Debugging & Tuning in Spark Shiao-An Yuan @sayuan 2016-08-11

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Debugging & Tuning in Spark
Shiao-An Yuan@sayuan
2016-08-11

Spark Overview
● Cluster Manager (aka Master)● Worker (aka Slave)
● Driver● Executor
http://spark.apache.org/docs/latest/cluster-overview.html

RDD (Resilient Distributed Dataset)
A fault-tolerant collection of elements that can be operated on in parallel

Word Count
val sc: SparkContext = ...
val result = sc.textFile(file) // RDD[String]
.flatMap(_.split(" ")) // RDD[String]
.map(_ -> 1) // RDD[(String, Int)]
.groupByKey() // RDD[(String, Iterable[Int])]
.map(x => (x._1, x._2.sum)) // RDD[(String, Int)]
.collect() // Array[(String, Int])

Lazy, Transformation, Action, Job
groupByKey mapmapflatMap collect

Partition, Shuffle
groupByKey mapmapflatMap collect

Stage, Task
groupByKey mapmapflatMap collect

DAG (Directed Acyclic Graph)
● RDD operations○ Transformation○ Action
● Lazy● Job● Shuffle● Stage● Partition● Task

Objective
1. A correct and parallelizable algorithm2. Parallelism3. Reduce the overhead from parallelization

Correctness and Parallelizable
● Use small input● Run locally
○ --master local○ --master local[4]○ --master local[*]


Non-RDD Operations
● Avoid long blocking on driver


Data Skew
● repartition() come to rescue?● Hotspots
○ Choose another partitioned key○ Filter unreasonable data
● Trace to it’s source

https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html

https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html
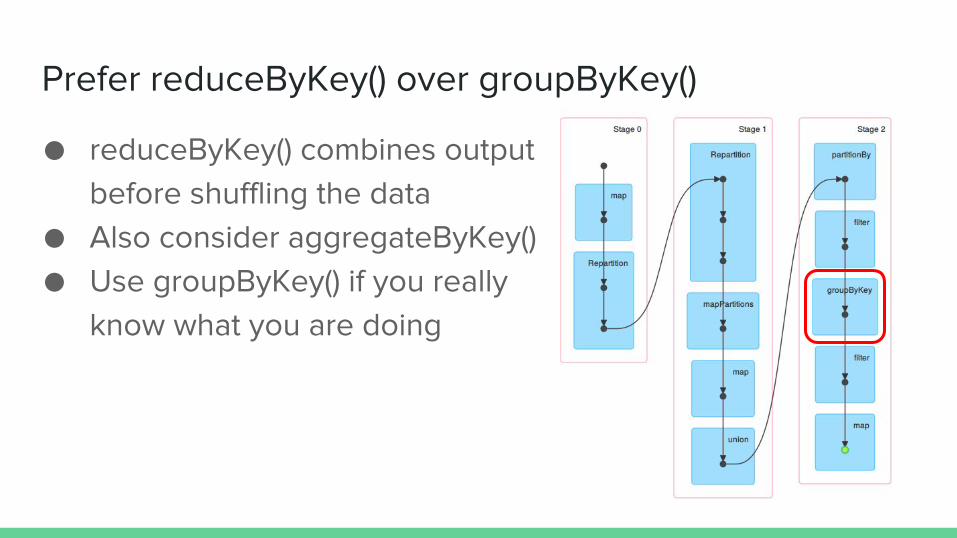
Prefer reduceByKey() over groupByKey()
● reduceByKey() combines output before shuffling the data
● Also consider aggregateByKey()● Use groupByKey() if you really
know what you are doing


Shuffle Spill
● Increase partition count● spark.shuffle.spill=false (default since Spark 1.6)● spark.shuffle.memoryFraction● spark.executor.memory

http://www.slideshare.net/databricks/new-developments-in-spark

Join
● partitionBy()● repartitionAndSortWithinPartitions()● spark.sql.autoBroadcastJoinThreshold (default 10 MB)● Join it manually by mapPartitions()
○ Broadcast small RDD■ http://stackoverflow.com/a/17690254/406803
○ Query data from database■ https://groups.google.com/a/lists.datastax.com/d/topic/spark-connector-user/63ILfPqPRYI/discussion

Broadcast Small RDD
val smallRdd = ...
val largeRdd = ...
val smallBroadcast = sc.broadcast(smallRdd.collectAsMap())
val joined = largeRdd.mapPartitions(iter => {
val m = smallBroadcast.value
for {
(k, v) <- iter
if m.contains(k)
} yield (k, (v, m.get(k).get))
}, preservesPartitioning = true)

Query Data from Cassandra
val conf = new SparkConf()
.set("spark.cassandra.connection.host", "127.0.0.1")
val connector = CassandraConnector(conf)
val joined = rdd.mapPartitions(iter => {
connector.withSessionDo(session => {
val stmt = session.prepare("SELECT value FROM table WHERE key=?")
iter.map {
case (k, v) => (k, (v, session.execute(stmt.bind(k)).one()))
}
})
})


Persist
● Storage level○ MEMORY_ONLY○ MEMORY_AND_DISK○ MEMORY_ONLY_SER○ MEMORY_AND_DISK_SER○ DISK_ONLY○ …
● Kryo serialization○ Much faster○ Registration needed
http://spark.apache.org/docs/latest/programming-guide.html#which-storage-level-to-choose

Common Failures
● Large shuffle blocks○ java.lang.IllegalArgumentException: Size exceeds Integer.MAX_VALUE
■ Increase partition count○ MetadataFetchFailedException, FetchFailedException
■ Increase partition count■ Increase `spark.executor.memory`■ …
○ java.lang.OutOfMemoryError: GC overhead over limit exceeded■ May caused by shuffle spill

java.lang.OutOfMemoryError: Java heap space
● Driver○ Increase `spark.driver.memory`○ collect()
■ take()■ saveAsTextFile()
● Executor○ Increase `spark.executor.memory`○ More nodes

java.io.IOException: No space left on device
● SPARK_WORKER_DIR● SPARK_LOCAL_DIRS, spark.local.dir● Shuffle files
○ Only delete after the RDD object has been GC

Other Tips
● Event logs○ spark.eventLog.enabled=true○ ${SPARK_HOME}/sbin/start-history-server.sh

Partitions
● Rule of thumb: ~128 MB per partition● If #partitions <= 2000, but close, bump to just > 2000
● Increase #partitions by repartition()● Decrease #partitions by coalesce()● spark.sql.shuffle.partitions (default 200)
http://www.slideshare.net/cloudera/top-5-mistakes-to-avoid-when-writing-apache-spark-applications

Executors, Cores, Memory!?
● 32 nodes● 16 cores each● 64 GB of RAM each● If you have an application need 32 cores, what is the
correct setting?
http://www.slideshare.net/cloudera/top-5-mistakes-to-avoid-when-writing-apache-spark-applications

Why Spark Debugging / Tuning is Hard?
● Distributed● Lazy● Hard to do benchmark● Spark is sensitive

Conclusion
● When in doubt, repartition!● Avoid shuffle if you can● Choose a reasonable partition count● Premature optimization is the root of all evil -- Donald Knuth

Reference
● Tuning and Debugging in Apache Spark● Top 5 Mistakes to Avoid When Writing Apache Spark
Applications ● How-to: Tune Your Apache Spark Jobs (Part 1)● How-to: Tune Your Apache Spark Jobs (Part 2)
Related Documents











