Extrac¸c˜ ao de rela¸ c˜oessemˆ anticas entre palavras a partir de um dicion´ ario: o PAPEL e sua avalia¸ c˜ao Hugo Gon¸calo Oliveira CISUC, Universidade de Coimbra, Portugal [email protected] Diana Santos Linguateca, SINTEF ICT, Noruega [email protected] Paulo Gomes CISUC, Universidade de Coimbra, Portugal [email protected] Resumo Neste artigo apresentamos o PAPEL, um recurso lexical para o portuguˆ es, constitu´ ıdo por rela¸c˜ oes entre palavras, extra´ ıdas de forma autom´ atica de um dicion´ ario da l´ ıngua geral atrav´ es da escrita manual de gram´ aticas para esse efeito. Depois de contextualizarmos o tipo de recurso e as op¸c˜ oes tomadas, fornecemos uma vis˜ ao do processo da sua constru¸c˜ ao, apresentando as rela¸c˜ oes inclu´ ıdas e a sua quantidade. Apresentamos tamb´ em uma primeira avalia¸ c˜ ao, que tomou duas formas: para asrela¸c˜ oes de sinon´ ımia, a compara¸ c˜ ao com o TeP 2.0, um recurso publicamente acess´ ıvel e de cobertura vasta; para as outras rela¸ c˜ oes, interrogando corpos em portuguˆ es. Esta segunda forma pode ser efectuada automaticamente, ou recorrendo a avaliadores. Nesta ´ ultima vertente, integrado no projecto AC/DC, ´ e oferecido mais um servi¸ co de valida¸c˜ aoderela¸c˜ oes ` a comunidade do processamento computacional da l´ ıngua portuguesa, onde qualquer utilizador pode actuar como avaliador. 1 Introdu¸c˜ao Cada vez mais os estudos do processamento da l´ ıngua exigem que haja acesso computacional a informa¸ c˜ ao semˆ antica, e ´ e cada vez mais frequente o recurso a redes ou ontologias lexicais que tentam cobrir o panorama lexical de uma l´ ıngua toda, ao inv´ es, ou como complemento, de terminologias, cujo objectivo ´ e descrever uma ´ area espec´ ıfica do conhecimento. A ontologia lexical paradigm´ atica ´ e a WordNet (Fellbaum, 1998), tamb´ em chamada WordNet de Prin- ceton (WordNet.Pr), embora uma ontologia mais relacionada com o nosso trabalho seja a MindNet (Richardson, Dolan e Vanderwende, 1998). Neste artigo apresentamos o PAPEL, Palavras Associadas Porto Editora - Linguateca, http:// www.linguateca.pt/PAPEL (desde 17 de Agosto de 2009 livre e publicamente acess´ ıvel), que ´ e pioneiro para o portuguˆ es, ao tentar obter uma ontologia lexical semi-automaticamente a partir de um dicion´ ario, o Dicion´ario PRO da L´ ıngua Portuguesa da Porto Editora (DLP, 2005). Como ´ e notado por Sampson (2000) na suaaprecia¸c˜ ao da WordNet.Pr, ´ e curioso que tenha sido uma abordagem manual a preferida pela comunidade do processamento de linguagem natural (PLN), mas o que ´ e certo ´ e que a maior parte dos projectos associados ou inspirados pela WordNet seguem uma metodologia que usa peritos para criar o recurso manualmente. Pensamos que uma das raz˜ oes para isto se deve ` a quest˜ ao dos direitos de autor, e nesse aspecto pode ser que o PAPEL seja o primeiro recurso totalmente p´ ublico baseado num dicion´ ario comercial, visto que a MindNet ´ e propriedade de uma empresa. Visto que n˜ ao existe ainda uma terminologia completamente consensual, cumpre indicar aqui, na senda de Veale (2007), o que designamos por ontologia lexical de uma dada l´ ıngua: • uma estrutura de conhecimento que relaci- ona itens lexicais (vulgo, palavras) de uma l´ ıngua entre si, por rela¸c˜ oes que tˆ em a ver com o significado desses mesmos itens; • uma estrutura que pretende abranger a l´ ıngua toda e n˜ ao conhecimento de um dom´ ınio em particular, ou seja, que n˜ ao se encontre restrita a campos espec´ ıficos. Deixamos desde j´ a bem claro que, dentro desta descri¸c˜ ao razoavelmente abrangente, existem muitas perguntas espec´ ıficas a que cada criador de recurso ter´ a de dar uma resposta, assim como n˜ ao h´ a respostas precisas para o que ´ e uma “palavra” (e de facto a maior parte das This work is licensed under a Creative Commons Attribution 3.0 License Linguam´ atica — ISSN: 1647–0818 Vol. 2 N´ um. 1 - Abril 2010 - P´ ag. 77–94

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Extraccao de relacoes semanticas entre palavras a partir de um
dicionario: o PAPEL e sua avaliacao
Hugo Goncalo OliveiraCISUC, Universidade de Coimbra, Portugal
Diana SantosLinguateca, SINTEF ICT, Noruega
Paulo GomesCISUC, Universidade de Coimbra, Portugal
Resumo
Neste artigo apresentamos o PAPEL, um recurso lexical para o portugues, constituıdo por relacoesentre palavras, extraıdas de forma automatica de um dicionario da lıngua geral atraves da escritamanual de gramaticas para esse efeito. Depois de contextualizarmos o tipo de recurso e as opcoestomadas, fornecemos uma visao do processo da sua construcao, apresentando as relacoes incluıdase a sua quantidade. Apresentamos tambem uma primeira avaliacao, que tomou duas formas: paraas relacoes de sinonımia, a comparacao com o TeP 2.0, um recurso publicamente acessıvel e decobertura vasta; para as outras relacoes, interrogando corpos em portugues. Esta segunda formapode ser efectuada automaticamente, ou recorrendo a avaliadores. Nesta ultima vertente, integrado noprojecto AC/DC, e oferecido mais um servico de validacao de relacoes a comunidade do processamentocomputacional da lıngua portuguesa, onde qualquer utilizador pode actuar como avaliador.
1 Introducao
Cada vez mais os estudos do processamento dalıngua exigem que haja acesso computacionala informacao semantica, e e cada vez maisfrequente o recurso a redes ou ontologias lexicaisque tentam cobrir o panorama lexical de umalıngua toda, ao inves, ou como complemento,de terminologias, cujo objectivo e descrever umaarea especıfica do conhecimento. A ontologialexical paradigmatica e a WordNet (Fellbaum,1998), tambem chamada WordNet de Prin-ceton (WordNet.Pr), embora uma ontologiamais relacionada com o nosso trabalho seja aMindNet (Richardson, Dolan e Vanderwende,1998).
Neste artigo apresentamos o PAPEL, PalavrasAssociadas Porto Editora - Linguateca, http://www.linguateca.pt/PAPEL (desde 17 de Agostode 2009 livre e publicamente acessıvel), que epioneiro para o portugues, ao tentar obter umaontologia lexical semi-automaticamente a partirde um dicionario, o Dicionario PRO da LınguaPortuguesa da Porto Editora (DLP, 2005).
Como e notado por Sampson (2000) nasua apreciacao da WordNet.Pr, e curioso quetenha sido uma abordagem manual a preferidapela comunidade do processamento de linguagemnatural (PLN), mas o que e certo e que a maior
parte dos projectos associados ou inspiradospela WordNet seguem uma metodologia queusa peritos para criar o recurso manualmente.Pensamos que uma das razoes para isto se devea questao dos direitos de autor, e nesse aspectopode ser que o PAPEL seja o primeiro recursototalmente publico baseado num dicionariocomercial, visto que a MindNet e propriedade deuma empresa.
Visto que nao existe ainda uma terminologiacompletamente consensual, cumpre indicar aqui,na senda de Veale (2007), o que designamos porontologia lexical de uma dada lıngua:
• uma estrutura de conhecimento que relaci-ona itens lexicais (vulgo, palavras) de umalıngua entre si, por relacoes que tem a vercom o significado desses mesmos itens;
• uma estrutura que pretende abranger alıngua toda e nao conhecimento de umdomınio em particular, ou seja, que nao seencontre restrita a campos especıficos.
Deixamos desde ja bem claro que, dentro destadescricao razoavelmente abrangente, existemmuitas perguntas especıficas a que cada criadorde recurso tera de dar uma resposta, assimcomo nao ha respostas precisas para o que euma “palavra” (e de facto a maior parte das
This work is licensed under aCreative Commons Attribution 3.0 License
Linguamatica — ISSN: 1647–0818Vol. 2 Num. 1 - Abril 2010 - Pag. 77–94

ontologias lexicais de que temos conhecimentousam tambem expressoes) ou o que e a “lınguatoda”.
De um ponto de vista operacional, e maisnatural desde ja afirmarmos que o PAPEL naopretende ser uma resposta definitiva a estasquestoes, mas sim uma abordagem concreta quese apoiou no trabalho de lexicografos. Quantoa nocao de palavra/entrada e ao conjunto deitens que fazem parte da lıngua geral, mas que,sabendo que a lıngua e uma entidade claramentedinamica, a nossa intencao e vir a expandir oPAPEL tendo em conta esse facto.
Ha no entanto duas questoes, completamenteortogonais, que nos parecem estabelecer umadelimitacao clara na paisagem das ontologiaslexicais, e sobre as quais posicionamos deimediato aqui o PAPEL:
• o caracter publico ou privado de um recurso:em que o PAPEL alinha com a WordNet, ouseja, e publico;
• a construcao manual ou automatica a partirde um dicionario com definicoes (ou seja,um recurso ja existente), em que o PAPELalinha com a MindNet, ou seja, e construıdoa partir de um recurso.
Outras opcoes tomadas, e que nos separam de ou-tros recursos ou abordagens, serao mencionadasa medida que as formos apresentando.
Por interessar mais a audiencia deste texto,e tambem a nos, vamos centrar a discussaonos recursos que existem para o portuguesde que temos conhecimento, nomeadamente aWordNet.PT (Marrafa, 2002), o TeP (Dias-Da-Silva e Moraes, 2003) (Maziero et al., 2008) e aWordNet.BR (Dias da Silva, Oliveira e Moraes,2002), e ainda a MultiWordNet.PT (http://mwnpt.di.fc.ul.pt).
E importante contudo referir que nao vemosnem desenvolvemos o PAPEL1 como sendo umcompetidor em relacao ao trabalho ja existente,mas sim como mais uma contribuicao para obterinformacao semantica de cobertura vasta para oportugues.
Consideramos, de facto, que a situacao idealseria a de ter uma ontologia lexical publica paratodo o portugues, embora naturalmente entrandoem conta com as diferencas entre as variedades
1Quando o projecto de construcao do PAPEL foiiniciado pela Linguateca em colaboracao com a PortoEditora, apos assinatura de um protocolo em Maio de2006, nao havia nenhum recurso publicamente disponıvelpara o portugues. Congratulamo-nos muitıssimo pelofacto de existirem agora varios.
ou variantes da lıngua (Barreiro, Wittmann ePereira, 1996). Em Santos et al. (2009), seguidode Santos et al. (2010), apresentamos umaprimeira comparacao entre varios recursos quesublinha a sua complementaridade.
Nessa linha, tentaremos convencer os leitoresde que as formas de avaliacao que descrevemosna seccao 4 constituem um bom inıcio para umaligacao e consequente actualizacao de ambos osrecursos envolvidos (o TeP e o PAPEL), alem deapresentarmos tambem uma oferta de validacaopara outros recursos existentes ou que venham aser desenvolvidos para o portugues em conjuntocom a interrogacao de corpos em portugues.
2 Contexto
Desde muito cedo que foi reconhecido que, pararealizar o processamento computacional de umalıngua, seria necessario o acesso a recursos degrande cobertura, como o sao as ontologiaslexicais, ou antes de esse termo ser cunhado,a dicionarios em forma electronica ou basesde dados lexicais, por um lado, ou bases deconhecimento sobre o mundo, por outro. Parauma excelente discussao da diferenca e relacaoentre ontologias e bases de dados lexicais, veja-se Hirst (2004). Outras abordagens interessantesem relacao a essa questao sao Dahlgren (1995) eMarcellino e Dias da Silva (2009).
2.1 Modelos de ontologia lexical
2.1.1 A escola da WordNet
A WordNet.Pr e uma ontologia lexical para oingles, construıda manualmente, que procurarepresentar a forma como o ser humano processao vocabulario. Esta disponıvel gratuitamente eao longo dos anos tem sido amplamente utilizadapela comunidade do PLN. A sua estrutura maisbasica e um grupo de sinonimos (do ingles,synset), ou seja, um conjunto de palavras que,em determinado contexto, podem ter o mesmosignificado e ser utilizadas para representar omesmo conceito. Uma rede semantica estabelece-se na WordNet.Pr atraves de ligacoes, correspon-dentes a relacoes semanticas, entre os nos, quecorrespondem aos grupos de sinonimos. Entre asrelacoes cobertas encontram-se a hiponımia e ameronımia (entre substantivos) e a troponımiae a implicacao (entre verbos). Ha ainda adizer que no lexico da WordNet.Pr ha uma claradistincao entre nos que sao substantivos, verbos,adjectivos, adverbios ou palavras gramaticais.Alem de ser possıvel levantar gratuitamentevarias versoes da WordNet.Pr, atraves da suapagina, em http://wordnet.princeton.edu etambem possıvel interrogar a sua versao mais
78– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

recente, a 3.0, atraves de uma interface na rede.Dado o enorme sucesso da WordNet.Pr, o seu
modelo foi seguido para representar ontologiaslexicais noutras lınguas. Dessas destacam-se aswordnets criadas para as lınguas presentes noprojecto EuroWordNet (Vossen, 1997; Vossen,1998), mais propriamente o holandes, castelhano,italiano, frances, alemao e estonio. A ideia doEuroWordNet foi alinhar varias wordnets com aWordNet.Pr.
Destacamos ainda as wordnets para a lınguaportuguesa, a WordNet.PT, para a varianteeuropeia, e a WordNet.BR, para a variantebrasileira2. Ha no entanto a lamentar que ambosos projectos tardem a tornar os seus conteudosacessıveis para o publico. Por exemplo, apesarda existencia de uma interface na rede parainterrogar a WordNet.PT (ou parte dela), apartir de http://cvc.instituto-camoes.pt:8080/wordnet/index.jsp, nao e costume serpossıvel realizar pesquisas porque o sistema se en-contra permanentemente em manutencao. Con-tudo, os grupos de sinonimos da WordNet.BR,bem como as relacoes de antonımia, encontram-se disponıveis no Thesaurus Electronico doPortugues, o TeP (Maziero et al., 2008), tambemele construıdo de acordo com os princıpios daWordNet.Pr.
Inspirado pelo EuroWordNet, o projectoMultiWordNet (Pianta, Bentivogli e Girardi,2002) procurou tambem alinhar varias wordnetscom a WordNet.Pr, mas desta vez, ao inves dese procurar as correspondencias possıveis entreas wordnets existentes nas diferentes lınguas ea WordNet.Pr, a ideia foi criar novas wordnetsonde fosse mantida a maior parte dos nos erelacoes presentes na WordNet.Pr. Desta forma,na MultiWordNet, wordnets para o italiano, oespanhol, o romeno, o hebraico, o latim e, maisrecentemente, o portugues (http://mwnpt.di.fc.ul.pt) estao alinhadas com a WordNet.Pr.
2.1.2 A MindNet
Alem do modelo da WordNet, outro tipo derecurso que pode ser visto como uma ontologialexical e a base de conhecimento MindNet.
A MindNet e mais do que um recursoestatico e pode ser visto como uma metodologiaque envolve um conjunto de ferramentas paraadquirir, estruturar, aceder e explorar, de formaautomatica, informacao lexico-semantica contidaem texto. Como, numa fase inicial, o recurso
2Para uma comparacao entre as ontologias lexicaisexistentes para o portugues, mais propriamente a Word-Net.PT, a WordNet.BR e o TeP, a MultiWordNet.PT, eainda o PAPEL, recomenda-se a leitura de Santos et al.(2010).
foi construıdo a partir de um dicionario paraa lıngua inglesa, a sua estrutura e baseada ementradas de dicionario. Desta forma, para cadapalavra definida, alem de informacao tıpica numdicionario (e.g. informacoes gramaticais) existeum conjunto de registos associados aos sentidosque a palavra pode ter. Por sua vez, paracada sentido, alem da definicao, encontram-seligacoes a outras entradas, sendo que cada ligacaotem um tipo correspondente a uma relacaogramatical (e.g. sujeito tıpico, predicado tıpico)ou semantica (e.g. sinonimo, hiperonimo, parte,causa, finalidade, maneira). Estas relacoes saoextraıdas com base na aplicacao de regras sobrearvores sintactico-semanticas, produzidas por umanalisador sintactico de vasta cobertura. Cadarelacao estabelecida tem um peso atribuıdo deacordo com a sua saliencia.
A MindNet pode ser interrogada atravesdo MindNet Explorer (MNEX) (Vanderwendeet al., 2005), a partir do http://stratus.research.microsoft.com/mnex/Main.aspx,onde e possıvel procurar caminhos (de relacoessemanticas) entre duas palavras.
2.1.3 Outros recursos semanticos
As bases de senso comum sao outro tipode recurso semantico, sendo o recurso maisconhecido o Cyc (Lenat, 1995), uma base deconhecimento baseada em logica de predicados deprimeira ordem, que vem sendo criada de formamanual.
Outro recurso deste tipo e a ConceptNet (Liue Singh, 2004), construıdo de forma automaticaa partir do preenchimento de frases matriz, talcomo The effect of eating food is ..., ou o Aknife is used for .... A ConceptNet utilizauma representacao semelhante a do WordNet.Pr,mas inclui conhecimento mais informal, de umanatureza mais pratica e alem disso tem um maiorelenco de relacoes (tais como propriedade de, sub-evento de, efeito de, utilizado para).
Tanto o Cyc como a ConceptNet temassociadas capacidades de raciocınio, de forma aser possıvel inferir novas relacoes. No entanto,enquanto no Cyc o raciocınio e realizado sobrepresentacoes em logica de predicados, na Con-ceptNet o raciocınio e feito sobre representacoesem linguagem natural.
A FrameNet (Baker, Fillmore e Lowe, 1998),por seu lado, e uma rede semantica baseadano conceito de enquadramentos (em ingles,frames) (Fillmore, 1982). Nesta representacao,cada enquadramento descreve um objecto, umevento ou um estado, que corresponde a umconceito e se pode relacionar com outros
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 79

enquadramentos, atraves de um conjunto derelacoes semanticas (e.g. heranca, sub-frame,causador, utiliza). Para o portugues existe jaum projecto seguidor deste modelo de recurso, oFrameNet Brasil (Salomao, 2009), http://www.framenetbr.ufjf.br/, veja-se tambem Afonso(2009).
Devemos tambem citar o Port4NooJ (Bar-reiro, No prelo), um conjunto de recursoslinguısticos construıdos no ambiente de de-senvolvimento linguıstico do NooJ (Silberzteine Varadi, No prelo), que tem em vista oprocessamento automatico do portugues. Estesrecursos encontram-se publicamente disponıveisem http://www.linguateca.pt/Repositorio/Port4Nooj/ e sao usados em varias ferra-mentas publicas para o portugues e outraslınguas. Os recursos correspondem a lexicos e agramaticas com finalidades diversas: analise mor-fologica, sintactico-semantica, desambiguacao,identificacao de unidades lexicais multipalavra,parafraseamento e traducao. O Port4NooJ incluialem disso uma extensao bilingue, permitindoa sua utilizacao em aplicacoes como a traducaoautomatica do portugues para o ingles. As dife-rentes propriedades associadas aos itens lexicaiscontidas nos recursos provem do OpenLogos,um sistema de traducao automatica em codigoaberto derivado do sistema Logos (Scott, 2003),mas novas propriedades tem sido adicionadasatraves do NooJ e encontram-se em fase devalidacao, entre as quais relacoes semanticas,como apresentado em Santos et al. (2010).
2.1.4 Sentidos numa ontologia lexical
Enquanto que, pela escola da WordNet, cada noda rede representa um sentido e uma “mesma”palavra pode pertencer a varios nos, que saosim as unidades basicas, no PAPEL a unicadistincao de sentidos feita tem a ver com acategoria gramatical, ou seja, um no do PAPELe uma palavra grafica (com uma dada categoria:substantivo, adjectivo, etc.). Esta opcao temduas razoes de ser: uma filosofica e outra pratica.A primeira prende-se com a concepcao de quea lıngua e soberana (Santos, 2006) e distincoesde sentido sao sempre imprecisas (Kilgarriff,1996) e artificiais; veja-se Saussure (1916) para adescricao de uma lıngua como sistema sincronico,e Edmonds e Hirst (2002) sobre o problemados quase-sinonimos. A segunda razao temque ver com o facto de, nas definicoes de umdicionario, as palavras que ocorrem nas definicoesnao aparecem indexadas pelos sentidos, tornandopor isso quase impossıvel fazer essa identificacaoautomaticamente.
Alias, confrontado com o mesmo problema,
no ambito da MindNet, Dolan (1994) proposfazer a “ambiguacao” de sentidos relacionados.Desta forma, numa primeira fase de construcao,a MindNet e uma rede entre palavras, tal e qualse encontram no dicionario, e os seus registos saorelativos a palavras. Apenas numa segunda fasese procura atribuir um sentido a cada uma destaspalavras, tirando partido dos campos de domınioou de co-ocorrencias nas definicoes.
Tambem a partir de uma rede onde a unidadebasica e a palavra, sem qualquer distincao desentidos, e onde as ligacoes, pesadas, apenasindicam a co-ocorrencia em corpos, Dorow (2006)aplica algoritmos estatısticos sobre grafos paraextrair informacao semantica interessante. Porexemplo, quando dois nos nao estao ligados outem uma ligacao muito fraca (isto e, as palavrasnao co-ocorrem frequentemente), mas tem umavizinhanca semelhante, e provavel que sejamsinonimos. Por outro lado, quando um no e aunica ligacao entre duas sub-redes, e provavel quese esteja perante uma palavra com dois sentidos.
Ainda relativamente a representacao dossentidos numa ontologia lexical, os recursos queresultam de uma traducao cega de um recursodeste tipo feito para uma lıngua diferente, comoas MultiWordNets, tem de lidar, adicionalmenteas questoes decorrentes da imprecisao existentena identificacao de sentidos, com problemasmais especıficos relacionados com a traducao.Como lınguas diferentes representam diferentesrealidades sociais e culturais, estas nao cobremexactamente a mesma parte do lexico e, mesmonas partes que lhes sao comuns, os variosconceitos sao normalmente lexicalizados de formadiferente (Hirst, 2004). Isto leva a que, porexemplo, na MultiWordNet.PT faltem palavraspara identificar alguns conceitos importadosda WordNet.Pr (Santos et al., 2009), assimcomo muito provavelmente faltarao conceitosespecıficos das realidades portuguesa e brasileira.
2.2 Abordagens para a construcao deuma ontologia lexical
Ha basicamente tres formas consagradas deconstrucao de um recurso semantico de coberturalarga: (i) trabalho manual; (ii) processamentode corpos; e (iii) processamento de dicionarios;apesar de novas ideias terem surgido nos ultimostempos, como por exemplo atraves da analise delogs (Costa e Seco, 2008) ou jogos colaborativos.
O PAPEL (Goncalo Oliveira et al., 2008)seguiu a terceira via: foi construıdo a partirda analise automatica das definicoes constantesnuma versao electronica do Dicionario PRO daLıngua Portuguesa . A utilizacao de dicionarios
80– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

em formato electronico com vista a construcao derecursos lexicais iniciou-se ha cerca de quarentaanos, com os estudos de Calzolari, Pecchia eZampolli (1973) para o italiano e de Amsler(1981) para o ingles. Os autores que utilizaramdicionarios apontam varias razoes para a suaescolha como ponto de partida para a construcaoautomatica de uma ontologia lexical: alemde serem uma enorme fonte de conhecimentolexical (Briscoe, 1991) e serem vistos comoautoridades no que diz respeito ao sentido daspalavras (Kilgarriff, 1997), a sua estrutura ea previsibilidade e simplicidade do vocabularioutilizado nas definicoes facilitam a sua utilizacaopara a extraccao e organizacao de informacaolexico-semantica. Com base no trabalho deAmsler (1981), Chodorow, Byrd e Heidorn (1985)criaram procedimentos semi-automaticos para aextraccao da relacao de hiperonımia a partirde um dicionario. Alshawi (1989) desenvolveuuma gramatica que tinha como unico objectivoa derivacao das definicoes de um dicionarioespecıfico, de forma a facilitar a extraccao derelacoes que eram depois organizadas em estru-turas semanticas. Montemagni e Vanderwende(1992), por outro lado, defenderam a utilizacaode um analisador sintactico de grande cobertura,com o argumento de que este seria melhor paraextrair informacao mais especıfica dentro de umadefinicao.
Apesar de varios trabalhos com este objectivo,a MindNet tera sido a primeira base de dadoslexical independente, criada de forma automaticaa partir de dicionarios, mas nao houve muitoscontinuadores nesta senda, talvez devido aanalise sobre a inconsistencia dos dicionariosfeita por Ide e Veronis (1995). Ainda assim,alguns trabalhos recentes nesta area sao O’Hara(2005), Nichols, Bond e Flickinger (2005) e Zesch,Muller e Gurevych (2008), este ultimo usando oWikcionario3.
Por outro lado, varios investigadores apon-taram o facto de que algum conhecimentoimportante para o PLN nao se encontravapresente em dicionarios: algumas aplicacoesnecessitam de conhecimento especıfico sobredeterminados domınios, que e mais facil de obterem corpos (Hearst, 1992; Riloff e Shepherd, 1997;Caraballo, 1999).
Para a extraccao de conhecimento que naose consegue encontrar nem em dicionario, nemem outros recursos de vasta cobertura, comoqualquer WordNet ja existente, iniciou-se oprocessamento de recursos nao estruturados.
No que diz respeito a utilizacao de recursos3http://wiktionary.org/
estruturados (ou semi-estruturados) para extrairconhecimento lexico-semantico, nos ultimos anostem tambem sido dada especial atencao autilizacao de recursos colaborativos, como aWikipedia4 ou o ja referido Wikcionario, veja-sepor exemplo Medelyan et al. (2009), Navarro etal. (2009) ou Herbelot e Copestake (2006).
A referencia mais conhecida no que dizrespeito a extraccao de conhecimento lexico-semantico a partir de corpos e o trabalhode Hearst (1992), que propoe um metodopara identificar padroes textuais indicadores darelacao de hiponımia e que aplica um conjunto depadroes para extrair automaticamente relacoesdeste tipo. Varios trabalhos tiveram comoprincipal inspiracao a abordagem de Hearst paradescobrir padroes e para extrair relacoes, nao sode hiponımia (Caraballo, 1999; Freitas e Quental,2007), mas tambem outros tipos de relacoes,como por exemplo causais (Girju e Moldovan,2002), ou de meronımia (ou parte de) (Berlande Charniak, 1999), e mais especificamentepara relacoes geograficas em portugues (Chaves,2009).
2.3 Abordagens para a avaliacao deontologias
Brank, Grobelnik e Mladenic (2005) apresentamquatro formas que tem sido utilizadas para ava-liar ontologias de domınio: (i) avaliacao manual;(ii) comparacao com um recurso dourado; (iii)realizacao de uma tarefa independente, definidapara avaliar uma ontologia; (iv) comparacao comum conjunto de dados sobre o mesmo domınio.
Apesar de, regra geral, estas formas deavaliacao se adaptarem a qualquer tipo deontologia, e preciso notar que temos de distinguirentre as ontologias propriamente ditas (Gruber,1993), que cobrem uma area especıfica e saobaseadas numa conceptualizacao de um domınio,e as ontologias lexicais que, como ja referimos,tentam descrever o sistema conceptual de umalıngua inteira. Isto leva naturalmente a quenem todos os metodos possam ser adaptadoscegamente a ontologias lexicais.
A avaliacao manual e uma forma habitual-mente escolhida para avaliar a qualidade de umrecurso. Muitos trabalhos efectuam este tipode avaliacao — por exemplo Riloff e Shepherd(1997), Caraballo (1999), ou mesmo Richardson,Vanderwende e Dolan (1993), no ambito do queviria a ser a MindNet — por ser provavelmentea forma mais fiavel. No entanto, esta sempredependente de trabalho por parte dos indivıduosque realizam a avaliacao. De forma a minimizar o
4http://wikipedia.org
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 81

esforco necessario para avaliar manualmente umaontologia obtida automaticamente, Navigli et al.(2004) geraram definicoes em linguagem naturala partir do conteudo dessa ontologia.
Para utilizar um recurso dourado, que podeeventualmente ser outra ontologia, e necessarioque exista um elevado nıvel de confianca nasua correccao, possivelmente por ter sido criadomanualmente por peritos. A qualidade de umaontologia pode ser assim medida atraves dasua comparacao com um recurso dourado, deacordo com determinados criterios. Neste tipode avaliacao, Santos (2007) refere que as medidasde precisao e abrangencia, tradicionalmenteutilizadas em recolha de informacao (Salton eMcGill, 1983), tem sido extremamente popularesem PLN, sendo muitas vezes propostas semuma total compreensao das suas limitacoes eadequacao.
Outro problema desta abordagem de avaliacaoe que, sendo a criacao de ontologias umassunto bastante recente, nem sempre existeum recurso dourado que se adeque aos criteriosda avaliacao. Para o ingles, no ambito dasontologias lexicais, muitos autores utilizam apropria WordNet.Pr como recurso dourado naavaliacao da sua ontologia (Hearst, 1992; Nichols,Bond e Flickinger, 2005).
Partindo do princıpio de que uma ontologiaserve para ser integrada noutras aplicacoes, como objectivo de realizar determinadas tarefas,alguns autores propoem avaliar uma ontologiade forma indirecta. Desta forma a ontologiae utilizada numa aplicacao para realizar umatarefa especıfica, cujos resultados serao alvode avaliacao. No entanto, e necessario teralgum cuidado com as ilacoes tiradas destetipo de avaliacao, ja que ha muitas variaveisenvolvidas e a qualidade dos resultados nao estaapenas dependente da qualidade da ontologia,mas tambem do resto da aplicacao. Cuadrose Rigau (2006) realizaram uma avaliacao indi-recta de varias ontologias lexicais, incluindo aWordNet.Pr, no ambito da desambiguacao dosentido das palavras. Curiosamente, os recursoscriados de forma automatica obtiveram melhoresresultados ao nıvel tanto da precisao como daabrangencia. Outra conclusao a que chegaramfoi a de que a qualidade dos resultados obtidos,ao combinar o conhecimento de todos os recursosutilizados no estudo, e muito proxima daquelaque apenas selecciona o sentido mais frequentepara cada palavra.
Quanto a ultima forma de avaliacao, acomparacao com outros dados referentes aomesmo domınio, Brewster et al. (2004) propoem
que a adequacao de uma ontologia de domınio aum dado corpo seja avaliada atraves do numerodos termos salientes do corpo, que sera sobre odomınio em questao, que tambem constam naontologia. Contudo, repare-se que, para obteros termos salientes num dado domınio, e precisoprecisamente compara-lo com a linguagem gerale outros domınios, e obter os termos salientes nalinguagem geral e algo que nao faz muito sentido.Ainda assim, sera possıvel medir a cobertura deum determinado corpo por um lexico, tal comoDemetriou e Atwell (2001) propoem. A coberturasera medida atraves do numero de palavras docorpo que se encontrarem no lexico.
A verdade, contudo, e que, tal como Ramane Bhattacharyya (2008) referem, a avaliacaoexplıcita de ontologias lexicais nao e uma praticacomum. A principal razao para esta situacaosera o facto de haver bastante confianca nestesrecursos, que sao na sua maioria criados manual-mente por peritos, o que minimiza a possibilidadede erros. De forma a verificar se a confiancae justificada, Raman e Bhattacharyya (2008)levaram a cabo uma validacao automatica dosgrupos de sinonimos (synsets) da WordNet.Pr,utilizando um dicionario. Nesse trabalho consi-deraram que uma palavra estava correctamenteincluıda num no da WordNet se na sua definicaofossem referidas palavras dos nos hiperonimosdesse no, ou outras palavras pertencentes aomesmo no (sinonimos). Como esperado, naoforam encontrados muitos problemas.
Ha ainda a referir um outro metodo deavaliacao que tira partido da quantidade detexto que se consegue encontrar hoje em diana Web, como fizeram, por exemplo, Etzioni etal. (2005) para calcular o nıvel de confianca derelacoes de hiperonımia entre classes e entidadesmencionadas. Para o efeito, as relacoes foramprimeiro transformadas em padroes textuaisdiscriminadores, semelhantes aos de Hearst(1992). Em seguida, procuraram esses padroes narede e calcularam o PMI-IR (Turney, 2001) entreos padroes envolvendo a entidade e as ocorrenciasda propria entidade.
3 Breve apresentacao do PAPEL
Nesta seccao descrevemos primeiro o procedi-mento semi-automatico utilizado para construir oPAPEL e de seguida apresentamos os conteudosda sua versao actual, incluindo a contabilizacaode itens lexicais, a contabilizacao de relacoes, eainda exemplos destas ultimas.
82– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

PARTE{nome:nome * PARTE_DE:INCLUI;nome:adj * PARTE_DE_ALGO_COM_PROPRIEDADE:PROPRIEDADE_DE_ALGO_QUE_INCLUI;adj:nome * PROPRIEDADE_DE_ALGO_PARTE_DE:INCLUI_ALGO_COM_PROPRIEDADE;
}
Figura 1: Exemplo da descricao do grupo de relacoes relativas a meronımia.
3.1 Construcao
De forma resumida, visto que ja foi detalhadonoutras publicacoes (Goncalo Oliveira et al.,2008; Goncalo Oliveira e Gomes, 2008b;Goncalo Oliveira e Gomes, 2008a), o processode construcao do PAPEL segue um ciclo de trespassos ate considerarmos ter chegado a um nıvelde desempenho suficiente, entrando depois noquarto e ultimo passo.
1. Criacao de gramaticas semanticas:foram criadas gramaticas para cada tipo derelacao que se pretende extrair, por cate-goria gramatical (fornecida pelo dicionario).Na tabela 1 mostramos alguns dos padroese as relacoes que pretendem descobrir e nafigura 1 mostramos de que forma as relacoesque pretendemos extrair sao descritas, deacordo com o grupo e especificando aindaa categoria dos argumentos e a sua relacaoinversa.
Padrao Relacao associadatipo|genero|classe|forma de Hiperonımiaparte|membro de Meronımiaque causa|provoca|origina Causausado|utilizado para Finalidadenatural|originario de Localuma palavra ou lista de palavras Sinonımia
Tabela 1: Exemplos de padroes usados nasgramaticas.
2. O processo de extraccao: usando umanalisador automatico, e feita a analisesuperficial das definicoes, a partir daqual sao automaticamente extraıdas relacoes(descritas no passo anterior) entre palavrasna definicao e a palavra definida, tambemchamada “verbete” (ver figura 2).
3. Inspeccao dos resultados: usando umsistema de regressao para identificar maisfacilmente as diferencas entre resultados an-teriores, procede-se a inspeccao manual dosresultados obtidos, com o eventual regressoao primeiro passo para corrigir problemasdetectados ou melhorar as gramaticas.
4. Ajuste das relacoes: aqui procura-secorrigir (ou eliminar) de forma automaticarelacoes com argumentos invalidos.
cometa, s. m. - astro
geralmente constituıdo por
nucleo, cabeleira e cauda
√nucleo PARTE DE cometa√cabeleira PARTE DE cometa√cauda PARTE DE cometa
[RAIZ]
[QUALQUERCOISA]
> [astro]
[QUALQUERCOISA]
> [geralmente]
[PADRAO_CONSTITUIDO]
[VERBO_PARTE_PP]
> [constituıdo]
[PREP]
> [por]
[ENUM_PARTE]
[PARTE_DE]
> [nucleo]
[VIRG]
> [,]
[ENUM_PARTE]
[PARTE_DE]
> [cabeleira]
[CONJ]
> [e]
[PARTE_DE]
> [cauda]
Figura 2: O resultado da analise da definicao decometa.
O ultimo passo e realizado em dois tempos.Inicialmente, todas as relacoes sao transformadasno tipo directo5. Por exemplo, manga INCLUIpunho e convertida para punho PARTE DEmanga, e dor RESULTADO DE distensao etransformada em distensao CAUSADOR DEdor.
Visto que as gramaticas nao fazem umaanalise sintactica das definicoes, nao atribuindopor exemplo a classe gramatical, e que asdefinicoes do dicionario apenas incluem aclassificacao da vedeta, em alguns casos oprocesso de construcao automatica do PAPELresulta em relacoes entre palavras de categoriaserradas. E por isso preciso verificar, tambemde uma forma automatica, esses casos, usandoprimeiro a propria lista de palavras/vedetasdo dicionario e em seguida o analisador mor-fologico Jspell (Simoes e Almeida, 2002). Seconseguirmos apurar que ha um desajuste nascategorias mas que pode ser corrigido atravesda escolha de outra relacao pertencente aomesmo grupo, substituımos, senao removemosesse triplo. Por exemplo, a relacao loucura AC-CAO QUE CAUSA desvario – que pressupoe umverbo como primeiro argumento – e transformadaautomaticamente em loucura CAUSADOR DEdesvario, visto que ambos os argumentos sao
5A escolha de um tipo directo e outro inverso foiarbitrariamente efectuada pelos criadores das gramaticaspor um criterio de naturalidade, e nao de frequencia, nodicionario ou em texto, e nao tem qualquer consequenciaexcepto a de facilitar a arrumacao e depuracao do recurso.
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 83

Categoria Simples Multipalavra Total
Substantivo 52.599 3.334 55.933Verbo 10.195 13.866 24.061
Adjectivo 21.000 1 21.001Adverbio 1.390 0 1.390
Tabela 3: Distribuicao dos items por categoriagramatical, no PAPEL 2.0
substantivos. Durante este processo, os casosdas palavras flexionadas sao tambem substituıdospelos seus lemas, quando essa informacao e dadapelo Jspell.
3.2 Conteudos
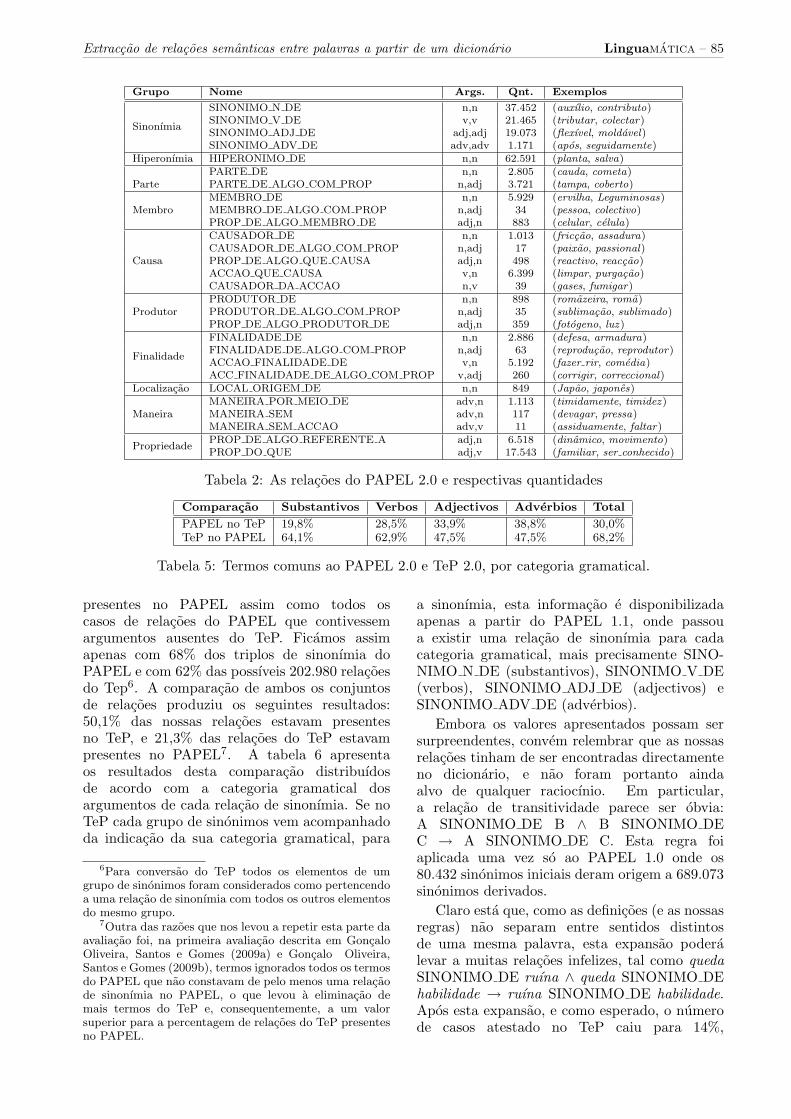
Apos realizadas as quatro fases da sua cons-trucao, a versao actual do PAPEL, 2.0, contemperto de 100.000 items lexicais, cujas categoriasgramaticais se distribuem de acordo com atabela 3, e perto de 200.000 relacoes, distribuıdasde acordo com a tabela 2. A sinonımia e ahiperonımia sao as relacoes mais frequentes, eainda podem ser aumentadas, como discutiremosabaixo, de uma forma semelhante ao feito noReRelEM (Freitas et al., 2008; Freitas et al.,2009).
Como tambem podemos ver na tabela 3, amaior parte dos itens lexicais sao expressoesde uma unica palavra. No entanto, o PAPELtambem inclui expressoes multipalavra, em casoscomo os seguintes:
• Substantivos seguidos das preposicoesde/do/dos/da/das e de uma outra palavra(e.g. sistema de rodas, dispositivo de mira);
• Verbos com o seu objecto directo (e.g. abriro apetite, produzir som);
4 Avaliacao do PAPEL
Aqui descrevemos uma avaliacao inicial doPAPEL, feita de duas formas diferentes: asrelacoes de sinonımia foram comparadas comas relacoes representadas num thesaurus para oportugues, enquanto que as restantes relacoes,apenas entre substantivos, foram validadasatraves das sua transformacao em padroestextuais e procura em texto por esses padroes.
Esta avaliacao foi incialmente feita sobre aprimeira versao publica do PAPEL (1.0) e osseus resultados publicados em Goncalo Oliveira,Santos e Gomes (2009b), junto com uma primeiramotivacao para o procedimento usado. Noentanto na versao 1.0 do PAPEL existia apenasum tipo de relacao de sinonımia, e nao umtipo para cada categoria gramatical, o quenao permitiu uma comparacao com base nesteponto. Sendo assim, partes dessa avaliacao
foram repetidas para a versao 2.0 do PAPEL ecompletadas com uma avaliacao da cobertura doPAPEL, com a qual iniciamos esta seccao. Noque diz respeito a avaliacao das demais relacoes,tal como a parte nao repetida da avaliacao dasinonımia, calculamos que os valores nao teraosofrido grandes alteracoes, por isso repetimosaqui os valores obtidos para a versao 1.0 doPAPEL.
Nas duas primeiras avaliacoes apresentadasa seguir, o TeP foi utilizado como recurso dereferencia, nao so por ser possıvel levanta-lo narede, mas tambem por se tratar de um recursocriado manualmente e que, tal como o PAPEL,pretende abranger toda a lıngua. Ainda assim,estamos conscientes das varias diferencas entreas variantes de portugues. O TeP 2.0 contem19.888 nos, ou seja grupos de unidades lexicaiscom o mesmo sentido, correspondendo a 43.118unidades lexicais (tambem designadas por termosneste artigo) ao todo.
4.1 Avaliacao da cobertura
Esta avaliacao teve como objectivo verificarquantos termos do TeP se encontravam tambemno PAPEL e vice-versa. Ao fim de compararambos os recursos, verificamos que existiam28.971 termos comuns a ambos os recursos, oque corresponde a 30,0% dos termos do PAPELe 68,2% dos termos do TeP.
Mais dados desta comparacao podem serconsultados nas tabelas 4 e 5 onde, respectiva-mente, se encontram os resultados separados portermos simples e multipalavra, ou a proporcaode termos comuns de acordo com a sua categoriagramatical. Tal como tambem e frisadopor Santos et al. (2010), estes resultadosrevelam que, apesar de ambos os recursosterem o mesmo objectivo procurarem representara mesma realidade, acabam por ser bastantecomplementares.
A tıtulo de curiosidade, indicamos ainda queos unicos tres termos multipalavra comuns aoPAPEL e ao TeP sao: corrente de ar, pena demorte e ainda tremor de terra.
Recurso Simples Multipalavra Total
PAPEL 79.337 82,2% 17.201 17,8% 96.538TeP 42.777 99,2% 341 0,8% 43.118Ambos 28.971 100% 3 0% 28.974
Tabela 4: Termos no PAPEL 2.0 e TeP 2.0.
4.2 Avaliacao da sinonımia
Para que a avaliacao da sinonımia pudesse prosse-guir sem enviesamento, comecamos por retirar dacomparacao os termos do TeP que nao estivessem
84– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes
Grupo Nome Args. Qnt. Exemplos
Sinonımia
SINONIMO N DE n,n 37.452 (auxılio, contributo)SINONIMO V DE v,v 21.465 (tributar, colectar)SINONIMO ADJ DE adj,adj 19.073 (flexıvel, moldavel)SINONIMO ADV DE adv,adv 1.171 (apos, seguidamente)
Hiperonımia HIPERONIMO DE n,n 62.591 (planta, salva)
PartePARTE DE n,n 2.805 (cauda, cometa)PARTE DE ALGO COM PROP n,adj 3.721 (tampa, coberto)
MembroMEMBRO DE n,n 5.929 (ervilha, Leguminosas)MEMBRO DE ALGO COM PROP n,adj 34 (pessoa, colectivo)PROP DE ALGO MEMBRO DE adj,n 883 (celular, celula)
Causa
CAUSADOR DE n,n 1.013 (friccao, assadura)CAUSADOR DE ALGO COM PROP n,adj 17 (paixao, passional)PROP DE ALGO QUE CAUSA adj,n 498 (reactivo, reaccao)ACCAO QUE CAUSA v,n 6.399 (limpar, purgacao)CAUSADOR DA ACCAO n,v 39 (gases, fumigar)
ProdutorPRODUTOR DE n,n 898 (romazeira, roma)PRODUTOR DE ALGO COM PROP n,adj 35 (sublimacao, sublimado)PROP DE ALGO PRODUTOR DE adj,n 359 (fotogeno, luz )
Finalidade
FINALIDADE DE n,n 2.886 (defesa, armadura)FINALIDADE DE ALGO COM PROP n,adj 63 (reproducao, reprodutor)ACCAO FINALIDADE DE v,n 5.192 (fazer rir, comedia)ACC FINALIDADE DE ALGO COM PROP v,adj 260 (corrigir, correccional)
Localizacao LOCAL ORIGEM DE n,n 849 (Japao, japones)
ManeiraMANEIRA POR MEIO DE adv,n 1.113 (timidamente, timidez )MANEIRA SEM adv,n 117 (devagar, pressa)MANEIRA SEM ACCAO adv,v 11 (assiduamente, faltar)
PropriedadePROP DE ALGO REFERENTE A adj,n 6.518 (dinamico, movimento)PROP DO QUE adj,v 17.543 (familiar, ser conhecido)
Tabela 2: As relacoes do PAPEL 2.0 e respectivas quantidades
Comparacao Substantivos Verbos Adjectivos Adverbios Total
PAPEL no TeP 19,8% 28,5% 33,9% 38,8% 30,0%TeP no PAPEL 64,1% 62,9% 47,5% 47,5% 68,2%
Tabela 5: Termos comuns ao PAPEL 2.0 e TeP 2.0, por categoria gramatical.
presentes no PAPEL assim como todos oscasos de relacoes do PAPEL que contivessemargumentos ausentes do TeP. Ficamos assimapenas com 68% dos triplos de sinonımia doPAPEL e com 62% das possıveis 202.980 relacoesdo Tep6. A comparacao de ambos os conjuntosde relacoes produziu os seguintes resultados:50,1% das nossas relacoes estavam presentesno TeP, e 21,3% das relacoes do TeP estavampresentes no PAPEL7. A tabela 6 apresentaos resultados desta comparacao distribuıdosde acordo com a categoria gramatical dosargumentos de cada relacao de sinonımia. Se noTeP cada grupo de sinonimos vem acompanhadoda indicacao da sua categoria gramatical, para
6Para conversao do TeP todos os elementos de umgrupo de sinonimos foram considerados como pertencendoa uma relacao de sinonımia com todos os outros elementosdo mesmo grupo.
7Outra das razoes que nos levou a repetir esta parte daavaliacao foi, na primeira avaliacao descrita em GoncaloOliveira, Santos e Gomes (2009a) e Goncalo Oliveira,Santos e Gomes (2009b), termos ignorados todos os termosdo PAPEL que nao constavam de pelo menos uma relacaode sinonımia no PAPEL, o que levou a eliminacao demais termos do TeP e, consequentemente, a um valorsuperior para a percentagem de relacoes do TeP presentesno PAPEL.
a sinonımia, esta informacao e disponibilizadaapenas a partir do PAPEL 1.1, onde passoua existir uma relacao de sinonımia para cadacategoria gramatical, mais precisamente SINO-NIMO N DE (substantivos), SINONIMO V DE(verbos), SINONIMO ADJ DE (adjectivos) eSINONIMO ADV DE (adverbios).
Embora os valores apresentados possam sersurpreendentes, convem relembrar que as nossasrelacoes tinham de ser encontradas directamenteno dicionario, e nao foram portanto aindaalvo de qualquer raciocınio. Em particular,a relacao de transitividade parece ser obvia:A SINONIMO DE B ∧ B SINONIMO DEC → A SINONIMO DE C. Esta regra foiaplicada uma vez so ao PAPEL 1.0 onde os80.432 sinonimos iniciais deram origem a 689.073sinonimos derivados.
Claro esta que, como as definicoes (e as nossasregras) nao separam entre sentidos distintosde uma mesma palavra, esta expansao poderalevar a muitas relacoes infelizes, tal como quedaSINONIMO DE ruına ∧ queda SINONIMO DEhabilidade → ruına SINONIMO DE habilidade.Apos esta expansao, e como esperado, o numerode casos atestado no TeP caiu para 14%,
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 85

contudo, 90% das relacoes no TeP puderamser encontradas no PAPEL 1.0. Fica assimdemonstrado que a combinacao dos dois recursospermite nao so melhorar ambos como separar otrigo do joio e mesmo alertar automaticamentepara palavras com varios sentidos.
4.3 Avaliacao das demais relacoes
Em relacao as outras relacoes, e na impos-sibilidade de comparar automaticamente comoutros recursos para o portugues, tivemos dedesenvolver uma metodologia diferente, inspiradanos varios trabalhos de extraccao automatica derelacoes semanticas em texto, ou de validacao dasmesmas em texto.
Para os nossos testes usamos o CE-TEMPublico (Rocha e Santos, 2000), atravesda interface do projecto AC/DC (Santos eBick, 2000; Santos e Sarmento, 2003; Costa,Santos e Rocha, 2009; Santos, 2009). Esteservico permitiu-nos alem disso ter acesso asfrequencias dos lemas respectivos. O trabalhorealizado tem de ser considerado preliminar, jaque, devido a limitacoes de ocorrencia de muitasdas unidades lexicais nos corpos que usamos, naotivemos possibilidade de as testar. Com efeito,nao so muitas das palavras no PAPEL eramdemasiado raras ou especializadas, como cedonos demos conta que em texto jornalıstico seriaquase impossıvel encontrar num mesmo contexto(numa mesma frase) pares ou relacoes como liqui-dar ACCAO QUE CAUSA liquidacao, fosforoPARTE DE ALGO COM PROPRIEDADE fos-foroso, visto que sao caracterısticos de textodicionarıstico ou enciclopedico.
Restringimos assim o processo de validacao,em primeiro lugar, apenas a relacoes entresubstantivos, e, alem disso, retiramos do testeas relacoes que envolvessem palavras cujos lemasestivessem ausentes do CETEMPublico. Mesmoassim, e por questoes de sobrecarga do servico,para as duas relacoes mais populosas do PAPEL,hiperonımia e meronımia, ainda escolhemosuma amostra aleatoria de relacoes a testar,correspondente respectivamente a 8% e 63% doscasos. Os resultados encontram-se na tabela 8.
Cerca de 20% destas relacoes parecem ser va-lidadas ou confirmadas pelo corpo, enquanto quea percentagem e menor para as outras relacoes.Estes resultados parecem-nos satisfatorios, tendoem conta que: o corpo e bastante pequeno; ospadroes usados foram muito simples (em textoreal ha uma mirıade de outras possibilidadesde indicar uma relacao); e os nossos valoresnao se encontram demasiado longe daquelesapresentados na literatura de confirmacao.
De qualquer maneira, e para mostrarmos queesta confirmacao esta longe de ser definitiva oumesmo conclusiva, na tabela 7 apresentamosalguns exemplos, quer de confirmacao certa querde espuria (ou seja, parecem confirmar mas naoo fazem).
Casos que nao foram confirmados emboraexistam ambas as palavras no CETEMPublicosao, por exemplo, fruto HIPERONIMO DEalperce, algoritmia PARTE DE matematica,ausencia CAUSADOR DE saudade, tamareiraPRODUTOR DE tamara, e aquecimento FINA-LIDADE DE salamandra.
5 Ferramentas
Esta seccao apresenta duas ferramentas associa-das ao PAPEL, para a sua exploracao e validacao.
5.1 Folheador
O Folheador e uma interface na rede desenvolvidapara navegar num conjunto de relacoes, comoas do PAPEL, depois de carregadas numa basede dados. Este sistema encontra-se actualmenteinstalado no URL http://sancho.dei.uc.pt/folheador/ e permite fazer procuras no PAPEL.
O seu funcionamento e muito simples: bastaprocurar por uma palavra e o sistema respondecom uma lista de todas as relacoes onde essapalavra entra. Se a palavra tiver mais de umacategoria gramatical possıvel, as relacoes saoseparadas de acordo com a categoria gramatical.Alem disso, e possıvel filtrar o resultado por tipode relacao e ainda, ao clicar nas palavras emargumentos das relacoes apresentadas, verificartodas as relacoes onde estas ultimas estejamenvolvidas. Na figura 3 e apresentada umaimagem do Folheador, depois de procurar pelapalavra vencedor.
5.2 VARRA
Para permitir uma validacao mais pormeno-rizada das relacoes presentes no PAPEL – epossivelmente noutros recursos – desenvolvemoso VARRA (Validacao, Avaliacao e Revisaode Relacoes no AC/DC), em conjunto com oprojecto AC/DC, de forma a obter julgamentosmais completos em relacao a seguinte questao:dado um triplo e uma possıvel frase que o ilustrae consequenetemente valida, obtida automatica-mente dos corpos do AC/DC, pedimos as pessoasque escolham uma das seis possıveis alternativas:
1. Relacao claramente incorrecta. Passe afrente
2. Relacao possivelmente correcta. O textoilustra a relacao entre as duas palavras?
86– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

Comparacao Substantivos Verbos Adjectivos Adverbios Total
PAPEL no TeP 47,6% 52,0% 53,4% 54,3% 50,1%TeP no PAPEL 28,4% 15,2% 24,4% 36,6% 21,3%
Tabela 6: Triplos comuns ao PAPEL 2.0 e TeP 2.0, por categoria gramatical.
Relacao Certa? Justificacao
lıngua HIPERONIMO DE italiano Sim As lınguas latinas, como o italiano ou o portugues, tornam-se mais faceis por causa das vogais.
arbusto PARTE DE floresta Sim A floresta e um conjunto de arvores, arbustos e ervas devarias qualidades e tamanhos.
colera CAUSADOR DE diarreia Sim A colera provoca fortes diarreias e vomitos e pode levar adesidratacao e, consequentemente, a morte em poucas horas.
oliveira PRODUTOR DE azeitona Sim Tambem a quantidade e tamanho das azeitonas produzidaspor uma oliveira biologica e inferior, ja que nao sao utilizadoscompostos de azoto que ajudam a planta a crescer.
recrutamento FINALIDADE DE inspeccao Sim Menos de metade dos jovens entre os 20 e os 22 anosapresentaram-se as inspeccoes para recrutamento, revelou oministro da Defesa.
musico PARTE DE musica Nao ... um espectaculo baseado na obra ”Cantos de Maldoror”,de Lautreamont, com musica composta pelo musico inglesSteven Severin...
fim FINALIDADE DE sempre Nao Sicilia aponta sempre para o fim do dia, para o fim da luz.
Tabela 7: Exemplos de validacao automatica do PAPEL 1.0 atraves do CETEMPublico (republicadosde Goncalo Oliveira, Santos e Gomes (2009a)).
Figura 3: Resultados para a procura pela palavravencedor, no Folheador.
(a) Sim
(b) Nao... E compatıvel mas nao exacta-mente.
(c) Nao... O texto e completamente naorelacionado.
(d) Nao... Pelo contrario, invalida-a.
(e) Nao sei
Esse servico, acessıvel a partir de http://www.linguateca.pt/ACDC/, e ilustrado na figura 4e encontra-se presentemente em fase de teste.Futuramente pretendemos alarga-lo de formaa que sirva tambem para avaliar outro tipode recursos e de padroes de procura, alem de
poder ser usado pedagogicamente na formacaode alunos na area de linguıstica com corpos.
6 Consideracoes finais
Apresentamos neste artigo um novo recursolexical para o portugues, o PAPEL, que podeser levantado integralmente no endereco acimacitado, junto com ampla documentacao sobreo mesmo. Tambem apresentamos algumasferramentas relacionadas com este recurso. Estaprimeira abordagem a avaliacao do PAPEL, ape-sar de bastante preliminar, pode ser interessantecomo exemplo de avaliacao, tambem para outrosrecursos.
Esperamos que em breve possamos tambemreferir trabalho de outros investigadores a usare a melhorar este recurso, que e para serpropriedade comum de todos os investigadorese desenvolvedores na area do processamentoda lıngua portuguesa. Para nossa satisfacaopodemos relatar que ja foi levantado por variosgrupos alguns dos quais nos deram retorno.
Salientamos novamente que o PAPEL naopretende ser um recurso final, mas sim umponto de partida para futuros projectos, que opoderao enriquecer recorrendo a outras fontes deinformacao.
Por exemplo, e visto que o TeP foi criado amao, um processo relativamente facil de melhoraro PAPEL seria apenas juntar-lhe (ao PAPEL) asrelacoes de sinonımia obtidas por transitividade(as 12%) que eram validadas no TeP, ou pelomenos a informacao adicional de “concordancia”com outros recursos.
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 87

Relacao Relacoes c/ args no CETEMPublico % Amostra % Encontradas %
Hiperonımia 40.079 63% 3.145 8% 560 18%Meronımia 3.746 35% 2.343 63% 521 22%Causa 557 50% 557 100% 20 4%Produtor 414 44% 414 100% 12 3%Finalidade 1.718 59% 1.718 100% 173 10%
Tabela 8: Resultados da validacao das relacoes excepto sinonımia (republicados de Goncalo Oliveira,Santos e Gomes (2009a)).
Figura 4: Exemplo de resultados da invocacao do VARRA
Pretendemos no futuro continuar a melhoraro conteudo do PAPEL atraves da obtencao denovos dados na rede assim como aperfeicoar avalidacao dos ja presentes.
Uma melhoria obvia que em breve implemen-taremos e a associacao de um grau de certeza,assim como um conjunto de validacao, a cadatriplo, veja-se Wandmacher et al. (2007).
Outro caminho a explorar sera adaptar aoportugues a metodologia proposta e testadaem Rigau, Rodrıguez e Agirre (1998) para ocastelhano a partir da WordNet para o ingles ede um dicionario bilingue, conforme sugerido porLluis Padro.
Finalmente, gostarıamos tambem de poder as-sociar a novas versoes do PAPEL um conjunto deferramentas simples para o processar, conformesugestao do Alberto Simoes.
Agradecimentos
Agradecemos a Claudia Freitas a colaboracaopreciosa no desenho do sistema VARRA, e atodos os co-autores do artigo de comparacao de
ontologias: Anabela Barreiro, Claudia Freitas,Jose Carlos Medeiros, Luıs Costa e Rosario Silva,as discussoes ferteis e o trabalho realizado.
Agradecemos tambem ao grupo de R&Dda Porto Editora a colaboracao na criacaodo PAPEL, ao CLIC e a Violeta Quentala colaboracao com a PUC-Rio, assim comoao Nuno Seco a sua anterior participacao noprojecto.
O projecto PAPEL foi desenvolvido no ambitoda Linguateca, co-financiada pelo GovernoPortugues, pela Uniao Europeia (FEDER eFSE), sob o contrato POSC/339/1.3/C/NAC,pela UMIC e pela FCCN.
Hugo Goncalo Oliveira e actualmente financi-ado pela FCT, bolsa SFRH/BD/44955/2008.
Agradecemos aos tres parceristas da Lin-guamatica, Lluis Padro, Gerardo Sierra e AlbertoSimoes, as suas recensoes e comentarios, que, senao foram todos levados em conta na presenteversao por falta de tempo, muito contribuiraopara uma melhoria significativa do projecto doPAPEL no futuro.
88– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

Referncias
Afonso, Susana. 2009. Uma FrameNet parao portugues, 29 de Junho - 3 de Julho,2009. Apresentacao na Escola de VeraoBelinda Maia (Edv 2009), Porto, Portugal,http://www.linguateca.pt/Repositorio/AfonsoFrameNetEdV2009.pdf.
Alshawi, Hiyan. 1989. Analysing the dictionarydefinitions. Em Bran Boguraev e TedBriscoe, editores, Computational lexicographyfor natural language processing, pp. 153–169, Nova Iorque, EUA. Longman PublishingGroup.
Amsler, Robert A. 1981. A taxonomy forenglish nouns and verbs. Em Proceedingsof the 19th annual meeting on Associationfor Computational Linguistics, pp. 133–138, Morristown, NJ, EUA. Association forComputational Linguistics.
Baker, Collin F., Charles J. Fillmore, e John B.Lowe. 1998. The Berkeley FrameNet Project.Em Proceedings of the 17th InternationalConference on Computational linguistics, pp.86–90, Morristown, NJ, EUA. Association forComputational Linguistics.
Barreiro, Anabela. No prelo. Port4NooJ:an open source, ontology-driven Portugueselinguistic system with applications in machinetranslation. Em Max Silberztein e TamasVaradi, editores, Proceedings of the 2008International NooJ Conference (NooJ’08),Cambridge, Reino Unido. Cambridge ScholarsPublishing.
Barreiro, Anabela, Luzia Helena Wittmann, eMaria de Jesus Pereira. 1996. Lexicaldifferences between European and BrazilianPortuguese. INESC Journal of Research andDevelopment, 5(2):75–101.
Berland, Matthew e Eugene Charniak. 1999.Finding parts in very large corpora. EmProceedings of the 37th Annual Meeting ofthe ACL on Computational Linguistics, pp.57–64, Morristown, NJ, EUA. Association forComputational Linguistics.
Brank, Janez, Marko Grobelnik, e DunjaMladenic. 2005. A survey of ontologyevaluation techniques. Em Proceedings of the8th International Conference on Data Miningand Data Warehouses (SiKDD), pp. 166–169.
Brewster, Christopher, Harith Alani, SrinandanDasmahapatra, e Yorick Wilks. 2004. Data-driven ontology evaluation. Em Maria Teresa
Lino, Maria Francisca Xavier, Fatima Fer-reira, Rute Costa, e Raquel Silva, editores,Proceedings of the 4th International Confe-rence on Language Resources and Evaluation(LREC’2004), pp. 164–168, Lisboa, Portugal,26-28 de Maio, 2004. European LanguageResources Association.
Briscoe, Ted. 1991. Lexical issues in naturallanguage processing. Em Ewan Klein e FrankVeltman, editores, Natural Language andSpeech: Symposium Proceedings. Springer,Berlim e Heidelberg, Alemanha, pp. 39–68.
Calzolari, Nicoletta, Laura Pecchia, e AntonioZampolli. 1973. Working on the Italianmachine dictionary: a semantic approach. EmProceedings of the 5th conference on Com-putational linguistics, pp. 49–52, Morristown,NJ, EUA. Association for ComputationalLinguistics.
Caraballo, Sharon A. 1999. Automaticconstruction of a hypernym-labeled nounhierarchy from text. Em Proceedings of the37th annual meeting of the ACL on Computa-tional Linguistics, pp. 120–126, Morristown,NJ, EUA. Association for ComputationalLinguistics.
Chaves, Marcirio Silveira. 2009. Uma Meto-dologia para Construcao de Geo-Ontologias.Tese de doutoramento, Faculdade de Ciencias,Universidade de Lisboa, Setembro, 2009.
Chodorow, Martin S., Roy J. Byrd, e George E.Heidorn. 1985. Extracting semantichierarchies from a large on-line dictionary.Em Proceedings of the 23rd annual meetingon Association for Computational Linguistics,pp. 299–304, Morristown, NJ, EUA. Associa-tion for Computational Linguistics.
Costa, Luıs, Diana Santos, e Paulo AlexandreRocha. 2009. Estudando o portugues talcomo e usado: o servico AC/DC. Em The7th Brazilian Symposium in Information andHuman Language Technology (STIL 2009), 8-11 de Setembro, 2009.
Costa, Rui P. e Nuno Seco. 2008. HyponymyExtraction and Web Search Behavior AnalysisBased on Query Reformulation. Em Pro-ceedings of the 11th Ibero-American Confe-rence on Artificial Intelligence (IBERAMIA),LNAI, pp. 332–341. Springer.
Cuadros, Montse e German Rigau. 2006. Qualityassessment of large scale knowledge resources.Em Proceedings of the 2006 Conferenceon Empirical Methods in Natural Language
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 89

Processing, pp. 534–541, Sydney, Australia,Julho, 2006. Association for ComputationalLinguistics.
Dahlgren, Kathleen. 1995. A linguisticontology. International Journal Human-Computer Studies, 43(5-6):809–818.
Demetriou, George e Eric Steven Atwell. 2001.A Domain-Independent Semantic Tagger forthe Study of Meaning Associations in EnglishText. Em Proceedings of the 4th Internati-onal Workshop on Computational Semantics(IWCS-4), pp. 67–80, 10-12 de Janeiro, 2001.
Dias da Silva, Bento C., Mirna Oliveira, eHelio Moraes. 2002. Groundwork forthe Development of the Brazilian PortugueseWordnet. Em Nuno Mamede e ElisabeteRanchhod, editores, Advances in NaturalLanguage Processing: Third InternationalConference, PorTAL 2002, Faro, Portugal,Junho 2002, Proceedings, volume 2389 ofLNAI, pp. 189–196. Springer.
Dias-Da-Silva, Bento Carlos e Helio Roberto deMoraes. 2003. A construcao de um thesauruseletronico para o portugues do Brasil. ALFA,47(2):101–115.
2005. Dicionario PRO da Lıngua Portuguesa.Porto Editora, Porto.
Dolan, William B. 1994. Word senseambiguation: clustering related senses. EmProceedings of the 15th conference on Compu-tational linguistics, pp. 712–716, Morristown,NJ, EUA. Association for ComputationalLinguistics.
Dorow, Beate. 2006. A Graph Model for Wordsand their Meanings. Tese de doutoramento,Institut fur Maschinelle Sprachverarbeitungder Universitat Stuttgart.
Edmonds, Philip e Graeme Hirst. 2002. Near-synonymy and lexical choice. ComputationalLinguistics, 28(2):105–144.
Etzioni, Oren, Michael Cafarella, Doug Downey,Ana-Maria Popescu, Tal Shaked, StephenSoderland, Daniel S. Weld, e AlexanderYates. 2005. Unsupervised named-entityextraction from the web: an experimentalstudy. Artificial Intelligence, 165(1):91–134.
Fellbaum, Christiane, editor. 1998. WordNet:An Electronic Lexical Database (Language,Speech, and Communication). The MITPress, Maio, 1998.
Fillmore, Charles J. 1982. Frame semantics. EmLinguistic Society of Korea, editor, Linguistics
in the morning calm. Hanshin Publishing Co.,Seoul, Coreia do Sul, pp. 111–137.
Freitas, Claudia e Violeta Quental. 2007.Subsıdios para a elaboracao automatica detaxonomias. Em Actas do XXVII Congressoda SBC - V Workshop em Tecnologia daInformacao e da Linguagem Humana (TIL),pp. 1585–1594.
Freitas, Claudia, Diana Santos, Cristina Mota,Hugo Goncalo Oliveira, e Paula Carvalho.2009. Detection of relations between namedentities: report of a shared task. EmProceedings of the NAACL HLT Workshop onSemantic Evaluations: Recent Achievementsand Future Directions, SEW-2009, pp. 129–137, Boulder, Colorado, EUA, 4 de Junho,2009.
Freitas, Claudia, Diana Santos, Hugo GoncaloOliveira, Paula Carvalho, e Cristina Mota.2008. Relacoes semanticas do ReRelEM:alem das entidades no Segundo HAREM.Em Cristina Mota, Diana Santos, CristinaMota, e Diana Santos, editores, Desafiosna avaliacao conjunta do reconhecimento deentidades mencionadas. Linguateca, pp. 77–96, 31 de Dezembro, 2008.
Girju, Roxana e Dan Moldovan. 2002. Textmining for causal relations. Em Susan M.Haller e Gene Simmons, editores, Proceedingsof the 15th International Florida Artifi-cial Intelligence Research Society Conference(FLAIRS), pp. 360–364.
Goncalo Oliveira, Hugo, Diana Santos, PauloGomes, e Nuno Seco. 2008. PA-PEL: a dictionary-based lexical ontologyfor Portuguese. Em Antonio Teixeira,Vera Lucia Strube de Lima, Luıs Caldasde Oliveira, e Paulo Quaresma, editores,Computational Processing of the PortugueseLanguage, 8th International Conference, Pro-ceedings (PROPOR 2008), volume 5190 ofLNAI, pp. 31–40. Springer.
Goncalo Oliveira, Hugo e Paulo Gomes.2008a. Apresentacao das relacoesextraıdas do Dicionario da Porto Editora.Relatorio tecnico, CISUC, Dezembro,2008. Relatorio do PAPEL num. 4,http://linguateca.dei.uc.pt/papel/GoncaloOliveiraetal2008relPAPEL4.pdf.
Goncalo Oliveira, Hugo e Paulo Gomes. 2008b.Utilizacao do (analisador sintactico) PENpara extraccao de informacao das definicoesde um dicionario. Relatorio tecnico, CISUC,Novembro, 2008. Relatorio do PAPEL num.
90– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

3, http://linguateca.dei.uc.pt/papel/GoncaloOliveiraetal2008relPAPEL3.pdf.
Goncalo Oliveira, Hugo, Diana Santos, e PauloGomes. 2009a. Avaliacao da extraccao derelacoes semanticas entre palavras portugue-sas a partir de um dicionario. Em The7th Brazilian Symposium in Information andHuman Language Technology (STIL 2009),8-11 de Setembro, 2009. Versao inicial dopresente artigo.
Goncalo Oliveira, Hugo, Diana Santos, e PauloGomes. 2009b. Relations extracted froma Portuguese dictionary: results and firstevaluation. Em Luıs Seabra Lopes, Nuno Lau,Pedro Mariano, e Luıs M. Rocha, editores,New Trends in Artificial Intelligence, LocalProceedings of the 14th Portuguese Conferenceon Artificial Intelligence (EPIA 2009), pp.541–552, Aveiro, Portugal, 12-15 de Outubro,2009.
Gruber, Thomas R. 1993. A translationapproach to portable ontology specifications.Knowledge Acquisition, 5(2):199–220.
Hearst, Marti A. 1992. Automatic acquisitionof hyponyms from large text corpora. EmProceedings of 14th conference on Computa-tional linguistics, pp. 539–545, Morristown,NJ, EUA. Association for ComputationalLinguistics.
Herbelot, Aurelie e Ann Copestake. 2006.Acquiring Ontological Relationships fromWikipedia Using RMRS. Em Proceedings ofthe ISWC 2006 Workshop on Web ContentMining with Human Language Technologies,Athens, GA, EUA, 6 de Novembro, 2006.
Hirst, Graeme. 2004. Ontology and the lexicon.Em Steffen Staab e Rudi Studer, editores,Handbook on Ontologies. Springer, pp. 209–230.
Ide, Nancy e Jean Veronis. 1995. Knowledgeextraction from machine-readable dictiona-ries: An evaluation. Em Petra Steffens,editor, Proceedings of Machine Translationand the Lexicon, Third International EAMTWorkshop, Heidelberg, Germany, 26-28 April,1993, pp. 19–34. Springer.
Kilgarriff, Adam. 1996. Word senses are notbona fide objects: implications for cognitivescience, formal semantics, NLP. Em Pro-ceedings of the 5th International Conferenceon the Cognitive Science of Natural LanguageProcessing, pp. 193–200, Dublin, Irlanda.
Kilgarriff, Adam. 1997. “I don’t believe inword senses”. Computing and the Humanities,31(2):91–113.
Lenat, Douglas B. 1995. Cyc: a large-scale investment in knowledge infrastructure.Communications of the ACM, 38(11):33–38.
Liu, H. e P. Singh. 2004. Conceptnet: Apractical commonsense reasoning toolkit. BTTechnology Journal, 22(4):211–226.
Marcellino, Erasmo Roberto e Bento Dias daSilva. 2009. Sistematizacao linguıstico-computacional do lexico do domınio concei-tual Industria do Bordado de Ibitinga. EmThe 7th Brazilian Symposium in Informationand Human Language Technology (STIL2009), 8-11 de Setembro, 2009.
Marrafa, Palmira. 2002. Portuguese WordNet:general architecture and internal semanticrelations. DELTA, 18:131–146.
Maziero, Erick G., Thiago A. S. Pardo, Ariani DiFelippo, e Bento C. Dias-da-Silva. 2008. ABase de Dados Lexical e a Interface Webdo TeP 2.0 - Thesaurus Eletronico para oPortugues do Brasil. Em VI Workshop emTecnologia da Informacao e da LinguagemHumana (TIL), pp. 390–392.
Medelyan, Olena, David Milne, Catherine Legg,e Ian H. Witten. 2009. Mining meaning fromWikipedia. International Journal of Human-Computer Studies, 67(9):716–754, Setembro,2009.
Montemagni, Simonetta e Lucy Vanderwende.1992. Structural patterns vs. string patternsfor extracting semantic information fromdictionaries. Em Proceedings of the 14thconference on Computational linguistics, pp.546–552, Morristown, NJ, EUA. Associationfor Computational Linguistics.
Navarro, Emmanuel, Franck Sajous, BrunoGaume, Laurent Prevot, ShuKai Hsieh,Tzu Y. Kuo, Pierre Magistry, e Chu R. Huang.2009. Wiktionary and NLP: Improvingsynonymy networks. Em Iryna Gurevyche Torsten Zesch, editores, Proceedings ofthe Workshop on The People’s Web MeetsNLP: Collaboratively Constructed SemanticResources, pp. 19–27, Suntec, Singapura.Association for Computational Linguistics.
Navigli, Roberto, Paola Velardi, Alessandro Cuc-chiarelli, e Francesca Neri. 2004. Quantitativeand qualitative evaluation of the ontolearnontology learning system. Em Proceedings of
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 91

the 20th International conference on Compu-tational Linguistics, Morristown, NJ, EUA.Association for Computational Linguistics.
Nichols, Eric, Francis Bond, e Dan Flickin-ger. 2005. Robust ontology acquisitionfrom machine-readable dictionaries. EmLeslie Pack Kaelbling e Alessandro Saffiotti,editores, Proceedings of the 19th InternationalJoint Conference on Artificial Intelligence(IJCAI), pp. 1111–1116. Professional BookCenter.
O’Hara, Thomas Paul. 2005. Empirical Acquisi-tion of Conceptual Distinctions via DictionaryDefinitions. Tese de doutoramento, NMSUCS, Agosto, 2005.
Pianta, Emanuele, Lusia Bentivogli, e ChristianGirardi. 2002. MultiWordNet: Developingan aligned multilingual database. EmProceedings of the 1st International WordNetConference, pp. 293–302, Mysore, India, 21-25de Janeiro, 2002.
Raman, J. e Pushpak Bhattacharyya. 2008.Towards Automatic Evaluation of WordnetSynsets. Em Attila Tanacs, Dora Csendes,Veronika Vincze, Christiane Fellbaum, e PiekVossen, editores, Proceedings of the 4th GlobalWordNet Conference (GWC 2008), Szeged,Hungria, 22-25 de Janeiro, 2008.
Richardson, Stephen D., William B. Dolan, eLucy Vanderwende. 1998. MindNet: ac-quiring and structuring semantic informationfrom text. Em Proceedings of the 17thInternational Conference on Computationallinguistics, pp. 1098–1102, Morristown, NJ,EUA, 10-14 de Agosto, 1998. Association forComputational Linguistics.
Richardson, Stephen D., Lucy Vanderwende, eWilliam Dolan. 1993. Combining dictionary-based and example-based methods for naturallanguage analysis. Em Proceedings of the 5thInternational Conference on Theoretical andMethodological Issues in Machine Translation,pp. 69–79, Kyoto, Japao.
Rigau, German, Horacio Rodrıguez, e EnekoAgirre. 1998. Building Accurate SemanticTaxonomies from Monolingual MRDs. EmProceedings of COLING-ACL’98, pp. 1103–1109.
Riloff, Ellen e Jessica Shepherd. 1997. Acorpus-based approach for building semanticlexicons. Em Proceedings of the 2ndConference on Empirical Methods in NaturalLanguage Processing, pp. 117–124.
Rocha, Paulo Alexandre e Diana Santos. 2000.CETEMPublico: Um corpus de grandesdimensoes de linguagem jornalıstica portu-guesa. Em Maria das Gracas Volpe Nunes,editor, V Encontro para o processamentocomputacional da lıngua portuguesa escrita efalada (PROPOR), pp. 131–140, Sao Paulo.ICMC/USP.
Salomao, Maria M. M. 2009. Framenet Brasil:Um trabalho em progresso. Calidoscopio,7(2).
Salton, G. e M. J. McGill. 1983. Introduction toModern Information Retrieval. McGraw-Hill,Nova Iorque, EUA.
Sampson, Geoffrey. 2000. Review of (Fellbaum,1998). International Journal of Lexicography,13(1):54–59.
Santos, Diana. 2006. What is naturallanguage? Differences compared to artificiallanguages, and consequences for naturallanguage processing. Palestra convidada noSBLP2006 e no PROPOR’2006, Itatiaia,RJ, Brasil, 15 de Maio de 2006, http://www.linguateca.pt/Diana/download/SantosPalestraSBLPPropor2006.pdf.
Santos, Diana. 2007. Evaluation in naturallanguage processing. Curso na EuropeanSummer School on Language, Logic andInformation ESSLLI, Dublin, Irlanda, 6-17 deAgosto, http://www.linguateca.pt/Diana/download/EvaluationESSLLI07.pdf.
Santos, Diana. 2009. Linguateca’s infrastructurefor Portuguese and how it allows thedetailed study of language varieties.Apresentacao no Workshop on researchinfrastructure for linguistic variation,Oslo, Noruega, 17-18 de Setembro, 2009,http://www.hf.uio.no/tekstlab/rilivs/slides/SantosRILiVS2009workshop.pdf.
Santos, Diana, Anabela Barreiro, LuısCosta, Claudia Freitas, Paulo Gomes,Hugo Goncalo Oliveira, Jose CarlosMedeiros, e Rosario Silva. 2009. O papeldas relacoes semanticas em portugues:Comparando o TeP, o MWN.PT e o PAPEL.Apresentacao no XXV Encontro Nacional daAssociacao Portuguesa de Linguıstica,Lisboa, Portugal, 22-24 de Outubro,2009, http://www.linguateca.pt/Diana/download/aprSantosetalAPL2009.pdf.
Santos, Diana, Anabela Barreiro, ClaudiaFreitas, Hugo Goncalo Oliveira, Jose CarlosMedeiros, Luıs Costa, Paulo Gomes, e Rosario
92– Linguamatica Hugo Goncalo Oliveira, Diana Santos & Paulo Gomes

Silva. 2010. Relacoes semanticas emportugues: comparando o TeP, o MWN.PT,o Port4NooJ e o PAPEL. Em Textosseleccionados apresentados ao XXV Encon-tro Nacional da Associacao Portuguesa deLinguıstica. Enviado para apreciacao.
Santos, Diana e Eckhard Bick. 2000. ProvidingInternet access to Portuguese corpora: theAC/DC project. Em Maria Gavrilidou,George Carayannis, Stella Markantonatou,Stelios Piperidis, e Gregory Stainhauer,editores, Proceedings of 2nd InternationalConference on Language Resources and Eva-luation (LREC), pp. 205–210, Atenas, Grecia,31 de Maio - 2 de Junho, 2000.
Santos, Diana e Luıs Sarmento. 2003. O projectoAC/DC: acesso a corpora/disponibilizacao decorpora. Em Amalia Mendes e Tiago Freitas,editores, Actas do XVIII Encontro Nacionalda Associacao Portuguesa de Linguıstica(APL 2002), pp. 705–717, Lisboa. APL.
Saussure, Ferdinand de. 1916. Cours deLinguistique Generale. Payot, Paris, Franca.Edicao empregue: 1972.
Scott, Bernard. 2003. The Logos Model: AnHistorical Perspective. Machine Translation,18(1):1–72.
Silberztein, Max e Tamas Varadi, editores. Noprelo. Proceedings of 2008 International NooJConference (NooJ’08), Cambridge, ReinoUnido. Cambridge Scholars Publishing.
Simoes, Alberto M. e Jose Joao Almeida. 2002.Jspell.pm – um modulo de analise morfologicapara uso em processamento de linguagemnatural. Em Actas do XVII Encontro daAssociacao Portuguesa de Linguıstica, pp.485–495, Lisboa, Portugal. APL.
Turney, Peter D. 2001. Mining the web forsynonyms: PMI–IR versus LSA on TOEFL.Em Luc De Raedt e Peter Flach, editores,Proceedings of the 12th European Conferenceon Machine Learning (ECML-2001), volume2167, pp. 491–502. Springer.
Vanderwende, Lucy, Gary Kacmarcik, HisamiSuzuki, e Arul Menezes. 2005. MindNet: AnAutomatically-Created Lexical Resource. EmProceedings of HLT/EMNLP on InteractiveDemonstrations, pp. 8–9. The Associationfor Computational Linguistics, 7 de Outubro,2005.
Veale, Tony. 2007. Enriched lexical ontologies:Adding new knowledge and new scope toold linguistic resources. Curso na European
Summer School on Language, Logic andInformation ESSLLI, Dublin, Irlanda, 6-17de Agosto, 2007, http://afflatus.ucd.ie/papers/Essilli_EnrichedLexiOnto.pdf.
Vossen, Piek. 1997. Eurowordnet: a multilingualdatabase for information retrieval. EmProceedings of the DELOS workshop on Cross-Language Information Retrieval, Zurique,Suıca, 5-7 de Marco, 1997.
Vossen, Piek, editor. 1998. EuroWordNet: AMultilingual Database with Lexical SemanticNetworks. Kluwer Academic Publishers,Dordrecht.
Wandmacher, Tonio, Ekaterina Ovchinnikova,Ulf Krumnack, e Henrik Dittmann. 2007.Extraction, evaluation and integration oflexical-semantic relations for the automatedconstruction of a lexical ontology. EmThomas Meyer e Abhaya C. Nayak, editores,3rd Australasian Ontology Workshop (AOW2007), volume 85 of CRPIT, pp. 61–69, GoldCoast, Australia. ACS.
Zesch, Torsten, Christof Muller, e IrynaGurevych. 2008. Using Wiktionaryfor computing semantic relatedness. EmA. Cohn, editor, Proceedings of the 23rdnational conference on Artificial intelligence,AAAI’08, pp. 861–866, Chicago, Illinois,EUA, 13-17 de Julho, 2008. AAAI Press.
Extraccao de relacoes semanticas entre palavras a partir de um dicionario Linguamatica – 93
Related Documents











