[email protected] Jointly embeddings text and Knowledge Graph for information extraction Armando Vieira Data Scientist @dataAI and @Stratified Medical

Extracting Knowledge from Pydata London 2015
Aug 06, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Jointly embeddings text and Knowledge Graph for information
extraction
Armando Vieira
Data Scientist @dataAI and @Stratified Medical

Summary
Why machines struggle to “understand” text?
The challenges of discover new knowledge in text
Deep Learning to the rescue
Words as distributed vectors
Combining text with knowledge graphs

Wouldn't it be great that...
We could extract “knowledge” expressed in text into a machine readable format?

Or that...
We could transform all biomedical information into an automated drug discovery process



Why understanding text is so hard for a machine?
The verbs nightmare
Nested structures
Syntactic is doable semantics is hard
Other challenges (negations,…)
Long range interactions







The Skip-gram algorithm
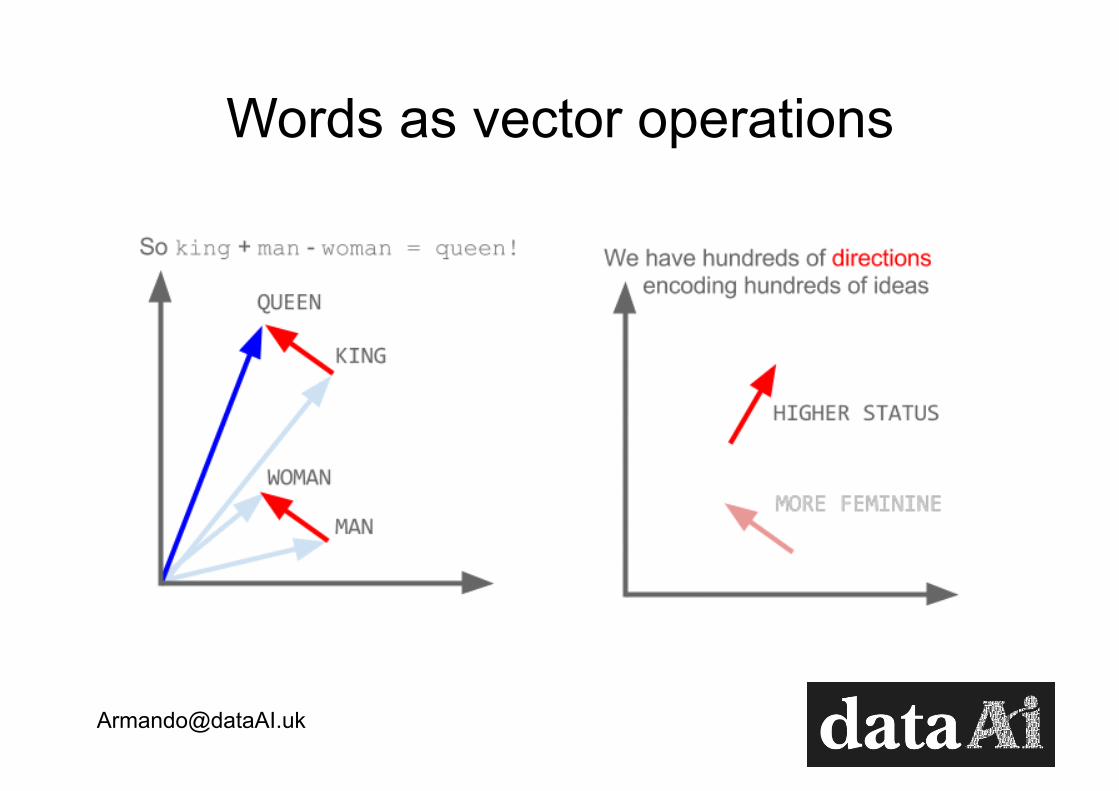
IDEA: Words together are semantically related Mikolov et al 2013

But its not the end of the story
The verbs nightmare
Nested relations structure
Syntactic is doable semantics is hard
Other challenges (negations,…)
Long range correlations





What does each similarity term mean?
Observe the joint features with explicit representations!
uncrowned Elizabeth majesty Katherine second impregnate
… …




Advantages
Efficient coding of words and relations
Capture both local and global semantics
Easy to parallelize
Completely unsupervised
Can easily handle ambiguity

Limitations of word embeddings
They are (bi)linear machines
Perform poorly on infrequent words
Can not incorporate external knowledge






Why its hard to expand knowledge?
Sparsely connected
Highest degree nodes are sometimes irrelevant
Some relations types are too vague
Integrate local and global (contextual) information





Data
Wikipedia 2014 • 3.5 billion word tokens • Vocabulary size: 2 million
Freebase • 44 million topics • 2.4 billion facts • > 1500 relation types



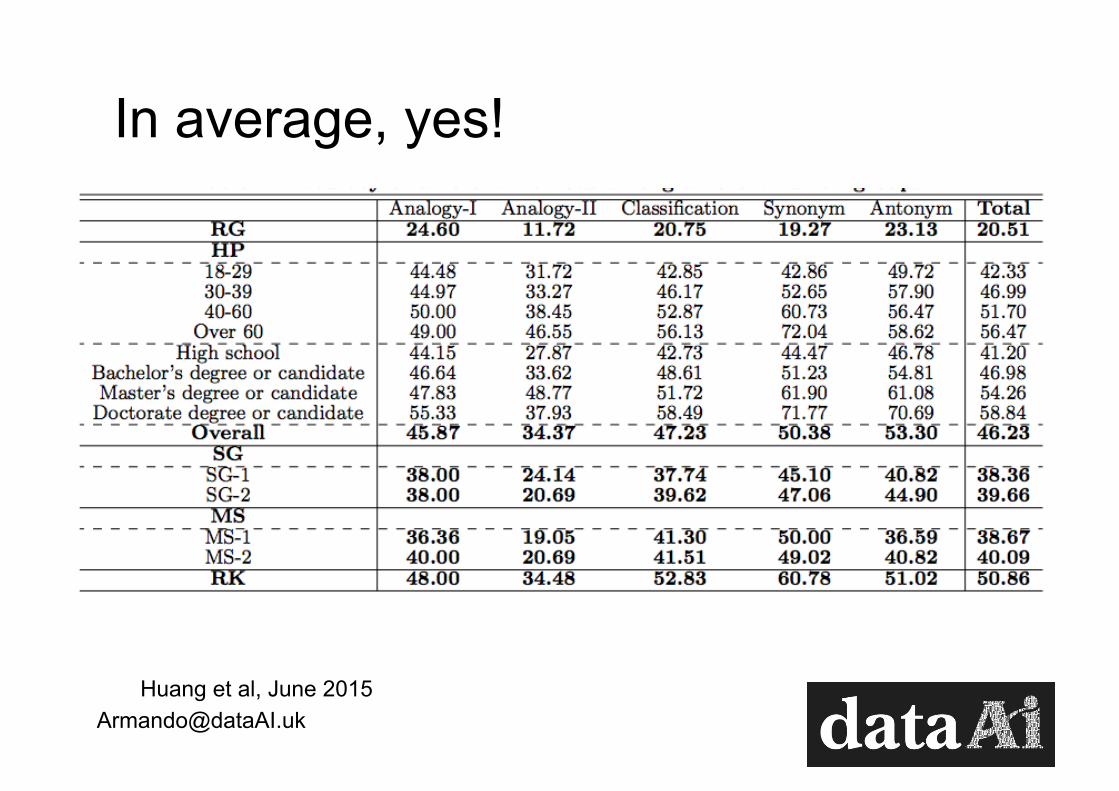
Beating humans in IQ test?
Analogy I Isotherm is to temperature as isobar is to: A) atmosphere, B) wind; C) Pressure; D) latitude; E) current
Analogy 2 Identify two words (one from each set of brackets) that form a connection (analogy) when paired with the words in capitals: CHAPTER (book, verse, read), ACT (stage, audience, play).
Classification Which is the odd one out? (i) calm, (ii) quiet, (iii) relaxed, (iv) serene, (v) unruffled.
Synonym Which word is closest to IRRATIONAL? (i) intransigent, (ii) irredeemable, (iii) unsafe, (iv) lost, (v) nonsensical.
Antonym Which word is most opposite to MUSICAL? (i) discordant, (ii) loud, (iii) lyrical, (iv) verbal, (v) euphonious

Resources
http://technology.stitchfix.com/blog/2015/03/11/word-is-worth-a-thousand-vectors/ Chris Moody
https://levyomer.wordpress.com Levy Omer

How about biomedical data?
Few data (25 million documents)
Complex interactions between entities
Fat tail
Incorporate constrains from Physics, Chemistry & Biology
Non-linearities: complex manifold

From here… Neuroinflammation is the local reaction of the brain to infection, trauma, toxic molecules or protein aggregates. The brain resident macrophages, microglia, are able to trigger an appropriate response involving secretion of cytokines and chemokines, resulting in the activation of astrocytes and recruitment of peripheral immune cells. IL-1β plays an important role in this response; yet its production and mode of action in the brain are not fully understood and its precise implication in neurodegenerative diseases needs further characterization. Our results indicate that the capacity to form a functional NLRP3 inflammasome and secretion of IL-1β is limited to the microglial compartment in the mouse brain. We were not able to observe IL-1β secretion from astrocytes, nor do they express all NLRP3 inflammasme components. Microglia were able to produce IL-1β in response to different classical inflammasome activators, such as ATP, Nigericin or Alum. Similarly, microglia secreted IL-18 and IL-1α, two other inflammasome-linked pro-inflammatory factors. Cell stimulation with α-synuclein, a neurodegenerative disease-related peptide, did not result in the release of active IL-1β by microglia, despite a weak pro-inflammatory effect. Amyloid-β peptides were able to activate the NLRP3 inflammasome in microglia and IL-1β secretion occurred in a P2X7 receptor-independent manner. Thus microglia-dependent inflammasome activation can play an important role in the brain and especially in neuroinflammatory conditions.

To here
If protein A interacts with gene G at cell types C what other proteins related to A may interact with gene G at cell types C1?
If chemical Q attach to target T at protein P what chemicals may attach to target T1 at protein P1?

Looking for new knowledge
We are not really looking to understand language
Rather
Extract and “validate” novel knowledge.
Related Documents











