Designing Scalable Communication and I/O Schemes for Accelerating Big Data Processing in the Cloud Shashank Gugnani The Ohio State University E-mail: [email protected] http://web.cse.ohio-state.edu/~gugnani/

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Designing Scalable Communication and I/O Schemes for Accelerating Big Data Processing in the Cloud
Shashank Gugnani
The Ohio State University
E-mail: [email protected]
http://web.cse.ohio-state.edu/~gugnani/

SC ‘18 2Network Based Computing Laboratory
• Big Data has changed the way people understand
and harness the power of data, both in the
business and research domains
• Big Data has become one of the most important
elements in business analytics
• Big Data and High Performance Computing (HPC)
are converging to meet large scale data processing
challenges
• Running High Performance Data Analysis (HPDA) workloads in the cloud is gaining popularity
• According to the latest OpenStack survey, 27% of cloud deployments are running HPDA workloads
Introduction to Big Data Analytics and Trends
http://www.coolinfographics.com/blog/tag/data?currentPage=3
http://www.climatecentral.org/news/white-house-brings-together-big-data-and-climate-change-17194

SC ‘18 3Network Based Computing Laboratory
Cloud Cloud
Drivers of Modern HPC Cloud Architectures
• Multi-core/many-core technologies
• Large memory nodes
• Remote Direct Memory Access (RDMA)-enabled networking (InfiniBand and RoCE)
• Single Root I/O Virtualization (SR-IOV)
• Solid State Drives (SSDs), Object Storage Clusters
High Performance Interconnects –InfiniBand (with SR-IOV)
<1usec latency, 200Gbps Bandwidth>Multi-core Processors
SSDs, Object Storage Clusters Large memory nodes
(Upto 2 TB)

SC ‘18 4Network Based Computing Laboratory
Summary of HPC Cloud Resources
• High-Performance Cloud systems have adopted advanced interconnects and
protocols
– InfiniBand, 40 Gigabit Ethernet/iWARP, RDMA over Converged Enhanced Ethernet (RoCE)
– Low latency (few micro seconds), High Bandwidth (200 Gb/s with HDR InfiniBand)
– SR-IOV for hardware-based I/O virtualization
• Vast installations of Object Storage systems (e.g. Swift, Ceph)
– Total capacity is in the PB range
– Offer high availability and fault-tolerance
– Performance and scalability is still a problem
• Large memory per node for in-memory processing

SC ‘18 5Network Based Computing Laboratory
Big Data in the Cloud: Challenges and Opportunities
• Scalability requirements significantly increased
• Explosion of data
• How do we handle huge amounts of this data?
• Requirement for more efficient and faster processing of Data
• Advancements in computing technology
– RDMA, SR-IOV, byte addressable NVM, NVMe
• How can we leverage the advanced hardware?

SC ‘18 6Network Based Computing Laboratory
Our Goal
• Scalable Cloud Storage
– Quality of Service and Consistency paramount
– Need for newer algorithms and protocols
• Performant Communication Middleware
– Use high-performance networking
– Topology-aware communication

SC ‘18 7Network Based Computing Laboratory
• Re-designed Swift architecture for improved scalability and performance
• Two proposed designs:
– Client-Oblivious Design: No changes required on the client side
– Metadata Server-based Design: Direct communication between client and object
servers; bypass proxy server
• RDMA-based communication framework for accelerating networking
performance
• High-performance I/O framework to provide maximum overlap between
communication and I/O
• New consistency model to enable legacy applications to run on cloud storage
Scalable Cloud Storage

SC ‘18 8Network Based Computing Laboratory
• No change required on the client side
• Communication between client and proxy
server using conventional TCP sockets
networking
• Communication between proxy server
using high-performance RDMA-based
networking
• Proxy Server is still the bottleneck!
Client-Oblivious Design
Client-Oblivious Design
(D1)

SC ‘18 9Network Based Computing Laboratory
• Re-designed architecture for improved
scalability
• Client-based replication for reduced
latency and high-performance
• All communication using high-
performance RDMA-based networking
• Proxy Server no longer the bottleneck!
Metadata Server-based Design
Metadata Server-based
Design (D2)
SC ‘18 10Network Based Computing Laboratory
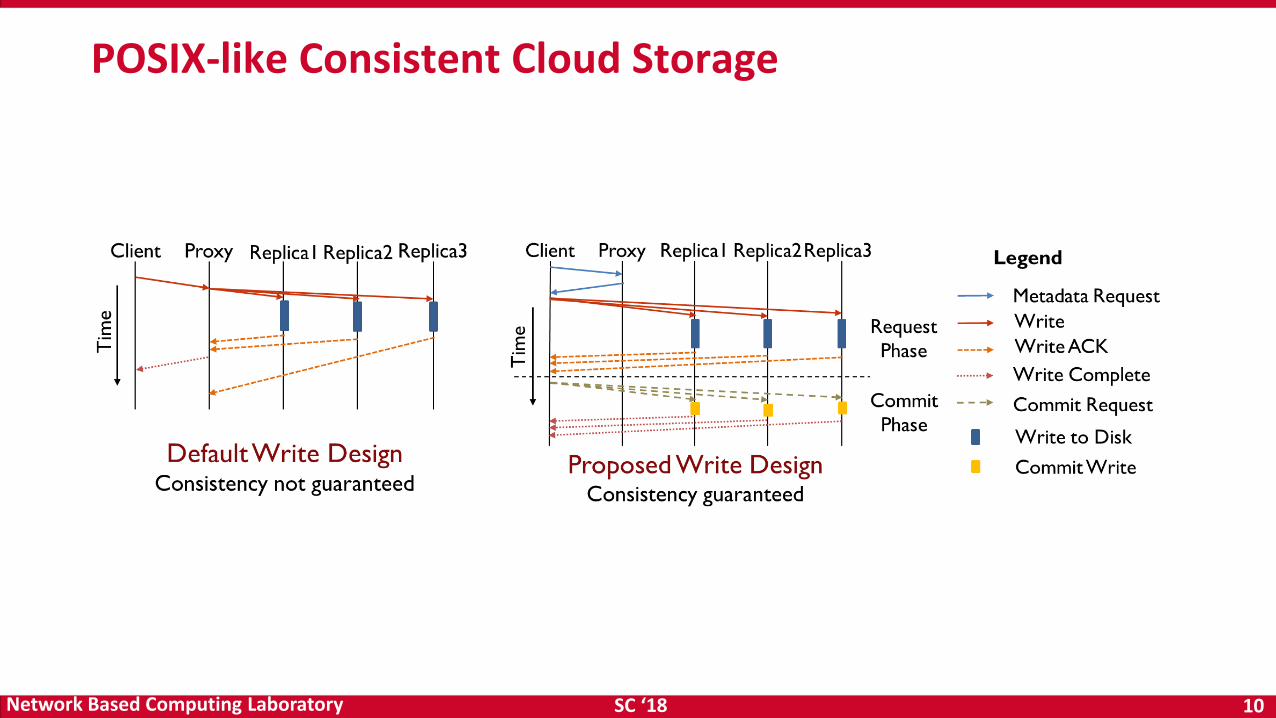
POSIX-like Consistent Cloud Storage
SC ‘18 11Network Based Computing Laboratory
0
500
1000
1500
2000
2500
20 GB 40 GB 60 GB
Exec
uti
on
Tim
e (s
)
Data Size
WordCount
HDFS SwiftFS SwiftX
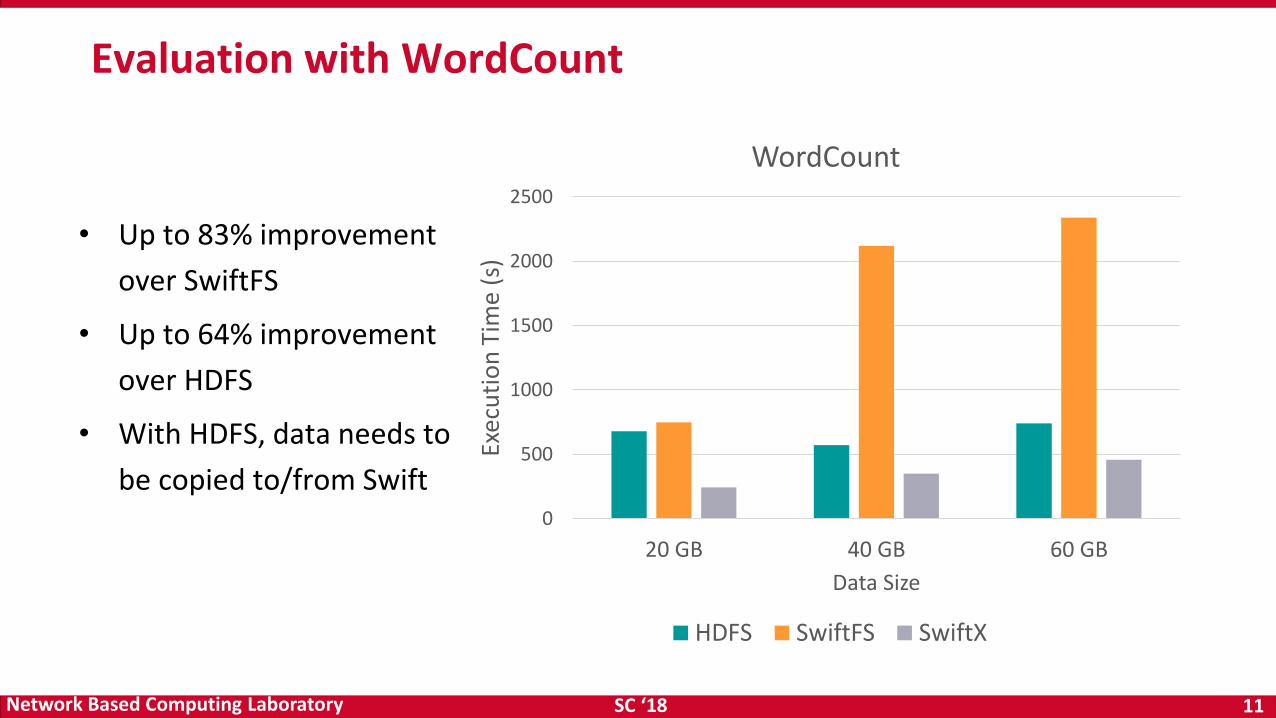
Evaluation with WordCount
• Up to 83% improvement
over SwiftFS
• Up to 64% improvement
over HDFS
• With HDFS, data needs to
be copied to/from Swift
SC ‘18 12Network Based Computing Laboratory
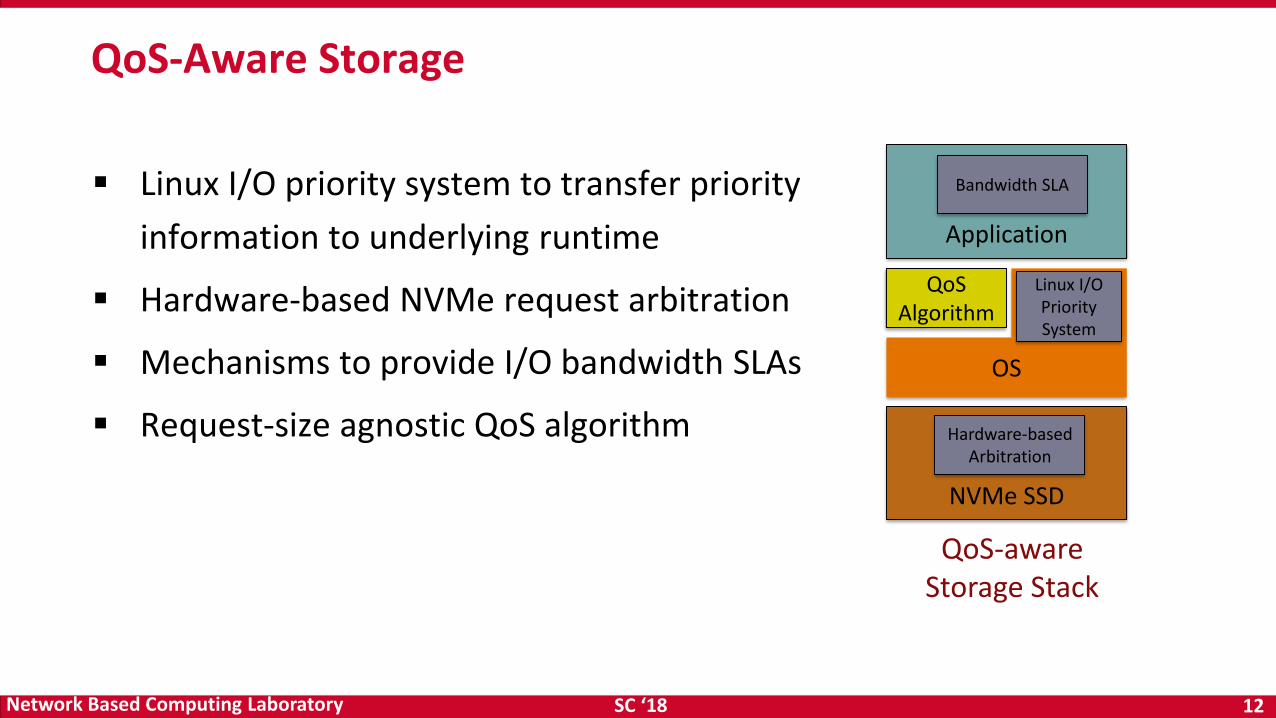
▪ Linux I/O priority system to transfer priority
information to underlying runtime
▪ Hardware-based NVMe request arbitration
▪ Mechanisms to provide I/O bandwidth SLAs
▪ Request-size agnostic QoS algorithm
QoS-Aware Storage
NVMe SSD
Hardware-based Arbitration
Application
Bandwidth SLA
QoS Algorithm
OS
Linux I/O Priority System
QoS-aware Storage Stack

SC ‘18 13Network Based Computing Laboratory
QoS-aware Storage
0
20
40
60
80
100
120
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49
Ban
dw
idth
(M
B/s
)
Time
Scenario 1
High Priority Job (WRR) Medium Priority Job (WRR)
High Priority Job (OSU-Design) Medium Priority Job (OSU-Design)
0
1
2
3
4
5
2 3 4 5
Job
Ban
dw
idth
Rat
io
Scenario
Synthetic Application Scenarios
SPDK-WRR OSU-Design Desired
• Synthetic application scenarios with different QoS requirements
– Comparison using SPDK with Weighted Round Robbin NVMe arbitration
• Near desired job bandwidth ratios
• Stable and consistent bandwidthS. Gugnani, X. Lu, and D. K. Panda, Analyzing, Modeling, and
Provisioning QoS for NVMe SSDs, UCC’18

SC ‘18 14Network Based Computing Laboratory
Topology-aware Communication: Map Task Scheduling
VM3
VM4
VM1
VM2
Rack 1
Host 2Host 1
Application Master
VM5 VM6
Rack 2
Host 3
Default Hadoop Policy1. Node local2. Rack local3. Off-rack
1 1 2 3
2 2 2 3
3 43 4
Hadoop-Virt Policy1. Node local2. Host local3. Rack local4. Off-rack
• Co-located VMs can communicate using loopback, without having to go through the network switch
• Maximize communication between co-located VMs
• Allocate Map tasks on a co-located VM before considering rack-local nodes or off-rack nodes
• Reduces inter-node network traffic through locality-aware communication

SC ‘18 15Network Based Computing Laboratory
Topology-aware Communication: Container Allocation
VM3
VM4
VM1
VM2
Rack 1
Host 2Host 1
Resource Manager
VM5 VM6
Rack 2
Host 3
Default Hadoop Policy1. Node local2. Rack local3. Off-rack
Container Request
1 1 2 3
2 2 2 3
3 43 4
Hadoop-Virt Policy1. Node local2. Host local3. Rack local4. Off-rack
• Co-located VMs can communicate using loopback, without having to go through the network switch
• Maximize communication between co-located VMs
• Allocate Containers on a co-located VM before considering rack-local nodes or off-rack nodes
• Reduces inter-node network traffic through locality-aware communication

SC ‘18 16Network Based Computing Laboratory
Evaluation with Applications
– 14% and 24% improvement with Default Mode for CloudBurst and Self-Join
– 30% and 55% improvement with Distributed Mode for CloudBurst and Self-Join
0
20
40
60
80
100
Default Mode Distributed Mode
EXEC
UTI
ON
TIM
ECloudBurst
RDMA-Hadoop RDMA-Hadoop-Virt
0
50
100
150
200
250
300
350
400
Default Mode Distributed Mode
EXEC
UTI
ON
TIM
E
Self-Join
RDMA-Hadoop RDMA-Hadoop-Virt
30% reduction55% reduction

SC ‘18 17Network Based Computing Laboratory
• Preliminary work to design Cloud-aware Storage and Communication
Middleware
• QoS, Consistency, Scalability, and Performance as design goals
• Experimental results on working prototype are encouraging
• Future work
– More work along storage direction
– Use of NVMe, NVM, etc.
– Additional design goals: Fault-tolerance and Availability
Conclusion

SC ‘18 18Network Based Computing Laboratory
The High Performance Big Data Project (HiBD)
http://hibd.cse.ohio-state.edu/
Thanks!
Network-Based Computing Laboratoryhttp://nowlab.cse.ohio-state.edu/
Related Documents











