2104 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007 Emulating DNA: Rigorous Quantification of Evidential Weight in Transparent and Testable Forensic Speaker Recognition Joaquin Gonzalez-Rodriguez, Member, IEEE, Phil Rose, Daniel Ramos, Student Member, IEEE, Doroteo T. Toledano, Member, IEEE, and Javier Ortega-Garcia, Member, IEEE Abstract—Forensic DNA profiling is acknowledged as the model for a scientifically defensible approach in forensic identification sci- ence, as it meets the most stringent court admissibility require- ments demanding transparency in scientific evaluation of evidence and testability of systems and protocols. In this paper, we propose a unified approach to forensic speaker recognition (FSR) oriented to fulfil these admissibility requirements within a framework which is transparent, testable, and understandable, both for scientists and fact-finders. We show how the evaluation of DNA evidence, which is based on a probabilistic similarity-typicality metric in the form of likelihood ratios (LR), can also be generalized to continuous LR estimation, thus providing a common framework for phonetic–lin- guistic methods and automatic systems. We highlight the impor- tance of calibration, and we exemplify with LRs from diphthongal F-pattern, and LRs in NIST-SRE06 tasks. The application of the proposed approach in daily casework remains a sensitive issue, and special caution is enjoined. Our objective is to show how traditional and automatic FSR methodologies can be transparent and testable, but simultaneously remain conscious of the present limitations. We conclude with a discussion on the combined use of traditional and automatic approaches and current challenges for the admissibility of speech evidence. Index Terms—Admissibility of speech evidence, calibration, Daubert, deoxyribonucleic acid (DNA), forensic speaker recogni- tion (FSR), likelihood ratio (LR). I. INTRODUCTION D NA evidence was first presented in court in the 1980s, and, after considerable debate, unanimously accepted in the 1990s [43], [44]. In the extremely short period of time since, DNA typing has not just become the reference to be emulated but has also brought into question all other identifi- cation-of-the-source forensic disciplines, some of them with a long tradition of expert testimony in court, such as fingerprints, handwriting, or ballistics [58]. The reasons for this success are many, but they can be summarized in two words: transparency and testability. Forensic evidence has been largely presented in court in the form of expert opinions, with conclusions Manuscript received April 16, 2007; revised June 4, 2007. This work was supported in part by the Spanish Ministry of Education under Grant TEC06- 13170-C02-01 and Guardia Civil. The associate editor coordinating the review of this manuscript and approving it for publication was Dr. Kay Berkling. J. Gonzalez-Rodriguez, D. Ramos, D. T. Toledano, and J. Ortega-Garcia are with ATVS-Universidad Autonoma de Madrid, 28049 Madrid, Spain (e-mail: [email protected]). P. Rose is with the Australian National University, Canberra ACT 0200, Aus- tralia (e-mail: [email protected]). Digital Object Identifier 10.1109/TASL.2007.902747 expressed in the form of individualisation (hard match), as cat- egorical opinion of identity of sources, exclusion (nonmatch) statements, or making use of verbal scales of probability of hypothesis, given evidence. The process leading from evidence to conclusion is often opaque, either because it lacks scientific rigor and is inherently unfalsifiable, or because the approach is inadequately tested, and thus cannot quote random match probabilities or estimate the chance of error. Not surprisingly, this has often resulted in legal discussion about the acceptance of expert testimony. Contrasting with this, DNA profiling [1], [5], [65] has solid and well-known scientific foundations, and is probabilistic [18], [60]. Avoiding individualization or exclusion statements for the determination of the source of the evidence, DNA evidence is often presented using frequencies, match probabilities, and inclusion or exclusion probabilities [24], but many influential forensic scientists [1], [16], [27], [26] advo- cate assessing the weight of the evidence with likelihood ratios (LRs) [24], [29]. This LR is a quotient of a similarity factor, which supports the hypothesis that a questioned sample was left by a given suspect, and a typicality factor, which quantifies support for the hypothesis that the questioned sample was left by someone else in a relevant population. In DNA typing, this likelihood-ratio approach for evidence analysis [1], [28] has been held up as a model of an explicit and probabilistic frame- work which allows scrutinizing and inspection by fact finders and forensic scientists [58], thus converting DNA typing into a transparent and understandable discipline. It is also testable, with referenced population data to assess reported performance levels, resulting in known potential and sufficiently low error rates, and widely accepted methods. In the Bayesian analysis of evidence, opinions about the hy- potheses are expressed in the form of posterior probabilities, as a product of the prior probabilities (province of the court) times the reported likelihood ratio (province of the forensic scientist). As the LR is a number with a meaning in itself (an estimation of the weight of the evidence), there is a need to measure not only the discrimination capabilities of the LR values but also their calibration loss, as even highly discriminant (or refined) systems may lead the fact finder to wrong posterior probabili- ties if they are not calibrated [23]. Recent work [10] has made it possible to assess discrimination and calibration of forensic LRs, as has been recently shown with glass and paint [3] and speech evidence [47]. However, neither traditional (auditory–phonetic–linguistic) nor automatic (signal processing and pattern recognition-based) speaker recognition shows the discrimination performance of 1558-7916/$25.00 © 2007 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

2104 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007
Emulating DNA: Rigorous Quantification ofEvidential Weight in Transparent and Testable
Forensic Speaker RecognitionJoaquin Gonzalez-Rodriguez, Member, IEEE, Phil Rose, Daniel Ramos, Student Member, IEEE,
Doroteo T. Toledano, Member, IEEE, and Javier Ortega-Garcia, Member, IEEE
Abstract—Forensic DNA profiling is acknowledged as the modelfor a scientifically defensible approach in forensic identification sci-ence, as it meets the most stringent court admissibility require-ments demanding transparency in scientific evaluation of evidenceand testability of systems and protocols. In this paper, we propose aunified approach to forensic speaker recognition (FSR) oriented tofulfil these admissibility requirements within a framework which istransparent, testable, and understandable, both for scientists andfact-finders. We show how the evaluation of DNA evidence, whichis based on a probabilistic similarity-typicality metric in the formof likelihood ratios (LR), can also be generalized to continuous LRestimation, thus providing a common framework for phonetic–lin-guistic methods and automatic systems. We highlight the impor-tance of calibration, and we exemplify with LRs from diphthongalF-pattern, and LRs in NIST-SRE06 tasks. The application of theproposed approach in daily casework remains a sensitive issue, andspecial caution is enjoined. Our objective is to show how traditionaland automatic FSR methodologies can be transparent and testable,but simultaneously remain conscious of the present limitations. Weconclude with a discussion on the combined use of traditional andautomatic approaches and current challenges for the admissibilityof speech evidence.
Index Terms—Admissibility of speech evidence, calibration,Daubert, deoxyribonucleic acid (DNA), forensic speaker recogni-tion (FSR), likelihood ratio (LR).
I. INTRODUCTION
DNA evidence was first presented in court in the 1980s,and, after considerable debate, unanimously accepted
in the 1990s [43], [44]. In the extremely short period of timesince, DNA typing has not just become the reference to beemulated but has also brought into question all other identifi-cation-of-the-source forensic disciplines, some of them with along tradition of expert testimony in court, such as fingerprints,handwriting, or ballistics [58]. The reasons for this success aremany, but they can be summarized in two words: transparencyand testability. Forensic evidence has been largely presentedin court in the form of expert opinions, with conclusions
Manuscript received April 16, 2007; revised June 4, 2007. This work wassupported in part by the Spanish Ministry of Education under Grant TEC06-13170-C02-01 and Guardia Civil. The associate editor coordinating the reviewof this manuscript and approving it for publication was Dr. Kay Berkling.
J. Gonzalez-Rodriguez, D. Ramos, D. T. Toledano, and J. Ortega-Garcia arewith ATVS-Universidad Autonoma de Madrid, 28049 Madrid, Spain (e-mail:[email protected]).
P. Rose is with the Australian National University, Canberra ACT 0200, Aus-tralia (e-mail: [email protected]).
Digital Object Identifier 10.1109/TASL.2007.902747
expressed in the form of individualisation (hard match), as cat-egorical opinion of identity of sources, exclusion (nonmatch)statements, or making use of verbal scales of probability ofhypothesis, given evidence. The process leading from evidenceto conclusion is often opaque, either because it lacks scientificrigor and is inherently unfalsifiable, or because the approachis inadequately tested, and thus cannot quote random matchprobabilities or estimate the chance of error. Not surprisingly,this has often resulted in legal discussion about the acceptanceof expert testimony. Contrasting with this, DNA profiling [1],[5], [65] has solid and well-known scientific foundations, and isprobabilistic [18], [60]. Avoiding individualization or exclusionstatements for the determination of the source of the evidence,DNA evidence is often presented using frequencies, matchprobabilities, and inclusion or exclusion probabilities [24], butmany influential forensic scientists [1], [16], [27], [26] advo-cate assessing the weight of the evidence with likelihood ratios(LRs) [24], [29]. This LR is a quotient of a similarity factor,which supports the hypothesis that a questioned sample wasleft by a given suspect, and a typicality factor, which quantifiessupport for the hypothesis that the questioned sample was leftby someone else in a relevant population. In DNA typing, thislikelihood-ratio approach for evidence analysis [1], [28] hasbeen held up as a model of an explicit and probabilistic frame-work which allows scrutinizing and inspection by fact findersand forensic scientists [58], thus converting DNA typing intoa transparent and understandable discipline. It is also testable,with referenced population data to assess reported performancelevels, resulting in known potential and sufficiently low errorrates, and widely accepted methods.
In the Bayesian analysis of evidence, opinions about the hy-potheses are expressed in the form of posterior probabilities, asa product of the prior probabilities (province of the court) timesthe reported likelihood ratio (province of the forensic scientist).As the LR is a number with a meaning in itself (an estimationof the weight of the evidence), there is a need to measure notonly the discrimination capabilities of the LR values but alsotheir calibration loss, as even highly discriminant (or refined)systems may lead the fact finder to wrong posterior probabili-ties if they are not calibrated [23]. Recent work [10] has madeit possible to assess discrimination and calibration of forensicLRs, as has been recently shown with glass and paint [3] andspeech evidence [47].
However, neither traditional (auditory–phonetic–linguistic)nor automatic (signal processing and pattern recognition-based)speaker recognition shows the discrimination performance of
1558-7916/$25.00 © 2007 IEEE

GONZALEZ-RODRIGUEZ et al.: EMULATING DNA: RIGOROUS QUANTIFICATION OF EVIDENTIAL WEIGHT 2105
DNA. Therefore, caution is needed if it is to be used in court[8], [9]. This paper is an attempt to move towards a rigorousframework for forensic speaker recognition (FSR) in orderto meet current admissibility criteria. The performance ofscore-based automatic speaker recognition systems showsconstant progress, successfully impelled by the yearly NISTSpeaker Recognition Evaluations (SRE) [64]. Thanks to thisperiodic evaluation, the methodologies and protocols for theassessment of automatic speaker recognition systems are con-verging. However, it is still necessary to stimulate a similarconvergence regarding forensic interpretation of the evidencein speaker recognition. In this sense, the Bayesian approachfor evidence analysis [1], [28] has been proposed as a commonframework for forensic interpretation of the evidence, and re-cent work demonstrates the adequacy of this technique for FSR[16], both using automatic [14], [31], [39], phonetic–acoustic[54], or semiautomatic “hybrid” approaches [34], [54]. Withsuch a framework, the fact finder can also be shown how toinfer posterior probabilities (also known as confidences [14])of the hypotheses being entertained in a logical and transparentway.
The paper is organized as follows. In Section II, we highlightthe meaning of transparent and testable procedures, and outlinereasonable requirements for FSR to be admissible in court.In Section III, the important topic of calibration for FSR isintroduced. Section IV deals with the different generative andnon-generative ways of estimating the likelihood ratio. Theexperimental part of the paper then shows how traditional andautomatic FSR can be transparent and testable. In Section V,two different experiments with traditional linguistic featuresare reported and assessed with the proposed methodology.Section VI, on the other hand, shows automatic speaker recog-nition systems assessed as proposed in challenging tasks suchas the NIST 2006 Speaker Recognition Evaluation. In order toshow its practical application, Section VII exemplifies FSR incourt. Section VIII summarizes the main contributions of thepaper, highlights the main problems that still lie ahead, andshows the biggest challenges for the future.
II. TOWARDS A NEW PARADIGM IN FSR
The existence and unquestioned success of DNA typing, to-gether with Daubert-like criteria for admissibility of scientificexpert testimony [22], has reopened the debate about the admis-sibility and soundness of forensic evidence in a court of law.The transformation of identification-of-the-source forensic dis-ciplines into empirically grounded sciences following the modelof DNA typing, which leads to Daubert compliant proceduresand techniques, has been dubbed “the coming paradigm shift”[58] in forensic science (a shift towards scientific methodologyis meant, not a Kuhnian paradigm shift [35]).
The possible adoption and implications of this paradigm shiftin the different disciplines is currently a hot topic in many sci-entific and legal fora [13], [40]. One of the main reasons forthis discussion is the U.S. Supreme Court Daubert ruling on theadmissibility of scientific evidence [22]. Briefly, according toDaubert, in order to be admitted in court, the judge, as gate-keeper, must decide whether any technique satisfies all or mostof the following conditions [7]:
1) It has been or can be tested.
2) It has been subjected to peer review or publication.3) There exist standards controlling its use.4) It is generally accepted in the scientific community.5) It has a known or potential (and acceptable) error rate.
According to these rules, scientifically sounding techniqueswith standard procedures demonstrating their testability, accu-racy and acceptance in the scientific community are likely tobe admitted in a U.S. federal court of law. On the other hand,nonscientific statements, such as expert testimony lackingscientific foundation, are likely to be rejected. The implicationsof these rules are in accordance with the opinions of manyleading forensic experts [1], [17], [18], [19], [28], [58] whodemand more transparent procedures and a scientific frame-work for the logical and testable interpretation of evidence.Daubert, together with evidence of egregious errors in somewell-established forensic areas, has led to the reconsiderationof procedures used in forensic interpretation and reporting [20],[33], [58].
A. Transparency
The two main desiderata for a transparent framework are 1)that it is based on received scientific principles, and 2) that theanalysis procedures and reporting of results perfectly accordwith the needs and roles of both forensic scientist and other in-terested legal parties. In FSR, linguistics and phonetics on oneside, and signal processing and pattern recognition on the other,are well-known and widely accepted scientific disciplines, andthey should try to accomodate to this new paradigm for FSR.Once this is done, any part of the process (methodologies, as-sumptions, computations, reporting, reference populations, etc.)is perfectly defensible, and transparency the result.
The Bayesian framework represents a mathematical and log-ical tool for evidence interpretation [1],1 showing many advan-tages in the forensic context. First, it allows the forensic sci-entist to obtain and give the court a meaningful value for thestrength of the evidence in the form of an LR [16]. Second, therole of the scientist is clearly defined, leaving to the court thetask of using prior judgements or costs in the decision process[62]. Third, probabilities can be interpreted as degrees of belief[61], allowing the use of subjective opinions as probabilities inthe inference process in a scientific way.
Assuming that the evidence is the information extractedfrom the questioned mark (e.g., a recovered wire-tapping) andthe suspect material (e.g., a recording from the suspect) the sim-ilarity/typicality approach2 in LR computation is summarized in
LR (1)
where (prosecution hypothesis: the suspect is the source ofthe questioned incriminating recording) and (defense hy-pothesis: another individual is the source) are the relevant hy-potheses, is the background information available in the case,
is any possible value of the evidence, and are estimatedprobability density functions according to the knowledge of the
1[Online]. Available: http://en.wikipedia.org/wiki2This similarity/typicality approach has been called a two-stage approach
[40], [47], but the term two-stage was also used to refer to a non-Bayesianprocess of first finding a match and then computing its probability [21]. Wetherefore eschew it here.

2106 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007
problem. In (1), the numerator gives a measure of the simi-larity between the questioned material and the suspect, and thedenominator is a measure of the typicality of the evidence ina relevant population of individuals. This similarity/typicalityapproach for LR estimation can be well documented by theforensic scientist and understood by fact finders [1], [19].
B. Testability
Testing is a key issue in the admissibility of forensic systemsor methodologies in courts [58]. The knowledge of a technique’serror rates required by Daubert demands unified protocols forthe scientific evaluation of a system. We identify two main fac-tors as critical for the achievement of this goal in FSR. First, aneffort is needed to generate common protocols and databases forforensic testing. In this sense, the work by NIST and NFI/TNOin their respective SREs [64] has been fundamental in the lastyears for automatic systems. Unfortunately, no such comparabletesting exists for traditional methods, and it is only recently, withthe advent of the likelihood ratio paradigm, that it is clear howsuch methods might be tested (examples are presented below).In this paper, we use the NIST 2006 SRE protocol for testing au-tomatic system performance, and the Bernard data set of vowelformants for 171 male Australian English speakers for testing atraditional LR approach. The second critical factor is the use ofa common methodology for presenting results in court, whichwill show how to properly measure and assess the opinions ofthe expert. In this paper, a possible way to achieve that secondobjective is proposed in the form of likelihood ratios, detectionerror tradeoff (DET), Tippett and applied probability of error(APE) plots, and values.
III. CALIBRATION IN BAYESIAN FSR
The concept of calibration was introduced in [23] in the con-text of weather forecasting. There, posterior probabilities (orconfidences) were used as degrees of belief about a given hy-pothesis (tomorrow it will rain) against its opposite (tomorrowit will not rain). Calibration is defined in [23], “ The conceptof calibration pertains to the agreement between a forecaster’spredictions (the probability x specified by the forecaster on anyparticular day) and the actual observed relative frequency ofrain. Roughly speaking, a forecaster is said to be well calibratedif among those days for which his prediction is x, the long-runrelative frequency of rain is also x. .” The forecaster’s accu-racy was then assessed by means of strictly proper scoring rules(SPSRs). These may be viewed as cost functions which assign apenalty to a given confidence depending on 1) the probabilisticvalue of the forecast and 2) which of the hypotheses was actu-ally correct.
For example, if a probabilistic forecast gives a high proba-bility of rain for tomorrow (value of the forecast) and tomorrowit does not rain, a SPSR will penalize the forecast, and viceversa. SPSRs have interesting properties. First, there is only oneconfidence value which optimizes an SPSR [23], and it is a ref-erence value, for example, an evaluator who knows the true an-swers of the hypotheses. Thus, the greater the deviation of theforecast from the evaluator’s reference probability value, thehigher the penalty. Second, in [23], it is demonstrated that anySPSR can be split into a refinement component, measuring the
discrimination capabilities of the confidence values elicited, anda calibration component measuring the deviation of such confi-dence values from the probabilities computed by the evaluator.
The use of SPSRs for assessing speaker recognition systemsdelivering LRs has been recently proposed in the literature [10],[14]. In the context of speaker recognition, each forecast is rep-resented with the confidence on the hypothesis “the speaker pro-duced the test utterance” or its opposite. This may be inferredfrom the LR computed by the speaker recognition system andthe prior probabilities. In [10], a likelihood ratio-based evalua-tion framework is proposed for speaker detection, assuming thatthe speaker detection system performance should be assessedwith independence of the prior probabilities and costs used inthe decision process. This likelihood ratio assessment frame-work [10] is suited for the methodology proposed in Section IIfor FSR because 1) the hypotheses and as defined inSection II-A have the same meaning as the equivalent and
defined in [10], 2) the prior probabilities and decision costs,which are the province of the court, are unknown by the forensicscientist, and 3) the LR is estimated by the FSR system.
A. Assessing Calibration in FSR
In NIST SREs, DET plots have been used to measure the dis-crimination performance of speaker detection technology. How-ever, LR values in FSR are not used primarily as a discrimi-nation score, but as an estimate of the degree of support (theweight of the evidence) for a hypothesis against its opposite oralternative. Combining the LR and the prior odds, we obtainan estimate of the posterior probability or confidence for eachhypothesis. Thus, the accuracy of the LR values does not onlydepend on their discrimination power for trials where oris true (as measured by the refinement of the LR values) but intheir actual values, which have a strong impact on calibration[23]. Therefore, in the LR-based analysis of forensic evidence,Tippett plots have been classically used for performance evalu-ation [27], [31], as in NFI/TNO forensic SRE [63]. In a Tippettplot, the distribution of the LR values being or respec-tively true are plotted together. Important information shown bythese curves (and not by DET plots) are the actual distributionsof the target and nontarget trial LR values and the rates of mis-leading evidence. This rate of misleading evidence is definedas the proportion of LR values giving support to the wrong hy-potheses LR LR when is true andLR when is true).
Recent work on the evaluation of speaker recognition systemshas proposed application-independent metrics such as [10],where application, as defined in [10], is the set of prior proba-bilities and decision costs involved in the decision process [62].
is a single scalar defined as
LR
LR (2)
where and are, respectively, the number of LR valuesin the evaluation set for or true. As can be seen in (2),hypothesis-dependent logarithmic cost functions are applied to

GONZALEZ-RODRIGUEZ et al.: EMULATING DNA: RIGOROUS QUANTIFICATION OF EVIDENTIAL WEIGHT 2107
the LR values being evaluated, and thus they are assessed de-pending on their numerical value. Highly misleading LR valueswill attract a strong penalty (high ) and vice versa.
presents several useful properties [10] as highlighted in[47] where an illustrative example on the effects of calibrationwith Tippett plots may also be found. Based on the value,the APE-curve [10] has also been proposed as a way of mea-suring the probability of error of the LR values computed bythe forensic system over a wide range of applications (differentcosts and priors). If the LR values computed by the forensic ex-pert are used by a court in order to take decisions, inevitably,errors will occur. The total probability of error, understood asan error in the decision about the hypothesis using the posterior,is given by
error error (3)
The APE curve plots the total probability of error with respect tothe prior probabilities (see sample APE plot in Fig. 3). Relativeto the of a neutral system, which is the one always providingLR both for and (upper dotted curve), the APE plotsshow the of the LRs estimated by the FSR system (middlecurve), and the of an optimally calibrated system, estimatedfrom a development set, eliciting LRs with exaclty the same dis-crimination of the FSR system (lower curve). Moreover, as isdescribed in detail in [10], is a cost function which inte-grates the probability of error over all possible priors and costs.Thus, the area below the middle APE curve will be , andthe area below the lower APE curve will be , which isthe value of the optimally calibrated system. The calibra-tion loss is directly shown as the difference between and
. Moreover, is an SPSR [10], and therefore it hasthe desirable properties described above.
In a forensic context, the prior probability is the provinceof the court, and therefore the assessment of a forensic expertshould treat the prior as a parameter, without assumptions aboutits value. Thus, is suited for the assessment of forensic sys-tems, because it represents the total probability of error of a factfinder who would use the LR values computed by the forensicexpert at any possible prior. With the APE plot, it is the factfinder who, case by case, has the possibility to assign (or not) aprior probability. If it is assigned, the fact finder is able to obtainin each case the probability of error when using the elicited LRin the estimation of the posterior probability.
B. Calibration Measures and Calibration Process
At this point, it is important to point out that the calibrationloss of any technique or system can be measured from an esti-mated LR set from known data. On the other hand, the processof calibration is intended to compensate the raw LR with the aimof making it more relevant in the Bayesian framework, lookingfor LR values with calibration loss as close as possible to theminimum calibration loss for the given discrimination of thesystem. It is merely a normalization technique, estimated fromdevelopment data, that affects the behavior of the LR. Becauseof this, calibrating a system does not necessarily lead to a cali-brated system. Even after calibration, the calibration loss of thesystem LR values will increase (sometimes dramatically) if theconditions of the data used for training the calibration process
(quality and amount of data, etc.) do not match closely those ofthe test data.
IV. OBTAINING LRS FROM SPEECH EVIDENCE
In this section, a review of LR estimation methods in speakerrecognition is presented, where we will describe generative andnon-generative methods found in the literature. With generativemethods, the objective is to solve the classification problem byfirst estimating the underlying unknown pdfs and then use themto assign a likelihood to the evidence, i.e., a probability of the ev-idence given each of the hypotheses. Non-generative methods,on the other hand, aim at solving the classification problems inother ways. For instance, the Naive Bayes classifier is genera-tive while logistic regression, its discriminative counterpart, isnon-generative [45].
A. Generative LR as Ratio of Similarity to Typicality
Computation of LRs in the forensic sciences has been largelyinfluenced by DNA typing. Forensic LRs are obtained relatingthe similarity between the test and control samples to the typi-cality in the population of interest of the test and control samplesunder evaluation [1], [5], [21], [31]. DNA deals with discreteprobabilities, and when single stain procedures are considered,if a match is found, the numerator of the LR is typically as-sumed to be one. The denominator is obtained from the randommatch probability in the population of interest. However, mostidentification-of-the-source disciplines deal with continuouslyvalued scores, so similarity and typicality measures are also tobe obtained in a generative way but from underlying unknowncontinuous distributions that have to be estimated [21]. Simi-larity is estimated from the evidence (e.g., the recovered- or test-recording) relative to within-source control data (e.g., speechrecordings from the suspect under conditions controlled to max-imize comparability), while typicality is estimated from the ev-idence relative to between-source reference data (e.g., speechrecordings from speakers other than the suspect). The use of (1)is intended to calibrate the evidence score E, providing an LRvalue with low calibration loss, where the better the estimatesof the involved pdfs, the smaller the resulting calibration loss.
B. Generative LR Estimation in Traditional FSR
In the past, FSR was largely dominated by auditory, phonetic,and linguistic analyses singly or in combination [36], [39], al-though the present consensus among practitioners is that bothauditory and acoustic analyses are required. Each of the featuresused (termed traditional because they relate to features used intraditional phonetic and linguistic analysis [52]) is known tovary across different speakers but also within speakers, so anLR can easily be obtained for each feature if adequate mea-sures of variation among reference populations are available,and measures of variation within the suspect can be extractedfrom known recordings. However, because of limits to the varia-tion from linguistic functionality and human anatomy, they usu-ally have limited individualizing power on their own, so some ormany of them must be combined. LRs are very easily combined[1] when the assumption of independence between them is valid,which is usually not the case. Then, it is crucial for correlationbetween variables to be taken into account in the computation

2108 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007
of the LR, and multivariate LR techniques [2], [53], [56], suchas those in Section V, are a must.
C. Generative LR Estimation in Automatic FSR
Pattern recognition-based speaker recognition systems (alsoknown as “automatic” speaker recognition) have seen contin-uous and significant advances over the last two decades [50],[64]. In the late 1990s, the generative techniques developed forglass evidence basing on refractive indices [21] were applied forthe first time to FSR [16], [32], [39]. The techniques then furtherevolved to be able to compute similarity-typicality-based LRs in1c1c tasks (one conversation for training and another for testing)in NFI-TNO 2003 FSR Evaluation and NIST 2004 SRE [31].Recently, suspect-adapted maximum a posteriori (MAP) esti-mation of within-source distributions [46] and measurements ofcalibration loss in FSR [47] have been proposed in forensic gen-erative LR computation.
D. Non-Generative LRs in Automatic FSR
During the decade-long NIST SRE series, most participantshave used score-based systems. This is where the higherthe score the greater the similarity between test and trainingsamples. Participants establish a system-dependent thresholddesigned to minimize [10], [64] as objective function,which is a simultaneous measure of discrimination and cal-ibration. When the score is compared with that threshold anacceptance or rejection decision is reported. This approach,valid for technology evaluation or commercial applications,is not adequate for FSR as it usurps the court’s role in de-termining the threshold [16]. With the introduction of asan application-independent evaluation measure [10] in NISTSRE 2006 [42], SRE participant systems are transforming theirscore-based outputs in LR values with a final calibration stageusing techniques like logistic regression [11], [45] or multilayerperceptrons [14].
E. Caution on the Use of FSR
In this paper, we focus on showing that FSR can be both trans-parent and testable, being then acceptable for use in court in thelight of the coming forensic identification paradigm shift. SRtechniques with good discrimination that have been submittedto calibration are more prone to provide output LR values thatare usable in the Bayesian framework independently of the pos-sible hypotheses priors and decisions costs. However, the degreeof calibration of a system can only be evaluated a posteriori, bymeasuring the calibration loss obtained on a development set,and similar performance can be expected only on similar data. Ifthe conditions of the assessment (linguistic and acoustic quality,reference population, durations, etc.) match those of the actualcase, or the technique has been shown to be robust to the presentlevel of mismatch, well-calibrated LR values can then be inter-preted as estimations of the weight of the evidence.
V. TESTING FORENSIC DISCRIMINABILITY
OF TRADITIONAL FEATURES
The centrality of testing forensic methodologies was referredto above in Section II-B. The LR lends itself beautifully to suchtesting: it can be used as a discriminant value, with known same-speaker and different-speaker pairs tested to see to what extent
they are correctly resolved. One of the commonest traditionalfeatures used in the forensic comparison of voice samples isF-pattern, since formant center frequencies can be transparentlyrelated to a speaker’s vocal tract dimensions and the speechsound they are making [52], [54]. Thus, the logical initial step inasking whether FSR with traditional features can emulate DNAtesting (in the sense of the title of this paper) is to see to whatextent same-speaker speech samples are discriminable from dif-ferent-speaker speech samples on the basis of their F-pattern,using an LR as discriminant value.
The aim of this section is to summarize two discriminationexperiments with F-pattern features which explore the discrim-inablity of vowel acoustics within the LR-based testing para-digm. The first experiment uses the F-pattern of four diphthongs/ai ei oi ou/ to show that Traditional features do indeed haveforensic discriminatory potential under relatively clean condi-tions. The second experiment, with just one diphthong /ai/, takesthis further and shows that the discriminability extends to non-contemporaneous data. The experiments are taken from [55] and[56]; the reader is referred to these publications for the exper-imental details. In both experiments, a two-level multivariatelikelihood ratio (MVLR) was used as discriminant function. TheMVLR was developed at the Joseph Bell Centre for ForensicStatistics and Legal Reasoning [2] for estimating LRs in ma-terial where predictor variables may be correlated, as may verywell be the case in diphthongal F-pattern [52]. MVLR estimatesthe LR as in (1) based in modeling within-source variability witha multivariate normal distribution and the between-source vari-ability with a multivariate kernel density distribution. Thus, cor-relation between variables is thereby accounted for, and multi-variate LR estimation is accomplished.
A. Bernard F-Pattern Reference Database
The Bernard corpus [6] was used. Collected in the late six-ties, this contains information on the F-pattern (F1–F3) of theeleven monophthongal and seven diphthongal phonemes of 171male Australian English speakers. Four of the diphthongs in theBernard corpus were tested: /ai/ as in by, /ei/ (bay), /oi/ (boy) and/ou/ (bone). Results are presented from discrimination using anoptimal combination of spectral and temporal information: theF-pattern at both diphthongal targets, together with the durationof the first target and the duration of the transition between thetargets (i.e., eight features per diphthong in all).
Bernard recorded his subjects saying their diphthongs inwords: once with the word in isolation and once with
the word embedded in a frame sentence. So, the data containonly two tokens per diphthong per speaker. With 171 speakers,a maximum of 171 target trials and 14 535 different-speakercomparisons were possible. Since there were two tokens perspeaker, this gave four nontarget trials per different-speakerpair, yielding in all 58 140 nontarget trials.
B. Experiment 1: Contemporaneous Speech
An experiment was first carried out with the MVLR on eachdiphthong separately. This resulted, for each diphthong, in oneset of log10LRs for the target trials, and four sets of log10LRsfor the nontarget trials. Results for all four diphthongs werethen fused via sum and logistic regression. This might repre-sent a case where both questioned and known samples contained
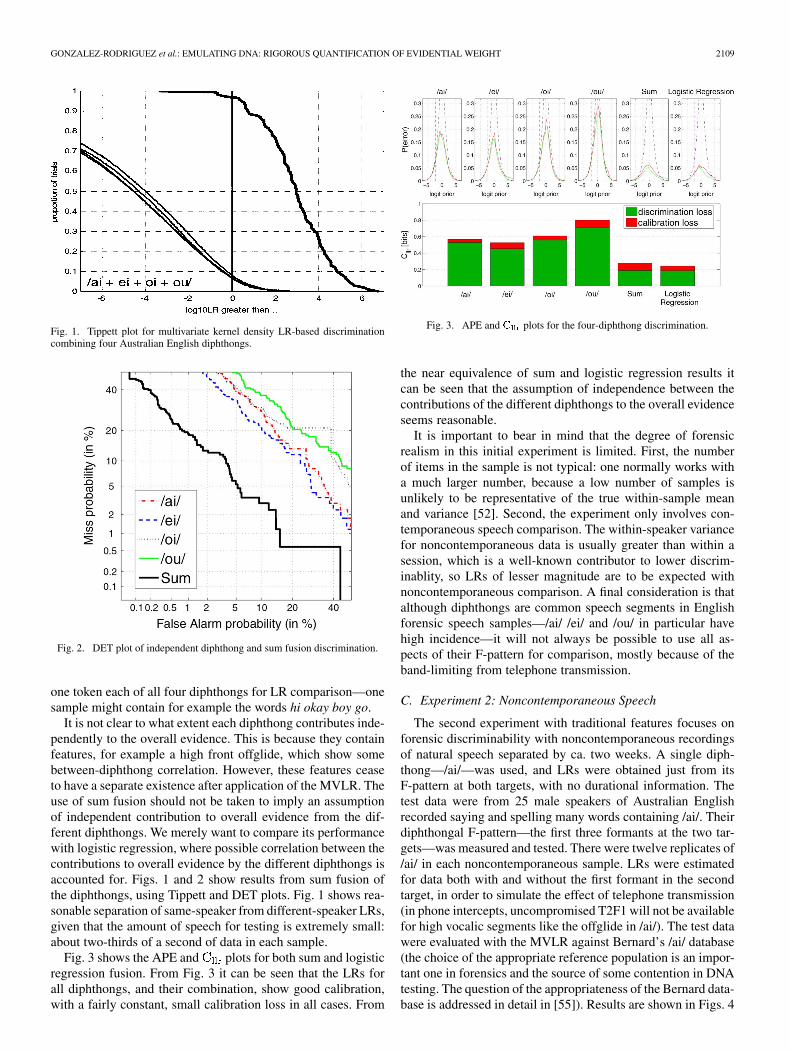
GONZALEZ-RODRIGUEZ et al.: EMULATING DNA: RIGOROUS QUANTIFICATION OF EVIDENTIAL WEIGHT 2109
Fig. 1. Tippett plot for multivariate kernel density LR-based discriminationcombining four Australian English diphthongs.
Fig. 2. DET plot of independent diphthong and sum fusion discrimination.
one token each of all four diphthongs for LR comparison—onesample might contain for example the words hi okay boy go.
It is not clear to what extent each diphthong contributes inde-pendently to the overall evidence. This is because they containfeatures, for example a high front offglide, which show somebetween-diphthong correlation. However, these features ceaseto have a separate existence after application of the MVLR. Theuse of sum fusion should not be taken to imply an assumptionof independent contribution to overall evidence from the dif-ferent diphthongs. We merely want to compare its performancewith logistic regression, where possible correlation between thecontributions to overall evidence by the different diphthongs isaccounted for. Figs. 1 and 2 show results from sum fusion ofthe diphthongs, using Tippett and DET plots. Fig. 1 shows rea-sonable separation of same-speaker from different-speaker LRs,given that the amount of speech for testing is extremely small:about two-thirds of a second of data in each sample.
Fig. 3 shows the APE and plots for both sum and logisticregression fusion. From Fig. 3 it can be seen that the LRs forall diphthongs, and their combination, show good calibration,with a fairly constant, small calibration loss in all cases. From
Fig. 3. APE and C plots for the four-diphthong discrimination.
the near equivalence of sum and logistic regression results itcan be seen that the assumption of independence between thecontributions of the different diphthongs to the overall evidenceseems reasonable.
It is important to bear in mind that the degree of forensicrealism in this initial experiment is limited. First, the numberof items in the sample is not typical: one normally works witha much larger number, because a low number of samples isunlikely to be representative of the true within-sample meanand variance [52]. Second, the experiment only involves con-temporaneous speech comparison. The within-speaker variancefor noncontemporaneous data is usually greater than within asession, which is a well-known contributor to lower discrim-inablity, so LRs of lesser magnitude are to be expected withnoncontemporaneous comparison. A final consideration is thatalthough diphthongs are common speech segments in Englishforensic speech samples—/ai/ /ei/ and /ou/ in particular havehigh incidence—it will not always be possible to use all as-pects of their F-pattern for comparison, mostly because of theband-limiting from telephone transmission.
C. Experiment 2: Noncontemporaneous Speech
The second experiment with traditional features focuses onforensic discriminability with noncontemporaneous recordingsof natural speech separated by ca. two weeks. A single diph-thong—/ai/—was used, and LRs were obtained just from itsF-pattern at both targets, with no durational information. Thetest data were from 25 male speakers of Australian Englishrecorded saying and spelling many words containing /ai/. Theirdiphthongal F-pattern—the first three formants at the two tar-gets—was measured and tested. There were twelve replicates of/ai/ in each noncontemporaneous sample. LRs were estimatedfor data both with and without the first formant in the secondtarget, in order to simulate the effect of telephone transmission(in phone intercepts, uncompromised T2F1 will not be availablefor high vocalic segments like the offglide in /ai/). The test datawere evaluated with the MVLR against Bernard’s /ai/ database(the choice of the appropriate reference population is an impor-tant one in forensics and the source of some contention in DNAtesting. The question of the appropriateness of the Bernard data-base is addressed in detail in [55]). Results are shown in Figs. 4
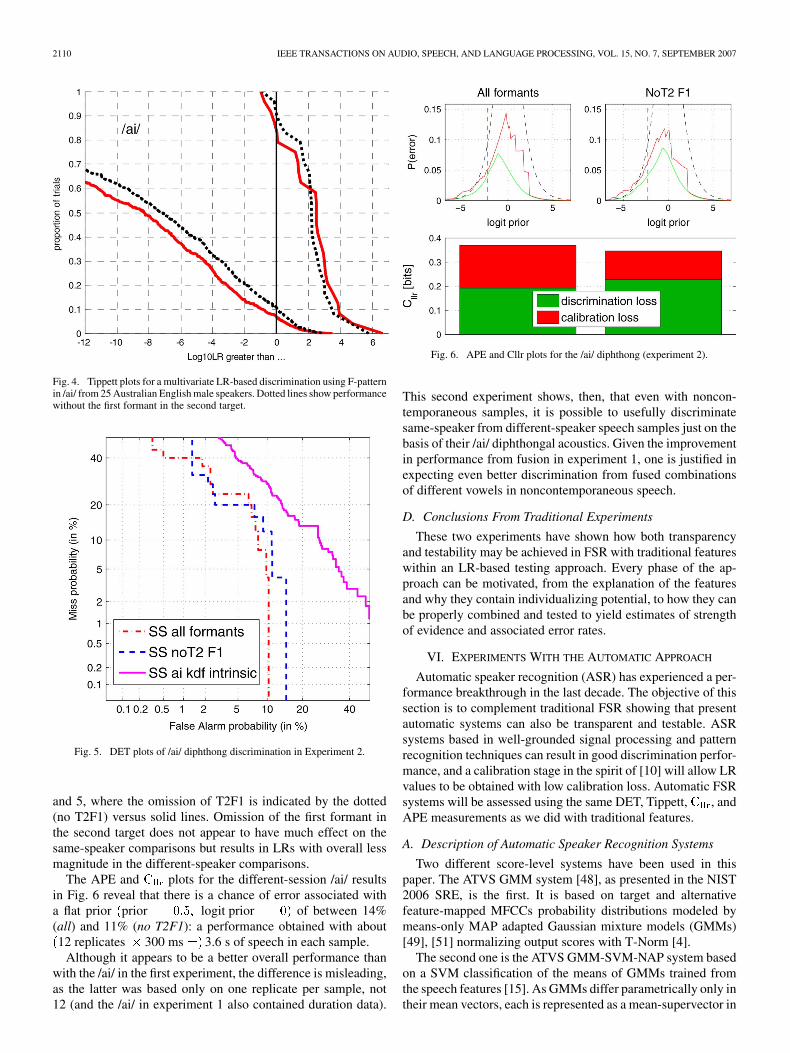
2110 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007
Fig. 4. Tippett plots for a multivariate LR-based discrimination using F-patternin /ai/ from 25 Australian English male speakers. Dotted lines show performancewithout the first formant in the second target.
Fig. 5. DET plots of /ai/ diphthong discrimination in Experiment 2.
and 5, where the omission of T2F1 is indicated by the dotted(no T2F1) versus solid lines. Omission of the first formant inthe second target does not appear to have much effect on thesame-speaker comparisons but results in LRs with overall lessmagnitude in the different-speaker comparisons.
The APE and plots for the different-session /ai/ resultsin Fig. 6 reveal that there is a chance of error associated witha flat prior prior logit prior of between 14%(all) and 11% (no T2F1): a performance obtained with about12 replicates 300 ms 3.6 s of speech in each sample.
Although it appears to be a better overall performance thanwith the /ai/ in the first experiment, the difference is misleading,as the latter was based only on one replicate per sample, not12 (and the /ai/ in experiment 1 also contained duration data).
Fig. 6. APE and Cllr plots for the /ai/ diphthong (experiment 2).
This second experiment shows, then, that even with noncon-temporaneous samples, it is possible to usefully discriminatesame-speaker from different-speaker speech samples just on thebasis of their /ai/ diphthongal acoustics. Given the improvementin performance from fusion in experiment 1, one is justified inexpecting even better discrimination from fused combinationsof different vowels in noncontemporaneous speech.
D. Conclusions From Traditional Experiments
These two experiments have shown how both transparencyand testability may be achieved in FSR with traditional featureswithin an LR-based testing approach. Every phase of the ap-proach can be motivated, from the explanation of the featuresand why they contain individualizing potential, to how they canbe properly combined and tested to yield estimates of strengthof evidence and associated error rates.
VI. EXPERIMENTS WITH THE AUTOMATIC APPROACH
Automatic speaker recognition (ASR) has experienced a per-formance breakthrough in the last decade. The objective of thissection is to complement traditional FSR showing that presentautomatic systems can also be transparent and testable. ASRsystems based in well-grounded signal processing and patternrecognition techniques can result in good discrimination perfor-mance, and a calibration stage in the spirit of [10] will allow LRvalues to be obtained with low calibration loss. Automatic FSRsystems will be assessed using the same DET, Tippett, , andAPE measurements as we did with traditional features.
A. Description of Automatic Speaker Recognition Systems
Two different score-level systems have been used in thispaper. The ATVS GMM system [48], as presented in the NIST2006 SRE, is the first. It is based on target and alternativefeature-mapped MFCCs probability distributions modeled bymeans-only MAP adapted Gaussian mixture models (GMMs)[49], [51] normalizing output scores with T-Norm [4].
The second one is the ATVS GMM-SVM-NAP system basedon a SVM classification of the means of GMMs trained fromthe speech features [15]. As GMMs differ parametrically only intheir mean vectors, each is represented as a mean-supervector in

GONZALEZ-RODRIGUEZ et al.: EMULATING DNA: RIGOROUS QUANTIFICATION OF EVIDENTIAL WEIGHT 2111
a high-dimensional space. This mean-supervector is constructedby concatenation of the means of the GMMs for each dimension[15]. In order to compensate for intersession problems in the su-pervector domain, a technique known as nuisance attribute pro-jection (NAP) has been applied [59]. We also perform T-Norm[4].
B. LR Computation Techniques
In order to show the adequacy of the proposed experimentalmethodology, we use two LR computation techniques found inthe literature, one generative and one discriminative.
1) Generative Suspect-Adapted: As in all generativetechniques, suspect-adapted LR computation [46] is basedon the modeling of the scores from an automatic speakerrecognition system in order to obtain their within-source andbetween-source variability distributions. The distributions
and in the LR formula (1) are estimated fromtarget and nontarget scores, respectively [31].
It has been shown that, even under the same conditions, thetarget scores coming from different speakers may present dif-ferent distributions [25]. Therefore, accuracy in within-sourceestimation may be improved by exploiting suspect specifici-ties. The proposed suspect-adapted technique for generative LRcomputation [46] is thus based on the MAP adaptation [30] ofthe speaker-independent target score distribution to the suspecttarget scores.
2) Discriminative Linear Logistic Regression: The aim oflogistic regression [11], [45] is to obtain an affine transformationof an input dataset to generate an output value which optimizesan objective function. Let be a set of scores from
different automatic speaker recognition systems. It may bedemonstrated that logistic regression leads to LR values withlow calibration loss from this score set. In particular, for a priorprobability of 0.5, it is seen that the logistic regression objectivefunction becomes [10].
Logistic regression can be used to reduce the calibration lossas well as for fusion. If the number of systems is more thanone, we will be fusing the input scores. As an additional ef-fect, because of the objective function optimization, the outputof such a fusion will also have a low calibration loss. On theother hand, if , then the input score is transformed byan affine mapping yielding a low calibration loss output. As thetransformation applied to the output score is affine, the applica-tion of logistic regression calibration to a system will not changeits discrimination performance. In this paper, we have either cal-ibrated an individual system or fused two of them. Logistic re-gression was done with the FoCal toolkit [11].
C. Database and Evaluation Protocol
Experiments have been performed using the evaluation pro-tocol proposed in NIST 2006 SRE [42]. All the results pre-sented in this paper are for the 1conv4w-1conv4w condition(608 speakers), where there is one conversation side for modeltraining and one conversation side for testing. The length of theconversations is typically 5 min, with an average of 2.5 minafter silence removal. For this condition, more than 50 000 scorecomputations per system were performed. The database usedin this evaluation has been partially extracted from the MIXERcorpus [12], but a significant amount of additional multichannel
Fig. 7. Discrimination performance of ATVS GMM and GMM-SVM-NAPSystems in NIST 1c1c SRE06 with suspect-adapted and LogReg LR.
and multilanguage data was acquired in order to complete thecorpus for the evaluation. It includes different communicationchannels, handsets, microphones, and languages and representswell the quality and diversity of real telephone conversations.
The NIST SRE 2005 database has been used as reference datafor LR computation. All the scores from the 1conv4w-1conv4wof the NIST SRE 2005 protocol [41] have been used for logisticregression training, as well as for obtaining the distributions forgenerative LR computation. In order to obtain the target scoresets for suspect MAP adaptation, we have selected all the targetscores for each speaker from the whole score set in the evalua-tion, except the score used as evidence in each LR computation[46].
D. Results From GMM Systems
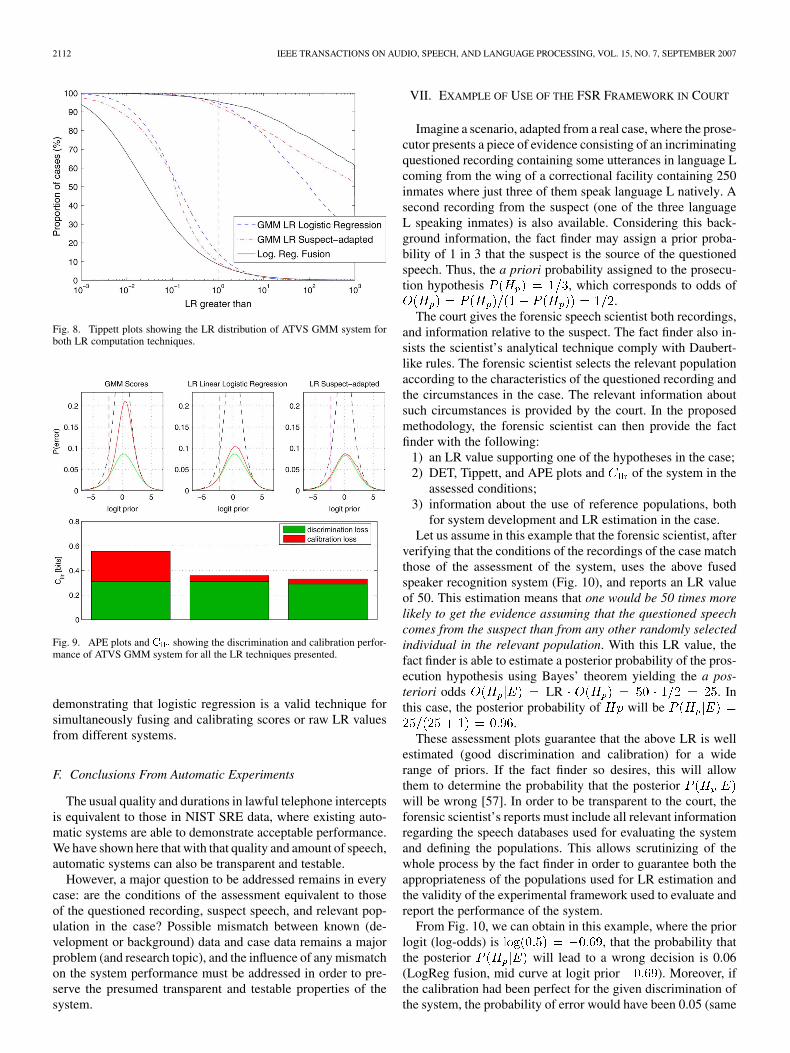
In Fig. 7, the DET plots with the discrimination performanceof the different evaluated LR computation techniques using theATVS GMM system are shown.
Fig. 8 shows the distribution of LR values in the form of Tip-pett plots for the GMM system. It can be seen that the magnitudeof the strength of misleading evidence (LR values supporting thewrong hypothesis) is quite limited for both cases. However, theTippett plots do not allow us to easily conclude which techniqueis better. Moreover, the calibration loss of the techniques is notexplicit.
Fig. 9 shows that the discrimination performance is very sim-ilar for all cases, though slightly better for the suspect-adaptedcase. The calibration performance is also very similar for bothLR computation techniques. On the other hand, values, rep-resented under the APE curves, give an overall metric which al-lows the ranking of the techniques.
E. Results From Logistic Regression Fusion
In this section, we use logistic regression fusion in order tocombine the outputs of the GMM system presented before withthe GMM–SVM–NAP system. The DET plots for the individualand fused system are also shown in Fig. 8 for compactness whileAPE plots and values are shown in Fig. 9. It is observedthat the calibration loss of the output-fused LR values is small,
2112 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007
Fig. 8. Tippett plots showing the LR distribution of ATVS GMM system forboth LR computation techniques.
Fig. 9. APE plots and C showing the discrimination and calibration perfor-mance of ATVS GMM system for all the LR techniques presented.
demonstrating that logistic regression is a valid technique forsimultaneously fusing and calibrating scores or raw LR valuesfrom different systems.
F. Conclusions From Automatic Experiments
The usual quality and durations in lawful telephone interceptsis equivalent to those in NIST SRE data, where existing auto-matic systems are able to demonstrate acceptable performance.We have shown here that with that quality and amount of speech,automatic systems can also be transparent and testable.
However, a major question to be addressed remains in everycase: are the conditions of the assessment equivalent to thoseof the questioned recording, suspect speech, and relevant pop-ulation in the case? Possible mismatch between known (de-velopment or background) data and case data remains a majorproblem (and research topic), and the influence of any mismatchon the system performance must be addressed in order to pre-serve the presumed transparent and testable properties of thesystem.
VII. EXAMPLE OF USE OF THE FSR FRAMEWORK IN COURT
Imagine a scenario, adapted from a real case, where the prose-cutor presents a piece of evidence consisting of an incriminatingquestioned recording containing some utterances in language Lcoming from the wing of a correctional facility containing 250inmates where just three of them speak language L natively. Asecond recording from the suspect (one of the three languageL speaking inmates) is also available. Considering this back-ground information, the fact finder may assign a prior proba-bility of 1 in 3 that the suspect is the source of the questionedspeech. Thus, the a priori probability assigned to the prosecu-tion hypothesis , which corresponds to odds of
.The court gives the forensic speech scientist both recordings,
and information relative to the suspect. The fact finder also in-sists the scientist’s analytical technique comply with Daubert-like rules. The forensic scientist selects the relevant populationaccording to the characteristics of the questioned recording andthe circumstances in the case. The relevant information aboutsuch circumstances is provided by the court. In the proposedmethodology, the forensic scientist can then provide the factfinder with the following:
1) an LR value supporting one of the hypotheses in the case;2) DET, Tippett, and APE plots and of the system in the
assessed conditions;3) information about the use of reference populations, both
for system development and LR estimation in the case.Let us assume in this example that the forensic scientist, after
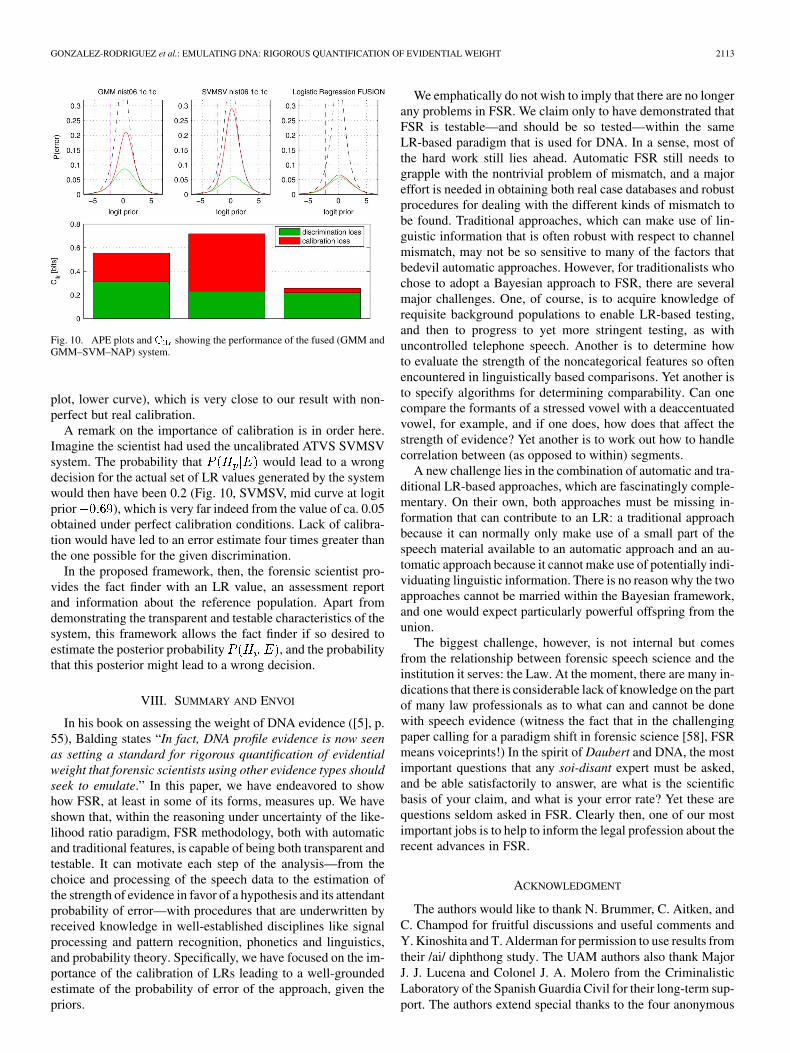
verifying that the conditions of the recordings of the case matchthose of the assessment of the system, uses the above fusedspeaker recognition system (Fig. 10), and reports an LR valueof 50. This estimation means that one would be 50 times morelikely to get the evidence assuming that the questioned speechcomes from the suspect than from any other randomly selectedindividual in the relevant population. With this LR value, thefact finder is able to estimate a posterior probability of the pros-ecution hypothesis using Bayes’ theorem yielding the a pos-teriori odds LR . Inthis case, the posterior probability of will be
.These assessment plots guarantee that the above LR is well
estimated (good discrimination and calibration) for a widerange of priors. If the fact finder so desires, this will allowthem to determine the probability that the posteriorwill be wrong [57]. In order to be transparent to the court, theforensic scientist’s reports must include all relevant informationregarding the speech databases used for evaluating the systemand defining the populations. This allows scrutinizing of thewhole process by the fact finder in order to guarantee both theappropriateness of the populations used for LR estimation andthe validity of the experimental framework used to evaluate andreport the performance of the system.
From Fig. 10, we can obtain in this example, where the priorlogit (log-odds) is , that the probability thatthe posterior will lead to a wrong decision is 0.06(LogReg fusion, mid curve at logit prior ). Moreover, ifthe calibration had been perfect for the given discrimination ofthe system, the probability of error would have been 0.05 (same
GONZALEZ-RODRIGUEZ et al.: EMULATING DNA: RIGOROUS QUANTIFICATION OF EVIDENTIAL WEIGHT 2113
Fig. 10. APE plots and C showing the performance of the fused (GMM andGMM–SVM–NAP) system.
plot, lower curve), which is very close to our result with non-perfect but real calibration.
A remark on the importance of calibration is in order here.Imagine the scientist had used the uncalibrated ATVS SVMSVsystem. The probability that would lead to a wrongdecision for the actual set of LR values generated by the systemwould then have been 0.2 (Fig. 10, SVMSV, mid curve at logitprior ), which is very far indeed from the value of ca. 0.05obtained under perfect calibration conditions. Lack of calibra-tion would have led to an error estimate four times greater thanthe one possible for the given discrimination.
In the proposed framework, then, the forensic scientist pro-vides the fact finder with an LR value, an assessment reportand information about the reference population. Apart fromdemonstrating the transparent and testable characteristics of thesystem, this framework allows the fact finder if so desired toestimate the posterior probability , and the probabilitythat this posterior might lead to a wrong decision.
VIII. SUMMARY AND ENVOI
In his book on assessing the weight of DNA evidence ([5], p.55), Balding states “In fact, DNA profile evidence is now seenas setting a standard for rigorous quantification of evidentialweight that forensic scientists using other evidence types shouldseek to emulate.” In this paper, we have endeavored to showhow FSR, at least in some of its forms, measures up. We haveshown that, within the reasoning under uncertainty of the like-lihood ratio paradigm, FSR methodology, both with automaticand traditional features, is capable of being both transparent andtestable. It can motivate each step of the analysis—from thechoice and processing of the speech data to the estimation ofthe strength of evidence in favor of a hypothesis and its attendantprobability of error—with procedures that are underwritten byreceived knowledge in well-established disciplines like signalprocessing and pattern recognition, phonetics and linguistics,and probability theory. Specifically, we have focused on the im-portance of the calibration of LRs leading to a well-groundedestimate of the probability of error of the approach, given thepriors.
We emphatically do not wish to imply that there are no longerany problems in FSR. We claim only to have demonstrated thatFSR is testable—and should be so tested—within the sameLR-based paradigm that is used for DNA. In a sense, most ofthe hard work still lies ahead. Automatic FSR still needs tograpple with the nontrivial problem of mismatch, and a majoreffort is needed in obtaining both real case databases and robustprocedures for dealing with the different kinds of mismatch tobe found. Traditional approaches, which can make use of lin-guistic information that is often robust with respect to channelmismatch, may not be so sensitive to many of the factors thatbedevil automatic approaches. However, for traditionalists whochose to adopt a Bayesian approach to FSR, there are severalmajor challenges. One, of course, is to acquire knowledge ofrequisite background populations to enable LR-based testing,and then to progress to yet more stringent testing, as withuncontrolled telephone speech. Another is to determine howto evaluate the strength of the noncategorical features so oftenencountered in linguistically based comparisons. Yet another isto specify algorithms for determining comparability. Can onecompare the formants of a stressed vowel with a deaccentuatedvowel, for example, and if one does, how does that affect thestrength of evidence? Yet another is to work out how to handlecorrelation between (as opposed to within) segments.
A new challenge lies in the combination of automatic and tra-ditional LR-based approaches, which are fascinatingly comple-mentary. On their own, both approaches must be missing in-formation that can contribute to an LR: a traditional approachbecause it can normally only make use of a small part of thespeech material available to an automatic approach and an au-tomatic approach because it cannot make use of potentially indi-viduating linguistic information. There is no reason why the twoapproaches cannot be married within the Bayesian framework,and one would expect particularly powerful offspring from theunion.
The biggest challenge, however, is not internal but comesfrom the relationship between forensic speech science and theinstitution it serves: the Law. At the moment, there are many in-dications that there is considerable lack of knowledge on the partof many law professionals as to what can and cannot be donewith speech evidence (witness the fact that in the challengingpaper calling for a paradigm shift in forensic science [58], FSRmeans voiceprints!) In the spirit of Daubert and DNA, the mostimportant questions that any soi-disant expert must be asked,and be able satisfactorily to answer, are what is the scientificbasis of your claim, and what is your error rate? Yet these arequestions seldom asked in FSR. Clearly then, one of our mostimportant jobs is to help to inform the legal profession about therecent advances in FSR.
ACKNOWLEDGMENT
The authors would like to thank N. Brummer, C. Aitken, andC. Champod for fruitful discussions and useful comments andY. Kinoshita and T. Alderman for permission to use results fromtheir /ai/ diphthong study. The UAM authors also thank MajorJ. J. Lucena and Colonel J. A. Molero from the CriminalisticLaboratory of the Spanish Guardia Civil for their long-term sup-port. The authors extend special thanks to the four anonymous

2114 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 7, SEPTEMBER 2007
reviewers for their exhaustive and constructive suggestions thathave significantly improved the quality of the final paper.
REFERENCES
[1] C. G. G. Aitken and F. Taroni, Statistics and the Evaluation of Evidencefor Forensic Scientists. Chichester, U.K.: Wiley, 2004.
[2] C. G. G. Aitken and D. Lucy, “Evaluation of trace evidence in the formof multivariate data,” Applied Statistics 53, pp. 109–122, with corri-gendum pp. 665–666, 2005.
[3] D. Ramos, J. Gonzalez-Rodriguez, G. Zadora, J. Zieba-Palus, andC. G. G. Aitken, “Information-theoretical comparison of likelihoodratio methods of forensic evidence evaluation,” in Proc. Int. WorkshopComput. Forensics, Manchester, U.K., 2007.
[4] R. Auckenthaler, M. Carey, and H. Lloyd-Tomas, “Score normaliza-tion for text-independent speaker verification systems,” Digital SignalProcess., vol. 10, pp. 42–54, 2000.
[5] D. J. Balding, Weight-of-Evidence for Forensic DNA Profiles. NewYork: Wiley, 2005.
[6] J. R. L. Bernard, “Some measurements of some sounds of AustralianEnglish,” Ph.D. dissertation, Univ. Sydney, Sydney, Australia, 1967.
[7] B. Black, F. J. Ayala, and C. Saffran-Brinks, “Science and the law inthe wake of Daubert: A new search for scientific knowledge,” TexasLaw Rev., vol. 72, no. 4, pp. 715–761, 1994.
[8] J. F. Bonastre, F. Bimbot, L.-J. Boe, J. P. Campbell, D. A. Reynolds,and I. Magrin-Chanolleau, “Person authentication by voice: A need forcaution,” in Proc. Eurospeech, 2003, pp. 33–36.
[9] A. Braun et al., “Is forensic speaker identification unethical?—Or canit be unethical not to do it,” Forensic Ling., vol. 5, no. 1, pp. 10–21,1998.
[10] N. Brummer and J. du Preez, “Application independent evaluationof speaker detection,” Comput. Speech Lang., vol. 20, no. 2-3, pp.230–275, 2006.
[11] N. Brummer, “Focal tlkt.” [Online]. Available: http://www.dsp.sun.ac.za/nbrummer/focal/
[12] J. P. Campbell, H. Nakasone, C. Cieri, D. Miller, K. Walker, A. F.Martin, and M. A. Przybocki, “The MMSR bilingual and crosschannelcorpora for speaker recognition research and evaluation,” in Proc.Odyssey, 2004, pp. 29–32.
[13] J. P. Campbell, “Linguistics and the science behind speaker identifi-cation,” 2005 [Online]. Available: http://www.nasonline.org/site/Page-Server?pagename=sackler_forensic_presentations
[14] W. M. Campbell, D. A. Reynolds, J. P. Campbell, and K. J. Brady, “Es-timating and evaluating confidence for forensic speaker recognition,”in Proc. ICASSP, 2005, pp. 717–720.
[15] W. M. Campbell, D. E. Sturim, and D. A. Reynolds, “Support vectormachines using GMM supervectors for speaker verification,” IEEESignal Process. Lett., vol. 13, no. 5, pp. 308–311, 2006.
[16] C. Champod et al., “The inference of identity in forensic speaker recog-nition,” Speech Commun., vol. 31, pp. 193–203, 2000.
[17] C. Champod, , J. Siegel, P. Saukko, and G. Knupfer, Eds., “Identifica-tion/individualization: Overview and meaning of ID,” in Encyclopediaof Forensic Science. London, U.K.: Academic, 2000, pp. 1077–1083.
[18] C. Champod et al., “A probabilistic approach to fingerprint evidence,”J. Forensic Ident., vol. 51, pp. 101–122, 2001.
[19] S. A. Cole, “A history of fingerprinting and criminal identification,”2005 [Online]. Available: http://www.nasonline.org/site/Page-Server?pagename=sackler_forensic_presentations
[20] S. A. Cole, “More than zero: Accounting for error in latent fingerprintidentification,” J. Criminal Law Criminol., vol. 95, no. 3, pp. 985–1078,2005.
[21] J. M. Curran et al., Forensic Interpretation of Glass Evidence. BocaRaton, FL: CRC, 2000.
[22] U.S. Supreme Court, “Daubert v. Merrell Dow Pharmaceuticals 509U.S. 579,” 1993.
[23] M. H. deGroot and S. E. Fienberg, “The comparison and evaluation offorecasters,” Statist., vol. 32, pp. 12–22, 1982.
[24] DNA Advisory Board, “Statistical and population genetics is-sues affecting the evaluation of the frequency of occurrence ofDNA profiles calculated from pertinent population database(s),”Forensic Sci. Commun., vol. 2, no. 3, 2000 [Online]. Available:http://www.fbi.gov/hq/lab/fsc/backissu/july2000/dnastat.htm
[25] G. Doddington et al., “Sheeps, goats, lambs and wolves: A statisticalanalysis of speaker performance in the NIST 1998 speaker recognitionevaluation,” in Proc. ICSLP, 1998.
[26] I. W. Evett, “Interpretation, a Personal Odyssey,” in The Use of Sta-tistics in Forensic Science, C. G. G. Aitken and D. A. Stoney, Eds.Chichester, U.K.: Ellis Horwood, 1991, pp. 9–22.
[27] I. W. Evett et al., “Statistical analysis of STR data,” in Advances inForensic Haemogenetics. New York: Springer-Verlag, 1996, vol. 6,pp. 79–86.
[28] I. W. Evett, “Towards a uniform framework for reporting opinions inforensic science casework,” Sci. Justice, vol. 38, no. 3, pp. 198–202,1998.
[29] L. A. Foreman et al., “Interpreting DNA evidence: A review,” Int.Statist. Rev., vol. 71, no. 3, pp. 473–495, 2003.
[30] J. L. Gauvain et al., “Maximum a posteriori estimation for multivariateGaussian mixture observations of Markov chains,” IEEE Trans. SpeechAudio Process., vol. 2, no. 2, pp. 291–298, Apr. 1994.
[31] J. Gonzalez-Rodriguez, A. Drygajlo, D. Ramos, M. Garcia-Gomar, andJ. Ortega-Garcia, “Robust estimation, interpretation and assessmentof likelihood ratios in forensic speaker recognition,” Comput. SpeechLang., vol. 20, no. 2-3, pp. 331–355, 2006.
[32] J. Gonzalez-Rodriguez, J. Ortega-Garcia, and J. J. Lucena-Molina,“On the application of the bayesian framework to real forensicconditions with GMM-based systems,” in Proc. Odyssey SpeakerRecognition Workshop, Crete, Greece, 2001, pp. 135–138.
[33] US Dept. of justice and office of the inspector general—Oversight andreview division, “A review of the FBI’s handling of the Brandon May-field case (unclassified and redacted),” Washington, DC, 2006.
[34] M. Khodai-Joopari, “Forensic speaker analysis and identification bycomputer: A Bayesian approach anchored in the cepstral domain,”Ph.D. dissertation, Univ. New South Wales, Sydney, NSW, Australia,2006.
[35] T. Kuhn, The structure of scientific revolutions. Chicago, IL: Univ.Chicago Press, 1962.
[36] H. J. Künzell, “Current approaches to forensic speaker recognition,”in Proc. ESCA Workshop Automatic Speaker Recognition, Martigny,Switzerland, 1994, pp. 135–141.
[37] D. V. Lindley, “A problem in forensic science,” Biometrika, vol. 64,no. 2, pp. 207–213, 1977.
[38] D. V. Lindley, “Bayesian thoughts,” Significance, vol. 1, no. 2, pp.73–75, Jun. 2004.
[39] D. Meuwly, “Reconaissance de locuteurs en sciences forensiques:l’apport d’une approche automatique,” Ph.D. dissertation, IPSC, Univ.Lausanne, Lausanne, Switzerland, 2001.
[40] National Academy of Sciences Sackler Colloquium, “Forensic science:The Nexus of science and the law.” 2005 [Online]. Available: http://www.nasonline.org/site/PageServer?pagename=sackler_forensic
[41] NIST, “2005 speaker recognition evaluation plan.” 2005 [Online].Available: http://www.nist.gov/speech/tests/spk/2005/index.htm
[42] NIST, “2006 speaker recognition evaluation plan.” 2006 [Online].Available: http://www.nist.gov/speech/tests/spk/2006/index.htm
[43] “National Research Council, Committee on DNA Technology inForensic Science,” in DNA Technology in Forensic Science. Wash-ington, DC: National Academy, 1992.
[44] “National research council—Committee on DNA forensic science,” inThe Evaluation of Forensic DNA Evidence. Washington, D.C: Na-tional Academy, 1996.
[45] S. Pigeon, P. Druyts, and P. Verlinde, “Applying logistic regressionto the fusion of the NIST’99 1-speaker submissions,” Digital SignalProcess., vol. 10, pp. 237–248, 2000.
[46] D. Ramos, J. Gonzalez-Rodriguez, A. Montero-Asenjo, and J. Or-tega-Garcia, “Suspect-adapted MAP estimation of within-sourcedistributions in generative likelihood ratio estimation,” in Proc. IEEEOdyssey-06, San Juan, PR, 2006, pp. 1–5.
[47] D. Ramos et al., “Likelihood ratio calibration in a transparent andtestable forensic speaker recognition framework,” in Proc. IEEEOdyssey-06, San Juan, PR, 2006, pp. 1–8.
[48] D. Ramos et al., “Speaker verification using speaker- and test-depen-dent fast score normalization,” Pattern Recognition Lett., vol. 28, no.1, pp. 90–98, 2006.
[49] D. A. Reynolds et al., “Speaker verification using adapted Gaussianmixture models,” Digital Signal Process., vol. 10, pp. 19–41, 2003.
[50] D. A. Reynolds, “An overview of speaker recognition technology,” inProc. ICASSP, 2003, pp. 4072–4075.
[51] D. A. Reynolds, “Channel robust speaker verification via feature map-ping,” in Proc. ICASSP, 2003, pp. 53–57.
[52] P. Rose, Forensic Speaker Identification. New York: Taylor &Francis, 2002.

GONZALEZ-RODRIGUEZ et al.: EMULATING DNA: RIGOROUS QUANTIFICATION OF EVIDENTIAL WEIGHT 2115
[53] P. Rose et al., “Strength of forensic speaker identification evi-dence—Multispeaker formant and cepstrum based segmental discrim-ination with a bayesian likelihood ratio as threshold,” Int. J. SpeechLang. Law, vol. 10, no. 2, pp. 179–202, 2003.
[54] P. Rose, “Technical forensic speaker recognition: Evaluation, typesand testing of evidence,” Comput. Speech Lang., vol. 20, no. 2–3, pp.159–191, 2006.
[55] P. Rose, Y. Kinoshita, and T. Alderman, P. Warren and C. Watson,Eds., “Realistic extrinsic forensic speaker discrimination with the diph-thong/ai/,” in Proc. 11th Australian Int. Conf. Speech Sci. Technol.,2006, pp. 329–334.
[56] P. Rose, P. Warren and C. Watson, Eds., “The intrinsic forensic dis-criminatory power of diphthongs,” in Proc. 11th Australian Int. Conf.Speech Sci. Technol., 2006, pp. 64–69.
[57] R. Royall, “On the probability of observing misleading statistical ev-idence,” J. Amer. Statist. Assoc., vol. 95, no. 451, pp. 760–768, Sep.2000.
[58] M. J. Saks and J. J. Koehler, “The coming paradigm shift in forensicidentification science,” Science, vol. 309, no. 5736, pp. 892–895, 2005.
[59] A. Solomonoff, W. M. Campbell, and I. Boardman, “Advancesin channel compensation for SVM speaker recognition,” in Proc.ICASSP, 2005, pp. 629–632.
[60] D. A. Stoney, “What made us ever think we could individualize usingstatistics?,” J. Forensic Sci. Soc., vol. 31, no. 2, pp. 197–199, 1991.
[61] F. Taroni et al., “De Finetti’s subjectivism, the assessment of probabil-ities and the evaluation of evidence: A commentary for forensic scien-tists,” Sci. Justice, vol. 41, no. 3, pp. 145–150, 2001.
[62] F. Taroni et al., “Decision analysis in forensic science,” J. Forensic Sci.,vol. 50, no. 4, pp. 894–905, 2005.
[63] D. van Leeuwen et al., “Results of the 2003 NFI-TNO forensic speakerrecognition evaluation,” in Proc. Odyssey, 2004, pp. 75–82.
[64] D. van Leeuwen, A. Martin, M. Przybocki, and J. Bouten, “The NIST2004 and TNO/NFI speaker recognition evaluations,” Comput. SpeechLang., vol. 20, no. 2–3, pp. 128–158, 2006.
[65] S. J. Walsh, C. M. Triggs, and J. S. Buckleton, Eds., Forensic DNAEvidence Interpretation. Boca Raton, FL: CRC, 2004.
Joaquín González-Rodríguez (M’96) received theM.S. degree in electrical engineering and Ph.D. de-gree (cum laude) in electrical engineering from theUniversidad Politécnica de Madrid, Madrid, Spain,in 1994 and 1999, respectively.
He has been an Associate Professor since May2006 at the Computer Science Department at theUniversidad Autónoma de Madrid.
Dr. González-Rodríguez is an invited member ofthe European Network of Forensic Science Institutes(ENFSI), and he has acted as member of several sci-
entific committees and as a reviewer to several international journals. He is alsoa member of the Program Committee of the Odyssey conferences on speaker andlanguage recognition and was Vice-Chair of Odyssey 2004 in Toledo, Spain.
Phil Rose received the M.A. degree in linguistics in1974 and the First Class Honors degree in Germanand Russian in 1972, both from Manchester Uni-versity, Manchester, U.K., and the Ph.D. degreein Chinese phonetics from Cambridge University,Cambridge, U.K., in 1982.
He is Reader in phonetics and chinese linguisticsat the Australian National University, Canberra,Australia, and was a British Academy VisitingProfessor at the Joseph Bell Centre for ForensicStatistics and Legal Reasoning, University of Edin-
burgh, Edinburgh, U.K. He is the author of Forensic Speaker Identification inthe Taylor and Francis Forensic Science Series (New York and London, U.K.,2002) and The Technical Comparison of Forensic Voice Samples in the LegalReference Series Expert Evidence (Sydney, Australia, 2003). He has publishedwidely on forensic speaker recognition and the phonetics of tone languages andhas done forensic speaker identification casework on Chinese and AustralianEnglish for about 15 years.
Daniel Ramos (S’06) received the M.S. degree inelectrical engineering from the Universidad Politec-nica de Madrid, Madrid, Spain, in 2001. He is cur-rently pursuing the Ph.D. degree in speaker recog-nition with forensic applications at the UniversidadAutonoma de Madrid.
Since 2004, he has been with the Universidad Au-tonoma de Madrid, where he is currently working asan Assistant Lecturer.
Mr. Ramos was awarded the IBM Research BestStudent Paper at IEEE Odyssey 2006: The Speaker
and Language Recognition Workshop for his paper “Likelihood ratio calibrationin a transparent and testable forensic speaker recognition framework.”
Doroteo T. Toledano (M’04) received the telecom-munication engineering degree and the Ph.D. degreein telecommunication engineering from the Univer-sidad Politecnica de Madrid, Madrid, Spain, in 1997and 2001, respectively.
He was with the Speech Technology Division ofTelefonica R&D from 1994 to April 2001. FromApril 2001 to October 2002, he was with the SpokenLanguage Systems Group, Laboratory for ComputerScience, Massachusetts Institute of Technology,Cambridge, as a Postdoctoral Research Associate.
After another short period at the Speech Technology Division of TelefonicaR&D, he moved to the Universidad Autonoma de Madrid in 2003, where he iscurrently an Assistant Professor.
Javier Ortega-García (M’96) received the M.S. de-gree and the Ph.D. degree (cum laude), both in elec-trical engineering, from the Universidad Politécnicade Madrid, Madrid, Spain, in 1989 and 1996, respec-tively.
Since May 2006, he has been an Associate Pro-fessor at the Computer Science Department, Univer-sidad Autónoma de Madrid.
Dr. Ortega-García has participated in severalscientific and technical committees. He was GeneralChair of the IEEE Odyssey 2004: The Speaker
Recognition Workshop, held in Toledo, Spain, in 2004.
Related Documents











