Exploring Tradeoffs in Failure Detection in P2P Networks Shelley Zhuang, Ion Stoica, Randy Katz HIIT Short Course August 18-20, 2003

Exploring Tradeoffs in Failure Detection in P2P Networks Shelley Zhuang, Ion Stoica, Randy Katz HIIT Short Course August 18-20, 2003.
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Exploring Tradeoffs in Failure Detection in P2P Networks
Shelley Zhuang, Ion Stoica, Randy KatzHIIT Short Course
August 18-20, 2003

Problem Statement
• One of the key challenges to achieve robustness in overlay networks: quickly detect a node failure
• Canonical solution: each node periodically pings its neighbors
• Propose keep-alive techniques• Study the fundamental limitations and tradeoffs
between detection time, control overhead, and probability of false positives

Outline
• Motivation
• Network Model and Assumptions
• Keep-alive Techniques
• Performance Evaluation
• Conclusion

Network Model and Assumptions
• P2P system with n nodes• Each node A knows d other nodes• Average path length = l• Node up-time ~ i.i.d. T = exponential(λf)• Failstop failures• If a neighbor is lost, a node can use another
neighbor to route the packet w/o affecting the path length

Packet Loss Probability
• δ = average time it takes a node to detect that a neighbor has failed
• Probability that a node forwards a packet to a neighbor that has failed is 1- e-λf δ δλf
P(T-t δ | Tt) = P(T<=δ)
• Probability that the packet is lost is pl lδλf
δT

Outline
• Motivation
• Network Model and Assumptions
• Keep-alive Techniques
• Performance Evaluation
• Conclusion

fl lp
2
2
Aliveness Techniques
• Baseline– Each node sends a ping message to each of its
neighbors every Δ seconds
A
B C
D

Aliveness Techniques• Information Sharing
– Piggyback failures of neighbors in acknowledgement messages
– Best case: completely connected graph of degree d
fld
dlp
d
d
log
log
B C
DA

Aliveness Techniques
• Boosting– When a node detects failure of a neighbor, D, it
announces to all other nodes that have D as their neighbor
– Best case: completely connected graph of degree d
fld
lp
d
1
1
B C
DA

Outline
• Motivation
• Network Model and Assumptions
• Keep-alive Techniques
• Performance Evaluation
• Conclusion

Performance Evaluation
• Case studies– d-regular network– Chord lookup protocol
• Chord event driven simulator– Gnutella join/leave trace– Packet loss rate– Control overhead
• Planetlab experiments– Planetlab event driven simulator– False positives

Loss Rate – Gnutella• Loss Rate = # Lookup timeouts / # Lookups• 20 lookups per second
Boosting (simple)- No additional state
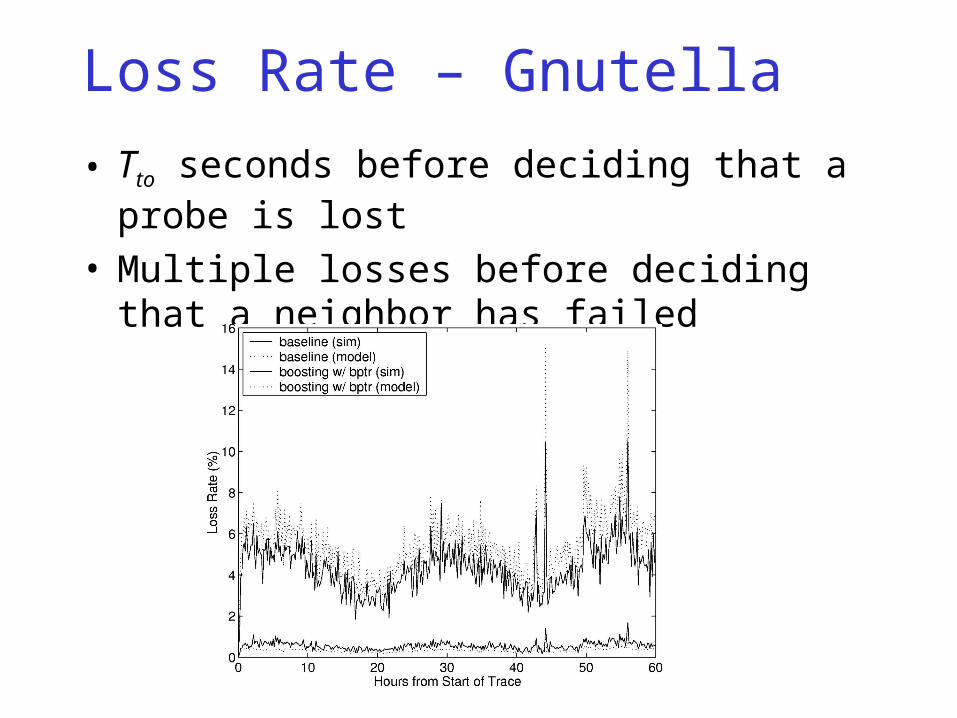
Loss Rate – Gnutella
• Tto seconds before deciding that a probe is lost
• Multiple losses before deciding that a neighbor has failed

Overhead (count) – Gnutella• Constant probing overhead (1 probe/second)
• Small difference due to boost messages

Overhead (bps) – Gnutella
• Boosting w/ bptr 1.29 times the baseline

Overhead (bps) – Gnutella
• Send backpointers every 10 probe acks

False Positive – Planetlab• Propagation of positive information
• Most false positives are of TO = 0, 1 increase probe timeout threshold

Overhead (bps) – Planetlab• Overhead from boost messages and positive information
correlate with the loss rate

Outline
• Motivation
• Network Model and Assumptions
• Keep-alive Techniques
• Performance Evaluation
• Conclusion

Conclusion
• Examined three keep-alive techniques in Chord with Gnutella join/leave trace
• By carefully designing keep-alive algorithms, it is possible to significantly reduce packet loss probability
• Probability of false positive for boosting with backpointer < 0.01 for loss rate ~ 8.6% by propagating positive information and increasing probe timeout threshold

Future Work
• Evaluate keep-alives schemes under massive failures and churn
• Optimal control resource allocation strategy for a given network topology, failure rate, and load distribution
• Other applications of keep-alive techniques?
Related Documents











