Chapter 1 Introduction A breach of information security can affect not only a single user’s work but also the economic development of companies, and even the national security of a country. The breach is the focus of research into unauthorised access attacks to a computer, which is the second greatest source of financial loss according to the 2006 CSI/FBI Computer Crime and Security Survey. Attacks on computer systems can be undertaken at the network, system and user levels. Most information security research undertaken in recent years is concerned with system and network- level attacks. However, there is a lack of research on attacks at the user level. User level attacks include the impostor or intruder who takes over from the valid user either at the start of a computer session or during the session. Depending on the risks in a particular environment, a single, initial authentication might be insufficient to guarantee security. It may also be necessary to perform continuous authentication to prevent user substitution after the initial authentication step. The impact of an intruder taking over during a session is the same as any kind of false representation at the beginning 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Chapter 1
IntroductionA breach of information security can affect not only a single user’s work but also the economic development of companies, and even the national security of a country. The breach is the focus of research into unauthorised access attacks to a computer, which is the second greatest source of financial loss according to the 2006 CSI/FBI Computer Crime and Security Survey. Attacks on computer systems can be undertaken at the network, system and user levels.
Most information security research undertaken in recent years is concerned with system and network-level attacks. However, there is a lack of research on attacks at the user level. User level attacks include the impostor or intruder who takes over from the valid user either at the start of a computer session or during the session. Depending on the risks in a particular environment, a single, initial authentication might be insufficient to guarantee security. It may also be necessary to perform continuous authentication to prevent user substitution after the initial authentication step. The impact of an intruder taking over during a session is the same as any kind of false representation at the beginning of a session. Most current computer systems authorise the user at the start of a session and do not detect whether the current user is still the initial authorised user, a substitute user, or an intruder pretending to be a valid user. Therefore, a system that continuously checks the identity of the user throughout the session is necessary. Such a system is called a continuous authentication system.
The majority of existing continuous authentication systems are built around biometrics. These continuous biometric authentication systems (CBAS) are sup-
plied by user traits and characteristics. There are two major forms of biometrics: those based on physiological attributes and those based on behavioural characteristics. The physiological type includes biometrics based on stable body traits, such as fingerprint, face, iris and hand, and are considered to be more
1

robust and secure. However, they are also considered to be more intrusive and expensive and require regular equipment replacement [86]. On the other hand, behavioural biometrics include learned movements such as handwritten signatures, keyboard dynamics (typing), mouse movements, gait and speech. Collecting of these biometrics is less obtrusive and they do not require extra hardware.
Recently, keystroke dynamics has gained popularity as one of the main sources of behavioural biometrics for providing continuous user authentication. Keystroke dynamics is appealing for many reasons:
• It is less obtrusive, since users will be typing on the computer keyboard anyway.
• It does not require extra hardware.
• Keystroke dynamics exist and are available after the authentication step at the start of the computer session.
Analysing typing data has proved to be very useful in distinguishing between users and can be used as a biometric authentication. Various types of analysis have been carried out on user’s typing data, to find features that are representative of user typing behaviour and to detect an impostor or intruder who may take over from the valid user session.
This research extends previous research on improving continuous user authentication systems (that are based on keystroke dynamics) by developing a new flexible technique that authenticates users and automates this technique to continuously authenticate users over the course of a computer session without the need for any predefined user typing model a-priori. Also, the technique introduces new features that represent the user typing behaviour effectively. The motivation for this research is provided in Section 1.1. Outcomes achieved by this research are identified in Section 1.2. and the organisation of this thesis is described in Section 1.3.
2

1.1 MotivationThis thesis focuses on developing automatic analysis techniques for continuous user authentication systems (that are based on keystroke dynamics) with the goal of detecting an impostor or intruder that may take over a valid user session. The main motivation of this research is that we need a flexible system that can authenticate users and must not be dependent on a pre-defined typing model of a user. This research is motivated by:
• the relative absence of research in CBAS utilising by biometric sources in general, and specifically usingS keystroke dynamics.
• the absence of a suitable model that considers a continuous authentication scenario identifying and understanding the characteristics and requirements of each type of CBAS and continuous authentication scenario.
• the need for new feature selection techniques that represent user typing behaviour which guarantee that frequently typed features are selected and inherently reflect user typing behavior.
• the lack of an automated CBAS based on keystroke dynamics, that is low in computational resource requirements and thus is suitable for real time detection.
1.2 Research ObjectivesAccording to the previous section, the objectives that need to be addressed in this thesis are:
1. To develop a generic model for identifying and understanding the characteristics and requirements of each type of CBAS and continuous authentication scenarios.
3

2. To identify optimum features that represent user typing behaviour which guarantee that frequently typed features are selected and inherently reflect user typing behaviour.
3. To discover whether a pre-defined typing model of a user is necessary for successful authentication.
4. To minimise the delay for an automatic CBAS to detect intruders.
1.3 Research QuestionsThe main research questions or problems that will be addressed in this thesis, are two.
1. "What is a suitable model for identifying and understanding the characteristics and requirements of each type of CBAS and continuous authentication scenarios?"
In this thesis we develop a generic model for most continuous authentication scenarios and CBAS. The model is developed based on detection capabilities of both continuous authentication scenarios and CBAS to better identify and understand the characteristics and requirements of each type of scenario and system. This model pursues two goals: the first is to describe the characteristics and attributes of existing CBAS, and the second is to describe the requirements of different continuous authentication scenarios.
From the model that we have developed, we found that the main characteristic of most existing CBAS typically depend on pre-defined user-typing models for authentication. However, in some scenarios and cases, it is impractical or impossible to gain a pre-defined typing model of all users in advance (before detection time). Therefore, the following question will be addressed in this thesis,
2. "Can users be authenticated without depending on a pre-defined typing model of a user? If so, how?"
4

In this thesis we develop a novel continuous authentication mechanism that is based on keystroke dynamics and is not dependent on a pre-defined typing model of a user. It is able to automatically detect the impostor or intruder in real time. The accuracy of CBAS is measured in terms of its detection accuracy rate. The aim is to maximize the detection accuracy: that is the percentage of detection of impostors or intruder that masquerade as genuine users, and minimise the false alarm rate: that is the percentage of genuine users that are identified as impostor or intruder. In order to detect or dis-tinguish between a genuine user and impostor in one computer session, we incorporate distance measure techniques in our approach.
Three further sub-questions that arise from the previous question are:
1. What are the optimum features that are representative of user typing behavior? To address this sub-question, we propose four statistical-based feature selection techniques. The first technique selects the most frequently occurring features. The other three consider different user typing behaviors by selecting: n-graphs that are typed quickly; n-graphs that are typed with consistent time; and n-graphs that have large time variance among users.
2. How accurately can a user-independent threshold determine whether two typing samples in a user session belong to the same user? In order to address this sub-question, we have examined four different variables that influence the accuracy of the threshold which directly manipulate the user samples for authentication: distance type, number of keystrokes, feature type and amount of features.
3. Can we automatically detect an impostor who takes over from a valid user during a computer session and the amount of typing data needed for a system to detect the imposter? To answer this sub-question, we need to first answer the questions 1 and 2, and use the answers to propose the automated system. For automated detection, a sliding window mechanism is used and the optimum size of the window is determined.
5

1.4 Research Outcomes
By addressing the research objectives and research questions, this thesis makes a number of contributions and achievements including:
1. A generic model is proposed for most continuous authentication scenarios and CBAS. The model of CBAS is proposed based on their detection capabilities to better identify and understand the characteristics and requirements of each type of scenario and system. This model pursues two goals: the first is to describe the characteristics and attributes of existing CBAS, and the second is to describe the requirements of different scenarios of CBAS. The research results were published in:
• Al solami, Eesa, Boyd, Colin, Clark, Andrew and Khandoker, Asadul Islam. Continuous biometric authentication : Can it be more practical? In: 12th IEEE International Conference on High Performance Computing and Communications, 1-3 September 2010, Melbourne.
2. We propose four statistical-based feature selection techniques that are representative of user typing behavior. The selected features have high statistical significance for user-representation and also, inherently reflect user typing behavior. The first is simply the most frequently typed n-graphs; it selects a certain number of highly occurring n-graphs. The other three encompass users’ different typing behaviors including:
(a) The quickly-typed n-graph selection technique; it obtains n-graphs that are typed quickly. The technique computes the average of n-graphs representing their usual typing time and then, selects the n-graphs having least typing time.
(b) The time-stability typed n-graph selection technique; it selects the ngraphs that are typed with consistent time. The technique computes the standard deviation of n-graphs representing the variance from their average typing time and then selects the n-graphs having least variance.
6

(c) The time-variant typed n-graph selection technique; it selects the ngraphs that are typed with noticeably different time.The technique computes the standard deviation of n-graphs among all users representing the variance from their average typing time and then, selects the n-graphs having large variance.
The research results were published in:
• Al solami, Eesa, Boyd, Colin, Clark, Andrew and Ahmed, Irfan . User representative feature selection for keystroke dynamics. In Sabrina De Capitani di Vimercati and Pierangela Samarati, editors, International Conference on Network and System Security, Università degli Studi di Milano, Milan, 2011.
3. A proposed user-independent threshold approach that can distinguish a user accurately without needing any predefined user typing model a-priori. The threshold can be fixed across a whole set of users in order to authenticate
1.5. Research Significance users without requiring pre-defined typing model for each user. The research results were published in:
• Al solami, Eesa, Boyd, Colin, Ahmed, Irfan, Nayak, Richi, and Marrington, Andrew. User-independent threshold for continuous user authentication based on keystroke dynamics. The Seventh International Conference on Internet Monitoring and Protection, May 27 - 1 June , 2012, Stuttgart, Germany.
4. The design of an automatic system that is capable of authenticating users based on the user-independent threshold.
7

1.5 Research Significance
This research advanced the knowledge in the area of CBAS by linking the continuous authentication scenarios with the relevant continuous biometric authentication schemes. It identifies and understands the characteristics and requirements of each type of CBAS and continuous authentication scenarios. The research helps to choose the right accuracy measurements for the relevant scenario or situation.
Furthermore, the research established a novel approach based on a user-independent threshold without needing to build user-typing models. The new approach helps to allow building new practical systems in a systemic way that can be used for user authentication and impostor detection during the entire session without the need for any predefined user typing model a-priori. The new system can be applicable in some cases where it is impractical or impossible to gain the predefined typing model of all users in advance (before detection time). Examples are in an open-setting scenario and in an unrestricted environment such as a public location where any user can use the system. For instance, consider a computer that has a guest account in a public location. In this instance, any user can interact with the system. Naturally, no pre-defined typing model for the user would be available prior to the commencement of the session.
Additionally, the implications of this method extend beyond typist authentication; it is generic and might be applied to any biometric source such as mouse movements, gait or speech. Another important implication is that unlike the existing schemes our method can distinguish two unknown user samples and decide whether they are from the same user or not. This might help in forensics investigation applications where you have two different typing samples and you want to decide if they related to one user or two different users.
8

Chapter 2
BackgroundThe goal of this thesis, as described in chapter 1, is to design and develop techniques for detection of the impostor who may take over from the authenticated user during a computer session using keystroke dynamics. This chapter provides an overview of the authentication concept and different types of authentication methods focusing on typist authentication methods. Also, the chapter gives an overview of the current anomaly detection techniques that can be used in our research problem with the emphasis on the related techniques that are used in this thesis.
This chapter is organized as follows. Section 2.1 provides an overview of authentication methods. Section 2.2 discusses in details the current schemes with typist authentication including static typist and continuous typist authentication. Section 2.3 provides an overview of the current anomaly detection techniques. Section 2.4 presents previous research related to work described in chapters 5 to 7. Later in section 2.5, research challenges associated with the analysis of keystroke dynamics for continuous user authentication are discussed. Finally, the chapter is summarized in section 2.6.
2.1 User Authentication in Computer SecurityAuthentication is the process of checking the identity of someone or something. User authentication is a means of identifying the user and verifying that the user is allowed to access some restricted environments or services. Security research has
determined that, for a positive identification, it is preferable that elements from at least two, and preferably all three, factors be verified. The three factors (classes) and some of elements of each factor are:
• the object factors: Something the user has (e.g., ID card, security token, smart card, phone, or cell phone)
9

• the knowledge factors: Something the user knows (e.g., a password, pass phrase, or personal identification number (PIN) and digital signature)
• the inherent factors: Something the user is or does (e.g., fingerprint, retinal pattern, DNA sequence (there are assorted definitions of what is sufficient), signature, face, voice, unique bio-electric signals, or other biometric identifier).
Any authentication system includes several fundamental elements that need to be in place :
• the initiators of activity on a target system, normally a user or a group of users that need to be authenticated.
• distinctive traits or attributes that make a distinction for a particular user or group from others such as knowledge of a secret password
• proprietor or administrator working on the proprieto’r s behalf who is responsible for the system being used and relies on automatic authentication to differentiate authorized users from other users.
• an authentication mechanism to verify the user or group of users of the distinguishing characteristic such as object factors, knowledge factors and inherent factors.
• some privilege allowed when the authentication of the user succeeds by using an access control mechanism, and the same mechanism denies the privilege if authentication of the user fails.
As we mentioned at the start of this section, the third class of the positive identifications factors is the inherent factors. Also, we mentioned that the biometric is based on inherent factors and since our research is focused on biometric authentication, we will limit our discussion only to biometric authentication in the next sub-section.
10

2.1. User Authentication in Computer Security
2.1.1 Biometric AuthenticationBiometrics is the automatic recognition of a person using distinguishing traits. Biometrics can be physical or behavioural. The physical biometric measures a static physical trait that does not change, or changes only slightly, over time. It is related to the shape of the human body like fingerprints, face recognition, hand and palm geometry, and iris recognition. Behavioural biometric measures the characteristics of a person by how they behave or act, like speaker and voice recognition, signature verification, keystroke dynamics, and mouse dynamics.
The advantage of physical biometrics is that it has high accuracy compared to behavioural biometrics. In contrast, physical biometric devices need to be implemented and this leads to some limitations such as high cost of implementation. Behavioural biometrics is one of the popular methods for the continuous authentication of a person, but it produces insufficient accuracy because behaviour is unstable and can change over time.
Identification and verification are the goals of both biometric techniques that involve determining who a person is; biometric verification involves determining if a person is who they say they are. Physical biometric authentication is the most foolproof form of person identity and the hardest to forge or spoof, compared to other traditional authentication methods like user name and password.
The operation of biometric identification or authentication technologies has four stages:
• Capture It is used in the registration phase and also in the identification or verification phases. The system can capture a physical or behavioural sample.
• Extraction Distinctive pattern or features is extracted from the sample by selecting the optimum features that represent the user effectively and then the profile is created for each user.
11

• Comparison The profile is then compared with a new sample in the testing phase.
• Match/Non Match The system then makes a decission if the features on the profile in the database are a match or non-match to the features on the new sample in the testing phase.
Jain et al. presented seven essential properties or features of biometric measure.• Universality Everyone should have the same measure.
• Uniqueness The measure distinguishes each user from all companions which means that no two people should have the same value.
• Permanence The measure should be consistent with time. However, behavioural biometric slightly changes with time as user learns and improve his skills for accomplishing tasks.
• Collectability The process of data collection should be quantitatively measurable.
• Performance The system should be accurate. Identification accuracy for most of the biometric sources is lower than verification accuracy.
• Acceptability The system should be willing to accept the measure by most of the people. However, the measure might be objected to for ethical or privacy reasons by some people.
• Circumvention The measure should not be easily fooled. However, once such knowledge is available, fabrication may be very easy. Therefore, it is important to keep the collected biometric data secure.
In the next section, we describe in detail the typist authentication as one of the behavioural biometric types.
12

2.2 Typist Authentication
Most of the previous features of biometric measure are represented in the keystroke dynamics or typing. Jain et al. mentioned that the typing behaviour has low permanence and performance, and medium collectability, acceptability and circumvention. We think all of the seven biometric measures are represented in keystroke dynamics or using the user’s typing behaviour for authentication. Universality that every user can type on the computer except the disabled person.collectability that the keyboard is able to collect and extract the user’s data even each keyboard has different specifications that may affect quality of the typing data. Uniqueness that each user typing differently from other users. It means that no two people have the same typing behaviour permanence that the user’s typing behaviour are normally consistent over the time and several studies conclude that the keystroke rhythm often has characteristics or features that represent consistent patterns of user typing behavior with time. However, some user’s typing behaviour may slightly change with time as the typing skills of the user can be changed over time. Acceptability that the keyboard is not intrusive instrument which can be acceptable by most of the users. Performance that the accuracy of using keystroke dynamics is normally high for representing the user typing behaviour effectively. Circumvention means that it’s difficult to copy some other user’s typing style. In this thesis we will consider and evaluate some of these measurements of the typing behaviour including universality, uniqueness, permanence and performance.
Typing "as a behavioural biometric for authentication" has been used for several years. By analysing user’s typing patterns, several studies conclude that the keystroke rhythm often has characteristics or features that represent consistent patterns of user typing behavior. Therefore it can be used for user authentication. In chapter 5, we will present extensive analysis in finding the features that can represent user’s typing patterns effectively and then they can be used for user authentication which is discussed later in chapters 6 and 7.
The input to a typist authentication or keystroke dynamics system is a stream of key events and the time that each one occurs. Each event is either a key-press
13

or a key-release. Most typist authentication techniques make use of the time between pairs of events, typically the digraph time or keystroke duration.
• The digraph time is the time interval between the first and the last of n subsequent key-presses. It is sometimes called keystroke latency or inter keystroke interval.
• The keystroke duration is the time between the key-press and key-release for a single key. This is sometimes known as the key-down time, dwell time or hold time.
There are two main types of keystroke analysis, keystroke static and keystroke dynamic (or continuous) analysis. Static keystroke analysis means that the analysis is performed on the same predefined text for all the individuals under observation. Most of the literature on keystroke analysis falls within this category. The intended application of static analysis is at login time, in combination with other traditional authentication methods.
Continuous analysis involves a continuous monitoring of keystrokes typing and is intended to be executed during the entire session, after the initial authentication step. It should be that keystroke analysis performed after the initial authentication step deals with the typing rhythms of whatever is entered by the users. It means that the system should deal with free text. In the next two sub-sections we will give in more details the existing schemes in both types of keystroke dynamics.
2.2.1 Static Typist AuthenticationStatic authentication involves authenticating users through stable methods like user name and password. Behavioural static authentication is a static authentication method that determines how the user acts and behaves with the authentication system; for example, how a user name and password typed. This method is used for additional authentication methods and to overcome some limitations of traditional authentication methods. Keystroke dynamics and mouse dynamics are the main examples of behavioural static authentication.
14

Keystroke dynamics analyse the typing patterns of users. Using keystroke dynamics as an authentication method is derived from handwriting recognition, which analyses hand writing movements. Table 2.1 summarises a few techniques that will be discussed in this section. These techniques are measured by two measurements: FRR when the system incorrectly rejects an access attempt by an authorised user and FAR when the system incorrectly accepts an access attempt by an unauthorised user.
In 1980, Gaines et al. were the first to use keystroke dynamics as an authentication method. They conducted an experiment with six users. Each participant was asked to retype two samples and the gap time between collection of the two samples was four months period. Each sample contained three paragraphs with varying lengths. They used specific digraphs as a feature that occurred during the paragraphs by analysing and collecting the keystroke latency timing. The most frequent five digraphs that appeared as distinguished features were in, io, no, on, ul. Then, they compared latencies between two sessions to see whether the average and mean values were the same at both sessions. The limitation of this experiment was that the data sample was too small to get reliable results. Also, there was no automated classification algorithm used between the participants but the results were claimed to be very encouraging.
Umphress and Williams asked 17 participants to type two samples. One typing sample used for training included about 1400 characters and a second sample used for testing included about 300 characters. They represent the features by
Reference FAR(%)
FRR( % )
Sample Content Method
Gaines et al.[29]
0.00 0.00 6000 characters Manual
Umphress andWilliams[100]
12.00 6.00 1400 characters for training and 300
characters for testing
Statistical
Leggett andWilliams[57]
5.5 5 1000 words Manual
15

Joyce and Gupta [46]
16.36 0.25 user name, a password and the last names
eight times for training and five times for
testing
Statistical
Bleha et al.[11]
8.1 2.80 Name and fixed phrase Bayes
Brown andRogers [12]
21.2 12.0 First and last names Neural network
Obaidat andSadoun[69, 70]
0.00 0.00 User names 225 times Neural network
Furnell et al.[28]
26 15 4400 characters Statistical
Bergadano et al. [10]
0.00 0.14 683 characters Nearest Neighbour
Sang et al.[88]
0.2 0.1 alphabetic password and numeric password
SVMs
Table 2.1: The accuracy of statistic typist authentication techniques grouping the characters in terms of words and then they calculated the time of the first 6 digraphs for each word. The classifier was based on statistical techniques by setting the condition that each digraph must fall within 0.5 standard deviations of its mean to be considered valid. Their system obtained a FRR of 12% and an FAR of 6 %.
Later, an experiment was conducted by Leggett and Williams inviting 17 programmers to type approximately 1000 words, which was similar to the Gaines et al. experiment, but there was a condition of accepting the user if more than 60% of the comparisons were valid. The results demonstrated that the FAR was 5.5% and the FRR was 5 %.
Joyce and Gupta recorded the keystroke during the log-in process by typing the user name, a password, and the last names of users eight times. 33 users participated in this experiment and they typed eight times to build historical profile, and five times for testing. The classifier was based on a statistical
16

approach. It requires that the digraph fall with 1.5 standard deviations of its reference mean to belong to a valid user. The result demonstrated that the FAR was 16.36% and the FRR was 0.25% .
Bleha et al. used the same approach that was proposed by Joyce and Gupta and they used digraph latencies as a feature to distinguish between samples of legal users and intruders. The experiment invited 14 participants as valid users and 25 as impostor users to create their profiles. The classifier method was based on Bayes classifier using the digraph times. Results show that the FAR was 8.1% and FRR was 2.8 %.
Brown and Rogers are the first to use the keystroke duration as a feature to distinguish between the samples of authenticated users and impostors. The experiment divided the participants into two groups (21 in the first group and 25 in the second group), and they were asked to type their first and last names. The neural network method was applied in this experiment to classify the data and results show a 0.0% false negative rate and 12.0% FRR in the first group and 21.2% FAR in the second group.
Furnell et al. used the digraph latencies as representative feature. Thirty users were invited to type the same text of 2200 characters twice, as a measure to build their profiles. For intruder profiles, the users were asked to type two different texts of 574 and 389 characters. Digraph latencies were computed by statistical analysis, and the results show that in the first 40 keystrokes of the testing sample, the FRR was 15% and the FAR were 26 %.
Obaidat and Sadoun used the keystroke duration and latency together as a feature to distinguish between the samples of authenticated users and impostors. The experiment invited 15 users to type their names 225 times each day over a period of eight weeks to build their profiles. Neural network was the classifier to classify the user samples. The results showed that both FAR and FRR were zero.
Bergadano et al. used single text of 683 characters for 154 participants and they considered the type errors and the intrinsic variability of typing as a feature that can distinguish users. They used the degree of disorder in trigraph latencies as a measure for dissimilarity metric and statistical method for classification to compute the average differences between the units in the array. The results show
17

that the FAR was 4.0% and FRR was 0.01%. This method in the experiment is suitable for the authentication of users at log-in, but it is not applicable for continuous authentication because it requires predefined data.
Sang et al. conducted the same experiment as Obaidat and Sadoun [69 , 70](duration and latency together) but with a different technique. The technique used support vector machine (SVM) to classify ten user profiles, and the results demonstrated that this technique is the best for classifying the data of user profiles, where more accurate results of 0.02% FAR and 0.1% FRR.
All of the previous techniques show that the static typist authentication had great success that can be used to distinguish different users effictively. It shows that the static typist authentication has different features that can be used to present the user typing behaviour. These features can be used for user authentication. In the next section, we will see whether the continuous typist authentication has different features that can be used effectively for user authentication similar to the static typist authentication .
2.2.2 Continuous Typist AuthenticationContinuous typist authentication using dynamic or free text applies when users are free to type whatever they want and keystroke analysis is performed on the available information. Continuous typist authentication using ‘dynamic’ or ‘free text’ is much closer to a real world situation than using static text. The literature on keystroke analysis of free text is pretty limited. This section describes most continuous typist authentication techniques. They are summarised in Table 2.2.
Monrose and Rubin [64] conducted an experiment on 31 users by collecting typ-
Reference FAR(%)
FRR(%)
Accuracy( % )
Sample content Method
Monrose and Rubin
[64]
- - 23 Few predefined and free sentences
Euclidean distance and
weighted probability
18

Dowland et al. [22]
- - 50 Normal activity on computers runing
WindowsNT
Statistical method
Dowland et al.[21]
- - 60 Normal activity on specific applications
such as Word
Statistical method
Bergadano et al. [9]
0 5.36 - Two different texts, each
300 charcters long
Distance measure
Nisenson et al. [68]
1.13 5.25 - Task response& each user typed
2551 ± 1866 keystrokes.
LZ78
Gunetti and
Picardi[32]
3.17 0.03 - Artificial emails &each user typed 15
samples&eachsample contains 700 to 900
keystrokes
Nearest Neighbour
Hu et al.[40]
3.17 0.03 - 19 users &each one provide5 typing data "free
text"
k-nearestneighbor
Bertacchini et al.[8]
- - - 62 different users typed 66 samples based on spanish
language
k-medoids
Hempstalk et al. [38]
- - - Real world emails150 email samples& 607 email samples
Gaussian density
estimationJanakirama
n and Sim[44]
- - - 22 users collected their data based on their daily activity
work of using email,
Based on a common list
of fixed strings
19

rangedfrom 30,000
keystrokes to 2 million keystrokes
Table 2.2: The accuracy of continuous typist authentication techniques ing samples in about 7 weeks. Users ran the experiment from their own computers at their convenience. They had to type predefined sentences from a list of available phrases and/or to enter a few sentences not predefined and completely free. To build a profile for each user, it is unknown how many characters the user should type. They consider the features that represent the user behaviour by calculating the mean latency and standard deviation of digraphs as well as the mean duration and standard deviation of keystrokes. For filtering the user profile, they compared each latency and duration with its respective mean and any values greater than standard deviations above the mean (that is, outliers) were removed from the user profile. Testing samples are manipulated in the same way by removing outliers and so turned into testing profiles to be compared to the reference profiles using three different distance measures:
• Euclidean distance
• Euclidean distance with calculation of the mean, and
• standard deviation time of latency and duration of digraph.
The last experiment used Euclidean distance and added weights to digraphs. The FRR is about 23% of correct classification in the best case (that is, using the weighted probability measure).
Dowland et al. applied different data mining algorithms and statistical techniques on four users, with data samples to distinguish between authenticated users and imposters. The users were observed for some weeks during their normal activity on computers using Windows NT. It means that there was no constraint in the user to use the computer and the user is free to use the computer in any way. Users’ profiles are decided to have features using the mean and standard deviation of digraph latency and only digraphs typed less frequently by all the
20

users in all samples are considered. To filter the user profile, there were two thresholds: any times less than 40ms or greater than 750ms were discarded. The results demonstrated a 50% correct classification rate. The same experiment was refined by Dowland et al. It included some application information for Power Point, Internet Explorer, Word, and Messenger. The experiment collected the data of eight users over three months and the results demonstrated that the FRR was 40 %.
Bergadano et al. calculated a new measure which was the time between the depression of the first key and the depression of the second key for each two characters in a sequence. Forty users were invited to build historical profiles by typing two different samples of text. Each text contained 300 characters and the participants were asked to type 137 samples. 90 new users were invited to build testing files by typing the second sample only. The mean distance was computed between unknown instance sample and each sample of a user’s profile and the mean distance was also computed between unknown instance sample and each user’s profile to classify unknown instance sample. The authors applied a supervised learning scheme for improving the false negative rate to compute the mean and standard deviation between every sample in user’s profile and every sample in a different user profile. Results demonstrated that the FRR was reduced to 5.36 % and the FAR was zero.
A longer experiment done by Dowland and Furnell collected about 3.5 million keystrokes from 35 users during three months. The sample content that were collected from users is based on the global logging. Global logging includes all possible typists’ behaviour.
Nisenson et al. collected free text samples from five users as normal users and 30 users behaving as attackers. The sample content was either an open answer to a question, copy-typing, or a block of free typing. The time differentials were calculated from typing data and used as a user feature. Each normal user typed between 2551 and 1866 keystrokes. Attackers were asked to type two open ended questions and were required to type the specific sentence, “To be or not to be. That is the question.” Also, they were allowed to type in free text between 660 to 597 keystrokes. Then, they trained these features on the LZ78-based classifier
21

algorithm. The accuracy of the system was attained with FRR 5.25% and FAR 1.13 %.
Gunetti and Picardi, used free text samples in their experiment by inviting 205 participants and they used the same technique that Bergadano et al. proposed in their work based on static typist authentication, discussed in the previous section. They created profiles for each user based on their typing characteristics in free text. The users performed a series of experiments using the degree of disorder to measure the distance between the test sample to reference samples from every other user in their database. The samples are transformed into a list of n graphs, sorted by their average times. To classify a new sample it is compared with each existing sample in terms of both relative and absolute timing. Only digraphs that appear in both reference and unknown samples are used for classification. The Gunetti study achieves very high accuracy when there are many registered users.
Many researchers have used clustering algorithms in order to authenticate users. Hu et al. , applied similar technique to that was proposed by Gunetti and Picardi . 19 users participated in this experiment with each of them providing five typing samples. Another 17 users provided 27 typing samples which were used as impostor data. Typing environment conditions were not controlled in this data collection. They proposed k-nearest neighbor classification algorithm which an input needs only to be authenticated against limited user profiles within a cluster. The main difference between the proposed algorithm by Hu et al. and the method of Gunetti and Picardi (GP method) is that the authentication process of the proposed algorithm is within a cluster while the GP method needs to go through the entire database. Also for a user profile X, the k-nearest neighbor classification algorithm uses only its representative profile in the authentication process while the GP method needs to compare with every sample of each user profile. They used the clustering algorithm to make a cluster for each user. First, each user provides several training samples and then the profile of each user is used for building. A representative user profile is built by averaging all such vectors from all training samples provided. Second, the k-nearest neighbour method is applied to cluster the representative profiles based on the distance measure. Finally, the authentication algorithm for new text is executed only on the user’s corresponding cluster. The success of the proposed algorithm depends upon the
22

threshold value, which is dependent on the registered users in the system. Moreover, the specific use of the proposed algorithm in classifying and authenticating only users who are already registered in the system makes the system less effective when new users interact with the system. The experiment shows that the proposed k-nearest neighbor classification algorithm can achieve the same level of FAR and FRR performance as the Gunetti and Picardi (PG) approach. However, the proposed approach has improved the authentication efficiency up to 66.7% compared to Gunetti and Picardi (PG) method.
Bertacchini et al., ran their experiment on one dataset. This dataset contains keystroke data of 66 labeled users based on Spanish language. The dataset contains a total of 66 samples, one sample per typing session, representing 62 different users. They also used clustering to classify users by making a cluster for each user. The number of clusters is based on the number of the users in the dataset. The proposed algorithm is Partitioning Around Medoids (PAM) which is an implementation of k-medoids, first proposed by Kaufman and Rousseeuw. It is partitioning technique that clusters the data set of n objects into k clusters known a-priori. It has the advantage over k-means that it does not need a definition of mean, as it works on dissimilarities; for this reason, any arbitrary measure distance can be used. It is also more robust to noise and outliers as compared to k-means because it minimises a sum of dissimilarities instead of a sum of squared Euclidean distances. So, the proposed approach worked successfully on the registered users in the system but it failed were new users are added to the system.
Hempstalk et al. collected typing input from real-world emails. They collected about 3000 emails over three months and then they processed into two final datasets. It included 150 email samples and 607 email samples respectively. Then, they created profiles only for valid users based on their typing characteristics in free text. They performed a series of experiments using the Gaussian density estimation techniques by applying and extending an existing classification algorithm to the one class classification problem that describes only the valid user typing data. Hempstalk applied a density estimator algorithm in order to generate a representative density for the valid user’s data in the training
23
phase, and then combined the predictions of the representative density of the valid user and the class probability model for predicting the new test cases.
Janakiraman and Sim, replicated the work of Gunetti and Picardi. They conducted the same experiment again but they did not avoid using the usual digraph and trigraph latencies directly as features. 22 users were invited over two weeks to conduct an experiment. Some of the users are skilled were typists and could type without looking at the keyboard. Other users are unskilled typists, but are still familiar with the keyboard as they have used it for many years. The users came from different backgrounds including Chinese, Indian or European origin, and all are fluent in English. Keystrokes were logged as users went about their daily activity work of using email, surfing the web, creating documents, and so on. The collected data from users ranged from 30,000 keystrokes to 2 million keystrokes. In total 9.5 million keystrokes were recorded for all users. Howevere, they did not report their findings in their paper.
One of the main limitation of Gunetti and Picardi approach is the high verification error rate which cause scalability issue. Gunetti and Picardi proposed a classical n-graph-based keystroke verification method (GP method), which can achieve a low False Acceptance Rate (FAR). However, the GP method suffers from a high False Rejection Rate (FRR) and a severe scalability issue. Thus, GP is not a feasible solution for some applications such as computing cloud application where scalability is a big issue. To overcome GP’s shortcomings, Xi et al. devloped the latest keystroke dynamic scheme for user vervication to overcome GP’s shortcomings. To reduce high FRR, they designed a new correlation measure using n-graph equivalent feature (nGdv) that enables more accurate recognition for genuine users. Moreover, correlation-based hierarchical clustering is proposed to address the scalability issue. The experimental results show that the nGdv-C can produce much lower FRR while achieving almost the same level of FAR as that of the GP method.
All of the previous techniques shows that the continuous typist authentication had great success similarly to the static typist authentication that can be used to distinguish users effectively. It shows that we can obtain some features from the typing data that can be used to represent the user typing behaviour. These features
24
can be used for successful user authentication. Howevere, the extracted features from the typing data of continous typist authentication do not guarantee features with strong statistical significance and also, do not inherently incorporate user typing behavior. Furthermore, one of the main limiatation of the previous continuous typist authentication technuiques is requiring the users’ data to be available in advance. In principle, the requirement of collecting the user’s data in advance restricts the systems to authenticate only known users whose typing samples are modelled. In some cases, it is impractical or impossible to gain the pre-defined typing model of all users in advance (before detection time). It should be possible to distinguish users without having pre-defined typing model which lead the system to be more practical.
In the next section, we present some related pioneering works in both supervised and unsupervised typist authentication. Supervised and unsupervised methods will help to link the existing continuous typist authentication schemes with the relevant setting environment or scenario.
However, open-setting environment might be conducted when the profile of the impostor and valid users are not available such as computer based TOEFL exam scenario.
2.3 Summary
In this chapter, past and current research into the analysis of user’s typing data or keystroke dynamics with emphasis on the continuous typist authentication schemes is presented. The chapter also presents a discussion of the current anomaly detection techniques. Two types of data analysis techniques have been widely used in keystroke dynamics, namely data mining and statistical analysis. Research in applying these techniques to keystroke dynamics has been reviewed. In addition, challenges of the current research are also presented. In the next chapter, we present our first contribution by proposing a generic model which will be the primary object of this thesis. The model can help in identifying and understanding the characteristics and requirements of each type of continuous typist authentication and continuous authentication scenarios.
25

Chapter 3
Model for Continuous Biometric Authentication
Chapter 2 provided an overview of current research into the continuous authentication based on biometrics with an emphasis on keystroke dynamics. It also identified the key research challenges and requirements regarding analysis of user typing data. In this chapter, we propose a new model that identifies and explains the characteristics and requirements of each type of continuous authentication system and continuous authentication scenario. The chapter presents the primary object of this thesis, to describe the characteristics and attributes of existing continuous authentication systems, and the second objective to describe the requirements of different continuous authentication scenarios. In particular, the chapter addresses Research Question 1 (outlined in chapter 1):
"What is the suitable model for identifying and understanding the characteristics and requirements of each type of CAS and continuous authentication scenarios?"
The chapter is organized as follows. The next section presents the background on CBAS and the motivation of the chapter. In Section 3.2, we present the continuous biometric authentication system CBAS model in order to describe the characteristics and attributes of existing CBAS, and to describe the requirements of different scenarios of CBAS. Following this in Section 3.3, we give some examples of continous authentication scenarios with different requirments and we show how these scenarios are different. In section 3.4, we relate the existing schemes to the proposed model. In Section 3.5, we describe a new class for CBAS without utilising training data. The final Section 3.6 summarizes the chapter.
3.1 Continuous Biometric Authentication System ( CBAS )
The majority of existing CBAS are built around the biometrics supplied by user traits and characteristics. There has been an ongoing pursuit of improving CBAS. Recently, efforts have been made to improve CBAS by either embedding intrusion detection into the CBAS itself or by adding a new biometric source tailored to the
26

detection system. However, these attempts do not consider the different limitations that might affect the practicability of existing CBAS in real world applications and continuous authentication scenarios. To our knowledge, there is no CBAS deployed in real world applications; it seems reasonable to assume that this is because existing systems lack practicality. There are a number of issues associated with existing schemes which may prevent CBAS from being applied in real world applications. These limitations include:
• the requirement for the training data to be available in advance;
• the need for a large size training data;
• variability of the behaviour biometric between the training and testing data; and
• variability of the behaviour biometric of the user from one context to another. For example, typing in email and typing in computer based exam.
There are several scenarios and situations that require the application of a continuous user authentication approach, but these scenarios cover a variety of possible situations and have different characteristics and requirements. The current CBAS may not consider the differences of requirements and characteristics. Thus each scheme might be applied to the wrong domain or scenario because the previous CBAS might not have chosen accurate measurements for the relevant scenario or situation and may not consider the type of setting environment or situation. Additionally, the time taken to detect the intruder might be too long.
For example, choosing the right source of biometric with the relevant application or system may not be considered by the existing CBAS. In other words, onemight rely on the keystroke dynamics as an input for providing continuous authentication, while, most actions of a user may be based on mouse dynamics. Another example, selecting a suitable algorithm with the relevant setting environment or situation might not be considered such as where a CBAS might use multi-class classification algorithm in an open setting environment. Multi-class classification requires the data to be available from both valid users and impostors before the profile of normal biometric data is generated but it is impossible to collect the data in advance from the possible impostors in open-setting environment. In an open-setting environment the
27

profile of the impostor is not available. The profile of valid users may or may not be available. In a closed-setting environment the profiles of all users, including a possible impostor, are available. This could be one of the main problems affecting existing schemes in meeting the European standards for acceptable commercial biometrics. That is, a false acceptance rate (FAR) of less than 0.001% and false reject rate (FRR) of less than 1% is necessary
A generic model is proposed in this thesis that attempts to define most continuous authentication (CA) scenarios and CBAS. The model of CBAS is proposed based on detection capabilities of continuous authentication (CA) scenarios and CBAS to better identify and understand the characteristics and requirements of each type of scenario and system. This model pursues two goals: the first is to describe the characteristics and attributes of existing CBAS and the second is to describe the requirements of different scenarios that a CBAS can be represented with. Also, we identify the main issues and limitations of existing CBAS, observing that all of the issues are related to the training data. Finally, we consider a new application for CBAS without requiring any training data either from intruders or from valid users in order to make the CBAS more practical.
3.2 CBAS Model
To date, CBAS have only been described by the techniques and algorithms that are used to detect an impostor and to decide whether or not to raise an alarm. Therefore, there is a need to build a generic model to ensure the identification of common characteristics and attributes of CBASs. The traditional authentication mechanisms, such as user name and password, are used to verify the user only at the start of a session and do not detect throughout the session whether or not the current user is still the initial authorised user. The CBAS is designed to overcome this limitation by continuously checking the identity of the user throughout the session based on physical traits or behavioral characteristics of the user. A CBAS can be thought of as a kind of intrusion detection system (IDS). An IDS monitors a series of events, with the aim of detecting unauthorised activities. In the case of the CBAS, the unauthorised activity is a person acting as an imposter by taking over the authenticated session of another (valid) user.
28

Figure 3.1: Continuous Biometric Authentication System Model
The CBAS attacks include imposters or intruders that take over from the valid user during the session. However, the IDS attacks include both external intrusion attacks caused by an outsider and misuse attacks caused by an insider. Most IDS operate at the system or network level, and very little research performed by the intrusion detection community has focused on monitoring user-level events; notable exceptions include the recent work by Killourhy and Maxion. In this chapter, we use the more specific term, CBAS, to describe a scheme which aims to detect imposters through the continuous monitoring of a user session.
There are six basic components to describe a typical CBAS (see Figure 3.1)
29
User
Sensor FeatureExtractions
Detector Response Unit
Administrator
passive response
Active response
Data Base User has existing Profile
User does not have existing profile
Type of setting (environment)
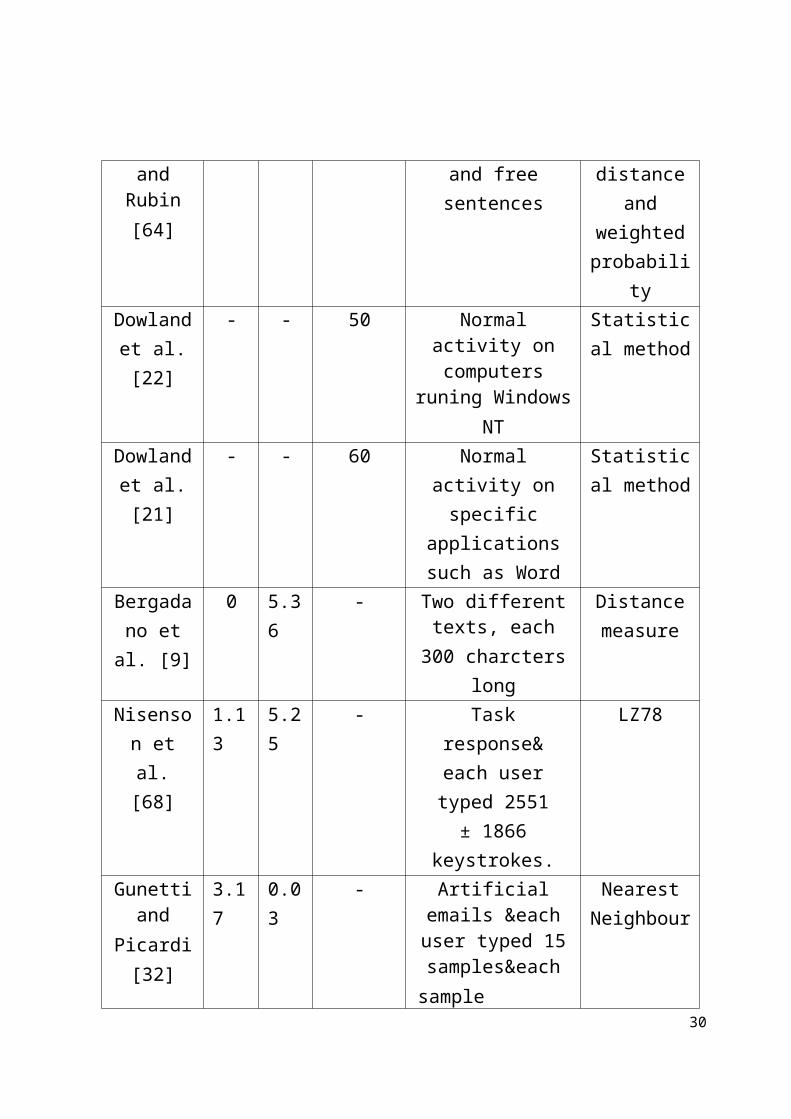
1. Subjects - initiators of activity on a target system, normally users.
2. Sensor - a device that collects biometric data from the user, either physically or behaviourally, and translates it into a signal that can be read by an observer or an instrument such as keyboard or camera.
3. Feature extractions - a process of selecting optimum features that model and represent the user actions.
4. Detector - compares profiles by analysing the biometric data and then performs measurements for errors that may detect the intruder. In order to determine the accuracy of the detector there are two popular measurements of CBAS: false acceptance rate (FAR) and false rejection rate ( FRR ).
5. Biometric database - storage of the biometric data and user actions are by profiles and this process might happen during the registration phase. The CBAS will use the database for comparison with the live data in the verification phase.
6. Response unit - taking an appropriate response for detecting the intruder or impostor. The CBAS has two popular types of responses either passive response or active response.
An additional aspect of the CBAS model is the type of setting (or scenario). A continuous authentication scenario might be conducted either in an open-setting environment or a closed setting environment. We defined the type of setting environments in thSSSe previous chapter section 2.3. Each of the six CBAS basic components is described in detail below.
3.2.1 SubjectsSubjects are initiators of activity on a target system, normally users, either authorised or unauthorised [20]. An authorised user is allowed to access a system by providing some form of identity and credentials. Also, they are allowed to deal with objects of the system during the session. The authorised user can be known to the system where
30
the biometric data of that user is registered in the system as a historical profile. On the other hand, the authorised user can be unknown to the system where there is no biometric data of that user registered in the system in advance. Unauthorised user can be the second type of user who does not have distinctive characteristics or recognition factors and would try to claim the identity of an authenticated user. The unauthorised user can be an adversary user acting maliciously towards the valid user or it can be a colluder invited by the valid user to complete an action on behalf of the user. In the first case of the non-authorised user, the victim who suffers from the attack would be the end user, but in the second case the victim is typically the system operator or the owner of the application.
3.2.2 SensorThe sensor is a device that collects biometric data from the user, either physically or behaviourally, and translates it into a signal that can be read by an observer or an instrument such as keyboard or camera. The system may have several sensors. Sensors in this model transform raw biometric data into a form suitable for further analysis by the detector. The location of the sensor module for collecting data which is the process of acquiring and preparing biometric data, can be centralised or distributed. The data can be collected from many different sources in a distributed fashion or it can be collected from a single point using the centralised approach. The aim of data collection is to obtain biometric data to keep on record, and to make further analysis of that data. The quality and nature of the raw data is significantly affected when the sensor used during registration and authentication is different [87]. The sensors are based on one or more physical traits or behavioral characteristics [55] for uniquely recognising humans. The physical type includes biometrics based on stable body traits, such as fingerprint, face, iris, and hand. The behavioural type includes learned movements such as handwritten signature, keyboard dynamics (typing), mouse movements, gait, and speech. The feature set is sensitive to several factors including:
1. Change in the sensor used for acquiring the raw data between registration and verification time. For example, using an optical sensor during registration and a solid state capacitive sensor during verification in a fingerprint system.
31

2. Variations in the environment. Very cold weather might affect the typing speed of the user, while dry weather resulting in faint fingerprints);
3. Improper user interaction such as incorrect facial pose during image acquisition, or drooping eye-lids in an iris system.
4. Temporary alterations to the biometric trait or characteristics itself ( e.g., cuts/scars on fingerprints, or injury in some fingers effecting the typing speed on a keyboard).
The sensors are based upon one or more physical traits or behavioral characteristics for uniquely recognizing humans. Behavioural biometric can be obtained directly from the user by keyboard and mouse or by indirect profiling of the operating system and its applications such as call-stack data operations. Each of the physical and behavioural sources have it’s own advantages and disadvantages. The physical type includes biometrics based on stable body traits, such as fingerprint, face, iris, and hand. The behavioural type includes learned movements such as handwritten signature, keyboard dynamics (typing), mouse movements, gait and speech. The disadvantages of the physical type are that it’s considered an intrusive interruption method and the cost of equipment for implementing physical biometric systems is very high. Other disadvantages of physical biometric methods are that they suffer from practical attacks [99] and require regular replacement [86]. However, it refers to any automatically measurable, robust, and distinctive physical characteristic or personal trait that can be used to identify an individual or verify the claimed identity of an individual. It is the automatic recognition of a person using distinguishing traits.
In contrast, behavioural biometrics can be made totally unobtrusive to the extent that the user is not even aware that they are being authenticated and avoid the use of any additional equipment. However, they are considered to be less accurate than physiological biometrics. Each one of these sources of biometrics is suitable for specific applications or scenarios.
3.2.3 Feature extractionsFeature extraction involves simplifying the amount of biometric data required to describe a large set of data accurately. Analysis with a huge number of variables requires a huge amount of memory and computation power or a classification
32

algorithm. Feature extractions is the method of choosing a subset of appropriate features from the biometric data for building robust learning models that can model or represent the user.
Since each biometric source has different characteristics and attributes, it requires selection of suitable feature selection technique with the relevant biometric source. In this component, we selected features that are user representative ( or reflecting a model of a user) based on the type of biometric sources. For each biometric source a representative features are generated and recorded as a requirement for the input of the next component ( detector ).
3.2.4 DetectorThe detector performs error detection that may lead to intruder detection, which is based on the biometric data gathered by the CBA sensor. The detector software might be implemented in the client computer either the system and does not known about the application or in the application by adding some functionality in that application. Also, the detection algorithm might be run in the server computer. The CBA detector is generally the most complex component of the CBAS. The detector operates in two modes: registration and identification/verification mode. The operation of each mode consists of the following three stages: in the first stage, a data capturing process is conducted by a sensor module, which captures all biometric data, and converts all of the raw data into a set of more organised and meaningful data. The data directly passes to this phase for data processing where the feature extraction is conducted. Then, these features build up all data features received from the previous stage over a pre-defined session period, and perform a number of algorithms on the data to produce the Mouse Dynamics Signature (MDS), Finger Print Signature (FPS), and Keystroke Dynamics Signature (KDS) for the user being monitored. Finally, the generated signature will directly pass to a database and be stored as a reference signature for the enrolled user. The detector stage in this mode is the verification process after the signature is calculated during the data processing stage. The sensor module is compared to the reference signature of the legitimate user.
There are two major families of algorithms of detection in the surveyed systems based on the historical profile of all the users or based on only the valid user profile. The first method is a type of machine learning algorithm that requires biometric data
33

about all users, either valid or possible impostors, to build a model for prediction. There are different algorithms that follow this method such as nearest neighbor, linear classification and Euclidean distance, which was proposed by Gunetti et. al. This type of classification algorithm is suitable for the closed setting and restricted environment also, the environment should be under access control to stop any user not registered in the system. The system will perform well when there are many registered users and fail completely when there is only one.
Another method of algorithm detection is a type of machine learning algorithm that requires only biometric data about a single target class in order to build a model that can be used for prediction. This type of classification algorithm is trying to distinguish one class of object from all other possible objects, by learning from a training set containing only the objects of that class. The method is different from, and more difficult than, the first method of classification problem, which tries to distinguish between two or more classes with the training set containing objects from all of the classes and this class is suitable for the open setting environment where any user can use the system.
The previous algorithms are used for decision-making in order to detect the attacker either in on-line or off-line mode. The online mode can be identified as a real-time (or near real-time) detection and off-line as a retrospective (or archival) detection. The online detection is necessary for detecting the intruder in real time or near real time when the system realizes any change of biometric data of the authenticated user. The surveyed systems in this group can also be run in the retrospective (or archival) mode. The off-line mode is used when it is unnecessary for detecting the intruder in real time.
The location of the previous data processing can be centralised within a particular location and/or group, or distributed on multiple computers. Data processing is a term used to describe a process of transforming the raw biometric data to suitable data, summarising and analysing the biometric data.
The accuracy of the correctness of a single measurement will be set in this component. Accuracy is determined by comparing the measurement against the true or accepted value. False acceptance rate, or FAR, measures the accuracy of the
34

CBAS. It measures the likelihood of whether the biometric security system will incorrectly accept an access attempt by an unauthorised user. A system’s FAR is typically stated as the ratio of the number of false acceptances divided by the number of identification attempts. False rejection rate, or FRR, is the second measure of likelihood a biometric security system will incorrectly reject an access attempt by an authorised user. A system’s FRR is typically stated as the ratio of the number of false rejections divided by the number of identification attempts.
3.2.5 Biometric databaseThe biometric database is a repository containing the profiles of users as historical data during the registration phase. The profiles can have the trait information of the users or the characteristics of their behaviour. This storage is for the registered users who have training data, and the system will use the training results for comparison in the verification phase. The location of a biometric database can be in the client/server depending on the requirements of the system. The CBAS will use the database for comparison with the live data in the verification phase.
3.2.6 Response unitThe reponse unit produces an appropriate response for detecting the intruder or imposter. The CBAS has two main types of response: either a passive response or an active response. A passive system will typically generate an alert to notify an administrator of the detected activity. An active system, on the other hand, performs some sort of response other than generating an alert. Such systems minimise the damage of the intruder by terminating network connections or ending the session, for example.
The previous description of the CBAS model components would help to identify the most common characteristics and attributes of CBAS. Thus we define the common characteristics of CBAS which can help to classify the CBAS into different classes and to differentiate between continuous authentication scenarios. Figure 3.2 gives an overview of the common characteristics of CBAS and the description of these characteristics will be explained in sections 3.3 and 3.4.
3.6 ConclusionIn this chapter we analysed existing continuous biometric authentication schemes and described sample continuous authentication scenarios. We identified the com-
35

Characteristics Class 1 Class 2 New classType of
environmentClosed Open Open
Training data Authorised / unauthorised
user
Authorised user
None
Unauthorised user
Adversary / colluder
Adversary Adversary / colluder
Victim type System operator/ owner of the
application
End user System operator
/ End user
Algorithm type Multi-class classification
One-class classification
Change point detection
( potentially )
Table 3.2: The differences between the first, second classes and the new class.
mon characteristics and attributes from the generic model of CBAS. To date there is no CBAS deployed in real world applications, probably because the existing systems lack practicality. We observed that the main limitations are related to the training data that prevent CBAS to be applicable in real world applications. The problems are the requirement of the training data to be available in advance, many training data samples required, the variability of the behaviour biometric between the training and testing phase in case of the comparison time and the variability of the behaviour biometric of the user from one context to another. Finally, the chapter considered a new class for sCBAS associated (potentially) with change point detection algorithms that does not require training data for both intruder and valid users which can overcome the identified limitations associated with the existing CBAS.
In chapter 7 we will consider this new class that is not dependent on training data using the results of chapter 5 and 6. The new class can overcome the identified limitations associated with the existing the CBAS. The new scheme is capable of distinguishing a user accurately without need for any predefined user typing model a-priori.
36

Chapter 4
Conclusion and Future Directions
Detecting the impostor or intruder that takes over the valid user session based on keystroke dynamics in real time or near real time is a challenging research problem. This thesis focuses on developing automatic analysis techniques for continuous user authentication systems (that are based on keystroke dynamics) with the goal of detecting the impostor or intruder that takes over the valid user session. The main motivation of this research has been the need for a flexible system that can authenticate users and must not be dependent on a pre-defined typing model of a user. Also, there are other motivations including the ignorance of the application scenarios by the current schemes and the need for new feature selection techniques that represent user typing behaviour which can guarantee selecting frequently-typed features and inherently reflect user typing behavior. Added to these motivations has been the lack of an automated continuous authentication system based on keystroke dynamics that is low in computational resource requirements and thus suitable for real time detection.
This thesis extends previous research on improving continuous user authentication systems (that are based on keystroke dynamics). The research sought to:
• Better identify and understand the characteristics and requirements of each type of continuous authentication scenario and system.
• Find new features that are representing the user typing behaviour which can guarantee selecting frequently-typed features and inherently reflect user
• Discover whether pre-defined typing model of a user is necessary for successful authentication.
• Develop new flexible technique that authenticate users and automate this technique to continuously authenticate users.
37

4.1 Summary of Contributions
This research has resulted in a number of significant contributions in each of these directions as following:
1. Model for continuous biometric authentication: A generic model was proposed for most continuous authentication (CA) scenarios and CBAS. The model of CBAS is proposed based on their detection capabilities to better identify and understand the characteristics and requirements of each type of scenario and system. This model pursues two goals: the first is to describe the characteristics and attributes of existing CBAS, and the second is to describe the requirements of different scenarios of CBAS.
2. User-representative feature selection for keystroke dynamics: We proposed four statistical-based feature selection techniques for keystroke dynamics. The first is simply the most frequently typed n-graphs and the other three consider different user typing behaviors by selecting: n-graphs that are typed quickly; n-graphs that are typed with consistent time; and n-graphs that have large time variance among users. We use 2-graph (as features) in our experiments and found that the most-frequent 2-graphs can represent user’s typing patterns effectively because of their highest statistical significance. We further substantiate our results by comparing it with three contemporary feature selection techniques (i.e popular Italian words, common n- graphs, and least frequent n-graphs). We found that our technique performed after selecting a certain number of 2- graphs.
3. User-independent threshold for continuous user authentication based on keystroke dynamics: We presented a new approach to continuous user authentication using behavioural biometrics provided by keystroke dynamics. Our approach focused on obtaining a user-independent threshold that can distinguish a user
38

4.2. Future Directions
accurately without needing any pre-defined typing samples. We evaluated the user-independent threshold with four different factors including distance type, number of keystrokes, feature set and feature amount in order to find the optimum factor values that are suitable for a whole set of users. We also evaluated the user-independent threshold among three different groups of users to depict how the user-independent threshold is sensitive to different user’s typing data. This increased our confidence surrounding the effectiveness of the optimum factor values. Using a well known dataset for keystroke dynamics, we showed experimentally that a user-independent threshold can be obtained if a sufficient number of keystrokes are used, number of features are used and Euclidean distance is used.
4. Automatic impostor detection based on user-independent threshold: We detail the design and evaluation of two novel sliding window techniques for analysis of the typing data in order to detect the impostor who may take over from the genuine user during the computer session in real time. The use of proposed sliding window (overlapping) technique resulted in better performance over the proposed sliding window(non-overlapping) in terms of fast detection. The user-independent threshold has been used practically demonstrates for detection the impostor in near real time.
5. This thesis has presented a framework for the analysis of continuous authentication system based on keystroke dynamics. The work described in the thesis points to various areas of future research. These future areas of research are presented below.
4.2.1 Application of the Proposed Technique to Different Datasets
In this thesis, we use GP keystroke dataset based on Italian language for experiments and obtain a reasonable user-independent threshold. The techniques provided in this thesis can be applied to other data sets in keystroke dynamics with different languages. We obtained the user-independent threshold based on Italian
39

language. However, we do not know about the influence of other languages on the user-independent threshold. Evaluation of other languages could be attempted to obtain the user-independent threshold. It will be interesting to analyse the effectiveness of the proposed techniques and this will help answer questions about how well the user-independent threshold can be generalised to other data sets.
4.2.2 Application of the Proposed Technique to Different Biometric Sources
we used keystroke dataset as one of the biometric sources for experiments in this thesis for providing continuous user authentication. The techniques provided in this thesis can be applied to other sources of biometric such as mouse dynamics and face recognition. We found that the pre-defined typing model of a user is not necessary for successful authentication. However, we do not know whether the predefined model for a user is necessary for successful authentication in other biometric sources. Evaluation of other biometric sources could be attempted to obtain the user-independent threshold. It will be interesting to analyse the effectiveness of the proposed techniques and this will help answer questions about how well the user-independent threshold can be generalised to other biometric sources.
4.2.3 Improvements to the Proposed the User-Independent Threshold
The promising capability of the proposed approach which authenticates users without requiring a pre-defined typing model from any user, motivated our investigations into improving the technique further. Further investigation is required to devise a methodology for automatically adapting the user-independent threshold parameters such as sliding window siz. Also, using dynamic threshold could improve the accuracy of the proposed user-independent threshold approach. Furthermore, a new mechanism is required for improving the authentication technique by reducing the data size.
4.2.4 Detection of Impostor in Real timeThe proposed techniques have been used in an offline mode to analyse the user’s typing data. We believe they can further be extended to analyse the user’s typing data in a real time manner. In this regard the performance of the proposed technique with respect to detection delays needs to be investigated. In addition, the potential of using typing data in supplementing other perimeter defense techniques needs to be explored. This direction can help in answering how well observed user typing
40

behaviour can be used in assisting other security solutions such as an aid to intrusion detection systems.
4.3 Concluding Remarks
This research has highlighted the challenges of analysing the user typing data in distinguishing between users and can be used as a biometric authentication. New methods for improving the analysis of user typing data in order to detect the impostor during the computer session were proposed. The analysis techniques provided in this thesis have been successfully used that are representative of user typing behavior and also distinguished a user accurately without need for any predefined user typing model a-priori.
41

Appendix A
Characteristics of user’s typing dataTyping
dataCharacteristics
User 2 User 3 User 4 User 5 User 7 User 14
User 15
Total characters
12903 20165 14950 21873 12335 16898 15267
Lower case 8978 12776 10067 15801 9427 5581 10443Uppercase 819 804 208 305 95 5801 181
Digits 20 13 20 48 4 22 2Notations and symbols (#, ”,
...)
306 554 5 818 496 648 539
Backspace 270 1668 1589 936 210 1291 601Enter 168 274 177 264 168 111 198Null 427 1657 322 550 117 993 1216
Appendix A. Characteristics of user’s typing data
42

Distribution Time
The following table presents the distribution time in milliseconds for 10 different users from the dataset. From the table, we can easily see typing delay is different for most of the users. For example, the average typing delay for sequence of two characters is significantly different for some users such as user3 and other users including user 2, 4, 5,7 and 8. Furthermore, from the table, it can be seen clearly that most of the typing delay of sequences of two characters happened in the category 101-200 ms. However, it is not the case for some users such as user 6 where most of his typing delay of sequence of two characters happened in category 201-300 ms.
43

Appendix A. Characteristics of user’s typing data
44

Screenshots
45

46

References
[1] R. Bolle A. Jain and S. Pankanti. Biometrics: Personal identification in a network society. MA: Kluwer Academic Publisher, Norwell, 1999.
[2] M.B. Ahmad and T.S. Choi. Local threshold and boolean function based edge detection. Consumer Electronics, IEEE Transactions on, 45(3):674 – 679, 1999.
47

[3] A.A.E. Ahmed and I. Traore. Anomaly intrusion detection based on biometrics. In Information Assurance Workshop, 2005. IAW’05. Proceedings from the Sixth Annual IEEE SMC, pages 452–453, 2005.
[4] E. Ahmed, A. Clark, and G. Mohay. A novel sliding window based change detection algorithm for asymmetric traffic. In Network and Parallel Computing, 2008. NPC 2008. IFIP International Conference on, pages 168–175 , 2008.
[5] L.C.F. Araujo, L.H.R. Sucupira Jr, M.G. Lizarraga, L.L. Ling, and J.B.T. Yabu-Uti. User authentication through typing biometrics features. Signal Processing, IEEE Transactions on, 53(2):851–855, 2005.
[6] A. Azzini and S. Marrara. Impostor Users Discovery Using a Multimodal Biometric Continuous Authentication Fuzzy System. Lecture Notes in Computer Science, 5178:371–378, 2008.
[7] M. Basseville and I.V. Nikiforov. Detection of abrupt changes: theory and application. Prentice Hall, 1993.
[8] Carlos E. Benitez, Maximiliano Bertacchini, and Pablo I. Fierens. User clustering based on keystroke dynamics. In CACIC’10, October 2010.
[9] F. Bergadano. Identity verification through dynamic keystroke analysis. Intelligent Data Analysis, 7(5):469–496, 2003.
48

[10] F. Bergadano, D. Gunetti, and C. Picardi. User authentication through keystroke dynamics. ACM Transactions on Information and System Security (TISSEC), 5(4):367–397, 2002.
[11] S. Bleha, C. Slivinsky, and B. Hussien. Computer-access security systems using keystroke dynamics. IEEE Transactions on Pattern Analysis and Machine Intelligence, 12(12):1217–1222, 1990.
[12] M. Brown and SJ Rogers. User identification via keystroke characteristics of types names using neural networks. International Journal of Man-Machine Studies, 39(6):999–1014, 1993.
[13] S. Budalakoti, A. Srivastava, R. Akella, and E. Turkov. Anomaly detection in large sets of high-dimensional symbol sequences. NASA Ames Research Center, Tech. Rep. NASA TM-2006-214553, 2006.
[14] V. Chandola, A. Banerjee, and V. Kumar. Anomaly detection: A survey. ACM Computing Surveys (CSUR), 41(3):15, 2009.
[15] S. Cho, C. Han, D.H. Han, and H.I. Kim. Web-based keystroke dynamics identity verification using neural network. Journal of organizational computing and electronic commerce, 10(4):295–307, 2000.
[16] L. Coetzee and E.C. Botha. Fingerprint recognition in low quality images. Pattern Recognition, 26(10):1441–1460, 1993.
[17] E. Council. Federal financial institutions examination council. Stat, 2160:2222, 1994.
[18] M. Dash, K. Choi, P. Scheuermann, and H. Liu. Feature selection for clustering-a filter solution. In Data Mining, 2002. ICDM 2002. Proceedings. 2002 IEEE International Conference on, pages 115–122. IEEE, 2002.
49

[19] H. Debar, M. Becker, and D. Siboni. A neural network component for an intrusion detection system. In Research in Security and Privacy, 1992. Proceedings., 1992 IEEE Computer Society Symposium on, pages 240–250. IEEE, 1992.
[20] D.E. Denning. An intrusion-detection model. IEEE Transactions on software engineering, pages 222–232, 1987.
[21] P. Dowland, S. Furnell, and M. Papadaki. Keystroke analysis as a method of advanced user authentication and response. Security in the Information Society: Visions and Perspectives, page 215, 2002.
[22] P. Dowland, H. Singh, and S. Furnell. A preliminary investigation of user authentication using continuous keystroke analysis. In Proceedings of the IFIP 8th Annual Working Conference on Information Security Management & Small Systems Security, Las Vegas, pages 27–28, 2001.
[23] P.S. Dowland and S.M. Furnell. A long-term trial of keystroke profiling using digraph, trigraph and keyword latencies. In Security and protection in information processing systems: IFIP 18th world computer congress: TC11 19 th international information security conference, 22-27 August 2004, Toulouse, France, page 275. Kluwer Academic Pub, 2004.
[24] T. Fawcett and F. Provost. Activity monitoring: Noticing interesting changes in behavior. In Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 53–62. ACM New York, NY, USA, 1999.
[25] H.H. Feng, O.M. Kolesnikov, P. Fogla, W. Lee, and W. Gong. Anomaly Detection Using Call Stack Information. In 2003 Symposium on Security and Privacy: proceedings: 11-14 May, 2003, Berkeley, California, page 62. IEEE, 2003.
50
Related Documents











