1!, ~35!
f 75C~0,1!1C~0,2!1C~0,3!1C~0,4!1C~0,5!1C~0,6!
1C~0,7!, ~36!
f 85C~1,2!1C~1,3!1C~1,4!1C~1,5!1C~1,6!1C~1,7!,~37!
f 95C~2,2!1C~2,3!1C~3,2!1C~3,3!1C~3,4!1C~4,3!
1C~4,4!1C~4,5!1C~5,4!1C~5,5!. ~38!
Extracting features from DCT-compressed imagesrectly is efficient for indexing an image database systeThe DCT coefficients represent some gray-level variatio
9-4 Jan–Mar 2005/Vol. 14(1)

th
areninure
es
ce
e
r
ted-
-
-
theed
, thethecal-ageso a
Fast indexing and searching strategies . . .
and dominant directions in the original image. Heref 1 isthe dc coefficient representing the average energy ofcorresponding image block;f 2 , f 3 , and f 4 represent fre-quency band characteristics; andf 5 , f 6 , f 7 , f 8 , and f 9represent spatial characteristics.24 Each 838 block pro-duces a 9-D feature vector (f 1 , f 2 ,...,f 9) and the meansand the variances of all the vectors within an imagecalculated. Then the corresponding nine means andvariances form an 18-D feature vector, which is the featvector representing a compressed image.
3.2 Proposed Inequalities for the Weighted SquareSum Error Distance
Assume thatx5(x1 ,x2 ,...,xk) and y5(y1 ,y2 ,...,yk) aretwo k-dimensional feature vectors representing two imagx andy, respectively, andw1 , w2 ,...,wk are the weightingcoefficients for feature vectors withwj>0, j 51,2,...,k and( j 51
k wj51. The weighted square sum error distand2(x,y) between two images or feature vectorsx andy isgiven by
d2~x,y!5(j 51
k
wj~xj2yj !2. ~39!
If the weighted sum mx and variance Vx2 of x
5(x1 ,x2 ,...,xk) are defined, respectively, as
mx5(j 51
k
wjxj , ~40!
Vx25(
j 51
k
wj~xj2mx!2, ~41!
a lemma can be given as follows.
Lemma 1. If x5(x1 ,x2 ,...,xk) and y5(y1 ,y2 ,...,yk)are two k-dimensional feature vectors, M x
5(mx ,mx ,...,mx) andM y5(my ,my ,...,my), then
d2~x,M x!<d2~x,M y!. ~42!
Based on Eqs.~39! to ~42!, the second lemma can bderived as follows.
Lemma 2. If x5(x1 ,x2 ,...,xk) and y5(y1 ,y2 ,...,yk)are twok-dimensional feature vectors, then
d2~x,y!>~mx2my!2, ~43!
d2~x,y!>~Vx2Vy!2, ~44!
d2~x,y!>~mx2my!21~Vx2Vy!2. ~45!
Similar to the IPMPS algorithm28,29 for VQ, if x is ak-dimensional feature vector withk5n3n, i.e., x5(x11,x12,...,xnn). Using two indices, i and j, twoweighted projections can be defined as
01301Journal of Electronic Imaging
e
e
,
1. weighted vertical projection:vpx~ j !5(i 51
n
wi j xi j 1
< j <n, ~46!
2. weighted horizontal projection:hpx~ i !5(j 51
n
wi j xi j 1
< i<n. ~47!
If x5(x11,x12,...,xnn) and y5(y11,y12,...,ynn) are twok-dimensional feature vectors withk5n3n, two simpledistance measures can be defined, respectively, as
1. dv2~x,y!5(
i 51
n
@vpx~ i !2vpy~ i !#2, ~48!
2. dh2~x,y!5(
i 51
n
@hpx~ i !2hpy~ i !#2. ~49!
Lemma 3. If x and y denote twok-dimensional featurevectors using two indices withk5n3n, then
1. d2~x,y!>dv2~x,y!, ~50!
2. d2~x,y!>dh2~x,y!. ~51!
Similar to the GIP model29 for VQ, a k-dimensional fea-ture vector can be segmented into any projection pair (p,q)with k5p3q, wherep andq are two positive integers. Foeach of thep segments of a feature vectorx, the weightedsum of q component values can be viewed as a weighprojection Px( l ), for l 51,2,...,p. A distance measure between two feature vectors is defined as
d~p,q!2 ~x,y!5(
l 51
p
@Px~ l !2Py~ l !#2, ~52!
wherePx( l ) andPy( l ) are the weighted projections of feature vectorsx andy, respectively, forl 51,2,...,p.
Lemma 4. If x andy are twok-dimensional feature vectors using two indices withk5p3q, wherep andq are twopositive integers, then
d2~x,y!>d~p,q!2 ~x,y!. ~53!
The set of inequalities~lemmas 2 to 4! based on theweighted square sum error distance is used to speed upindexing~clustering! and searching phases of the proposapproach.
3.3 Proposed Fast Indexing and SearchingStrategies
The proposed approach consists of two phases, namelyindexing~clustering! phase and the searching phase. Inindexing phase, the feature vectors for all images areculated and stored in the database system. And the im~feature vectors! in the database system are classified int
9-5 Jan–Mar 2005/Vol. 14(1)

s.
he
theasanal
n thfiedare
i-
lsoar
is a
t isys
thdi-
ies,
-e ofages70olors theEG-
es.
Kang and Leou
prespecified numberK of clusters withK cluster centers bythe proposed fast modifiedK-means clustering techniqueIn the searching phase, a small numberM of closest clus-ters ~based on the cluster centers! for the query image isfirst determined and then theN most similar images~ranks1,2,...,N) for the query image will be searched among tM closest clusters.
Within the indexing phase of the proposed approach,feature vectors and some auxiliary information, suchweighted sums, variances, and weighted projections,weighted generalized projections of feature vectors, forimages are calculated, sorted by variances, and stored idatabase system. Within the proposed fast modiK-means clustering algorithm using the weighted squsum error distance, a set of derived inequalities@Eqs.~43!to ~45!, ~50!, ~51!, and~53!# is used to speed up the modfied clustering algorithm.
On the other hand, the set of derived inequalities is aused to speed up the searching phase. The proposed seing approach is described as follows, where the inputquery image, an image database system containingK clus-ters, and a set of weighting coefficients, and the outputhe N most similar images within the image database stem of the query image.
1. Step 1. Extract the feature vectorx from the queryimage and calculate the auxiliary information.
2. Step 2. Find theM closest clusters,C1 , C2 ,...,CM ,among theK clusters ofx.
3. Step 3. For eachCi , i 51,2,...,M , of the M closestclusters, find theN closest feature vectors~images!amongCi of x.
4. Step 4. Determine theN closest feature vectors~im-ages! of x among theMN feature vectors~images!obtained in step 3.
The searching phase can be summarized in Fig. 3. Notethe six inequalities developed in this study can be ‘‘in
01301Journal of Electronic Imaging
dle
ch-
-
at
vidually’’ or ‘‘together’’ ~i.e., different sets of inequalities!used to speed up both the proposed indexing~clustering!and searching phase.
4 Simulation Results
Within the proposed fast indexing and searching strategan image database system containing 10,000 2563256 un-compressed images and 10,000 2563256 compressed images, respectively, is used to evaluate the performancthe proposed approaches. The 10,000 uncompressed imconsist of 1000 texture images with 256 gray levels,color texture images, 600 binary shape images, 30 cshape images, and 8300 natural color images, wherea10,000 compressed images are the corresponding JPcompressed version of the 10,000 uncompressed imag
Fig. 3 Proposed searching process.
Table 1 The processing times (in seconds) for clustering the 10,000 uncompressed images into 10,50, and 100 clusters by the ES and the proposed approaches applying different sets of inequalities: (a)weighting coefficient set 1 and (b) weighting coefficient set 2.
(a)
No. ofClusters ES
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 156.10 144.29 70.03 72.18 150.50 174.05 70.75 173.62 80.41
50 725.24 675.09 224.87 235.69 715.02 836.07 225.28 839.59 278.86
100 8377.35 7363.20 2024.44 2138.03 7886.21 9332.66 2037.24 9236.11 2583.42
(b)
No. ofClusters ES
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 151.82 116.99 65.97 64.70 123.59 132.70 63.77 122.59 74.37
50 1937.00 1178.65 515.86 467.14 1276.80 1328.60 442.97 1051.77 580.46
100 7486.68 3937.28 1603.83 1375.77 4161.65 4191.36 1251.70 2887.98 1702.80
9-6 Jan–Mar 2005/Vol. 14(1)
Fast indexing and searching strategies . . .
Journal of Electron
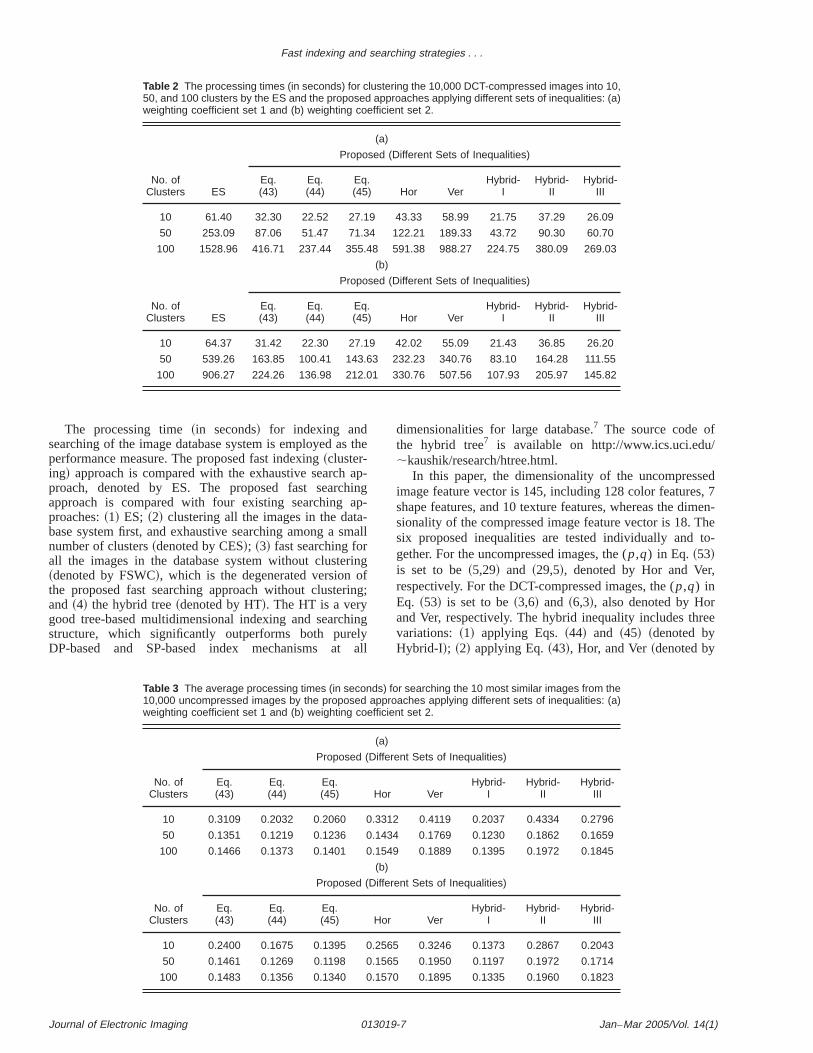
Table 2 The processing times (in seconds) for clustering the 10,000 DCT-compressed images into 10,50, and 100 clusters by the ES and the proposed approaches applying different sets of inequalities: (a)weighting coefficient set 1 and (b) weighting coefficient set 2.
(a)
No. ofClusters ES
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 61.40 32.30 22.52 27.19 43.33 58.99 21.75 37.29 26.09
50 253.09 87.06 51.47 71.34 122.21 189.33 43.72 90.30 60.70
100 1528.96 416.71 237.44 355.48 591.38 988.27 224.75 380.09 269.03
(b)
No. ofClusters ES
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 64.37 31.42 22.30 27.19 42.02 55.09 21.43 36.85 26.20
50 539.26 163.85 100.41 143.63 232.23 340.76 83.10 164.28 111.55
100 906.27 224.26 136.98 212.01 330.76 507.56 107.93 205.97 145.82
s t
aphinap--m
ringofing
inly
a
f/
ed, 7
men-he
to-
,
ee
The processing time~in seconds! for indexing andsearching of the image database system is employed aperformance measure. The proposed fast indexing~cluster-ing! approach is compared with the exhaustive searchproach, denoted by ES. The proposed fast searcapproach is compared with four existing searchingproaches:~1! ES; ~2! clustering all the images in the database system first, and exhaustive searching among a snumber of clusters~denoted by CES!; ~3! fast searching forall the images in the database system without cluste~denoted by FSWC!, which is the degenerated versionthe proposed fast searching approach without clusterand ~4! the hybrid tree~denoted by HT!. The HT is a verygood tree-based multidimensional indexing and searchstructure, which significantly outperforms both pureDP-based and SP-based index mechanisms at
01301ic Imaging
he
-g
all
;
g
ll
dimensionalities for large database.7 The source code othe hybrid tree7 is available on http://www.ics.uci.edu;kaushik/research/htree.html.
In this paper, the dimensionality of the uncompressimage feature vector is 145, including 128 color featuresshape features, and 10 texture features, whereas the disionality of the compressed image feature vector is 18. Tsix proposed inequalities are tested individually andgether. For the uncompressed images, the (p,q) in Eq. ~53!is set to be~5,29! and ~29,5!, denoted by Hor and Verrespectively. For the DCT-compressed images, the (p,q) inEq. ~53! is set to be~3,6! and ~6,3!, also denoted by Horand Ver, respectively. The hybrid inequality includes thrvariations: ~1! applying Eqs.~44! and ~45! ~denoted byHybrid-I!; ~2! applying Eq.~43!, Hor, and Ver~denoted by
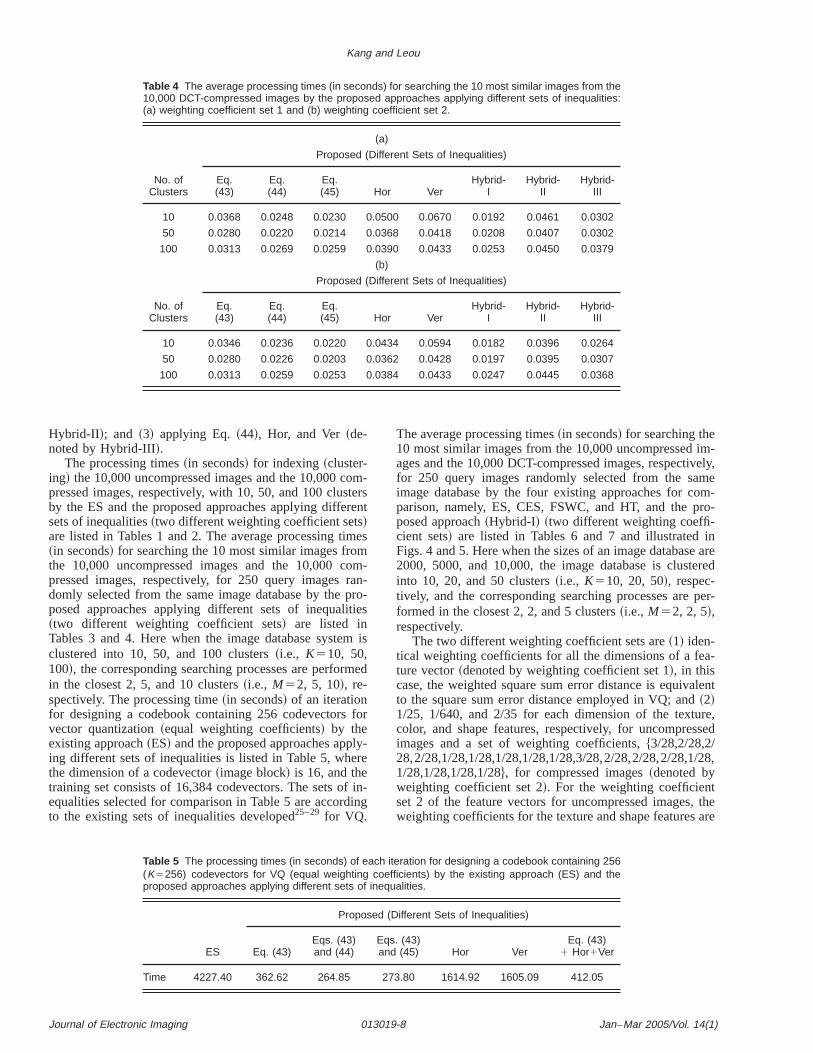
Table 3 The average processing times (in seconds) for searching the 10 most similar images from the10,000 uncompressed images by the proposed approaches applying different sets of inequalities: (a)weighting coefficient set 1 and (b) weighting coefficient set 2.
(a)
No. ofClusters
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 0.3109 0.2032 0.2060 0.3312 0.4119 0.2037 0.4334 0.2796
50 0.1351 0.1219 0.1236 0.1434 0.1769 0.1230 0.1862 0.1659
100 0.1466 0.1373 0.1401 0.1549 0.1889 0.1395 0.1972 0.1845
(b)
No. ofClusters
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 0.2400 0.1675 0.1395 0.2565 0.3246 0.1373 0.2867 0.2043
50 0.1461 0.1269 0.1198 0.1565 0.1950 0.1197 0.1972 0.1714
100 0.1483 0.1356 0.1340 0.1570 0.1895 0.1335 0.1960 0.1823
9-7 Jan–Mar 2005/Vol. 14(1)
Kang and Leou
Journal of Electron
Table 4 The average processing times (in seconds) for searching the 10 most similar images from the10,000 DCT-compressed images by the proposed approaches applying different sets of inequalities:(a) weighting coefficient set 1 and (b) weighting coefficient set 2.
(a)
No. ofClusters
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 0.0368 0.0248 0.0230 0.0500 0.0670 0.0192 0.0461 0.0302
50 0.0280 0.0220 0.0214 0.0368 0.0418 0.0208 0.0407 0.0302
100 0.0313 0.0269 0.0259 0.0390 0.0433 0.0253 0.0450 0.0379
(b)
No. ofClusters
Proposed (Different Sets of Inequalities)
Eq.(43)
Eq.(44)
Eq.(45) Hor Ver
Hybrid-I
Hybrid-II
Hybrid-III
10 0.0346 0.0236 0.0220 0.0434 0.0594 0.0182 0.0396 0.0264
50 0.0280 0.0226 0.0203 0.0362 0.0428 0.0197 0.0395 0.0307
100 0.0313 0.0259 0.0253 0.0384 0.0433 0.0247 0.0445 0.0368
omterren
memomranprotie
m
me
fo
ly-re
f inin
im-ively,meom-ro-
ine areered
per-
a-
lent
re,sed
/28,
theare
Hybrid-II!; and ~3! applying Eq.~44!, Hor, and Ver~de-noted by Hybrid-III!.
The processing times~in seconds! for indexing~cluster-ing! the 10,000 uncompressed images and the 10,000 cpressed images, respectively, with 10, 50, and 100 clusby the ES and the proposed approaches applying diffesets of inequalities~two different weighting coefficient sets!are listed in Tables 1 and 2. The average processing ti~in seconds! for searching the 10 most similar images frothe 10,000 uncompressed images and the 10,000 cpressed images, respectively, for 250 query imagesdomly selected from the same image database by theposed approaches applying different sets of inequali~two different weighting coefficient sets! are listed inTables 3 and 4. Here when the image database systeclustered into 10, 50, and 100 clusters~i.e., K510, 50,100!, the corresponding searching processes are perforin the closest 2, 5, and 10 clusters~i.e., M52, 5, 10!, re-spectively. The processing time~in seconds! of an iterationfor designing a codebook containing 256 codevectorsvector quantization~equal weighting coefficients! by theexisting approach~ES! and the proposed approaches apping different sets of inequalities is listed in Table 5, whethe dimension of a codevector~image block! is 16, and thetraining set consists of 16,384 codevectors. The sets oequalities selected for comparison in Table 5 are accordto the existing sets of inequalities developed25–29 for VQ.
01301ic Imaging
-st
s
---
s
is
d
r
-g
The average processing times~in seconds! for searching the10 most similar images from the 10,000 uncompressedages and the 10,000 DCT-compressed images, respectfor 250 query images randomly selected from the saimage database by the four existing approaches for cparison, namely, ES, CES, FSWC, and HT, and the pposed approach~Hybrid-I! ~two different weighting coeffi-cient sets! are listed in Tables 6 and 7 and illustratedFigs. 4 and 5. Here when the sizes of an image databas2000, 5000, and 10,000, the image database is clustinto 10, 20, and 50 clusters~i.e., K510, 20, 50!, respec-tively, and the corresponding searching processes areformed in the closest 2, 2, and 5 clusters~i.e., M52, 2, 5!,respectively.
The two different weighting coefficient sets are~1! iden-tical weighting coefficients for all the dimensions of a feture vector~denoted by weighting coefficient set 1!, in thiscase, the weighted square sum error distance is equivato the square sum error distance employed in VQ; and~2!1/25, 1/640, and 2/35 for each dimension of the textucolor, and shape features, respectively, for uncompresimages and a set of weighting coefficients,$3/28,2/28,2/28,2/28,1/28,1/28,1/28,1/28,1/28,3/28,2/28,2/28,2/28,11/28,1/28,1/28,1/28%, for compressed images~denoted byweighting coefficient set 2!. For the weighting coefficientset 2 of the feature vectors for uncompressed images,weighting coefficients for the texture and shape features
Table 5 The processing times (in seconds) of each iteration for designing a codebook containing 256(K5256) codevectors for VQ (equal weighting coefficients) by the existing approach (ES) and theproposed approaches applying different sets of inequalities.
ES
Proposed (Different Sets of Inequalities)
Eq. (43)Eqs. (43)and (44)
Eqs. (43)and (45) Hor Ver
Eq. (43)1 Hor1Ver
Time 4227.40 362.62 264.85 273.80 1614.92 1605.09 412.05
9-8 Jan–Mar 2005/Vol. 14(1)

Th145toal.feFoforionav
n-omd imre
m-
ow
evulaeo
stin
ble
ape i
q.ply
s 1pend
thesing--itiesata.
ality-dn-
less forim-f theES,d
n the
ex-t oftive
Fast indexing and searching strategies . . .
upgraded and that for the color features are degraded.color features consist of 128 dimensions among thedimensions, which may dominate the whole feature vecif the importances of all the 145 dimensions are identicWe select that the percentages for texture and shapetures are 40%, respectively, and 20% for color features.the weighting coefficient set 2 of the feature vectorsDCT-compressed images, the first and tenth dimenscorrespond to the dc information, which represent theerage energy~the most important features! of the image.Therefore, the weighting coefficients of these two dimesions are highlighted and the others are degraded. Squery results for several uncompressed and compresseages using two different weighting coefficient sets ashown in Figs. 6–11. The query results for an uncopressed image retrieved from only 1, 2, and 50~ES! (M51,2,5) closest clusters within the 50 (K550) clusters ofthe 10,000 uncompressed images are, respectively, shin Figs. 12–14.
5 Concluding Remarks
Based on the simulation results obtained in this study, seral observations can be found. First, based on the simtion results shown in Tables 1 and 2, the processing timfor clustering the stored images in the database systemthe proposed approaches are better than that of the exiapproach~ES! for comparison.
Second, based on the simulation results shown in Ta1 to 4, within both the indexing~clustering! and searchingphases, Eq.~44! and Hybrid-I @Eqs.~44! and ~45!# are thetwo most effective sets of inequalities for the proposedproaches applying different sets of inequalities. Becaus
Table 6 The average processing times (in seconds) for searchingthe 10 most similar images from the 10,000 uncompressed imagesby the four existing approaches ES, CES, FSWC, HT, and the pro-posed approach with K550 and M55 (weighting coefficient sets 1and 2 are denoted by Set 1 and Set 2, respectively).
ES CES FSWC HT Proposed
Percentage ofImprovementwith Respect
to HT
Set 1 0.5019 0.0635 0.2673 0.4192 0.0539 87.14%
Set 2 0.5074 0.0674 0.0474 0.4436 0.0496 88.82%
Table 7 The average processing times (in seconds) for searchingthe 10 most similar images from the 10,000 DCT-compressed im-ages by the four existing approaches ES, CES, FSWC, HT, and theproposed approach with K550 and M55 (weighting coefficient sets1 and 2 are denoted by Set 1 and Set 2, respectively).
ES CES FSWC HT Proposed
Percentage ofImprovementwith Respect
to HT
Set 1 0.0932 0.0106 0.0050 0.0060 0.0044 26.67%
Set 2 0.0998 0.0114 0.0062 0.0124 0.0048 61.29%
01301Journal of Electronic Imaging
e
r
a-r
s-
e-
n
--
sfg
s
-n
most cases, applying Hybrid-I is better than applying E~44!, it is recommended that the proposed approach apHybrid-I.
Third, based on the simulation results shown in Tableto 4, the performances of the proposed approaches deon the characteristics of feature-based image data. Foruncompressed image data, the proposed inequality uvariance@Eq. ~44!# is a good inequality to reject many unlikely feature vectors~images! so that a great deal of computation time can be saved, whereas the other inequalare not so good for such a type of feature-based image dFor the compressed image data, the proposed inequusing variance@Eq. ~44!# is a good inequality to reject unlikely feature vectors~images!, whereas the proposeHybrid-I is a better set of inequalities to reject many ulikely feature vectors~images!.
Fourth, based on the simulation results shown in Tab6 and 7 and Figs. 4 and 5, the average processing timesearching the 10 most similar images from the 10,000ages of the proposed approaches are better than that oexisting approaches for comparison, namely, ES, CFSWC, and HT. Although the HT is suitable for low- anmedium-dimensional vectors~e.g.,k518) and outperformsother tree-based approaches,7 the performance of the HT isdegraded, as compared to the proposed approach, whedimensionality of the feature vector is a large number~e.g.,k5145). The performance characteristics of the otheristing approaches, CES and FSWC, are similar to thathe HT. That is, the proposed approach is more insensi
Fig. 4 Average processing times (in seconds) for searching the 10most similar images from the 10,000 uncompressed images by thefour existing approaches, namely, ES, CES, FSWC, and HT, and theproposed approach (weighting coefficient set 1).
Fig. 5 Average processing times (in seconds) for searching the 10most similar images from the 10,000 DCT-compressed images bythe four existing approaches, namely, ES, CES, FSWC, and HT, andthe proposed approach (weighting coefficient set 1).
9-9 Jan–Mar 2005/Vol. 14(1)

Kang and Leou
Jou
Fig. 6 Query results for an uncompressed image using weighting coefficient set 1: (a) the query imageand the first retrieved image and (b) to (j) the retrieved images from ranks 2 to 10.
Fig. 7 Query results for an uncompressed image using weighting coefficient set 2: (a) the query imageand the first retrieved image and (b) to (j) the retrieved images from ranks 2 to 10.
Fig. 8 Query results for an uncompressed image using weighting coefficient set 1: (a) the query imageand the first retrieved image and (b) to (j) the retrieved images from ranks 2 to 10.
013019-10rnal of Electronic Imaging Jan–Mar 2005/Vol. 14(1)

heapte-tedn,rr t
be-ebece
s 1n-Dimor
hepeis-ltsdeap-ou. In
outg
hes-ges
hisd-ss
28heill
hendlar,
areeir
s 1ofs of
igs.
e-ance
val
rchterlus-ust
12esttheterge
50f the
Fast indexing and searching strategies . . .
to feature dimension variation than the existing approacfor comparison. The reason is that within the proposedproaches, a high-dimensional feature vector is projecinto the low-dimensional ‘‘working’’ vector space, including the weighted sum, the weighted variance, the weighvertical projection, and the weighted horizontal projectioetc., so that the dimensionality of the ‘‘working’’ vectospace is greatly reduced. Because the processing time ocomputational complexity of the distance calculationstween two feature vectors of the ‘‘working’’ vector spacwill be greatly reduced, the proposed approaches willmore efficient in high-dimensional feature vector spathan the existing approaches for comparison.
Fifth, based on the simulation results shown in Tableto 5, the weighting coefficients of feature vectors will ifluence the performances of the proposed approaches.ferent sets of inequalities are usually suitable for the safeature vectors using different weighting coefficients. Fexample, if all the weighting coefficients are identical, tweighted square sum error distance employed in this pawill be equivalently reduced to the square sum error dtance employed in VQ. Based on the simulation resushown in Table 5, the processing time for designing a cobook for vector quantization by using the proposedproaches using equal weighting coefficients is only ab6% of the processing time required by the ES approachVQ, a feature vector~codevector! is formed by the pixelswithin an image block, which are highly concentrated abthe feature~pixel! mean. That is, two image blocks havin
Fig. 9 Query results for an uncompressed image using weightingcoefficient set 1: (a) the query image and the first retrieved imageand (b) to (j) the retrieved images from ranks 2 to 10.
013019Journal of Electronic Imaging
s-d
he
f-e
r
-
t
similar pixel means may be very similar. Therefore, tinequalities developed for VQ are very effective for clutering codevectors. However, because the dynamic ranof different feature components are greatly different in tpaper, if the weighting coefficients are not properly ajusted, the proposed inequalities in this paper will be leeffective than that for VQ. For example, the sum of the 1color features is equal to the size of an image. If all tweighting coefficients are identical, the weighted sums wbe the same for all equal-sized images. Additionally, if tdimensionality of the color features is relatively high athe weighted sums of all feature vectors are very simithe proposed inequalities using the weighted sums@Eqs.~43!, ~50!, ~51!, and~53!# will not be effective. Therefore,all the stored images in an image database systemsorted according to their variances, instead of thweighted sums.
Sixth, based on the simulation results shown in Tableto 4, if the numberK of clusters is increased, some setsinequalities become more effective, whereas some setinequalities become less effective.
Seventh, based on the simulation results shown in F6 to 11, the retrieved images~ranks 1 to 10! may be differ-ent for different weighting coefficient sets. That is so bcause the values of the weighted square sum error distare different for different weighting coefficient sets.
Eighth, Jain and Vailaya addressed an image retriemethod for large image databases.6 They used CLUSTER,a squared-error clustering algorithm, to reduce the seaspace. The query image is compared only with the cluscenters to determine its cluster membership. Once the cter membership of the query image is established, it mbe matched only with images in that cluster~the closestcluster!. Based on the simulation results shown in Figs.to 14, the query results retrieved from only one closcluster may not be the same as that of the ES. That is,retrieved results may be incorrect if only one closest clusis considered. In this study, for example, the query imawill be compared with the five closest clusters within theclusters, and the query results are the same as that oexhaustive search approach.
Fig. 10 Query results for a DCT-compressed image using weighting coefficient set 1: (a) the queryimage and the first retrieved image and (b) to (j) the retrieved images from ranks 2 to 10.
-11 Jan–Mar 2005/Vol. 14(1)

Kang and Leou
Jou
Fig. 11 Query results for a DCT-compressed image using weighting coefficient set 2: (a) the queryimage and the first retrieved image and (b) to (j) the retrieved images from ranks 2 to 10.
Fig. 12 Query results for an uncompressed image retrieved from only one closest cluster within the 50clusters of the 10,000 uncompressed images: (a) the query image and the first retrieved image and (b)to (j) the retrieved images from ranks 2 to 10.
Fig. 13 Query results for an uncompressed image retrieved from two closest clusters within the 50clusters of the 10,000 uncompressed images: (a) the query image and the first retrieved image and (b)to (j) the retrieved images from ranks 2 to 10.
013019-12rnal of Electronic Imaging Jan–Mar 2005/Vol. 14(1)

Fast indexing and searching strategies . . .
Jou
Fig. 14 Query results for an uncompressed image retrieved by the exhaustive search from the 10,000uncompressed images: (a) the query image and the first retrieved image and (b) to (j) the retrievedimages from ranks 2 to 10.
r-
us
ines,p-re
’t-p-
pe
foosdis
datdthsesuar, thwitdfeatw
sedd tffi-ltssuntsoo
op-ultsly
ageulti-the
errorbook
un-4-
ing
ing
,’’
ure
x
igh-
igh-
ata
te
e:
Finally, referring to Eq.~8!, different query~searching!approaches may return slightly different results with diffeent processing times. A ‘‘good’’ query~searching! approachwill return the same result as that returned by the exhative search approach. Based on the ‘‘goodness’’~precision!criterion, the query~searching! approach proposed by Jaand Vailaya6 is one of the fast searching approachwhereas their query approach is not a ‘‘good’’ query aproach~Figs. 12 to 14!. Based on the performance measu~the processing time! and the ‘‘goodness’’~precision! crite-rion, the proposed query~searching! approaches are ‘‘fast’and ‘‘good’’ query ~searching! approaches. The four exising approaches for comparison are all ‘‘good’’ query aproaches based on the ‘‘goodness’’~precision! criterion, butthe proposed approaches outperform~are faster than! thefour existing approaches for comparison, based on theformance measure~the processing time!.
In this paper, fast indexing and searching strategiesimage database systems were proposed. A set of propinequalities based on the weighted square sum errortance is used to speed up both the image indexing~cluster-ing! and searching processes for feature-based imagebase systems. Based on the simulation results obtainethis paper, in terms of performance measure, namely,processing time for indexing and searching in feature-baimage database systems, the proposed approaches arerior to several existing approaches for comparison. In pticular, based on the test image databases in this studypercentage of improvement of the proposed approachrespect to the HT approach7 can achieve about 87.14 an88.82 and 26.67 and 61.29% for 145-D uncompressedture vectors and 18-D compressed feature vectors usingweighting coefficients sets, respectively.
Due to the fast that the performance of the propoapproach depends on the employed image features anselected weighting coefficients, different weighting coecients will lead to different clustering and searching resuBecause the selection of the weighting coefficients is ually application-dependent, only some sets of coefficiewere tested here. If the image features extracted are g
013019rnal of Electronic Imaging
-
r-
red-
a-inedpe--e
h
-o
he
.-
d
enough and the weighting coefficients are adjusted prerly, the proposed approaches will find the expected resefficiently. In addition, the proposed approach is not oneffective for indexing and searching in feature-based imdatabase systems, but is also suitable for any other mdimensional data indexing and searching based onweighted square sum error distance or the square sumdistance, such as closest code word search and codedesign in VQ.
Acknowledgments
This work was supported in part by National Science Cocil, Republic of China under Grants NSC 89-2213-E-19026 and NSC 90-2213-E-194-039.
References1. F. Idris and S. Panchanathan, ‘‘Review of image and video index
techniques,’’ J. Visual Commun. Image Represent8~2!, 146–166~1997!.
2. R. Baeza-Yates and B. Ribeiro-Neto,Modern Information Retrieval,Addison Wesley, Essex, England~1999!.
3. M. Flickner et al., ‘‘Query by image and video content: the QBICsystem,’’IEEE Comput. Graphics Appl.28~9!, 23–32~1995!.
4. C. Faloutsos, ‘‘Access methods for text,’’ACM Comput. Surv.1~1!,49–74~1985!.
5. W. B. Croft and P. Savino, ‘‘Implementing ranking strategies ustext signatures,’’ACM Trans. Office Inf. Syst.6~1!, 42–62~1988!.
6. A. K. Jain and A. Vailaya, ‘‘Image retrieval using color and shapePattern Recogn.29~8!, 1233–1244~1996!.
7. K. Chakrabarti and S. Mehrotra, ‘‘The hybrid tree: an index structfor high dimensional feature spaces,’’ inProc. 15th IEEE Int. Conf. onData Engineering, pp. 440–447~1999!.
8. S. Berchtold, D. Keim, and H. P. Kriegel, ‘‘The X-tree: an indestructure for high-dimensional data,’’ inProc. 22nd Conf. on VeryLarge Databases, pp. 28–39, Bombay, India~1996!.
9. N. Katayama and S. Satoh, ‘‘The SR-tree: an index structure for hdimensional nearest neighbor queries,’’ inProc. ACM SIGMOD Int.Conf. on Management of Data, pp. 369–380~1997!.
10. C. M. Eastman and M. Zemankova, ‘‘Partially specified nearest nebor searches using kd-trees,’’Inf. Process. Lett.15~2!, 53–56~1982!.
11. R. Mehrotra and J. E. Gary, ‘‘Similar-shape retrieval in shape dmanagement,’’IEEE Comput. Graphics Appl.28~9!, 57–62~1995!.
12. D. B. Lomet and B. Salzberg, ‘‘The hB-tree: a robust multi-attribuindexing method,’’ ACM Trans. Database. Sys.15~4!, 625–658~1990!.
13. S. Berchtold, C. Bohm, and H. P. Kriegel, ‘‘The pyramid-techniqutowards breaking the curse of dimensionality,’’ inProc. of ACM SIG-MOD’98, pp. 142–153, Seattle, WA~1998!.
-13 Jan–Mar 2005/Vol. 14(1)

dva
val
m-
ith
nd.
m
y-
s-.
ons
rch
thm.
hm
el
m
inget-
lor
es
for
Kang and Leou
14. B. G. Kim, J. H. Lee, S. H. Noh, and H. C. Lim, ‘‘A filtering methofor k-nearest neighbor query processing in multimedia data retrieapplications,’’ in Proc. IEEE Region 10 Conf. on TENCON’99, pp.337–340~1999!.
15. J. K. Wu, ‘‘Content-based indexing of multimedia databases,’’IEEETrans. Knowl. Data Eng.9~6!, 978–989~1997!.
16. Y. Gong, C. H. Chuan, and G. Xiaoyi, ‘‘Image indexing and retriebased on color histograms,’’Multimed. Tools Appl.2, 133–156~1996!.
17. M. Vazirgiannis, Y. Theodoridis, and T. Sellis, ‘‘Spatio-temporal coposition and indexing for large multimedia applications,’’MultimediaSyst.6, 284–298~1998!.
18. A. K. Jain and A. Vailaya, ‘‘Shape-based retrieval: a case study wtrademark image databases,’’Pattern Recogn.31~9!, 1369–1390~1998!.
19. M. J. Swain and D. H. Ballard, ‘‘Color indexing,’’Int. J. Comput. Vis.7~1!, 11–32~1991!.
20. B. S. Manjunath and W. Y. Ma, ‘‘Texture features for browsing aretrieval of image data,’’IEEE Trans. Pattern Anal. Mach. Intell18~8!, 837–842~1996!.
21. G. L. Gimel’Farb and A. K. Jain, ‘‘On retrieving textured images froan image database,’’Pattern Recogn.29~9!, 1461–1483~1996!.
22. B. Gunsel and A. M. Tekalp, ‘‘Shape similarity matching for querby-example,’’Pattern Recogn.31~7!, 931–944~1998!.
23. M. Shneier and M. Abdel-Mottaleb, ‘‘Exploiting the JPEG compresion scheme for image retrieval,’’IEEE Trans. Pattern Anal. MachIntell. 18~8!, 849–853~1996!.
24. H. J. Bae and S. H. Jung, ‘‘Image retrieval using texture basedDCT,’’ in Proc. 1st IEEE Int. Conf. on Information Communicationand Signal Processing, Vol. 2, pp. 1065–1068~1997!.
25. C. H. Lee and L. H. Chen, ‘‘High-speed closest codeword seaalgorithms for vector quantization,’’Signal Process.43, 323–331~1995!.
26. C. H. Lee and L. H. Chen, ‘‘Fast closest codeword search algorifor vector quantisation,’’IEE Proc. Vision Image Signal Process141~3!, 143–148~1994!.
27. S. J. Baek, B. K. Jeon, and K. M. Sung, ‘‘A fast encoding algoritfor vector quantization,’’IEEE Signal Process. Lett.4~12!, 325–327~1997!.
28. Y. C. Lin and S. C. Tai, ‘‘A fast Linde-Buzo-Gray algorithm in imagvector quantization,’’IEEE Trans. Circuits Syst., II: Analog DigitaSignal Process.45~3!, 432–435~1998!.
29. C. C. Chang and Y. C. Hu, ‘‘A fast LBG codebook training algorithfor vector quantization,’’ IEEE Trans. Consum. Electron.44~4!,1201–1208~1998!.
30. J. S. Pan and K. C. Huang, ‘‘A new vector quantization image codalgorithm based on the extension of the bound for Minkowski mric,’’ Pattern Recogn.31~11!, 1757–1760~1998!.
013019Journal of Electronic Imaging
l31. G. Pass, R. Zabih, and J. Miller, ‘‘Comparing images using co
coherence vectors,’’ inProc. 4th ACM Multimedia, pp. 65–78~1996!.32. R. M. Haralick, K. Shanmugam, and I. Dinstein, ‘‘Textural featur
for image classification,’’IEEE Trans. Syst. Man Cybern.3~6!, 610–621 ~1973!.
33. M. Nadler and E. P. Smith,Pattern Recognition Engineering, Wiley,New York ~1993!.
34. M. K. Hu, ‘‘Visual pattern recognition by moment invariants,’’IRETrans. Inf. Theory8, 179–187~1962!.
35. B. M. Mehtre, M. S. Kankanhalli, and W. F. Lee, ‘‘Shape measurescontent based image retrieval: a comparison,’’Inf. Process. Manage.33~3!, 319–337~1997!.
Li-Wei Kang received his BS and MS de-grees in computer science and informationengineering in 1997 and 1999, respec-tively, both from National Chung ChengUniversity, Chiayi, Taiwan, where sinceSeptember 1999, he has been working to-ward his PhD degree in computer scienceand information engineering. His currentresearch interests include image/video pro-cessing, image/video communication, andpattern recognition.
Jin-Jang Leou received his BS degree incommunication engineering in 1979, hisMS degree in communication engineeringin 1981, and his PhD degree in electronicsin 1989, all from National Chiao Tung Uni-versity, Hsinchu, Taiwan. From 1981 to1983, he was a communication officer withthe Chinese Army. From 1983 to 1984, hewas a lecturer with the National ChiaoTung University. Since August 1989, hehas been on the faculty of the Department
of Computer Science and Information Engineering at NationalChung Cheng University, Chiayi, Taiwan. His current research inter-ests include image/video processing, image/video communication,pattern recognition, and computer vision.
-14 Jan–Mar 2005/Vol. 14(1)
Related Documents











