EE 20105034 Seong-Heum Kim 1 Paper implementation Optimization Class, by Prof. Yu- Wing Tai

EE 20105034 Seong-Heum Kim 1 Paper implementation Optimization Class, by Prof. Yu-Wing Tai.
Dec 28, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
EE 20105034Seong-Heum Kim
Paper implementation
Optimization Class, by Prof. Yu-Wing Tai

2
Contents
• Introduction to MVOS (Multiple View Object Segmentation)
• Algorithm Overview
• Contribution of the paper Optimizing MVOS in space and time Efficient 3D sampling with 2D superpixel representation
• Implementation issues
• Evaluation
• Conclusion

3
Introduction to MVOS
• What is “Multi-View Object Segmentation”?
Methods Conditions Key ideas
Multi-View Object Segmentation More than 2 views Sharing a common geometric modelInteractive segmentation Single image with seeds Bounding-box (or strokes) priorsImage co-segmentation More than 2 images Sharing a common appearance model

4
Introduction to MVOS
• What is “Multi-View Object Segmentation”?
• Problem Definition Given 1) Images, I = {I1, I2, I3, …, In}
2) Projection matrices, KRT = {KRT1, KRT2, KRT3, …, KRTn} (Known intrinsic&extrinsic viewpoints) Take Segmentation maps, X = {X1, X2, X3, …, Xn}
Where = {: Colors(R,G,B) at the k-th pixel from the n-th viewpoint.
= {: Binary labels at the k-th pixel in the n-th image.
Methods Conditions Key ideas
Multi-View Object Segmentation More than 2 views Sharing a common geometric modelKnown projection rela-tions (matrices)
Bounding-boxes from camera posesNo common appearance models needed

5
Related works
• Building segmentations consistent with a single 3D object Zeng04accv: Silhouette extraction from multiple images of an unknown background Yezzi03ijcv: Stereoscopic segmentation
• Joint optimization of segmentation and 3D reconstruction Xiao07iccv: Joint affinity propagation for multiple view segmentation Campbell07bmvc: Automatic 3D object segmentation in multiple views using volumetric graph-cuts Guillemaut11ijcv: Joint multi-layer segmentation and reconstruction for free-viewpoint video application
• Recent formulations for better results Djelouah12eccv: N-tuple color segmentation for multi-view silhouette extraction Kowdle12eccv: Multiple view object co-segmentation using appearance and stereo cues Lee11pami: Silhouette segmentation in multiple views
• Optimizing MVOS in space and time Djelouah13iccv: Multi-view object segmentation in space and time (this paper)
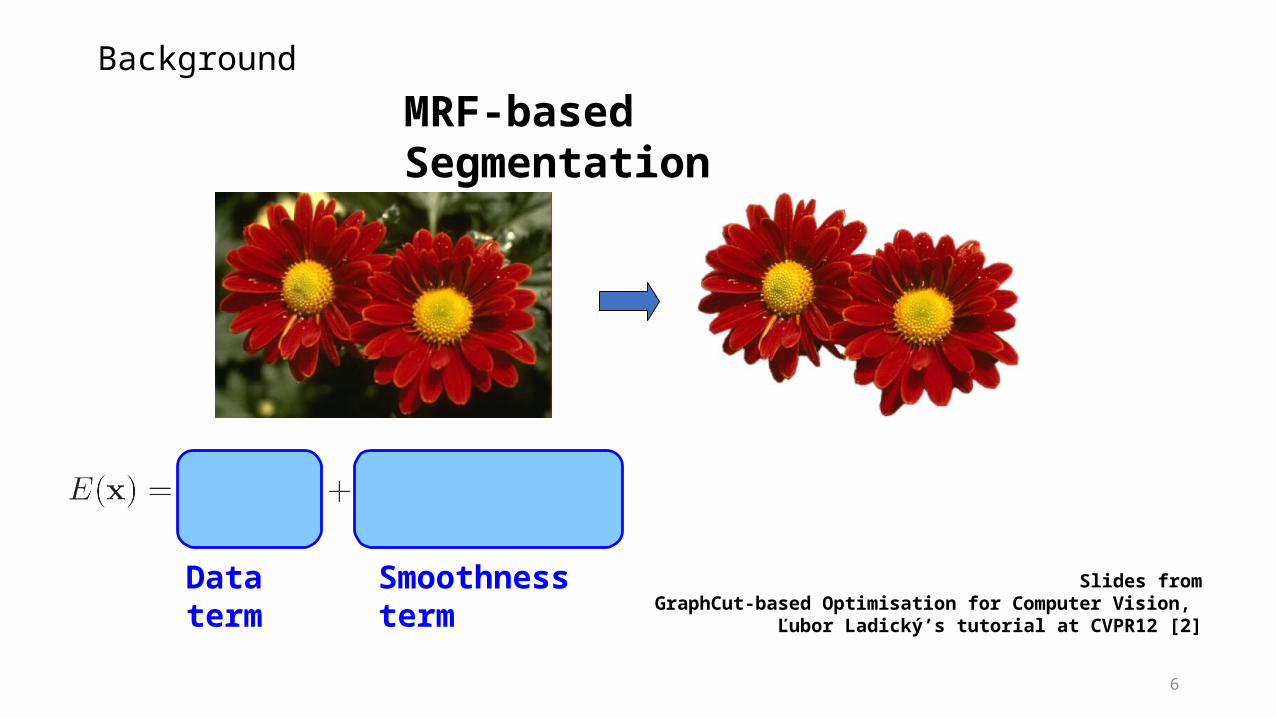
6
Background
MRF-based Segmentation
Slides fromGraphCut-based Optimisation for Computer Vision,
Ľubor Ladický’s tutorial at CVPR12 [2]
Data term Smoothness term

7
Background
Data term
Estimated using FG / BG colour models
Smoothness term
where
Intensity dependent smoothness

8
Background
Data term(Region)
Smoothness term(Boundary)
How to solve this optimization problem?
• Transform MAP problem to MRF min.
• Solve it using min-cut / max-flow algorithm
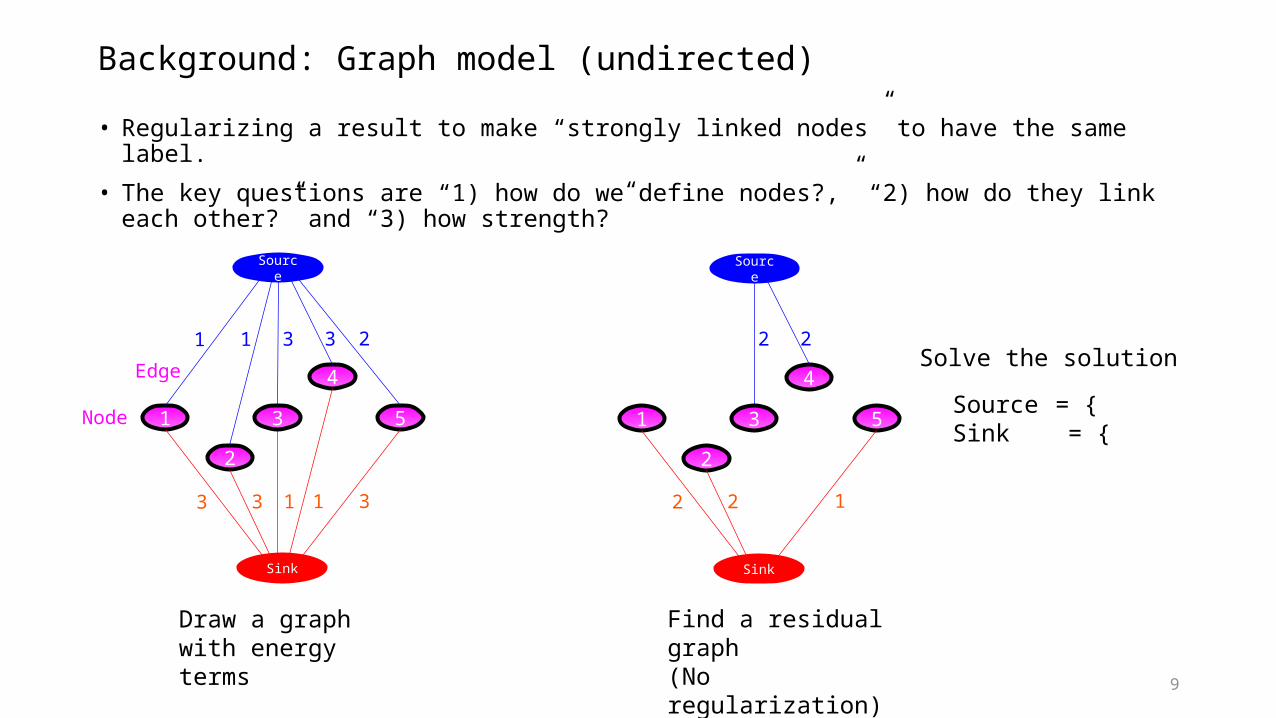
9
Background: Graph model (undirected)
• Regularizing a result to make “strongly linked nodes” to have the same label.
• The key questions are “1) how do we define nodes?,” “2) how do they link each other?” and “3) how strength?”
3 51
4
2
Sink
Source
Source = {Sink = {
3 51
4
2
Sink
Source
Draw a graphwith energy terms
Find a residual graph(No regularization)
Solve the solution
Node
Edge
1 1 23 3
3 3 31 1 2 2 1
2 2

10
Background: Graph model (undirected)
• Maxflow algorithm (Ford & Fulkerson algorithm, 1956)
• Iteratively “1) find active nodes,” “2) sum up bottleneck capacities” and “3) check there is no active flow”
3 51
4
2
Sink
Source
3 3 3
1
12
2
1 1
1 1 23 3
Link pixels withtheir similarity
Flow = 1
3 51
4
2
Sink
Source
2 3 3
1
12
2
1 1
1 23 3

11
Background: Graph model (undirected)
• Maxflow algorithm (Ford & Fulkerson algorithm, 1956)
• Iteratively “1) find active nodes,” “2) sum up bottleneck capacities” and “3) check there is no active flow”
3 51
4
2
Sink
Source
2 2 3
1
12
2
1 1
23 3
Flow = 3
3 51
4
2
Sink
Source
2 2 3
1
12
2
1
22 3
Flow = 2

12
Background: Graph model (undirected)
• Maxflow algorithm (Ford & Fulkerson algorithm, 1956)
• Iteratively “1) find active nodes,” “2) sum up bottleneck capacities” and “3) check there is no active flow”
3 51
4
2
Sink
Source
2 2 3
1
12
2
22 2
Flow = 5
3 51
4
2
Sink
Source
2 2 1
1
12
2
2 2
Flow = 4
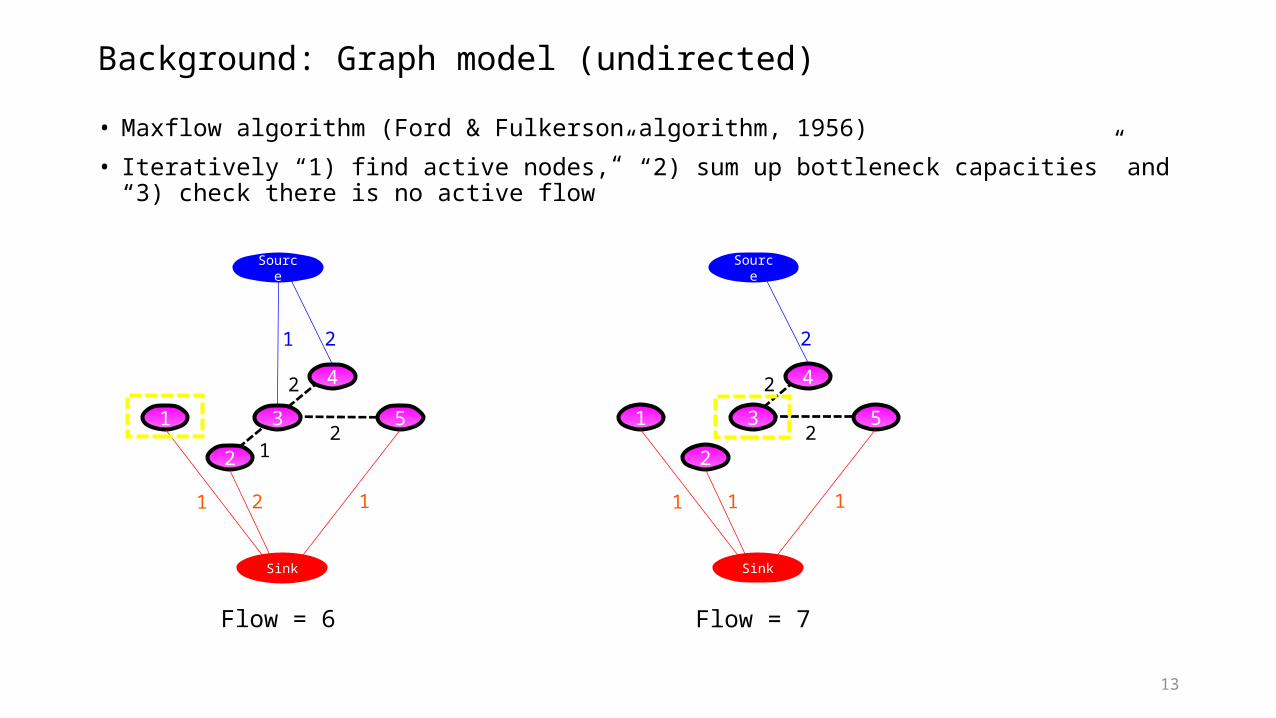
13
Background: Graph model (undirected)
• Maxflow algorithm (Ford & Fulkerson algorithm, 1956)
• Iteratively “1) find active nodes,” “2) sum up bottleneck capacities” and “3) check there is no active flow”
3 51
4
2
Sink
Source
1 2 1
12
2
1 2
Flow = 7
3 51
4
2
Sink
Source
1 1 1
2
2
2
Flow = 6

14
Background: Graph model (undirected)
• There is no more possible path
• Globally optimum in the two-terminal case (bc. any sub-bounds in the maximum bound ≤ 8)
3 51
4
2
Sink
Source
1 1
1
1
1
Maxflow = 8 Maximum bound
Source = {Sink = {
Solve the solution

15
Background: Graph-cut
• Duality of the min-cut problem
• Any cuts ≥ 8 + @
• Sub-modularity: E(0,1)+E(1,0) ≥ E(0,0)+E(1,1) (=0)
3 51
4
2
Sink
Source
1 1
1
1
1
Maxflow = 8 Min-cut
2) Solve it in MRF
Source = { Sink = {
1) Design a energy function for nodes, edges (linkages)
Sub-bound(Cut = 8+1)

16
Contribution of the paper
1. MRF optimization over all the viewpoints and sequences at the same time Linkages between 3D samples and the projected superpixels Linkages between correspondences in frames
2. Sparse 3D sampling with superpixel representation Fast and simple 3D model Richer representation of texture information (appearance) Bag-of-Word (BoW) model in a small patch

17
MVOS in space and time
• Multi-View Object Segmentation (MVOS) in space and time
• Problem Definition Given 1) Set of superpixels p in images at time t, = {,
2) Projection matrices, KRT = {KRT1, KRT2, KRT3, …, KRTn} (Fixed camera pose) Take superpixel segmentations = { for all viewpoints n and time t.
Where : Binary labels at the k-th superpixel of the n-th image in t-th time
= {, Set of pixels in superpixel p.
, Set of 3D samples in time t
Methods Conditions Key ideas
MVOS in space and time Known projection relations Bounding-boxes from camera posesMore than 2 viewpoints Sharing a common 3D samplesTemporal motions (SIFT-flow) Linking matched superpixels b.w frames.
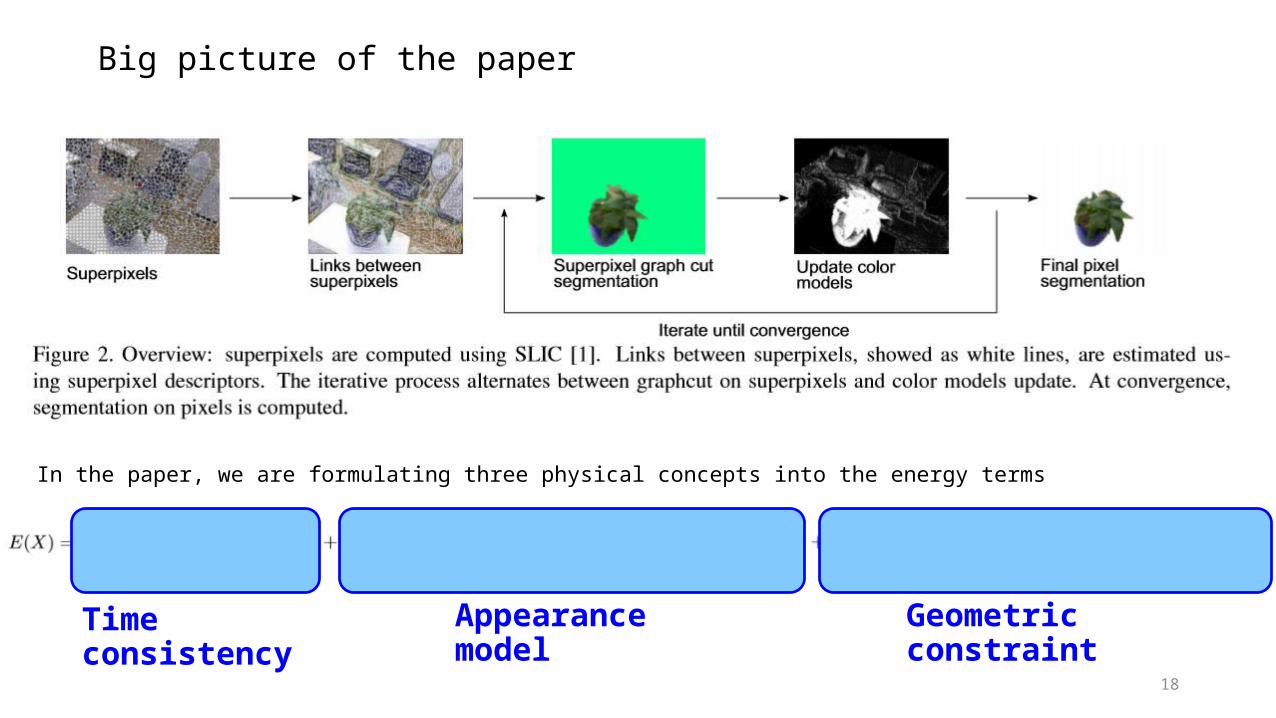
18
Big picture of the paper
In the paper, we are formulating three physical concepts into the energy terms
Time consistency Appearance model Geometric constraint

19
Big picture of the paper
Appearance data-term: color + texture
Appearance smoothness term: spatially neighboring superpixels
Appearance smoothness term: non-locally connected superpixels
3D sample data-term: probabilistic occupancy
Sample-superpixel junction term: sharing a coherent geometric model
Sample-projection data-term: giving a projection constraint

20
Overview
▲ One of input images (1/8)
▲ Superpixels in the img.

21
Overview
▲ Neighboring linkages
▲ Non-local linkages

22
Overview
▲ Constraint from camera poses

23
Overview
▲ Update the geometric model

24
Overview
▲ Mean accuracy: 95% (±1%)
25
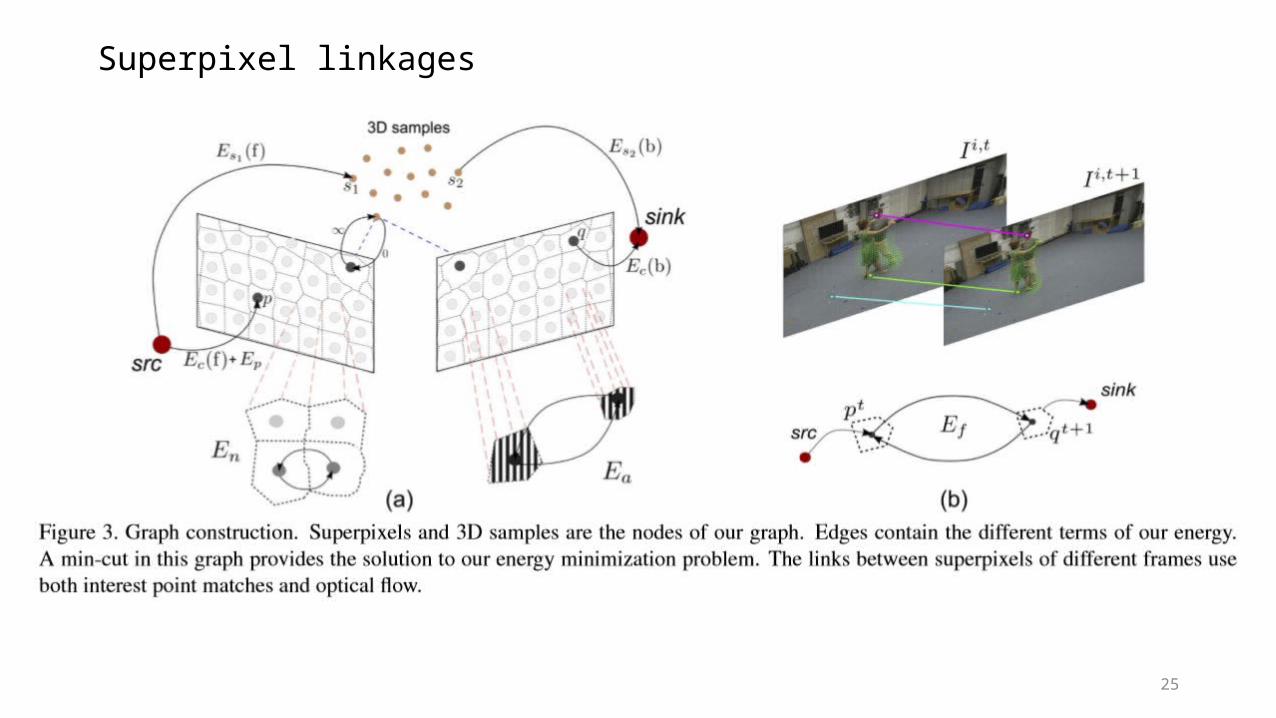
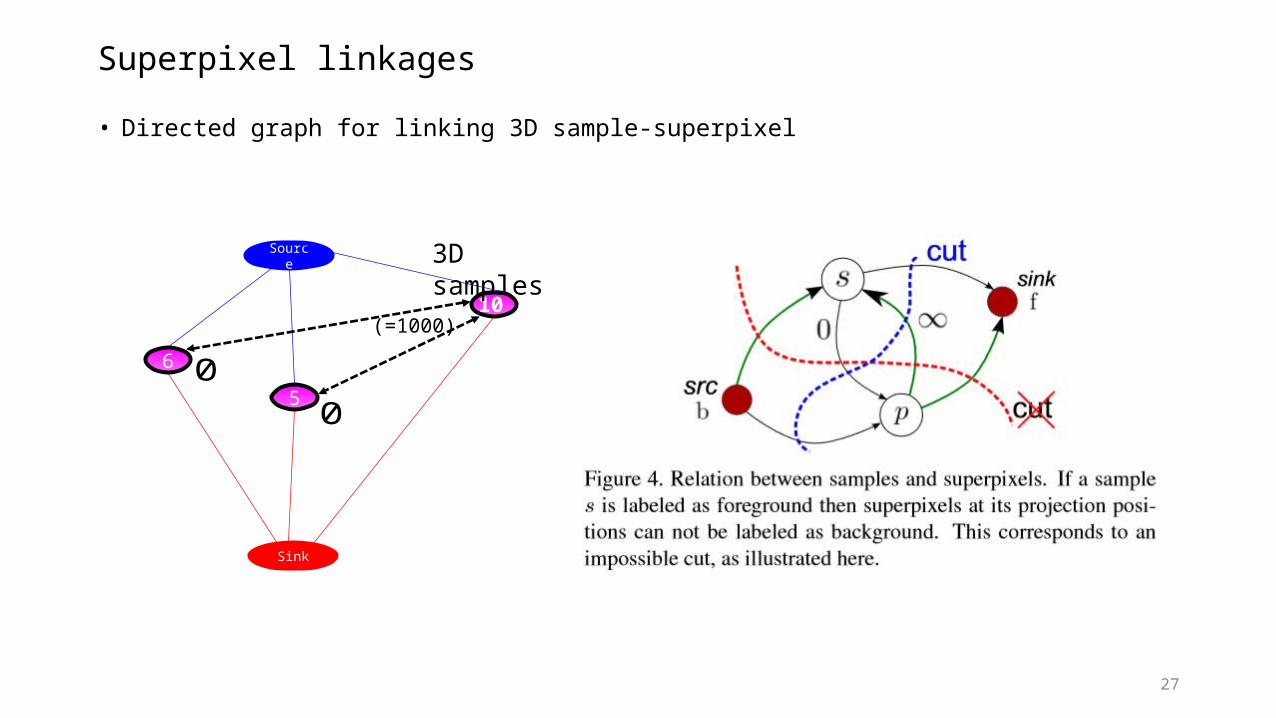
Superpixel linkages

26
• Directed graph for linking 3D sample-superpixel
Superpixel linkages
Sample-superpixel junction term: sharing a coherent geometric model
5
6
4
100
109
110
2
3
1
3D samples
Sink
Source
27
• Directed graph for linking 3D sample-superpixel
Superpixel linkages
5
Source
100
6
3D samples
(=1000)
00
Sink

28
• Linking temporal correspondences
Superpixel linkages
Time consistency term
5
6
4
2
3
1
Temporal motion fieldsFrom KLT, SIFT-flow
Sink
Source

29
Sparse 3D samples with superpixel representation
• Why we need super-pixels (a group of pixels) for segmentation? Superpixels require a fewer number of 3D samples → Efficiently computing quick, rough segmentations.
Colors in a single pixel are not enough information for encoding texture.
• Texture is, by its definition, a vector or a histogram of certain measures (ex. gradient) in a local “patch.”• Gradient magnitude response for 4 scales, Laplacian for 2 scales
• K-means for building texture vocabulary (60-150 words to create superpixel descriptors)
• Similarity of textures are modeled by chi-squared distances between the two normalized histograms in superpixels.
2D plane describ-ing the scene
Center of projection
3D samples in a scene
.Lower resolution
Center of projection
Fewer 3D samples needed
.

30
Implementation issues
• Work-in-progress Initializing a MVOS system Finding reliable matches between frames Sampling and keeping 3D points Making a better appearance model
• Softwares as used in the paper Getting datasets: VisualSFM (by Changchang Wuhttp://ccwu.me/vsfm/) Making superpixels: SLIC (by Radhakrishna Achanta, http://ivrg.epfl.ch/research/superpixels) Finding temporal correspondences: SIFT, SIFT-flow (by Ce Liu, http://people.csail.mit.edu/celiu/SIFTflow/) Solving the constructed MRF: Maxflow (by Yuri Boykov, http://www.csd.uwo.ca/~yuri/)

31
Implementation issues
• Initializing a MVOS system An object should be in the intersection of all the views Camera poses give a sort of bounding box (as an initial prior) → Eliminating about 20-25% pixels If not, 1) 5-10 pixels along the frame boundary can be additionally removed 2) User-given points in a few views might be required as an initial constraint
# of view ↑ = intersecting space tightly ↓

32
Implementation issues
• Finding reliable matches between frames Accurate correspondences in foreground are a few SIFT matches in background clutters are effectively connected between frames. Not every superpixels are temporally linked in the current implementation.
KLT, SIFT-flow are working well on the textured backgrounds
Some blobs (human head) or a few strong points can be linked,but wrong pairs may degrade the overall performance.

33
Implementation issues
• Sampling and keeping 3D samples Low-resolution images, superpixel representation reduce processing time and number of points needed. The visibility of 3D samples also removes unnecessary 3D points and helps right linking across views.
Method Processing Time3D reconstruction (SfS-based) [3] 3 min
3D ray (2D samples along epipolar lines) [4] 1 min
3D sparse samples [1] 5 sec
3D visible points 12 sec
[3] Campbell07bmvc: Automatic 3D object segmentation in multiple views using volumetric graph-cuts [4] Lee11pami: Silhouette segmentation in multiple views [1] Djelouah13iccv: Multi-view object segmentation in space and time (this paper)

34
Implementation issues
• Making a better appearance model Simple magnitudes of gradients are not very powerful with losing directional information. Slightly modified [5] for defining colors and textures.
[5] Shotton07IJCV, “TextonBoost for Image Understanding: Multi-Class Object Recognition and Segmentation by Jointly Modeling Texture, Layout, and Context"
Given: Colors at the k-th pixel in an image,
Take for color at a pixel, 1) the normalized L, a, b in Lab color-space (GMM) 2) Gaussians of R, G, B channel at two different scales for texture at a superpixel, 3) Derivatives of L (dx , dy , dxy , dyx) and derivatives of the Gaussian of L (BoW model) 4) Laplacian of L at three different scales
I1 I2 I3
I4 I5 I6
I7 I8 I9
I1 I2 I3
I4 I5 I6
I7 I8 I9
I1 I2 I3
I4 I5 I6
I7 I8 I9
I1 I2 I3
I4 I5 I6
I7 I8 I9
I1 I2 I3
I4 I5 I6
I7 I8 I9
dx = I5-I6 dy = I5-I8 dxy = I5-I9 dyx = I5-I7 Laplacian of L = 4I5-I2-I4-I6-I8
35
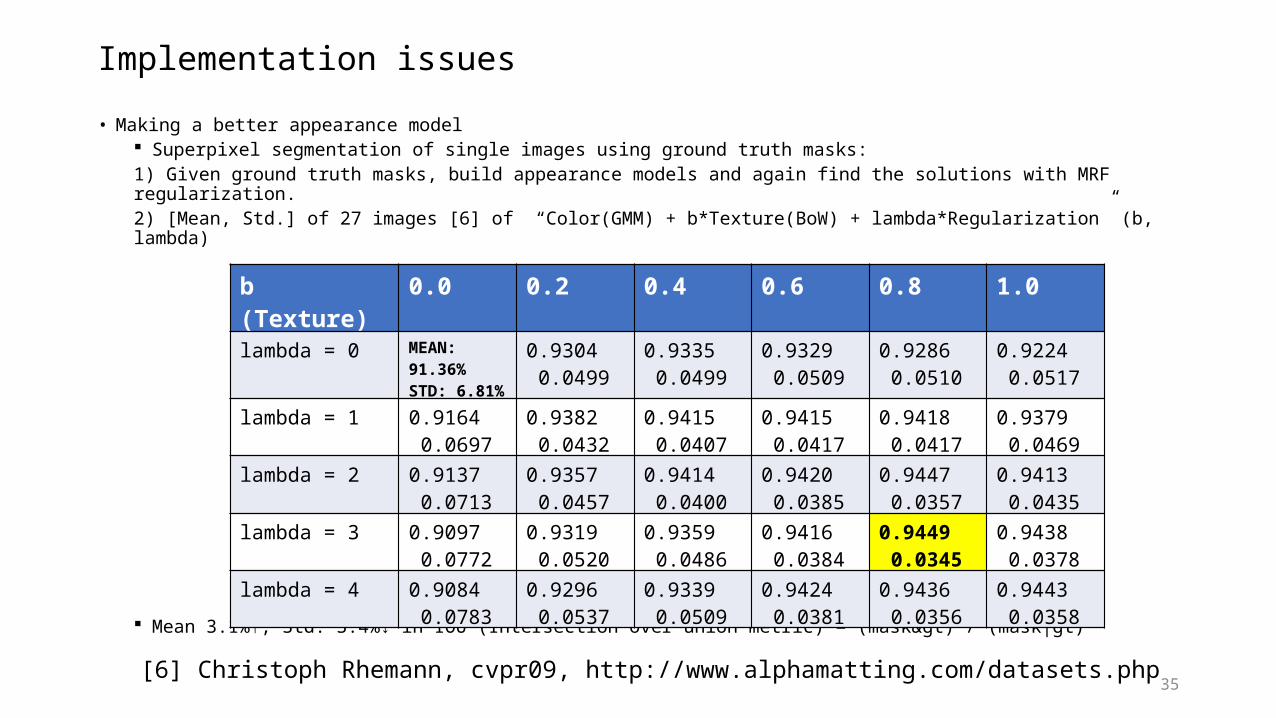
Implementation issues
• Making a better appearance model Superpixel segmentation of single images using ground truth masks:1) Given ground truth masks, build appearance models and again find the solutions with MRF regularization.2) [Mean, Std.] of 27 images [6] of “Color(GMM) + b*Texture(BoW) + lambda*Regularization” (b, lambda)
Mean 3.1%↑, Std. 3.4%↓ in IOU (Intersection over union metric) = (mask>) / (mask|gt)
[6] Christoph Rhemann, cvpr09, http://www.alphamatting.com/datasets.php
b (Texture) 0.0 0.2 0.4 0.6 0.8 1.0lambda = 0 MEAN:
91.36% STD: 6.81%
0.9304 0.0499
0.9335 0.0499
0.9329 0.0509
0.9286 0.0510
0.9224 0.0517
lambda = 1 0.9164 0.0697
0.9382 0.0432
0.9415 0.0407
0.9415 0.0417
0.9418 0.0417
0.9379 0.0469
lambda = 2 0.9137 0.0713
0.9357 0.0457
0.9414 0.0400
0.9420 0.0385
0.9447 0.0357
0.9413 0.0435
lambda = 3 0.9097 0.0772
0.9319 0.0520
0.9359 0.0486
0.9416 0.0384
0.9449 0.0345
0.9438 0.0378
lambda = 4 0.9084 0.0783
0.9296 0.0537
0.9339 0.0509
0.9424 0.0381
0.9436 0.0356
0.9443 0.0358

36
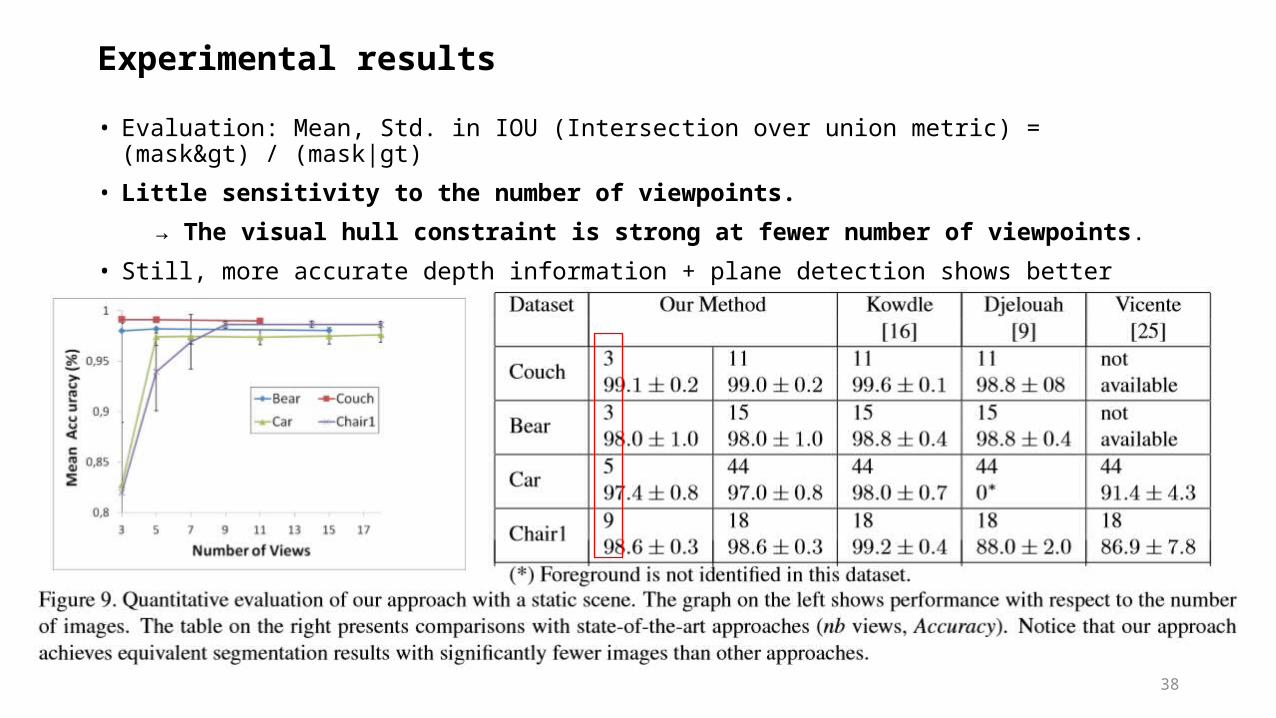
Experimental results
• Implementation issues
- Eliminating about 25% pixels by the initial constraint
- λ1=2, λ2=4 (2D smoothness), λ3=0.05 (3D data term) in the iterative optimization
- less than 10 iterations for the convergence, and each takes only 10sec
• Dataset
- COUCH, BEAR, CAR, CHAIR1 [7] for qualitative and quantitative evaluations
- BUSTE, PLANT [4] for qualitative evaluation
- DANCERS [8], HALF-PIPE [9] for the video segmentation
• Comparisons
- N-tuple color segmentation for multi-view silhouette extraction, Djelouah12eccv [10]
- Multiple view object cosegmentation using appearance and stereo cues, Kowdle12eccv[7]
- Object co-segmentation (without any multi-view constraints, Vicente11cvpr [11]

37
• Good enough
38
Experimental results
• Evaluation: Mean, Std. in IOU (Intersection over union metric) = (mask>) / (mask|gt)
• Little sensitivity to the number of viewpoints.
→ The visual hull constraint is strong at fewer number of viewpoints.
• Still, more accurate depth information + plane detection shows better results with the SfM framework [7]

39
Experimental results
• Evaluation: Mean, Std. in IOU (Intersection over union metric) = (mask>) / (mask|gt)
• Superpixel segmentations in my initial implementation (Not refined at pixel-level)
Name # of Imgs Mean Std. GT (Photo-shop)
1. Lion1 12 94.81% 0.89% Matte
2. Lion2 8 92.30% 1.21% Matte
3. Rabbit 8 92.51% 2.05% Matte
4. Tree 10 90.49% 1.90% Matte
5. Kimono 10 93.92% 2.87% Matte
6. Earth 8 96.66% 1.71% Binary mask
7. Person 8 93.23% 1.75% Binary mask
8. Person (Seq.) 8x3 95.14% 1.19% Binary mask
9. Bear [1] 8 92.48% 2.08% [1]
Avg. 93.5% 1.74% [1] Executable software was not available because they say it is the property of Technicolor, but the author sent me their datasets and ground truths (11/4 ) on which I am still evaluating the current implementation

Experimental results
• 2. Lion2
• 4. Tree
40

41
Experimental results
• 5. Kimono
• 9. Bear [1]

42
Experimental results
• 8. Person (Seq.)
t1:
t2:
t3:

43
Discuss & Conclusion
• An approach to solve the video MVOS in iterated joint graph cuts.
• Efficient superpixel segmentations (with sparse 3D samples) in a short time.
• It works well even at much fewer viewpoints presented.

44
References
[1] Djelouah13iccv: Multi-view object segmentation in space and time (this paper)
[2] Ľubor Ladický’s tutorial at CVPR12, “GraphCut-based Optimisation for Computer Vision”
[3] Campbell07bmvc: Automatic 3D object segmentation in multiple views using volumetric graph-cuts
[4] Lee11pami: Silhouette segmentation in multiple views
[5] Shotton07IJCV, “TextonBoost for Image Understanding: Multi-Class Object Recognition and Segmentation by Jointly Modeling Texture, Layout, and Context“
[6] Christoph Rhemann, cvpr09, http://www.alphamatting.com/datasets.php
[7] Kowdle12eccv, “Multiple view object cosegmentation using appearance and stereo cues.”
[8] Guillemaut11IJCV, “Joint multi-layer segmentation and reconstruction for free-viewpoint video applica-tions.”
[9] Hasler09cvpr, “Markerless motion capture with unsynchronized moving cameras.”
[10] Djelouah12eccv, N-tuple color segmentation for multi-view silhouette extraction,
[11] Vicente11cvpr, “Object co-segmentation”
[12] Marco Alexander Treiber, springer2013, “Optimization for Computer Vision: An Introduction to Core Con-cepts and Methods”
Related Documents











