Empirical Validation of Knowledge Packages as Facilitators for Knowledge Transfer Pasquale Ardimento * , Maria Teresa Baldassarre y , Marta Cimitile z and Giuseppe Visaggio x Department of Informatics, University of Bari Via Orabona 4, 70126 Bari, Italy SER & Practices s.r.l. Spino® of University of Bari * [email protected] y [email protected] z [email protected] x [email protected] Abstract. Transfer of research results in production systems requires, among others, that knowledge be explicit and under- standable by stakeholders. Such transfer is demanding, as so many researchers have been studying alternative ways to classic approaches such as books and papers that favour knowledge acquisition on behalf of users. In this context, we propose the concept of Knowledge Experience Package (KEP) with a speci¯c structure as an alternative. The KEP contains both the con- ceptual model(s) of the research results which make up the innovation, including all the necessary documentation ranging from papers or book chapters; and the experience collected in acquiring it in business processes, appropriately structured. The structure allows the identi¯cation of the knowledge chunk(s) that the developer, who is acquiring the knowledge, needs in order to simplify the acquisition process. The experience is nee- ded to point out the scenarios that the user will most likely face and therefore refer to. Both structure and experience are important factors for the innovation transferability and e±cacy. Furthermore, we have carried out an experiment which com- pared the e±cacy of this instrument with the classic ones, along with the comprehensibility of the information enclosed in a KEP rather than in a set of Papers. The experiment has pointed out that knowledge packages are more e®ective than traditional ones for knowledge transfer. Keywords : Knowledge package; knowledge base; open innovation. 1. Introduction The ever greater pressure of competition to which ¯rms are subjected has made product and process innovation a crucial issue. To increase the production and the delivery of technological innovation, the dynamic integration of many competences and di®erent knowledge produced and provided by di®erent organisations is necessary. Successful innovators must complement in-house knowledge with technologies from external sources (Chesbrough et al., 2006). Consequently, R&D is shifting from its traditional inward focus to more outward-looking management that draws on knowledge from networks comprised of universities, start-ups, suppliers and even competitors (Chesbrough, 2003). The above considerations are particularly valid within Software Engineering (SE). Indeed, knowledge is a critical production factor because software development (pro- duction and maintenance) is human centred and because software process products are meant to be used in order to enforce capabilities in each application domain. As such the knowledge needed is both of a technical and social nature. The ¯rst type includes knowledge of methods, techniques and processes for building and maintaining software products, in other words: knowledge of the technologies that apply to software development. The second type includes knowledge on the behaviour of the developer and stakeholder needs. Knowledge involves two types of problems: — Transferability and consequent reusability. Much of the knowledge used in development processes is tacit, and much is hidden in processes and in products (Foray, 2006). Indeed, it is known that tacit knowledge con- cepts emerge consequently to events that are not necessarily planned. Knowledge hidden in processes and products is not even readable by its authors in that it is spread out and confused in many of the process or product components (Foray, 2006; Laudon and Laudon, 2008). So, until knowledge is transferable or reusable, it cannot be considered as part of an organisation's assets (Foray, 2006). — Knowledge exploitation. Research produces knowledge that should be transferred to production processes as innovation in order to be valuable. This need is pointed Journal of Information & Knowledge Management, Vol. 8, No. 3 (2009) 229240 # . c World Scienti¯c Publishing Co. 229

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Empirical Validation of Knowledge Packages asFacilitators for Knowledge Transfer
Pasquale Ardimento*, Maria Teresa Baldassarrey,Marta Cimitilez and Giuseppe Visaggiox
Department of Informatics, University of BariVia Orabona 4, 70126 Bari, Italy
SER & Practices s.r.l. Spino® of University of Bari*[email protected]@[email protected]@di.uniba.it
Abstract. Transfer of research results in production systemsrequires, among others, that knowledge be explicit and under-standable by stakeholders. Such transfer is demanding, as somany researchers have been studying alternative ways to classicapproaches such as books and papers that favour knowledgeacquisition on behalf of users. In this context, we propose theconcept of Knowledge Experience Package (KEP) with a speci¯cstructure as an alternative. The KEP contains both the con-ceptual model(s) of the research results which make up theinnovation, including all the necessary documentation rangingfrom papers or book chapters; and the experience collected inacquiring it in business processes, appropriately structured. Thestructure allows the identi¯cation of the knowledge chunk(s)that the developer, who is acquiring the knowledge, needs inorder to simplify the acquisition process. The experience is nee-ded to point out the scenarios that the user will most likely faceand therefore refer to. Both structure and experience areimportant factors for the innovation transferability and e±cacy.Furthermore, we have carried out an experiment which com-pared the e±cacy of this instrument with the classic ones, alongwith the comprehensibility of the information enclosed in a KEPrather than in a set of Papers. The experiment has pointed outthat knowledge packages are more e®ective than traditional onesfor knowledge transfer.
Keywords: Knowledge package; knowledge base; open innovation.
1. Introduction
The ever greater pressure of competition to which ¯rms
are subjected has made product and process innovation a
crucial issue. To increase the production and the delivery
of technological innovation, the dynamic integration of
many competences and di®erent knowledge produced and
provided by di®erent organisations is necessary. Successful
innovators must complement in-house knowledge with
technologies from external sources (Chesbrough et al.,
2006). Consequently, R&D is shifting from its traditional
inward focus to more outward-looking management
that draws on knowledge from networks comprised of
universities, start-ups, suppliers and even competitors
(Chesbrough, 2003).
The above considerations are particularly valid within
Software Engineering (SE). Indeed, knowledge is a critical
production factor because software development (pro-
duction and maintenance) is human centred and because
software process products are meant to be used in order to
enforce capabilities in each application domain. As such
the knowledge needed is both of a technical and social
nature. The ¯rst type includes knowledge of methods,
techniques and processes for building and maintaining
software products, in other words: knowledge of the
technologies that apply to software development. The
second type includes knowledge on the behaviour of
the developer and stakeholder needs. Knowledge involves
two types of problems:
—Transferability and consequent reusability. Much of the
knowledge used in development processes is tacit, and
much is hidden in processes and in products (Foray,
2006). Indeed, it is known that tacit knowledge con-
cepts emerge consequently to events that are not
necessarily planned. Knowledge hidden in processes
and products is not even readable by its authors in that
it is spread out and confused in many of the process
or product components (Foray, 2006; Laudon and
Laudon, 2008). So, until knowledge is transferable or
reusable, it cannot be considered as part of an
organisation's assets (Foray, 2006).
—Knowledge exploitation. Research produces knowledge
that should be transferred to production processes as
innovation in order to be valuable. This need is pointed
Journal of Information & Knowledge Management, Vol. 8, No. 3 (2009) 229�240#.c World Scienti¯c Publishing Co.
229
November 12, 2009 4:17:57pm WSPC/188-JIKM 00235FA2

out by the continuous trend of open innovation (OI). In
other words, the phenomena of exchanging research or
innovation results among research groups or enterprises
(Chesbrough et al., 2006). The logic of OI characterises
the end of the XX century and forecasts that enterprises
develop their projects in collaborationwith other sites. In
contrast to the principles that had characterised Closed
Innovation, the divulging idea is that of: internal R&Ds
holding part of a knowledge that comes from external
R&D; creation of a business model that assumes a pri-
mary role in the knowledge development lifecycle; shar-
ing knowledge with other enterprises in order to achieve
higher quality levels (Chesbrough et al., 2006). OI sup-
ports solution of these issues through exchange of
research results: the enterprises or institutions export
research results that are not yet accessible and usable;
enterprises that are able to exploit the results in the short
term can import them from the organisations that make
them available. The logic behind OI emphasises knowl-
edge transfer, from research to production processes, i.e.
how research results are to be applied. Consequently,
domain knowledge must be enriched by technical and
economical knowledge that allows to identify the best
approach for introducing new knowledge in processes
together with the resources, risks and mitigation actions
(Reifer, 2003).
The ¯rst problem requires formalising knowledge so that it
is comprehensible and reusable by others who are not the
author of the knowledge. The second problem requires
experience packaging able to guide the user in applying
the knowledge in a context. Given these premises, this
paper describes an approach for Knowledge Experience
Packaging (KEP) and Representation and reports the
preliminary results of a ¯rst experimentation of the
approach. For clarity, in the rest of the paper, unless it is
explicitly mentioned, the set of conceptual models and
experience is referred to as knowledge.
In our proposed approach, we have formalised a KEP
and de¯ned some packages that are stored in a Knowledge
Experience Base [KEB] (Schneider and Schwinn, 2001;
Malone et al., 2003; Basili et al., 2007; Schneider and
Hunnius, 2003). The KEP is obtained by using paper and
other resources available on the Web and by giving them a
prede¯ned structure in order to facilitate stakeholders in
the comprehension and acquisition of the knowledge that
they contain.
We have conducted a preliminary validation through a
controlled experiment with the aim to answer to the fol-
lowing Search Questions:
Q1. Is the proposed knowledge description approach more
e±cacious than traditional ones?
Q2. Is the proposed knowledge description approach more
comprehensible than traditional ones?
In the ¯rst question, we introduce the concept of Knowl-
edge Description E±cacy, considered as the rapidity with
which a usable knowledge chunk can be selected within
the entire Knowledge Description contained in the KEP
without needing support from the knowledge authors.
In the second question, we introduce the concept of
Knowledge Description Comprehensibility which includes
the understandability of the contents and, most of all, the
capability to adopt the selected Knowledge in a business
process in a complete and correct way.
In this work, we named `traditional approach' the
approach based on the use of papers, book or, in general,
nonstructured text for knowledge transfer and acquisition.
The rest of the paper is organised as follows: related
works are described in Sec. 2; Sec. 3 illustrates the pro-
posed approach for knowledge representations; in Sec. 4,
an empirical investigation is described; Sec. 5 illustrates
the used measurement model; results of the study
including statistical analysis and lessons learned are pre-
sented in Sec. 6; ¯nally conclusions are drawn (Sec. 7).
2. Related Works
The problems related to knowledge transfer and valor-
isations are investigated in industrial and academic con-
tests and sometimes it is not possible to distinguish the
two contexts because there is a convergence between
industry and academia. Some companies have established
internal organisations whose task is to acquire new
knowledge (Hastbacka, 2004; Halvorsen, 2004; Philips
Research Password Magazine, 2004) to face knowledge
transfer needs. For example, Shell Chemical has organised
some groups with the scope to ¯nding knowledge from
outside sources (Hastbacka, 2004), Hewlett Packard is
commercialising not only its own ideas, but also inno-
vations from other entities (Halvorsen, 2004), Philips
Research is participating in consortiums that direct one-
to-one collaborations with innovative organisations (Phi-
lips Research Password Magazine, 2004).
There are also many studies that are focused on the use
of Internet together with its Search Engines for knowledge
di®usion and transfer (Demirci et al., 2007; Tumer
et al., 2009; Spink et al., 2006; Leighton, 1996; Chu and
Rosenthal, 1996; Clarke and Willett, 1997). These studies
con¯rm that also in the more recent investigations the
available Search Engines have more limitations and low
performances. In this direction, our analysis shows that
the Internet does not o®er appropriate technologies for
searching knowledge that is produced and published by a
230 P. Ardimento et al.
November 12, 2009 4:17:57pm WSPC/188-JIKM 00235FA2

research organisation nor by an enterprise, which is reu-
sable in innovation projects by other research organis-
ations or enterprises. A validation of this statement is
proposed in Ardimento et al. (2008). The most accredited
reason for this limitation is that usually general queries
produce a large amount of documents and that there is no
natural language interface for the search engine. The lat-
ter technology improves the search precision although it
does not overcome the problems described above.
There are also many approaches based on the use of
specialised search engines in the way to ¯nd search results
related to a speci¯c application domain (Kitchen-
ham, 2007).
Another approach to knowledge search and transfer is
based on the use of ontology (Zhang et al., 2004; Mingxia
et al., 2005). This approach is actually the object of many
studies which currently lack tools for creation and man-
agement. Much attention is being focused on these issues
but the available experimental evidence is not yet su±-
cient for large-scale use.
In this work, we proposed an alternative approach to
knowledge transfer based on concepts of knowledge
packaging and knowledge base. The problem of knowledge
packaging for better use is being studied by many research
centres and companies. The current knowledge bases in
literature sometimes have a semantically limited scope.
This is the case of the IESE base (Altho® et al., 2001) that
collects lessons learned or mathematical prediction models
or results of controlled experiments. In other cases, the
scope is wider but the knowledge is too general and
therefore not very usable. This applies to the MIT
knowledge base (Malone et al., 2003), that describes
business processes but only at one or two levels of
abstraction. There are probably other knowledge bases
that cover wider ¯elds with greater operational detail, but
we do not know much about them because they are pri-
vate knowledge bases; for example, the Daimler-Benz
Base (Schneider and Schwinn, 2001; Daimler-Benz
Knowledge Base, 2009). There is another recent KEB,
known as DAU (DoD Acquisition Best Practices Clear-
inghouse, 2009) which is not structured as our KEB but
has many key performance indicators similar to ours. As
such, we are designing a survey, in collaboration with the
authors of the DAU KEB, among stakeholders to verify
which of the two bases is more acceptable. If they are
comparable, we will evaluate them in terms of e±cacy and
comprehensibility.
3. Proposed Approach
Our approach focuses on a knowledge base, named
Prometheus (http://prometheus.serandpractices.com.),
whose contentsmake it easier to achieve knowledge transfer
among research centres; between research centres and
production processes; and among production processes.
The knowledge base must be public to allow one or more
interested communities to develop around it and exchange
knowledge (Ardimento et al., 2006). The knowledge that is
stored in the knowledge base must be formalised as a KEP.
AKEP is any cluster of knowledge, su±ciently familiar that
it can be remembered rather than derived.
3.1. Knowledge package structure
The proposed KEP structure includes all the elements
shown in Fig. 1. More details are provided in Cimi-
tile (2008) and Visaggio:
Fig. 1. Knowledge package structure.
Empirical Validation of Knowledge Packages as Facilitators for Knowledge Transfer 231
November 12, 2009 4:17:58pm WSPC/188-JIKM 00235FA2

A user can access one of the package components and
then navigate along all the components of the same
package according to her/his training or needs. Search
inside the package starting from any of its components is
facilitated by the component's attributes. For all the
components, these allow rapid selection of the relative
elements in the knowledge base (Ardimento et al., 2006;
Cimitile, 2008).
The Knowledge Content component (KC or Knowl-
edge) is the central one. It can be seen in Fig. 2 that KC
contains the KEP expressed in text form and may also
contain ¯gures, graphs, formulas, and whatever else may
help to understand the content. The content is struc-
tured as a tree. Starting from the root (level 0), navi-
gation to other levels (level 1, level 2…) occurs through
links. The higher the level of a node, the lower the
abstraction of the content, which focuses more and more
on operative elements. The root and each intermediate
node contain the reasoned index of the underlying com-
ponents. The content consists of the following: research
results for references, analysis of how far the results, used
for the innovation, can be integrated into the system;
analysis of the methods and details on how to transfer
them into the business processes which collect all the
experience and the changes occurred in time during
projects (each project is an experience of the application
of the innovation to a speci¯c scenario); details on the
indicators listed in the attributes of the KC inherent to
the speci¯c package, analysing and generalising the
experimental data evinced from the evidence and asso-
ciated projects; analysis of the results of any application
of the package in one or more projects, demonstrating
the success of the application or any improvements
required, made or in progress.
When knowledge of some concepts is a prerequisite
for understanding the content of a node, the package
points to an educational e-learning course (Ardimento
et al., 2006). But, if use of a demonstrational prototype is
required to become operative, the same package will point
to a training e-learning course (TE), as shown in Fig. 1
(Ardimento et al., 2006).
When a package also has support tools, rather than
merely demonstration prototypes, KC links the user to the
available tool. For the sake of clarity, we point out that
this is the case when the KEP has become an industrial
practice, so that the demonstration prototypes included in
the archetype they derived from have become industrial
tools. The tools are collected in the Tools component
(TO). Each available tool is associated to a corresponding
TE course which teaches how to use each tool.
Fig. 2. Example of a content of a knowledge package.
232 P. Ardimento et al.
November 12, 2009 4:17:58pm WSPC/188-JIKM 00235FA2

A KEP is generally based on conjectures, hypotheses
and principles. As they mature, their contents must all
become principle-based. The transformation of a state-
ment from conjecture through hypothesis to principle
must be based on experimentation showing evidence of
validity. The experimentation, details of its execution and
relative results, are collected in the Evidence component
(EV), duly pointed to by the KEP.
Finally, a mature KEP is used in one or more projects,
by one or more ¯rms. At this stage, the details describing
the project and all the measurements made during its
execution that express the e±cacy of use of the package
are collected in the Projects component (PR) associated
with the package.
4. Controlled Experiment
4.1. Research goals
The approach aims to verify the approach of knowledge
representation through KEP collected in the Prometheus
tool, compared with equivalent knowledge expressed in
papers and in sources extracted from the web and used for
the production of a knowledge package. In particular, in
accordance with the research questions, it investigates
quality characteristics of e±cacy and comprehensibility.
For e±cacy we investigate whether the analysis and
extraction of knowledge through a KEP requires less e®ort
than through papers; for comprehensibility we investigate
whether knowledge extraction is less prone to error if
KEPs are used rather than papers. Indeed, in the latter
case, knowledge is most likely scattered in various parts of
the paper or papers. With respect to this characteristic, we
also investigate whether given a topic (from here on
indicated as problem) it is more di±cult to understand the
problem and extract knowledge from papers rather than a
KEP.
The following Research Goals have been de¯ned:
RG 1
Analyse knowledge extraction using KEP
With the aim of evaluating it
With respect to e±cacy (compared to knowledge extrac-
ted from papers)
From the view point of the knowledge user
In the context of a controlled experiment on a knowledge
package tool called Prometheus
RG 2
Analyse knowledge extraction using KEP
With the aim of evaluating it
With respect to comprehensibility (compared to knowl-
edge extracted from papers)
From the view point of the knowledge user
In the context of a controlled experiment on a knowledge
package tool called Prometheus
In accordance with the above goal, the following research
hypotheses have been made:
E±cacy :
HEFF0 : There are no statistically signi¯cant di®erences in
terms of e®ort for solving problems assigned using KEP
rather than papers.
HEFF1 : There are statistically signi¯cant di®erences in
terms of e®ort for solving problems assigned using KEP
rather than papers.
Comprensibility :
HCOMPR0 : There are no statistically signi¯cant di®erences
in terms of the degree of correctness of answers using KEP
rather than papers.
HCOMPR1 : There are statistically signi¯cant di®erences in
terms of the degree of correctness of answers using KEP
rather than papers.
4.2. Experiment description
4.2.1. Experiment variables
The dependent variables of the study are E±cacy and
Comprehensibility. E±cacy of the KEB is measured in
terms of e®ort spent for extracting knowledge and
answering a speci¯c set of questions. Comprehensibility is
measured according to a score assigned to the content of
each answer. The same variables are measured for the
resources described in Prometheus and in Papers.
The independent variables are the two treatments: the
problems examined with KEP and with Papers in litera-
ture. Two di®erent types of problems were investigated:
Balanced Scorecard and Reengineering Process.
For each problem, a set of four questions have been
de¯ned. This has been considered an appropriate number
that balances the need for a su±cient amount of data
without having to count on an excessive amount of e®ort
and risk to bore and tire experimental subjects. Each
question has a di®erent complexity level (H or L). Two
questions have a H complexity level and other two are
rated as L for both treatments: KEP and Papers. For
clearness, the question is classi¯ed as complexity L if its
answer can be localised in a part of the document, not
larger than a page; rather it is considered H if the answer
to the question refers to information sparse in multiple
parts of the document that cover an area which is greater
than a page. Since the structure of KEP and Paper are
di®erent: the same question may have di®erent complexity
level, depending on the knowledge representation method
Empirical Validation of Knowledge Packages as Facilitators for Knowledge Transfer 233
November 12, 2009 4:17:58pm WSPC/188-JIKM 00235FA2
used, because the locating the answer may depend on how
the content is organised in PROMETHEUS rather than in
PAPERS.
4.2.2. Selection of experimental subjects
The experimental subjects involved in the experimen-
tation are ¯rst year students of a graduate course in
Informatics.
A total of 82 students have been divided into two
groups (Group A and Group B) by random assignment to
each one. Each group was asked to answer questions
assigned using KEP or Papers extracted from literature.
All of the students have previous knowledge of the
topic concerning Balanced Scorecard because it is part of
their course curricula, while they have previous knowledge
of the Reengineering Process topic.
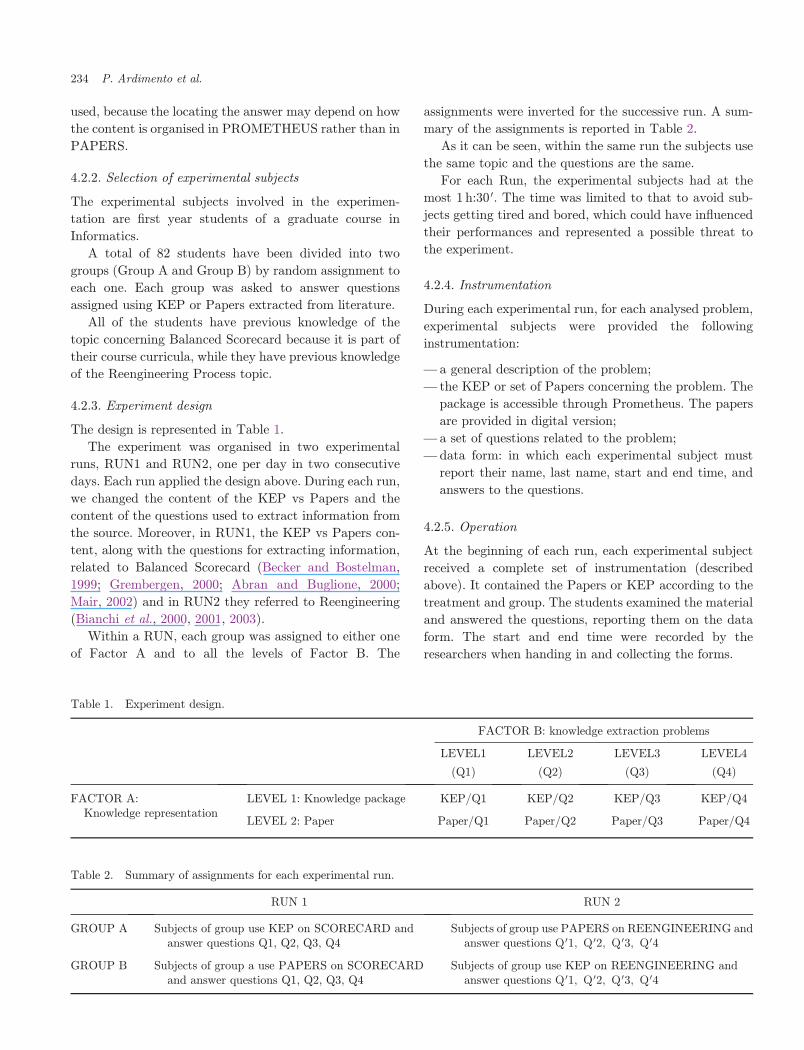
4.2.3. Experiment design
The design is represented in Table 1.
The experiment was organised in two experimental
runs, RUN1 and RUN2, one per day in two consecutive
days. Each run applied the design above. During each run,
we changed the content of the KEP vs Papers and the
content of the questions used to extract information from
the source. Moreover, in RUN1, the KEP vs Papers con-
tent, along with the questions for extracting information,
related to Balanced Scorecard (Becker and Bostelman,
1999; Grembergen, 2000; Abran and Buglione, 2000;
Mair, 2002) and in RUN2 they referred to Reengineering
(Bianchi et al., 2000, 2001, 2003).
Within a RUN, each group was assigned to either one
of Factor A and to all the levels of Factor B. The
assignments were inverted for the successive run. A sum-
mary of the assignments is reported in Table 2.
As it can be seen, within the same run the subjects use
the same topic and the questions are the same.
For each Run, the experimental subjects had at the
most 1 h:30 0. The time was limited to that to avoid sub-
jects getting tired and bored, which could have in°uenced
their performances and represented a possible threat to
the experiment.
4.2.4. Instrumentation
During each experimental run, for each analysed problem,
experimental subjects were provided the following
instrumentation:
— a general description of the problem;
— the KEP or set of Papers concerning the problem. The
package is accessible through Prometheus. The papers
are provided in digital version;
— a set of questions related to the problem;
— data form: in which each experimental subject must
report their name, last name, start and end time, and
answers to the questions.
4.2.5. Operation
At the beginning of each run, each experimental subject
received a complete set of instrumentation (described
above). It contained the Papers or KEP according to the
treatment and group. The students examined the material
and answered the questions, reporting them on the data
form. The start and end time were recorded by the
researchers when handing in and collecting the forms.
Table 1. Experiment design.
FACTOR B: knowledge extraction problems
LEVEL1 LEVEL2 LEVEL3 LEVEL4
(Q1) (Q2) (Q3) (Q4)
FACTOR A:Knowledge representation
LEVEL 1: Knowledge package KEP/Q1 KEP/Q2 KEP/Q3 KEP/Q4
LEVEL 2: Paper Paper/Q1 Paper/Q2 Paper/Q3 Paper/Q4
Table 2. Summary of assignments for each experimental run.
RUN 1 RUN 2
GROUP A Subjects of group use KEP on SCORECARD andanswer questions Q1, Q2, Q3, Q4
Subjects of group use PAPERS on REENGINEERING andanswer questions Q 01; Q 02; Q 03; Q 04
GROUP B Subjects of group a use PAPERS on SCORECARDand answer questions Q1, Q2, Q3, Q4
Subjects of group use KEP on REENGINEERING andanswer questions Q 01; Q 02; Q 03; Q 04
234 P. Ardimento et al.
November 12, 2009 4:17:59pm WSPC/188-JIKM 00235FA2

Comprehensibility was evaluated according to the
number of errors made, while the e®ort is reported on the
data form.
5. Measurement Model
Given the above research goals and the research hypoth-
eses, the dependent factors and the measures used to
calculate such factors have been de¯ned according to the
GQM quality model (Basili et al., 1994).
The introduced metrics are collected as Prometheus
and Paper metrics. The metrics described in Tables 3 and
4 have been collected on both types of knowledge extrac-
tion treatments. The introduced metrics according to the
E±cacy Factor are given in Table 3.
Another factor is Comprehensibility. It is measured as
the average scores Sij attributed for answering the ith
question of the jth experimental subject. All answers were
evaluated according to the interval scale reported in
Table 4.
For clearness, a wrong answer in this case would gen-
erate a threat of improper application of the innovation.
This could mean that investments made lead to di®erent
and incorrect results. A missing answer does not lead to
such a threat and outlines the need to improve the con-
tents of the KEP. As such, the ¯rst case is rated with a
lower score than the second. The scale in Table 4 is clear
for the other two cases.
Note that the researchers, as domain experts involved
in the investigation, corrected all the answers to the
questions given by the experimental subjects.
6. Experimental Results
The data collected during the experimentation have been
synthesised through descriptive statistics. This allows to
represent them graphically, identify possible outliers and
decide if they must be eliminated from the sample. Finally,
data has been analysed through hypothesis testing and
validated with respect to a signi¯cance level of � ¼ 5%.
In the next sections, the results have been commented
for both dependent variables: e®ort (used for measuring
e±cacy of the knowledge representation technique) and
comprehensibility of the technique adopted.
6.1. E±cacy
As pointed out in the experimental design section, in case
of e®ort, the design is reduced to a 1 factor 2 levels design,
in that it has been considered as overall time for answering
all four questions.
In RUN1, the subject performances, as shown in Fig. 3
are closer. The mean values are, respectively, 0.0643 for
PROMETHEUS and 0.0657 for PAPERS. Also, the dis-
persion of the results is very high for both knowledge
representation methods. It seems as if the performances
are independent from the technique used. Our explanation
is that the experimental subjects were familiar with the
topic (Balanced Scorecard) and so they used their pre-
vious experience and knowledge to answer the questions
rather than strictly relate on the technique assigned (KEP
or Papers).
Following to descriptive statistics, a parametric t-test
was carried out. As expected, the di®erences between
levels of treatments were not statistically signi¯cant
(Table 5). This con¯rms that experimental subjects scar-
cely used the techniques and relied on their previous skills
and knowledge to answer the questions.
Figure 4 illustrates the average e®ort in hours spent by
each experimental subject in RUN2. It can be seen that
there is less dispersion in the results for both knowledge
representation techniques. Also, it can be seen how sub-
jects using Papers spent, on average, a larger amount of
time for answering the questions. This suggests that the
structure of the packages promotes a more appropriate
search of the knowledge contents for answering a question.
Table 3. Details of e±cacy quality factor.
E±cacy
Metric name Metric description
Initial time (t) Time when packages/papers and forms aregiven to an experimental subject.
End time (t 0) Time when an experimental subject handsin the data form complete with answers.
E®ort (EF) The amount of e®ort, measured in person/hrs, spent by each subject for carryingout their task and answer the questions:EF ¼ t 0 � t
Table 4. Details of comprehensibility quality factor.
Comprehensibility
Evaluation of question Score Sij
Wrong answer: the jth subject gave a wrong answerto the i th question
0
Lacking answer: the question was not answered bythe j th subject
2
Incomplete answer: the j th subject gave a partiallycorrect answer to the ith question
4
Complete answer: the i th question has received acorrect answer by the jth subject
6
Empirical Validation of Knowledge Packages as Facilitators for Knowledge Transfer 235
November 12, 2009 4:18:00pm WSPC/188-JIKM 00235FA2

Table 5. Hypothesis testing for e®ort in RUN1.
T-tests; Grouping: Knowledge Representation-RUN1
Group 1: PROMETHEUS
Group 2: PAPERS
Mean Mean p Std.Dev. Std.Dev.
Variable PROMETHEUS PAPERS PROMETHEUS PAPER
E®ort in hours-RUN1 0,643229 0,657903 0,629719 0,152905 0,120458
Box Plot of Effort in hours-RUN1 grouped by Knowledge Representation-RUN1
Mean Mean±SE Non-Outlier Range
PROMETHEUS PAPERS
Knowledge Representation-RUN1
0,54
0,56
0,58
0,60
0,62
0,64
0,66
0,68
0,70
0,72
0,74
Eff
ort
in h
ou
rs-R
UN
1
Fig. 3. E®ort in prometheus and papers during RUN1.
Box Plot of Effort in hours- RUN2 grouped by Knowledge Representation-RUN2
Mean Mean±SE Non-Outlier Range
PROMETHEUS PAPERS
Knowledge Representation-RUN2
0,4
0,5
0,6
0,7
0,8
0,9
1,0
1,1
Eff
ort
in h
ou
rs-R
UN
2
Fig. 4. E®ort in prometheus and papers during RUN2.
236 P. Ardimento et al.
November 12, 2009 4:18:00pm WSPC/188-JIKM 00235FA2
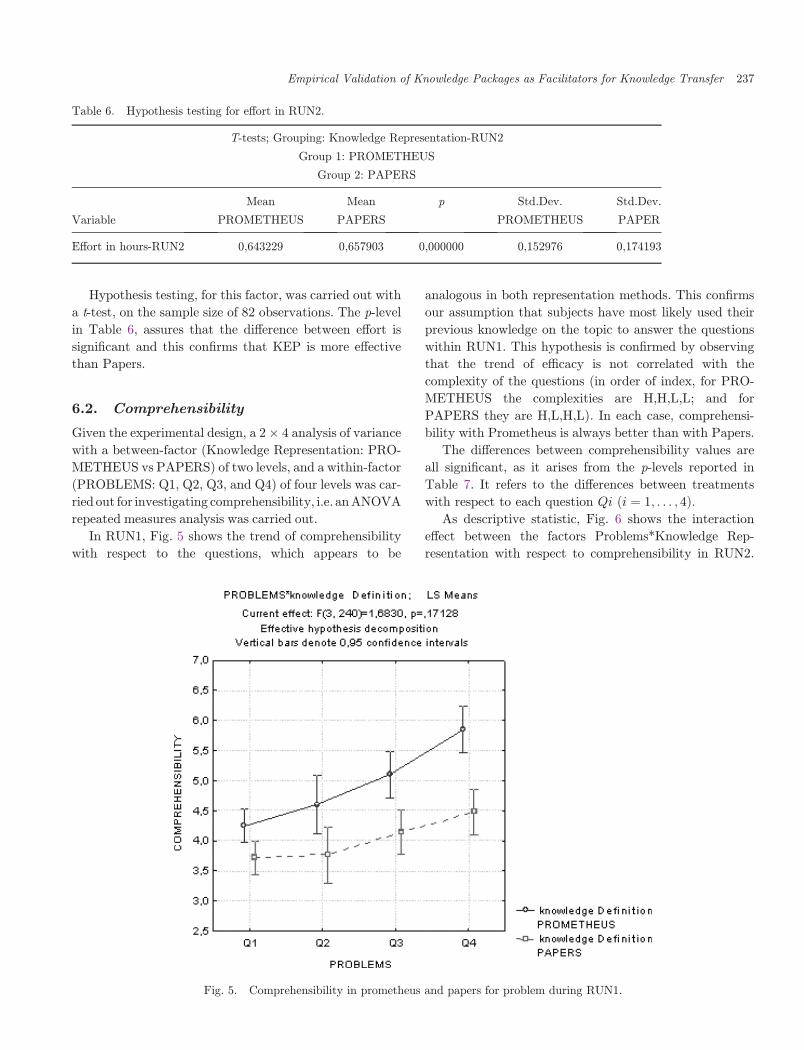
Hypothesis testing, for this factor, was carried out with
a t-test, on the sample size of 82 observations. The p-level
in Table 6, assures that the di®erence between e®ort is
signi¯cant and this con¯rms that KEP is more e®ective
than Papers.
6.2. Comprehensibility
Given the experimental design, a 2� 4 analysis of variance
with a between-factor (Knowledge Representation: PRO-
METHEUS vs PAPERS) of two levels, and a within-factor
(PROBLEMS: Q1, Q2, Q3, and Q4) of four levels was car-
ried out for investigating comprehensibility, i.e. anANOVA
repeated measures analysis was carried out.
In RUN1, Fig. 5 shows the trend of comprehensibility
with respect to the questions, which appears to be
analogous in both representation methods. This con¯rms
our assumption that subjects have most likely used their
previous knowledge on the topic to answer the questions
within RUN1. This hypothesis is con¯rmed by observing
that the trend of e±cacy is not correlated with the
complexity of the questions (in order of index, for PRO-
METHEUS the complexities are H,H,L,L; and for
PAPERS they are H,L,H,L). In each case, comprehensi-
bility with Prometheus is always better than with Papers.
The di®erences between comprehensibility values are
all signi¯cant, as it arises from the p-levels reported in
Table 7. It refers to the di®erences between treatments
with respect to each question Qi ði ¼ 1; . . . ; 4Þ:As descriptive statistic, Fig. 6 shows the interaction
e®ect between the factors Problems*Knowledge Rep-
resentation with respect to comprehensibility in RUN2.
Table 6. Hypothesis testing for e®ort in RUN2.
T-tests; Grouping: Knowledge Representation-RUN2
Group 1: PROMETHEUS
Group 2: PAPERS
Mean Mean p Std.Dev. Std.Dev.
Variable PROMETHEUS PAPERS PROMETHEUS PAPER
E®ort in hours-RUN2 0,643229 0,657903 0,000000 0,152976 0,174193
Fig. 5. Comprehensibility in prometheus and papers for problem during RUN1.
Empirical Validation of Knowledge Packages as Facilitators for Knowledge Transfer 237
November 12, 2009 4:18:00pm WSPC/188-JIKM 00235FA2
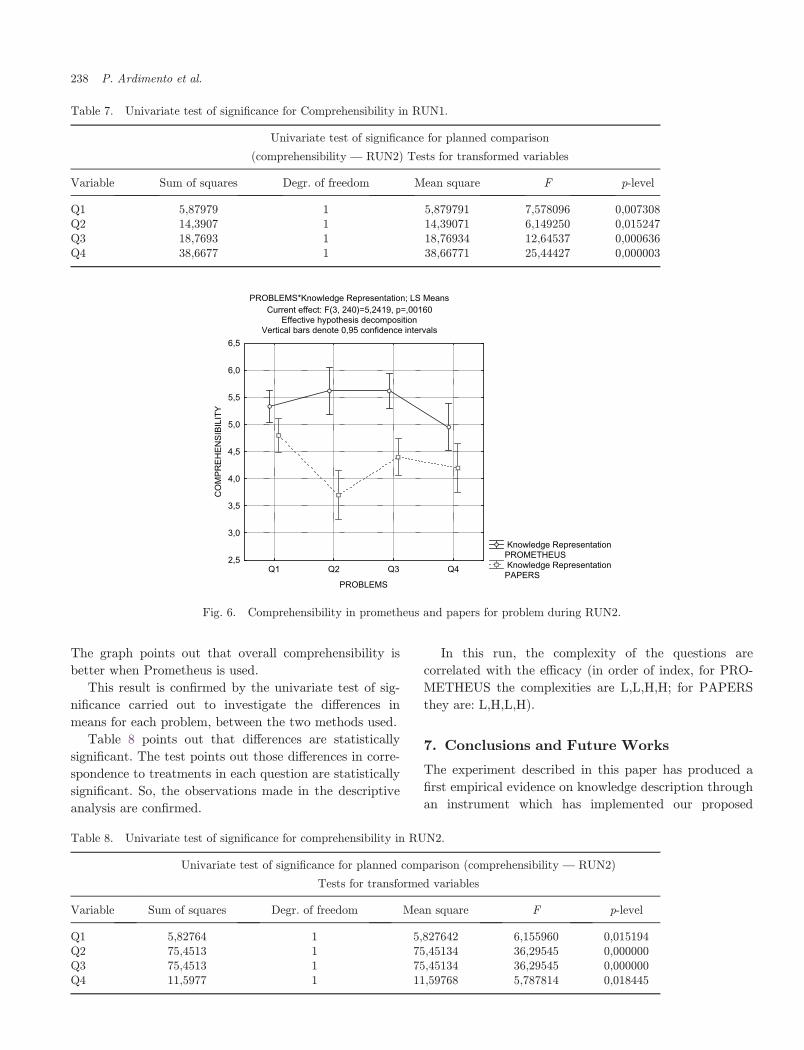
The graph points out that overall comprehensibility is
better when Prometheus is used.
This result is con¯rmed by the univariate test of sig-
ni¯cance carried out to investigate the di®erences in
means for each problem, between the two methods used.
Table 8 points out that di®erences are statistically
signi¯cant. The test points out those di®erences in corre-
spondence to treatments in each question are statistically
signi¯cant. So, the observations made in the descriptive
analysis are con¯rmed.
In this run, the complexity of the questions are
correlated with the e±cacy (in order of index, for PRO-
METHEUS the complexities are L,L,H,H; for PAPERS
they are: L,H,L,H).
7. Conclusions and Future Works
The experiment described in this paper has produced a
¯rst empirical evidence on knowledge description through
an instrument which has implemented our proposed
Table 7. Univariate test of signi¯cance for Comprehensibility in RUN1.
Univariate test of signi¯cance for planned comparison
(comprehensibility — RUN2) Tests for transformed variables
Variable Sum of squares Degr. of freedom Mean square F p-level
Q1 5,87979 1 5,879791 7,578096 0,007308Q2 14,3907 1 14,39071 6,149250 0,015247Q3 18,7693 1 18,76934 12,64537 0,000636Q4 38,6677 1 38,66771 25,44427 0,000003
PROBLEMS*Knowledge Representation; LS MeansCurrent effect: F(3, 240)=5,2419, p=,00160
Effective hypothesis decompositionVertical bars denote 0,95 confidence intervals
Knowledge RepresentationPROMETHEUS Knowledge RepresentationPAPERS
Q1 Q2 Q3 Q4
PROBLEMS
2,5
3,0
3,5
4,0
4,5
5,0
5,5
6,0
6,5
CO
MP
RE
HE
NS
IBIL
ITY
Fig. 6. Comprehensibility in prometheus and papers for problem during RUN2.
Table 8. Univariate test of signi¯cance for comprehensibility in RUN2.
Univariate test of signi¯cance for planned comparison (comprehensibility — RUN2)
Tests for transformed variables
Variable Sum of squares Degr. of freedom Mean square F p-level
Q1 5,82764 1 5,827642 6,155960 0,015194Q2 75,4513 1 75,45134 36,29545 0,000000Q3 75,4513 1 75,45134 36,29545 0,000000Q4 11,5977 1 11,59768 5,787814 0,018445
238 P. Ardimento et al.
November 12, 2009 4:18:02pm WSPC/188-JIKM 00235FA2

approach, called PROMETHEUS. The evidence collected
has provided a ¯rst attempt to con¯rm the validity of the
structure of a KEP in the tool.
Moreover, we can summarises that the structure of the
KEP:
— requires less e®ort for extracting information searched;
— represents explicit knowledge in a more comprehensible
form with respect to traditional descriptions used to
formalise knowledge, like papers and books.
The university context is generally considered of scarce
interest for empirical investigations, as students do not
have the same maturity of professional developers. In this
speci¯c case student subjects are considered to be appro-
priate in that knowledge transfer is more critical when
previous knowledge of users is low. To this end, note that
the experiment has pointed out the e±cacy of the KEP
technique when the subjects lacked of previous knowledge
on the topic.
These ¯rst empirical results induce us authors to con-
tinue our validation, with particular attention to indus-
trial contexts. As so, in order to generalise the validity of
the KEP proposed in this work many replications and
further studies extended to other contexts are needed. For
this reason, the authors intend replicating the experiment,
and to promote the collaboration of other researchers and
practitioners towards empirical validation of KEPs,
making instruments and material available to other
interested researchers.
For sake of completeness, it is the case to say that we are
aware that the structure of our KEB requires more e®ort for
producing KEP with respect to competitor KEB. It is
therefore important to prove that the higher e®ort needed is
repaid by a higher e±cacy. This investigation will be poss-
ible once we have collected a su±cient number of KEP.
References
Abran, A and L Buglione (2000). Balanced scorecards andGQM: What are the di®erences? In Proceedings of theFESMA-AEMES Software Measurement Conference.
Altho®, KD, B Decker, S Hartkopf, A Jedlitschka, M Nickand J Rech (2001). Experience management: TheFraunhofer IESE experience factory. In Proceedings ofthe Industrial Conf. Data Mining, P Perner (ed.).
Ardimento, P, D Caivano, M Cimitile and G Visaggio(2008). Empirical Investigation of the e±cacy and e±-ciency of tools for transferring software engineeringknowledge. Journal of Information Knowledge Manage-ment, 7(3), 197�207, doi: 10.1142/S0219649208002081.
Ardimento, P, M Cimitile and G Visaggio (2006).Knowledge management integrated with e-learning inopen innovation. Journal of e-Learning and KnowledgeSociety 2(3), 343�354.
Basili, VR, F Bomarius and RL Feldmann (2007). Getyour experience factory ready for the next decade —
ten years after \How to build and run one". In Pro-ceedings of 29th International Conference on SoftwareEngineering (ICSE'07 Companion), 167�168.
Basili, VR, G Caldiera and HD Rombach (1994). The goalquestion metric approach. In Encyclopedia of SoftwareEngineering, J Marciniak (ed). New York: Wiley.
Becker, AS and ML Bostelman (1999). Aligning strategicand project measurement systems, IEEE Software, 16(3), 46�51.
Bianchi, A, D Caiano and G Visaggio (2000). Method andprocess for iterative reengineering data in a legacysystem. In Proc. Working Conf. on Reverse Engineer-ing, 86�96.
Bianchi, A, D Caivano, V Marengo and G Visaggio (2001).Iterative reengineering of legacy functions. In Proc.IEEE Int'l Conf. Software Maintenance, 632�641.
Bianchi, A, D Caivano, V Marengo and G Visaggio (2003).Iterative reengineering of legacy systems, IEEE-Transactions on Software Engineering, 29(3), 225�241.
Chesbrough, H (2003). Open platform innovation:Creating value from internal and external innovation.Intel Technology Journal, 7(3), 5�9.
Chesbrough, H, W Vanhaverbeke and J West (2006).Open Innovation: Researching a New Paradigm.Oxford: Oxford University Press.
Chu, H and M Rosenthal (1996). Search engines for theworld wide web: A comparative study and evaluationmethodology. In Proc. ASIS Annual Conf., 127�135.
Cimitile, M (2008). Knowledge economy in softwareengineering. Computer Science PHD Thesis, Bari Uni-versity, Italy. (Available at http://www.tesionline.com/intl/thesis.jsp?idt=24941).
Clarke, S and P Willett (1997). Estimating the recallperformance of search engines. In ASLIB Proceedings,184�189.
Daimler-Benz Knowledge Base (2005). http://www.benzworld.org/forums/w140-s-class/1203330-know-lege-base-2.html (retrieved August 1, 2009).
DoD Acquisition Best Practices Clearinghouse, RetrievedAugust 1, 2009, http://bpch.dau.mil/Pages/default.aspx.
Foray, D (2006). The Economics of Knowledge. Cam-bridge, MA: MIT Press.
Grembergen, WV (2000). The balanced scorecard and ITgovernance. Information Systems Control Journal(previously IS Audit & Control Journal), 2, 40�43.
Gulcin Demirci, R, V Kismir and Y Bitirim (2007). Anevaluation of popular search engines on ¯nding Turkishdocuments. In Proceedings of Second InternationalConference on Internet and Web Applications andServices (ICIW07), IEEE.
Halvorsen, P (2004). Adapting to changes in the(National) Research Infrastructure. Hewlett PackerdDevelopment Company, L.P.
Empirical Validation of Knowledge Packages as Facilitators for Knowledge Transfer 239
November 12, 2009 4:18:02pm WSPC/188-JIKM 00235FA2

Hastbacka, MA (2004). Open innovation: What's mine ismine. What if yours could be mine too? TechnologyManagement Journal, December, 1�4.
Kitchenham, BA and S Charters (2007). Guidelines forPerforming Systematic Literature Reviews in SoftwareEngineering, Version 2003, Keele University, EBSETechnical Report, EBSE-2007-01.
Laudon, K and J Laudon (2008).Management InformationSystems, 11/E. New Jersey: Prentice Hall.
Leighton, H (1996). Performance of four WWW indexservices, Lycos, Infoseek, Webcrawler and WWWWorm. http://www.winona.edu/library/webind.htm(Retrieved June 10, 2005).
Malone, TW, K Crowston and GA Herman (2003).Organizing Business Knowledge — The MIT ProcessHandbook, Cambridge: MIT Press.
Mair, S (2002). A balanced scorecard for a small softwaregroup. IEEE Software, 19(6) 21�27, doi:10.1109/MS.2002.1049383.
Mingxia, G, L Chunnian and C Furong (2005). Anontology search based on semantic analysis. In Proc.Third Int. Conf. on Information Technology andApplications (ICITA2005) 1, 256�259, IEEE.
Philips Research Password Magazine (2004). Issue 20.http://www.research.philips.com.
Prometheus Knowledge Base. http://prometheus.serandpractices.com (Retrieved August 1, 2009).
Reifer, DJ (2003). Is the software engineering state of thepractice getting closer to the state of the art? IEEESoftware, 20(6), 78�83.
Schneider, K and T Schwinn (2001). Maturing experiencebase concepts at DaimlerChrysler. Software ProcessImprovement and Practice 6, 85�96.
Schneider, K and JV Hunnius (2003). E®ective experiencerepositories for software engineering. In Proceedings of25th International Conference on Software Engineering(ICSE'03), 534�539.
Spink, A, BJ Jansen, C Blakely and Koshman S (2006).Overlap amongmajorweb search engines. InProc. ThirdConf. on Information Technology (ITNG06), IEEE.
Tumer, D, MA Shah and Y Bitirim (2009). An empiricalinvestigation on semantic search performance of key-word based and semantic search engines: Google, Yahoo,MSN and Hakia. In Proceedings of Fourth Conferenceon Internet Monitoring and Protection (ICIMP), IEEE.
Visaggio, G (2008). Knowledge experience base and experi-ence factory. Technical Report, University of Bari (avail-able at http://serlab.di.uniba.it/prodotti_it/prometheus_it/KnowledgeBaseAndExperienceFactory.pdf).
Zhang, YY, W Vasconcelos and D Sleeman (2004).OntoSearch: An ontology search engine. In Proc.Twenty-fourth SGAI Int. Conf. on Innovative Tech-niques and Applications of Arti¯cial Intelligence (AI-2004), 58�69, Cambridge, UK.
Pasquale Ardimento has a PhD in Software Engineer-
ing from the University of Bari, and is an Assistant Pro-
fessor at University of Bari. His main research interest is in
knowledge and experience transfer to and from software
organizations.
Maria Teresa Baldassarre has a PhD in Software En-
gineering from the University of Bari, and is currently an
Assistant Professor. Her research interests focus on soft-
ware process improvement (SPI) and empirical software
engineering (ESE).
Marta Cimitile has a PhD in Software Engineering at
the University of Bari, and has a research contract with
the University of Bari. Her main research interest is in the
study and evolution of an Experience Base by investi-
gating topics related to knowledge management and
knowledge transfer.
Giuseppe Visaggio is a Professor of Software Engin-
eering at the University of Bari and is Chief of Research
at the Software Engineering Research Laboratory
(SER_Lab). His research interests are in maintenance,
focusing particularly on processes, quality improvement
and legacy systems.
240 P. Ardimento et al.
November 12, 2009 4:18:02pm WSPC/188-JIKM 00235FA2
Related Documents











