Dueling Network Architectures for Deep Reinforcement Learning 2016-06-28 Taehoon Kim

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Dueling�Network�Architectures�for�Deep�Reinforcement�Learning�
2016-06-28
Taehoon�Kim

Motivation
• Recent�advances• Design�improved�control�and�RL�algorithms
• Incorporate�existing�NN�into�RL�methods
• We,• focus�on�innovating�a�NN�that�is�better�suited�for�model-free�RL
• Separate
• the�representation�of�state�value
• (state-dependent)�action�advantages
2
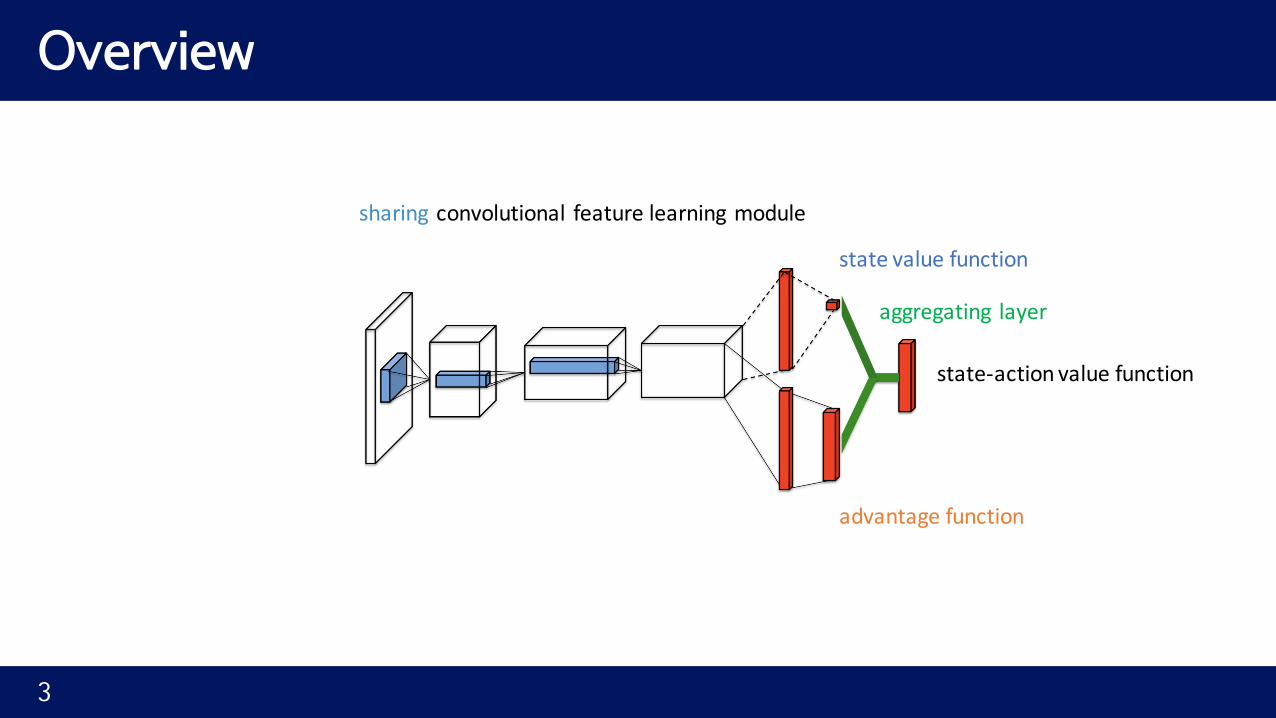
Overview
3
statevaluefunction
advantagefunction
sharing convolutional featurelearningmodule
aggregating layer
state-actionvaluefunction

Dueling�network
• Single�Q�network�with�two�streams
• Produce�separate�estimations�of�state�value�func and�advantage�func
• without�any�extra�supervision
• which�states�are�valuable?
• without�having�to�learn�the�effect�of�each�action�for�each�state
4

Saliency�map�on�the�Atari�game�Enduro
5
1.Focusonhorizon,wherenewcarsappear
2.Focusonthescore
Notpaymuchattentionwhentherearenocarsinfront
Attentiononcarimmediatelyinfrontmakingitschoiceofactionveryrelevant

Definitions
• Value 𝑉(𝑠),�how�good�it�is�to�be�in�particular�state�𝑠
• Advantage 𝐴(𝑠, 𝑎)
• Policy 𝜋
• Return 𝑅* = ∑ 𝛾./*𝑟.∞.1* ,�where�𝛾 ∈ [0,1]
• Q function 𝑄8 𝑠, 𝑎 = 𝔼 𝑅* 𝑠* = 𝑠, 𝑎* = 𝑎, 𝜋
• State-value function 𝑉8 𝑠 = 𝔼:~8(<)[𝑄8 𝑠, 𝑎 ]
6

Bellman�equation
• Recursively�with�dynamic�programming
• 𝑄8 𝑠, 𝑎 = 𝔼<` 𝑟 + 𝛾𝔼:`~8(<`) 𝑄8 𝑠`, 𝑎` |𝑠, 𝑎, 𝜋
• Optimal�Q∗ 𝑠, 𝑎 = max8𝑄8 𝑠, 𝑎
• Deterministic�policy�a = argmax:`∈𝒜
Q∗ 𝑠, 𝑎`
• Optimal�V∗ 𝑠 = max:𝑄∗ 𝑠, 𝑎
• Bellman�equation Q∗ 𝑠, 𝑎 = 𝔼<` 𝑟 + 𝛾max:`𝑄∗ 𝑠`, 𝑎` |𝑠, 𝑎
7

Advantage�function
• Bellman�equation Q∗ 𝑠, 𝑎 = 𝔼<` 𝑟 + 𝛾 max:`𝑄∗ 𝑠`,𝑎` |𝑠, 𝑎
• Advantage�function A8 𝑠, 𝑎 = 𝑄8 𝑠, 𝑎 − 𝑉8(𝑠)
• 𝔼:~8(<`) 𝐴8 𝑠, 𝑎 = 0
8

Advantage�function
• Value�𝑉(𝑠),�how�good�it�is�to�be�in�particular�state�𝑠
• Q(𝑠, 𝑎),�the�value�of�choosing�a�particular�action�𝑎 when�in�state�𝑠
• A = 𝑉 − 𝑄 to�obtain�a�relative�measure of�importance�of�each�action
9

Deep�Q-network�(DQN)
• Model�Free
• states�and�rewards�are�produced�by�the�environment
• Off�policy
• states�and�rewards�are�obtained�with�a�behavior�policy�(epsilon�greedy)
• different�from�the�online�policy�that�is�being�learned
10

Deep�Q-network:�1)�Target�network
• Deep�Q-network�𝑄 𝑠, 𝑎; 𝜽
• Target�network�𝑄 𝑠, 𝑎; 𝜽/
• 𝐿O 𝜃O = 𝔼<,:,Q,<` 𝑦OSTU − 𝑄 𝑠, 𝑎; 𝜽𝒊
W
• 𝑦OSTU = 𝑟 + 𝛾max
:`𝑄 𝑠`, 𝑎`; 𝜽/
• Freeze�parameters�for�a�fixed�number�of�iterations
• 𝛻YZ𝐿O 𝜃O = 𝔼<,:,Q,<` 𝑦OSTU − 𝑄 𝑠, 𝑎; 𝜽𝒊 𝛻YZ𝑄 𝑠, 𝑎; 𝜽𝒊
11
𝑠`
𝑠

Deep�Q-network:�2)�Experience�memory
• Experience�𝑒* = (𝑠*, 𝑎*, 𝑟*, 𝑠*\])
• Accumulates�a�dataset�𝒟* = 𝑒], 𝑒W,… , 𝑒*
• 𝐿O 𝜃O = 𝔼 <,:,Q,<` ~𝒰(𝒟) 𝑦OSTU − 𝑄 𝑠, 𝑎; 𝜽𝒊
W
12

Double�Deep�Q-network�(DDQN)
• In�DQN
• the�max operator�uses�the�same�values�to�both�select and�evaluate an�action
• lead�to�overoptimistic�value�estimates
• 𝑦OSTU = 𝑟 + 𝛾max
:`𝑄 𝑠`, 𝑎`;𝜽/
• To�migrate�this�problem,�in�DDQN
• 𝑦OSSTU = 𝑟 + 𝛾𝑄 𝑠`, argmax
:`𝑄(𝑠`, 𝑎`; 𝜃O) ; 𝜽/
13

Prioritized�Replay��(Schaul et�al.,�2016)�
• To�increase�the�replay�probability�of�experience�tuples
• that�have�a�high�expected�learning�progress
• use�importance�sampling�weight�measured�via�the�proxy�of�absolute�TD-error
• sampling�transitions�with�high�absolute�TD-errors
• Led�to�faster�learning�and�to�better�final�policy�quality
14

Dueling�Network�Architecture�:�Key�insight
• For�many�states
• unnecessary to�estimate�the�value�of�each�action�choice
• For�example,�move�left�or�right�only�matters�when�a�collision�is�eminent
• In�most�of�states,�the�choice�of�action�has�no�affect�on�what�happens
• For�bootstrapping based�algorithm
• the�estimation�of�state�value is�of�great�importance for�every�state
• bootstrapping:�update�estimates�on�the�basis�of�other�estimates.�
15

Formulation
• A8 𝑠, 𝑎 = 𝑄8 𝑠, 𝑎 − 𝑉8(𝑠)
• 𝑉8 𝑠 = 𝔼:~8(<) 𝑄8 𝑠, 𝑎
• A8 𝑠, 𝑎 = 𝑄8 𝑠, 𝑎 − 𝔼:~8(<) 𝑄8 𝑠, 𝑎
• 𝔼:~8(<) 𝐴8 𝑠, 𝑎 = 0
• For�a�deterministic�policy,�𝑎∗ = argmaxa`∈𝒜
𝑄 𝑠, 𝑎`
• 𝑄 𝑠,𝑎∗ = 𝑉(𝑠) and�𝐴 𝑠, 𝑎∗ = 0
16

Formulation
• Dueling�network�=�CNN�+�fully-connected�layers�that�output
• a�scalar�𝑉 𝑠; 𝜃, 𝛽
• an� 𝒜 -dimensional�vector�𝐴(𝑠, 𝑎; 𝜃, 𝛼)
• Tempt�to�construct�the�aggregating�module
• 𝑄 𝑠,𝑎; 𝜃, 𝛼, 𝛽 = 𝑉 𝑠; 𝜃, 𝛽 + 𝐴(𝑠, 𝑎; 𝜃, 𝛼)
17

Aggregation�module�1:�simple�add
• But�𝑄 𝑠, 𝑎; 𝜃, 𝛼, 𝛽 is�only�a�parameterized�estimate�of�the�true�Q-
function
• Unidentifiable
• Given�𝑄,�𝑉 and�𝐴 can’t�uniquely�be�recovered
• We�force�the�𝐴 to�have�zero at�the�chosen�action
• 𝑄 𝑠,𝑎; 𝜃, 𝛼, 𝛽 = 𝑉 𝑠; 𝜃, 𝛽 + 𝐴 𝑠,𝑎; 𝜃, 𝛼 −max:`∈𝒜
𝐴(𝑠, 𝑎`; 𝜃,𝛼)
18

Aggregation�module�2:�subtract�max
• For�𝑎∗ = argmaxa`∈𝒜
𝑄(𝑠, 𝑎`;𝜃, 𝛼, 𝛽) = argmaxa`∈𝒜
𝐴 𝑠, 𝑎; 𝜃, 𝛼
• obtain�𝑄 𝑠, 𝑎∗;𝜃, 𝛼, 𝛽 = 𝑉 𝑠; 𝜃, 𝛽
• 𝑄 𝑠,𝑎∗ = 𝑉(𝑠)
• An�alternative�module�replace�max�operator�with�an�average
• 𝑄 𝑠,𝑎; 𝜃, 𝛼, 𝛽 = 𝑉 𝑠; 𝜃, 𝛽 + 𝐴 𝑠,𝑎; 𝜃, 𝛼 − ]𝒜∑ 𝐴(𝑠, 𝑎`; 𝜃, 𝛼):`
19

Aggregation�module�3:�subtract�average
• An�alternative�module�replace�max�operator�with�an�average
• 𝑄 𝑠,𝑎; 𝜃, 𝛼, 𝛽 = 𝑉 𝑠; 𝜃, 𝛽 + 𝐴 𝑠,𝑎; 𝜃, 𝛼 − ]𝒜∑ 𝐴(𝑠, 𝑎`; 𝜃, 𝛼):`
• Now�loses�the�original�semantics�of�𝑉 and�𝐴
• because�now�off-target�by�a�constant,� ]𝒜 ∑ 𝐴(𝑠, 𝑎`; 𝜃, 𝛼):`
• But�increases�the�stability�of�the�optimization• 𝐴 only�need�to�change�as�fast�as�the�mean
• Instead�of�having�to�compensate any�change�to�the�optimal�action’s�advantage
20
max:`∈𝒜
𝐴(𝑠, 𝑎`; 𝜃, 𝛼)

Aggregation�module�3:�subtract�average
• Subtracting�mean�is�the�best
• helps�identifiability
• not�change�the�relative�rank�of�𝐴 (and�hence�Q)
• Aggregation�module�is�a�part�of�the�network�not�a�algorithmic�step
• training�of�dueling�network�requires�only�back-propagation
21

Compatibility
• Because�the�output�of�dueling�network�is�Q�function
• DQN
• DDQN
• SARSA
• On-policy,�off-policy,�whatever
22

Definition:�Generalized�policy�iteration
23

Experiments:�Policy�evaluation
• Useful�for�evaluating�network�architecture
• devoid of�confounding�factors�such�as�choice�of�exploration strategy,�and�
interaction�between�policy�improvement and�policy�evaluation
• In�experiment,�employ�temporal�difference�learning
• optimizing�𝑦O = 𝑟 + 𝛾𝔼:`~8(<`) 𝑄 𝑠`, 𝑎`, 𝜃O
• Corridor�environment
• exact�𝑄8(𝑠,𝑎) can�be�computed�separately�for�all� 𝑠, 𝑎 ∈ 𝒮×𝒜
24

Experiments:�Policy�evaluation
• Test�for�5,�10,�and�20�actions�(first�tackled�by�DDQN)
• The�stream�𝑽 𝒔; 𝜽, 𝜷 learn�a�general�value�shared�across�many�
similar�actions�at�𝑠
• Hence�leading�to�faster�convergence
25
Performancegapincreasingwiththenumberofactions

Experiments:�General�Atari�Game-Playing
• Similar�to�DQN�(Mnih et al.,�2015)�and add fully-connected layers
• Rescale�the�combined�gradient�entering�the�last�convolutional�layer�
by�1/ 2,�which�mildly�increases�stability
• Clipped�gradients�to�their�norm�less�than�or�equal�to�10
• clipping�is�not�a�standard�practice�in�RL
26

Performance:�Up-to�30�no-op�random�start
• Duel�Clip�>�Single�Clip�>�Single
• Good�job�Dueling�network
27

Performance:�Human�start
28
• Not�necessarily�have�to�generalize�well�to�play�the�Atari�games
• Can�achieve�good�performance�by�simply�remembering�sequences�of�
actions
• To�obtain�a�more�robust�measure�that�use�100�starting�points�
sampled�from�a�human�expert’s�trajectory
• from�each�starting�points,�evaluate�up�to�108,000�frames
• again,�good�job�Dueling�network

Combining�with�Prioritized�Experience�Replay�
• Prioritization�and�the�dueling�architecture�address very�different�
aspects�of�the�learning�process
• Although�orthogonal�in�their�objectives,�these�extensions�
(prioritization,�dueling�and�gradient�clipping)� interact�in�subtle�ways�
• Prioritization�interacts�with�gradient�clipping
• Sampling�transitions�with�high�absolute�TD-errors�more�often�leads�to�gradients�with�higher�
norms�so re-tuned�the�hyper�parameters
29

References
1. [Wang,�2015]�Wang,�Z.,�de�Freitas,�N.,�&�Lanctot,�M.�(2015).�Dueling�network�architectures�for�
deep�reinforcement�learning. arXiv preprint�arXiv:1511.06581.
2. [Van,�2015]�Van�Hasselt,�H.,�Guez,�A.,�&�Silver,�D.�(2015).�Deep�reinforcement�learning�with�
double�Q-learning. CoRR,�abs/1509.06461.
3. [Schaul,�2015]�Schaul,�T.,�Quan,�J.,�Antonoglou,�I.,�&�Silver,�D.�(2015).�Prioritized�experience�
replay. arXiv preprint�arXiv:1511.05952.
4. [Sutton,�1998]�Sutton,�R.�S.,�&�Barto,�A.�G.�(1998). Reinforcement�learning:�An�introduction(Vol.�
1,�No.�1).�Cambridge:�MIT�press.
30
Related Documents











