Efficient High-Level Programming on the AMT DAP PETER M. FLANDERS, RICHARD L. HELLIER, HUW D. JENKINS, CLIFF J. PAWLIN, AND SVEN VAN DEN BERGHE Invited Paper SIMD computers, typically comprising large numbers of simple process- ing elements, are increasinglyseen as the most viable way of achieving the level of pegormance required in certain application areas. Such processor arrays are ideally suited to implementation in current technology which favors the construction of systems by replication of a basic logic element and a simple, regular interconnection between elements. The main problem with this type of architecture is how to effectively exploit the performance potential from a high-level language. To date, systems which aim to achieve peak pegormanee have tended to restrict the high-level language to a mode of operation in which the extent of parallelism directly matches that of the hardware. The former implemen- tation of the language Fortran-Plus on the AMT DAP was an example of this. Although it extended Fortran 77 by the addition of high-level array processing facilities based on abstract operations on arrays, the arrays on which such operatwns could be performed were restricted in sue and Shape. In this paper, we describe the recent enhancementof Fortran-Plus which removed the restrictions on array shapes and sues, giving a language which is independent of the available hardwareparallelism. The enhanced Fortran-Plus has been implemented on the AIUT DAP using the concept of the virtual systems architecture (VM). VSA was developed under a collab- orative project within the United Kingdom governmentAIvey program. The power of enhanced Fortran-Plus in expressingparallel algorithms is demonstrated here in certain application areas. To show that the higher level of language has been implemented on the general VSA system without compromising per$ormance, the pegormance of these codes is discussed for a range of problem sizes. I. INTRODUCTION This paper is concerned with efficient use of the AMT DAP series of computers from a high-level machine- independent language. The AMT DAP is a single instruction multiple data stream computer (SIMD). It is described in [l], [2] and a more extensive review of DAP architecture and applications is given in [3]. The TMC Connection Machine has a somewhat similar architecture Manuscript received April 3, 1990; revised August 22, 1990. P. M. Flanders, R. L. Hellier, H. D. Jenkins, and C. J. Pavelin are with S. van den Berghe is with Robertson ERC Limited, Marlow, Bucks SL7 IEEE Log Number 9142939. Active Memory Technology Limited, Reading, Berks RG6 lAZ, U.K. 2LS, U.K. and an overview of its architecture and application is given in [4]. For a discussion of such SIMD computers in the context of parallel computer architecture in general, see [5]. The AMT DAP models referred to in this paper are: the DAP510 which is a 1024 processor array with the processor elements arranged 32*32 and a clock speed of 10 MHz; the DAP610 which is a 4096 processor array with the processor elements arranged 64*64 and a clock speed of 10 MHz. SIMD machines implement a model of parallelism which allows operations to be performed over whole data struc- tures rather than individual elements. This raises the level of abstraction for the programmer who can thus think in terms of whole array operations rather than selection and manipulation of elements one at a time. This form of “array abstraction” was exploited in the language Fortran-Plus [6] developed for the AMT DAP. Fortran-Plus essentially extended Fortran 77 by the addi- tion of array processing facilities which enabled arrays to be manipulated as single entities. However, in the original Fortran-Plus language, the size and shape of arrays which could be manipulated in parallel as complete objects were restricted to those arrays which directly matched the size and shape of the underlying DAP hardware. These machine- dependent restrictions were recently removed from Fortran- Plus making it considerably more general and powerful. The enhanced Fortran-Plus was implemented on the AMT DAP using the concept of the Virtual Systems Ar- chitecture (VSA) [7], [8]. VSA is a methodology for implementing a range of languages over different hardware. Essentially a high-level hardware-independent “Virtual Ar- ray Processor” is constructed by a combination of hardware and software; this virtual machine forms the target for com- pilers of different languages. The virtual array processor is a simple stack machine, capable of performing high-level ar- ray processing operations on abstract array data structures. 0018-9219/91/04004524$01.00 0 1991 IEEE 524 PROCEEDINGS OF THE IEEE, VOL. 19, NO. 4, APRIL 1991

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Efficient High-Level Programming on the AMT DAP PETER M. FLANDERS, RICHARD L. HELLIER, HUW D. JENKINS, CLIFF J. PAWLIN, AND SVEN VAN DEN BERGHE
Invited Paper
SIMD computers, typically comprising large numbers of simple process- ing elements, are increasingly seen as the most viable way of achieving the level of pegormance required in certain application areas.
Such processor arrays are ideally suited to implementation in current technology which favors the construction of systems by replication of a basic logic element and a simple, regular interconnection between elements.
The main problem with this type of architecture is how to effectively exploit the performance potential from a high-level language. To date, systems which aim to achieve peak pegormanee have tended to restrict the high-level language to a mode of operation in which the extent of parallelism directly matches that of the hardware. The former implemen- tation of the language Fortran-Plus on the AMT DAP was an example of this. Although it extended Fortran 77 by the addition of high-level array processing facilities based on abstract operations on arrays, the arrays on which such operatwns could be performed were restricted in sue and Shape.
In this paper, we describe the recent enhancement of Fortran-Plus which removed the restrictions on array shapes and sues, giving a language which is independent of the available hardware parallelism. The enhanced Fortran-Plus has been implemented on the AIUT DAP using the concept of the virtual systems architecture (VM). VSA was developed under a collab- orative project within the United Kingdom government AIvey program.
The power of enhanced Fortran-Plus in expressing parallel algorithms is demonstrated here in certain application areas. To show that the higher level of language has been implemented on the general VSA system without compromising per$ormance, the pegormance of these codes is discussed for a range of problem sizes.
I. INTRODUCTION This paper is concerned with efficient use of the AMT
DAP series of computers from a high-level machine- independent language. The AMT DAP is a single instruction multiple data stream computer (SIMD). It is described in [l], [2] and a more extensive review of DAP architecture and applications is given in [3]. The TMC Connection Machine has a somewhat similar architecture
Manuscript received April 3, 1990; revised August 22, 1990. P. M. Flanders, R. L. Hellier, H. D. Jenkins, and C. J. Pavelin are with
S. van den Berghe is with Robertson ERC Limited, Marlow, Bucks SL7
IEEE Log Number 9142939.
Active Memory Technology Limited, Reading, Berks RG6 lAZ, U.K.
2LS, U.K.
and an overview of its architecture and application is given in [4]. For a discussion of such SIMD computers in the context of parallel computer architecture in general, see [5].
The AMT DAP models referred to in this paper are: the DAP510 which is a 1024 processor array with the processor elements arranged 32*32 and a clock speed of 10 MHz; the DAP610 which is a 4096 processor array with the processor elements arranged 64*64 and a clock speed of 10 MHz.
SIMD machines implement a model of parallelism which allows operations to be performed over whole data struc- tures rather than individual elements. This raises the level of abstraction for the programmer who can thus think in terms of whole array operations rather than selection and manipulation of elements one at a time. This form of “array abstraction” was exploited in the language Fortran-Plus [6] developed for the AMT DAP.
Fortran-Plus essentially extended Fortran 77 by the addi- tion of array processing facilities which enabled arrays to be manipulated as single entities. However, in the original Fortran-Plus language, the size and shape of arrays which could be manipulated in parallel as complete objects were restricted to those arrays which directly matched the size and shape of the underlying DAP hardware. These machine- dependent restrictions were recently removed from Fortran- Plus making it considerably more general and powerful.
The enhanced Fortran-Plus was implemented on the AMT DAP using the concept of the Virtual Systems Ar- chitecture (VSA) [7], [8]. VSA is a methodology for implementing a range of languages over different hardware. Essentially a high-level hardware-independent “Virtual Ar- ray Processor” is constructed by a combination of hardware and software; this virtual machine forms the target for com- pilers of different languages. The virtual array processor is a simple stack machine, capable of performing high-level ar- ray processing operations on abstract array data structures.
0018-9219/91/04004524$01.00 0 1991 IEEE
524 PROCEEDINGS OF THE IEEE, VOL. 19, NO. 4, APRIL 1991

VSA was developed under a collaborative project within the United Kingdom government Alvey program involving Active Memory Technology, GLH (a United Kingdom software house), Marconi Maritime Research Laboratory, and the Universities of Edinburgh, London (QMW), Salford and Southampton.
The objectives for the implementation of VSA on the DAP were as follows:
to support, in the first instance, the enhanced Fortran- Plus language; to provide a high-performance system on codes de- veloped for the original Fortran-Plus language and on new codes taking advantage of the language general- izations; to provide a high integrity system allowing rapid applications development; to produce a retargetable system that could be readily adapted to future hardware development.
Various factors in the VSA system on the DAP contribute
powerful in-line code generation using functional pro-
compile-time emulation of the conceptual VSA stack; a form of software cacheing to retain items in registers.
Extensive compile-time and run-time checks contribute to both the high integrity and the potential of the system for rapid applications development. Also important in this respect are the interactive diagnostic capabilities of the run-time system.
The ability to retarget the system on to different hardware is important given the prolific rate of development of new forms of parallel hardware. The overall philosophy of the VSA approach and the internal structuring of the VSA system on the DAP are both important in achieving this objective.
The VSA system and its associated run-time support en- vironment were implemented on the DAP and the previous Fortran-Plus compiler was adapted for use on this system. For this, just the front end of the compiler was used; this was extended to cope with new features introduced into the language and was retargeted on to the VSA interface.
to the high performance These include:
gramming techniques;
11. FORTRAN-PLUS BACKGROUND The enhanced Fortran-Plus language is a compatible
extension of the previous version of Fortran for the DAP. The previous version, originally known as DAP Fortran [9], was available on the first generation of DAP hardware delivered to customers in 1979. It was a very successful language in the support of data-parallel programming and has had a significant influence on the array processing facilities of the proposed new ISO/ANSI standard for Fortran [lo].
The ability of the DAP hardware to perform the same operation simultaneously on a large number of data was reflected in DAP Fortran in the introduction of two new modes of data object: matrices and vectors. These had to match the DAP in size, so on a 32 x 32 DAP the
FLANDERS et al.: HIGH-LEVEL PROGRAMMING ON THE AMT DAP
declarations
INTEGER MATRIXl( , ) REAL VECTORl( )
represented a 32 x 32 matrix MATRIX1 and a 32-component vector VECTORl. The null dimensions distinguished these objects, which could take part in parallel operations, from ordinary Fortran arrays. Such matrices and vectors could occur as primaries in arithmetic expressions in which case the operations would take place simultaneously on a component-wise basis. There were a number of index- ing mechanisms and built-in operations which have been carried across into the new language (see Section IV).
For component-wise operations on matrices, each pro- cessor of the DAP would work on a different pair of corresponding operand components in order to produce one component of the result. On vectors, each row of 32 processors was allocated to the production of one result component (i.e., different processors within a single row worked together in parallel to produce different bits of a single result component). Since vectors and matrices precisely matched the DAP size, it was the programmer’s responsibility to map general size problems onto the DAP. To do this, arrays (or “sets”) of vectors or matrices could be declared as
INTEGER * 1 IMAGE(, ,16,16). This would declare a 16 x 16 array of DAP-sized (32 x
32) objects each of matrix mode. Thus the assignment statement
IMAGE(, , I, J) = 0
would simultaneously set all components of one 32 x 32 part of IMAGE to zero, but to set the whole of IMAGE to zero needs a loop
DO 10 I = 1,16 DO 10 J = 1,16 IMAGE(, , I, J) = 0
(4) 10 CONTINUE.
IMAGE might represent a 512 x 512 image but the corre- spondence between the components of IMAGE and the pixels in the image is determined by the programmer. The obvious way is to think of the image divided into tiles (submatrices), each 32 x 32 in size. Thus IMAGE (,,l,l) represents the top left hand 32 x 32 pixels, etc.
Setting the image to zero is then achieved as above, but certain operations on large data structures are not quite so easy. For example shifting a DAP-sized matrix “East” by one place is achieved very efficiently by a built-in function which returns the shifted matrix:
SHEP(MATA) (5)
(Zeros are shifted in on the West side).
525

However, shifting the 512 x 512 image East by one place would not quite be achieved by:
DO 10 I = 1,16 DO 10 J = 1,16 IMAGE(, ,I, J) = SHEP(IMAGE(, ,I, J))
10 CONTINUE. (6)
A further fix-up operation is necessary to set the West edges of all the tiles equal to the East edges of neighboring tiles.
Although having to explicitly map large problems onto the DAP in DAP Fortran could be tiresome, users found that such close control over the mapping enables very high performance to be achieved on applications where, for example, the straightforward tiling mentioned above is not the most suitable. A useful alternative way of mapping arrays larger than the DAP is to map each set of neighboring array points into the memory of a single processor element. In certain applications, the use of this type of mapping can significantly reduce the time spent routing data between processor elements [ 111.
111. OFUFXXIVES OF THE NEW LANGUAGE
The basic objective of enhanced Fortran-Plus was to significantly raise the level of the language by supporting matrices and vectors of any size (“unconstrained” data), including dynamically sized arrays (i.e., arrays whose sizes are not known at compile time). As well as the major programming benefits that this provides, it also means that the language is hardware-independent and therefore more portable.
Other design objectives were as follows.
The new language should be compatible with the old, thus all the syntax and operations relating to DAP-sized objects should continue to be accepted. The performance of the language should generally be at least as good as existing codes (i.e., codes whose arrays are constrained to be DAP-sized). Performance on codes using unconstrained data, for which the mapping of arrays on to the DAP is handled automatically by the system, should be at least as good as the same problem coded with arrays of constrained data for which the user has had to ex- plicitly program the mapping of unconstrained arrays. This assumes that the user has employed a similar, straightforward mapping strategy to that employed by the system. The programmer should not need any knowledge of characteristics of the DAP or how arrays are mapped.
Although much less used in the enhanced language, the concept of arrays of vectors and matrices still exists in order to:
support user partitioning as required to satisfy objec-
permit the handling of genuinely higher dimensional
All the indexing methods and built-in functions of DAP Fortran are carried across although some of the routines take extra arguments (since dimensions can no longer be assumed to be DAP-sized). The old style usage is still acceptable.
To meet the requirements of 5) and yet be able to process the same data as unconstrained where convenient, the user can use Fortran EQUIVALENCE to associate the storage of unconstrained vectors or matrices with arrays of DAP-sized objects. Although scarcely recommended programming style, this does allow the user to take control of the problem mapping rather than use that provided by the compilation system and still gain benefit from the unconstrained features.
The adoption of this language and the underlying com- piler technology will ease a future move to the new Fortran standard. Although Fortran 90 is not yet a ratified standard, its parallel array features are unlikely to change and very much mirror the facilities in Fortran-Plus. The reasons for enhancing Fortran-Plus prior to any attempt to intercept the emerging Fortran 90 standard are as follows.
Fortran-Plus provides forward compatibility for exist- ing DAP users. It provides a comprehensive set of array processing facilities which are a direct generalization of those previously available. These facilities have been proven in terms of their ability to express parallel algorithms naturally and in a manner which efficiently exploits the high level of parallelism of the DAP. It enables transparent, high-level programming to be closely integrated with machine-dependent high-level programming in those cases where the user requires closer control over the mapping of data. The PDT (parallel data transform [13]) facilities to efficiently handle complex data routing are closely integrated into Fortran-Plus.
Although AMT will produce a Fortran 90 compiler for the DAP, it is anticipated that, for the reasons previously stated, Fortran-Plus will continue to be a major tool since it allows near-assembler performance to be obtained from a high-level language. Such an achievement is commonplace for standard sequential machines but it is still rare on massively parallel systems.
tive 5);
arrays.
In spite of objective 4), it must be possible to take control over the mapping of problems if this is desirable to attain the highest possible performance. (It was recognized that there will often be complex mapping strategies appropriate to particular problems which can produce significant performance benefits P I . )
IV. OVERVIEW OF ENHANCED FoRTRAN-PLUS Fortran Plus is based on Fortran 77 with extensions to
exploit the parallel processing capabilities of the DAP. Most important among these extensions is the capabil- ity to manipulate the one-dimensional “vectors” and two-
PROCEEDINGS OF THE IEEE, VOL. 79, NO. 4, APRIL 1991
_ - 1 I
I - -- I

dimensional “matrices” as single “parallel” objects. This includes the ability to:
declare parallel vectors and matrices and indexable sets of them in a manner similar to the declaration of arrays of scalars in Fortran 77; apply the usual arithmetic, logical and comparison operations, component-wise, to complete objects or subsets of objects in assignments and expressions without explicit looping; access and update parts of objects by means of index- ing constructs; perform a variety of special operations which exploit the inherent structure of a parallel array (examples of such operations are matrix transposition which performs a regular reordering of the components of a matrix, and reduction functions such as summing the components of a vector or matrix); write functions which return these parallel objects.
Unlike Fortran 77, there is no requirement in Fortran-Plus to have all local arrays statically sized. They can be sized according to the value or dimension of an argument to the routine; this is also true of the arrays returned by matrix and vector functions. These features are demonstrated in Section IV-E.
To differentiate between ordinary scalar arrays and par- allel objects, the declarations of matrices and vectors have a * before the relevant dimensions. Thus
INTEGER ARRAY1(3,3) REAL VECTOR1(*34), MATRIX1(*27, *51) (7)
declares ARRAY1 to be a two-dimensional scalar array exactly as in Fortran 77, while VECTOR1 is a 34-component real vector and MATRIX1 a 27 x 51 real matrix.
Fortran-Plus has logical, character, integer, and real data types. Since the processor elements of the DAP are bit- oriented, the time taken to perform an operation on a data item depends on the precision of that item. To exploit this, Fortran-Plus has a wide range of precisions: from 3 to 8 bytes for real data and from 1 to 8 bytes for integer data. Thus higher performance and better memory utilization can be obtained by tailoring the precision of variables to just that required by the problem. Components of logical vectors and matrices occupy just a single bit, making operations on logical data very fast.
A. Vectors and Matrices
The components of vectors and matrices are distributed over the processor elements of the DAP, with each com- ponent, being operated on by a single processor. All of the processor elements conditionally perform the same operation together. The compiler organizes vectors that are larger than the total number of processor elements so that each processor element operates successively on more than one component. However, this is totally transparent to the user, as is any implicit looping involved. With matrices, processor elements operate on more than one component if either of the dimensions of the matrix exceeds the DAP size.
FLANDERS et al.: HIGH-LEVEL PROGRAMMING ON THE AMT DAP
Again, the user need not be aware of the mapping; although, as mentioned in Section 111, facilities do exist to make it explicit if the performance of the application requires this.
The language also allows the declaration of arrays of vectors and matrices, normally called vector sets and ma- trix sets, respectively. Each vector or matrix within a set is distributed over the processor elements, as previously described.
As in Fortran 77, the type of an expression is a function of the types of all its terms. The rules determining the type of the result are essentially as in Fortran 77; for example, the result of a mixed precision arithmetic operation has the same precision as the longer operand. The arithmetic, logical, and comparison operations of Fortran 77, such as addition and square root, are extended to apply component- wise to vectors and matrices. The operands of diadic operations may be two conforming vectors or matrices; alternatively a scalar may be combined with a vector or matrix and the scalar will be implicitly expanded to conform to the other vector or matrix operand. For example, assuming the aforementioned declarations,
MATRIX1 + 3 is a valid expression, the literal 3 being implicitly expanded to a matrix of “3’s” of the same size as MATRIXl.
B. Indexing
Much of the expressive power of Fortran-Plus comes from its wealth of indexing mechanisms. Whereas in For- tran 77, indexing can only select a single component from a declared array, in Fortan-Plus indexing can result in the selection of more than one component from a vector or matrix, and may be applied not only to declared variables but also to expressions and function results.
On the right-hand side of an assignment, indexing ex- tracts
a scalar from a scalar array; a scalar from a vector, vector set, matrix or matrix set; a vector from a vector set, matrix or matrix set; a matrix from a matrix set.
Selecting a scalar is done just as in Fortran 77:
INTEGER VECTOR1(*56), MATSET1(*87, *87,6) I = VECTORl(5) I = MATSET1(2,3,1) (9)
being valid examples. Null subscripts (meaning select all components in this
subscript position) are used to select vectors from the rows and columns of a matrix as in
INTEGER MATRIXl(*64, *60), ROWVEC(*60), COLVEC( *64), N
ROWVEC = MATRIXl(2,) COLVEC = MATRIXl(, N) (10)
where the vector ROWVEC is set equal to row 2 of the matrix MATRIXI, and the vector COLVEC is set equal to column N
521

of MATRIXl. Null subscripts are also used to select vectors and matrices from vector and matrix sets.
In a parallel subscript position, an integer subscript can be replaced by a logical vector (of suitable extent) which has exactly one component set “true”. Thus in the code
INTEGER VECTORl(*64) LOGICAL MASK(*64) MASK = .FALSE. MASK(56) = .TRUE.
I = VECTORI(MASK) (11)
I = VECTORl(56). (12)
the last statement is equivalent to
Similarly, it is possible to select a scalar from a matrix by indexing it with a conforming logical matrix having a single “true” component.
A single component may be selected from each row or column of a matrix. A null subscript is given in one subscript position and a vector of integers in the other. For example, in the code:
REAL MATRIXl(*256, *512), VECTORl(*256) INTEGER INTEGER(*256)
INDEX(2) = 22 INDEX(3) = 33
INDEX(^) = ii
VECTOR1 = MATRIXl(, INDEX). (13)
VECTOR1 is assigned the 11th value from the first row ofMATRIX1, the 22nd value from the second row, etc. Iff NDEX had been placed in the first subscript position (and declared as a 512-component vector), the selection would have been from the columns rather than the rows.
C. Indexed Assignment
The indexing techniques described previously can also be used on the left-hand side of assignment statements. In this case they specify the components of the object that are to be updated by the assignment. There are no restrictions on the number of components that may be updated. Thus while scalar indexing updates a single component:
CHARACTER CHARMAT(*78, *256)
CHARMAT(2,4) = %’ (14)
a logical matrix or vector index permits any subset of components to be updated:
CHARACTER CHARMAT(*78, *256) LOGICAL MASK(*78, *256), VMASK(*256) CHARMAT(MASK) = ’N’
CHAFlMAT(5, VMASK) = %’. (15)
528
In statements of this sort, the assignment takes place in
Logical vector and matrix expressions may be used as each position where the mask has a “true” value.
subscripts as in the code:
INTEGER MAT1(*45, *54), MAT2(*45, *54) MATl(MAT2 .NE. 0) = MATl/MAT2 (16)
which updates components of MATl only where the corre- sponding components ofMAT2 are nonzero.
D . Shifting Data
In many applications it is important to be able to com- bine neighboring components of a data structure. Built-in functions are provided to perform such shifts, such as the function SHEP mentioned in Section 11, which forms a matrix from its matrix argument by shifting all the values by one place to the East. This function has an optional second argument which may be an integer scalar giving the distance by which the data is to be shifted. This second argument to SHEC may also be a vector of integers specifying a different shift distance for each row of the matrix. This form of shifting, where different rows are shifted by different amounts, is used in Example 4 of Section V.
Functions SHWP, SHNP, and SHSP are similarly defined to shift matrices in the directions West, North, and South, respectively. The “P” at the end of each of these function names implies “plane geometry”-zeros shifted in at the edges. Similar functions with the “I”’ replaced by ‘‘c” employ “cyclic geometry” so that values shifted out of one edge appear at the opposite edge.
Vectors may be shifted to the left or right, with plane or cyclic geometry by the similarly defined functions SHLP, SHRP, SHLC, and SHRC.
An alternative method of specifying shifting is to use the characters plus and minus as subscripts of a vector or matrix appearing in an expression. The geometry used for shifting which is specified by this form of “shift indexing” is specified at the start of a subprogram and applies to all such shifts within the subprogram. The use of a “+” in a subscript position implies that the (I + 1)th component along the corresponding dimension is used rather than the Zth component. Thus for example, ifVEC1 is a vector, then VECl(+) has the same effect as SHLP(VECl), and VECl(-) has the same effect as SHRP(VEC1). (Assuming that the geometry for the subprogram is “plane”.) Similarly, if MATl is a matrix, then MATl(--) is equivalent to SHSP(SHEP(MAT~)).
E. Subroutines and Functions
As well as being used in simple expressions as shown above, vectors and matrices may be passed between sub- programs (either through COMMON or directly as arguments), and may be the results of functions.
When passed as arguments to subprograms, vectors and matrices may be declared within the called subprograms with “assumed size” dimensions. This facilitates the writing of generic subprograms. For example, the following code
PROCEEDINGS OF THE IEEE, VOL. 79, NO. 4, APRIL 1991

defines a function which takes two arguments which are integer vectors of any (matching) extent and returns as its value an integer scalar being the sum of the squares of the components of the vectors
FUNCTION SUMSQUARE(VEC1, VEC2) INTEGER SUMSQUARE, VECI(*), VEC2(*) SUMSQUARE = SUM(VECl* VECl + VEC2 * VEC2) RETURN
END. (17)
SUM is a Fortran-Plus intrinsic function which adds together all the components of its vector or matrix argument.
Local variables and function results can be declared which have parallel dimensions whose extents are deter- mined from the dimensions of another array. Such decla- rations make use of the intrinsic functionSIZE; this may have two arguments, PI and P2, and returns the extent of dimensionP2 of the array PI. For example, the following function returns the algebraic product of two arbitrarily sized matrices passed in as arguments:
FUNCTION MATMULT(MAT1, MAT2) REAL MATl(*, *), MAT2(*SIZE(MATl, 2), *) REAL MATMULT(*SIZE(MATl, 1), SIZE(MAT2,2)) MATMULT = 0.0 J = SIZE(MAT2,2) K = SIZE(MAT1,l) DO 10 I = 1, SIZE(MAT1,2) MATMULT = MATMULT + MATC(MATI( , I), J)* MATR(MAT2(I,),K)
10 CONTINUE RETURN END. (18)
The declaration of MAT2 indicates that its first dimension must be equal to the second dimension of MAT1. By default, the compiler will plant code to check this; such checks help to identify many potentially elusive coding errors. For maximum efficiency, these checks can be disabled once a program is fully debugged. MATC and MATR are Fortran-Plus intrinsic functions which replicate a vector by columns and rows, respectively to give a matrix result; the first argument is the vector to be replicated and the second argument is the number of replications. As well as being able to return a scalar, vector or matrix,
a function in Fortran-Plus may return a result which is any of the Fortran-Plus data types (integer, real, character, and logical) at any of the available precisions.
F. Built-in Functions and Subroutines
Fortran-Plus has a range of built-in functions and sub- routines. This includes many of the intrinsic functions of Fortran 77, but in Fortran-Plus they are extended to
FLANDERS et al.: HIGH-LEVEL PROGRAMMING ON THE AMT DAP
work on vectors and matrices and for any precision (where appropriate).
The functions available are classified as either com- ponent-wise or aggregate functions.
Component-wise operations and functions extend the familiar arithmetic, comparison and logical operations of Fortran 77 to work on vectors and matrices as well as scalars. Included in this class are:
- basic arithmetic operators such as addition and
- trigonometric functions and logarithmic functions; - functions that change the precision or type of their
- logical operations such as AND and NOT; - comparison operations such as .GT.
negation;
arguments;
Aggregate functions perform a variety of useful oper- ations involving vectors and matrices:
functions like MATC and MATR which produce a vector or matrix result by replication of scalars or vectors; functions which reorder the components of a vector or matrix, such as REV (reverse the order of the components of a vector) andTRAN (matrix transpose); the MERGE function which forms a vector (matrix) by selecting components from two conforming vectors (matrices) of the same type. Each compo- nent of the result is independently selected from the first or second argument depending on the value of the corresponding component of a third conforming logical vector (matrix) argument: reduction functions, so called because they reduce the rank of their argument by combining or select- ing components. Examples of reduction functions are:
* the SUM function which sums all the compo- nents of a parallel object;
* the MAXV function which determines the largest value in a parallel object;
* ALL which returns a logical scalar value equal to “true” if all the components of its array argument have the value “true”;
* ANY which returns a logical scalar value equal to “true” if any of the components of its array argument have the value “true”.
functions that perform shifts on vector and matrix arguments. inquiry functions (like SIZE above) that return the attributes of an object, such as its dimensions or rank. functions and routines that select or update sub- vectors and submatrices.
Exception management routines.
529

There are also routines which allow the user to control the effects of computational errors, such as arithmetic
subroutine to implement this algorithm is as follows.
overflow, that occur during the running of his program. Normally, the occurrence of a computational exception will
LMAX1(P, RESULT, N, M, THRESH1, THRESH2) INTEGER P( -1:N+2, -1:M+2), THRESHl, THRESH2,
AVE4, AVE8 stop the program. However, these facilities allow the user to suppress computational errors on selected components of vectors and matrices. LOGICAL RESULT( - 1:N+2, - 1:&2)
V. FORTRAN-PLUS EXAMPLES This section illustrates the use of Fortran-Plus by dis-
cussing some simple examples and comparing the Fortran- Plus implementation with a Fortran 77 implementation. Performance figures are given for a DAP 510 and a DAP 610. The examples have been chosen to illustrate the range of parallel programming constructs including data movement, broadcast, and reduction operations as well as the basic component-wise operations.
A. Example 1: Peak Finding This example is a local maxima algorithm drawn from
Image Processing. The aim is to create a logical array indicating where the local maxima of the input image can be found. A pixel is marked as a local maximum if it exceeds by some threshold the average of the four nearest neighbor pixels and also if the nearest neighbor average exceeds the average of the eight next nearest neighbor pixels by another threshold. That is, for a pixel p i , j :
and p i , j is a local maximum if
and
(ave4i,j - ave8i,j) > thresholdz. (21)
Every pixel has operations applied to it that are the same as, but independent of, the operations applied to every other pixel, so that computation is naturally parallel. The required computations include component-wise arithmetic applied to low precision integer data (16 bit) and operations to access the local neighborhood of each pixel. A (serial) Fortran 77
530
I
DO 100 J = 1,M DO 100 I = l,N
AVE4 = (P(I+l, J) + P(1, J+1) +P(I-1, J) + P(1,J-2))/4
AVE8 = (P(I+2, J) + P(1, J+2) +P(I-2, J) + P(1,J-2)
+ P(I+1, J+l) + P(1-1, J+1) +P(I+l, J-1) +P(I-l, 5-1))/8
-
RESULT^, J) =
((P(1, J) - AVE4) .GT. THRESHl) .AND. - ((Am4 - AVE8) .GT. THRESH2)
100 CONTINUE
RETURN END.
In Fortran-Plus the algorithm may be implemented as
SUBROUTINE LMAX2(P, RESULT, THRESHl, THRESH2) INTEGERQ P(*, *), THRESHl, THRESH2
INTEGERQ AVE4(*SIZE(P, 1), *SIZE(P, 2)) INTEGERQ AVE8(*SIZE(P, l), *SIZE(P, 2))
LOGICAL RESULT(*, *)
AVE4 = (SHNP(P) + SHSP(P) + SHEP(P) + SHWP(P))/4 AVE8 = (SHNP(P, 2) + SHSP(P, 2) + SHEP(P, 2)
- + SHWP(P, 2) + (SHWP(SHNP(P) + SHSP(P))+ SHEP( SHNP( P) + SHSP( P)))/8
RESULT = ((P - AVE4) .GT. TRHESHl) .AND. - ((AVE4 - AVE8) .GT. THRESH2)
RETURN END.
(23)
These codes are not the most efficient implementation but they are simple and illustrate some points in the comparison between Fortran-Plus and Fortran 77.
The Fortran-Plus code is more abstract than the Fortran 77 code. There is no obvious dependence on problem size as in the loop length and array dimensioning for Fortran 77. The organization of the data is implicit in the Fortran-Plus
PROCEEDINGS OF THE IEEE, VOL. 79, NO. 4, APRIL 1991

code whereas the Fortran 77 code requires explicit indexing calculations to select individual pixel values.
Although the Fortran 77 code is simple, it was necessary to have a border Of around the problem array*
more simply handled in shift functions employing plane geometry.
N~~~ that standard Fortran 77 does not allow short pre- cision data, although it is a extension. H ~ ~ ~ ~ ~ ~ , Fortran-Plus allows this and performs the computations at 16-bit precision. above.
There are some optimizations that can be made to both forms of the code; these are hinted at by the Fortran-Plus code where the computation of the A m 8 term contains an obviously repeated subexpression. In fact, the number
places shifted from 14 to 11 by saving some intermediate results. This is done in the following code which uses "+" and "-" subscripts to perform the shifts, rather than the explicit calls to shift functions in the Fortran-Plus code
However, in the Fortran-Plus code these edge effects are of additions can reduced from 9 to 6 and the number of
C
C
C
C
C
C
C
C
C
C
C
C
SUBROUTINE LMAXS(P, RESULT, THRESH1, THRESH2) INTEGERQ P(*, *), THRESHI, THRESH2 INTEGERQ AVE4(*SIZE(P, I), *SIZE(P, 2)) INTEGERQ AVEB(*SIZE(P, I), *SIZE(P, 2)) INTEGER*:! TEMP(*SIZE(P, I), *SIZE(P, 2)) LOGICAL RESULT(*, *)
Step 1: compute nearest neighbour averages (want a+b+c+d)
a - a+b -
d o b + - d+c - + - a+b+c+d - C - -
TEMP = P(+,) + P(, -) AVE4 = (TEMP + TEMP(-, +))/4
Step 2: next nearest neighbour averages (want res = a+b+c+d+e+f+g+h) we have a+b from Step 1
a - -
- - - h - b - -a+b+c
f - d g+f+e - -
g - 0 - c + - - h+o+d -- + - - res+o - - + res - - -
e - -
AVE8 = TEMP(-,) + P(+, +) AVE8 = (AVE8 + AVE8(-, +) + AVE8(+, -) - P)/8
RESULT = ((P - AVE4) .GT. THRESH1) .AND. ((AVE4 - AVE8) .GT. THRESH2)
RETURN END.
FLANDERS ef al.: HIGH-LEVEL PROGRAMMING ON THE AMT DAF' 531

Table 1 Performance for Example 1. Time for an N2 Problem in Milliseconds, Performance in Millions of Pixel Operations per Second (Mpops), Assuming 13 Operations per Pixel
n DAF'510 DAF'510 DAP610 DAF'610
ms Mpops ms Mpops
32 .25 53 .25 53
64 .72 74 .25 210
96 1.47 81 .72 166
128 2.50 85 .72 295
192 5.47 87 1.47 325
256 9.62 89 2.50 340
384 21.4 89 5.47 350
512 38.0 90 9.63 354
The performance of the second form of the code (LMAX3) is given in Table 1 for the DAP 510 and the DAP 610 for a variety of problem sizes. Note that the architecture of the DAP, though not evident in the code, is reflected in the performance and peaks are found for problems whose dimensions are multiples of the size of the DAP (32 for the 510 and 64 for the 610). Highest performance is obtained on the larger problems, although any size- independent contributions to the time are quickly amortized so that near peak performance is found for more than 128 squared (or 256 squared) problems.
B. Example 2: Shortest Path
This example is a shortest path problem drawn from network theory. Given a collection of N nodes and the distances between the nodes the problem is to find the shortest distance from any node to any other node. Since the distance from node i to nodej is not necessarily the same as that from node j to node i, the result is an N by N matrix whose (i , j) th entry is the shortest distance from node i to j. This algorithm and related work are discussed in [14].
The algorithm works iteratively; a record is kept of the length of the current best path and each step of the iterative process inserts a different path between nodes, retaining the new distance if it is better than the previous.
If L is a matrix where, l ; j , is the distance between nodes i and j, we initialize the matrix D to
and iterate
<,:' = min(<,j, di,T + dF,j) V i, j (30)
for
The algorithm requires O(n3) operations. All the entries of Dr+l can be computed in parallel so the inner loop can be expressed naturally in Fortran-Plus with a serial outer
532
-I I
loop for the N iterations. The inner loop computations are simple additions which can be done in integer arithmetic (of high enough precision, say 32 bit). However, the path insertion requires the ability to access parts of the data structure; rows and columns of the best path matrix. A Fortran 77 code to implement this algorithm is as follows:
SUBROUTINE MINPATH~(L, N, D) INTEGER L(N, N), D(N, N) INTEGER ROW( lOOO), COL( IOOO), WM, R
IF(N .GT. i 000 ) RETURN
DO 10 I = l,N DO 10 J = l,N
D( J, I) = L( J, I) 10 CONTINUE
DO 100 R = l,N
DO 20 I = l,N ROW(I) = D(R, I) COL(I) = R(I,R)
20 CONTINUE DO 30 I = l,N DO 30 J = l,N
WM = ROW(I) + COL(J) IF(WM .LT. D(J, I))D(J, I) = WM
30 CONTINUE 100 CONTINUE
RETURN
END. (33)
In Fortran-Plus the algorithm may be implemented as
SUBROUTINE MINPATH2(L, D) INTEGER L(*,*),D(*,*) INTEGER R, DIM, WM(*SIZE(L, l), *SIZE(L, 1))
DIM = SIZE(L, 1) D = L DO 100 R = 1,DIM
WM = MATC(D(, R), DIM) + MATR(D(R,), DIM) D(WM.LT.D) = WM
100 CONTINUE
RETURN END. (34)
PROCEEDINGS OF THE IEEE, VOL. 79, NO. 4, APRIL 1991

Table 2 Performance for Example 2. Time for an N Node Problem in Seconds, Performance in Millions of Operations per Second, Assuming 2 Operations per Inner Loop
n DAF'510 D M 5 1 0 DAP610 DAP610
S Mops S Mops
32 .005 14.2 .005 13.9
64 .022 24.0 .009 55.8
96 .062 28.8 .033 53.0
128 .13 31.5 .045 94.2
192 .41 34.4 .12 113.
256 .94 35.9 .27 124.
384 3.0 37.4 .83 136.
512 7.0 38.1 1.9 142.
The Fortran-Plus code is more abstract and high level than the Fortran 77 code, expressing the algorithm indepen- dently of the data mapping. It is also more succinct because Fortran-Plus is more expressive. The Fortran-Plus code is also more flexible since dynamic allocation allows any sized problem to be run. Moreover, conformance checking ensures that D and L are the same size and, through the dimensioning of WM, that D and L are square. The price paid is in storage: the Fortran 77 code uses temporary storage of order 2 * N + 1 components whereas the Fortran-Plus code explicitly uses N 2 components.
The performance of the Fortran-Plus code on a DAP 510 and a DAP 610 is given in Table 2. It is possible to run without change on the range of problem sizes but the sue of the PE array shows through in the performance, peaking at multiples of the edge sue.
C. Example 3: Molecular Dynamics
This example is drawn from a typical floating point application-Molecular Dynamics. The aim is to compute the motion of a group of interacting molecules. However, before doing this the molecules must be given velocities that have no net drift through the computational space and that relate to a determined temperature; i.e., have a known kinetic energy. The steps of this initialization section are:
compute the average motion in the 3 coordinate direc-
set the average motion to 0; compute the scale the total kinetic energy.
The core of the computation is the global summation to compute the average motion in each coordinate direction, which can be computed in a highly parallel fashion.
A Fortran 77 code to implement this algorithm is as follows:
tions;
SUBROUTINE INITIALIZEI(U, V, W, N, T)
REAL U(N) , V(N) , W(N) REAL U-SUM, V-SUM, W-SUM, KE
FLANDERS et al.: HIGH-LEVEL PROGRAMMING ON THE AMT DAP
U-SUM = 0.0 v-SUM = 0.0 w-SUM = 0.0
DO 10 I = l,N U-SUM = U-SUM + U( I) V-SUM = V-SUM + V( I) W-SUM = W-SUM + W( I)
10 CONTINUE
U-SUM = U-SUM/N V-SUM = V-SUM/N W-SUM = W-SUM/N
KE = 0.0 DO 20 I = 1,N
U( I) = U( I) - U-SUM v( I) = v( I) - v-SUM w(1) = w(1) - w-SUM KE = KE + U(I)*U(I) + V(I)*V(I) + W(I)*W(I)
20 CONTINUE
KE = SQRT(T/KE)
DO 30 I = l,N U(I) = KE*U(I) V(I) = KE*V(I) W(I) = KE*W(I)
30 CONTINUE
RETURN END. (35)
In Fortran-Plus, the algorithm may be implemented as
SUBROUTINE INITIALIZEl(U, V, W, T)
REAL U(*),V(*),W(*) REAL KE, N
N = SIZE(U)
U = U - SUM(U)/N V = V - SUM(V)/N W = W - SUM(W)/N KE = SQRT(T/SUM(U*U + V*V + W*W))
533
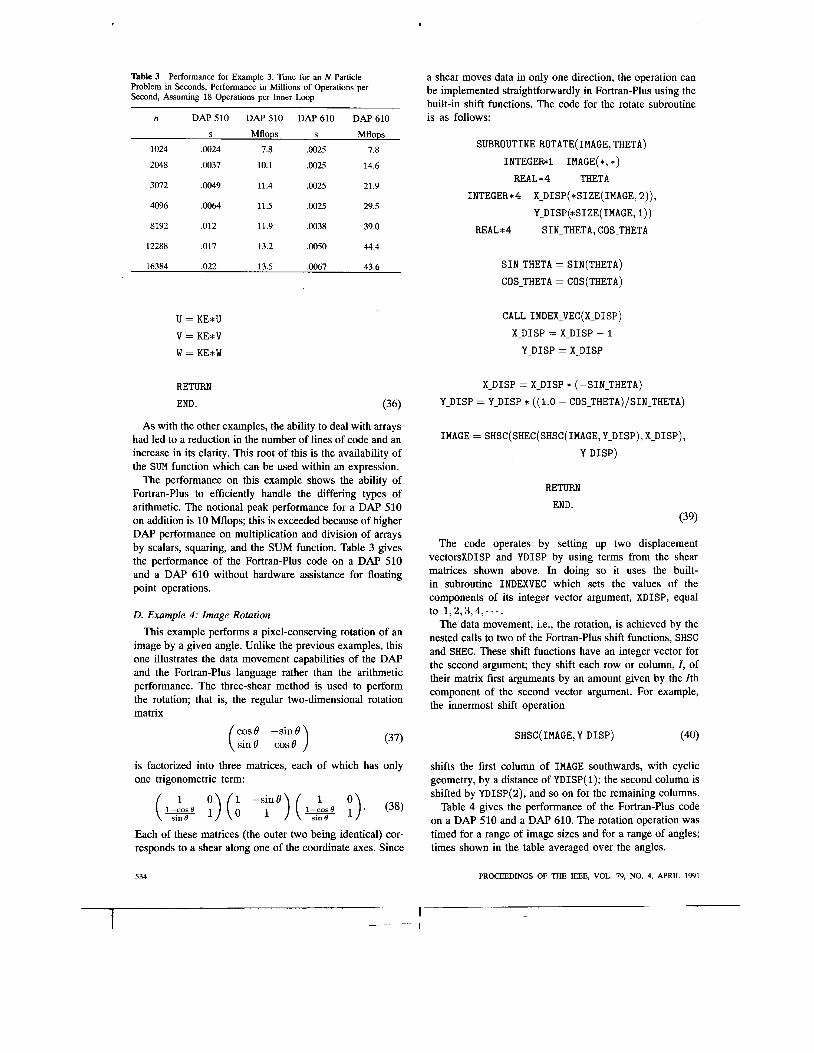
Table 3 Problem in Seconds, Performance in Millions of Operations per Second, Assuming 18 Operations per Inner Loop
Performance for Example 3. Time for an N Particle
n D M 5 1 0 DAF'510 DAP610 DAP610
S Mflops S Mflops
1024 BO24 7.8 ,0025 7.8
2048 "7 10.1 BO25 14.6
3072 .0049 11.4 .0025 21.9
4096 ,0064 11.5 .0025 29.5
8192 ,012 11.9 ,0038 39.0
12288 ,017 13.2 .0050 44.4
16384 .022 13.5 BO67 43.6
U = KE*U V = KE*V W = KE*W
RETURN END.
As with the other examples, the ability to deal with arrays had led to a reduction in the number of lines of code and an increase in its clarity. This root of this is the availability of the SUM function which can be used within an expression.
The performance on this example shows the ability of Fortran-Plus to efficiently handle the differing types of arithmetic. The notional peak performance for a DAP 510 on addition is 10 Mflops; this is exceeded because of higher DAP performance on multiplication and division of arrays by scalars, squaring, and the SUM function. Table 3 gives the performance of the Fortran-Plus code on a DAP 510 and a DAP 610 without hardware assistance for floating point operations.
D. Example 4: Image Rotation This example performs a pixel-conserving rotation of an
image by a given angle. Unlike the previous examples, this one illustrates the data movement capabilities of the DAP and the Fortran-Plus language rather than the arithmetic performance. The three-shear method is used to perform the rotation; that is, the regular two-dimensional rotation matrix
COS^ -sine ( sine cos0 (37) 1 is factorized into three matrices, each of which has only one trigonometric term:
1 1 -sine 1
Each of these matrices (the outer two being identical) cor- responds to a shear along one of the coordinate axes. Since
534
I
I - -- I
a shear moves data in only one direction, the operation can be implemented straightforwardly in Fortran-Plus using the built-in shift functions. The code for the rotate subroutine is as follows:
SUBROUTINE ROTATE( IMAGE, THETA) INTEGEWI IMAGE(*, *) REAL*4 THETA
INTEGER*4 X-DISP(*SIZE(IMAGE, 2)),
REAL*4 SIN-THETA, COS-THETA Y-DISP(*SIZE( IMAGE, I))
SIN-THETA = SIN(THETA) COS-THETA = COS(THETA)
CALL INDEX-VEC(X-DISP) X-DISP = X-DISP - 1 Y-DISP = X-DISP
X-DISP = X-DISP * (-SIN-THETA) Y-DISP = Y-DISP * ((1.0 - COS-THETA)/SIN-THETA)
IMAGE = SHSC(SHEC(SHSC(IMAGE, Y-DISP), X-DISP), Y-D I SP )
RETURN END.
(39)
The code operates by setting up two displacement vectorsXDISP and YDISP by using terms from the shear matrices shown above. In doing so it uses the built- in subroutine INDEXVEC which sets the values of the components of its integer vector argument, XDISP, equal
The data movement, i.e., the rotation, is achieved by the nested calls to two of the Fortran-Plus shift functions, SHSC and SHEC. These shift functions have an integer vector for the second argument; they shift each row or column, Z, of their matrix first arguments by an amount given by the Zth component of the second vector argument. For example, the innermost shift operation
to 1 ,2 ,3 ,4 , . . . .
SHSC(IMAGE, Y-DISP) (40)
shifts the first column of IMAGE southwards, with cyclic geometry, by a distance of YDISP( 1); the second column is shifted by YDISP(2), and so on for the remaining columns.
Table 4 gives the performance of the Fortran-Plus code on a DAP 510 and a DAP 610. The rotation operation was timed for a range of image sizes and for a range of angles; times shown in the table averaged over the angles.
PROCEEDINGS OF THE IEEE, VOL. 79, NO. 4, APRIL 1991

Table 4 Performance for Example 4. Time for an N*N Image Rotation in Milliseconds
n DAP 510 DAP 610
ms ms 128 4.30 2.17
256 14.28 5.85
512 54.53 20.39
1024 218.70 78.67
VI. SUMMARY This paper has described the background and nature of
the language Fortran-Plus. A variety of examples were used to demonstrate the following:
the expressiveness of the language in presenting par-
the efficiency of programs written in Fortran-Plus; the hardware independence of Fortran-Plus.
The expressiveness is demonstrated by the clarity with which the example programs reflect details of the prob- lem to be solved rather than details of the programming language or underlying hardware. The efficiency is shown by, the degree to which the notional performance of the hardware can be achieved on real problems without using any special compiler directives. On codes carried forward from the Fortran-Plus system, performance has been at least maintained but, in many cases, significant speedups have been achieved after recoding the problem at the higher level available in enhanced Fortran-Plus. The hardware independence is clear from the absence in the sample programs of any indication of the size or architecture of the DAP’s on which they were run.
The development of Fortran-Plus was achieved by using a general compiler methodology, namely VSA. The VSA system already caters for a range of DAP sizes and is well-structured to adapt to future developments in DAP languages and hardware.
allel algorithms;
REFERENCES
D. J. Hunt, “AMT DAP-A processor array in a workstation environment,” Comput. Syst. Sci. Eng., vol. 4, no. 2, Apr. 1989. D. Parkinson, D. J. Hunt, and K. S. MacQueen, “The AMT DAP 500,” in Proc. 33rd IEEE Computer Society Int. Conf., San Francisco, CA, Feb. 1988. D. Parkinson, J. Litt, “Massively Parallel Computing with the DAP,” in Research Monographs in Parallel and Distributed Computing. Cambridge, MA: MIT Press, ISBN 0953-7767, 1990. R. W. Hockney and C. R. Jesshope, Parallel Computers: Ar- chitecture Programming and Algorithms. Bristol, U.K.: Adam Hilger Ltd., 1981. W.D. Hillis, “The Connection Machine,” MIT Press series in artificial intelligence, Ph.D. dissertation, 1985, ISBN 0-262-
“Introduction to Fortran-Plus,” AMT Manual, Active Memory Technology Ltd., Reading, U.K., man. 001.04. P. M. Flanders, “Virtual Systems Architecture on the AMT DAP,” presented at CONPAR ’90-VAPP IV Joint Conf. on Vector and Parallel Processing, Zurich, Switzerland, Sept. 10-13, 1990.
08157-1.
FLANDERS et al.: HIGH-LEVEL PROGRAMMING ON THE AMT DAP
C. R. Jesshope and P. M. Flanders, “The VSA definition,” available from Active Memory Technology Ltd., Reading, U.K., Alvey project paper ARCH001D2. P.M. Flanders, “Fortran extensions for a highly parallel pro- cessor,” in Infotech State of the Art Report on Supercomputers, vol. 2, 1979. “Fortran 90,” in Document XSJ3/S8.115 of the Fortran Tech- nical Committee of the American National Standards Institute, June 1990. S. F. Reddaway, “Mapping images on to processor array hard- ware,” in 1987 Workshop on Parallel Architecture and Com- pufer VlsSion. London, U.K.: Oxford University Press, July 1988. P.M. Flanders, “A unified approach to a class of data move- ments on an array processor,” IEEE Trans. Comput., vol. C-31, Sept. 1982. P. M. Flanders, “The effective use of SIMD Processor Arrays,” presented at the IEE specialist seminar on “The design and application of parallel digital processors,” Lisbon, Portugal, Apr. 1988. J. Yadegar, D. Parkinson, A.M Frieze, and S . El-Horbaty, “Algorithms for shortest path problems on an Array Processor,” in Proc. 4th Int. Conj Superconducting, Santa Clara, CA, May 1989.
Peter M. Flanders received the BSc. degree in physics in 1969 and the Ph.D. degree in computer science in 1982, both from Queen Mary College, University of London, England.
He worked in ICL’s Research and Advanced Development Center in England for a num- ber of years and is now with Active Memory Technology in Reading, England. His major research interest is in parallel processing in the areas of system architecture, languages, and methodologies for exploiting parallel systems.
Richard L. Hellier received the B.Sc. degree in mathematics in 1979 from the University of Kent at Canterbury, England. He then studied for the Ph.D. degree on applying parallel processing to problems in numerical analysis.
He worked first for International Computers Ltd. on graphics, image processing, and sig- nal processing applications for the DAP. He is now with Active Memory Technology where he works on systems software for the DAP.
Huw D. Jenkins received the B.Sc. degree in mathematics in 1984 from the University of Southampton, England.
He worked first for Praxis Systems Ltd. in Bath, England where he was first introduced to parallel processing and also developed an inter- est in formal methods of software development, He is now with Active Memory Technology Ltd. where he has particular responsibility for parallel DAP-oriented language developments.
53s

Cliff J. Pavelin received the B.S. degree in mathematics from the University of Cambridge, London, and the Ph.D. degree in computer sci- ence from the University of Edinburgh, Scot- land.
In 1987, he joined AMT as Software Direc- tor. Previously, he was at Rutherford Appleton Laboratory where he was the head of Sys- tem Development in the Computer Center and subsequently Deputy Head of the Informatics
Sven van den Berghe has spent over a decade developing techniques to apply high performance computers to problems in science and engineer- ing. This has included periods of research in quantum chemistry, meteorology, and oil reser- voir simulation, followed by three years spent developing applications for the AMT DAP. Cur- rently, Sven is working on an integrated soft- ware system for oil exploration and production.
Division. He was heavily involved in technical management and support of parts of the United Kingdom Alvey program of advanced computing research.
536 PROCEEDINGS OF THE IEEE, VOL. 79, NO. 4, APRIL 1991
n I - _- I
Related Documents











