Fast and Simplified Streaming, Ad-Hoc and Batch Analytics with FiloDB and Spark Streaming and Evan Chan Helena Edelson March 2016

Fast and Simplified Streaming, Ad-Hoc and Batch Analytics with FiloDB and Spark Streaming
Apr 16, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Fast and Simplified Streaming,Ad-Hoc and Batch Analytics with
FiloDB and Spark Streaming and Evan Chan Helena Edelson
March 2016

Evan Chan
Distinguished Engineer,
User and contributor to Spark since 0.9, Cassandra since0.6Co-creator and maintainer of
Tuplejump@evanfchanhttp://velvia.github.io
Spark Job Server

Helena EdelsonVP of Product Engineering, Committer: Kafka Connect Cassandra, Spark CassandraConnectorContributor to Akka (2 new features in Akka Cluster), SpringIntegrationSpeaker @ Spark Summit, Kafka Summit, Strata, QCon, ScalaDays, Scala World, Philly ETE
Tuplejump
@helenaedelsonhttp://github.com/helena

Tuplejump is a big data technology leader providing solutions and
development partnership.Tuplejump

Open Source: on GitHubTuplejump - Subject of today's talk
- Kafka-Cassandra Source andSink
- The �rst Spark Cassandra integration - Lucene indexer for Cassandra - HDFS for Cassandra
FiloDBKafka Connect Cassandra
CalliopeStargateSnackFS

Tuplejump Consulting & Development

Tuplejump BlenderBuilds uni�ed datasets for fast querying, streaming and batch sources, ML and Analytics

TopicsModern streaming architectures and batch/ad-hocarchitecturesPrecise and scalable streaming ingestion using Kafka, Akka,Spark Streaming, Cassandra, and FiloDBHow a uni�ed streaming + batch stack can lower your TCOWhat FiloDB is and how it enables fast analytics withcompetitive storage costData Warehousing with Spark, Cassandra, and FiloDBTime series / event data / geospatial examplesMachine learning using Spark MLLib + Cassandra/FiloDB

The Problem DomainBuild scalable, adaptable, self-healing, distributed dataprocessing systems for
Massive amounts of dataDisparate sources and schemasDiffering data structuresComplex analytics and learning tasksTo run as large-scale clustereddata�ows24-7 UptimeGlobally clustered deploymentsNo data loss

Delivering MeaningDeliver meaning in sec/sub-sec latencyBillions of events per secondLow latency real time stream processingHigher latency batch processingAggregation of global data from thestream

While We Monitor, Predict & ProactivelyHandle
Massive event spikes & bursty traf�cFast producers / slow consumersNetwork partitioning & out of syncsystemsDC downNot DDOS'ing ourselves from fast streamsNo data loss when auto-scaling down
And stay within ourAWS
OpenStackRackspace...
budget

Use CaseI need fast access to historical data on the �y for predictive
modeling with real time data from the stream

Only, It's Not A Stream It's A FloodNet�ix
100 billion events per day1-2 million events per second atpeak
500 billion write events per day2.5 trillion read events per day4.5 million events per second at peak withKafkaPetabytes of streaming data
Con�dential
700 TB global ingested data (pre-�ltered)

Lambda ArchitectureA data-processing architecture designed to handle massive quantitiesof data by taking advantage of both batch and stream processingmethods.
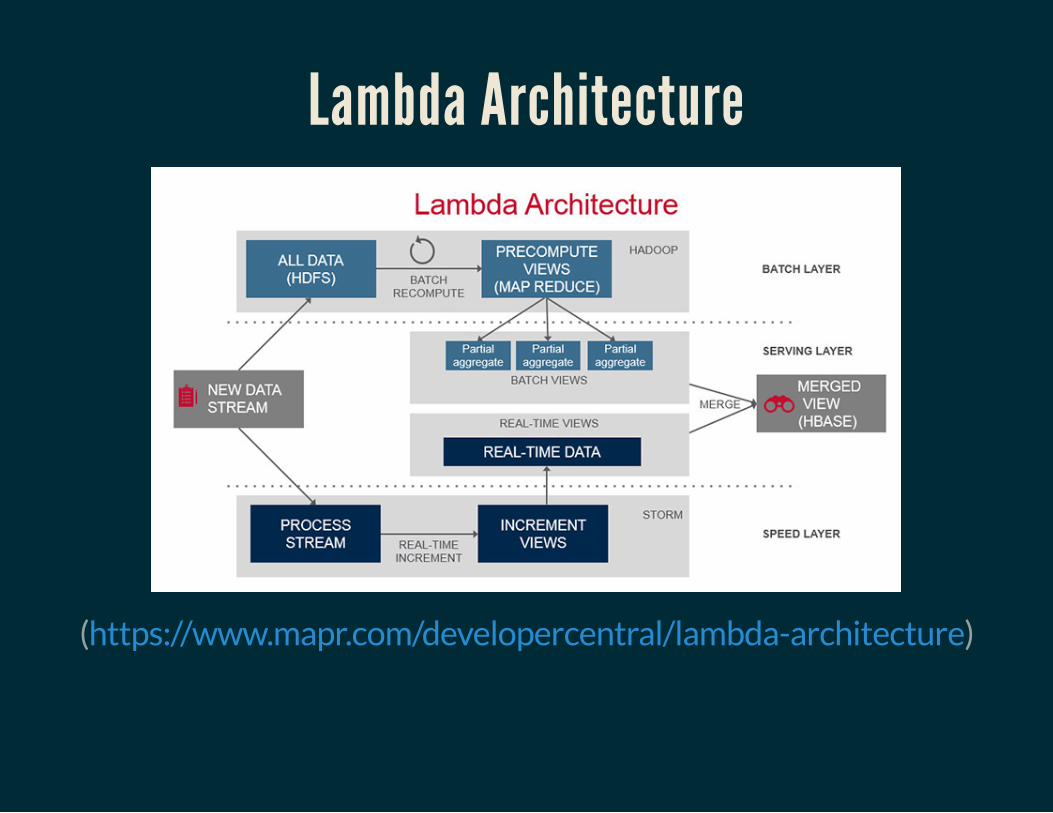
Lambda Architecture
( )https://www.mapr.com/developercentral/lambda-architecture

Challenge Assumptions"Ingest an immutable sequence of records is captured and fed into
a batch processing systemand a stream processing system
in parallel"

Lambda ArchitectureDual Analytics Systems
Many moving parts: KV store, real time, Batch technologiesRunning similar code and reconciling queries in dualsystems
Overly Complicated
PipelinesOps: e.g. performance tuning & monitoring, upgrades...Analytics logic changes: dev/testing/deploys of changes tocode bases, clusters

Ultimately High TCOAnd...
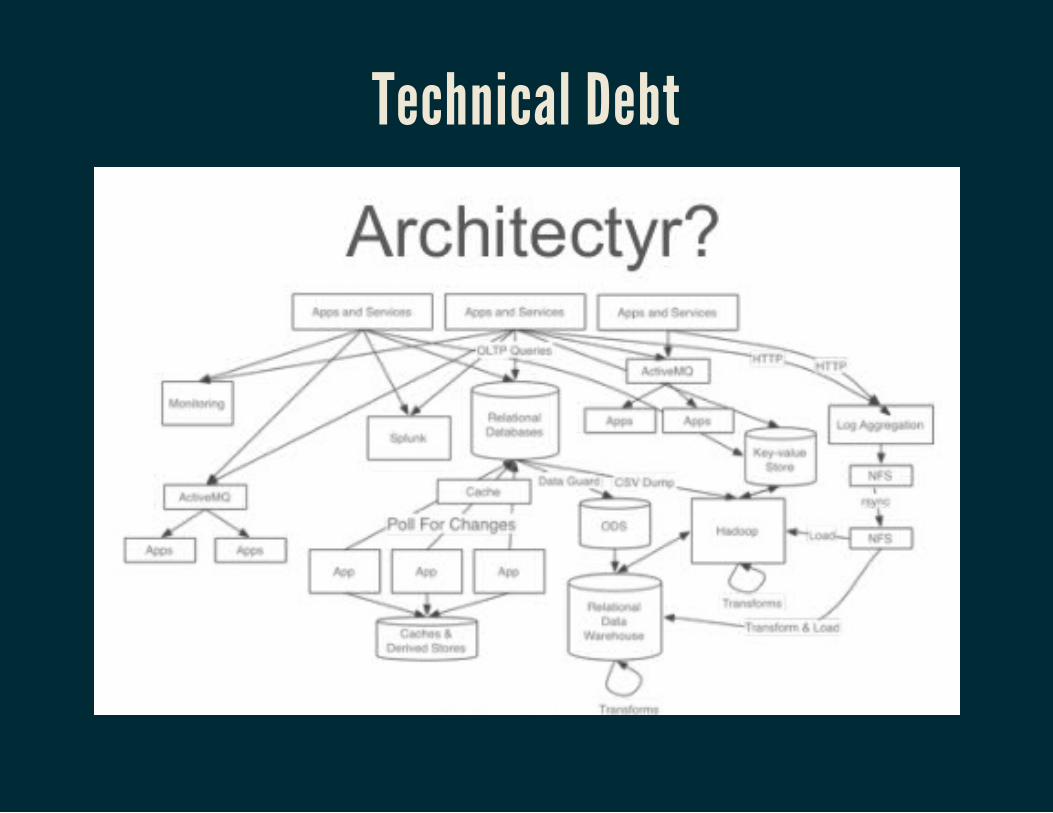
Technical Debt

Are Batch and Streaming SystemsFundamentally Different?
No.

A Unified Streaming ArchitectureEverything On The Streaming Platform
Scala / SparkStreamingMesosAkkaCassandraKafka
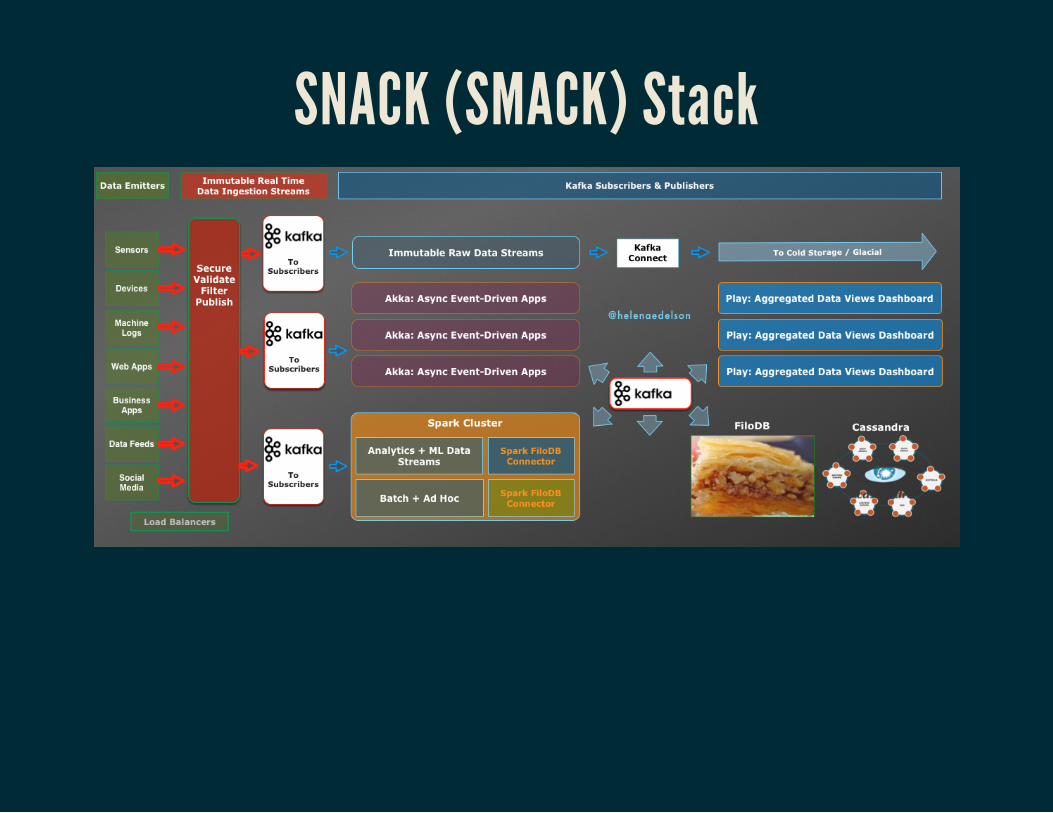
SNACK (SMACK) Stack
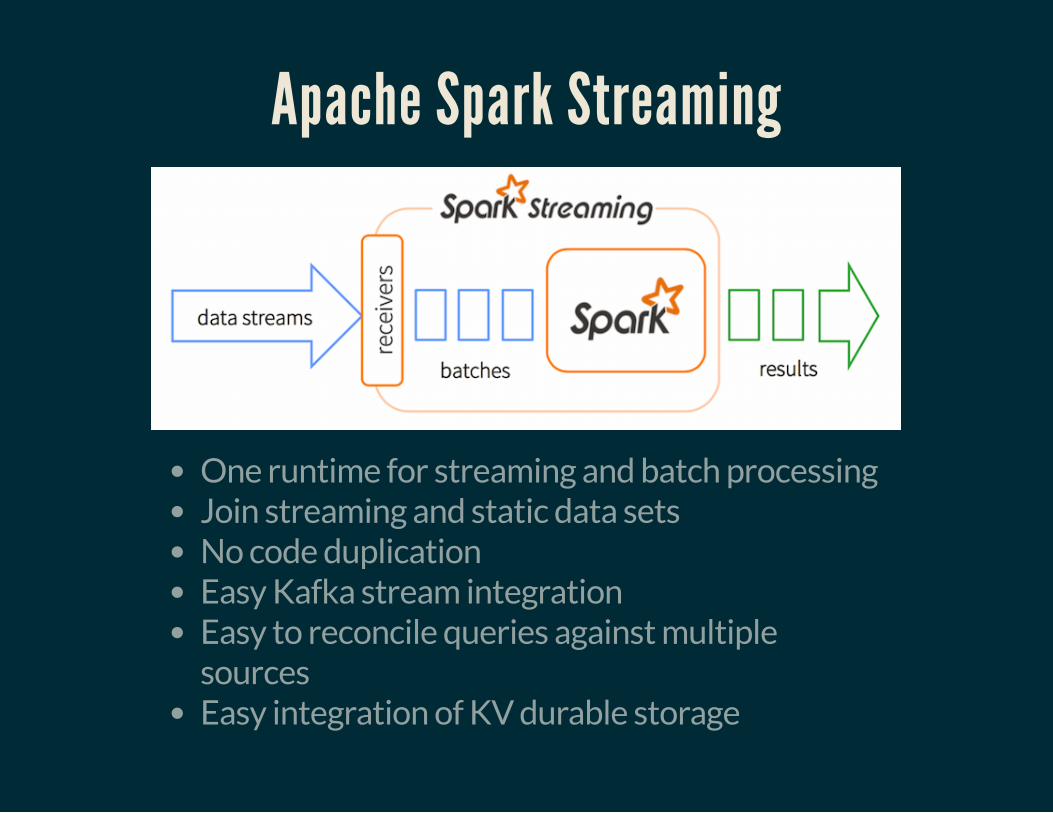
Apache Spark Streaming
One runtime for streaming and batch processingJoin streaming and static data setsNo code duplicationEasy Kafka stream integrationEasy to reconcile queries against multiplesourcesEasy integration of KV durable storage

High Throughput Distributed MessagingDecouples Data PipelinesHandles Massive Data LoadSupport Massive Number of ConsumersDistribution & partitioning across clusternodesAutomatic recovery from broker failures

Apache Cassandra
Horizontally scalableMulti-Region / Multi-DatacenterAlways On - Survive regional outagesExtremely fast writes: - perfect for ingestion of real time /machine dataVery �exible data modelling (lists, sets, custom data types)Easy to operateBest of breed storage technology, huge communityBUT: Simple queries onlyOLTP-oriented/center

High performance concurrency framework for Scala andJavaFault ToleranceAsynchronous messaging and data processingParallelizationLocation TransparencyLocal / Remote RoutingAkka: Cluster / Persistence / Streams

EnablesStreaming and Batch In One System
Streaming ML and Analytics for Predictions In The Stream
Show me the code

Immutable Raw Data From Kafka StreamReplay / reprocessing: for fault tolerance, logic changes..class KafkaStreamingActor(ssc: StreamingContext, settings: Settings) extends AggregationActor val stream = KafkaUtils.createDirectStream(...).map(RawWeatherData(_)) stream .foreachRDD(_.toDF.write.format("filodb.spark")) .option(rawDataKeyspace, rawDataTable) /* Pre-Aggregate data in the stream for fast querying and aggregation later. */ stream.map(hour => (hour.wsid, hour.year, hour.month, hour.day, hour.oneHourPrecip) ).saveToCassandra(CassandraKeyspace, CassandraTableDailyPrecip) }

Reading Data Back From CassandraCompute isolation in Akka Actor
class TemperatureActor(sc: SparkContext, settings: Settings) extends AggregationActor import settings._ import akka.pattern.pipe def receive: Actor.Receive = { case e: GetMonthlyHiLowTemperature => highLow(e, sender) } def highLow(e: GetMonthlyHiLowTemperature, requester: ActorRef): Unit = sc.cassandraTable[DailyTemperature](timeseriesKeyspace, dailyTempAggregTable) .where("wsid = ? AND year = ? AND month = ?", e.wsid, e.year, e.month) .collectAsync() .map(MonthlyTemperature(_, e.wsid, e.year, e.month)) pipeTo requester }

Spark Streaming, MLLibKafka, Cassandra
val ssc = new StreamingContext(sparkConf, Seconds(5) val testData = ssc.cassandraTable[String](keyspace,table) .map(LabeledPoint.parse) val trainingStream = KafkaUtils.createDirectStream[_,_,_,_](..) .map(transformFunc) .map(LabeledPoint.parse) trainingStream.saveToCassandra("ml_training_keyspace", "raw_training_data") val model = new StreamingLinearRegressionWithSGD() .setInitialWeights(Vectors.dense(weights)) .trainOn(trainingStream) model .predictOnValues(testData.map(lp => (lp.label, lp.features))) .saveToCassandra("ml_predictions_keyspace", "predictions")

Tuplejump OSS Roadmap gearpump-external-
�lodbKafka Connect FiloDB
Gearpump

What's Missing? One Pipeline For Fast +Big Data

Using Cassandra for Batch Analytics /Event Storage / ML?
Storage ef�ciency and scan speeds for reading large volumesof data (for complex analytics, ML) become importantconcernsRegular Cassandra CQL tables are not very good at eitherstorage ef�ciency or scan speedsA different, analytics-optimized solution is needed...

All hard work leads to pro�t, but mere talk leadsto poverty.- Proverbs 14:23

Introducing FiloDBA distributed, versioned, columnar analytics database.
Built for Streaming.
github.com/tuplejump/FiloDB

Fast Analytics StorageScan speeds competitive with Apache Parquet
Up to 200x faster scan speeds than with Cassandra 2.xFlexible �ltering along two dimensions
Much more ef�cient and �exible partition key �lteringEf�cient columnar storage, up to 27x more ef�cient thanCassandra 2.x

Comparing Storage Costs and Query Speeds
https://www.oreilly.com/ideas/apache-cassandra-for-analytics-a-performance-and-storage-analysis

Robust Distributed StorageApache Cassandra as the rock-solid storage engine. Scale outwith no SPOF. Cross-datacenter replication. Proven storage anddatabase technology.

Cassandra-Like Data ModelColumn A Column B
Partitionkey 1
Segment1
Segment2
Segment1
Segment2
Partitionkey 2
Segment1
Segment2
Segment1
Segment2
partition keys - distributes data around a cluster, and allowsfor �ne grained and �exible �lteringsegment keys - do range scans within a partition, e.g. by timesliceprimary key based ingestion and updates

Flexible FilteringUnlike Cassandra, FiloDB offers very �exible and ef�cient�ltering on partition keys. Partial key matches, fast IN queries onany part of the partition key.
No need to write multiple tables to work around answering differentqueries.

Spark SQL Queries!CREATE TABLE gdelt USING filodb.spark OPTIONS (dataset "gdelt"); SELECT Actor1Name, Actor2Name, AvgTone FROM gdelt ORDER BY AvgTone DESC LIMIT 15 INSERT INTO gdelt SELECT * FROM NewMonthData;
Read to and write from Spark DataframesAppend/merge to FiloDB table from SparkStreamingUse Tableau or any other JDBC tool

What's in the name?
Rich sweet layers of distributed, versioned database goodness

SNACK (SMACK) stack for all yourAnalytics
Regular Cassandra tables for highly concurrent, aggregate /key-value lookups (dashboards)FiloDB + C* + Spark for ef�cient long term event storage
Ad hoc / SQL / BIData source for MLLib / building modelsData storage for classi�ed / predicted / scored data
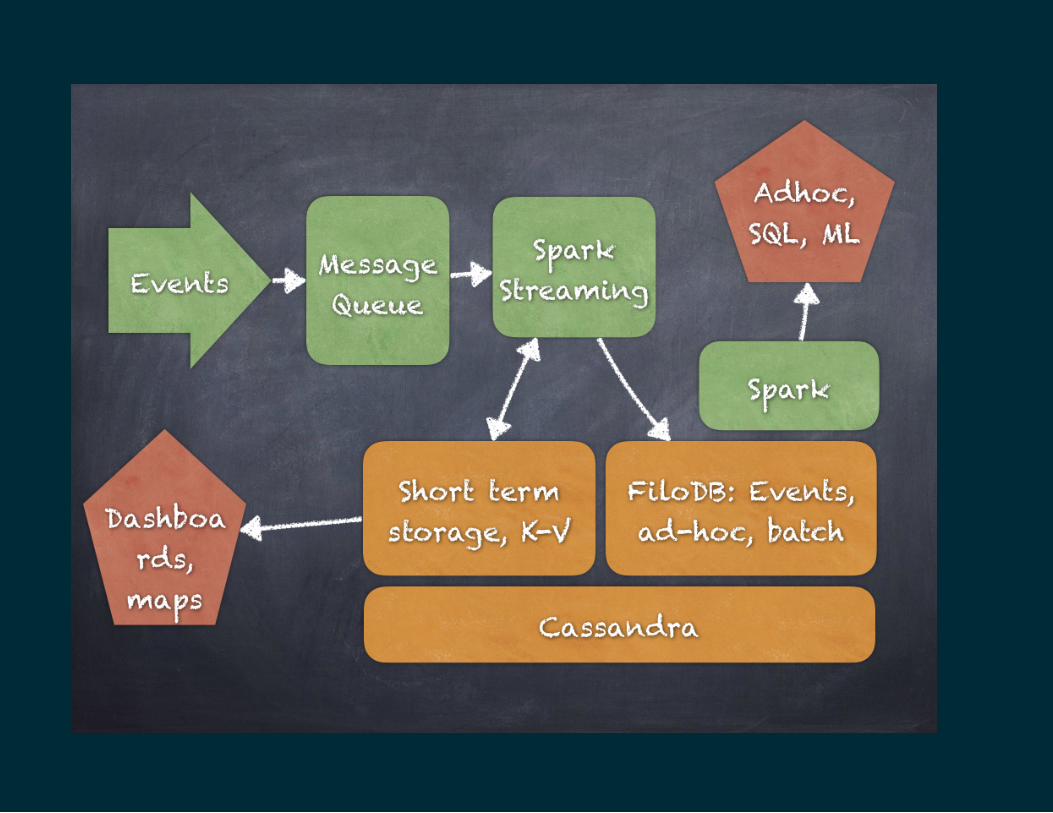

Being Productionized as we speak...One enterprise with many TB of �nancial and reporting data ismoving their data warehouse to FiloDB + Cassandra + SparkAnother startup uses FiloDB as event storage, feeds the eventsinto Spark MLlib, scores incoming data, then stores the resultsback in FiloDB for low-latency use cases
From their CTO: “I see close to MemSQL / Vertica or evenbetter” “More cost effective than Redshift”

Data Warehousing with FiloDB

ScenariosBI Reporting, concurrency + seconds latencyAd-hoc queriesNeeding to do JOINs with fact tables + dimensiontables
Slowly changing dim tables / hard to denormalizeNeed to work with legacy BI tools
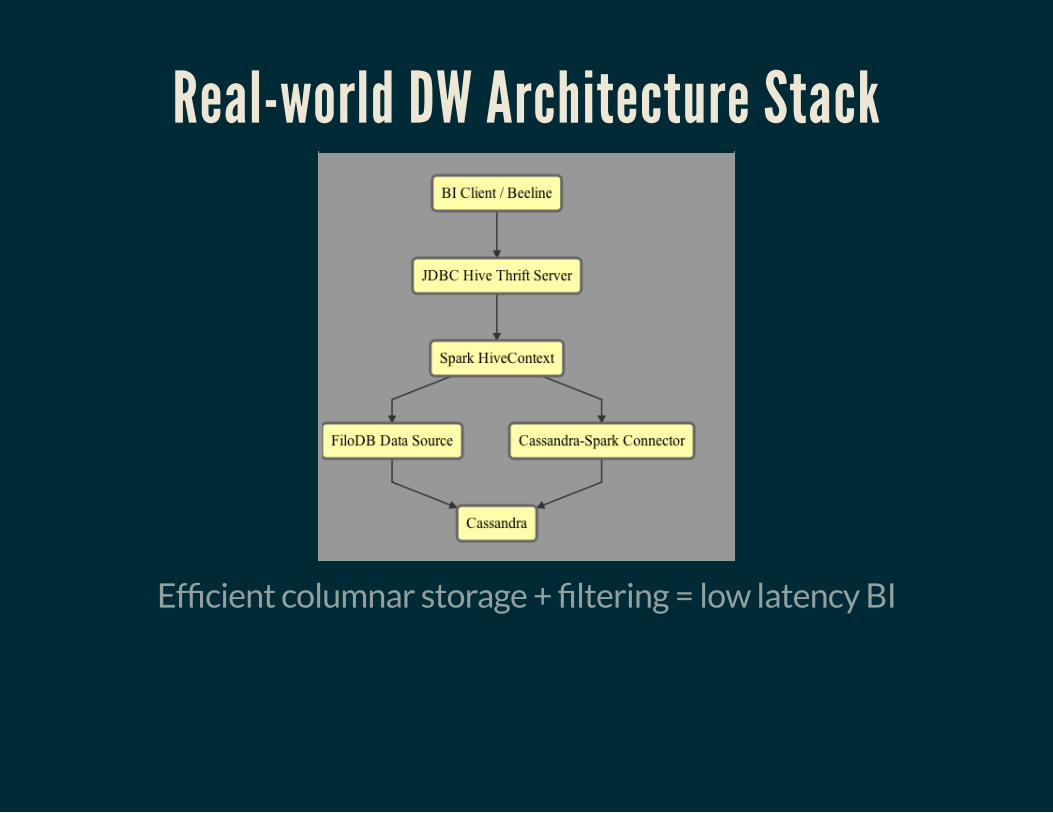
Real-world DW Architecture Stack
Ef�cient columnar storage + �ltering = low latency BI

Modeling Fact Tables for FiloDBSingle partition queries are really fast and take up only onethread
Given the following two partition key columns:entity_number, year_monthWHERE entity_number = '0453' ANDyear_month = '2014 December'
Exact match for partition key is pushed down as onepartition
Consider the partition key carefully

Cassandra often requires multiple tablesWhat about the queries that do not translate to one partition?Cassandra has many restrictions on partition key �ltering (as of2.x).
Table 1: partition key = (entity_number, year_month)Can push down: WHERE entity_number = NN ANDyear_month IN ('2014 Jan', '2014 Feb') aswell as equals
Table 2: partition key = (year_month, entity_number)Can push down: WHERE year_month = YYMM ANDentity_number IN (123, 456) as well as equals
IN clause must be the last column to be pushed down. Two tablesare needed just for ef�cient IN queries on either entity_numberor year_month.

FiloDB Flexible Partition Filters = WINWith ONE table, FiloDB offers FAST, arbitrary partition key�ltering. All of the below are pushed down:
WHERE year_month IN ('2014 Jan', '2014 Feb')(all entities)WHERE entity_number = 146 (all year months)Any combo of =, IN
Space savings: 27 * 2 = 54x

Multi-Table JOINs with just Cassandra

Sub-second Multi-Table JOINs with FiloDB

Sub-second Multi-Table JOINs with FiloDBFour tables, all of them single-partition queriesTwo tables were switched from regular Cassandra tables toFiloDB tables. 40-60 columns each, ~60k items in partition.Scan times went down from 5-6 seconds to < 250ms
For more details, please see this .Planet Cassandra blog post

Scalable Time-Series / Event Storage withFiloDB

Designed for StreamingNew rows appended via Spark Streaming or KafkaWrites are idempotent - easy exactly once ingestionConverted to columnar chunks on ingest and stored inC*FiloDB keeps your data sorted as it is being ingested
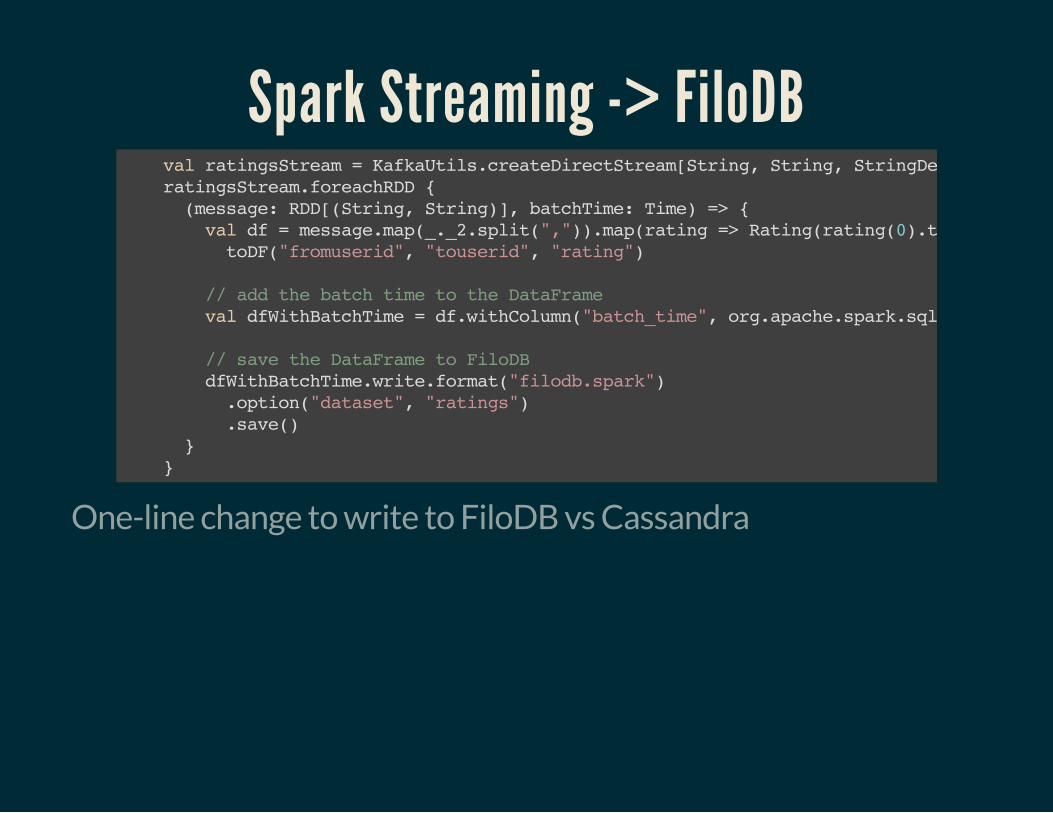
Spark Streaming -> FiloDB val ratingsStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) ratingsStream.foreachRDD { (message: RDD[(String, String)], batchTime: Time) => { val df = message.map(_._2.split(",")).map(rating => Rating(rating(0).trim.toInt, rating( toDF("fromuserid", "touserid", "rating") // add the batch time to the DataFrame val dfWithBatchTime = df.withColumn("batch_time", org.apache.spark.sql.functions.lit(batchTime.milliseconds)) // save the DataFrame to FiloDB dfWithBatchTime.write.format("filodb.spark") .option("dataset", "ratings") .save() } }
One-line change to write to FiloDB vs Cassandra

Modeling example: NYC Taxi DatasetThe public contains telemetry (pickup, dropofflocations, times) info on millions of taxi rides in NYC.
NYC Taxi Dataset
Medallion pre�x 1/1 - 1/6 1/7 - 1/12AA records records
AB records recordsPartition key - :stringPrefix medallion 2 - hashmultiple drivers trips into ~300 partitionsSegment key - :timeslice pickup_datetime 6dRow key - hack_license, pickup_datetime
Allows for easy �ltering by individual drivers, and slicing by time.

DEMO TIMENew York City Taxi Data Demo (Spark Notebook)
To follow along:https://github.com/tuplejump/FiloDB/blob/master/doc/FiloDB_Taxi_Geo_demo.snb

Fast, Updatable In-MemoryColumnar Storage
Unlike RDDs and DataFrames, FiloDB can ingest new data, andstill be fastUnlike RDDs, FiloDB can �lter in multiple ways, no need forentire table scanFAIR scheduler + sub-second latencies => web speed queries

700 Queries Per Second in Apache Spark!Even for datasets with 15 million rows!Using FiloDB's InMemoryColumnStore, single host / MBP,5GB RAMSQL to DataFrame caching
For more details, see .this blog post

Machine Learning with Spark, Cassandra,and FiloDB

Building a static model of NYC Taxi TripsPredict time to get to destination based on pickup point, timeof day, other varsNeed to read all data (full table scan)

Dynamic models are better than staticmodels
Everything changes!Continuously re�ne model based on recent streaming data +historical data + existing model
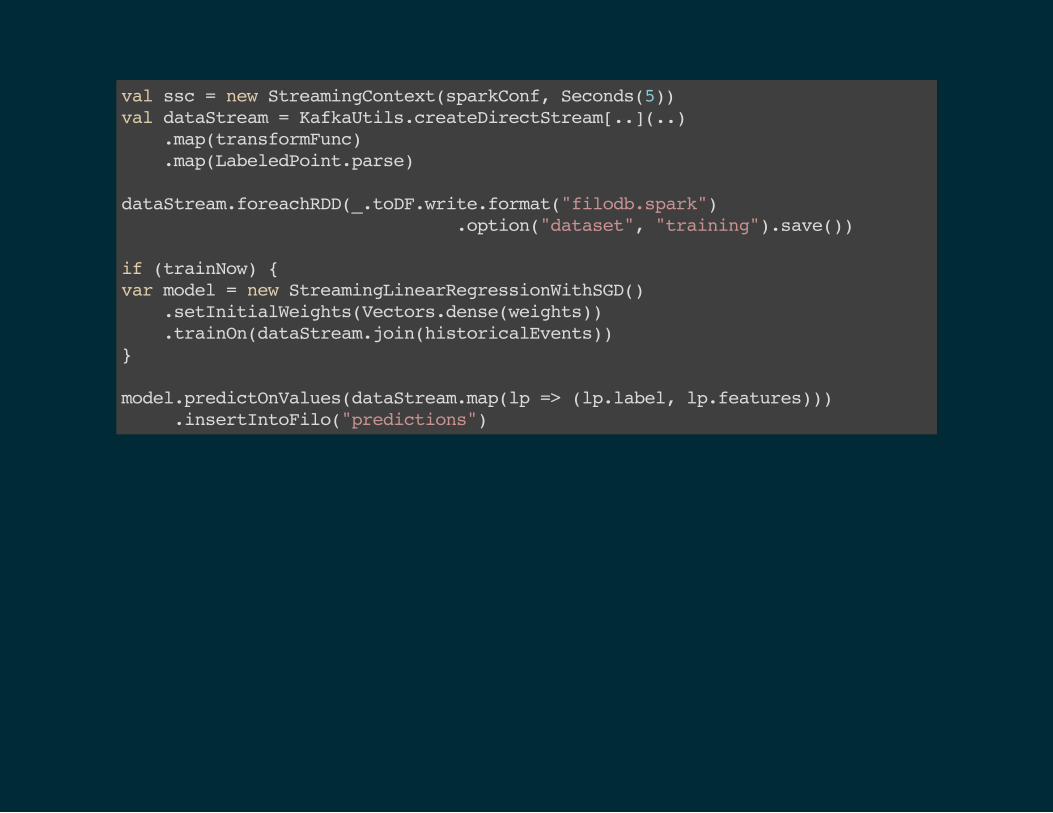
val ssc = new StreamingContext(sparkConf, Seconds(5)) val dataStream = KafkaUtils.createDirectStream[..](..) .map(transformFunc) .map(LabeledPoint.parse) dataStream.foreachRDD(_.toDF.write.format("filodb.spark") .option("dataset", "training").save()) if (trainNow) { var model = new StreamingLinearRegressionWithSGD() .setInitialWeights(Vectors.dense(weights)) .trainOn(dataStream.join(historicalEvents)) } model.predictOnValues(dataStream.map(lp => (lp.label, lp.features))) .insertIntoFilo("predictions")


The FiloDB Advantage for MLAble to update dynamic models based on massive data�ow/updates
Integrate historical and recent events to build modelsMore data -> better models!Can store scored raw data / predictions back in FiloDB
for fast user queries

FiloDB - RoadmapYour input is appreciated!
Productionization and automated stress testingKafka input API / connector (without needing Spark)In-memory caching for signi�cant query speedupTrue columnar querying and execution, using latematerialization and vectorization techniques. GPU/SIMD.Projections. Often-repeated queries can be sped upsigni�cantly with projections.

Thanks For Attending!@helenaedelson@evanfchan@tuplejump

EXTRA SLIDES

What are my storage needs?Non-persistent / in-memory: concurrentviewersShort term: latest trendsLonger term: raw event and aggregate storageML Models, predictions, scored data

Spark RDDsImmutable, cache in memory and/or ondiskSpark Streaming: UpdateStateByKeyIndexedRDD - can update bits of dataSnapshotting for recovery

Using Cassandra for Short Term Storage1020s 1010s 1000s
Bus A Speed, GPS
Bus B
Bus CPrimary key = (Bus UUID, timestamp)Easy queries: location and speed of single bus for a range oftimeCan also query most recent location + speed of all buses(slower)

FiloDB - How?

Multiple ways to Accelerate QueriesColumnar projection - read fewer columns, saves I/OPartition key �ltering - read less dataSort key / PK �ltering - read from subset of keys
Possible because FiloDB keeps data sortedVersioning - write to multiple versions, read from the one youchoose

Cassandra CQL vs Columnar LayoutCassandra stores CQL tables row-major, each row spans multiplecells:
PartitionKey 01:�rst 01:last 01:age 02:�rst 02:last 02:ageSales Bob Jones 34 Susan O'Connor 40
Engineering Dilbert P ? Dogbert Dog 1
Columnar layouts are column-major:
PartitionKey �rst last ageSales Bob, Susan Jones,
O'Connor34,40
Engineering Dilbert,Dogbert
P, Dog ?, 1

FiloDB Cassandra SchemaCREATE TABLE filodb.gdelt_chunks ( partition text, version int, columnname text, segmentid blob, chunkid int, data blob, PRIMARY KEY ((partition, version), columnname, segmentid, chunkid) ) WITH CLUSTERING ORDER BY (columnname ASC, segmentid ASC, chunkid ASC)
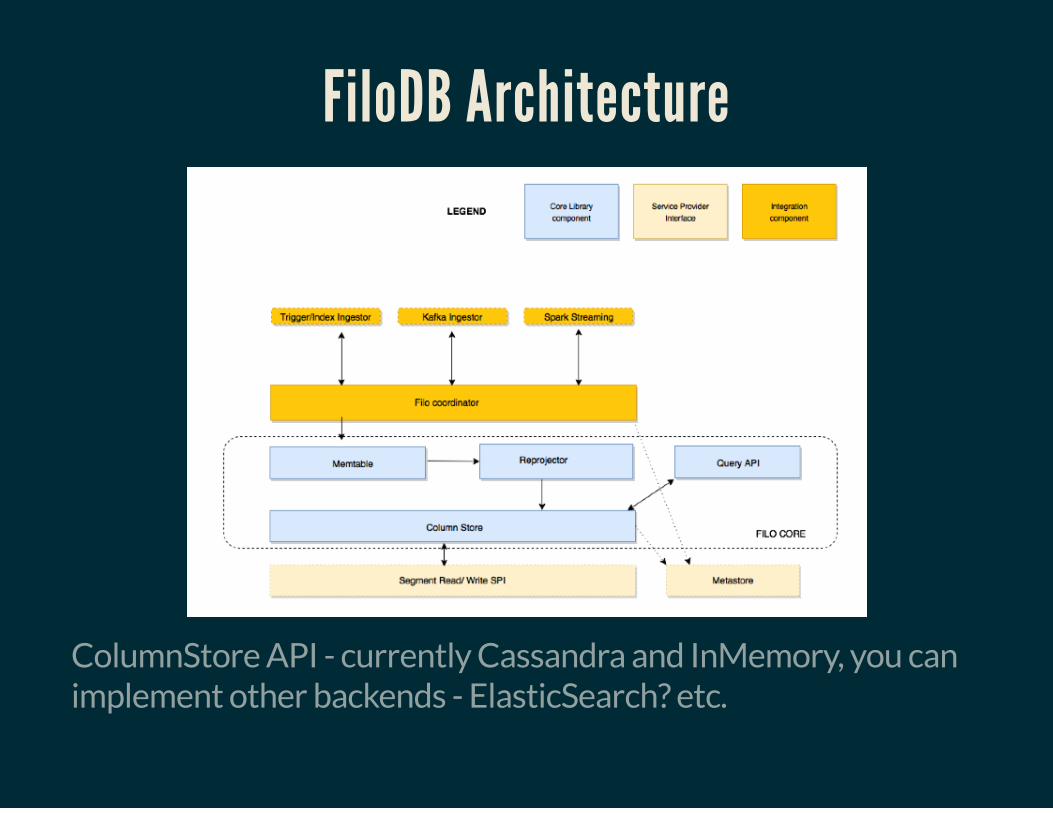
FiloDB Architecture
ColumnStore API - currently Cassandra and InMemory, you canimplement other backends - ElasticSearch? etc.
Related Documents











