Efficiently handling discrete structure in machine learning Stefanie Jegelka MADALGO summer school

Efficiently handling discrete structure in machine learning Stefanie Jegelka MADALGO summer school.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Efficiently handling discrete structure
in machine learning
Stefanie JegelkaMADALGO summer school

Overview
• discrete labeling problems (MAP inference)• (structured) sparse variable selection• finding informative / influential subsets
Recurrent questions:• how model prior knowledge / assumptions? structure• efficient optimization?
Recurrent themes:• convexity• submodularity• polyhedra


Intuition: min vs max

Sensing
Place sensors to monitor temperature
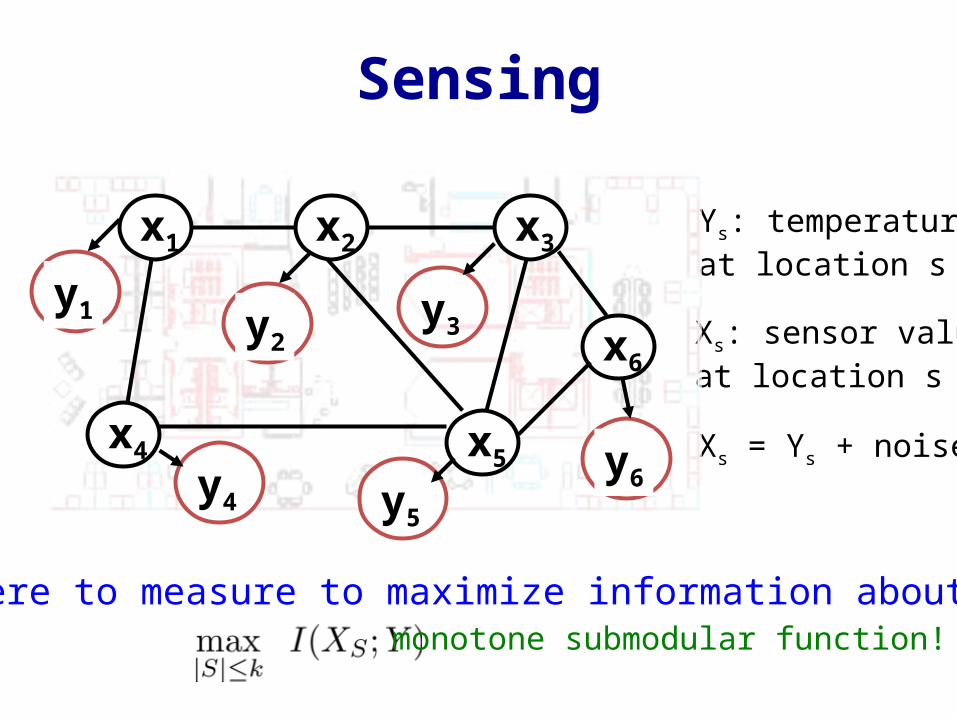
Sensing
Ys: temperatureat location s
Xs: sensor valueat location s
Xs = Ys + noise
x1 x2 x3
x6
x5x4
y1
y4
y3
y6y5
y2
Where to measure to maximize information about y?monotone submodular function!

Maximizing influence

Maximizing diffusioneach node• monotone submodular
activation functionand random threshold
• activated if
active neighbors
Theorem (Mossel & Roch 07)
is submodular. # active after n steps

Diversity priors
“spread out”

Determinantal point processes
• normalized similarity matrix
• sample Y:
repulsion
is submodular (not monotone)

Diversity priors
(Kulesza & Taskar 10)
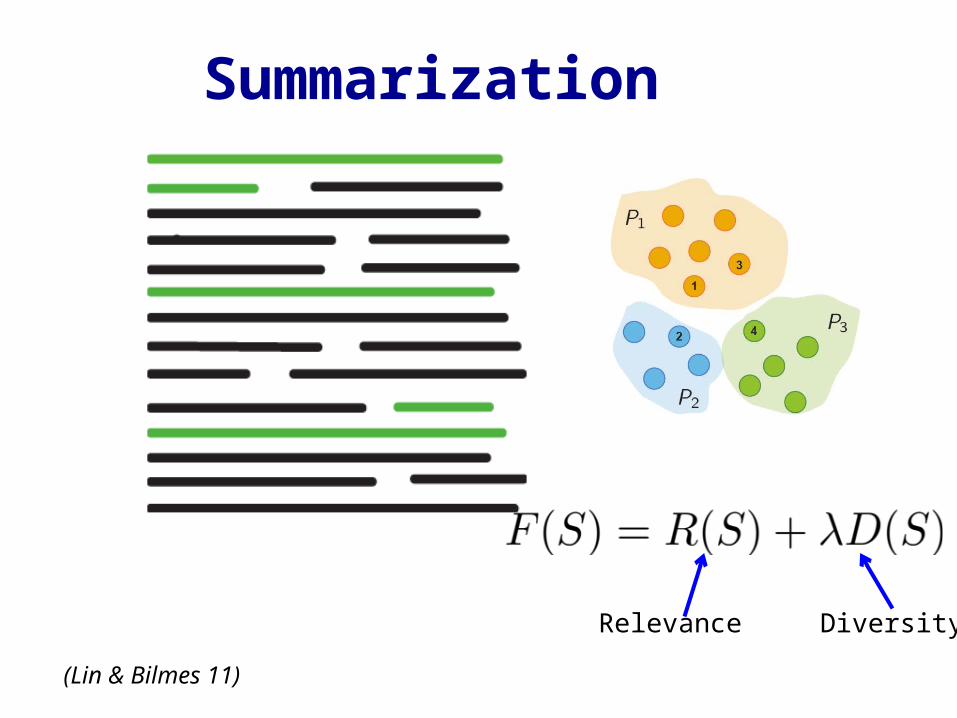
Summarization
(Lin & Bilmes 11)
Relevance Diversity

• assume
• generic case– bi-directional greedy (BFNS12)– local search (FMV07)
• monotone function (constrained)– greedy (NWF78)– relaxation (CCPV11)
• exact methods (NW81,GSTT99,KNTB09)
NP hard

Monotone maximization
greedy algorithm:

Monotone maximizationTheorem (NWF78)
SERVER
LAB
KITCHEN
COPYELEC
PHONEQUIET
STORAGE
CONFERENCE
OFFICEOFFICE50
51
52 53
54
46
48
49
47
43
45
44
42 41
3739
38 36
33
3
6
10
11
12
13 14
1516
17
19
2021
22
242526283032
31
2729
23
18
9
5
8
7
4
34
1
2
3540
sensor placement
info
rmati
on g
ain
optimalgreedy
empirically:
speedup in practice:“lazy greedy” (Minoux, 78)

More complex costraints
Ground setConfiguration:Sensing quality model
k
Configuration is feasible if no camera points in two directions at once

Matroids
17
S is independent if …
… |S| ≤ k
Uniform matroid
… S contains at most one element from each square
Partition matroid
… S contains no cycles
Graphic matroid
• S independent T S also independent
• Exchange property: S, U independent, |S| > |U| some can be added to U: independent
• All maximal independent sets have the same size

Matroids
18
S is independent if …
… |S| ≤ k
Uniform matroid
… S contains at most one element from each group
Partition matroid
… S contains no cycles
Graphic matroid
• S independent T S also independent
• Exchange property: S, U independent, |S| > |U| some can be added to U: independent
• All maximal independent sets have the same size

More complex costraints
Ground setConfiguration:Sensing quality model
k
Configuration is feasible if no camera points in two directions at once
Partition matroid
independence if

Maximization over matroids
greedy algorithm:

Maximization over matroidsTheorem (FNW78)
• better: relaxation (continuous greedy)approximation factor (CCPV11)

• concave in certain directions
• approximate by sampling
Multilinear relaxation vs. Lovász ext.
• convex
• computable in O(n log n)

• assume
• generic case– bi-directional greedy (BFNS12)– local search (FMV07)
• monotone function (constrained)– greedy (NWF78)– relaxation (CCPV11)
• exact methods (NW81,GSTT99,KNTB09)
NP hard

Non-monotone maximization
A B
a
b
c
d
e
f
a

Non-monotone maximization
A B
a
c
d
e
f
a
c

Non-monotone maximization
Theorem (BFNS12)

Summary• submodular maximization
NP-hard – ½ approximation
• constrained maximizationNP-hard, mostly constant approximation factors
• submodular minimizationexploit convexity – poly-time
• constrained minimization?special cases poly-time; many cases polynomial lower bounds

Constraints
28
cut matching path spanning tree
ground set: edges in a graph
minimum…

29
Recall: MAP and cuts
pairwise random field:
What’s the problem?
minimum cut: prefershort cut = short object boundary
aimreality

30
MAP and cutsMinimum cut
minimizesum of edge weights
implicit criterion:short cut = short boundary
minimize submodular function of edges
new criterion:boundary may be long if the boundary is homogeneous
Minimum cooperative cut
not a sum of edge weights!
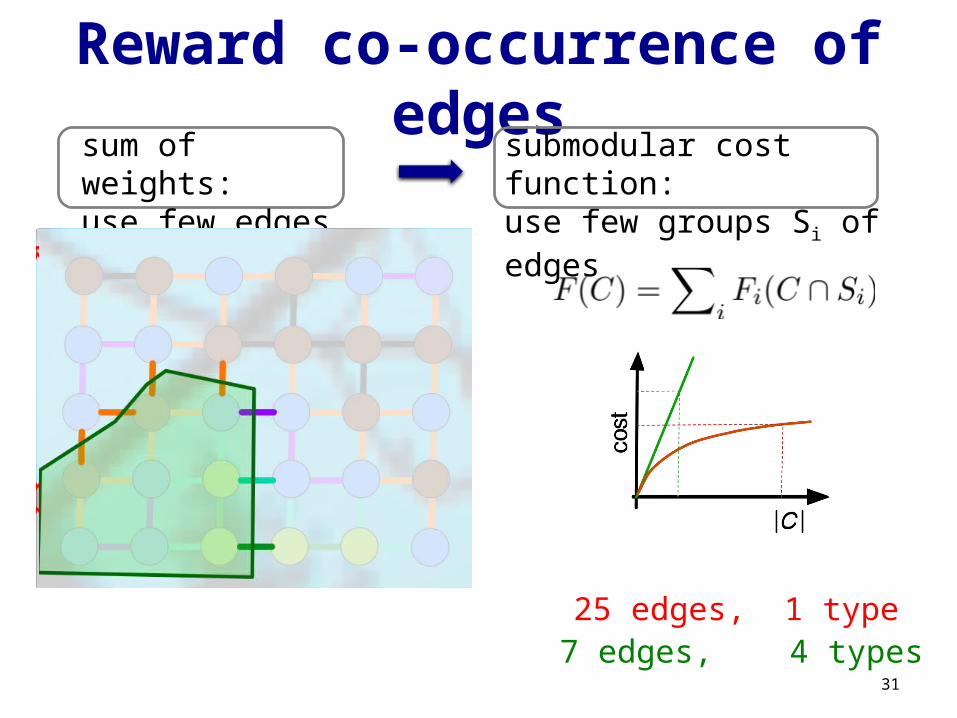
Reward co-occurrence of edges
31
submodular cost function:use few groups Si of edges
sum of weights:use few edges
7 edges, 4 types25 edges, 1 type

32
ResultsGraph cut Cooperative cut

Constrained optimization
33
cut matching path spanning tree
convex relaxation minimize surrogate function
(Goel et al.`09, Iwata & Nagano `09, Goemans et al. `09, Jegelka & Bilmes `11, Iyer et al. `13, Kohli et al `13...)
approximate optimization
approximation bounds dependent on F: polynomial – constant – FPTAS

Efficient constrained optimization
34
(JB11, IJB13)
2. Solve easy sum-of-weights problem:
and repeat.
minimize a series of surrogate functions
1. compute linear upper bound
• efficient• only need to solve sum-of-weights problems

Does it work?
35
Goemans et al 2009
majorize-minimize
1 iteration
optimalsolution
empirical results much better than theoretical worst-case bounds!?

36
Does it work?
approximate solution optimal solution
(Kohli, Osokin, Jegelka 2013)(Jegelka & Bilmes 2011)
minimum cut solution

37
Theory and practice
vs. worst-case Lower bound
trees, matchings
cuts
approximation
learning
bounds from (Goel et al.‘09, Iwata & Nagano‘09, Jegelka & Bilmes‘11, Goemans et al‘09, Svitkina& Fleischer‘08, Balcan & Harvey’12)
Good approximations in practice …. BUT not in theory?
theory says: no good approximations possible (in general)
What makes some (practical) problems easier than others?

38
Curvature
Theorems (IJB 2013).Tightened upper & lower bounds for constrained minimization, approximation, learning:
size of setfor submodular max: (Conforti & Cornuéjols`84, Vondrák`08)
marginal cost
single-item cost
small large
worst case
opt
cost

39
Curvature and approximations
smalleris
better

If there was more time…• Learning submodular functions• Adaptive submodular maximization• Online learning/optimization• Distributed algorithms• Many more applications…
• worst case vs. average practical case
pointers and references: http://www.cs.berkeley.edu/~stefje/madalgo/literature_list.pdfslides: http://www.cs.berkeley.edu/~stefje/madalgo/

Summary
• discrete labeling problems (MAP inference)• (structured) sparse variable selection• finding informative / influential subsets
Recurrent questions:• how model prior knowledge / assumptions? structure• efficient optimization?
Recurrent themes:• convexity• submodularity• polyhedra

Submodularity and machine learning
42
bla blablala oh bla bl abl lba bla gggg hgt dfg uyg sd djfkefbjalodh wdbfeowhjkd fenjk jj
bla blablala oh bla dw bl abl lba bla gggg hgt dfg uygsd djfkefbjal odh wdbfeowhjkd fenjk jj
bla blablala oh bla bl abl lba bla gggg hgt dfg uyg efefm o
sd djfkefbjal odh wdbfeowhjkd fenjk jj ef
owskf wu
distributions over labels, setsoften: tractability –
submodularitye.g. “attractive” graphical models,
determinantal point processes
(convex) regularizationsubmodularity: “discrete
convexity”e.g. combinatorial sparse estimation
diffusion processes,covering, rank,connectivity,
entropy,economies of scale,summarization, …submodular phenomena
submodularitybehind a lot of machine
learning!
Related Documents











