ALISON B LOWNDES AI DevRel | EMEA September 2016 ENABLING ARTIFICIAL INTELLIGENCE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

ALISON B LOWNDES
AI DevRel | EMEA
September 2016
ENABLING ARTIFICIAL
INTELLIGENCE

2
GE Revolution — The GPU choice when it really matters
The processor of #1 U.S. supercomputer and 9 of 10 of world’s most energy-efficient supercomputers
DGX-1: World’s 1st Deep Learning Supercomputer — The deep learning platform for AI researchers worldwide
100M NVIDIA GeForce Gamers — The world’s largest gaming platform
Pioneering AI computing for self-driving cars
NVIDIA Pioneered GPU Computing | Founded 1993 | $7B | 9,500 Employees
The visualization platform of every car company and movie studio

3 3
Deep Learning and Computer Vision
GPU Compute
NVIDIA GPU: MORE THAN GRAPHICS
Graphics

4
GPU Computing
NVIDIA Computing for the Most Demanding Users
Computing Human Imagination
Computing Human Intelligence

5

7
HOW

8
GPU Computing
x86

9
CUDA
A simple sum of two vectors (arrays) in C
GPU friendly version in CUDA
Framework to Program NVIDIA GPUs
__global__ void vector_add(int n, const float *a, const float *b, float *c) { int idx = blockIdx.x*blockDim.x + threadIdx.x; if( idx < n ) c[idx] = a[idx] + b[idx]; }
void vector_add(int n, const float *a, const float *b, float *c) { for( int idx = 0 ; idx < n ; ++idx ) c[idx] = a[idx] + b[idx]; }

10
EDUCATION
START-UPS
CNTK TENSORFLOW
DL4J
THE ENGINE OF MODERN AI
NVIDIA DEEP LEARNING PLATFORM
*U. Washington, CMU, Stanford, TuSimple, NYU, Microsoft, U. Alberta, MIT, NYU Shanghai
VITRUVIAN SCHULTS
LABORATORIES
TORCH
THEANO
CAFFE
MATCONVNET
PURINE MOCHA.JL
MINERVA MXNET*
CHAINER
BIG SUR WATSON
OPENDEEP KERAS

11
Biological vs artificial

12
Long short-term memory (LSTM)
Hochreiter (1991) analysed vanishing gradient “LSTM falls out of this almost naturally”
Gates control importance of
the corresponding
activations
Training
via
backprop
unfolded
in time
LSTM:
input
gate
output
gate
Long time dependencies are preserved until
input gate is closed (-) and forget gate is open (O)
forget
gate
Fig from Vinyals et al, Google April 2015 NIC Generator
Fig from Graves, Schmidhuber et al, Supervised
Sequence Labelling with RNNs

13
DeepMind’s WaveNet
https://drive.google.com/file/d/0B3cxcnOkPx9AeWpLVXhkTDJINDQ/view

14
Genetic Algorithms
Solution emergence through iterative simulated competition and improvement
”..harnessing the subtle but profound patterns that exist in chaotic data” Kurweil

15
WHY

16
CNN + RNN
NATURAL LANGUAGE PROCESSING

17
“Natural language understanding and grounded dialogue systems will revolutionise our access to information and how we interact with computers and the web. The impact in business, law, policy making and science will be profound. It will also bring us closer to understanding human intelligence” Nando de Freitas, DeepMind

18
Deep learning teaches robots
China Is Building a Robot Army of Model Workers
Amazon robot challenge winner counts on deep learning AI
Japan Must Refocus From US -dominated AI to Integrating Deep Learning into Manufacturing
19
Da Vinci medical robotics

20
Pieter Abbeel gym.openai.com
21
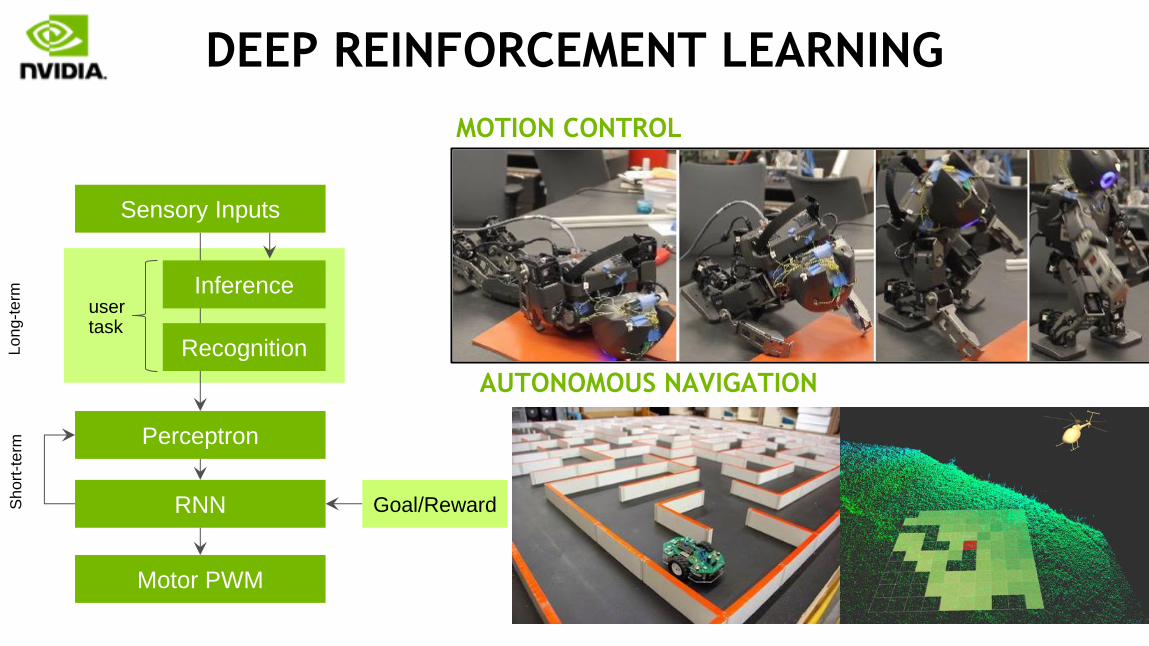
DEEP REINFORCEMENT LEARNING
Motor PWM
Sensory Inputs
Perceptron
RNN
Recognition
Inference
Goal/Reward
user task
Sh
ort
-te
rm
Lo
ng-t
erm
MOTION CONTROL
AUTONOMOUS NAVIGATION

22
GOOGLE DEEPMIND ALPHAGO CHALLENGE

23
WORLD’S FIRST AUTONOMOUS CAR RACE 10 teams, 20 identical cars | DRIVE PX 2: The “brain” of every car | 2016/17 Formula E season

24
Deep Learning Platform

25 NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
NVIDIA DEEP LEARNING PLATFORM
DEVELOPERS
DEEP LEARNING SDK
DL FRAMEWORK (CAFFE, CNTK,TENSORFLOW, THEANO, TORCH…)
DEPLOYMENT AUTOMOTIVE - DRIVEPX
EMBEDDED - JETSON
26
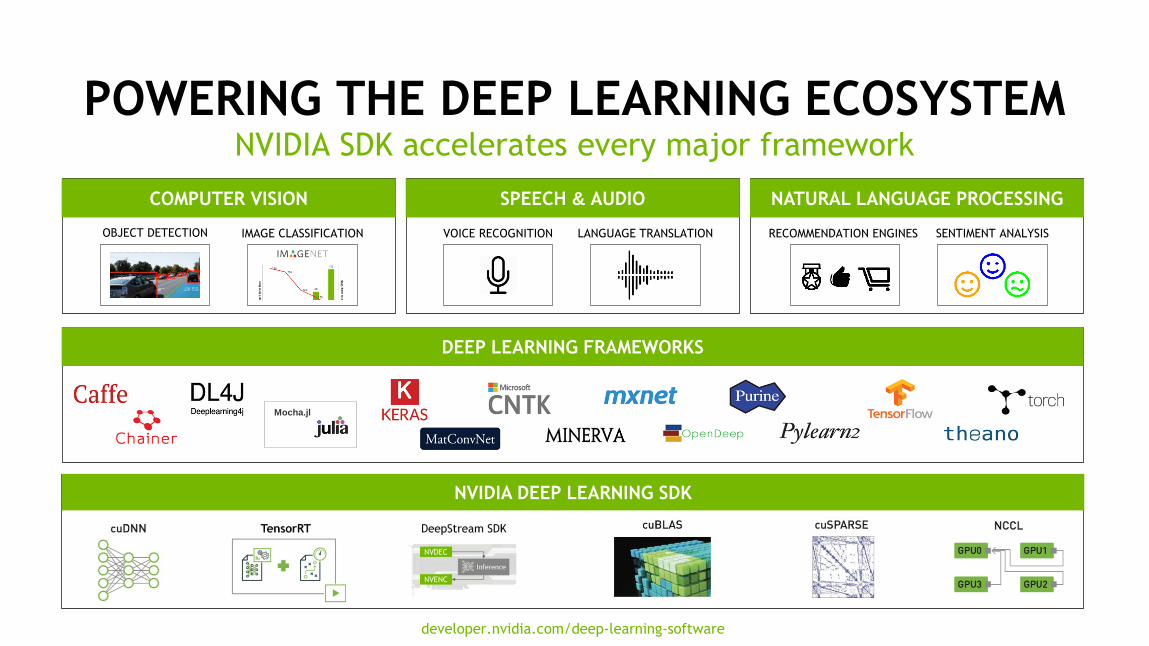
POWERING THE DEEP LEARNING ECOSYSTEM NVIDIA SDK accelerates every major framework
COMPUTER VISION
OBJECT DETECTION IMAGE CLASSIFICATION
SPEECH & AUDIO
VOICE RECOGNITION LANGUAGE TRANSLATION
NATURAL LANGUAGE PROCESSING
RECOMMENDATION ENGINES SENTIMENT ANALYSIS
DEEP LEARNING FRAMEWORKS
Mocha.jl
NVIDIA DEEP LEARNING SDK
developer.nvidia.com/deep-learning-software

27
cuDNN Deep Learning Primitives
IGNITING ARTIFICIAL
INTELLIGENCE
▪ GPU-accelerated Deep Learning
subroutines
▪ High performance neural network
training
▪ Accelerates Major Deep Learning
frameworks: Caffe, Theano, Torch
▪ Up to 3.5x faster AlexNet training
in Caffe than baseline GPU
Millions of Images Trained Per Day
Tiled FFT up to 2x faster than FFT
developer.nvidia.com/cudnn

28
WHAT’S NEW IN CUDNN 5?
LSTM recurrent neural networks deliver up to 6x speedup in Torch
Improved performance:
• Deep Neural Networks with 3x3 convolutions, like VGG, GoogleNet and ResNets
• 3D Convolutions
• FP16 routines on Pascal GPUs
Pascal GPU, RNNs, Improved Performance
Performance relative to torch-rnn (https://github.com/jcjohnson/torch-rnn)
DeepSpeech2: http://arxiv.org/abs/1512.02595 Char-rnn: https://github.com/karpathy/char-rnn
5.9x Speedup for char-rnn
RNN Layers
2.8x Speedup for DeepSpeech 2
RNN Layers

29
DIGITSTM
Quickly design the best deep neural network (DNN) for your data
Train on multi-GPU (automatic)
Visually monitor DNN training quality in real-time
Manage training of many DNNs in parallel on multi-GPU systems
Interactive Deep Learning GPU Training System
developer.nvidia.com/digits

30 30
DEEP VISUALIZATION TOOLBOX IMAGE RECOGNITION

31
DIGITS 4
• Object Detection Workflows for Automotive and Defense
• Targeted at Autonomous Vehicles, Remote Sensing
Object Detection Workflow
developer.nvidia.com/digits
https://devblogs.nvidia.com/parallelforall/
32
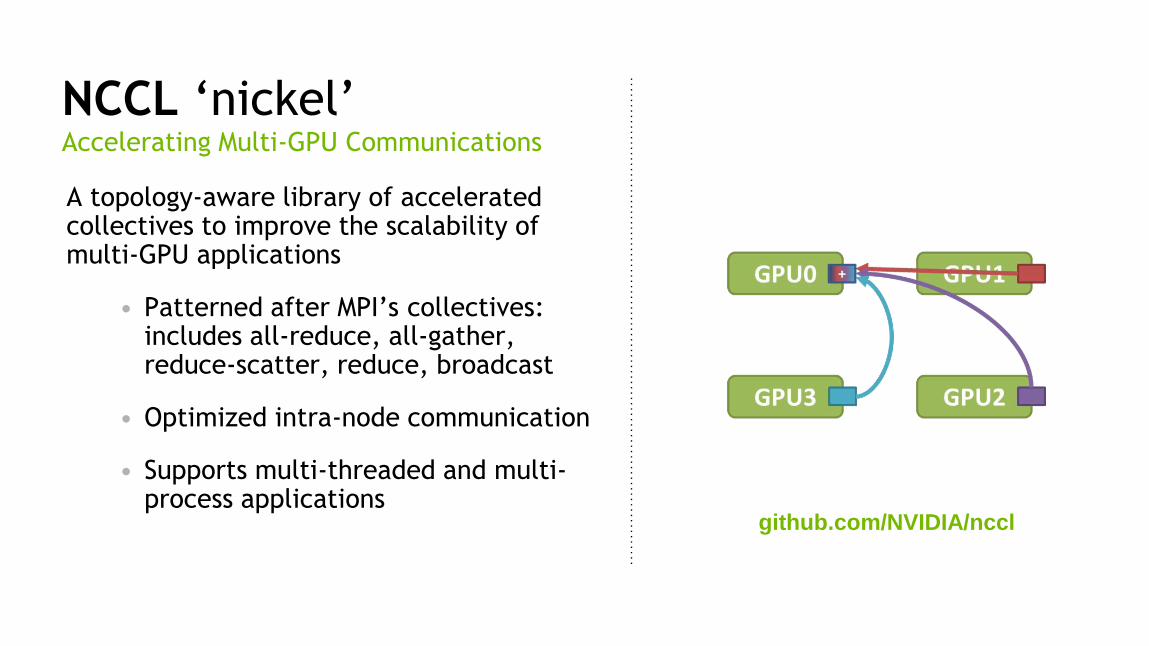
NCCL ‘nickel’
A topology-aware library of accelerated collectives to improve the scalability of multi-GPU applications
• Patterned after MPI’s collectives: includes all-reduce, all-gather, reduce-scatter, reduce, broadcast
• Optimized intra-node communication
• Supports multi-threaded and multi-process applications
Accelerating Multi-GPU Communications
github.com/NVIDIA/nccl

33
GRAPH ANALYTICS with NVGRAPH developer.nvidia.com/nvgraph
GPU Optimized Algorithms
Reduced cost & Increased performance
Standard formats and primitives
Semi-rings, load-balancing
Performance Constantly Improving
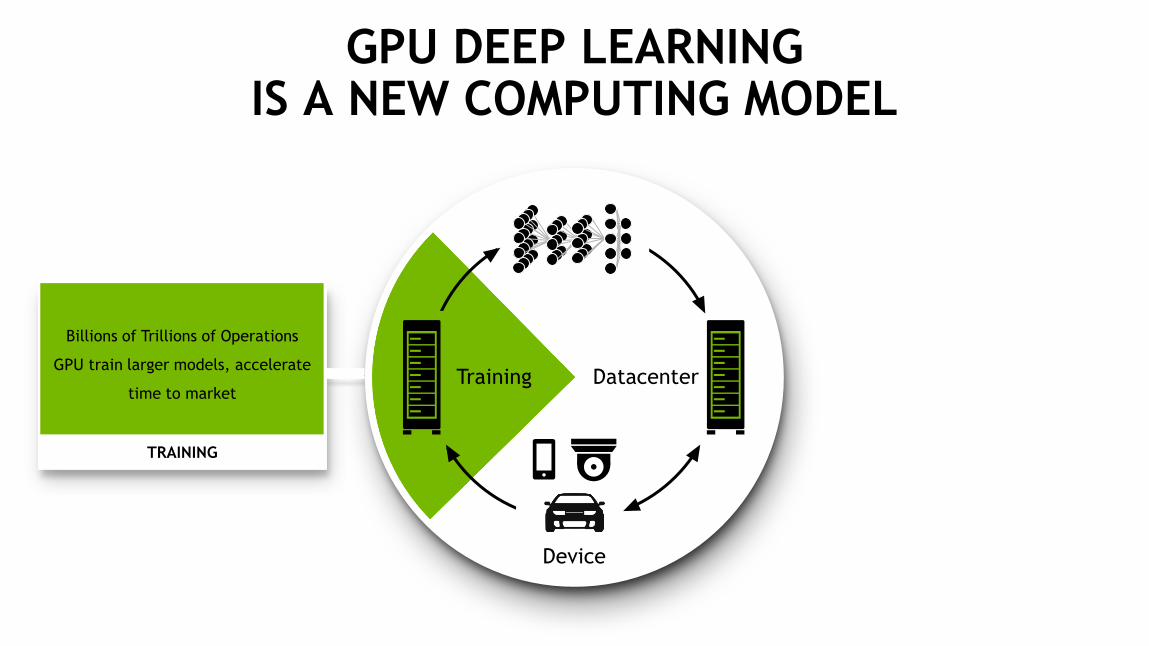
34
Training
Device
Datacenter
GPU DEEP LEARNING IS A NEW COMPUTING MODEL
TRAINING
Billions of Trillions of Operations
GPU train larger models, accelerate
time to market
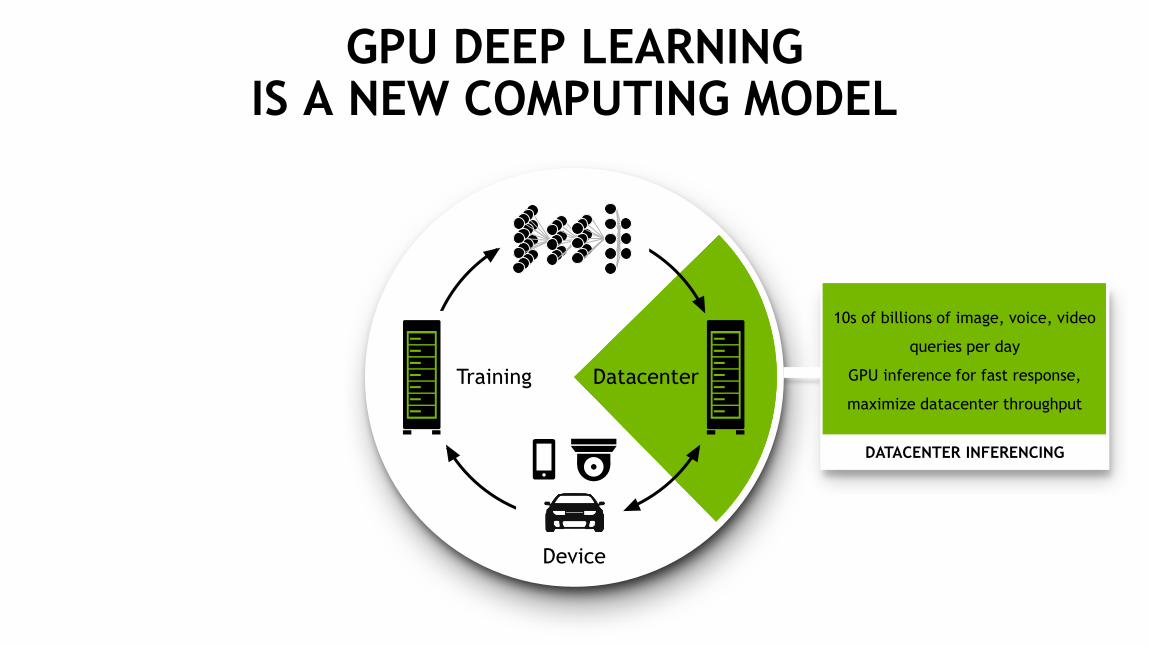
35
Training
Device
Datacenter
GPU DEEP LEARNING IS A NEW COMPUTING MODEL
DATACENTER INFERENCING
10s of billions of image, voice, video
queries per day
GPU inference for fast response,
maximize datacenter throughput

36
WHAT’S NEW IN DEEP LEARNING SOFTWARE
TensorRT
Deep Learning Inference Engine
DeepStream SDK
Deep Learning for Video Analytics
36x faster inference enables ubiquitous AND responsive AI
High performance video analytics on Tesla platforms

37
HARDWARE
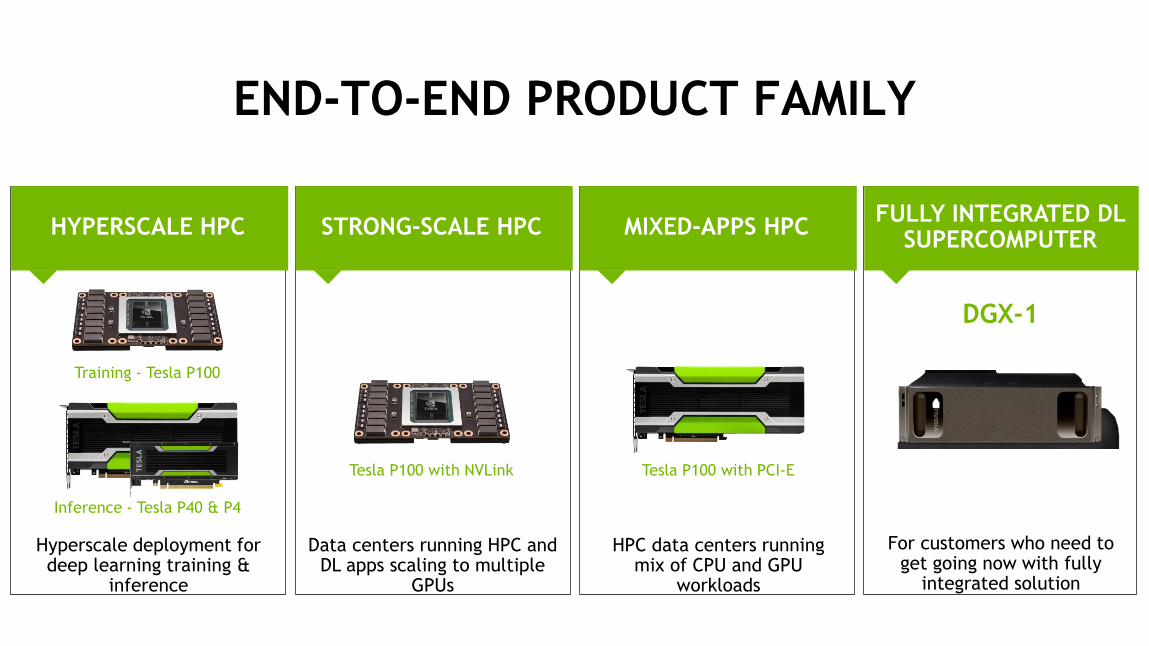
38
END-TO-END PRODUCT FAMILY
FULLY INTEGRATED DL SUPERCOMPUTER
DGX-1
For customers who need to get going now with fully
integrated solution
HYPERSCALE HPC
Hyperscale deployment for deep learning training &
inference
Training - Tesla P100
Inference - Tesla P40 & P4
STRONG-SCALE HPC
Data centers running HPC and DL apps scaling to multiple
GPUs
Tesla P100 with NVLink
MIXED-APPS HPC
HPC data centers running mix of CPU and GPU
workloads
Tesla P100 with PCI-E

39
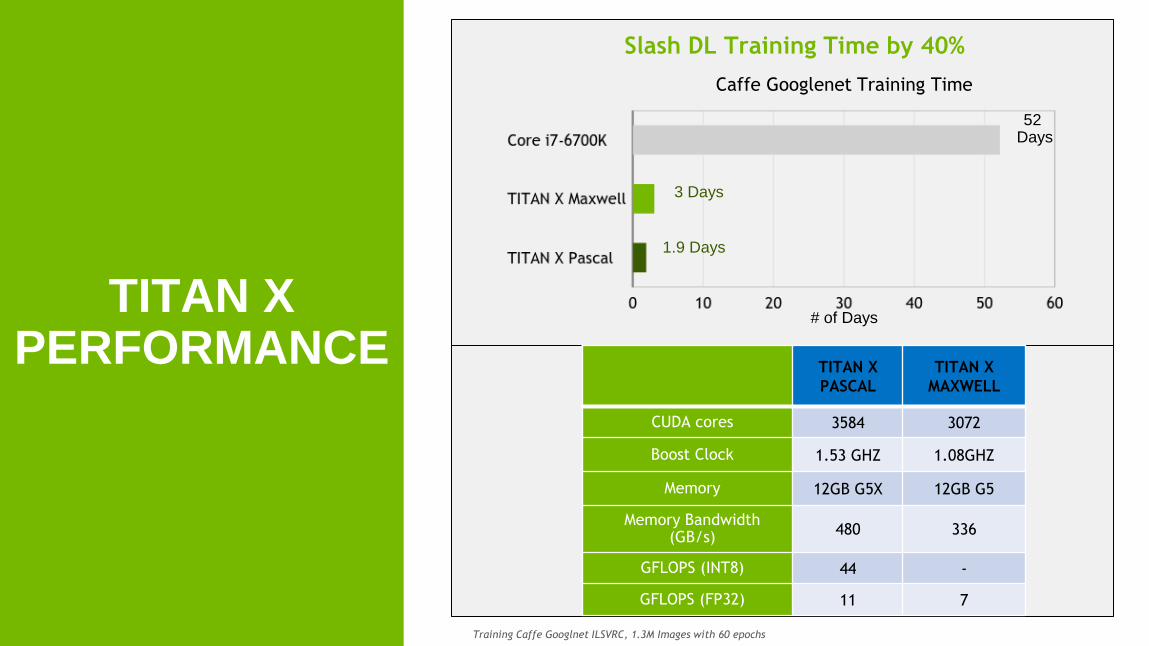
40 Training Caffe Googlnet ILSVRC, 1.3M Images with 60 epochs
Slash DL Training Time by 40%
# of Days
3 Days
Caffe Googlenet Training Time
1.9 Days
52 Days
TITAN X
PASCAL
TITAN X
MAXWELL
CUDA cores 3584 3072
Boost Clock 1.53 GHZ 1.08GHZ
Memory 12GB G5X 12GB G5
Memory Bandwidth (GB/s)
480 336
GFLOPS (INT8) 44 -
GFLOPS (FP32) 11 7
TITAN X PERFORMANCE

41

42
TESLA P40
P40
# of CUDA Cores 3840
Peak Single Precision 12 TeraFLOPS
Peak INT8 47 TOPS
Low Precision 4x 8-bit vector dot product
with 32-bit accumulate
Video Engines 1x decode engine, 2x encode engines
GDDR5 Memory 24 GB @ 346 GB/s
Power 250W
0
20,000
40,000
60,000
80,000
100,000
GoogLeNet AlexNet
8x M40 (FP32) 8x P40 (INT8)
Images/
Sec
4x Boost in Less than One Year
GoogLeNet, AlexNet, batch size = 128, CPU: Dual Socket Intel E5-2697v4
Highest Throughput for Scale-up Servers

43
40x Efficient vs CPU, 8x Efficient vs FPGA
0
50
100
150
200
AlexNet
CPU FPGA 1x M4 (FP32) 1x P4 (INT8)
Images/
Sec/W
att
Maximum Efficiency for Scale-out Servers P4
# of CUDA Cores 2560
Peak Single Precision 5.5 TeraFLOPS
Peak INT8 22 TOPS
Low Precision 4x 8-bit vector dot product
with 32-bit accumulate
Video Engines 1x decode engine, 2x encode engine
GDDR5 Memory 8 GB @ 192 GB/s
Power 50W & 75 W
AlexNet, batch size = 128, CPU: Intel E5-2690v4 using Intel MKL 2017, FPGA is Arria10-115 1x M4/P4 in node, P4 board power at 56W, P4 GPU power at 36W, M4 board power at 57W, M4 GPU power at 39W, Perf/W chart using GPU power
TESLA P4

44
NVLink Pascal Architecture
New AI
Algorithms
COWOS with HBM2 Stacked Memory
INTRODUCING TESLA P100 Five Technology Breakthroughs Made it Possible
16nm FinFET
45
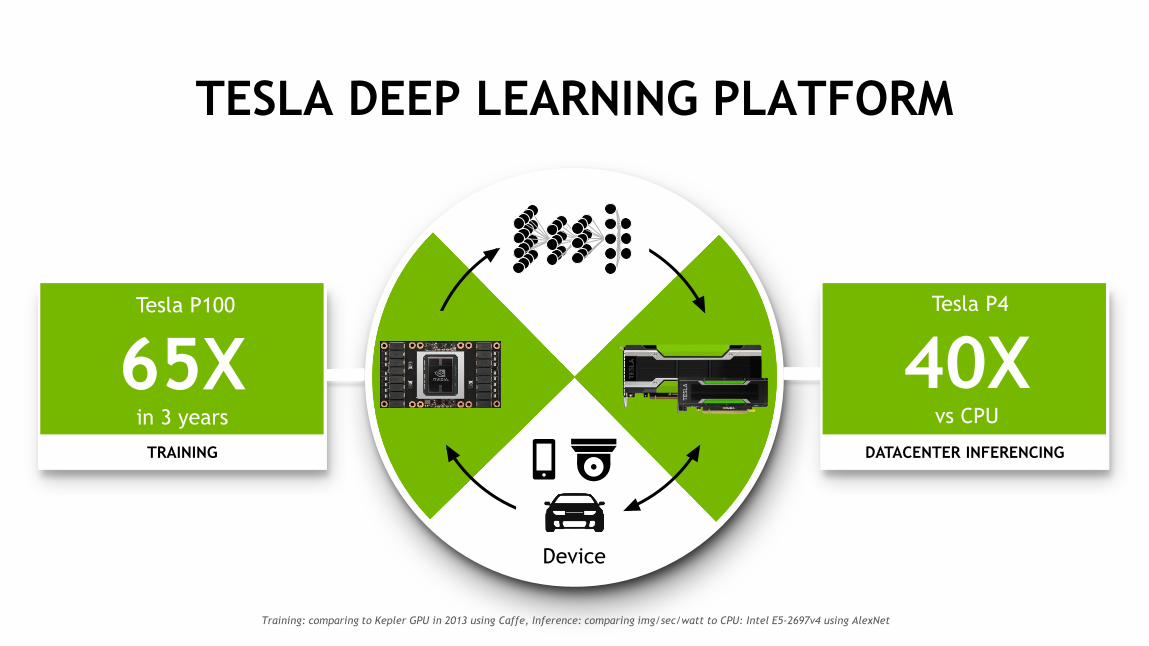
Device
TESLA DEEP LEARNING PLATFORM
TRAINING DATACENTER INFERENCING
Training: comparing to Kepler GPU in 2013 using Caffe, Inference: comparing img/sec/watt to CPU: Intel E5-2697v4 using AlexNet
65X in 3 years
Tesla P100
40X vs CPU
Tesla P4

46
Engineered for deep learning | 170TF FP16 | 8x Tesla P100
NVLink hybrid cube mesh | Accelerates major AI frameworks
NVIDIA DGX-1 WORLD’S FIRST DEEP LEARNING SUPERCOMPUTER

47
CUDA 8 – WHAT’S NEW
Stacked Memory
NVLINK
FP16 math
P100 Support Larger Datasets
Demand Paging
New Tuning APIs
Standard C/C++ Allocators
CPU/GPU Data Coherence &
Atomics
Unified Memory
New nvGRAPH library
cuBLAS improvements for Deep Learning
Libraries Critical Path Analysis
2x Faster Compile Time
OpenACC Profiling
Debug CUDA Apps on Display GPU
Developer Tools

48
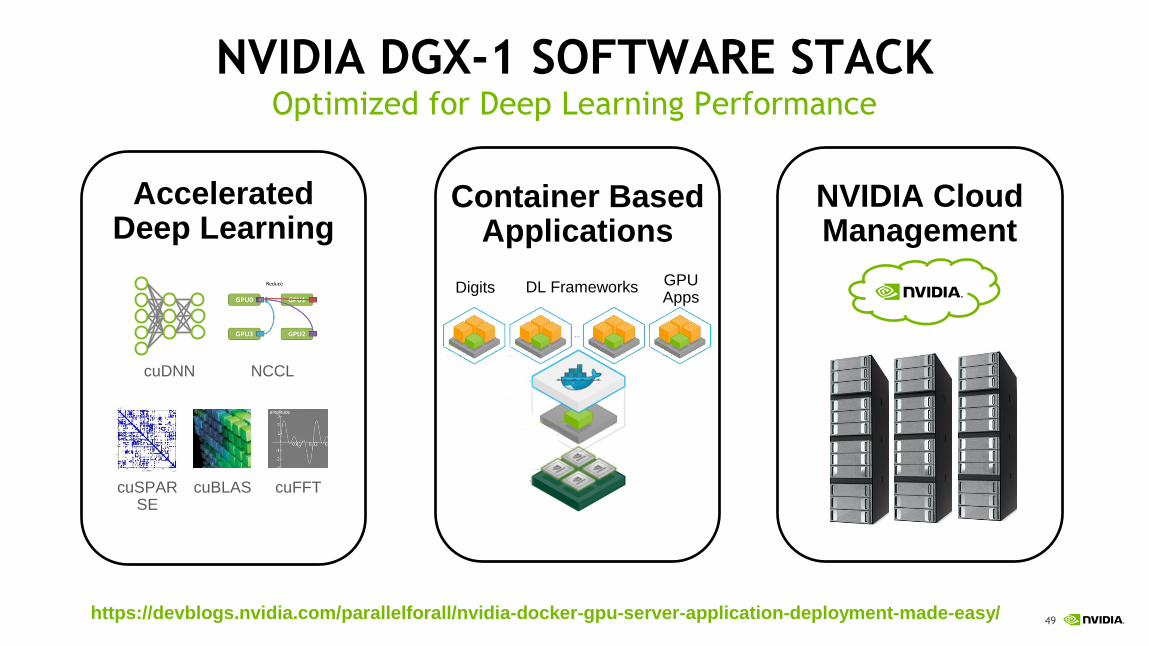
49
NVIDIA DGX-1 SOFTWARE STACK Optimized for Deep Learning Performance
Accelerated Deep Learning
cuDNN NCCL
cuSPARSE
cuBLAS cuFFT
Container Based Applications
NVIDIA Cloud Management
Digits DL Frameworks GPU Apps
https://devblogs.nvidia.com/parallelforall/nvidia-docker-gpu-server-application-deployment-made-easy/

50
A SUPERCOMPUTER FOR AUTONOMOUS MACHINES Bringing AI and machine learning to a world of robots and drones
Jetson TX1 is the first embedded computer designed to process deep neural networks
1 TeraFLOPS in a credit-card sized module

51 51
AT THE FRONTIER OF
AUTONOMOUS MACHINES
New use cases demand autonomy
GPUs deliver superior performance and efficiency
Onboard sensing and deep learning, enable autonomy
x2
x3
x4
x1

52
DIGITS Workflow VisionWorks Jetson Media SDK
and other technologies:
CUDA, Linux4Tegra, NSIGHT EE, OpenCV4Tegra, OpenGL, Vulkan, System Trace, Visual Profiler
Deep Learning SDK
NVIDIA JETPACK

53
Develop and deploy
Jetson TX1 and Jetson TX1 Developer Kit

54
WRAP UP

55
developer.nvidia.com

56
Getting started with deep learning developer.nvidia.com/deep-learning

57
DEEP LEARNING &
ARTIFICIAL INTELLIGENCE
Sep 28-29, 2016 | Amsterdam
www.gputechconf.eu #GTC16EU
AUTONOMOUS VEHICLES VIRTUAL REALITY &
AUGMENTED REALITY
SUPERCOMPUTING & HPC
GTC Europe is a two-day conference designed to expose the innovative ways developers, businesses and academics are
using parallel computing to transform our world.
EUROPE’S BRIGHTEST MINDS & BEST IDEAS
GET A 20% DISCOUNT WITH CODE ALLOGTCEU2016
2 Days | 1,000 Attendees | 50+ Exhibitors | 50+ Speakers | 10+ Tracks | 15+ Hands-on Labs| 1-to-1 Meetings

COME DO YOUR LIFE’S WORK JOIN NVIDIA
We are looking for great people at all levels to help us accelerate the next wave of AI-driven
computing in Research, Engineering, and Sales and Marketing.
Our work opens up new universes to explore, enables amazing creativity and discovery, and
powers what were once science fiction inventions like artificial intelligence and autonomous
cars.
Check out our career opportunities:
• www.nvidia.com/careers
• Reach out to your NVIDIA social network or NVIDIA recruiter at
Related Documents











