Distributed Learning Classifier Systems Hai H. Dam, Pornthep Rojanavasu, Hussein A. Abbass, Chris Lokan Artificial Life and Adaptive Robotics Laboratory School of Information Technology and Electrical Engineering The University of New South Wales Australian Defence Force Academy Canberra, Australia {z3140959,s3205770,abbass,cjl}@itee.adfa.edu.au http:://www.itee.adfa.edu.au/˜ alar Abstract. Genetics-based machine learning methods - also called learn- ing classifier systems - are evolutionary computation based data mining techniques. The advantages of these techniques are: they are rule-based models providing human-readable learning patterns; they are incremen- tal learners allowing the system to adapt quickly in dynamic environ- ments; and some of them have linear 0(n) learning complexity in the size of dataset. However, not too much effort has yet been made on inves- tigating these techniques in distributed environments. In this chapter, we investigate several issues of evolutionary learning classifier systems for distributed data mining such as knowledge passing in the system, knowledge combination methods at the server, and the effect of numbers of clients on system’s performance. 1 Introduction Pervasive computing has opened a new era of a flat world where people can easily access and/or transfer data around the world. Instead of tons of books, a huge amount of information can be preserved easily within small and affordable electronic systems. Moreover electronic data are produced in greater amounts with a greater frequency than at any time in the past. Data mining, the process of discovering novel and potentially useful patterns in databases [11], has become the most effective method to assist companies and organizations to discover the tacit knowledge hidden in the overwhelming amount of data. In many data mining problems, the ability to understand the discovered knowledge by the mining algorithms is sometimes as important as obtaining an accurate model. For instance, a company might want to profile customers’ expenditures in terms of their consumption, services, location, income, season, etc. The relationship between those features with regards to customers spend- ing habits can answer questions regarding their purchase behaviors. This sort of information might help managers to identify the best segments to target their marketing campaigns. Patterns in a database can be represented in different forms such as neural networks, decision trees, or rule-based systems. It is poten- tially easier to understand patterns represented using the latter form than those for example represented using a neural network.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Distributed Learning Classifier Systems
Hai H. Dam, Pornthep Rojanavasu, Hussein A. Abbass, Chris Lokan
Artificial Life and Adaptive Robotics LaboratorySchool of Information Technology and Electrical Engineering
The University of New South WalesAustralian Defence Force Academy
Canberra, Australia{z3140959,s3205770,abbass,cjl}@itee.adfa.edu.au
http:://www.itee.adfa.edu.au/˜ alar
Abstract. Genetics-based machine learning methods - also called learn-ing classifier systems - are evolutionary computation based data miningtechniques. The advantages of these techniques are: they are rule-basedmodels providing human-readable learning patterns; they are incremen-tal learners allowing the system to adapt quickly in dynamic environ-ments; and some of them have linear 0(n) learning complexity in the sizeof dataset. However, not too much effort has yet been made on inves-tigating these techniques in distributed environments. In this chapter,we investigate several issues of evolutionary learning classifier systemsfor distributed data mining such as knowledge passing in the system,knowledge combination methods at the server, and the effect of numbersof clients on system’s performance.
1 Introduction
Pervasive computing has opened a new era of a flat world where people caneasily access and/or transfer data around the world. Instead of tons of books, ahuge amount of information can be preserved easily within small and affordableelectronic systems. Moreover electronic data are produced in greater amountswith a greater frequency than at any time in the past. Data mining, the processof discovering novel and potentially useful patterns in databases [11], has becomethe most effective method to assist companies and organizations to discover thetacit knowledge hidden in the overwhelming amount of data.
In many data mining problems, the ability to understand the discoveredknowledge by the mining algorithms is sometimes as important as obtainingan accurate model. For instance, a company might want to profile customers’expenditures in terms of their consumption, services, location, income, season,etc. The relationship between those features with regards to customers spend-ing habits can answer questions regarding their purchase behaviors. This sort ofinformation might help managers to identify the best segments to target theirmarketing campaigns. Patterns in a database can be represented in differentforms such as neural networks, decision trees, or rule-based systems. It is poten-tially easier to understand patterns represented using the latter form than thosefor example represented using a neural network.

II
Genetics-based machine learning systems [13] is a rule-based evolutionarylearning classifier system, which is also known as Learning Classifier System(LCS). In essence, the system employs two biological metaphors to accomplishthe learning tasks by evolving a set of rules. The evolutionary component playsa key role in discovering novel and potentially useful rules. The learning com-ponent, on the other hand, is responsible for assigning credits to rules in thepopulation based on their contributions to execute some tasks and the feed-backs from the environment. Thereby, it guides the search by the evolutionarycomponent to move towards a better set of rules.
Work on LCSs normally falls in one of two categories: the Pittsburgh [22] andthe Michigan [17] approaches. The major difference between the two approachesis that an individual of the Pittsburgh approach is a set of rules representinga complete solution to the learning problem. In contrast, an individual of theMichigan approach is a single rule that represents a partial solution to the overalllearning task. Thus, the Michigan and the Pittsburgh systems are quite differentapproaches to learning. Many studies have compared the performance of the twoapproaches on several data mining problems in order to determine circumstancesin which one approach would perform better than the other [1] [2] [20]. Theirresults revealed in some cases that the Pittsburgh approach is more robust,but it is also computationally very expensive compared to the Michigan one. Inour current research in stream data mining, we hypothesize that Michigan-styleLCSs are more suitable, due to their abilities to learn incrementally on the flyand their smaller space complexity.
Many models of Michigan-style LCSs have been introduced in the last twodecades. Recently, the accuracy-based models have captured most attentionsfrom researchers in the field. XCS [23][24] is the first system of this type, whichworks for both supervised learning and reinforcement learning problems. UCS[4] is a derivation of XCS that specializes on classification tasks. Since we areworking at classification (supervised learning) problems, UCS was chosen as ourbaseline LCS learner.
Nowadays, most databases in large organizations are distributed physicallydue to globalization. For example, a company might have multiple branchesplaced in different cities, states, countries, etc. From management’s perspective,data generated from different nodes need to be combined into a single coherentknowledge base for the future decision making. With the large amount of datagenerated daily at each node, it is not possible to transfer all the data to acentral location for normal data mining due to security issues, limited networkbandwidth, and even because of the internal policies for some organizations.Distributed Data Mining (DDM), an extension of data mining techniques indistributed environments, was introduced to tackle this problem. Even if thedata is not physically distributed, DDM can be used effectively in order to speedup the data mining process.
The primary purpose of DDM is to discover and combine useful knowledgefrom databases that are physically distributed across multiple sites [21]. In 2005,we have proposed the framework of XCS in distributed computing environments

III
called DXCS [8][9]. In this framework, the distributed and central sites are de-scribed in terms of a system of clients and a server. To validate the system,we have compared it with a centralized XCS, which basically transfers all datafrom remote sites to a central location for normal data mining. The results re-vealed that DXCS is competitive as a distributed data mining system due totwo reasons. First, DXCS has similar accuracy to the centralized system. Sec-ond, the amount of data that are needed to be transferred to the central locationis reduced enormously in DXCS compared to a centralized XCS system.
In this paper, we will generalize this framework to LCS in general and UCSin specific. We will investigate the system on several issues such as knowledgepassing and data transmission. This paper will address the following researchquestions:
– How sensitive the system’s performance is with regard to the number ofclients? In previous papers, we only tested the distributed system with twoclients. More clients might make the system behave differently. We hypoth-esize that the system is able to perform better when adding more clients.
– How sensitive the system’s performance is to the method used for gating atthe server? We choose to compare the performance between the knowledgeprobing and majority voting approaches for combining local knowledge atthe server.
– How does the knowledge passing affect the system? In theory, clients needto update their knowledge at the server frequently by sending their models.In our previous paper, we transferred the whole population to the serverconstantly. However, we believe that sending only partial models would re-duce the traffic but still maintain the same level of predictive performance.Moreover, exchanging the knowledge between the clients (instead of limit-ing knowledge passing between clients and the server alone) would help toincrease the performance at clients and therefore at the server.
The paper is structured as follows. The next section provides a short review ofdistributed data mining followed by an introduction of LCS in general and UCSin specific. Section 4 describes our proposed framework. The experimental setupis explained in Section 5 followed by discussion sections. Finally, the conclusionis presented.
2 Distributed Data Mining
2.1 Overview
Distributed data mining has played an important role for two main reasons. First,centralized data mining often requires a huge amount of resources for storageand computation. To scale systems, the work load needs to be distributed amongseveral sites for parallel processing. Second, data is often physically distributedinto several databases, making a centralized processing of these data very in-efficient and prone to security risks. Distributed Data Mining (DDM) explorestechniques for applying Data Mining in a non-centralized way.

IV
DDM is a relatively new area but has been receiving much attention, espe-cially in distributed computing environments where trust between sites is notalways complete or mutual [18]. In many applications, data are privacy-sensitive,so that centralizing the data is usually not acceptable [12]. Therefore, DDM tech-nology are adopted in many applications to reduce the transmission of data andthus to protect raw data.
According to Kargupta [19], DDM applies data mining algorithms at bothlocal level, extracting potentially useful and novel knowledge at each distributedsite; and global level, combining and fusing the local knowledge in order to formthe global knowledge. The typical architecture of a DDM system is illustratedin Figure 1. It normally contains three main phases: mining at the local sites;transmission of data among remote sites; and combining the local knowledgeinto a single coherent knowledge base. For example, a company may have manybranches. Each local branch may receive different data which would result in dif-ferent learnt models. The central office of the company is responsible to combinethese local models in order to gain an overall view of the company as a whole.
Fig. 1. Typical architecture of DDM

V
Distributed databases can be divided into two main categories: homogeneousand heterogeneous. In the former case the databases located at different siteshave the same attributes in the same format (same data dictionary). In the lattercase, each local site may collect different data, thus it may have different numberof attributes, type of attributes, format of attributes, and etc. The focus of thispaper is on homogeneous databases.
2.2 Learning in Distributed Environments
There are three main approaches for mining distributed databases as follows [7]:
– Combining data: Combine the distributed databases logically as a singlelarge database during the learning process and allow communication of theintermediate results. The learned concept represents the distributed dataand can be applied to incoming data instances.
– Combining local models: Learn individual local sites independently and com-bine the locally learned models to form a global concept. Here the locallylearned model can be some kinds of rules or decision trees and the globalconcept is the final rule set or decision tree which will be used for classifica-tion on some incoming new instances.
– Combining the predictive models: When receiving an incoming new instance,local models are used to predict the class then the locally learned concept ineach local database is used to form a consensus classification. This strategyis to apply a classification technique on the local database to form somemeta-data for further classification training. Thus we have multiple levels ofclassifiers in a distributed environment.
The first approach or centralized data mining is the easiest one but is eitherineffective or infeasible due to several reasons:
– Storage Cost: It is obvious that the central storage system needs to be verylarge in order to host all data from the distributed sites. Assume a super-market with several stores. Data from local stores is sent to the centralizedsite daily, weekly, or monthly. A record at each store represents a singletransaction of a customer, which contains information of payment detailsand products purchase. A small store might have only a few hundreds oftransactions per day, but a large store might have an order of magnitudeor more transactions per day. The size of data of such a large store such asthe WalMart supermarket is reaching the scale of gigabytes and terabytesdaily and continuing to increase. Thus, central storage requires a huge datawarehouse which costs enormously.
– Communication Cost: To transfer huge volumes of data to the central sitemight take extremely long time and require huge network bandwidths. Since

VI
data at local sites is not static, their knowledge need to be updated fre-quently in order to maintain up-to-date knowledge at the central site. Anefficient algorithm needs to reduce the bottleneck of the transmission but atthe same time has to update data as frequently as possible.
– Computational Cost: The computational time at the central site is muchbigger than the aggregate cost of learning different models locally in parallelat local sites.
– Private and Sensitive Data: Sending raw data to the central site is not de-sirable since it puts privacy into risk at either the central location or duringtransmission in the network. In many cases, for example, local branchesmight need to compete with each other; thus they may wish to limit dataexchange to the knowledge level related to a particular data mining exercisewithout sending all of their raw data.
In short, the last two approaches are better than the first one due to twomain advantages. Firstly, the local model is normally much smaller than thelocal data: sending only the model thus reduces the load on the network andthe network bandwidth requirement. Secondly, sharing only the model, insteadof the data, gains reasonable security for some organizations since it overcomespartially the issues of privacy and security.
A number of approaches have been introduced in the literature for buildinga single rule set from a distributed database. Hall et. al. [15] [16] present amethod to convert a decision tree from each distributed sites into a set of rules;and combining those distributed rule sets into a single rule set. Cho et. al. [7]propose an alternative method that learns a single rule for each class at eachlocal site. The rule of each class is shortened by an order of importance withrespect to confidence, support, and deviation. The final rule set contains a set ofn first rules in the list. The most important part of this approach is to resolveconflicts while taking the union of the distributed rule sets.
In homogeneous data, a large fraction of DDM approaches focuses on thethird method. Combining a set of predictive models has emerged from empiricalexperimentation due to a requirement for a higher prediction accuracy. Recently,several researchers have treated distributed learning systems as a centralizedensemble-based method [10]. Several learning algorithms are applied at eachlocal sites on separate training data for mining local knowledge. A new datapoint is then classified/predicted from predictions of all local sites using ensemblemethods such as stacking, boosting, majority voting, simple average, or winner-take-all methods. In general, DDM approaches applied ensemble methods tominimize the communication costs and to increase the system prediction.
Meta-learning methodology was introduced by Chan and Stolfo [6] in 1993based on the idea of Stacked Generalization [26]. In this approach, each localsite may employ a different inductive learning algorithm for constructing its localmodel. A meta-classifier is trained using data generated by the local models. Thisprocess is applied recursively to produce an arbiter tree, which is a hierarchy of

VII
meta-classifiers. This approach has been showed to achieve better performancein comparison to majority voting for fraud detection in the banking domain. Analternative method built on the idea of meta-learning is the knowledge probing(KP) developed by Guo and Sutiwaraphun [14]. This method uses an indepen-dent dataset and does not build an arbiter tree. The output of a meta-learningsystem on this independent dataset together with the label vector of the samedataset are used to form a new training set for the learning algorithm that resultsin the final model. In our previous paper, we have applied the KP and achieveda good performance. This paper will compare the KP with a simple but effectiveapproach, the majority voting.
The next section provides a brief review about the evolutionary learningclassifier system.
3 Evolutionary Learning Classifier Systems
LCS is a rule-based evolutionary learning classifier system, in which each clas-sifier implements a partial task to the target problem. A typical goal of LCS isto evolve a population of classifiers [P ] to represent a complete solution to thetarget problem. LCS can be used either for reinforcement learning (e.g XCS) orsupervised learning (e.g UCS) for evaluating classifiers in the population. Thispaper focusses mainly on UCS (supervised classifier system).
Each classifier consists of the Condition (the body of the rule), the Action(the prediction of the classifier) and some parameters. The Condition refers toseveral environmental states, to which the classifier may match. The Action is anoutcome if the classifier is fired/activated. The key parameter associated with aclassifier is the fitness F, which measures how good the classifier is relative to therest of the population. Another two important parameters are the numerosityand experience. A classifier of LCS is a macro–classifier, which holds a distinctrule (a unique pair of Condition:Action) within the population. The numerosityparameter records the number of copies of the classifier in [P]. Whenever a newclassifier is introduced, the population is scanned through to check if a copy of italready exists. If it does not, the classifier is added to the population; otherwise,the numerosity value is incremented by one. The experience parameter indicateshow often the classifier is chosen for making the prediction; in other words, howgeneral the classifier is.
During the learning cycle, the system repeatedly receives an input from theenvironment. After processing the input, an appropriate outcome is producedand returned to the environment. Feedbacks by the environment is given imme-diately in terms of a reward (in the case of XCS) or a simple year/no answer (inthe case of UCS) reflecting how good the decision was.
A match set [M] is formed for each input, containing all classifiers in thepopulation [P] whose condition matches the input. Classifiers in [M] will worktogether to decide on the system’s outcome.

VIII
In exploitation phase, a prediction array [PA] is formed for estimating thevalue of each possible action in [M] with regards to their fitness. An action havingthe highest value in [PA] will be selected to be exported to the environment.
The exploration phase, on the other hand, is more complicated. A correct set[C] is formed, containing those classifiers in [M] that have the same action asthe input. If [C] is empty, covering is applied, where a classifier that matchesthe input, is created and assigned the same class with the input.
The parameters of classifiers in [M] are updated incrementally. GA is in-voked in [C] when the average experience of classifiers in [C] is higher than athreshold defined by the user. Two parents are selected from [C] with proba-bility proportional to their fitness. Two offspring are generated by reproducing,crossing–over, and mutating the parents with certain probabilities. Offspring areinserted in [P]. The parents also remain in [P] to compete with the offspring. Ifthe population size exceeds the predefined limit, some inaccurate classifiers areremoved from [P].
4 Distributed Learning Classifier Systems (DLCS)
This section describes the main features of our proposed system called the DLCS.Similar to DXCS, the system consists of a number of clients and a server. Aclient represents a distributed site and is responsible for gathering the localknowledge. The local knowledge is transferred to the server frequently. The serveris responsible to combine the knowledge collected from clients in order to forma descriptive model for the global environment.
4.1 The Framework of DLCS
Clients Each client employs a complete LCS which is trained independently byits local database. The population of LCS starts from an empty set and keepsevolving during the training process. Whenever a training instance is input to thelocal LCS, a suitable output is chosen with respect to its available knowledge.The output is then compared against the real class of that input instance. Ifthe system predicts correctly, that training instance is discarded; otherwise, itis kept in a memory so that it gets transferred to the server at a later stage fortraining at the server.
Each client transfers both its local learned model (the population of rules)and a set of misclassified instances to the server after a period of time, which isdefined by the user.
Server The server keeps all local models in its memory and avoids to modifytheir contents. These models are only updated by those new models received fromtheir local sites, to reflect the most up-to-date knowledge of the local databases.
The client’s models are aggregated at the server. Each input instance at theserver is processed by all client models. Different predictions might be producedaccording to the knowledge of the clients models. The final output at the server

IX
is decided between those predictions using several knowledge fusion methods.The next subsection will describe two methods for combining these predictions,which are tested in this paper.
4.2 Knowledge Combination at the Server
After receiving the updated models and training data from all clients, the serverwill combine the local models into a single coherent knowledge base. In our pre-vious paper, we have applied the knowledge probing technique in the distributedframework and obtained promising results. In this paper, we will compare knowl-edge probing with a majority voting gate at the server. We chose majority votingbecause it is an effective and very simple approach, which is widely used in en-semble learning.
Knowledge Probing An simple LCS is employed at the server to learn the out-puts from the client models. The misclassified instances from clients are treatedas the training instances of the LCS at the server. An algorithm to create a newtraining instance for the LCS is described as follows.
– Form New Inputs:• A set T of n server training instances
T = {(t1, c1); (t2, c2); ..; (tn, cn)} where t is a training instance and c isan associated class.
• A set L of m local XCS models L = {l1, l2, .., lm}• A learning algorithm XCS, which provides the descriptive output and
represents the global view of the database.– Prediction Phase: Obtain outputs from each model in L for each data item in
T and form an ensemble training instances. The outputs of the nth instancetn from set L models are a set On: On = {on1, on2, .., onm}. The set Oconsists of the ensemble training instances for XCS O = {O1, O2, ..On}. Thenew server training set becomes S = {(O1, c1); (O2, c2); ...; (On, cn)}
– Learning Phase: Learning from data entries in the server training set S,L∗ = XCS{(O1, c1); (O2, c2); ...; (On, cn)}
– Output: descriptive model L* obtained from the learning phase.
Majority Voting The output of the ensemble is the class which receives thevote of the majority of predictions in the ensemble.
4.3 Traffic Load
In [8], we have formed the formula for estimating the data transmission betweenclients and server for binary domain based on the Minimum Description Length(MDL) principle in a similar way as [3]. The formula evaluates the complexityand accuracy of the model in terms of data compression. The data needed for thetransmission between the client and the server includes the model, misclassified

X
samples, and training samples. Therefore, the cost of transmission is equivalentto the number of bits needed to encode the model (theory bits) plus misclassifiedand training samples (exception bits).
MDL = theory bits + exception bits
The length of the theory bits (TL) is the length of classifiers travelling to theserver. The classifiers have a common structure: Condition −→ Action andtherefore their lengths are defined as follows:
TL =nr∑
i=1
(TLi) +nr∑
i=1
(CLi) (1)
Where nr is the number of rules of the model; TLi and CLi are the length ofcondition and class respectively. They can be estimated as follows:
TLi = nb
CLi = log2(nc)
where nb is the number of bits required to encode a complete set of conditionsand nc is the cardinality of the set of possible classes. For example, in the 20-multiplexer problem, nc = 2 while nb = log2(320) since we have an alphabet of3 symbols {0, 1, #} to encode 20 attributes corresponding to the 320 instances.Therefore, the theory bits are estimated as:
TL = nr(nb + log2(nc))
Similarly, the exception part of the MDL principle (EL) is estimated as follows:
EL = (nm + nu)(na + log2(nc))
where nm is the number of misclassified samples, nu is the number of unusedtraining samples at the clients and na is the number of bits required to encodea training example.
Thus, the length of data sent from one client to its server is:
MDL = (nr)(nb) + (nm + nu)(na) + (nr + nm + nu)(log2(nc))
5 Experimental Setup
We conducted several experiments on the 6-bits and 11-bits multiplexer prob-lems. The DLCS system is developed in C++. Unless it is stated otherwise, UCSis setup with the same parameter values used by Wilson [25] and Bernado [4] asfollows: v = 10, θGA = 25, χ = 0.8, µ = 0.04, θdel = 20, θsub = 20, N = 800 for11-bits multiplexer and N = 2000 for 20-bits multiplexer. Two points crossoverand tournament selection are used.
XI
6 Combining Knowledge at the Server
This section will answer the second research question. In previous papers, wehave combined the knowledge at the server using the knowledge probing ap-proach and obtained promising results. In this section, we compare the knowledgeprobing approach with one of the most popular methods in ensemble learning,the majority voting. In this experiment, the clients in both cases will receive thesame data and the same parameter setups. The only difference occurs at theserver for combining the predictions from client models.
6.1 Noise free environments
0 100 200 300 400 5000.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
iterations (50 instances)
Per
form
ance
KPVOTING
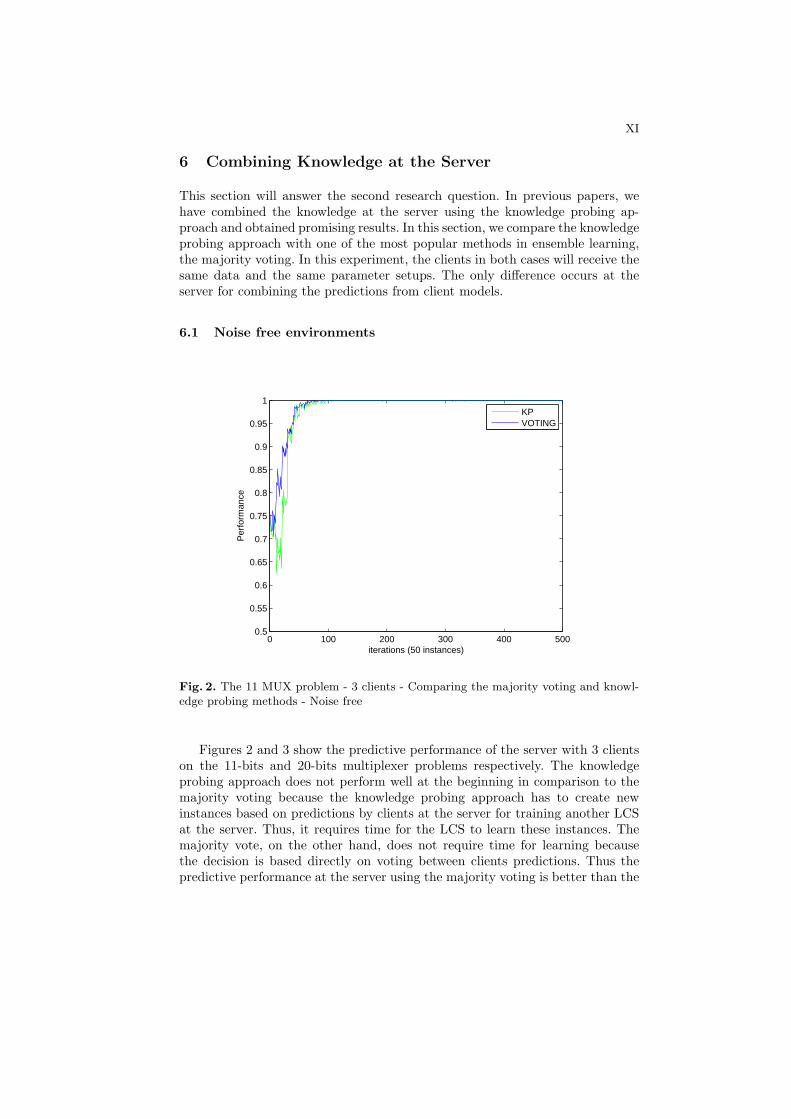
Fig. 2. The 11 MUX problem - 3 clients - Comparing the majority voting and knowl-edge probing methods - Noise free
Figures 2 and 3 show the predictive performance of the server with 3 clientson the 11-bits and 20-bits multiplexer problems respectively. The knowledgeprobing approach does not perform well at the beginning in comparison to themajority voting because the knowledge probing approach has to create newinstances based on predictions by clients at the server for training another LCSat the server. Thus, it requires time for the LCS to learn these instances. Themajority vote, on the other hand, does not require time for learning becausethe decision is based directly on voting between clients predictions. Thus thepredictive performance at the server using the majority voting is better than the
XII
0 100 200 300 400 5000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
KPVOTING
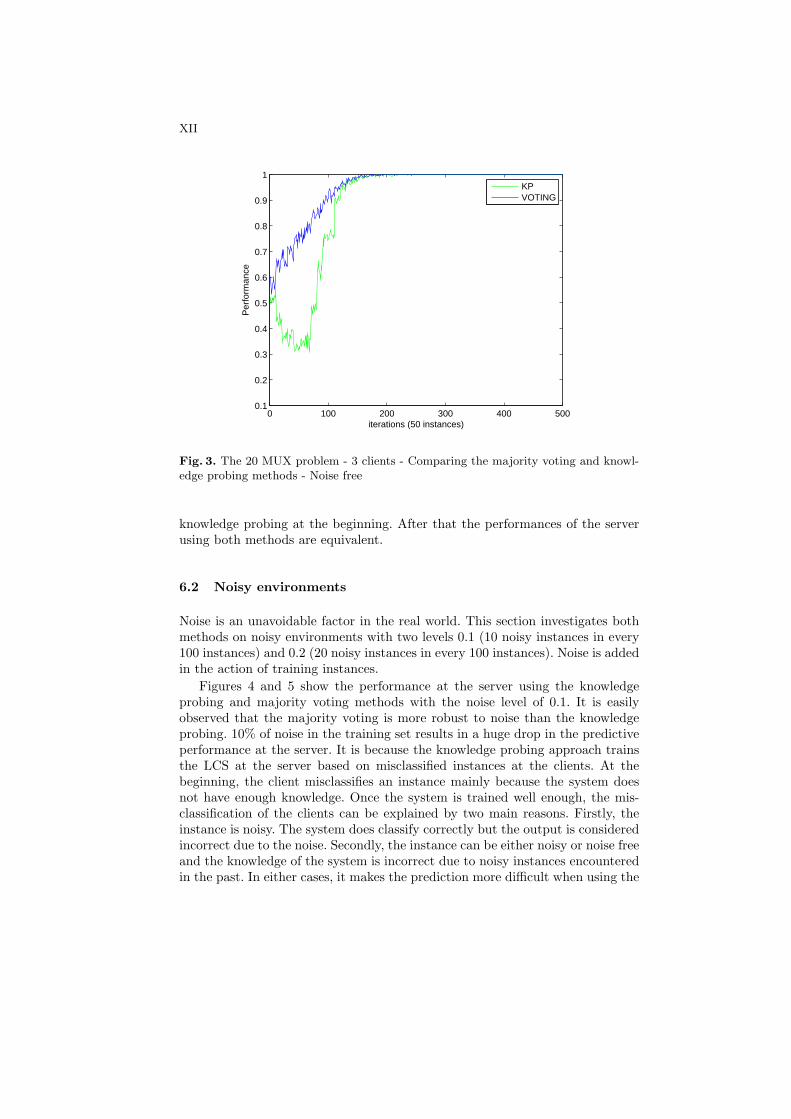
Fig. 3. The 20 MUX problem - 3 clients - Comparing the majority voting and knowl-edge probing methods - Noise free
knowledge probing at the beginning. After that the performances of the serverusing both methods are equivalent.
6.2 Noisy environments
Noise is an unavoidable factor in the real world. This section investigates bothmethods on noisy environments with two levels 0.1 (10 noisy instances in every100 instances) and 0.2 (20 noisy instances in every 100 instances). Noise is addedin the action of training instances.
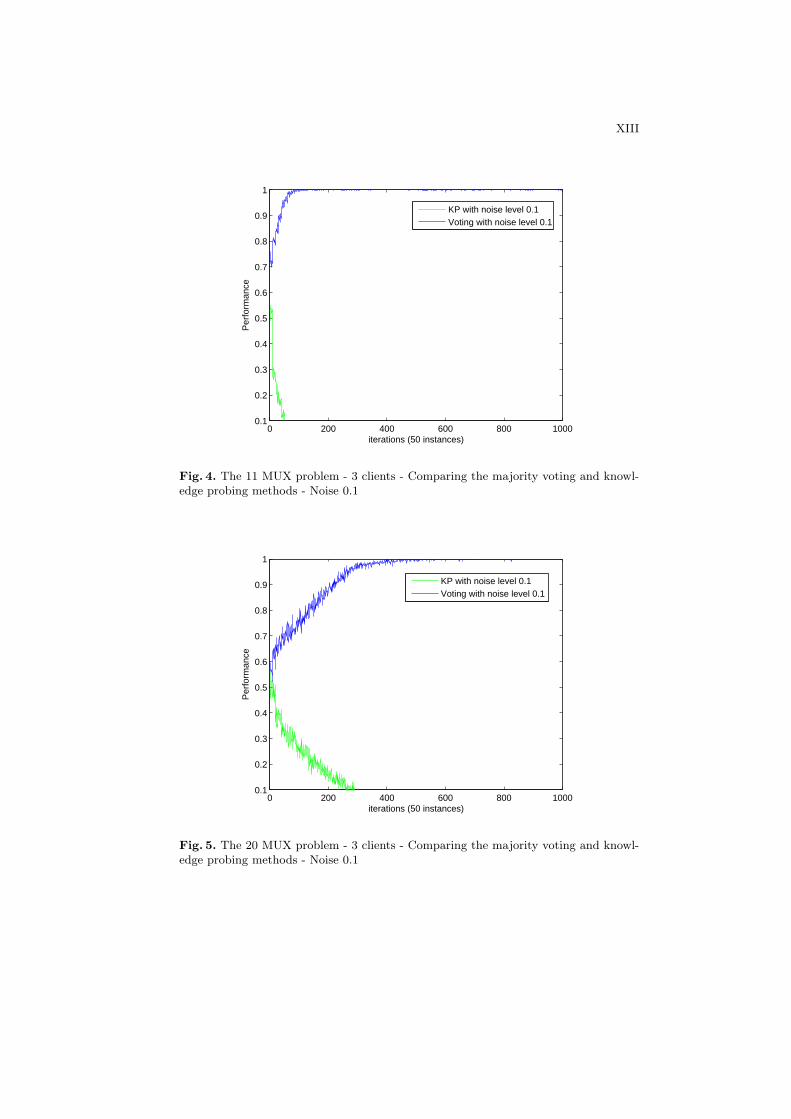
Figures 4 and 5 show the performance at the server using the knowledgeprobing and majority voting methods with the noise level of 0.1. It is easilyobserved that the majority voting is more robust to noise than the knowledgeprobing. 10% of noise in the training set results in a huge drop in the predictiveperformance at the server. It is because the knowledge probing approach trainsthe LCS at the server based on misclassified instances at the clients. At thebeginning, the client misclassifies an instance mainly because the system doesnot have enough knowledge. Once the system is trained well enough, the mis-classification of the clients can be explained by two main reasons. Firstly, theinstance is noisy. The system does classify correctly but the output is consideredincorrect due to the noise. Secondly, the instance can be either noisy or noise freeand the knowledge of the system is incorrect due to noisy instances encounteredin the past. In either cases, it makes the prediction more difficult when using the
XIII
0 200 400 600 800 10000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
KP with noise level 0.1Voting with noise level 0.1
Fig. 4. The 11 MUX problem - 3 clients - Comparing the majority voting and knowl-edge probing methods - Noise 0.1
0 200 400 600 800 10000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
KP with noise level 0.1Voting with noise level 0.1
Fig. 5. The 20 MUX problem - 3 clients - Comparing the majority voting and knowl-edge probing methods - Noise 0.1
XIV
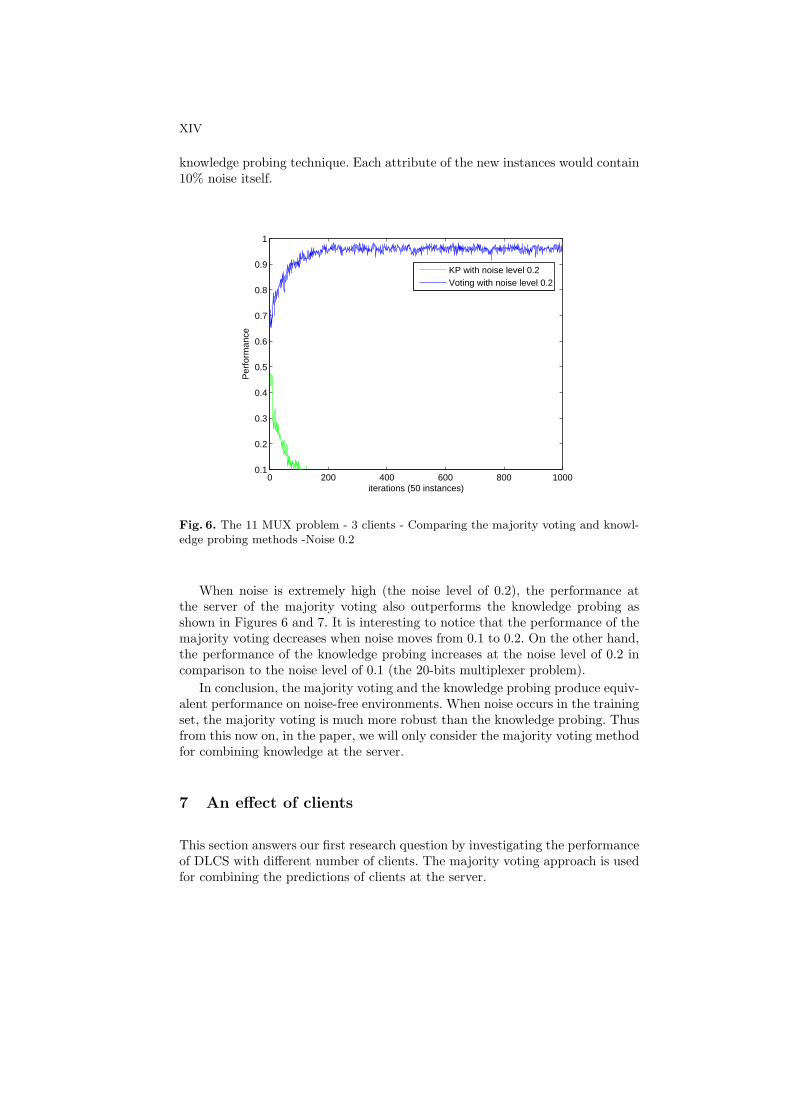
knowledge probing technique. Each attribute of the new instances would contain10% noise itself.
0 200 400 600 800 10000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
KP with noise level 0.2Voting with noise level 0.2
Fig. 6. The 11 MUX problem - 3 clients - Comparing the majority voting and knowl-edge probing methods -Noise 0.2
When noise is extremely high (the noise level of 0.2), the performance atthe server of the majority voting also outperforms the knowledge probing asshown in Figures 6 and 7. It is interesting to notice that the performance of themajority voting decreases when noise moves from 0.1 to 0.2. On the other hand,the performance of the knowledge probing increases at the noise level of 0.2 incomparison to the noise level of 0.1 (the 20-bits multiplexer problem).
In conclusion, the majority voting and the knowledge probing produce equiv-alent performance on noise-free environments. When noise occurs in the trainingset, the majority voting is much more robust than the knowledge probing. Thusfrom this now on, in the paper, we will only consider the majority voting methodfor combining knowledge at the server.
7 An effect of clients
This section answers our first research question by investigating the performanceof DLCS with different number of clients. The majority voting approach is usedfor combining the predictions of clients at the server.

XV
0 200 400 600 800 10000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
KP with noise level 0.2
Voting with noise level 0.2
Fig. 7. The 20 MUX problem - 3 clients - Comparing the majority voting and knowl-edge probing methods - Noise 0.2
7.1 Noise free environments
We experimented with a distributed system of 3 and 5 clients in noise freeenvironments.
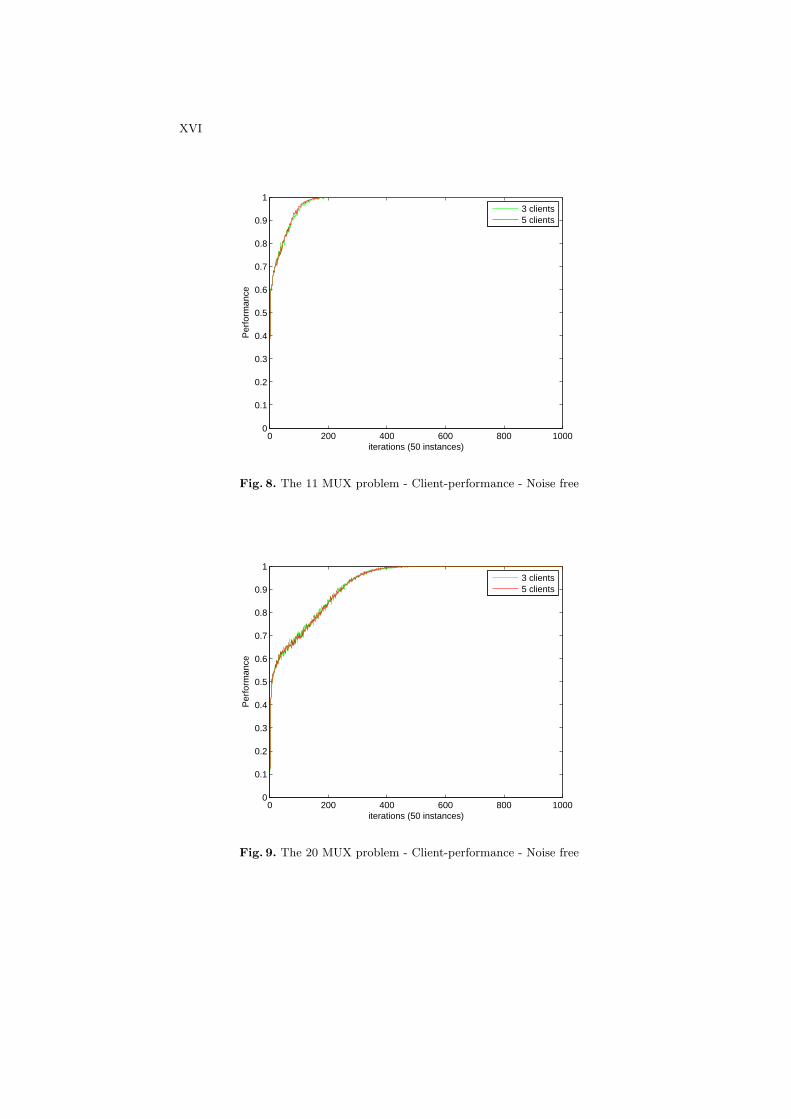
Figures 8 and 9 show the average accuracy at the clients on the 11-bitsand 20-bits multiplexer problems. Since each client employs an UCS and learnsindependently their local data, the predictive performance is not affected by thenumber of clients.
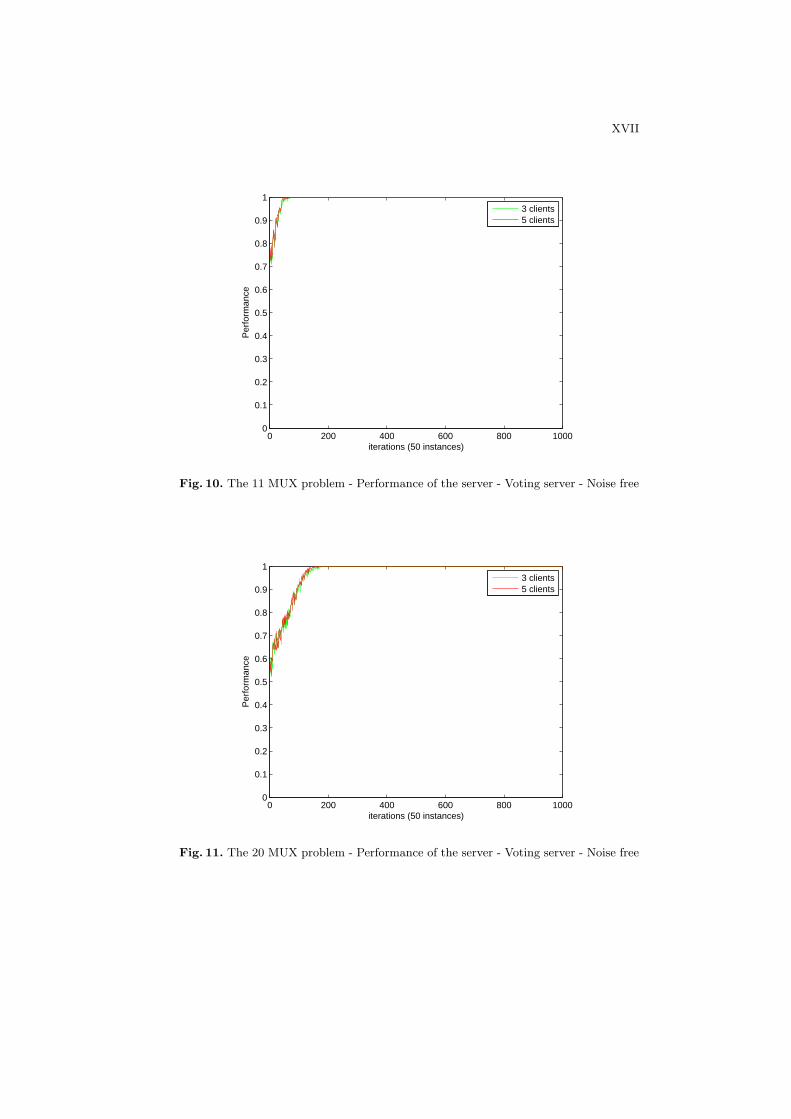
Figures 10 and 11 show the predictive performance at the server on the 11-bits and 20-bits multiplexer problems respectively. The server does not performwell at the beginning on both problems because the clients have not accumulatedenough knowledge from the local sites. When the clients achieve approximately100% accuracy, the server could reach as close as 100% accuracy in most cases.
7.2 Noisy environments
We tested the system on two levels of noise: (the medium level) 0.1 and (theextreme level) 0.2.
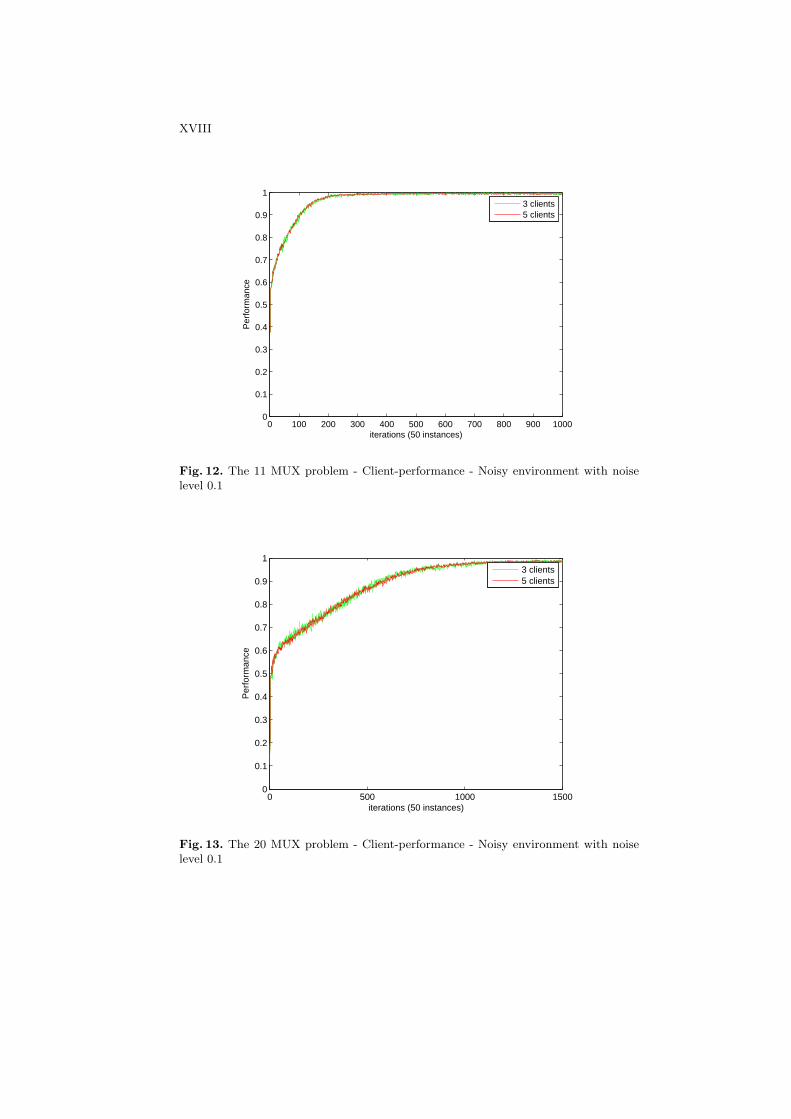
Predictive Performances at Clients Figures 12 and 13 show the performanceof the server on the 11-bits and 20-bits multiplexer problems with noise levelsof 0.1. The predictive performances of clients obviously decreases in noisy en-vironments. In both 11-bits and 20-bits multiplexer problems, the clients learn
XVI
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 8. The 11 MUX problem - Client-performance - Noise free
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 9. The 20 MUX problem - Client-performance - Noise free
XVII
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 10. The 11 MUX problem - Performance of the server - Voting server - Noise free
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 11. The 20 MUX problem - Performance of the server - Voting server - Noise free
XVIII
0 100 200 300 400 500 600 700 800 900 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 12. The 11 MUX problem - Client-performance - Noisy environment with noiselevel 0.1
0 500 1000 15000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 13. The 20 MUX problem - Client-performance - Noisy environment with noiselevel 0.1
XIX
much slower than the noise free environment. The performance of the 11-bitmultiplexer problem can still achieve as high as 100% accuracy, but the 20-bitmultiplexer problem requires much longer time in order to achieve as close as100% accuracy.
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 14. The 11 MUX problem - Client-performance - Noisy environment with noiselevel 0.2
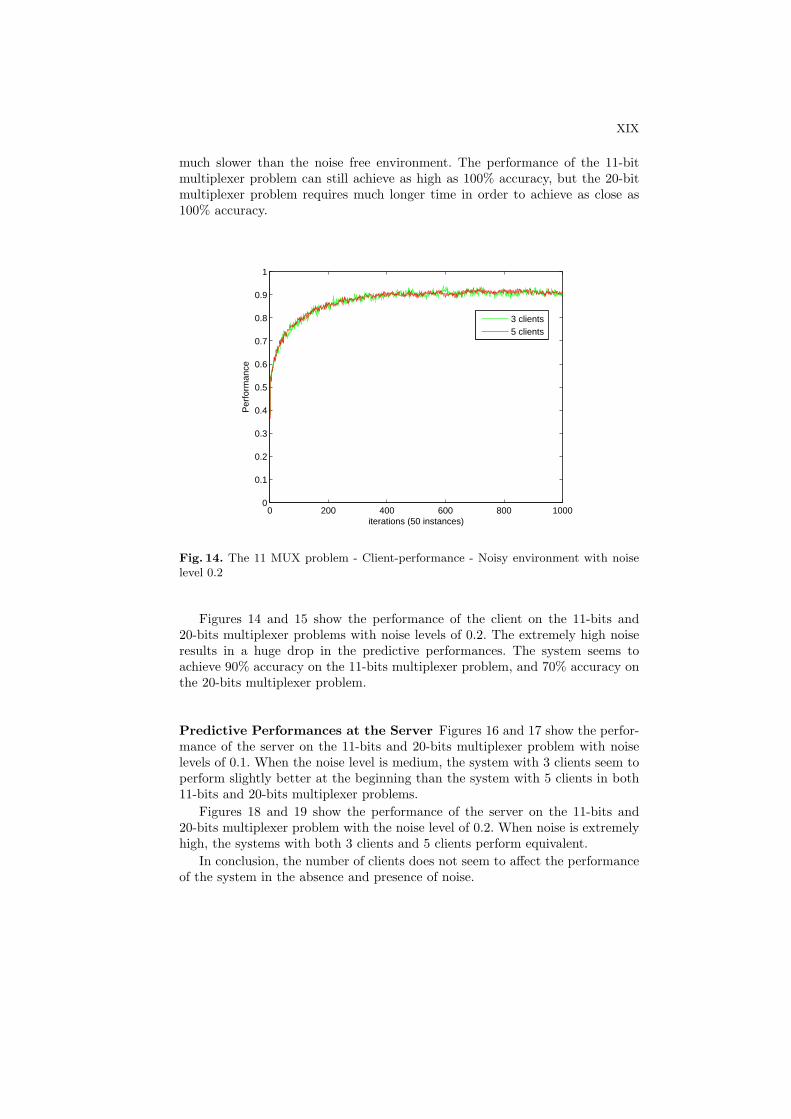
Figures 14 and 15 show the performance of the client on the 11-bits and20-bits multiplexer problems with noise levels of 0.2. The extremely high noiseresults in a huge drop in the predictive performances. The system seems toachieve 90% accuracy on the 11-bits multiplexer problem, and 70% accuracy onthe 20-bits multiplexer problem.
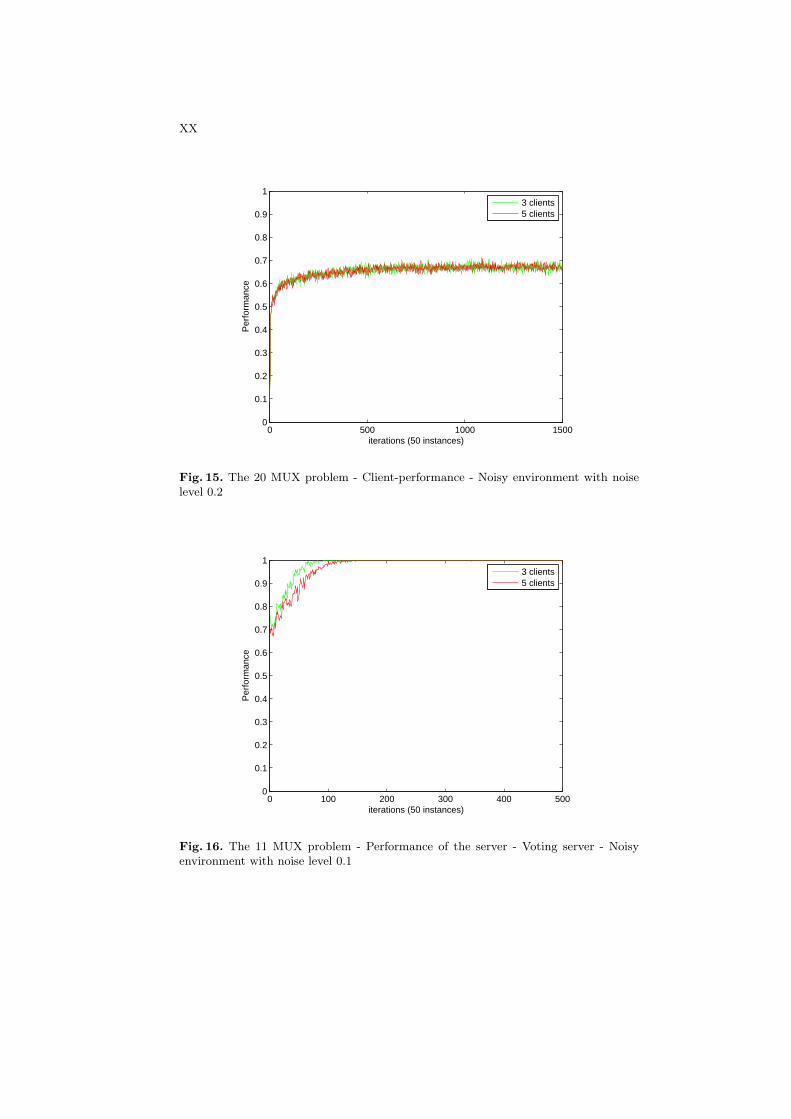
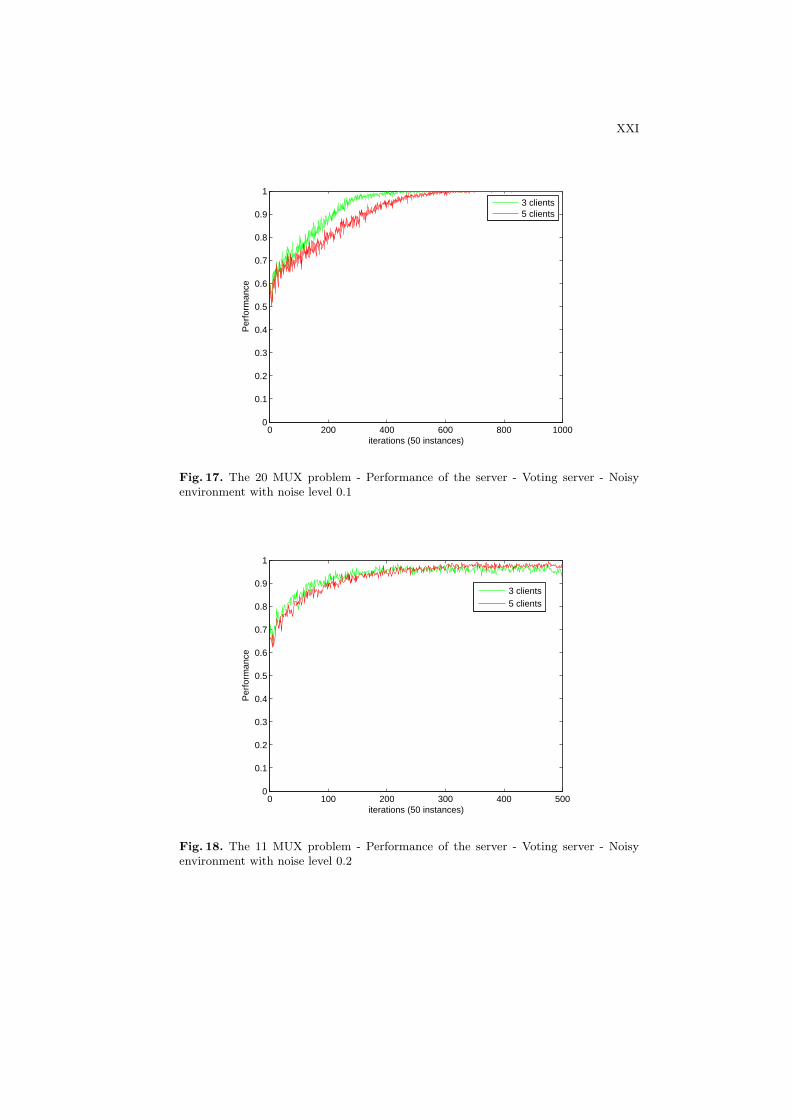
Predictive Performances at the Server Figures 16 and 17 show the perfor-mance of the server on the 11-bits and 20-bits multiplexer problem with noiselevels of 0.1. When the noise level is medium, the system with 3 clients seem toperform slightly better at the beginning than the system with 5 clients in both11-bits and 20-bits multiplexer problems.
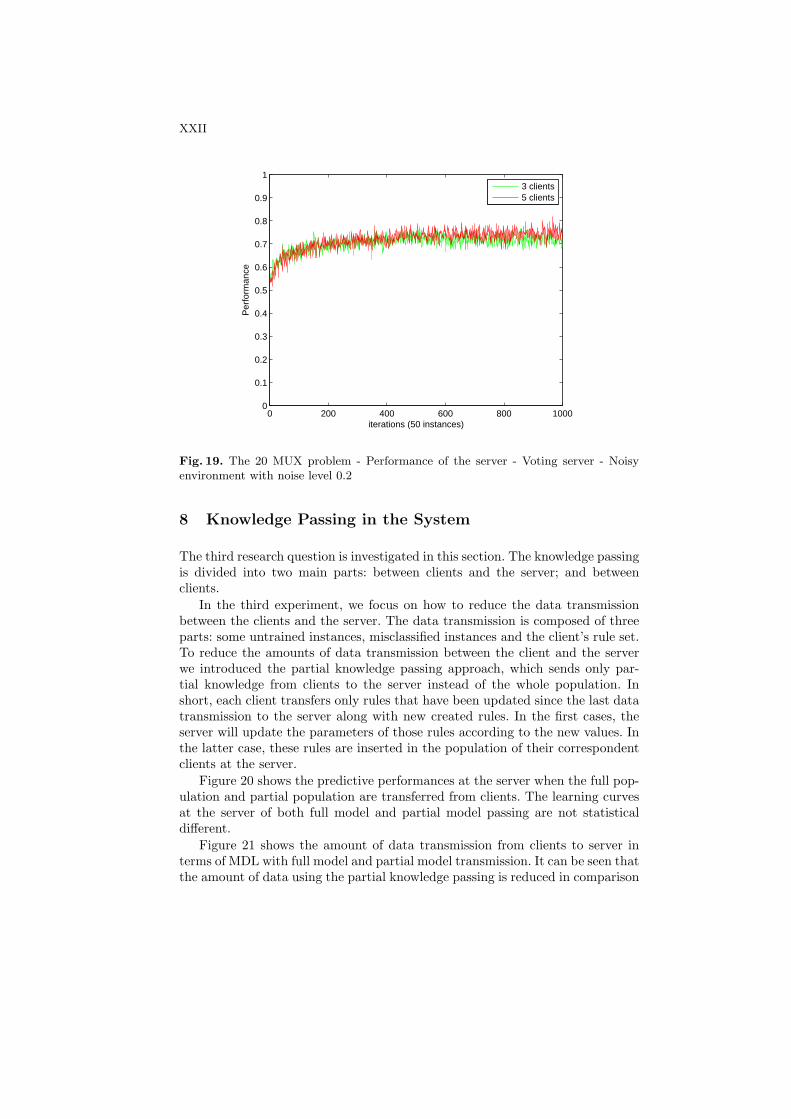
Figures 18 and 19 show the performance of the server on the 11-bits and20-bits multiplexer problem with the noise level of 0.2. When noise is extremelyhigh, the systems with both 3 clients and 5 clients perform equivalent.
In conclusion, the number of clients does not seem to affect the performanceof the system in the absence and presence of noise.
XX
0 500 1000 15000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 15. The 20 MUX problem - Client-performance - Noisy environment with noiselevel 0.2
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 16. The 11 MUX problem - Performance of the server - Voting server - Noisyenvironment with noise level 0.1
XXI
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 17. The 20 MUX problem - Performance of the server - Voting server - Noisyenvironment with noise level 0.1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 18. The 11 MUX problem - Performance of the server - Voting server - Noisyenvironment with noise level 0.2
XXII
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
3 clients5 clients
Fig. 19. The 20 MUX problem - Performance of the server - Voting server - Noisyenvironment with noise level 0.2
8 Knowledge Passing in the System
The third research question is investigated in this section. The knowledge passingis divided into two main parts: between clients and the server; and betweenclients.
In the third experiment, we focus on how to reduce the data transmissionbetween the clients and the server. The data transmission is composed of threeparts: some untrained instances, misclassified instances and the client’s rule set.To reduce the amounts of data transmission between the client and the serverwe introduced the partial knowledge passing approach, which sends only par-tial knowledge from clients to the server instead of the whole population. Inshort, each client transfers only rules that have been updated since the last datatransmission to the server along with new created rules. In the first cases, theserver will update the parameters of those rules according to the new values. Inthe latter case, these rules are inserted in the population of their correspondentclients at the server.
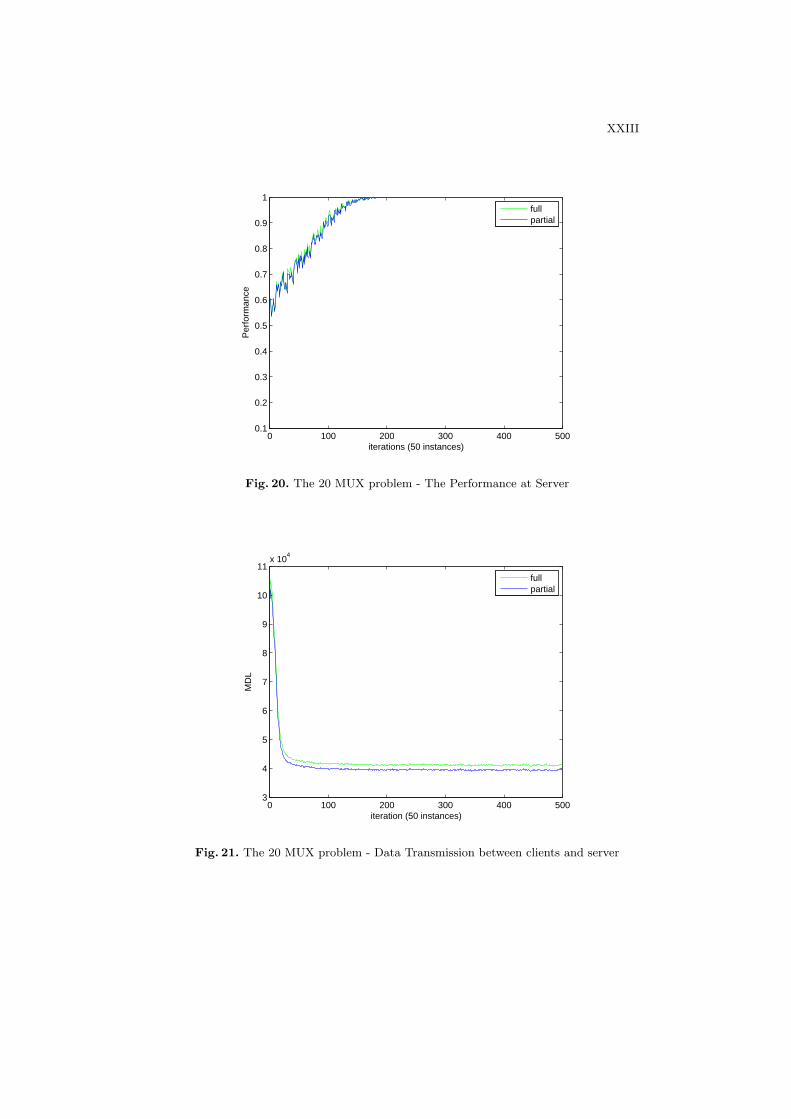
Figure 20 shows the predictive performances at the server when the full pop-ulation and partial population are transferred from clients. The learning curvesat the server of both full model and partial model passing are not statisticaldifferent.
Figure 21 shows the amount of data transmission from clients to server interms of MDL with full model and partial model transmission. It can be seen thatthe amount of data using the partial knowledge passing is reduced in comparison
XXIII
0 100 200 300 400 5000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
fullpartial
Fig. 20. The 20 MUX problem - The Performance at Server
0 100 200 300 400 5003
4
5
6
7
8
9
10
11x 10
4
MD
L
iteration (50 instances)
fullpartial
Fig. 21. The 20 MUX problem - Data Transmission between clients and server

XXIV
to sending the full model. Thus by sending only updated rules to the server helpsto save the traffic while maintaining the system performance.
8.1 Knowledge Sharing between Clients
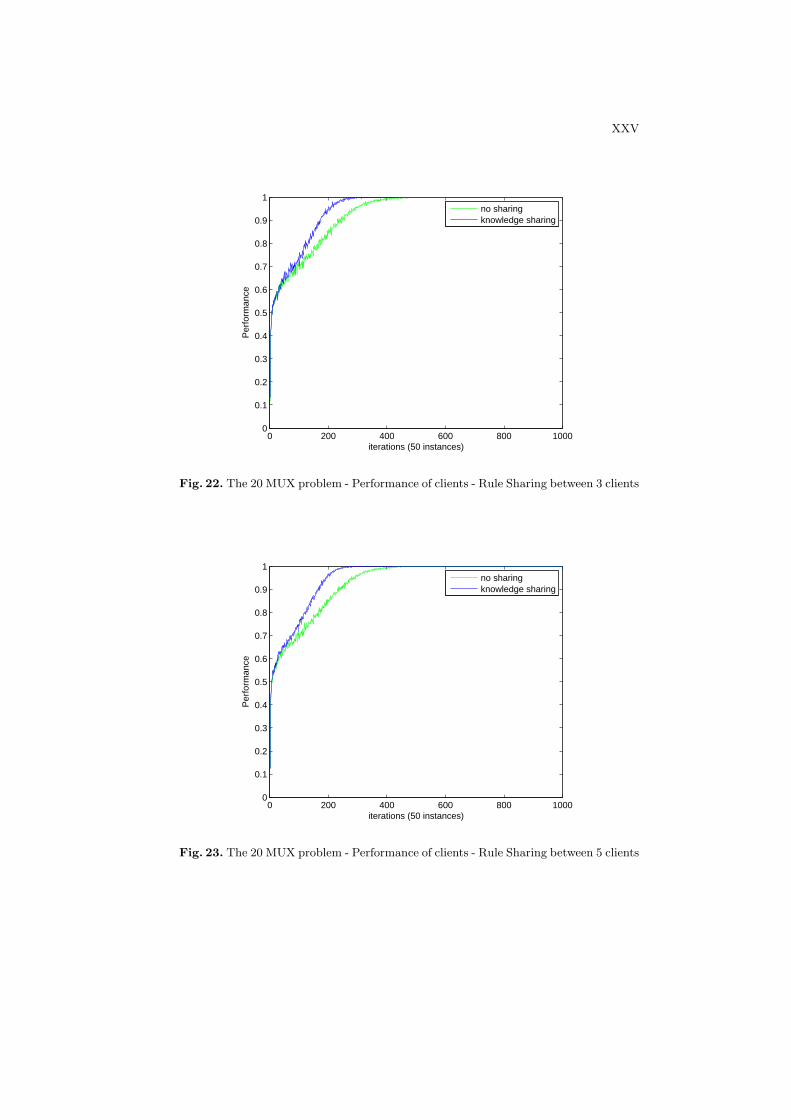
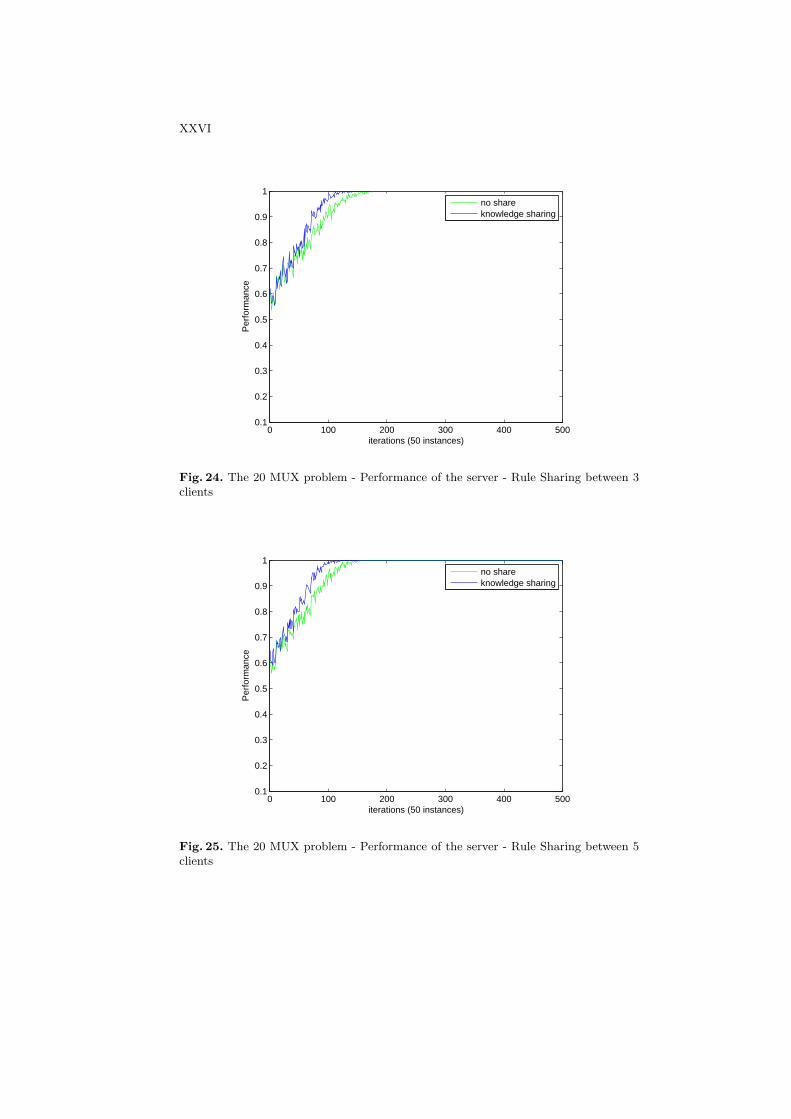
In this section, we focus on improving the system performance by sharing theknowledge between clients. Bull et al. [5] presented an idea of the rule sharingin ensembles of LCS. Their system is constructed by 10 LCSs and tested on the20-bits multiplexer problem. The final prediction of the system is computed bymajority voting among outputs from those LCSs. The rule migration mechanismwas proposed in order to improve the learning speed of the system. It is takenplace in an action set [A] when the average time since the last rule sharingexceeds a threshold defined by users. If the condition is met, a single rule ischosen according to their fitness using the standard roulette-wheel selection.This rule is sent to another population in the ensemble.
In our framework, we also apply this idea for sharing the knowledge betweenclients. The rule sharing is carried out at the client level, where clients exchangetheir available knowledge to each other. The main difference with Bull’s work isthat our clients are trained with independent datasets and the migration rulesare chosen in the population. The sharing decision is chosen after a fixed timewindow. Each client has its own temporary pools for keeping migration rulesfrom other sites. After a time window, in our experiment we set to 5 instances,each client chooses a rule from its population based on the fitness. The clientsends the rule to a random clients in the system. The rule is placed in the poolof that client waiting for integration into its population.
Figures 22 and 23 show the predictive performance of clients on the 11-bits multiplexer problem with and without knowledge sharing between clientson the system of 3 clients and 5 clients. We can see that the average clientperformance is improved when using knowledge sharing. The improvement ofeach client performance directly impact on the performance at the server as itis shown in Figures 24 and 25.
9 Conclusion
This paper investigates a learning classifier system in a distributed computingenvironment. We proposed a distributed client-server framework, where eachclient employs a complete learning classifier system that is trained on the localdata. The server stores the models of all clients in the memory and update themfrequently. The final decision at the server is combined between predictions ofthose clients.
We tested the system on the 11-bits and 20-bits multiplexer problems inorder to answer three main research questions stated in the introduction. Thefirst question is related to the number of clients in the system. We hypothesizedthat increasing the number of clients would help the server to learn faster. Theresults shown that the number of clients do not actually affect the predictive
XXV
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
no sharingknowledge sharing
Fig. 22. The 20 MUX problem - Performance of clients - Rule Sharing between 3 clients
0 200 400 600 800 10000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
no sharingknowledge sharing
Fig. 23. The 20 MUX problem - Performance of clients - Rule Sharing between 5 clients
XXVI
0 100 200 300 400 5000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
no shareknowledge sharing
Fig. 24. The 20 MUX problem - Performance of the server - Rule Sharing between 3clients
0 100 200 300 400 5000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
iterations (50 instances)
Per
form
ance
no shareknowledge sharing
Fig. 25. The 20 MUX problem - Performance of the server - Rule Sharing between 5clients

XXVII
performance at the server. In some cases (medium noise) the performance of asmaller number of clients is better than the one with more clients.
The second question refers to the effect of different methods for combiningknowledge at the server. We have compared the knowledge probing and majorityvoting methods. The result shows that different method does affect the predictiveperformance at the server in the initial stage in the noise-free environment.Majority voting seems to learn faster than knowledge probing. However, bothmethods perform equivalently in the latter stage. When noise occurs in the data,majority voting is more robust than knowledge probing.
The last question relates to an issue of knowledge passing in the system. Wefound out that sending partial population does indeed maintain the performanceat the server and also reduce the traffic load on the server. Also, sharing knowl-edge among clients helps to improve the performance of clients and thereforealso increase the performance at the server.
Acknowledgement Work reported in this paper was funded by the Aus-tralian Research Council Linkage grant number LP0453657
References
1. H. A. Abbass, J. Bacardit, M. V. Butz, and X. Llora. Online Adaptation in Learn-ing Classifier Systems: Stream Data Mining. Illinois Genetic Algorithms Labora-tory, University of Illinois at Urbana-Champaign, June 2004. IlliGAL Report No.2004031.
2. J. Bacardit and M. V. Butz. Data Mining in Learning Classifier Systems: Com-paring XCS with GAssist. Illinois Genetic Algorithms Laboratory, University ofIllinois at Urbana-Champaign, June 2004. IlliGAL Report No. 2004030.
3. J. Bacardit and J. M. Garrell. Bloat control and generalization pressure using theminimum description length principle for a Pittsburgh approach learning classifiersystem. In Sixth International Workshop on Learning Classifier Systems (IWLCS-2003), Chicago, July 2003.
4. E. Bernado and G.-G. Josep. Accuracy-based learning classifier systems: mod-els, analysis and applications to classification tasks. Evolutionary Computation,11(3):209–238, 2003.
5. L. Bull, M. Studley, A. Bagnall, and I. Whittley. On the use of rule sharingin learning classifier system ensembles. In Proceedings of the IEEE Congress onEvolutionary Computation, pages 612–617, 2005.
6. P. K. Chan and S. J. Stolfo. Toward parallel and distributed learning by meta-learning. In Working Notes AAAI Work. Knowledge Discovery in Databases, pages227–240, Washington, DC, 1993.
7. V. Cho and B. Wüthrich. Distributed mining of classification rules. Knowl-edge Information System, 4(1):1–30, 2002.
8. H. H. Dam, H. A. Abbass, and C. Lokan. DXCS: an XCS system for distributeddata mining. In Proceedings of the Genetic and Evolutionary Computation Con-ference, GECCO-2005, Washington D.C., USA, 2005.
9. H. H. Dam, H. A. Abbass, and C. Lokan. Investigation on DXCS: An XCS systemfor distribution data mining, with continuous-valued inputs in static and dynamicenvironments. In Proceedings of IEEE Cogress on Evolutionary Computation, Ed-inburgh, Scotland, 2005.

XXVIII
10. T. G. Dietterich. Machine-learning research: Four current directions. The AIMagazine, 18(4):97–136, 1998.
11. U. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy. From data miningto knowledge discovery: An overview. In Advances in Knowledge Discovery andData Mining, pages 1–36. The MIT Press, 1996.
12. C. Giannella, R. Bhargava, and H. Kargupta. Multi-agent systems and distributeddata mining. In Cooperative Information Agents VIII: 8th International Workshop,CIA 2004, pages 1–15, Erfurt, Germany, 2004.
13. D. E. Goldberg. Genetic Algorithms in Search, Optimization, and Machine Learn-ing. Addision-Wesley Publishing Company, INC., 1989.
14. Y. Guo, S. Rueger, J. Sutiwaraphun, and J. Forbes-Millott. Meta-learning forparallel data mining. In Proceedings of the Seventh Parallel Computing Worksop,1997.
15. L. Hall, N. Chawla, and K. Bowyer. Combining decision trees learned in parallel. InProceedings of the Workshop on Distributed Data Mining of the 4th ACM SIGKDDInternational Conference on Knowledge Discovery and Data Mining, 1997.
16. L. Hall, N. Chawla, and K. Bowyer. Decision tree learning on very large data sets.In Proceedings of the IEEE Conference on Systems, Man and Cybernetics, 1998.
17. J. H. Holland. Escaping Brittleness: The Possibilities of General-Purpose LearningAlgorithms Applied to Parallel Rule-Based Systems. In Mitchell, Michalski, andCarbonell, editors, Machine Learning, an Artificial Intelligence Approach. VolumeII, chapter 20, pages 593–623. Morgan Kaufmann, 1986.
18. C. Jones, J. Hall, and J. Hale. Secure distributed database mining: Principlesof design. In Advances in Distributed and Parallel Knowledge Discovery, pages277–294. The MIT Press, 2000.
19. H. Kargupta and P. Chan, editors. Advances in Distributed and Parallel KnowledgeDiscovery. The MIT Press, 2000.
20. T. Kovacs. Two views of classifier systems. In Fourth International Workshop onLearning Classifier Systems - IWLCS-2001, pages 367–371, San Francisco, Califor-nia, USA, 7 2001.
21. A. L. Prodromidis, P. K. Chan, and S. J. Stolfo. Meta-learning in distributed datamining systems: Issues and approaches. In Advances in Distributed and ParallelKnowledge Discovery, pages 81–114. The MIT Press, 2000.
22. S. F. Smith. A Learning System Based on Genetic Adaptive Algorithms. PhDthesis, University of Pittsburgh, 1980.
23. S. W. Wilson. Classifier fitness based on accuracy. Evolutionary Computation,3(2):149–175, 1995.
24. S. W. Wilson. Generalization in the XCS classifier system. In J. R. Koza,W. Banzhaf, K. Chellapilla, K. Deb, M. Dorigo, D. B. Fogel, M. H. Garzon, D. E.Goldberg, H. Iba, and R. Riolo, editors, Genetic Programming 1998: Proceedingsof the Third Annual Conference, pages 665–674, University of Wisconsin, Madison,Wisconsin, USA, 1998. Morgan Kaufmann.
25. S. W. Wilson. Mining oblique data with XCS. In P. L. Lanzi, W. Stolzmann, andS. W. Wilson, editors, Proceedings of the Third International Workshop (IWLCS-2000), Lecture Notes in Artificial Intelligence, pages 158–174, 2001.
26. D. H. Wolpert. Stacked generalization. Neural Networks, 5:241–259, 1992.
Related Documents











