
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


ii
Esta tesis fue realizada por Miguel Angel Pascual Miguel, bajo la dirección del Doctor Eduardo Gutiérrez González. Fue revisada y aprobada por el siguiente Comité Revisor y Jurado Examinador, para obtener el título de Licenciado en Estadística.
Chapingo, Texcoco, Edo. de México, Noviembre de 2012

iii
Agradecimientos A Dios que me dio la vida. A la Universidad Autónoma Chapingo por darme la oportunidad, apoyo y los recursos necesarios para formarme profesionalmente y por brindarme un hogar durante siete años. Al Dr. Eduardo Gutiérrez González, por su paciencia y su valioso tiempo brindado para la elaboración del presente trabajo.
Al Dr. Antonio Villanueva Morales, M.C. Margarito Soriano Montero, M.C. Angel Leyva Ovalle y al Ing. Carlos Francisco Romhan de la Vega, por la revisión y puntuales observaciones para la realización del presente trabajo. A los profesores del Departamento de Matemática y Cómputo, quienes contribuyeron en mi formación académica. Especialmente a mi familia por la infinita paciencia, comprensión, por todo el apoyo que me brindaron y por su gran muestra amor incondicional.

iv
Dedicatoria A mis padres queridos: Teresa y Alejandro, por haberme dado la vida. A mi madre por haberme apoyado en todo momento, por sus consejos, sus valores, por la motivación constante que me ha permitido ser una persona de bien, pero más que nada, por su amor. A mi padre por los ejemplos de perseverancia y constancia que lo caracterizan y que me ha infundado siempre, por el valor mostrado para salir adelante y por su amor. Gracias a ustedes he llegado a esta meta. A mis hermanas (os): Pascual, Mariola, Juanita, Alejandro y Ashley, que son parte importen en mi vida y que siempre me compartieron su apoyo y cariño. A mis abuelos: Pascual y Felipe, por sus sabios consejos durante esta etapa de mi vida. A la memoria de mis abuelas: María† y Juana†, que Dios los tenga en su santa gloria. A la familia Blancas, en especial a Don Memo y Doña Lupita por sus consejos y apoyo incondicional, que me enseñaron lo hermoso de la convivencia familiar y a sus dos hijos Leonardo Daniel y Saúl con quienes compartí momentos inolvidables. A mis amigos los majos con quienes conviví y compartí mis alegrías y tristezas, en especial a Eliud y Cecilia que suplieron el cariño de un hermano. A mi equipo de futbol soccer Toros Salvajes, donde el campo y el balón de futbol fue mi medicina para desestresarme, hacerme olvidar de los problemas y convivir momentos gratos, por hacerme de grandes amistades. A todos mis amigos(as) que durante esta etapa de mi vida aportaron un granito de arena para lograr esta meta.
Con Amor Miguel Angel (Chicorita 7)

v
Índice general
Índice General ....................................................................................................................... v
Índice de Figuras ................................................................................................................ viii
Índice de Tablas .................................................................................................................... ix
Resumen ................................................................................................................................ x
Abstract ................................................................................................................................ xi
Introducción ........................................................................................................................... 1
Planteamiento ........................................................................................................................ 3
Objetivos ................................................................................................................................. 4
Capítulo 1 ............................................................................................................................... 5
CONCEPTOS BÁSICOS ...................................................................................................... 5
1.1 Introducción .................................................................................................................. 5
1.2 Variables aleatorias ....................................................................................................... 5
1.3 Función de densidad de probabilidad ........................................................................... 6
1.4 Función de distribución de probabilidad ....................................................................... 7
1.4.1 Propiedades de la función de distribución acumulada ........................................... 8
1.5 Variable aleatoria Poisson ............................................................................................. 9
1.5.1 La distribución Poisson ........................................................................................ 10
1.5.1.1 Propiedades de la distribución Poisson ......................................................... 12
1.5.2 El proceso Poisson ............................................................................................... 12
1.5.2.1 Proceso para la distribución Poisson ............................................................ 13
1.5.2.2 Proceso para la distribución exponencial ..................................................... 14
1.5.2.3 Propiedades de los proceso Poisson ............................................................. 15

vi
1.6 Parámetros de las distribuciones ................................................................................. 16
1.6.1 Parámetros de localización ................................................................................... 16
1.6.2 Parámetros de escala ............................................................................................ 16
1.6.3 Parámetros de forma o asimetría .......................................................................... 17
1.7 Estimación de parámetros ........................................................................................... 17
1.7.1 Propiedades deseables de los estimadores puntuales ........................................... 18
1.7.1.1 Estimadores centrados .................................................................................. 18
1.7.1.2 Estimadores consistentes .............................................................................. 19
1.7.1.3 Eficiencia ...................................................................................................... 20
1.7.1.4 Suficiencia .................................................................................................... 20
1.7.2 Estimación puntual ............................................................................................... 20
1.7.3 Estimación por intervalo ...................................................................................... 21
1.8 Método de estimación de puntual ............................................................................... 21
1.8.1 Método de los momentos ..................................................................................... 21
1.8.2 Método de máxima verosimilitud ........................................................................ 22
1.8.2.1 Estimador de máxima verosimilitud (EMV) ................................................ 23
1.8.2.2 Procedimiento para obtener el E.M.V. de θ ................................................ 24
1.8.2.3 Propiedades del E.M.V ................................................................................. 25
Capítulo 2 ............................................................................................................................. 27
TEORIA DE VALORES DE EXCEDENTES ................................................................... 27
2.1 Introducción ................................................................................................................ 27
2.2 Teoría clásica: análisis de máximos ............................................................................ 28
2.3 Función de excesos ..................................................................................................... 30
2.3.1 Distribución límite de los excesos........................................................................ 32
2.3.2 Breve justificación del teorema 2.2 para el modelo generalizada de Pareto ........ 34
2.3.3 Propiedades de la distribución generalizada de Pareto ........................................ 35
2.3.4 Momentos de la distribución generalizada de Pareto ........................................... 44
2.3.5 Función cuantil de la distribución generalizada de Pareto .................................. 44

vii
2.4 Modelando excedentes sobre el umbral ...................................................................... 45
2.4.1 Selección del umbral ............................................................................................ 47
2.5 Estimación de parámetros ........................................................................................... 50
2.6 Nivel de retorno .......................................................................................................... 51
2.7 Revisión del umbral elegido ....................................................................................... 55
2.8 Verificación del modelo .............................................................................................. 56
Capítulo 3 ............................................................................................................................. 58
CASO DE ESTUDIO ........................................................................................................... 58
3.1 Introducción ................................................................................................................ 58
3.2 Planteamiento del problema ........................................................................................ 59
3.3 Descripción de los datos ............................................................................................. 61
3.3.1 Malla en MAYA v1.0 .......................................................................................... 61
3.3.2 El algoritmo de interpolación ............................................................................... 63
3.3.3 Obtención de los nodos a estudiar ........................................................................ 63
3.4 Elección del umbral .................................................................................................... 67
3.4.1 Datos para la elección del umbral ........................................................................ 67
3.4.2 Gráficos de exceso medio .................................................................................... 68
3.5 Estimación del modelo para el total de valores muestrales ........................................ 71
3.6 Revisión del ajuste del modelo distribución generalizada de Pareto .......................... 74
Conclusiones ........................................................................................................................ 78
Bibliografía .......................................................................................................................... 79
Anexos .................................................................................................................................. 81

viii
Índice de Figuras
2.1 Ejemplo del gráfico de vida media de datos del ejemplo de Denver .......................... 49
3.1 Estado de Tabasco y sus fronteras .............................................................................. 59
3.2 Producto MAYA v1.0 ................................................................................................. 62
3.3 Ubicación de los nodos seleccionados y las subcuencas del rio Grijalva-Usumacinta y rio Tonalá .......................................................................................................................... 64
3.4 Ubicación de los nodos seleccionados y las subcuencas respectivas ........................ 66
3.5 Registro de precipitación diaria .................................................................................. 68
3.6 Gráfico de vida media de datos de precipitación diarios ........................................... 69
3.7 Gráfico del parámetro de escala .................................................................................. 70
3.8 Gráfico del parámetro de forma .................................................................................. 70
3.9 Calidad de gráficos ajustados para el modelo de la distribución generalizada de Pareto ................................................................................................................................ 74
3.10 Gráfico de probabilidad normal de la distribución generalizada de Pareto ............. 75
3.11 Gráfico de la función de distribución acumulada estimada vs distribución acumulada empírica de la distribución generalizada de Pareto ........................................................... 75

ix
Índice de Tablas
3.1 Descripción de los 22 nodos a estudiar ....................................................................... 65
3.2 Estimación de los parámetros ..................................................................................... 71
3.3 Algunos valores calculados para los niveles de retorno ............................................. 41
3.4 Estimación del valor de la prueba de Kolmogorov-Smirnov ...................................... 77

x
Resumen
La teoría del valor extremo es una disciplina estadística que desarrolla un conjunto de modelos y métodos tanto paramétricos como no paramétricos con el objeto de describir, cuantificar y modelar los casos raros; esto es, los que se distribuyen, no bajo la ‘ley de los grandes números’, sino bajo la ley de los pequeños números. Estos eventos raros son los que pertenecen a la cola de la distribución y son los que están alejados del grueso de la distribución (media, mediana). La teoría del valor extremo ha experimentado un importante desarrollo en los últimos 50 años, gracias a su aplicabilidad a múltiples disciplinas, tales como mercados financieros, sector asegurador, ingenierías, biología, hidrología, medio ambiente, etc. Las mayores aplicaciones han sido en el campo ambiental: niveles del mar, velocidades del viento, concentraciones de contaminantes, etc.; ya que niveles altos de estas variables son peligrosos. Más recientemente, los modelos de valores extremos se han usado en aplicaciones a datos financieros, evaluación de daños y records deportivos.
En este trabajo se proporciona una breve introducción de la teoría clásica: análisis de máximos, un planteamiento general y la distribución que siguen los excedentes sobre un umbral de una secuencia de variables aleatorias. En la teoría clásica se plantea el teorema de Fisher y Tippett del cual se desarrolla la teoría de la distribución asintótica para modelar máximos conocidos como distribución de valores extremos generalizada. Después el teorema de Pickands-Balkema-de Haan (Balkema y de Haan -1974- Pickands -1975- ) daría lugar al modelo que concierne a la distribución de los excesos por encima de un umbral, donde cobra interés el comportamiento del valor extremo una vez alcanzado un elevado nivel. Esta distribución truncada por la izquierda, se conoce como distribución generalizada de Pareto.
El trabajo concluye con una aplicación a datos de lluvia de 22 nodos los cuales tienen registros de las precipitaciones diarias de los años 1961 a 2000 de varias subcuencas del Rio Grijalva-Usumacinta y Rio Tonalá del estado de Tabasco. Se ajusta la distribución generalizada de Pareto a los datos que exceden el umbral, para lo cual se utiliza el programa R en el ajuste de la distribucion.

xi
Abstract
Extreme value theory is a statistical discipline that develops a group of models and methods so much parametric as not parametric in order to describing, to quantify and to model the strange cases; that is, those that are distributed, don't lower the “law of the big numbers”, but under the law of the small numbers. These strange events are those that belong to the tail of the distribution and they are far from the thick of the distribution (median, medium). Extreme value theory has emerged as one of the most important statistical disciplines for the applied sciences over the last 50 years, thanks to its applicability to multiple disciplines. The extreme value techniques are also becoming widely used in many other disciplines. For example: financial markets, sector insurer, engineerings, biology, hydrology, environment, etc. The biggest applications have been in the environmental field: levels of the sea, speeds of the wind, concentrations of pollutants, etc.; since high levels of these variables are dangerous. Plus recently, the models of values extreme have been used in applications to financial data, evaluation of damages and sport records.
In this work a brief introduction of the classic theory is provided: analysis of maxima, a general position and the distribution that follow the surpluses on a threshold of a sequence of random variables. In classical theory raise theorem of Fisher and Tippett of which the theory of the asymptote distribution is developed to model well-known maxima as generalized extreme value distribution. Then the theorem of Pickands-Balkema-of Haan (Balkema and of Haan -1974 - Pickands -1975- ) would give place to the model that involves the distribution of the excesses above a threshold, where it collects interest once the behavior of the extreme value reached a high level. This distribution truncated by the left, is known the generalized Pareto distribution.
The test concludes with an application to data of rain of 22 nodes which have registrations of the everyday precipitations of the years 1961 at 2000 of several sub-basins of the river Grijalva-Usumacinta and river Tonalá in Tabasco´s state. Setting generalized Pareto distribution the data that exceed the threshold, for that which the program R is used in the setting of the distribution.

1
Introducción
Clásicamente cuando se realiza cualquier tipo estudio de datos, la tendencia es ignorar los valores extremos, lo cual estaría correcto si se busca hacerlos uniformes para ajustar un modelo a su tendencia. Pero en algunos casos los eventos que producen estos valores extremos se pueden tomar en cuenta como si fueran de baja probabilidad pero de alto impacto; para estos casos no es conveniente hacer una aproximación clásica de análisis de datos ya que lo que se está buscando es describir precisamente los eventos que no son muy usuales y no ignorarlos.
Por ello, los modelos de valores extremos describen la dinámica estocástica hacia los estados con poca probabilidad de realización y más allá del rango de los datos observados, por esta razón son adecuados en la medición de la cola de la distribución. La literatura sobre teoría de valores extremos se ha incrementado considerablemente en las últimas décadas con aplicaciones prácticas muy interesantes en muchos campos que incluyen análisis financiero (Embrechts et al., 2003), ciencias ambientales (Reiss and Thomas, 2007), ingeniería (Castillo et al., 2004) entre otras, y en todas las aplicaciones, el interés es el riesgo a la ocurrencia de eventos extremos. Se han propuesto muchos desarrollos teóricos para estudiar apropiadamente las colas de las distribuciones (para un estudio más extensivo de este campo ver Embrechts, Klüppelberg and Mikosch, 1997).
Desde el punto de vista estadístico, el problema de la teoría de valores extremos es básicamente un problema de extrapolación. La idea básica de esta extrapolación es encontrar un buen modelo paramétrico para la cola del proceso que genera los datos y luego ajustar este modelo a las observaciones extremas. La extrapolación se obtiene por el análisis del comportamiento del modelo más allá del rango de los datos observados. El rendimiento del modelo se mide de acuerdo con que tan bien describe el comportamiento de la cola para la distribución que siguen los datos observados. Si el modelo proporciona un buen ajuste entonces se usa para extrapolar las cantidades de interés, como por ejemplo ciertos cuantiles extremos, junto con la estimación de la incertidumbre asociada a la extrapolación.
Los modelos de valores extremos se han vuelto más populares pero también más sofisticados. En los últimos años, las investigaciones se han dirigido a tomar en cuenta covariables para manejar la estacionaridad (Smith, 1989; Davison and Ramesh, 2000; Pauli and Coles, 2001) y modelar extremos multivariados (He_ernan and Tawn, 2004). Sin embargo, un enfoque más sencillo para modelar datos extremos es considerar la distribución de los excedentes por arriba de un umbral lo suficientemente grande.
En este trabajo que trata sobre la modelación de excedentes de lluvia a partir de un umbral, se desarrolla una propuesta de estimación del umbral a través de un abordaje

2
semiparamétrico. Para ello se asumirá que existe un umbral a partir del cual la distribución excedente pertenece a la familia Pareto generalizada. Es decir, el modelo propuesto asume que la distribución por debajo del umbral pertenece a una familia con densidades no especificadas mientras que la distribución por encima del umbral pertenece a la familia Pareto Generalizada. Para cada valor de u se calculará una pseudo-verosimilitud indexada en el umbral, que combina la estimación no paramétrica de la densidad para las observaciones menores a u, con la estimación de máxima verosimilitud para las observaciones excedentes al umbral. Se estimara el parámetro de interés como el menor valor a partir del cual se maximiza la pseudo-verosimilitud.
Para poder desarrollar el trabajo del estudio de caso sobre modelación de excedente de lluvia, se estructuró en tres capítulos, mismos que se desarrollaron de la siguiente manera.
En el Capítulo 1 se definen los conceptos básicos y se proporciona un breve resumen sobre los términos que se usarán en el desarrollo de la tesis.
En el Capítulo 2 se da una introducción a la teoría de Valores Extremos. Para ello, en primer lugar, se describe de forma teórica las dos distribuciones importantes que conforman la Teoría del Valor Extremo: la distribución generalizada del valor extremo y la distribución generalizada de Pareto, esta última distribución es el de interés donde se hablará de su totalidad, también se describe el método de cómo hacer la elección del umbral, cómo se ajustan los excedentes a una Pareto y el nivel de retorno que sirvió para calcular el tiempo que ha de transcurrir para que vuelva a ocurrir un valor sobre el umbral y por último la verificación del elección de la umbral y el ajuste.
Finalmente en el Capítulo 3, se presenta una propuesta y se desarrolla un estudio que permite evaluar el comportamiento de la misma, bajo la aplicación de la teoría de los excesos con datos reales, donde se encuentra el umbral adecuado para ajustar el modelo de la distribución generalizada de Pareto a los datos que exceden el umbral y la comprobación del ajuste, también algunos cálculos de periodo de retorno de algunos valores sobre el umbral.

3
Planteamiento
El modelaje de la lluvia ha sido un tópico de mucho interés y desarrollo en los últimos 30 años, sobre todo por la importancia que tiene en el marco de la resolución de problemas en el campo de la hidrología, la climatología, la agricultura, la ecología y más recientemente, en la evaluación de riesgos y desastres. En los últimos años, se han desarrollado diferentes modelos cuyos grados de sofisticación han ido en aumento para así poder capturar toda la dinámica física que gobierna a este fenómeno físico. Los modelos estocásticos para la lluvia han sido motivados tanto por el interés científico de comprender la estructura probabilística de este proceso como por el gran interés en determinar los posibles efectos que tiene el cambio climático y el efecto invernadero en el planeta sobre las reservas de agua.
La literatura del modelaje de la lluvia es extensa y se han propuestos muchos modelos que van desde aquéllos en tiempo discreto a modelos en tiempo continuo para un punto dado en el espacio. Hay además modelos que incluyen la variabilidad espacial para diferentes localidades (modelos multivariados), o modelos que representan la lluvia en cualquier punto del espacio (modelos multidimensionales). También ha habido un desarrollo considerable en los modelos que representan a la lluvia de manera continua en el espacio.
Por lo tanto, podemos utilizará la teoría de valores extremos para desarrollar modelos y técnicas que permitan estimar el comportamiento de eventos inusuales o raros. Dentro del contexto del modelaje de los valores extremos se encuentran los métodos de umbrales, se basan en la hipótesis de que la ocurrencia de excesos sobre un umbral estricto en una serie de variables aleatorias i.i.d. presenta un comportamiento Poisson, y que los excesos tienen una distribución exponencial o, más generalmente, Pareto generalizada, (Davison & Smith 1990).
Por ello, en el trabajo se utilizará un modelo de valores extremos enfocado a dar las herramientas necesarias y poder desarrollar un método para modelar los datos máximos a partir de un umbral de ciertos fenómenos que ocurren en la naturaleza, en nuestro caso de un fenómeno meteorológico como lo es la lluvia.
El presente trabajo tiene como fin utilizar el modelo umbral en la caracterización de los eventos extremos de lluvia en el estado de Tabasco, utilizando 22 nodos ubicados en varias subcuencas de la región hidrológica Grijalva – Usumacinta y Tonalá. Con el propósito de ajustar una distribución generalizada de Pareto a las precipitaciones máximas diarias de estas subcuencas excedentes sobre un determinado umbral, para poder calcular los periodos de retorno para cualquier valor.

4
Objetivos
Los objetivos del presente trabajo son:
Objetivo general: Ajustar un modelo a los datos de excedentes de lluvia por municipios en el estado de Tabasco que ayude a calcular las inundaciones futuras debido a excedencias.
Objetivos específicos: Para lograr la meta principal del trabajo se tuvieron las siguientes metas secundarias:
• Realizar un planteamiento general de la teoría de excedencias.
• Realizar un estudio sobre las áreas y ejemplos de aplicación de excedencias.
• Desarrollar métodos de estimación de los parámetros para los modelos de excedencias.
• Desarrollar un procedimiento para ajustar el modelo más adecuado a los datos de excedencias de lluvia.
• Proponer otros problemas a los que se pueda utilizar el procedimiento desarrollado en el trabajo.

5
CAPÍTULO 1
CONCEPTOS BÁSICOS
1.1 Introducción
En este capítulo serán revisados los conceptos básicos de la Probabilidad y Estadística necesarios para la aplicación de la teoría de excedencias en la descripción del comportamiento sobre las inundaciones en el estado de Tabasco.
El capítulo inicia con los conceptos básicos de espacio muestral y variable aleatoria, continuando con una clasificación simple de estas últimas cuya importancia radica en introducir modelos matemáticos en el cálculo de probabilidades.
En este capítulo se considerarán las distribuciones de probabilidades de variables aleatorias calculando sus momentos y en particular la media y varianza. Serán revisadas algunas distribuciones, pero sólo a detalle se discutirá la distribución Poisson, debido a que es una distribución base para la teoría de excedencias.
1.2 Variables Aleatorias
Cuando se realiza un experimento probabilístico y se tiene los resultados de éste, es de vital importancia definir y denotar al conjunto que abarca todos los resultados posibles del experimento. Iniciando de esta manera la formalización del estudio de las probabilidades.
Definición 1.1 (Espacio muestral). El conjunto de todos los resultados posibles de un experimento probabilístico es denotado por S o Ω , y se le conoce como espacio muestral. Un elemento del espacio muestral se llama punto muestral.

6
Definición 1.2 (Variable). Se denomina variable a la entidad que puede tomar un valor cualesquiera durante la duración de un proceso dado. Si la variable toma un solo valor durante todo el proceso se llama constante.
Definición 1.3 (Variable aleatoria). De manera formal se dice que una variable aleatoria es una función en donde el dominio es el espacio muestral y rango o contradominio un subconjunto de los números reales. En general las variables aleatorias se suelen denotar por las letras X, Y, Z…
Una variable aleatoria se puede clasificar con base en el rango en:
Discreta. Cuando el rango es un conjunto a lo más contable.
Continua. Cuando el rango es un intervalo en los números reales.
Definición 1.4 (Variable aleatoria discreta). Una variable discreta proporciona datos que son llamados cuantitativos discretos y se obtiene de respuestas numéricas que resultan de un conteo. Es decir, si el rango de valores ( )xR de la variable aleatoria X es finito o infinito numerable o contable. Se dice que estas variables tienen la particularidad de obtenerse a través de conteos.
• La cantidad de alumnos regulares en un grupo escolar.
• El número de águilas en cinco lanzamientos de una moneda.
• Número de circuitos en una computadora.
Definición 1.5 (Variable aleatoria continua). Es aquélla que se encuentra dentro de un intervalo comprendido entre dos valores cualesquiera; ésta puede asumir un número infinito de valores y tiene la particularidad de obtenerse a través de mediciones. Es decir, su rango de valores ( )xR es infinito no numerable.
• La estatura de un alumno de un grupo escolar.
• El peso en gramos de una moneda.
• La edad de un hijo de familia.
1.3 Función de Densidad de Probabilidad
La función de densidad de probabilidad se utiliza en estadística con el propósito de conocer cómo se distribuyen las probabilidades de un suceso o evento, en relación al resultado del suceso.

7
Definición 1.6. Sea X una variable aleatoria discreta, se llamará a ( ) ( )xXPxp == función de probabilidad de la variable aleatoria X , si se satisfacen las siguientes propiedades:
1. ( ) 0≥xp para todos los valores x de X ,
2. ( ) 1=∑xxp .
En teoría de la probabilidad, la función de densidad de probabilidad (fdp) de una variable aleatoria continua es una función, usualmente denotada por ( )xf que describe la densidad de la probabilidad en cada punto del espacio muestral de tal manera que la probabilidad de que la variable aleatoria tome un valor dentro de un determinado conjunto es la integral de la función de densidad sobre dicho conjunto.
Definición 1.7. Matemáticamente se tendrá una función de densidad de probabilidad de una variable aleatoria continúa X, si existe, es una función ( )xf , que cumple las siguientes propiedades
1. ( ) 0≥xf para toda x .
2. El área total bajo la curva es igual a 1
( ) 1=∫∞
∞−dxxf .
3. La probabilidad de que X tome un valor en el intervalo [ ]ba, es el área bajo la curva de la función de densidad en ese intervalo o lo que es lo mismo, la integral definida en dicho intervalo. La gráfica ( )xf se conoce a veces como curva de densidad.
( ) ( )∫=≤≤b
adxxfbXaP .
1.4 Función de Distribución de Probabilidad
En teoría de la probabilidad y estadística, la distribución de probabilidad de una variable aleatoria X es una función que asigna a cada suceso definido sobre la variable aleatoria la probabilidad de que dicho suceso ocurra. La distribución de probabilidad está definida sobre el conjunto de todos los sucesos, cada uno de ellos es el rango de valores de la variable aleatoria. Cuando la variable aleatoria toma valores en el conjunto de los números reales, la distribución de probabilidad está completamente especificada por la función de distribución, cuyo valor en cada valor real x es la probabilidad de que la variable aleatoria sea menor o igual que x .

8
Las distribuciones de probabilidad se pueden clasificar en:
Distribuciones discretas
Distribuciones continuas
Definición 1.8 (Distribuciones discretas). Son aquéllas donde las variables que son a lo más contables, por ejemplo el número de años de estudio. Algunos ejemplos de distribuciones discretas son: binomial, hipergeométrica, multinomial, Poisson.
Definición 1.9 (Distribuciones continuas). Son aquellas donde las variables en un estudio pueden asumir cualquier valor dentro de un intervalo; por ejemplo, la estatura de un estudiante. Algunas distribuciones continuas son: uniforme, exponencial, normal
Definición 1.10 (Función de distribución acumulada). Dada una variable aleatoria X , su función de distribución, ( )xFX es
( ) ( )xXPxFX ≤= .
Por simplicidad, cuando no hay lugar a confusión, suele omitirse el subíndice X y se escribe, simplemente ( )xF .
1.4.1 Propiedades de la Función de Distribución Acumulada
Como consecuencia casi inmediata de la definición, la función de distribución acumulada:
1. Es una función continua por la derecha.
2. Es una función monótona no decreciente.
Además, cumple
( ) 0lim =−∞→
xFx
y ( ) 1lim =+∞→
xFx
.
Para dos números reales cualesquiera a y b tal que ( )ba < , los sucesos ( )aX ≤ y son ( )bXa ≤< mutuamente excluyentes y su unión es el suceso ( )bX ≤ , entonces
( ) ( ) ( )bXaPaXPbXP ≤<+≤=≤
( ) ( ) ( )aXPbXPbXaP ≤−≤=≤<
finalmente

9
( ) ( ) ( )aFbFbXaP −=≤< .
Por lo tanto una vez conocida la función de distribución ( )xF para todos los valores de la variable aleatoria es posible conocer completamente la distribución de probabilidad de la variable. Para realizar cálculos es más cómodo conocer la distribución de probabilidad, y sin embargo, para ver una representación gráfica de la probabilidad es más práctico el uso de la función de densidad.
Definición 1.11 (Valor esperado). Sea X una variable aleatoria discreta, se conoce como valor esperado a la esperanza matemática de X , denotado por [ ]XE o µ , a
[ ] ( )∑==x
xxPXEµ
y la varianza de X , denotada por 2σ o ( )Xvar . Definida por
( ) ( )[ ] [ ] 2222 var µµσ −=−== XEXEX .
Definición 1.12 (Distribución de variable continua). En el caso de una variable aleatoria continua la distribución de probabilidad acumulada es la integral de la función de densidad, por lo que se tiene que:
( ) ( ) ( )dxxfxXPxFx
∫ ∞−=≤= .
Es fácil ver que la definición análoga al valor esperado de X , para la variable aleatoria continua X es
[ ] ( )dxxxfXE ∫∞
∞−==µ
y la varianza como
( ) ( )[ ] [ ] 2222 var µµσ −=−== XEXEX .
1.5 Variable Aleatoria Poisson
Existen fenómenos o experimentos en los que los eventos ocurren en intervalos continuos de tiempo o espacio (áreas y volúmenes), donde sólo importa la ocurrencia del fenómeno, ya que la no ocurrencia no tiene sentido. Por ejemplo, si en cierta región ocurren en promedio de dos terremotos por año, la variable aleatoria será el número de terremotos por año y es claro que no tiene sentido hablar del número de no terremotos por año.

10
Lo mismo sucede para otros fenómenos, como: número de errores en una página, derrumbes anuales en una región montañosa, accidentes de tráfico diarios en cierto crucero, personas atendidas en un banco en un período de diez minutos, partículas de polvo en cierto volumen de aire, nacimientos de niños en un periodo, rayos que caen en una tormenta, llamadas que llegan a un conmutador telefónico en un minuto, insectos por planta en un cultivo, etc. También es de importancia mencionar que cada ocurrencia puede considerarse como un evento en un intervalo de tiempo determinado.
Si se considera que:
1. La esperanza de ocurrencia de un evento en un intervalo es la misma que la esperanza de ocurrencia del evento en otro intervalo cualquiera, sin importar donde empiece el intervalo.
2. Las ocurrencias de los eventos son independientes, sin importar donde ocurran.
3. La probabilidad de que ocurra un evento en un intervalo de tiempo depende de la longitud del intervalo.
4. Las condiciones del experimento no varían.
5. Es de interés analizar el número promedio de ocurrencias en el intervalo.
Entonces se puede afirmar, que la variable aleatoria mencionada en los fenómenos descritos es una variable Poisson.
1.5.1 La Distribución Poisson
La distribución Poisson se llama así en honor a Simeón Dennis Poisson (1781 - 1840), francés que desarrolló esta distribución basándose en estudios efectuados en la última parte de su vida.
La distribución Poisson es una de las más importantes para una variable aleatoria discreta. Desempeña un papel muy importante por derecho propio como modelo probabilístico apropiado para un gran número de fenómenos aleatorios. Sus principales aplicaciones hacen referencia a la modelización de situaciones en las que es de interés determinar el número de hechos de cierto tipo que se pueden producir en un intervalo de tiempo o de espacio, bajo presupuestos de aleatoriedad y ciertas circunstancias restrictivas. Otro de sus usos frecuentes es la consideración límite de procesos dicotómicos reiterados en un gran número de veces si la probabilidad de obtener un éxito es muy pequeña.
Características: En este tipo de experimento los éxitos buscados son expresados por unidad de área, tiempo, pieza, etc.
• de defectos de una tela por m2,
• de aviones que aterrizan en un aeropuerto por día, hora, minuto, etc.

11
• de bacterias por cm2 de cultivo,
• de llamadas telefónicas a un conmutador por hora, minuto, etc.
• de llegadas de embarcaciones a un puerto por día, mes, etc.
Definición 1.13 (Distribución Poisson). Una variable aleatoria X tiene distribución Poisson con parámetro 0>λ si toma valores en el conjunto ,...2,1,0 y probabilidades dadas por
( ) ( )!k
ekXPxfkλλ−===
donde
k es el número de ocurrencias del evento o fenómeno (la función da la probabilidad de que el evento suceda precisamente k veces en el intervalo indicado). λ es un parámetro positivo que representa el número de veces que se espera que ocurra el fenómeno durante un intervalo dado y e es la base de los logaritmos naturales (e = 2,71828...)
Para verificar que lo anterior representa una legítima distribución de probabilidad, se puede observar que:
( ) 1!! 000
===== −∞
=
−∞
=
−∞
=∑∑∑ λλλλ λλ ee
ke
kekXP
k
k
k
k
k.
Teorema 1.1. Si X tiene una distribución Poisson con parámetros λ , entonces ( ) λ=XE y ( ) λ=Xvar .
Demostración:
( ) ( )∑∑∞
=
−∞
=
−
−==
10 !1! k
k
k
k
ke
kkeXE λλ λ
λ
haciendo 1−= ks , se encuentra que se transforma
( ) λλλλλ λλλλ ==== −∞
=
−∞
=
+− ∑∑ ee
se
seXE
s
s
s
s
00
1
!!; donde λλ e
ss
s
=∑∞
=0 !
De modo semejante
( ) ( )∑∑∞
=
−∞
=
−
−==
10
22
!1! k
k
k
k
kek
kekXE λλ λλ

12
haciendo nuevamente 1−= ks , se obtiene
( ) ( ) λλλλλλλ λλλ
+=+=+= ∑∑∑∞
=
−∞
=
−∞
=
+−2
000
12
!!!1
s
s
s
s
s
s
se
ses
sesXE .
Para la varianza:
( ) ( ) ( )( ) λλλλ =−+=−= 2222var XEXEX .
Observación: La variable aleatoria Poisson tiene la particularidad de que su esperanza es igual a su varianza.
1.5.1.1 Propiedades de la Distribución Poisson
1. El número de resultados que ocurren en un intervalo o región especifica es independiente del número que ocurre en cualquier otro intervalo o región del espacio disjunto. De esta forma el proceso Poisson no tiene memoria.
2. La probabilidad de que ocurra un sólo resultado durante el intervalo muy corto o en una región pequeña es proporcional a la longitud del intervalo o al tamaño de la región y no depende del número de resultados que ocurren fuera de este intervalo o región.
3. La probabilidad de que ocurra más de un resultado en un intervalo pequeño o que caiga en tal región pequeña es insignificante.
1.5.2 El Proceso Poisson
El proceso Poisson es un proceso estocástico de tiempo continuo sobre un espacio de estados discreto. Se suele utilizar para contar el número de sucesos ( )tN que ocurren en el intervalo de tiempo [ ]t,0 . El suceso que interesa estudiar aquí es el número de llegadas que se producen en un sistema en el tiempo t .
Se dice que ( )tN , para 0≥t es un Proceso Poisson si se cumplen las cuatro condiciones siguientes:
1. ( ) 00 =N
2. El número de llegadas que se producen en intervalos que no se traslapan son mutuamente independientes,
3. Para un intervalo de tiempo lo suficiente pequeño [ ]ttt ∆+, se cumple que:
• La probabilidad de que llegue un cliente es ( )tt ∆∅+∆λ

13
• La probabilidad de que lleguen dos o más clientes es ( )t∆∅
• La probabilidad de que no llegue ningún cliente es ( )tt ∆∅+∆− λ1
donde ( )t∆∅ representa una cantidad que tiende a cero más rápidamente que t∆ , es decir:
( ) 0lim0
=∆∆∅
→∆ tt
t.
4. Las tres probabilidades anteriores dependen de t∆ pero no de t .
1.5.2.1 Proceso para la Distribución Poisson
Se va a calcular la probabilidad de que lleguen i trabajos en el intervalo [ ]t,0 . Para ello, se supone que el intervalo [ ]t,0 está dividido en m subintervalos iguales de duración mtt =∆ . Por el punto 2, el hecho de que se produzca una llegada en un subintervalo es independiente de lo que haya ocurrido en los demás. Si m es suficientemente grande, se puede pensar que los intervalos considerados forman una sucesión de Bernoulli con una probabilidad que produzca una llegada en el intervalo mtt =∆ igual a
mtp λ= .
La probabilidad de más de una llegada por intervalo es despreciable únicamente si mtt =∆ es muy pequeño. Por tanto, la probabilidad que haya i llegadas será el límite de una
distribución binomial cuando t∆ tienda a cero:
( ) ( ) ( )( ) ( )( ) imi
tttttt
im
tmibtN −
→∆→∆∆∅+∆−∆∅+∆
=∆= λλλ 1lim,,lim
00.
Desarrollando esta expresión se obtiene
( )
( )( ) ( )
( ) ( ) ( ) im
mim
i
im
m
i
m
im
m
i
m
imi
m
mt
mimmm
it
mt
mt
iimmm
mt
mt
mt
mt
iimm
mt
mt
mt
mt
im
tN
−
∞→∞→
−
∞→∞→
−
∞→∞→
−
∞→
−
+−−=
−
+−−
=
∅+−
∅+
−
=
∅+−
∅+
=
λλ
λλ
λλ
λλ
1lim1...1lim!
1lim!
1...1lim
1lim!!
!lim
1lim

14
de donde
( ) teittN λλ −=!
que es la probabilidad de que se produzcan i llegadas en [ ]t,0 y es la función de densidad Poisson con parámetro tλ . Se trata de una distribución bien conocida, y se sabe que:
( )[ ] ttNE λ= y ( )[ ] ttN λ=var .
1.5.2.2 Proceso Para la Distribución Exponencial
Una propiedad interesante de la distribución Poisson es que la distribución del tiempo entre llegadas consecutivas es exponencial.
Sea T una variable aleatoria que representa el intervalo desde el origen de tiempos (elegido arbitrariamente) al instante en que se produce la primera llegada. Se puede obtener fácilmente la distribución de T , teniendo en cuenta que no se producirán llegadas en el intervalo [ ]t,0 si y sólo si tT > . Es decir, ( )[ ] [ ]tTtN >== Pr0Pr donde ( )tN representa el número de llegadas en [ ]t,0 . Luego, como se sabe por la distribución Poisson que
( )[ ] tetN λ−== 0Pr
entonces
[ ] [ ] tetTtT λ−−=>−=≤ 1Pr1Pr
por tanto
( ) tT etF λ−−= 1 para 0≥t
y
( ) ( ) tTT e
dttdFtf λλ −== para 0≥t .
Con lo que queda demostrado que para un proceso de llegada Poisson, el tiempo que transcurre entre un instante arbitrario y el instante de la primera llegada tiene una distribución exponencial con media λ1 .
Nótese que el origen de tiempos ha sido elegido arbitrariamente. Si se elige como origen el instante de una llegada, entonces T representa el tiempo entre llegadas. En conclusión, en un proceso Poisson el tiempo entre llegadas tiene una distribución exponencial

15
con valor medio λ1 y una desviación típica también igual a λ1 . Es conveniente recordar que la distribución exponencial posee la propiedad de carecer de memoria (propiedad de Markov).
Sea it el instante de la i -ésima llegada. Se supone que han transcurrido t unidades de tiempo antes de que se produzca la siguiente llegada. Sea R la variable aleatoria que representa el tiempo que resta para que se produzca la siguiente llegada, es decir tTR −= , donde T es el tiempo entre llegadas. Para calcular la distribución de R para un valor de t determinado,
[ ] [ ][ ]
[ ][ ]tT
rtTttT
tTrRrR
≥+≤≤
=≥
≥≤=≤
PrPr
PrPr
Pr .
Desarrollando el numerador queda:
[ ] ( )ttrt
t
x eedxertTt λλλλ −−+ − −==+≤≤ ∫ 1Pr
y el denominador,
[ ] [ ] ( ) ttt x eeetTtT λλλλ −−
∞−
− =−−=−=≤−=≥ ∫ 111Pr1Pr
por tanto,
[ ] [ ][ ]
[ ][ ]
( ) tt
tt
ee
eetT
rtTttT
tTrRrR λ
λ
λλ−
−
−−
−=−
=≥
+≤≤=
≥
≥≤=≤ 11
PrPr
PrPr
Pr
de donde se ve que R tiene una distribución exponencial con tasa λ que es la misma que tiene T .
1.5.2.3 Propiedades de los Procesos Poisson
A continuación, se van a enunciar, sin demostración, otras dos propiedades interesantes de los procesos Poisson:
1. Superposición de procesos Poisson
Se consideran m fuentes independientes y se supone que cada una de ellas es un proceso Poisson con tasa kλ , para mk ,...,1= . Si se combinan estas fuentes en una sola, se obtiene un nuevo proceso Poisson con tasa
∑=
=m
kk
1λλ .

16
2. Descomposición de un proceso Poisson
Se considera el caso en el que un proceso Poisson se divide en m vías. Si la tasa de llegada es λ y la salida por cada una de las ramas se elige independientemente con probabilidad kp , entonces en la k -ésima genera un proceso Poisson con tasa kpλ , para mk ,...,1= y además los m canales son estadísticamente independientes.
1.6 Parámetros de las Distribuciones
En el estudio de la distribución de una muestra los parámetros juegan un papel importante para determinar la distribución poblacional, puesto que la población puede tener la distribución supuesta pero con otros parámetros que no sean los propuestos. De esta forma crece el interés en conocer y estudiar los parámetros de la distribución que se supone tiene la población.
Una distribución de probabilidad está caracterizada, de manera general, por una o más cantidades que reciben el nombre de parámetros de la distribución. Un parámetro puede tomar cualquier valor de un conjunto dado y, en ese sentido, define una familia de distribuciones de probabilidad, que tendrán la misma función genérica de probabilidad o función de densidad de probabilidad. Los parámetros generalmente son del siguiente tipo.
1.6.1 Parámetro de Localización
Un parámetro de localización relaciona la función de densidad de probabilidad con el origen de la escala de medición, localizándola sobre el eje de las x sin tener algún efecto sobre su apariencia. La presencia de un parámetro de localización µ en la función de probabilidad es siempre de la forma ( )µ−x . Este tipo de parámetro generalmente se relaciona con la media o alguna medida de tipo central, se caracteriza por realizar un desplazamiento en una distribución de referencia, que comúnmente se llama distribución estándar.
1.6.2 Parámetro de Escala
Un parámetro de escala es una cantidad que relaciona las unidades físicas de la variable aleatoria y de esta forma la escala. Un parámetro de escala influye sobre la dispersión de una variable aleatoria, y de esta forma afecta la apariencia de la función de probabilidad. La aparición de un parámetro de escala en la función de probabilidad es de la forma θx o xθ . Este tipo de parámetro es relacionado con la desviación estándar o alguna medida de variación, se caracteriza por mostrar en el caso de la distribución normal la pesadez o la ligereza de las colas, es decir, la amplitud de la gráfica sobre el eje de las ordenadas o dicho de otra manera, la misma forma que toma la gráfica pero en escala diferente sobre el eje de las ordenadas, lo que hace que la distribución tenga colas más ligeras o más pesadas.

17
1.6.3 Parámetro de Forma o asimetría
Un parámetro de forma afecta el sesgo o la simetría de la distribución de probabilidad en diversos grados lo que se refleja en la forma de la distribución, dependiendo del modelo en particular. A pesar de que en muchas ocasiones el parámetro de forma se encuentra en un exponente en la función de probabilidad, no existe ninguna forma estándar en la que pueda asociarse a la variable aleatoria x sin importar su aparición en la función de probabilidad. Ya que para algunos valores la distribución puede ser creciente o decreciente en un mismo segmento de estudio.
1.7 Estimación de Parámetros
El estudio de poblaciones estadísticas supone, en general, el conocimiento de la función de probabilidad que gobierna el comportamiento aleatorio de la variable de interés. En muchos casos se sabe o presume conocer la familia distribucional de una población. Se tiene por ejemplo que la población es aproximadamente normal; pero se desconoce la media y la varianza poblacionales. También se sabe que la variable de interés es binomial pero se desconoce la probabilidad de éxito poblacional o el número de pruebas de Bernoulli. Se infiere que se puede tratar de un proceso Poisson pero se desconoce el número de eventos raros por intervalos. Se asume que la variable es exponencial pero se desconoce el parámetro que precisa la distribución exponencial poblacional.
Lógicamente, en todas estas situaciones la función de probabilidad de la variable en estudio se concreta determinando los parámetros poblacionales correspondientes y para lograrlo se utilizan los denominados métodos de estimación de parámetros. La estimación de uno o varios parámetros poblacionales desconocidos es posible construyendo funciones de probabilidad de variables aleatorias muestrales, más conocidos como estimadores muestrales. Dichos estimadores garantizarán un cálculo o una aproximación satisfactoria del parámetro poblacional desconocido siempre que cumplan propiedades de: insesgamiento o máxima simetría, varianza mínima o máxima concentración de los datos alrededor del parámetro estimado y máxima probabilidad.
La estimación de un parámetro representa uno de los problemas centrales de la Estadística inferencial y sobre el que se tienen muchos desarrollos y resultados matemáticos fuertes. Este problema involucra el uso de los datos muestrales en conjunción con alguna estadística. Existen diferentes formas de llevar a cabo lo anterior, las más comunes son: la estimación puntual y la estimación por intervalo.
En la estimación puntual se busca un estimador que, con base en los datos muestrales, dé origen a una estimación univaluada del valor del parámetro y que recibe el nombre de estimado puntual. Para la segunda, se determina un intervalo en el que, en forma probable, se encuentra el valor del parámetro. Este intervalo recibe el nombre de intervalo de confianza estimado.

18
Uno de los ingredientes clave en inferencia estadística es la “estadística” con base en la cual se formula la inferencia.
Definición 1.14. Un estadístico es cualquier función de la muestra aleatoria, de manera que esta función no contiene a los parámetros.
Considere la muestra nXXX ,...,, 21=X que consiste de n variables aleatorias i.i.d. con una función de densidad de probabilidad ( )θ;xf que depende de un parámetro desconocido θ . Supóngase que se definen funciones como:
( ) ( )( ) ( )( ) ,
,
,
213
2221
212
211
XXTnXXXT
nXXXT
n
n
+=+++=
+++=
XX
X
y así sucesivamente. Todas ellas son estadísticas porque se determinan de manera completa por las variables aleatorias que contiene la muestra. De manera similar denótese una estadística por ( )XuT = , que será utilizada para estimar el parámetro desconocido θ , entonces T recibe el nombre de estimador de θ , y el valor especifico de t como un resultado de los datos muestrales recibe el nombre de estimación de θ . Esto es, un estimador es una estadística que identifica al mecanismo funcional por medio del cual, una vez que las observaciones en la muestra se realizan, se obtiene una estimación.
Una estadística es, sustancialmente, diferente de un parámetro. Un parámetro es una constante pero una estadística es una variable aleatoria. Además, un valor del parámetro describe de manera completa un modelo de probabilidad (suponiendo una distribución uniparamétrica); ningún valor de la estadística puede desempeñar tal papel si cada uno de éstos depende del valor de las observaciones de las muestras y dado que las muestras se toman en forma aleatoria, ninguna muestra es más válida que cualquier otra que se haya tomado con el mismo fin.
1.7.1 Propiedades Deseables de los Estimadores Puntuales
Los estimadores son funciones de las variables aleatorias de una muestra aleatoria dada, es decir para un mismo parámetro se puede tener una infinidad de estimadores. Entonces es de interés conocer propiedades de los estimadores que indiquen cuáles de ellos son más deseados para un parámetro en particular.
1.7.1.1 Estimadores Centrados
Sea θ un estadístico que se empleará para estimar el parámetro poblacional θ . Se dice que θ es un estimador Centrado o Insesgado, de θ si se verifica que ( ) θθ =ˆE . De esta forma, para cualquier estimador insesgado de θ , la distribución de muestreo de la sucesión de las variables aleatorias se encuentran centradas alrededor de θ . Por el contrario se dice que el

19
estimador es Sesgado, si ( ) ( )θθθ bE +=ˆ , denominándose sesgo del estimador a la cantidad ( )θb .
1.7.1.2 Estimadores Consistentes
Intuitivamente un estimador consistente es aquél que se aproxima, al crecer el tamaño de la muestra, al verdadero valor del parámetro.
De acuerdo a la definición de estimador consistente, en caso de dudar si se debe incrementar el tamaño de la muestra para conseguir más información sobre un parámetro, primero se averigua si el estadístico es un estimador consistente. Se define:
Estimador consistente en media cuadrática.
Estimador consistente o convergente en probabilidad.
Definición 1.15. Un estadístico θ utilizado para estimar θ basado en una muestra de tamaño n , se dice consistente en media cuadrática si:
( ) ( )[ ] 0ˆlimˆlim 2=−=
∞→∞→θθθ EECM
nn
De acuerdo con la definición de ECM, una condición necesaria y suficiente para θ sea consistente es que cumpla las dos condiciones siguientes:
1. Que sea asintóticamente centrado, ( ) θθ =∞→ˆlim En .
2. Que la varianza tienda a cero, ( ) 0ˆvarlim =∞→ θn .
Definición 1.16. Sea θ una estimación (basada en una muestra aleatoria nXXX ,...,, 21 ) del
parámetro θ , se dice que θ es un estimador de θ consistente o convergente en probabilidad si cumple:
θθ →Pˆ
Esto es, si
[ ] 0ˆlim =>−∞→
εθθPn
para toda 0>ε
o equivalentemente, si
[ ] 1ˆlim =≤−∞→
εθθPn
para toda 0>ε

20
1.7.1.3 Eficiencia
Si para estimar el mismo parámetro θ disponemos de varios estimadores 1θ y 2θ , se dice que
2θ es más eficiente, que 1θ , si la varianza del primero es menor que la varianza del segundo:
( ) ( )12ˆvar<ˆvar θθ
La Eficiencia Relativa de 2θ respecto de 1θ , se define como el cociente entre ambas Varianzas:
( ) ( )( )2
112 ˆvar
ˆvarˆˆθθ
θθ =eff
Por ejemplo para estimar 2σ , podemos usar 2S o 2cS
( ) ( ) ( ) ( )424
22
12var,12var σσ−
=−
=n
SnnS c
( ) ( )2222 1−= nnSSeff c
1.7.1.4 Suficiencia
Un estimador θ del parámetro θ es suficiente, si contiene tanta información como la contenida en la propia muestra, de forma que ningún otro estimador pueda proporcionar información adicional sobre el parámetro desconocido de la población.
Se dice que un estadístico ( )nXXXT ,...,, 21 es suficiente para θ si la distribución de
nXXX ,...,, 21 dado T es independiente del valor del parámetro θ .
1.7.2 Estimación Puntual
La Estimación Puntual es el método más elemental, basado en asignar los valores obtenidos de la muestra (estadísticos) a toda la población (parámetros). Esta teoría fue desarrollada por R. A. Fisher (1890-1962).
Los métodos de estimación puntual buscan un estimador, con base a los datos muestrales, que proporcione un único valor del valor del parámetro. Estimar un parámetro θ

21
no es más que dar una función de las observaciones que no dependa del parámetro desconocido,
( )nXXX ,...,,ˆˆ21θθ = .
Cada valor de la muestra asigna un valor al estimador del parámetro θ . La función se denomina estimador y cada valor proporciona estimaciones del parámetro.
Los parámetros se pueden estimar por diferentes métodos, entre los más comunes se tiene: Método de Momentos, Método de Máxima Verosimilitud. Más adelante se desarrolla a fondo el método de máxima verosimilitud porque es el método que se utilizará para encontrar los parámetros de estudio.
1.7.3 Estimación por Intervalo
Es la estimación de un parámetro de la población dado por dos números que forman un intervalo que contiene al parámetro con una cierta probabilidad. Es el estimador más eficiente, no es probable que estime con exactitud el valor del parámetro de la población. Una estimación por intervalo, de un parámetro θ , es un intervalo de la forma SI θθθ ˆˆ << tal que se verifique,
( ) γ=<< SIP θθθ ˆˆ
con γ suficientemente próximo a 1. Mientras Iθ y Sθ son variables aleatorias, denominadas Límites de Confianza. Mientras γ es el Coeficiente de Confianza.
1.8 Métodos de Estimación Puntual
En esta sección se expondrá sobre los dos métodos clásicos de estimación puntual.
1.8.1 Método de los Momentos
Quizás es el método más antiguo par la estimación de parámetros. Éste consiste en igualar los momentos apropiados de la distribución de la población con los correspondientes momentos muestrales para estimar un parámetro desconocido de la distribución.
Este método fue propuesto por Pearson (1857-1936) y consiste en igualar un determinado número de momentos teóricos de la distribución de la población con los correspondientes momentos muestrales, para obtener una o varias ecuaciones que, resueltas, permiten estimar los parámetros desconocidos de la distribución poblacional.

22
Definición 1.17. Sea nXXX ,...,, 21 una muestra aleatoria de una distribución con función (densidad) de probabilidad ( )θ;xf . El r-ésimo momento alrededor del cero se define como
∑=
=n
i
ri
tr X
nM
1
1
El método de momentos proporciona una alternativa razonable cuando no se pueden determinar los estimadores de máxima verosimilitud. Recuérdese que los parámetros son, en general, funciones de momentos teóricos.
Por ejemplo sea nXXX ,...,, 21 una muestra aleatoria simple (m.a.s.) de una distribución con función de densidad ( )21 ,; θθxf . Como se tiene dos parámetros, se toman los dos primeros momentos respecto al origen,
( ) ( )dxxfxXn
dxxxfXn
n
ii
n
ii ∫∑∫∑
∞
∞−=
∞
∞−=
== 212
1
221
1,;1;,;1 θθθθ
1.8.2 Método de Máxima Verosimilitud
El método de estimación por máxima verosimilitud, selecciona como estimador a aquel valor del parámetro que tiene la propiedad de maximizar el valor de la probabilidad de la muestra aleatoria observada. Se basa en la función de densidad conjunta de n variables aleatorias
nXX ,,1 , dependientes de los parámetros mθθ ,,1 , sobre los cuales se maximice la función de densidad conjunta para el caso de una realización nxx ,,1 .
En otras palabras, el método consiste en encontrar el valor del parámetro que maximiza la función de verosimilitud. El método de máxima verosimilitud es simple en su esencia, pero obviamente tiene todas las dificultades de la localización de máximos en una función, en donde se aplican las diferentes técnicas del cálculo como son: máximos y mínimos relativos, máximos y mínimos absolutos y extremos de funciones monótonas, así como métodos numéricos.
De lo anterior se puede apreciar que el método de máxima verosimilitud es posible dividir en dos partes; una para espacios paramétricos discretos y la otra para espacios paramétricos continuos.
Definición 1.18 (Función de verosimilitud). La función de verosimilitud de n variables aleatorias nXX ,...,1 está definida como la densidad conjunta de las n variables, es decir, ( )mnxxf θθ ,...,;,..., 11 , la cual es considerada como una función de mθθ ,...,1 . En

23
particular, si nXX ,...,1 es una muestra aleatoria de densidad ( )mxf θθ ,...,; 1 , entonces la función de verosimilitud es:
( ) ( )mi
n
imn xfxxf θθθθ ,...,;,...,;,..., 1
111 ∏
=
= .
Observaciones:
La función de verosimilitud es una función de mθθ ,,1 y se suele utilizar la notación
( ) ( ) ( )mnnm xxfxxLL θθθθ ,...,;,...,,...,;,..., 1111 ==θ
• La notación ( )θL indica que L es una función de θ y no de nxx ,...,1 .
• θ puedes ser un escalar o un vector ( )mθθ ,...,1=θ .
• El subíndice θ en la función de probabilidad o de densidad indica que dicha función depende del valor del parámetro.
La función de verosimilitud ( )nm xxL ,...,;,..., 11 θθ da la verosimilitud cuando las variables aleatorias asumen un valor particular de nxx ,...,1 . La verosimilitud es el valor de una función de densidad y, en el caso de las variables aleatorias discretas se ha visto que la verosimilitud es una probabilidad.
1.8.2.1 Estimador de Máxima Verosimilitud (EMV)
Se denota por Ω al espacio de parámetros, se tiene que el problema de los estimadores de máxima verosimilitud consiste en determinar el valor de ( ) Ω∈= θmθθ ,...,1 , el cual se
denotará por θ , y será tal que maximiza la función de verosimilitud ( )nxxL ,...,; 1θ . El valor de
θ , que maximiza la función de verosimilitud en general es una función de nxx ,...,1 . Es decir,
( )nxxg ,...,ˆ1=θ .
Cuando esto sucede la variable aleatoria ( )nXXg ,...,ˆ1=Θ es llamada el estimador de
máxima verosimilitud del parámetro θ .
Definición 1.19 (Estimador de Máxima Verosimilitud). Sea ( ) ),...,;( 1 nxxLL θθ = la función
de verosimilitud para las variables aleatorias. Si θ (donde ( )nxxg ,...,ˆ1=θ es una función de
las observaciones nxx ,...,1 ) es el valor de Ω∈θ con el que se maximiza ( )θL , entonces la
variable aleatoria ( )nXXg ,...,ˆ1=Θ es el estimador de máxima verosimilitud de θ . Mientras

24
que ( )nxxg ,...,ˆ1=θ es el estimador de máxima verosimilitud de θ para la realización nxx ,...,1 .
Para cada muestra particular ),...,( 1 nxx , la estimación de máxima verosimilitud de θ es el
valor MVθ que maximiza la verosimilitud. Es decir:
),...,;(max),...,;ˆ( 11 nnMV xxLxxL θθθ
= .
Para hallar el máximo se emplearan algunas técnicas de análisis matemático. En concreto:
1. La función ( )xln es una función creciente, por lo que el máximo de ( )xf se alcanzará en el mismo punto que el máximo de ( )( )xfln . Esto permite derivar más fácilmente, pues el ( )xln transforma los productos en sumas.
2. El máximo de una función ( )xf en un intervalo [ ]ba, se alcanza en algún punto crítico (puntos que anulan la derivada de ( )xf ) o en los extremos del intervalo.
3. El máximo de una función ( )yxf , , con R∈yx, , se alcanza en algún punto crítico (puntos que anulan las derivadas parciales de ( )yxf , :
( ) ( ) 0,,0, =∂∂
=∂∂ yxf
yyxf
x.
1.8.2.2 Procedimiento Para Obtener el E.M.V. de θ
Por ello, para hallar el estimador de máxima verosimilitud de θ , se emplearán los siguientes pasos:
1. Definir la función ( ) ( )∏=
=n
iixfxL
1
;| θθ
2. Definir la función ( ) ( ) ( )∑=
==n
iixfxLxl
1;log|log| θθθ
3. Hallar el máximo de ( )xl |θ :
• Resolver la ecuación ( ) 0| =xldd θθ
.
• Si θ sólo puede tomar valores en un intervalo, estudiar si el máximo se alcanza en los extremos de dicho intervalo.

25
1.8.2.3 Propiedades del E.M.V.
1. Invarianza (Principio de máxima verosimilitud):
Si θ es el estimador máximo verosímil de θ , entonces ( )θh es el estimador máximo verosímil de ( )θh .
2. Consistencia:
Bajo ciertas condiciones generales, θ es un estimador consistente de θ .
3. Insesgado asintóticamente:
Se verifica que [ ] θθ =∞→ nn E ˆlim .
4. Normalidad asintótica:
Bajo ciertas condiciones generales,
( ) ( )
− −10,~ˆ θIθθ Nn
A
donde
( ) ( )
∂∂
=2
;ln XθθI fEθ
es la matriz de información de Fisher correspondiente a una observación.
La matriz de información de Fisher correspondiente a n observaciones es
( ) ( ) ( )
∂∂
⋅=
∂∂
=2..2
1 ;ln,,;ln XθθθI fEnXXfEsam
n θθ
Se tiene que
( ) ( ) ( )
∂
∂−=
∂∂
= nn XXfEXXfE ,,;ln,,;ln 12
22
1 θθθIθθ
La varianza asintótica de MVθ es:

26
[ ]( ) ( ) ( )
( ) θθθ
θθθ
θ
ˆ2
2
12
2
1
,,;ln
111ˆvar
=∂∂
−≈
∂∂
−==⋅
=
θ
θ n
A
XXfEIin
La aproximación final es muy útil en la práctica.
Un problema grande que tienen los estimadores de máxima verosimilitud consiste en que no siempre existen y cuando existen puede ser difícil su cálculo. En este caso se suelen utilizar programas estadísticos o matemáticos para resolver el problema.

27
Capítulo 2
TEORÍA DE VALORES EXCEDENTES
2.1 Introducción
En este capítulo se presentan las definiciones y resultados fundamentales de la teoría de valores extremos que serán la base de las propiedades y modelos desarrollados en el capítulo siguiente. Se pretende dar una visión general de su evolución hasta su estado actual.
El objetivo central de la teoría de valores extremos consiste en desarrollar procedimientos, estadísticamente justificables, para estimar la cola de una distribución desconocida, F, a partir de una muestra de datos. Este objetivo surge para dar respuesta a problemas que se plantean en multitud de áreas de aplicación, en particular en estudios de carácter medio-ambiental.
Los modelos clásicos de la Teoría de los Valores Extremos, denotada por EVT, se ocupan de los límites de las distribuciones que normalizan valores máximos (y mínimos) de variables aleatorias independientes e idénticamente distribuidas (i.i.d). Este método se conoce con el nombre Block Máxima porque los datos son divididos en m bloques con n observaciones correspondientes a n intervalos. Los valores extremos son definidos como los máximos de las n variables aleatorias.
Ahora bien, la Teoría de los Valores Extremos es llamada a realizar el análisis pertinente sobre la cola de la distribución de los eventos extremos que se presenten en los datos obtenidos, ya que hasta ahora por medio de esta teoría es como mejor se ha podido interpretar el comportamiento de estos datos atípicos. Formalmente, la Teoría del Valor Extremo es una rama de la estadística que estudia las desviaciones de la media de las distribuciones de probabilidad. Hay dos clases de distribuciones para ajustar valores extremos: Distribución Generalizada del Valor Extremo (DGVE) y la Distribución Generalizada de Pareto (DGP). Cada distribución tiene un método propio para extraer los valores extremos.

28
A continuación presentamos los aspectos teóricos de los dos modelos y describimos las expresiones analíticas que se utilizan en la estimación de ajuste de las distribuciones de los valores extremos. Para poder entender la Teoría del Valor Extremo comenzaremos haciendo una aproximación mediante la Distribución Generalizada del Valor Extremo.
2.2 Teoría Clásica: Análisis de máximos
El trabajo de Gumbel (1958) es la referencia clásica para métodos cuyo objetivo es caracterizar el comportamiento del máximo de muestras aleatorias.
Dada la serie nXXX ,, 21 de variables aleatorias i.i.d. con distribución F , se cumple
njxXPxF j ≤≤≤= 1),()( .
Si se define la variable aleatoria nM como
nn XXXM ,...,,max 21= .
Entonces
( ) ( )
).(
)(
)()()(,...,,
1
21
21
xF
xXP
xXPxXPxXPxXxXxXPxMP
n
i
n
i
n
nn
=
≤=
≤≤≤=≤≤≤=≤
∏=
La ecuación anterior no es de utilidad cuando la muestra es grande, debido a que 1)(0 << xF , entonces 0)( →xF n cuando ∞→n . En ese caso la distribución límite )(xF n
es degenerada, es decir, sólo toma los valores 0 y 1.
Las siguientes definiciones son parte de los conceptos necesarios para resolver esta dificultad.
Definición 2.1 Se dice que dos distribuciones 1H y 2H son del mismo tipo, si existen constantes BA ,0> tales que
)()( 21 BAxHxH += .

29
Definición 2.2 Si H , F son distribuciones, entonces se dice que F pertenece al dominio de atracción de H si existen constantes 0>na y nb tales que
)()(lim xHbxaF nnn
n=+
∞→.
En el caso particular de la variable aleatoria nM , es posible encontrar constantes de
escala 0>na y nb cuando ∞→n que cumplen
( )
).( nnn
nnnn
nn
bxaF
bxaMPxa
bMP
+=
+≤=
≤
−
Esta propiedad es un caso particular del teorema de valores extremos que se enuncian a continuación.
Teorema 2.1. (Fisher-Tippett(1928), Gnedenko (1943)). Si existen sucesiones de constantes,
na y nb , tales que cuando ∞→n , nM tiene una distribución límite no degenerada con
función de distribución G
)(lim xGxa
bMP
n
nn
n=
≤
−∞→
.
Para alguna distribución no degenerada )(xG , entonces )(xG es del mismo tipo de una de las siguientes distribuciones:
1. Distribución tipo Gumbel (colas medias)
∞<<∞−−= xxxG ,)exp(exp)(
2. Distribución tipo Frechet (colas pesadas)
0,0),exp()( >>−= − αα xxxG
3. Distribución tipo Weibull (colas ligeras)
( )( )
><<∞−−−
=.00
,0exp)(x
xxxGα

30
Los tres tipos de distribuciones anteriores se pueden obtener como casos particulares de la familia de distribuciones conocida como distribución generalizada de valores extremos (DGVE), dada por
−+−=
− ξ
σµ
ξ1
1expexp)(x
xG .
Una distribución de tres parámetros es obtenida para H. Un parámetro de localidad (que puede ser la media de los valores máximos) R∈µ , un parámetro de escala 0>σ y un parámetro de forma ξ . Esta distribución es generalizada en el sentido que asume tres tipos de distribuciones dependiendo del valor del parámetro ξ :
1. Si 0>ξ , la distribución es Frechet,
2. Si 0=ξ la distribución es Gumbell y
3. cuando 0<ξ la distribución es Weibull.
La distribución Gumbel se aproxima a cero exponencialmente mientras la Frechet sigue una función de potencia y por consiguiente se aproxima a cero más lentamente.
Gnedenko (1943) dio la condición necesaria y suficiente para que la función de distribución )(xF de nM pudiera ser asociada con uno de los tres tipos de distribución mencionados.
La familia Frechet incluye las distribuciones de colas más pesadas como son la Pareto y t-student, por esto su uso es apropiado en finanzas en el área de gestión del riesgo. Las distribuciones con colas ligeras como la normal o log normal están contempladas en la familia Gumbell.
2.3 Función de excesos
Los métodos de estimación estudiados hasta ahora no hacen el mejor uso de la información disponible, pues de cada bloque sólo se utiliza un dato, el valor máximo. Sin embargo, otros valores altos en el mismo bloque pueden tener información útil sobre la cola de la distribución de la muestra, que deberían ser tomados en cuenta. Si se tiene información sobre la serie completa de datos, una alternativa es dejar a un lado el procedimiento de bloques y estudiar todos los valores altos de la muestra. Dentro del contexto del modelaje de los valores

31
extremos, han surgido otros métodos que incorporan más datos extremos en lugar de sólo tomar el máximo anual para su análisis.
Históricamente, la primera clase de tales métodos alternativos, fueron los métodos de umbrales; que fue propuesto inicialmente en el área de Hidrología y luego formalizado por R.L. Smith en base a resultados obtenidos previamente por Pickands, donde todas las observaciones a considerar exceden un umbral específico que luego son modelados con alguna distribución, que de nuevo es asintótica.
Los métodos de excesos sobre un umbral, EOT (Excesses Over Thresholds), se basan en la hipótesis de que la ocurrencia de excesos sobre un umbral estricto en una serie de variables aleatorias i.i.d. presenta un comportamiento Poisson, y que los excesos tienen una distribución exponencial o, más generalmente, Pareto generalizada, (Davison & Smith 1990).
Sea nXXX ,,, 21 una secuencia de variables aleatorias independientes e idénticamente distribuidas, que tienen una función de distribución marginal F . Es natural considerar como eventos extremos aquellos iX que exceden algún umbral (límite) alto u . Denotando a un
término arbitrario en la sucesión de iX por X , sigue una descripción de la conducta estocástica de los eventos extremos se da por la probabilidad condicional
( )( )
( )1.2.0,1
1)( >
−+−
=>+>= yuF
yuFuXyuXPyFu
En donde, )(yFu puede interpretarse como la probabilidad de que una pérdida exceda
el umbral u por un valor igual o menor a y , supuesto que el umbral u ha sido excedido. Si la principal distribución F fuese conocida, la distribución de los excedentes del umbral en (2.1) también se conocería. Ya que, en las aplicaciones prácticas no sucede así, se buscan aproximaciones que son ampliamente aplicables para los valores altos del umbral. Es similar el uso de VEG como una aproximación a la distribución de máximos de sucesiones largas cuando la población principal es desconocida.
Una propiedad conocida es que )(~ λεX si y sólo si, )(yFu no depende de u , esto
significa que )()( xHxFu = , para alguna función H .
En general las funciones exceso cumplen una ley asintótica, para ∞→u . La teoría utilizada para obtenerla está extremadamente relacionada con las leyes para el máximo de una muestra aleatoria. Así, resultados de la teoría de valores extremos se utilizan para estimaciones de funciones de excesos y viceversa.

32
2.3.1 Distribución Límite de los Exceso
La distribución límite del exceso uX es una distribución Pareto Generalizada (DGP), definida como:
=
−−
≠
+−
=
−
0,~exp1
0,~11)(
1
ξσ
ξσξ ξ
y
y
yH
donde 0 y 0yσ > ≥ cuando 0ξ ≥ y en caso contrario ξσ~0 −≤≤ y .
Se define ξ como el parámetro de forma o “índice cola” (que puede ser negativo, positivo o cero) y σ es el parámetro de escala. El índice de cola ξ da una indicación de la pesadez de la cola; cuanto más grande sea, más gruesa es la cola, es decir la distribución es de cola pesada.
El principal resultado está contenido en el siguiente teorema que permite caracterizar el modelo asintótico de los excedentes de un umbral dado.
Teorema 2.2. Sea 1 2, ,...X X una secuencia de variables aleatorias independientes e idénticamente distribuidas con función de distribución F común, y sea
nn XXXM ,...,,max 21= .
Denotando un término arbitrario en la sucesión de iX por X , y suponiendo que F satisface
el Teorema 2.1, entonces para n grande
( )Pr ,nM z G z≤ ≈
donde
( )1
exp 1 zG zξ
µξσ
− − = − +
Para algún , > 0 y µ σ ξ . Entonces, para un µ
suficientemente grande la función de
distribución de ( )X µ− condicionado bajo ( )>X µ es aproximadamente

33
( ) ( )2.2~,~11)(1
σξσξ ξ
Dyy
yH ∈
+−=
−
definida bajo ( ) : > 0 y 1 > 0 ,y y yξ σ+
donde
( )[ )[ ]0, si 0.
,0, si 0.
Dξ
ξ σσ ξ ξ
∞ ≥= − <
( ) ( )3.2~ µξσσ −+= u
El teorema 2.2 puede hacerse más preciso, justificando (2.2) como una distribución límite cuando u crece.
La familia de distribuciones definida por la ecuación (2.2), se llama la familia Pareto generalizada. Por lo tanto, para un umbral u lo suficientemente grande, existe algún σ que depende de u y algún ξ para los cuales la distribución generalizada de Pareto es una muy buena aproximación a la distribución de los excedentes de u .
El Teorema 2.2 implica que si el bloque máximo tiene aproximadamente una distribución G, entonces los excesos del umbral tienen una distribución aproximada correspondiente dentro de la familia de Pareto generalizada. Además, los parámetros de la distribución de Pareto generalizada de los excesos del umbral son singularmente determinados por aquéllos máximos del bloque asociados a la distribución de GEV. En particular, el parámetro ξ en (2.2) es igual al de la correspondiente distribución de GEV. Escogiendo un bloque diferente, pero aún grande, de tamaño n afectarían los valores de los parámetros de GEV, pero no aquéllos de la correspondiente distribución de Pareto generalizada de excesos del umbral: ξ es invariante para el tamaño del bloque, mientras el cálculo de σ~ en (2.3) es inalterable por los cambios en µ y σ los cuales se compensan igual.
La dualidad entre el GEV y familias de medias de la distribución Pareto generalizada se refiere a que el parámetro de forma ξ es dominante, determinando el comportamiento de la distribución de Pareto generalizada, así como lo es para la distribución de GEV.
1. Si 0ξ < la distribución de los excedentes tiene un límite superior de ;u σ ξ−
2. Si 0ξ > la distribución no tiene límite superior.

34
3. La distribución tampoco tiene límite si 0ξ = , que debe interpretarse de nuevo tomando el límite cuando 0ξ → en (2.2), obteniendo
( )4.2.0,~exp1)( >
−−= yyyH
σ
Correspondiente a una distribución exponencial con parámetros 1 .σ
2.3.2 Breve Justificación del teorema 2.2 para el Modelo Generalizada de Pareto
En esta sección se revisa una breve demostración del teorema 2.1; para un argumento más preciso revisar el trabajo de Leadbetter et al. (1983).
Sea X una variable aleatoria con función de distribución F . Por afirmación del Teorema 2.1 para una n lo suficiente grande,
( )1
exp 1n zF zξ
µξσ
− − ≈ − +
Para algunos parámetros , 0 y . Ya que,µ σ ξ>
( ) ( )5.21log1 ξ
σµξ
−
−
+−≈zzFn
Para valores grandes de z , la distribución acumulada se aproxima a 1, entonces el logaritmo se aproxima a cero y es posible obtener una expresión de Taylor
( ) ( ) log 1 .F z F z≈ − −
Sustituyendo en (2.5), seguido por un reacomodo, se obtiene
( )1
11 1 uF un
ξµξ
σ
− − − ≈ +
para u grande. De manera similar cuando 0,y >
( ) ( )6.2.11
11 ξ
σµ
ξ−
−+
+≈+−yu
nyuF

35
En consecuencia,
( )[ ]( )[ ]
( )( ) ( )
ξ
ξ
ξ
ξ
σξ
σµξσµξ
σµξσµξ
1
1
11
11
~1
7.21
1
11Pr
−
−
−−
−−
+=
−+−++
=
−+−++
≈>+>
y
uyu
unyunuXyuX
donde
( ) ,uσ σ ξ µ= + −
de esta manera se demuestra el resultado del teorema 2.2.
Al igual que con la DGVE, para esta distribución también se estudian los tres casos que dependen del signo del parámetro ξ : 0,0 >< ξξ y 0=ξ .
1. Si 0ξ > se cumple ( ) 11 con 0H y cy cξ−− ∼ > que coincide con la forma de la
cola de una distribución de Pareto.
2. Si 0ξ < , entonces G tiene un punto extremo ( ) ξσω ~=H , semejante al tipo
Weibull de la teoría clásica de valores extremos.
3. Si 0ξ = , el valor límite cuando 0ξ → es
−−=
σ~exp1)(
yyH .
Caso similar a la distribución límite Gumbel que corresponde a la distribución exponencial con parámetro σ .
2.3.3 Propiedades de la DGP
1. Supongamos que )(~ yHX , entonces ( ) ∞<X si y sólo si 1<ξ . En este último caso
a) ξξσ
ξ 1,
11
~1 −>+
=
+
−
rr
XE
r

36
b) ,!~1log ∈=
+ kkXE k
k
ξσξ
c) ( )( )( )( ) ,11
~
+−+=
rrXHXE
r
ξσ
Si 01 11 >−⇒>⇒< −− rrr ξξξ con N∈r , entonces
d) [ ] ( )( ) !.1
~11
1
rrXE r
rr
−+
−
+Γ−Γ
=ξξ
ξσ
Para demostrar el inciso a), b), c) y d) se procede de la siguiente manera.
Función de densidad de la DGP
( )ξ
σξ
σ
11
~1~1
)()(+−
+==
yyH
dyd
yh para 0≥y .
Para inciso a) ξξσ
ξ 1,
11
~1 −>+
=
+
−
rr
XE
r
.
( )
( )
( )
( )
∞→
=
−−
∞→
=
−−
∞−+−
∞−+−
∞+−−−
+−
+
=
−−
+
=
+=
+=
+
+=
+
∫
∫
∫
x
x
r
x
x
r
r
r
rr
r
x
r
x
dxx
dxx
dxxxXE
0
1
0
1
0
11
0
11
0
11
1
~1
1~11
~~11
~1~1
~1~1
~1~1
ξσξ
ξ
σξ
ξ
σξ
σξ
ξ
σξ
σ
σξ
σσξ
σξ
ξ
ξ
ξ
ξ
ξ

37
( )
r
r
r
ξ
ξσξ ξ
+=
+−
+
−=
−−
11
1
~)0(1
0
1
b) N∈=
+ kkX
E kk
,!~1log ξσξ
. Denotando
( )
dxxxX
Ekk
k ∫∞
+−
+
+=
+=∆0
1
~1~1
~1log~1logξξ
σξ
σσξ
σξ
.
Resolviendo la integral por partes, en donde
( )ξξ
ξ
σξ
σξ
σ
σξ
σξ
σξ
σξ
11
11
~1,~1~1
~~1~1log,~1log
−+
−
−−
+−=
+=
+
+=
+=
xvdxxdv
dxxxkduxukk
Entonces
dxxx
kx
xxudv
k
k
k
∫
∫
∞−−−
∞−
∞
+
+
+−−
+−
+==∆
0
111
0
1
0
~~1~1log~1
~1~1log
σξ
σξ
σξ
σξ
σξ
σξ
ξ
ξ
Pero 01011 <−−⇒<−⇒< rξξξ , de donde
0~1
11
→
+ ∞→
+−
x
r
x ξ
σξ
.
Además, 0~)0(
1log =
+σξ
se tiene

38
000~1~1log
0
1
=−=
+−
+
∞−−
ξξ
σξ
σξ
rkxx
.
Con este resultado
dxxx
kx
k
k ∫∞
−−−
+
+
++=∆
0
111
~~1~1log~10σξ
σξ
σξ
σξ ξ
.
Simplificando la integral
1
0
111
0
111
~1~1
~1log~~1~1log~1
−
∞−−−
∞−−−
∆=
+
+=
+
+
+ ∫∫
k
kk
k
dxxx
kdxxx
kx
ξ
σξ
σσξ
ξσξ
σξ
σξ
σξ ξξ
Es decir, obtenemos la fórmula recursiva
1−∆=∆ kk kξ
Desarrollando la fórmula recursiva
00
0321
!)1()2)(1(
)1()2()1()2()1()1(
∆=∆−−=
∆−−==∆−−=∆−=∆=∆ −−−
kkkkkk
kkkk
kkkkkkkkk
ξξ
ξξξξξξξξξ
Pero 10 =∆ porque se está integrando la función de densidad. Con esto queda concluido el inciso (b)
c) ( )( )( )( ) .11
~
+−+=
rrXHXE
r
ξσ
Si
( ) ( )ξξ
σξ
σξ 11
~1~1111−−
+=
+−−=−=
xxXHXH
Entonces

39
( )( )
( )
( ) ( )
∫
∫∞
−+−
∞+−−
−
−
+=
+
+=
+=
+=
0
11
0
11
1
~1
~1
~1~1
~1
~1
~1
dxx
x
dxxx
x
XXE
XXEXHXE
r
r
r
rr
σσξ
σξ
σσξ
σξ
σξ
ξξ
ξξ
ξ
ξ
Utilizando otra vez la integral por partes, en donde
dxduxu == , y ( ) ( )
( )
( )ξ
ξξ
σξ
σσξ
rr xr
vdxx
dv
+−−+−
++
−=
+=
111
~11
1,~
1~1
Sustituyendo
( )( )( )
( )
( )
( )
dxx
rx
rxXHXE
rrr
∫∞
+−
∞+−
++
+
++
−=
0
1
0
1
~11
1~1
1ξξ
σξ
σξ
Por otra parte
( )
( )
( )
( )
( )
( )
000
~)0(
11
0~1
1lim~1
1
11
0
1
=−=
+
+−
++
=
++
+−
+−
∞→
∞+−
ξξξ
σξ
σξ
σξ
rr
x
r
rx
rxx
rx
Sustituyendo en el valor esperado
( )( )( )
( )
( )
( ) ∞→
=
+−
∞+
−
++−+
=
++
=
∫
x
x
r
rr
xrr
dxx
rXHXE
0
1
0
1
~1)1(
~
11
~11
1
ξξ
ξ
σξ
ξσ
σξ

40
Como se está considerando 01011 <−−⇒<−⇒< rξξξ , entonces
( ) ( ) ( )
110~)0(
1~1lim~1
11
0
0
1
−=−=
+−
+=
+
+−+−
→
∞→
=
+−ξ
ξξ
ξξ
ξ
σξ
σξ
σξ
rr
x
x
x
rxx
.
Podemos concluir
( )( )( ) ( ) )1(1
~)1(
)1(
~
11
ξσ
ξσ
−++=−
+−+=
rrrrXHXE
r.
d) [ ] ( )( ) !.1
~11
1
rrXE r
rr
−+
−
+Γ−Γ
=ξξ
ξσ Denotando
dxx
xm
rmr ∫
∞+−
+=∆0
1
, ~1ξ
σξ
,
resulta [ ] 1,~1
−∆= rrXE
σ. Integrando por partes a 1,−∆r
( )ξξ
σξ
ξξσ
σξ
1
1
11
1
~10
1~,~1
,−
−
−−
−
+−
−=
+=
==
xvdx
xdv
dxrxduxu rr
0,11
0
01
11
0
1
11
0
1
11,
0
~~1
0
~
~10
1~~1
01~
−−
∞+−
−−
∞−
−−
∞−
−−
∆−
=
+−
=
+−
+
+−
−=∆
∫
∫
r
r
rrr
r
dxx
xr
dxrx
xx
x
ξξσ
σξ
ξξσ
σξ
ξξσ
σξ
ξξσ
ξ
ξξ
Es decir, obtuvimos la fórmula recursiva
0,111, 0
~−−− ∆
−=∆ rr
rξξ
σ.

41
Desarrollando la fórmula hasta 1,0 −∆ r
1,01111
1,1111
2,3111
1,211
0,111,
))1(()2)(1)(0(!~
)1()1(~
22~
11~
0
~
22~
11~
0
~1
1~
0
~0
~
−−−−−
−−−−−−
−−−−
−−−
−−−
∆−−−−−
=
∆
−−−−
−−
−−
−=
∆
−−
−−
−=
∆
−−
−=
∆−
=∆
r
r
rrr
r
r
rr
rr
rrrrrr
rrr
rr
r
ξξξξξσ
ξξσ
ξξσ
ξξσ
ξξσ
ξξσ
ξξσ
ξξσ
ξξσ
ξξσ
ξξσ
Por otro lado, calculando 1,0 −∆ r
rrx
rdx
xx
x
rr
r −=
−+−=
+−
−=
+=∆−−
∞→
=
+−
−
∞−+−
− ∫ 11
0
1
10
11
1,01~1~
0~11~
~1ξξ
σξξ
σσξ
ξξσ
σξ ξξ
.
Sustituyendo el resultado de 1,0 −∆ r en la fórmula recursiva
)()2)(1)(0(!~
1~
))1(()2)(1)(0(!~
1111
1
111111,
rr
rrr
r
r
r
−−−−
=
−−−−−−
=∆
−−−−
+
−−−−−−
ξξξξξσ
ξξσ
ξξξξξσ
De donde
[ ]
)()2)(1)(0(1!~
)()2)(1)(0(!~
~1
11111
1111
1
rr
rrXE
r
r
rr
−−−−=
−−−−
=
−−−−+
−−−−
+
ξξξξξσ
ξξξξξσ
σ
Para obtener la representación deseada tomamos en cuenta que

42
)()()2)(1)(0(
)2()12)(1()12()1()1()1()11()()1(
11111
1111111
11111111
rr −Γ−−−−=
−Γ+−−=+−Γ−=
−Γ−=+−Γ=Γ=+Γ
−−−−−
−−−−−−−
−−−−−−−−
ξξξξξ
ξξξξξξξ
ξξξξξξξξ
dividiendo entre )( 1 r−Γ −ξ
)()1(
)()2)(1)(0(1
11111
rr
−Γ+Γ
=−−−−−
−−−−−
ξξ
ξξξξ .
reciproco
)1()(
)()2)(1)(0(1
1
1
1111 +Γ−Γ
=−−−− −
−
−−−− ξξ
ξξξξr
r
Finalmente se obtiene la expresión deseada
[ ])1()(!~
1
1
1 +Γ−Γ
=−
−
+ ξξ
ξσ rrXE r
rr .
De esta manera se demuestra el resultado del teorema 2.2.
2. Para ( )GF,ξ ∈∈R si y sólo si
0)()(suplim0
=−−<<↑
xHxFuFxFu ωω
.
Para alguna función positiva σ~ .
Esta propiedad dice que las DGP son aproximaciones adecuadas para la f.d. de excesos F para u grande. Este resultado se debe a Pickands y puede reformularse como sigue.
Para alguna función σ que se estima a partir de los datos,
( ) ( ) ( ) , 0.F x P X u x X u H x x= − > > ≈ >
Es necesario que u sea suficientemente grande.
Esta propiedad da una idea de la relación existente entre la ley asintótica para el máximo y la ley asintótica para la función distribución de excesos. En primer lugar establece

43
que aquellas distribuciones que están en el dominio de atracción de G, cumplen tener una distribución límite para la función F; y en segundo lugar, indica que el parámetro ξ es el mismo en la función G y en la función H. La propiedad de estabilidad es un concepto importante que tiene la distribución Pareto. Coloquialmente significa que si la familia Pareto ajusta bien a la función de excesos para un valor u0, lo mismo ocurrirá para todo u > u0.
3. Supongamos que ( ), , 1, 2,ix D iξ σ∈ = entonces
( )( ) ( )1 2
21
H x xH x
H x+
= .
Esta propiedad puede reformularse diciendo que la clase de las DGP es cerrada respecto a cambios de umbral. El lado izquierdo es la probabilidad condicional de que, dado que la variable en consideración está por encima de 1x , también está por encima de
1 2x x+ . El lado derecho dice que esta probabilidad también es una DGP.
4. Sea ( )N Pois λ∼ , independiente de la sucesión i.i.d. ( )nX con DGP de parámetros ξ
y σ~ . Entonces
( ) ( ),~1exp ,;
1
xGxxMP N ψµξ
ξ
σξλ =
+−=≤
−
donde ( )1~ 1 −= − ξλξσµ y ξλσψ ~= .
Esta propiedad dice que en un modelo en el cual el número de excedencias es exactamente Poisson y la f.d. de excesos es exactamente una DGP, el máximo de estos excesos tiene como distribución una DGVE.
5. Supongamos que X tiene una DGP con parámetros 1<ξ y σ~ . Entonces para Fu ω< ,
( ) .0~,1
~)( >+
−+
=>−= ξµσξξµσuXuXEue
En conjunto, (2) y (5) proveen una técnica gráfica para escoger un umbral u suficientemente alto como para que la aproximación de función de densidad de excesos F por una DGP se justifique:

44
Dados los valores de una muestra aleatoria 1,..., nx x construimos una función media de
excesos empírica ( )ne u como una versión muestral de la función media de excesos ( )e u . A
partir de (5) vemos que la función media de excesos de una DGP es lineal, entonces buscamos una regresión de valores u donde la gráfica de ( )ne u sea aproximadamente lineal. Para estos
valores de u parece razonable aproximar por una DGP.
2.3.4 Momentos de DPG
En cuanto a los valores descriptivos, la media )(YE existe si 1ξ < , la varianza )var(Y existe
si 1 2ξ < , y se calculan como
( ) ( )( )( )ξξ
σξ
σ211
~var,
1
~ 2
−−=
−= YYE .
La media condicional, de excedencia sobre ω , utilizada posteriormente, es
( ) .1,1
~<
−+
=>− ξξξωσ
ωω XXE
2.3.5 Función Cuantil de DPG
Cuando 0ξ ≠ ,
( ) ( ) 1 1 1 1 .H q q ξξ ξ
−− = − −
Para la exponencial cdf, ( ) ( )10 log 1 .H q q− = − −
Ejemplos
1. Para el modelo exponencial, ( ) 1 ,xF x e−= − para > 0x . Por cálculo directo,
( )( )
( )
( )1
1
u yy
u
F u y e eF u e
− +−
−
− += =
−
Para todo > 0y . En consecuencia, la distribución límite de los excedentes de un límite es una distribución exponencial, que corresponde a 0ξ = y 1σ = en la familia Pareto generalizada. Además, éste es un resultado exacto para todos los umbrales > 0u .

45
2. Para un modelo estándar Fréchet, ( ) 1exp ,F xx
= −
para > 0.x Entonces,
( )( )
( ) ( )
1 1
1
1 exp11
1 1 exp
u yF u y yF u uu
−−
−
− − +− + = ∼ + − − −,
cuando u →∞ , para toda > 0y . Esto corresponde a una distribución de Pareto generalizada con 1ξ = y .uσ =
3. Para el modelo de la distribución uniforme ( )0,1 ,U ( ) ,F x x= para 0 1.x≤ ≤
Entonces,
( )( )
( )1 11
1 1 1F u y u y y
F u u u− + − +
= = −− − −
para 0 1 .y u≤ ≤ − Esto corresponde a una distribución de Pareto generalizada con 1ξ = − y 1 .uσ = −
La comparación de las familias límites obtenidas para los excedentes de un umbral con los correspondientes (límites de máximos de bloque) bloques máximos límites obtenidos en Sección 2.1.5 confirma la dualidad de los dos modelos límites formulados implicados por el Teorema 2.1.
En particular, los valores de ξ son comunes por los dos modelos. Además, el valor de σ se encuentra para ser umbral dependiente, excepto en el caso donde el modelo límite tiene
0ξ = , como implicado por la ecuación (2.3).
Hasta este punto se ha usado la notación σ para denotar el parámetro de escala de la distribución Pareto generalizada, así como para distinguirlo del correspondiente parámetro de la distribución de GEV. Para la conveniencia de la notación se eliminará tal distinción, usando σ para denotar el parámetro de escala dentro de cualquier familia.
2.4 Modelando Excedentes Umbral
Los métodos de umbrales son más flexibles que los métodos basados en el máximo anual porque primero toman todos los excedentes por arriba de un umbral, adecuadamente alto, y de esta manera se usan muchos más datos. Segundo, ellos son fácilmente extendidos a situaciones

46
donde se quiere estudiar la dependencia entre los niveles extremos de una variable y alguna otra variable x; así por ejemplo, y puede ser el nivel de ozono de la troposfera en un día particular y x un vector de variables meteorológicas para ese día (Smith y Shively, 1985). Este tipo de problemas es casi imposible de manejar a través de la metodología del máximo anual.
Al ajustarse los excesos sobre el umbral, la dificultad se encuentra en la elección del umbral apropiado, ya que la teoría no propone una solución general al respecto. La elección de este umbral está sujeto al problema de elección entre varianza y sesgo, esto es, si se disminuye el umbral, se incrementa el número de observaciones para formar la serie muestral y la estimación del índice de cola será más precisa (con menor varianza) pero sesgada, ya que algunas observaciones del centro de la distribución se introducirán en la serie. Por otro lado, si se reduce el número de observaciones (con un umbral más elevado), se reduce el sesgo pero hace que la estimación del índice sea más volátil al realizarse con un menor número de observaciones.
El método implementado presupone que es posible encontrar un umbral apropiado, esto quiere decir, suficientemente alto para que la aproximación sugerida por el teorema de Pickands (1975), Balkema y de Haan (1974) sea buena y sobre el cual se cuente aún con suficientes datos para lograr estimadores precisos de los parámetros desconocidos. Dentro de la literatura revisada se encontraron tres métodos utilizados comúnmente en las aplicaciones prácticas del método para escoger un umbral adecuado, éstos son análisis gráficos que permiten seleccionar dicho umbral u de manera apropiada buscando así un buen ajuste de la distribución a los datos.
El primero de estos métodos es denominado gráfica QQ (o de cuantiles) y está explicado detalladamente en McNeil (1996). Un desvío cóncavo de la forma ideal (de una f.d. exponencial) indica que la distribución posee colas pesadas, mientras que la convexidad indica una distribución de colas pequeñas. En general, entre más datos se tengan, más claro será el mensaje de la gráfica QQ.
La otra herramienta gráfica descrita es la función de la media muestral de los excesos, una definición de ésta se encuentra en McNeil & Saladin (1997, p. 5, 6). McNeil (1996, p.11) afirma “Si los puntos muestran una tendencia positiva, entonces ésta es una señal de comportamiento de colas densas o pesadas. Datos distribuidos exponencialmente deberían dar aproximadamente una línea horizontal y aquellos provenientes de una de cola pequeña deberían mostrar una tendencia negativa. En particular, si la gráfica empírica parece seguir razonablemente una línea recta con pendiente positiva alrededor de un cierto valor de u, entonces esto es una indicación de que los datos siguen una distribución Generalizada de Pareto con parámetro de forma positivo en el área de la cola cercana a u”.

47
Por último en Melo & Becerra, (2005, p. 35, 36) se encuentra la explicación de otra herramienta utilizada para seleccionar el umbral, éste es el gráfico de Hill, en el cual se gráfica
el estimador de Hill para diferentes valores de k5, asociados a distintos umbrales. El conjunto
de valores apropiados para k se determina con base en el rango de valores de k para el cual el estimador de Hill es estable.
2.4.1 Selección del Umbral
El Teorema 2.2 sugiere la siguiente estructura para modelar valores extremos. La naturaleza de los datos consiste en una secuencia de medidas independientes e idénticamente distribuidas
1,..., .nx x Los eventos extremos son identificados definiendo un límite alto u , para los cuales
los excedentes son : >i ix x u . Se pueden etiquetar esos excedentes por ( ) ( )1 ,..., ,kx x y definir
los excedentes del límite por ( ) , para 1,...,j jy x u j k= − = . Por el Teorema 2.2, la jy puede ser
considerado como realizaciones independientes de una variable aleatoria cuya distribución puedes ser aproximada como un elemento de la familia Pareto generalizada, la inferencia consiste en adecuar la familia Pareto generalizada a los excedentes del límite observado, seguidos por modelos de verificación y extrapolación.
Este contraste aproximado con los bloques máximos completa la caracterización de una observación como extremo si excede un umbral alto. Pero el problema de la elección del umbral es análogo a la elección del tamaño del bloque en los bloques máximos aproximados, implicando un equilibrio entre sesgo y variación. Un valor demasiado grande conducirá a pocas excedencias y en consecuencia un gran varianza de las estimaciones, mientras un valor muy bajo es posible que comprometa la justificación asintótica del modelo lo que nos llevará a una tendencia. En la práctica es normal adoptar un umbral tan bajo como sea posible, sujeto al modelo del límite que proporciona una aproximación razonable. Dos métodos están disponibles para este propósito:
1. Uno es una técnica exploratoria llevada a cabo antes de estimar el modelo;
2. El otro es una contribución de la estabilidad de los parámetros estimados, basado en la adecuación de modelos por un rango de umbrales diferentes.
En más detalle, el primer método se basa en la media de la distribución de Pareto generalizada. Si Y tiene una distribución de Pareto generalizada con los parámetros σ y ξ , entonces
( ) ( )8.21
~
ξσ−
=YE

48
siempre que <1ξ ; cuando 1ξ ≥ la media es infinita.
Ahora, suponga que la distribución Pareto generalizada es válida como modelo para excedentes de un límite 0u generado por una serie 1,..., ,nX X de la que un término arbitrario denotado X . Por (2.8),
( )ξ
σ
−=>−
1
~0
00uuXuXE ,
siempre que <1ξ . Cuando adoptamos la convención de usar 0
~uσ para denotar el parámetro de
escala correspondiente a los excedentes del umbral 0u . Pero si la distribución Pareto
generalizada es válida para excedentes del umbral 0u , debe ser igualmente válido para todos
los umbrales 0>u u , sujeto a los apropiados cambios del parámetro de escala para uσ~ . Ahora,
para 0>u u ,
( )
( )9.21
~1
~
0
ξξσ
ξσ
−
+=
−=>−
u
uXuXE
u
u
Con base en (2.3), así para 0>u u , ( )> E X u X u− es una función lineal de u .
Además, ( )> E X u X u− es simplemente la media de los excedentes del umbral u , para los
cuales la media muestral de los excedentes del umbral u proporciona una estimación empírica.
La función empírica de exceso medio se estima con la siguiente expresión cuando se da una muestra ordenada de forma descendente:
( )( )
( ),
,1
1
ˆ1
i n
n
i ni
n n
X ui
X ue u =
>=
−=∑
∑.
En el numerador se encuentra la suma de los excesos sobre la prioridad y en el denominador el número de valores que cumplen la condición de ser superiores al umbral, determinando la media aritmética de los valores que exceden u.

49
De acuerdo a (2.9), esos estimadores se espera que cambien linealmente con u , en niveles de u para los que el modelo Pareto generalizado es apropiado. Esto lleva al siguiente procedimiento. El sitio de puntos
( )( )1
1, : < max ,un
iiu
u x u u xn =
−
∑
donde ( ) ( )1 ,...,unx x consiste de las un observaciones que exceden u , y maxx es el más grande de
los iX , es denominado gráfica de la vida media residual. Arriba de un umbral 0u en la que se prueba que la distribución Pareto generalizada es una aproximación válida para la distribución de los excedentes, la gráfica de la vida media residual debe ser aproximadamente lineal en u .
Fig. 2.1 Ejemplo del Grafico de vida media de datos del ejemplo de Denver.
Fuente: Data Analysis in Extreme Value Theory. Xin Liu. Department of Statistics and Operations Research University of North Carolina at Chapel Hill. April 30, 2009
Es así que, de acuerdo a la tendencia observada en el gráfico, pueden ser deducidas las siguientes conclusiones:

50
• Tendencia creciente: distribución de cola pesada
• Tendencia decreciente: distribución de cola corta
• Sin tendencia: distribución exponencial
Los intervalos de confianza pueden ser agregados a la gráfica, basados en la normalidad aproximada de las medias muestrales. La interpretación de la gráfica de la vida media residual no es siempre simple en la práctica.
El segundo método para la selección del umbral es estimar el modelo en un rango de umbrales. Sobre un nivel 0u en la que la motivación asintótica para la distribución Pareto
generalizada es válida, el estimador del parámetro de forma ξ debe ser aproximadamente constante, mientras el estimador uσ debe ser lineal en u , debido a (2.9).
2.5 Estimación de Parámetros
Habiendo determinado un umbral, los parámetros de la distribución Pareto generalizada pueden ser estimados por máxima verosimilitud. Suponga que los valores 1,..., ky y son i.i.d.
que son los k excedentes de un umbral u . Para 0ξ ≠ la función de densidad se deriva de (2.2) como
( )ξ
σξ
σ
11
~1~1
)()(+−
+==y
yHdydyh .
Entonces se calcula la log verosimilitud de la siguiente manera:
( )( )
( )( )
( ) ( )
( ) ( )10.2~1log11~log
~1log11~log1log
~1~1
log,
~1~1
,
1
1
1
11
1
11
∑
∑
∑
∏
=
=
=
+−
=
+−
++−−=
++−−=
+=
+=
k
i
i
k
i
i
k
i
i
k
i
i
yk
y
y
yL
σξ
ξσ
σξ
ξσ
σξ
σξσ
σξ
σξσ
ξ
ξ

51
siempre que ( ) 0~1 1 >+ −iyξσ para ki ,...,1= ; de otra forma, ( ) −∞=ξσ ,~ . En el caso 0ξ = la
log verosimilitud se obtiene de (2.4) como
( ) ∑=
−−−=k
iiyk
1
1~~log~ σσσ .
La maximización analítica de la log verosimilitud no es posible, así que se requieren técnicas numéricas, teniendo cuidado para evitar las inestabilidades numéricas cuando 0ξ ≈ en (2.10), y asegurando que el algoritmo no falle debido a una evaluación fuera del espacio paramétrico aceptable. Los errores estándar e intervalos de confianza para la distribución Pareto generalizada se obtienen en la forma usual estándar de la teoría de verosimilitud.
2.6 Niveles de Retorno
Ahora, suponga que se tiene una distribución Pareto generalizada con parámetros σ~ y ξ como modelo adecuado para excedentes de un límite u para una variable X . Eso es, para
ux > ,
ξ
σξ
1
~1|Pr−
−
+=>>uxuXxX
Se sigue que
( )11.2~1Pr
1ξ
σξζ
−
−
+=>uxxX u
donde uXPru >=ζ . Por lo tanto, el nivel mx que excede en promedio una vez cada m observaciones es la solución de
( )2.121
~1
1
mux
u =
−
+−ξ
σξζ
Despejando x
( )[ ] ( )13.21~
ξζσ ξ −
+=m
ux um

52
Siempre que m sea lo suficientemente grande para asegurar que uxm > . Todo esto
asumiendo que 0≠ξ . Si 0=ξ
( ) ( )2.14log um mux ζσ+=
Nuevamente si m es lo suficientemente grande. Para explicar a mx como el nivel de
retorno de la ésimam − observación, de (2.11) y (2.12), graficando mx contra m en una escala logarítmica produce la misma representación cualitativa como el nivel de retorno graficado basado en el modelo de VEG:
1. lineal si 0=ξ ;
2. cóncava si 0>ξ ;
3. convexo si 0<ξ .
Por presentación, es más conveniente dar niveles de retorno en una escala anual, tal que el nivel de retorno del ésimoN − año será el nivel esperado que sea excedido una vez cada N años. Si hay yn observaciones por año, este corresponde al nivel de retorno de la
ésimam − observación, donde ynNm ×= . Por lo tanto, el nivel de retorno del
ésimoN − año se define por
( ) ξ
ζσ 1~ −+= uy
N
Nnuz .
A menos que 0=ξ , en tal caso
( )uyN Nnuz ζσ log~+=
La estimación de los niveles de retorno requiere de la sustitución de los valores de los parámetros por sus estimados. Para σ~ y ξ esto corresponde a sustituir por los correspondientes estimadores de máxima verosimilitud, pero un estimador de uζ , la
probabilidad de una observación individual que exceda el límite u , es también necesario. Un estimador natural de uζ es
nk
u =ζ

53
Como la parte muestreada de puntos que exceden u . Puesto que el número de
excedentes de u sigue una distribución binomial ( )unBin ζ, , donde uζ es también el
estimador de máxima verosimilitud de uζ .
Los errores estándar o intervalos de confianza para mx pueden ser derivados por el
método delta, pero la varianza del estimador de uζ también debe ser incluida en el cálculo.
El Método Delta se define de la siguiente manera:
Teorema 2.3. (Método Delta) si
( ) ( ),1,0NYn dn →−
σµ
y g es diferenciable, talque ( ) ,0´ ≠µg entonces
( ) ( )( )( ) ( ),1,0
´N
ggYgn dn →
−σµ
µ
es decir si
≈
nNY n
2
,σµ
entonces
( ) ( ) ( )( ) ,´,2
2
≈
nggNYg n
σµµ
De las propiedades estándar de la distribución binomial,
( ) ( )nζζ
Var uuu
ˆ1ˆˆ −
≈ζ
Así la matriz completa de varianzas y covarianza para ( )ξσζ ˆ,~,ˆ es aproximadamente

54
( )
−
=
v v v v
nζζ
V
,,
,,
uu
2212
2111
00
001
i,jv denota el ( ) ésimoj,i − término de la matriz de varianza y covarianza de σ~ y ξ . Por lo
tanto, por el método delta
( ) ( )2.15ˆ mTmm xVxxVar ∇∇≈
donde
( ) ( ) ( ) ( )
+
−−
−=
∂∂
∂∂
∂∂
=∇
−
ξmζmζ
σξ
mζσ,
ξmζ
, ζmσ
xxxz
uξ
uξ
uξ
uξu
ξ
mm
u
mTp
log~1~1~
,~,
21
ξσζ
Evaluado en ( )ξσζ ˆ,~,ˆu .
Como con los modelos anteriores, se obtienen los mejores estimadores de precisión para los parámetros y niveles de retorno de la verosimilitud del perfil apropiado, para niveles de retorno, se requiere de una reparametrización. La duración se hace simple por ignorar la varianza de uζ , la cual es usualmente pequeña relativo al de los otros parámetros. Haciendo los despejes de (2.13) y (2.14) se obtiene la varianza:
( )( )
( )
=−
≠−
−
=0 si ,
log
0 si ,1~
ξm
ux
ξm
ux
u
m
u
m
ζ
ζξ
σξ
Con una mx adecuada, la verosimilitud de un parámetro puede ser maximizado con
respecto de ξ , como una función de mx , esto es la log-verosimilitud del perfil para el nivel de
retorno de la ésimam − observación.

55
2.7 Revisión del Umbral Elegido
La gráfica de la vida media de residuales puede ser difícil de interpretar como un método de la selección del umbral. Una técnica complementaria es adecuar la distribución Pareto generalizada en un rango de umbral, y buscar la estabilidad de los parámetros estimados. El argumento es como sigue.
Por el teorema 2.2, si una distribución Pareto generalizada es un modelo razonable para excedentes de un límite más alto 0u , entonces los excesos de un umbral más alto u deben también seguir una distribución de Pareto generalizada. Los parámetros de forma de las dos distribuciones son idénticos. Sin embargo, denotando por σ~ el valor del parámetro de escala de la Pareto generalizada para un umbral de 0>u u , se sigue de (2.3) que
( ) ( )16.2~~00
uuuu −+= ξσσ
Así que el parámetro de escala cambia con u a menos que 0ξ = . Esta dificultad puede ser remediada reparametrizando el parámetro de escala de la Pareto generalizada como
uu ξσσ −= ~~* ,
la cual es constante con respecto a u en virtud de (2.16). Consecuentemente, los estimadores de ambos *~σ y ξ deben ser constantes por encima de ou , si ou es un umbral valido para excedentes que siguen una distribución Pareto generalizada. La variabilidad muestral significa que los estimadores de esas cantidades no serán exactamente constantes, pero deben ser estables después de tomar en consideración sus errores estándares.
Este argumento sugiere graficar ambos *~σ y ξ contra u , juntos con intervalos de
confianza para cada cantidad, y seleccionando 0u como el valor más bajo de u para los cuales
los estimadores restantes son cercanamente constantes. Los intervalos de confianza para ξ se obtienen inmediatamente de la matriz de varianza y covarianzas V . Los intervalos de
confianza para *~σ requiere del método delta, usando
( ) *** ~~~var σσσ ∇∇≈ VT ,
Donde
[ ]uu
T −=
∂∂
∂∂
=∇ ,1~
,~~
~**
*
ξσ
σσ
σ .

56
2.8 Verificación del Modelo
Las gráficas de probabilidad, cuantil, nivel de retorno y de densidad son todas útiles para evaluar la calidad del ajuste de un modelo de Pareto generalizado. Asumiendo un umbral u ,
los excesos del umbral ( ) ( )kyy ≤≤1 y un modelo estimado H , la gráfica de probabilidad
consiste en los pares
( ) ( )( )( ) kiyHki i ,...,1;ˆ,1 =+ ,
donde
ξ
σ
ξ1
~ˆ
11)(ˆ−
+−=
yyH ,
con tal de que 0ˆ ≠ξ . Si 0ˆ =ξ , la gráfica se construye usando (4.4) en lugar de (4.2). De
nuevo asumiendo 0ˆ ≠ξ , la gráfica de cuantil consiste de los pares
( )( ) ( )( ) kiykiH i ,...,1;,1ˆ 1 =+− ,
donde
[ ]1ˆ
~)(ˆ ˆ1 −+= −− ξ
ξ
σ yuyH .
Si el modelo de Pareto generalizado es razonable para los excesos modelados de u , entonces ambas graficas de probabilidad y cuantil deben consistir en puntos que son aproximadamente lineales.
Una gráfica de nivel de retorno consiste en la ubicación de puntos ( ) mxm ˆ, para los
valores grandes de m , donde mx es el nivel de retorno estimado de m -observación:
( )
−+= 1ˆ
ˆ
~ˆ
ξζ
ξ
σum mux ,
de nuevo modificar sí 0ˆ =ξ . Como con el GEV, la gráfica de nivel de retorno, es usual trazar la curva del nivel de retorno en una escala logarítmica para dar énfasis al efecto de

57
extrapolación, y también para agregar los límites de confianza y las estimaciones empíricas de los niveles de retorno.
Finalmente, la función de densidad que se ajusta del modelo de Pareto generalizado puede compararse a un histograma de excedentes del umbral.

58
Capítulo 3
CASO DE ESTUDIO
3.1 Introducción
El objeto del análisis de frecuencia de parámetros hidrológicos mediante el uso de distribuciones de probabilidad se realiza para relacionar la magnitud de los eventos extremos con su frecuencia de ocurrencia. Para ello, se supone que la información hidrológica analizada es independiente y se distribuye de forma uniforme, y que el sistema hidrológico que lo produce no depende del espacio y del tiempo.
Existe un sinnúmero de funciones de distribución utilizadas en hidrología las cuales, en general, no pueden ser deducidas teóricamente a partir de los procesos físicos, y por lo tanto normalmente se adopta alguna función arbitrariamente, se estiman sus parámetros con los datos muestrales disponibles y se verifica que dicha función de distribución se ajuste satisfactoriamente a los datos y si esto sucede se supone que dicha función de distribución es aplicable a toda la población. Entre las funciones de distribución utilizadas en hidrología pueden mencionarse las siguientes: Normal (Yevjevich 1972), Log-Normal (Chow 1954), Gamma (Yevjevich 1972), LogGamma (Yevjevich 1972), Logistic, loglogistic (Beirlant, Teugels y Vynckier 1996) y Pareto.
En la Teoría del Valor Extremo (EVT) hay dos tipos de enfoques que generalmente se aplican, los cuales se enuncian a continuación:
1. El más tradicional es el modelo de bloques máximos (block-máxima). Éstos son modelos para grandes observaciones recolectadas a partir de grandes muestras de observaciones idénticamente distribuidas. Consiste fundamentalmente en partir las observaciones por bloques y en éstos encontrar el máximo. Este método lleva a producir un error por la mala selección del tamaño de los bloques.

59
2. Algunos modelo más modernos y poderosos son aquéllos de exceso de umbral (thershold exceedances). Éstos son modelos para todo tamaño de observaciones que exceden algún nivel superior, y son en general los más utilizados en aplicaciones prácticas debido a su eficacia en el manejo de los valores extremos. Al igual que el método block-máxima, éste lleva a un error en la mala selección del umbral. Los métodos de umbrales son más flexibles que los métodos basados en el máximo anual porque primero toman todos los excedentes por arriba de un umbral, adecuadamente alto, y de esta manera utilizan muchos más datos.
En este trabajo emplearemos un modelo para excedencias.
3.2 Planteamiento del Problema
El estado de Tabasco es una de las 32 entidades federativas que conforman la República Mexicana, se localiza en el Sureste de México y se extiende desde la llanura costera del golfo de México, hasta las sierras del sur de Chiapas. Colinda al Norte con el Golfo de México; al Este con la República de Guatemala y el estado de Campeche; al Sur con el estado de Chiapas y al Oeste con el estado de Veracruz. Ver figura 3.1.
Fig. 3.1 Estado de Tabasco y sus fronteras.
Fuente: Elaboración propia con ArcView.

60
Tabasco se ubica en la confluencia y delta de los dos principales ríos de México: el Grijalva y el Usumacinta, los cuales suman aproximadamente el 30% del total del escurrimiento de México. El río Grijalva se encuentra parcialmente controlado por un sistema de presas de generación de energía que cumplen también la función de control de crecientes. Un importante sistema de ríos, que confluye con el río Grijalva prácticamente en la ciudad de Villahermosa, es el sistema de ríos de La Sierra. Otro río importante, que descarga al océano parte de los caudales provenientes de la presa Peñitas, es el río Samaria, el cual resulta de la bifurcación del río Mezcalapa aguas debajo de la citada presa, en donde da origen al mencionado Samaria y el río Carrizal. El río Usumacinta y el sistema de ríos de la Sierra no tienen presas de control de crecientes, por lo que su caudal no se puede regular.
La enorme planicie del estado de Tabasco que se ha formado a lo largo de miles de años debido a la aportación de grandes cantidades de sedimentos y volúmenes de agua que dieron lugar a una intrincada red de cauces, lagunas y zonas inundables, han hecho de la cuenca Grijalva-Usumacinta, la más importante y compleja del país; al presentarse periódicamente grandes avenidas que cubrían grandes extensiones de esta planicie y al descender los niveles de agua después de cada inundación, dejaba capas de sedimentos ricos en nutrientes que favorecían a la agricultura y levantaban paulatinamente los terrenos.
Esto permitió que las antiguas culturas como la olmeca y la maya, lograran desarrollar una estrecha vinculación con su medio ambiente, vinculando la cuenca hidrológica con los sistemas costeros y marinos, lo que les permitió establecer pueblos a las orillas de los ríos y construir importantes poblaciones que se asentaron en la cuenca del Grijalva-Usumacinta, creando verdaderas sociedades hidráulicas como lo atestiguan las numerosas obras hidráulicas que construyeron; también supieron explotar sin agotar los recursos naturales creando policultivos y sistemas hidráulicos, que permitieron sustentar y alimentar a los grandes núcleos de población asentados en estas tierras, desde antes de la conquista por los españoles, y crearon una red de navegación fluvial y costera, que les permitió llevar a cabo los intercambios comerciales que abarcan desde el altiplano de México hasta Guatemala y Honduras, siendo Tabasco reconocido desde la época prehispánica por sus intercambios comerciales.
A lo largo de la historia de Tabasco, la planicie ha sufrido drásticas transformaciones que han modificado la libre circulación del agua en los cauces de los ríos, presentándose en las condiciones actuales lo que podríamos llamar una red hidrológica de “ríos encadenados”, ya que se ha modificado radicalmente el comportamiento de los ríos de Tabasco.
La red hidrológica de la cuenca Grijalva-Usumacinta, además de ser la más importante del país, es a la vez una de las más complejas, no solamente por la alta precipitación y desbordamiento de sus cauces en la época de avenidas, sino por la alteración que la

61
explotación de sus recursos ha provocado en la estructura de sus ecosistemas y el cambio de uso del suelo por el crecimiento de las ciudades.
Tabasco se localiza en la zona del trópico húmedo, por lo que éste presenta un tipo de clima cálido húmedo con temperaturas medias anuales mayores a 22°C. Debido a su geografía es un lugar que con gran frecuencia presenta fenómenos de lluvias extremas; estas lluvias se intensifican en el verano cuando se dan los grandes aguaceros, mientras que en otoño e invierno se presentan los nortes, que son tormentas acompañadas de fuertes vientos provenientes del Golfo de México. De acuerdo con la Comisión Nacional del Agua (CONAGUA) la precipitación anual que ocurre en la región se encuentra entre las más altas del mundo (2,750 mm en la zona costera y hasta 4,000 en las estribaciones de las sierras), siendo en consecuencia la más alta en la República Mexicana (CONAGUA, 1996).
Por ello el presente trabajo toma a este estado como objeto de estudio para poder modelar los excedentes de lluvia registrados durante los años 1961 al 2000 a partir de un umbral.
3.3 Descripción de los Datos
La información de precipitación se obtuvo de las mediciones de las estaciones en la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM, esto para cada uno de los días de los 12 meses, enero-diciembre, desde 1961 hasta el año 2000, en su versión interpolada en malla regular de 0.2 grados de longitud×0:2 grados de latitud (la denominada MAYA v1.0).
3.3.1 Malla en Maya v1.0
La malla regular de nodos en el producto MAYA v1.0 es una que cubre la totalidad del territorio continental de México. Va de la longitud -117.2º (o 117.2º W) a la longitud -86.0o (o 86.0o W) y de la latitud (norte) +14.0o a la latitud (norte) +33.0o. Se trata de una malla de 96 renglones por 157 columnas, es decir de 15,072 nodos.
Los nodos están separados entre sí por 0.2º en ambas direcciones ortogonales. Por supuesto, muchos de estos nodos caen sobre zonas marítimas y por ende no tienen su valor definido (no se miden variables climatológicas sobre el mar); 4,542 nodos tienen un valor definido al encontrarse sobre tierra y 10,530 no lo tienen por estar sobre el mar. La separación entre nodos equivale en forma burda a aproximadamente 20 km de distancia, es decir se tiene un valor por cada 400 km2 del territorio nacional. Ver figura 3.2.

62
Fig. 3.2 Producto MAYA v1.0.
Fuente: Elaboración propia con ArcView
El intervalo cubierto de las observaciones de lluvia es de 40 años, desde el 1º de enero de 1961 hasta el 31 de diciembre de 2000, es decir 14,600 días. Los días 29 de febrero de los años 1964, 1968, 1972, 1976, 1980, 1984, 1988, 1992, 1996 y 2000 no aparecen en la base de datos.
Tres de las cinco variables que se miden cuantitativamente en las estaciones climatológicas tradicionales se manejan en MAYA v1.0:
1. La temperatura mínima diaria (oC).
2. La temperatura máxima diaria (oC).
3. La precipitación pluvial (mm).
Las otras dos son temperatura ambiente a la hora de la lectura (8 horas local) y evaporación diaria. Los datos se manejan en dos “vistas” (formas de visualizar los datos) distintas:

63
1. Como mallas regulares diarias desde el 1º de enero de 1961 hasta el 31 de diciembre de 2000, o sea 14,600 matrices de 96 x 157 valores para cada una de las tres variables,
2. Como series de tiempo de 14,600 valores cada una, para cada uno de los 4,542 nodos sobre el territorio continental de México.
La primera forma es adecuada para estudiar los campos de las variables (sus “mapas”) y la segunda forma es adecuada para estudiar la evolución casi puntual de las variables en el tiempo.
3.3.2 El Algoritmo de Interpolación
De los numerosos algoritmos de interpolación posibles se seleccionó uno de los más simples y utilizados: El de promedio ponderado de los valores en las estaciones vecinas con pesos proporcionales al inverso del cuadrado de la distancia de cada estación al nodo en cuestión. Se utilizaron un máximo de las 24 estaciones vecinas más cercanas manteniendo el mínimo número de estaciones que producen un valor nodal en 5 estaciones vecinas. La búsqueda de las 24 estaciones vecinas se realiza en cuatro cuadrantes alrededor del nodo (NW, NE, SW, SE) con hasta 6 estaciones en cada cuadrante.
3.3.3 Obtención de los nodos a estudiar
Con el programa ArcView se trabajaron las Figuras 3.2, 3.3, 3.4.
En la figura 3.2. con el programa ArcView se ubican los nodos a nivel país. Para poder realizar esto se tuvo que capturar las coordenadas geográficas de cada nodo en un block de notas; después ya con el programa se convierte a un dBase para poder proyectar los nodos sobre el mapa de la República Mexicana, mapa que ya viene definido en el programa como Shape.
Ahora pasamos a nivel estado, ubicación de los nodos seleccionados y las subcuencas respectivas. Como se ve en la figura 3.3. con el programa se seleccionan los estados en donde caen los nodos seleccionados y los convertimos en un nuevo Shape, después de esto proyectamos todas las subcuencas de la región 29 y 30 que corresponden a los ríos Grijalva-Usumacinta y rio Tonalá
Región Hidrológica No. 29 Tonalá y Región Hidrológica No. 30 Grijalva - Usumacinta, los podemos descargar en la siguiente dirección: de internet del sitio oficial de INEGI en la siguiente ruta INEGI → Geografía → Recursos Naturales → Hidrología → Red Hidrológica escala 1:50 000, descargamos los archivos pertenecientes a dicha región, archivos que junto con el programa ARCVIEW utilizamos para delimitar las subcuencas y valores nodales.

64
Fig. 3.3 Ubicación de los nodos seleccionados y las subcuencas del rio Grijalva-Usumacinta y Rio
Tonalá.
Fuente: Elaboración propia

65
La información de la tabla 3.1 corresponde a las descripciones de los 22 nodos a estudiar; donde cada nodo contiene los registros de las precipitaciones diarias, en mm, registradas en las cuencas de la región de 1961-2000.
Número Número de Nodo
Estado Coordenada
Región Hidrológica
Zona Cuenca Subcuenca Latitud Norte
Longitud Oeste
1 674 Tabasco 18.40 93.20 30 Grijalva-Usumacinta 37 Caxcuchapa
2 673 Tabasco 18.40 93.00 30 Grijalva-Usumacinta 33 El Carrizal
3 672 Tabasco 18.40 92.80 30 Grijalva-Usumacinta 74 Grijalva
4 599 Tabasco 18.20 93.20 30 Grijalva-Usumacinta 37 Caxcuchapa
5 598 Tabasco 18.20 93.00 30 Grijalva-Usumacinta 36 Samaria
6 597 Tabasco 18.20 92.80 30 Grijalva-Usumacinta 34 Tabasquillo
7 530 Tabasco 18.00 93.40 29 Tonalá 7 Santa Anita
8 529 Tabasco 18.00 93.20 30 Grijalva-Usumacinta 36, 33
Samaria, Carrizal
9 528 Tabasco 18.00 93.00 30 Grijalva-Usumacinta 36 Samaria
10 527 Tabasco 18.00 92.80 30 Grijalva-Usumacinta 74 Grijalva
11 464 Tabasco 17.80 93.40 30 Grijalva-Usumacinta 32 Mezacalapa
12 463 Chiapas 17.80 93.20 30 Grijalva-Usumacinta 52
Viejo Mezcalapa
13 462 Chiapas, tabasco 17.80 93.00 30
Grijalva-Usumacinta 51 Pichucalco
14 461 Tabasco 17.80 92.80 30 Grijalva-Usumacinta 74 Grijalva
15 402 Chiapas, tabasco 17.60 93.40 30
Grijalva-Usumacinta 31 Platanar
16 401 Chiapas 17.60 93.20 30 Grijalva-Usumacinta 30 Paredon
17 400 Chiapas, tabasco 17.60 93.00 30
Grijalva-Usumacinta 51 Pichucalco
18 399 Tabasco 17.60 92.80 30 Grijalva-Usumacinta 48 Tacotalpa
19 350 Chiapas 17.40 93.40 30 Grijalva-Usumacinta 28 Zayula
20 349 Chiapas 17.40 93.20 30 Grijalva-Usumacinta 31 Platanar
21 348 Chiapas 17.40 93.00 30 Grijalva-Usumacinta 30 De la Sierra
22 347 Tabasco 17.40 92.80 30 Grijalva-Usumacinta 46 Almendro
Tabla 3.1 Descripción de los 22 nodos a estudiar.
Fuente: Elaboración propia

66
Fig. 3.4 Ubicación de los nodos seleccionados y las subcuencas respectivas.
Fuente: Elaboración propia con información de Arcview y de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM
Una vez ya localizados los nodos, se busca en la base de datos las coordenadas de cada uno. Y los registros de precipitaciones diarias en cada nodo se juntan en una sola hoja de Excel y se ordenan las precipitaciones de menor a mayor. Cada nodo tiene series de tiempo 14,600 diarias y como son 22 nodos entonces se tiene un total de 321, 200 series de tiempo, total de nuestros dato a estudiar.
NOTA:
Los Shapefiles son archivos de datos con formato nativo de ArcView, los cuales comprenden
tres diferentes tipos de datos con extensiones: .SHP, .SHX, y .DBF
• Los archivos .SHP almacena la geometría del elemento (información sobre la forma y
la localización).

67
• Los archivos .SHX almacena el índice de la geometría del elemento.
• Los archivos .DBF son archivos dBase que almacenann la información de atributos de
elementos.
Los Shapefiles solamente pueden almacenar una clase de rasgos (puntos o líneas o
polígonos)
3.4 Elección del Umbral
En este apartado se aplica la Teoría del Valor Extremo al conjunto de datos disponibles con el objetivo de llegar a un ajuste que modele los valores muestrales que exceden un determinado umbral y, tal como se indicó anteriormente, en virtud del teorema de Pickands-Balkema-de Haan, la distribución generalizada de Pareto es la más adecuada para modelar los excesos sobre el umbral cuando éste es elevado, abordando los siguientes aspectos:
• Selección del umbral óptimo por encima del cual la distribución de Pareto generalizada pueda ser ajustada a los excesos sobre dicho valor.
• Descripción de la muestra a modelar.
• Estimación de los parámetros del modelo.
• Comprobación de la bondad del ajuste realizado a través de los gráficos de cuantil-cuantil.
• Inferencia con base en el modelo estimado. Es importante recordar que se trata de una distribución condicionada y que por tanto la inferencia también lo está a que el siniestro sea superior al umbral elegido.
3.4.1 Datos para la elección del umbral
Los datos utilizados para la realización de esta aplicación hacen referencia a las precipitaciones diarias registradas de los años 1961 al 2000.
En la serie de precipitación, los registros diarios están disponibles para un periodo de 40 años, a partir de 1961 hasta el 2000. Según la teoría asintótica, tomando observaciones diarias, al estar independiente e idénticamente distribuidas, es común modelar los extremos usando el modelo del umbral (POT), que consiste en una distribución generalizada de Pareto para el exceso sobre las magnitudes del umbral.

68
A continuación en la figura 3.5 se presenta el grafico del conjunto de datos históricos disponibles y las características esenciales de la muestra que se desprenden del mismo.
Fig. 3.5 Registro de precipitación diaria.
Fuente: Elaboración propia con información de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM.
3.4.2 Gráficos de Exceso Medio
La elección del umbral requiere de cierto cuidado, como hemos dicho buscar un equilibrio entre tendencia y varianza. Un valor demasiado grande conducirá a pocas excedencias y en consecuencia una gran varianza de las estimaciones, mientras un valor muy bajo es posible que comprometa la justificación asintótica del modelo lo que nos llevará a una tendencia. Por tanto, el gráfico de media residual es usado para elegir el umbral.
La Figura 3.6, muestra el grafico de la vida residual media y el intervalo de confianza del 95% para los datos de precipitación diarios.

69
Fig. 3.6 Grafico de vida media de datos de precipitación diarios.
Fuente: Elaboración propia con información de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM.
De la observación de la gráfica de la vida media residual se nota una tendencia creciente de los datos, indicativa de una distribución de cola pesada. Esto sugiere que los valores de la muestra pueden ser modelados con éxito mediante la distribución generalizada de Pareto.
Como esta distribución se ajusta a los datos que exceden un determinado umbral, resulta necesaria la elección de dicho umbral como el punto a partir del cual la función empieza a crecer. El crecimiento de la función se inicia en los valores más inferiores aunque se observa un crecimiento más pronunciado para valores que exceden precipitaciones de 120 mm, lo que supone un valor de k = 528, donde k es en número de excedente sobre el umbral.
Además para ayudar la elección del umbral con el método de la gráfica de vida media, una técnica complementaria es adecuar la distribución Pareto generalizada en un rango de umbral, y buscar la estabilidad de los parámetros estimados. Verifique lo descrito en Sección 2.7.
A continuación en las figuras 3.7 y 3.8 se muestran las gráficas de *~σ y ξ comparados con .u

70
Fig. 3.7 Gráfico del parámetro de escala.
Fig. 3.8 Gráfico del parámetro de forma.
Fuente: Elaboración propia con información de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM.

71
En la figura 3.8 el cambio en el patrón para umbrales muy altos que se observaron en la gráfica de vida media residual también está claro aquí, pero ahora las perturbaciones se ven relativamente pequeñas para probar los errores. Por lo tanto, el umbral seleccionado 120=u es razonable. Elegir el umbral u , o análogamente el número de valores k que quedan por encima de u , es importante porque se pretende ajustar la distribución de Pareto generalizada a los valores que excedan ese valor.
Seleccionado u, se estiman los parámetros de la distribución, índice de escala ( )σ e
índice de cola ( )ξ siendo el parámetro de localización el propio umbral elegido si se ajustan los excedentes o cero si se ajustan los excesos.
3.5 Estimación del Modelo para el Total de Valores Muestrales
Los parámetros obtenidos de la estimación para la distribución generalizada de Pareto independiente referida a las precipitaciones de cada uno de los días se realizan por el método de máxima verosimilitud.
Parámetros
ξ 0.07477
σ 32.76194
Tabla 3.2 Estimación de los parámetros.
Fuente: Elaboración propia
Analíticamente será:
( )07477.01
76194.3207477.0
11−
+−=y
yH.
La matriz de varianza-covarianza resulta
−
−001477.0043406.0043406.0606914.3
obteniendo de los errores estándares de 1.89919 y 0.03843 para *~σ y ξ respectivamente. En particular, para seguir un intervalo de confianza de 95% para ξ se obtiene como:
( )15009.0,00055.003843.096.107477.0 −=×± .

72
Corresponde a la estimación de máxima verosimilitud, por tanto, a una distribución
infinita (desde 0ˆ >ξ ), y la evidencia para esto es razonablemente satisfactoria, ya que el
intervalo para ξ está exclusivamente en el dominio positivo.
Puesto que hubo 528 excedentes del umbral, 120=u , de los datos completos de 321,200, la estimación de máxima verosimilitud para la probabilidad del excedente es
00164.0321200
528ˆ ===nk
uζ
con varianza aproximada
( ) ( ) ( ) 91010938.5321200
00164.0100164.0ˆ1ˆˆvar −×=
−=
−=
nζζ
ζ uuu
Entonces, la matriz de varianza - covarianza completa para ( )ξσ ˆ,~,ˆuζ es:
.001477.0043406.00043406.0606914.30001010938.5 9
−−
×=
−
V
Ya que 0ˆ >ξ , no es útil llevar a cabo una inferencia detallada del límite superior. En cambio, se enfoca en los niveles del retorno extremo.
Los datos son diarios, así que el nivel de retorno de 100 años corresponde al nivel de retorno de m-observación con m = 365 x 100. Sustituyendo en (4.13) y (4.15) se obtiene
( )[ ]( )[ ]
9364.2760747.0
136500*00164.07614.32120
ˆ1ˆ~
ˆ
0747.0
ˆ
=
−+=
−+=
ξζσ ξm
ux um
Pero, ( ) mTmm xVxxVar ∇∇≈ˆ , entonces

73
( ) [ ]
018906.3825401.1456
790205.434.27068
*
001477.0043406.00043406.0606914.30001010938.5
*401.1456,790205.4,34.27068ˆ
9
=
−
−−
×−≈
−
mxVar
donde
( ) ( ) ( ) ( )
( ) ( ) ( )
( )( )
( ) ( )
[ ]401.1456,790205.4,34.27068
0747.000164.036500log00164.036500
7614.320747.0
100164.0365007614.32
0747.0100164.036500
00164.0365007614.32
ˆ
ˆlogˆ~ˆ
1ˆ~ˆ
1ˆ~
0747.0
2
0747.0
0747.010747.00747.0
ˆ
2
ˆˆ
1ˆˆ
−=
××××+
−××−
−×=
+
−−
−=∇
−
−
, ,
ξ
ζmζmσ
ξ
ζmσ,
ξ
ζm, ζmσx u
ξ
u
ξ
u
ξ
uξu
ξTp
con un intervalo de confianza del 95% para mx de
( )156.398,7168.155018906.382596.19364.276 =±
La figura 3.9 se muestran los gráficos de diagnóstico para el modelo ajustado GPD
referente a los datos de precipitación.
A la vista de estos gráficos, indican un buen ajuste del modelo, pues los datos están más o menos dispuestos sobre la línea recta del gráfico probabilístico y el de cuantiles. En el gráfico de niveles de retorno, se puede ver sin más que extrapolar que aproximadamente un nivel de retorno igual a 275 corresponde a un período de retorno cercano a los 100 años pero este valor está un poco alejado sobre la línea de tendencia, con esto se puede dar cuenta de que conforme aumenta el periodo de retorno la confiabilidad de la predicción se va perdiendo, ya que el intervalo de confianza se hace más ancho como se puede ver en la tabla 3.3.
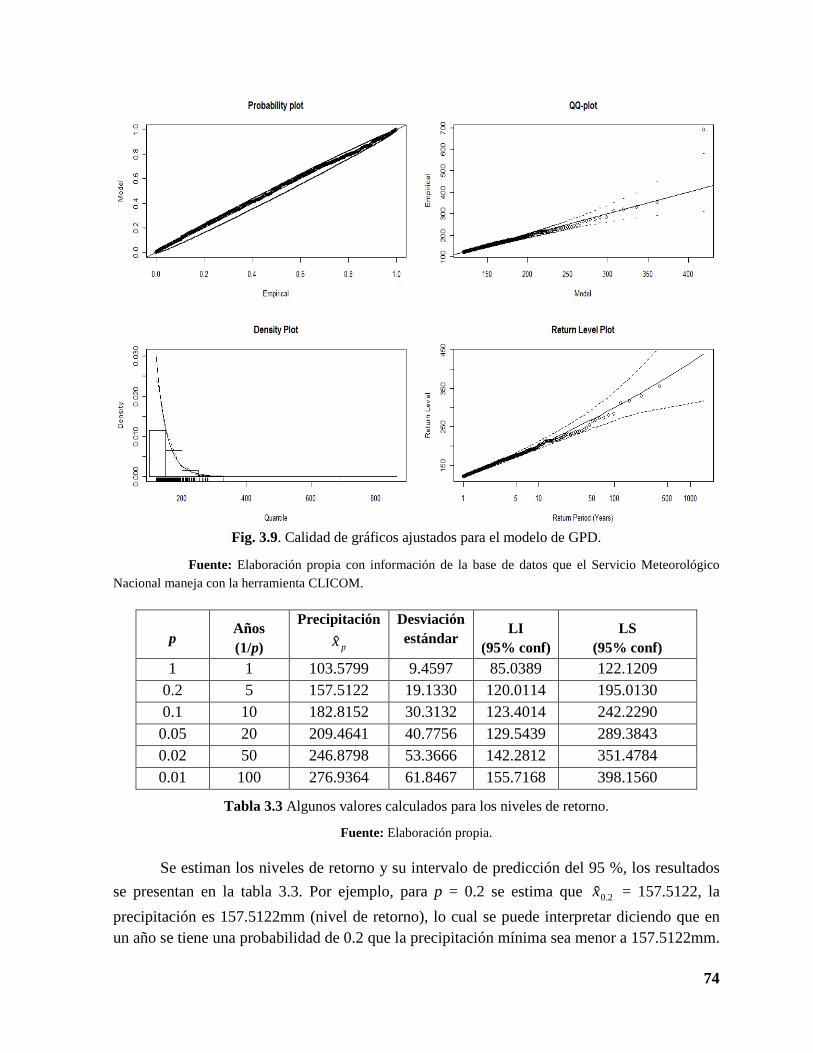
74
Fig. 3.9. Calidad de gráficos ajustados para el modelo de GPD.
Fuente: Elaboración propia con información de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM.
p
Años (1/p)
Precipitación
px Desviación estándar
LI (95% conf)
LS (95% conf)
1 1 103.5799 9.4597 85.0389 122.1209 0.2 5 157.5122 19.1330 120.0114 195.0130 0.1 10 182.8152 30.3132 123.4014 242.2290 0.05 20 209.4641 40.7756 129.5439 289.3843 0.02 50 246.8798 53.3666 142.2812 351.4784 0.01 100 276.9364 61.8467 155.7168 398.1560
Tabla 3.3 Algunos valores calculados para los niveles de retorno.
Fuente: Elaboración propia.
Se estiman los niveles de retorno y su intervalo de predicción del 95 %, los resultados se presentan en la tabla 3.3. Por ejemplo, para p = 0.2 se estima que 2.0x = 157.5122, la precipitación es 157.5122mm (nivel de retorno), lo cual se puede interpretar diciendo que en un año se tiene una probabilidad de 0.2 que la precipitación mínima sea menor a 157.5122mm.
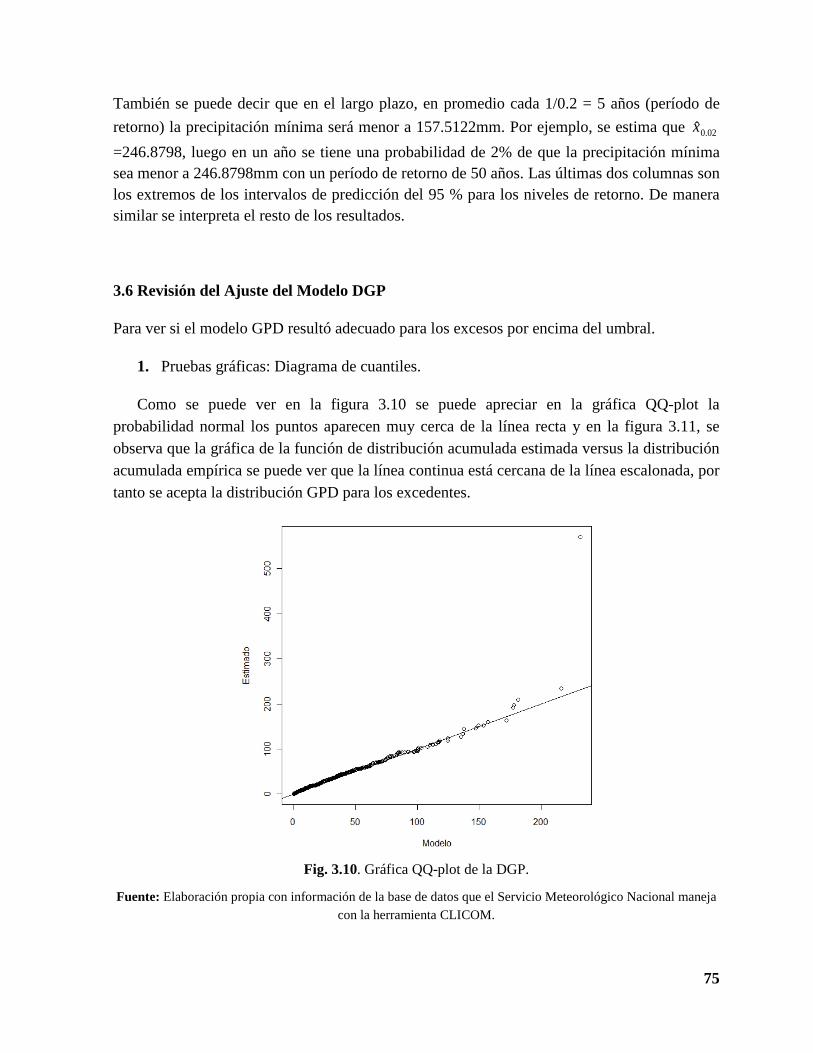
75
También se puede decir que en el largo plazo, en promedio cada 1/0.2 = 5 años (período de retorno) la precipitación mínima será menor a 157.5122mm. Por ejemplo, se estima que 02.0x=246.8798, luego en un año se tiene una probabilidad de 2% de que la precipitación mínima sea menor a 246.8798mm con un período de retorno de 50 años. Las últimas dos columnas son los extremos de los intervalos de predicción del 95 % para los niveles de retorno. De manera similar se interpreta el resto de los resultados.
3.6 Revisión del Ajuste del Modelo DGP
Para ver si el modelo GPD resultó adecuado para los excesos por encima del umbral.
1. Pruebas gráficas: Diagrama de cuantiles.
Como se puede ver en la figura 3.10 se puede apreciar en la gráfica QQ-plot la probabilidad normal los puntos aparecen muy cerca de la línea recta y en la figura 3.11, se observa que la gráfica de la función de distribución acumulada estimada versus la distribución acumulada empírica se puede ver que la línea continua está cercana de la línea escalonada, por tanto se acepta la distribución GPD para los excedentes.
Fig. 3.10. Gráfica QQ-plot de la DGP.
Fuente: Elaboración propia con información de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM.
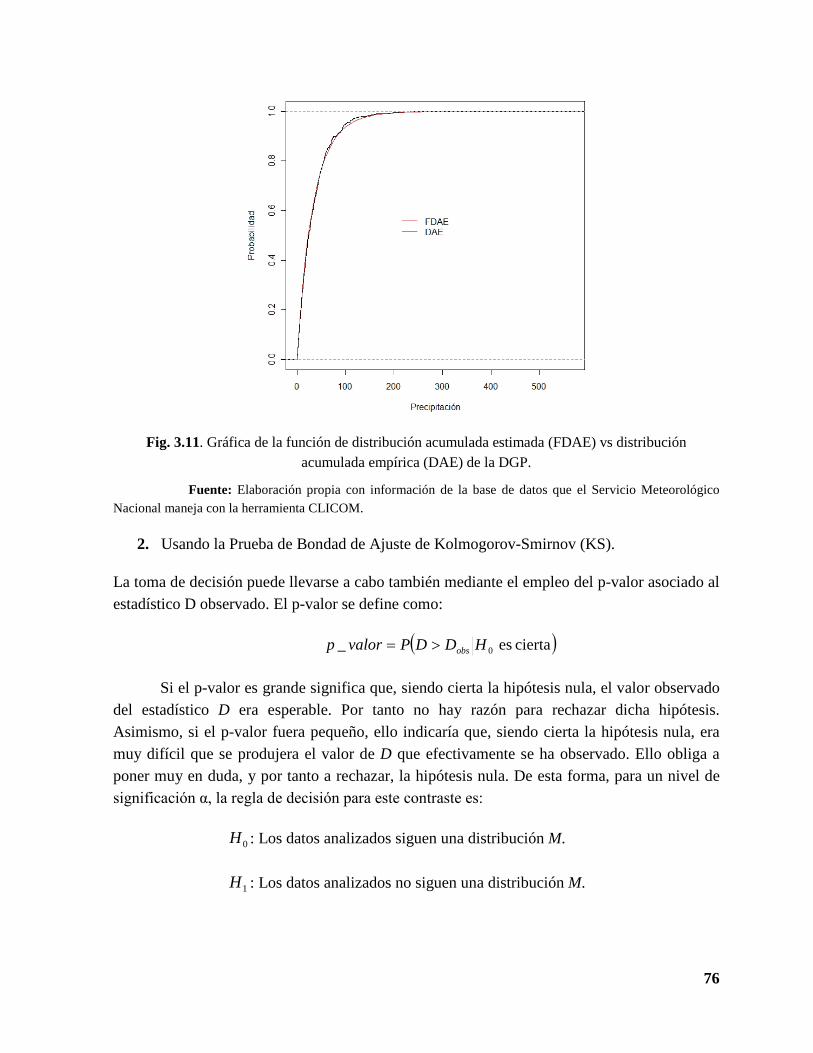
76
Fig. 3.11. Gráfica de la función de distribución acumulada estimada (FDAE) vs distribución
acumulada empírica (DAE) de la DGP.
Fuente: Elaboración propia con información de la base de datos que el Servicio Meteorológico Nacional maneja con la herramienta CLICOM.
2. Usando la Prueba de Bondad de Ajuste de Kolmogorov-Smirnov (KS).
La toma de decisión puede llevarse a cabo también mediante el empleo del p-valor asociado al estadístico D observado. El p-valor se define como:
( )cierta es_ 0HDDPvalorp obs>=
Si el p-valor es grande significa que, siendo cierta la hipótesis nula, el valor observado del estadístico D era esperable. Por tanto no hay razón para rechazar dicha hipótesis. Asimismo, si el p-valor fuera pequeño, ello indicaría que, siendo cierta la hipótesis nula, era muy difícil que se produjera el valor de D que efectivamente se ha observado. Ello obliga a poner muy en duda, y por tanto a rechazar, la hipótesis nula. De esta forma, para un nivel de significación α, la regla de decisión para este contraste es:
0H : Los datos analizados siguen una distribución M.
1H : Los datos analizados no siguen una distribución M.

77
Si p-valor ≥ α ⇒ Aceptar 0H
Si p-valor < α ⇒ Rechazar 0H
Obviamente, la obtención del p-valor requiere conocer la distribución de D bajo la hipótesis nula y hacer el cálculo correspondiente. En el caso particular de la prueba de Kolmogorov Smirnov, la mayoría de los paquetes de software estadístico realizan este cálculo y proporcionan el p-valor directamente. Aquí nosotros usaremos un %95=α .
Con el programa Project_R se obtiene los valores de KS y p_valor
KS 0.6143 p-valor 1
Tabla 3.4 Estimación del valor de la prueba de Kolmogorov-Smirnov.
Fuente: Elaboración propia
Como el valor p-valor= 1 > 0.05, no se rechaza 0H y se acepta que los datos se distribuyen como una Pareto generalizada.

78
Conclusiones
• En esta tesis se proporciona una ilustración de como la Teoría del Valor Extremo puede ser usada como un práctico instrumento para la solución de problemas en los fenómenos climatológicos. La teoría del Valor Extremo proporciona una técnica simple para estimar las probabilidades de futuros niveles extremos en un proceso en función de datos históricos y reducirá la incertidumbre en el proceso de modelado, en este caso con el modelo de excedentes.
• Los métodos paramétricos y no paramétricos tradicionales trabajan bien en áreas de la distribución empírica donde hay muchas observaciones, pero proporcionan un ajuste pobre en las colas extremas de la distribución; ya que La Teoría del Valor Extremo se centra en el modelado del comportamiento de la cola de una distribución de datos usando el valor solo extremo más que en el conjunto de datos.
• Por último de la aplicación se concluye que los objetivos planteados se cumplen, de acuerdo a los resultados obtenidos. Para los datos analizados se concluye que la cola de la distribución es pesada, por eso se ajusta la distribución generalizada de Pareto que se obtuvo un buen ajuste a los datos reales de precipitación con un umbral de 120 mm, donde las estimaciones se hicieron por medio del programa estadístico R.
Con esto evidencia que para el entorno geográfico donde se ubica las cuencas
hidrológicas Grijalva–Usumacinta y Tonalá puede esperarse la ocurrencia de eventos muy extremos de lluvia lo que caracteriza el entorno climático de esta zona. El cálculo de los niveles de retorno para los registros de lluvia diaria de estas cuencas, que permiten describir el comportamiento de los cuantiles extremos y así medir el ajuste del modelo en la cola de la distribución. Los niveles de retorno calculados con el modelo de la distribución generalizada de Pareto indican que puede ser frecuente la ocurrencia de valores muy altos de lluvia lo que evidencia una cola pesada para la distribución de los datos analizados, y en consecuencia un buen ajuste del modelo.

79
Bibliografía
A. F. Jenkinson (1955). The frequency distribution of the annual maximum (or minimum) values of meteorological events. Quaterly Journal of the Royal Meteorological Society, 81:158-172.
Alexander J. McNeil & Thomas Saladin. (1997). The peaks over thresholds method for estimating high quantiles of loss distributions. Departement Mathematik. ETH Zentrum CH-8092 Zurich
Balakrishnan, N. and Nevzorov, V. B. (2003). A primer on statistical distribution. John Wiley & Sons, New York.
Balkema, A. A. and de Haan, L. (1974). Residual life time at high age Ann. Probab, 792-804.
Beirlant, J. and et al. Statistics of extreme: theory and applications. John Wiley & Sons Ltd, England.
C. Kluppelberg and T. Mikosch. (1997). Large deviations of heavy-tailed random sums with applications in insurance and finance. Journal of Applied Probability, 34(2):293-308.
Castillo, E., Hadi, A. S., Balakrishnan, N. y Sarabia, J. M. (2005). Extreme value and related models with applications in engineering and science. John Wiley & Sons, Hoboken, New Jersey.
Coles, S. (2001). An introduction to statistical modeling of extreme values. Springer-Verlag, London England.
Comisión de Asuntos Hidráulicos de la Cámara de Senadores. (2008). Informe de las inundaciones de 2007 en el estado de Tabasco diagnóstico preliminar.
Comisión Nacional del Agua. (2011). Manual para el control de inundaciones.
Davison, A. & Smith, R. (1990), Models for exceedances over high thresholds (with discussion', Journal of the Royal Statistical Society, Series B 52, 393-442.
De Haan, L. and Ferreira, A. (2006). Extreme Value Theory: An Introduction. Springer Science-Business Media. New York.
E. Castillo. Extreme value and related models with applications in engineering and science. Wiley_Interscience, University of Cantahria and University of Castilla La Manchu.
Embrechts, P., Kluppelberg, C. & Mikosch, T. (1997), Modelling extremal events for insurance and finance, Springer Verlag, Berlin. To appear.

80
Embrechts, P.; Resnick, S. I.; Samorodnitsky, G. (1999). Extreme Value Theory as a Risk management Tool. North American Actuarial Journal, Volume 3, no 2, 30-41.
Fernando J. González Villarreal. Evaluación de la vulnerabilidad del sistema de presas del río Grijalva ante los impactos del cambio climático. INE/A1-027/2009. Octubre 2009.
George C. Canavos. (1988) - Probabilidad y estadística aplicaciones y métodos. McGRAW-HILL/Interamericana de México, S.A. DE C.V. Edo. de México.
Gilleland, E., R. Katz y G. Young (2010). extRemes: Extreme value toolkit. R package version 1.62. http://CRAN.R-project.org/package=extRemes.
Gutiérrez González Eduardo. (2010). Fundamentos de estadística descriptiva e inferencial con aplicaciones. NAUKA Educación, México.
J.R.M. Hosking and J.R. Wallis. (1987). Parameter and quantile estimation for the generalized pareto distribution. Technometrics, 29(3):339-349.
Leadbetter, M. R. Lindgren, G. and Rectzen, A. (1983). Extremes and related properties of random sequences and series. Springer Verlag, New York.
Liang Peng and A.H. Welsh. (2001). Robust estimation of the generalized pareto distribution. Extremes, 4(1): 53-65.
Mathieu Ribatet. (2011). A User's Guide to the POT Package (Version 1.4). Department of Mathematics. University of Montpellier II.
http://cran.r- roject.org/web/packages/POT/vignettes/POT.pdf
Mcneil, A. J.; Saladin, T. (1997). The Peak over Thresholds Method for Estimating High Quantiles of loss Distributions. www.math.ethz.ch/~mcneil/pub_list.html Norman Giraldo Gómez. (2011). Modelos estocásticos en econometría financiera, Gestión de Riesgos y Actuaría. Mini-curso para el VIII coloquio internacional de estadística. Universidad Nacional de Colombia ITM. Medellín.
Paul L. Meyer. (1973). Probabilidad y Aplicaciones Estadísticas. Departamento de Matemáticas. Washington State University.
Pickands, J., “Statistical inference using extreme order statistics”. Ann. Statist. 3, 1975, pág. 119-131.
R.A. Fisher and L.H. Tippett. (1928). Limiting forms of the frequency distribution of the largest or smallest member of a sample. In Proceedings of the Cambridge Philosophical Society, volume 24, pages 180-190.
Ross, Sheldon M. (2006). A First Course in Probability – 7th ed. Pearson Prentice Hall. University of Southern California.
S.F. Juarez and W.R. Schucany. Robust and eficient estimation for the generalized pareto distribution. Extremes, 7(3):237-251, 2004. ISSN 13861999 (ISSN).

81
Anexos
1. Tabla de las precipitaciones máximas que exceden el umbral.
# Precipitación Fecha 1 120.76 20/03/1965 2 121.19 25/10/1990 3 121.94 27/08/1970 4 123.35 19/11/1969 5 123.63 29/04/1996 6 124.53 23/09/1989 7 125.35 31/10/1979 8 126.21 20/10/1968 9 127.04 08/12/1979
10 127.07 19/10/1989 11 127.49 30/08/1976 12 128.00 22/06/1992 13 128.87 28/09/1996 14 129.74 27/10/1997 15 130.00 30/10/1980 16 131.31 01/12/1996 17 132.22 04/01/2000 18 132.55 02/10/1965 19 135.62 15/12/1972 20 138.74 29/12/1983 21 141.01 28/05/1986 22 142.20 04/10/1979 23 152.02 12/01/1968 24 154.87 25/09/1984 25 155.37 22/10/1993 26 156.92 29/05/1986 27 157.00 06/12/1977 28 159.19 15/10/1978 29 160.08 28/09/1967 30 160.25 15/10/1961 31 161.68 07/09/1975 32 164.19 30/05/1986 33 164.30 01/05/1976 34 164.45 05/12/1964 35 165.53 10/11/1977 36 168.35 09/10/1976 37 171.64 17/10/1967 38 176.65 15/09/1989 39 178.22 29/09/1992 40 179.39 09/11/1990 41 187.52 11/02/1981 42 191.51 20/03/1986 43 192.30 19/09/1974 44 192.67 02/01/1978 45 201.06 21/08/1973 46 212.4 09/12/1978 47 215.88 29/10/1975
48 220.49 05/04/1974 49 229.67 28/11/1973 50 235.09 22/12/1967 51 247.01 04/12/1990 52 120.45 07/11/1978 53 120.51 16/01/1976 54 122.88 07/09/1975 55 122.98 02/10/1974 56 123.89 30/01/1970 57 125.29 30/10/1980 58 125.56 31/01/1980 59 125.89 21/12/1977 60 126.28 15/10/1961 61 126.41 12/01/1968 62 130.09 19/10/1989 63 131.96 21/10/1968 64 132.12 20/12/1977 65 133.99 26/11/1980 66 135.73 11/02/1981 67 135.74 20/03/1986 68 135.77 08/10/1976 69 136.06 01/02/1980 70 141.34 05/10/1985 71 141.36 15/09/1979 72 141.44 16/03/1978 73 141.99 09/10/1976 74 144.76 11/11/1974 75 146.86 29/10/1980 76 147.2 02/01/1983 77 147.93 17/10/1967 78 158.65 01/03/1980 79 160.67 05/02/1988 80 163.67 29/12/1983 81 164.18 15/12/1972 82 168.35 28/09/1967 83 171.67 14/10/1982 84 175.6 04/01/1982 85 177.75 21/08/1973 86 181.48 05/12/1964 87 194.17 10/11/1977 88 198.05 04/12/1990 89 201.94 29/09/1992 90 204.52 06/02/1982 91 210.28 22/12/1967 92 212.22 29/10/1975 93 212.89 19/09/1974 94 218.8 28/11/1973 95 234.29 05/04/1974
96 235.88 09/12/1978 97 121.27 30/10/1980 98 121.65 29/10/1975 99 122.02 17/10/1967
100 122.05 15/09/1979 101 137.31 10/11/1977 102 144.7 15/12/1972 103 147.51 28/09/1967 104 150.69 09/12/1978 105 150.74 29/09/1992 106 151.98 05/12/1964 107 174.07 28/11/1973 108 175.87 19/09/1974 109 182.36 05/04/1974 110 189.1 04/12/1990 111 193.06 22/12/1967 112 120.09 29/01/1990 113 120.85 22/12/1989 114 121.39 06/06/1977 115 121.74 27/11/1992 116 123.37 23/10/1993 117 124.47 15/09/1989 118 124.69 03/05/1970 119 125.61 18/10/1966 120 125.8 28/11/1978 121 126.18 24/09/1979 122 126.72 08/11/1996 123 127.17 18/12/1975 124 128.01 23/11/1963 125 128.09 01/10/1991 126 128.09 10/01/1962 127 128.96 05/01/1972 128 129.03 30/09/1989 129 129.33 15/09/1979 130 129.59 20/12/1961 131 130.41 30/09/1970 132 132.77 30/10/1993 133 133.87 24/04/1995 134 133.92 14/05/1979 135 134.08 16/10/1997 136 134.5 28/09/1970 137 134.51 17/10/1967 138 137.13 18/01/1994 139 137.46 28/11/1973 140 137.48 06/09/1995 141 138.26 10/12/1995 142 138.75 24/12/1996 143 138.85 14/09/1967

81
144 139.43 23/12/1967 145 139.76 14/12/1964 146 141.25 01/03/1961 147 141.48 09/11/1977 148 141.5 20/10/1992 149 142.44 10/11/1977 150 143.93 27/10/1981 151 145 25/12/1965 152 148.23 22/11/1964 153 148.32 13/12/1964 154 148.63 06/10/1993 155 148.72 21/10/1968 156 148.75 25/08/1973 157 149.87 29/09/1992 158 151.49 19/09/1974 159 151.71 04/11/1992 160 152.13 05/10/1975 161 153.22 11/11/1995 162 153.73 30/01/1970 163 154.23 20/03/1965 164 156.73 09/10/1994 165 157.34 20/03/1963 166 159.67 23/09/1989 167 159.74 19/11/1969 168 160.7 04/12/1990 169 160.71 20/08/1973 170 162.5 01/10/1974 171 162.54 24/09/1990 172 165.68 09/06/1979 173 167.1 17/12/1979 174 171.01 05/12/1964 175 171.18 08/10/1998 176 174.42 30/10/1976 177 175.57 19/10/1999 178 180.04 15/12/1972 179 189.25 15/10/1961 180 202.65 31/01/1991 181 214.99 22/10/1993 182 216.41 09/12/1978 183 224.5 04/10/1965 184 271.5 05/04/1974 185 329.87 22/10/1990 186 354.59 22/12/1967 187 121.23 22/10/1993 188 122.36 29/09/1992 189 126.19 22/10/1990 190 133.34 05/12/1964 191 136.08 15/12/1972 192 143.18 04/10/1964 193 147.07 22/09/1975 194 148.99 30/10/1980 195 151.99 22/12/1967 196 169.47 28/09/1967 197 122.11 19/11/2000 198 122.14 29/10/1980 199 123.33 30/01/1970 200 124.34 04/12/1990 201 124.95 21/06/1973 202 125.73 09/12/1978 203 128.14 06/12/1964 204 129.37 15/10/1961 205 129.6 17/12/1979 206 131.48 07/11/1978 207 136.59 10/11/1977 208 143.61 05/12/1964 209 148.54 05/02/1988 210 163.35 15/12/1972
211 170.62 05/04/1974 212 171.12 30/10/1980 213 175.58 28/09/1967 214 177.14 29/09/1992 215 188.22 05/10/1985 216 211.12 22/12/1967 217 120.96 03/09/1997 218 122.48 03/05/1970 219 122.86 20/10/1992 220 122.93 08/09/1982 221 123.02 30/10/1980 222 123.19 22/11/1976 223 123.21 30/05/1986 224 123.46 16/10/1966 225 124.26 14/12/1963 226 124.81 09/06/1979 227 127.13 15/09/1979 228 127.14 03/02/1972 229 128.61 15/09/1989 230 129.11 29/05/1986 231 129.68 14/09/1967 232 129.82 20/03/1986 233 130.36 21/08/1973 234 131.35 10/08/1962 235 133.12 29/04/1965 236 133.28 09/10/1976 237 135.12 20/03/1965 238 135.42 28/11/1973 239 136.19 25/12/1965 240 137.54 17/12/1979 241 138.99 27/01/1967 242 144.37 17/10/1967 243 147.05 29/10/1975 244 147.94 07/08/1987 245 148.93 19/10/1989 246 150.28 12/01/1968 247 152.42 07/11/1978 248 153.72 05/02/1988 249 156.47 10/11/1977 250 159.99 18/01/1994 251 164.6 19/09/1974 252 165.33 29/09/1973 253 166.23 30/01/1970 254 166.24 06/12/1964 255 167.16 23/01/1963 256 167.57 09/12/1978 257 167.84 16/11/1976 258 174.85 26/06/1993 259 176.01 04/12/1990 260 179.72 19/11/2000 261 181.87 15/10/1961 262 186.66 15/12/1972 263 190.36 11/02/1981 264 191.01 21/10/1968 265 191.83 28/09/1967 266 205.74 05/10/1985 267 212.84 05/04/1974 268 229.61 05/12/1964 269 253.18 22/12/1967 270 279.53 29/09/1992 271 120.04 16/10/1982 272 121.34 12/12/1982 273 121.4 22/10/1983 274 121.41 19/03/1971 275 124.27 05/10/1965 276 125.21 26/06/1966 277 127.08 11/02/1981
278 130.61 19/11/2000 279 132.84 12/01/1968 280 133.35 24/11/1974 281 134.07 27/01/1967 282 134.09 10/08/1962 283 134.4 19/10/1989 284 135.57 21/08/1973 285 136.57 20/03/1965 286 137.54 08/08/1987 287 138.06 29/10/1975 288 138.62 05/02/1988 289 138.84 20/01/1968 290 138.97 24/07/1964 291 142.07 19/09/1974 292 142.77 27/01/1976 293 143.65 03/09/1991 294 143.95 15/10/1961 295 145.24 15/08/1987 296 145.38 24/10/1966 297 147.92 16/11/1976 298 151.2 07/11/1978 299 154.7 31/05/1981 300 155.71 08/07/1984 301 155.97 28/09/1967 302 156.33 27/09/1992 303 159.03 31/01/1991 304 162.33 26/10/1981 305 162.84 15/10/1978 306 163.78 15/12/1972 307 164.61 04/09/1987 308 166.98 17/10/1967 309 176.37 30/01/1970 310 177.83 15/09/1989 311 178.41 20/10/1992 312 183.15 09/10/1976 313 185.47 09/12/1978 314 186.84 24/12/1981 315 190.37 05/12/1964 316 195.05 31/10/1979 317 203.87 24/06/1995 318 213.45 18/08/1992 319 216.61 10/11/1977 320 220.71 05/04/1974 321 231.23 23/01/1963 322 238.14 29/05/1986 323 238.6 25/11/1986 324 242.98 02/10/1965 325 266.25 29/09/1992 326 311.95 21/10/1968 327 317.5 22/12/1967 328 690.71 04/12/1990 329 120.53 18/01/1994 330 120.9 29/05/1986 331 128.87 05/04/1974 332 139.49 04/12/1990 333 139.81 29/09/1992 334 140.26 31/01/1991 335 140.65 19/11/2000 336 150.47 09/10/1976 337 160.22 28/09/1967 338 163.72 30/10/1980 339 168.86 15/12/1972 340 171.2 22/12/1967 341 129.52 10/11/1977 342 133.32 29/10/1980 343 137.21 08/10/1976 344 138.52 04/12/1990

82
345 161.45 30/10/1980 346 161.48 19/11/2000 347 163.5 22/12/1967 348 169.9 28/09/1967 349 171.87 15/12/1972 350 195.38 29/09/1992 351 123.76 05/01/1972 352 124.95 30/10/1980 353 125.58 21/10/1999 354 126.12 15/10/1961 355 126.44 20/10/1999 356 128.82 21/06/1973 357 143.95 22/12/1967 358 154.33 28/09/1967 359 157.29 15/12/1972 360 123.52 05/09/1969 361 126.85 22/09/1966 362 127.43 02/10/1974 363 128.99 15/12/1972 364 130.4 24/01/1963 365 136.69 22/09/1975 366 137.28 19/08/1962 367 140.2 21/10/1999 368 144.01 21/11/1984 369 145.76 14/08/1976 370 155.07 23/11/1963 371 157.68 21/06/1973 372 159.54 08/09/1970 373 185.14 30/10/1980 374 122.39 24/11/1991 375 125.98 24/11/1974 376 126.84 28/09/1967 377 132.96 07/10/1991 378 136.59 10/11/1977 379 137.04 14/12/1964 380 137.58 23/11/1991 381 137.88 15/10/1997 382 137.95 30/09/1995 383 139.2 24/06/1974 384 141.15 23/09/1980 385 141.78 29/10/1980 386 144.88 04/11/1992 387 148.57 12/05/1979 388 148.81 21/11/1984 389 148.92 21/06/1973 390 150.27 15/12/1972 391 152.91 20/10/1999 392 162.62 31/10/1980 393 171.83 04/10/1964 394 173.64 22/09/1975 395 176.68 03/11/1991 396 180.15 21/10/1999 397 181.34 30/10/1980 398 215.63 28/10/1970 399 283.62 08/10/1976 400 120.48 05/10/1988 401 122.7 05/01/1972 402 126.08 24/09/1963 403 126.55 15/12/1999 404 127.18 30/09/1992 405 134.47 20/10/1999 406 137.78 02/10/1965 407 137.98 03/10/1961 408 140.53 28/10/1970
409 147.13 15/12/1972 410 147.92 02/10/1961 411 151.79 03/11/1991 412 174.08 22/09/1975 413 179.8 08/10/1976 414 190.64 21/10/1999 415 229.95 27/09/2000 416 122.43 30/09/1992 417 130.8 22/12/1967 418 132.23 11/10/1995 419 132.63 02/10/1965 420 141 21/10/1965 421 146.06 29/10/1980 422 157.85 03/10/1988 423 173.84 15/12/1972 424 183.12 28/09/1967 425 213.51 08/10/1976 426 228.5 30/10/1980 427 120.63 13/08/1988 428 130.92 18/01/1994 429 131.95 22/12/1967 430 132.4 21/10/1965 431 133.81 29/09/1995 432 144.3 11/10/1995 433 155.59 04/02/1990 434 162.74 15/12/1972 435 175.77 08/10/1976 436 178.61 28/09/1967 437 190.22 30/10/1980 438 264.16 03/10/1988 439 120.3 04/09/1998 440 121.67 26/09/1963 441 126.91 31/05/1981 442 135.22 31/01/1991 443 139.31 18/01/1994 444 155.91 15/12/1972 445 161.72 21/10/1965 446 175.33 28/09/1967 447 206.08 08/10/1976 448 211.05 29/09/1992 449 120.93 30/09/1992 450 123.69 18/01/1994 451 128.28 21/10/1965 452 130.16 30/10/1980 453 131.06 28/09/1967 454 133.89 05/11/1992 455 137.18 10/11/1977 456 138.27 03/10/2000 457 140.31 22/09/1975 458 141.31 29/09/1995 459 143.19 11/10/1995 460 147.53 21/10/1999 461 150.02 28/10/1970 462 154.38 22/10/1999 463 157.35 15/12/1972 464 162.2 24/09/1963 465 168.75 30/09/1995 466 187.52 01/10/1995 467 272.53 08/10/1976 468 122.44 12/10/1977 469 125.76 25/09/1963 470 125.78 23/10/1993 471 126.96 21/10/1965 472 128.88 21/10/1999
473 128.96 21/07/1985 474 130.13 26/09/1963 475 132.06 11/10/1995 476 134.39 02/10/1965 477 146.77 30/09/1995 478 148.39 06/10/1993 479 149.29 16/10/1974 480 154.17 01/10/1995 481 154.41 15/12/1972 482 163.36 24/09/1963 483 164.62 05/01/1972 484 173.21 28/10/1970 485 190.49 22/09/1975 486 190.5 08/10/1976 487 203.43 30/10/1980 488 222.68 31/10/1980 489 121.22 21/10/1999 490 122.43 28/09/1967 491 129.04 30/09/1995 492 129.25 02/10/1965 493 131.46 05/01/1972 494 133.91 01/10/1995 495 134.57 26/09/1963 496 144.17 15/12/1972 497 153.29 31/10/1980 498 153.39 28/10/1970 499 153.57 24/09/1963 500 167.26 30/10/1980 501 169.11 22/09/1975 502 213.52 08/10/1976 503 121.65 28/10/1970 504 122.27 30/09/1995 505 123.54 10/11/1977 506 125.17 11/10/1995 507 129.23 24/09/1979 508 130.59 22/09/1980 509 130.79 24/09/1963 510 133.59 15/12/1972 511 133.79 01/10/1995 512 139.53 30/10/1980 513 141.29 31/10/1980 514 147.8 02/10/1965 515 165.69 22/09/1975 516 171.36 26/09/1963 517 213.92 08/10/1976 518 120.87 04/10/1964 519 123.02 15/12/1972 520 127.74 23/09/1980 521 128.35 28/09/1967 522 131.83 02/10/1965 523 132.96 24/09/1979 524 133.67 19/09/1979 525 137.7 22/09/1975 526 147.46 30/12/1992 527 168.44 26/09/1963 528 183.61 08/10/1976

80
2. Código en R utilizado para las estimaciones. ### LIBRERÍAS NECESARIAS PARA REALIZAR LAS OPERACIONES: library(MASS) # para fitdistrb library(truncgof) # para las pruebas ad y ks library(actuar) # para aggregateDist library(fBasics) # para asimetria y curtosis library(POT) # para ajuste GPD library(chron) # para función years ###UBICACIÓN DE DATOS datos<-read.table (file="D:/AAA_TESIS/TESIS/PARA APLICACION/DATOS/DATOS_NODOS.txt", sep="",col.names=c("x","y"),skip=1) ## # GRAFICAS #1_ GRAFICA DE REGISTRO DE PRECIPITACIÓN DIARIA plot(datos$x,datos$y,col="blue", xlab="Precipitación (mm)",ylab="Día") title(main="Gráfica de Registro de Precipitación Diarios") # 2_ GRAFICA DE LA VIDA MEDIA RESIDUAL par(mfrow = c(1,1)) mrlplot(datos$x) abline( v = 120, col = "red") # 3_ GRAFICA PARA PARAMENTROS par(mfrow = c(1,1)) #Parámetro de escala tcplot(datos$x, which = 1) abline( v = 120, col = "red") # Parámetro de forma tcplot(datos$x, which = 2) abline( v = 120, col = "red") # ## UMBRAL u=120

81
### FRECUENCIA DE CASOS: # Numero toal de precipitaciones que exceden el umbral nu = sum(datos$x >= u) # Valor de las precipitaciones que exceden el umbral exc= datos$x[datos$x > u] # Valores estimados y = datos$x[datos$x > u]-u ### AJUSTE DE LA DISTRIBUCIÓN PARETOGENERALIZADA CON LOS DATOS DE EXCESO SOBRE EL UMBRAL mle=fitgpd(datos$x,u,"mle")$param # Valor estimado de los parámetros sigma = mle[1] xi = mle[2] ## Un análisis más general sobre la máxima verosimilitud fitted <- fitgpd(datos$x, u, 'mle') gpd.fishape(fitted) gpd.fiscale(fitted) ## Graficas de probabilidad, cuantil, de densidad y periodo de retorno par(mfrow=c(2,2)) plot(fitted) ### EXAMEN DEL AJUSTE DEL MODELO ##1) Use las pruebas gráficas: #diagrama de cuantiles par(mfrow=c(1,1)) x.teo<-rgpd(n=length(y), loc = 0, scale = mle[1], shape = mle[2]) qqplot(x.teo,y,main="QQ-plot de la DGP",xlab="Modelo",ylab="Estimado") abline(0,1)

82
# Gráfica de la función de distribución acumulada estimada vs distribución acumulada empírica de la DGP par(mfrow=c(1,1)) ejex = seq(0,max(y),length.out = 100) plot(ejex, pgpd(ejex,loc = 0, scale = mle[1], shape = mle[2]), type="l",ylab="Probabilidad",xlab="Precipitación", col="red", main="Gráfica de la Función de Distribución Acumulada Estimada (FDAE) vs Distribución Acumulada Empírica (DAE) de la DGP",) plot(ecdf(y),add=TRUE,verticals= TRUE, do.points = FALSE) legend(200,0.6, c("FDAE","DAE"), col=c("red","black"), text.col="black", lty=c(1), bty="n", cex=1) ##2) Use la prueba KS ks.test(y,"pgpd", list(loc = 0, scale = sigma, shape = xi), H = NA)
Related Documents





![1] Deskripsi Materi Pertemuan 3 UJI KOLMOGOROV-SMIRNOV](https://static.cupdf.com/doc/110x72/577c841e1a28abe054b78f0f/1-deskripsi-materi-pertemuan-3-uji-kolmogorov-smirnov.jpg)





