Maret 2015 ETS ANALISIS MULTIVARIAT

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Maret 2015ETS ANALISIS MULTIVARIAT

BAB I
PENDAHULUAN
1.1 Latar Belakang
Metode analisis multivariat adalah suatu metode statistik
yang digunakan untuk menganalisis data yang terdiri atas
banyak variabel dan diduga antar variabel saling
berhubungan. Metode analisis multivariat dapat
diklasifikasikan menjadi dua yaitu metode dependen dan
metode interdependen.
Metode analisis dependen adalah suatu metode dimana suatu
variabel atau suatu kumpulan variabel yang diketahui sebagai
variabel dependen diprediksi atau dijelaskan oleh variabel
lain yang disebut variabel independen. Sedangkan metode
analisis interdependen adalah suatu metode dimana tidak ada
satu atau sekelompok variabel pun yang didefinisikan sebagai
variabel dependen maupun interdependen.
Metode analisis dependen dibagi menjadi beberapa metode
analisis yakni analisis regresi berganda, analisis
diskriminan, analisis multivariate varian (MANOVA), analisis
conjoint, dan analisis korelasi kanonikal. Sedangkan pada
metode interdependen dibagi menjadi analisis faktor,
analisis cluster dan multidimensional scaling.
Pada makalah ini tidak akan membahas metode-metode analisis
multivariat secara keseluruhan akan tetapi hanya membahas

beberapa metode analisis multivariat saja diantaranya
adalah analisis faktor, analisis cluster dan analisis
multivariate varian (MANOVA).
Salah satu dari beberapa metode analisis multivariat yang
akan dilakukan dalam makalah ini adalah analisis faktor.
Analisis faktor adalah salah satu analisis yang banyak
digunakan pada statistik multivariat. Analisis faktor
merupakan salah satu teknik untuk menyederhanakan kumpulan
variabel yang banyak dan saling berkorelasi menjadi suatu
kumpulan variabel baru yang ringkas dan tidak saling
berkorelasi yang disebut faktor. Didalam analisis varian,
analisis regresi dan analisis diskriminan, satu variabel
merupakan variabel independen. Didalam analisis faktor,
variabel-variabel tidak dikelompokan menjadi variabel
independen dan dependen. Metode estimasi dalam analisis
faktor terdiri dari metode non-iteratif dan metode iteratif.
Akan tetapi metode estimasi yang akan dipakai dalam
penyelesaian masalah dalam makalah ini adalah metode
analisis yang paling populer yaitu analisis komponen utama
(principal component analysis) yang termasuk dalam metode non-
iteratif.
Metode interdependen lain yang dilakukan selain dengan
menggunakan analisis faktor adalah analisis cluster.
Analisis cluster merupakan salah satu teknik multivariat
yang mempunyai tujuan utama untuk mengelompokan objek-objek
berdasarkan karakteristik yang dimilikinya. Sehingga dalam

analisis ini tidak ada pembedaan variabel dependent dan
variabel independen. Tujuan analisis cluster adalah untuk
mengklasifikasi objek ke dalam kelompok-kelompok yang
relatif homogen yang didasarkan pada suatu kumpulan variabel
yang dipertimbangkan akan diteliti. Tahapan pengklusteran
disajikan dalam dendogram yang memungkinkan penelusuran
pengklusteran obyek-obyek yang diamati dengan lebih mudah
dan informatif. Untuk menggunakan teknik ini persyaratan
yang harus dipenuhi, diantaranya ialah:
Data yang digunakan untuk analisis ini ialah data
kuantitatif berskala interval atau rasio.
Metode yang ada ialah hubungan antara kelompok
(between-groups linkage), hubungan dalam kelompok (within-
groups linkage), kelompok terdekat (nearest neighbor),
kelompok berikutnya (furthest neighbor), kluster centroid
(centroid clustering), kluster median (median clustering), dan
metode Ward's.
Selain metode interdependent, terdapat salah satu metode
dependet yakni analisis varian multivariat (MANOVA) yang
sering digunakan untuk menghitung pengujian signifikansi
perbedaan rata-rata secara bersamaan antara kelompok untuk dua
atau lebih variable dependent. Teknik ini bermanfaat untuk
menganalisis variabel-variabel dependent lebih dari dua yang
berskala interval atau rasio. Untuk menggunakan MANOVA
beberapa persyaratan yang harus dipenuhi ialah:
Variabel tergantung harus dua atau lebih dengan
skala interval

Variabel bebas satu dengan menggunakan skala
nominal.
Untuk semua variabel tergantung, data diambil dengan
cara random sample dari vektor-vektor populasi
normal multivariate dalam suatu populasi, dan untuk
matrik-matrik variance-covariance untuk semua sel
sama
1.2 Permasalahan
1) Bagaimana menguraikan hubungan antar banyak variabel
dengan menggunakan faktor pada analisis faktor dengan
metode analisis komponen utama (principal component
analysis)?
2) Bagaimana cara mengelompokan data berdasarkan
karakteristik yang dimilikinya dengan menggunakan
analisis cluster?
3) Bagaimana menghitung pengujian signifikansi perbedaan
rata-rata secara bersama antar kelompok untuk dua atau
lebih variabel dependen dengan menggunakan analysis
varian multivariat (MANOVA)?
1.3 Tujuan
1) Menguraikan hubungan antar banyak variabel dengan
menggunakan faktor pada analisis faktor dengan metode
analisis komponen utama (principal component analysis).
2) Mengelompokan data berdasarkan karakteristik yang
dimilikinya dengan menggunakan analisis cluster.
3) Menghitung pengujian signifikansi perbedaan rata-rata
secara bersama antar kelompok untuk dua atau lebih

variabel dependen dengan menggunakan analysis varian
multivariat (MANOVA).
BAB II
TINJAUAN PUSTAKA
A. Kaiser Meyer Oikin (KMO)
Uji Kaiser-Meyer-Olkin bertujuan untuk mengetahui apakah semua
data yang telah terambil telah cukup untuk difaktorkan (uji
kecukupan data). Hipotesis dari Kaiser-Meyer-Olkin adalah sebagai
berikut.
Hipotesis :
H0 : Jumlah data cukup untuk difaktorkan
H1 : Jumlah data tidak cukup untuk difaktorkan
Statistik uji :

KMO=∑i=1
p
∑j=1
prij2
∑i=1
p
∑j=1
prij2 +∑
i=1
p
∑j=1
paij2
(1)
dengan
i = 1, 2, 3, ..., p dan j = 1, 2, ..., p i≠jrij = Koefisien korelasi antara variabel i dan j
aij = Koefisien korelasi parsial antara variabel i dan j
Apabila nilai KMO lebih besar dari 0,5 maka gagal tolak H0
sehingga dapat disimpulkan jumlah data telah cukup difaktorkan
[1].
B. Uji Bartlett’s (Kebebasan Antar Variabel)
Uji Bartlett’s bertujuan untuk mengetahui apakah terdapat
hubungan antar variabel dalam kasus multivariat. Jika variabel
X1, X2,…,Xp independent (bersifat saling bebas), maka matriks
korelasi antar variabel sama dengan matriks identitas.
Hipotesis dari uji Bartlett’s sebagai berikut.
H0 : ρ = I
H1 : ρ ≠ I
Statistik Uji :
rk=1
p−1∑i=1prik k = 1,2,...p
(4)
r=2
p(p−1)∑∑
i<krik
(2)
γ̂=(p−1 )2 [1−(1−r )2 ]p−(p−2 ) (1−r )2
(3)

dengan
rk = rata-rata elemen diagonal pada kolom atau baris ke k dari
matrik R (matrik korelasi)
r = rata-rata keseluruhan dari elemen diagonalDaerah penolakan :
tolak H0, jika
T=(n−1 )(1−r )2 [∑∑
i<k(rik−r)2−γ̂∑
k=1
p
(rk−r )2]>χ(p+1) (p−2 )/2,α2 (4)
Maka variabel-variabel saling berkorelasi, hal ini berarti
terdapat hubungan antar variabel. Jika H0 ditolak maka analisis
multivariat layak untuk digunakan terutama metode analisis
komponen utama dan analisis faktor [2].
C. Principle Component Analysis
Analisis komponen utama adalah analisis statistika yang
bertujuan untuk mereduksi dimensi data dengan cara
membangkitkan variabel baru (komponen utama) yang merupakan
kombinasi linear dari variabel asal sedemikan hingga varians
komponen utama menjadi maksimum dan antar komponen utama
bersifat saling bebas [2].
Model analisis komponen utama dapat ditulis sebagai
berikut.
[Y1
Y2
Y3
⋮Ym
]=[a11 a12 a13 … a1pa21 a22 a23 … a2pa31 a32 a33 … a3p⋮ ⋮ ⋮ ⋮ ⋮am1 am2 am3 … amp
][X1
X2
X3
⋮Xm
] ,m≤p (5)

Dengan
Y1 = komponen utama pertama, komponen yang mempunyai varians
terbesar
Y2 = komponen utama kedua, komponen yang mempunyai varians
terbesar kedua
Ym = komponen utama ke-m, komponen yang mempunyai varians
terbesar ke-m
X1 = variabel asal pertama
X2 = variabel asal kedua
Xp = variabel asal ke-p
m = banyaknya komponen utama
p = banyaknya variabel asal
Dengan analisis komponen utama diharapkan lebih mudah
melakukan interpretasi tanpa kehilangan banyak informasi
tentang data, bahkan informasi yang didapat menjadi lebih
padat dan bermakna.
Jika terdapat vektor random X = [X1,X2,X3,….Xp ]yang berisisejumlah pengamatan terhadap p variabel mempunyai rata-rata
dan matrik kovarians dengan eigenvalue. λ1≥λ2≥….≥λp≥∅.Maka
dapat ditulis suatu variabel baru yang merupakan kombinasi
linier dari variabel asal sebagai berikut.
Y1=l1X=l11X1+l21X2+…lp1XpY2=l2X=l12X1+l22X2+…lp2Xp
⋮
Yp=lpX=l1pX1+l2pX2+…lppXp (6) atau dapat ditulis dengan
notasi Yi=liX dimana l adalah matrik transformasi yang akan
mengubah variabel asal X menjadi Y yang disebut principal
component, dimana :

Var (Yi)=li∑ lii=1,2,….p
(8)
Cov (Yi,Yk)=li∑ lki,k=1,2,….p (7)
Komponen utama adalah kombinasi linier Y1,Y2,Y3,…,Yp yang tidak
berkorelasi dan mempunyai varians sebesar mungkin.
D. Scree Plot
Scree plot adalah tampilan grafis dari varians dari masing-
masing komponen dalam data set yang digunakan untuk menentukan
berapa banyak komponen yang harus dipertahankan untuk
menjelaskan persentase yang tinggi dari variasi dalam data.
Pada pendekatan ini akar karakteristik dari masing-masing
komponen utama diplot berdasarkan urutan besarnya akar
karakteristik. Dasar pemikiran dari scree plot adalah hasil
komponen utama sudah diurutkan berdasarkan besarnya akar
karakteristik, maka komponen utama pertama akan muncul
pertama, diikuti komponen utama lainnya yang mempunyai
proporsi keragaman yang lebih kecil. Plot menunjukkan varians
untuk komponen pertama dan komponen berikutnya dimana nilai
eigenvalue turun. Ketika penurunan berhenti dan kurva membuat
siku ke arah penurunan yang kurang tajam (ekstrim) maka nilai
tersebutlah yang bisa dijadikan acuan untuk menentukan banyak
faktor atau untuk mengambil jumlah komponen utama berdasarkan
jumlah akar karakteristik sebelum terjadinya garis lurus[2].
E. Analisis Faktor
Tujuan dari analisis faktor adalah untuk menggambarkan
hubungan-hubungan kovarian antara beberapa variabel yang
mendasari tetapi tidak teramati. Vektor random teramati X

dengan ∑p komponen, memiliki rata-rata μdan matrik kovarian.Model analisis faktor adalah sebagai berikut[2].
X1−μ1=l11F1+l12F2+…l1mFm+ε1
Xp−μp=lp1F1+lp2F2+…lpmFm+εp (10)
Atau dapat ditulis dalam notasi matrik sebagai berikut.
Xpxl=μ(pxl )+L(pxm)F(mxl )+ε(pxl ) (11)
Dengan μi=¿rata-rata variabel i
εi=¿faktor spesifik ke – i
Fj=¿common faktor ke- j
lij=¿loading dari variabel ke – i pada faktor ke-j
Bagian dari varian variabel ke – i dari m common faktor
disebut komunalitas ke – i yang merupakan jumlah kuadrat dari
loading variabel ke – i pada m common faktor dengan rumus
sebagai berikut [1].
hi2=li1
2 +li22 +…+lℑ
2 (12)
Tujuan analisis faktor adalah menggunakan matriks korelasi
hitungan untuk
1.) Mengidentifikasi jumlah terkecil dari faktor umum (yaitu
model faktor yang paling parsimoni) yang mempunyai
penjelasan terbaik atau menghubungkan korelasi diantara
variabel indikator.
2.) Mengidentifikasi, melalui faktor rotasi, solusi faktor
yang paling masuk akal.
3.) Estimasi bentuk dan struktur loading, komunality dan
varian unik dari indikator.
4.) Intrepretasi dari faktor umum.
5.) Jika perlu, dilakukan estimasi faktor skor

F. Matriks Komponen yang Dirotasi
Bila dalam analisis terdapat suatu faktor yang memiliki satu
variabel atau pembagian variabel-variabel pada masing-masing
faktor masih banyak yang rancu karena loading faktor pada
faktor 1, faktor 2 dan seterusnya karena selisih nilai loading
faktor tidak berbeda jauh, maka digunakan matrik komponen yang
dirotasi. Transformasi ortogonal dari faktor pembebanan, serta
transformasi ortogonal tersirat dari faktor-faktor disebut
faktor rotasi.
Jika L̂ adalah matriks pxm estimasi beban faktor diperoleh
dengan metode apapun (komponen utama, maksimum likelihood)
maka[1].
L̂¿=L̂ T,dimana TT’ = T’T= I (13)
* berukuran pxm dari matriks yang dirotasi. Maka dari itu,
estimasi kovarian atau matriks korelasi tetap tidak berubah,
karena
L̂L̂'+ Ψ̂=L̂TT'L̂+Ψ̂=L̂¿ L̂¿ '+Ψ̂ (14)
dan matrik rotasi yang baru ditentukan dari hubungan berikut.
L̂¿=L̂ TDimana :
L̂¿: matrik berukuran px2
L̂: matrik berukuran px2
T : matrik berukur

BAB III
METODOLOGI
3.1 Data dan Variabel
Sumber data
Data yang digunakan dalam makalah ini adalah data car
sales yang merupakan data sampel SPSS. Data ini adalah
adalah data penjualan jenis-jenis mobil yang diproduksi
oleh beberapa pabrikan mobil bersama dengan beberapa
variabel yang mendukung.

Variabel
Dengan jumlah data (n) sebanyak 98 pabrikan mobil yang
menghasilkan berbagai jenis mobil, terdapat beberapa
variabel:
= sales (in thousand)
= log-transformed sales (insales)
= 4-year resale value
= price in thousand
= engine size
= horse power
= wheel base
= width
= length
= curb weight
= fuel capacity
= fuel efficiency
3.2 Langkah analisis
Sebelum data diolah akan dilakukan pre-processing terlebih
dahulu. Tujuan dilakukannya pre-processing adalah Tahap
pre-processing dilakukan dengan menggunakan software SPSS.

Hal-hal yang dilakukan dalam tahap pre processing adalah
sebagai berikut:
1) Analisis missing value
Missing value adalah informasi yang tidak tersedia untuk
sebuah objek atau kasus. Missing value terjadi karena
informasi tentang sebuah objek tidak diberikan, sulit
dicari , atau memang informasi tersebut tidak ada. Pada
dasarnya missing value tidak ada masalah bagi keseluruhan
data, misal hanya 1% dari keseluruhan data. Namun jika
persentase data yang hilang cukup besar maka perlu
dilakukan penanganan lebih lanjut.Penanganan yang
dilakukan yaitu dengan mengisi data yang missing
tersebut. Biasanya diisi dengan mean/rata rata data dari
variabel tersebut.
2) Deteksi outlier
Bisa dilihat melalui box plot. Jika ada data yang outlier
maka ada beberapa cara menangani data outlier. Salah
satunya adalah dengan menghilangkan data outlier
tersebut.
Setelah data sudah melalui tahap pre processing, maka data
tersebut sudah siap untuk selanjutnya diolah dengan
menggunakan metode-metode analisis yang diperlukan.
Langkah-langkah dalam melakukan analisis faktor:
1) Uji asumsi
Identifikasi kecukupan data dengan menggunakan
Measure of Sampling Adequacy (MSA) dan Kaiser-Meyer-Olkin
(KMO).

Data dikatakan memenuhi kecukupan data jika nilai
MSA atau KMO > 0,5
Cek MSA untuk masing-masing variabel:
o Lihat nilai anti image correlation
o Keluarkan variabel dengan nilai terkecil <0,5
o Ulangi proses pengujian sampai semua nilai
MSA >0,5
Identifikasi korelasi antar variabel.
o Hipotesis:
Ho: matriks korelasi adalah matriks
identitas
H1: matriks korelasi bukan matriks identitas
o Jika nilai signifikansi<α maka tolak H0 atauada korelasi antar variabel.
o Nilai signifikansi dapat dilihat dari Bartlett’s
test.
2) Proses ekstraksi.
Dalam melakukan proses ekstraksi metode yang paling
populer digunakan adalah PCA (principal component
analysis).
Langkah-langkah dalam proses ekstraksi adalah:
Penentuan jumlah faktor
Ada tiga cara menentukan banyaknya faktor dalam
PCA, yaitu:
o Scree Plot
o Jumlah nilai eigen yang lebih besar 1
o Total variansi yang bisa dijelaskan adalah
>70%

Pengelompokan variabel ke dalam faktor
Pemberian nama faktor
3) Interpretasi output
Langkah-langkah dalam melakukan analisis cluster:
BAB IV
HASIL DAN PEMBAHASAN
Pada bagian ini akan dijabarkan penerapan analisis faktor,
analisis cluster dan analisis varian multivariat (MANOVA) pada
data car sales.
4.1 aplikasi analisis faktor pada data car sales
1) Pre-processing data
Data asli car sales terdapat cukup banyak missing value.
Dari tabel dibawah ini dapat diketahui berapa banyak
missing value yang terdapat di masing-masing variabel.
Untuk menangani masalah missing value yang terjadi pada
data cukup diatasi dengan menggunakan mean/rata-rata
data tiap variabel. Caranya adalah dengan mengisi mean
dari data tiap variabel pada cell data yang missing.
Proses ini dapat dilakukan dengan menggunakan bantuan
software SPSS.
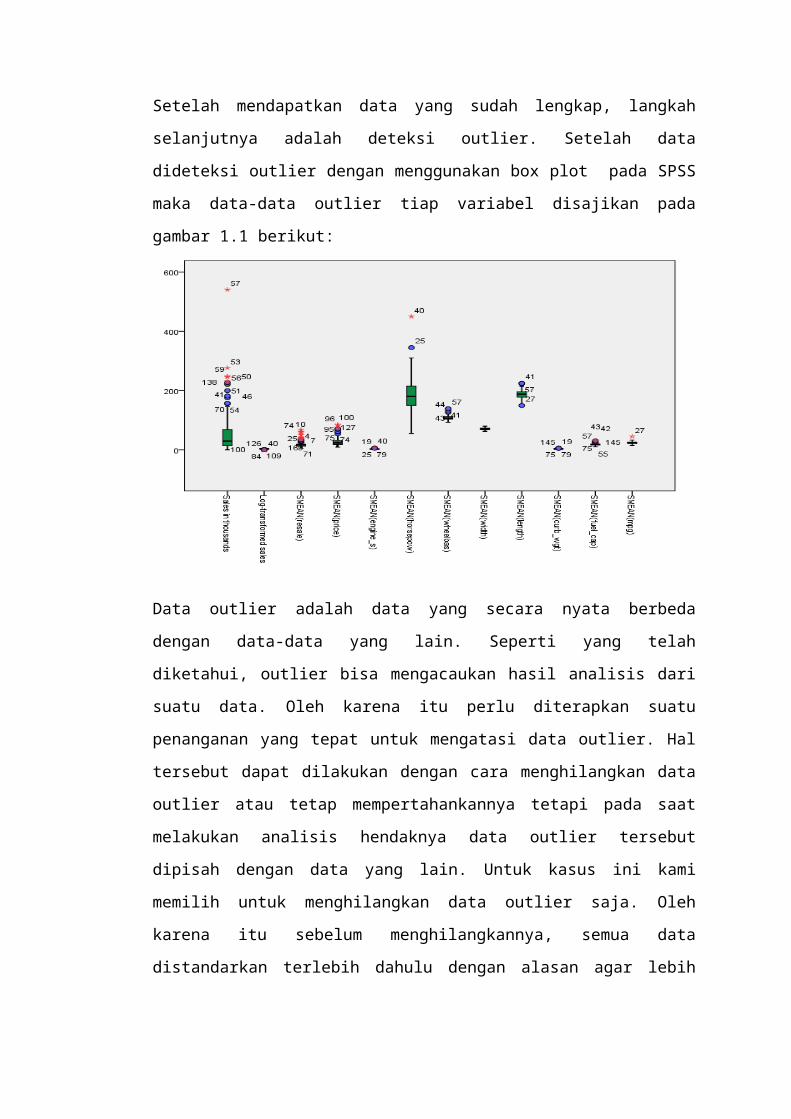
Setelah mendapatkan data yang sudah lengkap, langkah
selanjutnya adalah deteksi outlier. Setelah data
dideteksi outlier dengan menggunakan box plot pada SPSS
maka data-data outlier tiap variabel disajikan pada
gambar 1.1 berikut:
Data outlier adalah data yang secara nyata berbeda
dengan data-data yang lain. Seperti yang telah
diketahui, outlier bisa mengacaukan hasil analisis dari
suatu data. Oleh karena itu perlu diterapkan suatu
penanganan yang tepat untuk mengatasi data outlier. Hal
tersebut dapat dilakukan dengan cara menghilangkan data
outlier atau tetap mempertahankannya tetapi pada saat
melakukan analisis hendaknya data outlier tersebut
dipisah dengan data yang lain. Untuk kasus ini kami
memilih untuk menghilangkan data outlier saja. Oleh
karena itu sebelum menghilangkannya, semua data
distandarkan terlebih dahulu dengan alasan agar lebih
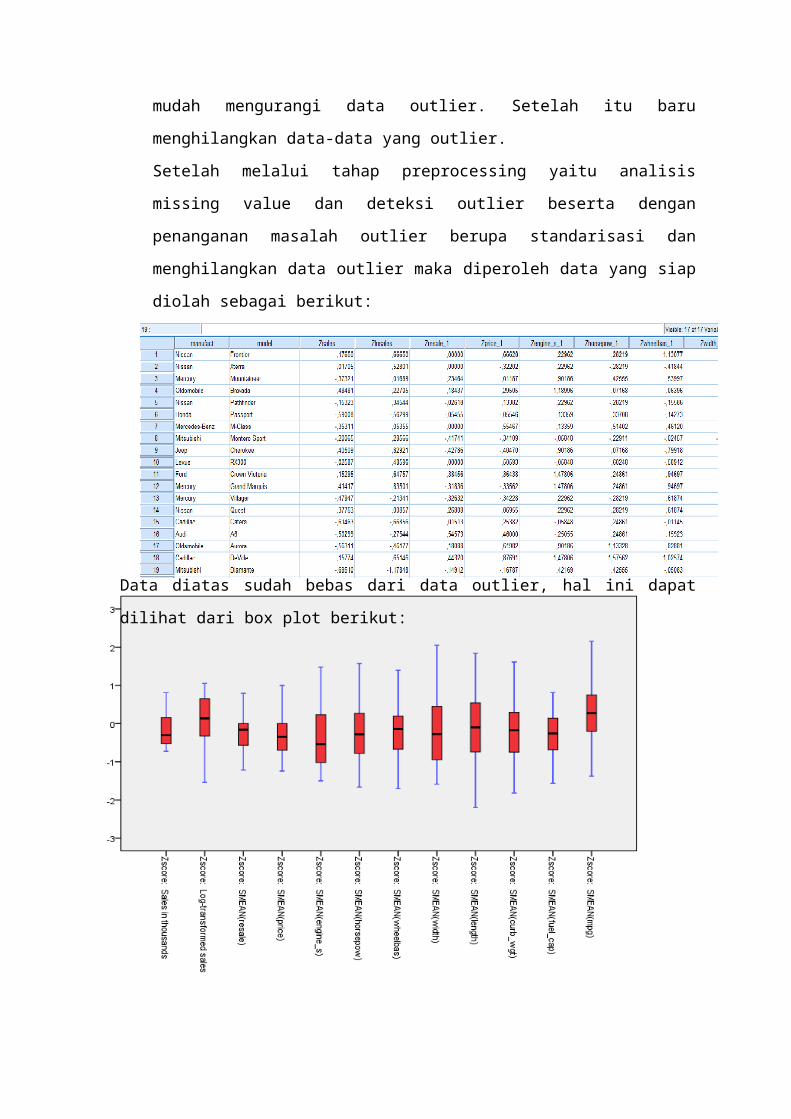
mudah mengurangi data outlier. Setelah itu baru
menghilangkan data-data yang outlier.
Setelah melalui tahap preprocessing yaitu analisis
missing value dan deteksi outlier beserta dengan
penanganan masalah outlier berupa standarisasi dan
menghilangkan data outlier maka diperoleh data yang siap
diolah sebagai berikut:
Data diatas sudah bebas dari data outlier, hal ini dapat
dilihat dari box plot berikut:

2) Uji asumsi
Identifikasi kecukupan data
Karna
nilai KMO dan MSA adalah 0,842 > 0,5 maka dapat
disimpulkan bahwa secara keseluruhan data dikatakan
memenuhi kecukupan data.
Sedangkan untuk melihat kecukupan data masing-masing
variabel dapat dilihat dari nilai MSA masing-masing
varibel berikut:
KMO and Bartlett's TestKaiser-Meyer-Olkin Measure of Sampling Adequacy.
,842
Bartlett's Test of Sphericity
Approx. Chi-Square 1253,574df 66Sig. ,000

a. Measure of sampling adequacy
Karna semua nilai MSA >0,5 maka tidak ada variabel yang
perlu dikeluarkan sehingga tidak perlu mengulangi proses
pengujian. Dilihat dari nilai MSA tiap variabel yang > 0,5
menunjukan bahwa asumsi kecukupan data sudah dipenuhi oleh
masing-masing variabel.
Identifikasi korelasi antar variabel
o Hipotesis
Ho= matriks korelasi adalah matriks identitas
H1= matriks korelasi bukan matriks identitas
o Statistik uji
Dengan ∝= 0,5 maka jika dilihat dari Bartlett’s Test,
karena nilai signifikansi adalah 0,000 < 0,5 maka tolak Ho.
Jadi kesimpulannya matriks korelasi bukan matriks identitas
sehingga ada korelasi antar variabel.
3) Proses ekstraksi
Metode yang digunakan adalah principal component analysis.
Dengan menggunakan SPSS diperoleh tabel berikut:
KMO and Bartlett's TestKaiser-Meyer-Olkin Measure of Sampling Adequacy.
,842
Bartlett's Test of Sphericity
Approx. Chi-Square 1253,574df 66Sig. ,000
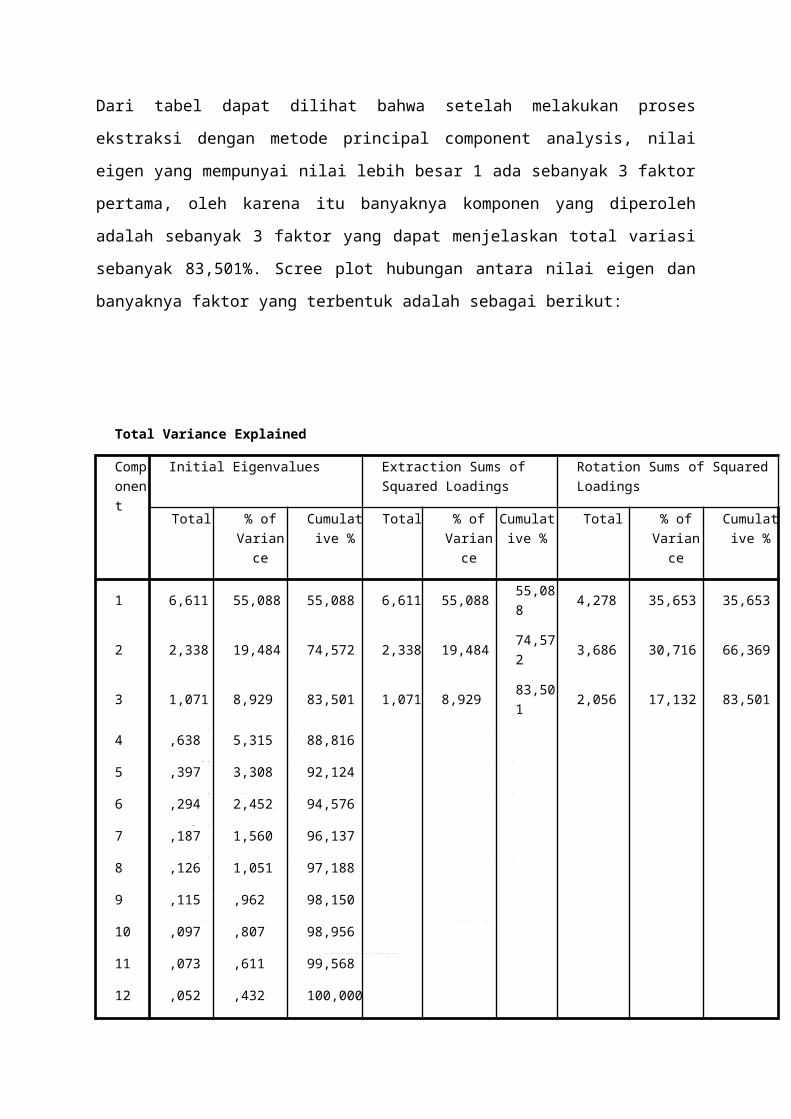
Dari tabel dapat dilihat bahwa setelah melakukan proses
ekstraksi dengan metode principal component analysis, nilai
eigen yang mempunyai nilai lebih besar 1 ada sebanyak 3 faktor
pertama, oleh karena itu banyaknya komponen yang diperoleh
adalah sebanyak 3 faktor yang dapat menjelaskan total variasi
sebanyak 83,501%. Scree plot hubungan antara nilai eigen dan
banyaknya faktor yang terbentuk adalah sebagai berikut:
Total Variance Explained
Component
Initial Eigenvalues Extraction Sums of Squared Loadings
Rotation Sums of Squared Loadings
Total % ofVariance
Cumulative %
Total % ofVariance
Cumulative %
Total % ofVariance
Cumulative %
1 6,611 55,088 55,088 6,611 55,088 55,088 4,278 35,653 35,653
2 2,338 19,484 74,572 2,338 19,484 74,572 3,686 30,716 66,369
3 1,071 8,929 83,501 1,071 8,929 83,501 2,056 17,132 83,501
4 ,638 5,315 88,816
5 ,397 3,308 92,124
6 ,294 2,452 94,576
7 ,187 1,560 96,137
8 ,126 1,051 97,188
9 ,115 ,962 98,150
10 ,097 ,807 98,956
11 ,073 ,611 99,568
12 ,052 ,432 100,000
Extraction Method: Principal Component Analysis.
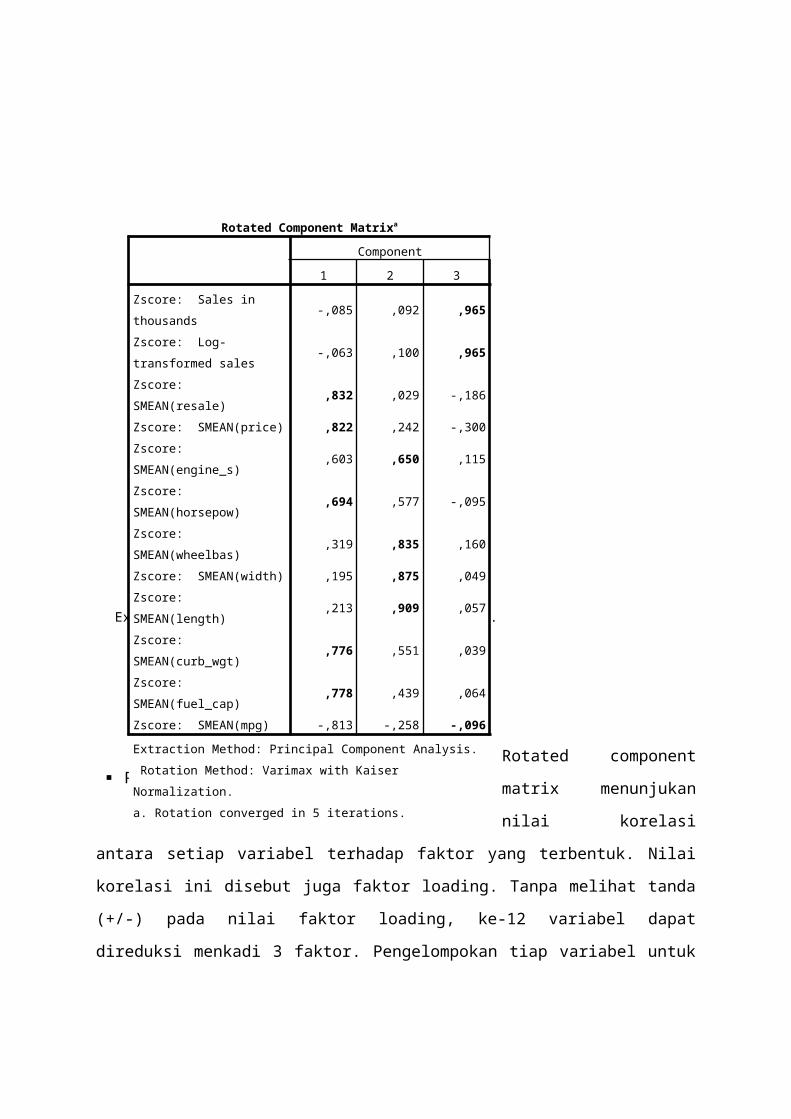
Pengelompokan variabel kedalam faktorRotated component
matrix menunjukan
nilai korelasi
antara setiap variabel terhadap faktor yang terbentuk. Nilai
korelasi ini disebut juga faktor loading. Tanpa melihat tanda
(+/-) pada nilai faktor loading, ke-12 variabel dapat
direduksi menkadi 3 faktor. Pengelompokan tiap variabel untuk
Rotated Component Matrixa
Component1 2 3
Zscore: Sales in thousands
-,085 ,092 ,965
Zscore: Log-transformed sales
-,063 ,100 ,965
Zscore: SMEAN(resale)
,832 ,029 -,186
Zscore: SMEAN(price) ,822 ,242 -,300Zscore: SMEAN(engine_s)
,603 ,650 ,115
Zscore: SMEAN(horsepow)
,694 ,577 -,095
Zscore: SMEAN(wheelbas)
,319 ,835 ,160
Zscore: SMEAN(width) ,195 ,875 ,049Zscore: SMEAN(length)
,213 ,909 ,057
Zscore: SMEAN(curb_wgt)
,776 ,551 ,039
Zscore: SMEAN(fuel_cap)
,778 ,439 ,064
Zscore: SMEAN(mpg) -,813 -,258 -,096Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization.a. Rotation converged in 5 iterations.
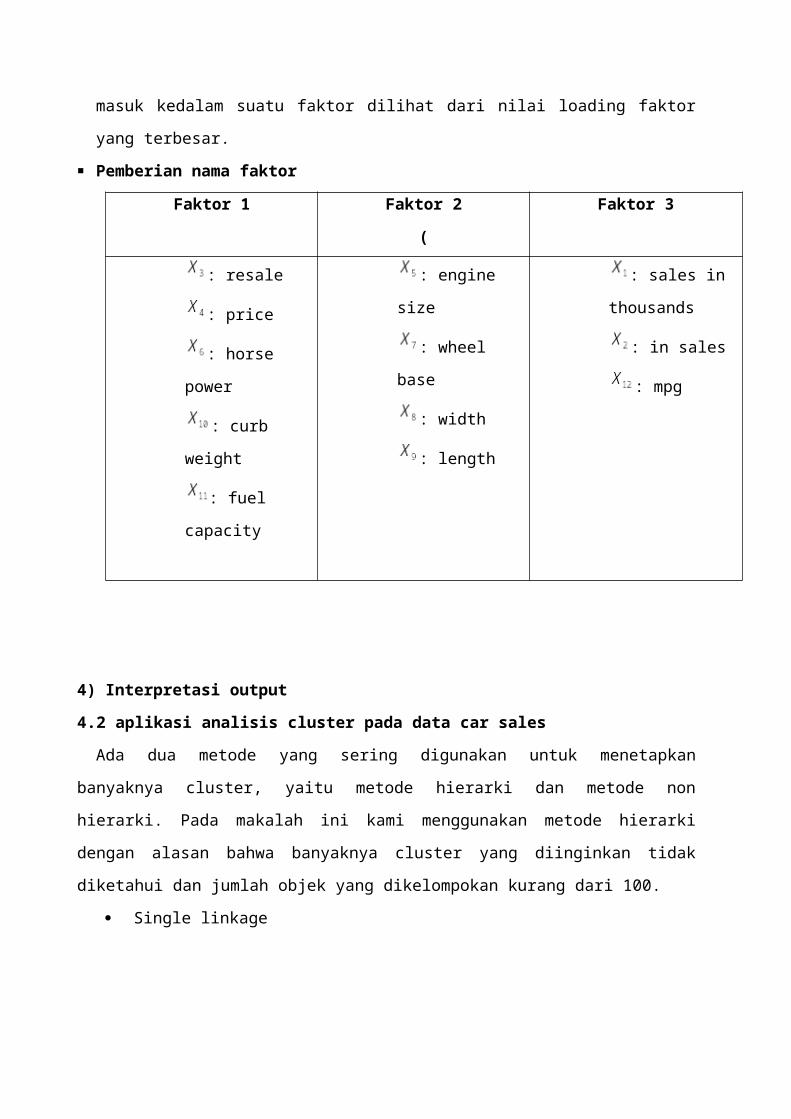
masuk kedalam suatu faktor dilihat dari nilai loading faktor
yang terbesar.
Pemberian nama faktor
Faktor 1 Faktor 2
(
Faktor 3
: resale
: price
: horse
power
: curb
weight
: fuel
capacity
: engine
size
: wheel
base
: width
: length
: sales in
thousands
: in sales
: mpg
4) Interpretasi output
4.2 aplikasi analisis cluster pada data car sales
Ada dua metode yang sering digunakan untuk menetapkan
banyaknya cluster, yaitu metode hierarki dan metode non
hierarki. Pada makalah ini kami menggunakan metode hierarki
dengan alasan bahwa banyaknya cluster yang diinginkan tidak
diketahui dan jumlah objek yang dikelompokan kurang dari 100.
Single linkage

Jarak antar dua cluster diukur dengan menggunakan jarak
terdekat (nearest neighbour) antar sebuah objek dalam cluster
yang satu dengan sebuah objek dalam gerombol yang lain.
Related Documents

![MSG 366 Multivariate Analysis [Analisis Multivariat] file[Analisis Multivariat] Duration : 3 hours [Masa : 3 jam] Please check that this examination paper consists of FOURTY TWO pages](https://static.cupdf.com/doc/110x72/5d14de9888c993e8108ba1c8/msg-366-multivariate-analysis-analisis-multivariat-analisis-multivariat-duration.jpg)




![MSG 366 Multivariate Analysis [Analisis Multivariat]eprints.usm.my/38838/1/MSG366.4_Multivariate_Analysis_(Dr... · MSG 366 – Multivariate Analysis [Analisis Multivariat] Duration](https://static.cupdf.com/doc/110x72/5b14286a7f8b9a397c8b92ab/msg-366-multivariate-analysis-analisis-multivariat-dr-msg-366-multivariate.jpg)




