Department of Computer Science 1 Data Mining / KDD Let us find something interesting! Definition := “KDD is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” (Fayyad)

Department of Computer Science 1 Data Mining / KDD Let us find something interesting! Definition := “KDD is the non-trivial process of identifying valid,
Dec 26, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Department of Computer Science1
Data Mining / KDD
Let us find something interesting!
Definition := “KDD is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” (Fayyad)

Department of Computer Science
Research Focus of UH-DMML
Christoph F. Eick
Data MiningGeographical
Information Systems (GIS)
High Performance
Computing
Machine Learning
Helping Scientists to Make Sense of
their Data
Output: Graduated 12 PhD students (5 in 2009-11) and 79 Master Students

Department of Computer Science
Research Areas and Projects1.Data Mining and Machine Learning Group Its research is focusing on:
1. Spatial Data Mining 2. Clustering3. Helping Scientists to Make Sense out of their Data4. Classification and Prediction
2.Current and Planned Projects1. Spatial Clustering Algorithms with Plug-in Fitness Functions
and Other Non-Traditional Clustering Approaches2. Patch-based Prediction Techniques3. Mining Point of Interest (POI) Datasets and its Application to
Urban Computing and Understanding Causes of Alcohol Addiction
4. Data Mining with a Lot of Cores5. Educational Data Mining
UH-DMML

Department of Computer Science
Mining POI Datasets Motivation: A lot of POI datasets (e.g. in Google Earth) are becoming available now. http://bloomington.in.gov/documents/viewDocument.php?document_id=2455;dir=building/buildingfootprints/shape https://data.cityofchicago.org/Buildings/Building-Footprints/w2v3-isjw
Buildings of the City of Chicago (830,000 Polygons) :
Challenges: Extract Valuable Knowledge from such datasets Data Mining Facilitate Querying and Visualizing of such dataset HPC / BigData
Initiative

Department of Computer Science
Summarizing the Composition of Spatial Datasets
Given: A Spatial Dataset which Covers an Area of Interest
Output: A Partitioning of the Area of Interest into Uniform Regions
Applications: Urban Computing(http://www.cs.uic.edu/~urbcomp2013/index.html ) / Alcohol Addiction
Ch. Eick
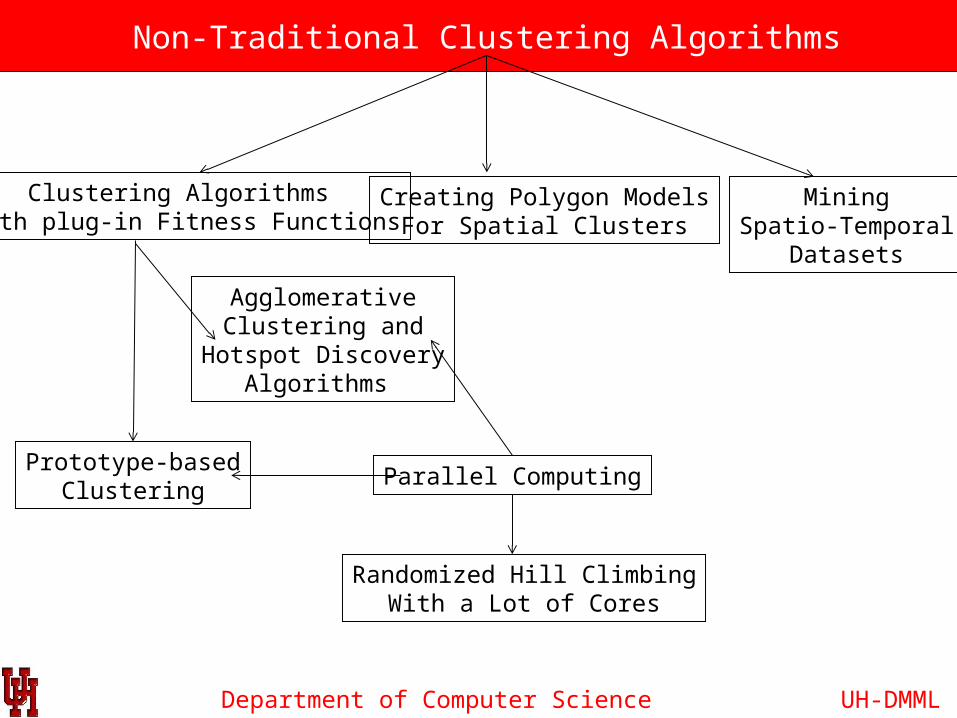
Department of Computer Science
Non-Traditional Clustering Algorithms
UH-DMML
Clustering Algorithms With plug-in Fitness Functions
MiningSpatio-Temporal
Datasets
Parallel ComputingPrototype-based
Clustering
Randomized Hill ClimbingWith a Lot of Cores
AgglomerativeClustering and
Hotspot DiscoveryAlgorithms
Creating Polygon ModelsFor Spatial Clusters

Department of Computer Science
Current Suite of Spatial Clustering Algorithms Representative-based: SCEC, CLEVER Grid-based: SCMRG,… Agglomerative: MOSAIC Density-based: DCONTOUR (not really plug-in but some fitness functions
can be simulated)
Clustering Algorithms
Density-based
Agglomerative-basedRepresentative-based
Grid-based
Remark: All algorithms partition a dataset into clusters by maximizing a reward-based, plug-in fitness function.

Department of Computer Science
MOSAIC—a Clustering Algorithm that Supports Plug-in Fitness Functions
Fig. 6: An illustration of MOSAIC’s approach
(a) input (b) output
MOSAIC supports plug-in fitness functions and provides a generic framework that integrates representative-based clustering, agglomerative clustering, and proximity graphs, and which approximates arbitrary shape clusters using unions of small convex polygons.

Department of Computer Science
Patch-based Prediction Techniques
a. New Algorithms for Regression Tree Induction
b. New Decision Tree Induction Algorithms
c. Multi-Target Regression
d. Spatial Prediction Techniques
Ch. Eick

Department of Computer Science
Helping Scientists to Make Sense Out of their Data
Ch. Eick
Figure 1: Co-location regions involving deep andshallow ice on Mars
Figure 2: Interestingness hotspots where both income and CTR are high.
Figure 3: Mining hurricane trajectories

Department of Computer Science
Other Unassigned Research Topics Trajectory Classification and Prediction Collocation Mining Creating Parallel Versions of Existing Clustering Algorithms Models for the Evolution of Spatial Datasets Hierarchical Learning Algorithms …
? Ozone HotspotEvolution
3p 5p7p

Department of Computer Science
UH-DMML Mission Statement
The Data Mining and Machine Learning Group at the University of Houston aims at the development of data analysis, data mining, and machine-learning techniques and to apply those techniques to challenging problems in geology, astronomy, urban computing, ecology, environmental sciences, web advertising and medicine. In general, our research group has a strong background in the areas of clustering and spatial data mining. Areas of our current research include: clustering algorithms with plug-in fitness functions, association analysis, mining related spatial data sets, patch-based prediction techniques, summarizing the composition of spatial datasets, change and progression analysis, and data mining with a lot of cores.
Website: http://www2.cs.uh.edu/~UH-DMML/index.html
Research Group Publications: http://www2.cs.uh.edu/~ceick/pub.html
Data Mining Course Website: http://www2.cs.uh.edu/~ceick/DM/DM.html Machine Learning Course Website: http://www2.cs.uh.edu/~ceick/ML/ML.html
Ch. Eick

Department of Computer Science
Reading Material
Urban Computing/Spatial Clustering: SIGKDD Urban Computing Workshop 2013 PaperAgglomerative Clustering: R. Jiamthapthaksin, C. F. Eick, and S. Lee,
GAC-GEO: A Generic Agglomerative Clustering Framework for Geo-referenced Datasets, in Knowledge and Information Systems (KAIS).
Patch-based Prediction Techniques: MLDM 2013 Paper, ACM-GIS 2010 PaperData Mining with a lot of Cores: ParCo 2011 PaperGIS/Creating Polygon Models: ACM-GIS 2013 SubmissionMachine Learning Course Website: http://www2.cs.uh.edu/~ceick/ML/ML.html Collocation Mining: ACM-GIS 2008 PaperSpatial Clustering and Association Analysis: W. Ding, C. F. Eick, X. Yuan, J. Wang, and J.-P. Nicot,
A Framework for Regional Association Rule Mining and Scoping in Spatial Datasets, Geoinformatica (2011) 15:1-28, DOI 10.1007/s10707-010-0111-6, January 2011.
Supervised Clustering: TAI 2005 Paper
Ch. Eick

Department of Computer Science
What Courses Should You Take to Conduct Research in this Research Group?
I. Data Mining II.Machine LearningIII.Parallel Programming, AI, Software Design,
Data Structures, Databases, Visualization, Evolutionary Computing, Image Processing, GIS courses, Geometry, Optimization.
UH-DMML

Department of Computer Science
Some UH-DMML Graduates 1
Christoph F. Eick
Dr. Wei Ding, Assistant Professor Department of Computer Science,
University of Massachusetts, Boston
Sharon M. Tuttle, Professor,Department of Computer Science,
Humboldt State University, Arcata, California
Tae-wan Ryu, Professor, Department of Computer Science,
California State University, Fullerton

Department of Computer Science
Some UH-DMML Graduates 2
Christoph F. Eick
Ruth Miller Ruth Miller, PhD Washington Unversity in St. Louis, Postdoc - Midwest Alcohol Research Center, Department of Psychiatry. Adjunct Instructor - Department of Computer Science
Chun-sheng Chen, PhD TidalTV, Baltimore (an internet advertizing company)
Rachsuda Jiamthapthaksin PhD Lecturer Assumption University, Bangkok, Thailand
Justin Thomas MS Section Supervisor at Johns Hopkins University Applied Physics Laboratory
Mei-kang Wu MS Microsoft, Bellevue, Washington
Jing Wang MS AOL, California

Department of Computer Science
Models for Progression of Hotspots and Other Spatial Objects
Ch. Eick
? Ozone HotspotEvolution
? Building Evolution
? Progression of Glaucoma
3p 5p7p

Department of Computer Science
Mining Related Datasets Using Polygon Analysis
Work on a methodology that does the following:1. Generate polygons from spatial cluster extensions / from
continuous density or interpolation functions.2. Meta cluster polygons / set of polygons3. Extract interesting patterns / create summaries from polygonal
meta clusters
Christoph F. Eick
Analysis of Glaucoma Progression Analysis of Ozone Hotspots29 29.2 29.4 29.6 29.8 30 30.2 30.4
-95.8
-95.6
-95.4
-95.2
-95
-94.8

Department of Computer Science
Clustering and Hotspot Discovery in Labeled Graphs
Ch. Eick
Potential Problems to be investigated: 1. Clustering Protein Based on Their Interactions 2. Generalize Region Discovery Framework to Graphs Partitioning Using Plug-in Interestingness Functions 3. … 4. …

Department of Computer Science
Subtopics:
• Disparity Analysis/Emergent Pattern Discovery (“how do two groups differ with respect to their patterns?”) [SDE10]
• Change Analysis ( “what is new/different?”) [CVET09]
• Correspondence Clustering (“mining interesting relationships between two or more datasets”) [RE10]
• Meta Clustering (“cluster cluster models of multiple datasets”)
• Analyzing Relationships between Polygonal Cluster Models
Example: Analyze Changes with Respect to Regions of High Variance of Earthquake Depth.
Novelty (r’) = (r’—(r1 … rk))
Emerging regions based on the novelty change predicate
Time 1 Time 2
UH-DMML
Methodologies and Tools toAnalyze and Mine Related Datasets

Department of Computer Science
Mining Spatial Trajectories
Goal: Understand and Characterize Motion Patterns Themes investigated: Clustering and summarization of
trajectories, classification based on trajectories, likelihood assessment of trajectories, prediction of trajectories.
UH-DMML
Arctic Tern
Arctic Tern Migration Hurricanes in the Golf of Mexico
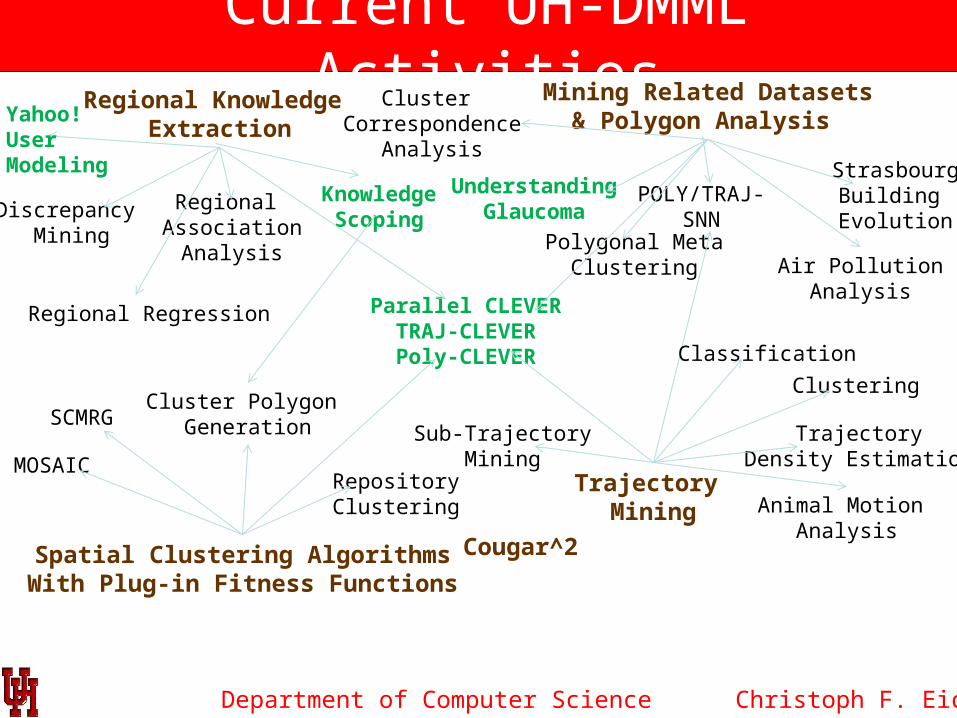
Department of Computer Science
Current UH-DMML Activities
Christoph F. Eick
Regional Knowledge Extraction
Spatial Clustering AlgorithmsWith Plug-in Fitness Functions
Mining Related Datasets& Polygon Analysis
Trajectory Mining
Discrepancy Mining
Regional Association
Analysis
KnowledgeScoping
Regional Regression Parallel CLEVERTRAJ-CLEVERPoly-CLEVER
SCMRG
StrasbourgBuilding Evolution
POLY/TRAJ-SNN
Polygonal MetaClustering
UnderstandingGlaucoma
Air PollutionAnalysis
Cluster Correspondence
Analysis
Cluster Polygon Generation
MOSAIC
Animal Motion Analysis
TrajectoryDensity Estimation
Classification
Sub-TrajectoryMining
RepositoryClustering
Yahoo! User Modeling
Clustering
Cougar^2

Data Mining & Machine Learning Group CS@UHACM-GIS08
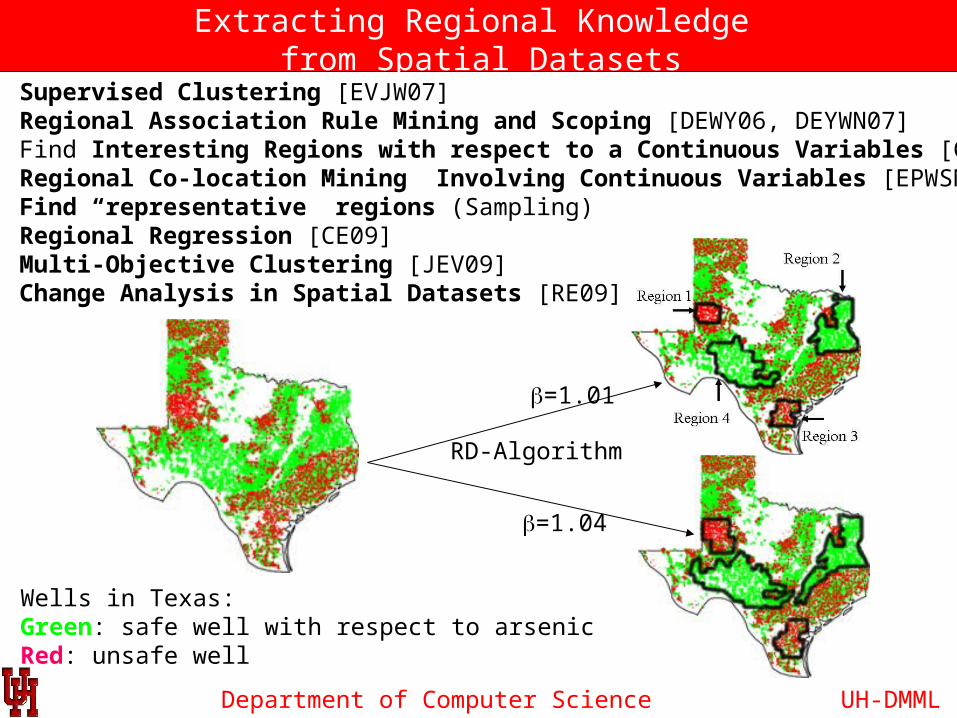
Department of Computer Science
Extracting Regional Knowledge from Spatial Datasets
RD-Algorithm
Application 1: Supervised Clustering [EVJW07]Application 2: Regional Association Rule Mining and Scoping [DEWY06, DEYWN07]Application 3: Find Interesting Regions with respect to a Continuous Variables [CRET08]Application 4: Regional Co-location Mining Involving Continuous Variables [EPWSN08]Application 5: Find “representative” regions (Sampling)Application 6: Regional Regression [CE09]Application 7: Multi-Objective Clustering [JEV09]Application 8: Change Analysis in Spatial Datasets [RE09]
Wells in Texas:Green: safe well with respect to arsenicRed: unsafe well
b=1.01
b=1.04
UH-DMML
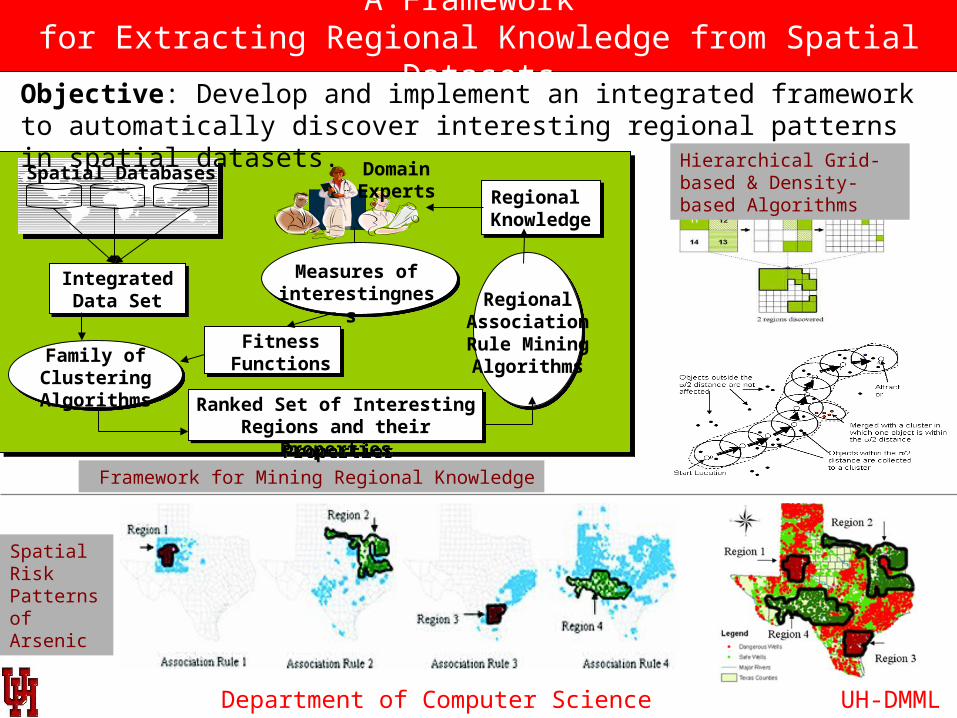
Department of Computer Science
A Framework for Extracting Regional Knowledge from Spatial Datasets
Framework for Mining Regional Knowledge
Spatial Databases
Integrated Data Set
Integrated Data Set
DomainExperts
Fitness FunctionsFamily of
Clustering Algorithms
Regional Association Rule MiningAlgorithms
Ranked Set of Interesting Regions and their Properties
Ranked Set of Interesting Regions and their Properties
Measures ofinterestingness
Regional KnowledgeRegional Knowledge
Objective: Develop and implement an integrated framework to automatically discover interesting regional patterns in spatial datasets.
Hierarchical Grid-based & Density-based Algorithms
Spatial Risk Patterns of Arsenic
UH-DMML
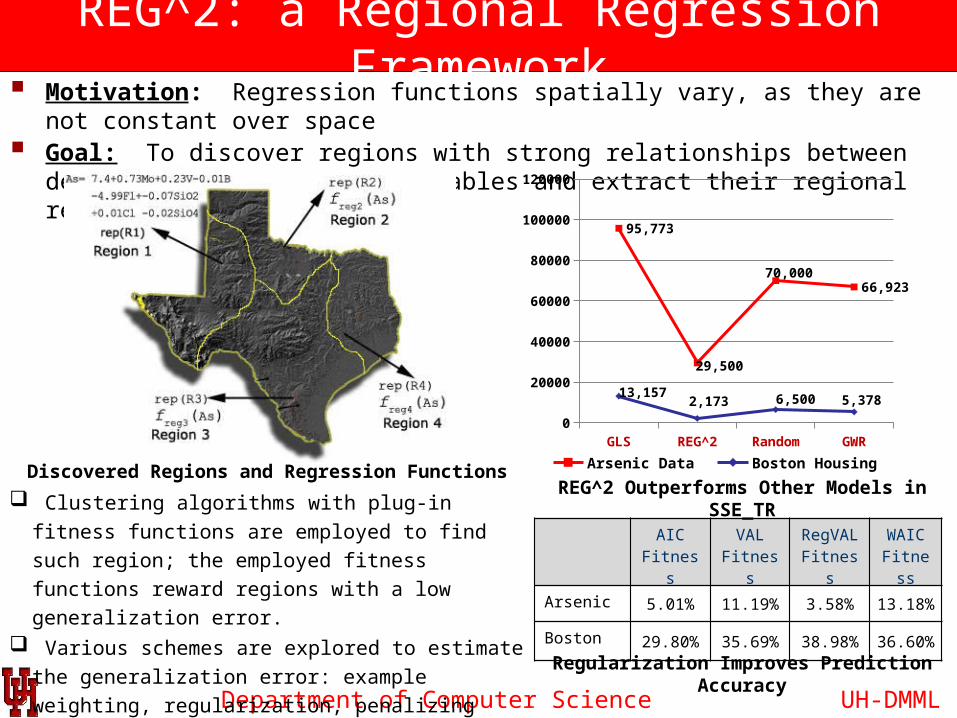
Department of Computer Science
REG^2: a Regional Regression Framework Motivation: Regression functions spatially vary, as they are not constant over space Goal: To discover regions with strong relationships between dependent &
independent variables and extract their regional regression functions.
UH-DMML
AIC Fitness
VAL Fitness
RegVAL Fitness
WAIC Fitness
Arsenic 5.01% 11.19% 3.58% 13.18%
Boston 29.80% 35.69% 38.98% 36.60%
Clustering algorithms with plug-in fitness functions are
employed to find such region; the employed fitness
functions reward regions with a low generalization error. Various schemes are explored to estimate the
generalization error: example weighting, regularization,
penalizing model complexity and using validation sets,…
Discovered Regions and Regression Functions
GLS REG^2 Random GWR0
20000
40000
60000
80000
100000
120000
95,773
29,500
70,00066,923
13,1572,173 6,500 5,378
Arsenic Data Boston Housing
REG^2 Outperforms Other Models in SSE_TR
Regularization Improves Prediction Accuracy

Department of Computer Science
Finding Regional Co-location Patterns in Spatial Datasets
Objective: Find co-location regions using various clustering algorithms and novel fitness functions.
Applications:1. Finding regions on planet Mars where shallow and deep ice are co-located, using point and raster datasets. In figure 1, regions in red have very high co-location and regions in blue have anti co-location.
2. Finding co-location patterns involving chemical concentrations with values on the wings of their statistical distribution in Texas’ ground water supply. Figure 2 indicates discovered regions and their associated chemical patterns.
Figure 1: Co-location regions involving deep andshallow ice on Mars
Figure 2: Chemical Co-location patterns in Texas Water Supply
UH-DMML
Related Documents

![SOFT SET THEORY FORDATA REDACTION Student Name …umpir.ump.edu.my/id/eprint/7000/1/CD7689.pdf · database. [2]. 2.1.2 KDD Processes KDD is a non-trivial process of identifying valid,](https://static.cupdf.com/doc/110x72/5d231a0888c99324108bc5ff/soft-set-theory-fordata-redaction-student-name-umpirumpedumyideprint70001.jpg)

![Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 1 Knowledge Discovery in Data [and Data Mining] (KDD) Let us find something interesting!](https://static.cupdf.com/doc/110x72/56649ed05503460f94bde2d1/christoph-f-eick-introduction-knowledge-discovery-and-data-mining-kdd-1.jpg)







