Edit Distances William W. Cohen

Edit Distances
Dec 30, 2015
Edit Distances. William W. Cohen. Midterm progress reports. Talk for 5min per team You probably want to have one person speak Talk about The problem & dataset The baseline results What you plan to do next Send Brendan 3-4 slides in PDF by Mon night. Plan for this week. - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Edit Distances
William W. Cohen

Midterm progress reports
• Talk for 5min per team– You probably want to have one person speak
• Talk about– The problem & dataset– The baseline results– What you plan to do next
• Send Brendan 3-4 slides in PDF by Mon night

Plan for this week• Edit distances
– Distance(s,t) = cost of best edit sequence that transforms st
– Found via….
• Learning edit distances– Probabilistic generative model: pair HMMs
– Learning now requires EM• Detour: EM for plain ‘ol HMMS
– EM for pair HMMs
• Why EM works• Discriminative learning for pair HMMs

Motivation
• Common problem: classify a pair of strings (s,t) as “these denote the same entity [or similar entities]”– Examples:
• (“Carnegie-Mellon University”, “Carnegie Mellon Univ.”)
• (“Noah Smith, CMU”, “Noah A. Smith, Carnegie Mellon”)
• Applications:– Co-reference in NLP
– Linking entities in two databases
– Removing duplicates in a database
– Finding related genes
– “Distant learning”: training NER from dictionaries

Levenshtein distance - example
• distance(“William Cohen”, “Willliam Cohon”)
W I L L I A M _ C O H E N
W I L L L I A M _ C O H O N
C C C C I C C C C C C C S C
0 0 0 0 1 1 1 1 1 1 1 1 2 2
s
t
op
cost
alignment
gap

Computing Levenshtein distance - 2
D(i,j) = score of best alignment from s1..si to t1..tj
= minD(i-1,j-1) + d(si,tj) //subst/copyD(i-1,j)+1 //insertD(i,j-1)+1 //delete
(simplify by letting d(c,d)=0 if c=d, 1 else)
also let D(i,0)=i (for i inserts) and D(0,j)=j

Computing Levenshtein distance – 4
D(i,j) = minD(i-1,j-1) + d(si,tj) //subst/copyD(i-1,j)+1 //insertD(i,j-1)+1 //delete
C O H E N
M 1 2 3 4 5
C 1 2 3 4 5
C 2 3 3 4 5
O 3 2 3 4 5
H 4 3 2 3 4
N 5 4 3 3 3
A trace indicates where the min value came from, and can be used to find edit operations and/or a best alignment (may be more than 1)

Extensions
• Add parameters for differential costs for delete, substitute, … operations– Eg “gap cost” G, substitution costs dxy(x,y)
• Allow s to match a substring of t (Smith-Waterman)
• Model cost of length-n insertion as A + Bn instead of Gn– “Affine distance”
– Need to remember if a gap is open in s, t, or neither

Forward-backward for HMMs
0.1]][1[
) is statestart Pr(]][0[
iT
ii
: stateeach for i
:1for ...Tt : stateeach for i
)(]][1[)(]][[ state
ijjtxiitj
t :1for T...t
: stateeach for i
j
t jtxjjiit state
]][1[)()(]][[
Txxx ... :string a and ,:Given 21
All paths to st=i and all emissions up to and including tAll paths after st=i and all emissions after t

EM for HMMs
: stateeach for i
]][1[)()(]][[1
)(
1
t
t
new
jtxjjiitZ
ji
)...,();...,(;... string ;:Given 111 TTT xxxxxx
i
iTZ state
]][[ where :pair stateeach for i,j
1):?0 ( ]][[]][[1
)( axititZ
ai tt
new
pass thru state i at t and emit a at t
pass thru states i,j at t,t+1 …and con’t to end

Pair HMM Example
1
e Pr(e)
<a,a> 0.10
<e,e> 0.10
<h,h> 0.10
<e,-> 0.05
<h,t> 0.05
<-,h> 0.01
... ..
Sample run: zT = <h,t>,<e,e><e,e><h,h>,<e,->,<e,e>Strings x,y produced by zT: x=heehee, y=teehe
Notice that x,y is also produced by z4 + <e,e>,<e,-> and many other edit strings

Distances based on pair HMMs
),,(:),,(:
)Pr()Pr()|,Pr(VTnnVTnn yxzEDITz i
i
yxzEDITz
nVT zzyx
)|,Pr(log),(stochastic TTTT yxyxd
)|Pr(maxarglog),(),,(:
viterbi n
yxzEDITz
TT zyxdTTnn
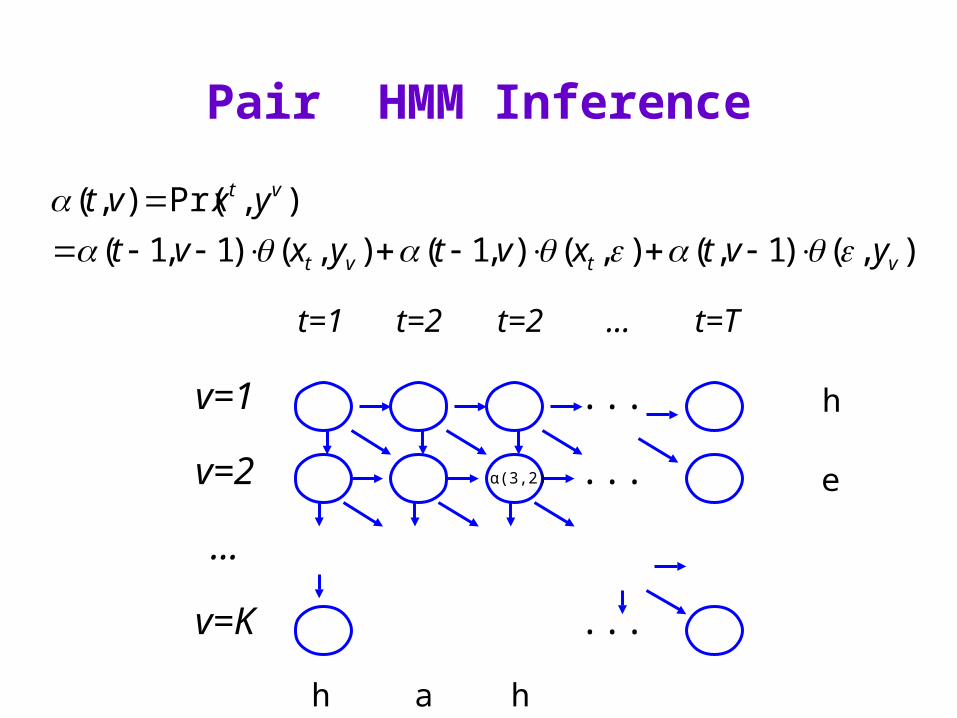
Pair HMM Inference
),()1,(),(),1(),()1,1(
),Pr(),(
vtvt
vt
yvtxvtyxvt
yxvt
t=1 t=2 t=2 ... t=T
v=1 ...
v=2 ...
...
v=K ...
h
e
h a h
α(3,2)
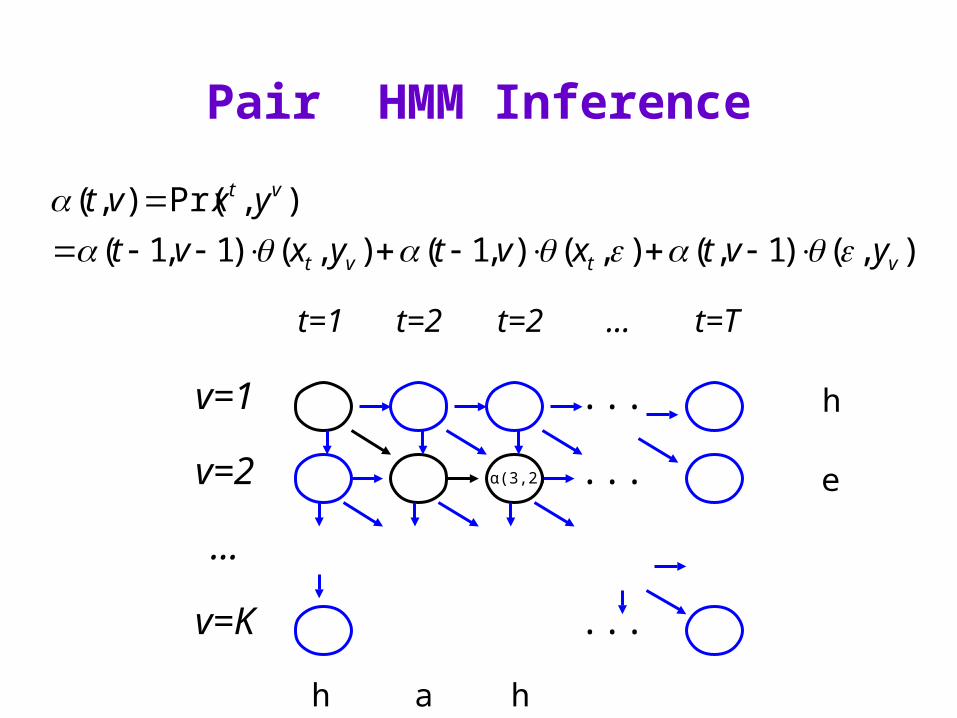
Pair HMM Inference
),()1,(),(),1(),()1,1(
),Pr(),(
vtvt
vt
yvtxvtyxvt
yxvt
t=1 t=2 t=2 ... t=T
v=1 ...
v=2 ...
...
v=K ...
h
e
h a h
α(3,2)

Pair HMM Inference: Forward-Backward
)1,(),(),1(),()1,1(),(
),Pr(),(),Pr(),(),Pr(),(
),Pr(),(
),Pr(),())','(),(Pr(
1111
''1
jiyjixjiyx
yxyyxxyxyx
yxji
yxjijirjir
jiji
Vj
Tij
Vj
Tii
Vj
Tiji
Vj
Ti
Vj
Tikk
t=1 t=2 t=2 ... t=T
v=1 ...
v=2 ...
...
v=K ...

EM to learn edit distances
• Is this really like edit distances? Not really:– Sim(x,x) ≠1– Generally sim(x,x) gets smaller with longer x– Edit distance is based on single best sequence;
Pr(x,y) is based on weighted cost of all successful edit sequences
• Will learning work?– Unlike linear models no guarantee of global
convergence: you might not find a good model even if it exists

Back to R&Y paper...
• They consider “coarse” and “detailed” models, as well as mixtures of both.
• Coarse model is like a back-off model – merge edit operations into equivalence classes (e.g. based on equivalence classes for chars).
• Test by learning distance for K-NN with an additional latent variable

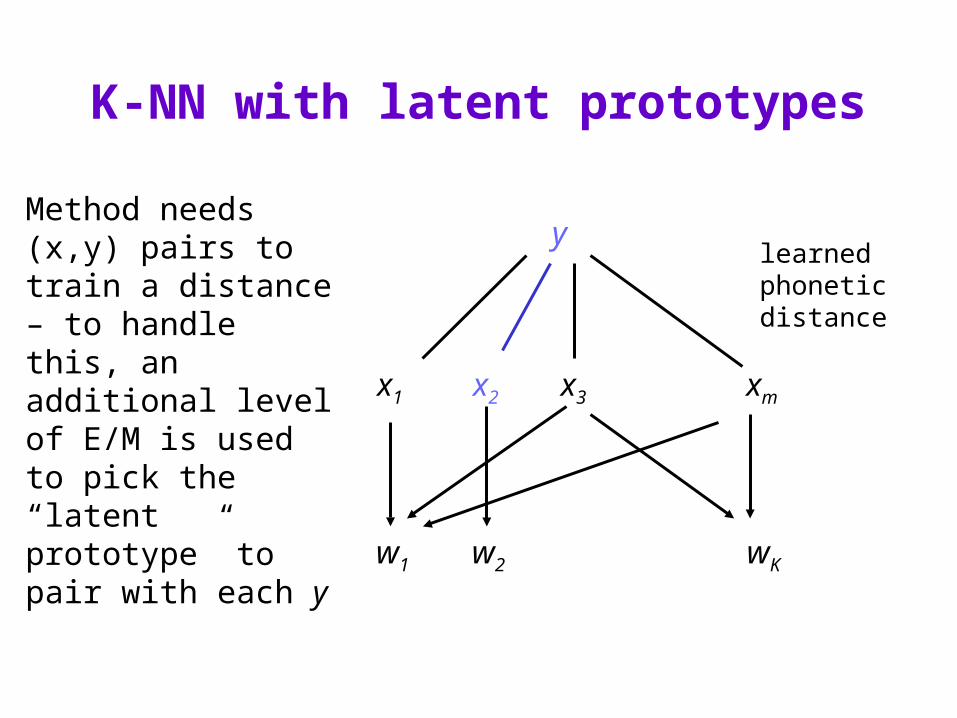
K-NN with latent prototypes
test example y (a string of phonemes)
possible prototypes x (known word pronounciation )
x1 x2 x3 xm
words from dictionary
y
w1 w2 wK
learned phonetic distance
K-NN with latent prototypes
x1 x2 x3 xm
y
w1 w2 wK
learned phonetic distance
Method needs (x,y) pairs to train a distance – to handle this, an additional level of E/M is used to pick the “latent prototype” to pair with each y

Plan for this week• Edit distances
– Distance(s,t) = cost of best edit sequence that transforms st– Found via….
• Learning edit distances: Ristad and Yianolis– Probabilistic generative model: pair HMMs– Learning now requires EM
• Detour: EM for plain ‘ol HMMS
– EM for pair HMMs
• Why EM works• Discriminative learning for pair HMMs

• Mixturess: z is hidden mixture component …• HMMs: z is hidden state sequence string• Pair HMMs: z is hidden sequence of pairs (x1,y1),… given (x,y)• Latent-variable topic models (e.g., LDA): z is assignment of words to topics• ….
X = data
θ = modelz = something you can’t observeProblem:
Algorithm: Iteratively improve θ1 θ2 …
Θn=
“complete data likelihood”
EM:

Jensen’s inequality…

Jensen’s inequality
x3
and f convex
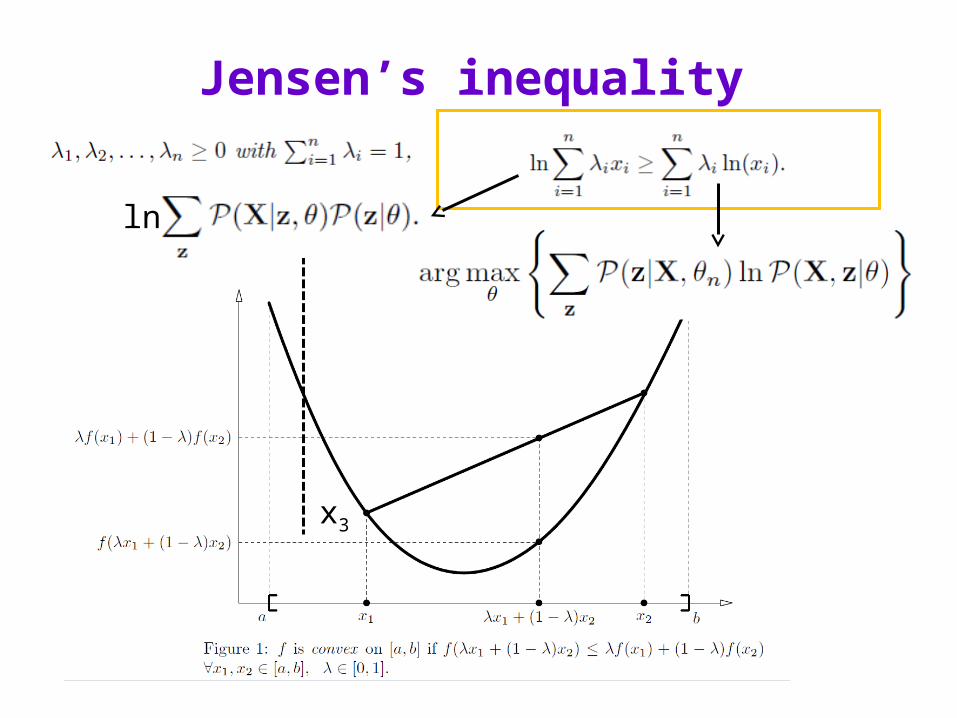
Jensen’s inequality
x3
ln

X = data
θ = model
z = something you can’t observe
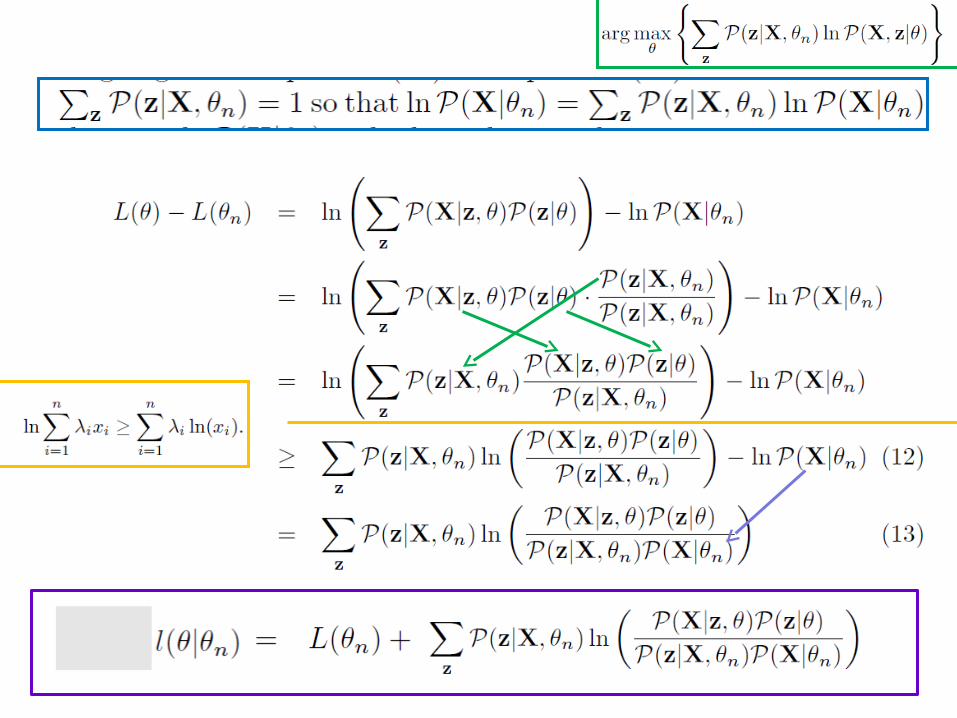
Let’s think about moving from θn (our current parameter vector) to some new θ (the next one, hopefully better)
We want to optimize L(θ)- L(θn ) …. using something like…

z zX,
zX,X|z
)|(
)|(ln),(
nn P
PP



Comments
• Nice because we often know how to– Do learning in the model (if hidden variables are
known)– Do inference in the model (to get hidden
variables)– And that’s all we need to do….
• Convergence: local, not global
• Generalized EM: E but don’t M, just improve


Key ideas
• Pair of strings (x,y) associated with a label: {match,nonmatch}
• Classification done by a pair HMM with two non-initial states: {match, non-match} w/o transitions between them
• Model scores alignments – emissions sequences – as match/nonmatch.

Key ideas
Edit sequence is featurized:
Score the alignment sequence:
Marginalize over all alignments to score match v nonmatch:

Key ideas
To learn, combine EM and CRF learning:• compute expectations over (hidden) alignments• use LBFGS to maximize (or at least improve )the parameters, λ• repeat……
Initialize the model with a “reasonable” set of parameters:• hand-tuned parameters for matching strings• copy match parameters to non-match state and shrink them to zero.

Results
We will come back to this family of methods in a couple of weeks (discriminatively trained latent-variable models).
Related Documents











