Evolving HDFS to a Generalized Storage Subsystem Sanjay Radia Chief Architect, Founder, Hortonworks

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Evolving HDFS to a Generalized Storage Subsystem
Sanjay RadiaChief Architect, Founder,Hortonworks

2 © Hortonworks Inc. 2011 – 2016. All Rights Reserved© Hortonworks Inc. 2013 - Confidential
Hello, my name is Sanjay Radia Chief Architect, Founder, Hortonworks
Part of the original Hadoop team at Yahoo! since 2007–Chief Architect of Hadoop Core at Yahoo!– Apache Hadoop PMC and Committer
Prior– Data center automation, virtualization, Java, HA, OSs, File Systems
– Startup, Sun Microsystems, Inria …– Ph.D., University of Waterloo
Page 2Architecting the Future of Big Data

3 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Overview
HDFS – Evolution in past and motivations for the futureScaling HDFS• Where we do well (# of clients/cluster size, raw storage)• Where we have challenges (Small files and blocks)• Solution
• Partial namespace (Briefly)• Block Containers - But we are generalizing the storage layer to support this
Storage Containers to Generalize the Storage Layer

4 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Background: HDFS Layering
DN 1 DN 2 DN m.. .. ..
NS1Foreign NS n
... ... NS k
Block Management Layer
Block Pool nBlock Pool kBlock Pool 1
NN-1 NN-k NN-n
Common Storage
Bloc
k St
orag
eN
ames
pace

5 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Security in virtualized compute env
HDFS Dimensions Large # of compute clients: 100K cores
Reliability Reliability Reliability, Disk/DN FTHA, DR, Snapshots ….
PBs of Data (Big Data)Horizontal Scaling
Bad AppsMulti-tenancy Resource Mgt/Isolation, Audit
Large number of files and blocks
Beyond files: optimized storage
Heterogeneous storage
Erasure codes (In Beta)
Performance
File co-location
Fat DataNodes BRs
TransparentEncryption

6 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
ScalabilityThe Problems and the Solutions

7 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Scalability – What HDFS Does Well
• HDFS NN stores all namespace metadata in memory (as per GFS)• Scales to large clusters (5K) since all metadata in memory
– 60K-100K tasks can share the Namenode– Low latency
• Large data if files are large • Proof points of large data and large clusters
– Single Organizations have over 600PB in HDFS– Single clusters with over 200PB using federation– Large clusters over 4K multi-core nodes bombarding a single NN
Metadata in memory the strength of the original GFS and HDFS designBut also its weakness in scaling number of files and blocks

8 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Scalability - The Challenges
• Challenges• Large number of files (> 350 million)• NN’s strength has become a limitation
• Number of File operations• Need to improve concurrency move to multiple name servers
HDFS Federation is the current solution• Add NameNodes to scale number of files & operations• Deployed at Twitter
• Cluster with three NameNodes > 5000 node cluster (Plans to grow to 10,000 nodes)
• Back ported and used at Facebook to scale HDFS

9 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Scaling Files and Blocks
1. Scale Namespace• Keep only partial namespace in memory - the workingSet
• Of last 3-5 years data only small portion is actively used – the working set metadata fits in memory
- Do not want to page the working set =>still large NN memory to scale to 100K tasks
2. Scale Block Management• Keeping only part of the BlockMap in mem does not work• Soln: Containers of blocks (2GB-16GB+)
• Will reduce BlockMap• Reduce Number of Block/Container reports
But extend DN to support generalized Storage Container

10 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Big Picture A Brief Interlude on Partial Namespace + Volumes
Partial Namespace in Memory is not focus of this talk

11 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Partial Namespace - Briefly
• Has been prototyped• Benchmarks so that model works well• Most file systems keep only partial namespace in memory but not at this scale
– Hence Cache replacement policies of working-set is important
• Work in progress to get it into HDFS
• Namespace Volumes – a better way to Federate the Namespace service• Partial Namespace in Memory will allow multiple namespace volumes• Scale both namespace and number of operations using multiple servers• BTW Nameservers can run on DataNodes if you prefer …

12 © Hortonworks Inc. 2011 – 2016. All Rights Reserved© Hortonworks Inc. 2013 - Confidential
Big Picture on HDFS Namespace + Volumes .. Only WorkingSet of namespace in memory
› Scale beyond memory of NN NameServer – Containers for namespaces
› More namespace volumes– Chosen per user/tenant/DBs– Management policies (quota, backup, DR …)– Mount tables for unified namespace
• Can be managed by a central volume server
Number of NameServers = › Sum of (Namespace working set) +› Sum of (Namespace throughput)› Move namespace for balancing
› N+K Failover amongst NameServers
12
Datanode Datanode…
…
NameServers as Containers of Namespaces
Storage Layer

13 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Storage Containers: Better HDFS and Beyond
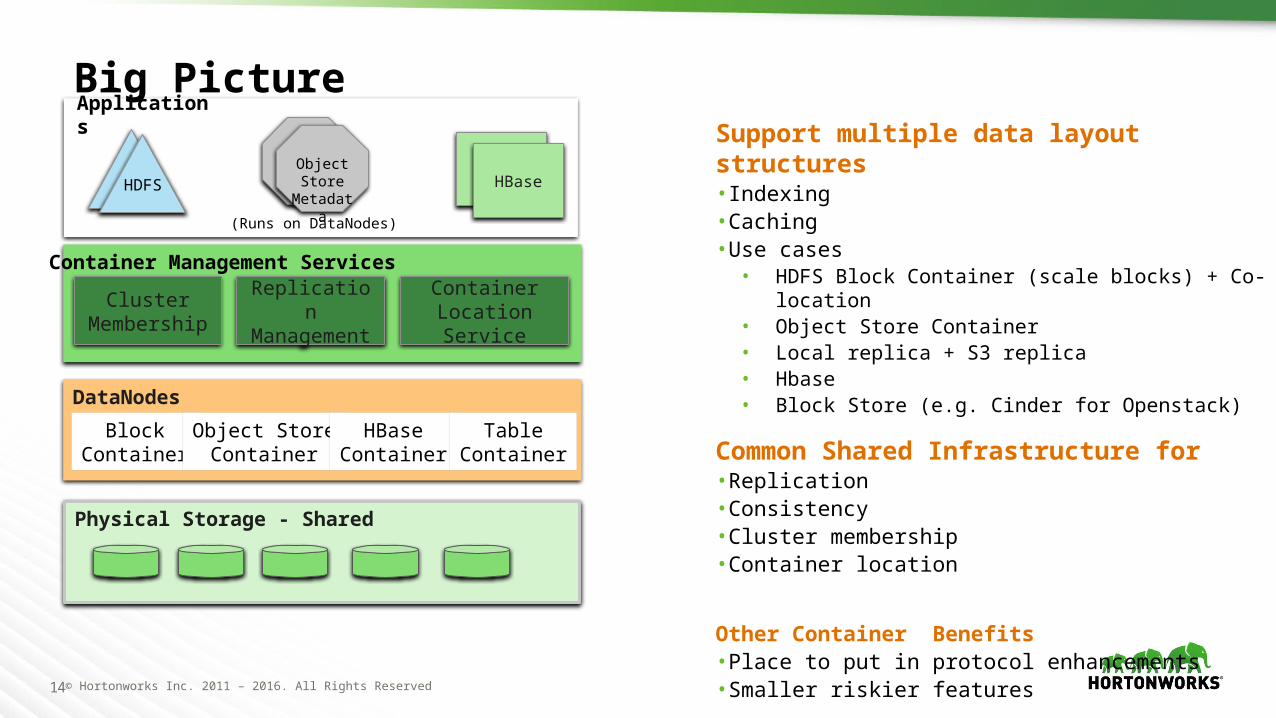
14 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
DataNodes
Big PictureSupport multiple data layout structures• Indexing• Caching• Use cases
• HDFS Block Container (scale blocks) + Co-location• Object Store Container• Local replica + S3 replica• Hbase• Block Store (e.g. Cinder for Openstack)
Common Shared Infrastructure for• Replication • Consistency • Cluster membership• Container location
Other Container Benefits• Place to put in protocol enhancements• Smaller riskier features
BlockContainer
Object StoreContainer
HBaseContainer
TableContainer
ClusterMembership
ReplicationManagement
ContainerLocation Service
Container Management Services
(Runs on DataNodes)
HBaseObject Store
Metadata
Applications
HDFS
Physical Storage - Shared

15 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Current vs New World (Storage Containers)Current• Namespace (in NameNode)
• File=BlockIds[]
• BlockManager (In NameNode)• BlockMap: BlockId->locations
• PipeLine repair• Replication management
• BlockData in DataNode• BlockId->Data
• Other • Generation Id (note BlockId=Gen#+Number)
• File/Block Completion coordination
New World• Namespace (in NameNode)
• File=BlockIds[] (but BlockId=ContainerId+LocalBid)
• ContainerManager (logically central)• ContainerMap: ContainerId->locations
• Replication management
• Cluster membership
• Containers (in DataNode)• Container’s BlockMetadata + Data
• BlockId->Data
• PipeLine repair
• Block Completion
• GenerationId equivalent? (Epoc of Raft?)

16 © Hortonworks Inc. 2011 – 2016. All Rights Reserved© Hortonworks Inc. 2013 - Confidential
Storage Container Contains data for many blocks with different block ids
Recall how the client will perform the mapping:–file blockId[] (NN)–blockId ->ContainerLocation (Container Manager)–Container maps the blockId to data (DataNode)
A container can be viewed as a local key-value store.–Block Id is the key and Block data is the value
Page 16

17 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Container Structure (Using LevelDB/RocksDB)
ContainerIndex
Chunk data file
Chunk data file
Chunk data file
Chunk data file
Key 1
LSMLevelDB/RocksDB
Key N
Chunk Data File
NameOffset Lengt
h
An embeddable key-value store BlockId is the key and filename of local
chunk file is value Optimizations
– Small blocks (< 1MB) can be stored directly in rocksDB
– Compaction for block data to avoid lots of files • But this can be evolved over time

18 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Container Structure Can Support Random Writes
4KB Chunks can be atomically updated in K-V store Chunk Data can be added at end of Chunk file (Log structured FSs)
ContainerIndex
Chunk data file
Chunk data file
Chunk data file
Chunk data file
Key 1LSMe.g
LevelDB/RocksDBKey N
Chunk Data File Name Offset Length

19 © Hortonworks Inc. 2011 – 2016. All Rights Reserved© Hortonworks Inc. 2013 - Confidential
Replication: Possible Approaches Data pipeline
– Data pipeline as a form of chain-replication has been successfully used for data– However, its correctness depended on central coordinator– Needs to be extended for block metadata, but hard to get it right given no
central coordinator
Use RAFT replication instead of data pipeline, for both data and metadata– Proven to be correct– Has been primarily used for small updates and transactions, fits well for
metadata– Performance concerns for large streaming writes, needs prototyping
Hybrid: RAFT + Pipeline– Hybrid approach: It can be viewed as if central coordinator is replaced by RAFT– Data pipeline approach for the data + the raft protocol -- under discussion
Page 19

20 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Next steps• Remove Block management layer’s locking with Namespace
• Reduce lock contention, remove the tight coupling (immediate benefit)
• Allows us to implement a cleanly separated Container Management layer
• Block container (to support tens of billions of blocks)• 2-4gb block containers initially => reduction of 40-80 in BR and block map
• Reduce BR pressure in on NN
• Early release:– Single Replica Containers for a Cloud Storage Caching FS (Similar to HDFS-9806)
• Partial Namespace (to billions of files per volume)• Will take us to 2B files initially and then more as we gain experience on file-working-set management
• Volumes + N+K failover • Scale both ops and namespace + operational improvement for HA
• Other containers• Local Replica & Cloud storage (e.g. S3) replica (Caching Mount)
• Object store, HBase …..

21 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Summary
• HDFS scale proven in real production systems• 4K+ clusters• Raw Storage >200PB in single federated NN cluster and >30PB in non-federated clusters• But very large number of small files is a challenge
• Important Area of Current Focus: Scaling # Files and Blocks• Partial Namespace: initially scale to 2B files, later 5-10B files per volume + multiple volumes• Block containers: initially scale to 6B-12B blocks, later to 100B+ blocks
– However we are implementing this to extend the storage layer
• Restructuring storage layer to support generalized storage containers• Support storage needs beyond HDFS: Object Store, better HBase support, etc.

22 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Q&A
Thank You
Related Documents











