Design and Characterization of SRAMs for Ultra Dynamic Voltage Scalable (U-DVS) Systems by K. R. Viveka Submitted to the Department of Electrical Communication Engineering in partial fulfillment of the requirements for the degree of at the INDIAN INSTITUTE OF SCIENCE February 2016

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Design and Characterization of SRAMs forUltra Dynamic Voltage Scalable (U-DVS)
Systems
by
K. R. Viveka
Submitted to the
Department of Electrical Communication Engineering
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
at the
INDIAN INSTITUTE OF SCIENCE
February 2016

I certify that I have read this thesis and that, in my opinion, it is fully
adequate in scope and quality as a thesis for the degree of Doctor of
Philosophy.
(Dr. Bharadwaj Amrutur) Principal Advisor
ii

© Copyright by K. R. Viveka 2016
All Rights Reserved
iii

To My Parents
iv

Abstract
The ever expanding range of applications for embedded systems continues to
offer new challenges (and opportunities) to chip manufacturers. Applications rang-
ing from exciting high resolution gaming to routine tasks like temperature control
need to be supported on increasingly small devices with shrinking dimensions and
tighter energy budgets. These systems benefit greatly by having the capability to op-
erate over a wide range of supply voltages, known as ultra dynamic voltage scaling
(U-DVS). This refers to systems capable of operating from nominal voltages down
to sub-threshold voltages. Memories play an important role in these systems with
future chips estimated to have over 80% of chip area occupied by memories.
This thesis presents the design and characterization of an ultra dynamic volt-
age scalable memory (SRAM) that functions from nominal voltages down to sub-
threshold voltages without the need for external support. The key contributions of
the thesis are as follows:
1) A variation tolerant reference generation for single ended sensing: We present
a reference generator, for U-DVS memories, that tracks the memory over a wide
range of voltages and is tunable to allow functioning down to sub-threshold volt-
ages. Replica columns are used togenerate the reference voltage which allows the
technique to track slow changes such as temperature and aging. A few configurable
cells in the replica column are found to be sufficient to cover the whole range of
voltages of interest. The use of tunable delay line to generate timing is shown to
help in overcoming the effects of process variations.
2) Random-sampling based tuning algorithm: Tuning is necessary to overcome
the increased effects of variation at lower voltages. We present an random-sampling
based BIST tuning algorithm that significantly speed-up the tuning ensuring that
the time required to tune is comparable to a single MBIST algorithm. Further, the

use of redundancy after delay tuning enables maximum utilization of redundancy
infrastructure to reduce power consumption and enhance performance.
3) Testing and Characterization for U-DVS systems: Testing and characterization
is an important challenge in U-DVS systems that has remained largely unexplored.
We propose an iterative technique allows realization of on-chip oscilloscope with
minimal area overhead. The all digital nature of the technique makes it simple to
design and implement across technology nodes.
Combining the proposed techniques allows the designed 4 Kb SRAM array to
function from 1.2 V down to 310 mV with reads functioning down to 190 mV.
This would contribute towards moving ultra wide voltage operation a step closer
towards implementation in commercial designs.
ii

Acknowledgements
Several people have contributed immeasurably in making this study possible. I take
this opportunity to offer my sincere gratitude to each of them for the many ways in
which their support and encouragement has helped me through this journey.
First and foremost, I thank my advisor Prof. Bharadwaj Amrutur for his in-
valuable guidance and encouragement during my Ph.D. His immense knowledge,
patience and attitude are qualities I will always strive to achieve. Thank you for
giving me the freedom to explore, and guidance to recover from mistakes resulting
in an unique and enjoyable environment for pursuing research.
I would like thank other faculty members Prof. Navakanta Bhat, Prof. Gaurab
Banerjee, Prof. Kuruvilla Varghese, Prof. T V Prabhakar, Prof. P Venkatram, Prof.
S V Gopalaiah, Prof. Chandra Murthy, and Prof. Kausik Majumdar for their en-
couragement and support during our interactions. Thank you Vedavalli madam for
supporting the license of VLSI tools over the years. Thanks also to Ms. Babitha
from Cadence and Mr. Erwin Deumens from IMEC for your quick and prompt in
responses during crucial tapeout deadlines.
My friends from the ”tree”: Ammu, Baba, Chikki, Abhi, Uday and Teju - have
been a constant support through this journey, for which I will always be grateful.
I thank my lab mates over the years: BT, Pratap, Karthik, Rajath, Pushkar,
i

Sagar, Kaushik, Manikandan, Hitesh, Auritro, Chaitanya, Tejasvi, Syam, Janakira-
man, Vikram, Mohan, Nandish, Satyam, Siva and Bhargava; and members of other
labs: Zaira, Vishal, Immanual, Javed, Jaideep, Neeraj and Manas for informative
discussions and maintaining an enjoyable work environment. Karthik and Pratap
deserve special mention for the your generous dose of encouragement and guidance
over the years.
My CEDT family: Abhilasha, Prajkta, Smitha, Nehal madam, Venu, Anil, Nayan,
Anand, Hemant, Animesh, Kamlesh, Ankuj, Gautam, Guru, Gajanan, YPP and Chai-
tanya have been a source of constant support, encouragement, timely help, coun-
sellings and much more. I deeply cherish your friendship.
Thanks to numerous friends from IISc Gymkhana: OSCA and other Cricket club
members, Badminton and Table-tennis friends - for providing refreshing moments
away from the department.
I take this opportunity to thank the administrative members of ECE department
especially Srinivas Murthy and C T Nagaraj for their support on numerous occa-
sions. A special thanks also to Radhika and Subhashini for help with purchases,
travel arrangements and reimbursements.
Attending the International Solid-State Circuits Conference (ISSCC) in San Fran-
cisco, CA, USA was one of the highlights of my PhD and had a significant impact on
my outlook towards research. I thank the Department of Science and Technology
(DST) and IEEE Solid-State Circuits Chapter for awarding travel grants to make this
possible.
The interaction with students as TA during several semesters of Digital VLSI
and Advanced VLSI courses was refreshing, providing me with an opportunity to
develop and sharpen my teaching skills. I am thankful to both my advisor and the
numerous students over the years for this opportunity.
This thesis would not have been possible without the constant support from my
parents and sister. I thank them for their patience and understanding during these
ii

years. The unconditional love from my Grandparents and Chikkamma continues to
surprise me and I am deeply thankful for this. I am grateful for the support from
cousins, uncles and aunts.
This work was supported by Department of Electronics and Information Tech-
nology, Govt. of India.
iii

Publications from this thesis
Peer-Reviewed Journal Articles
• Viveka Konandur Rajanna and Bharadwaj Amrutur, ”A Variation Tolerant Replica
Based Reference Generation Technique for Single-Ended Sensing in Wide Volt-
age Range SRAMs”, IEEE Transactions on Very Large Scale Integration (VLSI)
Systems. (under minor revision).
• Viveka Konandur Rajanna and Bharadwaj Amrutur, ”A 1.2 to 0.4 V Low Area
Characterization System for Wide Voltage Range Systems: SRAMs” (manuscript
under preparation).
Conference Presentations
• K R Viveka and Bharadwaj Amrutur, ”Digitally Controlled Variation Toler-
ant Timing Generation Technique for SRAM Sense Amplifiers”, Asian Sym-
posium on Quality Electronics Design (ASQED) 2013, August 26-28, Penang,
Malaysia.
• K R Viveka and Bharadwaj Amrutur, ”Energy Efficient Memory Decoder De-
sign for Ultra-Low Voltage Systems”, 27th International Conference on VLSI
Design, January 2014, Mumbai, India.
iv

• Viveka Konandur Rajanna and Bharadwaj Amrutur, Presentation at the 2015
International Solid-State Circuits Conference (ISSCC), Student Research Pre-
view session, San Francisco, CA, USA (Feb 2015).
v

Contents
Acknowledgements i
Publications from this thesis iv
1 Introduction 1
1.1 Motivation for U-DVS . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Memories in U-DVS Systems . . . . . . . . . . . . . . . . . . . 4
1.2 Scope of Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Literature review 7
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Challenges in U-DVS SRAM Design . . . . . . . . . . . . . . . . . . . 8
2.2.1 Sense-Amplifier Reference Voltage . . . . . . . . . . . . . . . 12
2.2.2 Timing Generation . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Cell modifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 Read buffers . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.2 Controlling feedback . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.3 Sizing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.4 Schmitt trigger based cell . . . . . . . . . . . . . . . . . . . . 16
vi

2.4 Peripheral Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1 Virtual Supply voltages . . . . . . . . . . . . . . . . . . . . . . 17
2.4.2 Wordline assist . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.3 Bitline assist . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4.4 Body Bias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.5 Other techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3 SRAM Array Design 20
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2 SRAM Cell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3 Write . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Read . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.4.1 U-DVS Reference Voltage Generation Technique . . . . . . . . 27
3.5 Timing Generation Using Tunable Delay Lines . . . . . . . . . . . . . 33
3.5.1 Timing Generation Techniques . . . . . . . . . . . . . . . . . 34
3.5.2 Implemented Delay Line . . . . . . . . . . . . . . . . . . . . . 40
3.6 Tuning Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.7 Simulation results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4 Random Sampling Based Tuning 54
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.2 Optimized Repair and Tuning . . . . . . . . . . . . . . . . . . . . . . 54
4.2.1 Conventional Approach: Repair followed by tuning . . . . . . 55
4.2.2 Proposed Approach: Delay tuning followed by redundancy
repair . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.2.3 Random Sampling: Reducing number of reads . . . . . . . . . 58
4.2.4 Proposed Algorithm: Tuning using random-sampling followed
by repair . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
vii

4.3 Results and Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5 Experimental Setup and Measured Results 65
5.1 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.2 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.3 Measured System Performance . . . . . . . . . . . . . . . . . . . . . 69
5.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6 Testing of Low Voltage Designs 75
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
6.2 Sub-sampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
6.3 Sense-amplifiers as ADCs for bitline voltage measurements . . . . . . 79
6.4 Measured Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
7 Conclusions 88
7.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
7.2 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
A Optimal Placement of Level Converters in Memory Decoders 91
A.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
A.2 Sub-threshold to Above Threshold Level Shifter . . . . . . . . . . . . 93
A.3 Memory Interface Architecture . . . . . . . . . . . . . . . . . . . . . 93
A.4 Row Decoder Design . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
A.5 Implementation and Simulation Results . . . . . . . . . . . . . . . . 101
A.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
viii

B Simulating Effect of Tuning Algorithm 106
ix

List of Tables
3.1 Measured delay-line parameters at different supply voltages . . . . . 43
5.1 Measured memory performance for various combinations of read-
supply and memory-supply . . . . . . . . . . . . . . . . . . . . . . . 70
5.2 Comparison of this work with other U-DVS designs . . . . . . . . . . 72
A.1 Architectural options for placement of level shifters at different stages
along the row decoder . . . . . . . . . . . . . . . . . . . . . . . . . . 97
x

List of Figures
1.1 Performance requirements for common applications of H.264/AVC. . 2
1.2 Raw data requirement for various levels of HEVC standard [4]. . . . 3
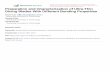
2.1 Simplified block diagram of an SRAM array. . . . . . . . . . . . . . . 8
2.2 Typical variation in bitline characteristics and timing signals due to
local process variation between different SRAM cells in a chip. . . . . 9
2.3 Simulated results showing effect of supply scaling on (a) Variation
in bitline fall-time, obtained using Monte-Carlo simulations for local
variation, post-layout, for 8T SRAM [13] cell array with 256 cells/BL
(b) Offset voltage of an NMOS-input sense-amplifier [32, 33], de-
signed to have a maximum offset of 20 mV at 1.2 V, in 130nm process. 11
2.4 Simulated maximum ∆VBL and the ∆VBL available using the replica
technique at different supply voltages (using 6σ variation). . . . . . . 13
3.1 (a) Schematic and (b) Layout of 8T SRAM cell used with transistor
sized annotated. 1X refers to minimum sized transistor. . . . . . . . 20
3.2 Timing waveform, showing relative delay between signals generated
for the memory. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Butterfly diagram showing hold Static Noise Margin (SNM) of the
implemented 8T SRAM cell at (a) 1.2 V and (b) 0.35 V. . . . . . . . . 22
xi

3.4 Read SNM of the implemented 8T SRAM cell at different supply volt-
ages. Both the mean value and its coefficient of variance are shown. 22
3.5 Write noise margin of the implemented 8T SRAM cell at different
supply voltages. Both the mean value and its coefficient of variance
are shown. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.6 Simulated time taken for a read and write operation at different sup-
ply voltages. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.7 Single-ended read in U-DVS memories using (a) Inverter - causing
rail-to-rail swing of BL (b) Sense-Amplifier (using a reference) for
higher speed and lower power. . . . . . . . . . . . . . . . . . . . . . 25
3.8 Simulation results comparing the (a) Time taken and (b) BL swing
(during a read operation) when using a sense-amplifier, an inverter,
and an inverter with shorter BLs (hierarchical BL with 16 cells per
local BL) for sensing. . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.9 Typical variation in bitline characteristics due to local process varia-
tion between different SRAM cells in a chip. . . . . . . . . . . . . . . 27
3.10 Proposed schematic that equalizes charge on replica columns REFL
and REFH, mimicking BL0 and BL1 respectively, to generate the re-
quired reference voltage. . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.11 Organization in layout, of the various blocks in the implemented
memory. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.12 Simulated worst-case error due to non-ideal modeling of off-cells on
replica bitlines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.13 Sized pseudo-SRAM cells used for fine tuning of the reference voltage. 32
3.14 Timing generation technique used in SRAMs for SAE generation . . . 34
3.15 Process variation causes uncertainty in bitline fall-time and SAE gen-
eration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
xii

3.16 Correlation between bitline fall time and SAE timing generated using
Inverter delay chain. . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.17 Correlation between bitline fall time and SAE timing generated using
Replica bitline. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.18 Correlation between bitline fall time and SAE timing generated using
Tunable replica bitline. . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.19 Tunable delay line used to generate timing signals for SRAM. . . . . 40
3.20 (a) Schematic and (b) Layout of the implemented Fine Delay Cells
(FDC). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.21 (a) Schematic and (b) Layout of the implemented Coarse Delay Cells
(CDC). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.22 Measured tunability of delay lines, used in SRAM timing generator
block, at different supply voltages. It may be noted that the delay
values for each of the curves is normalized to its respective value at
code = 0. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.23 Random-sampling based algorithm used to tune the timing and ref-
erence generator for reads, at a given supply voltage. . . . . . . . . . 44
3.24 Sketch to illustrate the variation characteristics of BL0, BL1, and VREF
and options available for tuning. . . . . . . . . . . . . . . . . . . . . 45
3.25 Variation of (a) Time taken by tuning algorithm (in terms of number
of full memory reads) and (b) tSAE with various tuning algorithms.
These simulation results are obtained for a 10 KB memory. The time
taken by standard memory BIST algorithms is also shown. The error
bars in this figure are too small to be seen. . . . . . . . . . . . . . . . 46
3.26 Simulated effect of local mismatch on BL0, BL1, and VREF (for N =
1, 2 and 3) at (a) 1.2 V and (b) 0.45 V. The error bars here span the
range from the µ + 3σ to µ − 3σ. Fewer error bars are shown in (b)
for clarity. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
xiii

3.27 Signal waveforms during a typical read operation at 400 mV. . . . . . 50
3.28 Simulated results showing the tracking of the reference voltage, gen-
erated using the proposed technique, with the ideal reference as the
supply is scaled. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.29 Simulated effect of temperature and process corners on the percent-
age error between the ideal and generated reference voltage at differ-
ent supply voltages and aspect ratios. Timing signals were generated
using a tunable delay line that was tuned at TT, −40 ◦C. . . . . . . . 51
3.30 Simulated reference voltage tunability achieved using additional rows
of sized SRAM cells (Fig. 3.13), for different supply voltages. . . . . . 53
4.1 Existing delay tuning algorithm [48] [47] . . . . . . . . . . . . . . . 55
4.2 Proposed delay tuning algorithm. A further optimization in block A
is to ”Test Nsample Cells” where Nsample << total number of cells . . . 56
4.3 Normalized tSAE vs Percentage Repair . . . . . . . . . . . . . . . . . 60
4.4 Number of samples vs Percentage redundancy for various values of
confidence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.5 Actual redundancy used vs specified redundancy . . . . . . . . . . . 62
4.6 tSAE vs redundancy specified during calculation of Nsample . . . . . . 63
4.7 Number of samples vs Memory size . . . . . . . . . . . . . . . . . . . 63
5.1 (a) Die photograph and (b) Layout snapshot of the fabricated chip in
UMC 130nm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.2 Measurement setup showing the fabricated chip, FPGA-board, and
other interface equipment, used for characterization of chips. . . . . 66
5.3 Test setup: FPGA board (left) interfaced to the PCB (right) with the
fabricated chip. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5.4 Screen-shot of the sub-sampled waveforms of timing signals, gener-
ated at 350 mV, with a delay amplification factor of 390. . . . . . . . 67
xiv

5.5 Measured maximum operating frequency of memory as the supply is
scaled. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.6 Measured effect of supply voltage on Energy per access, Leakage
power, and Read power. . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.1 Sub-sampling technique used to accurately measure delay between
two periodic signals. . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.2 Illustrative waveform showing the amplified input delay between
sub-sampled signals. . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6.3 Block diagram of the proposed voltage measurement technique. . . . 79
6.4 Implementation of the sub-sampling technique to characterize the
SRAM array, fabricated in the UMC 130nm. . . . . . . . . . . . . . . 81
6.5 Chip Micrograph showing the sub-sampling block implemented in
UMC 130nm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.6 Measured probability density function of 16 sense-amplifiers, at (a)VDD =
1.2 V and (b)VDD = 0.36 V, which is used to characterize their offset-
voltage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.7 Measured reference voltage VREF versus wordline pulse width at (a)
Supply = 1.2 V and (b) Supply = 0.4 V. . . . . . . . . . . . . . . . . 85
A.1 Generic memory interface of a multi-voltage domain system with
level shifters placed before the memory macro. . . . . . . . . . . . . 92
A.2 (a) Wilson current mirror based sub-threshold level shifter [118]. (b)
Layout of 8T SRAM and level shifter of equal pitch. . . . . . . . . . . 92
A.3 Timing diagram of the memory interface shown in Fig A.1. . . . . . . 93
A.4 Variation of FO4 delay and level shifter delay with VDD CORE. . . . 95
A.5 Modified memory interface diagram with the level shifters being placed
inside the memory macro next to the row-decoders. . . . . . . . . . . 96
xv

A.6 Proposed Row-Decoder architecture showing various architectural
options for placement of level shifters. . . . . . . . . . . . . . . . . . 98
A.7 Typical memory interface leakage power break-up with all sections
of the memory operating at 550 mV. . . . . . . . . . . . . . . . . . . 99
A.8 Decoder leakage power in various level shifter positions. . . . . . . . 100
A.9 Decoder Energy/cycle in different level shifter positions for minimum
and maximum decoder activity and variation of decoder delay with
level shifter position. . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
A.10 Variation of absolute Energy/cycle and combinational delay with VDD CORE.102
A.11 Percentage saving in Energy/cycle for various values of VDD CORE,
for extreme values of decoder activity. . . . . . . . . . . . . . . . . . 104
xvi

Chapter 1
Introduction
1.1 Motivation for U-DVS
The ever expanding range of applications for embedded systems continue to offer
new challenges (and opportunities) to chip manufacturers. Applications ranging
from exciting high resolution gaming to mundane tasks like temperature control
need to be supported on increasingly small devices with shrinking dimensions and
tighter energy budgets.
Parallelism, custom hardware and voltage scaling have emerged as some of our
best options for achieving the energy goals for future designs. Voltage scaling in
particular offers huge improvement in energy efficiency. This combined with fre-
quency scaling (DVFS) enables multiple orders of magnitude reduction in energy
with supply voltage [1]. However emerging applications such as the Internet of
Things (IoTs) demand wider range of performance and add tighter constraints on
energy consumption. This translates to systems that must be capable of operating
over a wider range of voltages to support these applications efficiently. Such systems
are known as Ultra dynamic voltage Scalable (U-DVS), which refers to systems that
are capable of operating at voltages ranging from nominal down to sub-threshold
voltages.
A typical application requiring U-DVS are biomedical systems such as neonatal
monitors where energy efficiency is of paramount importance. Under normal con-
ditions these systems monitor simple vital signs such as temperature [2], oxygen
saturation (using pulse oximetry) and heart rate that can be achieved by operating
the system at lower frequencies (hundred’s of kilohertz). However more complex
1

Chapter 1. Introduction 2
0.01
0.1
1
10
MobileVideo
VideoConferencing
DVD HDTV HD-DVD
Com
pre
ssed-b
it-r
ate
(in
Mbps)
Upto 400Xdifference in load
Figure 1.1: Performance requirements for common applications of H.264/AVC.
analysis may be performed if irregularities are detected in these signs. This may in-
volve running more complex algorithms on these basic signals or monitoring addi-
tional signals such as multi-point ECG. During such phases the system performance
requirements can increase by up to 78 times [3].
Another example is video monitoring for security (burglar alarms) or personal
care (monitoring infants or senior citizens). Here again, during nominal operation
low resolution video is captured at low frame rates putting low performance re-
quirements on the embedded system. However when anomalies are detected (such
as movement in case of burglar alarms), more detailed analysis is warranted. This
involves capturing and processing higher resolution video, running more complex
algorithms such as face detection and selectively compressing and transmitting the
data. The performance requirements in such system can thus greatly vary.
Mobile devices today need to support a wide range of applications with greatly

Chapter 1. Introduction 3
0.1
1
10
100
1000
10000
1 2.x 3.x 4.x 5.x 6.x
Raw
data
rate
(in
MB
ps)
HEVC Levels
Upto 8000Xdifference in load
Figure 1.2: Raw data requirement for various levels of HEVC standard [4].
varying performance requirements. Fig. 1.1 shows the range of video applications
supported by H.264/AVC and the bandwidth of their compressed bitstreams. These
bit-rates translate directly to real time processing requirements [5]. Future stan-
dards are expected to further increase this range of requirements as shown in
Fig. 1.2 [4, 6]. SRAMs are primarily used as caches in these systems and hence
their performance is also required to scale over these wide ranges. This trend for
widely varying performance is also seen in DRAMs whose data bandwidth for vari-
ous interface standards used over the years is illustrated in [7]. Such devices would
greatly benefit from having U-DVS systems to enhance their energy efficiency across
these applications.

Chapter 1. Introduction 4
1.1.1 Memories in U-DVS Systems
Memories play an important role in these systems with future chips estimated to
have up to 90% of chip area occupied by memories [8]. Thus the memory power has
a major impact on the system power efficiency. Also, the memory (cache) speed and
size have a direct effect on the system performance [9]. Hence these systems need
caches, which are implemented using Static Random Access Memories (SRAMs),
that are also capable of functioning well across a wide range of voltages.
1.2 Scope of Thesis
Conventional static CMOS based logic circuits and systems are generally robust
to extreme supply voltage scaling and have been shown to function well down
to sub-threshold voltages [1, 10, 11]. Further, some modifications in circuit style
allow functioning down to 62 mV [12]. However enabling low voltage operation in
memories, specifically SRAMs has proven to be more challenging. We examine the
various steps in designing an SRAM array in a U-DVS system and present the design
of SRAM that functions from nominal down to sub-threshold voltages.
We begin at the interface between logic circuitry and the memory macro in
systems that are targeted to operate at sub-threshold voltages. Due to inherent lim-
itations, the memory macro tends to be operated at higher voltages compared to
logic circuitry in these systems. Level shifters are therefore used to communicate
between these two blocks. We present a technique for reduction in energy by plac-
ing the level-shifters further into the memory macro (inside the address-decoder)
without sacrificing performance in such systems.
The elements of the SRAM array such as design of the SRAM cell and its read
and write paths are presented that enable high-speed operation at nominal volt-
ages, while extending operation down to sub-threshold voltages. A conventional

Chapter 1. Introduction 5
8T SRAM cell is chosen as it provides a good trade-off between low voltage opera-
tion and area penalty [13]. We size the 6T section of the cell for better writability
by reducing the effect of variation. Single-ended read is performed using sense-
amplifiers with a replica column based reference generation circuitry. We report
a variation tolerant reference generation mechanism suitable for U-DVS systems
which tracks the bitline voltages as the supply is scaled. The technique uses replica
bitlines to track process variations and other slow changes affecting the memory.
The key contributions of this work are: (i) Technique for generation of a suitable
reference voltage internally, which provides robustness against process variation
(ii) Extension of the operating range of the memory using tunable delay lines for
timing generation that employs a random-sampling based algorithm to significantly
speed-up the tuning process and (iii) SRAM test and characterization methodology
using sub-sampling circuits.
Combining the above techniques allows a prototype 4 Kb SRAM array to function
from 1.2 V down to 310 mV without any external support and achieves good perfor-
mance over a wide voltage range, beyond what has been reported in literature so
far.
1.3 Organization
We first review existing literature on design of U-DVS systems and low-voltage
SRAMs in Chapter 2. The design of the SRAM array components such as the SRAM
cell, read and write paths, and our proposed reference and timing generation mech-
anism are discussed in Chapter 3. We then present the random sampling based
tuning algorithm in Chapter 4. This is followed by the measurement results of our
test chip fabricated in 130nm technology that incorporates the proposed techniques
in Chapter 5. The testing and characterization technique suitable for such U-DVS
systems in presented in Chapter 6. We then present our conclusions in Chapter 7.

Chapter 1. Introduction 6
Appendix A discusses the options for placement of level-shifters along the mem-
ory decoder in systems where the logic and memory operate at different supply
voltages. The steps involved in obtaining simulation results for the reference gen-
eration technique using the proposed tuning algorithm is described in Appendix B.

Chapter 2
Literature review
2.1 Introduction
Ultra dynamic voltage scalable (U-DVS) systems have received considerable atten-
tion in recent literature [3, 14, 15]. These are systems capable of operating over a
very wide range of voltages ranging from nominal down to sub-threshold voltages.
This is mainly motivated by an increase in demand for applications requiring U-DVS
systems as elaborated in Chapter 1.
Sub-threshold design has been around from late 1970s [16, 17]. Initial work
reported analog circuits targeted mainly for watches that require extended battery
life at very low performance [18–21]. The first digital sub-threshold design was re-
ported in 1972 by Swanson and Meindl [22] which was followed by an implemen-
tation that demonstrated the functioning of a ring oscillator down to 100 mV [23].
Several low voltage designs were reported after that but they mostly operated the
transistor in strong-inversion even at low voltages by using low or zero-threshold
voltage devices [24–27].
Sub-threshold designs were revived in 2001 for hearing aid applications that
require very low frequency clocks [28, 29]. Different logic styles for sub-threshold
operation were explored in this work that demonstrated an adder in 0.35µm tech-
nology that functioned down to 0.47 V. In 2002, a ring oscillator based voltage con-
trolled oscillator (VCO) was demonstrated to function down to 80 mV in 180nm
technology with a nominal voltage of 1.8 V [30]. A configurable FFT processor
was then implemented in 2004 that operated down to 180 mV in 0.18µm technol-
ogy [10]. Further, schmitt trigger based standard cells were used to implement a
7

Chapter 2. Literature review 8
De
cod
er a
nd
W
ord
-Lin
e (W
L) d
rive
rs
Precharge Block
Timinggenerator
RBL
ɸ
ɸ
SAESAESA0 SAM-1
SRAMcell
WL0
WL1
WLN-1
BL0 BLB0 BLM-1 BLBM-1
D[0] D[M-1]
ɸ
Replicacolumn
ReplicaSRAM cells
Write Driver(and other column circuitry)
BLX: Bitline, WLX: WordlineSAX: Sense Amplifier
Note:
Figure 2.1: Simplified block diagram of an SRAM array.
multiplier in 0.13µm technology that functioned down to 62 mV [31].
Scaling the supply voltage of memories has proven to be more challenging. An
initial sub-threshold design thus used MUX based hierarchical read-path adding a
large area overhead [10]. One of the first sub-threshold SRAMs was reported in
2006 that used a 10T SRAM cell in 65nm technology. Several designs have been
reported that use modifications in SRAM cell and/or assistance from peripheral cir-
cuitry to extend SRAM operation down to sub-threshold voltages. We first describe
two major challenges in design of U-DVS SRAMs followed by a brief review of the
literature reported for improving SRAM performance at lower voltages.
2.2 Challenges in U-DVS SRAM Design
An SRAM memory block is organized as an array of rows and columns containing
SRAM cells, each of which stores one bit of information as shown in Fig. 2.1. Each

Chapter 2. Literature review 9
PrechargePhase
Read Phase
VDDR
Read Wordline
Bitlines
Sense Amplifier Enable
Variation in Timing Generation
BL1
BL0
BL FalltimeVariation
ΔVBL
BL S
win
g
Figure 2.2: Typical variation in bitline characteristics and timing signals due to localprocess variation between different SRAM cells in a chip.
row roughly corresponds to one word of data at a particular address location (no
column MUXing is assumed here for simplicity of explanation). All cells on a column
share common bitlines that acts as the read and write ports for the SRAM cell. The
access to these ports are controlled using wordlines that run horizontally in Fig. 2.1
connecting all cells on a row. The address decoder block activates the wordline on
the row corresponding to the address location being accessed.
The SRAM cell is designed to occupy minimum area, helping in maximizing
storage capacity and hence system performance. The cell thus requires additional
peripheral circuitry to support reading and writing of data such as sense-amplifiers
and timing generators. This is in contrast to a standard logic based latch that can
also store one bit of data and does not require any amplifier circuitry.
SRAM cells are read by first precharging the BLs and activating the appropriate

Chapter 2. Literature review 10
wordline, as shown in Fig. 2.2. Based on the data stored in the cell, the BL either re-
mains high (BL1) or begins to discharge (BL0). Once a sufficient differential voltage
develops, the sense-amplifiers are enabled. The sense-amplifier then compares the
BL voltage against a reference voltage VREF, (for single-ended reads) and estimates
the data stored in the cell.
Effects such as Random Dopant Fluctuation (RDF) and line edge roughness
cause variation between individual cells in an SRAM array. This is shown as spread
in BL0 and BL1 transition waveforms in Fig. 2.2. The effect of supply scaling on
this variation is shown in Fig. 2.3(a), which plots the time taken for the bitline to
fall to 90% of VDD and it’s coefficient of variation. It may be seen that, at lower
voltages both the delay and its variation increase exponentially. This is due to the
exponential dependence of currents on the threshold voltage of transistors at these
low supply voltages.
The offset of the sense-amplifier is also affected by the increased variation at
lower voltages as shown in Fig. 2.3(b). The figure plots the variation of 3σ and 6σ
value of the offset voltage for the NMOS-input sense-amplifier [32], designed to
have a maximum offset less than 30 mV at 1.2 V, in 130nm process [33]. Offset
is caused by the mismatch in currents of the transistors of the sense-amplifier. Its
variation with supply voltage and causes of this are described in [34]. As can be
seen from Fig. 2.3(b), at voltages below 0.35 V, the probability of failure increases
sharply. This is because of the fact that even the maximum differential voltage
(VDD/2) may be insufficient to support the increased offset voltages of the sense-
amplifiers.
The earliest instant at which the sense-amplifier may be enabled is when the
difference in voltages between the slowest BL0 (or the fastest BL1) and VREF is
greater than its offset voltage. On the other hand, enabling the sense-amplifiers too
late causes increased BL swing which adversely affects the memory read power and
latency. Thus margins must be added during design in order to accommodate these

Chapter 2. Literature review 11
0.1
1
10
100
1000
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 1
10
100
t fall
90%
(in
ns)
σ/µ
%
Supply voltage, VDD (in Volts)
7.4X
680X
σ/µ%
tfall 90%
(a)
0.01
0.1
1
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Voltage n
orm
aliz
ed to V
DD
Supply voltage, VDD (in Volts)
VDD/2
6σSA-offset
3σSA-offset
Probability of failureincreases sharply
VDD/2
6σOffset Voltage
3σOffset Voltage
(b)
Figure 2.3: Simulated results showing effect of supply scaling on (a) Variation inbitline fall-time, obtained using Monte-Carlo simulations for local variation, post-layout, for 8T SRAM [13] cell array with 256 cells/BL (b) Offset voltage of an NMOS-input sense-amplifier [32,33], designed to have a maximum offset of 20 mV at 1.2 V,in 130nm process.

Chapter 2. Literature review 12
variations. Non-idealities in the timing-generation mechanism further add to this
margin. We would hence like to minimize the sources of variation by (1) having a
robust reference generation mechanism and (2) enable the sense-amplifier at the
optimal time. The following sub-sections illustrate these two challenges.
2.2.1 Sense-Amplifier Reference Voltage
Most U-DVS SRAM cells proposed [3,13,15,35] employ a conventional inverter pair
(as the storage element) and an additional read-buffer to isolate the read-current
from going into the cell. An exception to this is the schmitt-trigger based cell [36],
whose performance degrades at nominal voltages. Therefore, we have chosen a
simple 8T SRAM cell (Fig. 3.1) [13] as representative of the most promising cell
designs for U-DVS. Use of a read-buffer implies that, the cells only support single-
ended read, since using two sets of read-buffers [37] (11T) would significantly
increase the cell area. Single-ended sensing using a simple inverter requires the
BL to swing from almost rail-to-rail [38, 39], which is prohibitively expensive at
nominal voltages, as mentioned earlier. Alternatively, the use of a sense-amplifier
requires a reference voltage.
A simple resistive divider may be used to internally generate the reference volt-
age, as a fixed ratio of the supply voltage. However, the required reference voltage
does not scale as a fixed fraction of the supply voltage (as we will show in Sec-
tion 3.7, Fig. 3.28). At higher voltages, the sense-amplifier’s inputs are closer to the
supply, whereas at lower voltages the inputs (BLs) are closer to ground, at the time
of their activation [15]. One reported design [40] uses a pseudo-NMOS inverter
(along side each sense-amplifier) connected to the BL to generate the reference
voltage. However, this approach affects the access speed at higher voltages.
Another option for generating the reference voltage is to use an internal Digi-
tal to Analog Converter (DAC). This requires a controlling logic that monitors the
memory supply voltage and generates a suitable reference using a pre-configured

Chapter 2. Literature review 13
0.1
1
10
100
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Voltage n
orm
aliz
ed to S
Aoffset voltage
Supply voltage, VDD (in Volts)
∆VBL-MAX
∆VBL-Replica
Reads FAIL below this line
Figure 2.4: Simulated maximum ∆VBL and the ∆VBL available using the replicatechnique at different supply voltages (using 6σ variation).
look-up-table, and a conventional DAC design can lead to a large area and power
overhead. Using an externally generated reference [15,41] requires additional pins
for sensing the memory conditions and to supply the required reference voltage.
Also these approaches do not track the memory with slow varying changes such as
temperature, Bias Temperature Instability (BTI) and aging.
2.2.2 Timing Generation
While the conventional replica technique [42] for generating timing signals for
SRAM works well at nominal voltages, its performance degrades in the presence
of increased variation at lower voltages. Fig. 2.4 compares the maximum ∆VBL
available at each supply voltage against the ∆VBL obtained using the replica tech-
nique. ∆VBL initially increases sharply with time and reaches a maxima, before be-
ginning to decrease slowly. Replica [42] and other non-programmable techniques
for generating the timing perform poorly with the changes in timing of occurrence

Chapter 2. Literature review 14
of maximum ∆VBL as the supply is reduced. This results in degradation of ∆VBL
(which causes reads to fail) at lower voltages as can be seen from Fig. 2.4.
Various techniques have been reported for the generation of timing signals that
employ either averaging or tuning to reduce the effect of variation. Increased av-
eraging may be achieved by activating greater number of cells on the replica BL,
and then using a timing multiplier circuit to increase the delay such that it is suf-
ficient for correctly sensing the BLs [43]. This technique is however limited by the
quantization in the timing multiplier circuit and offers no flexibility for tuning post
fabrication. Another approach is to monitor all the BLs in the design and generate
the timing signal in steps using the order in which the BLs discharge [44]. Although
this design provides extensive averaging, it requires about 4% additional height of
the memory macro (with 128 cells/BL) and its applicability over a wide range of
voltages is not discussed.
Tunable delay lines offer best tracking with process variations [45], especially in
the presence of extreme variation as seen at sub-threshold voltages. They offer the
flexibility of maximizing ∆VBL at each supply voltage. We use BIST infrastructure to
tune these delay lines, as reported in literature [46–49], to track variation caused
by manufacturing artifacts.
2.3 Cell modifications
The standard 6T SRAM cell, consisting of a pair of cross-coupled inverters and
two access NMOS transistors, is not suitable for low voltage operation due to the
increased effect of variation at these voltages [50]. We look at designs reporting
alternate SRAM cells to improve performance at lower voltages.

Chapter 2. Literature review 15
2.3.1 Read buffers
One of the main issues in using the conventional 6T cell at lower voltages is the
necessity to ensure relative strength between transistor for both read and write
stability. This may be alleviated using additional transistors as read-buffer along
with a separate read bitline (RBL) and read wordline (RWL) [13]. This decouples
the read and write noise margin requirements increasing the robustness of the cell
at lower voltages.
Leakage power is a major concern in memories as data retention requirements
dictate that the memory must remain powered continuously i.e. it may not be
switched-off to conserve leakage power. The leakage in 8T cell may be reduced by
using a 9T cell where stacking is used to reduce the leakage through RBL [51, 52].
Further reduction in RBL leakage may be achieved using 10T cells that add an-
other transistor (to make a total of 4 transistors) in the read-buffer section of
the cell [35, 53]. Another approach to reducing RBL leakage uses 10T cell with
an inverter driving a transmission gate connected to the RBL [54]. The inverter
drives the RBL depending on the data stored in the cell thus preventing the need
for precharging. Additionally this prevents toggling of RBL if data being read re-
mains unchanged. This property is valuable in applications such as video processing
where the data is expected to remain unchanged from frame to frame [54,55]. The
paper [54] also reports another 10T cell that contains a 2T read-buffer on each
side, enabling a differential read at the expense of increased area. The above cells
however suffer from the half-select issue preventing them from being used with
bit-interleaving. This may be overcome using the read disturb free differential 10T
cells proposed [56,57].

Chapter 2. Literature review 16
2.3.2 Controlling feedback
The contradicting requirements for read and write stability may also be resolved
by selectively affecting the feedback between the cross-coupled inverters. An ad-
ditional NMOS is added to the cross-coupled inverters that is turned-OFF during
writes using an WL-bar signal, making the cell easier to write [58]. A more ex-
treme approach adds a PMOS header device to an 8T cell, whose gate is con-
nected to a charge storing node resulting in an asymmetric cell with improved
write-ability [59].
2.3.3 Sizing
Device sizing has also been reported to improve performance by changing the rela-
tive strength between transistors [60]. Sizing the devices is ineffective in maintain-
ing relative strength between transistors to overcome variation, as the transistor
current depends linearly on device dimensions but exponentially on the threshold
voltage in sub-threshold region [39]. Longer length transistors have lower thresh-
old voltage due to reverse short channel effect [61]. This effect is shown to be
stronger in sub-threshold regime [62]. Increasing length also reduces the impact
of variations due to random dopant fluctuations [63]. This important effect is also
used in [39] to reduce the effect of variation. Write-ability is improved by increas-
ing the length of the access transistor [38] and read performance by increasing the
length of transistors in the read-buffer [64].
2.3.4 Schmitt trigger based cell
Another interesting cell reported for low voltage operation uses schmitt trigger in-
verters to construct a 10T cell [36]. The hysteresis in switching thresholds of the
inverter is utilized to decouple and simultaneously enhance both read and write
margins. However the performance of this cell degrades at nominal voltages.

Chapter 2. Literature review 17
2.4 Peripheral Techniques
Modifying each cell can significantly increase the array area due to the large num-
ber of cells present in an array. Peripheral assist techniques amortize area penalty
by sharing resources across the cells. These are used in conjunction with other
techniques to further enhance low voltage operation.
2.4.1 Virtual Supply voltages
Virtual ground voltages have been used to reduce leakage in cells. Agarwal et al.
use a footer consisting of an NMOS transistor in parallel with a diode to bump-up
the ground voltage of unselected cells resulting in reduction in the cell leakage [65].
Read bitline leakage is reduced by driving high the feet of the read-buffers that are
not being accessed [64,66].
Virtual supplies are also reported to improve write noise margins by weakening
feed-back inverter in the cell being written. The supply of both inverters in the
cell is reduced in [64, 66–68], whereas only the inverter connected to the bitline
through a transmission gate is reduced in [39]. Kulkarni et al. propose to use
the capacitive coupling between the write bitlines and the cell supply to lower the
supply just before performing a write operation [69].
2.4.2 Wordline assist
Read stability may be improved by driving the wordline with a lower voltage making
the access transistor weaker thus lowering the chance of causing a read disturb [67,
68, 70]. The amount of under-drive can also be made adaptive to ensure it tracks
variations in process and slow changes such as temperature by using bitcell based
sensor [71]. Chang et al. suggest a variation in this technique where the wordline
swing is suppressed for a short time, and then allowed to swing to full rail providing
a good trade-off between read stability and performance [72].

Chapter 2. Literature review 18
Wordline boosting is also reported to improve write stability. Kulkarni et al.
proposed to use the capacitive coupling between write wordline and write bitline to
boost the write wordline without the need for a charge pump or level shifter [69].
Sinangil et al. however choose to boost the wordline using a separate voltage source
and level-shifter [73].
2.4.3 Bitline assist
The bitline voltage can also be modulated to improve performance at lower volt-
ages. Chang et al. employ negative bitline boosting along with wordline assist by
driving the bitline lower than zero after some time of the start of WRITE opera-
tion [72]. They use a replica write circuit to get the timing of negative drive correct
which is important for maximum effectiveness. Similar approach is also employed
by Song et al. in their high density cell to improve write-ability [70]. Bitline assist is
also used in their high performance cell where the bitlines are pre-charged to lower
than full supply to ensure that the half selected cells are not disturbed.
2.4.4 Body Bias
The exponential dependence of sub-threshold current on the threshold voltage
makes body-biasing particularly effective in older process nodes [62]. This effect
is utilized in [74] to increase the threshold voltage all 4 NMOS transistors in the
6T SRAM cell on cache lines that are unlikely to be accessed, resulting in a re-
duction in leakage currents. A similar approach in [75] implements the SRAM
cell using high-threshold devices to reduce the overall leakage of the array. The
performance degradation resulting from this is recovered by forward body biasing
the row being accessed. The time penalty of activating the body-bias is hidden by
suitable prediction. Body-bias is also reported to generally match the NMOS and
PMOS characteristics across the chip by varying the body bias of PMOS transistor

Chapter 2. Literature review 19
to reduce error rates at low voltages [39].
2.5 Other techniques
Sense-amplifier offset voltage increases sharply as the supply voltage is lowered as
shown in Section 2.2. This problem is compounded by the fact that most SRAM
cells reported for low voltage problem do not support bit-interleaving implying
that sense-amplifiers cannot be shared across columns. This results in each sense-
amplifier using smaller transistors, thus increasing the effect of variation [63].
One interesting solution to this problem was proposed by Verma et al., who
employ redundant sense-amplifiers. They show that statistically at least one of the
redundant sense-amplifiers is likely to have an offset lower than the required limit.
A simple state machine than chooses the appropriate sense-amplifier on boot-up
using a dummy bit-cell. Another work uses body-bias to bring the sense-amplifier
offset within bounds [73]. Here also at startup the polarity of offset voltage is
determined and the body bias of the PMOS input transistor is set to either VDD or
VDDB (higher than VDD).

Chapter 3
SRAM Array Design
3.1 Introduction
In this chapter we will discuss the design of the SRAM cell, Write and Readability
of this cell, Timing generation block, and post fabrication tuning algorithms that is
necessary at low voltages. Finally some simulation results will be presented show-
ing the effectiveness of the techniques proposed in this chapter.
3.2 SRAM Cell
WBLB WBL RBL
WWLRWL
1X
1X
1.5X
1X
1X
1.5X
1X
1X
(a)
4.965 µm
1.6
8 µ
m
(b)
Figure 3.1: (a) Schematic and (b) Layout of 8T SRAM cell used with transistor sizedannotated. 1X refers to minimum sized transistor.
Several SRAM cells have been proposed for low-voltage and wide voltage range
operation as discussed in Section 2.3. We choose the traditional 8T cell as it offers
the benefit of low-voltage operation with minimum area penalty. The cell is also
representative of other cells proposed for ULV operation as it decouples read and
write noise margins, and contains a single-ended read-port. The schematic and
layout of the cell with device sizes is shown in Fig 3.1. The access NMOS transistors
have been up-sized for better writability at lower voltages.
20

Chapter 3. SRAM Array Design 21
CLK
PRE
RWL
SA-EN(Sense Amp. Enable)
DATA(at Output of SA)
DATA(Latched for PISO)
Read Access Time= 1/(Frequency)
SAPulse Width
≈
tSAE = SA Enable Timing
tRWL
Figure 3.2: Timing waveform, showing relative delay between signals generated forthe memory.
The sketch of timing waveforms during a typical read operation is illustrated in
Fig. 3.2. The definition of various timing parameters used in this thesis are also
shown. We denote tSAE as the time between Read Wordline (RWL) activation and
sense-amplifier activation. The definition used for access-frequency, reported in
measured results (Chapter 5) is also seen here.
We first analyze the Static Noise Margin (SNM) of the cell at different voltages.
Fig. 3.3 shows the hold SNM plots at 1.2 V and 0.35 V. For the 8T cell being used,
this is almost identical to the read SNM. The effect of supply voltage on this mean
read SNM and its coefficient of variance is shown in Fig. 3.4. A detailed analysis
of this behavior and the dependence of SNM on various parameters is available
in [76].

Chapter 3. SRAM Array Design 22
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
QB
(N
orm
aliz
ed
to
VD
D)
Q (Normalized to VDD)
SNM =
312 mV
(a)
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
QB
(N
orm
aliz
ed
to
VD
D)
Q (Normalized to VDD)
SNM =
88 mV
(b)
Figure 3.3: Butterfly diagram showing hold Static Noise Margin (SNM) of the im-plemented 8T SRAM cell at (a) 1.2 V and (b) 0.35 V.
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 4
5
6
7
8
9
10
11
12
13
Re
ad
ma
rgin
(m
ea
n)
σ/µ
%
Supply voltage, VDD (in Volts)
Figure 3.4: Read SNM of the implemented 8T SRAM cell at different supply volt-ages. Both the mean value and its coefficient of variance are shown.

Chapter 3. SRAM Array Design 23
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 3
4
5
6
7
8
9
10
11
12
Write
ma
rgin
(m
ea
n)
σ/µ
%
Supply voltage, VDD (in Volts)
Our Sizing
ConventionalSizing
Figure 3.5: Write noise margin of the implemented 8T SRAM cell at different supplyvoltages. Both the mean value and its coefficient of variance are shown.
3.3 Write
Static noise margin plots offer a conservative estimate of the cell’s robustness to
noise [77]. Several methods have been proposed in literature [78–80] to redefine
the write margin in SRAM cells. Out of these, the definition proposed by Gierczynski
et al. [80] is most commonly used [81]. Fig. 3.5 plots this definition of write margin
of the designed cell at different supply voltages. Also plotted in Fig. 3.5 is the write
margin of a conventionally sized cell, where the pull-down NMOS transistors are
sized 1.5X and the access NMOS transistors are minimum sized. The benefit of
up-sizing the access transistor improves the mean-value of write margin at higher
voltages. More importantly, sizing helps in reducing the effects of variation as seen
in Fig. 3.5. This is especially helpful at lower voltages where very little margin is
available.
Increasing the size of access transistors however reduces the cells robustness
to the half-select issue. Other SRAM cells reported may be used in SRAM array

Chapter 3. SRAM Array Design 24
0.1
1
10
100
0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Tim
e n
orm
aliz
ed
to
FO
4 d
ela
y
Supply voltage, VDD (in Volts)
Read-Time (µ + 6σ)
Read-Time (µ)
Write-Time (µ + 6σ)
Write-Time (µ)
Figure 3.6: Simulated time taken for a read and write operation at different supplyvoltages.
architectures with bit-interleaving.
Fig. 3.6 shows the time taken to complete write and read operation at various
supply voltages. It may be seen that reads take significantly longer than a write
across the wide voltage range. This is true in general as reads require the weak
SRAM cell to drive the large bitline capacitance. Read-time is measured when read-
ing using a sense-amplifier and an external reference voltage. This is explained in
further detail in Section 3.4 with regard to Fig. 3.8.
3.4 Read
The most promising SRAM cells for U-DVS employ single-ended read ports [3].
Single-ended reads require either the bitlines to have a nearly rail-to-rail swing
(Fig. 3.7(a)) [38, 39] or an external reference voltage (Fig. 3.7(b)) [15, 41]. The
BL fall-time and BL swing for these two sensing options (shown in Fig. 3.7), are

Chapter 3. SRAM Array Design 25
WL[0]
WL[1]
WL[255]
PRE
VDDR
BL
Data
WL[0]
WL[1]
WL[255]
PRE
SA-EN
VDDR
ReferenceGenerator Reference Voltage
BL
Data
(a) (b)
SkewedInverter
Figure 3.7: Single-ended read in U-DVS memories using (a) Inverter - causing rail-to-rail swing of BL (b) Sense-Amplifier (using a reference) for higher speed andlower power.
compared in Fig. 3.8. It may be seen that the inverter based sensing (Fig. 3.7(a))
is significantly slower and causes larger swings on the BL at higher supply voltages.
The effect of these large BL swings on power consumption can be reduced using
hierarchical BLs. Fig. 3.8 also compares the performance of such a design with
just 16 cells/BL [39]. All three designs are implemented with comparable macro
area. While inverter with lower cells/BL performs better at lower voltages, it is not

Chapter 3. SRAM Array Design 26
10
20
30
0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
BL d
ischarg
e tim
e n
orm
aliz
ed to F
O4 d
ela
y
Supply voltage, VDD (in Volts)
SA (256 cells/BL)
INV (16 cells/BL)
INV (256 cells/BL)
(a)
0.1
0.2
0.3
0.4
0.5
0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
BL s
win
g n
orm
aliz
ed to V
DD
Supply voltage, VDD (in Volts)
SA (256 cells/BL)
INV (16 cells/BL)
INV (256 cells/BL)
(b)
Figure 3.8: Simulation results comparing the (a) Time taken and (b) BL swing(during a read operation) when using a sense-amplifier, an inverter, and an inverterwith shorter BLs (hierarchical BL with 16 cells per local BL) for sensing.
as good as sense-amplifiers at higher voltages. Also hierarchical BLs generally in-
cur larger area overheads [82–84]. On the other hand, high-speed sense-amplifiers
require a reference voltage which is either generated externally [41] or from an
internal Digital-to-Analog Converter (DAC). Interestingly, there is no technique re-
ported regarding the generation of reference voltage internally in U-DVS systems.
In the following section, we propose a new variation tolerant reference generation
mechanism suitable for U-DVS systems which tracks the bitline voltages as the sup-
ply is scaled.

Chapter 3. SRAM Array Design 27
VDDR
Bitlines
Ideal VREF
BL1
BL0
BL FalltimeVariation
ΔVBL
BL S
win
g
Greatest Lower Bound
Least Upper Bound
(Fastest BL1)
(Slowest BL0)
WordlineActivated
Figure 3.9: Typical variation in bitline characteristics due to local process variationbetween different SRAM cells in a chip.
3.4.1 U-DVS Reference Voltage Generation Technique
Ideally, the reference generation technique should generate a voltage that is mid-
way between the slowest BL0 (least upper bound) and the fastest BL1 (greatest
lower bound), as shown in Fig. 3.9, i.e.
VREF = (VBL0(µ+6σ) + VBL1(µ−6σ))/2 (3.1)
The key idea is to use two replica columns, one representing each of BL0 (REFL)
and BL1 (REFH) as shown in Fig. 3.10. The charge on these lines can then be
equalized to obtain a reference voltage in-between BL0 and BL1. However in a
naive implementation, equalizing the voltages on REFL and REFH can take signifi-
cant amount of time, especially at lower supply voltages. Instead, the columns are
shorted using switch S1, such that the columns REFL and REFH discharge together
at the rate shown as Ideal VREF in Fig. 3.9.
The generated reference voltage must be distributed to each of the sense-amplifiers
(SA), which increases capacitance of the replica columns. This load is equally dis-
tributed on REFL and REFH, by connecting each of these lines to alternate sense-
amplifiers as shown in Fig. 3.10 (labeled as even and odd SAs). However, the
additional load causes REFL and REFH to systematically differ from BL0 and BL1
respectively. This is alleviated by enabling a configurable number of replica cells to
discharge the reference lines.

Chapter 3. SRAM Array Design 28
RWLREF
‘m’Cells
X[1]
X[m]
X[0]
‘256-m’Cells
RWL[0]
RWL[256-m-1]
RWLREF
Y[1]
Y[m]
Y[0]
RWL[0]
RWL[256-m-1]
S1 S2
S3ExternalReference
D[0] D[1] D[15]
BL
[0]
BL
[1]
BL
[15
]
SRAMArray
256 rows x 16 columns
PRE PRE
REFL
ColumnREFH
Column
Db[1]Db[0]
Odd SA’s
Even SA’s
Cells for fine tuning
Placed in column circuitry
‘1’
‘1’
‘1’
‘1’
Additional SAs used for testing
Reference Voltage (VREF)distributed on these two lines
(For Testing)
Data Output
RE
FL
RE
FH
Figure 3.10: Proposed schematic that equalizes charge on replica columns REFL
and REFH, mimicking BL0 and BL1 respectively, to generate the required referencevoltage.
Our proposed reference generator consists of two replica SRAM columns and
two columns of AND gates. During a read operation, the cells on REFL and REFH are
activated using an additional timing signal RWLREF. This signal is the regular RWL
delayed by a replica path used to mimic delay through the address decoder. This
ensures that, during a read-operation, the cells on the replica columns are activated
at the same time as regular memory array bits.
The cells on these replica columns are written similar to regular memory bits.

Chapter 3. SRAM Array Design 29
Deco
der
Ref. C
olu
mns
SRAMArray(LSB)
WL L
ocal D
river
Ref. C
olu
mns
(Red
un
dan
t)
SRAMArray(MSB)
Column Circuitry(Write Driver, Precharge, SA,
Pseudo-SRAM cells)
8 Columns
25
6 R
ow
s
8 Columns
25
6 R
ow
s
SRAMCell
SRAMCell
WL G
lobal D
rive
r
Timing Generator
RWLLSB [p]+
WWLLSB [p]+
RWLMSB [p]+
WWLMSB [p]+
RWLLSB [q]+
WWLLSB [q]+
RWLMSB [q]+
WWLMSB [q]+‘m’ c
ells
RE
FL
RE
FH
BL
[0]
BL
[1]
BL
[7]
Column Circuitry(Write Driver, Precharge, SA,
Pseudo-SRAM cells)
BL
[8]
BL
[9]
BL[1
5]
CLK
A*
C*
D*
BlockSelect
B*
Config.Bits
Drivers
* Timing Signals:A – RWL or WWL Enable PulseB – RWLREF
C – PRED – SA-EN
+0 ≤ p ≤ 256-m-1
256-m ≤ q ≤ 255
78 µm 17µm 43 µm 43 µm 30 µm 17µm
47
4 µ
m
Figure 3.11: Organization in layout, of the various blocks in the implemented mem-ory.
Each of the two replica columns contain m cells that are connected to RWLREF by a
column of AND gates. These m cells are written to contain a data of ‘1’ as shown
in Fig. 3.10. The number of cells activated at a time, is controlled by setting the
configuration bits X[m:1] and Y[m:1].
By activating exactly one cell in REFL, and deactivating all the cells on REFH, the
replica columns behave similar to BL0 and BL1 respectively, as explained earlier.
However, as these columns have the additional capacitance of SAs, multiple cells

Chapter 3. SRAM Array Design 30
may need to be activated to generate the ideal reference. We denote the number
of active cells as N in this thesis. As the two columns, REFL and REFH are identical,
activating two cells on REFL is equivalent to activating one cell each on REFL and
REFH. The number of active cells is equally divided among the two columns to
minimize any difference in their rates of discharge. The reference voltage may thus
be varied by changing N, which is done using the control bits X[m:1] and Y[m:1].
It is to be noted that, the value of m is determined during design whereas, N is
tunable after fabrication.
The organization of these replica columns and other blocks in the implemented
layout of a 4 Kb SRAM array is shown in Fig. 3.11. The memory, implemented in
UMC 130nm, is organized as 256 rows by 16 columns. RWLREF signal runs vertically
with a load of 2m AND-gates. The write-wordlines (WWLs) are routed normally, ex-
tending over the replica columns on each row. The RWL is however, routed slightly
differently. In the first 256−m rows, the RWL drives an additional two AND gates,
along each row (Fig. 3.10) whereas in last m rows, the RWL connects to only the
regular cells (no additional load). Bits X[0] and Y[0] are set to zero, ensuring that
the 256−m SRAM cells are not activated during normal operation. The switches S1,
S2, and S3, have been added to only provide debug and characterization capability
with their state during normal operation shown in Fig. 3.10. These switches are
sized such that the drop across them is insignificant.
The area penalty of this technique depends on the size of the memory array. Our
implementation uses 2 additional columns of SRAM cells per 16 regular columns
which results in a 4.5% increase in the overall area of the memory macro. The
percentage increase is estimated to be 0.87% for a 32 Kb array and 0.45% for a
64 Kb array. Each estimate uses just one pair of replica columns for the entire array
and has the same 256 cells/BL.

Chapter 3. SRAM Array Design 31
6.5 %
7 %
7.5 %
8 %
8.5 %
9 %
9.5 %
10 %
10.5 %
11 %
11.5 %
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Perc
enta
ge E
rror
Supply voltage, VDD (in Volts)
Worst case data applied to all
cells on BL1, REFL and REFH
(Conservatively high estimate)
Figure 3.12: Simulated worst-case error due to non-ideal modeling of off-cells onreplica bitlines.
Differences in modeling
The proposed approach however causes some differences in replicating BL0 and
BL1. The off-cells on BL1 have a higher drain-to-source voltage across their read
access NMOS transistors (compared to the corresponding cells on REFH), resulting
in a higher leakage current. Fig. 3.12 quantifies the error due to this inaccurate
modeling of ”off-cell” leakage current at different supply voltages. Here percentage
error is calculated as the difference in charge contributed by ”off-cells” on regular
bitlines and the ”off-cells” on replica bitlines normalized to the charge contributed
by the ”on-cell” on the replica bitline. Worst-case error is obtained by applying a
data pattern such that the mismatch in modeling is maximized for all 255 (out of
256) cells on both the regular and replica bitlines. This can result in up to 7% to
11.5% higher VREF under worst case data-patterns (if no tuning were performed).
Also with technology scaling this error is expected to increase due to drain induced
barrier lowering (DIBL) effect. However, we will show in Fig. 3.28 that the pro-
posed scheme is able to generate nearly ideal reference voltage despite the above

Chapter 3. SRAM Array Design 32
RWLREF
Z[4]
‘1’ 2Lmin
Z[3]
‘1’ 4Lmin
Z[2]
‘1’ 8Lmin
Z[1]
‘1’ 16Lmin
Z[0]
‘1’ 16Lmin
‘1’ 16Lmin
REFL/H
Width (in layout) same as Reference Columns
Digital CodeWord (5-bit)
Split due to column width limitation
Figure 3.13: Sized pseudo-SRAM cells used for fine tuning of the reference voltage.
mentioned mismatch because of the multiple tuning knobs present: on-cell selec-
tion and number of on-cells.
The leakage of the active cell (with RWL high) on BL1 is also not replicated on
REFH as its contribution is negligible. However in scaled technologies, with higher
leakage, this behavior can be easily modeled by storing the corresponding data in
one of the ’2m’ cells and setting the corresponding X[m:1] or Y[m:1] bits to ’1’. We
also do not initialize the content of 2(256 −m) cells (’256−m’ on each of REFL and
REFH) as this does not change the generated reference voltage significantly (less
than 1.1%). In technologies with higher leakage, the content of these cells can in
fact be used as a mechanism to fine-tune VREF.

Chapter 3. SRAM Array Design 33
Finer-tunability is provided using additional rows of cells connected to the ref-
erence bitlines (as shown in Fig. 3.13). These cells are binary weighted and are
controlled using digital control bits. The cells are matched in width to the reference
columns and are easily accommodated as part of the column circuitry in layout.
3.5 Timing Generation Using Tunable Delay Lines
One of the key challenges in design of Static Random Access Memories (SRAMs) is
the accurate generation of sense amplifier enable (SAE) timing signal. If the sense
amplifier is enabled too early, the insufficient differential voltage on the bitlines
will result in an erroneous read. A delayed enable signal, on the other hand, will
result in greater voltage swings on the bitlines, than necessary, causing increased
power consumption and longer access times. Thus, SAE generation directly affects
both the performance and power consumption of memories. As SRAMs continue
to occupy increasingly greater portion of SoC area [8], their yield and power con-
sumption significantly impact the system performance.
With increased variation effects such as Random Dopant Fluctuation (RDF), ac-
curate generation of timing signal is proving to be extremely challenging. The con-
ventional way of generating SAE is to use a replica bitline (RBL) [42] that consists
of an additional column of SRAM cells that tracks the process (global) variation
in SRAM array (Fig. 3.14). However, the increased local variation, due to RDF,
causes the replica column’s characteristics to vary significantly. In order to achieve
higher yields, designers trade-off performance by adding margins for these varia-
tions. Several modifications to this technique have been proposed as detailed in
Section 2.2.2.
Another approach to accurately generate timing signals is to use a programmable
delay line and tune the delay post fabrication [48] [47] [49]. This enables mini-
mizing of margins to track SRAM delay accurately while maintaining yield targets.

Chapter 3. SRAM Array Design 34
Deco
der a
nd
Wor
d-Li
ne (W
L) d
river
s
Precharge Block
Timinggenerator
RBL
ɸ
ɸ
SAESAE
SAE SAEɸ RBL SAERBL
(a)Inverter based
delay chain
(b)Replica BL technique
(c)Replica BL based
tunable delay technique
SA0 SAM-1
SRAMcell
WL0
WL1
WLN-1
BL0 BLB0 BLM-1 BLBM-1
D[0] D[M-1]
Inverter switching threshold VTH
Tunable Delay block
ɸ
Replicacolumn
ReplicaSRAM cells
Figure 3.14: Timing generation technique used in SRAMs for SAE generation
Programming of the delay line however requires additional tester time which in-
turn increases the cost per chip. Hence the algorithm used in tuning the delay-line
plays is significant role in determining the effectiveness of this technique. The al-
gorithms proposed in literature [48] [47] [49] however consume large amounts of
time in tuning and do not exploit the tunable delay technique completely.
3.5.1 Timing Generation Techniques
The SAE signal is required to enable the sense-amplifier to read the data on bitlines
during a memory read operation. A read is performed by first precharging the
bitlines, and then activating the wordline corresponding to the address being read
as shown in Fig. 3.15. Depending on the data stored in a particular SRAM cell,

Chapter 3. SRAM Array Design 35
VDDR
Wordline
BL/BLB
Sense Amplifier Enable
Ideal VREF
BL1
BL0tBL
(mean)
ΔVBL > k VSA-Offset*
tSAE
(mean)
Variation in timing generation
tBL
Fre
quency
tBL(µ+3σ)
tSAE(µ-3σ)
tSAE
Margin
Variation in BLfalltime
1 for differential sensing2 for single-ended sensing
* k =
Figure 3.15: Process variation causes uncertainty in bitline fall-time and SAE gen-eration
one of the bitlines (per bit being read - assuming a SRAM cell with differential
read) begins to discharge. The sense-amplifier is then activated, after a sufficient
differential voltage develops between the bitlines, to determine the data stored in
the cell. Bitlines are highly capacitive due to large number of SRAM cells connected
to them. The SRAM cell, which contains mostly minimum sized transistor, thus
requires a large amount of time to discharge the BL. Also to conserve power, we
would like to minimize the voltage swing on these highly capacitive bitlines. Ideally
the sense-amplifier is therefore activated immediately after the bitlines develop a
differential voltage greater than the offset voltage of the sense-amplifiers.
Process variation however causes the bitline fall-time to vary across the memory
array (local-variation) and from one chip to another (global variation), causing the
bitline fall time to have a normal distribution as shown in Fig. 3.15 [48]. The
timing generation circuit, used to generate SAE, also undergoes similar variation
and may be modeled by a normal distribution. To ensure error free functionality,
the SAE must arrive after a differential voltage greater than the sense-amplifier’s
offset voltage is developed on the bitlines. This is done by adding appropriate

Chapter 3. SRAM Array Design 36
margins during design, depending the trade-offs between yield requirements and
power consumption, as shown in Fig 3.15.
In order to minimize margins the variance in SAE generation needs to be re-
duced. Several techniques have been proposed in literature to address this issue.
The remainder of this section examines and evaluates some of these techniques
shown in Fig. 3.14.
We evaluate the techniques using scatter-plots between bitline fall time and cor-
responding timing generation technique. Each point in the plot corresponds to a
1000-point Monte-Carlo simulation at a given global process point, simulating vari-
ation corresponding to only local mismatch (not global variation). The process
corner (global mismatch) is then varied randomly (with Gaussian distribution spec-
ified by the foundry) and a Monte-Carlo variation for local mismatch is performed
for each of the process points to obtain the various points in the plot. At each
global process-point the bitline fall time and delay generated using the timing tech-
nique corresponding to a fixed yield point (99.73%) are noted and plotted as the x
and y-axis respectively. With local mismatch corresponding to variation in a given
chip and global mismatch corresponding to variation across different chips, the plot
enables us study the tracking capability of the SAE generation technique. Good
tracking manifests as higher correlation and thus implies lower margins required
during design.
Standard Logic Based Delay Line
This technique employs a standard logic based delay chain, whose configuration
is determined at design time. Although this approach is seldom used, it has been
included here to illustrate the mismatch between logic and memory circuits.
Fig. 3.16 shows the scatter-plot between bitline fall time and inverter chain
based delay line, with variation in process conditions (global mismatch) for 130nm
UMC SRAM cells at 500 mV. The memory is run at a lower voltage to enhance the

Chapter 3. SRAM Array Design 37
20
25
30
35
40
45
50
55
20 25 30 35 40 45 50 55
Inve
rte
r ch
ain
de
lay (
in n
s)
Bitline falltime (in ns)
Correlation = 56.01%
Figure 3.16: Correlation between bitline fall time and SAE timing generated usingInverter delay chain.
effects of variation in order to mimic the increased variability in deep submicron
processes. As seen from Fig. 3.16, the standard logic based delay line offers poor
tracking with a correlation of just 56.01%.
Replica Bitline
The conventional technique used commonly in SRAMs currently, is the Replica Bit-
line technique [42]. This technique uses an additional column in the SRAM array
to track process variations in the memory. The bitline on the additional column
is known as the replica bitline (RBL). Multiple SRAM cells are activated on RBL
together and the time-taken by the RBL to fall below a preset threshold voltage is
used to generate SAE signal. This techniques provide better tracking as can be seen
in Fig. 3.17 with a correlation of 90.99%.

Chapter 3. SRAM Array Design 38
20
25
30
35
40
45
20 25 30 35 40 45
Re
plic
a b
itlin
e f
allt
ime
(in
ns)
Bitline falltime (in ns)
Correlation = 90.99%
Figure 3.17: Correlation between bitline fall time and SAE timing generated usingReplica bitline.
Other Circuit Techniques
Another approach [43] is to use a larger multiple of SRAM cells on the RBL, to pro-
vide averaging against random variation followed by a timing multiplier circuit to
obtain the required timing. [44] proposes yet another technique that monitors all
the bitlines in memory and ranks them in the order of speed using order extraction
circuits. This ranking is used to estimate the correct timing to obtain a predeter-
mined yield. These techniques however, provide limited improvement in tracking
and reduction in variance of the SAE timing. Also they offer little flexibility and
provide no insight into silicon’s performance.
Replica Bitline with Tunable Delay
An alternative approach is to use a replica bitline along with a tunable delay con-
troller to modify the timing generator after fabrication to achieve close tracking in
the presence of process variation [48] [47] [49]. This technique allows reduction
of the margins to the maximum extent, limited only by the delay tuning resolution.

Chapter 3. SRAM Array Design 39
20
25
30
35
40
45
20 25 30 35 40 45
Tu
ne
d D
ela
y (
in n
s)
Bitline falltime (in ns)
Correlation ≈ 100%
Figure 3.18: Correlation between bitline fall time and SAE timing generated usingTunable replica bitline.
The tuning can be performed based on yield targets providing post fabrication flex-
ibility. The delay setting finally used also readily enables binning of chips. Another
advantage, is the capability to maintain functionality with slow varying changes
such as aging.
The tracking obtained using this technique is evaluated using Monte-Carlo sim-
ulations similar to the previous scatter plots. For a given global process point, the
tuning algorithm sets a switched capacitor based delay-chain to obtain a target yield
of 99.73%. This is then repeated at various global process points (corresponding
to different chips) and the actual delay required and target delay set by the tuning
controller are plotted as the y and x-axis respectively in Fig 3.18. Hence the spread
in bitline delay due to local mismatch determines the x-coordinate of each point and
delay set using tuning determines the y-coordinate. Tracking is only limited by the
value of delay step size and its variation due to local mismatch. Thus the worst-case
error is determined by highest resultant delay step. This technique clearly offers the
best tracking with nearly ideal correlation (≈ 100%).
As mentioned earlier, the tuning algorithm used here plays an important role in

Chapter 3. SRAM Array Design 40
Fine Delay Block (FDB)(16-FDCs)
Coarse Delay Block (CDB)(16-CDCs)
Binary to Thermometric Encoder
Binary to Thermometric Encoder
16
4 4
16
Configuration Bits
Input Output
FDB Bypass Path CDB Bypass Path
Figure 3.19: Tunable delay line used to generate timing signals for SRAM.
reducing the tester time required to set the delay controller. The issues related to
these algorithms is examined in the following section.
3.5.2 Implemented Delay Line
The timing generator is responsible for ensuring that sufficient differential voltage
is available for the SAs, as discussed earlier in Section 2.2. Using a tunable delay
line allows the design to adapt the timing to increase the differential voltage, to
meet the offset requirement of SAs. We have thus used a tunable delay line to
generate the necessary timing signals for the SRAM array across the wide range of
supply voltages of interest. Although tunable delay lines have been employed to
counter the effects of variation [47,48], their use as effective timing generators for
dynamic voltage scaling is not reported to the best of our knowledge.
The designed tunable delay line (Fig. 3.19) consists of a Fine Delay Block (FDB),
a Coarse Delay Block (CDB), two binary to thermometric encoders, and additional
MUXes that provide the capability to bypass either of the delay blocks. The FDB is
implemented using a series of sixteen identical Fine Delay Cells (FDC), as shown in
Fig. 3.20. Each cell consists of a buffer with a switchable load capacitor CL. Control-
ling the switches (S0 to S15) varies the capacitance at the intermediate nodes, thus

Chapter 3. SRAM Array Design 41
S0 S1 S15Input Output
CL CL CL
(a)
40 µm
24 µ
m
Binary to Thermometricconverter
Fine Delay Cells
(b)
Figure 3.20: (a) Schematic and (b) Layout of the implemented Fine Delay Cells(FDC).
controlling the delay of the block. The switches are implemented as simple pass-
gate NMOS transistors. The capacitors are implemented using the gate capacitance
of regular transistors and are sized to obtain the necessary the delay step. This
resulted in a width of 3µm and length of 200nm (higher than the minimum value
to reduce the effect of variation). A series of identically sized cells are chosen, over
binary weighted cells, to ensure monotonic increase in delay with the input code.
This simplifies the delay tuning algorithm. This design however causes the FDB to
have a large inertial-delay (delay at minimum code setting). MUXes have therefore

Chapter 3. SRAM Array Design 42
Sstart
S0
S0
S1
S14
S15
Output
Input
Forward Path
Return Path
(a)
70 µm
20 µ
m
Binary to Thermometricconverter
Coarse Delay Cells
(b)
Figure 3.21: (a) Schematic and (b) Layout of the implemented Coarse Delay Cells(CDC).
been added with the capability to bypass this block if necessary.
The CDB implementation (Fig. 3.21) controls the delay by varying the signal
path based on the thermometric code [85]. A select bit (one for each of the 16 cells)
determines if the signal is propagated to the next cell or is routed back, at that cell,
on the return path. This design allows multiple cells to be cascaded to obtain a large
range of delays without affecting the inertial delay. However, the jitter at the output
of this block is code dependent, making it less suitable for other applications.
As both the FDB and CDB accept thermometric codes to vary the delay, a bi-
nary to thermometric encoder is included (with each block) to reduce the number
of configuration bits necessary to control the delay. Fig. 3.22 shows the delays

Chapter 3. SRAM Array Design 43
1
10
0 2 4 6 8 10 12 14
Dela
y n
orm
aliz
ed to their r
espective
valu
e a
t code =
0
Control word (4-bit)
Coarse Delay
Cells (CDC)
Fine Delay
Cells (FDC)
FDC-1.2VFDC-0.7VFDC-0.4VCDC-1.2VCDC-0.7VCDC-0.4V
Figure 3.22: Measured tunability of delay lines, used in SRAM timing generatorblock, at different supply voltages. It may be noted that the delay values for eachof the curves is normalized to its respective value at code = 0.
measured for various digital-code-word settings, at three supply voltages, on the
test-chip fabricated in UMC 130nm technology. Accurate measurement of on-chip
delays was achieved using sub-sampling and a delay measurement unit described
elsewhere [86]. The 16 FDCs and CDCs provide linearly increasing delay, and thus
the necessary timing range, to operate the memory across the wide range of supply
voltages. Step size and linearity parameters of the delay-line are summarized in
Table 3.1: Measured delay-line parameters at different supplyvoltages
FDC CDC
Supply(in V)
Step(in ns)
INL1
(LSB)DNL(LSB)
Step(in ns)
INL1
(LSB)DNL(LSB)
1.2 0.041 0.48 0.20 0.183 0.67 0.190.7 0.079 0.26 0.20 0.509 0.20 0.120.4 0.173 1.94 0.69 5.156 0.42 0.75
1 End-Point INL

Chapter 3. SRAM Array Design 44
Randomly Sample M-rows & Test
Start with N = NMIN & tSAE = tSAE-MAX
Pass ?
YES
NO
BL0 Failor BL1?
Reselect(latest first)
Increase N
Decrease tSAE
Randomly Sample M-rows & Test
Pass ?YES
NO
Use last passing tSAE
Test ALL rows
Pass ? Increase tSAE
Save tSAE and N value
YESNO
B
A
Random Sampling based Tuning
Tune N
BL0
BL1
Figure 3.23: Random-sampling based algorithm used to tune the timing and refer-ence generator for reads, at a given supply voltage.
Table 3.1. It may be noted that tuning is simplified by having a monotonically in-
creasing delay, linearity is not necessary. The tunable delay line, shown in Fig. 3.19,
occupies 1.54% of the 4 Kb memory block area.
3.6 Tuning Algorithm
The configuration bits necessary to generate timing signals using the tunable delay
line and the value of N used in the reference generator are determined using a tun-
ing algorithm. Thus this algorithm sets the absolute value of reference voltage and
the worst-case margins for the SAs. These algorithms are commonly implemented

Chapter 3. SRAM Array Design 45
BL0
BL1
Ideal VREF
IncreasingN1
23
His
tog
ram
VoltageVREFMargin for SA offset
µ
BL0(µ+3σ) BL1(µ-3σ)
VREF
CellSelection
Figure 3.24: Sketch to illustrate the variation characteristics of BL0, BL1, and VREF
and options available for tuning.
using BIST infrastructure [46–48] and must be run before the memory can be used
for the first time. The algorithms are iterative in nature and thus can take signif-
icant amount of time to converge to a final configuration bit settings. Minimizing
this time reduces the cost associated with tuning [87] thus allowing more frequent
running of the tuning process as necessary. The algorithm also determines the effec-
tiveness of the proposed reference generator in minimizing the BL swing and access
time at different supply voltages.
The proposed algorithm (Fig. 3.23) uses random-sampling based tuning [45] to
quickly determine the SA timing (tSAE) and N-value to be used for a given supply
voltage. Faster tuning is achieved using random-sampling, by first estimating the
settings using a small subset of the memory array. If necessary, these are further
tuned and verified for the entire memory. This significantly reduces the tuning
time especially for larger memories [45]. The details regarding optimization of the
tuning algorithm is examined in Chapter 4. It may be noted that the SA enable
signal is generated from RWL pulse as shown in Fig. 3.2.
A checkered-pattern is first written to the memory using a conservatively high
value of write-timing. The read-timing is then set using the tuning algorithm shown

Chapter 3. SRAM Array Design 46
1
10
100
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Test tim
e (
# full
mem
ory
reads)
Supply voltage, VDD (in Volts)
Read Write March
Read Write Read March March C+ Bang Go/No-Go
Conven.R-fine
R-C-fineR-Multi.
1
2
34
5
1
2 3 4 5
(a)
0
2
4
6
8
10
12
14
16
18
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
t SA
E (
norm
aliz
ed to F
O4 d
ela
y)
Supply voltage, VDD (in Volts)
Coarse-Fine architecturereduces tuning time at theexpense of tSAE
R-Multi allows functioningin the presence of increasedvariation at low voltages
Conven.R-fine
R-C-fineR-Multi.
(b)
Figure 3.25: Variation of (a) Time taken by tuning algorithm (in terms of number offull memory reads) and (b) tSAE with various tuning algorithms. These simulationresults are obtained for a 10 KB memory. The time taken by standard memory BISTalgorithms is also shown. The error bars in this figure are too small to be seen.

Chapter 3. SRAM Array Design 47
in Fig. 3.23. Once the read-timings are set, the same WL pulse width is used for
writes, as writing is known to take lower time compared with reads.
The algorithm starts with a conservatively minimum value for N (NMIN) and
a conservatively maximum value for tSAE (tSAE-MAX). These values are then tested
against a randomly selected set of M-rows, where M is determined by the confi-
dence required in the estimation. A failure to sense BL0’s at this stage, indicates
that the VREF is lower than the desired value. As N is already set to a minimum
value, the only way to increase VREF is by choosing a different set of active cells
on the replica columns [88] labeled as cell selection in Fig. 3.24. On the other
hand if BL1’s are found to fail, VREF is decreased by increasing N. Following this,
tSAE is reduced iteratively (again using random sampling) to determine the lowest
functioning value of tSAE. Once the random-sampling based tuning is complete, the
entire memory is tested using the set values. tSAE is then adjusted, if required, to
ensure that the settings enable the entire memory to function correctly. It may be
noted that the algorithm in Fig. 3.23 is simplified to exclude exit conditions of loops
(on reaching limits of various parameters) in the interest of clarity.
The mean performance of four variants of the tuning algorithm on 1000 instances
of a 10 KB memory is shown in Fig. 3.25. Here, Conven. refers to conventional tun-
ing without random-sampling [46–48] and R-fine refers to the random-sampling
based algorithm shown in Fig. 3.23 which significantly reduces the tuning time.
The time required for tuning can be further reduced using the coarse-fine archi-
tecture of the tunable delay line (R-C-fine) which comes with a small penalty in
tSAE (Fig. 3.25(b)). This is achieved using coarse steps in block A and fine steps
in block B of Fig. 3.23. However the R-fine and R-C-fine algorithms cause failures
at 400 mV and below. This is alleviated by tuning the memory to obtain multiple
pairs of N and tSAE that function, and choosing the setting with lower tSAE (repre-
sented as R-Multi.). While this increases the tuning time (as expected), it allows the
memory to function down to 350 mV. Fig. 3.25(a) also shows that the time required

Chapter 3. SRAM Array Design 48
for tuning at higher voltages is significantly lower in comparison to standard mem-
ory BIST (MBIST) algorithms [89] and is comparable at lower voltages. Multiple
such MBIST algorithms are typically run on each instance of the memory. Hence,
while the technique adds to the tuning time, the increase in total tuning time is
not significant. It may be noted that the tuning time is influenced by various other
parameters such as the initial estimate and step-size of tSAE. These values may be
chosen appropriately to trade-off between tSAE and tuning-time.
The frequency of tuning is determined by factors such as the tracking required
(or margins acceptable) for slow varying changes, the delay steps implemented
and storage space available for configuration settings. Tuning may either be done
each time the memory supply is varied, or the settings may be determined once
at each supply voltage and stored in a look-up-table for later use. The number
of configuration bits to be stored can be reduced by suitably dividing the voltage
range of interest in to smaller regions and storing one set of values per region. This
approach trades-off performance for lower configuration bits and can be especially
useful in large memories that contain multiple instances.
3.7 Simulation results
The proposed reference generation scheme is evaluated using an SRAM array in
130nm with 256 cells/BL. The effect of local variation on BL0, BL1, and VREF (for
N = 1, 2 and 3) at 1.2 V and 0.45 V is shown in Fig. 3.26. The time axis in Fig. 3.26
begins from the time that the wordlines are activated and extends till the time
at which ∆VBL is maximum. It may be seen that, while it is easy for the tuning
algorithm to find a set of functioning settings at higher supplies, at lower voltages
the increased variation may require multiple rounds of re-selection to converge on
the final setting. The detailed simulated waveforms during a typical read operation
at 0.4 V is shown in Fig. 3.27.

Chapter 3. SRAM Array Design 49
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0 2 4 6 8 10
Voltage (
in V
olts)
Time (in ns)
BL1
VREF (N = 1)
Ideal VREF
BL0
VREF
VREF
(N = 2)
(N = 3)
(a)
-0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0 10 20 30 40 50 60 70 80 90
Voltage (
in V
olts)
Time (in ns)
BL1
VREF (N = 1)
Ideal VREF
BL0
VREF
VREF
(N = 2)
(N = 3)
(b)
Figure 3.26: Simulated effect of local mismatch on BL0, BL1, and VREF (for N =1, 2 and 3) at (a) 1.2 V and (b) 0.45 V. The error bars here span the range from theµ+ 3σ to µ− 3σ. Fewer error bars are shown in (b) for clarity.

Chapter 3. SRAM Array Design 50
0
100
200
300
400
0 10 20 30 40 50
Voltage (
in m
V)
Time (in ns)
RWL
SA-EN
BL0
BL1
REFL
REFH
D[0](SA Output)
D[0]
Figure 3.27: Signal waveforms during a typical read operation at 400 mV.
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Voltage n
orm
aliz
ed to V
DD
Supply voltage, VDD (in Volts)
Generated
Ideal
Simulated at TT Corner
VREF is closer to VDD
VREF
VREF
at 27°C
at higher supplies
with local variation
Figure 3.28: Simulated results showing the tracking of the reference voltage, gener-ated using the proposed technique, with the ideal reference as the supply is scaled.
Fig. 3.281 shows the generated and ideal reference voltage at different supply
1Appendix B describes the steps used to generate this graph.

Chapter 3. SRAM Array Design 51
0 %
0.5 %
1 %
1.5 %
2 %
2.5 %
3 %P
erc
en
tag
e e
rro
r in
VR
EF
(a) 1.2 V (16 col.)
SSTTFF
0 %
0.5 %
1 %
1.5 %
2 %
2.5 %
3 %
(b) 0.4 V (16 col.)
0 %
1 %
2 %
3 %
4 %
5 %
-40 0 40 80 120
Pe
rce
nta
ge
err
or
in V
RE
F
Temperature in °C
(c) 1.2 V (128 col.)
0 %
5 %
10 %
15 %
20 %
25 %
-40 0 40 80 120
Temperature in °C
(d) 0.4 V (128 col.)
Figure 3.29: Simulated effect of temperature and process corners on the percentageerror between the ideal and generated reference voltage at different supply voltagesand aspect ratios. Timing signals were generated using a tunable delay line that wastuned at TT, −40 ◦C.
voltages. Here the ideal VREF is evaluated at the timing setting determined by the
tuning algorithm. It may seen that the proposed technique closely tracks the ideal
VREF, as the supply is scaled from 1.2 V down to 350 mV.
It may also be observed that VREF (and the bitlines) are closer to the supply at
nominal voltages while they are relatively closer to the ground at lower voltages,
when the sense amplifiers are activated [15]. At higher voltages the effect of vari-
ation is lower, which allows a sufficient ∆VBL to develop early in time. Thus the
BL0’s (plural here implies statistically) are closer to VDD at the time of SA activation.
This results in VREF also being closer to VDD. In contrast, at lower voltages the in-
creased effect of variation results in the bitlines taking a longer time for a sufficient
∆VBL to develop. Thus at the time of SA activation the BL1’s droop quite low (due

Chapter 3. SRAM Array Design 52
to the leakage through off-cells for a long time). At this time most of the BL0’s
(statistically) would have discharged to ground. This results in VREF being closer to
ground.
The proposed scheme also tracks the memory with global process variation and
changes in temperature, as shown in Fig. 3.29. Fig. 3.29(a) and (b) plot results
for a 256 rows by 16 column array where as Fig. 3.29(c) and (d) report tracking
for a wider array with 256 rows by 128 columns. In each case only one pair of
replica columns were used. These results were obtained using a tunable delay line
to generate the timing signals. The delay line, and N, were tuned at TT corner at
−40 ◦C for each configuration, following which the temperature and process was
varied. This represents conservative results as tuning each chip would account for
global process variation.
The proposed technique achieves good tracking with process and temperature
due to the use of replica columns which are almost identical to regular bitlines.
The tracking does degrade for wider arrays. This is mainly due to gate dominated
capacitance of the sense-amplifiers compared to the drain dominated capacitance
of SRAM cells. Also large SRAM arrays will have systematic variation in transistor
characteristics from one part of the array to another. Hence in such cases multiple
replica columns may be employed for better matching.
The fine-tunability is provided by varying the 5-bit digital code to the cells shown
in Fig. 3.13. The effect of this code on the reference voltage is shown in Figure 3.30.
It may be seen that, across the range of supply voltages of interest, the digital bits
provide significant tunability.
3.8 Conclusion
This chapter presented the design of the core blocks of an SRAM array capable of
operating from nominal voltages down to sub-threshold voltages. We found that

Chapter 3. SRAM Array Design 53
0.65
0.7
0.75
0.8
0.85
0.9
0 5 10 15 20 25 30
VR
EF n
orm
aliz
ed to V
DD
Digital Code Word
VREF tunability using
additional rows of sized SRAM cells
1.2 V
0.7 V
0.5 V
0.35 V
VDD = 1.2 V
VDD = 0.7 V
VDD = 0.5 V
VDD = 0.35 V
Figure 3.30: Simulated reference voltage tunability achieved using additional rowsof sized SRAM cells (Fig. 3.13), for different supply voltages.
sizing the conventional 8T SRAM cell increased the noise margins sufficiently to
allow wide voltage operation. The reference voltage necessary for reading the single
ended cell was generated using a pair of replica columns. This allows the technique
to track slow varying changes such as temperature and aging. Tunable delay lines
were found necessary to generate timing signals due to the increased variation at
lower voltages (and new technologies). A random-sampling based algorithm using
BIST infrastructure was presented which significantly speeds-up the tuning required
by the reference and timing generation blocks. Simulation results show that the
proposed SRAM design functions well from 1.2 V down to sub-threshold voltages
while tracking slow varying changes such as temperature.

Chapter 4
Random Sampling Based Tuning
4.1 Introduction
Generation of timing signals using programmable delay lines provides the best
tracking with process variation, as shown in section 3.5. In order to reduce the
testing cost it is important to optimize the algorithm used to tune this delay line.
We propose a tuning algorithm that takes advantage of the random nature of the
variation to reduce the sample-set used to tune the delay line. This translates to
lower number of reads during tuning and hence shorter tester time. It is also shown
that performing tuning before redundancy repair enables reduction in power con-
sumption and faster access times in memories that have lower failure rates than
expected.
The rest of this chapter is organized as follows. Section 4.2 describes the ex-
isting and proposed tuning algorithms. This is followed by the simulation results
evaluating the effectiveness of the proposed techniques in Section 4.3. Section 4.4
then concludes the chapter.
4.2 Optimized Repair and Tuning
Delay tuning algorithms, used to set the sense amplifier enable (SAE) timing (tSAE),
are iterative in nature and can take a significant amount of time (measured as
number of reads) depending on the implementation. We would like to minimize
this time, especially if tuning requires time on the tester, as this adds to the cost of
the chip. Also the effectiveness of the delay-tuning technique in minimizing power
54

Chapter 4. Random Sampling Based Tuning 55
Figure 4.1: Existing delay tuning algorithm [48] [47]
and increasing access speeds is determined by the algorithm. Hence the tuning
algorithm plays a significant role in determining the efficiency of the delay tuning
technique.
4.2.1 Conventional Approach: Repair followed by tuning
Fig. 4.1 shows the generalized flowchart of algorithms proposed in [48] [47]. Here
the controller starts off with a worst case estimate for SAE timing (tSAE), based
on simulations. The entire memory is then tested for correct functionality using
the memory’s built in self test (MBIST) state-machine. Any failures at this stage
are corrected, if possible, using redundancy. Once the memory passes with the
initial tSAE setting, the controller then iteratively reduces tSAE and determines the
minimum tSAE for which the entire memory functions correctly.
This treatment of post-silicon tuning algorithms in previous works is, however,

Chapter 4. Random Sampling Based Tuning 56
Figure 4.2: Proposed delay tuning algorithm. A further optimization in block A isto ”Test Nsample Cells” where Nsample << total number of cells
brief. While they serve as a good starting point, they fail to take advantage of several
flexibilities enabled by this tunable technique. This work proposes an enhanced
algorithm that integrates several improvements that significantly reduce tester-time
requirement and improves the effectiveness of this tunable technique.

Chapter 4. Random Sampling Based Tuning 57
4.2.2 Proposed Approach: Delay tuning followed by redundancy
repair
The algorithms proposed in literature [48] [47] perform redundancy repair prior
to delay tuning as discussed earlier. However for chips in which the number of
failures is lower than that repairable using redundancy, the additional redundant
SRAM cells remain unused. The tuning technique may be utilized to improve the
performance of such chips by performing delay tuning before redundancy repair as
shown in Fig. 4.2 (loop L1).
As shown in the figure, the controller starts with a conservative estimate of
tSAE obtained through simulations and tests the entire memory for this value of
tSAE. If the number of cells failing is less than that repairable using redundancy,
then the controller continues to reduce tSAE until the available redundancy is just
sufficient to repair all the failing cells. The algorithm, of course, declares the chip
as failed in the worst-case scenario where the redundancy available is insufficient
to repair the memory even when the maximum tSAE timing is used. For chips in
which available redundancy is higher than failure rates (when a conservative tSAE
is used), the proposed approach utilizes the remaining redundancy infrastructure
to further reduce tSAE.
The memory array read power consumption is given by [48]:
Parray = NBLIctWLVddf (4.1)
whereNBL is the number of bitlines in the array, Ic denotes the average read current
per SRAM cell, Vdd is memory supply voltage, f is the operating frequency and tWL
is the wordline pulse width, which closely tracks tSAE. Hence a reduction in tSAE
translates directly to dynamic power savings of the array.

Chapter 4. Random Sampling Based Tuning 58
4.2.3 Random Sampling: Reducing number of reads
The conventional tuning algorithms (Fig. 4.1) check the entire memory at each
iteration of delay setting (Block A). While this approach ensures no loss in yield
during tuning, the process may require a large number of reads, depending on the
initial tSAE setting and the delay step used in the delay-line. Performing delay
tuning before redundancy repair provides us with an additional margin for error
in setting the sense amplifier timing. We propose to take advantage of this margin
to reduce the number of reads in Block A of Fig. 4.1, via random sampling during
delay tuning. This significantly reduces the time required for tuning.
From statistics [90] it is known that, in order to estimate the probability of
success p in a binomial distribution, from a sample of size nwith at least 100(1−α)%
probability of being within a distance d of p, the sample size n should be no smaller
than
n =z2α/24d2
(4.2)
where zα/2 is the value for which P (Z ≥ zα/2) = α/2. If p is known to be greater
than some number p′, then this information can be used to further reduce the num-
ber of samples required. n is then given by:
n =z2α/2d2
p′(1− p′) (4.3)
The above theorem can be applied to the tuning algorithm by expressing the
problem as follows. During tuning, at each iteration, we are trying to estimate the
number of SRAM cells passing for a given tSAE setting. We would like make this
estimate with a high level of confidence, as any violation would cause the controller
(Fig. 4.2) to iterate through the entire memory to find the correct tSAE setting, as
explained before. The error tolerance d, is set equal to the amount of redundancy
r available. This enables us to repair any errors in our estimate using redundancy.
However for low values of redundancy, setting d to a higher value yields significant

Chapter 4. Random Sampling Based Tuning 59
reduction in number of samples while causing an insignificant increase in error of
the estimate. We thus set
d =
2 ∗ r, if r ≤ 3%
r, if r > 3%
(4.4)
Setting d to 2r for all values of redundancy would however increase the error
in estimate resulting in the controller spending greater time in loop L2, adversely
affecting the time required for tuning.
4.2.4 Proposed Algorithm: Tuning using random-sampling fol-
lowed by repair
The proposed delay tuning algorithm combines the above two techniques to effec-
tively utilize available redundancy and significantly speed up the tuning process.
The final algorithm is obtained by replacing the content of the block labeled ”A”
in Fig. 4.2 with ”Randomly test Nsample cells”, where Nsample is the sample size ob-
tained for random sampling. The controller starts off with an estimate for SAE
timing tSAE based on simulations, similar to the conventional technique. This value
is then tuned iteratively, in loop L1, using random sampling until the available re-
dundancy is just sufficient to repair all cells failing for the current tSAE setting.
This is then followed by redundancy repair using MBIST, similar to one done
in conventional algorithms, to set the final SAE timing. Random sampling may
however provide a slightly aggressive estimate for tSAE. Thus redundancy repair is
done iteratively in loop L2, where tSAE is increased if necessary. While the proposed
approach significantly improves over conventional approaches, loop L2 ensures that
it at least matches the conventional technique in the worst case.
Note that the proposed approach requires a pseudo random number genera-
tor (PNRG), in addition to the resources required by existing algorithms. MBIST

Chapter 4. Random Sampling Based Tuning 60
0.72
0.74
0.76
0.78
0.8
0.82
0.84
0.86
0 % 2 % 4 % 6 % 8 % 10 %
No
rma
lize
d t
SA
E
Percentage repair
Figure 4.3: Normalized tSAE vs Percentage Repair
controllers typically contain PNRGs, hence this technique incurs no area overhead.
4.3 Results and Discussion
The proposed approach is tested on UMC 130nm process using extensive Monte-
Carlo simulations. The design employs a 6T SRAM cell, however the results are
directly valid for other SRAM cells that have a similar two transistor read-path as
they would have similar bitline leakage and variation characteristics. The effects of
variation were exacerbated by running the circuits at a lowered supply of 500 mV,
making the results applicable to lower technology nodes. The models allow for
independently varying parameters to simulate either local variation which corre-
spond to different instances of a circuit on a single chip, or global variation which
represents variation across multiple chips.
Fig. 4.3 shows the effect of preforming delay tuning before redundancy repair,

Chapter 4. Random Sampling Based Tuning 61
on tSAE with varying amount of redundancy. The results are obtained by first sim-
ulating local variation using Monte-Carlo runs. This step is then repeated at over
200 process points (corresponding to memories on different chips) with a Gaussian
distribution specified by the manufacturer. The proposed algorithm is then applied
to each of the process points (representing the tuning algorithm algorithm on dif-
ferent chips). The average across these process points then gives a measure of the
typical tSAE used. These steps are then repeated for varying amounts of redundancy
repair capability, while the failure-rate (due to manufacturing, is fixed at 1%). If
the redundancy capability is lower than the failure-rate, the chip is discarded.
The values shown in Fig. 4.3 are normalized with the value of tSAE obtained
using conventional technique. For example, if the redundancy capability is 5%,
the proposed algorithm enables a 25% reduction in tSAE. The reduction in tSAE
for different failure rates can also be obtained from the figure. For instance, if
the failure rate is 2%, then the same 5% redundancy would provide about 6.5%
reduction in tSAE.
Fig. 4.4 shows the variation of number of samples required with the redundancy
value r used in Eqns. (4.3) and (4.4). As the yield requirements are generally high
in memories we set p′ in Eqn. 4.3 conservatively at 90%. It can be seen that as
the amount of redundancy available decreases, the number of samples required in
estimation increases exponentially as a higher accuracy in estimation is necessary.
Also the sample size increases if a greater confidence is required in estimation.
However this increase is not very significant, hence a large confidence value can
used. Note that the discontinuity observed at r = 3% is contributed by Eqn. (4.4).
The effectiveness of the above random sampling is evaluated on normal distri-
butions with 10% coefficient of variance (σ/µ). A confidence of 99.73% was used
to obtain the results shown in Fig. 4.5. The figure plots the redundancy value r
set to compute the number of samples and the actual amount of redundancy re-
quired when the tSAE setting, obtained from random sampling based tuning, was

Chapter 4. Random Sampling Based Tuning 62
10
100
1000
10000
0 % 2 % 4 % 6 % 8 % 10 %
Nu
mb
er
of
sa
mp
les
Percentage redundancy
Confidence = 95%97%99%
99.73%99.99%
Figure 4.4: Number of samples vs Percentage redundancy for various values ofconfidence
0
2
4
6
8
10
12
0 % 2 % 4 % 6 % 8 % 10 %
Actu
al re
du
nd
an
cy r
eq
uire
d
Redundancy value used to calculate number of samples
Identity Line
Figure 4.5: Actual redundancy used vs specified redundancy
applied to the complete 10 Kb memory. It may be seen that the results track very
well, verifying the effectiveness of the above technique. The good tracking ensures

Chapter 4. Random Sampling Based Tuning 63
0.9
0.91
0.92
0.93
0.94
0.95
0.96
0.97
0.98
0.99
1
0 % 2 % 4 % 6 % 8 % 10 %
No
rma
lize
d t
SA
E s
et
Redundancy value used to calculate number of samples
Figure 4.6: tSAE vs redundancy specified during calculation of Nsample
0
10
20
30
40
50
60
70
80
90
10 kb 100 kb 1 Mb
Num
ber
of re
ads (
in m
illio
ns)
Memory size
95%Reduction
Faster tuning using
Random-Sampling
Higher impact of algorithmfor larger memories
Conventional Tuning (check entirememory in each iteration)
Random-Sampling based Tuning
Figure 4.7: Number of samples vs Memory size
that the loop L2 in Fig. 4.2 is executed a very small number of times (at most 3) if
redundancy percentage is sufficient to repair the chip.

Chapter 4. Random Sampling Based Tuning 64
The variation of SAE pulse width with redundancy is shown in Fig. 4.6. The
pulse widths in Fig. 4.6 are normalized with the value used at 1% redundancy, thus
the y-intercepts directly correspond to reduction in pulse width due to use of higher
redundancy. As expected, tSAE reduces if higher redundancy is available. This can
be used to trade redundancy for reduction in power consumption and access time
in SRAMs. The reduction in tuning time however is a weak function of the amount
of redundancy r available. The technique provides approximately 95% reduction in
tuning time when a step size equal to 10% σBL is used for 10 Kb memory. Fig. 4.7
compares the time taken for tSAE tuning (Block A in Fig. 4.2) by the conventional
and proposed technique for different memory sizes. As the number of samples
required is independent of the memory size, the technique is highly effective for
large blocks of memory.
Thus random sampling can be used to significantly reduce the time taken to per-
form post silicon delay tuning. The amount of redundancy available and confidence
required, is used to determine the number of samples (Nsample) which is used in
the proposed algorithm shown in Fig. 4.2. Note that setting Nsample equal to the
total number of cells in memory would cause the proposed algorithm to perform
identical to existing algorithms.
4.4 Conclusion
The chapter demonstrates the effectiveness of a tunable delay line, in tracking mem-
ory performance and minimizing margins, for generation of SAE in SRAMs. The
proposed delay tuning algorithm, that employs random-sampling, is shown to sig-
nificantly reduce tester time thus directly contributing to reduction in cost. Further,
the use of redundancy after delay tuning enables maximum utilization of redun-
dancy infrastructure to reduce power consumption and enhance performance.

Chapter 5
Experimental Setup and Measured
Results
4-KbSRAM
ScanChain
Sub-Sampling Block
1 mm
1 m
m
OtherTest
Circuitry
(a) (b)
Figure 5.1: (a) Die photograph and (b) Layout snapshot of the fabricated chip inUMC 130nm.
5.1 Implementation
The proposed techniques were evaluated using a test-chip fabricated in UMC 130nm
Mixed-Mode/RF process. The chip (Fig. 5.1) implemented a 4 Kb memory orga-
nized as 256 rows by 16 columns. The conventional 8T SRAM cell (6T conventional
+ 2T read-buffer) was used with no additional cell modifications. The schematic of
the cell with annotated devices dimensions is shown in Fig 3.1. The two write ac-
cess NMOS transistors are made stronger for increased writability at low voltages.
The cell was designed using logic layout rules and occupies 8.341 µm2. The design
65

Chapter 5. Experimental Setup and Measured Results 66
FF
FF
FF
FF
Signal Generator(Agilent 81150A)
Voltage Source(Agilent U2722A)
Sub-Sampling Clock
LEVEL
SHIFTERS
DelayMeasurementUnit (DMU)
Characterizationand
Debug Logic
FPGA (Xilinx Virtex 5)
Serial Port
USB
Oscilloscope(LeCroy 204Xi)
S1*
S2*
* S1, S2 are Sub-Sampled signals
SCAN-CHAIN
PISO
Timing Generator
CLK
Chip (130nm)
MemoryBlock(4-Kb)
SubSampling
Block
Figure 5.2: Measurement setup showing the fabricated chip, FPGA-board, and otherinterface equipment, used for characterization of chips.
Figure 5.3: Test setup: FPGA board (left) interfaced to the PCB (right) with thefabricated chip.

Chapter 5. Experimental Setup and Measured Results 67
500 HzCLK
Precharge
RWL
SA-EN
350 mV
Figure 5.4: Screen-shot of the sub-sampled waveforms of timing signals, generatedat 350 mV, with a delay amplification factor of 390.
1
10
100
1000
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 0.1
1
10
100
1000
Ma
xim
um
op
era
tin
g F
req
ue
ncy (
in M
Hz)
Pu
lse
wid
th (
in n
s)
Supply voltage (in Volts)
FrequencyRWL Pulse width
SA Pulse width
Figure 5.5: Measured maximum operating frequency of memory as the supply isscaled.
implements the proposed reference generation scheme (Fig. 3.10) with the capa-
bility to vary N from 0 to 8 independently on each of the reference replica columns

Chapter 5. Experimental Setup and Measured Results 68
1
10
100
1000
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 1
10
100
1000
10000
100000E
ne
rgy p
er
acce
ss (
in p
J)
Po
we
r (in
uW
)
Supply voltage (in Volts)
N = 1
N = 1
N = 1
N = 2
N = 3
N = 2
Energy/accessLeakage power
Read power
Figure 5.6: Measured effect of supply voltage on Energy per access, Leakage power,and Read power.
(m = 8). Tunable delay lines have been implemented, with 16 steps each of fine
delay and coarse delay, to generate the required timing signals for the SRAM array.
The fabricated chip also contains additional circuits that were used to test and
characterize the system such as scan-chain, parallel-in-serial-out (PISO) block, and
sub-sampling blocks. These were designed using a pruned standard-cell library that
eliminates cells with more that two stacked devices and large multiplexers [10,91].
These cells enabled the support circuity in the fabricated chip to function down to
350 mV.
5.2 Experimental Setup
The fabricated chips were characterized using the setup shown in Fig. 5.2. A pho-
tograph showing the PCB with the fabricated chip and FPGA board is shown in

Chapter 5. Experimental Setup and Measured Results 69
Fig. 5.3.
The internally generated pulse widths were measured using sub-sampling flip-
flops and an externally generated sub-sampling clock (Fig. 5.2) [86]. Fig. 5.4 shows
the sub-sampled signals with the memory operating at 350 mV. The input clock
frequency is 195.3 kHz and a sub-sampling clock of 194.8 kHz was used. Hence the
sub-sampled signals shown, are at a difference frequency of 500 Hz (195.3 kHz −
194.8 kHz). This provides a delay amplification of
T + ∆T
∆T=
(1/194.8 kHz)
((1/194.8 kHz)− (1/195.3 kHz))≈ 390. (5.1)
5.3 Measured System Performance
The overall performance of the memory with supply voltage scaling is shown in
Fig. 5.5. Also seen in this figure are the pulse widths of the read-wordline (RWL)
and the sense-amplifier (SA). The tuning algorithm, shown in Fig. 3.23, was used to
obtain the settings at each supply voltage. The memory functions from the nominal
supply of 1.2 V down to 310 mV, using the internally generated reference voltage.
The variation of Energy per access with supply voltage is shown in Fig. 5.6. The
multiplicity factor (N) (also annotated in the graph) does not need tuning from
1.2 V down to 0.5 V. However, for values of supply voltages of 400 mV and below,
this had to be varied in order to generate the proper reference voltage. Fig. 5.6 also
shows the effect of supply voltage on leakage and read power. It may be observed
that the energy optimum point occurs at 400 mV, with 0.115 pJ/bit/access.
An independent read supply voltage was used to verify the performance of the
reference generation technique at voltages lower than 310 mV. Operating the mem-
ory at 350 mV, the read bitline’s precharge-voltage was lowered down to 190 mV,
while continuing to use the internally generated reference to perform reads. Various

Chapter 5. Experimental Setup and Measured Results 70
Table 5.1: Measured memory performance for various combina-tions of read-supply and memory-supply
ReadSupply(in mV)
MemorySupply(in mV)
Max.Frequency(in kHz)
ReadPower(in µW)
LeakagePower(in µW)
N
310 310 1288.3 8.30 2.17 3240 310 912.2 3.96 2.51 3200 350 912.2 3.78 2.15 3190 350 709.2 2.47 1.78 3
combination of read-supply and memory voltages were evaluated. The correspond-
ing memory performance, is summarized in Table 5.1. While scaling the SRAM
array supply is limited by the choice of SRAM cell used, the reference generation
technique continues to function down to 190 mV, making it suitable for use with
other cell-designs proposed in literature.
In general increasing N increases averaging, providing better tolerance to the
increased effects of variation at lower voltages. However the final settings for N
and configuration bits for the delay line, depend on the random distribution of
various parameters such as sense-amplifier offset voltages, variation in SRAM cell
characteristics and variation in the cells of the delay line. Also choosing different
cells on the reference lines (REFL and REFH) can lead to different values of N, due to
random variation between cells on these lines. The N values shown in Fig. 5.6 are
obtained by the tuning algorithm for one such random distribution of cells in a chip.
While the settings can be predicted easily at nominal voltages using simulations, the
increased variation makes it difficult to determine these settings at sub-threshold
voltages.
It is to be noted that the maximum value of N used is 3, which implies that a
value of m = 2 is sufficient. This also provides sufficient options for re-selecting
when lower values of N are used at higher supply voltages. Using higher values
of N provides averaging thus lowering the requirement for re-selecting. Also, fine-
tunability is not used. Thus only 4 configuration-bits are required for the reference

Chapter 5. Experimental Setup and Measured Results 71
generation technique. The delay generation technique requires 4 (FDB) + 4 (CDB) =
8 bits, making a total of 12 bits, that are necessary for the proposed design to operate
over the entire range of supplies.

Chapter
5.Experim
entalSetu
pan
dM
easured
Resu
lts72
Table 5.2: Comparison of this work with other U-DVS designs
PaperDetails
[35]2006FebISSCC
[41]2007FebISSCC
[38]2008FebJSSC
[39]2008OctJSSC
[15]2009NovJSSC
[37]2010JunTCAS-II
[36]2012FebTVLSI
[40]2013OctJSSC
ThisWork
Technology 65nm 65nm 130nm 130nm 65nm 90nm 130nm 65nm 130nm
Vmin380 mV320 mV1 350 mV 200 mV 208 mV
193 mV2 250 mV 160 mV 320 mV 260 mV 310 mV190 mV1
Memory size 256 Kb 256 Kb 480 Kb 2 Kb 64 Kb 8 Kb 2 Kb 32 Kb 4 Kb
Cell 10T 8T6 10T6 6T6 8T6 11T 10T 7T 8T
Cells/BL 256 256 1024 16 64 256 128 256 256
Freq(@ VDD)
90 kHz(0.38 V)
25 kHz(0.35 V)
120 kHz(0.2 V)
21.5 kHz(0.21 V)
20 kHz(0.25 V)
200 kHz(0.16 V)
270 kHz(0.3 V)
1.8 MHz(0.26 V)
1.3 MHz(0.31 V)
Max.Freq(@ VDD)
200 MHz3
(1.2 V)3.5 MHz(0.7 V)
4.5 MHz(0.5 V)
10 MHz(0.6 V)
200 MHz(1.2 V)
15 MHz(1 V)
NR5 NR5 460 MHz(1.2 V)
Energy/access7
(@ VDD)4 fJ/Kb(0.38 V)
NR5 NR5 390 fJ/Kb(0.3 V)
172 fJ/Kb(0.4 V)
3 pJ/Kb(0.16 V)
NR5 175 fJ/Kb(0.26 V)
1.6 pJ/Kb(0.31 V)
PLeak7
(@ VDD)11.3 nW/Kb(0.38 V)
8.6 nW/Kb(0.35 V)
4.3 nW/Kb(0.2 V)
25 nW/Kb(0.21 V)
6.3 nW/Kb(0.25 V)
NR5 55 nW/Kb(0.3 V)
NR5 542 nW/Kb8
(0.31 V)
Single-endedRead
Yes Yes Yes Yes Yes No No Yes Yes
ReferenceMechanism
NA4 External NA4 NA4 External NA4 NA4 Internal Internal
Vol.Range(in V)
0.7-0.381.23
0.7-0.35
0.5-0.2 1.2-0.193 1.2-0.25 1-0.16 1-0.32 0.8-0.26
1.2-0.311.2-0.191
Timinggen.technique
NR5 NR5 NR5 Tunable External Selfgenerated
NR5 Replica Tunable
1 Read, 2 With tuning, 3 Simulated, 4 Not Applicable, 5 Not Reported, 6 Modified, 7 Normalized with memory size (in Kb), 8 40 nW/Kb bySRAM cell array, rest by peripheral and other debug circuitry

Chapter 5. Experimental Setup and Measured Results 73
Table 5.2 compares our work with other U-DVS implementations reported. The
proposed design enables a higher frequency of operation at nominal voltages, due to
the use of sense-amplifiers with an internally generated reference. This significant
speed advantage, over other designs, is maintained across the full range of supplies
with the exception of the design [40] implemented in a faster technology (65nm).
The energy and power numbers are comparable to other reported works, with the
exception of the design [39] containing only 16 cells/BL.
Our proposed design operates at a higher frequency, than other designs, from
nominal voltage down to sub-threshold voltages making it suitable for a wide range
of applications. Also the conventional 8T SRAM cell used, requires no additional
peripheral circuitry such as a virtual power/ground generator [39], WL boosting
mechanism [69] or substrate bias generator. The present implementation, in con-
trast with other reported designs, does not require external support, either in the
form of a reference voltage or timing generation circuitry, thus making it a more
integrated solution.
5.4 Discussion
We found that the technique presented generates a nearly ideal reference voltage
for single-ended sensing over a wide range of voltages. Although tuning is used
to minimize margins during design and push performance over a greater range of
supply voltages, the technique can be applied without tuning. Simulations results
show that the technique can be used without tuning, along with the conventional
timing generation technique [42], from 1.2 V down to 0.65 V.
The area penalty may be reduced by using only one replica column as both REFL
and REFH are identical. Another option is to use a shorter replica BL. However, both
these options will lead to coarser tuning resolution as they cause the capacitance of
the replica column to reduce, but strength of each SRAM cell remains unchanged.

Chapter 5. Experimental Setup and Measured Results 74
Also the lowest setting of N = 1 may still result in the reference voltage being lower
than the ideal value (even with cell selection). This loss in resolution can then be
compensated using fine tunability, which can be achieved using appropriately sized
pseudo-SRAM cells. Fine tunability can also be used to further lower tSAE at nominal
voltages.
The speed and power advantage of SAs (over inverters) decreases as the supply
is reduced, as seen from Fig. 3.8. Also the penalty of storing additional configu-
ration bits is mainly contributed by the requirement to operate the SAs at lower
voltages. Hence it may be optimum to switch between using SAs at super-threshold
voltages and inverters at sub-threshold voltages.
5.5 Conclusion
This chapter presented the measured results for a 4 Kb SRAM array designed and
fabricated in UMC 130nm technology. The conventional 8T SRAM cell was sized
to allow operation down to sub-threshold voltages. Replica columns are used to
generate the reference voltage which allows the technique to track slow changes
such as temperature and aging. A few configurable cells in the replica column are
found to be sufficient to cover the whole range of voltages of interest. The use of
tunable delay line to generate timing is shown to help in overcoming the effects
of process variations. Effective tuning is achieved by the random-sampling based
algorithm that uses BIST hardware, which reduces the tuning time significantly for
large SRAMs. The memory achieves good performance from super to sub-threshold
voltages. Combining the proposed techniques is shown to allow the memory to
function from 1.2 V down to 310 mV, and read down to 190 mV (using an indepen-
dent supply), using internally generated reference voltage and timing signals thus
requiring no external support.

Chapter 6
Testing of Low Voltage Designs
6.1 Introduction
On-chip measurement of signals offers various advantages in testing and charac-
terization of designs. This eliminates the need for dedicated IO pads, avoids use
of large power hungry analog buffers to drive signals off-chip, and prevents load-
ing of sensitive analog nodes. Application of these circuits ranges from providing
generic on-chip oscilloscopes [92–94] to more specific applications such as moni-
toring power-supply [95,96], measuring supply noise [97,98], and jitter [99–101].
Traditionally Analog to Digital converters (ADC) were used to perform voltage
measurements on-chip [92, 102–104]. However with technology scaling and de-
creasing voltage headroom, Time to digital converters (TDCs) have gained popu-
larity as they take advantage of improved transition times in newer technologies
that are tuned for digital designs [105–107]. The voltage to be measured is first
converted into timing information in one of two ways. First approach is to use a
voltage controller oscillator (VCO), whose frequency (and phase) varies with the
input voltage [97,98]. Another option is to use a voltage to delay converter (VCD)
cell that converts the voltage of interest to a delay value [108, 109]. The timing
information is then converted to a digital value by using a TDC. However these
converters occupy significant area and offer limited (or no) flexibility to scale their
supply voltage. Apart from applications such as BIST, this silicon-area is seldom
used once the chip has been deployed in the final system making any investment
in area for testability even more expensive. Also they require sensitive signals of
interest to be routed over large distances adding noise to the measurements.
75

Chapter 6. Testing of Low Voltage Designs 76
Sub-Sampling Clock
D1D Q
CLK
D2D Q
CLK
S1
S2
DelayMeasurementUnit (DMU)
InputSignals
Sub-SampledSignals
Figure 6.1: Sub-sampling technique used to accurately measure delay between twoperiodic signals.
Voltage and timing samplers have been proposed that reduce silicon-area at the
expense of increased time for measurement. These systems sub-sample the signal of
interest after making the signal of interest periodic [86,110]. This allows the system
to achieve high effective sampling rate while operating the measurement circuitry
at a lower frequency. Voltage samplers are implemented using comparators that
act as 1-bit ADCs. Complete voltage waveform is then reconstructed by varying a
programmable reference voltage and making successive comparisons.
One such work [93] uses a variable reference voltage to first generate a timing
signal with variable delay that is used to sample the signal of interest. The differ-
ence between this sampled value and a second reference voltage is then converted
to a delay using a VCD. This delay is then amplified to enable a low resolution
on-chip TDC to measure the delay.
A more recent work [94] measures eye-diagram and jitter by first buffering and
sub-sampling the input differential signal. The sampled values are then compared
against two iteratively set variable reference voltages using a clocked-comparator.
The system iteratively estimates the input signal frequency and uses this to deter-
mine the jitter and estimate the eye-diagram.

Chapter 6. Testing of Low Voltage Designs 77
However none of the techniques reported thus far are suitable for systems oper-
ating over a wide range of voltages. Some of them offer limited voltage scalability
down to 700 mV [98] and 600 mV [106,107] but will require extensive calibration at
each supply voltage. The voltage range is mainly limited by the use to analog com-
ponents such as buffers, and VCD cells. VCOs offer an interesting alternative but
they draw power from the voltage being measured, unless the voltage is buffered
first.
While design of circuits for low (and wide) voltage operation has received con-
siderable attention recently [3], the testability aspect of these designs has been
mostly ignored. Foundries rarely provide device models tuned at multiple volt-
ages with fine granularity, making characterization more critical in these systems as
simulation results are less reliable. Increased variability at low voltages further in-
creases the need for testing and tunability at lower voltages. We propose the use of
sub-sampling [86] and sense-amplifier characterization in measuring time and volt-
age respectively for the testing and characterization of wide voltage range circuits -
specifically memories.
6.2 Sub-sampling
The delay measurement is done by first converting the delay of interest (δ) into a
skew two between periodic signals. In memories, this is achieved by repeating an
operation, such as a read operation, on every cycle [110] (with a time period of say
T). Each of these periodic signals (D1 and D2) is then sampled using a sub-sampling
clock of slightly different frequency (with a time period of say T+∆T, where ∆T can
be either positive or negative) as shown in Fig. 6.1. This sampling action produces
beat signals (S1 and S2) with a significantly lower frequency, with a time period of
(T + ∆T )(T/∆T ) as illustrated in Fig. 6.2. Sub-sampling also amplifies the delay
between input signals D1 and D2 (δ) to (δ/T )(T + ∆T ) [86]. The amplified delay

Chapter 6. Testing of Low Voltage Designs 78
D1
D2
SubSampling
Clock
S1
S2
Initial delay (δ)
Amplified delay = (δ/T)x(T+ΔT)
T
T
T+ΔT
(T+ΔT)x(T/ΔT)x0.5
Figure 6.2: Illustrative waveform showing the amplified input delay between sub-sampled signals.
can then be easily estimated using a digital block known as Delay Measurement
Unit (DMU). As the sub-sampled signals are in a lower frequency domain, they
are more tolerant to mismatches in routing and other loading effects making them
suitable for processing off-chip. The DMU may thus be implemented off-chip saving
precious silicon area.
The delay measurement unit cleans the sub-sampled signals (typically debounc-
ing) and averages the measurement over several (K) cycles to provide an estimate
of the delay. The upper bound for the standard deviation of this estimate is given
by [86]
σS =1√
2K+1(6.1)
Thus averaging over more samples, in the presence of random noise, allows the
technique to achieve higher precision, which is well understood [111]. Higher
number of samples translates to increased measurement time.
While the accuracy of the technique is affected by the sub-sampling distribution
network and mismatch between the sampling flip-flops, it has been shown [86]
that accuracy is largely limited by the measurement time. More importantly, the

Chapter 6. Testing of Low Voltage Designs 79
Circuit Under Test
Tim
ing
Ge
ne
rato
r
FF
FF
Input
Voltage
VREF
ClockedComparator
Latc
h
S1
S2
Low-frequencysub-sampled
Signals
Sub-Sampling Clock
SystemClock
D1
D2
0
VDD
Config. bits for varying timing
Stored inShift-Register
Figure 6.3: Block diagram of the proposed voltage measurement technique.
precision of the technique is not limited by jitter. In systems where the sub-sampling
clock frequency is rationally related to the input signal frequency, jitter actually
helps in reducing error in measurements by randomizing the position of the sub-
sampling clock edge. This makes the technique ideally suited for application over a
wide range of supply voltages.
6.3 Sense-amplifiers as ADCs for bitline voltage mea-
surements
The block diagram of the proposed voltage measurement system is shown in Fig. 6.3.
The input voltage of interest is determined by comparing it against a set of prede-
termined voltage steps using a variable voltage reference and clocked-comparator

Chapter 6. Testing of Low Voltage Designs 80
(which acts a 1-bit quantizer). Higher effective sample rates are achieved by sub-
sampling the voltage of interest using a programmable timing signal. The combi-
nation of the above two steps enables us to plot internal voltage versus time wave-
forms.
We adapt this technique to measure bitline voltages in SRAM using already ex-
isting infrastructure with just an additional reference voltage, thereby minimizing
area-overhead. We first characterized the sense-amplifiers to measure their offset
voltages using a reference voltage source. These are then used as comparators to
measure the bitline voltages. Timing signals for the clocked comparator (sense-
amplifiers) are generated internally using the programmable timing generator of
SRAM. These are already included in SRAMs as low voltage operation requires
tunable timing generators to counter the effect of increased variation at these volt-
ages [45,47–49].
All blocks employed in the proposed implementation are completely digital, alle-
viating the concerns in using analog blocks as detailed in Section 6.1. The measure-
ment system outputs digital bits from the latch and two low-frequency sub-sampled
signals. These three outputs are then easily processed by a digital block present on
or off-chip.
The technique incurs almost no area-penalty when used to measure the bitline
voltages in an SRAM as all the blocks necessary are already present. When measur-
ing other analog signals we only require an additional sense-amplifier and a latch
for each analog voltage being measured adding minimal area overhead. The small
area of the voltage samplers (comparators + latch) also avoids routing of sensitive
internal analog signals over long distances, avoiding the associated noise issues.
Only one set of sub-sampling flops are necessary to measure the timing signals
again insignificantly adding to the system area. Multiple such sub-sampling blocks
may be placed when the signals to be measured are spread across a large chip to
increase the accuracy by measuring the skew in the timing signal routed to the

Chapter 6. Testing of Low Voltage Designs 81
FF
FF
FF
FF
Sub-Sampling Clock
S1
S2
SRAMTiming
Generator
Sub-Sampling Block
FF
FF
FF
UnusedSamplers
4:1
4:1
4:1
D1
D2
D11
Config.Bits
2
2
Figure 6.4: Implementation of the sub-sampling technique to characterize theSRAM array, fabricated in the UMC 130nm.
various comparators.
The advantage of having lower silicon area comes at the expense of increased
time for testing and characterization. The calibration of comparator offset voltage
must be done at each supply voltage of interest. For each timing setting the refer-
ence is swept across a range of voltages in steps at voltage of interest. This step
must then be repeated for the timing range of interest to obtain a voltage versus
time plot.
6.4 Measured Results
Sub-sampling technique was implemented in the test chip fabricated in UMC 130nm
Mixed-Mode/RF process. This was used to make accurate measurement of signals
from the timing generator of the 4 Kb SRAM array as shown in Fig. 6.4. Fig. 6.5
shows the layout of the sub-sampling block, along with output drivers, in the con-
text of the chip. The chips contains 17 samplers (flip-flops) which were used to

Chapter 6. Testing of Low Voltage Designs 82
4-KbSRAM
ScanChain
1 mm
1 m
m
OtherTest
Circuitry
Sub-Sampling Block
93 µm
47
µm
Figure 6.5: Chip Micrograph showing the sub-sampling block implemented in UMC130nm.
measure various (11) signals internal to the timing generator. Multiplexers are
placed in the sub-sampled domain ensuring that they have little effect on the mea-
surements. Additionally a common timing signal, D1, is connected to both paths
(S1 and S2) to characterize away any mismatch in routing S1 and S2 to the DMU.
The sub-sampling clock is provided from an off-ship signal generator in our im-
plementation. However it can be generated internally by suitably modulating the
system clock [86].
The sub-sampling block consists of just 17 flip-flops and 5 MUXes (4:1) (Fig. 6.4)
which add minimal area overhead. The area shown in Fig. 6.5 includes a conserva-
tively designed isolation ring around the sub-sampler block and the output drivers
designed to drive the sub-sampled signal off-chip (along with some decoupling ca-
pacitors for the same). DMU was implemented off-chip on a Xilinx Virtex 5 FPGA as
shown in the test-setup of Fig. 5.2 and occupies approximately 1K NAND2 equiv-
alent gates. Hence the technique can be implemented with very little overhead in
area.
On-chip timing measurement allowed for at-speed testing of SRAM across the
voltage range without the need to operate IO ports at high frequencies. The fre-
quency and timing values shown in Fig. 3.22 and Fig. 5.5 were measured using the

Chapter 6. Testing of Low Voltage Designs 83
sub-sampling technique.
One additional sense-amplifier (and latch) was placed on each of the reference
columns REFL and REFH to enable measurements. This was used to measure the
generated reference voltage described in Chapter 3.
The sense-amplifiers were first characterized to determine their offset voltages
at each supply voltage of interest. This is done by 1) varying an externally generated
reference voltage which is connected to one input of the sense-amplifier and 2) the
read precharge voltage which connects to the bitline and hence the other input of
the sense-amplifier.
Multiple reads are performed at each voltage setting to determine the switching
point (and hence the offset voltage) of each sense-amplifier. Fig. 6.6 shows the
probability density function of the sense-amplifiers at 1.2 V and 360 mV. It may be
seen that, at lower voltages the variation in offset voltage is significantly higher
in accordance with the simulation results discussed with respect to Fig. 2.3(b).
The voltage was varied in steps of 2 mV which was the limitation of the accuracy
of the voltage source (Agilent U2722A). The sense-amplifiers were then used to
make voltage measurements at described in Section 6.3. The timing signal and sub-
sampling clock were generated externally as the internal timing block was limited
in range (the block was designed to provide timing signals to enable sensing of
bitlines to read data stored in cells and not for measurement applications). The
actual delay generated on-chip, from the externally generated timing signals was
measured using the sub-sampling technique.
Fig. 6.7(a) shows the estimate of internal voltage generated at 1.2 V. In addi-
tion to the two sense-amplifiers mentioned above, the estimates from the sense-
amplifiers on a redundant reference column are also shown (as SA-3 and SA-4).
While this testing technique works fine at higher voltages, at lower voltages the
results are very noisy as seen from the estimates at 0.4 V (Fig. 6.7(b)). Also, only
two of the four sense-amplifiers used for debugging, were found to be functioning

Chapter 6. Testing of Low Voltage Designs 84
0 %
20 %
40 %
60 %
80 %
100 %
-0.15 -0.1 -0.05 0 0.05 0.1 0.15
Perc
enta
ge o
f outp
uts
read h
igh
Sense amplifier differential input voltage
VDD = 1.2V
(a)
0 %
20 %
40 %
60 %
80 %
100 %
-0.15 -0.1 -0.05 0 0.05 0.1 0.15
Perc
enta
ge o
f outp
uts
read h
igh
Sense amplifier differential input voltage
VDD = 0.36V
(b)
Figure 6.6: Measured probability density function of 16 sense-amplifiers, at(a)VDD = 1.2 V and (b)VDD = 0.36 V, which is used to characterize their offset-voltage.

Chapter 6. Testing of Low Voltage Designs 85
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 2 4 6 8 10 12
VR
EF n
orm
aliz
ed to V
DD
Wordline pulse width (in ns)
VDD = 1.2 V
N = 1
N = 2
SA 1SA 2SA 3SA 4
(a)
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
40 60 80 100 120 140 160 180 200 220
VR
EF n
orm
aliz
ed to V
DD
Wordline pulse width (in ns)
VDD = 0.4 V
N = 1
N = 2
SA 1SA 2
(b)
Figure 6.7: Measured reference voltage VREF versus wordline pulse width at (a)Supply = 1.2 V and (b) Supply = 0.4 V.

Chapter 6. Testing of Low Voltage Designs 86
well at 0.4 V. However, all 16 sense-amplifiers connected to regular BLs continue
to function down to 310 mV. The results show the control over internally gener-
ated reference with both the multiplicity factor N and wordline pulse width. The
measured results also match well with the simulation results shown in Fig. 3.26.
6.5 Discussion
We found that the proposed characterization system performs well across the wide
range of voltages from 1.2 V to 0.4 V. Voltage measurements were preformed at
steps of 2 mV. This voltage resolution may be increased by either using a higher
accuracy voltage reference or by performing multiple measurements at lower res-
olution [111]. Both these options will incur longer measurement times to achieve
higher accuracy.
Sub-sampling was used to achieve a amplification factor of 390 of the delays at
350 mV. Using internally generated delay allows us to achieve an effective sampling
rate of about 24 GHz at 1.2 V and 5.7 GHz at 0.4 V (Table 3.1). But the internal
delay generators provide limited range. Significantly higher effective sampling rates
may be achieved using externally generated timing signals which may be easily
generated [112–115]. The sub-sampling technique has been shown to measure
sub pico-second delays which can enable extreme effective sampling rates, again
at the expense of increased measurement time [86]. Hence the proposed system
can be used to make suitable trade-offs between resolution of voltage and time
measurements and measurement-time.
Sense-amplifiers require more time to resolve the voltage at their inputs when
operating at lower voltages. Thus the sense-amplifier enable pulse-width needs
to be increased as the supply voltage is reduced, limiting the timing resolution of
measurements. In the absence of a sample and hold circuit, the increased pulse-
width also increases the noise in measurements at lower voltages, as seen from

Chapter 6. Testing of Low Voltage Designs 87
Fig. 6.7(b). The offset voltage of the comparators restrict the range of voltages that
can be measured. The range of measurement is limited to either VDD − Voffset to 0
or VDD to Voffset depending on the sign of the offset voltage. This may be overcome
using techniques proposed for sense-amplifier offset compensation such as using
body bias [73] or choosing one of multiple redundant sense-amplifiers [41]. Some
sense-amplifiers may also fail at extremely low voltages, limiting the supply voltage
range over which measurements may be done. This may be overcome by adding
redundant sense-amplifier as the area overhead of doing so is negligible [41].
The characterization capability enabled by the proposed technique can be used
to provide valuable insights into future ultra wide voltage designs. Simple modifi-
cations of the technique can be incorporated in BIST infrastructure to improve the
robustness of systems, especially at lower voltages. These would move wide voltage
operation a step closer to being implemented in commercial industrial designs.
6.6 Conclusion
One of the first approaches for testing and characterization of ultra wide voltage
range circuits has been proposed in this chapter. The system relies on sub-sampling
to achieve high effective sampling rates at the expense of increased measurement
time. First the signal of interest is made periodic and its value at a given time is
determined iteratively using a programmable reference voltage. The time instant
of sampling is then varied to obtain the value of signal at each time instant. Sub-
sampled signals are processed using minimal logic circuitry to obtain final voltage
versus time waveforms. A completely digital approach that uses flip-flops and sense-
amplifiers is presented, that enables operation over a wide range of voltages. This
also ensures that the area overhead of the technique is negligible. The low fre-
quency of sub-sampled timing signals and digital output from the comparator can
also be easily taken off-chip, further reducing area overhead for characterization.

Chapter 6. Testing of Low Voltage Designs 88
The technique also allows the flexibility of choosing the trade-off between accuracy
and measurement-time making it suitable for a wide range of applications rang-
ing from BIST to non-destructive characterization and debug of wide voltage range
circuits.

Chapter 7
Conclusions
7.1 Contributions
This thesis presents the design and characterization of an ultra dynamic voltage
scalable memory (SRAM) that functions from nominal voltages down to sub-threshold
voltages without the need for external support. The key contributions of the thesis
are as follows:
A variation tolerant reference generation for single ended sensing: We present
a reference generator, for U-DVS memories, that tracks the memory over a wide
range of voltages and is tunable to allow functioning down to sub-threshold volt-
ages. Replica columns are used to generate the reference voltage which allows the
technique to track slow changes such as temperature and aging. A few configurable
cells in the replica column are found to be sufficient to cover the whole range of
voltages of interest. The use of tunable delay line to generate timing is shown to
help in overcoming the effects of process variations.
Random-sampling based tuning algorithm: Tuning is necessary to overcome the
increased effects of variation at lower voltages. We present a random-sampling
based BIST tuning algorithm that significantly speeds-up the tuning ensuring that
the time required to tune is comparable to a single MBIST algorithm. Further, the
use of redundancy after delay tuning enables maximum utilization of redundancy
infrastructure to reduce power consumption and enhance performance.
Testing and Characterization for U-DVS systems: Testing and characterization
is an important challenge in U-DVS systems that has remained largely unexplored.
We propose an iterative technique that allows realization of an on-chip oscilloscope
89

Chapter 7. Conclusions 90
with minimal area overhead. The all digital nature of the technique makes it simple
to design and implement across technology nodes.
Combining the proposed techniques allows the designed 4 Kb SRAM array to
function from 1.2 V down to 310 mV with reads functioning down to 190 mV. This
would contribute towards moving ultra wide voltage operation a step closer to-
wards implementation in commercial designs.
Memory interface design: We briefly describe the interface between logic and
memory which typically operate at different voltages requiring the use of level-
shifters. We present a technique for reduction in energy by placing the level-shifters
further into the memory macro (inside the address-decoder) without sacrificing
performance in such systems.
7.2 Future Directions
Operating systems over a wide range of voltages is essential to support the varied
applications in emerging markets such as the Internet of Things (IoTs). Memories in
particular are challenging to design in this regime due to the contradictory require-
ments of low area and high-yield. While researchers have reported several promis-
ing approaches there still remain exciting opportunities that need exploration.
The conventional 6T SRAM cell has been the clear winner for design of memo-
ries at nominal voltages across many generations of technology. However the choice
of cell for wide voltage range memories remains unclear. The right trade-off be-
tween cell modifications, that invariably come with increase in area, and peripheral
assist techniques needs to be determined. Relative importance of design metrics
such as leakage, speed, and area will be application specific. Thus the solution to
the trade-off is also expected to be dependent on the final application.
Tuning is proposed as the better approach in coping with increased variation that
come with both technology and supply scaling. However this adds to system cost

Chapter 7. Conclusions 91
as tuning is necessary at each supply operating point. Also the tuned settings must
be stored reliably, which adds to the area overhead. While just a few operating
points are shown to be sufficient to achieve a good approximation of continuous
voltage and frequency tracking [116], more effective strategies of tuning need to
be explored that allow compression of configuration bit settings.
Another interesting issue is in testing of such memories. It remains unclear
whether testing is necessary at each supply voltage to determine a good die. An
analysis to determine the minimum number of supply voltages at which testing is
necessary to ascertain that a chip as good, would be very beneficial in reducing the
cost of testing.
On-chip measurements have higher significance at lower voltages as explained
in Chapter 6. The technique proposed in this thesis makes progress in this direction
but is still limited at lower voltages. This area of testability across a wide range of
voltages remains largely unexplored and thus requires further investigation.
With these wide range of challenges and opportunities, U-DVS SRAM design is
expected to remain an exciting area of research in the near future.

Appendix A
Optimal Placement of Level
Converters in Memory Decoders
A.1 Introduction
While conventional CMOS logic circuits have been demonstrated to function down
to 180 mV and simple variations of logic style allow operation down to 62 mV, the
supply voltage of memories has not scaled proportionately. Although SRAMs that
function down to 200 mV have been reported [39], memories in general tend to be
operated at higher supply voltages compared to logic circuits [91].
Fig. A.1 shows a typical system, similar to implementations reported in [91]
and [1], highlighting the memory interface section of the design. It may be observed
here that level shifters are used to interface the core, operating at a lower supply,
with the memory that operates at a higher supply voltage. These implementations
place the level shifters before the flip-flop (FF) present at the memory interface as
shown in the figure. However, memory macros contain logic circuitry such as row
decoders that can potentially be operated at lower supplies similar to the core logic.
Only the SRAM cells in the memory macro require higher supply voltages to operate
reliably.
This chapter evaluates an alternate memory interface architecture that enables
lower energy/cycle by moving the level shifter into the memory macro. Although
level shifters are commonly placed next to the SRAM array [117], this chapter eval-
uates the feasibility, trade-offs and applicability of placing level shifters at various
stages along the decoder for ULV systems.
92

Appendix A. Optimal Placement of Level Converters in Memory Decoders 93
CLK_H
FF
Level Shifters
FF
Row Decod
er
Col. Precharge
Sense Amps.
FFSRAMArray
CLK_L
VDD_MEMVDD_CORE VDD_CORE
CL
Timing Gen.
WL Driver
Typical Memory Macro
Figure A.1: Generic memory interface of a multi-voltage domain system with levelshifters placed before the memory macro.
V1
VDDH
VDDLIN
OUT
M2M1
M3
M4 M5
IN
180n200n
160n3µ
180n150n
180n330n
600n330n
745n240n
145n270n
(a)
2.6 µm
7.66 µm
1.42 µm
1.42 µm
SRAM
Level Shifter
(b)
Figure A.2: (a) Wilson current mirror based sub-threshold level shifter [118]. (b)Layout of 8T SRAM and level shifter of equal pitch.
The rest of this chapter is organized as follows. Section A.2 explains the sub-
threshold level shifter used in our implementation, which is followed by a descrip-
tion of the memory interface architecture in section A.3. Section A.4, then presents
the various row decoder architectural design options. Simulation results are pre-
sented in section A.5, we then conclude in section A.6.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 94
CLK_L
MemoryInputs
CLK_H
MemoryOutputs
tLS
t1 t2 t3
0
VDD_CORE
VDD_CORE
0
0
VDD_MEM
0
VDD_MEM
Figure A.3: Timing diagram of the memory interface shown in Fig A.1.
A.2 Sub-threshold to Above Threshold Level Shifter
Several level shifters capable of translating sub-threshold voltages to nominal level
have been proposed in literature [119] [118]. The Wilson current mirror based
design proposed in [118] employs a technique that lowers the contention between
the NMOS pull-down path and the PMOS pull-up path present in conventional level
shifters making it suitable for ULV designs.
The level shifters presented in [119] and [118] were designed, and the Wil-
son current mirror based design [118] (Fig. A.2) was chosen, as simulation results
showed it to be superior to that of Wooter’s design [119] in all performance metrics;
delay, leakage power and energy per transition. The design supports a wide range
of supplies with V DDLmin = 100mV and V DDHmax = 1.2V , and the case when
V DDL > VDDH (with V DDLmax = 1.2V and V DDHmin = 300mV ).
A.3 Memory Interface Architecture
Fig. A.1 shows the typical memory interface in modern SoCs. A memory control unit
(VDD CORE) generates the inputs required by the memory such as address, chip-
select, read/write enable, and write-data, and reads back the data returned from

Appendix A. Optimal Placement of Level Converters in Memory Decoders 95
the memory. The memory block is typically available as a macro and is operated at a
higher voltage (VDD MEM). Fig. A.3 shows the timing diagram of this system. The
system clock (CLK L) is given to the memory after level-shifting (CLK H), which
causes the memory inputs to be latched with a delay equal to the level shifter delay
(tLS) at time t2 as against t1. However, the memory output is latched at t3 using
CLK L. Hence the cycle time, Tcycle, for this system is given by:
Tcycle = max(tcq + tCL+ tsetup, tMEM + tLS) (A.1)
where tcq represents the Clk-to-Q delay of a flop, tCLis the delay in the combina-
tional block labeled CL in Fig. A.1 (tCLrepresents the critical logic path delay, which
need not be in the memory controller block), tsetup is the setup time of a flop, and
tMEM is used to represent the delay in the entire memory path (including any flop
setup and Clk-to-Q delay). As the core supply is scaled, to meet demands of lower
power consumption, the delay of each pipeline stage scales differently. The new
cycle time is then given by:
T ′cycle = max(t′cq + t′CL+ t′setup, tMEM + t′LS) (A.2)
where the ′ represents the new (increased) delay corresponding to the reduced core
supply voltage. Note that the memory delay has not changed as it continues to
operate at the higher supply.
Fig. A.4 shows the variation of level shifter delay and 20 fan-out-four (FO4)
inverter delay (typical gates per pipeline stage in processors [1]), as the supply
is scaled. It may be seen that the combinational delay increases at a significantly
faster rate compared to the level shifter delay as the supply is reduced. Depending
on whether critical path was in memory, before scaling the supply, there are two
possible design scenarios.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 96
1
10
100
1000
10000
0.2 0.3 0.4 0.5 0.55
Del
ay (
in n
s)
Core Supply (in Volts)
54%
153%
100 mV
20 FO4 delayLevel shifter delay
Figure A.4: Variation of FO4 delay and level shifter delay with VDD CORE.
1. Case 1: If logic path was critical before reducing the supply i.e.
Tcycle = tcq + tCL+ tsetup (A.3)
This implies that there is already some slack in the memory path and this slack
will increase further as the core supply is reduced.
2. Case 2: If the cycle time was limited by the memory before the supply is
reduced i.e.
Tcycle = tMEM + tLS (A.4)
Depending on the initial slack in logic path, as the supply is scaled there exists
a crossover point where the logic path becomes critical and slack develops on
the memory path. With the crossover point given by
t′cq + t′CL+ t′setup = tMEM + t′LS (A.5)
Fig. A.4 shows that even for a 100 mV difference in supplies (core at 0.45 V
and memory at 0.55 V) the core delay increases by 153% as compared to level

Appendix A. Optimal Placement of Level Converters in Memory Decoders 97
Level Shifters
FF
Row Decod
er
Col. Precharge
Sense Amps.
FFSRAMArray
VDD_MEM
Timing Gen.
WL Driver
CLK_H
FF
CLK_L
VDD_CORE
CL
VDD_CORE
Figure A.5: Modified memory interface diagram with the level shifters being placedinside the memory macro next to the row-decoders.
shifter delay, which increases by just 54%. Hence even if the supply is scaled
by a small amount and for reasonable amounts of initial slack in logic path,
the memory path quickly becomes non-critical.
Thus as the supply is scaled, in either of the two cases, a slack develops in the
memory path. This slack may be utilized to operate some sections of the memory
at the lower voltage, enabling a reduction in system power. In order to do so the
level shifter must be moved into the memory macro. The first step, in doing so, is
to move the level shifter beyond the flip-flop as shown in Fig. A.5. This causes the
level shifter delay to be a part of the memory access path. Thus the cycle time for
this system is the same as in Eqn. (A.1). Now that the level shifter has been placed
just before the memory (preceding the memory address decoder or row decoder)
without affecting the timing, we can push it further in as explained in the next
section on row decoder design.
A.4 Row Decoder Design
The function of the row decoder is to decode the address bits (typically 8-bit as
explained in section A.5) into multiple Word-line (WL) enables, one for each row
of the SRAM array. Fig. A.6 illustrates an 8-bit decoder with multiple stages of
pre-decoding. The address bits are decoded in 3 stages using 2 or 3-input AND

Appendix A. Optimal Placement of Level Converters in Memory Decoders 98
Table A.1: Architectural options for placement of level shifters at different stagesalong the row decoder
Mode Predecodestage 1
Bufferstage 1
Predecodestage 2
Bufferstage 2
Finaldecoder
Bufferstage 3
No. oflevelshifters
LS0 High High High High High High 0LS1 High High High High High High 8LS2 Low High High High High High 16LS3 Low Low Low High High High 32LS4 Low Low Low Low Low High 256
High – indicates that the block operates at the higher voltage (VDD MEM)Low – indicates that the block operates at the lower voltage (VDD CORE)
(NAND + NOT) gates as shown in Fig. A.6. All NAND gates are only loaded by 1X
(minimum sized) inverters to minimize the effort of the higher fan-in gates (NAND).
The outputs of these gates are then buffered to drive their respective load.
The options available for placing the level shifter at various positions in the de-
coder are also shown in Fig. A.6. Mode LS1 represents the case where the level
shifters are placed in front of the address decoder (following the flip-flops, as men-
tioned in the previous section). All blocks of the decoder operate at the higher sup-
ply (VDD MEM) in this mode (table A.1). This is the supply at which memory runs.
The next option would be to place the level shifter at the output of predecode stage
1, denoted as LS2. In this mode the predecode stage 1 blocks would be operating
at the lower supply (VDD CORE) and all other blocks will operate at VDD MEM. In
general all blocks from the input A[7:0] till the level shifters operate at VDD CORE
and the blocks following the level shifter operate at VDD MEM. The next option is
shown as LS3 in the figure where the 32 level shifters are placed at the output of
predecode stage 2. The final option is then to place the level shifters just before the
word-line drivers (LS4). The number of level shifters required in each mode is also
shown in the Fig. A.6 and table A.1. An additional mode, denoted by LS0, is added
which is identical to LS1 but with the absence of the level shifters. This mode is
used to quantify the penalty incurred by the use of level shifters.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 99
4KbSRAM
Decode
r
A[0]A[1]A[2]A[3]A[4]A[5]A[6]A[7]
WL255
WL0
WL1
Sense Amplifiers
Timing generator
Bitline Precharge
Predecodestage 1
Bufferstage 1
Predecodestage 2
Bufferstage 2
Bufferstage 3
LS18 level shifters
LS332 level shifters
LS216 level shifters
LS4256 level shifters
CS (latched)
Figure A.6: Proposed Row-Decoder architecture showing various architectural op-tions for placement of level shifters.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 100
Row decoder16%
WL Driver53%
Sense Amps10%
Timing generator
5%
Misc16%
Figure A.7: Typical memory interface leakage power break-up with all sections ofthe memory operating at 550 mV.
As the level shifter is placed closer to the SRAM WL, more blocks operate at a
lower supply voltage. Hence we would expect the delay to increase as we move
from mode LS1 towards mode LS4. The energy per transaction, on the other hand,
is expected to reduce as more blocks operate at a lower supply and thus consume
lower energy. However this trend may be offset by the increase in number of level
shifters required as we move from LS1 to LS4. The leakage power will also be
affected similarly by the above factors. Another interesting factor, adding to this, is
the number of level shifters switching, in each mode, for a given number of address-
bits transitioning. As the level shifters are moved closer to the word-line, fewer of
them switch for a given number of address bit transitions. However, moving the
level shifters closer to the word-lines also causes an increase in area. The results of
these trade-offs are studied in next section.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 101
0
10
20
30
40
50
60
70
LS0 LS1 LS2 LS3 LS4
Leak
age
pow
er (
in n
W)
Level Shifter position
15.4%
Decoder power without LSLevel-shifter power
Figure A.8: Decoder leakage power in various level shifter positions.
10
15
20
25
30
35
40
45
LS0 LS1 LS2 LS3 LS4 0
20
40
60
80
100
120
140
160
180
Row
dec
oder
Ene
rgy
per
cycl
e (in
fJ)
Del
ay (
in n
s)
Level Shifter position
55.2%
17.3%
35%
Min activityMax activityDelay
Figure A.9: Decoder Energy/cycle in different level shifter positions for minimumand maximum decoder activity and variation of decoder delay with level shifterposition.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 102
A.5 Implementation and Simulation Results
In order to demonstrate and evaluate the proposed technique, a 4 Kb SRAM (orga-
nized as 256 rows by 16 columns) interface has been designed in UMC 65nm low-
leakage process. Larger SRAM arrays would generally use column MUXing and/or
split word-line architecture to address a larger memory space. Hence the analysis
presented here is valid even for larger memory sizes reported in [91] and [1].
The SRAM uses an 8T cell (layout in Fig. A.2(b)) [66] that contains two transis-
tors for read-buffer in addition to the conventional 6T cell. The memory operates at
a fixed voltage of 0.55 V (VDD MEM) while the core voltage (VDD CORE) is scaled
down to a minimum of 0.2 V, similar to the design presented in [91].
The break-up of leakage power in memory interface circuitry is shown in Fig. A.7.
The configurations explored in this work only affect the row-decoder power, while
the contribution of other blocks remain almost unaffected and act as a static off-
set to memory power as the modes are varied. We therefore focus only on the
row-decoder metrics in this section.
The design presented in [91] operates the memory at 0.55 V and logic, as low
as 0.28 V. At these voltages the combinational logic determines the clock frequency
to be 5 MHz. Fig. A.8 shows the variation of the decoder leakage power as the
level shifter position is changed under these conditions (with the contribution of
the level-shifters and the rest of the decoder shown separately). As the level shifter
is moved closer to the WL the total leakage power remains almost constant from
mode LS1 through LS3. Mode LS4, on the other hand, provides a 15.4% reduction
in leakage power over LS1, thanks to the large buffer stage 2 being operated at the
lower supply.
Fig. A.9 plots the energy/cycle of the row decoder under aforementioned condi-
tions as the level shifter position is varied, for extreme values in activity factor of the
decoder. The minimum activity occurs when only one address bit transitions while

Appendix A. Optimal Placement of Level Converters in Memory Decoders 103
10
20
30
40
50
60
70
80
90
100
110
0.2 0.3 0.4 0.5 0.55 1
10
100
1000
10000
En
erg
y/c
ycle
of
Ro
w d
eco
de
r (in
fJ)
De
lay (
in n
s)
Core Supply (in Volts)
LS1LS3LS4
20 FO4 delay
Figure A.10: Variation of absolute Energy/cycle and combinational delay withVDD CORE.
the worst case activity is observed when all eight address bits transition. Moving
the level shifters closer to the WL clearly offers energy benefits with LS4 providing
35% to 55.2% decrease, and LS3 providing up to 17.3%, decrease in energy/cycle
over LS1. The figure also plots the increase in delay of the decoder as level shifters
are moved closer to the WL. Comparing this with the Fig. A.4 (at 0.28 V), shows
that the delay increase in combinational logic (195.1 ns) is greater than the delay
increase in decoder in mode LS4 (129.7 ns), thus making all modes feasible.
The core voltage may be varied based on system performance requirements
which affects the trade-offs in level shifter placement. This was tested by vary-
ing VDD CORE from 550 mV down to 200 mV. For this entire range, it was noted
that the increase in delay of decoder (in mode LS4), as supply is reduced, is less
than the delay increase in combinational path, thus making LS4 mode feasible over
the entire range of voltages.
Fig. A.10 shows the variation in absolute energy/cycle of the decoder for modes
LS1, LS3 and LS4 as VDD CORE is varied, with VDD MEM held constant at 0.55

Appendix A. Optimal Placement of Level Converters in Memory Decoders 104
V. The critical path delay is also plotted, in the figure, to show that the system fre-
quency decreases exponentially as the supply is scaled down. Reducing the supply
decreases the dynamic energy/cycle while the leakage energy/cycle increases. This
implies that there exists an energy optimal point at which the energy/cycle is min-
imum. This optimum point occurs at a supply of approximately 300 mV for most
processors [1] and Fig. A.10 shows that this is indeed the case for the decoder as
well. Mode LS4 causes both the dynamic and leakage energy/cycle to reduce as
more sections of the decoder operate a lower voltage. This results in a reduction in
total energy/cycle as seen from the figure.
The savings obtained by moving to the architectures LS3 and LS4 are quantified
in Fig. A.11. The figure plots variation in percentage savings in energy/cycle of LS4
and LS3 over LS1, as the supply is varied. The results are shown for extreme values
of decoder activity. It may be seen that excepting the particular case when both
core and memory operate at 0.55 V and only a few address bits transition, mode
LS4 always enables reduction of energy/cycle with a maximum savings of 57.4%.
The savings are noted to peak in the 300 to 400 mV range (energy optimum VDD)
due to the minima in energy/cycle curve in this range.
Mode LS4 requires the level shifters layout to be designed to match the SRAM
array pitch, as shown in Fig. A.2(b). The 256 level shifters in this mode cause the
decoder area to increase by 41%. However in modes LS3, LS2 and LS1 the level
shifters are hidden under the long wires at the output of buffer stage 2 avoiding
any increase in decoder area. Hence from a practical perspective, LS3 offers a good
trade-off with energy savings of up to 20% (Fig. A.11) and negligible area overhead.
The minimum energy perspective [1] recommends designing low activity blocks
with higher threshold devices to reduce leakage, but running them on a higher sup-
ply to maintain performance. As activity in the decoder decreases as one approaches
the final WL drivers, LS3 offers a good compromise of separating the higher activity
predecoders from the low activity but higher voltage WL drivers.

Appendix A. Optimal Placement of Level Converters in Memory Decoders 105
-20 %
-10 %
0 %
10 %
20 %
30 %
40 %
50 %
60 %
70 %
0.2 0.3 0.4 0.5 0.55
Perc
enta
ge s
avin
gs in E
nerg
y/c
ycle
over
LS
1
Core Supply (in Volts)
Min activity - LS4Max activity - LS4Min activity - LS3Max activity - LS3
Figure A.11: Percentage saving in Energy/cycle for various values of VDD CORE,for extreme values of decoder activity.
The only modification required to implement mode LS3, is to shift the buffer
stage 2 to make space for the level shifters and separate the power domains appro-
priately. Thus making this technique amenable to implementation using memory
compilers.
A.6 Conclusion
The memory interface circuitry for a 256x16-bit SRAM has been designed in UMC
65nm low-leakage process. The core (logic) is operated at supply voltages ranging
from nominal down to the sub-threshold regime while the memory operates at a
fixed voltage of 550 mV. It has been demonstrated, for a wide range of core volt-
ages, that moving the level shifters into the memory macro and placing them close
to the word-line drivers enables a reduction in energy/cycle of the row-decoder.
This is done by utilizing the slack in memory path obtained by scaling down the

Appendix A. Optimal Placement of Level Converters in Memory Decoders 106
core voltage. The technique proposed is shown to be beneficial irrespective of the
timing slack present in the core and memory paths before scaling down the core
supply. The proposed architecture of pushing the level shifters after the predecoders
provides up to 20% reduction in energy/cycle of the row-decoder with negligible
area and system-delay overheads.

Appendix B
Simulating Effect of Tuning
Algorithm
In this appendix we describe the steps involved in obtaining simulation results for
the reference generation technique using the proposed random-sampling based al-
gorithm described in Section 3.4.1.
Fig. 3.28 shows the mean values obtained by running the tuning algorithm at
each supply voltage on 1000 instances of 10 KB memories. Each instance of memory
is created using the local mismatch data supplied by the foundry. The detailed steps
are listed below:
1. First a memory instance is created with the characteristics of each of the 10 KB
SRAM cells (plus the replica columns) derived from the local process variation
(local mismatch only) data provided by the foundry.
2. The tuning algorithm is run on this instance of the memory and the final value
of VREF and timing value (tSAE) is recorded.
3. The above two steps are repeated for 1000 instances of memory.
4. The average value of VREF and tSAE for the 1000 instances is recorded.
5. This VREF is then normalized to the supply voltage VDD and plotted in Fig. 3.28
as Generated VREF - black curve.
6. The Ideal VREF (blue curve) is then determined by evaluating Eqn. 3.1 at tSAE
from step 4. Here again local mismatch data from foundry is used.
107

Appendix B. Simulating Effect of Tuning Algorithm 108
7. The above steps are repeated at each supply voltage.
Please note that the memory is assumed to contain 1% redundancy. This pre-
vents reduction in yield at low voltages.

Bibliography
[1] M. Alioto, “Ultra-low power VLSI circuit design demystified and explained:
A tutorial,” IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 59, no. 1, pp. 3 –29,
jan. 2012.
[2] H. Rao, D. Saxena, S. Kumar, S. G. V., B. Amrutur, P. Mony, P. Thankachan,
K. Shankar, S. Rao, and S. R. Bhat, “Low power remote neonatal temperature
monitoring device,” in Int. Conf. Biomed. Electron. Syst., Mar 2014.
[3] A. Chandrakasan, D. Daly, D. Finchelstein, J. Kwong, Y. Ramadass,
M. Sinangil, V. Sze, and N. Verma, “Technologies for ultradynamic voltage
scaling,” Proc. IEEE, vol. 98, no. 2, pp. 191–214, 2010.
[4] G. Sullivan, J. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high effi-
ciency video coding (HEVC) standard,” IEEE Trans. Circuits Syst. Video Tech-
nol., vol. 22, no. 12, pp. 1649–1668, Dec 2012.
[5] M. Alvarez, E. Salami, A. Ramirez, and M. Valero, “A performance character-
ization of high definition digital video decoding using H.264/AVC,” in IEEE
Int. Workload Characterization Symp., Oct 2005, pp. 24–33.
[6] V. Sze, M. Budagavi, and G. J. Sullivan, “High efficiency video coding
(HEVC).” Springer International Publishing, 2014.
109

BIBLIOGRAPHY 110
[7] S. Narendra, L. Fujino, and K. Smith, “Through the looking glass - the 2015
edition: Trends in solid-state circuits from ISSCC,” IEEE Solid-State Circuits
Mag., vol. 7, no. 1, pp. 14–24, winter 2015.
[8] International Technology Roadmap for Semiconductors (ITRS). [Online].
Available: http://www.itrs.net/
[9] J. L. Hennessy and D. A. Patterson, Computer Architecture, Fifth Edition: A
Quantitative Approach, 5th ed. San Francisco, CA, USA: Morgan Kaufmann
Publishers Inc., 2011.
[10] A. Wang and A. Chandrakasan, “A 180mV FFT processor using subthreshold
circuit techniques,” in IEEE ISSCC Dig. Tech. Papers, feb. 2004, pp. 292 – 529
Vol.1.
[11] B. Calhoun, A. Wang, and A. Chandrakasan, “Modeling and sizing for mini-
mum energy operation in subthreshold circuits,” IEEE J. Solid-State Circuits,
vol. 40, no. 9, pp. 1778–1786, Sept 2005.
[12] N. Lotze and Y. Manoli, “A 62mV 0.13µm CMOS standard-cell-based design
technique using schmitt-trigger logic,” in IEEE ISSCC Dig. Tech. Papers, Feb
2011, pp. 340–342.
[13] L. Chang, D. Fried, J. Hergenrother, J. Sleight, R. Dennard, R. Montoye,
L. Sekaric, S. McNab, A. Topol, C. Adams, K. Guarini, and W. Haensch, “Sta-
ble SRAM cell design for the 32 nm node and beyond,” in Proc. IEEE Symp.
VLSI Circuits, June 2005, pp. 128–129.
[14] B. Calhoun and A. Chandrakasan, “Ultra-dynamic voltage scaling using sub-
threshold operation and local voltage dithering in 90nm CMOS,” in IEEE
ISSCC Dig. Tech. Papers, Feb 2005, pp. 300–599 Vol. 1.

BIBLIOGRAPHY 111
[15] M. Sinangil, N. Verma, and A. Chandrakasan, “A reconfigurable 8T ultra-
dynamic voltage scalable (U-DVS) SRAM in 65 nm CMOS,” IEEE J. Solid-
State Circuits, vol. 44, no. 11, pp. 3163–3173, 2009.
[16] J. Schade, O., “BiMOS micropower ICs,” in IEEE ISSCC Dig. Tech. Papers, vol.
XXI, Feb 1978, pp. 230–231.
[17] Y. Tsividis and R. Ulmer, “A CMOS voltage reference,” IEEE J. Solid-State
Circuits, vol. 13, no. 6, pp. 774–778, Dec 1978.
[18] E. Vittoz and O. Neyroud, “A low-voltage CMOS bandgap reference,” IEEE J.
Solid-State Circuits, vol. 14, no. 3, pp. 573–579, June 1979.
[19] E. Vittoz, “Micropower switched-capacitor oscillator,” IEEE J. Solid-State Cir-
cuits, vol. 14, no. 3, pp. 622–624, Jun 1979.
[20] F. Krummenacher, “Micropower switched capacitor biquadratic cell,” IEEE J.
Solid-State Circuits, vol. 17, no. 3, pp. 507–512, Jun 1982.
[21] E. Vittoz, M. Degrauwe, and S. Bitz, “High-performance crystal oscillator
circuits: theory and application,” IEEE J. Solid-State Circuits, vol. 23, no. 3,
pp. 774–783, June 1988.
[22] R. Swanson and J. Meindl, “Ion-implanted complementary MOS transistors
in low-voltage circuits,” IEEE J. Solid-State Circuits, vol. 7, no. 2, pp. 146–
153, Apr 1972.
[23] R. Swanson, “Complementary MOS transistors in micropower circuits,” Ph.D.
dissertation, Stanford University, USA, 1974.
[24] J. Burr and J. Shott, “A 200 mV self-testing encoder/decoder using Stanford
ultra-low-power CMOS,” in IEEE ISSCC Dig. Tech. Papers, Feb 1994, pp. 84–
85.

BIBLIOGRAPHY 112
[25] J. Burr, “Cryogenic ultra low power CMOS,” in Int. Symp. Low Power Electron.
Design (ISLPED), Oct 1995, pp. 82–83.
[26] A. Bryant, J. Brown, P. Cottrell, M. Ketchen, J. Ellis-Monaghan, and
E. Nowak, “Low-power CMOS at Vdd = 4kT/q,” in Device Research Conf.,
June 2001, pp. 22–23.
[27] M. Miyazaki, J. Kao, and A. Chandrakasan, “A 175 mV multiply-accumulate
unit using an adaptive supply voltage and body bias (ASB) architecture,” in
IEEE ISSCC Dig. Tech. Papers, vol. 1, Feb 2002, pp. 58–444 vol.1.
[28] B. Paul, H. Soeleman, and K. Roy, “An 8x8 sub-threshold digital CMOS
carry save array multiplier,” in Solid-State Circuits Conference, 2001. ESSCIRC
2001. Proceedings of the 27th European, Sept 2001, pp. 377–380.
[29] C. Kim, H. Soeleman, and K. Roy, “Ultra-low-power DLMS adaptive filter for
hearing aid applications,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst.,
vol. 11, no. 6, pp. 1058–1067, Dec 2003.
[30] M. Deen, M. H. Kazemeini, and S. Naseh, “Ultra-low power VCOs - perfor-
mance characteristics and modeling (invited),” in Int. Caracas Conf. Devices
Circuits Syst., 2002, pp. C033–1–C033–8.
[31] N. Lotze and Y. Manoli, “A 62 mV 0.13 µm CMOS standard-cell-based design
technique using schmitt-trigger logic,” IEEE J. Solid-State Circuits, vol. 47,
no. 1, pp. 47 –60, jan. 2012.
[32] T. Kobayashi, K. Nogami, T. Shirotori, and Y. Fujimoto, “A current-controlled
latch sense amplifier and a static power-saving input buffer for low-power
architecture,” IEEE J. Solid-State Circuits, vol. 28, no. 4, pp. 523–527, Apr
1993.

BIBLIOGRAPHY 113
[33] T. Matthews and P. Heedley, “A simulation method for accurately determin-
ing DC and dynamic offsets in comparators,” in Midwest Symp. Circuits Syst.,
2005, pp. 1815–1818 Vol. 2.
[34] J. Ryan and B. Calhoun, “Minimizing offset for latching voltage-mode sense
amplifiers for sub-threshold operation,” in Int. Symp. Quality Electron. Design
(ISQED), March 2008, pp. 127–132.
[35] B. Calhoun and A. Chandrakasan, “A 256kb sub-threshold SRAM in 65nm
CMOS,” in IEEE ISSCC Dig. Tech. Papers, Feb 2006, pp. 2592–2601.
[36] J. Kulkarni and K. Roy, “Ultralow-voltage process-variation-tolerant schmitt-
trigger-based SRAM design,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst.,
vol. 20, no. 2, pp. 319–332, 2012.
[37] S.-C. Luo and L.-Y. Chiou, “A sub-200-mV voltage-scalable SRAM with toler-
ance of access failure by self-activated bitline sensing,” IEEE Trans. Circuits
Syst. II, Exp. Briefs, vol. 57, no. 6, pp. 440–445, 2010.
[38] T.-H. Kim, J. Liu, J. Keane, and C. Kim, “A 0.2 V, 480 kb subthreshold SRAM
with 1 k cells per bitline for ultra-low-voltage computing,” IEEE J. Solid-State
Circuits, vol. 43, no. 2, pp. 518–529, 2008.
[39] B. Zhai, S. Hanson, D. Blaauw, and D. Sylvester, “A variation-tolerant sub-
200 mV 6-T subthreshold SRAM,” IEEE J. Solid-State Circuits, vol. 43, no. 10,
pp. 2338 –2348, oct. 2008.
[40] M.-F. Chang, M.-P. Chen, L.-F. Chen, S.-M. Yang, Y.-J. Kuo, J.-J. Wu, H.-Y. Su,
Y.-H. Chu, W.-C. Wu, T.-Y. Yang, and H. Yamauchi, “A sub-0.3 V area-efficient
L-shaped 7T SRAM with read bitline swing expansion schemes based on
boosted read-bitline, asymmetric-VTH read-port, and offset cell VDD bias-
ing techniques,” IEEE J. Solid-State Circuits, vol. 48, no. 10, pp. 2558–2569,
Oct 2013.

BIBLIOGRAPHY 114
[41] N. Verma and A. Chandrakasan, “A 65nm 8T sub-Vt SRAM employing sense-
amplifier redundancy,” in IEEE ISSCC Dig. Tech. Papers, 2007, pp. 328–606.
[42] B. Amrutur and M. Horowitz, “A replica technique for wordline and sense
control in low-power SRAM’s,” IEEE J. Solid-State Circuits, vol. 33, no. 8, pp.
1208–1219, 1998.
[43] Y. Niki, A. Kawasumi, A. Suzuki, Y. Takeyama, O. Hirabayashi, K. Kushida,
F. Tachibana, Y. Fujimura, and T. Yabe, “A digitized replica bitline delay tech-
nique for random-variation-tolerant timing generation of SRAM sense am-
plifiers,” IEEE J. Solid-State Circuits, vol. 46, no. 11, pp. 2545–2551, 2011.
[44] A. Kawasumi, Y. Takeyama, O. Hirabayashi, K. Kushida, F. Tachibana, Y. Niki,
S. Sasaki, and T. Yabe, “A 47% access time reduction with a worst-case
timing-generation scheme utilizing a statistical method for ultra low voltage
SRAMs,” in Symp. VLSI Circuits (VLSIC), 2012, pp. 100–101.
[45] K. R. Viveka and B. Amrutur, “Digitally controlled variation tolerant timing
generation technique for SRAM sense amplifiers,” in Asia Symp. Quality Elec-
tron. Design (ASQED), Aug 2013, pp. 233–239.
[46] C. Brennan, S. Eustis, J. Goss, A. Humphrey, M. Ouellette, J. Rowland, and
M. Fragano, “BIST controlled variable sense amp timing for 90nm embedded
SRAM,” in Proc. IEEE Custom Integrated Circuits Conf. (CICC), Oct 2004, pp.
345–348.
[47] Y.-C. Lai and S.-Y. Huang, “Robust SRAM design via BIST-assisted timing-
tracking (BATT),” IEEE J. Solid-State Circuits, vol. 44, no. 2, pp. 642–649,
2009.
[48] M. Abu-Rahma, M. Anis, and S.-S. Yoon, “Reducing SRAM power using fine-
grained wordline pulsewidth control,” IEEE Trans. Very Large Scale Integr.
(VLSI) Syst., vol. 18, no. 3, pp. 356–364, 2010.

BIBLIOGRAPHY 115
[49] A. Neale and M. Sachdev, “Digitally programmable SRAM timing for nano-
scale technologies,” in Int. Symp. Quality Electron. Design (ISQED), 2011, pp.
1–7.
[50] A. Bhavnagarwala, X. Tang, and J. Meindl, “The impact of intrinsic de-
vice fluctuations on CMOS SRAM cell stability,” IEEE J. Solid-State Circuits,
vol. 36, no. 4, pp. 658–665, Apr 2001.
[51] S. Verkila, S. Bondada, and B. Amrutur, “A 100MHz to 1GHz, 0.35V to 1.5V
supply 256 x 64 SRAM block using symmetrized 9T SRAM cell with con-
trolled read,” in Int. Conf. VLSI Design (VLSID), Jan 2008, pp. 560–565.
[52] S. Lin, Y.-B. Kim, and F. Lombardi, “A highly-stable nanometer memory for
low-power design,” in IEEE Int. Workshop Design Test Nano Devices Circuits
Syst., Sept 2008, pp. 17–20.
[53] T.-H. Kim, J. Liu, J. Keane, and C. Kim, “A high-density subthreshold SRAM
with data-independent bitline leakage and virtual ground replica scheme,”
in IEEE ISSCC Dig. Tech. Papers, Feb 2007, pp. 330–606.
[54] H. Noguchi, S. Okumura, Y. Iguchi, H. Fujiwara, Y. Morita, K. Nii,
H. Kawaguchi, and M. Yoshimoto, in IEEE Int. Conf. Integrated Circuit De-
sign Technology Tutorial.
[55] M. Sinangil and A. Chandrakasan, “Application-specific SRAM design using
output prediction to reduce bit-line switching activity and statistically gated
sense amplifiers for up to 1.9x lower Energy/Access,” IEEE J. Solid-State Cir-
cuits, vol. 49, no. 1, pp. 107–117, Jan 2014.
[56] I. J. Chang, J.-J. Kim, S. P. Park, and K. Roy, “A 32kb 10T subthreshold SRAM
array with bit-interleaving and differential read scheme in 90nm CMOS,” in
IEEE ISSCC Dig. Tech. Papers, Feb 2008, pp. 388–622.

BIBLIOGRAPHY 116
[57] S. Okumura, Y. Iguchi, S. Yoshimoto, H. Fujiwara, H. Noguchi, K. Nii,
H. Kawaguchi, and M. Yoshimoto, “A 0.56-V 128kb 10T SRAM using column
line assist (CLA) scheme,” in Int. Symp. Quality Electron. Design (ISQED),
March 2009, pp. 659–663.
[58] K. Takeda, Y. Hagihara, Y. Aimoto, M. Nomura, Y. Nakazawa, T. Ishii, and
H. Kobatake, “A read-static-noise-margin-free SRAM cell for low-Vdd and
high-speed applications,” in IEEE ISSCC Dig. Tech. Papers, Feb 2005, pp. 478–
611 Vol. 1.
[59] A. Teman, L. Pergament, O. Cohen, and A. Fish, “A 250 mV 8 kb 40 nm
ultra-low power 9T supply feedback SRAM (SF-SRAM),” IEEE J. Solid-State
Circuits, vol. 46, no. 11, pp. 2713–2726, Nov 2011.
[60] A. Kawasumi, T. Yabe, Y. Takeyama, O. Hirabayashi, K. Kushida, A. Tohata,
T. Sasaki, A. Katayama, G. Fukano, Y. Fujimura, and N. Otsuka, “A single-
power-supply 0.7V 1GHz 45nm SRAM with an asymmetrical unit-β-ratio
memory cell,” in IEEE ISSCC Dig. Tech. Papers, Feb 2008, pp. 382–622.
[61] C.-Y. Lu and J. Sung, “Reverse short-channel effects on threshold voltage in
submicrometer salicide devices,” IEEE Electron Device Lett., vol. 10, no. 10,
pp. 446–448, Oct 1989.
[62] S. Hanson, B. Zhai, M. Seok, B. Cline, K. Zhou, M. Singhal, M. Minuth,
J. Olson, L. Nazhandali, T. Austin, D. Sylvester, and D. Blaauw, “Performance
and variability optimization strategies in a sub-200mV, 3.5pJ/inst, 11nW
subthreshold processor,” in Symp. VLSI Circuits (VLSIC), June 2007, pp. 152–
153.
[63] M. Pelgrom, A. C. Duinmaijer, and A. Welbers, “Matching properties of MOS
transistors,” IEEE J. Solid-State Circuits, vol. 24, no. 5, pp. 1433–1439, Oct
1989.

BIBLIOGRAPHY 117
[64] J. Kwong, Y. Ramadass, N. Verma, and A. Chandrakasan, “A 65 nm sub-Vt
microcontroller with integrated SRAM and switched capacitor DC-DC con-
verter,” IEEE J. Solid-State Circuits, vol. 44, no. 1, pp. 115 –126, jan. 2009.
[65] A. Agarwal and K. Roy, “A noise tolerant cache design to reduce gate and
sub-threshold leakage in the nanometer regime,” in Int. Symp. Low Power
Electron. Design (ISLPED), Aug 2003, pp. 18–21.
[66] N. Verma and A. Chandrakasan, “A 256 kb 65 nm 8T subthreshold SRAM
employing sense-amplifier redundancy,” IEEE J. Solid-State Circuits, vol. 43,
no. 1, pp. 141 –149, Jan. 2008.
[67] S. Ohbayashi, M. Yabuuchi, K. Nii, Y. Tsukamoto, S. Imaoka, Y. Oda, T. Yoshi-
hara, M. Igarashi, M. Takeuchi, H. Kawashima, Y. Yamaguchi, K. Tsukamoto,
M. Inuishi, H. Makino, K. Ishibashi, and H. Shinohara, “A 65-nm SoC embed-
ded 6T-SRAM designed for manufacturability with read and write operation
stabilizing circuits,” IEEE J. Solid-State Circuits, vol. 42, no. 4, pp. 820–829,
April 2007.
[68] E. Karl, Y. Wang, Y.-G. Ng, Z. Guo, F. Hamzaoglu, U. Bhattacharya, K. Zhang,
K. Mistry, and M. Bohr, “A 4.6GHz 162Mb SRAM design in 22nm tri-gate
CMOS technology with integrated active VMIN -enhancing assist circuitry,” in
IEEE ISSCC Dig. Tech. Papers, Feb 2012, pp. 230–232.
[69] J. Kulkarni, B. Geuskens, T. Karnik, M. Khellah, J. Tschanz, and V. De,
“Capacitive-coupling wordline boosting with self-induced VCC collapse for
write VMIN reduction in 22-nm 8T SRAM,” in IEEE ISSCC Dig. Tech. Papers,
2012, pp. 234–236.
[70] T. Song, W. Rim, J. Jung, G. Yang, J. Park, S. Park, K.-H. Baek, S. Baek, S.-K.
Oh, J. Jung, S. Kim, G. Kim, J. Kim, Y. Lee, K. S. Kim, S.-P. Sim, J. S. Yoon,
and K.-M. Choi, “A 14nm FinFET 128Mb 6T SRAM with VMIN -enhancement

BIBLIOGRAPHY 118
techniques for low-power applications,” in IEEE ISSCC Dig. Tech. Papers, Feb
2014, pp. 232–233.
[71] H. Nho, P. Kolar, F. Hamzaoglu, Y. Wang, E. Karl, Y.-G. Ng, U. Bhattacharya,
and K. Zhang, “A 32nm high-κ metal gate SRAM with adaptive dynamic
stability enhancement for low-voltage operation,” in IEEE ISSCC Dig. Tech.
Papers, Feb 2010, pp. 346–347.
[72] J. Chang, Y.-H. Chen, H. Cheng, W.-M. Chan, H.-J. Liao, Q. Li, S. Chang,
S. Natarajan, R. Lee, P.-W. Wang, S.-S. Lin, C.-C. Wu, K.-L. Cheng, M. Cao,
and G. Chang, “A 20nm 112Mb SRAM in high-κ metal-gate with assist cir-
cuitry for low-leakage and low-VMIN applications,” in IEEE ISSCC Dig. Tech.
Papers, Feb 2013, pp. 316–317.
[73] Y. Sinangil and A. Chandrakasan, “A 128 Kbit SRAM with an embedded en-
ergy monitoring circuit and sense-amplifier offset compensation using body
biasing,” IEEE J. Solid-State Circuits, vol. 49, no. 11, pp. 2730–2739, Nov
2014.
[74] C. Kim and K. Roy, “Dynamic Vt SRAM: a leakage tolerant cache memory
for low voltage microprocessors,” in Int. Symp. Low Power Electron. Design
(ISLPED), 2002, pp. 251–254.
[75] C. Kim, J.-J. Kim, S. Mukhopadhyay, and K. Roy, “A forward body-biased low-
leakage SRAM cache: device, circuit and architecture considerations,” IEEE
Trans. Very Large Scale Integr. (VLSI) Syst., vol. 13, no. 3, pp. 349–357, March
2005.
[76] B. Calhoun and A. Chandrakasan, “Analyzing static noise margin for sub-
threshold SRAM in 65nm CMOS,” in European Solid-State Circuits Conf. (ES-
SCIRC), Sept 2005, pp. 363–366.

BIBLIOGRAPHY 119
[77] E. Vatajelu, G. Panagopoulos, K. Roy, and J. Figueras, “Parametric failure
analysis of embedded SRAMs using fast & accurate dynamic analysis,” in
IEEE European Test Symp. (ETS), May 2010, pp. 69–74.
[78] A. Bhavnagarwala, S. Kosonocky, C. Radens, K. Stawiasz, R. Mann, Q. Ye,
and K. Chin, “Fluctuation limits & scaling opportunities for CMOS SRAM
cells,” in IEDM Tech. Dig., Dec 2005, pp. 659–662.
[79] K. Takeda, H. Ikeda, Y. Hagihara, M. Nomura, and H. Kobatake, “Redefini-
tion of write margin for next-generation SRAM and write-margin monitoring
circuit,” in IEEE ISSCC Dig. Tech. Papers, Feb 2006, pp. 2602–2611.
[80] N. Gierczynski, B. Borot, N. Planes, and H. Brut, “A new combined methodol-
ogy for write-margin extraction of advanced SRAM,” in Proc. IEEE Int. Conf.
Microelectron. Test Struct., March 2007, pp. 97–100.
[81] H. Makino, S. Nakata, H. Suzuki, S. Mutoh, M. Miyama, T. Yoshimura,
S. Iwade, and Y. Matsuda, “Reexamination of SRAM cell write margin defini-
tions in view of predicting the distribution,” IEEE Trans. Circuits Syst. II, Exp.
Briefs, vol. 58, no. 4, pp. 230–234, April 2011.
[82] B.-D. Yang and L.-S. Kim, “A low-power SRAM using hierarchical bit line and
local sense amplifiers,” IEEE J. Solid-State Circuits, vol. 40, no. 6, pp. 1366–
1376, June 2005.
[83] S. Ishikura, M. Kurumada, T. Terano, Y. Yamagami, N. Kotani, K. Satomi,
K. Nii, M. Yabuuchi, Y. Tsukamoto, S. Ohbayashi, T. Oashi, H. Makino,
H. Shinohara, and H. Akamatsu, “A 45 nm 2-port 8T-SRAM using hierarchi-
cal replica bitline technique with immunity from simultaneous R/W access
issues,” IEEE J. Solid-State Circuits, vol. 43, no. 4, pp. 938–945, April 2008.

BIBLIOGRAPHY 120
[84] Q. Li and T. Kim, “Analysis of SRAM hierarchical bitlines for optimal perfor-
mance and variation tolerance,” in Int. SoC Design Conf. (ISOCC), Nov 2011,
pp. 412–415.
[85] P. Das, “Precise on-chip clock skew measurement using sub-sampling and
applications,” Ph.D. dissertation, Indian Institute of Science, India, 2012.
[86] B. Amrutur, P. Das, and R. Vasudevamurthy, “0.84 ps resolution clock skew
measurement via subsampling,” IEEE Trans. Very Large Scale Integr. (VLSI)
Syst., vol. 19, no. 12, pp. 2267–2275, Dec 2011.
[87] R. Rajsuman, “Design and test of large embedded memories: An overview,”
IEEE Des. Test. Comput., vol. 18, no. 3, pp. 16–27, May 2001.
[88] U. Arslan, M. McCartney, M. Bhargava, X. Li, K. Mai, and L. Pileggi,
“Variation-tolerant SRAM sense-amplifier timing using configurable replica
bitlines,” in Proc. IEEE Custom Integrated Circuits Conf. (CICC), Sept 2008,
pp. 415–418.
[89] Cortex-A9 MBIST controller technical reference manual. [Online].
Available: http://infocenter.arm.com/help/topic/com.arm.doc.ddi0414i/
DDI0414I cortex a9 mbist controller r4p1 trm.pdf
[90] R. Larsen and M. Marx, “An introduction to mathematical statistics and its
applications.” Prentice Hall, 2001.
[91] S. Jain, S. Khare, S. Yada, V. Ambili, P. Salihundam, S. Ramani, S. Muthuku-
mar, M. Srinivasan, A. Kumar, S. Gb, R. Ramanarayanan, V. Erraguntla,
J. Howard, S. Vangal, S. Dighe, G. Ruhl, P. Aseron, H. Wilson, N. Borkar,
V. De, and S. Borkar, “A 280mV-to-1.2V wide-operating-range IA-32 proces-
sor in 32nm CMOS,” in IEEE ISSCC Dig. Tech. Papers, feb. 2012, pp. 66 –68.

BIBLIOGRAPHY 121
[92] R. Partridge, “Oscilloscope on a chip,” IEEE J. Solid-State Circuits, vol. 3,
no. 3, pp. 312–312, Sept 1968.
[93] M. Safi-Harb and G. Roberts, “70-GHz effective sampling time-base on-chip
oscilloscope in CMOS,” IEEE J. Solid-State Circuits, vol. 42, no. 8, pp. 1743–
1757, Aug 2007.
[94] B. Dehlaghi, S. Magierowski, and L. Belostotski, “A 12.5-Gb/s on-chip oscillo-
scope to measure eye diagrams and jitter histograms of high-speed signals,”
IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 22, no. 5, pp. 1127–
1137, May 2014.
[95] Y. Ramadass and A. Chandrakasan, “Minimum energy tracking loop with
embedded DC-DC converter delivering voltages down to 250mV in 65nm
CMOS,” in IEEE ISSCC Dig. Tech. Papers, Feb 2007, pp. 64–587.
[96] S. Gubbi and B. Amrutur, “All digital energy sensing for minimum energy
tracking,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 23, no. 4, pp.
796–800, April 2015.
[97] E. Alon, V. Stojanovic, and M. Horowitz, “Circuits and techniques for high-
resolution measurement of on-chip power supply noise,” IEEE J. Solid-State
Circuits, vol. 40, no. 4, pp. 820–828, April 2005.
[98] V. Abramzon, E. Alon, B. Nezamfar, and M. Horowitz, “Scalable circuits
for supply noise measurement,” in European Solid-State Circuits Conf. (ES-
SCIRC), Sept 2005, pp. 463–466.
[99] T. Xia and J.-C. Lo, “Time-to-voltage converter for on-chip jitter measure-
ment,” IEEE Trans. Instrum. Meas., vol. 52, no. 6, pp. 1738–1748, Dec 2003.

BIBLIOGRAPHY 122
[100] T. Xia, H. Zheng, J. Li, and A. Ginawi, “Self-refereed on-chip jitter measure-
ment circuit using vernier oscillators,” in Symp. VLSI Circuits (VLSIC), May
2005, pp. 218–223.
[101] J. Liang, M. Jalali, A. Sheikholeslami, M. Kibune, and H. Tamura, “On-chip
measurement of clock and data jitter with sub-picosecond accuracy for 10
Gb/s multilane CDRs,” IEEE J. Solid-State Circuits, vol. 50, no. 4, pp. 845–
855, April 2015.
[102] P. Fasang, “Boundary scan and its application to analog-digital ASIC testing
in a board/system environment,” in Custom Integrated Circuits Conference,
1989., Proceedings of the IEEE 1989, May 1989, pp. 22.4/1–22.4/4.
[103] M. Toner and G. Roberts, “A BIST scheme for a SNR, gain tracking, and
frequency response test of a sigma-delta ADC,” Circuits and Systems II: Analog
and Digital Signal Processing, IEEE Transactions on, vol. 42, no. 1, pp. 1–15,
Jan 1995.
[104] L. Milor, “A tutorial introduction to research on analog and mixed-signal cir-
cuit testing,” Circuits and Systems II: Analog and Digital Signal Processing,
IEEE Transactions on, vol. 45, no. 10, pp. 1389–1407, Oct 1998.
[105] R. Staszewski, K. Muhammad, D. Leipold, C.-M. Hung, Y.-C. Ho, J. Wall-
berg, C. Fernando, K. Maggio, R. Staszewski, T. Jung, J. Koh, S. John,
I. Y. Deng, V. Sarda, O. Moreira-Tamayo, V. Mayega, R. Katz, O. Friedman,
O. Eliezer, E. de Obaldia, and P. Balsara, “All-digital TX frequency synthe-
sizer and discrete-time receiver for bluetooth radio in 130-nm CMOS,” IEEE
J. Solid-State Circuits, vol. 39, no. 12, pp. 2278–2291, Dec 2004.
[106] A. Agnes, E. Bonizzoni, P. Malcovati, and F. Maloberti, “A 9.4-ENOB 1V 3.8
µw 100kS/s SAR ADC with time-domain comparator,” in IEEE ISSCC Dig.
Tech. Papers, Feb 2008, pp. 246–610.

BIBLIOGRAPHY 123
[107] S.-K. Lee, S.-J. Park, H.-J. Park, and J.-Y. Sim, “A 21 fJ/Conversion-step 100
kS/s 10-bit ADC with a low-noise time-domain comparator for low-power
sensor interface,” IEEE J. Solid-State Circuits, vol. 46, no. 3, pp. 651–659,
March 2011.
[108] K. Soumyanath, S. Borkar, C. Zhou, and B. Bloechel, “Accurate on-chip inter-
connect evaluation: a time-domain technique,” IEEE J. Solid-State Circuits,
vol. 34, no. 5, pp. 623–631, May 1999.
[109] R. Vasudevamurthy, P. Das, and B. Amrutur, “Time-based all-digital tech-
nique for analog built-in self-test,” IEEE Trans. Very Large Scale Integr. (VLSI)
Syst., vol. 22, no. 2, pp. 334–342, Feb 2014.
[110] R. Ho, B. Amrutur, K. Mai, B. Wilburn, T. Mori, and M. Horowitz, “Applica-
tions of on-chip samplers for test and measurement of integrated circuits,”
in Symp. VLSI Circuits (VLSIC), June 1998, pp. 138–139.
[111] R. Gray and J. Stockham, T.G., “Dithered quantizers,” IEEE Trans. Inf. Theory,
vol. 39, no. 3, pp. 805–812, May 1993.
[112] R. Bhatti, M. Denneau, and J. Draper, “Duty cycle measurement and correc-
tion using a random sampling technique,” in Proc. IEEE Int. Midwest Symp.
Circuits Syst., Aug 2005, pp. 1043–1046 Vol. 2.
[113] P. Hanumolu, V. Kratyuk, G.-Y. Wei, and U.-K. Moon, “A sub-picosecond res-
olution 0.5-1.5 GHz digital-to-phase converter,” IEEE J. Solid-State Circuits,
vol. 43, no. 2, pp. 414–424, Feb 2008.
[114] P. Chen, P.-Y. Chen, J.-S. Lai, and Y.-J. Chen, “FPGA vernier digital-to-time
converter with 1.58 ps resolution and 59.3 minutes operation range,” IEEE
Trans. Circuits Syst. I, Reg. Papers, vol. 57, no. 6, pp. 1134–1142, June 2010.

BIBLIOGRAPHY 124
[115] P. Das and B. Amrutur, “An accurate fractional period delay generation sys-
tem,” IEEE Trans. Instrum. Meas., vol. 61, no. 7, pp. 1924–1932, July 2012.
[116] V. Gutnik and A. Chandrakasan, “Embedded power supply for low-power
DSP,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 5, no. 4, pp. 425–
435, Dec 1997.
[117] K. Brock. (2009) Virage logic: Minimizing design complexity with power-
optimized physical IP. [Online]. Available: http://www.powerforward.org/
media/p/177.aspx
[118] S. Lutkemeier and U. Ruckert, “A subthreshold to above-threshold level
shifter comprising a wilson current mirror,” IEEE Trans. Circuits Syst. II, Exp.
Briefs, vol. 57, no. 9, pp. 721 –724, sept. 2010.
[119] S. Wooters, B. Calhoun, and T. Blalock, “An energy-efficient subthreshold
level converter in 130nm CMOS,” IEEE Trans. Circuits Syst. II, Exp. Briefs,
vol. 57, no. 4, pp. 290 –294, april 2010.
Related Documents