8/21/2012 1 Era of Customization and Era of Customization and Specilization Specilization Jason Cong Chancellor’s Professor, UCLA Computer Science Department [email protected] Director, Center for Domain-Specific Computing 1 www.cdsc.ucla.edu Focus of Our Research: Energy Efficient Computing Focus of Our Research: Energy Efficient Computing Parallelization Parallelization Customization Customization Adapt the architecture to Adapt the architecture to Application domain Application domain 2 Application domain Application domain

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

8/21/2012
1
Era of Customization and Era of Customization and SpecilizationSpecilization
Jason CongChancellor’s Professor, UCLA Computer Science Department
[email protected], Center for Domain-Specific Computing
11
www.cdsc.ucla.edu
Focus of Our Research: Energy Efficient ComputingFocus of Our Research: Energy Efficient Computing
ParallelizationParallelization
CustomizationCustomization
Adapt the architecture to Adapt the architecture to
Application domainApplication domain
22
Application domainApplication domain
8/21/2012
2
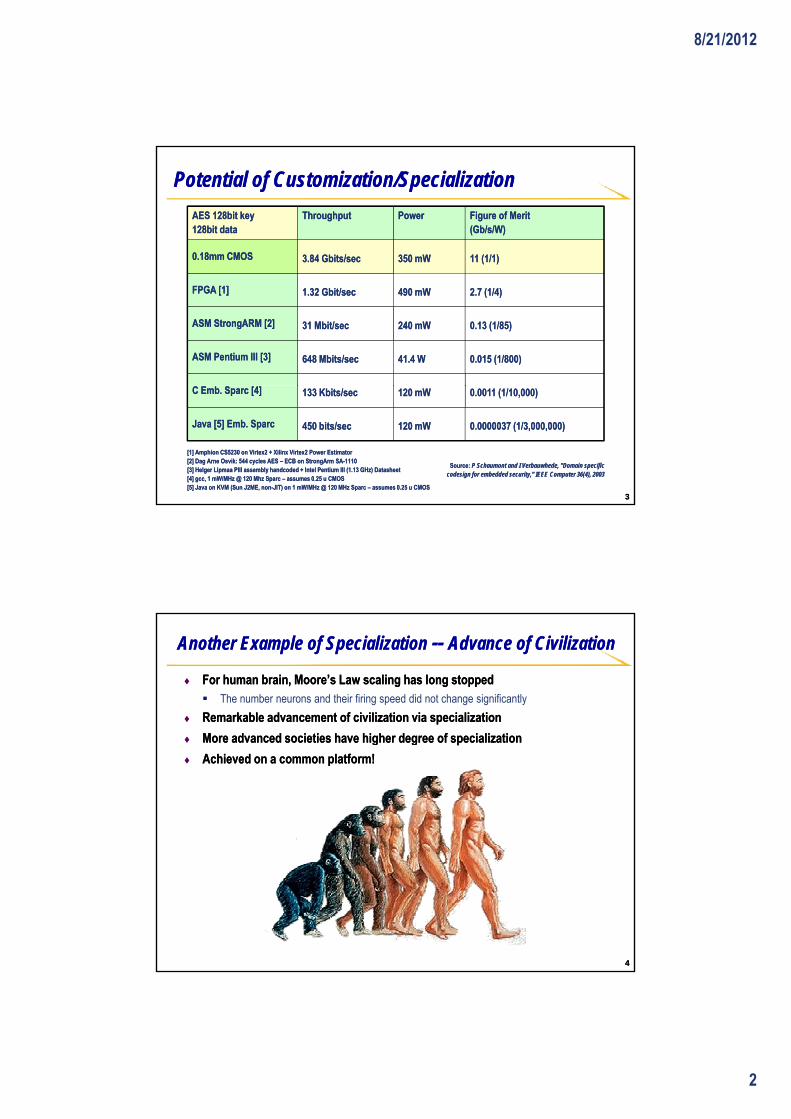
Potential of Customization/SpecializationPotential of Customization/Specialization
350 mW350 mW350 mW350 mW
PowerPowerPowerPower
11 (1/1)11 (1/1)11 (1/1)11 (1/1)3.84 3.84 GbitsGbits/sec/sec3.84 3.84 GbitsGbits/sec/sec0.18mm CMOS0.18mm CMOS0.18mm CMOS0.18mm CMOS
Figure of MeritFigure of Merit(Gb/s/W)(Gb/s/W)Figure of MeritFigure of Merit(Gb/s/W)(Gb/s/W)
ThroughputThroughputThroughputThroughputAES 128bit keyAES 128bit key128bit data128bit dataAES 128bit keyAES 128bit key128bit data128bit data
350 mW350 mW
PowerPower
11 (1/1)11 (1/1)3.84 3.84 GbitsGbits/sec/sec0.18mm CMOS0.18mm CMOS
Figure of MeritFigure of Merit(Gb/s/W)(Gb/s/W)
ThroughputThroughputAES 128bit keyAES 128bit key128bit data128bit data
648 Mbits/sec648 Mbits/sec648 Mbits/sec648 Mbits/secASM Pentium III [3]ASM Pentium III [3]ASM Pentium III [3]ASM Pentium III [3] 41.4 W41.4 W41.4 W41.4 W 0.015 (1/800)0.015 (1/800)0.015 (1/800)0.015 (1/800)
1.32 Gbit/sec1.32 Gbit/sec1.32 Gbit/sec1.32 Gbit/secFPGA [1]FPGA [1]FPGA [1]FPGA [1] 490 mW490 mW490 mW490 mW 2.7 (1/4)2.7 (1/4)2.7 (1/4)2.7 (1/4)
ASM ASM StrongARMStrongARM [2][2]ASM ASM StrongARMStrongARM [2][2] 240 240 mWmW240 240 mWmW 0.13 (1/85)0.13 (1/85)0.13 (1/85)0.13 (1/85)31 Mbit/sec31 Mbit/sec31 Mbit/sec31 Mbit/sec
648 Mbits/sec648 Mbits/secASM Pentium III [3]ASM Pentium III [3] 41.4 W41.4 W 0.015 (1/800)0.015 (1/800)
1.32 Gbit/sec1.32 Gbit/secFPGA [1]FPGA [1] 490 mW490 mW 2.7 (1/4)2.7 (1/4)
ASM ASM StrongARMStrongARM [2][2] 240 240 mWmW 0.13 (1/85)0.13 (1/85)31 Mbit/sec31 Mbit/sec
33
[1] Amphion CS5230 on Virtex2 + Xilinx Virtex2 Power Estimator[1] Amphion CS5230 on Virtex2 + Xilinx Virtex2 Power Estimator[2] Dag Arne Osvik: 544 cycles AES [2] Dag Arne Osvik: 544 cycles AES –– ECB on StrongArm SAECB on StrongArm SA--11101110[3] Helger Lipmaa PIII assembly handcoded + Intel Pentium III (1.13 GHz) Datasheet[3] Helger Lipmaa PIII assembly handcoded + Intel Pentium III (1.13 GHz) Datasheet[4] gcc, 1 mW/MHz @ 120 Mhz Sparc [4] gcc, 1 mW/MHz @ 120 Mhz Sparc –– assumes 0.25 u CMOSassumes 0.25 u CMOS[5] Java on KVM (Sun J2ME, non[5] Java on KVM (Sun J2ME, non--JIT) on 1 mW/MHz @ 120 MHz Sparc JIT) on 1 mW/MHz @ 120 MHz Sparc –– assumes 0.25 u CMOSassumes 0.25 u CMOS
Source: Source: P Schaumont and I Verbauwhede, "Domain specific P Schaumont and I Verbauwhede, "Domain specific codesign for embedded security," IEEE Computer 36(4), 2003codesign for embedded security," IEEE Computer 36(4), 2003
Java [5] Emb. SparcJava [5] Emb. SparcJava [5] Emb. SparcJava [5] Emb. Sparc 450 bits/sec450 bits/sec450 bits/sec450 bits/sec 120 mW120 mW120 mW120 mW 0.0000037 (1/3,000,000)0.0000037 (1/3,000,000)0.0000037 (1/3,000,000)0.0000037 (1/3,000,000)
C C EmbEmb. . SparcSparc [4][4]C C EmbEmb. . SparcSparc [4][4] 133 Kbits/sec133 Kbits/sec133 Kbits/sec133 Kbits/sec 0.0011 (1/10,000)0.0011 (1/10,000)0.0011 (1/10,000)0.0011 (1/10,000)120 mW120 mW120 mW120 mW
Java [5] Emb. SparcJava [5] Emb. Sparc 450 bits/sec450 bits/sec 120 mW120 mW 0.0000037 (1/3,000,000)0.0000037 (1/3,000,000)
C C EmbEmb. . SparcSparc [4][4] 133 Kbits/sec133 Kbits/sec 0.0011 (1/10,000)0.0011 (1/10,000)120 mW120 mW
Another Example of Specialization Another Example of Specialization ---- Advance of Civilization Advance of Civilization
♦♦ For human brain, Moore’s Law scaling has long stoppedFor human brain, Moore’s Law scaling has long stopped The number neurons and their firing speed did not change significantly
♦♦ Remarkable advancement of civilization via specializationRemarkable advancement of civilization via specialization
♦♦ More advanced societies have higher degree of specializationMore advanced societies have higher degree of specialization
♦♦ Achieved on a common platform!Achieved on a common platform!
44
8/21/2012
3
More Justifications: Utilization More Justifications: Utilization Wall Wall [[G. G. VenkateshVenkatesh et.alet.al. ASPLOS’10]. ASPLOS’10]
♦♦ Assuming 80W power budget,Assuming 80W power budget, At 45 nm TSMC process, less than 7% of a 300mmAt 45 nm TSMC process, less than 7% of a 300mm22 die can be die can be p ,p ,
switched.switched.
♦♦ ITRS roadmap and CMOS scaling theory:ITRS roadmap and CMOS scaling theory: Less than 3.5% in 32 nmLess than 3.5% in 32 nm
Almost half with each process generationAlmost half with each process generation
Even further with 3Even further with 3--D integration.D integration.
55
Dark Silicon and the End of Multicore Scaling Dark Silicon and the End of Multicore Scaling [H. Esmaeilzadeh et. al., ISCA'11][H. Esmaeilzadeh et. al., ISCA'11]
♦♦ Power wall:Power wall: At 22 nm, 31% of a fixedAt 22 nm, 31% of a fixed--size size
chip must be powered offchip must be powered offp pp p
At 8 nm, more than 50%.At 8 nm, more than 50%.
♦♦ A growing gap A growing gap between between achievable achievable vsvs possiblepossible Due to power and parallelism Due to power and parallelism
limitationslimitations
Speedup Speedup gap of at least 22x at 8 gap of at least 22x at 8 t h lt h l
Percent dark silicon: geomeanPercent dark silicon: geomean
66
nm nm technologytechnology

8/21/2012
4
Moore’s Moore’s Law Supports Customization and SpecializationLaw Supports Customization and Specialization
♦♦ Previous architecturesPrevious architectures Transistor limited –> maximize device reuse
♦♦ Future architecturesFuture architectures♦♦ Future architecturesFuture architectures Power/energy limited -> maximize device efficiency
♦♦ A story of specializationA story of specialization
77
Example of Customizable Platforms: FPGAsExample of Customizable Platforms: FPGAs Configurable logic Configurable logic
blocksblocks
IslandIsland--style configurable style configurable mesh routingmesh routing
Dedicated componentsDedicated components Specialization allows Specialization allows
optimizationoptimization Memory/MultiplierMemory/Multiplier I/O, ProcessorI/O, Processor Anything that the FPGA Anything that the FPGA
88
Anything that the FPGA Anything that the FPGA architect wants to put in!architect wants to put in!
Source: I. Kuon, R. Tessier, J. Rose. FPGA Source: I. Kuon, R. Tessier, J. Rose. FPGA
Architecture: Survey and Challenges. 2008.Architecture: Survey and Challenges. 2008.

8/21/2012
5
More Opportunities for Customization to be ExploredMore Opportunities for Customization to be Explored
Core parametersCore parameters
Our Proposal: Customizable Heterogeneous Platform (CHP)Our Proposal: Customizable Heterogeneous Platform (CHP)
$$ $$ $$ $$
Cache parametersCache parametersCache size & configurationCache size & configurationCache vs SPMCache vs SPM……
Frequency & voltageFrequency & voltageDatapath bit widthDatapath bit widthInstruction window sizeInstruction window sizeIssue widthIssue widthCache size & Cache size & configurationconfigurationRegister file organizationRegister file organization# of thread contexts# of thread contexts……
NoC parametersNoC parametersInterconnect topology Interconnect topology # of virtual channels# of virtual channelsRouting policyRouting policyLink bandwidthLink bandwidthRouter pipeline depthRouter pipeline depthNumber of RFNumber of RF--I enabled I enabled routersroutersRFRF I channel and I channel and
FixedFixedCoreCore
FixedFixedCoreCore
FixedFixedCoreCore
FixedFixedCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
PP PP
99
Key questions:Key questions: Optimal tradeOptimal trade--off between efficiency & customizabilityoff between efficiency & customizabilityWhich options to fix at CHP creation? Which to be set by CHP mapper?Which options to fix at CHP creation? Which to be set by CHP mapper?
Custom instructions & acceleratorsCustom instructions & acceleratorsShared vs. private acceleratorsShared vs. private acceleratorsChoice of acceleratorsChoice of acceleratorsCustom instruction selectionCustom instruction selectionAmount of programmable fabric Amount of programmable fabric ……
RFRF--I channel and I channel and bandwidth allocationbandwidth allocation……
ProgProgFabricFabric
ProgProgFabricFabric
acceleratoracceleratoracceleratoraccelerator acceleratoracceleratoracceleratoraccelerator
Reconfigurable RFReconfigurable RF--I busI busReconfigurable optical busReconfigurable optical busTransceiver/receiverTransceiver/receiverOptical interfaceOptical interface
Customizable Heterogeneous Platform Customizable Heterogeneous Platform (CHP)(CHP)
$$ $$ $$ $$ DRAMDRAM I/OI/O CHPCHP
Research Scope in CDSC (Center for DomainResearch Scope in CDSC (Center for Domain--Specific Computing)Specific Computing)
FixedFixedCoreCore
FixedFixedCoreCore
FixedFixedCoreCore
FixedFixedCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
ProgProgFabricFabric
ProgProgFabricFabric
acceleratoracceleratoracceleratoraccelerator acceleratoracceleratoracceleratoraccelerator
DRAMDRAM CHPCHP CHPCHP
Reconfigurable RFReconfigurable RF--I busI busReconfigurable optical busReconfigurable optical bus
DomainDomain--specificspecific--modelingmodeling(healthcare applications)(healthcare applications)
1010
Reconfigurable optical busReconfigurable optical busTransceiver/receiverTransceiver/receiverOptical interfaceOptical interface
CHP mappingCHP mappingSourceSource--toto--source CHP mapper source CHP mapper
Reconfiguring & optimizing backendReconfiguring & optimizing backendAdaptive runtimeAdaptive runtime
CHP creationCHP creationCustomizable computing engines Customizable computing engines
Customizable interconnectsCustomizable interconnects
Architecture Architecture
modelingmodeling
Customization Customization
settingsettingDesign onceDesign once Invoke many timesInvoke many times

8/21/2012
6
Current Focus Current Focus –– AcceleratorAccelerator--Rich Architectures (ARC)Rich Architectures (ARC)♦♦ Accelerators provide high powerAccelerators provide high power--efficiency over generalefficiency over general--purpose processorspurpose processors IBM wire-speed processor Intel Larrabee
♦♦ ITRS 2007 System drivers prediction: Accelerator number close to 1500 by 2022 ITRS 2007 System drivers prediction: Accelerator number close to 1500 by 2022
♦♦ Two kinds of acceleratorsTwo kinds of accelerators Tightly coupled – part of datapath Loosely coupled – shared via NoC
♦♦ ChallengesChallenges Accelerator extraction and synthesisAccelerator extraction and synthesis Efficient accelerator managementEfficient accelerator management
S h d liS h d li
1111
•• SchedulingScheduling•• SharingSharing•• Virtualization …Virtualization …
Friendly programming modelsFriendly programming models
Architecture Support for AcceleratorArchitecture Support for Accelerator--Rich CMPs (ARC) Rich CMPs (ARC) [DAC’2012][DAC’2012]
CPUCPU Accelerator Accelerator ManagerManager AcceleratorAccelerator
MotivationMotivation
Operation Latency (# Cycles)
1 core 2 cores 4 cores 8 cores 16 cores
Invoke 214413 256401 266133 308434 316161
RD/WR 703 725 781 837 885
AppApp
OSOS
1212
♦♦ Managing accelerators through the OS is expensiveManaging accelerators through the OS is expensive
♦♦ In an accelerator rich CMP, management should be cheaper both in In an accelerator rich CMP, management should be cheaper both in terms of time and energyterms of time and energy Invoke “Open”s the driver and returns the handler to driver. Called once.
RD/WR is called multiple times.

8/21/2012
7
Overall Architecture of ARCOverall Architecture of ARC
♦♦ Architecture of ARCArchitecture of ARC Multiple cores and accelerators Global Accelerator Manager Global Accelerator Manager
(GAM) Shared L2 cache banks and NoC
routers between multiple accelerators
1313
GAMGAMAccelerator + Accelerator +
DMA+SPMDMA+SPMShared Shared RouterRouterCoreCore
Shared Shared
L2 $L2 $Memory Memory
controllercontroller
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM11
1.1. The core requests for a given type of accelerator (lcaccThe core requests for a given type of accelerator (lcacc--req).req).
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory LCA
1414

8/21/2012
8
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM22
2.2. The GAM responds with a “list + waiting time” or NACKThe GAM responds with a “list + waiting time” or NACK
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory LCA
1515
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM33
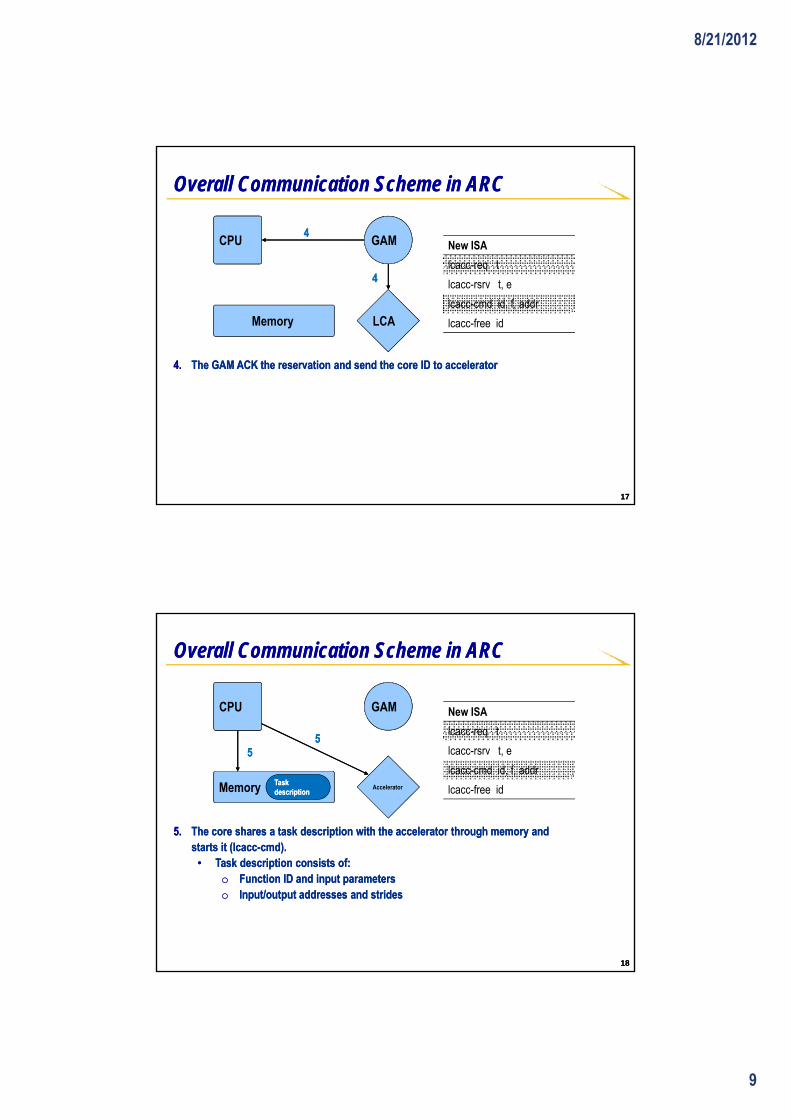
3.3. The core reserves (lcaccThe core reserves (lcacc--rsv) and waits.rsv) and waits.
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory LCA
1616
8/21/2012
9
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM44
4.4. The GAM ACK the reservation and send the core ID to acceleratorThe GAM ACK the reservation and send the core ID to accelerator
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory LCA
44
1717
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM
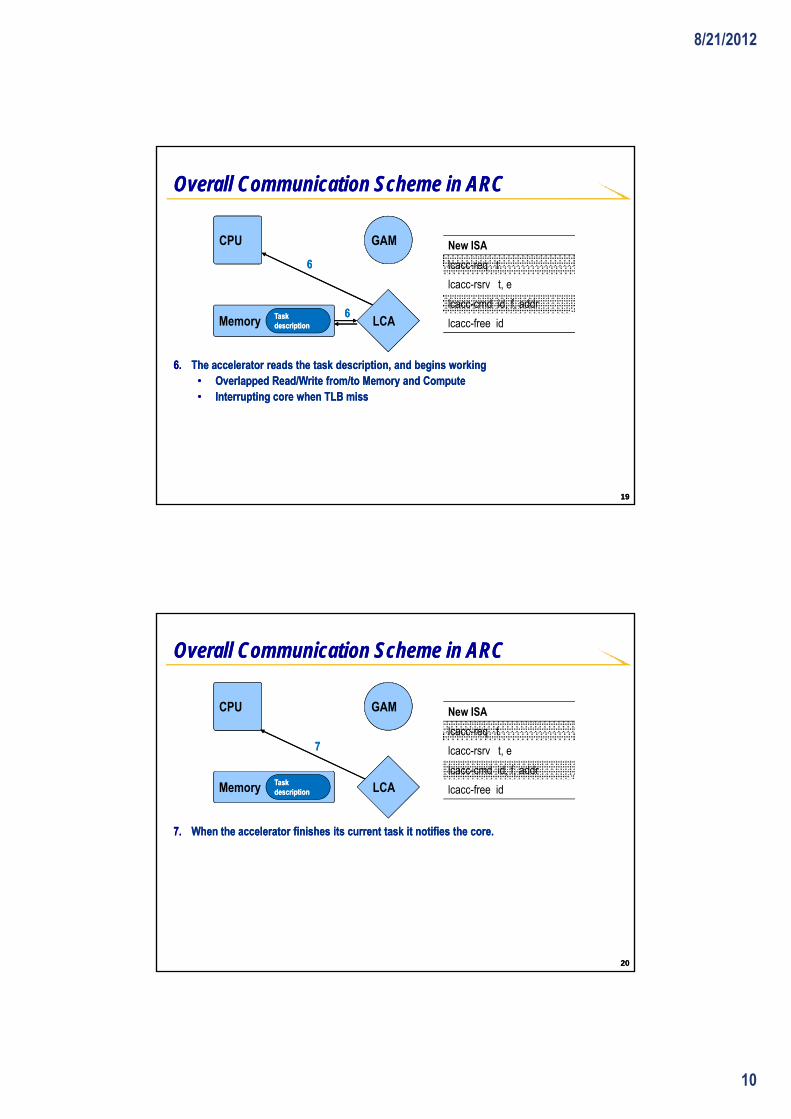
5.5. The core shares a task description with the accelerator through memory and The core shares a task description with the accelerator through memory and starts it (lcaccstarts it (lcacc--cmd).cmd).
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory Task Task descriptiondescription
Accelerator
5555
1818
(( ))•• Task description consists of:Task description consists of:
oo Function ID and input parametersFunction ID and input parametersoo Input/output addresses and stridesInput/output addresses and strides
8/21/2012
10
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM
66
6.6. The accelerator reads the task description, and begins workingThe accelerator reads the task description, and begins working•• Overlapped Read/Write from/to Memory and ComputeOverlapped Read/Write from/to Memory and Compute
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory Task Task descriptiondescription LCA
66
66
1919
pp y ppp y p•• Interrupting core when TLB miss Interrupting core when TLB miss
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM
7.7. When the accelerator finishes its current task it notifies the core.When the accelerator finishes its current task it notifies the core.
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory Task Task descriptiondescription LCA
77
2020
8/21/2012
11
Overall Communication Scheme in ARCOverall Communication Scheme in ARC
New ISA
lcacc-req t
CPU GAM88
8.8. The core then sends a message to the GAM freeing the accelerator (lcaccThe core then sends a message to the GAM freeing the accelerator (lcacc--free).free).
lcacc-req t
lcacc-rsrv t, e
lcacc-cmd id, f, addr
lcacc-free idMemory Task Task descriptiondescription LCA
2121
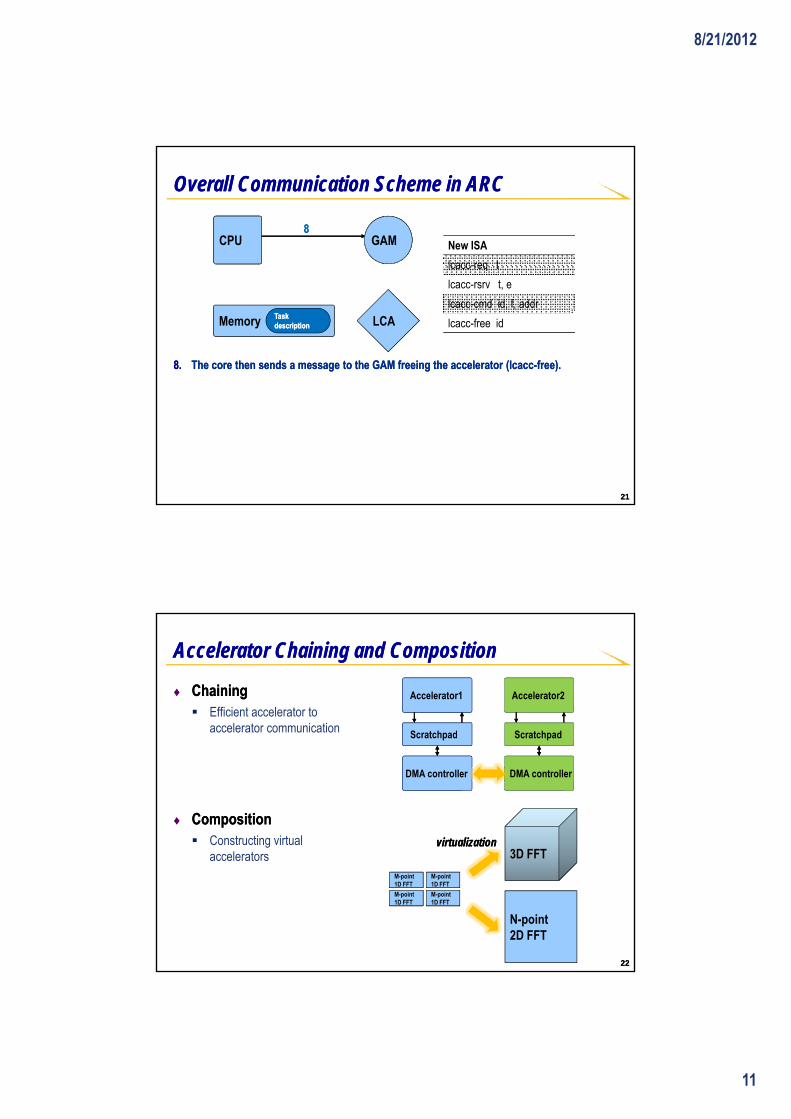
Accelerator Chaining and CompositionAccelerator Chaining and Composition
♦♦ ChainingChaining Efficient accelerator to
accelerator communication
Accelerator1
S t h d
Accelerator2
S t h daccelerator communication
♦♦ Composition Composition Constructing virtual
l t
Scratchpad
DMA controller
Scratchpad
DMA controller
3D FFTvirtualizationvirtualization
2222
acceleratorsM-point1D FFT
M-point1D FFT
3D FFT
N-point2D FFT
M-point1D FFT
M-point1D FFT

8/21/2012
12
Accelerator VirtualizationAccelerator Virtualization♦♦ Application programmer or compilation framework selects highApplication programmer or compilation framework selects high--
level functionalitylevel functionality
♦♦ Implementation viaImplementation viapp Monolithic accelerator Distributed accelerators composed to a virtual accelerator Software decomposition libraries
♦♦ Example: Implementing a 4x4 2Example: Implementing a 4x4 2--D FFT using 2 4D FFT using 2 4--point 1point 1--D FFT D FFT
2323
Accelerator VirtualizationAccelerator Virtualization♦♦ Application programmer or compilation framework selects highApplication programmer or compilation framework selects high--
level functionalitylevel functionality
♦♦ Implementation viaImplementation viapp Monolithic accelerator Distributed accelerators composed to a virtual accelerator Software decomposition libraries
♦♦ Example: Implementing a 4x4 2Example: Implementing a 4x4 2--D FFT using 2 4D FFT using 2 4--point 1point 1--D FFT D FFT
2424
Step 1: 1D FFT on Row 1 and Row 2Step 1: 1D FFT on Row 1 and Row 2

8/21/2012
13
Accelerator VirtualizationAccelerator Virtualization♦♦ Application programmer or compilation framework selects highApplication programmer or compilation framework selects high--
level functionalitylevel functionality
♦♦ Implementation viaImplementation viapp Monolithic accelerator Distributed accelerators composed to a virtual accelerator Software decomposition libraries
♦♦ Example: Implementing a 4x4 2Example: Implementing a 4x4 2--D FFT using 2 4D FFT using 2 4--point 1point 1--D FFT D FFT
2525
Step 2: 1D FFT on Row 3 and Row 4Step 2: 1D FFT on Row 3 and Row 4
Accelerator VirtualizationAccelerator Virtualization♦♦ Application programmer or compilation framework selects highApplication programmer or compilation framework selects high--
level functionalitylevel functionality
♦♦ Implementation viaImplementation viapp Monolithic accelerator Distributed accelerators composed to a virtual accelerator Software decomposition libraries
♦♦ Example: Implementing a 4x4 2Example: Implementing a 4x4 2--D FFT using 2 4D FFT using 2 4--point 1point 1--D FFT D FFT
2626
Step 3: 1D FFT on Col 1 and Col 2Step 3: 1D FFT on Col 1 and Col 2

8/21/2012
14
Accelerator VirtualizationAccelerator Virtualization♦♦ Application programmer or compilation framework selects highApplication programmer or compilation framework selects high--
level functionalitylevel functionality
♦♦ Implementation viaImplementation viapp Monolithic accelerator Distributed accelerators composed to a virtual accelerator Software decomposition libraries
♦♦ Example: Implementing a 4x4 2Example: Implementing a 4x4 2--D FFT using 2 4D FFT using 2 4--point 1point 1--D FFT D FFT
2727
Step 4: 1D FFT on Col 3 and Col 4Step 4: 1D FFT on Col 3 and Col 4
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
LCA
2828

8/21/2012
15
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
Request/Reserve Request/Reserve
LCA
Request/Reserve Request/Reserve Confirmation and Confirmation and NACKNACKSent by GAMSent by GAM
2929
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
TLB MissTLB Miss
LCA
TLB MissTLB MissTask DoneTask Done
3030
8/21/2012
16
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
TLB MissTLB Miss
LCA
TLB MissTLB MissTask DoneTask Done
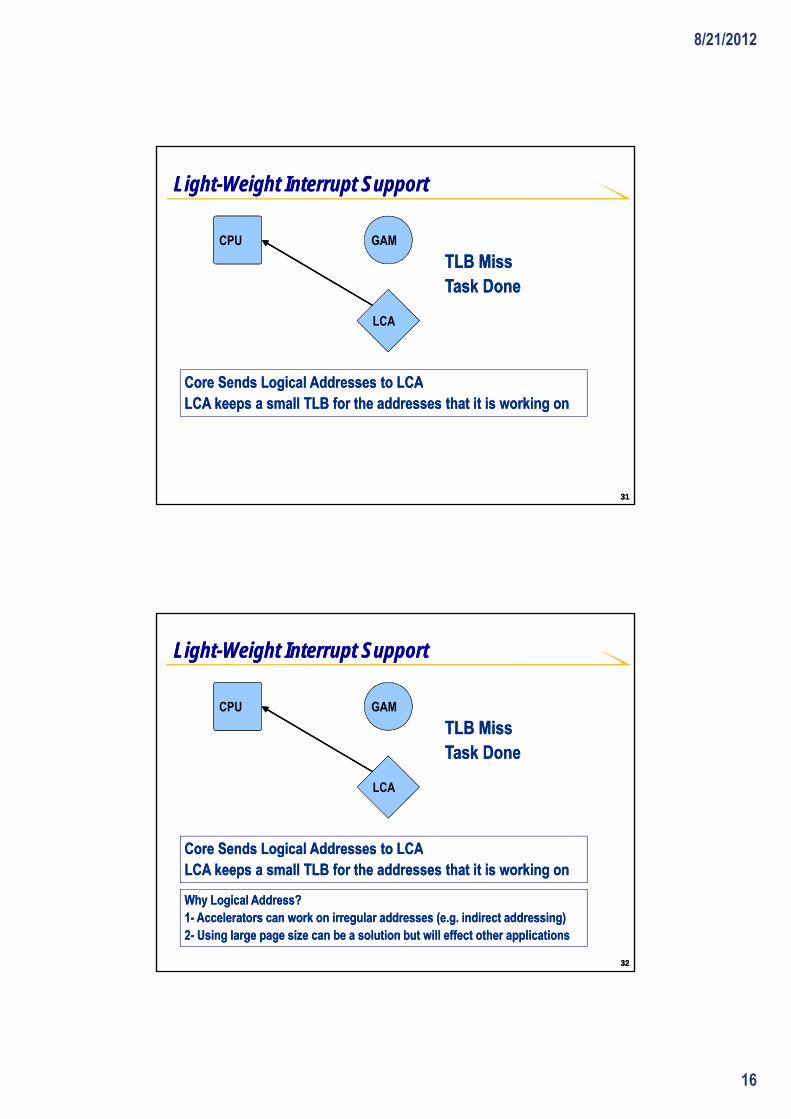
Core Sends Logical Addresses to LCACore Sends Logical Addresses to LCA
3131
Core Sends Logical Addresses to LCACore Sends Logical Addresses to LCALCA keeps a small TLB for the addresses that it is working onLCA keeps a small TLB for the addresses that it is working on
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
TLB MissTLB Miss
LCA
TLB MissTLB MissTask DoneTask Done
Core Sends Logical Addresses to LCACore Sends Logical Addresses to LCA
3232
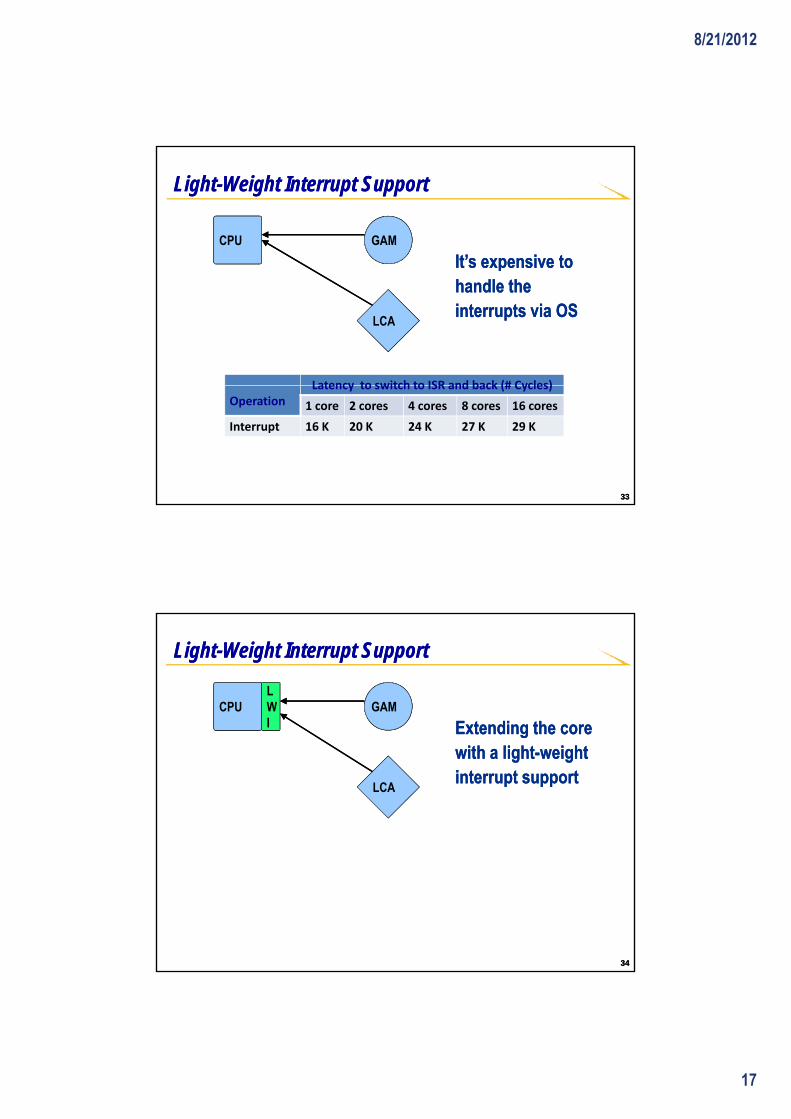
Core Sends Logical Addresses to LCACore Sends Logical Addresses to LCALCA keeps a small TLB for the addresses that it is working onLCA keeps a small TLB for the addresses that it is working on
Why Logical Address?Why Logical Address?11-- Accelerators can work on irregular addresses (e.g. indirect addressing)Accelerators can work on irregular addresses (e.g. indirect addressing)22-- Using large page size can be a solution but will effect other applications Using large page size can be a solution but will effect other applications
8/21/2012
17
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
It’s expensive to It’s expensive to
LCA
Latency to switch to ISR and back (# Cycles)
It s expensive to It s expensive to handle the handle the interrupts via OSinterrupts via OS
3333
OperationLatency to switch to ISR and back (# Cycles)
1 core 2 cores 4 cores 8 cores 16 cores
Interrupt 16 K 20 K 24 K 27 K 29 K
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
Extending the core Extending the core
LWI
LCA
Extending the core Extending the core with a lightwith a light--weight weight interrupt supportinterrupt support
3434

8/21/2012
18
LightLight--Weight Interrupt SupportWeight Interrupt Support
CPU GAM
Extending the core Extending the core
LWI
LCA
Extending the core Extending the core with a lightwith a light--weight weight interrupt supportinterrupt support
Two main components added:Two main components added: A table to store ISR info
3535
An interrupt controller to queue and prioritize incoming interrupt packets
Each thread registers: Each thread registers: Address of the ISR and its arguments and lw-int source
Limitations:Limitations: Only can be used when running the same thread which LW interrupt belongs to
OS-handled interrupt otherwise
Evaluation methodologyEvaluation methodology♦♦ BenchmarksBenchmarks Medical imaging
Vision & Navigation
3636
8/21/2012
19
compressive compressive sensingsensing
Application Domain: Medical Image ProcessingApplication Domain: Medical Image Processingr
econ
stru
ctio
nre
cons
truc
tion
voxels
2
points sampled
)(-ARmin
:theoryNyquist -Shannon classical rate a
at sampled be can and sparsity,exhibit images Medical
ugradSuu
fluid fluid registrationregistration
total variational total variational algorithmalgorithmd
enoi
sing
de
nois
ing
reg
istr
atio
nre
gist
ratio
n
h
zyS
i,jvolumevoxel
ji
S
kkk
eiZ
wjfwi
1
21
2
j
2, )(
1 ,2)()(u :voxel
)()()()( uxTxRuxTvv
uvtu
v
3737
level set level set methodsmethodss
egm
enta
tion
segm
enta
tion
ana
lysi
san
alys
is
0t)(x, : xvoxels)(surface
div),(F
t
datat
3
12
23
1
),(
),()(
ji
j
ij
j ij
ij
i txfx
vv
xp
xv
vtv
txfvpvvtv
NavierNavier--StokesStokesequationsequations
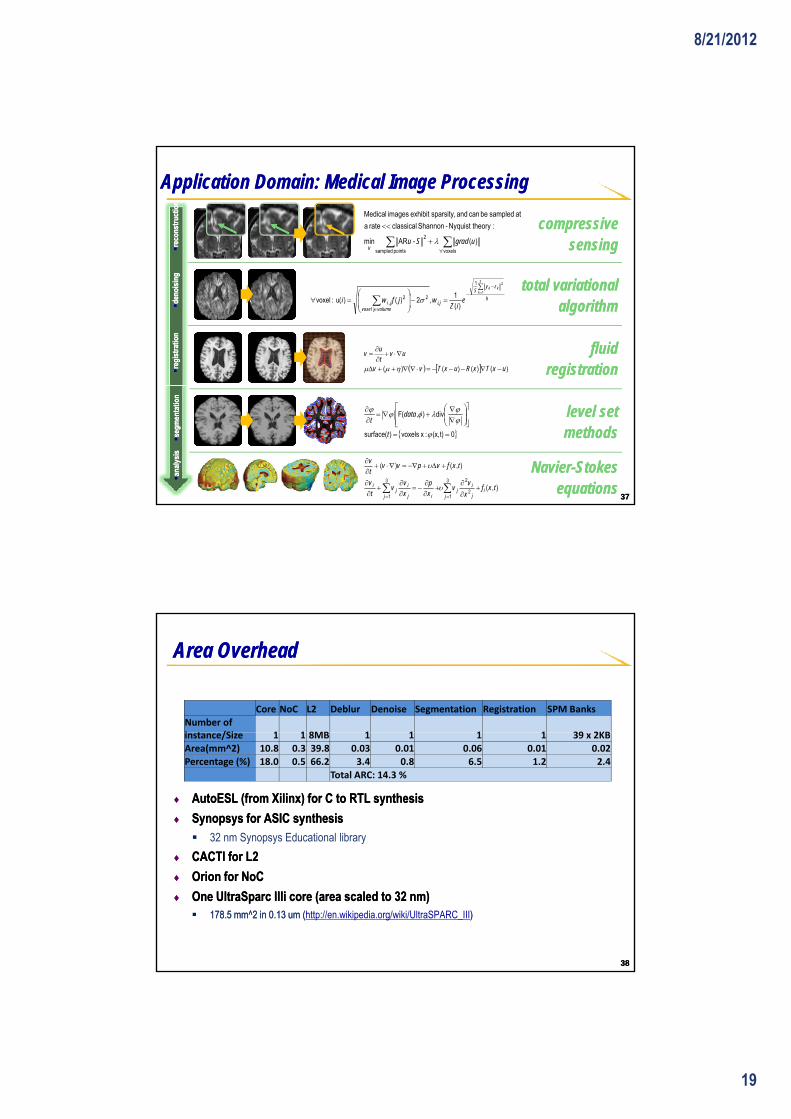
Area OverheadArea Overhead
Core NoC L2 Deblur Denoise Segmentation Registration SPM Banks Number of i t /Si 1 1 8MB 1 1 1 1 39 2KB
♦♦ AutoESLAutoESL (from Xilinx) for C to RTL synthesis(from Xilinx) for C to RTL synthesis
♦♦ Synopsys for ASIC synthesisSynopsys for ASIC synthesis 32 nm Synopsys Educational library
CACTI f L2CACTI f L2
instance/Size 1 1 8MB 1 1 1 1 39 x 2KBArea(mm^2) 10.8 0.3 39.8 0.03 0.01 0.06 0.01 0.02Percentage (%) 18.0 0.5 66.2 3.4 0.8 6.5 1.2 2.4
Total ARC: 14.3 %
3838
♦♦ CACTI for L2CACTI for L2
♦♦ Orion for Orion for NoCNoC
♦♦ One One UltraSparcUltraSparc IIIiIIIi core (area scaled to 32 nm)core (area scaled to 32 nm) 178.5 mm^2 in 0.13 um (178.5 mm^2 in 0.13 um (http://en.wikipedia.org/wiki/UltraSPARC_III))
8/21/2012
20
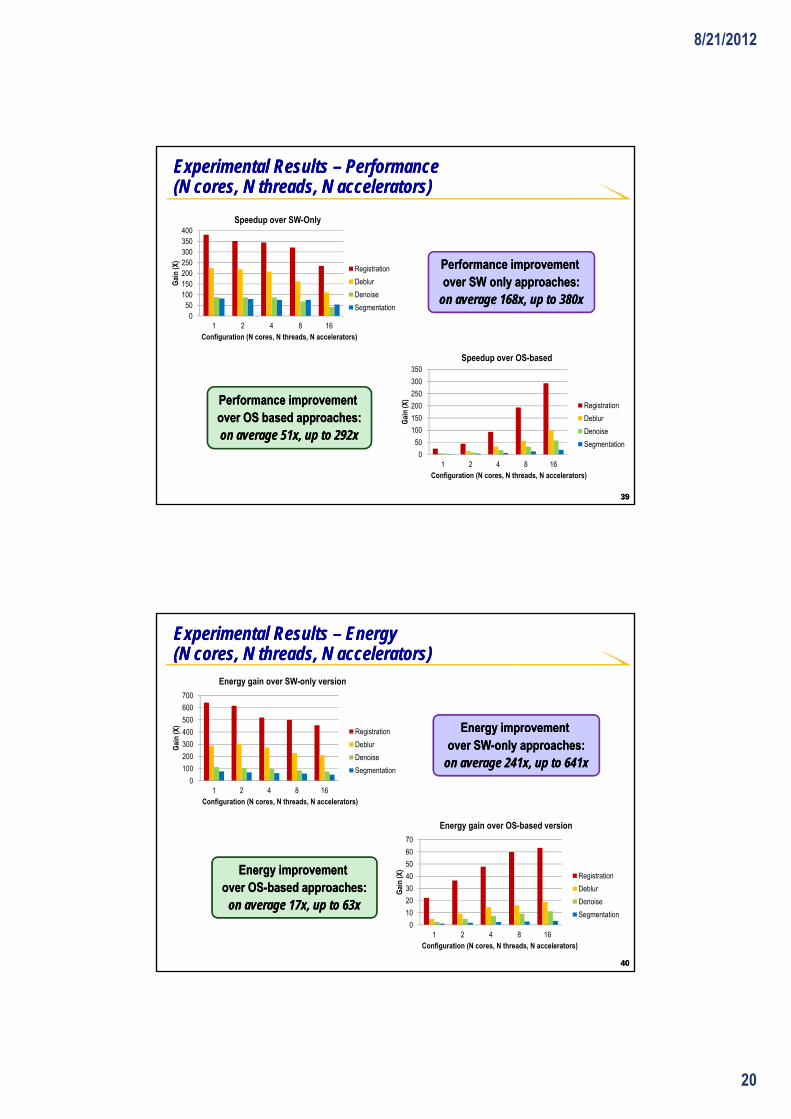
Experimental Results Experimental Results –– PerformancePerformance(N cores, N threads, N accelerators)(N cores, N threads, N accelerators)
Performance improvement Performance improvement 250300350400
X)
Speedup over SW-Only
R i t ti Performance improvement Performance improvement over SW only approaches:over SW only approaches:
on average 168x, up to 380xon average 168x, up to 380x0
50100150200
1 2 4 8 16
Gai
n (X
Configuration (N cores, N threads, N accelerators)
Registration
Deblur
Denoise
Segmentation
300
350Speedup over OS-based
3939
Performance improvement Performance improvement over OS based approaches:over OS based approaches:on average 51x, up to 292xon average 51x, up to 292x
0
50
100
150
200
250
1 2 4 8 16
Gai
n (X
)
Configuration (N cores, N threads, N accelerators)
Registration
Deblur
Denoise
Segmentation
Experimental Results Experimental Results –– Energy Energy (N cores, N threads, N accelerators)(N cores, N threads, N accelerators)
Energy improvement Energy improvement 400
500
600
700
X)
Energy gain over SW-only version
Registration gy pgy pover SWover SW--only approaches:only approaches:
on average 241x, up to 641xon average 241x, up to 641x0
100
200
300
400
1 2 4 8 16
Gai
n (
Configuration (N cores, N threads, N accelerators)
Registration
Deblur
Denoise
Segmentation
60
70
Energy gain over OS-based version
4040
Energy improvement Energy improvement over OSover OS--based approaches:based approaches:
on average 17x, up to 63xon average 17x, up to 63x0
10
20
30
40
50
60
1 2 4 8 16
Gai
n (X
)
Configuration (N cores, N threads, N accelerators)
Registration
Deblur
Denoise
Segmentation

8/21/2012
21
What are the Problems with ARC? What are the Problems with ARC?
♦♦ Dedicated accelerators are inflexible Dedicated accelerators are inflexible An LCA may be useless for new algorithms or new domains
Often under-utilized Often under-utilized
LCAs contain many replicated structures • Things like fp-ALUs, DMA engines, SPM
• Unused when the accelerator is unused
♦♦ We want flexibility and better resource utilization We want flexibility and better resource utilization Solution: CHARM
4141
Solution: CHARM
♦♦ Private SPM is wastefulPrivate SPM is wasteful Solution: BiN
A Composable Heterogeneous AcceleratorA Composable Heterogeneous Accelerator--Rich Rich Microprocessor (CHARM) [ISLPED’12]Microprocessor (CHARM) [ISLPED’12]
♦♦ MotivationMotivation Great deal of data parallelism
• Tasks performed by accelerators tend to have a great deal of data parallelism Variety of LCAs with possible overlap
• Utilization of any particular LCA being somewhat sporadic• Utilization of any particular LCA being somewhat sporadic It is expensive to have both:
• Sufficient diversity of LCAs to handle the various applications • Sufficient quantity of a particular LCA to handle the parallelism
Overlap in functionality
• LCAs can be built using a limited number of smaller, more general LCAs: Accelerator building blocks (ABBs)
4242
♦♦ IdeaIdea Flexible accelerator building blocks (ABB) that can be composed into accelerators
♦♦ Leverage economy of scaleLeverage economy of scale

8/21/2012
22
Micro Architecture of CHARMMicro Architecture of CHARM♦♦ ABBABB Accelerator building blocks (ABB) Primitive components that can be
composed into acceleratorsp♦♦ ABB islandsABB islands Multiple ABBs Shared DMA controller, SPM and
NoC interface
♦♦ ABCABC Accelerator Block Composer
(ABC)
4343
• To orchestrate the data flow between ABBs to create a virtual accelerator
• Arbitrate requests from cores
♦♦ Other componentsOther components Cores L2 Banks Memory controllers
An Example of ABB Library (for Medical Imaging)An Example of ABB Library (for Medical Imaging)
Internal Internal
of Polyof Poly
4444

8/21/2012
23
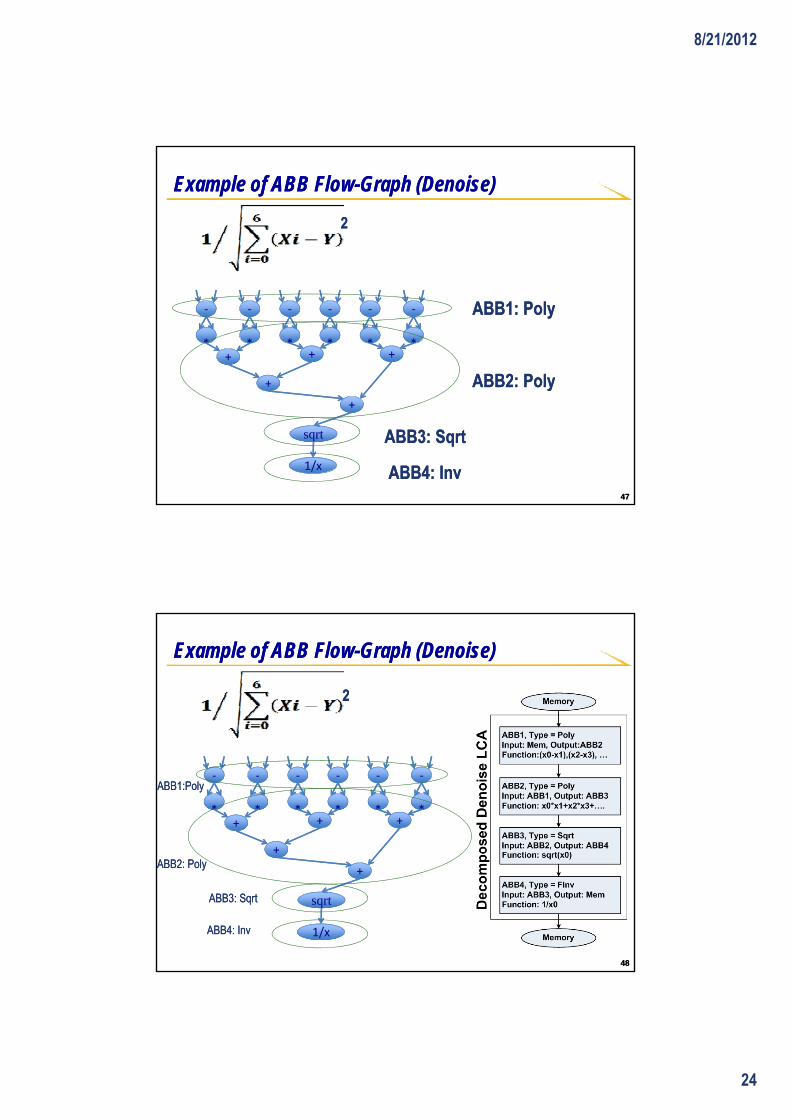
Example of ABB FlowExample of ABB Flow--Graph (Denoise)Graph (Denoise)
22
4545
Example of ABB FlowExample of ABB Flow--Graph (Denoise)Graph (Denoise)
22
‐‐
**
‐‐
**
‐‐
**
‐‐
**
‐‐
**
‐‐
**++ ++ ++
++
4646
++
++
sqrtsqrt
1/x1/x
8/21/2012
24
Example of ABB FlowExample of ABB Flow--Graph (Denoise)Graph (Denoise)
22
‐‐
**
‐‐
**
‐‐
**
‐‐
**
‐‐
**
‐‐
**++ ++ ++
++
ABB1: PolyABB1: Poly
ABB2: PolyABB2: Poly
4747
++
++
sqrtsqrt
1/x1/x
ABB2: PolyABB2: Poly
ABB3: SqrtABB3: Sqrt
ABB4: InvABB4: Inv
Example of ABB FlowExample of ABB Flow--Graph (Denoise)Graph (Denoise)
22
‐‐
**
‐‐
**
‐‐
**
‐‐
**
‐‐
**
‐‐
**++ ++ ++
++
ABB1:PolyABB1:Poly
4848
++
++
sqrtsqrt
1/x1/x
ABB2: PolyABB2: Poly
ABB3: SqrtABB3: Sqrt
ABB4: InvABB4: Inv

8/21/2012
25
LCA Composition ProcessLCA Composition Process
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
xx
yy
xx
ww
4949
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
LCA Composition ProcessLCA Composition Process
1.1. Core initiationCore initiation Core sends the task description: task flow-
graph of the desired LCA to ABC together with l h d l f i t d t t
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
polyhedral space for input and output
xx
yy
xx
wwx
Task descriptionTask description
5050
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
y z
10x10 input and output10x10 input and output

8/21/2012
26
LCA Composition ProcessLCA Composition Process
2.2. TaskTask--flow parsing and taskflow parsing and task--list creationlist creation ABC parses the task-flow graph and breaks the request
into a set of tasks with smaller data size and fills the task list
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
task list
xx
yy
xx
wwABC generates internallyABC generates internally
5151
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zzNeeded ABBs: “x”, “y”, “z”Needed ABBs: “x”, “y”, “z”
With task size of 5x5 block, With task size of 5x5 block,
ABC generates 4 tasksABC generates 4 tasks
LCA Composition ProcessLCA Composition Process3.3. Dynamic ABB mappingDynamic ABB mapping ABC uses a pattern matching algorithm to
assign ABBs to islands Fills the composed LCA table and resource
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
pallocation table
xx
yy
xx
wwIsland ID
ABB Type
ABB ID Status
1 x 1 Free
5252
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
1 y 1 Free
2 x 1 Free
2 w 1 Free
3 z 1 Free
3 w 1 Free
4 y 1 Free
4 z 1 Free

8/21/2012
27
LCA Composition ProcessLCA Composition Process3.3. Dynamic ABB mappingDynamic ABB mapping ABC uses a pattern matching algorithm to
assign ABBs to islands Fills the composed LCA table and resource
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
pallocation table
xx
yy
xx
wwIsland ID
ABB Type
ABB ID Status
1 x 1 Busy
5353
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
1 y 1 Busy
2 x 1 Free
2 w 1 Free
3 z 1 Busy
3 w 1 Free
4 y 1 Free
4 z 1 Free
LCA Composition ProcessLCA Composition Process4.4. LCA cloningLCA cloning Repeat to generate more LCAs if ABBs are
available
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
xx
yy
xx
wwCore ID
ABB Type
ABB ID Status
1 x 1 Busy
5454
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
1 y 1 Busy
2 x 1 Busy
2 w 1 Free
3 z 1 Busy
3 w 1 Free
4 y 1 Busy
4 z 1 Busy

8/21/2012
28
LCA Composition ProcessLCA Composition Process
5.5. ABBs finishing taskABBs finishing task When ABBs finish, they signal the ABC. If
ABC has another task it sends otherwise it frees the ABBs
DONEDONE
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
frees the ABBs
xx
yy
xx
ww
Island ID
ABB Type
ABB ID Status
1 x 1 Busy
1 y 1 Busy
2 x 1 Busy
5555
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
2 w 1 Free
3 z 1 Busy
3 w 1 Free
4 y 1 Busy
4 z 1 Busy
LCA Composition ProcessLCA Composition Process
5.5. ABBs being freedABBs being freed When an ABB finishes, it signals the ABC. If
ABC has another task it sends otherwise it frees the ABBs
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
frees the ABBs
xx
yy
xx
ww
Island ID
ABB Type
ABB ID Status
1 x 1 Busy
1 y 1 Busy
2 x 1 Free
5656
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
2 w 1 Free
3 z 1 Busy
3 w 1 Free
4 y 1 Free
4 z 1 Free

8/21/2012
29
LCA Composition ProcessLCA Composition Process
6.6. Core notified of end of taskCore notified of end of task When the LCA finishes ABC signals the
core
ABB ABB
ISLAND1ISLAND1
ABB ABB
ISLAND2ISLAND2
xx
yy
xx
ww
Island ID
ABB Type
ABB ID Status
1 x 1 Free
1 y 1 Free
2 x 1 Free
DONEDONE
5757
ABBABB
ISLAND3ISLAND3
ABB ABB
ISLAND4ISLAND4
zz
ww
yy
zz
2 w 1 Free
3 z 1 Free
3 w 1 Free
4 y 1 Free
4 z 1 Free
ABC Internal DesignABC Internal Design♦♦ ABC subABC sub--componentscomponents Resource Table(RT): To keep track of
available/used ABBs Composed LCA Table (CLT): Eliminates
CComposedDFG
Cores
Accelerator Block Composer
the need to re-compose LCAs Task List (TL): To queue the broken LCA
requests (to smaller data size) TLB: To service and share the translation
requests by ABBs Task Flow-Graph Interpreter (TFGI):
Breaks the LCA DFG into ABBs LCA Composer (LC): Compose the LCA
using available ABBs
♦♦ ImplementationImplementationResource
Composed LCA Table
TLB
Task List
DFG Interpreter
LCA Composer
To ABBs
(allocate(allocate
5858
♦♦ ImplementationImplementation RT, CLT, TL and TLB are implemented
using RAM TFGI has a table to keep ABB types and an
FSM to read task-flow-graph and compares LC has an FSM to go over CLT and RT and
check mark the available ABBs
TableTLB
From ABBs(Done signal)(Done signal)
ABBs(TLB service)(TLB service)

8/21/2012
30
Evaluation MethodologyEvaluation Methodology
♦♦ Simics+GEMS based simulationSimics+GEMS based simulation
♦♦ AutoPilot/Xilinx+ Synopsys for AutoPilot/Xilinx+ Synopsys for ABB/ABC/DMAABB/ABC/DMA--C synthesisC synthesis
♦♦ Cacti for memory synthesis (SPM)Cacti for memory synthesis (SPM)
♦♦ Automatic flow to generate the CHARM Automatic flow to generate the CHARM software and simulation modulessoftware and simulation modules
♦♦ Case studiesCase studies Physical LCA sharing with Global
Accelerator Manager (LCA+GAM)
Physical LCA sharing with ABC
5959
Physical LCA sharing with ABC (LCA+ABC)
ABB composition and sharing with ABC (ABB+ABC)
♦♦ Medical imaging benchmarksMedical imaging benchmarks Denoise, Deblur, Segmentation and
Registration
Area Overhead AnalysisArea Overhead Analysis
♦♦ AreaArea--equivalentequivalent The total area consumed by
the ABBs equals the total the ABBs equals the total area of all LCAs required to run a single instance of each benchmark
♦♦ Total CHARM area is 14% Total CHARM area is 14% of the 1cmx1cm chipof the 1cmx1cm chip
A bit l th LCA b d
6060
A bit less than LCA-based design

8/21/2012
31
Results: Improvement Over LCAResults: Improvement Over LCA--based based DesignDesign
♦♦ N’xN’x’ ’ has has N N times area times area --equivalent accelerators equivalent accelerators
♦♦ PerformancePerformance 1
1.2
1.4
1.6
Normalized Performance
LCA GAM
2.5X vs. LCA+GAM (max 5X)
1.4X vs. LCA+ABC (max 2.6X)
♦♦ EnergyEnergy 1.9X vs. LCA+GAM (max 3.4X)
1.3X vs. LCA+ABC (max 2.2X)
♦♦ ABB+ABC has better ABB+ABC has better energy energy
0
0.2
0.4
0.6
0.8
1x 2x 4x 8x 1x 2x 4x 8x 1x 2x 4x 8x 1x 2x 4x 8x
Deb Den Reg Seg
LCA+GAM
LCA+ABC
ABB+ABC
1.2
1.4
Normalized Energy
6161
and performance and performance ABC starts composing ABBs to
create new LCAs
Creates more parallelism 0
0.2
0.4
0.6
0.8
1
1x 2x 4x 8x 1x 2x 4x 8x 1x 2x 4x 8x 1x 2x 4x 8x
Deb Den Reg Seg
LCA+GAM
LCA+ABC
ABB+ABC
Results: Platform FlexibilityResults: Platform Flexibility♦♦ Two applications from two Two applications from two
unrelated domains to MIunrelated domains to MI Computer vision
• Log-Polar Coordinate Image Patches (LPCIP)
Navigation
• Extended Kalman Filter-based Simultaneous Localization and Mapping (EKF-SLAM)
♦♦ Only one ABB is addedOnly one ABB is addedMAX Benefit over
LCA+GAM 3 64X
6262
♦♦ Only one ABB is addedOnly one ABB is added Indexed Vector Load
LCA+GAM 3.64XAVG Benefit over
LCA+GAM 2.46XMAX Benefit over
LCA+ABC 3.04XAVG Benefit over
LCA+ABC 2.05X

8/21/2012
32
Memory Management for AcceleratorMemory Management for Accelerator--Rich Rich Architectures Architectures [ISLPED’2012][ISLPED’2012]♦♦ Providing a private buffer for each accelerator is very inefficient. Providing a private buffer for each accelerator is very inefficient. Large private buffers: occupy a considerable amount of chip area Large private buffers: occupy a considerable amount of chip area Small private buffers: less effective for reducing offSmall private buffers: less effective for reducing off--chip bandwidthchip bandwidth
♦♦ Not all accelerators are poweredNot all accelerators are powered--on at the same time on at the same time Shared buffer [Lyonsy et al. TACO’12]Shared buffer [Lyonsy et al. TACO’12] Allocate the buffers in the cache onAllocate the buffers in the cache on--demand [demand [Fajardo et al.Fajardo et al. DAC’11DAC’11][Cong et al. ][Cong et al.
ISLPED’11]ISLPED’11]
♦♦ Our solution Our solution BiN: A BufferBiN: A Buffer--inin--NUCA Scheme for AcceleratorNUCA Scheme for Accelerator--Rich CMPsRich CMPs
6363
Buffer Size vs. OffBuffer Size vs. Off--chip Memory Access Bandwidthchip Memory Access Bandwidth♦♦ Buffer size Buffer size ↑ ↑ -- offoff--chip memory bandwidth chip memory bandwidth ↓↓: covering longer reuse distance [Cong et al. : covering longer reuse distance [Cong et al.
ICCAD’11]ICCAD’11]
♦♦ Buffer size vs. bandwidth curve: BBBuffer size vs. bandwidth curve: BB--CurveCurve
♦♦ Buffer utilization efficiencyBuffer utilization efficiency♦♦ Buffer utilization efficiencyBuffer utilization efficiency Different for various accelerators Different for various accelerators
Different for various inputs for one acceleratorDifferent for various inputs for one accelerator
♦♦ Prior work: no consideration of global allocation at runtimePrior work: no consideration of global allocation at runtime Accept fixedAccept fixed--size buffer allocation requestssize buffer allocation requests
Rely on the compiler to select a single, ‘best’ point in the BBRely on the compiler to select a single, ‘best’ point in the BB--CurveCurve
6464
0
500,000
1,000,000
1,500,000
2,000,000
2,500,000
9 27 119 693
Buffer size (KB)
Off-
chip
mem
ory
acc
ess
es
input image: cube(28)
input image: cube(52)
input image: cube(76)
DenoiseDenoise
High buffer utilization efficiencyHigh buffer utilization efficiency
Low buffer utilization efficiencyLow buffer utilization efficiency

8/21/2012
33
Resource FragmentationResource Fragmentation♦♦ Prior work allocates a Prior work allocates a contiguouscontiguous space to each buffer to simplify buffer accessspace to each buffer to simplify buffer access
♦♦ Requested buffers have unpredictable space demand and come in dynamically: Requested buffers have unpredictable space demand and come in dynamically: resource fragmentationresource fragmentation
♦♦ NUCA complicates buffer allocations in cacheNUCA complicates buffer allocations in cache The distance of the cache bank to the accelerator also mattersThe distance of the cache bank to the accelerator also matters
♦♦ To support fragmented resources: paged allocationTo support fragmented resources: paged allocation Analogous to a typical OSAnalogous to a typical OS--managed virtual memorymanaged virtual memory
♦♦ Challenges:Challenges: Large private page tables have high energy and area overheadLarge private page tables have high energy and area overhead Indirect access to a shared page table has high latency overheadIndirect access to a shared page table has high latency overhead
6565
Indirect access to a shared page table has high latency overheadIndirect access to a shared page table has high latency overhead
Shared buffer space: 15KBShared buffer space: 15KB
Buffer 1: 5KB, duration: 1K cyclesBuffer 1: 5KB, duration: 1K cycles
Buffer 2: 5KB, duration: 2K cyclesBuffer 2: 5KB, duration: 2K cycles
Buffer 3: 10KB, duration: 2K cycles Buffer 3: 10KB, duration: 2K cycles
BiN: BufferBiN: Buffer--inin--NUCANUCA♦♦ Goals of BufferGoals of Buffer--inin--NUCA (BiN)NUCA (BiN) Towards optimal onTowards optimal on--chip storage utilizationchip storage utilization
Dynamically allocate buffer space in the NUCA among a large number of competing Dynamically allocate buffer space in the NUCA among a large number of competing accelerators accelerators
♦♦ Contributions of BiN:Contributions of BiN: Dynamic intervalDynamic interval--based global (DIG) buffer allocation: address the buffer resource based global (DIG) buffer allocation: address the buffer resource
contentioncontention
Flexible paged buffer allocation: address the buffer resource fragmentation Flexible paged buffer allocation: address the buffer resource fragmentation
6666

8/21/2012
34
AcceleratorAccelerator--Rich CMP with BiNRich CMP with BiN♦♦Overall architecture of ARC [Cong et al. DAC Overall architecture of ARC [Cong et al. DAC 2011] with BiN2011] with BiN Cores (with private L1 caches)Cores (with private L1 caches) AcceleratorsAccelerators AcceleratorsAccelerators
●● Accelerator logicAccelerator logic●● DMADMA--controller controller ●● A small storage for the control structureA small storage for the control structure
The accelerator and BiN manager (ABM)The accelerator and BiN manager (ABM)●● Arbitration over accelerator resourcesArbitration over accelerator resources●● Allocates buffers in the shared cache (BiN Allocates buffers in the shared cache (BiN
management)management) NUCA (shared L2 cache) banksNUCA (shared L2 cache) banks (1) The core sends the accelerator and buffer allocation
6767
( )( ) (1) The core sends the accelerator and buffer allocation request with the BB-Curve to ABM.
(2) ABM performs accelerator allocation, buffer allocationin NUCA, and acknowledges the core.
(3) The core sends the control structure to the accelerator.(4) The accelerator starts working with its allocated buffer.(5) The accelerator signals to the core when it finishes.(6) The core sends the free-resource message to ABM.(7) ABM frees the accelerator and buffer in NUCA.
Dynamic IntervalDynamic Interval--based Global (DIG) Allocationbased Global (DIG) Allocation♦♦Perform global allocation for buffer allocation requests in an intervalPerform global allocation for buffer allocation requests in an interval
Keep the interval short (10K cycles): Minimize waitingKeep the interval short (10K cycles): Minimize waiting--inin--intervalinterval
If 8 or more buffer requests, the DIG allocation will start immediatelyIf 8 or more buffer requests, the DIG allocation will start immediately
A l 2 b ff ll ti tA l 2 b ff ll ti t♦♦An example: 2 buffer allocation requestsAn example: 2 buffer allocation requests
Each point (b, s)Each point (b, s)
●● s: buffer sizes: buffer size
●● b: corresponding bandwidth requirement at sb: corresponding bandwidth requirement at s
●● Buffer utilization efficiency at each point: Buffer utilization efficiency at each point:
The points are in nonThe points are in non--decreasing order of buffer sizedecreasing order of buffer size
( 1) ( 1)( ) /( )ij i j ij i jb b s s
6868
10 10( , )b s
11 11( , )b s
12 12( , )b s
04 04( , )b s
00 00( , )b s
01 01( , )b s
02 02( , )b s
01 00
01 00
( )
( )
b b
s s
02 01
02 01
( )
( )
b b
s s
11 10
11 10
( )
( )
b b
s s
12 11
12 11
( )
( )
b b
s s
00s 10s
01s01 00 11 10
01 00 11 10
( ) ( )
( ) ( )
b b b b
s s s s
11 10 02 01
11 10 02 01
( ) ( )
( ) ( )
b b b b
s s s s
02 0112 11
12 11 02 01
( )( )
( ) ( )
b bb b
s s s s
11s
12s
02s

8/21/2012
35
Flexible Paged AllocationFlexible Paged Allocation♦♦ Set the page size according to buffer size: FixedSet the page size according to buffer size: Fixed total number of pages for each buffer total number of pages for each buffer
♦♦ BiN manager locally keep the information of the current contiguous buffer space in each L2 bankBiN manager locally keep the information of the current contiguous buffer space in each L2 bank
Since all of the buffer allocation and free operations are performed by BiN manager Since all of the buffer allocation and free operations are performed by BiN manager
♦♦ Allocation: starting from the nearest L2 bank to this accelerator, to the farthestAllocation: starting from the nearest L2 bank to this accelerator, to the farthest
♦♦ We allow the last page (source of page fragments) of a buffer to be smaller than the other We allow the last page (source of page fragments) of a buffer to be smaller than the other pages of this bufferpages of this buffer
No impact on the page table lookup No impact on the page table lookup
The max page fragment will be smaller than the minThe max page fragment will be smaller than the min--page page
The page fragments do not waste capacity since they can be used by cacheThe page fragments do not waste capacity since they can be used by cache
6969
Buffer Allocation in NUCABuffer Allocation in NUCA♦♦ Total buffer sizeTotal buffer size
Buffers are allocated onBuffers are allocated on--demanddemand
Set an upperSet an upper--bound of the total buffer size: reduce the impact on cachebound of the total buffer size: reduce the impact on cache
StateState--ofof--thethe--art cache partitioning can be used to dynamically tune the upper boundart cache partitioning can be used to dynamically tune the upper bound●● E.g. [Qureshi & Patt, MICRO’06]E.g. [Qureshi & Patt, MICRO’06]
dealII gcc gobmk hmmer milc namd omnetpp perl povray sphinxxalancbmk0.00
0.25
0.50
0.75
1.001st bar: 2p-28, 2nd bar: 2p-52, 3rd bar: 2p-76, 4th bar: 2p-100
Cache BiN upper bound
Per
cent
of c
apac
ity
7070
♦♦ Buffer allocations among cache banksBuffer allocations among cache banks
Distribute the imposed upper bound onto cache banksDistribute the imposed upper bound onto cache banks
●● Avoid creating high contention in a particular cache bankAvoid creating high contention in a particular cache bank
StateState--ofof--thethe--art NUCA management schemes can be used to further mitigate contention art NUCA management schemes can be used to further mitigate contention introduced by buffer allocationintroduced by buffer allocation●● E.g., page reE.g., page re--coloring scheme [Cho & Jin, MICRO’06]coloring scheme [Cho & Jin, MICRO’06]

8/21/2012
36
Hardware Overhead of BiN ManagementHardware Overhead of BiN Management♦♦Storage: Storage:
32 SRAMs: contiguous spaces info in cache banks32 SRAMs: contiguous spaces info in cache banks●● 77--entry: at most 7 contiguous spaces in a 64KB cache bank with a minentry: at most 7 contiguous spaces in a 64KB cache bank with a min--page of 4KBpage of 4KB
●● 14 bits wide (10 bits: the starting block ID, 4 bits: the space length in terms of min14 bits wide (10 bits: the starting block ID, 4 bits: the space length in terms of min--page)page)
8 SRAMs: the BB8 SRAMs: the BB--curves of the buffer requests curves of the buffer requests ●● 88--entry: at most 8 BBentry: at most 8 BB--Curve pointsCurve points●● 5B wide: 2B for the buffer size and 3B for the buffer usage efficiency5B wide: 2B for the buffer size and 3B for the buffer usage efficiency
Total storage overhead: 768B, area: 3,282umTotal storage overhead: 768B, area: 3,282um22 (HP Cacti @ 32nm)(HP Cacti @ 32nm)
♦♦Logic: Logic:
9,725um9,725um22 @ 2GHz (Synopsys DC, SAED library @ 32nm)@ 2GHz (Synopsys DC, SAED library @ 32nm)
An average latency of 0.6us (1.2K cycles @ 2GHz) to perform the buffer allocationsAn average latency of 0.6us (1.2K cycles @ 2GHz) to perform the buffer allocations
7171
♦♦The total area of the buffer allocation module is less than 0.01% for a medium size 1cmThe total area of the buffer allocation module is less than 0.01% for a medium size 1cm22 chip chip
( 1)
( 1)
ij i j
ij i j
b b
s s
ijs
Simulation Infrastructure & BenchmarksSimulation Infrastructure & Benchmarks♦♦ Extend the fullExtend the full--system cyclesystem cycle--accurate Simics+GEMS simulation platform to support ARC+BiNaccurate Simics+GEMS simulation platform to support ARC+BiN
CPU 4 Ultra-SPARC III-i cores @ 2GHz
L1 data/instruction cache 32KB for each core, 4-way set-associative, 64B cache block, 3-cycle access latency, pseudo-LRU, MESI directory coherence by L2 cache
♦♦Benchmarks: 4 medical imaging applications in a Benchmarks: 4 medical imaging applications in a medical imaging pipelinemedical imaging pipeline
L2 cache (NUCA) 2MB, 32 banks, each bank is 64KB, 8-way set-associative, 64B cache block, 6-cycle access latency, pseudo-LRU
Network on chip 4X8 mesh, XY routing, wormhole switching, 3-cycle router latency, 1-cycle link latency
Main memory 4GB, 1000-cycle access latency
7272
Use the accelerator extraction method of [Cong et.al., DAC’12]Use the accelerator extraction method of [Cong et.al., DAC’12]
Accelerator is synthesized by AutoESL from XilinxAccelerator is synthesized by AutoESL from Xilinx
♦♦Experimental benchmark naming conventionExperimental benchmark naming convention
mPmP--n: m copies of pipelines, the input to each is a unique n^3 pixels image n: m copies of pipelines, the input to each is a unique n^3 pixels image ●● No Fragmentation: Used to show the gain of DIG allocation only No Fragmentation: Used to show the gain of DIG allocation only
mPmP--mix: m copies of pipelines, the inputs are randomly selected mix: m copies of pipelines, the inputs are randomly selected ●● Fragmentation occurs: Used to show the gain of both DIG and paged allocationFragmentation occurs: Used to show the gain of both DIG and paged allocation

8/21/2012
37
Reference Design SchemesReference Design Schemes♦♦ Accelerator Store (AS) [Lyonsy, et al. TACO’12]Accelerator Store (AS) [Lyonsy, et al. TACO’12] Separate cache and shared buffer moduleSeparate cache and shared buffer module
Set the buffer size 32% larger than maximum buffer size in BiN: overhead of bufferSet the buffer size 32% larger than maximum buffer size in BiN: overhead of buffer--inin--cachecache
Partition the shared buffer into 32 banks distributed them to the 32 NoC nodesPartition the shared buffer into 32 banks distributed them to the 32 NoC nodesPartition the shared buffer into 32 banks distributed them to the 32 NoC nodesPartition the shared buffer into 32 banks distributed them to the 32 NoC nodes
♦♦ BiC [BiC [Fajardo, et al. DAC’11Fajardo, et al. DAC’11]] BiC dynamically allocates contiguous cache space to a bufferBiC dynamically allocates contiguous cache space to a buffer
Upper bound: limiting buffer allocation to at most half of each cache bankUpper bound: limiting buffer allocation to at most half of each cache bank
Buffers can span multiple cache banks Buffers can span multiple cache banks
♦♦ BiNBiN--PagedPaged Only has the proposed paged allocation scheme Only has the proposed paged allocation scheme
♦♦ BiNBiN--Dyn Dyn
7373
yy Based on BiNBased on BiN--Paged, it also performs dynamic allocation without consideration of near future buffer Paged, it also performs dynamic allocation without consideration of near future buffer
requestsrequests
It responds to a request immediately by greedily satisfying the request with the current available resourcesIt responds to a request immediately by greedily satisfying the request with the current available resources
♦♦ BiNBiN--FullFull This is the entire proposed BiN schemeThis is the entire proposed BiN scheme
Impact of Dynamic IntervalImpact of Dynamic Interval--based Global Allocationbased Global Allocation♦♦ BiNBiN--Full consistently outperforms Full consistently outperforms
the other schemes the other schemes
The only exception: 4PThe only exception: 4P--mix3mix30.6
0.8
1.0
1.2
1.4
ized
Run
tim
e
●● 1.32X larger capacity of the AS 1.32X larger capacity of the AS can accommodate all buffer can accommodate all buffer requestsrequests
♦♦ Overall, compared to the Overall, compared to the accelerator store and BiC, BiNaccelerator store and BiC, BiN--Full Full reduces the runtime reduction by reduces the runtime reduction by 32% and 35%, respectively32% and 35%, respectively
0.0
0.2
0.4
0.6
1P-2
8
1P-5
2
1P-7
6
1P-1
002P
-28
2P-5
2
2P-7
6
2P-1
004P
-28
4P-5
2
4P-7
6
4P-1
00
4P-m
ix1
4P-m
ix2
4P-m
ix3
4P-m
ix4
4P-m
ix5
4P-m
ix6
Nor
mal
i
BiC BiN-Paged BiN-Dyn BiN-Full
1 0
1.2
mem
Comparison results of runtime
7474
0.0
0.2
0.4
0.6
0.8
1.0
1P-2
8
1P-5
2
1P-7
6
1P-1
002P
-28
2P-5
2
2P-7
6
2P-1
004P
-28
4P-5
2
4P-7
6
4P-1
00
4P-m
ix1
4P-m
ix2
4P-m
ix3
4P-m
ix4
4P-m
ix5
4P-m
ix6
Nor
mal
ized
Off-
chip
mac
cess
cou
nts
BiC BiN-Paged BiN-Dyn BiN-Full
Comparison results of off-chip memory accesses
8/21/2012
38
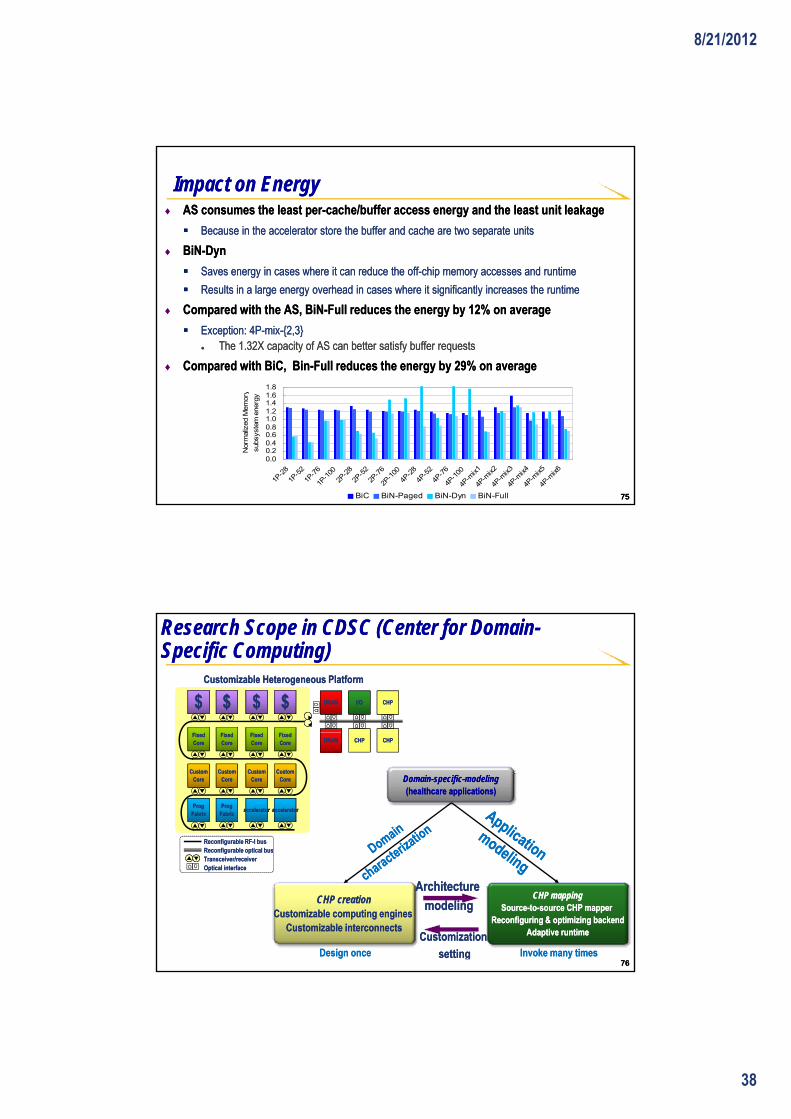
Impact on EnergyImpact on Energy♦♦ AS consumes the least perAS consumes the least per--cache/buffer access energy and the least unit leakagecache/buffer access energy and the least unit leakage
Because in the accelerator store the buffer and cache are two separate unitsBecause in the accelerator store the buffer and cache are two separate units
♦♦ BiNBiN--DynDyn
Saves energy in cases where it can reduce the offSaves energy in cases where it can reduce the off--chip memory accesses and runtime chip memory accesses and runtime
Results in a large energy overhead in cases where it significantly increases the runtimeResults in a large energy overhead in cases where it significantly increases the runtime
♦♦ Compared with the AS, BiNCompared with the AS, BiN--Full reduces the energy by 12% on averageFull reduces the energy by 12% on average
Exception: 4PException: 4P--mixmix--{2,3}{2,3}●● The 1.32X capacity of AS can better satisfy buffer requestsThe 1.32X capacity of AS can better satisfy buffer requests
♦♦ Compared with BiC, BinCompared with BiC, Bin--Full reduces the energy by 29% on averageFull reduces the energy by 29% on average1 8
7575
0.00.20.40.60.81.01.21.41.61.8
1P-2
8
1P-5
2
1P-7
6
1P-1
00
2P-2
8
2P-5
2
2P-7
6
2P-1
00
4P-2
8
4P-5
2
4P-7
6
4P-1
00
4P-m
ix1
4P-m
ix2
4P-m
ix3
4P-m
ix4
4P-m
ix5
4P-m
ix6
Nor
mal
ized
Mem
ory
subs
yste
m e
nerg
y
BiC BiN-Paged BiN-Dyn BiN-Full
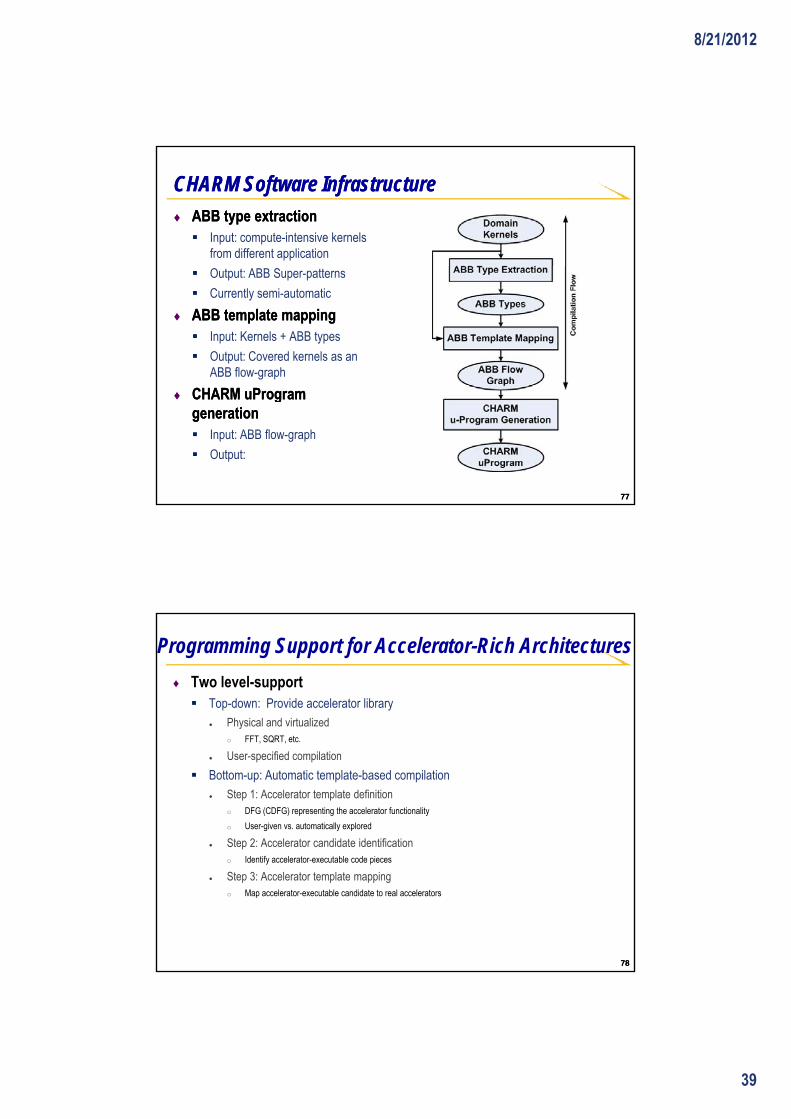
Customizable Heterogeneous Platform Customizable Heterogeneous Platform (CHP)(CHP)
$$ $$ $$ $$ DRAMDRAM I/OI/O CHPCHP
Research Scope in CDSC (Center for DomainResearch Scope in CDSC (Center for Domain--Specific Computing)Specific Computing)
FixedFixedCoreCore
FixedFixedCoreCore
FixedFixedCoreCore
FixedFixedCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
CustomCustomCoreCore
ProgProgFabricFabric
ProgProgFabricFabric
acceleratoracceleratoracceleratoraccelerator acceleratoracceleratoracceleratoraccelerator
DRAMDRAM CHPCHP CHPCHP
Reconfigurable RFReconfigurable RF--I busI busReconfigurable optical busReconfigurable optical bus
DomainDomain--specificspecific--modelingmodeling(healthcare applications)(healthcare applications)
7676
Reconfigurable optical busReconfigurable optical busTransceiver/receiverTransceiver/receiverOptical interfaceOptical interface
CHP mappingCHP mappingSourceSource--toto--source CHP mapper source CHP mapper
Reconfiguring & optimizing backendReconfiguring & optimizing backendAdaptive runtimeAdaptive runtime
CHP creationCHP creationCustomizable computing engines Customizable computing engines
Customizable interconnectsCustomizable interconnects
Architecture Architecture
modelingmodeling
Customization Customization
settingsettingDesign onceDesign once Invoke many timesInvoke many times
8/21/2012
39
CHARM Software InfrastructureCHARM Software Infrastructure♦♦ ABB type extraction ABB type extraction Input: compute-intensive kernels
from different application
Output: ABB Super-patterns
Currently semi-automatic
♦♦ ABB template mappingABB template mapping Input: Kernels + ABB types
Output: Covered kernels as an ABB flow-graph
7777
♦♦ CHARM uProgram CHARM uProgram generationgeneration Input: ABB flow-graph
Output:
Programming Support for Accelerator-Rich Architectures
♦ Two level-support Top-down: Provide accelerator library
● Physical and virtualized o FFT, SQRT, etc.
● User-specified compilation
Bottom-up: Automatic template-based compilation ● Step 1: Accelerator template definition
o DFG (CDFG) representing the accelerator functionality
o User-given vs. automatically explored
● Step 2: Accelerator candidate identification
7878
o Identify accelerator-executable code pieces
● Step 3: Accelerator template mappingo Map accelerator-executable candidate to real accelerators

8/21/2012
40
Template-Based Compilation Flow♦ Accelerator candidate identification Given an input data flow graph G and accelerator template T, identify all the accelerator
candidates in G, which can run on the accelerator unitsS bgraph isomorphism ith pre filtering (feat re ector [Cong et al FPGA’08])● Subgraph-isomorphism with pre-filtering (feature vector [Cong, et.al. FPGA’08])
+ +
+
+*
+ +
+
+
1 2 3 4
5 6 7
8 9
2 3 41 6 7 85
10 11 129
i0 i1 i2 i3 i4 i5 i6 i7 i8 i9 i10 i11 i12 i13 i14 i15
o0 o1 o2 o3 o4 o5 o6 o7
o8 o9 o10 o11
7979
*+
/
*+
11
10 12
131
4(a) Kernel DFG of rician-denoise
15
1413
o12 o13
o14arithmetic/logical/move
(b) User-defined accelerator template
Template-based Compilation Flow♦ Accelerator template mapping Given an input data flow graph G and a set of identified accelerator candidates, select a
subset of accelerator candidates which can cover the entire G optimally and map each selected accelerator candidate to an accelerator unitselected accelerator candidate to an accelerator unit.
+ +
+
+*
+ +
+
+
1 2 3 4
5 6 7
8 9
acc1
2 3 41
109
15
13
acc1
6 7 85
1211
14
8080
*+
/
*+
1110
12 13
14
(a) One mapping solution
acc22 3 41
109
15
13
(b) Accelerator configure of (a)
acc2
6 7 85
1211
14

8/21/2012
41
Accelerator Template Definition♦ Text-based interface Node declaration
● ni:op1;op2;op3…opn
● Specify the set of operations supported by each template node ni
Edge declaration● ni->nj:k
● Specify the data flow between template node ni and njo The result of node ni will be sent to node nj as the kth operand
ExampleNode declaration
8181
● Node declaration
o n1: *
o n2: +
o n3: *;+
o n4: /
• Edge declaration
n1->n2:1
n2->n4:1
n3->n4:2
*
+
/
{+,*}
xPilot: Behavioral-to-RTL Synthesis Flow [SOCC’2006]
Behavioral spec. Behavioral spec. in C/C++/SystemCin C/C++/SystemC
Advanced transformtion/optimizationsAdvanced transformtion/optimizations Loop unrolling/shifting/pipeliningLoop unrolling/shifting/pipelining Strength reduction / Tree height reductionStrength reduction / Tree height reduction
Bit idth l iBit idth l iPlatform Platform
SSDMSSDM
Bitwidth analysisBitwidth analysis Memory analysis …Memory analysis …
FrontendFrontendcompilercompiler
Platform Platform descriptiondescription
Core behvior synthesis optimizationsCore behvior synthesis optimizations SchedulingScheduling Resource binding, e.g., functional unit Resource binding, e.g., functional unit
binding register/port bindingbinding register/port binding
8282
RTL + constraintsRTL + constraints ArchArch--generation & RTL/constraints generation & RTL/constraints
generationgeneration Verilog/VHDL/SystemCVerilog/VHDL/SystemC FPGAs: Altera, Xilinx FPGAs: Altera, Xilinx ASICs: Magma, Synopsys, …ASICs: Magma, Synopsys, …
FPGAs/ASICsFPGAs/ASICs

8/21/2012
42
AutoPilot Compilation Tool (based UCLA xPilot system)
♦ Platform-based C to FPGA synthesis
C/C++/SystemCC/C++/SystemC
Sim
uS
imu
Compilation &Compilation & A t Pil tA t Pil tTMTM
Co
mm
Co
mm
User ConstraintsUser Constraints
Design SpecificationDesign Specification
y
♦ Synthesize pure ANSI-C and C++, GCC-compatible compilation flow
♦ Full support of IEEE-754 floating point data types & operations
♦ Efficiently handle bit-accurate fixed-point arithmetic
Platform Platform Characterization Characterization
LibraryLibrary
==
ulatio
n, V
erification
, and
Pro
ulatio
n, V
erification
, and
Pro
Compilation & Compilation & ElaborationElaboration
Presynthesis OptimizationsPresynthesis Optimizations
Behavioral & CommunicationBehavioral & Communication
Synthesis and OptimizationsSynthesis and Optimizations
AutoPilotAutoPilotTMTMon
Testben
cho
n Testb
ench
ES
L S
ynth
esisE
SL
Syn
thesis
8383
p
♦ More than 10X design productivity gain
♦ High quality-of-results
Timing/Power/Layout Timing/Power/Layout ConstraintsConstraints
RTL HDLs &RTL HDLs &RTL SystemCRTL SystemC
FPGAFPGACoCo--ProcessorProcessor
oto
typin
go
totyp
ing
Developed by AutoESL, acquired by Xilinx in Jan. 2011Developed by AutoESL, acquired by Xilinx in Jan. 2011
Toplevel Block Diagram
HMatrix
multiplyMatrix
multiplyQRDBack
Subst.
4x4 Matrix Inverse NormSearch/Reorder
4x4
AutoPilot Results: Sphere Decoder (from Xilinx)AutoPilot Results: Sphere Decoder (from Xilinx)
• Wireless MIMO Sphere Decoder
– ~4000 lines of C code
Matrixmultiply
MatrixmultiplyQRD
BackSubst.
3x3 Matrix Inverse NormSearch/Reorder
3x3
Matrixmultiply
MatrixmultiplyQRD
BackSubst.
2x2 Matrix Inverse NormSearch/Reorder
2x2
8x8 RVDQRD
Tree Search Sphere Detector
Stage 1 Stage 8Min
Search…Metric RTL
ExpertAutoPilot Expert
Diff (%)
– Xilinx Virtex-5 at 225MHz
• Compared to optimized IP – 11-31% better resource
usage
84848/21/2012 UCLA VLSICAD
LUTs 32,708 29,060 -11%
Registers 44,885 31,000 -31%
DSP48s 225 201 -11%
BRAMs 128 99 -26%
TCAD April 2011 (keynote paper)“High-Level Synthesis for FPGAs: From Prototyping to Deployment”
84

8/21/2012
43
AutoPilot Results: Optical Flow (from BDTI)AutoPilot Results: Optical Flow (from BDTI)♦♦ ApplicationApplication Optical flow, 1280x720 progress scanOptical flow, 1280x720 progress scan
Design too complex for an RTL teamDesign too complex for an RTL team
Input VideoInput Video
♦♦ Compared to highCompared to high--end DSP: end DSP: 30X higher throughput, 40X better cost/fps30X higher throughput, 40X better cost/fps
Chip Unit Cost
Highest Frame Rate @ 720p (fps)
Cost/performance ($/frame/second)
Xilinx $27 183 $0 14
Output Video
8585
Xilinx Spartan3ADSP XC3SD3400A chip
$27 183 $0.14
Texas Instruments TMS320DM6437 DSP processor
$21 5.1 $4.20
BDTi evaluation of AutoPilot http://www.bdti.com/articles/AutoPilot.pdf 85
AutoPilot Results: DQPSK Receiver (from BDTI)AutoPilot Results: DQPSK Receiver (from BDTI)
♦♦ ApplicationApplication DQPSK receiverDQPSK receiver
18 75Msamples @75MHz clock 18 75Msamples @75MHz clock
Hand-coded RTL
AutoPilot
18.75Msamples @75MHz clock 18.75Msamples @75MHz clock speedspeed
♦♦ Area better than handArea better than hand--codedcodedXilinx XC3SD3400A chip utilization ratio (lower the better)
5.9% 5.6%
BDTi evaluation of AutoPilot http://www.bdti.com/articles/AutoPilot.pd
8686
8/21/2012 UCLA VLSICAD 86

8/21/2012
44
CHP Mapping OverviewCHP Mapping OverviewGoal: Goal: Efficient mapping of domainEfficient mapping of domain--specific application to customizable hardwarespecific application to customizable hardware
Adapt the CHP to a given application so as to optimize performance/power efficiencyAdapt the CHP to a given application so as to optimize performance/power efficiency
Domain-specific applications
Abstract execution
Programmer
Domain-specific programming model(Domain-specific coordination graph and domain-specific language extensions)
Source-to source CHP Mapper (Rose)
Application characteristics
CHP architecture models
C/C++ code
C/C++ front-end
Accelerator
C/C++
RTL Synthesizer
Accelerator kernelROSE SAGE IR
ROSE LLVM translator
8787
Reconfiguring and optimizing back-end (LLVM)
Binary code for fixed & customized cores
Accelerator code
compiler/library
Performance feedback
Unified Adaptive Runtime system(maps tasks across CPUs, GPUs, Accelerators, FPGA processors)
CHP architectural prototypes(CHP hardware testbeds, CHP simulation
testbed, full CHP)
RTL for prog fabric
(AutoPilot/xPilot)
Programming Model and Runtime Support Programming Model and Runtime Support [LCTES12][LCTES12]
♦♦ Concurrent Collection (CnC) programming model Concurrent Collection (CnC) programming model Clear separation between application description and Clear separation between application description and
implementationimplementationpp
Fits domain expert needsFits domain expert needs
♦♦ CnCCnC--HC: Software flow CnC => HabaneroHC: Software flow CnC => Habanero--C(HC)C(HC)♦♦ CrossCross--device workdevice work--stealing in Habanerostealing in Habanero--CC Task affinity with heterogeneous componentsTask affinity with heterogeneous components
♦♦ Data driven runtime in CnCData driven runtime in CnC--HCHC
8888
♦♦ Data driven runtime in CnCData driven runtime in CnC--HCHC
8/21/2012
45
CnC Building BlocksCnC Building Blocks
♦♦ StepsSteps Computational unitsComputational units
Functional with respects to their inputsFunctional with respects to their inputs Functional with respects to their inputsFunctional with respects to their inputs
♦♦ Data ItemsData Items Means of communication between stepsMeans of communication between steps
Dynamic single assignmentDynamic single assignment
♦♦ Control ItemsControl Items Used to create (prescribe) instances of a computation stepUsed to create (prescribe) instances of a computation step
8989
Used to create (prescribe) instances of a computation stepUsed to create (prescribe) instances of a computation step
Intel® Intel® X ® X ®
Application Application Engine Hub Engine Hub
Application Engines Application Engines (AEs)(AEs)
Direct Direct Data Data
“Commodity” Intel Server“Commodity” Intel Server Convey FPGAConvey FPGA--based coprocessorbased coprocessor
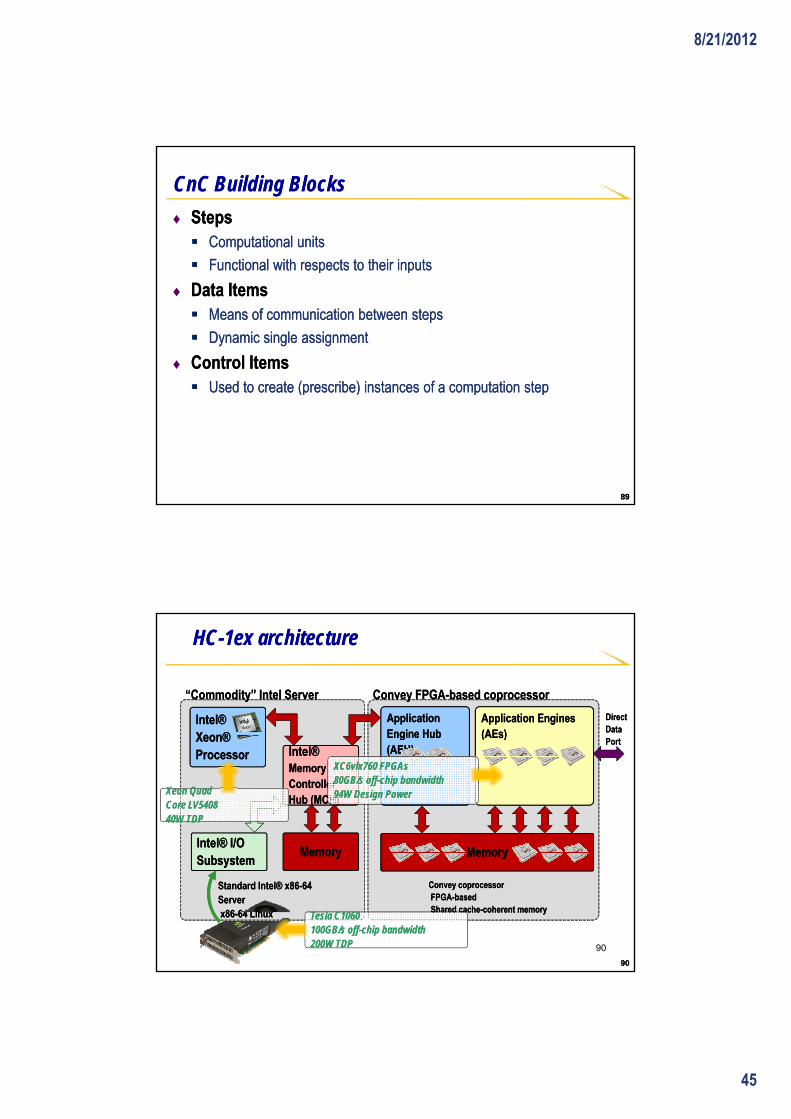
HCHC--1ex architecture1ex architecture
Xeon® Xeon® ProcessorProcessor
( )( )
Intel® Intel® Memory Memory Controller Controller Hub (MCH)Hub (MCH)
Intel® I/O Intel® I/O MemoryMemory MemoryMemory
Engine Hub Engine Hub (AEH)(AEH)
(AEs)(AEs) Data Data PortPort
Xeon QuadXeon QuadCore LV5408Core LV540840W TDP40W TDP
XC6vlx760 FPGAsXC6vlx760 FPGAs80GB/s off80GB/s off--chip bandwidthchip bandwidth94W Design Power94W Design Power
9090
SubsystemSubsystemMemoryMemory MemoryMemory
Standard Intel® x86Standard Intel® x86--64 64 ServerServerx86x86--64 Linux64 Linux
Convey coprocessorConvey coprocessorFPGAFPGA--basedbasedShared cacheShared cache--coherent memorycoherent memory
Tesla C1060Tesla C1060100GB/s off100GB/s off--chip bandwidthchip bandwidth200W TDP200W TDP 90

8/21/2012
46
Runtime Support Experimental resultsRuntime Support Experimental results
♦♦ Performance for medical imaging kernelsPerformance for medical imaging kernels
Denoise Registration Segmentation
Num iterations 3 100 50
CPU (1 core) 3.3s 457.8s 36.76s
GPU 0.085s (38.3 ×) 20.26s (22.6 ×) 1.263s (29.1 ×)
FPGA 0.190s (17.2 ×) 17.52s (26.1 ×) 4.173s (8.8 ×)
9191
( ) ( ) ( )
Experimental Results (Cont’d)Experimental Results (Cont’d)
• Execution times and active energy with dynamic work stealingwork stealing
9292

8/21/2012
47
Static vs Dynamic bindingStatic vs Dynamic binding
♦♦ Static bindingStatic binding
♦♦ Dynamic BindingDynamic Binding
9393
93
Concluding Remarks♦♦ Despite of end of scaling, there is plenty of opportunity with Despite of end of scaling, there is plenty of opportunity with
customization and specialization for energy efficient computingcustomization and specialization for energy efficient computing
♦♦ Many opportunities and challenges for architecture supportMany opportunities and challenges for architecture supporty pp g ppy pp g pp Cores
Accelerators
Memory
Network-on-chips
♦♦ Software support is also critical Software support is also critical
9494

8/21/2012
48
Acknowledgements: CDSC Faculty
Aberle Aberle (UCLA)(UCLA)
Baraniuk Baraniuk (Rice)(Rice)
Bui Bui (UCLA)(UCLA)
Cong (Director) Cong (Director) (UCLA)(UCLA)
Cheng Cheng (UCSB)(UCSB)
Chang Chang (UCLA)(UCLA)
9595
Reinman Reinman (UCLA)(UCLA)
Palsberg Palsberg (UCLA)(UCLA)
Sadayappan Sadayappan (Ohio(Ohio--State)State)
SarkarSarkar(Associate Dir) (Associate Dir)
(Rice)(Rice)
Vese Vese (UCLA)(UCLA)
Potkonjak Potkonjak (UCLA)(UCLA)
More Acknowledgements
Mohammad Ali GhodratMohammad Ali Ghodrat
Yi ZouYi ZouChunyue Chunyue LiuLiu
Hui HuangHui HuangMichael GillMichael Gill BeaynaBeaynaGrigorianGrigorian
9696
♦♦ This research is partially supported by the Center for DomainThis research is partially supported by the Center for Domain-- Specific Specific Computing (CDSC) funded by the NSF Expedition in Computing Award CCFComputing (CDSC) funded by the NSF Expedition in Computing Award CCF--0926127, GSRC under contract 20090926127, GSRC under contract 2009--TJTJ--1984.1984.
LiuLiu GrigorianGrigorian
8/21/2012
49
Examples of EnergyExamples of Energy--Efficient CustomizationEfficient Customization
♦♦ Customization of processor coresCustomization of processor cores♦♦ Customization of onCustomization of on--chip memorychip memory♦♦ Customization of onCustomization of on--chip interconnectschip interconnects
9797
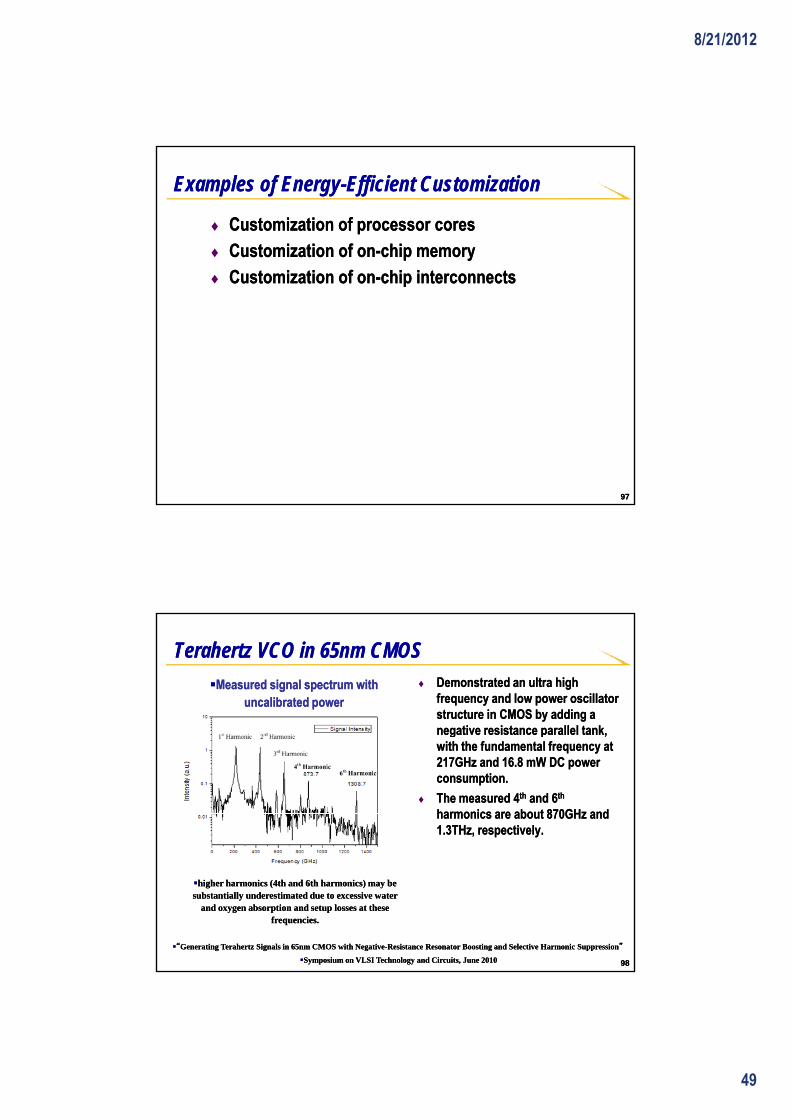
Terahertz VCO in 65nm CMOSTerahertz VCO in 65nm CMOS♦♦ Demonstrated an ultra high Demonstrated an ultra high
frequency and low power oscillator frequency and low power oscillator structure in CMOS by adding a structure in CMOS by adding a negative resistance parallel tank negative resistance parallel tank
Measured signal spectrum with Measured signal spectrum with uncalibrated poweruncalibrated power
negative resistance parallel tank, negative resistance parallel tank, with the fundamental frequency at with the fundamental frequency at 217GHz and 16.8 mW DC power 217GHz and 16.8 mW DC power consumption. consumption.
♦♦ The measured 4The measured 4thth and 6and 6thth
harmonics are about 870GHz and harmonics are about 870GHz and 1.3THz, respectively. 1.3THz, respectively.
9898
higher harmonics (4th and 6th harmonics) may be higher harmonics (4th and 6th harmonics) may be substantially underestimated due to excessive water substantially underestimated due to excessive water
and oxygen absorption and setup losses at these and oxygen absorption and setup losses at these frequencies.frequencies.
““Generating Terahertz Signals in 65nm CMOS with NegativeGenerating Terahertz Signals in 65nm CMOS with Negative--Resistance Resonator Boosting and Selective Harmonic SuppressionResistance Resonator Boosting and Selective Harmonic Suppression””
Symposium on VLSI Technology and Circuits, June 2010Symposium on VLSI Technology and Circuits, June 2010
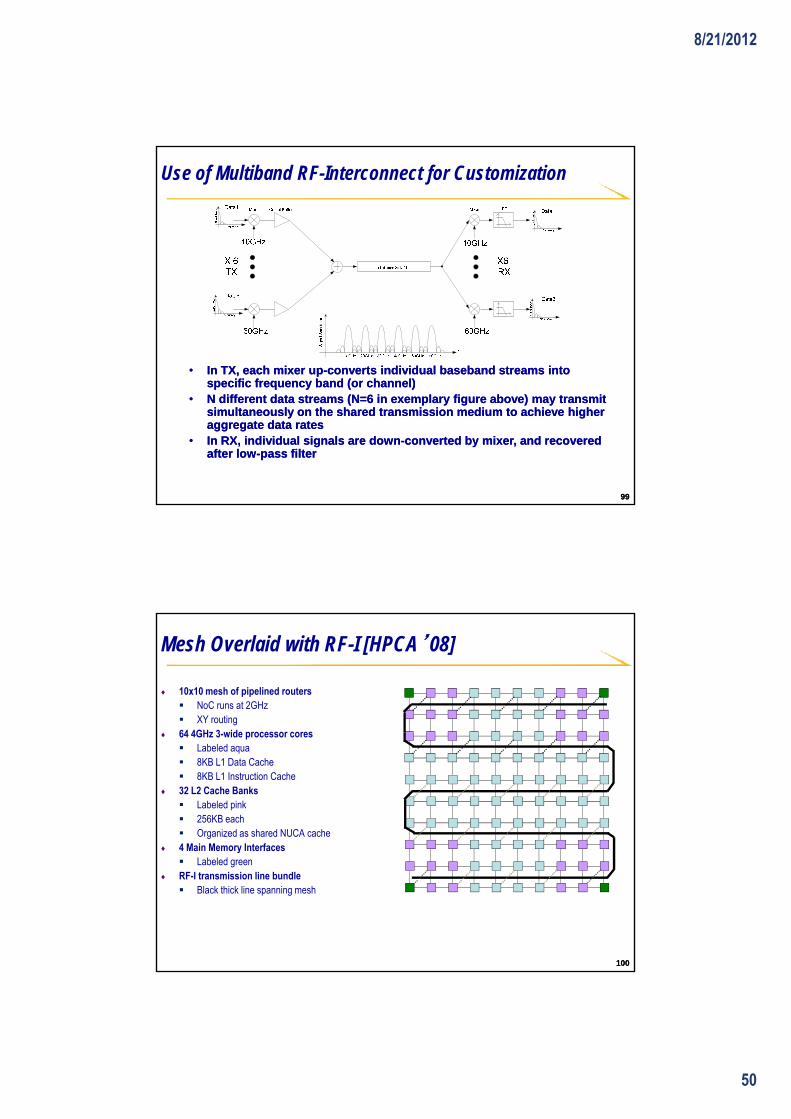
8/21/2012
50
Use of Multiband RF-Interconnect for Customization
•• In TX, each mixer upIn TX, each mixer up--converts individual baseband streams into converts individual baseband streams into specific frequency band (or channel)specific frequency band (or channel)
9999
specific frequency band (or channel)specific frequency band (or channel)•• N different data streams (N=6 in exemplary figure above) may transmit N different data streams (N=6 in exemplary figure above) may transmit
simultaneously on the shared transmission medium to achieve higher simultaneously on the shared transmission medium to achieve higher aggregate data rates aggregate data rates
•• In RX, individual signals are downIn RX, individual signals are down--converted by mixer, and recovered converted by mixer, and recovered after lowafter low--pass filterpass filter
Mesh Overlaid with RF-I [HPCA’08]
♦ 10x10 mesh of pipelined routers NoC runs at 2GHz XY routing64 4GHz 3 wide processor cores♦ 64 4GHz 3-wide processor cores Labeled aqua 8KB L1 Data Cache 8KB L1 Instruction Cache
♦ 32 L2 Cache Banks Labeled pink 256KB each Organized as shared NUCA cache
♦ 4 Main Memory Interfaces
100100
y Labeled green
♦ RF-I transmission line bundle Black thick line spanning mesh
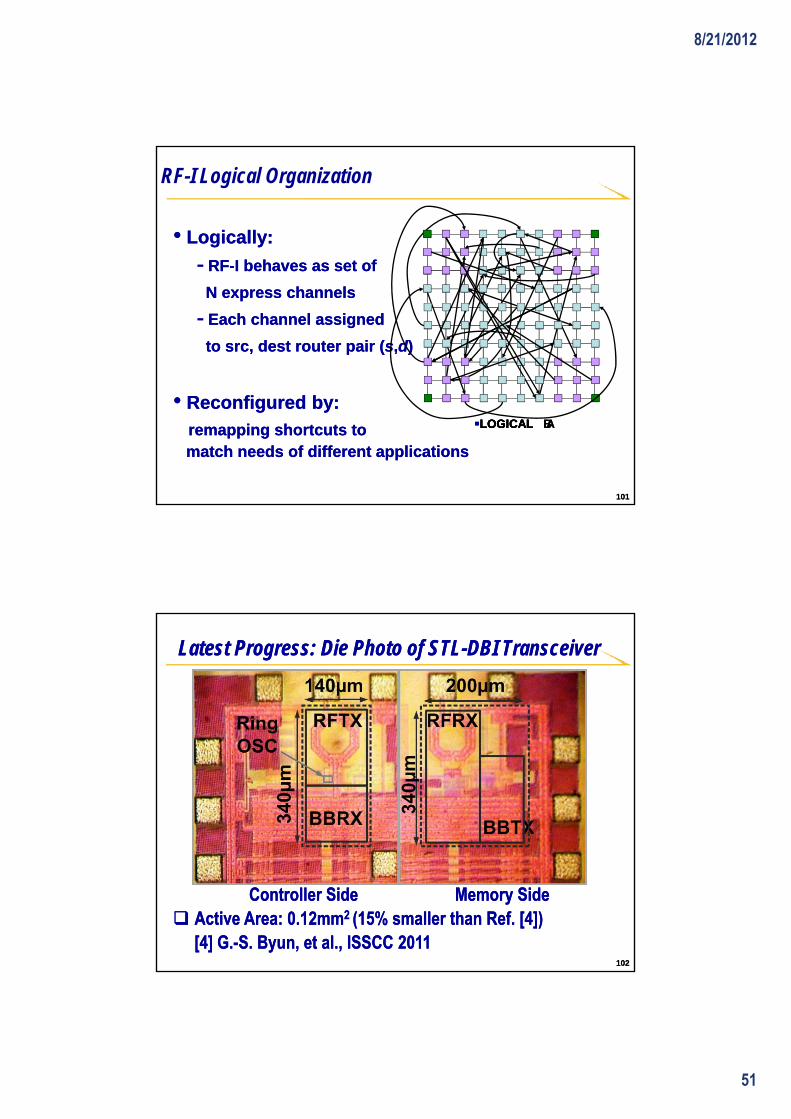
8/21/2012
51
RF-I Logical Organization
•• Logically:Logically:
-- RFRF--I behaves as set ofI behaves as set of-- RFRF--I behaves as set of I behaves as set of
N express channelsN express channels
-- Each channel assigned Each channel assigned
to to srcsrc, , destdest router pair (router pair (ss,,dd))
101101
•• Reconfigured by:Reconfigured by:
remapping remapping shortcuts to shortcuts to match match needs of differentneeds of different applicationsapplications
LOGICAL ALOGICAL ALOGICAL BLOGICAL B
Latest Progress: Die Photo of STLLatest Progress: Die Photo of STL--DBI TransceiverDBI Transceiver
102102
Controller SideController Side Memory SideMemory Side Active Area: 0.12mmActive Area: 0.12mm2 2 (15% smaller than Ref. [4])(15% smaller than Ref. [4])
[[4] G.4] G.--S. S. ByunByun, et al., ISSCC 2011, et al., ISSCC 2011

8/21/2012
52
Comparison with StateComparison with State--ofof--thethe--artartThis Work JSSC 2009[1] ISSCC 2009[2] JSSC 2010[3] ISSCC 2011[4]
Technology 65nm 180nm 130nm 40nm 65nm
Signaling Single-Ended Single-Ended Single-Ended Differential Differential
Link Type SBD Bidirectional Bidirectional Bidirectional SBD
Aggregatedata rate/pin
8Gb/s/pin 5Gb/s/pin 6Gb/s/pin 2.15Gb/s/pin4.2Gb/s/pin
Total Power14.4mW(BB)17.6mW(RF)
87mW 95mW 14.4mW12mW (BB)11mW (RF)
Energy/bit/pin 4pJ/bit/pin 17.4pJ/bit/pin 15.8pJ/bit/pin 6.6pJ/bit/pin 5pJ/bit/pin
Chip Area 0.12mm2 0.52mm2 0.30mm2 0.9mm2 0.14mm2
FoM 2 08 0 11 0 21 0 17 1 30
103103
FoM 2.08 0.11 0.21 0.17 1.30
mJmm
pinGb
PowerArea
pinDRFoM
2
//
[1] K.[1] K.--I. Oh, et al., JSSC2009 (Samsung)I. Oh, et al., JSSC2009 (Samsung)
[2] K.[2] K.--S. Ha, et al., ISSCC2009 (Samsung)S. Ha, et al., ISSCC2009 (Samsung)
[3] B. Leibowitz, et al., JSSC2010 (Rambus)[3] B. Leibowitz, et al., JSSC2010 (Rambus)
[4] G.[4] G.--S. Byun, et al., ISSCC 2011 (UCLA)S. Byun, et al., ISSCC 2011 (UCLA)
104104
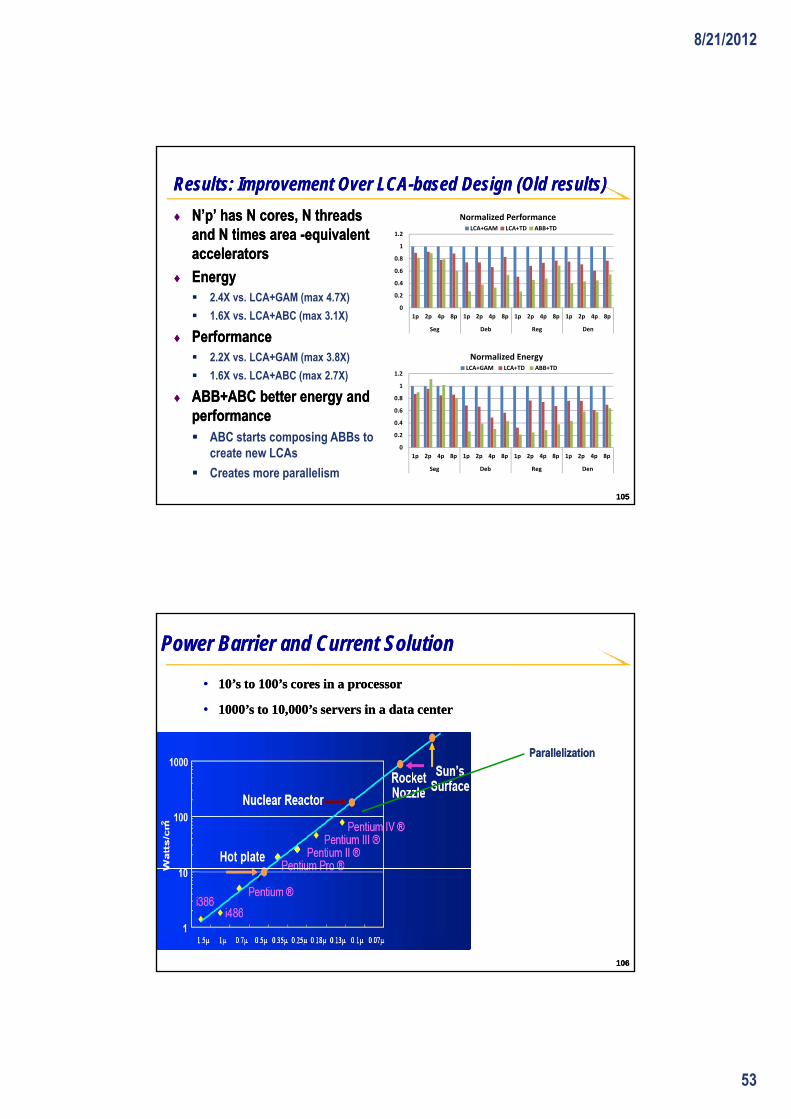
8/21/2012
53
Results: Improvement Over LCAResults: Improvement Over LCA--based based Design (Old results)Design (Old results)
♦♦ N’pN’p’ has N cores, N threads ’ has N cores, N threads and N times area and N times area --equivalent equivalent accelerators accelerators 0.8
1
1.2
Normalized PerformanceLCA+GAM LCA+TD ABB+TD
♦♦ EnergyEnergy 2.4X vs. LCA+GAM (max 4.7X)
1.6X vs. LCA+ABC (max 3.1X)
♦♦ PerformancePerformance 2.2X vs. LCA+GAM (max 3.8X)
1.6X vs. LCA+ABC (max 2.7X)
0
0.2
0.4
0.6
1p 2p 4p 8p 1p 2p 4p 8p 1p 2p 4p 8p 1p 2p 4p 8p
Seg Deb Reg Den
1
1.2
Normalized EnergyLCA+GAM LCA+TD ABB+TD
105105
♦♦ ABB+ABC better energy and ABB+ABC better energy and performance performance ABC starts composing ABBs to
create new LCAs
Creates more parallelism
0
0.2
0.4
0.6
0.8
1
1p 2p 4p 8p 1p 2p 4p 8p 1p 2p 4p 8p 1p 2p 4p 8p
Seg Deb Reg Den
Power Barrier and Current SolutionPower Barrier and Current Solution
•• 10’s to 100’s cores in a processor10’s to 100’s cores in a processor
•• 1000’s to 10,000’s servers in a data center1000’s to 10,000’s servers in a data center
ParallelizationParallelization
106106

8/21/2012
54
Examples of EnergyExamples of Energy--Efficient CustomizationEfficient Customization
♦♦ Customization of processor coresCustomization of processor cores♦♦ Customization of onCustomization of on--chip memorychip memory♦♦ Customization of onCustomization of on--chip interconnectschip interconnects
107107
Related Documents










