EE (CE) 6304 Computer Architecture Lecture #7 (9/18/13) Myoungsoo Jung (9/18/13) Myoungsoo Jung Assistant Professor Department of Electrical Engineering Department of Electrical Engineering University of Texas at Dallas

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

EE (CE) 6304 Computer Architecture
Lecture #7
(9/18/13)
Myoungsoo Jung
(9/18/13)
Myoungsoo Jung Assistant Professor
Department of Electrical EngineeringDepartment of Electrical EngineeringUniversity of Texas at Dallas

Virtual Memory Reviewy

Views of MemoryViews of Memory
• Real machines have limited amounts of memory640KB? A f GB?– 640KB? A few GB?
– (This laptop = 2GB)• Programmer doesn’t want to be bothered
– Do you think, “oh, this computer only has y , , p y128MB so I’ll write my code this way…”
– What happens if you run on a different What happens f you run on a d fferentmachine?

Programmer’s ViewProgrammer s View• Example 32-bit memory
– When programming, you don’t care about Kernel
0-2GBy
how much realmemory there is
Text– Even if you use a lot, memory can always b d di k
Text
Data
be paged to disk Heap
Stack4GBA K A Vi t l Add 4GBA.K.A. Virtual Addresses

Programmer’s ViewProgrammer s View• Really “Program’s View”y g• Each program/process gets its own 4GB space
– Or much, much more with a 64-bit processorOr much, much more with a 64 bit processorKernel
Kernel
Text
TextDataHeap
DataHeap
Kernel
Text
p
Stack
StackDataHeap
Stack

CPU’s ViewCPU s View
• At some point, the CPU is going to have to load-from/store-to memory all it knows is the real A K Afrom/store to memory… all it knows is the real, A.K.A. physical memory
• … which unfortunatelyyis often < 4GB
• … and is almost neverm4GB per process
• … and is never… and is never16 exabytes per process

PagesPages
• Memory is divided into pages, which are nothing more than fixed sized and aligned regions of memorythan fixed sized and aligned regions of memory– Typical size: 4KB/page (but not always)
0-4095 Page 0
4096-8191 Page 1
8192-12287
12288-16383
Page 2
Page 312288 16383
…
g

Page TablePage Table
• Map from virtual addresses to physical locations• Map from virtual addresses to physical locations0K
4K
Physical
Addresses
0K
4K
8K
4K
8K
12KPage Table implements8K
12K16K
20K
this VP mapping
Virtual
24K
28KEntry Entry includes includes
Addressespermissions permissions (e.g., read(e.g., read--
only)only)
“Physical Location” mayinclude hard-disk

Need for TranslationNeed for Translation
Vi t l Add0xFC51908B
Virtual Address
Virtual Page Number Page Offset
Physical
Address
PageTable
MainMainMemoryMemory
0x001520xFC519
0x0015208B

Page TablesPage Tables0K
4K
Physical Memory
0K
4K
8K
4K
8K
12K8K
12K16K
20K
24K
28K0K
4K
8K
12K

What is in a Page Table Entry (PTE)?What is in a Page Table Entry (PTE)?• What is in a Page Table Entry (or PTE)?
– Pointer to actual pageP i i bit lid d l d it it l– Permission bits: valid, read-only, read-write, write-only
• Example: Intel x86 architecture PTE:– Address same format previous slide (10, 10, 12-bit offset)
I di bl ll d “Di i ”– Intermediate page tables called “Directories”Page Frame Number
(Physical Page Number)Free(OS) 0 L D A
PCDPW
T U W P
P: Present (same as “valid” bit in other architectures)
(Physical Page Number) (OS) D T
01234567811-931-12
W: WriteableU: User accessible
PWT: Page write transparent: external cache write-throughPCD: Page cache disabled (page cannot be cached)
A: Accessed: page has been accessed recentlyD: Dirty (PTE only): page has been modified recentlyy y p g yL: L=14MB page (directory only).
Bottom 22 bits of virtual address serve as offset

Three Advantages of Virtual MemoryThree Advantages of Virtual Memory• Translation:
– Program can be given consistent view of memory, even though g g y gphysical memory is scrambled
– Makes multithreading reasonable (now used a lot!)– Only the most important part of program (“Working Set”) must Only the most mportant part of program ( Work ng Set ) must
be in physical memory.– Contiguous structures (like stacks) use only as much physical
memory as necessary yet still grow later.memory as necessary yet still grow later.• Protection:
– Different threads (or processes) protected from each other.Different pages can be given special behavior– Different pages can be given special behavior
» (Read Only, Invisible to user programs, etc).– Kernel data protected from User programs– Very important for protection from malicious programs
• Sharing:– Can map same physical page to multiple usersan map same phys cal page to mult ple users
(“Shared memory”)

Large Address Space SupportPhysicalAddress:
OffsetPhysicalPage #
L g p pp10 bits 10 bits 12 bits
Virtual OffsetVirtualP2 i d
VirtualP1 i d
4KB
Address: P2 indexP1 index
PageTablePtr
4 bytes
• Single-Level Page Table Large– 4KB pages for a 32-bit address 1M4KB pages for a 32 bit address 1M
entries– Each process needs own page table!
• Multi-Level Page TableCan allow sparseness of page table– Can allow sparseness of page table
– Portions of table can be swapped to disk 4 bytes

TLB Review

Translation Look-Aside Buffers• Translation Look-Aside Buffers (TLB)
Cache on translations
Translation Look Aside Buffers
– Cache on translations– Fully Associative, Set Associative, or Direct Mapped
hit
CPU TLB CacheMain
Memory
VA PA miss
Memory
hit
T ns
missTranslationwith a TLB
data
Trans-
lation
• TLBs are:– Small – typically not more than 128 – 256 entries
data
yp y– Fully Associative

Caching Applied to Address Translationg ppTLBVirtual
AddressPhysicalddC h d?CPU Physical
MemoryNo
Address AddressYes
Cached?
Translate
Data Read or Write
(MMU)
• Question is one of page locality: does it exist?– Instruction accesses spend a lot of time on the same page
Data Read or Write(untranslated)
Instruction accesses spend a lot of time on the same page (since accesses sequential)
– Stack accesses have definite locality of reference– Data accesses have less page locality but still someData accesses have less page locality, but still some…
• Can we have a TLB hierarchy?– Sure: multiple levels at different sizes/speeds

What Actually Happens on a TLB Miss?What Actually Happens on a TLB Miss?• Hardware traversed page tables:
– On TLB miss hardware in MMU looks at current page table toOn TLB miss, hardware in MMU looks at current page table to fill TLB (may walk multiple levels)
» If PTE valid, hardware fills TLB and processor never knows» If PTE marked as invalid, causes Page Fault, after whichIf PTE marked as invalid, causes Page Fault, after which
kernel decides what to do afterwards• Software traversed Page tables (like MIPS)
– On TLB miss, processor receives TLB faultOn TLB miss, processor receives TLB fault– Kernel traverses page table to find PTE
» If PTE valid, fills TLB and returns from fault» If PTE marked as invalid internally calls Page Fault handler» If PTE marked as invalid, internally calls Page Fault handler
• Most chip sets provide hardware traversal– Modern operating systems tend to have more TLB faults since
they use translation for many thingsthey use translation for many things– Examples:
» shared segments» user level portions of an operating system» user-level portions of an operating system

Implementing LRUImplementing LRU
• Have LRU counter for each line in a setWhen line accessed• When line accessed– Get old value X of its counter– Set its counter to max value– For every other line in the sety
» If counter larger than X, decrement it• When replacement neededW p m
– Select line whose counter is 0

Clock Algorithm: Not Recently UsedSingle Clock Hand:
Advances only on page fault!
Clock Algorithm: Not Recently Used
Set of all pages
Advances only on page fault!
Check for pages not used recently
Mark pages as not used recentlyPage Tablein Memory
p g y
...
g
1 0useddirty
1 0
• Clock Algorithm:– Approximate LRU (approx to approx to MIN)
1 00 11 10 0Approximate LRU (approx to approx to MIN)
– Replace an old page, not the oldest page• Details:
– Hardware “use” bit per physical page:
0 0
p p y p g» Hardware sets use bit on each reference» If use bit isn’t set, means not referenced in a long time
– On page fault:Ad l k h d ( t l ti )» Advance clock hand (not real time)
» Check use bit: 1→used recently; clear and leave alone0→selected candidate for replacement

Example: R3000 pipelineExample: R3000 pipeline
Inst Fetch Dcd/ Reg ALU / E.A Memory Write RegMIPS R3000 Pipeline
Inst Fetch g ALU / E.A Memory Write RegTLB I-Cache RF Operation WB
E.A. TLB D-Cache
TLB
64 entry, on-chip, fully associative, software TLB fault handler
ASID V. Page Number Offset
Virtual Address Space
12206
0xx User segment (caching based on PT/TLB entry)
100 Kernel physical space, cached
101 Kernel physical space, uncached
11x Kernel virtual spacepAllows context switching among
64 user processes without TLB flush

Reducing translation time further• As described, TLB lookup is in serial with cache lookup:
Reducing translation time further
Virtual AddressVirtual Address
V page no. offset10
TLB Lookup
AV AccessRights
PA
P page no. offset10
Ph i l Add
• Machines with TLBs go one step further: they overlap TLB lookup with cache access
Physical Address
TLB lookup with cache access.– Works because offset available early

Overlapping TLB & Cache Access• Here is how this might work with a 4K cache:
assoc
Overlapping TLB & Cache Access
TLB 4K Cacheindex 1 K
assoclookup
32
10 200
4 bytespage # disp
20
Hit/Miss
FN Data Hit/=FN
• What if cache size is increased to 8KB?– Overlap not complete
Miss
Overlap not complete– Need to do something else
• Another option: Virtual Caches– Tags in cache are virtual addresses– Translation only happens on cache misses

Summary: TLB Virtual MemorySummary: TLB, Virtual Memory• Page tables map virtual address to physical address
TLB i f f l i• TLBs are important for fast translation– TLB misses are significant in processor
fperformance– most systems can’t access all of 2nd level cache without TLB misses!
• Caches, TLBs, Virtual Memory all understood by i i h th d l ith 4 tiexamining how they deal with 4 questions:
1) Where can block be placed?2) How is block found?2) How is block found? 3) What block is replaced on miss? 4) How are writes handled?
• Today VM allows many processes to share single memory without having to swap all processes to disk;

Exceptions: Traps and InterruptsExceptions: Traps and Interrupts
(H d )(Hardware)

Exceptions: Traps and Interrupts

Exception vs InterruptException vs. Interrupt
• Exception: An unusual event happens to an instruction during its execution
– Examples: divide by zero, undefined opcode• Interrupt: Hardware signal to switch the processor
to a new instruction streamto a new instruction stream – Example: a sound card interrupts when it needs more audio output samples (an audio “click” happens if it is left waiting)happens if it is left waiting)

Problems with PipeliningProblems with Pipelining
• Problem: It must appear that the exception or interrupt must appear between 2 instructions (Ii and Ii+1)Ii+1)
– The effect of all instructions up to and including Ii is completeN ff t f i t ti ft I t k– No effect of any instruction after Ii can take place
• The interrupt (exception) handler either aborts p ( p )program or restarts at instruction Ii+1

Example: Device Interrupt(Say, arrival of network message) Raise priority( y, f m g )
…Reenable All Ints
Save registersadd r1,r2,r3
subi r4,r1,#4
Save registers
…
lw r1,20(r0)pt ”
slli r4,r4,#2
Hiccup(!)
lw r2,0(r1)
addi r3,r0,#5Inte
rrup
Han
dler
”
Hiccup(!)
lw r2,0(r4)sw 0(r1),r3
…xter
nal
terr
upt
H
lw r3,4(r4)
add r2,r2,r3
Restore registers
Clear current Int
E
“Int
sw 8(r4),r2
…Disable All Ints
Restore priorityp y
RTE

Alternative: Polling( i f i l f t k )(again, for arrival of network message)
Disable Network Intrup
t…
subi r4,r1,#4slli r4 r4 #2In
terr
u
slli r4,r4,#2lw r2,0(r4)lw r3,4(r4)dd 2 2 3Ex
tern
al
add r2,r2,r3sw 8(r4),r2lw r1,12(r0)
E
Polling Point( h k d i i t )beq r1,no_mess
lw r1,20(r0)lw r2,0(r1)
(check device register)
addi r3,r0,#5sw 0(r1),r3Clear Network Intr
“Handler”
…no_mess:

Polling is faster/slower than InterruptsPolling is faster/slower than Interrupts.• Polling is faster than interrupts because
– Compiler knows which registers in use at polling point Hence– Compiler knows which registers in use at polling point. Hence, do not need to save and restore registers (or not as many).
– Other interrupt overhead avoided (pipeline flush, trap p i iti t )priorities, etc).
• Polling is slower than interrupts because– Overhead of polling instructions is incurred regardless ofOverhead of polling instructions is incurred regardless of
whether or not handler is run. This could add to inner-loop delay.
– Device may have to wait for service for a long timeDevice may have to wait for service for a long time.• When to use one or the other?
– Multi-axis tradeoff» Frequent/regular events good for polling, as long as device
can be controlled at user level.» Interrupts good for infrequent/irregular events» Interrupts good for infrequent/irregular events» Interrupts good for ensuring regular/predictable service of
events.

Trap/Interrupt classificationsTrap/Interrupt classifications
• Traps: relevant to the current processTraps: relevant to the current process– Faults, arithmetic traps, and synchronous traps– Invoke software on behalf of the currently executingInvoke software on behalf of the currently executing process
• Interrupts: caused by asynchronous, outside events– I/O devices requiring service (DISK, network)– Clock interrupts (real time scheduling)
h h k d b h d f l• Machine Checks: caused by serious hardware failure– Not always restartableI di t th t b d thi h h d– Indicate that bad things have happened.
» Non-recoverable ECC error» Machine room fire» Machine room fire» Power outage

A related classification: Synchronous vs. AsynchronousSynchronous vs. Asynchronous
• Synchronous: means related to the instruction stream, i e during the execution of an instructioni.e. during the execution of an instruction
– Must stop an instruction that is currently executing– Page fault on load or store instructionPage fault on load or store instruction– Arithmetic exception– Software Trap Instructionsp
• Asynchronous: means unrelated to the instruction stream, i.e. caused by an outside event.
D h d h l d– Does not have to disrupt instructions that are already executing
– Interrupts are asynchronousInterrupts are asynchronous– Machine checks are asynchronous
• SemiSynchronous (or high-availability interrupts): SemiSynchronous (or high availability interrupts)– Caused by external event but may have to disrupt current instructions in order to guarantee service

Interrupt Priorities Must be HandledInterrupt Priorities Must be Handled
Raise priority
…add r1,r2,r3
Raise priorityReenable All IntsSave registers
ptCould b
subi r4,r1,#4slli r4,r4,#2
Hiccup(!)
…lw r1,20(r0)lw r2,0(r1)addi r3,r0,#5In
terr
ube interr
Hiccup(!)
lw r2,0(r4)
lw r3,4(r4)
addi r3,r0,#5sw 0(r1),r3
…Restore registers
Net
work
rupted bylw r3,4(r4)add r2,r2,r3sw 8(r4),r2
…
Clear current IntDisable All IntsRestore priority
Ny disk
Restore priorityRTE
N t th t i it t b i d t id i i t t !Note that priority must be raised to avoid recursive interrupts!
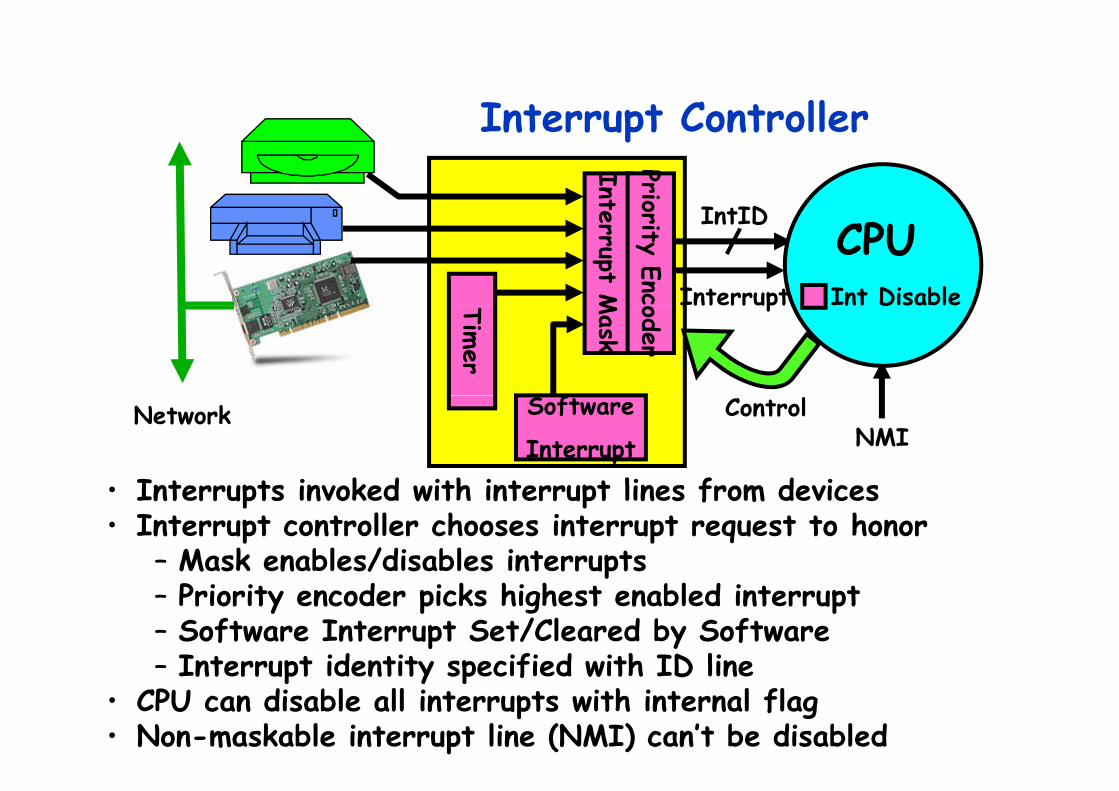
Interrupt ControllerInterrupt Controller
IntID
Inte
Prior IntID
Interrupt
errupt M
CPU
rity Enc Int DisablepMask
f
oder
Timer
D
Interrupts inv ked with interrupt lines fr m devices
Network ControlSoftware
Interrupt NMI
• Interrupts invoked with interrupt lines from devices• Interrupt controller chooses interrupt request to honor
– Mask enables/disables interruptsp– Priority encoder picks highest enabled interrupt – Software Interrupt Set/Cleared by Software– Interrupt identity specified with ID line– Interrupt identity specified with ID line
• CPU can disable all interrupts with internal flag• Non-maskable interrupt line (NMI) can’t be disabled

Interrupt controller hardware and mask levelsmask levels
• Operating system constructs a hierarchy of masks that• Operating system constructs a hierarchy of masks that reflects some form of interrupt priority.
• For instance:P i it E lPriority Examples
0 Software interrupts 2 Network Interrupts2 Network Interrupts4 Sound card 5 Disk Interrupt5 Disk Interrupt6 Real Time clock ∞ Non-Maskable Ints (power)
– This reflects the an order of urgency to interrupts– For instance, this ordering says that disk events can interrupt the interrupt handlers for network
p
interrupt the interrupt handlers for network interrupts.

Can we have fast interrupts?Can we have fast interrupts?
…dd 1 2
Raise priorityReenable All IntsSave registerst
Could
add r1,r2,r3subi r4,r1,#4slli r4,r4,#2
Save registers…
lw r1,20(r0)lw r2,0(r1)In
terr
upt d be inte
Hiccup(!)
lw r2,0(r4)
, ( )addi r3,r0,#5sw 0(r1),r3
…Grain
Ierrupted
lw r3,4(r4)add r2,r2,r3sw 8(r4),r2
Restore registersClear current IntDisable All Ints
Fine
d by disk
P l D C b E
sw 8(r4),r2… Restore priority
RTE
• Pipeline Drain: Can be very Expensive • Priority Manipulations
R i t S /R t• Register Save/Restore– 128 registers + cache misses + etc.

Precise Interrupts/ExceptionsPrecise Interrupts/Exceptions• An interrupt or exception is considered precise if
there is a single instruction (or interrupt point) for hi hwhich:– All instructions before that have committed their state– No following instructions (including the interrupting instruction)– No following instructions (including the interrupting instruction)
have modified any state.• This means, that you can restart execution at the y
interrupt point and “get the right answer”– Implicit in our previous example of a device interrupt:
I t t i t i t fi t l i t ti» Interrupt point is at first lw instruction…
add r1,r2,r3bi 4 1 #4rr
upt
In
subi r4,r1,#4slli r4,r4,#2
lw r2,0(r4)erna
lInt
ernt handle
lw r3,4(r4)add r2,r2,r3sw 8(r4),r2
…
Exte
er

Precise Exceptions in Static PipelinesPrecise Exceptions in Static Pipelines
Key observation: architected state only change in memory and register write stages.

Precise interrupt point may require multiple PCsmay require multiple PCs
addi r4,r3,#4sub r1,r2,r3bne r1,thereand r2,r3,r5
PC:PC+4:
Interrupt point described as <PC,PC+4>, ,
<other insts> PC+4:
addi r4,r3,#4sub r1,r2,r3bne r1,thereand r2,r3,r5
Interrupt point described as:
<PC+4 there> (branch was taken)PC:
PC+4: and r2,r3,r5<other insts>
<PC+4,there> (branch was taken)or
<PC+4,PC+8> (branch was not taken)
PC+4:
• On SPARC, interrupt hardware produces “pc” and “npc” (next pc)p ( p )
• On MIPS, only “pc” – must fix point in software

Why are precise interrupts desirable?Why are precise interrupts desirable?• Many types of interrupts/exceptions need to be
restartable Easier to figure out what actuallyrestartable. Easier to figure out what actually happened:
– I.e. TLB faults. Need to fix translation, then restart load/store– IEEE gradual underflow, illegal operation, etc:
e.g. Suppose you are computing:Th f 0 x
xxf )sin()( =Then, for , 0→x
operationillegalNaNf _00)0( +=
x
• Restartability doesn’t require preciseness. However, i k it l t i t t t
Want to take exception, replace NaN with 1, then restart.
preciseness makes it a lot easier to restart.• Simplify the task of the operating system a lot
Less state needs to be saved away if unloading process– Less state needs to be saved away if unloading process.– Quick to restart (making for fast interrupts)

Precise Exceptions in simple 5-stage pipeline:5 stage pipeline:
• Exceptions may occur at different stages in pipeline (I.e. out of order):
– Arithmetic exceptions occur in execution stage– TLB faults can occur in instruction fetch or memory stage
Wh b i ? Th d ’ d f “d h ”• What about interrupts? The doctor’s mandate of “do no harm” applies here: try to interrupt the pipeline as little as possible
• All of this solved by tagging instructions in pipeline as “cause y gg g p pexception or not” and wait until end of memory stage to flag exception
– Interrupts become marked NOPs (like bubbles) that areInterrupts become marked NOPs (like bubbles) that are placed into pipeline instead of an instruction.
– Assume that interrupt condition persists in case NOP flushedflushed
– Clever instruction fetch might start fetching instructions from interrupt vector, but this is complicated by need for
p i m d it h in f n m PC tsupervisor mode switch, saving of one or more PCs, etc

Summary: InterruptsSummary: Interrupts• Interrupts and Exceptions either interrupt the current
instruction or happen between instructionsinstruction or happen between instructions– Possibly large quantities of state must be saved before interruptingsaved before interrupting
• Machines with precise exceptions provide one single point in the program to restart executionp p g– All instructions before that point have completedp
– No instructions after or including that point have completedhave completed

Related Documents











