Detection and Extraction of Artificial Text from Videos PROJECT France Télécom Research & Development 001B575 Laboratoire de Reconnaissance de Formes et Vision Bât. Jules Verne INSA 69621 Villeurbanne CEDEX 10 th July 2001 Christian Wolf and Jean-Michel Jolion http://rfv.insa-lyon.fr/~{wolf,jolion}

Detection and Extraction of Artificial Text from Videos PROJECT France Télécom Research & Development 001B575 Laboratoire de Reconnaissance de Formes et.
Dec 30, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Detection and Extraction of Artificial Text from Videos
PROJECT France Télécom Research & Development 001B575
Laboratoire de Reconnaissance de Formes et VisionBât. Jules Verne INSA
69621 Villeurbanne CEDEX
10th July 2001
Christian Wolf and Jean-Michel Jolion
http://rfv.insa-lyon.fr/~{wolf,jolion}

Plan of the presentationIntroductionDetection Image enhancement - multiple frame
integrationBinarisation of the text boxesSetup of the experimentsResults
Detection Binarisation OCR
Conclusion and outlook
683
1011
6
246
Slides:
Intro Detection Enhancement Binarisation ResultsExperiments

Content based image retrieval
SimilarityFunction
ResultExample image
Indexing phase
Detection Enhancement Binarisation ResultsExperimentsIntro

Similarity measures
similar
similar
Not similar
Detection Enhancement Binarisation ResultsExperimentsIntro
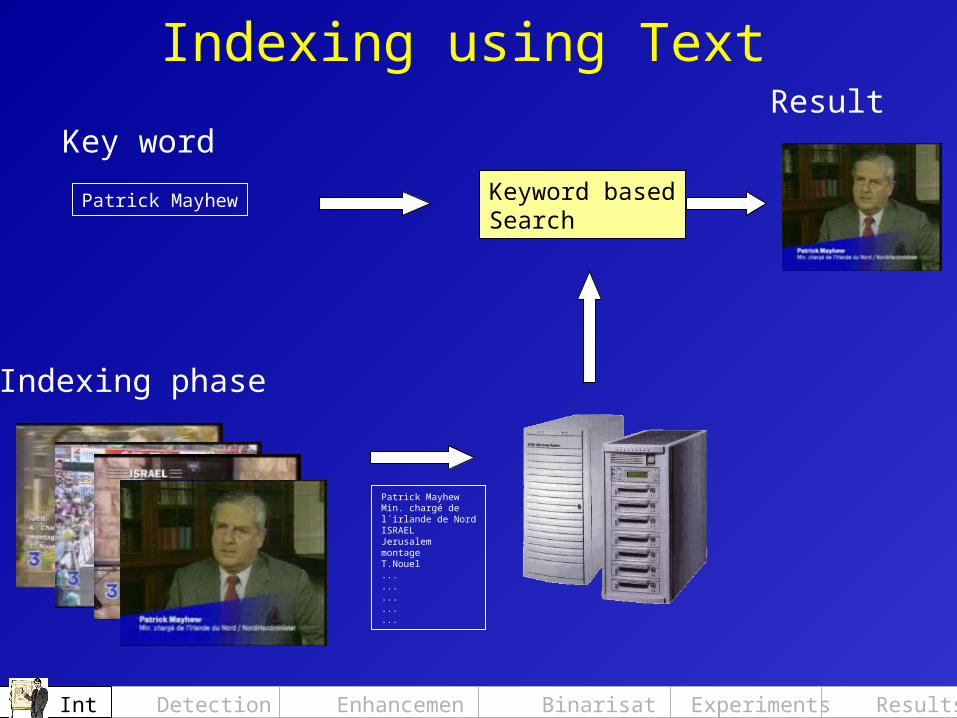
Indexing using Text
Keyword basedSearch
Patrick Mayhew
Patrick MayhewMin. chargé de l´irlande de NordISRAELJerusalemmontageT.Nouel...............
ResultKey word
Indexing phase
Detection Enhancement Binarisation ResultsExperimentsIntro

Video properties
80 px
12 px 8 px
Detection Enhancement Binarisation ResultsExperimentsIntro

Text extraction: general scheme
TrackingDetection of the text in single frames
Image enhancement - Multiple frame integration
Segmentation/Binarisation
OCR
"EVENEMENT""ACTU""SPELEOS""Gouffre Berger (Isére)""aujourd'hui""France 3 Alpes""un spéléologue sauveteur"
Video
Intro Detection Enhancement Binarisation ResultsExperiments

Detection in single frames
Calculation of the gradient
Accumulation
Binarisation
MathematicalMorphology
Connected componentsAnalysis
Verification of geometric constraints
Combination of the rectangles
Verification of special cases
Video
List ofrectangles
Intro Detection Enhancement Binarisation ResultsExperiments
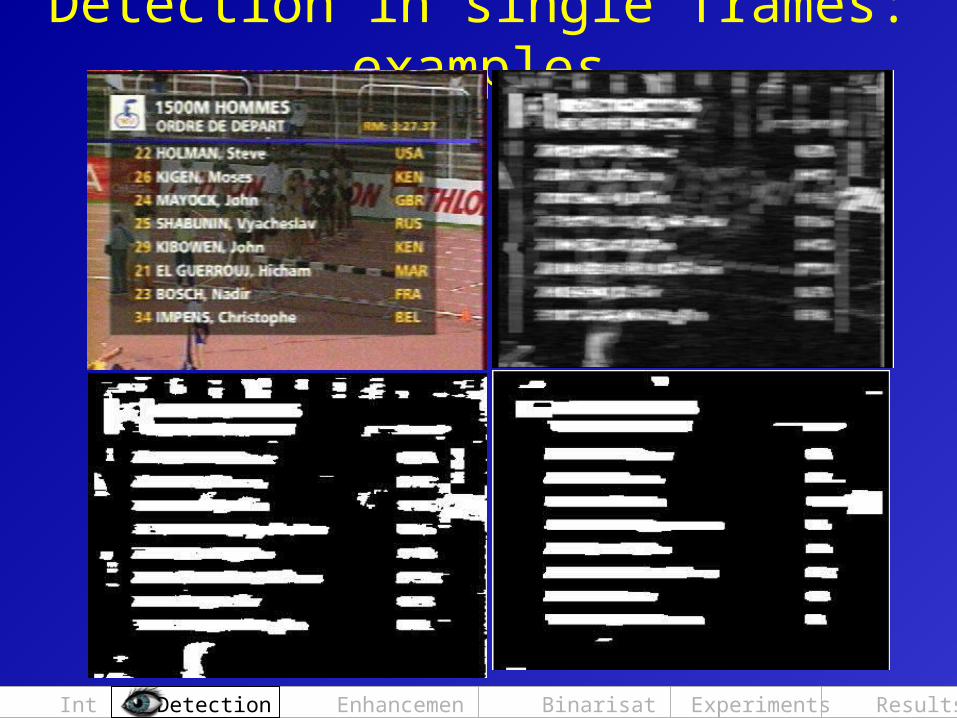
Detection in single frames: examples
Intro Detection Enhancement Binarisation ResultsExperiments

A filter for text detection
SG yx
1,
2S
x
2S
x
dxxI
Accumulation of horizontal gradients. Justification: Text forms a regular texture containing vertical edges which are aligned horizontally. W
0m 1m
M-W
fk
1
2
01 ))(1( mmMW
MW
S
Intro Detection Enhancement Binarisation ResultsExperiments

Mathematical morphology
Close
Deletion of small bridgesbetween the components
dilate (special) toconnect characters
erode (special) toconnect characters
erode horizontally
dilate horizontally
Intro Detection Enhancement Binarisation ResultsExperiments
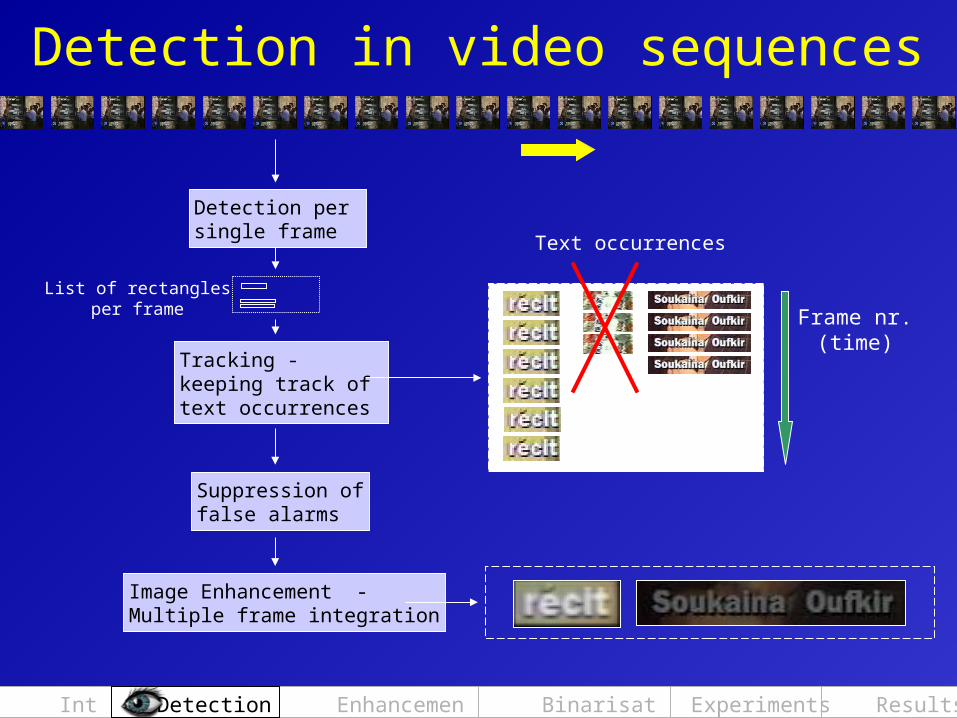
Detection in video sequences
Detection per single frame
List of rectanglesper frame
Tracking -keeping track of text occurrences
Suppression offalse alarms
Image Enhancement -Multiple frame integration
Text occurrences
Frame nr.(time)
Intro Detection Enhancement Binarisation ResultsExperiments

Integration of the rectangles occurrences
At every new frame, the detected rectangles must be matched with the stored text occurrences
List of rectangles detected for the current frame
Text occurrences
Frame nr.(time)
List containing the most recent rectangleof each text occurrence
The integration is done using overlap information (overlap matrix)
Intro Detection Enhancement Binarisation ResultsExperiments

Suppression of false alarms: Examples
All detections
Aftersuppression
of false alarms
Intro Detection Enhancement Binarisation ResultsExperiments

Image enhancementSuper-resolution(interpolation)
Multiple frame integration:Averaging
Intro Detection Enhancement Binarisation ResultsExperiments
Integration of multiple frames to create a single image of higher quality.
)(
)()(1
1
k
kk
i
i
k
MV
MMMFg
M1
M4
M2
M3
Fi ith imageM Mean imageV Std.deviation image
An additional weight is included into the interp.scheme:
Robust bi-linear Robust bi-cubic

Interpolation: Examples
Bi-linear interpolation
Robust bi-linear interpolation
Robust bi-cubic interpolation
Intro Detection Enhancement Binarisation ResultsExperiments

Interpolation: thresholded examples
Bi-linear interpolation
Robust bi-linear interpolation
Robust bi-cubic interpolation
Intro Detection Enhancement Binarisation ResultsExperiments

Binarisation
Different Binarisation algorithms have been implemented and evaluated:
• Fisher/Otsu and windowed Fisher/Otsu algorithm
• Yanowitz-Bruckstein• Niblack, Sauvola• Our adaptive version of Niblack/Sauvola´s
method.
Intro Detection Enhancement Binarisation ResultsExperiments

Binarisation methodsYanowitz Bruckstein: The threshold surface is calculated from the edge information.
Windowed-Fisher, Niblack-Sauvola: The threshold surface is calculated from the statistics collected in a window which is shifted across the image.
Threshold surface
Threshold surface
Intro Detection Enhancement Binarisation ResultsExperiments

Binarisation by Niblack
Niblack proposed a method which calculates a threshold surface by gliding a rectangular window over the image and calculating statistics on this window:
skmT m mean s standard deviationk parameter, = -0.2
0
50
100
150
200
250
300
value
mean
std.dev.
niblack
Intro Detection Enhancement Binarisation ResultsExperiments
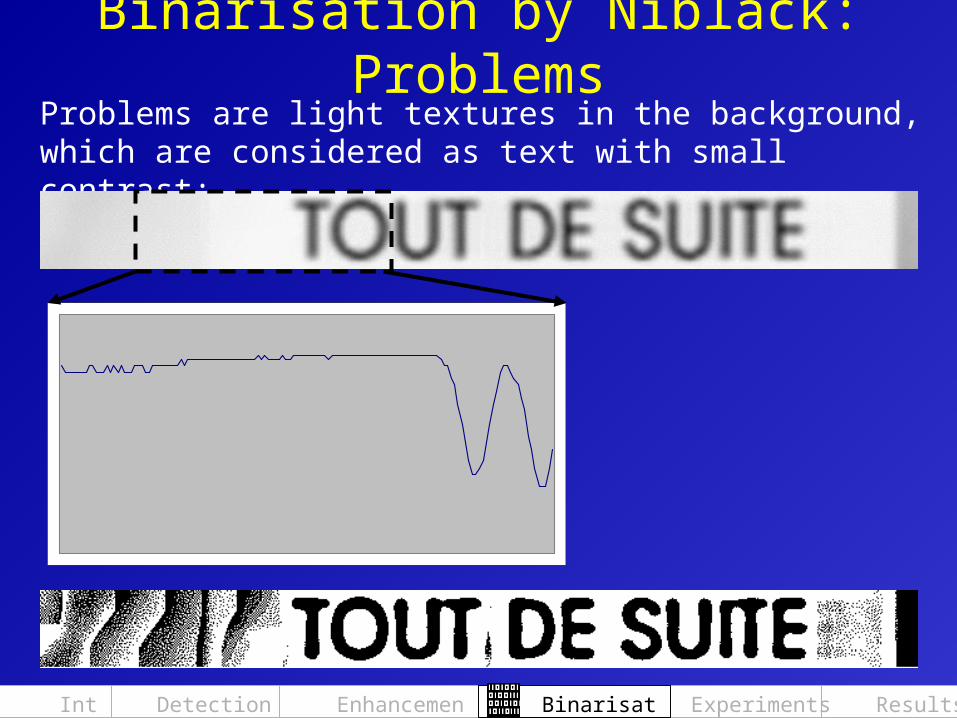
Binarisation by Niblack: ProblemsProblems are light textures in the background, which are considered as text with small contrast:
Intro Detection Enhancement Binarisation ResultsExperiments

Binarisation: Improvement by Sauvola
m mean s standard deviationk parameter, = 0.5R parameter (dynamic
range of std.dev.), R = 128
To overcome these problems, Sauvola et al. proposed a new improved formula to calculate the threshold:
))1(1(Rs
kmT
Reformulation shows, that a hypothesis on the gray values of text and non-text are used to remove the noise produced by background textures:
kmmT Rs1
Intro Detection Enhancement Binarisation ResultsExperiments

Binarisation by Sauvola, examples
Original image
Binarised using Niblack´s method
Binarised using Sauvola et al.´s method
Intro Detection Enhancement Binarisation ResultsExperiments

Improvement: Adaptive dynamic range
Nib
Sauv.R=128
R ad.
Fixing the dynamic range R=128 might be ok for document images, but not for text boxes taken from videos. Binarisation will not be correct, if the contrast of the image is smaller. We therefore set the parameter R to the
maximum standard deviation for all windows calculated:
)max(sR
To avoid two passes of the windowing algorithm, the mean and standard deviation can be stored in a table during the first pass and the threshold
surface calculated on this data.
Intro Detection Enhancement Binarisation ResultsExperiments
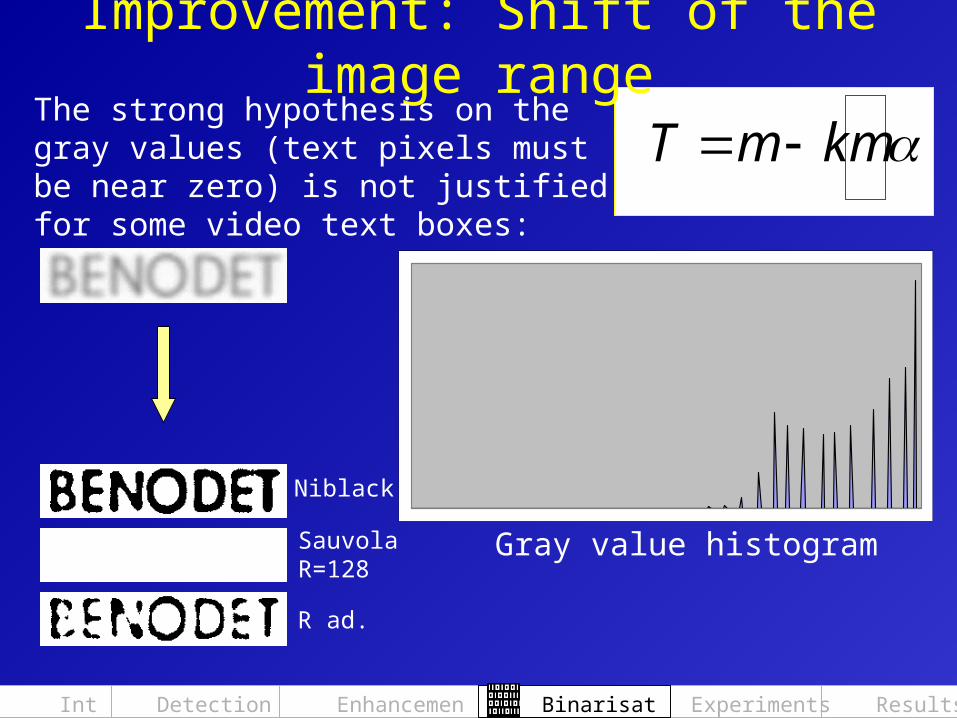
Improvement: Shift of the image rangeThe strong hypothesis on the gray values (text pixels must be near zero) is not justified for some video text boxes:
Gray value histogram
Niblack
SauvolaR=128
R ad.
kmmT
Intro Detection Enhancement Binarisation ResultsExperiments

Improvement: Shift of the image rangeA correction of the image´s histogram resolves this problem:
Original image Corrected image binarised, R adaptive
Intro Detection Enhancement Binarisation ResultsExperiments
)max(sR
)min(IM
m mean s standard deviationk parameter, = 0.5R = maximum of the
std.dev. of all windows
M = minimum gray value of the text box
The same effect can also be achieved by changing the threshold formula:
Rs1
)( MmkmT

Fast incremental calculationMean and variance can be calculated in one pass:
)(1 2
2
Na
bN
s aN
m1
ixa 2
ixb
RyxLyx
tt yxIyxIaa),(),(
1 ),(),(
2
),(),(
21 ),(),(
RyxLyx
tt yxIyxIbb
L
R
At the beginning of each line, the full window is calculated and the variables a and b kept. After each shift, a and b are calculated incrementally by subtracting the column of pixels which left the window and adding the column which entered the window.
Mean and standard deviation are stored in 2d tables, then the maximum R=max(s) is computed before calculating the threshold surface
Intro Detection Enhancement Binarisation ResultsExperiments

The experimentsDescription of the experimentsThe videos used in the experiments.Description of the evaluation process (OCR Evaluation).
Results for:Text detection BinarisationOCR
Intro Detection Enhancement Binarisation ResultsExperiments

Test videos
We performed experiments on 5 different MPEG 1 videos of resolution 384x288:
Video Length(min) Length(frames) OccurencesAIM2,AIM3,AIM4,AIM5 provided by INA. We used the first 15000 frames of each file
40 60000 322
Video provided by France Télécom, used in its entire length
22 33000 91
Total 62 93000 413
Intro Detection Enhancement Binarisation ResultsExperiments

AIM3News
AIM4Cartoon, News
AIM5News
AIM2Commercials
Intro Detection Enhancement Binarisation ResultsExperiments

Video example - France Télécom
~22 minutes of video~33000 frames
Intro Detection Enhancement Binarisation ResultsExperiments

The interface to the OCR softwareIdeal situation:Pass individual (binarised) text boxes to an OCR software which recognises the contents box after box.
In reality:We used standard commercial OCR software for our tests. This software has been designed to recognise scanned A4 or US letter pages and cannot directly process text boxes.
A4 page
Intro Detection Enhancement Binarisation ResultsExperiments

OCR Page - Manual An input image,ready for the OCR
Intro Detection Enhancement Binarisation ResultsExperiments
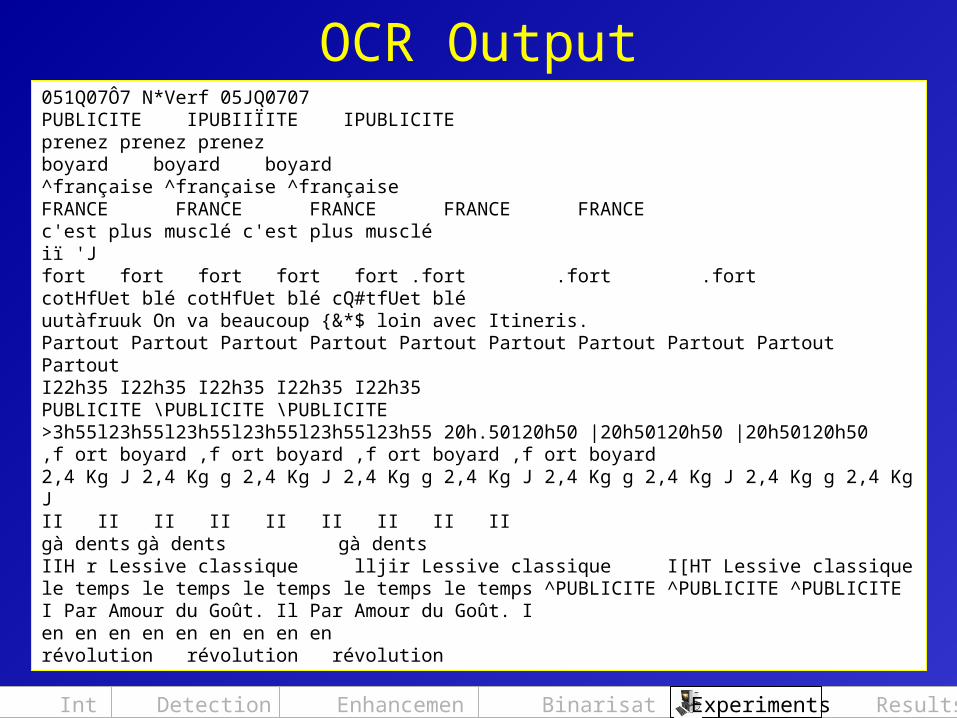
OCR Output051Q07Ô7 N*Verf 05JQ0707PUBLICITE IPUBIIÏITE IPUBLICITEprenez prenez prenezboyard boyard boyard^française ^française ^françaiseFRANCE FRANCE FRANCE FRANCE FRANCEc'est plus musclé c'est plus muscléiï 'Jfort fort fort fort fort .fort .fort .fortcotHfUet blé cotHfUet blé cQ#tfUet bléuutàfruuk On va beaucoup {&*$ loin avec Itineris.Partout Partout Partout Partout Partout Partout Partout Partout Partout PartoutI22h35 I22h35 I22h35 I22h35 I22h35PUBLICITE \PUBLICITE \PUBLICITE>3h55l23h55l23h55l23h55l23h55l23h55 20h.50120h50 |20h50120h50 |20h50120h50,f ort boyard ,f ort boyard ,f ort boyard ,f ort boyard2,4 Kg J 2,4 Kg g 2,4 Kg J 2,4 Kg g 2,4 Kg J 2,4 Kg g 2,4 Kg J 2,4 Kg g 2,4 Kg JII II II II II II II II IIgà dents gà dents gà dentsIIH r Lessive classique lljir Lessive classique I[HT Lessive classiquele temps le temps le temps le temps le temps ^PUBLICITE ^PUBLICITE ^PUBLICITEI Par Amour du Goût. Il Par Amour du Goût. Ien en en en en en en en enrévolution révolution révolution
Intro Detection Enhancement Binarisation ResultsExperiments

Post processing of OCR output
23h55051Q07Ô7
PUBLICITEprenez
boyard^françaiseFRANCEc'est plus musclé
fort
blé cotHfUetuutàfruukOn va beaucoup {&*$ loin avec Itineris.
PartoutI22h35PUBLICITE \>3h55l20h.50
,f ort boyard
dimanche23h55N Vert 05100707BerlingoPUBLICITEprenezdiffusion simultanée en stéréo surboyardfrançaiseFRANCEc'est plus muscléPUBLICITEfortCoralblé completfruitsOn va beaucoup Plus loin avec Itineris.BohêmePartout22h35PUBLICITE23h5520h50fortfort boyard
Post processed OCR output Ground truth
Intro Detection Enhancement Binarisation ResultsExperiments

Automatic evaluation using markersThe manual processing of the OCR output (separation of the output strings and search of the corresponding input box) is time consuming and error prone, especially in cases where the quality of the OCR output is very poor.
Automatic OCR output processing can be achieved by placing marker images between the text boxes. The marker boxes contain text which is easily recognised by the OCR software.
In the results section we will present results for both types of evaluation.
Intro Detection Enhancement Binarisation ResultsExperiments

An input image with markers,ready for the OCR
Intro Detection Enhancement Binarisation ResultsExperiments

OCR Evaluation
Tkenchar 037 Tkenchar 037'gfrançaise 'gfrançaise 'gfrançaise 'gfrançaiseTkenchar 038 Tkenchar 038Mpe pire de| fj^e pire de| fj^e pire de|Tkenchar 039 Tkenchar 039
@S Par Amour du Goût.@S en@S révolution@S la@S française@S le pire de@S 20H45
OCR output Raw ground truth
Search output for individual text boxes
List of strings, each corres-ponding to the output for a text box, but eventually multiple times
# Page 1:P 1T 1 2M 1 2T 2 3M 2 2T 3 2
Structure log
Prepare ground truth
List of strings, each corresponding to the ground truth for a text box. Each string is repeated the same number of times as the corresponding text image in the OCR input image
Evaluation
Transformation costRecallPrecision
Intro Detection Enhancement Binarisation ResultsExperiments

OCR Evaluation: Wagner & Fischer
ba ),( bacost
b ),( bcost
a ),( acost
Substitution:
Insertion:
Deletion:
AirbagGtroônn
Airbag Citroën
A measure for resemblance of two character strings. The cost to transform string A into string B is calculated. Basic transformation operations are used, which correspond to a certain cost. The cost function is minimised.
Intro Detection Enhancement Binarisation ResultsExperiments

Detection results - INA VideosAIM2 % AIM3 % AIM4 % AIM5 % Total %
Pred. Text 102 93,6 80 94,1 59 93,7 60 92,3 301 93,5Pred. Non-Text 7 5 4 5 21Total 109 85 63 65 322
Positives 114 78 72 86 350False alarms 138 185 374 250 947Logos 12 0 34 29 75Scene text 22 5 28 17 72Pos+Log+Scene 148 51,7 83 31,0 134 26,4 132 34,6 497 34,4Total 286 268 508 382 1444
Video FT AIM2-5 TotalPred. Text 82 90,1 301 93,5 383 92,7Pred. Non-Text 9 21 30Total 91 322 413Positives 189 350 539False alarms 482 947 1429Logos 21 75 96Scene text 50 72 122Pos+Log+Szene 260 35,0 497 34,4 757 34,6Total 742 1444 2186
85 93,416
911898362252
263 23,91099
Video FT
No suppression of false alarms
Intro Detection Enhancement Binarisation ResultsExperiments
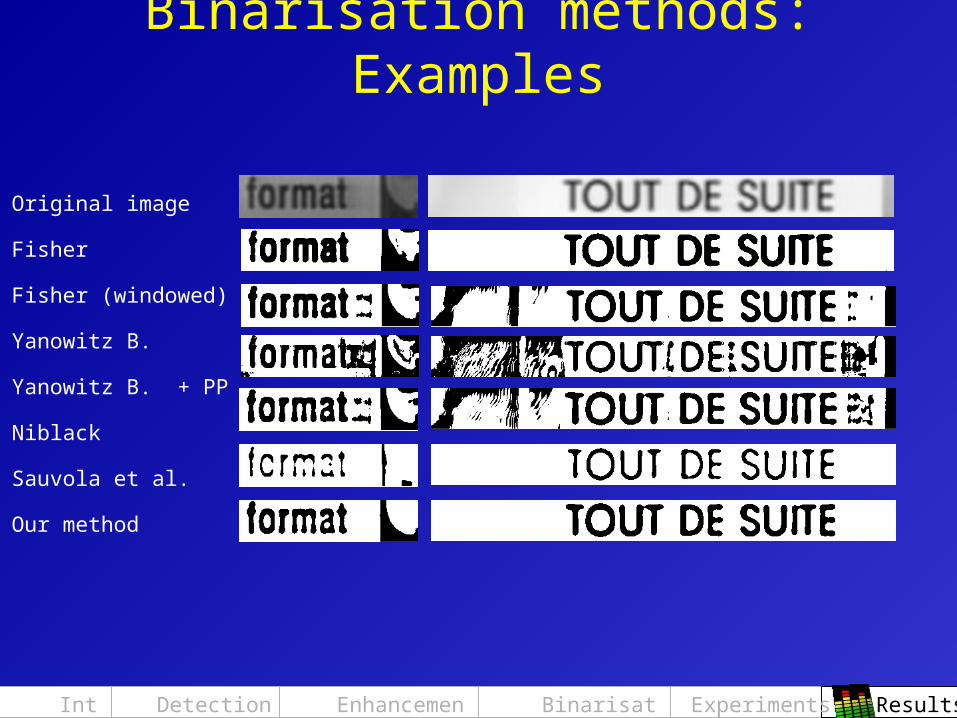
Binarisation methods: Examples
Original image
Fisher
Fisher (windowed)
Yanowitz B.
Yanowitz B. + PP
Niblack
Sauvola et al.
Our method
Intro Detection Enhancement Binarisation ResultsExperiments

Binarisation methods: ExamplesOriginal image
Fisher
Fisher (windowed)
Yanowitz B.
Yanowitz B. + PP
Niblack
Sauvola et al.
Our method
Intro Detection Enhancement Binarisation ResultsExperiments

OCR Results - Classification by binarisation method
Input Bin. method Recall Precision CostAIM2 Niblack 67,4 87,5 499
Sauvola R=128 53,8 87,6 616,5R=ad 75,0 87,8 384,5R=ad, shift 78,4 90,4 344,5
AIM3 Niblack 92,5 78,1 196Sauvola R=128 69,9 89,6 206R=ad 85,3 92,5 110R=ad, shift 96,2 95,3 51,00
AIM4 Niblack 78,5 92,0 252,00Sauvola R=128 48,6 87,7 490,50R=ad 69,8 84,8 360,50R=ad, shift 80,1 90,4 211,50
AIM5 Niblack 62,1 71,4 501,50Sauvola R=128 66,7 89,3 324,50R=ad 64,8 90,1 328,00R=ad, shift 69,0 91,0 294,50
Total Niblack 73,1 82,6 1448,5Sauvola R=128 58,4 88,5 1637,5R=ad 73,0 88,4 1183R=ad, shift 79,6 91,5 901,5
Results obtained using the manual evaluation method (no markers in the input page).
44 pages
Robust bi-cubic interpolation
Intro Detection Enhancement Binarisation ResultsExperiments
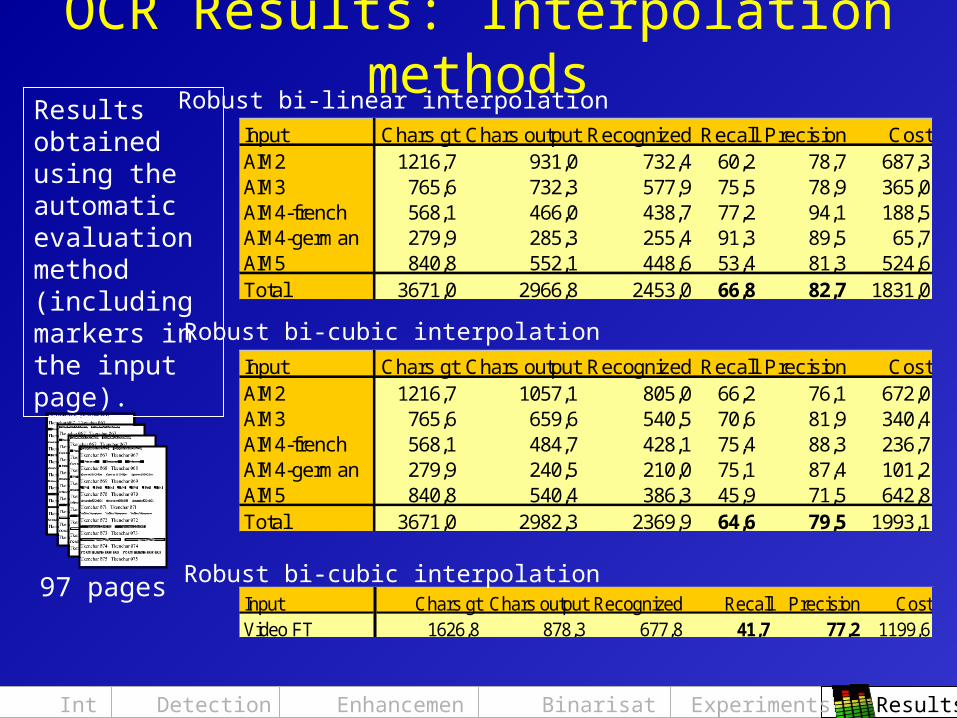
OCR Results: Interpolation methods
Input Chars gt Chars output Recognized Recall Precision CostAIM2 1216,7 931,0 732,4 60,2 78,7 687,3AIM3 765,6 732,3 577,9 75,5 78,9 365,0AIM4-french 568,1 466,0 438,7 77,2 94,1 188,5AIM4-german 279,9 285,3 255,4 91,3 89,5 65,7AIM5 840,8 552,1 448,6 53,4 81,3 524,6Total 3671,0 2966,8 2453,0 66,8 82,7 1831,0
Input Chars gt Chars output Recognized Recall Precision CostAIM2 1216,7 1057,1 805,0 66,2 76,1 672,0AIM3 765,6 659,6 540,5 70,6 81,9 340,4AIM4-french 568,1 484,7 428,1 75,4 88,3 236,7AIM4-german 279,9 240,5 210,0 75,1 87,4 101,2AIM5 840,8 540,4 386,3 45,9 71,5 642,8Total 3671,0 2982,3 2369,9 64,6 79,5 1993,1
Robust bi-linear interpolation
Robust bi-cubic interpolation
97 pages
Results obtained using the automatic evaluation method (including markers in the input page).
Input Chars gt Chars output Recognized Recall Precision CostVideo FT 1626,8 878,3 677,8 41,7 77,2 1199,6
Robust bi-cubic interpolation
Intro Detection Enhancement Binarisation ResultsExperiments

ConclusionWe developed a system for detection, tracking,
enhancement and binarisation of text.A detection performance of 93.5% is obtained.We derived a new binarisation method adapted to the type
of text found in videos.The total recognition rate is surprisingly high, given the
quality of the text, but not yet good enough for indexation purposes.
OCR integration problem: No software development kits for direct access to the recognition functions available. A collaboration with an OCR company seems to be inevitable.
Intro Detection Enhancement Binarisation ResultsExperiments

OutlookThe perspectives of our work are situated in the extension of the existing algorithms to text with more difficult properties, and the enhancement and deeper studies of the existing techniques:
Scene text: The binarisation techniques developed in the last 30 years are aimed either at document images or images from computer vision. The method we introduced in the framework of this project is an improvement of the work already presented, but the quality of the text is not yet satisfying enough. Especially the binarisation of scene text will demand the development of new methods.
Detection recall: We are convinced, that the recall of the detection system can still be increased by further research, e.g. on the binarisation technique applied to the map of accumulated gradients.
Intro Detection Enhancement Binarisation ResultsExperiments
Related Documents











