© 2021 Arm Arm AI Tech Talk - March 8th, 2022 Demo of the world’s fastest inference engine for Arm Cortex-M Cedric Nugteren Plumerai

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© 2021 Arm
Arm AI Tech Talk - March 8th, 2022
Demo of the world’s fastest inference engine
for Arm Cortex-M
Cedric Nugteren
Plumerai

© 2021 Arm
Welcome!
Tweet us: @ArmSoftwareDev -> #AIVTT
Check out our Arm Software Developers YouTube channel
Signup now for our next AI Virtual Tech Talk: www.arm.com/techtalks

3 © 2021 Arm
Our upcoming Arm AI Tech Talks
Visit: www.arm.com/techtalks

4 © 2021 Arm
Presenters
Cedric Nugteren is a software engineer focussed on writing efficient code for deep learning applications. After he received his MSc and PhD from Eindhoven University of Technology he optimized GPU and CPU code for various companies using C++, OpenCL and CUDA. Then, he worked for 4 years on deep learning for autonomous driving at TomTom, after which he joined Plumerai where he is now writing fast code for the smallest microcontrollers.
Pictures taken during Cedric’s PhD internship at Arm in Cambridge in 2012

Cedric Nugteren - [email protected] Arm AI Tech Talk - March 8th, 2022
Demo of the world’s fastest inference engine for Arm Cortex-M
(and some Tetris)

An introduction to Plumerai
6
Our goal: run complex computer vision tasks on
tiny devices efficiently

Person detection
7
Person Presence DetectionOn STM32L4R9Arm Cortex-M4 at 120 MHz
◼ Latency: 474 ms
◼ Peak RAM usage: 172 KiB
◼ Binary size: 156 KiB
On NXP RT1060Arm Cortex-M7 at 600 MHz
◼ Latency: 61 ms
◼ Peak RAM usage: 172 KiB
◼ Binary size: 147 KiB
On Raspberry Pi 4Arm Cortex-A72 at 1.5 GHzSingle core
◼ Latency: 7 ms
Person No Person
Person DetectionOn STM32H7B3Arm Cortex-M7 at 280 MHz
◼ Latency: 434 ms
◼ Peak RAM usage: 206 KiB
◼ Binary size: 895 KiB
On NXP RT1060Arm Cortex-M7 at 600 MHz
◼ Latency: 222 ms
◼ Peak RAM usage: 205 KiB
◼ Binary size: 895 KiB
On Raspberry Pi 4Arm Cortex-A72 at 1.5 GHzSingle core
◼ Latency: 22 ms
Example:Smart doorbell
Example:Smart offices
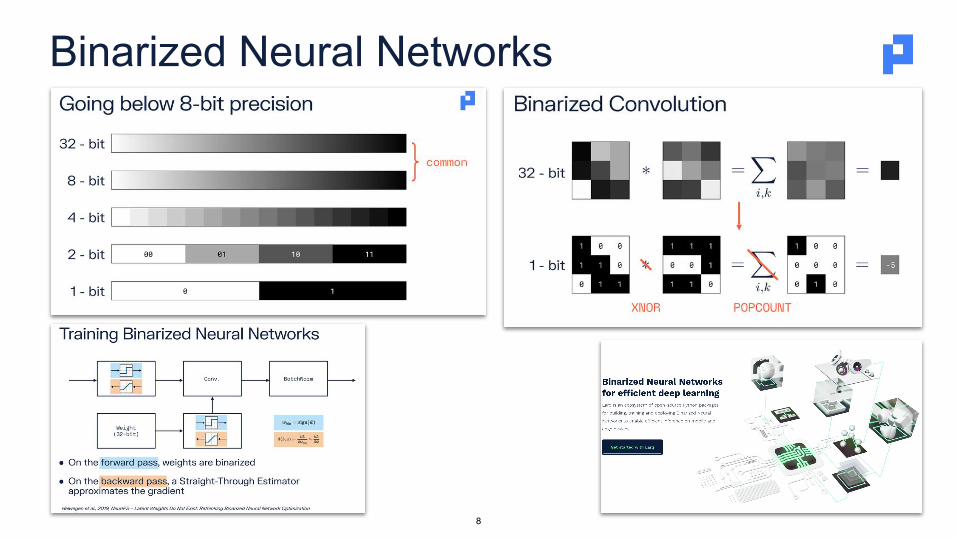
Binarized Neural Networks
8
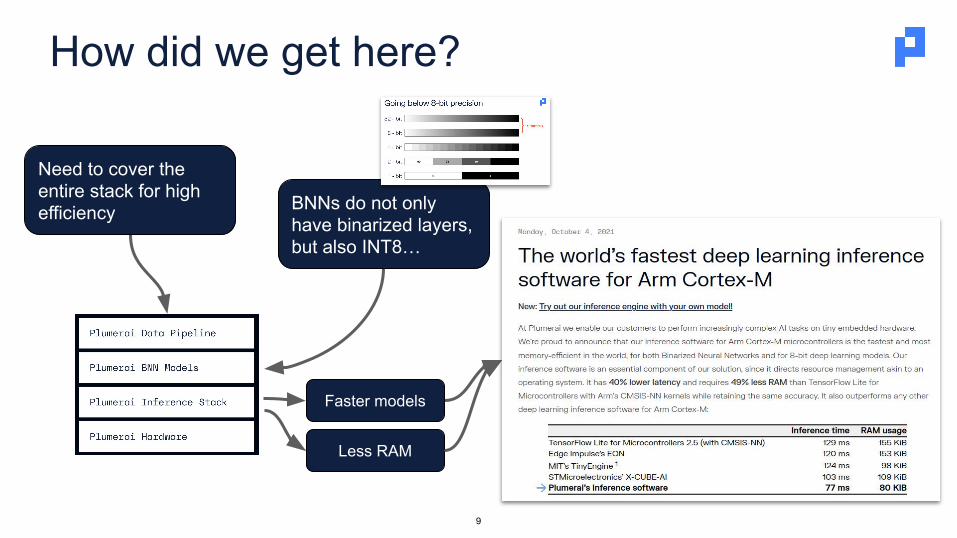
How did we get here?
Faster models
Less RAM
9
BNNs do not only have binarized layers, but also INT8…
Need to cover the entire stack for high efficiency

Overview of today’s talk1. What is an inference engine?
2. Are we really that efficient?
3. Live demo of public benchmarking service
4. What did we do to become so efficient?
10

1. What is an inference engine?

The machine learning flow
12Model flow image taken from: https://www.aldec.com/en/company/blog/177
Deploy INT8 quantized model on device
Runs optimizedcode

The tasks of an inference engine
13
1. Execute the layers of the model in the correct order
2. Plan the activations and weights in memory efficiently
3. Provide optimized INT8 code for each layer type(e.g. convolution, fully connected)
Network image from Netron, CMSIS image taken from: https://www.keil.com/pack/doc/CMSIS/NN/html/Memory image from: https://commons.wikimedia.org/wiki/File:Swissbit_2GB_PC2-5300U-555.jpg

2. Are we really that efficient?
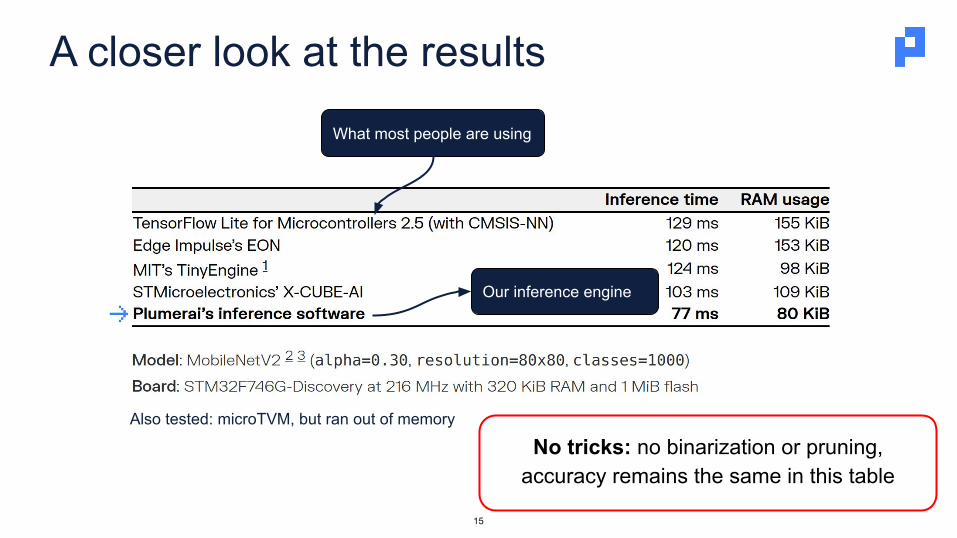
A closer look at the results
15
What most people are using
Our inference engine
No tricks: no binarization or pruning,accuracy remains the same in this table
Also tested: microTVM, but ran out of memory

Just good on MobileNetV2?
16
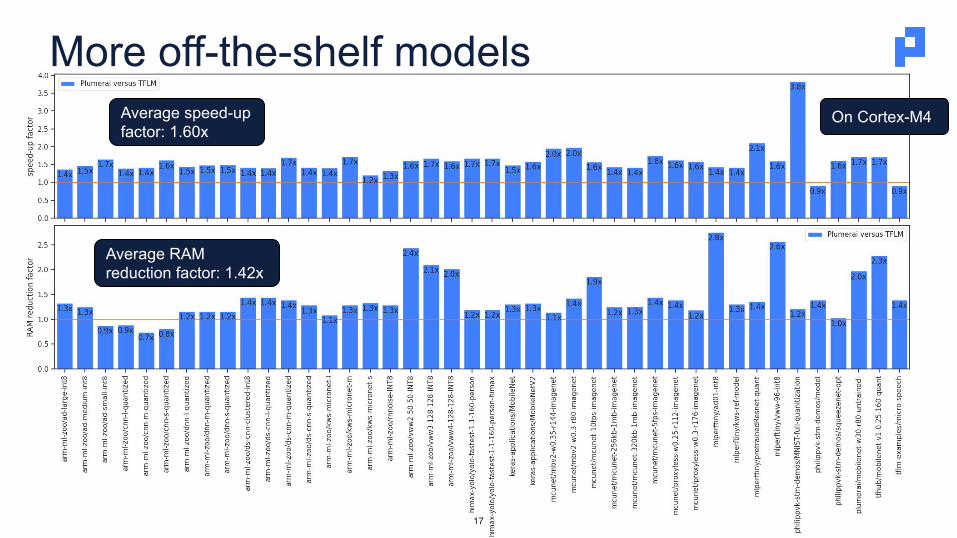
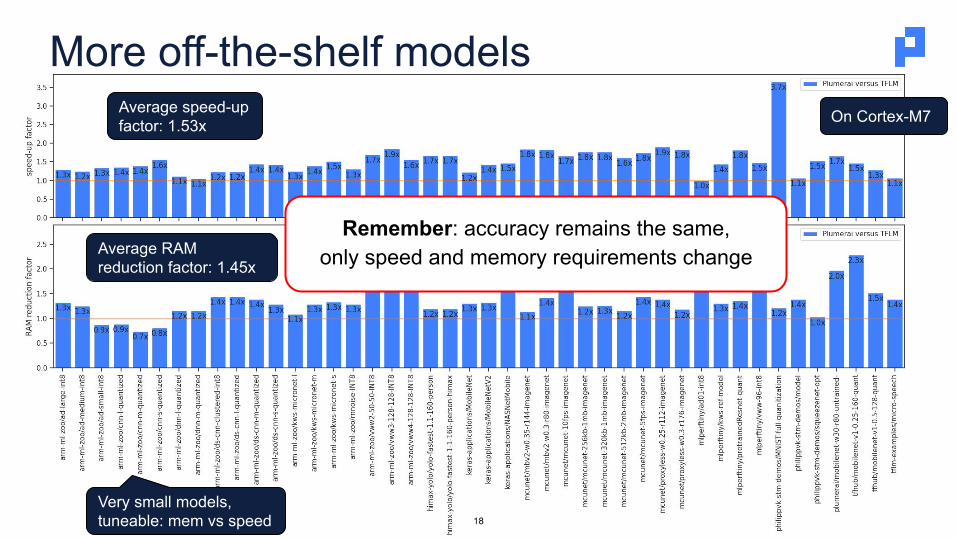
More off-the-shelf models
17
On Cortex-M4
Average RAM reduction factor: 1.42x
Average speed-up factor: 1.60x
More off-the-shelf models
18
On Cortex-M7
Average RAM reduction factor: 1.45x
Average speed-up factor: 1.53x
Remember: accuracy remains the same,only speed and memory requirements change
Very small models, tuneable: mem vs speed

RAM versus latency trade-off
19
● We can tune some knobs to use more RAM to get better latency
● Our solutions are Pareto-optimal
● Currently optimized for general case, can be tuned on demand depending on requirements
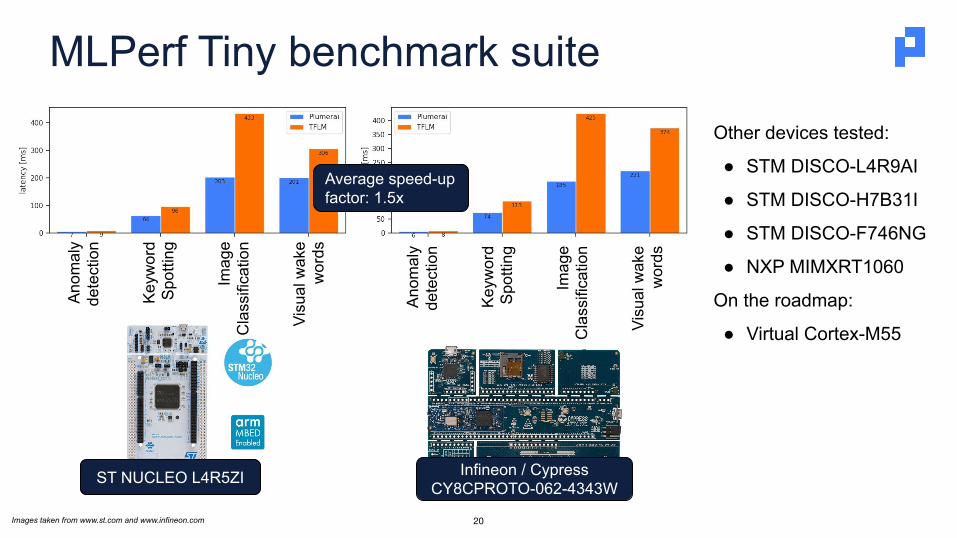
MLPerf Tiny benchmark suite
20
Ano
mal
y de
tect
ion
Key
wor
dS
potti
ng
Imag
eC
lass
ifica
tion
Visu
al w
ake
wor
ds
Ano
mal
y de
tect
ion
Key
wor
dS
potti
ng
Imag
eC
lass
ifica
tion
Visu
al w
ake
wor
ds
ST NUCLEO L4R5ZI
Images taken from www.st.com and www.infineon.com
Infineon / CypressCY8CPROTO-062-4343W
Other devices tested:
● STM DISCO-L4R9AI
● STM DISCO-H7B31I
● STM DISCO-F746NG
● NXP MIMXRT1060
On the roadmap:
● Virtual Cortex-M55
Average speed-up factor: 1.5x

MLPerf Tiny benchmark suite
21
Ano
mal
y de
tect
ion
Key
wor
dS
potti
ng
Imag
eC
lass
ifica
tion
Visu
al w
ake
wor
ds
RAM: factor 2 reduction!
Images taken from www.st.com and www.infineon.com
Submitted to MLPerf Tiny 0.7:● Measurements according to standard● Latency results verified on device● Accuracy verified on device

3. Live demo ofpublic benchmarking service
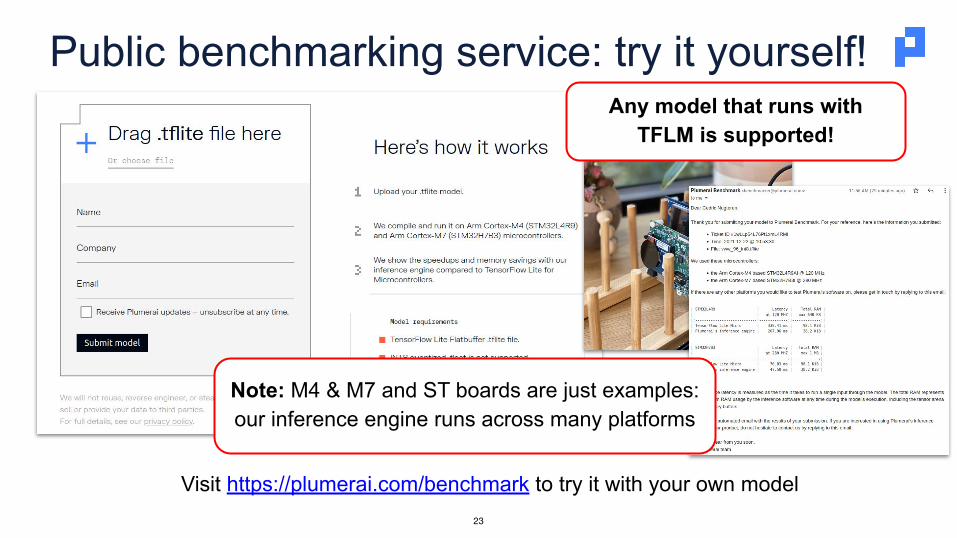
Public benchmarking service: try it yourself!
Visit https://plumerai.com/benchmark to try it with your own model23
Any model that runs withTFLM is supported!
Note: M4 & M7 and ST boards are just examples: our inference engine runs across many platforms

4. What did we do tobecome so efficient?
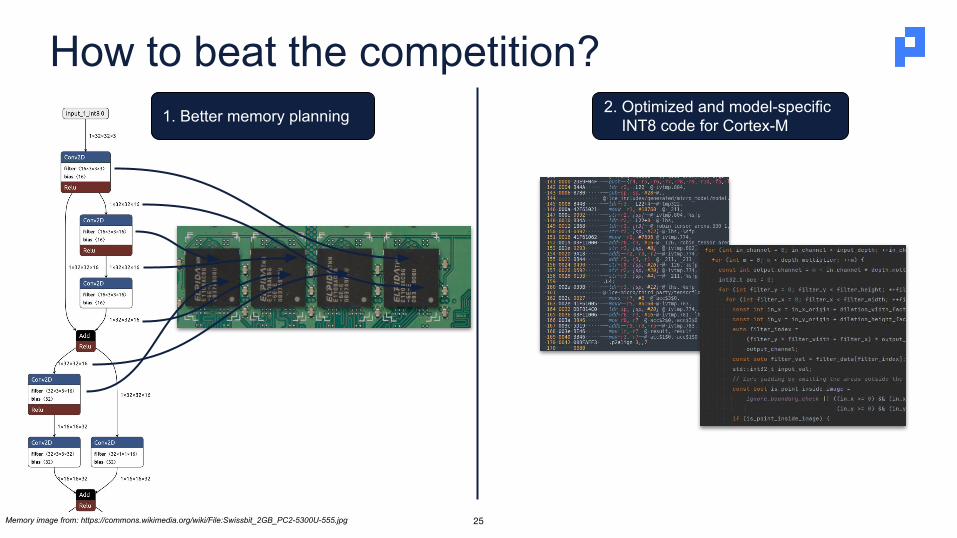
How to beat the competition?
25
1. Better memory planning 2. Optimized and model-specific INT8 code for Cortex-M
Memory image from: https://commons.wikimedia.org/wiki/File:Swissbit_2GB_PC2-5300U-555.jpg
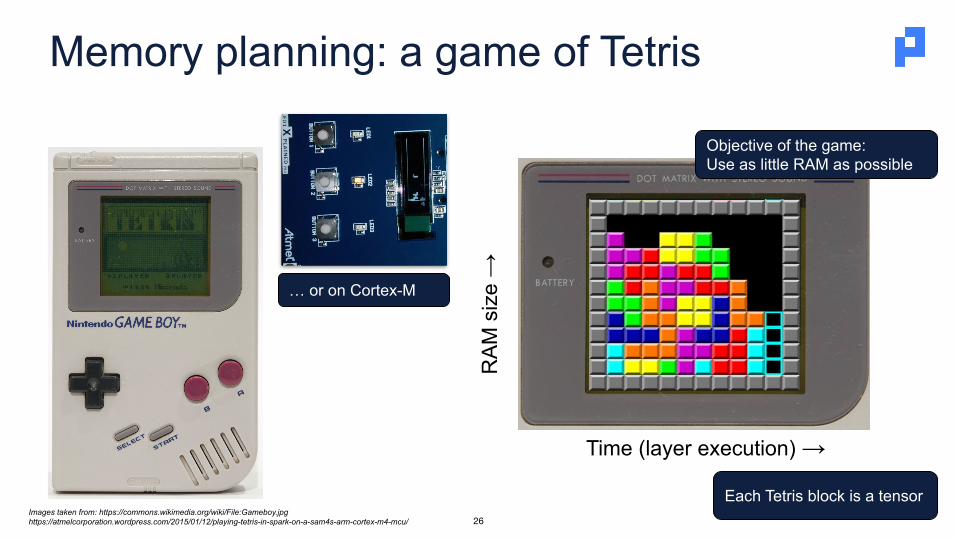
Memory planning: a game of Tetris
26
Each Tetris block is a tensorR
AM
siz
e →
Time (layer execution) →
Objective of the game:Use as little RAM as possible
Images taken from: https://commons.wikimedia.org/wiki/File:Gameboy.jpghttps://atmelcorporation.wordpress.com/2015/01/12/playing-tetris-in-spark-on-a-sam4s-arm-cortex-m4-mcu/
… or on Cortex-M
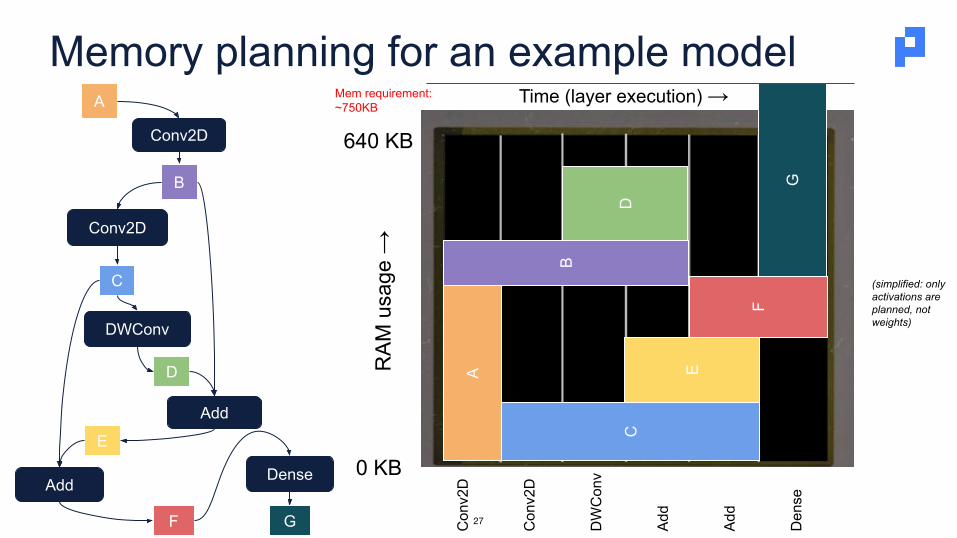
Memory planning for an example model
27
RA
M u
sage
→
Time (layer execution) →
0 KB
640 KBConv2D
Conv2D
DWConv
Add
DenseA
B
CD
E
F
A
B
C
D
E
F
(simplified: only activations are planned, not weights)
Add
G
G
Con
v2D
Con
v2D
DW
Con
v
Add
Add
Den
se
Mem requirement: ~750KB
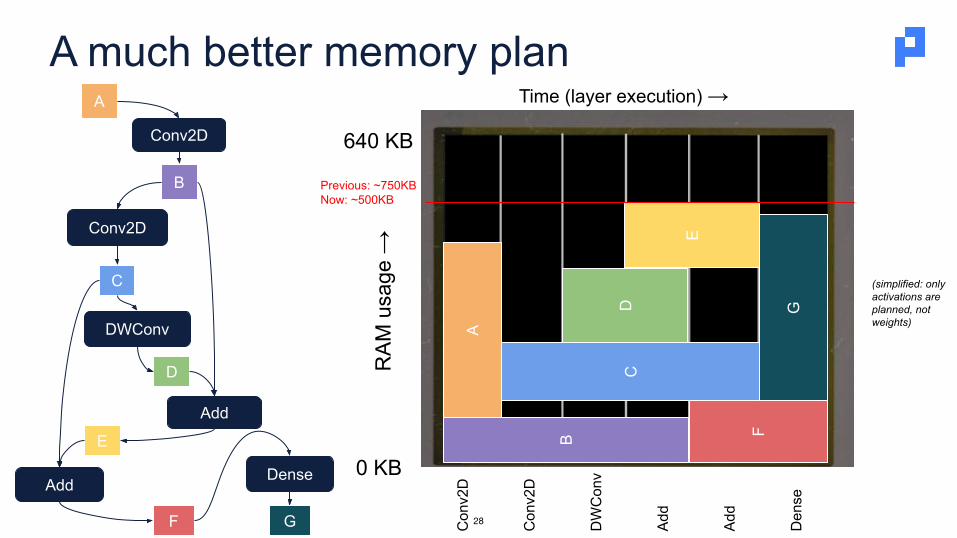
A much better memory plan
28
RA
M u
sage
→
Time (layer execution) →
0 KB
640 KBConv2D
Conv2D
DWConv
Add
DenseA
B
CD
E
F
A
B
C
D
E
F
(simplified: only activations are planned, not weights)
Add
G
G
Con
v2D
Con
v2D
DW
Con
v
Add
Add
Den
se
Previous: ~750KBNow: ~500KB
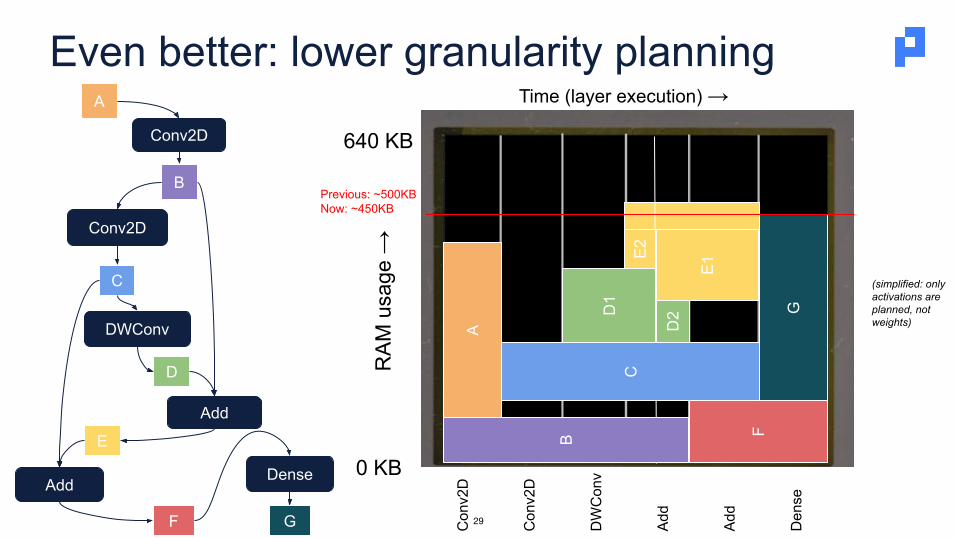
E
D
Even better: lower granularity planning
29
RA
M u
sage
→
Time (layer execution) →
0 KB
640 KBConv2D
Conv2D
DWConv
Add
DenseA
B
CD
1
E1
F
A
B
C
D
E
F
(simplified: only activations are planned, not weights)
Add
G Con
v2D
Con
v2D
DW
Con
v
Add
Add
Den
se
Previous: ~500KBNow: ~450KB
E2
D2 G
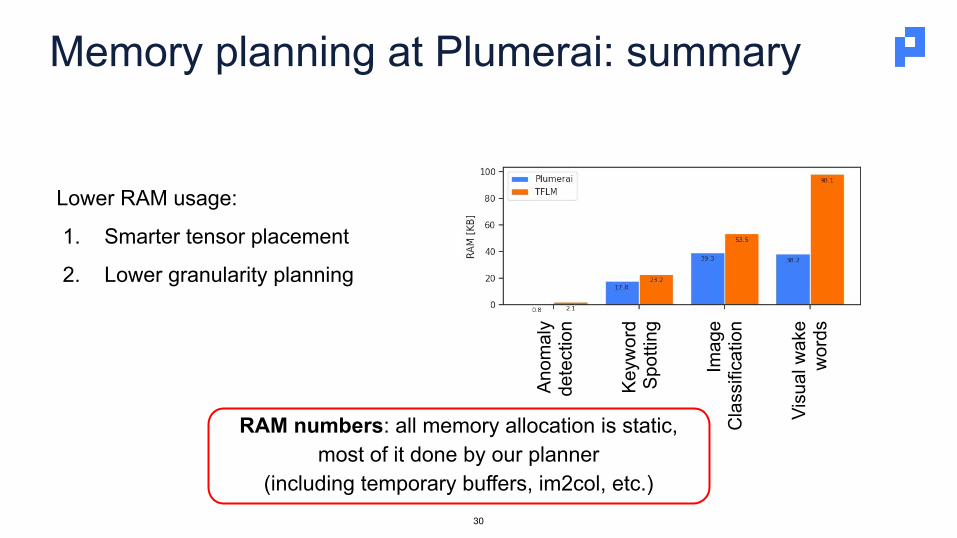
Memory planning at Plumerai: summary
Ano
mal
y de
tect
ion
Key
wor
dS
potti
ng
Imag
eC
lass
ifica
tion
Visu
al w
ake
wor
ds
Lower RAM usage:
1. Smarter tensor placement
2. Lower granularity planning
30
RAM numbers: all memory allocation is static, most of it done by our planner
(including temporary buffers, im2col, etc.)
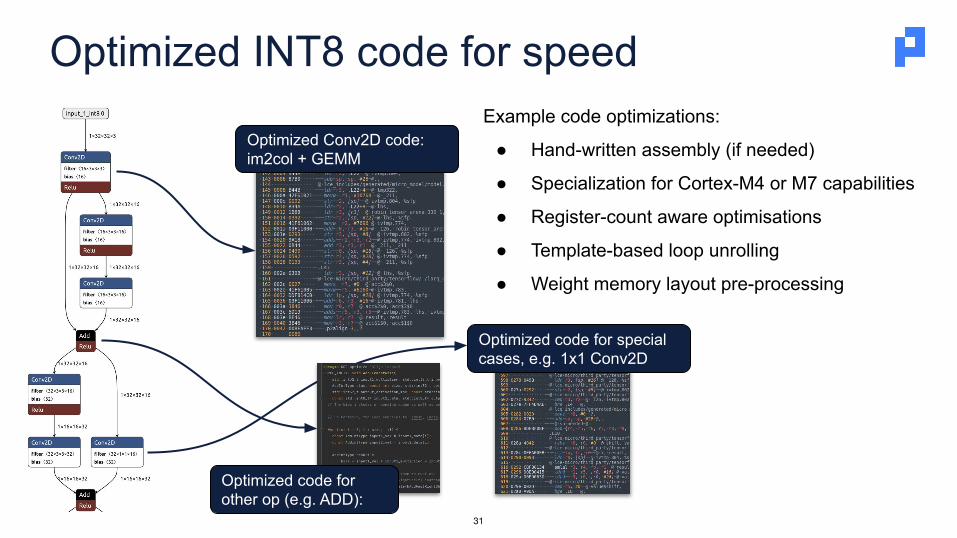
Optimized INT8 code for speed
31
Optimized Conv2D code:im2col + GEMM
Optimized code for other op (e.g. ADD):
Optimized code for special cases, e.g. 1x1 Conv2D
Example code optimizations:
● Hand-written assembly (if needed)
● Specialization for Cortex-M4 or M7 capabilities
● Register-count aware optimisations
● Template-based loop unrolling
● Weight memory layout pre-processing
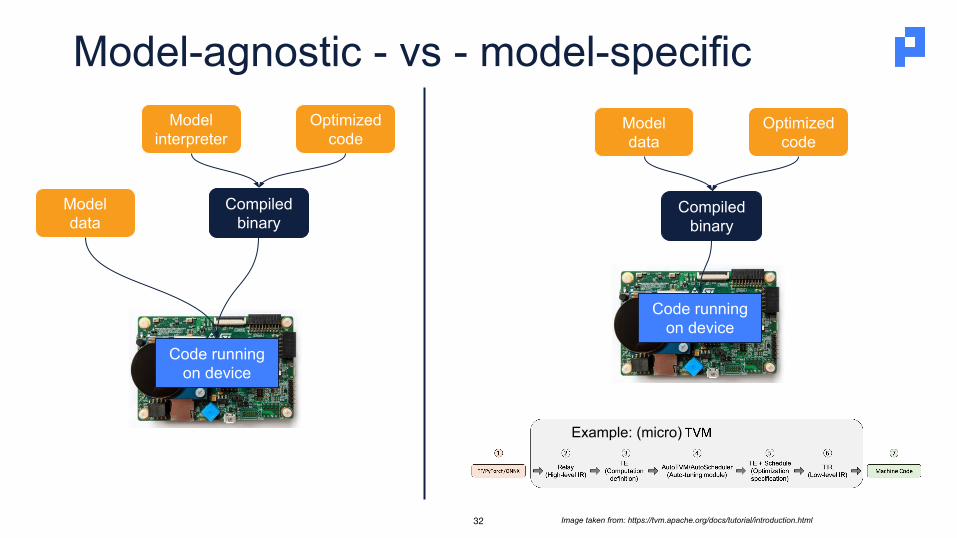
Model-agnostic - vs - model-specific
Image taken from: https://tvm.apache.org/docs/tutorial/introduction.html
Compiledbinary
Optimized code
Model data
Modelinterpreter
Code runningon device
Example: (micro)
Compiledbinary
Optimized code
Model data
Code runningon device
32

Model-specific code generation
33From the Godbolt compiler explorer at: https://godbolt.com
Unrolled code with only add, load and stores
Generic code with compare and branch
instructions

Better speed at Plumerai: summary
Ano
mal
y de
tect
ion
Key
wor
dS
potti
ng
Imag
eC
lass
ifica
tion
Visu
al w
ake
wor
ds
Lower latency, better speed:
1. Optimized code for Cortex-M
2. Model-specific code generation
34
You’ve got mail!

5. Conclusion
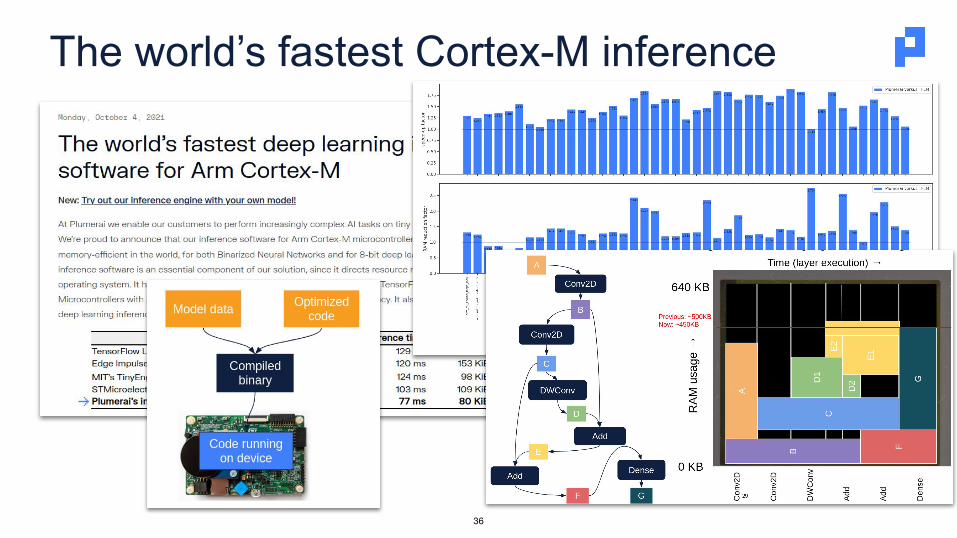
The world’s fastest Cortex-M inference
36

What can Plumerai mean for you?
37
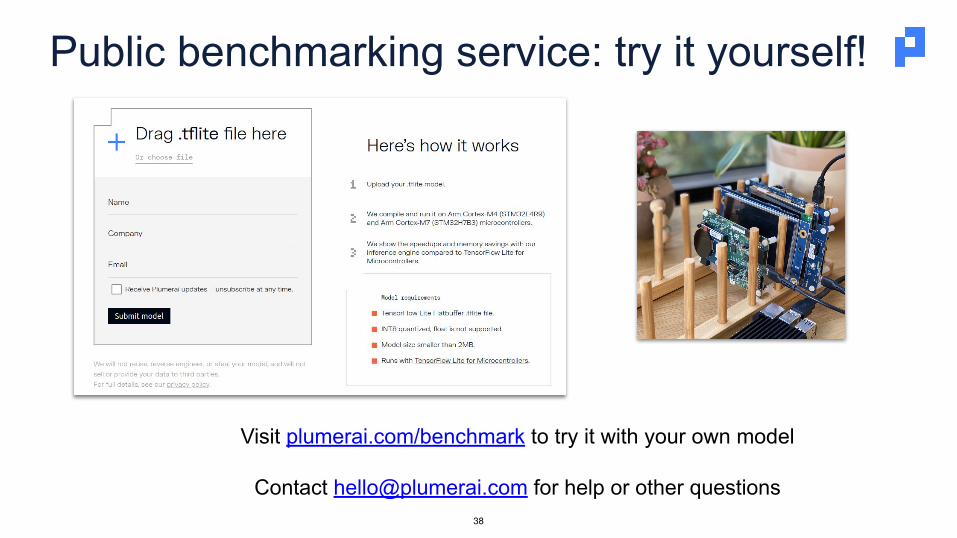
Public benchmarking service: try it yourself!
Visit plumerai.com/benchmark to try it with your own model
Contact [email protected] for help or other questions38

Thank YouDankeMerci谢谢
ありがとうGracias
Kiitos감사합니다
धन्यवाद شكًرا
תודה
AI Virtual Tech Talks Series

© 2021 Arm
Thank you!
Tweet us: @ArmSoftwareDev -> #AIVTT
Check out our Arm Software Developers YouTube channel
Signup now for our next AI Virtual Tech Talk: www.arm.com/techtalks
Related Documents











