Error Propagation in Large Software Projects M. Faisal Shehzad, M. IkramUllah Lali, M. Idrees and M. Saqib Nawaz Department of Computer Science & IT, University of Sargodha, Sargodha, Pakistan {faisal,drAkramullah}@uos.edu.pk,{midrees65,saqib_dola}@yahoo.com Abstract. In software development, various debugging techniques are used to remove errors that are found in the program. However, in some situations, errors still remain in the code after debugging process. Also, debugging provides no mechanism to find out pattern of bugs in different versions of the project. In this article, our focus is to find the reasons why these errors propagate in different releases of the software and how the developers can focus on it. We focused on extending debugging process by including the functionality of mining software repositories in order to find out those patterns of errors. Source code as per revision of the projects can be found on the central servers. Our job is to investigate how these errors propagate between different revisions of project and to apply the software mining techniques on the repositories to extract the useful information to detect real defects in projects and finding the pattern of errors that propagate in different revisions of projects. Keywords: Software Development · Software Repository · Data Mining · Error Prop- agation · Eclipse · CVS · Source Code Revisions. 1 Introduction Software development refers to activities performed to develop software. There are different stages in software development that can be organized in the form of System Development Life Cycle (SDLC). SDLC consist of different phases that include planning, analysis, design, implementation, testing, software deployment and maintenance. Different models are intro- duced to represent the activities of software development such as Water Fall model, Spiral model, Rapid Application Development (RAD) model and Agile SDLC model [1]. Software engineering is a combination of different techniques and tools and a systematic, disciplined and quantifiable approach that helps in developing cost effective, reliable and quality software in time according to the users requirements [2]. Different process models in software engineer- ing are used for requirement gathering, analysis of requirement and architecture, testing and maintenance [1]. A major area of software engineering that is now in focus is repository mining [3]. Many researchers and developers are using software repositories to extract and analyze source code. Software repositories are the storage locations for software products. A large amount of data is stored in repository. As the software development is performed, data about the software and its releases is stored in central repositories. Software repositories are valuable source of information for tracking the elements of defects in software products. Concurrent Versions System (CVS) [5] is a free version control in the software development field. Eclipse [6] is a popular and widely used open source framework tool and application. Knowledge discovery or data mining is a technique of analyzing data from different per- spective and generating a summarized and useful form of information. Data mining provide different tools for analyzing data from multiple dimensions, categories or from different angles to construct and identify the relationships between data elements [7]. Usually data mining is applied to find out patterns and trends about data and helps in decision making about busi- ness. In broader sense, we can say that data mining provides the patterns and associations between different data components in large data storage such as a large database [8]. Data First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper) 26-28 February, 2014, Nawabshah, Pakistan

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Error Propagation in Large Software Projects
M. Faisal Shehzad, M. IkramUllah Lali, M. Idrees and M. Saqib Nawaz
Department of Computer Science & IT, University of Sargodha, Sargodha, Pakistan{faisal,drAkramullah}@uos.edu.pk,{midrees65,saqib_dola}@yahoo.com
Abstract. In software development, various debugging techniques are used to removeerrors that are found in the program. However, in some situations, errors still remainin the code after debugging process. Also, debugging provides no mechanism to findout pattern of bugs in different versions of the project. In this article, our focus is tofind the reasons why these errors propagate in different releases of the software andhow the developers can focus on it. We focused on extending debugging process byincluding the functionality of mining software repositories in order to find out thosepatterns of errors. Source code as per revision of the projects can be found on thecentral servers. Our job is to investigate how these errors propagate between differentrevisions of project and to apply the software mining techniques on the repositories toextract the useful information to detect real defects in projects and finding the patternof errors that propagate in different revisions of projects.
Keywords: Software Development · Software Repository · Data Mining · Error Prop-agation · Eclipse · CVS · Source Code Revisions.
1 Introduction
Software development refers to activities performed to develop software. There are differentstages in software development that can be organized in the form of System DevelopmentLife Cycle (SDLC). SDLC consist of different phases that include planning, analysis, design,implementation, testing, software deployment and maintenance. Different models are intro-duced to represent the activities of software development such as Water Fall model, Spiralmodel, Rapid Application Development (RAD) model and Agile SDLC model [1]. Softwareengineering is a combination of different techniques and tools and a systematic, disciplinedand quantifiable approach that helps in developing cost effective, reliable and quality softwarein time according to the users requirements [2]. Different process models in software engineer-ing are used for requirement gathering, analysis of requirement and architecture, testing andmaintenance [1]. A major area of software engineering that is now in focus is repository mining[3]. Many researchers and developers are using software repositories to extract and analyzesource code.
Software repositories are the storage locations for software products. A large amount ofdata is stored in repository. As the software development is performed, data about the softwareand its releases is stored in central repositories. Software repositories are valuable source ofinformation for tracking the elements of defects in software products. Concurrent VersionsSystem (CVS) [5] is a free version control in the software development field. Eclipse [6] is apopular and widely used open source framework tool and application.
Knowledge discovery or data mining is a technique of analyzing data from different per-spective and generating a summarized and useful form of information. Data mining providedifferent tools for analyzing data from multiple dimensions, categories or from different anglesto construct and identify the relationships between data elements [7]. Usually data mining isapplied to find out patterns and trends about data and helps in decision making about busi-ness. In broader sense, we can say that data mining provides the patterns and associationsbetween different data components in large data storage such as a large database [8]. Data
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

2 M. Faisal Shehzad et al.
mining is also used for knowledge discovery from large databases using historical patternsand identifying future trends [9].
Debugging process came soon after the development of programming languages [26]. Fromthe beginning of debugging to the present day, researchers and developers have proposeda surplus of tools to find errors in the programs. Although different debugging tools arecommonly used and are very effective but they are really missing one specific area that weare talking about, is the repository mining. In this technique, we analyze different releases ofthe same project to see the errors that were not caught by debugging tools and we will usethis idea along with existing debugging rules to further investigate these type of errors andthe pattern of their propagation.
1.1 Related Work
Software maintenance is the process of modifying a software system or component after de-livery in order to correct reported bugs and errors, to improve performance of the softwareor to adapt the changing environment as well as due to other attributes [2]. Different staticanalysis tools are available that verify the properties of produced code and are available aspart of development tools. Moreover, some tool like Lint or Metal searches for patterns toflag common errors [3], but they can produce false positive which frustrate customers. Bentonand Fischer [10] introduced a framework named as DIMPLE for Java, that provides not onlyrepresentation of byte code in database of relations but also a declarative domain specificlanguage of analysis as queries over the database.
Error propagation is properly understandable only when all the code in all the releases ofthe softwares are available for inspection. In program analysis, the main task is to analyzethe errors. Once an error is understood we may rewrite, reset or can find its propagation [22].Change propagation is the reason of error propagation. Change propagation means changesrequired to other components of the software system to ensure the consistency of assumptionsin a software system after a particular change in the software [11]. In 1972, Parnas [23]introduced a technique of information hiding in designing systems that was used for thechange propagation. Technique based on Aspect Oriented Programming (AOP) encapsulatesconcepts which cross-cut the structures [24]. In [25], they designed a tool named C-REXfor the extraction of data from the repositories. Gall et al. [12] in their article proposed atechnique named as CAESAR for the pattern detection.
Co-change is one of the most frequently used techniques for mining version archives.Zimmermann et al. [9] used annotation graph for mapping co-changed lines at line level. Thearticle introduced an algorithm named as GNU’s diff for finding difference between differentversion of the same software [9]. A tool named as CVSSearch was proposed and developedby Chen et al. [13]. This tool annotates the source code with the help of log messages. Datamining techniques are also applied by Zimmermann et al. [14] and Ying et al. [15] in theirpapers, to map co-changes in the related methods and files of the revision.
Mapping the lines of different revisions is the main focus now a days. In [9], they introducedan annotation graph for mapping lines. This graph considers each part as one element of asingle revision and the nodes are created as single line and edges as origin of line from onerevision to other revision due to addition or modification or due to deletion. Our focus isalso on mapping lines in different revision but instead of using annotation graph, we havedeveloped our own technique with the help of annotation graph for mapping the lines.
1.2 Overview
Much has been written about mining the software repositories to extract useful informationfor various purposes. But the area that has not been focused too much is the analysis ofsoftware repositories for tracking bugs that propagate from version to version and cause thefailure of projects. In section 2, CVS and eclipse repositories are analzed for research work.
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

Error Propagation in Large Software Projects 3
In order to analyze software repositories, it is necessary to first extract raw data from theversion control and problem tracking systems. But these systems are designed for keepingthe specific purpose in mind and are not useful to analyze the exact patterns of defects. Insection 3, we present our methodology to analyze software repositories in order to find outnot only the error propagation but also their patterns. In Section 4, error pattern recognitionand propagation of errors is discussed. In section 5, conclusions are drawn.
Main activities in this work involve extraction of code from the eclipse project. Extractedcode is then explored at line level and its mapping to previous revisions to find errors thatnot only propagate in different files of a project but also in different releases of the files inthe project. Finally the pattern of errors that propagate are categorized in this work.
2 Concurrent Versions System and Eclipse Repository
CVS (Concurrent Versions System) [5] is a tracking system for all the modification andwork done in source code. It is used to keep track of all changes in different versions of thesoftware release and synchronize changes by multiple developers in source code. Its structureis combination of directories in a hierarchy which contain source code for revision files. It isbased on two main components: repository and working directory. The repository containshistorical data about different versions of the same project. Developers can take source codeof a revision for editing and developing new version of the file in working directory and thencan upload again that code in repository [14]. As the developers modify the code of a revision,add some code, delete some code or may found some errors in the previous version and savechanges in the source code, it will be called a new revision and a number like 2.1.1 will beassigned to that file. This file is also saved in the repository and it is a different version of afile. The most latest and current revision is called as head revision. We can use log commandon root directory of the project in the repository and can extract all information that areavailable in repository.
Eclipse [6] is a popular and widely used open source framework tool and application. Itprovides Java integrated development environment as well as advance design techniques andimplementation. It is an open source but publically licensed and have a lot of extension thatcan be added by different developers [19]. Eclipse provides intellectual property, developmentprocess, IT infrastructure and eco-systems. Our focus is on IT infrastructure as it maintainsopen source projects and code repositories. Eclipse is continuously evolving to include moresophisticated applications and tools [20].
To develop Java applications, JDT provides plug-in tools, eclipse plug-in’s and differenteditors, refactoring tools, builders, wizards and advance techniques for software developments.The JDT project consist of 5 components APT (Java 5.0 Annotation processing infrastruc-ture), Core (Java IDE headless infrastructure), Debug (Debug support for Java), Text (Javaediting support) and UI (Java IDE user interface). Debug component is selected for this study.Debug component of JDT support in code running and debugging. It is compatible with Javavirtual machine and can work independent of language by the platform debugger [21].
3 Methodolgy
Historical repositories contains large amount of source code. Projects can be selected formthese repositories. Selection of the projects depends upon some factors such as maturity,acceptability, well documentation and supporting community of the projects [20]. Eclipserepositories contain more code, patches, traces and a large numbers of projects as well as itis open source and easily available, so eclipse project named as org.eclipse.jdt.core is selectedfor data extraction.
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

4 M. Faisal Shehzad et al.
3.1 Data Extraction and Preparation
Data extraction is performed on two most important software repositories: eclipse and CVSrepositories. Revisions data is taken from CVS [19]. MYSQL database is used to store revisionsdata. A Java source code named as log parser program is used to store revisions data intoMySQL database. This program inserts data into two tables. One of the tables store data ofRCS files and its related data. Second table is used to store revision logs of these RCS files.MySQL command CONSOL is used for querying, importing and exporting data.
Org.eclipse.jd.core repository contains various directories and we have selected the 5 direc-tories for extraction of difference files. These directories are ant, antadapter, batch, codeassistand compiler. Data extracted form eclipse repository is stored in MySQL database. We havedifferent files in database that contain the different information about the revision files. Thefirst file extracted from eclipse repository is rcsfilesjdtcore log. This file has the log informationabout the the revision files. The details of the dataset are given in the table 1. The attributesof this file are also given in table 1. These attributes provide us the detailed information ofthe revision file. But we have to find the difference between different revisions of the samefile.
Table 1: Data Set with Label and Revision Files
Label Decsription
Rcscode Revision file id
Rf, Wf Revision file repository file and Work file
Wfd Work file detailed path
Tr Total number of revisions of each file
Rev Revision number
Date, Time Date and time of revision performed
Author, State Which author performed the revision and state of revision
Lines0, Lines1 Starting and ending line number for that revision
Branches Origin of that revision
Des Description of that revision
Bug, Bug id Bug reported and id of that bug
Change id Change hunk representing the difference area in two files
Change code Actual code changed in that revision
Loc Total lines of code in each revision
To find the difference between revision files, we have created a file named as files log. Thisfile will help us in finding the difference between revision from the CVS repositoties. We haveused the files log for finding the difference between revision of the same file.
3.2 Total Lines of Code in each Revision and Source Code Files
CVS commands only provide the difference code in only the last revision of the file. Thisinformation is not sufficent for our analysis. So we have find the total number of lines of codein each file so that we can extract all code in each revision of the file. We found total linesof code in each revision from eclipse repository by searching through each file. Now we haveinformation about the total lines of code in each revision. We can extract the source codefiles of each revision.
Source code in all the files have been extracted revision wise. Now this source code isavailable for mapping the lines in different releases. These files are transformed into a databasefor performing different operation on the source code.
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

Error Propagation in Large Software Projects 5
3.3 Reading the diff Hunks
In order to map the lines in different revision of the file, we used an algorithm named asGNU’s diff. This program find the textual difference between two revisions of the file, the lastrevision and its previous revision. The program provides the regions of difference where twofiles differ. This point is named as hunk. The pattern of this command is (e.g 2d5,6). Hereinteger before d character represents the latest revisions line number and after d representsthe previous revisions line numbers. Character c represents the type of change made in thisregion. Figure 1 shows hunk of two revisions.
Fig. 1: Hunk information for two revisions
The hunk command provides three type of information. Addition in the revision meanssome line have added in the next current revision of the file. For example 5a11 means thatline 11 was inserted in revision 1.12 of the file. Deletion in revisions such as 5d11 shows thatline 5 was deleted in the revision 1.11. Modification of lines such as 5c6 represents that line6 has been modified in the current revision. Hunk such as 5,6 c 7,8 represents that line 5 to6 in revision 1.11 are modified and now these are 7 to 8 lines in 1.12 revision. At this stagewe are able to find the difference between all the revisions of the same file. On the bases ofthese results we can find the propagation of errors and patterns of errors.
4 Error Propagation and Error Patterns
Error propagation in large software projects can be found only by thorough study of sourcecode in all revisions of all the files in a project. SCM and other software repositories containssource code of projects file wise as well as revision wise. But these repositories have limitedfunctionality of data comparison at revision level. They only provide the difference of lasttwo revisions only. This information in not sufficient for finding the propagation of errors inall revesion. We have downloaded the source code of all files revision wise form the eclipserepository org.eclipse.jdt.core and store that code in database for further process. Errors maybe propagated in different revisions of the file. Eclipse log file provides only the change hunks,having information about the changed area in the two revisions of the file. The data set usedfor finding the propagation of errors is given in table 2.
In table 2, we can see that we have some information of author, error and error id. Thisinformation is helpful for finding the propagation of errors. We can identify the error in a file
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan
6 M. Faisal Shehzad et al.
Table 2: Data Set with Label and Revision Files
Label Decsription
Rcscode Revision file id
File name, Revision no Name of file and revision number of the file
Date, Time Date and time at which line or file is modified
Author, Status Author of file changed and status of the change
Line0 Line change range in previous revision
Line1 Line change range in next revision
Description Brief description of change
Error, Error id Actual Error and error id with reference to file
Change id Hunk change between revisions
Change code Code in which changes has done
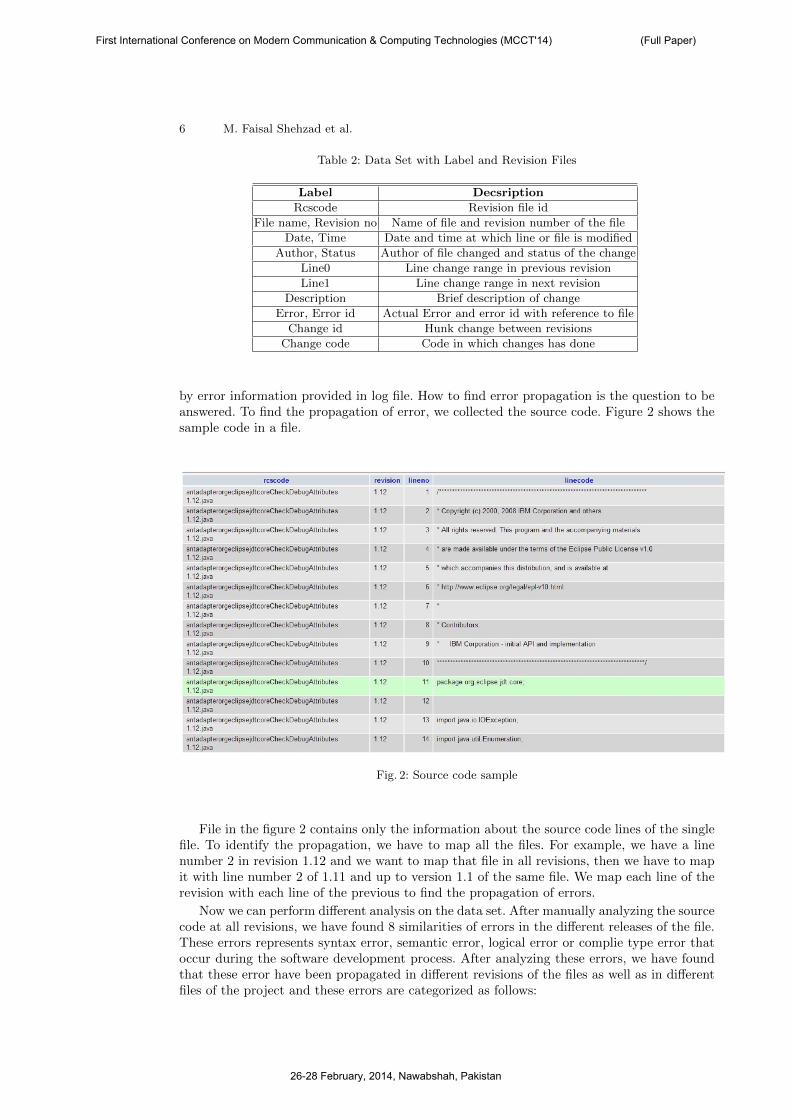
by error information provided in log file. How to find error propagation is the question to beanswered. To find the propagation of error, we collected the source code. Figure 2 shows thesample code in a file.
Fig. 2: Source code sample
File in the figure 2 contains only the information about the source code lines of the singlefile. To identify the propagation, we have to map all the files. For example, we have a linenumber 2 in revision 1.12 and we want to map that file in all revisions, then we have to mapit with line number 2 of 1.11 and up to version 1.1 of the same file. We map each line of therevision with each line of the previous to find the propagation of errors.
Now we can perform different analysis on the data set. After manually analyzing the sourcecode at all revisions, we have found 8 similarities of errors in the different releases of the file.These errors represents syntax error, semantic error, logical error or complie type error thatoccur during the software development process. After analyzing these errors, we have foundthat these error have been propagated in different revisions of the files as well as in differentfiles of the project and these errors are categorized as follows:
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

Error Propagation in Large Software Projects 7
Input Output Exception Handling Error: Input Output (I/O) exceptions generallyoccur while reading or writing to a file. This must be handled carefully. During string matchingand lines mapping, we have found the missing I/O exception throws. This errors is found in4 files of different revision. This error indicate missing exception handling or throwing ofexception in these files. As this error found in the different revisions and files of the the sameproject, we can say that errors propagate in different revisions of the same project. Figure3 shows this error with their file name and related revisions. In ClassPathDirectory.java fileat line 14 in revision 1.32, exception handling is added in source code which was missing inversion 1.31. Similary this error found in FileSystem.java at line 53 and other 2 files in figurealso indicate this error is found in their revisions. So we can say that generally this type oferror propagate in different revision.
Fig. 3: Missing exception handling
String Literal and NON-NLS Comments: In eclipse framework, NON-NLS are used torepresent string literals. The main idea behind NON-NLS is that User Interface (UI) messagesshould not be treated as string literal. Similarly some strings like regular expressions shouldnot be treated as UI messages. So NON-NLS comments are added with string literal. AnyNON-NLS comments without string literal is considered as warning and may produce errors.During string matching, the pattern of this type of error is found in 52 different source filesand in different revisions of these file. This also proves the propagation of same error indifferent releases as well as in different files of the same project.
Unnecessary Duplicated Entries: In eclipse framework and in Java, we have two pathfor any entry to be specified. One is class path and other is source path. Source path issearched for source and class path is searched for binaries. Both of these must be preserved,but generally programmers keep one of them. This may leads to errors. The same situationhas been found in 5 different files. The authors are unnecessary duplicating entries in a class.Same type of error found in all the files shows that error propagate in different files.
Reading Directory Path Error: In eclipse, it is found that source code may be readingfiles from different directories at different locations. Directory path must be normalized for
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

8 M. Faisal Shehzad et al.
reading and writing to files. If the source code is not supporting the character operations,errors are produced. The same error has been found in 4 different files and in different revisionsof theses files. This error represents compile type nature of error.
Absolute Targeted Path not Followed: Absolute path and normalized path are twodifferent approaches used in Java. Absolute path may be different in different platform. Thismay lead not to follow the targeted path in source code. This type of error is found in 4 filesof the same directory but in different regions of theses file. This error represents that the paththat was indicated in source code in not being honored.
Missing Encoding Scheme: As different encoding scheme are available and Java sourcecode must support these encoding scheme. If the source code is reading a file that is notsupported by Java then this may produce errors. This type of error is found in two files but indifferent revisions of the files. It is an error of missing encoding scheme for these files. Figure4 shows that error found in JDTCompilerAdapter.java at revision 1.69 is repeated in revision1.68.4.1. Similarly error found in Main.java in revision 1.353 is repeated again in revision1.346.2.6. This indicates that same error was repeated in revisions of same file.
Fig. 4: Missing encoding schemas
Empty String Constants: Constants in Java by nature are single static reference to in-stances in a thread. String are generally enclosed in (“ ”). When the compiler parse the codeand (“ ”) appeared in code then the compiler will consider it as a string. Strings are alsodefined in this manner. How the compiler will not read and treat a string constant just like astring? There is no proper way for this. When this confusion arises, the parser will not parseproperly and lead to errors. This type of error is found in 52 files of the same project. As inthese files, string and string constants are declared in the same way. The parser may generatethe unexpected result. This error exist in different revision of files.
Local Variable Scope: Local variable have scope limited to function in which they aredeclared. In class inheritance, a child class can access the variables that are declared in
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

Error Propagation in Large Software Projects 9
the parent class. If variables in the parent class are declared as private or protected, thenchild class cannot access these variables or can have limited access. During lines mapping indifferent revisions, we have observe a pattern where local variable are accessed multiple timesin protected mode. It may produce error. This error was found in 8 files. In some files, thiserror is repeated multiple times. This indicate that errors propagate in different revisions aswell as in different files. Figure 5 shows some files having same type of error.
Fig. 5: Local variables scope
5 Conclusion
In this work, a new approach for finding the evolution of lines as per revision is proposed.This work also addresses the different categories of errors on the basis of dependencies andthe error propagation. An eclipse repository org.eclipse.jdt.core is selected for source codeextraction. Source code from all revisions of all files is extracted for miming. The work doneincludes exploring the file at line level and its mapping to previous revisions in order to finderrors propagation in different files in a project as well as in different releases of the files inthe project. Finally the pattern of errors that propagate is discussed in this work.
Data mining is very effective tool for analyzing the source code as per revision but it isan expensive and time consuming process. In future, we will address the factors given below.
– Enhancing Mining Performance: Finding the error pattern and their propagation requiresmore time and is extensive. Finding other optimization techniques for pattern recognitionwill be focused as compared to existing history information techniques.
– Plug-in Support: The future need is to add this technique in the form of plug in. We willfocus on designing plug in to support development tools for the exploration of evolutionof line and annotation of lines.
– Automation of Error Pattern Detection: During the study, it was difficult to detect pat-terns of errors on the basis of similarity. As tools did not support much in this respect.Our focus in future will be to automate this process.
– Actual Origin of Lines: In this study we have focused on line number in different revision.Future work will focus on how to apply origin analysis algorithm to find the actual originof line. This will provide the more close result for line mapping.
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan

10 M. Faisal Shehzad et al.
References
1. Roger S. Pressman. Software Engineering: A Practitioners Approach, 7th edition. McGraw-HillPublishers, 2001.
2. IEEE Standard Glossary of Software Engineering Terminology. IEEE Standard, September 1990.3. Jim Whitehead and Thomas Zimmermann. Introduction to the Special Issue on Mining Software
Repositories (MSR). Empirical Software Engineering, 17[4-5]:500-502, August 2012.4. Keith H. Bennett and Rajlich. Software Maintenance and Evolution: A Roadmap. In Proceedings
of the Conference on The Future of Software Engineering, pp. 73-87, NY, USA, ACM, 2000.5. Harald Gall, Mehdi Jazayeri and Jacek Krajewski. CVS Release History Data for Detecting
Logical Couplings. In Proceedings of the 6th International Workshop on Principles of SoftwareEvolution, pp. 13-23, IEEE Computer Society, 2003.
6. Eclipse Foundation. About the Eclipse Foundation, 19th July 2011.7. Jiawei Han, Michelline Kamber and Jian Pei. Data Mining: Concepts and Techniquese, 3rd
edition. Morgan Kaufmann Publishers, 2011.8. Bill Palace. Data Mining: What is Data Mining? 15th September 1996.9. Thomas Zimmermann, Sunghun Kim, Andreas Zeller, and E. James Whitehead Jr. Mining Ver-
sion Archives for Co-changed Lines, 2006.10. William C. Benton and Charles N. Fischer. Interactive, Scalable, Declarative Program Analysis:
From Prototype to Implementation. In proceedings of the 9th ACM SIGPLAN InternationalConference on Principles and Practice of Declerative Programming, pp. 13-24, NY, USA, 2007.
11. Ahmed E. Hassan and Richard C. Holt. Predicting Change Propagation in Software Systems. InProceedings of the 20th IEEE International Conference on Software Maintenance, pp. 284-293,IEEE Computer Society, Washington, DC, USA, 2004.
12. Harald Gall, Karin Hajek and Mehdi Jazayeri. Detection of Logical Coupling Based on ProductRelease History. Technical Report, University of Zurich, 1998.
13. Annie Chen, Eric Chou, Joshua Wong, Andrew Y. Yao, Qing Zhang, Shao Zhang, and AmirMichail. CVSSearch: Searching Through Source Code using CVS Comments. In IEEE Interna-tional Conference on Software Maintenance, pp. 364-373, 2009.
14. Thomas Zimmermann, Peter Weissgerber, Stephan Diehl and Andreas Zeller. Mining VersionHistories to Guide Software Changes. IEEE Trans. on Software Engineering, 31[6]:429-445, 2005.
15. Annie T. T. Ying, Gail C. Murphy, Raymond Ng, and Mark C. Chu-Carroll. PredictingSource Code Changes by Mining Change History. IEEE Transactions on Software Engineer-ing, 30[9]:574-586, 2004.
16. Sunghun Kim, Kai Pan and E. James Whitehead. When Functions Change their Names: Auto-matic Detection of Origin Relationships. In Proceedings of 12th Working Conference on ReverseEngineering, IEEE Computer Society, pp. 143-152, 2005.
17. Michael W. Godfrey and Lijie Zou. Using Origin Analysis to Detect Merging and Splitting ofSource code Entities. IEEE Transactions on Software Engineering, 31[2]:166-181, 2005.
18. Ranjith Purushothaman and Dewayne E. Perry. Toward Understanding the Rhetoric of smallSource Sode Changes. IEEE Transactions on Software Engineering, 31[6]:511-526, 2005.
19. Eclipse Foundation. Eclipse Projects, 14th June 2011.20. J. Gonnet. Data Mining within Eclipse: Building a Data Mining Framework with Weka and
Eclipse: Diploma Thesis. University of Zurich, Department of Informatics, 2007.21. Eclipse Foundation. Eclipse Debug Project, 14th June 2011.22. Douglas Thain and Miron Livny. Error Scope on a Computational Grid: Theory and Practice.
In Proceedings of the 11th IEEE Symposium on High Performance Distributed Computing, IEEEComputer Society, pp. 199-208, 2002.
23. David Lorge Parnas. A Technique For Software Module Specification with Examples. j-CACM,15:330-336, 1972.
24. Tzilla Elrad, Robert E. Filman and Atef Bader. Aspect-Oriented Programming: Introduction.Commun. ACM, 44[10]:29-32, 2001.
25. Ahmed E. Hassan and Cahmed E. Hassan. Mining Software Repositories to Assist Developersand Support Managers. Technical Report, University of Waterloo, 2004.
26. Chris Parnin and Alessandro Osro. Are Automated Debugging Techniques Actually HelpingProgrammers? In proceedings of the 2011 International Symposium on Software Testing andAnalysis, pp. 199-209, 2011.
First International Conference on Modern Communication & Computing Technologies (MCCT'14) (Full Paper)
26-28 February, 2014, Nawabshah, Pakistan
Related Documents











