DBDA Chapter 17: Metric Predicted Variable with Mul9ple Metric Predictors オーマ株式会社 Agchbayar Amarsanaa (アマル)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

DBDA Chapter 17: Metric Predicted Variable
with Mul9ple Metric Predictors
オーマ株式会社 Agchbayar Amarsanaa (アマル)

導入
次のシチュエーションを考える • ある人の高校の成績と大学入試スコアから大学の成績を予測したい • あるひとの身長と体調から血圧を予測したい
• 一つのメトリックな値を複数のメトリックな値から予測する • 1行3列目のケースを紹介(Ch.14 p.385)
– 説明変数の加法的なコンビネーション(重回帰分析) – 加法的ではない(交互作用のある)場合

目次
17.1 Mul9ple Linear Regression 17.1.1 The Pe

詩
When I was young two plus two equaled four, but Since I met you things don’t add up no more. My keel was even before I was kissed, but Now my predic9ons all come with a twist.
若いごろの私の人生は単純そのもので、2+2=4のような世界だった
でも君に出会ってからもはや計算が合わなくなってしまった 私の心は安定そのものだった
でも君とキスしてから予測ひとつできないものになってしまった

17.1 Mul9ple Linear Regression
次のモデルを考える、
• 説明変数x1,x2の分布は与えられていない • x1,x2のどの点においてもyの分散は一定(同次性)
y ~ N µ,τ( )µ = β0 +β1x1 +β2x2

17.1.1 The Perils of Correlated Predictors
(x1,x2の分布が異なる)同じモデルの例を見てみる
Fig 17.1 x1,x2が一様な分布の時

17.1.1 The Perils of Correlated Predictors
(x1,x2の分布が異なる)同じモデルの例を見てみる
Fig 17.2 x1,x2がマイナス相関があるとき

17.1.1 The Perils of Correlated Predictors
説明変数に相関がある時、間違った解釈がなされる恐れがある • Fig 17.2の場合、x1が増えるとyが減る印象
具体例 • 州が教育にかける予算と、 大学入試スコア平均が逆関係? • 実は、
– 受験率が増えると、スコア平均が 著しく低くなる – 予算と受験率はプラスの相関がある
• 説明変数同士の相関が強くなると 個々の影響を特定しにくくなる
Fig 17.3

17.1.2 The Model and BUGS Program
• 前章の単回帰(Fig 16.3 p.423)の拡張
• 係数ごとに事前分布(同一な正規分布)を設定する – 事前分布が必ずしも同じである必要はない
• Improf(内積)関数を使って、式を表現している(14行目)

17.1.2.1 MCMC Efficiency: Standardizing and Ini9alizing
• 正規化 – 正規化後の係数から正規後前の係数を求める – 16.2式の拡張
• 初期化 – 正規化後に、Rのlm(線形モデル関数)を使えばMLE(maximum-‐likelihood es9mate)が求まる。
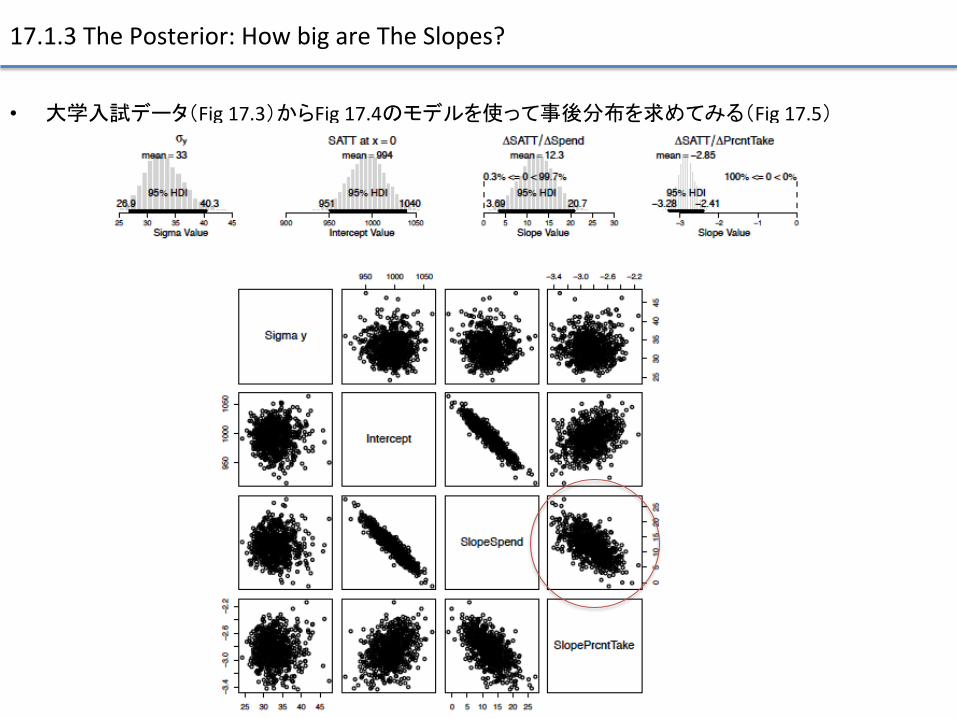
17.1.3 The Posterior: How big are The Slopes?
• 大学入試データ(Fig 17.3)からFig 17.4のモデルを使って事後分布を求めてみる(Fig 17.5)

17.1.3 The Posterior: How big are The Slopes?
大学入試データ(Fig 17.3)からFig 17.4のモデルを使って事後分布を求めてみる(Fig 17.5) • 説明変数の係数同士がトレードオフ関係にある
– データ上相関が見えるから、自然だよね
• ベイズ解析のいいところの一つは、係数同士の相関(冗長度)が明らか – 伝統的な統計手法では、「最も合う(例えばMLE)」値を提供する
• 説明変数の相関が強いと係数のjoint uncertainty(接合部不確実性)が明らかになりながらも、事後分布を生成する。 – 伝統的なone-‐best-‐solu9onは相関の高い説明変数の場合ロバスト性にかける

17.1.4 Posterior Predic9on
• 線形モデルは、xの値からyの値を予測する為に使われることが多い。 – 特定のxの値に基づいてyを大量に生成し、HDIと平均値を求める
• 1ステップごとにyの値を1個生成する(yPostPredが1個ずつ増える) • xPostPred: 説明変数の値 • bSamp: 事後係数 • cbind:行ベクトルを列ベクトルにする

17.2 Hyperpriors and Shrinkage of Regression Coefficients
• ある人の大学の成績を – 高校の成績と大学入試スコアから予測したい – 高校入試の点数 – 学生の収入、親の収入 – 親の学歴 – 学生の身長・体調 – ・・・ – 靴のサイズなどなど
• 全ての変数に対して係数を推測するべきか? – おそらくNO – 説明変数同士が関連するものが多い – ほとんどが関係が薄いと思われるもの – 数少ない説明変数が大きな影響を与えている という前提知識はある
• t分布をつかったモデル

17.2 Hyperpriors and Shrinkage of Regression Coefficients
• 事前の知識を分かり安く表現できる – ことんどの係数が0に近ければ、精度τが上がる
• False alarmの検知に有効 – Fig 17.4のモデルとの違い(Fig 17.7)
– Hyperpriorsモデルでは、17.6のモデルと比べて係数が縮小する
Hyperpriorsモデルでは • 係数は平均に向かって縮小する(必ずしも0ではない) • Hyperpriorがt分布の場合というのは、ほとんどの説明変すの予測能力は同じで少数の「はずれ値」があると
きに使える • 説明変数を暗黙に選んでいる場合などは、違う分布になる。
• 便利な分布の使い過ぎに気をつける必要がある
Fig 17.6
Fig 17.7

17.2.1 Informa9ve Priors, Sparse Data, and Correlated Predictors
• (この本では)ゆるくに決定された事前情報を利用すべきだと強調している – ゆるい事前情報は納得されやすい – ゆるい事前情報から強い事後(結論)を出せたら一番望ましい – しかし一般的には少ないデータの場合、不正確な事前情報から不正確な事後が出がち
• 重回帰の場合「説明変数に相関がある場合係数にも相関がある」という事実を利用すれば、少ないデータから正確な事後を導きだすことができる。 – 1つの係数が他の係数に強い影響を持っているから
• その1つ目の説明変数の事前情報が正確である必要がある

17.3 Mul9plica9ve Interac9on of Metric Predictors
• 予測したい値が単純足し算で出てこない倍がある • (主観的な)幸せを健康とお金で説明しようとすると、
– 健康であればある程、お金持ちであればある程幸せだが、 – 重病の億万長者は幸せ度が著しく減ってしまう
係数の解釈に注意 ・次数の低い係数は解釈が難しい

17.3.1 The Hierarchical Model and BUGS Code
• 変数の数が増えると、相互作用の可能性も増えてくる • 係数はほとんど0に近いので、t分布が使える

17.3.1.1 Standardizing the Data and Ini9alizing the Chains
• 正規かによって係数の相関が減る(なくならない) • 初期化によって相互作用係数を0に近づけることができ、相互作用ないMLEで始めることを可能にする
• 変数の数を増えると行列を使った表現をせざるを得ない(BUGSは行列表現が不得意)

17.3.2 Interpre9ng the Posterior
• 大学入試の例を使う。相互作用は直感的にありそう – 受験者数が多いと教育予算を多くなる – 相互作用を考えたモデルによる事後を出してみる(Fig 17.9)
• 相互作用係数の平均が0より高い – しかし95% HDIは0を含んでいる。→強い精度が持てない – 受験率係数と強い相関がある
• (上)真ん中のヒストグラムは「予算が影響ない」という勘違いを生む可能性が – 受験率0%時の値なので意味を持たない – Fig 17.10のように、受験率が増えると予算係数の平均も上がっていく

17.3.2 Interpre9ng the Posterior
• 予算係数HDIの幅は一定ではない。 – β1+β1x2x2なので受験率x2に依存する – β1のβ1x2の相関度(プラスかマイナスか)による
• 適度なx2の場合不確実性が低くなる • 相互作用の推測が精度が低くても(HDIが0を含んでいても)、相互作業が説明変数の解釈に少なからぬ影響を与えているという事実

17.4 Which Predictors Should be Included?
• 研究活動において、 – 説明変数をと相互作業をあらかじめ分かっている場合 – 既存のデータが与えられた状態で、どの変数が目的変数をよく説明できるか分からないとき – (又は、両方の要因がある場面)
• どの変数をモデルに入れるか – 基本的には、関係あると思われる説明変数・相互作用を全部取り入れたほうが良い
• 入れない=変数0という強い確信
– 結果精度よく予測したい場合は、出来るだけ全ての変数を使った方が良い – 結果に説明を付けたい場合意味のある説明変数だけを入れた方が良い
• 変数が増える代償 – 結果の解釈が難しくなる。数学的に扱いにくい
• 幸福度を説明する為に靴のサイズが関係あるか?
– False alarm問題(Sec 17.2) – Noise問題(Sec 17.3)
Related Documents











