모 형 의 평 가 및 선 택 김 진 석 Department of Statistics and Information Science Dongguk University E-mail:[email protected] 2008 년 9 월 0-0

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

모형의평가및선택
김진석
Department of Statistics and Information Science
Dongguk University
E-mail:[email protected]
2008년 9월
0-0

차례
제 1 절 Test Error and Model Complexity 0-2
제 2 절 Variable selection 0-6
제 3 절 Regularization methods 0-113.1 Ridge regression (능형회귀) . . . . . . . . . . . . . . . . . 0-113.2 LASSO: Least Absolute Shrinkage and Selection Operator0-15
0-1

• Model Selection은 서로 다른 여러개의 모형들을 비교하여 가장
좋은 모형을 선택하는 것을 의미하고, 따라서 모형의 선택을 위해서는 모형의 성능을 측정해야 한다.
• Model Assessment: 모형평가는 최종 모형이 선택되었을 경우 그모형이 새로운 데이터에 대한 예측력(prediction error, generaliza-tion error)을 평가하는 것을 뜻한다. 예측력은 최종 선택된 모형의 quality를 의미한다.
제 1절 Test Error and Model Com-
plexity
• 손실함수 : 입력변수 X에 대한 모형의 예측치를 f̂(X)라고 하자.모형의 성능(오차)를 계산하기 위해서 f̂(X)와 실제 타겟변수 Y
0-2
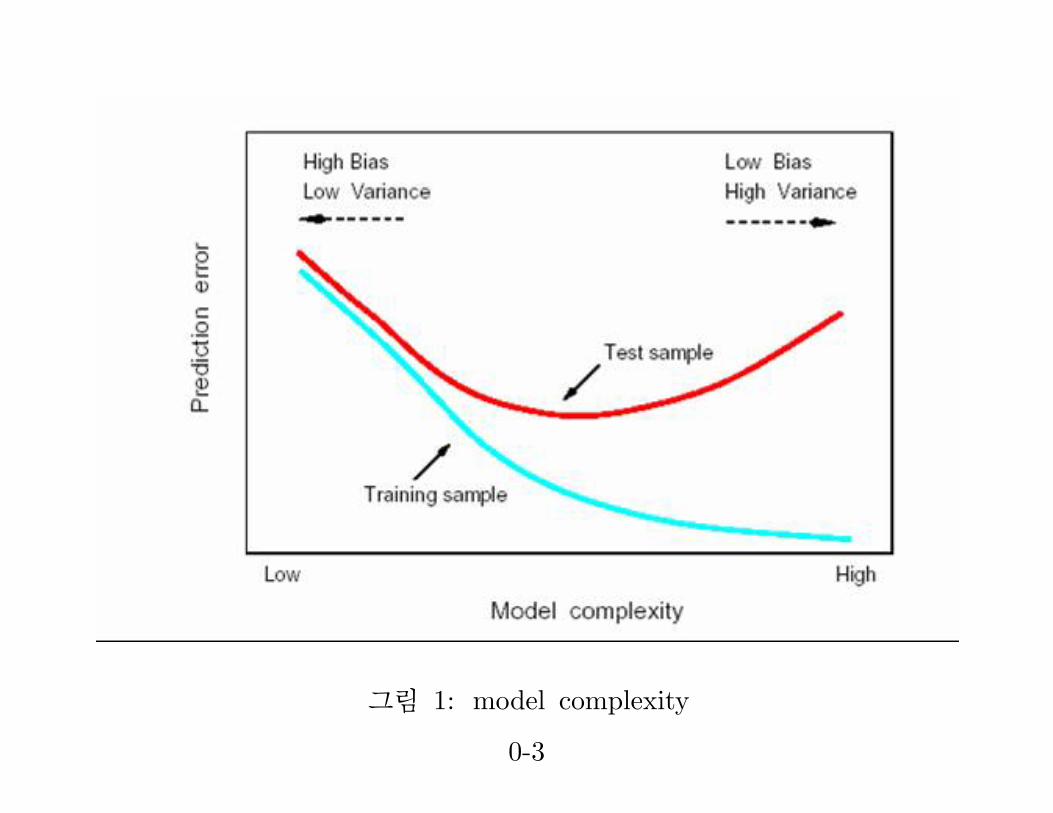
그림 1: model complexity
0-3

의 차이를 측정하는 함수가 필요한 데, 이를 손실함수(loss func-tion)라고 한다.
L(Y, f̂(X)) = (Y − f̂(X))2, squared error loss,
= |Y − f̂(X)|, absolute error loss.
L(Y, f̂(X)) = I(Y 6= f̂(X)), 0-1 loss
L(Y, p̂(X)) = Y log p̂(X) + (1− Y ) log(1− p̂(X)), binomial log-likelihood loss,
= log(1 + e−2Y ′f(X)), where Y ′ = 2Y − 1.
• Test error (generalization error) : the expected prediction errorover an independent test sample.
Err = E(L(Y, f̂(X)))
0-4

• Training Error : the average loss over the training sample.
err =1n
n∑i=1
(L(yi, f̂(xi)))
• The cross-validation estimate of prediction error:
CV =1n
n∑i=1
(L(yi, f̂−κ(i)(xi))),
where κ : {1, . . . , n} → {1, . . . ,K}.
• GCV, Boostrap estimate, etc.
0-5

제 2절 Variable selection
• p개의 입력변수가 있다고 하자, 이 때 k(k ≤ p)개의 input vari-ables를 포함하는 모형 중에서 가장 성능이 좋은 모형 (residualmean squared error측면에서) 을 Mk로 표현하자.
• k를 0에서부터 p까지 증가 시키면서 이러한 최적의 모형을 찾을
수 있고 이를 M0, . . . ,Mp로 표현한다.
• 이 때 각 모형의 복잡도(complexity)는 k에 비례하여 증가한다.
• 만일 p가 아주 큰 수라고 한다면 (이를테면 40보다 큰 수) 최적모형을 찾는 것은 거의 불가능하다.
• 따라서 heuristic 방법을 이용하는 데 forward selection, backwardelimination 혹은 stepwise selection이 그것이다.
0-6

library(leaps)
ll<-leaps(swiss[,-1], swiss[,1])
ss<-unique(ll$size)
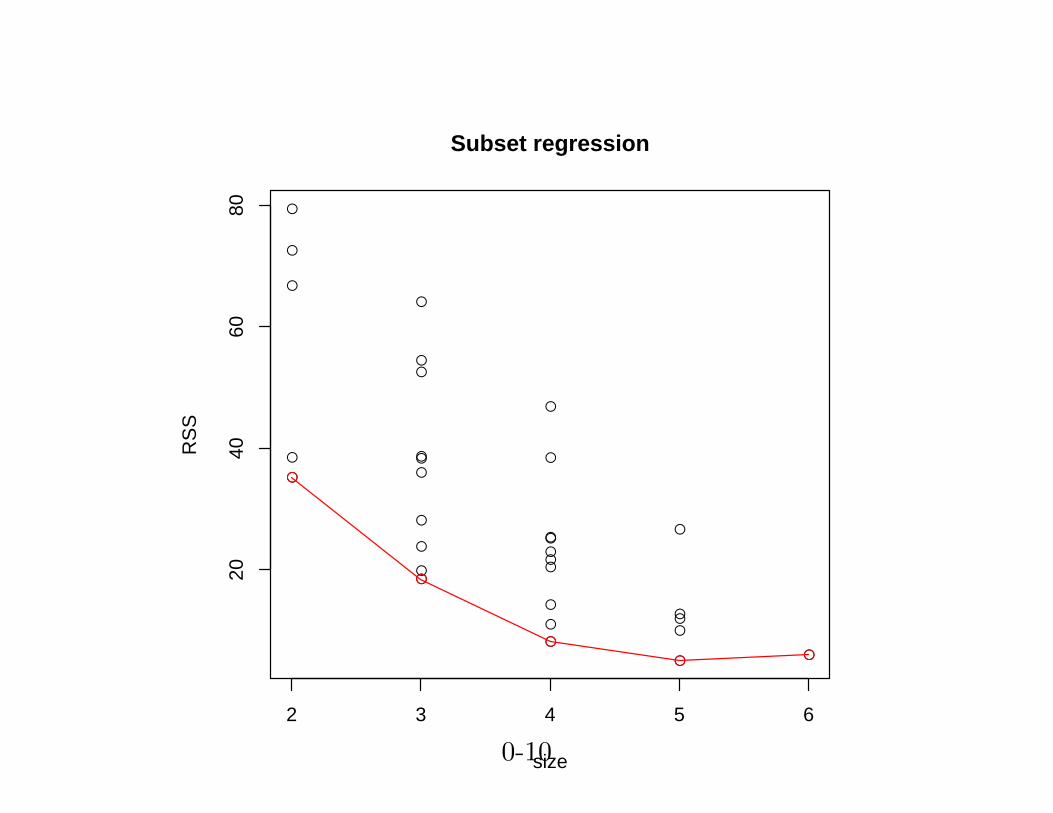
m<-sapply(ss, FUN=function(k) min(ll$Cp[ll$size==k]))
> m
[1] 35.204895 18.486158 8.178162 5.032800 6.000000
> names(swiss[,-1])[ll$which[which.min(ll$Cp),]]
[1] "Agriculture" "Education" "Catholic" "Infant.Mortality"
pdf("bestsubset.pdf")
plot(ll$size,ll$Cp, xlab="size", ylab="RSS", main="Subset regression")
points(unique(ll$size), m, col="red")
lines(unique(ll$size), m, col="red")
0-7

dev.off()
best.m<-lm(Fertility~Agriculture+Education+Catholic+Infant.Mortality, swiss)
summary(best.m)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 62.10131 9.60489 6.466 8.49e-08 ***
Agriculture -0.15462 0.06819 -2.267 0.02857 *
Education -0.98026 0.14814 -6.617 5.14e-08 ***
Catholic 0.12467 0.02889 4.315 9.50e-05 ***
Infant.Mortality 1.07844 0.38187 2.824 0.00722 **
---
Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1
0-8

Residual standard error: 7.168 on 42 degrees of freedom
Multiple R-Squared: 0.6993, Adjusted R-squared: 0.6707
F-statistic: 24.42 on 4 and 42 DF, p-value: 1.717e-10
변수선택법의 불안정성(instability)Variable selection methods는 불안정하다고 알려져 있다 (Breiman, 1996).여기서 불안정(unstable)하다는 의미는 훈련 데이터의 조그만 변화에도
불구하고 최종 선택된 모형(추정치)에 큰 영향을 준다는 의미이다. 이는변수선택법이 본질적으로 hard decision rule을 따르기 떄문이다.(surviveor die). 또한 이러한 변수선택이 지니는 불안정성 때문에 결과적으로 모형의 예측력을 떨어뜨릴 수 있다. 그러면 예측력을 저하시키지 않는 방법은 없을까 ? 다음에 소개할 Shrinkage 방법이 좋은 대안이 될 수 있다.
0-9
●
●
●
●
●
●●
●
●
●●●
●●
●
●
●
●
●●●●●
●
●
●
●●●
●
●
2 3 4 5 6
2040
6080
Subset regression
size
RS
S
●
●
●
●●
그림 2: best subset selection
0-10

제 3절 Regularization methods
3.1 Ridge regression (능형회귀)
Ridge estimator
βridge = argminn∑i=1
(yi − β0 −
p∑k=1
xikβk
)2
subject to∑pk=1 β
2k ≤ s or equivalently
βridge = argminn∑i=1
(yi − β0 −
p∑k=1
xkβk
)2
+ λ
p∑k=1
β2k. (1)
0-11

위에서 s = 0이면 모형은 상수항(intercept term)만을 포함한다. 반대로 s =∞이면 최소제곱법으로 추정된 모형과 동일하다.
이 ridge estimator는 Hoerl and Kennard (1970)이 소개하였고, p > n
일 때 최소제곱추정량을 계산하기 위해 고안 되었다.
선형회귀에서 통상적인 최소제곱추정량은 아래와 같다.
β̂ = (X′X)−1X′y
where X = (x′1, . . . ,x′n)′ and y = (y1, . . . , yn)′.
하지만 p > n 경우, (X′X)−1을 계산할 수가 없다(존재하지 않는다).보통 이 경우, 다음 식을 푸는데, 이 경우에는 해가 여러개 존재한다.
(X′X)β̂ = X′y
0-12

위의 식(1)에서 ridge estimator는 최소제곱추정량의 (X′X)−1 부분을
(X′X + λI)−1로 치환한 값이다. 즉,
β̂ridge
= (X′X + λI)−1X′y
또는
β̂jridge
= β̂j/(1 + λ), j = 1, . . . , p.
library(MASS)
data(longley) # not the same as the S-PLUS dataset
names(longley)[1] <- "y"
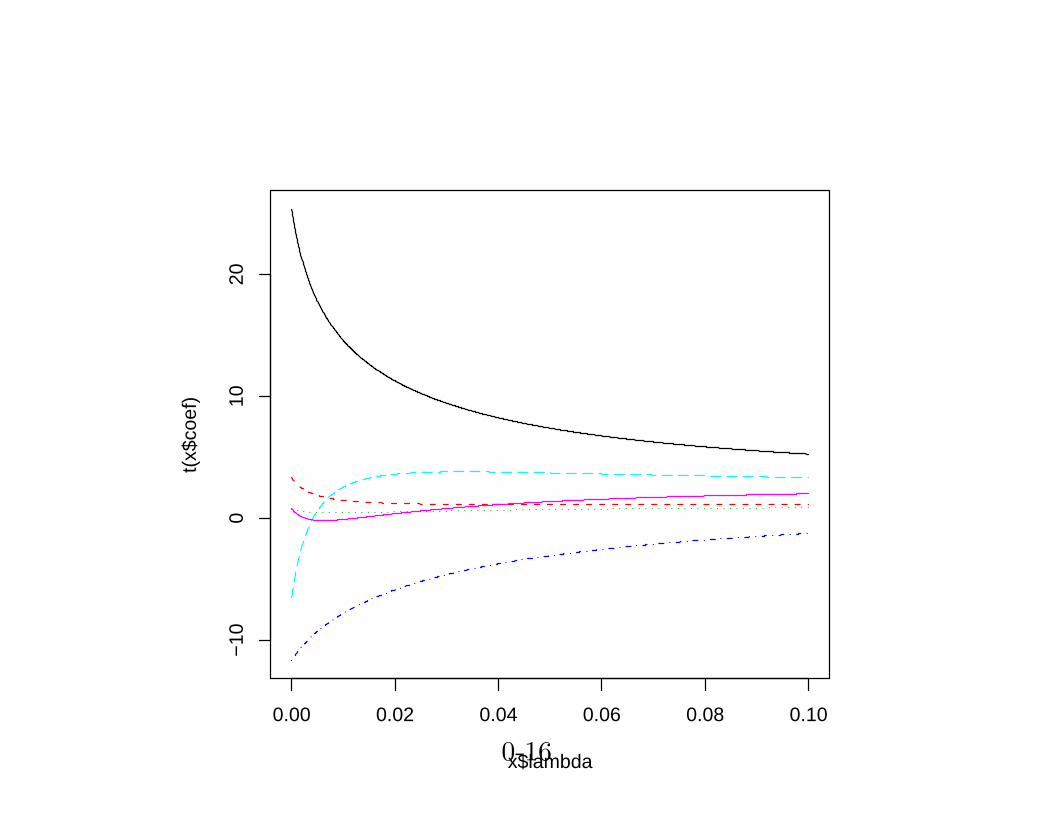
lm.r<- lm.ridge(y ~ ., longley, lambda = seq(0,0.1,0.0001))
pdf("ridge.pdf")
plot(lm.r)
dev.off()
0-13
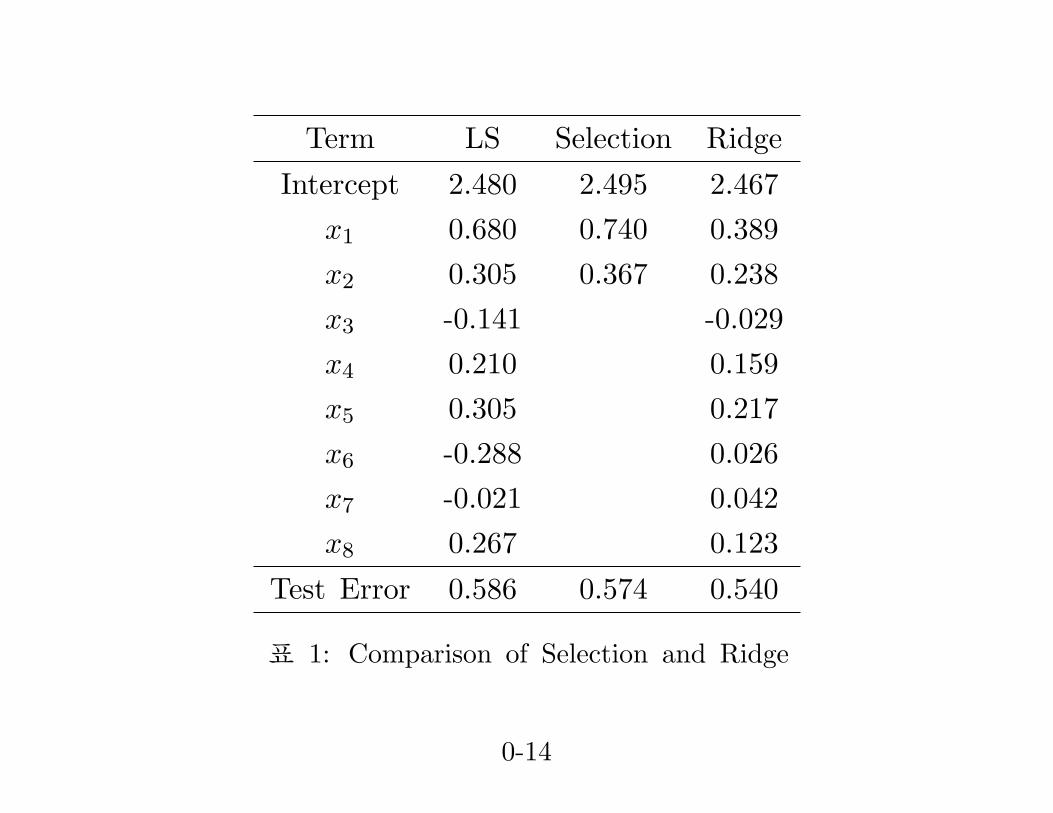
Term LS Selection Ridge
Intercept 2.480 2.495 2.467x1 0.680 0.740 0.389x2 0.305 0.367 0.238x3 -0.141 -0.029x4 0.210 0.159x5 0.305 0.217x6 -0.288 0.026x7 -0.021 0.042x8 0.267 0.123
Test Error 0.586 0.574 0.540
표 1: Comparison of Selection and Ridge
0-14

best.lambda<-which.min(lm.r$GCV)
> rbind(coef(lm(y ~ ., longley)),coef(lm.r)[best.lambda,])
Intercept GNP Unemployed Armed.Forces Population Year Employed
LS 2947 0.264 0.0365 0.01116 -1.74 -1.419 0.2313
Ridge -247 0.179 0.0197 0.00661 -1.34 0.222 -0.0575
3.2 LASSO: Least Absolute Shrinkage and
Selection Operator
Ridge regression의 단점으로는 모든 input 변수들이 모형에 포함되어
있어 모형에 대한 해석이 용이하지 않다는 데 있다.
그렇다면 변수선택과 예측력 향상을 동시에 가능하게 하는 방법은 없
을까 ?
0-15
0.00 0.02 0.04 0.06 0.08 0.10
−10
010
20
x$lambda
t(x$
coef
)
그림 3: Coefficients in ridge regression
0-16

놀랍게도 그런 방법이 있으며, Tibshirani (1996)가 제안한 LASSO (LeastAbsolute Shrinkage and Selection Operator)라는 방법이다.
LASSO방법은 다음의 목적함수를 최소화 하는 β를 찾는다.
n∑i=1
l(yi,x′
iβ) + λ
p∑j=1
|βj |︸ ︷︷ ︸penalty function
.
ridge와 다른 점은 penalty function이 제곱에서 절대값으로 바뀌었다
는 것밖에 없다.
이러한 penalty를 l1 penalty라고 부른다, 반면에 Ridge의 penalty를l2 penalty라고 함
0-17
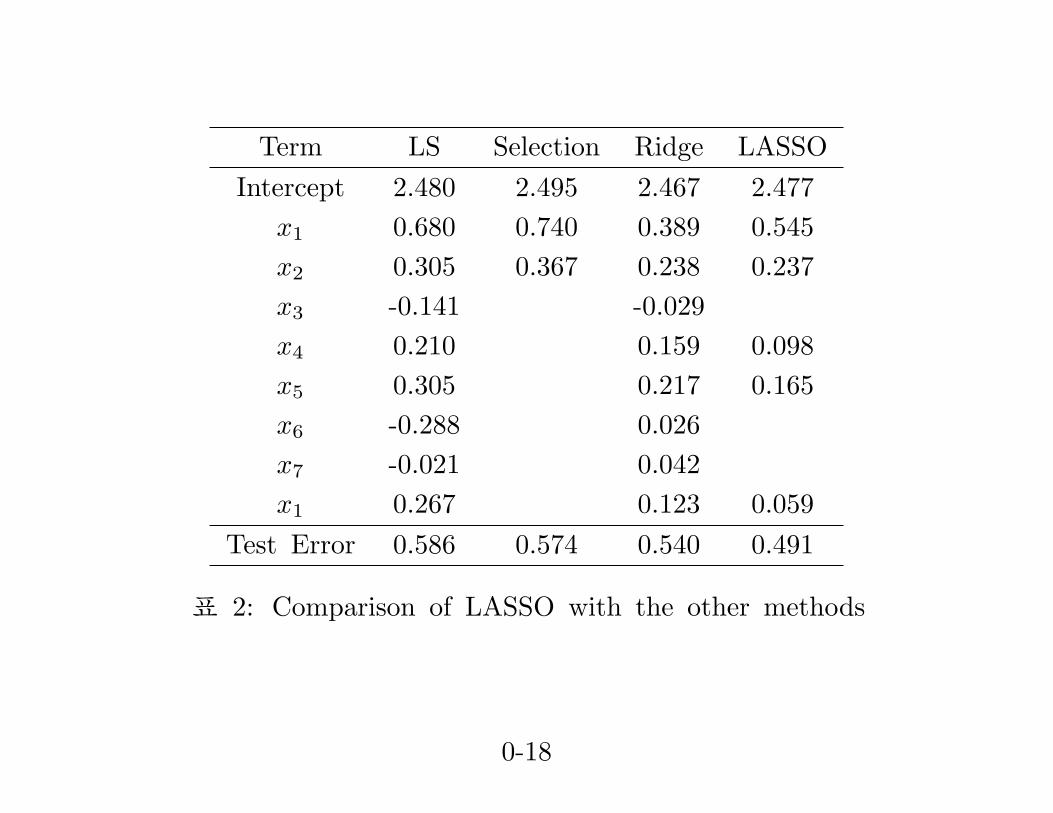
Term LS Selection Ridge LASSOIntercept 2.480 2.495 2.467 2.477
x1 0.680 0.740 0.389 0.545x2 0.305 0.367 0.238 0.237x3 -0.141 -0.029x4 0.210 0.159 0.098x5 0.305 0.217 0.165x6 -0.288 0.026x7 -0.021 0.042x1 0.267 0.123 0.059
Test Error 0.586 0.574 0.540 0.491
표 2: Comparison of LASSO with the other methods
0-18

그림 4: Why is LASSO sparse?0-19
Related Documents
![7월-4.오픈소스 통계분석 R의 이해.ppt [호환 모드]datamining.dongguk.ac.kr/R/7월-4.오픈소스 통계분석 R의... · R, 그리고빅데이터 제30회Open Technet-빅데이터오픈소스플랫폼기술세미나](https://static.cupdf.com/doc/110x72/5a813f647f8b9a9d308d0e58/7-4-r-ppt-4.jpg)






![[제14주차] 범죄예방전략에대한이해와전망 주재진교수elearning.kocw.net/KOCW/document/2015/dongguk/joojaejin2/14.pdf · 사회환경개선을통한범죄예방모델](https://static.cupdf.com/doc/110x72/6083d3b50e7fb366616255a5/oe14-eeeeoeoee-e-oeeeoeoeeeee.jpg)



