EECC722 - Shaaban EECC722 - Shaaban #1 Lec # 2 Fall 2010 9-6-20 Simultaneous Simultaneous Multithreading (SMT) Multithreading (SMT) • An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue processors (superscalars). • SMT has the potential of greatly enhancing superscalar processor computational capabilities by: – Exploiting thread-level parallelism (TLP) in a single processor core, simultaneously issuing, executing and retiring instructions from different threads during the same cycle. • A single physical SMT processor core acts as a number of logical processors each executing a single thread – Providing multiple hardware contexts, hardware thread scheduling and context switching capability. – Providing effective long latency hiding. • e.g FP, branch misprediction, memory latency

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

EECC722 - ShaabanEECC722 - Shaaban#1 Lec # 2 Fall 2010 9-6-2010
Simultaneous Multithreading (SMT)Simultaneous Multithreading (SMT)• An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at
the University of Washington that aims at reducing resource waste in wide issue processors (superscalars).
• SMT has the potential of greatly enhancing superscalar processor computational capabilities by:
– Exploiting thread-level parallelism (TLP) in a single processor core, simultaneously issuing, executing and retiring instructions from different threads during the same cycle.
• A single physical SMT processor core acts as a number of logical processors each executing a single thread
– Providing multiple hardware contexts, hardware thread scheduling and context switching capability.– Providing effective long latency hiding.
• e.g FP, branch misprediction, memory latency

EECC722 - ShaabanEECC722 - Shaaban#2 Lec # 2 Fall 2010 9-6-2010
SMT IssuesSMT Issues• SMT CPU performance gain potential.• Modifications to Superscalar CPU architecture to support SMT.• SMT performance evaluation vs. Fine-grain multithreading, Superscalar, Chip
Multiprocessors.• Hardware techniques to improve SMT performance:
– Optimal level one cache configuration for SMT.– SMT thread instruction fetch, issue policies.
– Instruction recycling (reuse) of decoded instructions.• Software techniques:
– Compiler optimizations for SMT.– Software-directed register deallocation.– Operating system behavior and optimization.
• SMT support for fine-grain synchronization.• SMT as a viable architecture for network processors.• Current SMT implementation: Intel’s Hyper-Threading (2-way SMT)
Microarchitecture and performance in compute-intensive workloads.
Ref. PapersSMT-1, SMT-2
SMT-3
SMT-7
SMT-4
SMT-8 SMT-9

EECC722 - ShaabanEECC722 - Shaaban#3 Lec # 2 Fall 2010 9-6-2010
Evolution of MicroprocessorsEvolution of Microprocessors
Source: John P. Chen, Intel Labs
Pipelined(single issue)
Multi-cycle Multiple Issue (CPI <1) Superscalar/VLIW/SMT/CMP
Single-issue Processor = Scalar ProcessorInstructions Per Cycle (IPC) = 1/CPI
IPC
1 GHzto ???? GHz
General Purpose Processors (GPPs)
T = I x CPI x C
Original(2002)IntelPredictions15 GHz

EECC722 - ShaabanEECC722 - Shaaban#4 Lec # 2 Fall 2010 9-6-2010
Microprocessor Frequency TrendMicroprocessor Frequency Trend
Result:Deeper PipelinesLonger stallsHigher CPI(lowers effective performance per cycle)
1. Frequency used to double each generation2. Number of gates/clock reduce by 25%3. Leads to deeper pipelines with more stages (e.g Intel Pentium 4E has 30+ pipeline stages)
Realty Check:Clock frequency scalingis slowing down!(Did silicone finally hit the wall?)
386486
Pentium(R)
Pentium Pro(R)
Pentium(R) II
MPC750604+604
601, 603
21264S
2126421164A
2116421064A
21066
10
100
1,000
10,000
1987
1989
1991
1993
1995
1997
1999
2001
2003
2005
Mh
z
1
10
100
Gat
e D
elay
s/ C
lock
Intel
IBM Power PC
DEC
Gate delays/clock
Processor freq scales by 2X per
generation
Why?1- Power leakage2- Clock distribution delays
T = I x CPI x C
Possible Solutions?- Exploit Thread-Level Parallelism (TLP) at the chip level (SMT/CMP)- Utilize/integrate more-specialized computing elements other than GPPs

EECC722 - ShaabanEECC722 - Shaaban#5 Lec # 2 Fall 2010 9-6-2010
Tran
sist
ors
1,000
10,000
100,000
1,000,000
10,000,000
100,000,000
1970 1975 1980 1985 1990 1995 2000 2005
Bit-level parallelism Instruction-level Thread-level (?)
i4004
i8008i8080
i8086
i80286
i80386
R2000
Pentium
R10000
R3000
Parallelism in Microprocessor VLSI GenerationsParallelism in Microprocessor VLSI Generations
Simultaneous Multithreading SMT:e.g. Intel’s Hyper-threading
Chip-Multiprocessors (CMPs)e.g IBM Power 4, 5 Intel Pentium D, Core 2 AMD Athlon 64 X2 Dual Core Opteron Sun UltraSparc T1 (Niagara)
Chip-LevelParallelProcessing
Even more importantdue to slowing clock rate increase
Multiple micro-operations per cycle(multi-cycle non-pipelined)
Superscalar/VLIWCPI <1Single-issue
PipelinedCPI =1
Not PipelinedCPI >> 1
(ILP)
Single Thread
(TLP)
Improving microprocessor generation performance by exploiting more levels of parallelism
Thread-Level Parallelism (TLP)

EECC722 - ShaabanEECC722 - Shaaban#6 Lec # 2 Fall 2010 9-6-2010
Microprocessor Architecture TrendsMicroprocessor Architecture TrendsC IS C M ac h i n e s
ins truc tio ns take var iable t im e s to c o m ple te
R IS C M ac h i n e s ( m i c r o c o d e )s im ple ins truc tio ns , o ptim ize d fo r spe e d
R IS C M ac h i n e s ( p i p e l i n e d )s am e individual ins truc tio n late nc y
gre ate r thro ughput thro ugh ins truc tio n "o ve r lap"
S u p e r s c a l ar P r o c e s s o r sm ultiple ins truc tio ns e xe c uting s im ultane o us ly
M u l t i t h r e ad e d P r o c e s s o r saddit io nal H W re so urc e s ( re gs , P C , SP )e ac h c o nte xt ge ts pro c e s so r fo r x c yc le s
V L IW"Supe r ins truc tio ns " gro upe d to ge the r
de c re ase d H W c o ntro l c o m ple xity
S i n g l e C h i p M u l t i p r o c e s s o r sduplic ate e ntire pro c e s so rs
( te c h so o n due to M o o re 's Law)
S IM U L TA N E O U S M U L TITH R E A D IN Gm ultiple H W c o nte xts ( re gs , P C , SP )e ac h c yc le , any c o nte xt m ay e xe c ute
CMPs
(SMT)
SMT/CMPs e.g. IBM Power5,6,7 , Intel Pentium D, Sun Niagara - (UltraSparc T1) Intel Nehalem (Core i7)
SingleThreaded{
(e.g IBM Power 4/5, AMD X2, X3, X4, Intel Core 2)
e.g. Intel’s HyperThreading (P4)
(Single or Multi-Threaded)
General Purpose Processor (GPP)
Chip-level TLP

EECC722 - ShaabanEECC722 - Shaaban#7 Lec # 2 Fall 2010 9-6-2010
CPU Architecture Evolution:CPU Architecture Evolution:
Single Threaded/Issue PipelineSingle Threaded/Issue Pipeline
• Traditional 5-stage integer pipeline.• Increases Throughput: Ideal CPI = 1
F etc h M em oryExec uteD ec ode W ritebac k
M em ory Hierarc hy (M anagem ent)
Regis ter F ile
P C
S P

EECC722 - ShaabanEECC722 - Shaaban#8 Lec # 2 Fall 2010 9-6-2010
F etc h i M em ory iExec ute iD ec ode i W ritebac k i
Regis ter F ile
P C
S P
F etc h i+ 1 M em ory i+ 1Exec ute i+ 1D ec ode i+ 1W ritebac k
i+ 1
Mem
ory Hierarchy (M
anagement)
F etc h i M em ory iExec ute iD ec ode i W ritebac k i
CPU Architecture Evolution:CPU Architecture Evolution:
Single-Threaded/Superscalar ArchitecturesSingle-Threaded/Superscalar Architectures• Fetch, issue, execute, etc. more than one instruction per cycle (CPI < 1).• Limited by instruction-level parallelism (ILP). Due to single thread limitations

EECC722 - ShaabanEECC722 - Shaaban#9 Lec # 2 Fall 2010 9-6-2010
• Empty or wasted issue slots can be defined as either vertical waste or horizontal waste: – Vertical waste is introduced when the processor issues no
instructions in a cycle.– Horizontal waste occurs when not all issue slots can be filled in a
cycle.
Superscalar Architecture Limitations:Superscalar Architecture Limitations:Issue Slot Waste Classification
Example:
4-IssueSuperscalar
Ideal IPC =4Ideal CPI = .25
Instructions Per Cycle = IPC = 1/CPIAlso applies to VLIW
Result of issue slot waste: Actual Performance << Peak Performance

EECC722 - ShaabanEECC722 - Shaaban#10 Lec # 2 Fall 2010 9-6-2010
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
Average IPC= 1.5instructions/cycleissue rate
Sources of Unused Issue Cycles in an 8-issue Superscalar Processor.
Processor busy represents the utilized issue slots; allothers represent wasted issue slots.
61% of the wasted cycles are vertical waste, theremainder are horizontal waste.
Workload: SPEC92 benchmark suite.
Ideal Instructions Per Cycle, IPC = 8Here real IPC about 1.5
Real IPC << Ideal IPC
1.5 << 8
(CPI = 1/8)
~ 81% of issue slots wasted
(18.75 % of ideal IPC)
(wasted)
SMT-1

EECC722 - ShaabanEECC722 - Shaaban#11 Lec # 2 Fall 2010 9-6-2010
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
Superscalar Architecture Limitations :Superscalar Architecture Limitations :All possible causes of wasted issue slots, and latency-hiding or latency reducing
techniques that can reduce the number of cycles wasted by each cause.
Main Issue: One Thread leads to limited ILP (cannot fill issue slots)
Solution: Exploit Thread Level Parallelism (TLP) within a single microprocessor chip:
Simultaneous Multithreaded (SMT) Processor:-The processor issues and executes instructions from a number of threads creating a number of logical processors within a single physical processor e.g. Intel’s HyperThreading (HT), each physical processor executes instructions from two threads
AND/OR
Chip-Multiprocessors (CMPs):- Integrate two or more complete processor cores on the same chip (die)- Each core runs a different thread (or program)- Limited ILP is still a problem in each core (Solution: combine this approach with SMT)
How?
SMT-1

EECC722 - ShaabanEECC722 - Shaaban#12 Lec # 2 Fall 2010 9-6-2010
VLIW: Intel/HPVLIW: Intel/HP IA-64
Explicitly Parallel Instruction Computing (EPIC)Explicitly Parallel Instruction Computing (EPIC)
• Strengths: – Allows for a high level of instruction parallelism (ILP).– Takes a lot of the dependency analysis out of HW and places focus
on smart compilers.
• Weakness: – Limited by instruction-level parallelism (ILP) in a single thread.– Keeping Functional Units (FUs) busy (control hazards).– Static FUs Scheduling limits performance gains.– Resulting overall performance heavily depends on compiler
performance.
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#13 Lec # 2 Fall 2010 9-6-2010
Single Chip Multiprocessors (CMPs)Single Chip Multiprocessors (CMPs)• Strengths:
– Create a single processor block and duplicate.– Exploits Thread-Level Parallelism.– Takes a lot of the dependency analysis out of HW and places focus on
smart compilers.
• Weakness: – Performance within each processor still limited by individual thread
performance (ILP).– High power requirements using current VLSI processes.
• Almost entire processor cores are replicated on chip.• May run at lower clock rates to reduce heat/power consumption.
Advanced CPU Architectures:Advanced CPU Architectures:
e.g IBM Power 4/5, Intel Pentium D, Core Duo, Core 2 (Conroe), Core i7
AMD Athlon 64 X2, X3, X4, Dual/quad Core Opteron
Sun UltraSparc T1 (Niagara) …
AKA Multi-Core Processors
at chip level

EECC722 - ShaabanEECC722 - Shaaban#14 Lec # 2 Fall 2010 9-6-2010
Advanced CPU Architectures:Advanced CPU Architectures:
Regis ter F ile i
P C i
S P i
R e g is t e r F i le i+ 1
P C i+ 1
S P i+ 1
Regis ter F ile n
P C n
S P n
S upers c alar (T w o-w ay) P ipelinei
S upers c alar (T w o-w ay) P ipelinei+ 1
S upers c alar (T w o-w ay) P ipelinen
Mem
ory Hierarchy (M
anagement)
Contro lUnit
i
Contro lUniti+ 1
Contro lUnit
n
Single Chip Multiprocessor (CMP)
Or 4-way
CMP with n cores

EECC722 - ShaabanEECC722 - Shaaban#15 Lec # 2 Fall 2010 9-6-2010
Current Dual-Core Chip-Multiprocessor (CMP) Architectures Single DieShared L2 Cache
Single DiePrivate CachesShared System Interface
Two Dice – Shared PackagePrivate CachesPrivate System Interface
Cores communicate using shared cache(Lowest communication latency)
Examples:IBM POWER4/5Intel Pentium Core Duo (Yonah), ConroeSun UltraSparc T1 (Niagara)Quad Core AMD K10(shared L3 cache)
Cores communicate over external Front Side Bus (FSB)(Highest communication latency)
Example:Intel Pentium D
Cores communicate using on-chipInterconnects (shared system interface)
Examples:AMD Dual Core Opteron, Athlon 64 X2Intel Itanium2 (Montecito)
Source: Real World Technologies,
http://www.realworldtech.com/page.cfm?ArticleID=RWT101405234615
FSBOn-chip crossbar/switch

EECC722 - ShaabanEECC722 - Shaaban#16 Lec # 2 Fall 2010 9-6-2010
Fine-grained or Traditional Multithreaded ProcessorsFine-grained or Traditional Multithreaded Processors
• Multiple hardware contexts (PC, SP, and registers).• Only one context or thread issues instructions each cycle.• Performance limited by Instruction-Level Parallelism (ILP)
within each individual thread:– Can reduce some of the vertical issue slot waste.– No reduction in horizontal issue slot waste.
• Example Architecture: The Tera Computer System
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#17 Lec # 2 Fall 2010 9-6-2010
Fine-grain or Traditional Multithreaded ProcessorsFine-grain or Traditional Multithreaded Processors
The Tera (Cray) Computer System• The Tera computer system is a shared memory multiprocessor
that can accommodate up to 256 processors.
• Each Tera processor is fine-grain multithreaded:
– Each processor can issue one 3-operation Long Instruction Word (LIW) every 3 ns cycle (333MHz) from among as many as 128 distinct instruction streams (hardware threads), thereby hiding up to 128 cycles (384 ns) of memory latency.
– In addition, each stream can issue as many as eight memory references without waiting for earlier ones to finish, further augmenting the memory latency tolerance of the processor.
– A stream implements a load/store architecture with three addressing modes and 31 general-purpose 64-bit registers.
– The instructions are 64 bits wide and can contain three operations: a memory reference operation (M-unit operation or simply M-op for short), an arithmetic or logical operation (A-op), and a branch or simple arithmetic or logical operation (C-op).
Source: http://www.cscs.westminster.ac.uk/~seamang/PAR/tera_overview.html
From one thread

EECC722 - ShaabanEECC722 - Shaaban#18 Lec # 2 Fall 2010 9-6-2010
SMT: Simultaneous Multithreading• Multiple Hardware Contexts (or threads) running at the same time (HW
context: registers, PC, and SP etc.).
• A single physical SMT processor core acts (and reports to the operating system) as a number of logical processors each executing a single thread
• Reduces both horizontal and vertical waste by having multiple threads keeping functional units busy during every cycle.
• Builds on top of current time-proven advancements in CPU design: superscalar, dynamic scheduling, hardware speculation, dynamic HW branch prediction, multiple levels of cache, hardware pre-fetching etc.
• Enabling Technology: VLSI logic density in the order of hundreds of millions of transistors/Chip.– Potential performance gain is much greater than the increase in chip area
and power consumption needed to support SMT.• Improved Performance/Chip Area/Watt (Computational Efficiency) vs. single-threaded
superscalar cores.
2-way SMT processor 10-15% increase in areaVs. ~ 100% increase for dual-core CMP

EECC722 - ShaabanEECC722 - Shaaban#19 Lec # 2 Fall 2010 9-6-2010
SMT• With multiple threads running penalties from long-latency
operations, cache misses, and branch mispredictions will be hidden:– Reduction of both horizontal and vertical waste and thus
improved Instructions Issued Per Cycle (IPC) rate.
• Functional units are shared among all contexts during every cycle:
– More complicated register read and writeback stages.
• More threads issuing to functional units results in higher resource utilization.
• CPU resources may have to resized to accommodate the additional demands of the multiple threads running.– (e.g cache, TLBs, branch prediction tables, rename registers)
context = hardware thread
Thus SMT is an effective long latency-hiding technique

EECC722 - ShaabanEECC722 - Shaaban#20 Lec # 2 Fall 2010 9-6-2010
SMT: Simultaneous MultithreadingRegis ter F ile i
P C i
S P i
R e g is t e r F i le i+ 1
P C i+ 1
S P i+ 1
Regis ter F ile n
P C n
S P n
S upers c alar (T w o-w ay) P ipelinei
S upers c alar (T w o-w ay) P ipelinei+ 1
S upers c alar (T w o-w ay) P ipelinen
Mem
ory Hierarchy (M
anagement)
Control U
nit (Chip-W
ide)Modified out-of-order Superscalar Core
One n-way SMT Core
n H
ard
war
e C
onte
xts

EECC722 - ShaabanEECC722 - Shaaban#21 Lec # 2 Fall 2010 9-6-2010
The Power Of SMTThe Power Of SMT1 1
1
1 1 1 1
1 1
1
1 1
2 2
3 3
4
5 5
1 1 1 1
2 2 2
3
4 4 4
1 1 2
2 2 3
3 3 4 5
2 2 4
4 5
1 1 1 1
2 2 3
1 2 4
1 2 5
Tim
e (p
roce
ssor
cyc
les)
Superscalar Traditional Multithreaded
Simultaneous Multithreading
Rows of squares represent instruction issue slotsBox with number x: instruction issued from thread xEmpty box: slot is wasted
(Fine-grain)(Fine-grain)
EECC722 - ShaabanEECC722 - Shaaban#22 Lec # 2 Fall 2010 9-6-2010
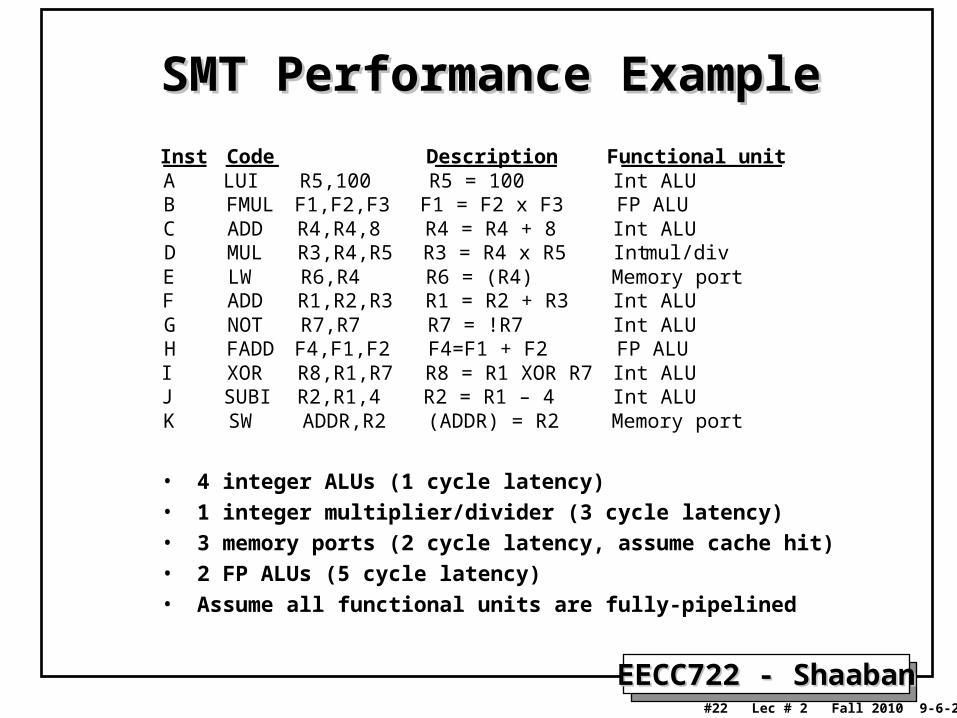
SMT Performance ExampleSMT Performance Example
Inst Code Description Functional unitA LUI R5,100 R5 = 100 Int ALUB FMUL F1,F2,F3 F1 = F2 x F3 FP ALUC ADD R4,R4,8 R4 = R4 + 8 Int ALUD MUL R3,R4,R5 R3 = R4 x R5 Int mul/divE LW R6,R4 R6 = (R4) Memory portF ADD R1,R2,R3 R1 = R2 + R3 Int ALUG NOT R7,R7 R7 = !R7 Int ALUH FADD F4,F1,F2 F4=F1 + F2 FP ALUI XOR R8,R1,R7 R8 = R1 XOR R7 Int ALUJ SUBI R2,R1,4 R2 = R1 – 4 Int ALUK SW ADDR,R2 (ADDR) = R2 Memory port
• 4 integer ALUs (1 cycle latency)
• 1 integer multiplier/divider (3 cycle latency)
• 3 memory ports (2 cycle latency, assume cache hit)
• 2 FP ALUs (5 cycle latency)
• Assume all functional units are fully-pipelined

EECC722 - ShaabanEECC722 - Shaaban#23 Lec # 2 Fall 2010 9-6-2010
SMT Performance Example SMT Performance Example (continued)(continued)
Cycle Superscalar Issuing Slots SMT Issuing Slots1 2 3 4 1 2 3 4
1 LUI (A) FMUL (B) ADD (C) T1.LUI (A) T1.FMUL(B)
T1.ADD (C) T2.LUI (A)
2 MUL (D) LW (E) T1.MUL (D) T1.LW (E) T2.FMUL (B) T2.ADD (C)3 T2.MUL (D) T2.LW (E)45 ADD (F) NOT (G) T1.ADD (F) T1.NOT (G)6 FADD (H) XOR (I) SUBI (J ) T1.FADD (H) T1.XOR (I) T1.SUBI (J ) T2.ADD (F)7 SW (K) T1.SW (K) T2.NOT (G) T2.FADD (H)8 T2.XOR (I) T2.SUBI (J )9 T2.SW (K)
• 2 additional cycles for SMT to complete program 2• Throughput:
– Superscalar: 11 inst/7 cycles = 1.57 IPC
– SMT: 22 inst/9 cycles = 2.44 IPC
– SMT is 2.44/1.57 = 1.55 times faster than superscalar for this example
4-way
2-thread SMT
Ideal speedup = 2
i.e 2nd thread

EECC722 - ShaabanEECC722 - Shaaban#24 Lec # 2 Fall 2010 9-6-2010
Modifications to Superscalar CPUs to Support SMTModifications to Superscalar CPUs to Support SMT
Necessary Modifications:Necessary Modifications:
• Multiple program counters and some mechanism by which one fetch unit selects one each cycle (thread instruction fetch/issue policy).
• A separate return stack for each thread for predicting subroutine return destinations.
• Per-thread instruction issue/retirement, instruction queue flush, and trap mechanisms.
• A thread id with each branch target buffer entry to avoid predicting phantom branches.
Modifications to Improve SMT performance:Modifications to Improve SMT performance:
• A larger rename register file, to support logical registers for all threads plus additional registers for register renaming. (may require additional pipeline stages).
• A higher available main memory fetch bandwidth may be required.
• Larger data TLB with more entries to compensate for increased virtual to physical address translations.
• Improved cache to offset the cache performance degradation due to cache sharing among the threads and the resulting reduced locality.
– e.g Private per-thread vs. shared L1 cache.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
i.e thread state

EECC722 - ShaabanEECC722 - Shaaban#25 Lec # 2 Fall 2010 9-6-2010
SMT ImplementationsSMT Implementations• Intel’s implementation of Hyper-Threading (HT) Technology (2-thread
SMT):– Originally implemented in its NetBurst microarchitecture (P4 processor
family). – Current Hyper-Threading implementation: Intel’s Nehalem (Core i7 –
introduced 4th quarter 2008): 2, 4 or 8 cores per chip each 2-thread SMT (4-16 threads per chip).
• IBM POWER 5/6: Dual cores each 2-thread SMT.
• The Alpha EV8 (4-thread SMT) originally scheduled for production in 2001.
• A number of special-purpose processors targeted towards network processor (NP) applications.
• Sun UltraSparc T1 (Niagara): Eight processor cores each executing from 4 hardware threads (32 threads total).
– Actually, not SMT but fine-grain multithreadedultithreaded (each core issues one instruction from one thread per cycle).
• Current technology has the potential for 4-8 simultaneous threads per core (based on transistor count and design complexity).

EECC722 - ShaabanEECC722 - Shaaban#26 Lec # 2 Fall 2010 9-6-2010
A Base SMT Hardware Architecture.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
In-Order Front End Out-of-order CoreModified Superscalar Speculative TomasuloFetch/Issue

EECC722 - ShaabanEECC722 - Shaaban#27 Lec # 2 Fall 2010 9-6-2010
Example SMT Vs. Superscalar PipelineExample SMT Vs. Superscalar Pipeline
• The pipeline of (a) a conventional superscalar processor and (b) that pipeline modified for an SMT processor, along with some implications of those pipelines.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
Based on the Alpha 21164
SMT-2
Two extra pipeline stages added for reg. Read/write to account for the size increase of the register file

EECC722 - ShaabanEECC722 - Shaaban#28 Lec # 2 Fall 2010 9-6-2010
Intel Hyper-Threaded (2-way SMT) P4 Intel Hyper-Threaded (2-way SMT) P4 Processor PipelineProcessor Pipeline
Source: Intel Technology Journal , Volume 6, Number 1, February 2002. SMT-8
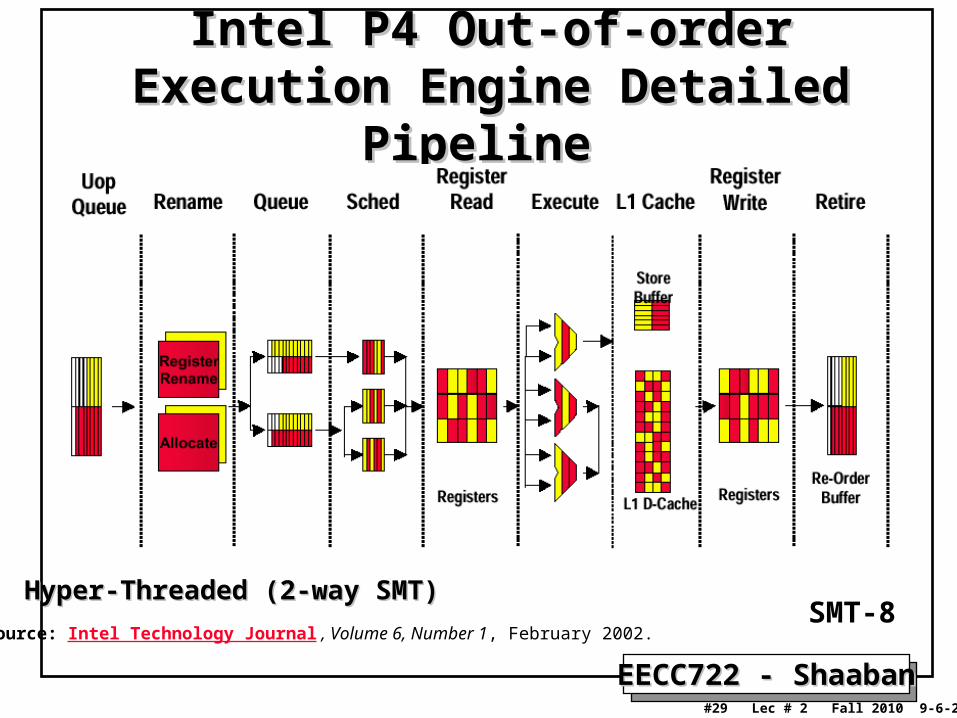
EECC722 - ShaabanEECC722 - Shaaban#29 Lec # 2 Fall 2010 9-6-2010
Intel P4 Out-of-order Execution Engine Intel P4 Out-of-order Execution Engine Detailed Pipeline Detailed Pipeline
Source: Intel Technology Journal , Volume 6, Number 1, February 2002. SMT-8Hyper-Threaded (2-way SMT)Hyper-Threaded (2-way SMT)

EECC722 - ShaabanEECC722 - Shaaban#30 Lec # 2 Fall 2010 9-6-2010
SMT Performance ComparisonSMT Performance Comparison• Instruction throughput (IPC) from simulations by Eggers et al. at The University of Washington, using both multiprogramming and parallel workloads:
Multiprogramming workload
Superscalar Traditional SMTThreads Multithreading 1 2.7 2.6 3.1 2 - 3.3 3.5 4 - 3.6 5.7 8 - 2.8 6.2
Parallel Workload
Superscalar MP2 MP4 Traditional SMTThreads Multithreading 1 3.3 2.4 1.5 3.3 3.3 2 - 4.3 2.6 4.1 4.7 4 - - 4.2 4.2 5.6 8 - - - 3.5 6.1
Multiprogramming workload = multiple single threaded programs (multi-tasking)Parallel Workload = Single multi-threaded program
(MP = Chip-multiprocessor)
i.e Fine-grained
IPC
IPC

EECC722 - ShaabanEECC722 - Shaaban#31 Lec # 2 Fall 2010 9-6-2010
• The following machine models for a multithreaded CPU that can issue 8 instruction per cycle differ in how threads use issue slots and functional units:
• Fine-Grain Multithreading:– Only one thread issues instructions each cycle, but it can use the entire issue width of the
processor. This hides all sources of vertical waste, but does not hide horizontal waste. • SM:Full Simultaneous Issue:
– This is a completely flexible simultaneous multithreaded superscalar: all eight threads compete for each of the 8 issue slots each cycle. This is the least realistic model in terms of hardware complexity, but provides insight into the potential for simultaneous multithreading. The following models each represent restrictions to this scheme that decrease hardware complexity.
• SM:Single Issue,SM:Dual Issue, and SM:Four Issue:– These three models limit the number of instructions each thread can issue, or have active in the
scheduling window, each cycle.
– For example, in a SM:Dual Issue processor, each thread can issue a maximum of 2 instructions per cycle; therefore, a minimum of 4 threads would be required to fill the 8 issue slots in one cycle.
• SM:Limited Connection. – Each hardware context is directly connected to exactly one of each type of functional unit.
– For example, if the hardware supports eight threads and there are four integer units, each integer unit could receive instructions from exactly two threads.
– The partitioning of functional units among threads is thus less dynamic than in the other models, but each functional unit is still shared (the critical factor in achieving high utilization).
Possible Machine Models for an 8-way Multithreaded Processor
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
i.e SM: Eight Issue
EECC722 - ShaabanEECC722 - Shaaban#32 Lec # 2 Fall 2010 9-6-2010
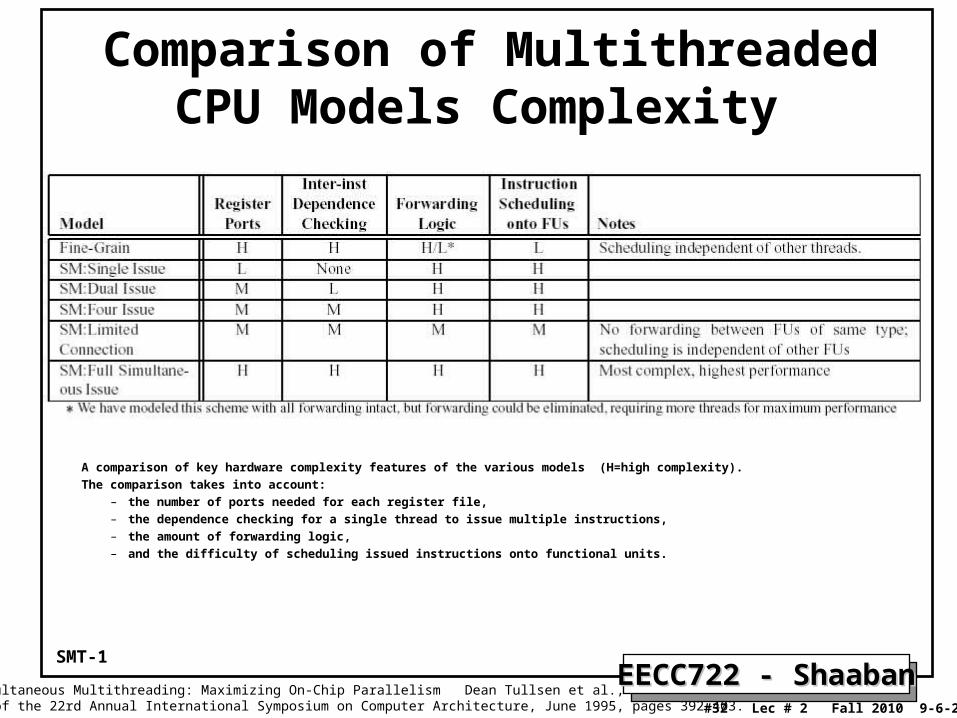
Comparison of Multithreaded CPU Models Complexity
A comparison of key hardware complexity features of the various models (H=high complexity).
The comparison takes into account:– the number of ports needed for each register file, – the dependence checking for a single thread to issue multiple instructions,– the amount of forwarding logic, – and the difficulty of scheduling issued instructions onto functional units.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1

EECC722 - ShaabanEECC722 - Shaaban#33 Lec # 2 Fall 2010 9-6-2010
Simultaneous Vs. Fine-Grain Multithreading Performance
Instruction throughput as a function of the number of threads. (a)-(c) show the throughput by thread priority for particular models, and (d) shows the total throughput for all threads for each of the six machine models. The lowest segment of each bar is the contribution of the highest priority thread to the total throughput.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
Workload:SPEC92
IPC
IPC

EECC722 - ShaabanEECC722 - Shaaban#34 Lec # 2 Fall 2010 9-6-2010
• Results for the multiprocessor MP vs. simultaneous multithreading SM comparisons.The multiprocessor always has one functional unit of each type per processor. In most cases the SM processor has the same total number of each FU type as the MP.
Simultaneous Multithreading (SM) Vs. Single-Chip Multiprocessing (MP)
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1

EECC722 - ShaabanEECC722 - Shaaban#35 Lec # 2 Fall 2010 9-6-2010
Impact of Level 1 Cache Sharing on SMT PerformanceImpact of Level 1 Cache Sharing on SMT Performance • Results for the simulated cache configurations, shown relative to the
throughput (instructions per cycle) of the 64s.64p
• The caches are specified as:
[total I cache size in KB][private or shared].[D cache size][private or shared]
For instance, 64p.64s has eight private 8 KB I caches and a shared 64 KB data
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
Best overall performance of configurations consideredachieved by 64s.64s(64K instruction cache shared 64K data cache shared)
64K instruction cache shared64K data cache private (8K per thread)
Instruction Data
Notation:

EECC722 - ShaabanEECC722 - Shaaban#36 Lec # 2 Fall 2010 9-6-2010
The Impact of Increased Multithreading on Some Low LevelMetrics for Base SMT Architecture
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
More threads supported may lead to more demand on hardware resources(e.g here D and I miss rated increased substantially, and thus need to be resized)

EECC722 - ShaabanEECC722 - Shaaban#37 Lec # 2 Fall 2010 9-6-2010
Possible SMT Thread Instruction Fetch Scheduling PoliciesPossible SMT Thread Instruction Fetch Scheduling Policies• Round Robin:
– Instruction from Thread 1, then Thread 2, then Thread 3, etc. (eg RR 1.8 : each cycle one thread fetches up to eight instructions
RR 2.4 each cycle two threads fetch up to four instructions each)
• BR-Count: – Give highest priority to those threads that are least likely to be on a wrong path
by by counting branch instructions that are in the decode stage, the rename stage, and the instruction queues, favoring those with the fewest unresolved branches.
• MISS-Count:– Give priority to those threads that have the fewest outstanding Data cache misses.
• ICount:– Highest priority assigned to thread with the lowest number of instructions in
static portion of pipeline (decode, rename, and the instruction queues).
• IQPOSN:– Give lowest priority to those threads with instructions closest to the head of either
the integer or floating point instruction queues (the oldest instruction is at the head of the queue).
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
Instruction Queue (IQ) Position

EECC722 - ShaabanEECC722 - Shaaban#38 Lec # 2 Fall 2010 9-6-2010
Instruction Throughput For Round Robin Instruction Fetch Scheduling
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
Best overall instruction throughput achieved using round robin RR.2.8(in each cycle two threads each fetch a block of 8 instructions)
Workload: SPEC92
RR.2.8
RR with best performance

EECC722 - ShaabanEECC722 - Shaaban#39 Lec # 2 Fall 2010 9-6-2010
Instruction throughput & Thread Fetch Policy
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202. SMT-2
Workload: SPEC92
All other fetch heuristics provide speedup over round robinInstruction Count ICOUNT.2.8 provides most improvement5.3 instructions/cycle vs 2.5 for unmodified superscalar.
ICOUNT.2.8
ICOUNT: Highest priority assigned to thread with the lowest number of instructions in static portion of pipeline (decode, rename, and the instruction queues).

EECC722 - ShaabanEECC722 - Shaaban#40 Lec # 2 Fall 2010 9-6-2010
Low-Level Metrics For Round Robin 2.8, Icount 2.8
ICOUNT improves on the performance of Round Robin by 23%by reducing Instruction Queue (IQ) clog by selecting a better mix of instructions to queue
SMT-2

EECC722 - ShaabanEECC722 - Shaaban#41 Lec # 2 Fall 2010 9-6-2010
Possible SMT Instruction Issue PoliciesPossible SMT Instruction Issue Policies• OLDEST FIRST: Issue the oldest instructions (those
deepest into the instruction queue, the default).
• OPT LAST and SPEC LAST: Issue optimistic and speculative instructions after all others have been issued.
• BRANCH FIRST: Issue branches as early as possible in order to identify mispredicted branches quickly.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202. SMT-2
Instruction issue bandwidth is not a bottleneck in SMT as shown above
ICOUNT.2.8 Fetch policy used for all issue policies above

EECC722 - ShaabanEECC722 - Shaaban#42 Lec # 2 Fall 2010 9-6-2010
SMT: Simultaneous Multithreading• Strengths:
– Overcomes the limitations imposed by low single thread instruction-level parallelism.
– Resource-efficient support of chip-level TLP.– Multiple threads running will hide individual control hazards
( i.e branch mispredictions) and other long latencies (i.e main memory access latency on a cache miss).
• Weaknesses: – Additional stress placed on memory hierarchy.– Control unit complexity.– Sizing of resources (cache, branch prediction, TLBs etc.)– Accessing registers (32 integer + 32 FP for each HW context):
• Some designs devote two clock cycles for both register reads and register writes. Deeper pipeline
Related Documents











