University of Cyprus Department of Computer Science EPL 660: Lab 2 Apache Lucene Part II Andreas Kamilaris

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

University of CyprusDepartment of Computer Science
EPL 660: Lab 2Apache Lucene Part II
Andreas Kamilaris

University of CyprusIndexing with Lucene• Fundamental Lucene classes for indexing text:
– IndexWriter– Analyzer– Document– Field
• IndexWriter is used to create a new index and to add Documents to an existing index
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusIndexing with Lucene• Before text is indexed, it is passed through an
Analyzer.• Analyzers extract indexable tokens out of text to
be indexed, and eliminating the rest.• Lucene comes with a few different Analyzer
implementations:– Some of them deal with skipping stop words
(frequently-used words that don't help distinguish onedocument from the other, such as "a," "an," "the” etc.)
– Some deal with converting all tokens to lowercaseletters, so that searches are not case-sensitive.
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusIndexing with Lucene• An index consists of a set of Documents.• Each Document consists of one or more Fields.• Each Field has a name and a value:
– Think of a document as a row in a database table andfields as columns in that row.
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusField Types• Lucene offers four different types of fields:
– Keyword, – UnIndexed, – UnStored, – Text
• Keyword fields: not tokenized, but indexed andstored in the index verbatim. This field is suitable for fields whose original valueshould be preserved in its entirety, such as URLs, dates, personal names, telephone numbers etc.
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusField Types• UnIndexed fields: neither tokenized nor indexed,
but their value is stored in the index as it is. • This field is suitable for fields that you will display
with search results, but whose values you ‘ll neversearch directly (URL, database primary key).
• Because this type of field is not indexed, searchesagainst it are slow.
• Since the original value of a field of this type isstored in the index, this type is not suitable forstoring fields with very large values, if index sizeis an issue.
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusField Types• UnStored fields: the opposite of UnIndexed fields.
Fields of this type are tokenized and indexed, butare not stored in the index (as they are). This field is suitable for indexing large amounts of text that does not need to be retrieved in itsoriginal form, such as the bodies of Web pages, or any other type of text document.
• Text fields: are tokenized, indexed, and stored in the index. This implies that fields of this type canbe searched, but be cautious about the size of thefield stored as Text field.
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusOverview of different field types
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusSimple Scenario
Text stored in a String variable
Lucene stores the index in a directory on the file system
IndexWriter’sconstructor
Standard Analyzer eliminatesstop words, converts tokens to lower case, and performs a fewother small input modifications, such as eliminating periodsfrom acronyms
createFlag: when true, tells IndexWriter to create a new index in the specifieddirectory, or overwrite an index in that directory, if it already existsA value of false instructs IndexWriter to instead add Documents to an existing index.
LuceneIndexExample.java

University of Cyprus
add it to the index via the instance of IndexWriter
Simple Scenario
IndexWriter’sconstructor
Create blank document
add a Field called fieldname to the document, with a value of theString that we want to index
LuceneIndexExample.java
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusAnalyzers• Components that pre-process input text.• Also used for searching:
– Because the search string has to be processed thesame way that the indexed text was processed, it iscrucial to use the same Analyzer for both indexing andsearching. Not using the same Analyzer will result in invalid search results.
• Analyzer class is an abstract class.• Lucene comes with a few concrete analyzers that
pre-process their input in different ways.• Custom analyzers can be also implemented.
Tutorial based on http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusThe PorterStemAnalyzer• Porter stemming algorithm is a process for
removing the more common morphological andinflexional endings from words in English.
• This analyzer will use an implementation of thePorter stemming algorithm provided by Lucene'sPorterStemFilter class.
PorterStemAnalyzer Tutorial: http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusThe PorterStemAnalyzer
Standard Analyzer’s constructor acceptsa File with stopwords
PorterStemAnalyzer’s constructors

University of CyprusThe PorterStemAnalyzer
Core method of the PorterStemAnalyzer
• lower-cases input, • eliminates stop words, • uses the PorterStemFilter to removecommon morphological and inflexionalendings
To use the new PorterStemAnalyzer class, we need to modify a single line of ourLuceneIndexExample class, to instantiate PorterStemAnalyzer instead of StandardAnalyzer:
The rest of the code remains unchanged
PorterStemAnalyzer Tutorial: http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1
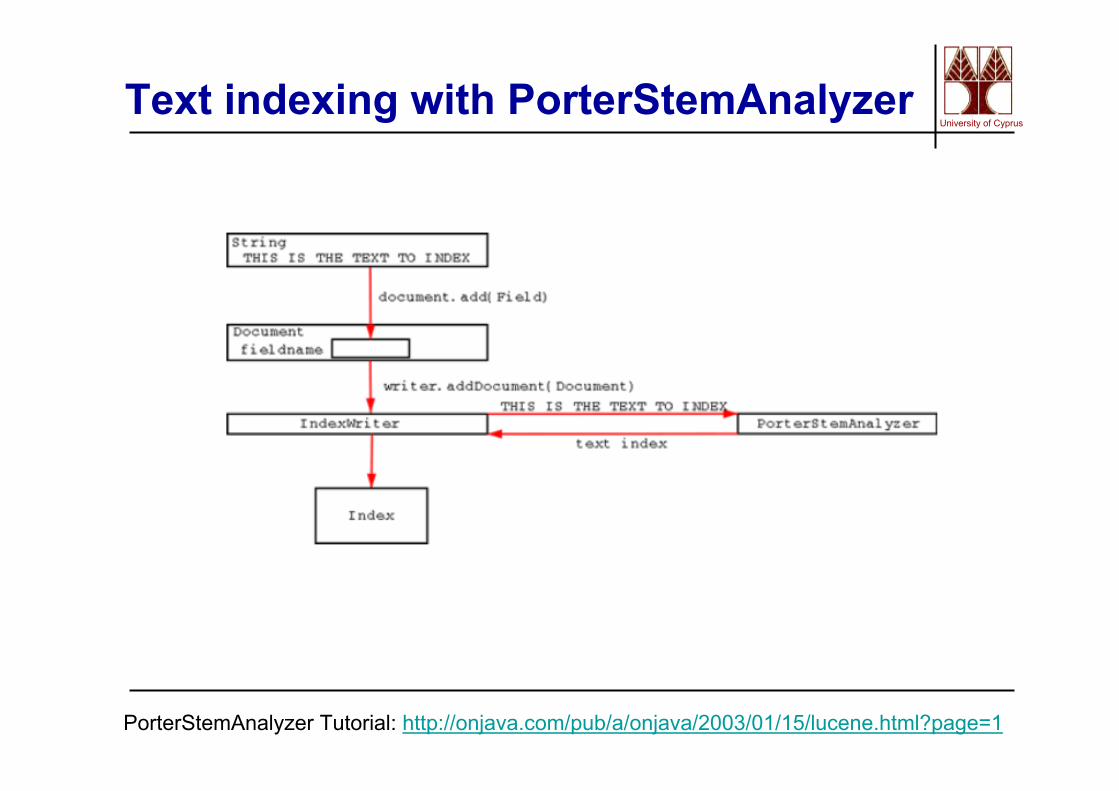
University of CyprusText indexing with PorterStemAnalyzer
PorterStemAnalyzer Tutorial: http://onjava.com/pub/a/onjava/2003/01/15/lucene.html?page=1

University of CyprusLucene in 5 minutes!
allocate memory in RAM to store the index
create a new index, overwriting anyexisting index
add document to the index
create a new doc add a title field
Source: http://www.lucenetutorial.com

University of CyprusLucene in 5 minutes!
the "title" argumentspecifies the defaultfield to use when nofield is explicitlyspecified in the query
Source: http://www.lucenetutorial.com
The QueryParser uses the same analyzer as the IndexWriter

University of CyprusLucene in 5 minutes!
Source: http://www.lucenetutorial.com

University of CyprusLucene in 5 minutes!
Source: http://www.lucenetutorial.com
Full source code is shown here: http://www.lucenetutorial.com/lucene-in-5-minutes.html

University of CyprusExamples• Get deeper into source code…
<lucene_dir>src/org/apache/lucene/demo
• Under <lucene_dir> run:java org.apache.lucene.demo.IndexFiles /src
• This program builds an index. It produces a subdirectory called index which contains an index of all of the Lucene source code files.
• To search the index type: java org.apache.lucene.demo.SearchFiles

University of CyprusUseful Info• Official Apache Lucene site: http://lucene.apache.org/java/docs/• Lucene-java Wiki: http://wiki.apache.org/lucene-
java/FrontPage?action=show&redirect=FrontPageEN• Lucene Intro (java.net):
http://today.java.net/pub/a/today/2003/07/30/LuceneIntro.html• Lucene Tutorial.com: http://www.lucenetutorial.com/
Related Documents











