2014 © Trivadis BASEL BERN BRUGG LAUSANNE ZÜRICH DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. HAMBURG MÜNCHEN STUTTGART WIEN 2014 © Trivadis DWH-Modellierung mit Data Vault in Kombination mit ODI 12c - Erfahrungen aus der Praxis Claus Jordan Senior Consultant DOAG-Konferenz 2014 Ansicht > Kopf und Fusszeile 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

2014 © Trivadis
BASEL BERN BRUGG LAUSANNE ZÜRICH DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. HAMBURG MÜNCHEN STUTTGART WIEN
2014 © Trivadis
DWH-Modellierung mit Data Vaultin Kombination mit ODI 12c - Erfahrungen aus der Praxis
Claus JordanSenior Consultant
DOAG-Konferenz 2014Ansicht > Kopf und Fusszeile
1

2014 © Trivadis
Zu meiner Person
DOAG-Konferenz 2014DWH-Modellierung mit Data Vault und ODI
2
� bei Trivadis seit 2003
� Themengebiete� Data Warehouse, Architektur und ETL� Analyse und Reporting
� Technologien� Oracle RDMBS� Oracle OLAP� Oracle BI Enterprise Edition
CLAUSJORDAN
SENIORCONSULTANT
BUSINESSINTELLIGENCE

2014 © Trivadis
Trivadis ist führend bei der IT-Beratung, der Systemintegration, dem Solution-Engineering und der Erbringung von IT-Services mit Fokussierung auf und Technologien im D-A-CH-Raum.
Unsere Leistungen erbringen wir aus den strategischen Geschäftsfeldern:
Trivadis Services übernimmt den korrespondierenden BetriebIhrer IT Systeme.
Unser Unternehmen
DOAG-Konferenz 2014Trivadis – das Unternehmen
B E T R I E B
3

2014 © Trivadis
Mit über 600 IT- und Fachexperten bei Ihnen vor Ort
4
12 Trivadis Niederlassungen mitüber 600 Mitarbeitenden
200 Service Level Agreements
Mehr als 4'000 Trainingsteilnehmer
Forschungs- und Entwicklungs-budget: CHF 5.0 Mio. / EUR 4.0 Mio.
Finanziell unabhängig undnachhaltig profitabel
Erfahrung aus mehr als 1'900 Projekten pro Jahr bei über 800 Kunden
Stand 12/2013
Hamburg
Düsseldorf
Frankfurt
FreiburgMünchen
Wien
BaselZürichBern
Lausanne
4
Stuttgart
DOAG-Konferenz 2014Trivadis – das Unternehmen
4
Brugg

2014 © Trivadis
AGENDA
� Von den Anforderungen zum Data Vault Datenmodell� Anforderungen� Datenmodell� Historisierung in Data Vault� Bewertung von Data Vault
� ETL-Logik und -Prozesse mit ODI 12c� Topology� Models und Mappings
� ODI Knowledge-Module (Code Templates)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
Von den Anforderungen zum Data Vault Datenmodell
Systemlandschaft & Anforderungen

2014 © Trivadis
Systemlandschaft „Heute“
21.11.2014DWH-Modellierung mit Data Vault und ODI
UnterschiedlicheSchnittstellen
Flatfile (*.csv )oder
ODBC-Verbindung
OLTP (Operative HR-Systeme) OLAP (HR-Planungs- / Reportingssysteme)
OLTP (Operative Non HR-Systeme)OLTP (Operative HR-Drittsysteme)
Extrakte für Werkreporting

2014 © Trivadis
Systemlandschaft „Morgen“
21.11.2014DWH-Modellierung mit Data Vault und ODI
OLTP (Operative HR-Systeme) OLAP (HR-Planungs- / Reportingssysteme)
OLTP (Operative Non HR-Systeme)OLTP (Operative HR-Drittsysteme)
HR Data Warehouse
Datenbank: Oracle 11g oder 12c
Tools:Oracle Data Integrator 12cOracle SQL DeveloperOracle SQL Data Modeler

2014 © Trivadis
Konzept und Datenmodell
HR Data Warehouse – Konzept (Teil 1)
� Aufbau und Technologie
� Vorgehensweise
HR Data Warehouse – Datenmodell (Teil 2)
� ER Diagramm
� Physische Datenmodelle
21.11.2014DWH-Modellierung mit Data Vault und ODI
HR Data Warehouse
Stage Core MartCleanse

2014 © Trivadis
Data Vault Modelling
von Dan Linstedt (1990-2000)
Die zentrale Komponente des Data Warehouses – in unserer Architektur das Core – wird bei diesem Modellierungsansatz als Data Vault bezeichnet. Ein Data Vault besteht aus drei verschiedenen Strukturen, die als Tabellen implementiert werden:
Hubs enthalten ausschliesslich die Business Keys der fachlichen Entitäten sowie einen künstlichen Schlüssel, der von Links und Satellites referenziert wird. Beschreibende Attribute werden nie in Hubs abgespeichert, sondern in Satellites ausgelagert.
Links beschreiben Beziehungen zwischen Entitätstypen (Hubs) und erlauben generell die Definition von n-zu-n- Beziehungen zwischen verschiedenen Hubs. Auf eine fachliche Abbildung der Kardinalitäten (1:1, 1:n, n:n) wie in der klassischen relationalen Datenmodellierung wird hier verzichtet.
Satellites umfassen sämtliche beschreibenden Attribute von Entitätstypen oder Beziehungen in versionierter Form. Ein Satellite wird via Fremdschlüsselbeziehung einem Hub oder einem Link zugeordnet. Pro Hub/Link können mehrere Satellites definiert werden.
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Umfang und Ziel des Prototyps
Umfang
� Für eine begrenzte Anzahl von Entitäten und Beziehungen soll mit Hilfe des ETL Werkzeugs ODI ein Prototyp für das HR Data Warehouse erstellt werden.
� Für für die zentrale Schicht (Core) soll die Modellierungsmethode Data Vault zum Einsatz kommen.
Ziel
Es soll am praktischen Beispiel gezeigt werden,
� dass ODI das richtige Werkzeug und
� dass Data Vault für die aktuellen und zukünftigen Anforderung geeignet ist.
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
Von den Anforderungen zum Data Vault Datenmodell
Datenmodell

2014 © Trivadis
Ausgangspunkt ist das logisches Datenmodell ..
.. zum Beispiel für die Objekte Mitarbeiter + Adresse(n)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
HR DWH - Physisches Datenmodell
21.11.2014DWH-Modellierung mit Data Vault und ODI
MA.csv
LOC.csv
CoreCleanseStage Data Mart
HR Data Warehouse
? ? ??

2014 © Trivadis
1. Core (Data Vault Methode)
21.11.2014DWH-Modellierung mit Data Vault und ODI
MA.csv
LOC.csv
CoreCleanseStage Data Mart
HR Data Warehouse
? ? ??

2014 © Trivadis
2. Cleanse
21.11.2014DWH-Modellierung mit Data Vault und ODI
MA.csv
LOC.csv
CoreCleanseStage Data Mart
HR Data Warehouse
? ? ??

2014 © Trivadis
3. Stage
21.11.2014DWH-Modellierung mit Data Vault und ODI
MA.csv
LOC.csv
CoreCleanse Data Mart
HR Data Warehouse
? ? ?
Stage
?

2014 © Trivadis
4. Data Mart
21.11.2014DWH-Modellierung mit Data Vault und ODI
MA.csv
LOC.csv
CoreCleanse Data Mart
HR Data Warehouse
? ? ?
Stage

2014 © Trivadis
HR DWH - Physisches Datenmodell
21.11.2014DWH-Modellierung mit Data Vault und ODI
MA.csv
LOC.csv
CoreCleanseStage Data Mart
HR Data Warehouse

2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
Bewertung von Data Vault

2014 © Trivadis
Bewertungskriterien für das Datenmodell
� Anzahl Tabellen / Anzahl ETL-Prozesse
� ETL - Komplexität für das
� Laden aus Cleanse in Core
� Laden aus Core in Data Marts
� Erweiterbarkeit („Agile BI“)
� Datenredundanz / Datenvolumen
� Parallelisierbarkeit
� Abfragen von historisch korrekten Zeitreihen (Nachvollziehbarkeit)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Bewertung von Data Vault (1) Methode
Kritieren \ mit Data Vault
Anzahl Tabellen und ETL-Prozesse
Relativ Hoch ����.. weil pro Entität zwei oder mehr Tabellen, plus eine oder mehrere Tabelle für jede Beziehung zwischen Entitäten, notwendig sind. Dies ermöglicht jedoch, gerade bei „breiten Entitäten“ (z.B. Mitarbeiter), eine gezielte Gruppierung von Attributen und erleichtert somit die Übersicht. Pro Tabelle resultiert ein ETL-Prozess.
ETL-Komplexität für das Laden aus Cleanse in Core
Gering ☺☺☺☺.. zumal keine performanceintensiven Updates notwendig sind. D.h. Datensätze werden nur dann eingefügt, wenn tatsächlich Änderungen an den betreffenden Attributen vorkommen.
ETL-Komplexität für das Laden aus Core in Data Marts
Mittel bis hoch ��������
.. aufgrund der Transformation vom normalisierten in das denormalisierte Datenmodell (Star- / Snowflake), und vor allen Dingen wegen der Bildung von neuen Gültigkeitsintervallen bei der Verknüpfung von unabhängig versionierten Stammdatenentitäten. Diese Logik kann beispielsweise in Datenbank-Views implementiert werden. Dadurch ist der Zugriff ähnlich einfach wie im dimensionalen Datenmodell und stellt somit kein KO-Kriterium dar.
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Bewertung von Data Vault (2) Methode
Kritieren \ mit Data Vault
Erweiterbarkeit („Agile BI“)
Hoch ☺☺☺☺.. aufgrund fehlender Referenzen zwischen Entitäten, die jeweils unanabhängig voneinander erweitert oder angepaßt werden können.
Datenredundanz / Datenvolumen
Gering ☺☺☺☺.. durch Normalisierung (geringe Datenredundanz) und Splittung der Attribute, welche zu einer einer Hub-Table gehören, in mehrere Satellitentabellen
Parallelisierbarkeit Hoch ☺☺☺☺.. sowohl bei der Implementierung als auch im laufenden Betrieb beim Laden der Daten. Sämtliche Hub-Tables können parallel implementiert / geladen werden. Dasselbe gilt für alle Link-Tables und für die Satellite-Tables (jeweils Voraussetzung sind die Hub-Tables)
Historisierung / Nachvollziehbarkeit
Sehr hoch ☺☺☺☺.. weil standardmäßig in den Satellite-Tables der DWH-Schicht Core jede Änderung historisiert wird und sei sie noch so gering.
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
ETL-Logik und ETL-Prozesse mit ODI 12c

2014 © Trivadis
Themen
Wie funktioniert all dies im Prototyp?
� ODI Mappings
� ETL-Logik für Core-Mappings (Data Vault)
� ODI Knowledge-Module (Code-Templates)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
ODI - Designer
„Models“:
� Reengineering von Dateien und Datenbankobjekten basierend auf der logischen Architektur (Tab „Topology“)
„Projects“:
� ODI Mappings (ETL-Strecken)
� Knowledge-Module (generische Ladestrategien)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Beispiel für ein ODI Mapping
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Mappings für verschiedene Aufgaben
� Stage-Mappings: Laden aus verschiedenen Datenquelle in die Stage-Tables. Attribute der Stage-Tables vom Typ VARCHAR2(4000), Truncate-Insert
� Cleanse-Mappings: Filterung (where), Verknüpfung (Join), Mengenoperationen (Union, Minus, ..), Transformation (concat, nvl, to_date, ...), Truncate-Insert
� Core-Mappings: Vergleichen und ggf. Historisieren (Merge, Insert). Updates und Deletes sollten möglichst vermieden werden!
� Mart-Mappings: Joins, Aggregation, Kalkulation, Stichtagstabellen (pro Data Mart sehr individuell)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Core-Mappings für Data Vault (3 Typen)
Mappings für
� Hub-Tables:Welche Datensätze sind neu? Diese Datensätze einfügen (Insert)
� Link-Tables: Lookup zu den Hub-TablesWelche Datensätze sind neu? Diese Datensätze einfügen (Insert)
� Satellite-Tables:Lookup zur Hub-Table bzw. zu den Link-Tables Welche Datensätze sind neu oder haben sich geändert (Dabei werden nur die Attribute der zu ladenden Satellite-Tabelle berücksichtigt)? Diese Datensätze einfügen (Insert)
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
ETL Logik für Hub-Tables
Cleanse-Table MA
PERS_ID NAME
1006 Maier
21.11.2014DWH-Modellierung mit Data Vault und ODI
Hub-Table MA_H
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
Cleanse-Table MA
PERS_ID NAME
1006 Mayer
Hub-Table MA_H
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
t
• Änderungen von beschreibenden Attributen haben keine Auswirkung auf Hub-Tables
t2
t1

2014 © Trivadis
ETL Logik für Hub-Tables
Cleanse-Table MA
PERS_ID NAME
1006 Maier
21.11.2014DWH-Modellierung mit Data Vault und ODI
Hub-Table MA_H
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
Cleanse-Table MA
PERS_ID NAME
1006 Mayer
Hub-Table MA_H
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
t
t2
t1INSERT INTO
SELECT
FROM
WHERE
INSERT INTO MA_H (PERS_ID, LOAD_DATE)
SELECTcls.PERS_ID, SYSDATE
FROMMA cls
WHERE NOT EXISTS(SELECT * FROM MA_H hub WHERE hub.PERS_ID = cls.PERS_ID

2014 © Trivadis
ODI-Mapping für Hub-Tables
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Knowledge Module für Hub-Tables
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
ETL Logik für Link-Tables
Cleanse-Table MA_RE
PERS_ID REGION
1006 N
21.11.2014DWH-Modellierung mit Data Vault und ODI
Link-Table MA_RE_L
SK SK_MA SK_RE LOAD_DATE
300 1 10 19.09.2014
Hub-Table MA_H
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
Hub-Table RE_H
SK REGION LOAD_DATE
10 N 01.01.2000
20 S 01.01.2000
Cleanse-Table MA_RE
PERS_ID REGION
1006 S
Link-Table MA_RE_L
SK SK_MA SK_RE LOAD_DATE
300 1 10 19.09.2014
301 1 20 21.09.2014 ?
t
Ist das richtig so?• Ja. Wenn aber diese alte Beziehung als „Ungültig“ oder „Nicht Aktuell“ gesetzt
werden soll, so wird für diese Link-Table eine Satellite-Table benötigt
t2
t1

2014 © Trivadis
ETL Logik für Link-Tables
Cleanse-Table MA_RE
PERS_ID REGION
1006 N
21.11.2014DWH-Modellierung mit Data Vault und ODI
Link-Table MA_RE_L
SK SK_MA SK_RE LOAD_DATE
300 1 10 19.09.2014
Hub-Table MA_H
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
Hub-Table RE_H
SK REGION LOAD_DATE
10 N 01.01.2000
20 S 01.01.2000
Cleanse-Table MA_RE
PERS_ID REGION
1006 S
Link-Table MA_RE_L
SK SK_MA SK_RE LOAD_DATE
300 1 10 19.09.2014
301 1 20 21.09.2014 ?
t
t2
t1
WHERE
INSERT INTO MA_RE_L (SK_MA, SK_RE, LOAD_DATE)
SELECTMA_H.SK SK_MA, RE_H.SK SK_RE, SYSDATEFROMMA_RE clsJOIN MA_H ON (cls.PERS_ID = MA_H.PERS_ID) JOIN RE_H ON (cls.REGION = RE_H.REGION)
WHERE NOT EXISTS(SELECT * FROM MA_RE_L linkWHERE link.SK_MA = MA_H.SK AND
link.SK_RE = RE_H.SK)

2014 © Trivadis
ETL Logik für Sat-Tables (4HUB)
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Maier N
21.11.2014DWH-Modellierung mit Data Vault und ODI
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Mayer S
t
• Ein Insert in die Sat-Table erfolgt nur, wenn sich ein Attribut ändert!
t3
t1
Sat-Table MA_S
SK_HUB NAME LOAD_DATE
1 Maier 19.09.2014
Hub-Table MA
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
Sat-Table MA_S
SK_HUB NAME LOAD_DATE
1 Maier 19.09.2014
1 Mayer 21.09.2014
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Maier S
t2
Sat-Table MA_S
SK_HUB NAME LOAD_DATE
1 Maier 19.09.2014

2014 © Trivadis
ETL Logik für Sat-Tables (4HUB)
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Maier N
21.11.2014DWH-Modellierung mit Data Vault und ODI
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Mayer S
t
t3
t1
Sat-Table MA_S
SK_HUB NAME LOAD_DATE
1 Maier 19.09.2014
Hub-Table MA
SK PERS_ID LOAD_DATE
1 1006 19.09.2014
Sat-Table MA_S
SK_HUB NAME LOAD_DATE
1 Maier 19.09.2014
1 Mayer 21.09.2014
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Maier S
t2
Sat-Table MA_S
SK_HUB NAME LOAD_DATE
1 Maier 19.09.2014
INSERT INTO
SELECT
FROM
WHERE
AND
INSERT INTO MA_S (SK_HUB, NAME, LOAD_DATE)
SELECT sat.SK_HUB cls.NAME, SYSDATE
FROMMA_H hubJOIN MA_REG cls ON (hub.PERS_ID = cls.PERS_ID) JOIN MA_S sat ON (hub.SK = sat.SK_HUB)
WHEREsat.LOAD_DATE = (SELECT MAX(LOAD_DATE)
FROM MA_S WHERE SK_HUB = sat.SK_HUB)
AND (cls.NAME != sat.NAME ORcls.BIRTHDAY != sat.BIRTHDAY OR...)

2014 © Trivadis
ETL Logik für Sat-Tables (4LINK)
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Maier N
21.11.2014DWH-Modellierung mit Data Vault und ODI
Cleanse-Table MA_RE
PERS_ID NAME REGION
1006 Maier S
Link-Table MA_RE_L
SK SK_MA SK_RE LOAD_DATE
300 1 10 20.09.2014
301 1 20 21.09.2014
t
• Wenn die Beziehung zu Region „N“ ab t2 nicht mehr gültig ist, so wird in einem speziellen Attribut das entsprechende Datum eingetragen.
• Hier ist also ein Update unumgänglich
Sat-Table MA_RE_S
SK_LNK OUT_OF_DATE LOAD_DATE
300 21.09.2014 20.09.2014
301 21.09.2014
t2
t1
Link-Table MA_RE_L
SK SK_MA SK_RE LOAD_DATE
300 1 10 20.09.2014
Sat-Table MA_RE_S
SK_LNK OUT_OF_DATE LOAD_DATE
300 20.09.2014

2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
Knowledge-Module
(Code Templates)
Funktionsweise

2014 © Trivadis
Typen von Knowledge-Modulen (KM‘s)
Es gibt unterschiedliche KM-Typen für
� Reverse-Engineering (RKM‘s)
� Loading (LKM‘s)
� Check (CKM‘s)
� Integration (IKM‘s)
� ..
KM‘s für verschiedenste Technologien werden mitgeliefert� Kopieren und anpassen
KM‘s können auch von Grund auf neu entwickelt werden
Einem Mapping werden ein oder mehrere KM‘s zugeordnet� z.B. LKM, IKM und CKM
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
KM (1)
21.11.2014DWH-Modellierung mit Data Vault und ODI
2014 © Trivadis
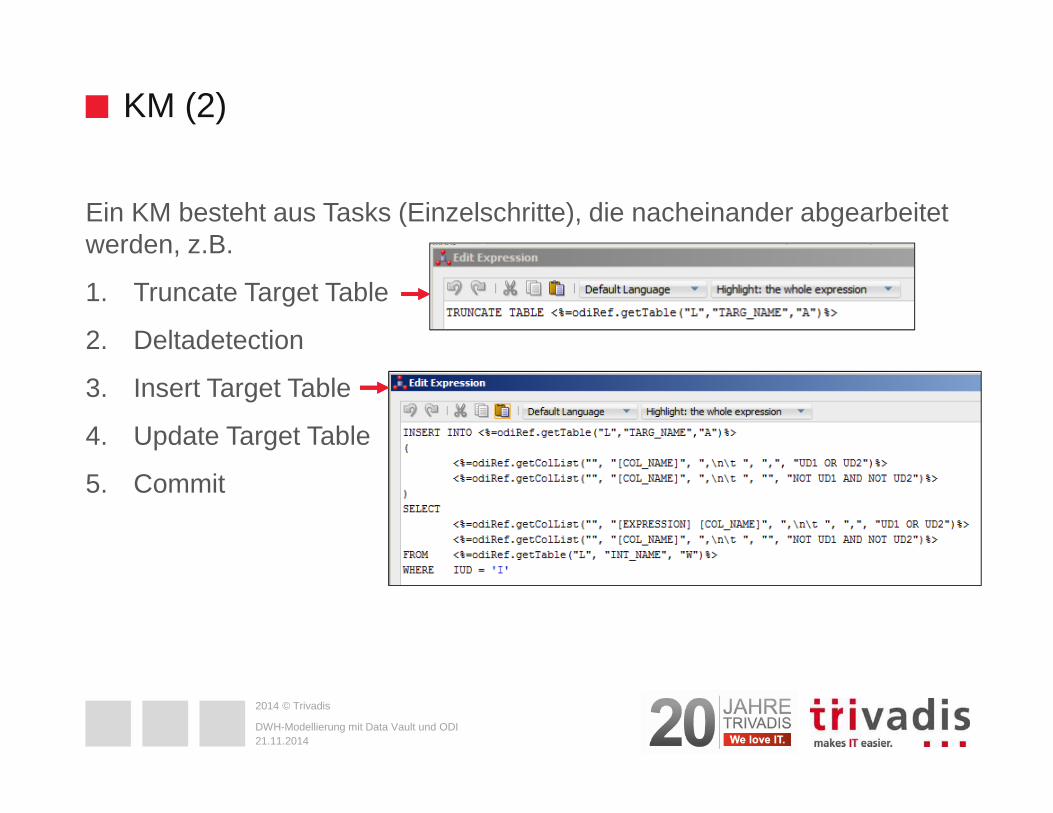
KM (2)
Ein KM besteht aus Tasks (Einzelschritte), die nacheinander abgearbeitet werden, z.B.
1. Truncate Target Table
2. Deltadetection
3. Insert Target Table
4. Update Target Table
5. Commit
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
Zusammenfassung

2014 © Trivadis
Zusammenfassung
� Durch die mehrschichtige Architektur des HR Data Warehouse sind Datenströme und Transformationen sehr gut nachvollziehbar. Außerdem sind die Mappings dadurch wenig komplex.
� Das Data Vault Datenmodell ist ideal ..� .. wenn eine lückenlose Historisierung der Daten erwünscht ist� .. wenn wenig Datenredundanz und damit hohe Datenkonsistenz
notwendig ist� .. wenn der Aufwand für das Hinzufügen neuer Entitäten, Attribute und
Beziehungen möglichst klein sein soll� .. wenn rückwirkende Änderung von Stamm- und Bewegungsdaten
jederzeit möglich sein sollen� .. Wenn parallel entwickelt werden soll
� Mit den Knowledge Modulen von ODI können alle möglichen Ladestrategien und Sonderfälle effizient abgebildet werden
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
Weitere Informationen
� ODI 12c Trainings 2. HJ 2014http://www.trivadis.com/training/oracle-training/business-intelligence/oracle-data-integrator-workshop-fuer-praktiker-o-odi.html
� Trivadis Whitepaper „Comparison of Data Modeling Methods for a Core Data Warehouse”
21.11.2014DWH-Modellierung mit Data Vault und ODI

2014 © Trivadis
BASEL BERN BRUGG LAUSANNE ZÜRICH DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. HAMBURG MÜNCHEN STUTTGART WIEN
Fragen und Antworten...
2014 © Trivadis
21.11.2014DWH-Modellierung mit Data Vault und ODI
Claus JordanSenior ConsultantStuttgart
Tel. +49-162-295 96 [email protected]

2014 © Trivadis
DOAG-Konferenz 2014DWH-Modellierung mit Data Vault und ODI
Trivadis an der DOAG
Ebene 3 - gleich neben der Rolltreppe
Wir freuen uns auf Ihren Besuch.
Denn mit Trivadis gewinnen Sie immer.
Related Documents











