Evaluating Question Answering over Linked Data ✩ Vanessa Lopez a,* , Christina Unger b , Philipp Cimiano b , Enrico Motta c a IBM Research, Smarter Cities Technology Centre, Mulhuddart, Dublin, Ireland b Semantic Computing Group, CITEC, Universit¨ at Bielefeld, Bielefeld, Germany c Knowledge Media Institute, The Open University, Milton Keynes, UK Abstract The availability of large amounts of open, distributed and structured semantic data on the web has no precedent in the history of computer science. In recent years, there have been important advances in semantic search and question answering over RDF data. In particular, natural language interfaces to online semantic data have the advantage that they can exploit the expressive power of Semantic Web data models and query languages, while at the same time hiding their complexity from the user. However, despite the increasing interest in this area, there are no evaluations so far that systematically evaluate this kind of systems, in contrast to traditional question answering and search interfaces to document spaces. To address this gap, we have set up a series of evaluation challenges for question answering over linked data. The main goal of the challenge was to get insight into the strengths, capabilities and current shortcomings of question answering systems as interfaces to query linked data sources, as well as benchmarking how these interaction paradigms can deal with the fact that the amount of RDF data available on the web is very large and heterogeneous with respect to the vocabularies and schemas used. Here we report on the results from the first and second of such evaluation campaigns. We also discuss how the second evaluation addressed some of the issues and limitations which arose from the first one, as well as the open issues to be addressed in future competitions. Keywords: Evaluation, Question Answering, Semantic Web, Linked Data, Natural Language 1. Introduction With the rapid growth of semantic information published on the web, in particular through the linked data initiative [5], the question how typ- ical web users can search and query these large amounts of heterogeneous and structured semantic data has become increasingly important. Promis- ing research directed towards supporting end users to profit from the expressive power of these stan- dards, while at the same time hiding the complex- ity behind an intuitive and easy-to-use interface, ✩ The authors wish to thanks Chris Welty for his invited talk “Inside the mind of Watson” at the QALD-1 workshop, and all participants in the open challenges QALD-1 and QALD-2 for valuable feedback and contributions. * Corresponding author Email addresses: [email protected] (Vanessa Lopez), [email protected] (Christina Unger), [email protected] (Philipp Cimiano), [email protected] (Enrico Motta) is offered by search and query paradigms based on natural language interfaces to semantic data [22, 28]. For example, question answering (QA) systems based on natural language allow users to express arbitrarily complex information needs in an intuitive fashion. The main challenge when devel- oping such systems lies in translating the user’s in- formation need into a form that can be evaluated using standard Semantic Web query processing and inferencing techniques. In recent years, there have been important ad- vances in semantic search and QA over RDF data –a survey of existing systems and the challenges they face is presented by Lopez et al. [28]. In par- allel to these developments in the Semantic Web community, there has been substantial progress in the areas of QA over textual data [34], natural lan- guage interfaces to databases (NLIDB) [2], as well as natural language search interfaces over struc- tured knowledge. The latter are typically based Preprint submitted to Journal of Web Semantics May 2, 2013 brought to you by CORE View metadata, citation and similar papers at core.ac.uk provided by Publications at Bielefeld University

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Evaluating Question Answering over Linked DataI
Vanessa Lopeza,∗, Christina Ungerb, Philipp Cimianob, Enrico Mottac
aIBM Research, Smarter Cities Technology Centre, Mulhuddart, Dublin, IrelandbSemantic Computing Group, CITEC, Universitat Bielefeld, Bielefeld, Germany
cKnowledge Media Institute, The Open University, Milton Keynes, UK
Abstract
The availability of large amounts of open, distributed and structured semantic data on the web has noprecedent in the history of computer science. In recent years, there have been important advances insemantic search and question answering over RDF data. In particular, natural language interfaces to onlinesemantic data have the advantage that they can exploit the expressive power of Semantic Web data modelsand query languages, while at the same time hiding their complexity from the user. However, despite theincreasing interest in this area, there are no evaluations so far that systematically evaluate this kind ofsystems, in contrast to traditional question answering and search interfaces to document spaces. To addressthis gap, we have set up a series of evaluation challenges for question answering over linked data. The maingoal of the challenge was to get insight into the strengths, capabilities and current shortcomings of questionanswering systems as interfaces to query linked data sources, as well as benchmarking how these interactionparadigms can deal with the fact that the amount of RDF data available on the web is very large andheterogeneous with respect to the vocabularies and schemas used. Here we report on the results from thefirst and second of such evaluation campaigns. We also discuss how the second evaluation addressed someof the issues and limitations which arose from the first one, as well as the open issues to be addressed infuture competitions.
Keywords: Evaluation, Question Answering, Semantic Web, Linked Data, Natural Language
1. Introduction
With the rapid growth of semantic informationpublished on the web, in particular through thelinked data initiative [5], the question how typ-ical web users can search and query these largeamounts of heterogeneous and structured semanticdata has become increasingly important. Promis-ing research directed towards supporting end usersto profit from the expressive power of these stan-dards, while at the same time hiding the complex-ity behind an intuitive and easy-to-use interface,
IThe authors wish to thanks Chris Welty for his invited talk“Inside the mind of Watson” at the QALD-1 workshop,and all participants in the open challenges QALD-1 andQALD-2 for valuable feedback and contributions.
∗Corresponding authorEmail addresses: [email protected] (Vanessa Lopez),[email protected] (Christina Unger),[email protected] (Philipp Cimiano),[email protected] (Enrico Motta)
is offered by search and query paradigms basedon natural language interfaces to semantic data[22, 28]. For example, question answering (QA)systems based on natural language allow users toexpress arbitrarily complex information needs in anintuitive fashion. The main challenge when devel-oping such systems lies in translating the user’s in-formation need into a form that can be evaluatedusing standard Semantic Web query processing andinferencing techniques.
In recent years, there have been important ad-vances in semantic search and QA over RDF data–a survey of existing systems and the challengesthey face is presented by Lopez et al. [28]. In par-allel to these developments in the Semantic Webcommunity, there has been substantial progress inthe areas of QA over textual data [34], natural lan-guage interfaces to databases (NLIDB) [2], as wellas natural language search interfaces over struc-tured knowledge. The latter are typically based
Preprint submitted to Journal of Web Semantics May 2, 2013
brought to you by COREView metadata, citation and similar papers at core.ac.uk
provided by Publications at Bielefeld University

on data that is by and large manually coded andhomogeneous (e.g., True Knowledge1).
Semantic search is also increasingly becoming in-teresting for commercial search engines. GoogleKnowledge Graph can be seen as a huge knowledgebase that Google intends to exploit for enhancingsearch results, moving from a search engine to aknowledge engine. Wolfram Alpha2 is a knowledgeinference engine that computes answers to factualqueries from a comprehensive structured knowledgebase about the world, rather than providing a listof documents.
However, a great challenge for the Semantic Weband natural language processing (NLP) communi-ties is scaling QA approaches to the large amount ofdistributed interlinked data that is available nowa-days on the web, dealing with its heterogeneityand intrinsic noise [28]. Automatically finding an-swers to questions among the publicly availablestructured sources on the web has not been pos-sible with NLIDB approaches. As databases arenot interoperable and distributed over the web,NLIDB approaches focus on the exploitation ofstructured data in closed-domain scenarios. In con-trast, ontology-based QA systems are able to han-dle a much more expressive and structured searchspace, where, as opposed to databases, the informa-tion is highly interconnected. For ontology-basedapproaches the knowledge and semantics encodedin an ontology, together with the use of domain-independent linguistic and lexical resources, are theprimary sources for understanding user queries.
On the other hand, QA systems over free text areable to answer questions in open-domain environ-ments. Such systems use information retrieval (IR)techniques to process large amounts of unstructuredtext and as such to locate the documents and para-graphs in which the answer might appear. IR meth-ods scale well but often do not capture enough se-mantics. Documents containing the answer couldbe easily missed if the answer is expressed in a formthat does not match the way the query is formu-lated, or if the answer is unlikely to be available inone document but must be assembled by aggregat-ing answers from multiple documents [44]. Seman-tic QA systems over structured data can greatlybenefit from exploiting ontological relationships inorder to understand and disambiguate a query, in-heriting relationships and linking word meanings
1http://www.trueknowledge.com2http://www.wolframalpha.com
across datasets.
Advances in information retrieval have long beendriven by evaluation campaigns such as TREC3 andCLEF [16]. For example, open question answeringover unstructured documents or free text has beenin the focus of the open-domain QA track intro-duced by TREC from 1999 to 2007. Recent evalua-tion campaigns for semantic search, such as SEALS[43, 31] and entity search evaluations [7, 20], workwith structured RDF data rather than unstructuredtext. However, for natural language based ques-tion answering tools over linked data there are nosystematic and standard evaluation benchmarks inplace yet. Therefore, evaluations of such systemsare typically small-scale and idiosyncratic in thesense that they are specific for certain settings orapplications [38].
The lack of independent evaluation set-ups andframeworks undermines the value of direct com-parisons across systems and the ability to evalu-ate the progress and assess the benefits of ques-tion answering technologies for the Semantic Web.In this paper we describe public evaluation chal-lenges for question answering systems over linkeddata: QALD. The first instantiation of this chal-lenge, QALD-1, was organised in the context of theESWC workshop Question Answering Over LinkedData in 2011; the second instantiation, QALD-2,was run in the context of the ESWC workshopInteracting With Linked Data in May 2012. Thesecond workshop, Interacting with Linked Data,had a broader scope than the first one and aimedat including other paradigms for interacting withlinked data, to bring together research and ex-pertise from different communities, including NLP,Semantic Web, human-computer interaction, anddatabases, and to encourage communication acrossinteraction paradigms.
After giving an overview of existing evaluationapproaches in Section 2, we will present the aimsand methodology of the QALD challenge in Sec-tion 3 and the results from running QALD-1 andQALD-2 in Section 4. In Section 4 we also discusswhat has been learned by developing a standardevaluation benchmark for these systems. In par-ticular, as an improvement to the limitations thatarose from QALD-1, in QALD-2 we aimed at fur-ther facilitating the comparison between differentopen QA approaches according to the challenges
3http://trec.nist.gov/
2

intrinsic to the different types of questions. In Sec-tion 5, we draw conclusions and highlight the mainissues to be addressed in future competitions.
2. Existing evaluation methods and compe-titions
There is an increasing number of question answer-ing systems over semantic data, evaluated throughusability studies such as the one presented by Kauf-mann & Bernstein [22]. But despite growing inter-est, there is a lack of standardized evaluation bench-marks to evaluate and compare the quality and per-formance of ontology-based question answering ap-proaches at large scale [28].
To assess their current strengths and weaknesses,a range of such systems, for example GINGSENG[4], NLPReduce [23], Querix [21], FREyA [13] andPANTO [41], made use of the independent Mooneydatasets4 and corresponding queries. These are theonly shared datasets that have been used to objec-tively5 compare different ontology-based questionanswering systems for a given ontology or dataset.Standard precision and recall metrics have beenadapted to evaluate these systems. Precision is con-sistently taken as the ratio of the number of cor-rectly covered questions to the number of coveredquestions, i.e., questions for which the system pro-duced some output, whether correct or not. Recall,on the other hand, is defined differently among sys-tems. Damljanovic et al. [13] define recall as theratio of the number of questions correctly answeredby the system to the total number of all questionsin the dataset, while for Wang et al. [41] recall isthe ratio of the number of questions that deliversome output—independently of whether the outputis valid or not—to the total number of all questions.Such differences, together with discrepancies in thenumber of queries evaluated, render a direct com-parison difficult.
Other systems, for example ORAKEL [10] andAquaLog [25], used their own datasets for evalua-tion purposes.
4Raymond Mooney and his group from the University ofTexas at Austin provide three datasets [35]: one on thedomain of geography (9 classes, 28 properties and 697 in-stances), one on jobs (8 classes, 20 properties and 4141instances) and one on restaurants (4 classes, 13 propertiesand 9749 instances). They were translated to OWL for thepurpose of evaluation in [23].
5Objective in the sense that they have been created by otherparties than those performing the evaluation.
In contrast to the previously mentioned evalua-tion approaches, which are restricted to a specificdomain ontology, the evaluation presented by Fer-nandez et al. [15] exploits the combination of in-formation spaces provided by the Semantic Weband the (non-semantic) web. This evaluation wasperformed over an integrated system that includesthe multi-ontology question answering system Pow-erAqua [27] as well as a semantic information re-trieval system [15]. The ontology entities retrievedby PowerAqua are used to support query expansionin the information retrieval step. The output ofthe combined system consists of ontology elementsthat answer the user question together with a com-plementary ranked list of relevant documents. Inorder to judge the performance of this combinedsearch tool, the TREC WT10G collection was usedas an ontology-based evaluation benchmark. Themain advantage is that the queries and relevancejudgements are provided by external parties thatdo not participate in the competition, leading tothe creation of objective gold standards that arenot biased against any particular system, e.g., theTREC-9 and TREC 2001 collections.6
However, as argued by Fernandez et al. [15],there are several limitations of this benchmarkwhen applied to data retrieval and ontology-basedquestion answering systems. First, it does not di-rectly evaluate the performance of these systemsin returning answers, but rather how they performwithin a query expansion task. Second, the queriesselected for TREC-9 and 2001 were extracted fromreal web search engine logs, such that the queriesare tailored to traditional keyword-based search en-gines and do not exploit the capabilities of ontology-based models in addressing more complex queries.Third, the approach is overshadowed by the sparse-ness of the knowledge available on the SemanticWeb compared to the web. Indeed, at the timethe study described by Fernandez et al. was con-ducted [15], only about 20 % of the query topicsin the TREC dataset were covered to some extentby RDF data and ontologies available through the
6However, one flaw in the standard TREC methodology isthat the evaluation is biased towards systems that con-tribute to the so called pooled assessment in which the top-ranked documents from many systems are evaluated by hu-man assessors. Systems retrieving relevant documents thathave not been part of the pooled assessment might thus bepenalized for finding actually relevant documents that arejudged as irrelevant (see [39]).
3

semantic search engines Watson7 and Swoogle8.As already mentioned, prevailing differences in
evaluation set-ups and techniques, including differ-ences with respect to query samples and evalua-tion measures, undermine the value of direct com-parisons, even over a common dataset. There-fore, efforts are being made towards the establish-ment of common datasets and methodologies toevaluate semantic technologies, most notably theSEALS evaluation methodology for semantic search[43]. SEALS implements a two-phase approach inwhich tools with different interfaces (in particularkeyword-based, form-based and natural languageinterfaces) are evaluated and compared in a con-trolled scenario, both in a fully automated fash-ion as well as within a user study. SEALS usesa particular domain-specific ontology for the auto-mated evaluation as well as the Mooney geogra-phy dataset to evaluate scalability and usability as-pects. The most critical aspect of the SEALS evalu-ation, besides difficulties involved in benchmarkinguser experiences [43], is that systems are evaluatedw.r.t. performance in a strictly controlled environ-ment rather than their ability to solve open-ended,real-life problems. For example, the SEALS evalua-tion is based on a single well-defined, homogeneousontology and is thus not particularly relevant inthe context of applications that exploit the Seman-tic Web as a large-scale, distributed and loosely-coupled source of information.
A slightly different kind of semantic evaluationchallenge was provided by the entity search chal-lenges, which were started in 2010 and were tar-geted at keyword-based entity search over semanticdata [20, 7]. The goal was to retrieve a ranked listof RDF documents in response to a keyword query.The 2011 competition used a dataset that was basedon the Billion Triple Challenge 2009 dataset, con-taining 1.4 billion triples describing 114 million ob-jects. The competition provided queries obtainedfrom Yahoo query logs that directly mention theentity in question in addition to hand-selected listqueries that do not necessarily mention the entity tobe retrieved. Assessments were crowd-sourced us-ing Amazon Mechanical Turk9. In this scenario itturned out that approaches targeting list queries10
7http://kmi-web05.open.ac.uk/WatsonWUI/8http://swoogle.umbc.edu/9https://www.mturk.com/10Results of the list track can be found at http://
semsearch.yahoo.com/results.php
either applied a combination of NLP and IR tech-niques in order to retrieve RDF data [24, 33], or re-lied on Wikipedia articles [3] and did not actuallytake advantage of the structure of semantic data.To Shah and Arora [33] this “seems like going in thewrong direction [. . . ], as the whole point of RDFwas to move away from unstructured documentstowards semantic data”. According to them, oneof the reasons for applying traditional informationretrieval techniques is that “traditional SPARQLqueries on data of a large magnitude is not practi-cal”. This indicates that if a competition wants toattract and compare semantic approaches, it shouldbe designed in a way that strongly encourages ap-proaches to make use of the structure of the seman-tic data available nowadays and to deal with its sizeand heterogeneity.
In contrast to traditional IR approaches, whichuse the same type of input (keywords) and output(ranked documents), there is no standard model ofontology-based search. Thus, there has been nogeneral adoption of evaluation regimes or meth-ods for semantic search systems. Indeed, as wehave seen, most of the state-of-the-art evaluationsfor question answering systems are generally con-ducted with respect to small scale and idiosyn-cratic tasks tailored to the evaluation of particu-lar systems. The Semantic Web community hasnot yet adopted standard evaluation benchmarksfor semantic question answering that focus on theability to answer open-ended real life queries overreal world datasets. With the goal of progressingon this issue, the evaluation challenge presented inthis paper, QALD, aims to evaluate natural lan-guage based question answering interfaces to linkeddata sources, i.e., sources that are characterized bytheir large scale, openness, heterogeneity and vary-ing levels of quality.
3. Evaluation methodology of QALD
The main goal of the QALD challenge is to evalu-ate and compare question answering systems thatmediate between semantic data and users who ex-press their information needs in natural language,especially with respect to their ability to copewith large amounts of heterogeneous and structureddata. The main motivation behind QALD is toprovide a common evaluation benchmark that al-lows for an in-depth analysis of the strengths andshortcomings of current semantic question answer-
4

ing systems and, potentially, their progress overtime.
The task for participating systems is to return,for a given natural language question and a RDFdata source, a list of entities that answer the ques-tion, where entities are either individuals identifiedby URIs or labels, or literals such as strings, num-bers, dates and booleans.
In order to set up a common benchmark, the fol-lowing basic ingredients are provided:
• Datasets: a collection of linked data sourcesin RDF format
• Gold standard: a set of natural lan-guage questions annotated with correspondingSPARQL queries and answers for the purposeof training and testing
• Evaluation method: a set of procedures andmetrics for assessing the performance of a sys-tem on the task
• Infrastructure: a SPARQL endpoint and anonline evaluation tool which is able to assessthe correctness of the answers returned by theparticipating systems
In the following, we describe these ingredients inmore detail.
3.1. Datasets
The selected datasets needed to contain real, largescale data, being challenging enough to assess theabilities and shortcomings of the systems. Twodifferent datasets with complementary propertiesand requirements were selected: DBpedia and Mu-sicBrainz.
• The DBpedia11 project [6] is increasingly be-coming the central interlinking hub for theemerging linked data cloud. The official DB-pedia dataset for English describes more than3.5 million entities extracted from Wikipedia,roughly half of them modelled in a consistentontology with over 320 classes and 1650 prop-erties. Version 3.6 (used for QALD-1) containsa total of about 280 million RDF triples, andversion 3.7 (used for QALD-2) contains a totalof about 370 million RDF triples. Both includelinks to YAGO12 categories.
11http://dbpedia.org12http://www.mpi-inf.mpg.de/yago-naga/yago/
• MusicBrainz13 is a collaborative open-content music database. A RDF export of theMusicBrainz dataset was provided, containingall of MusicBrainz’ artists and albums as wellas a subset of its tracks, leading to a totalof roughly 15 million RDF triples. This datais modelled with respect to a small ontologywith just a few classes and relations—the Mu-sicBrainz ontology in case of QALD-1 and themore standard Music Ontology14 in the case ofQALD-2.
The reason for choosing closed datasets insteadof using all the linked data available on the webis two-fold. First, they are large enough to raisescalability and heterogeneity issues [26], but not solarge that indexing and the processing of queries us-ing semantic technologies would require computa-tional resources outside the scope of most researchgroups. Second, by using closed datasets we cre-ate controllable and reproducible settings in whichall systems can be evaluated under the same con-ditions. Furthermore, the combination of these twodifferent datasets allows to assess different aspectsof semantic question answering systems.
DBpedia, on the one hand, requires the abil-ity to scale to large data sources and to dealwith incomplete and noisy data. For example,DBpedia contains heterogeneous terminology, pri-marily due to employing two partly overlappingnamespaces for properties15. Also, entities aremodelled at different levels of granularity, e.g.,by means of a combination of simple DBpediaconcepts and by means of single complex YAGOcategories (such as yago:CapitalsInEurope andyago:PresidentsOfTheUnitedStates). Whileontology-based question answering systems over re-stricted domains often interpret a question withrespect to an unambiguous ontology, in the caseof large open-domain ontologies such as DBpediathey encounter a wide range of ambiguous words—suddenly one query term can have multiple inter-pretations within the same ontology. These sys-tems are therefore required to apply disambiguationor ranking algorithms. Furthermore, the DBpediadataset is incomplete and contains modelling errors.
13http://musicbrainz.org14http://musicontology.com15The ontology namespace comprises of properties modelled
in the hand-crafted DBpedia ontology, while the property
namespace comprises of automatically extracted proper-ties and thus contains a considerable amount of noise.
5

Question answering systems thus have to be able tocope with this incompleteness and lack of rigor ofthe ontology, including missing domain and rangeinformation for properties, undefined entity types,complex semantic entity labels, redundant proper-ties within the same dataset (such as birthPlace
and placeOfBirth) or even modelling errors (e.g.,incorrect property range).
MusicBrainz, on the other hand, offers a smalland clean ontology, but requires the ability toadapt to a specific (and sometimes peculiar)domain-dependent modelling of the data. For in-stance, in the MusicBrainz ontology, the proper-ties beginDate and endDate relate a date with dif-ferent kinds of entities. In the case of a person,these relations refer to the day of birth or death.In the case of a group, the dates represent thedate when a group was founded or broke up. Andwhen the artist is related to a blank node that islinked to a group, then the begin and end dateof this blank node indicate when an artist joinedor left the band. Another example is the use ofthe property releaseType to identify the type ofan instance (e.g., TypeAudiobook) instead of usingthe relation rdf:type. Thus in order to query thisdataset, some domain-specific configurations, inter-activity or learning mechanisms are required to mapthe meaning of natural language expressions to con-cepts in the ontology.
For QALD-2, the RDF export of the MusicBrainzdata is no longer based on the MusicBrainz ontol-ogy but follows the BBC Music data model, i.e.,relies mainly on the Music Ontology [32]. Thismakes the data available in terms of a more stan-dard vocabulary, while the domain-specificity ispreserved. That is, the MusicBrainz dataset canserve to test the ability of a question answeringsystem to query homogeneous, high-quality domainontologies with specific domain-dependent vocabu-lary, structure and modelling conventions.
3.2. Gold standard queries
User questions of varying complexity were providedin order to evaluate a system’s ability to serve asa natural language interface to the above men-tioned datasets, going beyond the expressivity ofcurrent keyword-based search engines. In the con-text of QALD-1, each dataset was made availabletogether with a set of 50 training and 50 test ques-tions each. For QALD-2, both QALD-1 sets havebeen combined to build a new training set, pro-vided together with a newly created test set, lead-
ing to 100 training and 100 test questions for DB-pedia, and 100 training and 50 test questions forMusicBrainz. Also, a few out-of-scope questionswere added to each question set, i.e., questions towhich the datasets do not contain the answer, inorder to test the ability of participating systems tojudge whether a failure to provide an answer liesin the dataset or the system itself. In addition, weprovided a small set of questions that could onlybe answered by combining information from bothdatasets, DBpedia and MusicBrainz, thus testing asystem’s ability to combine several linked informa-tion sources when searching for an answer.16
All questions were annotated with correspond-ing SPARQL queries. Both questions and querieswere hand-crafted. Some of the queries were pickedfrom the PowerAqua query log, but since the mainfocus was not on quantity but rather on covering awide range of challenges involved in mapping natu-ral language to SPARQL, aiming at reflecting realuser questions, and in order not to bias the resultstowards any particular system, most of the ques-tions were generated by students not familiar withthe functionalities of particular question answeringsystems.
The collected results were aimed to be completeand the best possible answers given the data. Butof course answers are noisy and incomplete as linkeddata sources are, and validating the correctness andtrust of these sources is out of the scope of thischallenge.
Since the questions are often linguistically com-plex (containing prepositions, quantifiers, conjunc-tions, and so on), they are tailored to systems basedon natural language and penalise keyword-basedapproaches. In order to avoid this, we annotatedall QALD-2 questions with keywords. Addition-ally, systems were allowed to reformulate the query(e.g., inserting quotes to identify named entities,or translating the questions into a controlled lan-guage), as long as the changes were documented.This way we wanted to encourage also other rel-evant methods that can benefit from the datasets,e.g., methods for dynamic ontology matching, wordsense disambiguation, fusion and ranking technolo-gies, to report their results.
16We also invited participants to contribute questions ontheir own, as part of a participant’s challenge, in order toallow them to point to challenges that we as organizerswere not aware of. But unfortunately, this opportunitywas not used by the participants.
6

The appendix shows examples of queries for bothdatasets. The entire query sets and datasets areavailable at http://www.purl.org/qald/home.
3.3. Evaluation and infrastructure
As briefly stated above, the task is to extract a listof correct answers (resources or literals) from eachof the two provided RDF datasets, given a naturallanguage question. In order to access the datasets,they can either be downloaded or queried by meansof a provided SPARQL endpoint. Evaluation takesplace with respect to the same SPARQL endpoint17
(and not the official DBpedia endpoint, for exam-ple), in order to ensure invariable and thereforecomparable results.
Training questions for each dataset were madeavailable to the participants a couple of months inadvance of the deadline for submitting results; testquestions were then released two weeks in advanceof the deadline.
The training questions are annotated with cor-responding SPARQL queries and query results re-trieved from the SPARQL endpoint. Annotationsare provided in a proprietary XML format shownin Figure 1. The overall document is enclosed bya tag that specifies an ID for the question set, ex-pressing whether the questions refer to DBpedia orMusicBrainz, and whether they are for the train-ing or test phase. Also, each of the questions inthe question set has an ID, and moreover specifiesthe natural language question, the correspondingSPARQL query, and the answers to the query. Theanswers can be either a literal (boolean, date, num-ber or string) or a list of resources, for which boththe URI as well as the English label (if it exists) arespecified. For QALD-2, we annotated each questionwith additional metadata in the form of keywordsextracted from the natural language question, andattributes indicating i) the answer type, ii) whetherthe question relies on classes and properties notcontained in the DBpedia ontology (onlydbo), andiii) whether it requires aggregation or not, i.e., anySPARQL construct that goes beyond pure triplepattern matching, such as counting and filters.
Submission of results by participating systemswas required in the same XML format. For all
17Some systems reported difficulties connecting to theSPARQL endpoint provided for the challenge, due to alimited server timeout, which was not sufficient for exe-cuting some of the systems’ SPARQL queries.
questions, the ID was obligatory. Beyond that, sys-tems were free to specify either a SPARQL query orthe answers—and in the case of returning resourcescould decide whether to return the URI, the labelor both. The reason for requiring that all submis-sions comply with the same XML format was tofacilitate the automatic comparison of the answersprovided by the system with the ones provided bythe gold standard XML document.
Participating systems were evaluated in terms ofprecision and recall, both on the level of single ques-tions as well as on the level of the whole questionset. With respect to a single question q, recall is de-fined as the ratio of the number of correct answersprovided by the system to the number of gold stan-dard answers, and precision is defined as the ratioof the number of correct answers provided by thesystem to the number of all answers provided bythe system:
Recall(q) =number of correct system answers for q
number of gold standard answers for q
Precision(q) =number of correct system answers for q
number of system answers for q
For example, if a system returns Mongolia andnothing else as answer for the question depicted inFigure 1, it achieves a precision of 100 %, as thereturned answer is among the gold standard an-swers, but has a recall of only 50 %, as it failedto return Russia. If it had provided Mongolian
People’s Republic or Mongol country, the an-swer would not have been counted as right, as itdoes not match the gold standard answer Mongolia.The questions were designed such that the datapoints to unique answers (e.g. the countries listedfor the resource Yenisei river are only Mongolia
and Russia, and not further variants), but this is-sue has to be taken into account in future evalua-tions.
Global precision and recall values were defined asthe average mean of the precision and recall valuesof all single questions. Additionally, the global F-measure was computed in the familiar fashion:
F-measure =2× Precision× Recall
Precision + Recall
Note that for the global question set we did nottake into account the set of all gold standard ques-tions but only those questions for which the par-ticipating system provided answers. This penalises
7

<question id="36" answertype="resource" aggregation="false" onlydbo="false">
<string>Through which countries does the Yenisei river flow?</string>
<keywords>Yenisei river, flow through, country</keywords>
<query>
PREFIX res: <http://dbpedia.org/resource/>
PREFIX dbp: <http://dbpedia.org/property/>
SELECT DISTINCT ?uri ?string WHERE {res:Yenisei River dbp:country ?uri .
OPTIONAL { ?uri rdfs:label ?string . FILTER (lang(?string) = "en") }}</query>
<answers>
<answer>
<uri>http://dbpedia.org/resource/Mongolia</uri>
<string>Mongolia</string>
</answer>
<answer>
<uri>http://dbpedia.org/resource/Russia</uri>
<string>Russia</string>
</answer>
</answers>
</question>
Figure 1: A query example from the QALD-2 DBpedia training set in the specified XML format.
systems that have a high coverage but provide a lotof incorrect answers, compared to systems that havelower coverage but provide answers with higherquality. This, however, has been the source of manydiscussions and thus was decided to be changed inthe third instantiation of the challenge. Also, whenreporting evaluation results in the next session, wewill include F-measure values computed over thetotal number of questions.
For all submissions, these metrics were computedautomatically by an evaluation tool, to which re-sults could be submitted online. During trainingand test phases, each participating system was al-lowed to submit their results as often as desired inorder to experiment with different configurations oftheir system.
During the training phase, evaluation resultswere returned immediately, while during the testphase the results were returned only after submis-sion was closed.
If participants were submitting a paper, theywere also encouraged to report performance, i.e.,the average time their system takes to answer aquery.
4. Evaluation results
In this section we report on results of both QALDevaluations. In total, seven question answering sys-tems participated in the test phase of the challenge;three of them in QALD-1: FREyA, covering bothdatasets, PowerAqua covering DBpedia, and SWIPcovering MusicBrainz; and four systems in QALD-2: SemSeK, Alexandria, MHE and QAKis, all cov-ering the DBpedia question set.
4.1. Overview of evaluated systems
The systems that participated in the evaluation rep-resent an array of approaches to question answeringover linked data. In the following we will briefly dis-cuss their main characteristics.
PowerAqua [27] performs question answeringover structured data on the fly and in an opendomain scenario, not making any particular as-sumption about the vocabulary or structure of thedataset, thus being able to exploit the wide rangeof ontologies available on the Semantic Web. Pow-erAqua follows a pipeline architecture. The userquery is first transformed into query triples of theform 〈subject,property, object〉 by means of linguis-tic processing (not covering comparisons and su-
8

perlatives, which occur in some of the QALD ques-tions). At the next step, the query triples arepassed on to a mapping component that identi-fies suitable semantic resources in various ontologiesthat are likely to describe the query terms (includ-ing a WordNet search in order to find synonyms,hypernyms, derived words and meronyms). Giventhese semantic resources, a set of ontology triplesthat jointly cover the user query is derived. Finally,because each resulting triple may lead to only par-tial answers, they need to be combined into a com-plete answer. To this end, the various interpreta-tions produced in different ontologies are mergedand ranked.
PowerAqua was evaluated on the DBpedia ques-tion set. It accesses the DBpedia ontology througha local version of Virtuoso18 as backend, provid-ing efficient query and full text searches. To gen-erate answers on the fly and in real time, Power-Aqua uses iterative algorithms and filter and rank-ing heuristics to obtain the most precise resultsfirst, as a compromise between performance andprecision/recall.FREyA [14] allows users to enter queries in any
form. In a first step it generates a syntactic parsetree in order to identify the answer type. The pro-cessing then starts with a lookup, annotating queryterms with ontology concepts using an ontology-based gazetteer. If there are ambiguous annota-tions, the user is engaged in a clarification dialog.In this case, the user’s selections are saved and usedfor training the system in order to improve its per-formance over time. Next, on the basis of the onto-logical mappings, triples are generated, taking intoaccount the domain and range of the properties. Fi-nally the resulting triples are combined to generatea SPARQL query.
FREyA is the only system that was evaluatedusing both datasets, thereby proving its porta-bility. In order to perform the ontology-basedlookup, FREyA automatically extracts and indexesontological lexicalizations, which requires scanningthrough the whole RDF data. Thus, the initial-ization of the system can take considerable time forlarge datasets—50.77 hours in the case of DBpedia.SWIP [12] was evaluated on MusicBrainz and
did not use the provided natural language ques-tions as input but rather a translation of them intoa semi-formal keyword-based language.19 The sys-
18http://www.openlinksw.com19The exact input that was used is documented in the eval-
tem transforms the keyword-based input represen-tation into a semantic graph query as follows: First,the keywords are transformed into concepts and aset of ranked patterns that are semantically closeto those concepts are identified. These patterns arechosen from a set of predefined patterns that havebeen generated by experts beforehand on the ba-sis of typical user queries. The system then asksthe users to choose the query pattern that bestexpresses the meaning of a particular input key-word. From the chosen representations the finalquery graph is generated.
FREyA and SWIP are the only of the participat-ing systems that rely on manual intervention at runtime, where FREyA can also run without any man-ual intervention (with better results when grantedsome training beforehand).
QAKiS [9] is a question answering system overDBpedia that focuses on bridging the gap betweennatural language expressions and labels of ontologyconcepts by means of the WikiFramework reposi-tory. This repository was built by automaticallyextracting relational patterns from Wikipedia freetext, that specify possible lexicalizations of prop-erties in the DBpedia ontology. For example oneof the natural language patterns that express therelation birthDate is was born on. For QALD-2,QAKiS focused on a subset of the DBpedia trainingand test questions, namely simple questions thatcontain one named entity that is connected to theanswer via one relation. First, QAKiS determinesthe answer type as well as the type of the named en-tity, and next matches the resulting typed questionwith the patterns in the WikiFramework repository,in order to retrieve the most likely relation, whichis then used to build a SPARQL query.
Although the coverage of the system is still quitelow, the approach of using a pattern repository (asalso done by the TBSL system, see 4.3 below) rep-resents a promising tool for bridging the lexical gapbetween natural language expressions and ontologylabels.
SemSek [1] is a question answering system thatalso focuses on matching natural language expres-sions to ontology concepts. It does so by means ofthree steps: a linguistic analysis, query annotation,and a semantic similarity measure. Query annota-tion mainly looks for entities and classes in a DBpe-
uation reports for QALD-1 and QALD-2, that can be ac-cessed at http://www.purl.org/qald/qald-1 and http:
//www.purl.org/qald/qald-2.
9

dia index that match the expressions occuring in thenatural language question. This process is guidedby the syntactic parse tree provided by the linguis-tic analysis. Starting from the most plausible of theidentified resources and classes, SemSek retrieves anordered list of terms following the dependency tree.In order to match these terms to DBpedia concepts,SemSek then involves two semantic similarity mea-sures, one being Explicit Semantic Analysis basedon Wikipedia, and one being a semantic relatednessmeasure based on WordNet structures.
SemSek thus mainly relies on semantic related-ness as an important tool in order to match naturallanguage expressions with ontology labels in a vo-cabulary independent way. Similar means were alsoexploited, e.g., by Freitas et. al [18] (see 4.3 below),who additionally use graph exploration techniques,which offer a way to build SPARQL queries withoutprior knowledge about the modelling of the data,similar to graph matching algorithms, as used inMHE (Multi-Hop Exploration of Entity Graph).
MHE is a method for retrieving entities from anentity graph given an input query in natural lan-guage. It was developed by Marek Ciglan at theInstitute of Informatics at the Slovak Academy ofSciences. The method relies on query annotation,where parts of the query are labeled with possiblemappings to the given knowledge base. The annota-tions comprise entities and relations, and were gen-erated by means of a gazetteer, in order to expandrelations with synonyms, and a Wikifier tool, in or-der to annotate entities. From those annotations,MHE constructs possible sub-graphs as query in-terpretation hypotheses and matches them againstthe entity graph of DBpedia.
Alexandria20 [42] is a German question answer-ing system over a domain ontology that was builtprimarily with data from Freebase, parts of DB-pedia, and some manually generated content, andcontains information on persons, locations, worksetc., as well as events, including temporal ones, andn-ary relations between entities. Alexandria ad-dresses the task of mapping natural language ques-tions to SPARQL queries as a graph mapping prob-lem. The syntactic structure of the question is rep-resented by a dependency tree. Then, first the nat-ural language tokens are mapped to ontology con-cepts based on a hand-crafted lexicon for propertiesand an index for named entity recognition. Here
20http://alexandria.neofonie.de
disambiguation choices can be (but do not have tobe) provided by the user and are stored for laterlookup. Second, the edges of the dependency parsetree are aggregated into a SPARQL graph pattern,by means of a compositional process. The model-ing of n-ary relations in the ontology schema allowsAlexandria to match simple linguistic expressionswith complex triple patterns.
It is noteworthy that, since Alexandria so far onlycovers German, the QALD-2 questions were firsttranslated into German. Also, since Alexandria re-lies on its own ontology schema, the evaluation withrespect to the QALD-2 gold standard suffers fromdata mismatches.
4.2. Results
The results for both datasets for each participat-ing system are shown in Table 1 for QALD-1 andTable 2 for QALD-2, listing the global precision,recall and F-measure values for the whole ques-tion set. The column answered states for howmany of the questions the system provided an an-swer, right specifies how many of these questionswere answered with an F-measure of 1, and par-tially specifies how many of the questions were an-swered with an F-measure strictly between 0 and1. A detailed listing of precision, recall and F-measure results for each question are available athttp://www.purl.org/qald/home. We also indi-cate the global F-measure values in brackets asthey would be if computed over the total numberof questions and not only the number of questionsthat were processed by the system (cf. Section 3.3above).
Additionally, FREyA reports an average perfor-mance of 36 seconds using the DBpedia dataset,PowerAqua reports in [27] an average of 20 secondsfor a scalability evaluation based on DBpedia andother semantic data, and Alexandria reports an av-erage of less than 20 miliseconds for their algorithmand in-memory SPARQL processing.
4.3. Overview and results of non-participant sys-tems
In addition to the above mentioned systems, othersystems such as C-Phrase, Treo, TBSL and BELAdid not take part in the online evaluation but usedthe datasets and questions for their own evaluationpurposes.
Granberg and Minock [19] report on the adapta-tion of their system C-Phrase to the MusicBrainz
10
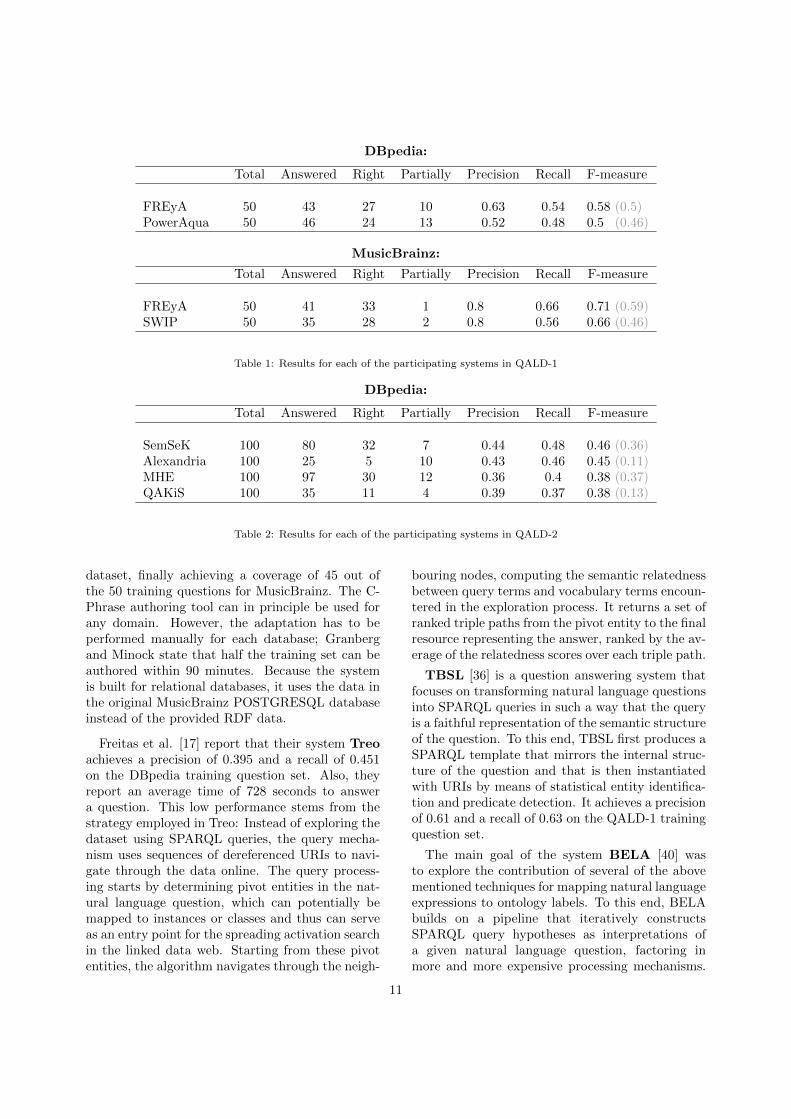
DBpedia:
Total Answered Right Partially Precision Recall F-measure
FREyA 50 43 27 10 0.63 0.54 0.58 (0.5)PowerAqua 50 46 24 13 0.52 0.48 0.5 (0.46)
MusicBrainz:
Total Answered Right Partially Precision Recall F-measure
FREyA 50 41 33 1 0.8 0.66 0.71 (0.59)SWIP 50 35 28 2 0.8 0.56 0.66 (0.46)
Table 1: Results for each of the participating systems in QALD-1
DBpedia:
Total Answered Right Partially Precision Recall F-measure
SemSeK 100 80 32 7 0.44 0.48 0.46 (0.36)Alexandria 100 25 5 10 0.43 0.46 0.45 (0.11)MHE 100 97 30 12 0.36 0.4 0.38 (0.37)QAKiS 100 35 11 4 0.39 0.37 0.38 (0.13)
Table 2: Results for each of the participating systems in QALD-2
dataset, finally achieving a coverage of 45 out ofthe 50 training questions for MusicBrainz. The C-Phrase authoring tool can in principle be used forany domain. However, the adaptation has to beperformed manually for each database; Granbergand Minock state that half the training set can beauthored within 90 minutes. Because the systemis built for relational databases, it uses the data inthe original MusicBrainz POSTGRESQL databaseinstead of the provided RDF data.
Freitas et al. [17] report that their system Treoachieves a precision of 0.395 and a recall of 0.451on the DBpedia training question set. Also, theyreport an average time of 728 seconds to answera question. This low performance stems from thestrategy employed in Treo: Instead of exploring thedataset using SPARQL queries, the query mecha-nism uses sequences of dereferenced URIs to navi-gate through the data online. The query process-ing starts by determining pivot entities in the nat-ural language question, which can potentially bemapped to instances or classes and thus can serveas an entry point for the spreading activation searchin the linked data web. Starting from these pivotentities, the algorithm navigates through the neigh-
bouring nodes, computing the semantic relatednessbetween query terms and vocabulary terms encoun-tered in the exploration process. It returns a set ofranked triple paths from the pivot entity to the finalresource representing the answer, ranked by the av-erage of the relatedness scores over each triple path.
TBSL [36] is a question answering system thatfocuses on transforming natural language questionsinto SPARQL queries in such a way that the queryis a faithful representation of the semantic structureof the question. To this end, TBSL first produces aSPARQL template that mirrors the internal struc-ture of the question and that is then instantiatedwith URIs by means of statistical entity identifica-tion and predicate detection. It achieves a precisionof 0.61 and a recall of 0.63 on the QALD-1 trainingquestion set.
The main goal of the system BELA [40] wasto explore the contribution of several of the abovementioned techniques for mapping natural languageexpressions to ontology labels. To this end, BELAbuilds on a pipeline that iteratively constructsSPARQL query hypotheses as interpretations ofa given natural language question, factoring inmore and more expensive processing mechanisms.
11

BELA starts with a simple index lookup, then ex-ploits string similarity, next involves a WordNet-based lexical expansion, and finally computes se-mantic similarity based on Explicit Semantic Anal-ysis. Each of these steps increase the results ofthe system on the DBpedia training and test ques-tions, and in sum outperform most of the abovementioned systems. BELA also identifies the gapbetween the linguistic structure of the natural lan-guage question and the underlying structure of thedata as one of the major challenges to be addressedin question answering over linked data.
4.4. Discussion
The results are encouraging, showing that currentsystems performing question answering over linkeddata can deliver answers to quite complex informa-tion needs expressed in natural language, using het-erogeneous semantic data. At the same time, thetraining and test questions were challenging enoughto show that there is still plenty room for improve-ment.
Cimiano and Minock [11] present an analysis ofcharacteristic problems involved in the task of map-ping natural language to formal queries. Most ofthese problems were also encountered in the QALDchallenge:
• Lexical gap:The gap between the vocabulary of the userand that of the ontology cannot always bebridged by the use of string distance metricsor generic dictionaries such as WordNet [29].For instance, the question In which countrydoes the Nile start? requires mapping start tothe ontological property sourceCountry, andfor the question Who is the mayor of NewYork City? the expression mayor needs to bematched with the property leaderName.
59 % of the QALD-2 DBpedia training ques-tions and 65 % of the QALD-2 DBpedia testquestions require more than string similarityand WordNet expansion in order to bridge thelexical gap (cf. [40]).
• Lexical ambiguities:Lexical ambiguities arise if one word can beinterpreted in different ways, i.e., it can refer todifferent entities or concepts. For example, thename Lincoln can refer to a range of differententities (Abraham Lincoln, other people calledLincoln, a fair amount of cities, a mountain,
a band, a movie, a novel, and so on). Thecorrect answer can only be obtained by usingthe contextually relevant mapping.
Considering only DBpedia resources, 25 % ofthe expressions used in the QALD-2 questionsto refer to these resources are ambiguous.
• Light expressions:A lot of semantically light expression such asthe verbs to be and to have, and prepositions ofand with either refer to an ontological propertyin a massively underspecified way (e.g., in Giveme all movies with Tom Cruise, the proposi-tion with needs to be mapped to the ontolog-ical property starring) or do not correspondto any property at all.
Around 10 % of the MusicBrainz questions andslightly more than 20 % of the DBpedia ques-tions contain semantically light expressions.
• Complex queries:In addition to lexical and structural ambigu-ities, the QALD question sets included infor-mation needs that can only be expressed usingcomplex queries containing aggregation func-tions, comparisons, superlatives, and temporalreasoning. 24 % of the QALD-2 questions wereof this nature.
Lexical ambiguities were handled well by open-domain approaches, mainly exploiting the ontol-ogy semantics and the user query context combinedwith ranking algorithms (in the case of PowerAqua)and clarification dialogs (in the case of FREyA).Only in very few cases, properties were mapped tothe wrong entity, e.g., for the query Since when isTom Araya a member of Slayer, FREyA gave thebirthday of Tom Araya instead of the date when hejoined the band [14].
Most failures occured when trying to bridge thelexical gap or were due to the complexity of thequeries in general, where complexity had the fol-lowing sources:
• Aggregating functions, e.g., counting, as inHow many bands broke up in 2010?, sometimescombined with ordering, as in Which countrieshave more than two official languages?, or withsuperlatives, as in How many members does thelargest group have?
• Comparisons, like in Who recorded more sin-gles than Madonna? and Which bridges are ofthe same type as the Manhattan Bridge?
12

• Superlatives, e.g., Which rock album has themost tracks? and What is the highest moun-tain?
• Temporal reasoning, as in Which artistshave their 50th birthday on May 30? and Whowas born on the same day as Frank Sinatra?
Note that queries containing linguistic superla-tives or comparatives are not considered complexqueries if no mechanisms are required to understandthe comparison within the ontology. For example,in What is the highest place of Karakoram? thesuperlative is directly mapped to the ontologicalproperty highestPlace, such that no aggregationis needed. This mapping process is very differentin terms of complexity from the query What moun-tain is the highest after the Annapurna, where high-est should be mapped to the ontological propertyelevation and the values for all mountains firstneed to be filtered, so that only the ones with lesselevation than the elevation of the Annapurna arekept, and then need to be sorted in descending or-der, so the first one can be picked as answer.
Failures when trying to bridge the lexical gapoften arise from the heterogeneity with respectto different levels of granularity at which en-tities are modelled. Complex conjunctive on-tological terms, such as the YAGO categoryPresidentsOfTheUnitedStates, are notoriouslydifficult to handle. In total, only 14 % of the DBpe-dia questions are translated into purely conjunctivecategories. For example, the question When didGermany join the EU is expressed by the followingtriple:
res:Germany dbp:accessioneudate ?date.
That is, the verb phrase join the EU maps tothe single ontological property accessioneudate,which has no domain or range defined in DBpedia.
Another difficulty that often keeps questionanswering systems from achieving 100 % re-call is that DBpedia contains many redun-dant classes and properties that have a sim-ilar or overlapping meaning but are modelledwith different URIs (e.g., dbo:President andyago:President as well as the more specificyago:PresidentsOfTheUnitedStates). Thus,there might be more than one ontological corre-spondent for a natural language term, leading topartial answers. For instance, the query Whichcompanies are in the computer software industry?
required to find not only companies with the prop-erty industry “computer software”, but also “com-puter hardware, software” and “computer softwareand engineering”.
Most of the mentioned difficulties arise from theheterogeneity of the data available on the SemanticWeb and therefore need to be addressed by all sys-tems striving for successful question answering overlinked data. One of the aims of the QALD challengeis to highlight these difficulties and invite questionanswering systems to present their solutions. Theevaluation results indicate that the provided ques-tion sets achieve a good balance between complex-ity and feasibility, i.e., the problem was challeng-ing enough but nevertheless participating systemscould obtain decent results to allow for meaningfulcomparison.
4.5. Comparison of results based on question andanswer types
User questions in the context of questions answeringover RDF data are in principle not different fromthe questions used in TREC or CLEF challenges, asit is not the information needs that differ but themeans to answer them. Nevertheless, the QALDquestions were mainly designed to incorporate thechallenges that arise from retrieving answers fromRDF data sources, as discussed in the previous sec-tion.
In order to compare how the different systemsperform according to the different challenges, weannotated the QALD-2 questions according tothe complexity required to transform the naturallanguage question into the appropriate SPARQLquery, especially with respect to the use of aggrega-tion functions such as counting, unions and filters,as well as the combination of schemas in additionto the DBpedia ontology. We now use these an-notations to quantitatively assess the current cov-erage and shortcomings for the participating ques-tion answering systems. To this end, we exploitthe average F-measure of the systems as a measureindicating to which degree each annotation type af-fects the system’s ability to find the correct answers.The average F-measure for a given annotation isthen calculated by considering the F-measures forall questions containing this annotation, regarde-less of whether the system did or did not providean answer to the question.
As all QALD-2 participants only submitted re-sults for the DBpedia question set, we cannot make
13

any statements regarding MusicBrainz and the fu-sion questions across DBpedia and MusicBrainz.The results with respect to the question type areshown in Table 3. The column aggregation refersto queries for which aggregation functions are re-quired, e.g. questions with comparisons (often re-quiring filters) or superlatives (requiring ordering ofresults), and how many question (requiring count-ing). The column other schema shows the resultsfor all queries that require the use of other schemathan the DBpedia ontology. This comprises theDBpedia property namespace as well as YAGO andFOAF. Finally, we call list queries those which donot contain aggregations or do not require the useof other schema. From the 100 test questions, 73are list questions, 18 require aggregations and 44require the use of other schema. Note that somequeries require both the use of other schema andaggregation functions to find the appropriate an-swers. Also note that the results for Alexandria inthe last column are not very meaningful, as it didnot use DBpedia as a data basis.
In order to answer list questions, the systemsneeded to bridge the lexical gap, to handle lexi-cal ambiguities, and in the case of other schemasbeing relevant, also to deal with the heterogeneityof the data sources—YAGO, for example, includesrather complex conjunctive ontological terms. Toanswer aggregation queries the systems needed tobe able to detect the linguistic constructions usedin the natural language questions to denote aggre-gations, such as superlatives and comparisons, andto construct corresponding SPARQL queries usingunions, filters, ordering and counting predicates.In Table 3, we can see that the systems were do-ing much better on list questions than on the otherquestion types, and especially struggled with aggre-gation questions. In fact, only half of the systems,MHE and Alexandria, were able to handle to someextent aggregation questions and queries requiringother schema. This shows both that the task of an-swering questions using linked data is not straight-forward, and that the complexity of the QALD-2questions is very high considering the current per-formance of the systems, therefore leaving quite alot of space for improvement and further challenges.
Table 4 shows the results with respect to thetype of the answer that the questions expect, in-dependent of whether they require aggregationsor other schema, comprising the following answertypes: numbers or a count of the result answers (15queries), literals or strings (3 queries), booleans (8
queries), dates (3 queries) and a resource or a listof resources (70 queries). Here, MHE is the onlyQALD-2 participant that provided answers to alltypes of questions, performing best on string anddate questions. All systems provided answers fornumeral and resource queries, which make up thebiggest part of the question set, covering 85 % of allquestions. The lower F-measure on those questionsstems from the fact that when retrieving a list of re-sources, some answers may be missing or incorrectand thus cause a decrease of the overall score.
5. Conclusions and future evaluations
The importance of interfaces that bridge the gapbetween the end user and Semantic Web data havebeen widely recognised [8]. QALD is the first pub-lic challenge aiming at providing a common bench-mark for evaluating the success of question answer-ing systems in answering information needs by tak-ing into account data available on the SemanticWeb.
For the QALD challenge, we simplified the evalu-ation process as much as possible. Participants rantheir system locally and submitted the results inan XML file via an online form. An alternative ap-proach is for participants to implement a wrapper,so their system can be run on a central server, ashas been done for the SEALS semantic search eval-uation in 2010. The main advantage is that perfor-mance across systems can be fairly measured. How-ever, it also introduces a major overhead for bothparticipants and organizers. In particular, it in-volves several infrastructural issues and challenges.Current systems are based on very different infras-tructures, e.g., they may use the provided SPARQLendpoint or not, they might be based on differentsemantic database servers (such as Jena, Sesame,or Virtuoso), they may require indexes to optimizeperformance, as well as different configurations andlibraries (such as GATE, gazetteers, or WordNet).For the QALD challenges we therefore designed anevaluation with the goal of facilitating participationas much as possible.
Future evaluation campaigns of the QALD seriescan develop in several directions. On the one hand,we want to extend the evaluation to new datasetsand questions. Since participants of future chal-lenges will have access to all training and test datafrom previous challenges, we are increasingly cre-ating a public test corpus to facilitate standard-ized evaluations and comparison across systems to
14

DBpedia:
List Aggregation Other schema
SemSeK 0.49 0 0.32MHE 0.44 0.14 0.17QAKiS 0.17 0 0.06Alexandria 0.13 0.04 0.07
Table 3: F-measure average for each of the participating systems in QALD-2 by question type
DBpedia:
Boolean Date Numeral Resource String
SemSeK 0 0.67 0.33 0.38 0.67MHE 0.38 0.67 0.47 0.3 0.67QAKiS 0 0 0.13 0.15 0Alexandria 0.25 0 0.03 0.11 0
Table 4: F-measure average for each of the participating systems in QALD-2 by answer type
progress on this field and foster research in thisnovel and challenging area. On the other hand, fu-ture challenges can focus on extending the currentevaluation methodologies to assess further aspectsof question answering systems, such as performanceand usability.
However, both evaluation challenges showed thatparticipants were all more familiar and interestedin finding better ways to query large linked datacollections covering heterogeneous schema and do-mains, such as DBpedia, rather than domain-specific homogeneous datasets following a partic-ular schema, such as MusicBrainz.
The third challenge will focus on multilingual-ity as one aspect of querying linked data collec-tions. Multilinguality has become an issue of ma-jor interest for the Semantic Web community, asboth the number of actors creating and publishingopen data in languages other than English as wellas the amount of users that access this data andspeak native languages other than English is grow-ing substantially. In particular, DBpedia is becom-ing inherently language-independent as the EnglishDBpedia contains multilingual labels and versionsof DBpedia in other languages are prepared andpublished, such as the Spanish21 and the French22
DBpedia. Thus we will extend our evaluation by
21http://es.dbpedia.org22http://wimmics.inria.fr/projects/dbpedia/
providing questions and open domain datasets indifferent languages in order to also evaluate multi-lingual and non-English based question answeringsystems.
Another very important aspect is addressing thelinked in linked data, i.e., the ability to answerquestions across sources, as already introduced inQALD-2, eventually scaling to the whole linkeddata cloud.
One limitation of the QALD challenges arisesfrom the fact that they focus on structured dataonly and do not consider the possibility of par-ticipants incorporating information retrieval tech-niques, for example extracting results from literalssuch as DBpedia abstracts. It is quite likely that fu-ture question answering systems build on a hybridapproach, combining structured and unstructureddata sources. This scenario is very appealing butwill require much more sophisticated methods ofevaluation.
Appendix
In the following we list a few examples of queriestogether with their SPARQL annotation, as used inthe QALD-2 training phase.23
23Using the following prefixes for DBpedia:
15

DBpedia
1. Who is the daughter of Bill Clinton marriedto?
SELECT DISTINCT ?uri ?string WHERE {res:Bill Clinton dbo:child ?child .
?child dbp:spouse ?string .
?uri rdfs:label ?string .
}
2. Which actors were born in Germany?
SELECT DISTINCT ?uri ?string WHERE {?uri rdf:type dbo:Actor .
{ ?uri dbo:birthPlace res:Germany . }UNION
{ ?uri dbo:birthPlace ?city .
?city rdf:type yago:StatesOfGermany . }OPTIONAL { ?uri rdfs:label ?string .
FILTER (lang(?string) = ’en’) }}
3. Which caves have more than 3 entrances?
SELECT ?uri ?string WHERE {?uri rdf:type dbo:Cave .
?uri dbo:numberOfEntrances ?entrance .
FILTER (?entrance > 3) .
OPTIONAL { ?uri rdfs:label ?string .
FILTER (lang(?string) = ’en’) }}
4. Who produced the most films?
SELECT DISTINCT ?uri ?string WHERE {?film rdf:type dbo:Film .
?film dbo:producer ?uri .
OPTIONAL { ?uri rdfs:label ?string .
FILTER (lang(?string) = ’en’) }} ORDER BY DESC(COUNT(?film)) LIMIT 1
MusicBrainz
5. Give me all live albums by Michael Jackson.
• res for http://dbpedia.org/resource/
• dbo for http://dbpedia.org/ontology/
• dbp for http://dbpedia.org/property/
And the following prefixes for MusicBrainz:
• mm for http://musicbrainz.org/mm/mm-2.1
• ar for http://musicbrainz.org/ar/ar-1.0#
• dc for http://purl.org/dc/elements/1.1/
SELECT DISTINCT ?album ?title WHERE {?album rdf:type mm:Album .
?album mm:releaseType mm:TypeLive .
?album dc:title ?title .
?album dc:creator ?artist .
?artist dc:title ’Michael Jackson’ .
}
6. Did the Sex Pistols already break up?
ASK WHERE {?artist dc:title ’Sex Pistols’.
?artist mm:endDate ?endDate.
FILTER (bound(?endDate))
}
7. In which bands did Kurt Cobain play?
SELECT DISTINCT ?band ?title WHERE {?artist dc:title ’Kurt Cobain’ .
?artist ar:memberOfBand ?bandinstance.
?bandinstance ar:toArtist ?band .
?band dc:title ?title .
}
8. Give me all Thrash Metal albums.
SELECT DISTINCT ?album ?name WHERE {?album rdf:type mo:Record .
?album dc:description ?tag .
?album dc:title ?name .
FILTER regex(?tag,"thrash metal","i")
}
Questions across datasets
Finally, we list an example of the seven addi-tional questions we provided that require informa-tion from both datasets to be answered.
9. In which country was the singer of the DrunkenLullabies by Flogging Molly born?
SELECT DISTINCT ?uri ?string WHERE {?album rdf:type mo:Record .
?album dc:title ’Drunken Lullabies’ .
?album mo:singer ?mb singer .
?album foaf:maker ?mb band .
?mb band foaf:name ’Flogging Molly’ .
?dbp singer owl:sameAs ?mb singer .
?dbp singer dbo:birthPlace ?city .
?city dbo:country ?uri .
?uri rdf:type dbo:Country .
OPTIONAL { ?uri rdfs:label ?string .
FILTER (lang(?string) = ’en’) }}
16

References
[1] N. Aggarwal, P. Buitelaar, A System Description of Nat-ural Language Query over DBpedia, in: Proc. of Inter-acting with Linked Data (ILD 2012) [37] (2012), 96–99.http://ceur-ws.org/Vol-913/08-ILD2012.pdf
[2] L. Androutsopoulos, Natural Language Interfaces toDatabases – An Introduction, Journal of Natural Lan-guage Engineering 1 (1995), 29–81.
[3] K. Balog, M. Ciglan, R. Neumayer, W. Wei and K.Nørvag, NTNU at SemSearch 2011, in: Proc. of the4th International Semantic Search Workshop (SEM-SEARCH ’11) at the World Wide Web conference 2011(2011).
[4] A. Bernstein, E. Kaufmann, C. Kaiser and C. Kiefer,Ginseng: A Guided Input Natural Language Search En-gine, in: Proc. of the 15th Workshop on InformationTechnologies and Systems (WITS 2005) (2006), 45–50.
[5] C. Bizer, T. Heath and T. Berners-Lee, Linked Data—The Story So Far, International Journal on SemanticWeb and Information Systems 5 (2009), 1–22.
[6] C. Bizer, J. Lehmann, G. Kobilarov, S. Auer, C. Becker,R. Cyganiak and S. Hellmann, DBpedia: A Crystalliza-tion Point for the Web of Data, Journal of Web Seman-tics: Science, Services and Agents on the World WideWeb 7 (2009), 154–165.
[7] R. Blanco, H. Halpin, D. Herzig, P. Mika, J. Pound,H.S. Thompson and T.-T. Duc, Entity Search Evaluationover Structured Web Data, in: Proc. of the 1st Interna-tional Workshop on Entity-Oriented Search at SIGIR2011 (2011).
[8] P. Buitelaar, T. Declerck, N. Calzolari and A. Lenci, Lan-guage Resources and the Semantic Web, Proc. of theELSNET/ENABLER Workshop, Paris, France (2003).
[9] E. Cabrio, A. Palmero Aprosio, J. Cojan, B. Magnini, F.Gandon, A. Lavelli, QAKiS @ QALD-2. In: Proceedingsof Interacting with Linked Data (ILD 2012) [37] (2012),87–95. http://ceur-ws.org/Vol-913/07-ILD2012.pdf
[10] P. Cimiano, P. Haase and J. Heizmann, Porting NaturalLanguage Interfaces between Domains—An Experimen-tal User Study with the ORAKEL System, in: Proc. ofthe International Conference on Intelligent User Inter-faces (2007), 180–189.
[11] P. Cimiano and M. Minock, Natural Language Inter-faces: What’s the Problem?—A Data-driven Quanti-tative Analysis, in: Proc. of the International Confer-ence on Applications of Natural Language to Informa-tion Systems (NLDB 2009) (2009), 192–206.
[12] C. Comparot, O. Haemmerle and N. Hernandez, Aneasy way of expressing conceptual graph queries fromkeywords and query patterns, in: Conceptual Struc-tures: From Information to Intelligence, 18th Inter-national Conference on Conceptual Structures (ICCS2010), Kuching, Sarawak, Malaysia, July 26-30, 2010,Proceedings, M. Croitorou, S. Ferre, D. Lukose, eds.,Springer, LNCS 6280 (2010), 84–96.
[13] D. Damljanovic, M. Agatonovic and H. Cunningham,Natural Language interface to ontologies: Combiningsyntactic analysis and ontology-based lookup throughthe user interaction, in: Proc. of the European SemanticWeb Conference, Heraklion, Greece, Springer (2010).
[14] D. Damljanovic, M. Agatonovic and H. Cunningham,FREyA: an Interactive Way of Querying Linked Datausing Natural Language, in: Proc. of 1st Workshop onQuestion Answering over Linked Data (QALD-1) at the
8th Extended Semantic Web Conference (ESWC 2011)(2011).
[15] M. Fernandez, V. Lopez, E. Motta, M. Sabou, V.Uren, D. Vallet and P. Castells, Using TREC for cross-comparison between classic IR and ontology-based searchmodels at a Web scale, in: Proc. of the Semantic searchworkshop, collocated with the 18th International WorldWide Web Conference, Madrid, Spain (2009).
[16] P. Forner, D. Giampiccolo, B. Magnini, A. Penas, A.Rodrigo and R. Sutcliffe, Evaluating Multilingual Ques-tion Answering Systems at CLEF, in: Proc. of the Con-ference on Language Resources and Evaluation (LREC),Malta (2010).
[17] A. Freitas, J. Gabriel de Oliveira, S. O’Riain, E. Curryand J.J.C. Pereira da Silva, Treo: Combining Entity-Search, Spreading Activation and Semantic Relatednessfor Querying Linked Data, in: Proc. of 1st Workshop onQuestion Answering over Linked Data (QALD-1) at the8th Extended Semantic Web Conference (ESWC 2011)(2011).
[18] A. Freitas, J.G. Oliveira, S. O’Riain, E. Curry, J.C.P.Da Silva, Querying linked data using semantic relat-edness: a vocabulary independent approach, in: Proc.of the 16th International Conference on Applications ofNatural Language to Information Systems (NLDB ’11)(2011).
[19] J. Granberg and M. Minock, A Natural Language In-terface over the MusicBrainz Database, in: Proc. of1st Workshop on Question Answering over Linked Data(QALD-1) at the 8th Extended Semantic Web Confer-ence (ESWC 2011) (2011).
[20] H. Halpin, D. Herzig, P. Mika, R. Blanco, J. Pound,H.S. Thompson and T.-T. Duc, Evaluating Ad-Hoc Ob-ject Retrieval, in: Proc. of the International Workshopon Evaluation of Semantic Technologies (IWEST 2010)at the 9th ISWC (2010).
[21] E. Kaufmann, A. Bernstein and R. Zumstein, Querix:A Natural Language Interface to Query OntologiesBased on Clarification Dialogs, in: Proc. of the 5th In-ternational Semantic Web Conference, Athens, USA,Springer, LNCS 4273 (2006), 980–981.
[22] E. Kaufmann and A. Bernstein, How Useful Are Natu-ral Language Interfaces to the Semantic Web for CasualEnd-Users?, in: Proc. of the 6th International SemanticWeb Conference, Busan, Korea, Springer, LNCS 4825(2007), 281–294.
[23] E. Kaufmann, A. Bernstein and L. Fischer, NLP-Reduce: A “naive” but domain-independent NaturalLanguage Interface for Querying Ontologies, in: Proc. ofthe 4th European Semantic Web Conference, Innsbruck,Springer (2007).
[24] X. Liu, C.-L. Yao and H. Fang, A study of Seman-tic Search in SemSearch 2011, in: Proc. of the 4th In-ternational Semantic Search Workshop (SEMSEARCH’11) at the International World Wide Web Conference(2011).
[25] V. Lopez, V. Uren, E. Motta and M. Pasin, AquaLog:An ontology-driven question answering system for orga-nizational semantic intranets, Journal of Web Seman-tics: Science Service and Agents on the World WideWeb 5 (2007), 72–105.
[26] V. Lopez, A. Nikolov, M. Sabou, V. Uren, E. Motta andM. d’Aquin, Scaling up Question-Answering to LinkedData, in: Proc. of the 17th Knowledge Engineeringand Knowledge Management by the Masses (EKAW),
17

Springer (2010), 193–210.[27] V. Lopez, M. Fernandez, E. Motta and N. Stieler, Pow-
erAqua: Supporting Users in Querying and Exploringthe Semantic Web, Semantic Web Journal (2011).
[28] V. Lopez, V. Uren, M. Sabou and E. Motta, Is QuestionAnswering fit for the Semantic Web? A Survey, SemanticWeb 2 (2011), 125–155.
[29] G. A. Miller, WordNet: A Lexical Database for English,Communications of the ACM 38 (1995), 39–41.
[30] M. Minock, C-Phrase: A System for Building RobustNatural Language Interfaces to Databases, Journal ofData and Knowledge Engineering 69 (2010), 290–302.
[31] L. Nixon, R. Garcıa-Castro, S. Wrigley, M. Yatskevich,C. Santos and L. Cabral, The State of Semantic Tech-nology Today—Overview of the First SEALS EvaluationCampaigns, in: Proc. of the 7th International Confer-ence on Semantic Systems (I-SEMANTICS) (2011).
[32] Y. Raimond, S. Abdallah, M. Sandler and F. Giasson,The music ontology, in: Proc. of the International Con-ference on Music Information Retrieval (2007), 417–422.
[33] S. Shah and G. Arora, Information Retrieval on seman-tic data—Semsearch 2011 List Search Track system de-scription, Information Retrieval 2 (2011).
[34] T. Strzalkowski and S. Harabagiu, Advances in OpenDomain Question Answering, Springer (2006).
[35] L.R. Tang and R.J. Mooney, Using multiple clause con-structors in inductive logic programming for semanticparsing, in: Proc. of the 12th European Conference onMachine Learning (ECML-2001) (2001), 466–477.
[36] C. Unger, L. Buhmann, J. Lehmann, A.-C. NgongaNgomo, D. Gerber, P. Cimiano: SPARQL Template-Based Question Answering, in: Proc. of the 22nd In-ternational World Wide Web Conference (WWW 2012)(2012).
[37] C. Unger, P. Cimiano, V. Lopez, E. Motta, P. Buite-laar, R. Cyganiak (eds.), Proceedings of Interacting withLinked Data (ILD 2012), workshop co-located with the9th Extended Semantic Web Conference, May 28, 2012,Heraklion, Greece (2012). http://ceur-ws.org/Vol-913
[38] V. Uren, M. Sabou, E. Motta, M. Fernandez, V. Lopez,and Y. Lei, Reflections on five years of evaluating seman-tic search systems, International Journal of Metadata,Semantics and Ontologies 5 (2010), 87–98.
[39] E. Voorhees, Evaluation by Highly Relevant Docu-ments, in: Proc. of the 24th Annual International ACMSIGIR Conference on Research and Development in In-formation Retrieval (2001), 74–82.
[40] S. Walter, C.Unger, P. Cimiano, D. Bar, Evaluationof a layered approach to question answering over linkeddata, in: Proc. of the 11th International Semantic WebConference (ISWC 2012) (2012).
[41] C. Wang, M. Xiong, Q. Zhou, and Y. Yu, PANTO: Aportable Natural Language Interface to Ontologies, in:Proc. of the 4th European Semantic Web Conference,Innsbruck, Austria, Springer (2007), 473–487.
[42] M. Wendt, M. Gerlach, H. Duwiger: Linguistic Mod-eling of Linked Open Data for Question Answering.In: Proceedings of Interacting with Linked Data (ILD2012) [37] (2012), 75–86. http://ceur-ws.org/Vol-913/06-ILD2012.pdf
[43] S. Wrigley, K. Elbedweihy, D. Reinhard, A. Bernsteinand F. Ciravegna, Evaluating semantic search tools us-ing the SEALS Platform, in: Proc. of the InternationalWorkshop on Evaluation of Semantic Technologies(IWEST 2010) at the International Semantic Web
Conference (2010). Campaign 2010 results at: http://
www.sealsproject.eu/seals-evaluation-campaigns/
semantic-searchtools/results-2010
[44] C. Hallet, D. Scott and R.Power, Composing Questionsthrough Conceptual Authoring, in Computational Lin-guistics 33, (2007), 105–133.
18
Related Documents











