Desiderata for Annotating Data to Train and Evaluate Bootstrapping Algorithms Ellen Riloff School of Computing University of Utah

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Desiderata for Annotating Data to Train and Evaluate Bootstrapping Algorithms
Ellen RiloffSchool of ComputingUniversity of Utah

Outline
• Overview of Bootstrapping Paradigm
• Diversity of Seeding Strategies
• Criteria for Generating Seed (Training) Data
• Annotating Data for Evaluation
• Conclusions

The Bootstrapping Era
Unannotated Texts
+Manual Annotation
+or
Automatic Annotationvia Seeding

Why Bootstrapping?
• Manually annotating data:
– is time-consuming and expensive
– is deceptively difficult
– often requires linguistic expertise
• NLP systems benefit from domain-specific training
– it is not realistic to expect manually annotated data for every domain and task.
– domain-specific training is sometimes essential

Additional Benefits of Bootstrapping
• Dramatically easier and faster system development time.
– Allows for free-wheeling experimentation with different categories and domains.
• Encourages cross-resource experimentation.
–Allows for more analysis across domains, corpora, genres, and languages.

Outline
• Overview of Bootstrapping Paradigm
• Diversity of Seeding Strategies
• Criteria for Generating Seed (Training) Data
• Annotating Data for Evaluation
• Conclusions

Automatic Annotation with Seeding
• A common goal is to avoid the need for manual text annotation.
• The system should be trainable with seeding that can be done by anyone!
• Seeding is often is done using “stand-alone” examples or rules.
• Fast, less expertise required, but noisier!

Seeding strategies
• seed words
• seed patterns
• seed rules
• seed heuristics
• seed classifiers
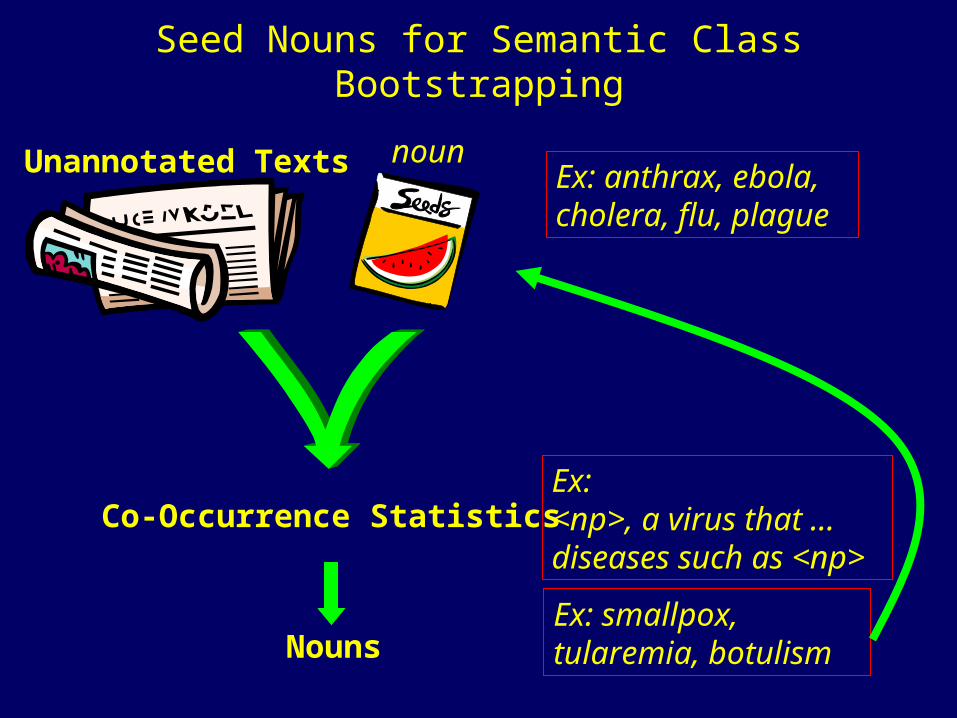
Seed Nouns for Semantic Class Bootstrapping
Unannotated Texts Ex: anthrax, ebola, cholera, flu, plague
Ex:<np>, a virus that …diseases such as <np>
Ex: smallpox,tularemia, botulism
noun
Co-Occurrence Statistics
Nouns
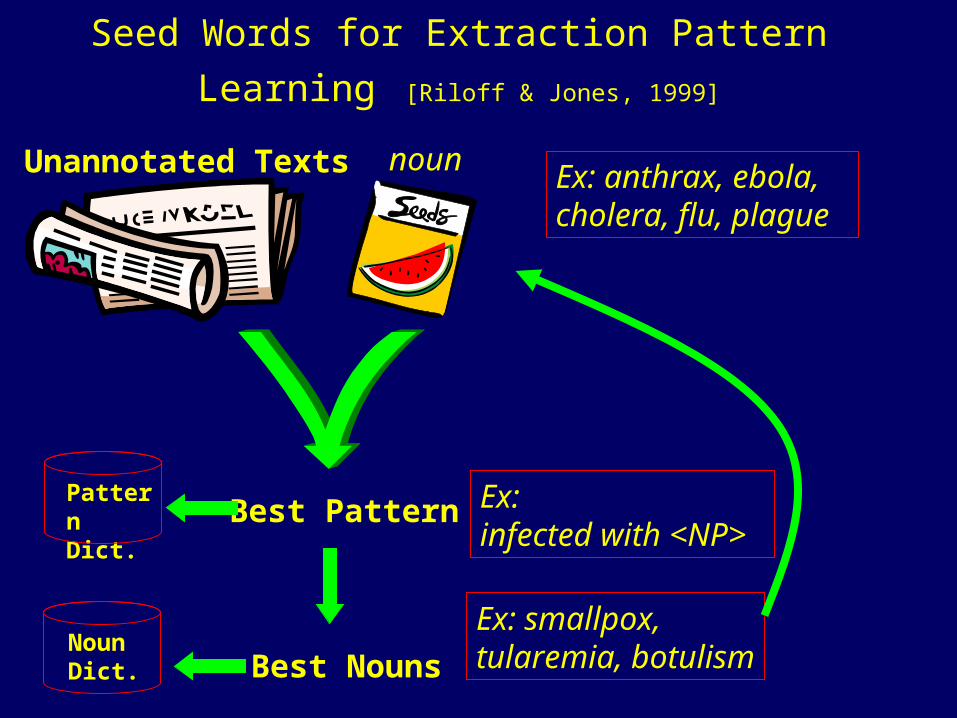
Seed Words for Extraction Pattern Learning [Riloff & Jones, 1999]
Unannotated Texts Ex: anthrax, ebola, cholera, flu, plague
Ex:infected with <NP>
Ex: smallpox,tularemia, botulism
noun
Best PatternPatternDict.
Best NounsNounDict.
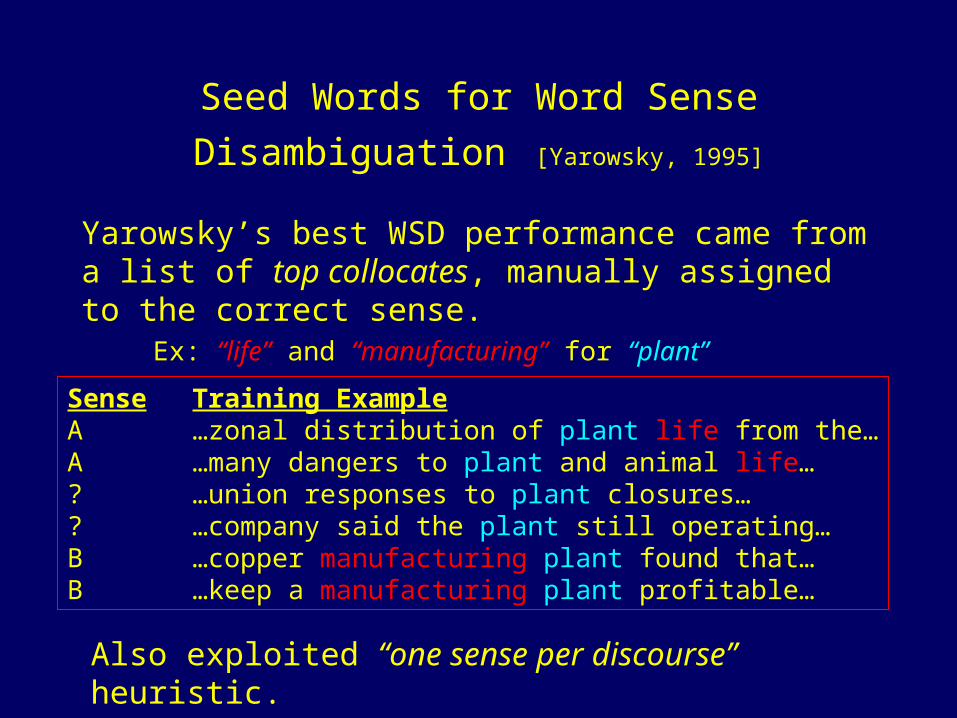
Seed Words for Word Sense Disambiguation [Yarowsky, 1995]
Yarowsky’s best WSD performance came from a list of top collocates, manually assigned to the correct sense.
Ex: “life” and “manufacturing” for “plant”
Sense Training ExampleA …zonal distribution of plant life from the…A …many dangers to plant and animal life…? …union responses to plant closures…? …company said the plant still operating…B …copper manufacturing plant found that…B …keep a manufacturing plant profitable…
Also exploited “one sense per discourse” heuristic.

Seed Patterns for Extraction Pattern Bootstrapping [Yangarber et al. 2000]
best pattern
Ranked Candidate Patterns
Pattern Setbootstrapping
Relevant IrrelevantUnannotated
pattern
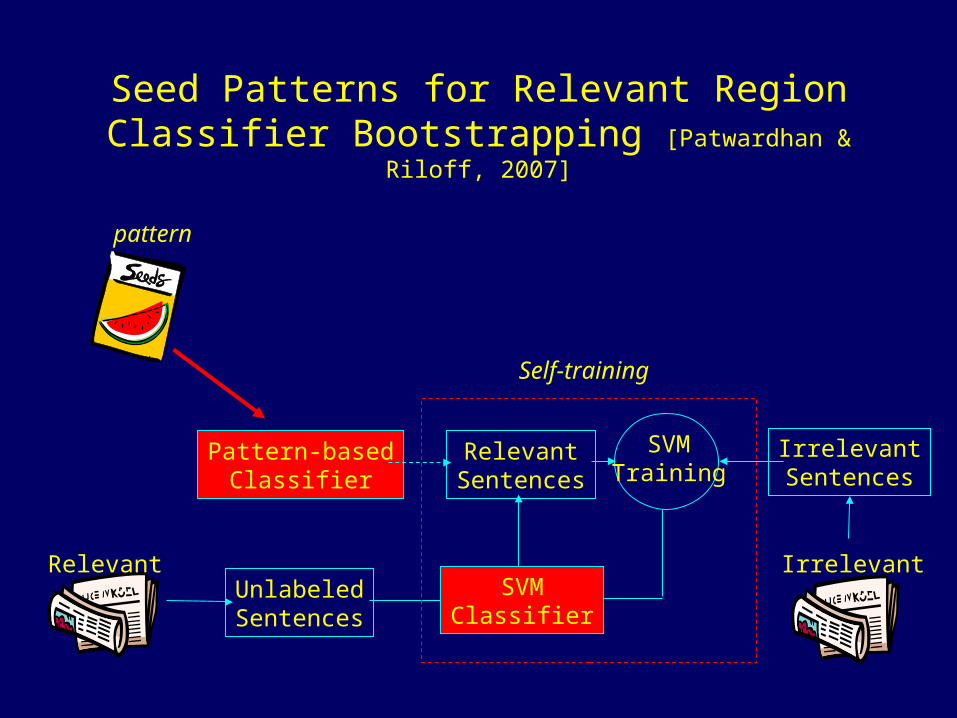
Seed Patterns for Relevant Region Classifier Bootstrapping [Patwardhan & Riloff, 2007]
UnlabeledSentences
RelevantSVM
Classifier
Self-training
SVMTraining
IrrelevantSentences
Irrelevant
Pattern-basedClassifier
RelevantSentences
pattern

Seed Rules for Named Entity Recognition Bootstrapping [Collins & Singer, 1999]
Full-string=New_York LocationFull-string=California LocationFull-string=U.S. LocationContains(Mr.) PersonContains(Incorporated) OrganizationFull-string=Microsoft OrganizationFull-string=I.B.M. Organization
rule
SPELLING RULES
rule
CONTEXTUALRULES
Unannotated

Seed Heuristics for Coreference Classifiers [Bean & Riloff, 2005; Bean & Riloff, 1999]
Existential NPLearning
Existential NPKnowledge
heuristicUnannotated
Contextual RoleLearning
Contextual RoleKnowledge
Candidate AntecedentEvidence Gathering
ResolutionDecision Model
heuristic
NewText
Reliable CaseResolutions
Non-ReferentialNP Classifier
Reliable CaseResolutionsCaseframe
Generation &Application

Example Coreference Seeding Heuristics
• Non-Anaphoric NPs: noun phrases that appear in the first sentence of a document are not anaphoric.
• Anaphoric NPs:
Reflexive pronouns with only 1 NP in scope.The regime gives itself the right…
Relative pronouns with only 1 NP in score.The brigade, which attacked…
Simple appositives of the form “NP, NP”Mr. Cristiani, president of the country…
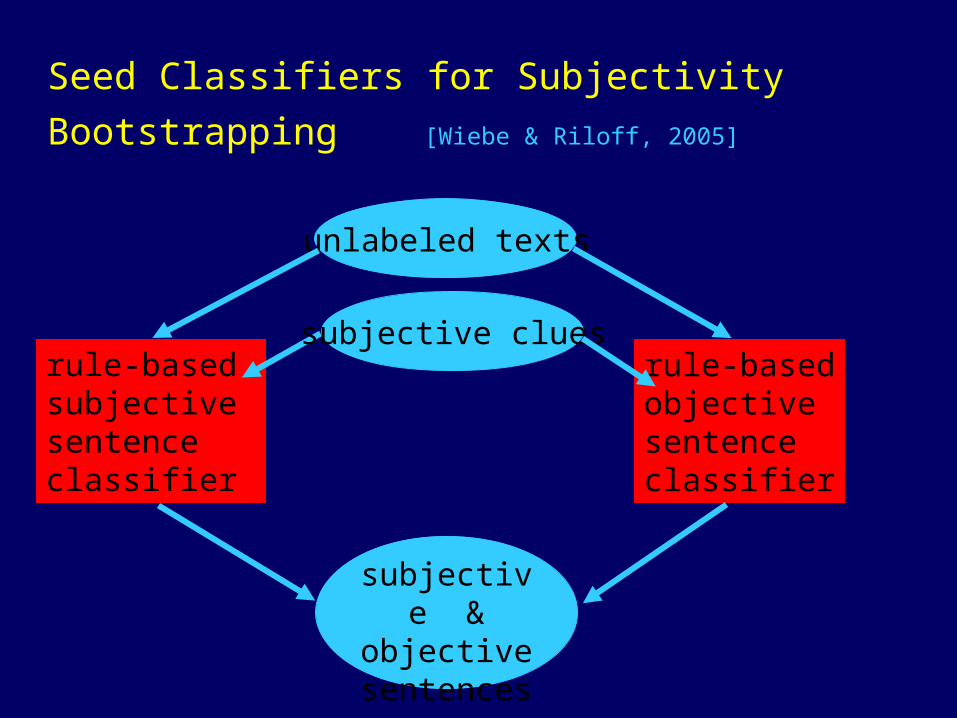
Seed Classifiers for Subjectivity Bootstrapping [Wiebe & Riloff, 2005]
rule-based subjectivesentenceclassifier
rule-basedobjectivesentenceclassifier
subjective & objective sentences
unlabeled texts
subjective clues

Outline
• Overview of Bootstrapping Paradigm
• Diversity of Seeding Strategies
• Criteria for Generating Seed (Training) Data
• Annotating Data for Evaluation
• Conclusions

The Importance of Good Seeding
Poor seeding can lead to a variety of problems:
• Bootstrapping learns only low-frequency cases high precision but low recall
• Bootstrapping thrashes only subsets learned
• Bootstrapping goes astray / gets derailedthe wrong concept learned
• Bootstrapping sputters and diesnothing learned

General Criteria for Seed Data
Seeding instances should be FREQUENT
Want as much coverage and contextual diversity as possible!
Bad animal seeds: coatimundi, giraffe, terrier

Common Pitfall #1
Assuming you know what phenomena are most frequent.
… except yours!
Seed instances must be frequent in your training corpus. Never assume you know what is frequent!
Something may be frequent in nearly all domains and corpora

General Criteria for Seed Data
Seeding instances should be UNAMBIGUOUS
Bad animal seeds: bat, jaguar, turkey
Ambiguous seeds create noisy training data.

Common Pitfall #2
Careless inattention to ambiguity.
Something may seem like a perfect example at first, but further reflection may reveal other common meanings or uses.
If a seed instance does not consistently represent the desired concept (in your corpus), then bootstrapping can be derailed.

General Criteria for Seed Data
Seeding instances should be: REPRESENTATIVE
Want instances that:• cover all of the desired categories• are not atypical category members
Bad bird seeds: penguin, ostrich, hummingbird
Why? Bootstrapping is fragile in its early stages…

Common Pitfall #3
Insufficient coverage of different classes or contexts.
It is easy to forget that all desired classes and types need to be adequately represented in the seed data.
Seed data for negative instances may need to be included as well!
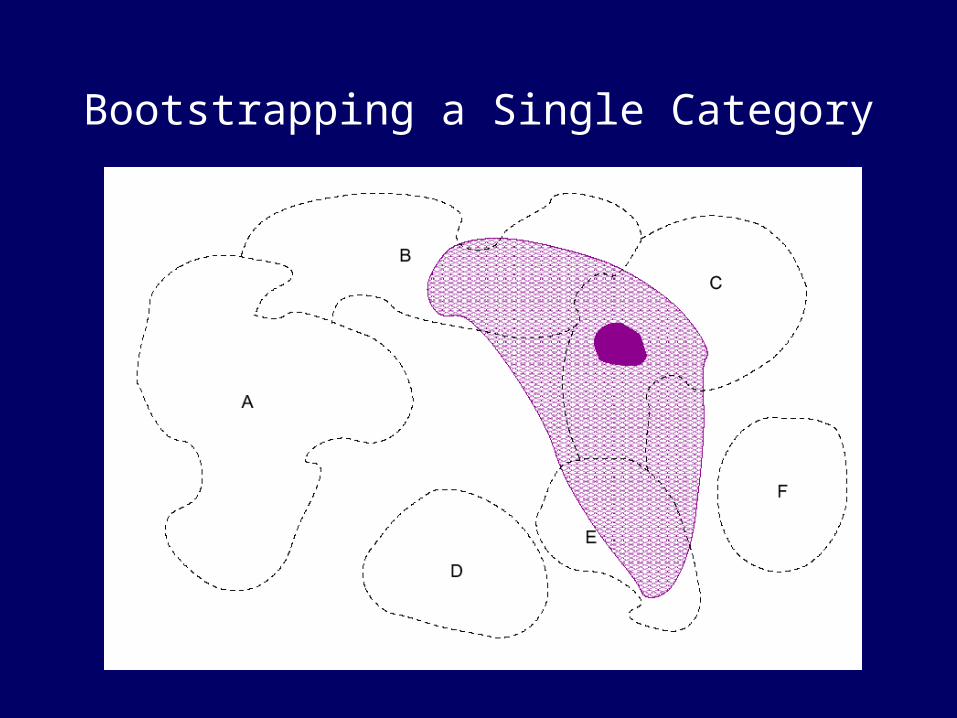
Bootstrapping a Single Category

Bootstrapping Multiple Categories

General Criteria for Seed Data
Seeding instances should be: DIVERSE
Bad animal seeds: cat, cats, housecat, housecats…
Want instances that cover different regions of the search space.
Bad animal seeds: dog, cat, ferret, parakeet

Commont Pitfall #4
Need a balance between coverage and diversity.
Diversity is important, but need to have critical mass representing different parts of the search space.
One example from each of several wildly different classes may not provide enough traction.

Outline
• Overview of Bootstrapping Paradigm
• Diversity of Seeding Strategies
• Criteria for Generating Seed (Training) Data
• Annotating Data for Evaluation
• Conclusions

Evaluation
• A key motivation for bootstrapping algorithms is to create easily retrainable systems.
• And yet …bootstrapping systems are usually evaluated on just a few data sets.
–Bootstrapping models are typically evaluated no differently than supervised learning models!
• Manually annotated evaluation data is still a major bottleneck.

The Road Ahead: A Paradigm Shift?
• Manual annotation efforts have primarily focused on the need for large amounts of training data.
• As the need for training data decreases, we have the opportunity to shift the focus to evaluation data.
• The NLP community has a great need for more extensive evaluation data!
– from both a practical and scientific perspective

Need #1: Cross-Domain Evaluations
• We would benefit from more analysis of cross-domain performance.
– Will an algorithm behave consistently across domains?
– Can we characterize the types of domains that a given technique will (or will not) perform well on?
– Are the learning curves similar across domains?
– Does the stopping criterion behave similarly across domains?

Need #2: Seeding Robustness Evaluations
• Bootstrapping algorithms are sensitive to their initial seeds. We should evaluate systems using different sets of seed data and analyze:
– quantative performance
– qualitative performance
– learning curves
• Different bootstrapping algorithms should be evaluated on the same seeds!

Standardizing Seeding?
• Since so many seeding strategies exist, it will be hard to generate “standard” training seeds.
• My belief: training and evaluation regimens shouldn’t have to be the same.
• Idea: domain/corpus analyses of different categories and vocabulary could help researchers take a more principled approach to seeding.
Example: analysis of most frequent words, syntactic constructions, and semantic categories in a corpus.

If you annotate it, they will come
• People are starved for data! If annotated data is made available, people will use it.
• If annotated data exists for multiple domains, then evaluation expectations will change.
• Idea: create a repository of annotated data for different domains, coupled with well-designed annotation guidelines
– Other researchers can use the guidelines to add their own annotated data to the repository.

Problem Child: Sentiment Analysis
• Hot research topic du jour -- everyone wants to do it! But everyone wants to use their own favorite data.
• Manual annotations are often done simplistically, by a single annotator.
– impossible to know the quality of the annotations
– impossible to compare results across papers
• Making annotated data available for a suite of domains might help.
• Making standardized annotation guidelines available might help and encourage people to share data.

Conclusions
• Many different seeding strategies are used, often for automatic annotation.
• Bootstrapping methods are sensitive to their initial seeds. Want seed cases that are:
– frequent, unambiguous, representative, and diverse
• A substantial need exists for manually annotated evaluation data!
– To better evaluate claims of portability
– To better understand bootstrapping behavior
Related Documents











