Deadlocks in Distributed Systems Ryan Clemens, Thomas Levy, Daniel Salloum, Tagore Kolluru, Mike DeMauro

Deadlocks in Distributed Systems Ryan Clemens, Thomas Levy, Daniel Salloum, Tagore Kolluru, Mike DeMauro.
Dec 16, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Deadlocks in Distributed Systems
Ryan Clemens, Thomas Levy, Daniel Salloum, Tagore Kolluru, Mike
DeMauro

Outline
• Distributed systems• Deadlock basics• Strategies• Algorithms• Simulation

What is a distributed system?
• A collection of sites which communicate via message passing.– Centralized– Decentralized

What is a deadlock?
• A deadlock occurs when all elements of a set, comprised of multiple processes, request a resource which is held by another process in the set.– In distributed systems, a deadlock may arise when
waiting for messages in addition to resources.

Conditions for a Deadlock
• Necessary– Mutual Exclusion– Hold and Wait– No Preemption
• Sufficient– Circular Wait

Mutual Exclusion
• When one process enters its critical state while accessing a resource no other process can enter their critical state to access the same resource.– Without this, multiple processes could access the
same resource, which would mean they would not have to wait, which would prevent the deadlock.• This would cause data corruption.
– When messages are the resources, mutual exclusion is guaranteed.

Hold and Wait
• Occurs when a process gathers and retains certain resources, but is still awaiting other resources before it can continue execution.- Without this, there could be no deadlocks because
if process A is waiting on a resource held by process B, process B is guaranteed to be able to proceed.- This limits what we can program.

No Preemption
• No process can take resources held by another process.– If preemption is allowed and mutual exclusion is
maintained, once a resource has been preempted, the process which previously had the resource needs to be placed in a state where it no longer has it.• This may mean killing the process.
– If there is no mutual exclusion, there can be no concept of preemption.

Circular Wait
• A set of nodes with transitive relationship are in circular wait if the dependency chain of a node leads back to itself.– Without this, the dependency graph becomes a directed
acyclic graph, which will have a sink which can continue.• The standard way of preventing circular wait is to
create a partial ordering of the resources and only allow a process to request resources which are higher in the ordering than the current highest held.– This is inconvenient if the resources needed by a process
are not known beforehand.

Prevention
• Prevention is preventing a process from requesting a resource which would lead to a deadlock.
• A standard method of prevention is to force processes to acquire all their required resources before execution.
• Another method is to remove one of the four conditions for deadlocks.

Avoidance
• Avoidance is when a resource is granted to a process only when the resulting state is safe.– A safe state if there is an execution sequence which does not lead
to a deadlock.• Banker’s algorithm: This algorithm needs to know the
current amount of available resources the system has free, the amount of resources each process has, and an upper bound on the amount of resources each process will hold during its execution. It will only grant a request for resources to a process if it leaves the system with enough resources to fulfill the biggest possible request for resources for at least one process.

Detection
• No resource checking done in advance• State is stored in some fashion• Periodically checks state for deadlocks
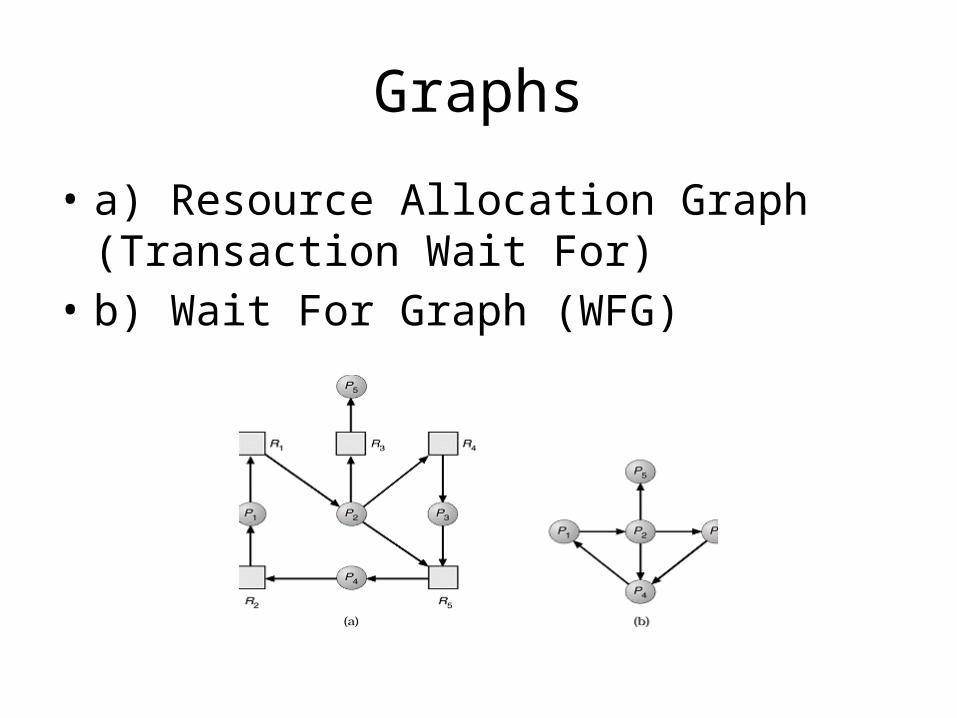
Graphs
• a) Resource Allocation Graph (Transaction Wait For)
• b) Wait For Graph (WFG)

Recovery
• Kill Member of Detected Deadlock– Random Kill– Priority Kill– Kill Youngest
• Time-out approach

Distributed Issues
• False (Phantom) Deadlock• Detection

Algorithm Considerations
• Message Passing– Traffic– Length
• Resolution Efficiency

Resource Models
• Single-resource• AND• OR• AND-OR

Detection Algorithm Classes
• Path-Pushing• Edge-Chasing (probe based)• Diffusing Computations• Global State Detection

Selected Algorithms
• Obermarck’s – Path-Pushing– AND model– Obsoleted for inaccurate WFG
• Hermann and Chandy’s – AND-OR– Diffusing computation
• Bracha and Toueg’s– AND-OR– Global state detection

Algorithms
• Mitchell and Merritt’s – Single-Resource– Edge chasing– Benefits• Simple• Only one cycle detects deadlock• Not always phantom deadlocks
– Complexity – O(s(s-1)/2)

Chandy and Misra’s Algorithm
• Multiple Resource• Diffusing computation• AND Model• Complexity: O(N(N-1))

Algorithms
• Probe-based Algorithms– Chandy-Mirsa-Haas– Roesler
• Hierarchical Algorithms– Ho-Ramamoorthy

Algorithms (cont)
• Online deadlock detection (Isloor-Marsland)– Immediate deadlock detection

Difficulty of Proof
• TWF graphs can form in many ways, which makes it difficult to study all situations
• Deadlocks are sensitive to the timing of requests
• In distributed systems, message latency is unpredictable and there is no global memory

Requirements foralgorithm correctness
• At least one process can proceed• No process will be restarted an indefinite
number of times

Simulation
• Partial reversion of process instead of killing it• Uses a WFG of the entire system to detect
deadlocks• This algorithm honors mutual exclusion and
implements preemption.• Causes more data corruption than simply
killing the youngest process.– A solution to this is programmers writing their
code anticipating the possibility of a reversion.

References• Knapp, Edgar. Deadlock detection in distributed databases, ACM Computing Surveys, Volume 19 Issue 4, Dec. 1987• Natalija Krivokapić, Alfons Kemper, Ehud Gudes. Deadlock detection in distributed database systems: a new algorithm and a
comparative performance analysis. The VLDB Journal — The International Journal on Very Large Data Bases , Volume 8 Issue 2, October 1999– doi:10.1007/s007780050075– URL: http://portal.acm.org/citation.cfm?id=765509.765510&coll=DL&dl=ACM&CFID=17423245&CFTOKEN=33985983
• Singhal, M.; , "Deadlock detection in distributed systems," Computer , vol.22, no.11, pp.37-48, Nov 1989– doi: 10.1109/2.43525
URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=43525&isnumber=1667
Related Documents











