@michaelneale #DV14 Changing wheels of a moving car Replacing core technologies in a growing startup Michael Neale CloudBees

Devoxx 2014 michael_neale
Jul 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

@michaelneale#DV14
Changing wheels of a moving car
Replacing core technologies in a growing startup
Michael Neale CloudBees

@michaelneale#DV14
This talk
• lucky early decisions
• transitions and containers
• lessons learned on changing continuously
• finally: monitoring, alerting, health - ops for devs. (rarely talked about)

@michaelneale#DV14
ABOUT ME
• Co-founder CloudBees (the Jenkins company)
• Developer with an interest in Ops
• built DEV@cloud RUN@cloud

@michaelneale#DV14
Working with Cloud Platforms
• not as “friendly” as traditional hosting:
• Awesome power at fingertips: try everything, try all hardware
• Iterate rapidly
• But:
• APIs have lower QoS than hosts
• Servers are cattle, not pets
• Jenkins (and others) still need filesystems (not always easy on cloud)
• multi tenancy for scale/cost

@michaelneale#DV14
Lucky decisions we made
• Isolate EC2 apis with fault tolerant REST app for provisioning
• API can behave strangely - backoff and retry, API limits and more
• Build pathological API simulator
• Enable replacement of servers via termination
• “chaos monkey” approach
• Reality: I didn’t understand chef. So replace AMI by terminating, new latest takes its place
• Done as a “hack” but core platform value today
• ie. we are always changing, always replacing “naturally”

@michaelneale#DV14
NetflixOSS productised this!
https://github.com/Netflix/Hystrix
https://github.com/Netflix/SimianArmy
netflixoss.ci.cloudbees.com
http://netflix.github.io

@michaelneale#DV14
Chaos monkeying to upgrade
• OS change: new AMI == terminate, let system replace
• (in ec2: autoscale groups can do this for you)
• Security patch? == terminate.
• Server a bit sick? TERMINATE
• (we actually use chef for minor config changes and some app level upgrades… relax…)
• If in doubt.. you get the idea…

@michaelneale#DV14
A bad year for security
• Heartbleed
• Shell-shock
• POODLE
• XEN guest flaw, aws-reboot-a-thon

@michaelneale#DV14
But a great year for logos:
Xen

@michaelneale#DV14
Upgrades…
• In place or… TERMINATE?
• Often easier and safer to swap out:
• eg revproxy (nginx) cluster replacement process:
• warm new server, cut over IP and traffic, terminate old
• No half-measures, half-upgrades, clean slate
• (elastic IP helped in this case)

@michaelneale#DV14
More benefits of terminate …
• “Retirement notices” from AWS - daily event!
• Even “new” servers - 3 days until “retire”
• No you can’t see the server in retirement home.
• Reboot at some vague time - TERMINATE
• Encourages immutable servers
• predictable state
• security advantages of being “locked down” in image

@michaelneale#DV14
But what about data…
• Some say filesystem dependency is “legacy”
• I say “you aren’t trying hard enough”
• APIs such as EBS allow quick volume creation based on snapshots:
• Continuous (delta) snapshotting of data
• Can quickly restore service in healthy data centers
• Faster time to recovery, route around failing zones
• Ideal: use distributed data in all forms if you can!

@michaelneale#DV14
Containment challenge:
A P P S
J E N K I N S M A S T E R S
B U I L D E X E C U T O R S

@michaelneale#DV14
Containment
• Apps (paas) can do anything
• Builds DO do anything
• Need a clean slate for users
• Process cleanup
• Jenkins masters have plugins
• Multi tenancy: cost effective, higher density, better elasticity (fine grained processes vs autoscale groups)

@michaelneale#DV14
Containment Evolution
• Unix user isolation + cgroups
• LXC (builds on cgroups, namespaces)
• Docker (builds on cgroups, namespaces, NOT lxc)
• Natural current end point and so hot right now:

@michaelneale#DV14
Containment challenge:
http://developer-blog.cloudbees.com/2013/05/inside-linux-containers-lxc-with.html

@michaelneale#DV14
Security benefits of containers?
• Not complete
• Not a replacement for current measures, but help
• Lots of (changing) content online
• Next: linux user-namespace for “fake root user”
• “coming real soon now??” already in lxc, not in docker at this time.

@michaelneale#DV14
Transition of a build service
• Initial: discrete build nodes, “recycled” between use
• Pools with “mark and sweep” garbage collection of unused build servers
• unix user and cgroup/namespace isolation
• Attach build data from snapshots

@michaelneale#DV14
Transition of a build service
• Next: use LXC for containment isolation
• Finally: Use multi-tenant pools with full container isolation
• Pool disks for IO and EBS resilience (ZFS)
• Use larger more economical server (more burst power)
• Consistent hashing to get server with warm “build cache”
• (sorry if your maven re-downloads the world, hopefully not all the time)

@michaelneale#DV14
Transition of a build service
• Done continually over a year
• Limited user opt-in/out, majority do not notice
• Strategy options:
• roll out to 10%, 50%
• roll out to tiered users (ie freemium users get new/unstable?)
• roll out to all - incremental uptake due to natural restarting/reprovisioning
• ALWAYS dog food

@michaelneale#DV14
Dog food
• Always roll out to self first
• (occasionally joyously discover bootstrapping problem if it goes bad!)
• True indicator of confidence
• We get used to change, from users point of view

@michaelneale#DV14
• How we apply Jenkins with CD:
U P S T R E A M C H A N G E
C H E F R E C I P E M A S T E R B R A N C H
T E S T E N V
C H E F R E C I P E P R O D U C T I O N B R A N C H
P R O D E N Vrollout strategy
terminate at any time

@michaelneale#DV14
@michaelneale#DV14
Wide feedback
• Provide something community want to try:
• https://registry.hub.docker.com/_/jenkins/
• Helps them, helps us learn

@michaelneale#DV14
Lessons on continual change
• Cost of change == F(gap between deployments)
• CD etc etc (you will hear a lot elsewhere)
• Keep MTTR (mean time to recovery) low
• If short enough, people will blame internet connection (ssshhhh)

@michaelneale#DV14
Lessons on continual change• Always be doing DR
• People ask about “DR” strategy
• If you DR often, then it isn’t really DR - just BAU*, TMA*?
• Normal service restoration and termination exercises “backups”

@michaelneale#DV14
Changes in a SaaS• If people use a SaaS, upgrades/change expected
• Communicate to users on changes, let them know how much work you do for them! It isn’t easy!
• Some changes visible, some not (some you thought invisible, but were visible) - let people know.
• Even outages can create good will:
• Explanations and understanding == appreciation, it happens
• Proactive security patching this year
• “we don’t want to run this ourselves”

@michaelneale#DV14
Monitoring and alerting
• Not often talked about in classic dev circles
• Increasingly passionate in “devops” circles (monitorama)
• Alerting a staple of traditional ops and “on call”
• These roles now smearing out amongst all devs

@michaelneale#DV14
Why monitoring?
• SaaS always changing
• The Question:
• Are things better or worse than before?
• Did the change make things better or worse
• Not so much:
• Is everything perfect (it won’t be)

@michaelneale#DV14
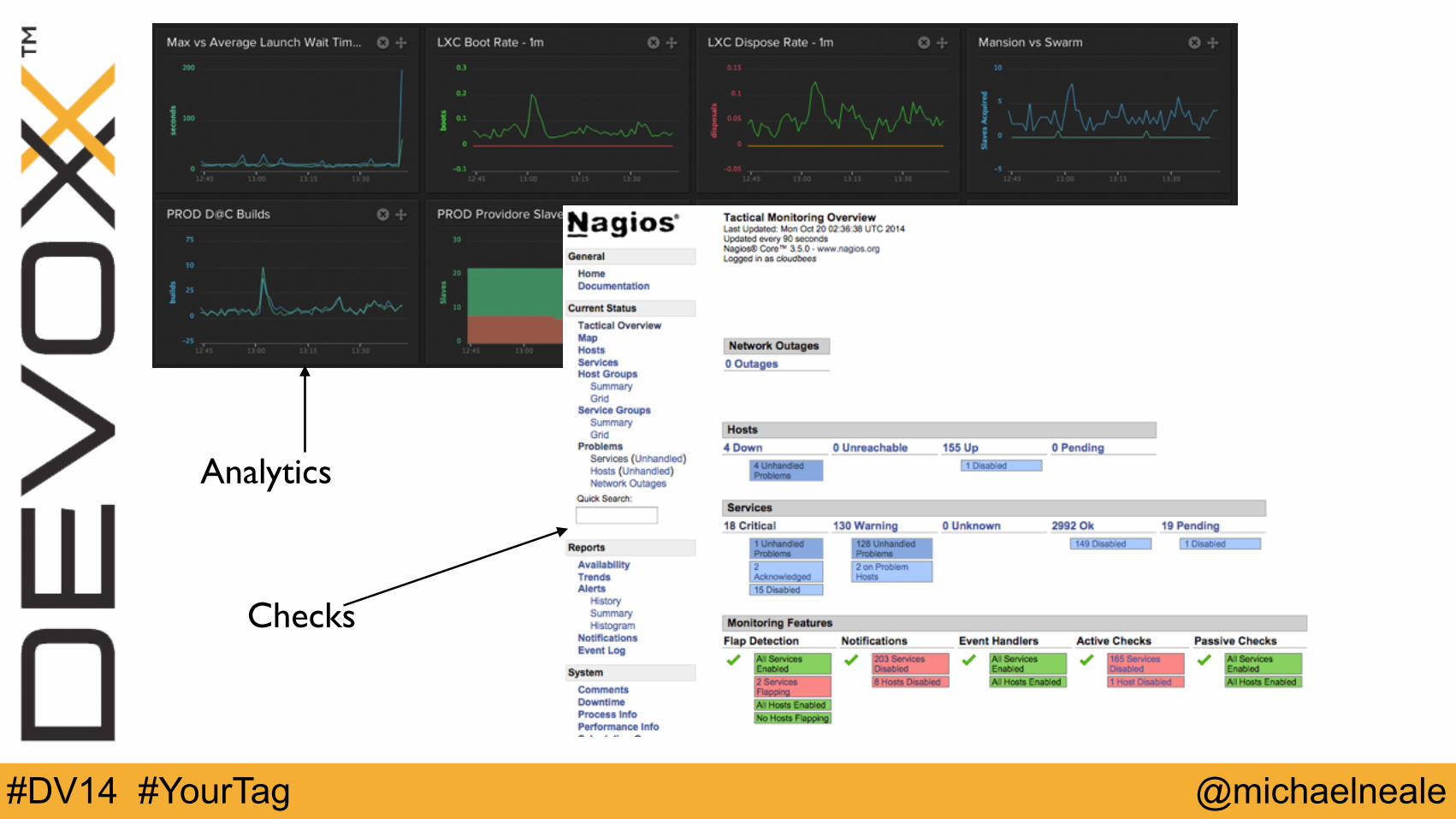
Monitoring and alerting
• Roughly split:
• “check engines” (nagios, pingdom etc)
• receive events, work if service up/down
• “notifications” - pagerduty and email, sms
• tell people about things
• analytics and monitoring (librato, boundary, new relic and more)
• DASHBOARDS AND GRAPHS EVERYWHERE
@michaelneale#DV14 #YourTag
Analytics
Checks

@michaelneale#DV14
All exist to inform you
• Graphic dashboards can overwhelm
• Some people treat them as end goal
• Too much information often - are things OK Y/N?
• Aim is to get insight (eg new relic like an online profiler) WHEN problems are happening
• Aim is to tell people when problems are happening
• Reports/graphs can be useful, but not at the expense of “health” monitoring

@michaelneale#DV14 #YourTag
If you must graph, a most important feature:
Deploy happened here!

@michaelneale#DV14
Alert and information fatigue
• A real (world) problem:
• http://fractio.nl/2014/08/26/cardiac-alarms-and-ops/
• Eg: cardiac monitors:
• Thresholds adjusted until only life critical
• No “ACK” of noisy alerts (no “WARNING”)
• Increased urgency, but reduced volume
• reduced noise, reduced fatigue and fatalities! (counterintuitive?)

@michaelneale#DV14
Alert and information fatigue
• Avoid “warnings” that interrupt people
• (remember each interruption is > 1 hour really)
• Push messages to chat rooms “chat ops”
• Allow people already distracted to act
• Alerts/info as “streams” people can dip into and help out
• Avoid escalation
• Follow the sun support! (if your team has it! Great!)

@michaelneale#DV14
End to End test monitor
• Why save testing for dev time only
• Apply a kind of integration test to production
• Can be a “synthetic transaction”
• eg: signup, run some process, exit
• Run it continually
• Increases confidence
• “Out Of Band End To End Test” “oobetet”
• technically monitoring, not testing!

@michaelneale#DV14
Codahale metrics
• https://dropwizard.github.io/metrics/3.1.0/
• Simple metrics to your app:
• Binary health checks “foo.widget.thing is OK”
• Numerical metrics:
• Gauges, meters, histograms and more
• Lots of statistical goodness baked in (so you don’t have to)
• Expose via /health URL and JSON, push to metrics services and more (can use a servlet):

@YourTwitterHandle#DV14 #YourTag
metrics.register(“important thing”, ”size”), new Gauge<Integer>() { @Override public Integer getValue() { return queue.size(); } });
Gauge measurement:

@YourTwitterHandle#DV14 #YourTag
private final Timer responses = metrics.timer(“important thing”);
public String handleRequest(Request request, Response response) { final Timer.Context context = responses.time(); try { // do some work; return "OK"; } finally { context.stop(); }}
trace percentile of times spent in..

@michaelneale#DV14
Minimal points to take away
• Give codahale/dropwizard stuff a good look!
• Instrument at least a /health check that can be wired in later
• *think* about monitoring
• Replace/restore as matter of “routine”
• Change becomes the normal
• Terminate, restart, are often an OK way to recover!

@michaelneale#DV14
Thank you!Questions?
@michaelneale
developer-blog.cloudbees.com
Related Documents











