Exploiting Detachability Hashem H. Najaf-abadi Eric Rotenberg

Exploiting Detachability
Jan 01, 2016
Exploiting Detachability. Hashem H. Najaf-abadi Eric Rotenberg. Different jobs, Different tools. Different applications have different characteristics and therefore different resource needs. Therefore a single fixed architecture compromises the performance of the individual, - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Exploiting Detachability
Hashem H. Najaf-abadi
Eric Rotenberg

Different jobs, Different tools
• Different applications have different characteristics and therefore different resource needs.
• Therefore a single fixed architecture compromises the performance of the individual,
for the performance of all.

Architectural changeability (Transformation)
• In silicon-based technology;
performance of a changeable (polymorphic) design in a fixed configuration
is less thana non-changeable implementation of the same configuration.
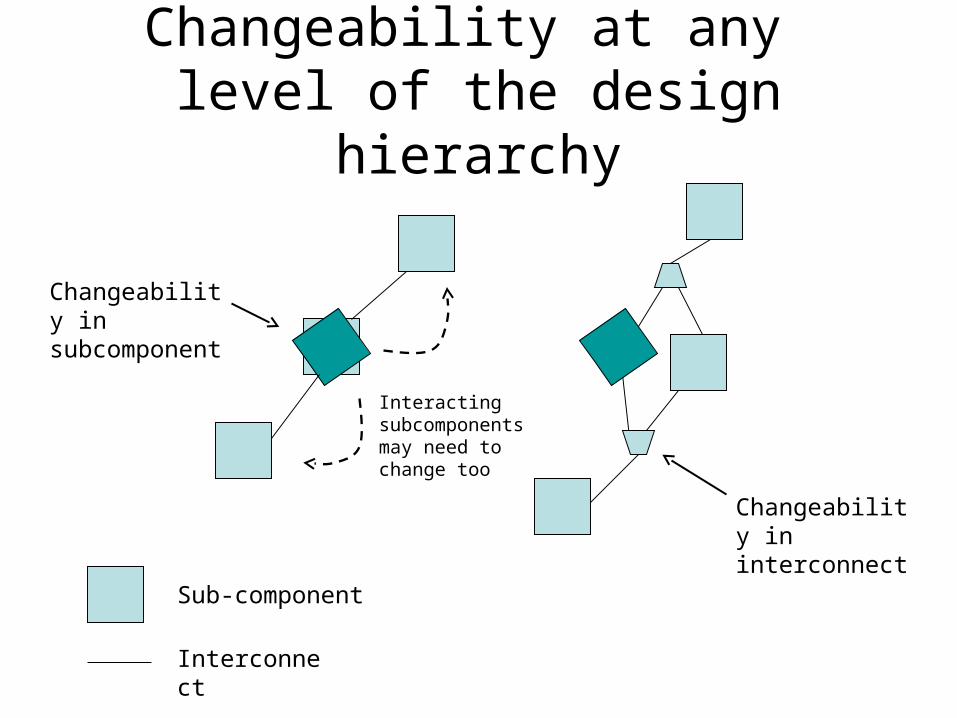
Changeability in subcomponent
Changeability at any level of the design hierarchy
Changeability in interconnect
Sub-component
Interconnect
Interacting subcomponents may need to change too

Changeability at logic-circuit level
• In an adder for instance;
F.A.F.A.F.A.F.A.
carry
• Or the bypasses;
F.U. F.U. F.U. F.U.

Changeability at the pipeline level
• In the execution for instance;
fetch
decode
dispatch
issue
execute
write-back
execute

Changeability at the processor level
L2 cache
Core A
Core B
Core C
• At least there’s no higher level for changeability to spread to.

Heterogeneity
• Pros: • No low-level changeability
• Cons:• Poor scalability (die area is consumed,
burdening access to system resources)
• Inflexible (once configurations are placed in the system, they are permanent,
while their need is user dependent)

Spread Heterogeneity to numerous chips
• Pros:• Increases the overall die area, thus
ameliorating the unscalability
• Cons:• Exacerbates the burdening of access to
system resources • Remains inflexible in the forms of
architectural diversity that are made available

Exploiting Detachability
• Detachability: a property that already exists (due to marketing and packaging issues).
• Pros:• No suboptimality due to limited die are or
burdening of access to system resources. • Flexible in the forms of architectural diversity

Exploiting Detachability
• Other advantages:
• A substrate for gradual employment of alternate technologies (which tend to be application dependent)
• A paradigm where architects can focus on innovations for enhancing architectures for specific applications, rather than tweaking the same old design.

Changeability in real world applications
• Rough automatic design-space exploration for the integer SPEC2000 benchmarks
• Randomly varied the L1 and L2 cache sizes, the processor width, issue queue size, and clock period.

Customization results
bzip gap gcc gzip mcf parser perl twolf vortex vpr crafty
No. mem. access cycles 345 345 345 345 278 323 228 298 328 183 302
No. front-end cycles 13 13 13 13 11 12 9 11 13 7 12
Processor width 3 3 3 3 5 5 3 4 2 7 6
Issue queue size 64 64 64 64 64 64 16 16 64 64 64
B-to-Back lat. of dep. inst. 14 14 14 14 12 14 9 12 13 8 13
Clock period 0.1447 0.1447 0.1447 0.1447 0.1797 0.1547 0.2187 0.1676 0.1522 0.2718 0.165
No. L1 access cycles 7 8 8 8 9 10 8 10 10 6 14
No. L1-cache lines 32 128 64 128 1024 512 512 512 128 128 128
L1-cache line-size 16 32 64 32 64 32 8 128 8 32 64
L1-cache associativity 1 1 1 1 1 1 4 1 2 1 8
No. L2 access cycles 13 15 19 18 55 32 12 28 20 16 16
No. L2-cache lines 32 64 32 128 4096 1024 1024 512 256 1024 1024
L2-cache line-size 32 64 512 256 128 16 32 128 64 32 16
L2-cache associativity 16 16 16 8 4 1 4 16 16 16 8
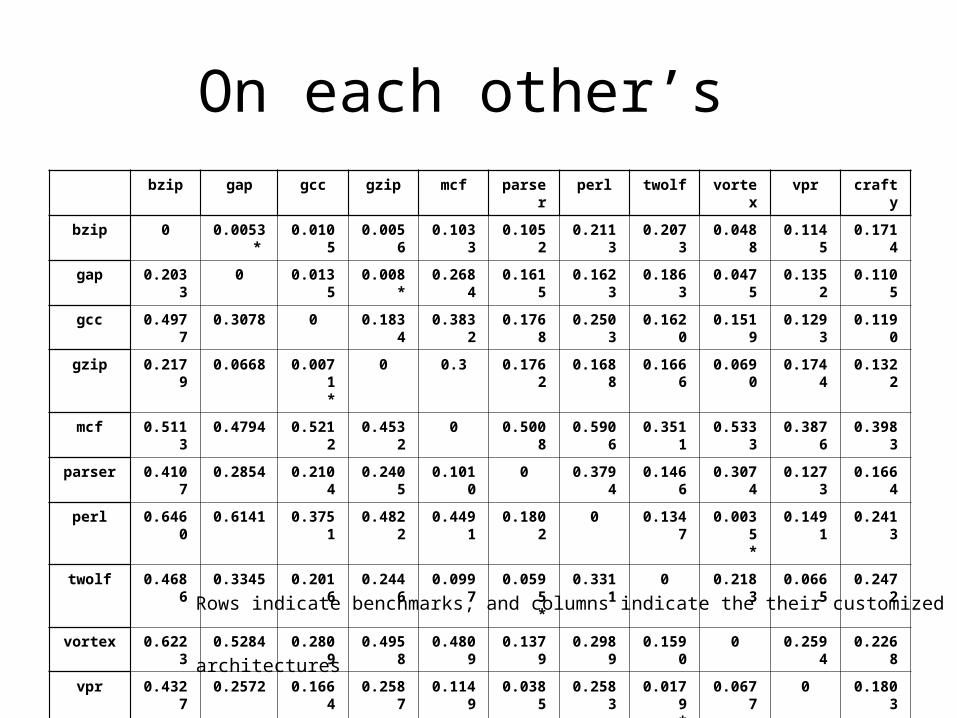
On each other’s bzip gap gcc gzip mcf parser perl twolf vortex vpr crafty
bzip 0 0.0053* 0.0105 0.0056 0.1033 0.1052 0.2113 0.2073 0.0488 0.1145 0.1714
gap 0.2033 0 0.0135 0.008* 0.2684 0.1615 0.1623 0.1863 0.0475 0.1352 0.1105
gcc 0.4977 0.3078 0 0.1834 0.3832 0.1768 0.2503 0.1620 0.1519 0.1293 0.1190
gzip 0.2179 0.0668 0.0071* 0 0.3 0.1762 0.1688 0.1666 0.0690 0.1744 0.1322
mcf 0.5113 0.4794 0.5212 0.4532 0 0.5008 0.5906 0.3511 0.5333 0.3876 0.3983
parser 0.4107 0.2854 0.2104 0.2405 0.1010 0 0.3794 0.1466 0.3074 0.1273 0.1664
perl 0.6460 0.6141 0.3751 0.4822 0.4491 0.1802 0 0.1347 0.0035* 0.1491 0.2413
twolf 0.4686 0.3345 0.2016 0.2446 0.0997 0.0595* 0.3311 0 0.2183 0.0665 0.2472
vortex 0.6223 0.5284 0.2809 0.4958 0.4809 0.1379 0.2989 0.1590 0 0.2594 0.2268
vpr 0.4327 0.2572 0.1664 0.2587 0.1149 0.0385 0.2583 0.0179* 0.0677 0 0.1803
crafty 0.7088 0.5850 0.1886 0.1886 0.6225 0.3351 0.1827 0.3524 0.0875* 0.2837 0
average 0.429 0.3458 0.1795 0.2632 0.2822 0.197 0.2576 0.1866 0.1718 0.166 0.1812
Rows indicate benchmarks, and columns indicate the their customized architectures

Representative architectures
• Assigning surrogates:
gcc
gzip
parser
perl
twolf
vortex
vpr
crafty
gap
7
6
bzip
5
mcf
3
4
2
1

Customization results
gcc mcfparse
rvorte
x crafty
No. mem. access cycles 345 278 323 328 302
No. front-end cycles 13 11 12 13 12
Processor width 3 5 5 2 6
Issue queue size 64 64 64 64 64
B-to-Back lat. of dep. inst. 14 12 14 13 13
Clock period 0.1447 0.17970.154
70.152
2 0.165
No. L1 access cycles 8 9 10 10 14
No. L1-cache lines 64 1024 512 128 128
L1-cache line-size 64 64 32 8 64
L1-cache associativity 1 1 1 2 8
No. L2 access cycles 19 55 32 20 16
No. L2-cache lines 32 4096 1024 256 1024
L2-cache line-size 512 128 16 64 16
L2-cache associativity 16 4 1 16 8
Related Documents











