Epitomic Location Epitomic Location Recognition Recognition A generative approach for location A generative approach for location recognition recognition K. Ni, A. Kannan, A. Criminisi and J. Winn K. Ni, A. Kannan, A. Criminisi and J. Winn In proc. CVPR 2008. Anchorage, Alaska.

Epitomic Location Recognition A generative approach for location recognition K. Ni, A. Kannan, A. Criminisi and J. Winn In proc. CVPR 2008. Anchorage,
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Epitomic Location Epitomic Location RecognitionRecognition
A generative approach for location recognitionA generative approach for location recognition
K. Ni, A. Kannan, A. Criminisi and J. WinnK. Ni, A. Kannan, A. Criminisi and J. Winn
In proc. CVPR 2008. Anchorage, Alaska.


Location RecognitionLocation Recognition
Where am I?Where am I?Instance recognitionInstance recognition
Category recognition (more difficult)Category recognition (more difficult)
Lobby? Cubicle? Hallway? Kitchen?

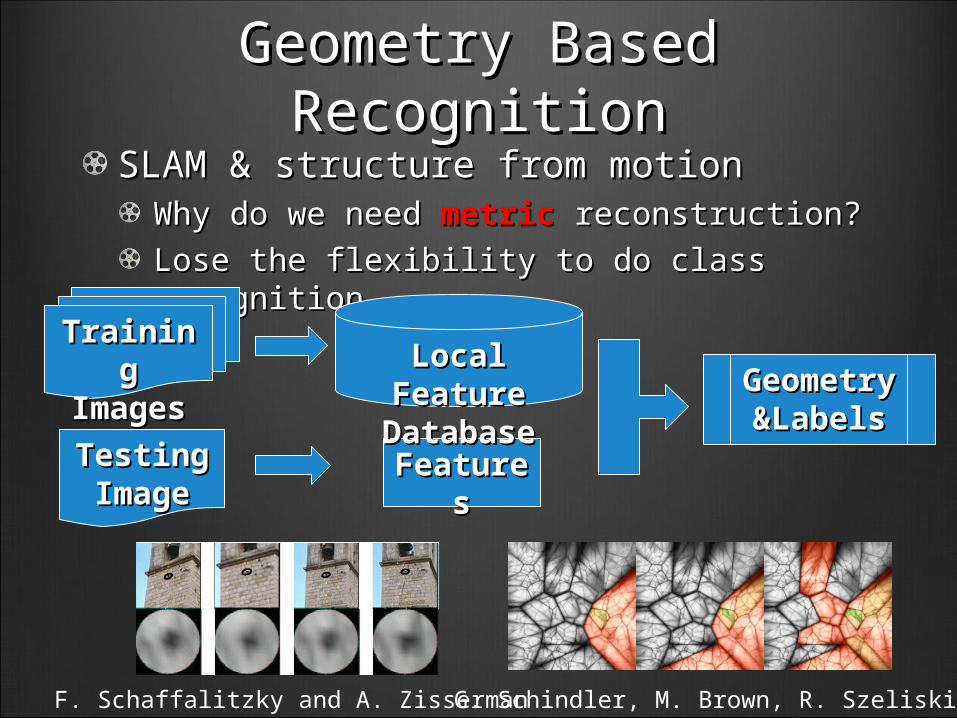
Geometry Based Geometry Based RecognitionRecognition
SLAM & structure from motionSLAM & structure from motionWhy do we need Why do we need metric metric reconstruction?reconstruction?
Lose the flexibility to do class recognition.Lose the flexibility to do class recognition.
F. Schaffalitzky and A. Zisserman
Training Training ImagesImages
Testing Testing ImageImage
Geometry Geometry &Labels&Labels
FeaturesFeatures
Local Feature Local Feature DatabaseDatabase
G. Schindler, M. Brown, R. Szeliski
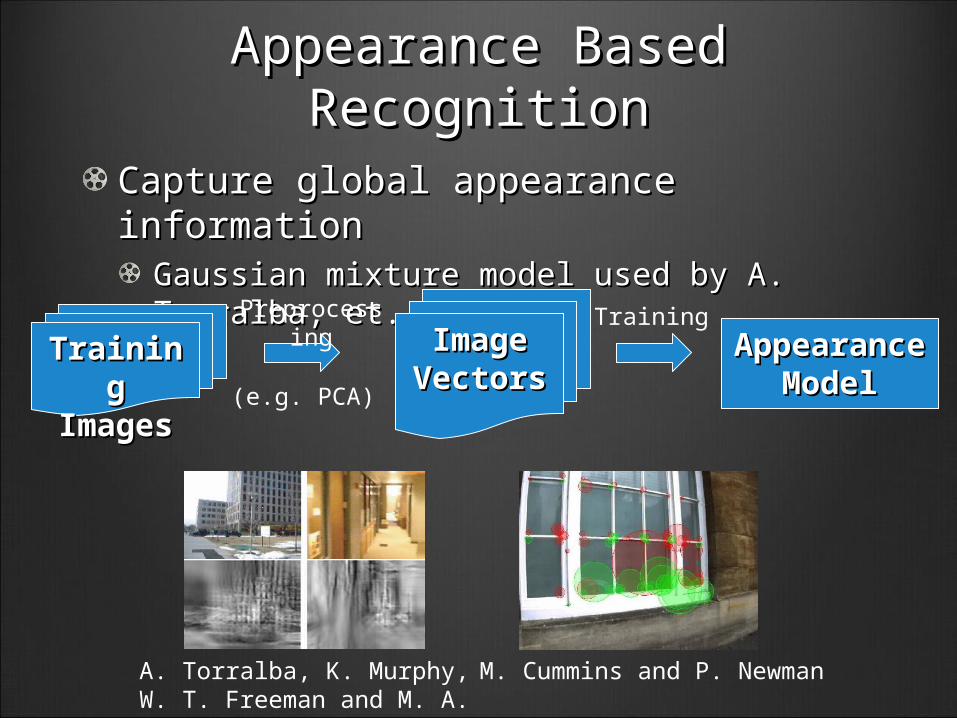
Appearance Based Appearance Based RecognitionRecognition
Capture global appearance informationCapture global appearance informationGaussian mixture model used by A. Gaussian mixture model used by A. Torralba, et. alTorralba, et. al
Training Training ImagesImages
ImageImageVectorsVectors
Appearance Appearance ModelModel
Preprocessing Training
A. Torralba, K. Murphy, W. T. Freeman and M. A. Rubin
M. Cummins and P. Newman
(e.g. PCA)

Appearance or Geometry?Appearance or Geometry?
Can we do better by fusing both Can we do better by fusing both information together?information together?
A small example with 2 location labels: cubicle and corridor

The Simplest ModelThe Simplest Model
Nearest neighbor classificationNearest neighbor classificationNaive but still effective with Naive but still effective with enoughenough samples.samples.
A small shift may disrupt the recognition.A small shift may disrupt the recognition.
Does not capture uncertainty.Does not capture uncertainty.

How to Incorporate Translation How to Incorporate Translation Invariance?Invariance?
We need something better than a “bag of frames” We need something better than a “bag of frames” modelmodel
Training images
Testing image

PanoramaPanorama
It models both appearance & geometryIt models both appearance & geometryAdapts to camera rotation and focal length Adapts to camera rotation and focal length changechange
M. Brown and D. G. Lowe
GenerativeGenerativeAn image is a patch “extracted” from the panoramaAn image is a patch “extracted” from the panorama

Cons of PanoramasCons of PanoramasNot easy to build a panorama due to Not easy to build a panorama due to parallaxparallax
Do not capture uncertaintyDo not capture uncertainty
Only work for location Only work for location instanceinstance recognition recognition
No compact representation for repetitive No compact representation for repetitive scenesscenes

Gaussian Mixture ModelGaussian Mixture Model
Six mixtures trained as in Torralba et al’s Six mixtures trained as in Torralba et al’s paperpaper
Handles uncertainties but no translation Handles uncertainties but no translation invarianceinvariance
Means
Variances
Remove boundariesMuch more blurred

A Weak PanoramaA Weak Panorama
3D motions can be roughly modeled by 3D motions can be roughly modeled by 2D translation + scaling.2D translation + scaling.
2D translation
Scaling

Epitome = Panorama + Epitome = Panorama + GMMGMM
EpitomeEpitomeGenerative model for image patches /video Generative model for image patches /video framesframes
Captures repetitive patterns in the original Captures repetitive patterns in the original imageimage
Mapping = 2D translation + scalingMapping = 2D translation + scaling
A source image Image patches
Epitome
N. Jojic et.al., ICCV 2003; N. Petrovic, et.al., CVPR 2006

Means
Variances
Location Epitome
Epitome as Probabilistic Epitome as Probabilistic PanoramaPanorama
Model 3D scenes rather than a single 2D Model 3D scenes rather than a single 2D imageimage
Environment = Virtual panorama

Learning the Location Learning the Location EpitomeEpitome
Initialize epitome randomlyInitialize epitome randomly
EM IterationsEM IterationsE-step: infer the posteriors over all E-step: infer the posteriors over all mappingsmappings
M-step: use the posteriors as weights to update M-step: use the posteriors as weights to update the the meanmean and and variancevariance of epitome pixels of epitome pixels
Free energy EM iterations

Model ComparisonModel ComparisonEpitome is a smart mixture of Gaussians model with parameters sharing among components
For the same number of parameters, the epitome generalizes better


Build Label MapsBuild Label MapsThe label maps are the posterior of the The label maps are the posterior of the label given the mapping label given the mapping
Epitome
Label maps
Corridor label map
Cubicle label map

Recognition from Location Recognition from Location EpitomesEpitomes
Fast correlation: infer the best mapping region
Sum the pixel-wise votes
Temporal smoothing using HMMInput testing image Best matching patch
Corridor label map
Cubicle label map
Location epitome


Color is not always the best Color is not always the best featurefeature
Other features besides RGBOther features besides RGBFor example, stereo feature captures the For example, stereo feature captures the depth info.depth info.
Do not need high stereo accuracy (efficient DP Do not need high stereo accuracy (efficient DP here)here)
Corridor Cubicle Kitchen

B
G
R
Stereo
Integrating Multiple Integrating Multiple FeaturesFeatures
Stack multiple feature “channels”Stack multiple feature “channels”

Local HistogramsLocal Histograms
Enable better translation invariance and more Enable better translation invariance and more generalizationgeneralization
Error rate: Error rate: 0.49 0.49 0.36 0.36 in a test, 4-class datasetin a test, 4-class dataset
Improve the efficiency dramatically: Improve the efficiency dramatically: 30 30 times speed-times speed-upup

Supervised LearningSupervised LearningIncorporates training image labelsIncorporates training image labels
Helps discriminate images with similar Helps discriminate images with similar features but different location labels.features but different location labels.
An example epitome
An example label feature
A monitor in the cubicle
A microwave in the kitchen
Discriminative features


MIT Image DatabaseMIT Image Database
Created by Created by Antonio Torralba, and et. al.Antonio Torralba, and et. al.17 sequences, 62 locations, 7 categories, 17 sequences, 62 locations, 7 categories, 72077 images72077 images
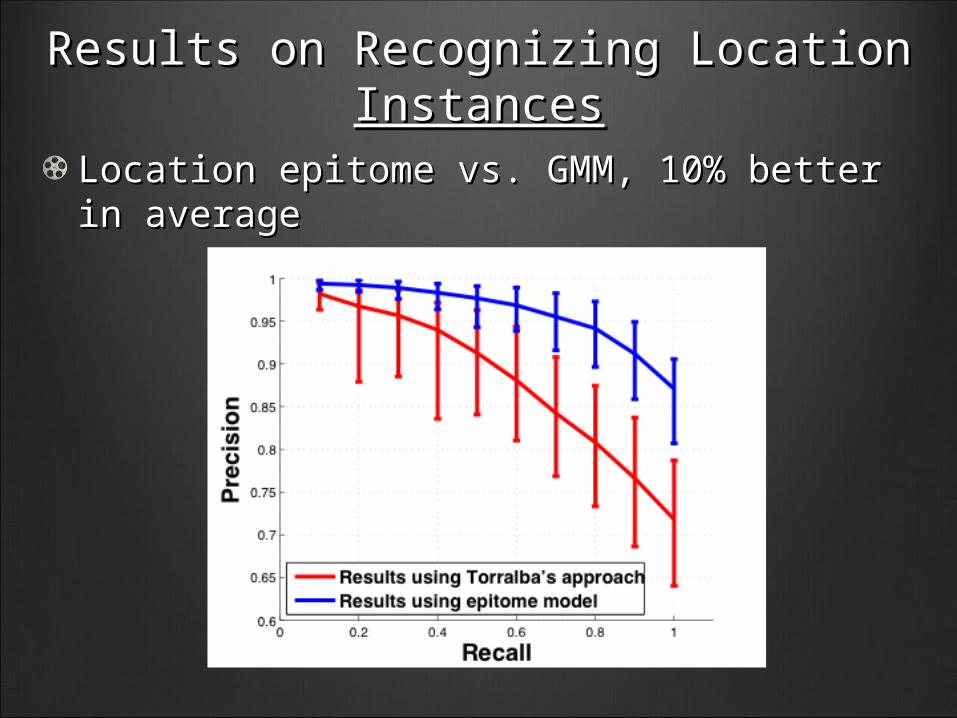
Results on Recognizing Location Results on Recognizing Location InstancesInstances
Location epitome vs. GMM, 10% better in Location epitome vs. GMM, 10% better in averageaverage

Results on Recognizing Location Results on Recognizing Location ClassesClasses
Location Epitome vs. GMM, 10%-20% Location Epitome vs. GMM, 10%-20% betterbetter

MSRC Data SetMSRC Data Set
Captured with a Captured with a stereo camerastereo camera5409 images collected at the speed of 5409 images collected at the speed of 44 fps fps
11 sequences and 7 classes11 sequences and 7 classes
corridor_visionlab cubicle_mlp kitchen-fl2-north lectureroom-large
lectureroom-small stairs-1st-to-2nd stairs-2nd-to-1st

Integrate Integrate Depth Depth CuesCues
corridor_visionlab cubicle_mlp kitchen-fl2-north lectureroom-large
lectureroom-small stairs-1st-to-2nd stairs-2nd-to-1st

Instance Recognition with Multiple Instance Recognition with Multiple FeaturesFeatures
RGB & Stereo overwhelms the other RGB & Stereo overwhelms the other featuresfeatures
Learning: Learning: 5.75.7 fps fps
Recognition: Recognition: 116 116 fps = fps = 2929 times the capture times the capture speedspeed

SummarySummaryA generative model for the recognition of A generative model for the recognition of both location both location instancesinstances and and classesclasses
FastFast: capable of real-time applications: capable of real-time applications
FlexibleFlexible: capable of integrating various features: capable of integrating various features
ProbabilisticProbabilistic: capable of capturing : capable of capturing uncertaintiesuncertainties
Future applicationsFuture applicationsNavigation for visually impaired peopleNavigation for visually impaired people
Appearance-based loop closing for SLAM Appearance-based loop closing for SLAM problemsproblems

Epitomic Location Epitomic Location RecognitionRecognition
A generative approach for location recognitionA generative approach for location recognition
K. Ni, A. Kannan, A. Criminisi and J. WinnK. Ni, A. Kannan, A. Criminisi and J. Winn
Thank you !

Local Histograms (2)Local Histograms (2)
Improves efficiency (both training and Improves efficiency (both training and testing)testing)
The bottle neck: convoluting epitome and The bottle neck: convoluting epitome and imagesimages
Compression rate: 3*(CCompression rate: 3*(C11CC22))22/50 = 2400/50 = 2400
Learning: 3 hours Learning: 3 hours 6 mins, 6 mins, 3030 times times fasterfaster
Convolute 3-dimension RGB features Convolute 50-dimension local histograms
M
N
ImageEpitome Me
Ne
M/C1
N/C2
****
Me/C1
Ne/C2
Related Documents







![Wavelet-Based Inpainting for Object Removal from Image Seriesagas/Public/Vetter2010WIF.pdf · Wavelet-Based Inpainting for Object Removal from Image Series 5 Criminisi [2] Ign´acio](https://static.cupdf.com/doc/110x72/5e70ee819b7bbc5855666dc7/wavelet-based-inpainting-for-object-removal-from-image-series-agaspublicvetter2010wifpdf.jpg)



